
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor Work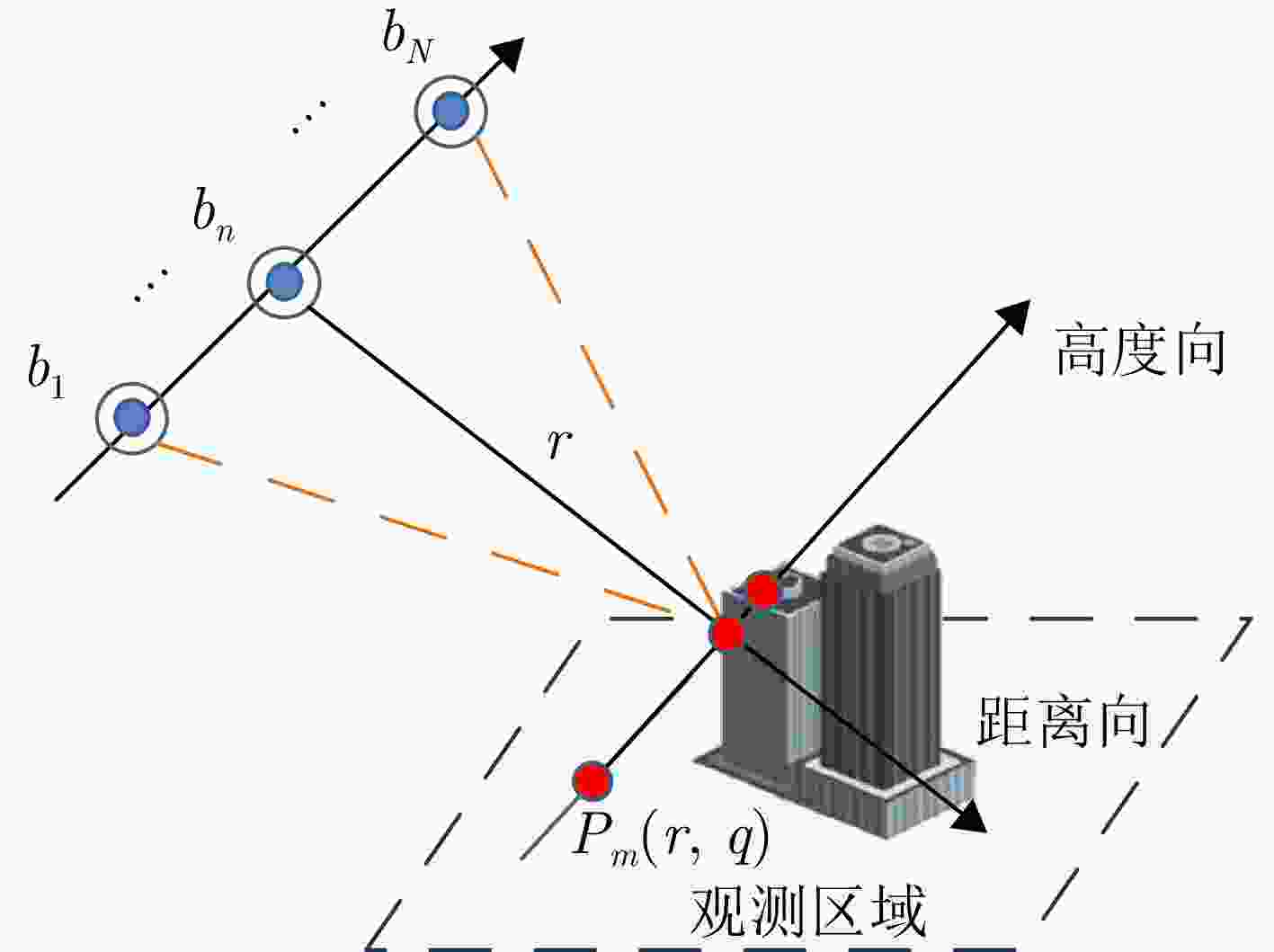


Display Method:
 Abstract
Abstract 5740KB
5740KB
Vortex Electromagnetic Wave Radar (VEWR) leverages the orthogonality of Orbital Angular Momentum (OAM) modes, introducing a new physical dimension that theoretically overcomes the azimuth resolution limitations of conventional radar systems and enables enhanced micro-motion perception and forward-looking imaging. However, in practical engineering applications, the limited number of available OAM modes and the presence of complex electromagnetic noise often cause severe mode aliasing and resolution degradation. Existing sparse imaging methods face inherent trade-offs between accuracy and computational efficiency and exhibit limited robustness to noise. To address these issues, this paper proposes a super-resolution imaging framework that integrates Mode Correlation Weighting and Adaptive Regularization (MCWAR). First, a forward-looking imaging geometry and a wavefront-modulated signal model for VEWR are established. Subsequently, an OAM mode correlation matrix is designed to characterize the nonuniform distribution of radiation energy among modes, where Bessel-function-modulated weights reinforce the low-rank constraints of dominant radiation components. Finally, a compound optimization model combining sparsity and low-rankness priors is developed, incorporating an adaptive weighting mechanism that dynamically balances structural preservation and noise suppression. A joint optimization framework based on the Alternating Direction Method of Multipliers (ADMM) and Augmented Lagrange Multiplier (ALM) algorithms is constructed, in which the core image-updating subproblem is efficiently solved using a momentum-accelerated Two-Dimensional Conjugate Gradient Least Squares (2D-CGLS) method. Numerical simulations and electromagnetic experiments verify that the proposed method preserves target structural integrity under limited modes and strong noise, while effectively improving both computational efficiency and imaging quality.
Vortex Electromagnetic Wave Radar (VEWR) leverages the orthogonality of Orbital Angular Momentum (OAM) modes, introducing a new physical dimension that theoretically overcomes the azimuth resolution limitations of conventional radar systems and enables enhanced micro-motion perception and forward-looking imaging. However, in practical engineering applications, the limited number of available OAM modes and the presence of complex electromagnetic noise often cause severe mode aliasing and resolution degradation. Existing sparse imaging methods face inherent trade-offs between accuracy and computational efficiency and exhibit limited robustness to noise. To address these issues, this paper proposes a super-resolution imaging framework that integrates Mode Correlation Weighting and Adaptive Regularization (MCWAR). First, a forward-looking imaging geometry and a wavefront-modulated signal model for VEWR are established. Subsequently, an OAM mode correlation matrix is designed to characterize the nonuniform distribution of radiation energy among modes, where Bessel-function-modulated weights reinforce the low-rank constraints of dominant radiation components. Finally, a compound optimization model combining sparsity and low-rankness priors is developed, incorporating an adaptive weighting mechanism that dynamically balances structural preservation and noise suppression. A joint optimization framework based on the Alternating Direction Method of Multipliers (ADMM) and Augmented Lagrange Multiplier (ALM) algorithms is constructed, in which the core image-updating subproblem is efficiently solved using a momentum-accelerated Two-Dimensional Conjugate Gradient Least Squares (2D-CGLS) method. Numerical simulations and electromagnetic experiments verify that the proposed method preserves target structural integrity under limited modes and strong noise, while effectively improving both computational efficiency and imaging quality.
High-value artificial target detection is a critical application of Synthetic Aperture Radar (SAR). Existing deep learning-based detection methods often fail to adequately reuse parameterized knowledge from trained models and demonstrate limited generalization across different datasets. This limitation hinders their practical application in new scenarios. To address this issue, this study proposes a SAR image artificial target detection method based on YOLO model merging, adopting a Learning From Models (LFM) approach. The core idea is to use multiple homogeneous models as knowledge sources. The method integrates the feature extraction, multiscale feature fusion, and target discrimination capabilities developed in these source models into a unified detection framework, thereby transforming existing model knowledge into improved detection performance. Specifically, based on a shared pretrained backbone, the neck network parameters of multiple source models are first transferred to the merged model. Multiscale feature fusion is then achieved through channel concatenation and point-wise convolution. In addition, parallel detection head branches are introduced at each feature scale to preserve the discriminative capabilities of the source models. Experimental results on three public SAR datasets (SADD, SSDD, and HRSID) demonstrate that the proposed method effectively improves the detection performance of man-made targets in SAR images. Consistent improvements are observed in Recall, mAP50, and mAP50-95, particularly under high intersection-over-union thresholds and limited-sample scenarios, where the proposed method exhibits superior robustness and generalization ability.
High-value artificial target detection is a critical application of Synthetic Aperture Radar (SAR). Existing deep learning-based detection methods often fail to adequately reuse parameterized knowledge from trained models and demonstrate limited generalization across different datasets. This limitation hinders their practical application in new scenarios. To address this issue, this study proposes a SAR image artificial target detection method based on YOLO model merging, adopting a Learning From Models (LFM) approach. The core idea is to use multiple homogeneous models as knowledge sources. The method integrates the feature extraction, multiscale feature fusion, and target discrimination capabilities developed in these source models into a unified detection framework, thereby transforming existing model knowledge into improved detection performance. Specifically, based on a shared pretrained backbone, the neck network parameters of multiple source models are first transferred to the merged model. Multiscale feature fusion is then achieved through channel concatenation and point-wise convolution. In addition, parallel detection head branches are introduced at each feature scale to preserve the discriminative capabilities of the source models. Experimental results on three public SAR datasets (SADD, SSDD, and HRSID) demonstrate that the proposed method effectively improves the detection performance of man-made targets in SAR images. Consistent improvements are observed in Recall, mAP50, and mAP50-95, particularly under high intersection-over-union thresholds and limited-sample scenarios, where the proposed method exhibits superior robustness and generalization ability.
In near-field imaging with Multiple-Input Multiple-Output (MIMO) radar, spatial resolution is effectively enhanced by extending the aperture of a two-dimensional MIMO array. The proposed system is based on a time-division multiple-access waveform and performs near-field aperture synthesis imaging using the MIMO array. High-resolution three-dimensional coverage of the near-field region is achieved by coherently accumulating multichannel raw echo data in the wavenumber domain. Compared with traditional mechanical scanning, this system is considered more suitable for scenarios with extremely high real-time requirements, such as civil aviation security inspection. However, millimeter waves have a short wavelength, so numerous transmit/receive elements must be placed in MIMO arrays to satisfy the Nyquist sampling criterion. This necessity leads to a substantial resource overhead. Thus, the Cooperative Multi-Constraint of Sparse Array (CMC-SA) algorithm is proposed for MIMO radar near-field imaging. Under the constraints of maintaining constant main lobe gain and suppressing sidelobe levels in the array pattern, an optimization model for near-field MIMO radar array configurations is constructed, with the weight \begin{document}$ {\ell}_{\rm P} $\end{document} \begin{document}$ {\ell}_{\rm P} $\end{document}
Polarimetric Inverse Synthetic Aperture Radar (ISAR) is an important tool for obtaining high-resolution information about satellite targets. Compact polarization provides an optimal balance between system complexity and polarization information capacity and has been widely used in various ground-based ISAR systems. However, during satellite transit, the onboard antenna components often undergo independent mechanical rotation relative to the satellite main body to adjust the observation area. This motion introduces additional frequency modulation into the echo signals, resulting in defocused ISAR images. Existing deep learning-based refocusing methods primarily focus on the global refocusing of ISAR images and often overlook the frequency feature variations induced by component motion, thereby limiting the model’s focusing capabilities. To address these challenges, this study proposes a novel refocusing method for satellite antenna motion in compact polarimetric ISAR imaging based on a spatial-frequency feature-guided Brownian bridge diffusion model. The core idea behind this method is to utilize the Brownian bridge diffusion model to learn the intricate mapping between defocused and focused ISAR images. Simultaneously, spatial and frequency features are extracted from the ISAR images to guide this learning process, thereby achieving precise refocusing of the moving components. To validate this approach, an electromagnetic simulation dataset for polarimetric ISAR satellite targets is established, and comparative experiments are conducted. The results show that the proposed method achieves superior performance in refocusing moving components and exhibits enhanced generalization capabilities.
Polarimetric Inverse Synthetic Aperture Radar (ISAR) is an important tool for obtaining high-resolution information about satellite targets. Compact polarization provides an optimal balance between system complexity and polarization information capacity and has been widely used in various ground-based ISAR systems. However, during satellite transit, the onboard antenna components often undergo independent mechanical rotation relative to the satellite main body to adjust the observation area. This motion introduces additional frequency modulation into the echo signals, resulting in defocused ISAR images. Existing deep learning-based refocusing methods primarily focus on the global refocusing of ISAR images and often overlook the frequency feature variations induced by component motion, thereby limiting the model’s focusing capabilities. To address these challenges, this study proposes a novel refocusing method for satellite antenna motion in compact polarimetric ISAR imaging based on a spatial-frequency feature-guided Brownian bridge diffusion model. The core idea behind this method is to utilize the Brownian bridge diffusion model to learn the intricate mapping between defocused and focused ISAR images. Simultaneously, spatial and frequency features are extracted from the ISAR images to guide this learning process, thereby achieving precise refocusing of the moving components. To validate this approach, an electromagnetic simulation dataset for polarimetric ISAR satellite targets is established, and comparative experiments are conducted. The results show that the proposed method achieves superior performance in refocusing moving components and exhibits enhanced generalization capabilities.
To address communication interference in complex electromagnetic environments and overcome the limitations of traditional fixed-aperture antennas in terms of real-time beam reconfiguration and dynamic adaptation to jamming, this paper proposes an anti-jamming Orbital Angular Momentum (OAM) Mode Shift Keying (OMSK) communication system based on Reconfigurable Intelligent Surfaces (RIS). First, a system channel model is established, and an analytical relationship between the bit error rate and OAM mode purity is derived. This analysis reveals that mode purity is the core bottleneck constraining the system’s anti-jamming performance, which provides a theoretical basis for the design of high-purity RIS hardware. Second, a 2-bit dual-polarized RIS operating at 5.1 GHz is designed. Simulations confirm that the purity of each excited mode exceeds 88%, whereas the measured purity exceeds 74%. Finally, a complete OMSK wireless communication prototype system is constructed. Comparative experiments verify the strong orthogonal isolation between OAM beams and plane waves as well as between different OAM modes. Anti-jamming communication tests are then conducted based on multiple mode-hopping coding sequences. The results show that at an extremely low transmission power of 10 mW, the receiver-side RIS reduces the system packet loss rate from over 80% to below 15%, with an equivalent error vector magnitude improvement of approximately 10 dB. Distance tests further quantify the effective communication boundary constrained by beam divergence. These results demonstrate that the RIS-based OMSK system can achieve reliable wireless communication under low-power conditions.
To address communication interference in complex electromagnetic environments and overcome the limitations of traditional fixed-aperture antennas in terms of real-time beam reconfiguration and dynamic adaptation to jamming, this paper proposes an anti-jamming Orbital Angular Momentum (OAM) Mode Shift Keying (OMSK) communication system based on Reconfigurable Intelligent Surfaces (RIS). First, a system channel model is established, and an analytical relationship between the bit error rate and OAM mode purity is derived. This analysis reveals that mode purity is the core bottleneck constraining the system’s anti-jamming performance, which provides a theoretical basis for the design of high-purity RIS hardware. Second, a 2-bit dual-polarized RIS operating at 5.1 GHz is designed. Simulations confirm that the purity of each excited mode exceeds 88%, whereas the measured purity exceeds 74%. Finally, a complete OMSK wireless communication prototype system is constructed. Comparative experiments verify the strong orthogonal isolation between OAM beams and plane waves as well as between different OAM modes. Anti-jamming communication tests are then conducted based on multiple mode-hopping coding sequences. The results show that at an extremely low transmission power of 10 mW, the receiver-side RIS reduces the system packet loss rate from over 80% to below 15%, with an equivalent error vector magnitude improvement of approximately 10 dB. Distance tests further quantify the effective communication boundary constrained by beam divergence. These results demonstrate that the RIS-based OMSK system can achieve reliable wireless communication under low-power conditions.
Radar emitter signal deinterleaving separates pulse sequences from individual emitters within overlapping pulse streams. This is a critical step in radar signal intelligence processing, as its performance directly affects the accuracy of subsequent tasks such as waveform recognition, behavior analysis, and threat assessment. Current methods typically use pulse description words as the primary features, assigning pulse attribution based on parameter differences among emitters. However, in complex electromagnetic environments, the reliability of pulse description word estimation is highly susceptible to noise, measurement errors, and waveform overlap. These issues reduce the feature separability of pulses from different emitters, thereby limiting further improvements in deinterleaving performance. To address these challenges, this study proposes FSUNet, an end-to-end pulse stream deinterleaving network based on structured state modeling. FSUNet directly accepts the pulse stream within an observation window as input and jointly models intrapulse local morphological features and interpulse temporal dependencies within a unified framework. This enables an end-to-end mapping from raw signals to deinterleaving results. Specifically, FSUNet first utilizes a multiscale adaptive offset mechanism to extract pulse boundaries and local transient features. It then introduces a structured state space module to recursively model cross-pulse contextual dependencies, enhancing long-range temporal representation and improving the consistency of deinterleaving results. Finally, skip connections are combined with an attention-based fusion mechanism to adaptively integrate local details with global state information. Experimental results show that FSUNet achieves high deinterleaving accuracy and robustness across various scenarios while maintaining computational efficiency.
Radar emitter signal deinterleaving separates pulse sequences from individual emitters within overlapping pulse streams. This is a critical step in radar signal intelligence processing, as its performance directly affects the accuracy of subsequent tasks such as waveform recognition, behavior analysis, and threat assessment. Current methods typically use pulse description words as the primary features, assigning pulse attribution based on parameter differences among emitters. However, in complex electromagnetic environments, the reliability of pulse description word estimation is highly susceptible to noise, measurement errors, and waveform overlap. These issues reduce the feature separability of pulses from different emitters, thereby limiting further improvements in deinterleaving performance. To address these challenges, this study proposes FSUNet, an end-to-end pulse stream deinterleaving network based on structured state modeling. FSUNet directly accepts the pulse stream within an observation window as input and jointly models intrapulse local morphological features and interpulse temporal dependencies within a unified framework. This enables an end-to-end mapping from raw signals to deinterleaving results. Specifically, FSUNet first utilizes a multiscale adaptive offset mechanism to extract pulse boundaries and local transient features. It then introduces a structured state space module to recursively model cross-pulse contextual dependencies, enhancing long-range temporal representation and improving the consistency of deinterleaving results. Finally, skip connections are combined with an attention-based fusion mechanism to adaptively integrate local details with global state information. Experimental results show that FSUNet achieves high deinterleaving accuracy and robustness across various scenarios while maintaining computational efficiency.
To address partial observability, reward sparsity, and distorted credit assignment in cooperative jamming against networked radars in complex electromagnetic environments, this paper proposes an intelligent cooperative jamming strategy learning method with an offline reward backfilling mechanism. The multi-jammer cooperative jamming process is formulated as a partially observable Markov decision process. A two-level reward design is introduced, integrating immediate rewards with offline reward backfilling to improve the evaluation of jamming effectiveness and policy learning. Specifically, within each aggregation period, each jammer performs online adaptations of interception rhythm and transmission behavior based on local observations. At the end of the period, multi-jammer interaction data are aggregated to retrospectively assess the effectiveness of joint jamming actions. The resulting evaluation is backfilled into policy optimization to refine the policy gradient signal. This design enhances the policy’s ability to capture the actual jamming effectiveness. Accordingly, under the centralized training and decentralized execution framework, an offline reward backfilling-based multi-agent proximal policy optimization algorithm, termed ORB-MAPPO, is developed to realize collaborative time-frequency jamming strategy learning for multiple jammers. Simulation results demonstrate that the proposed method stably learns effective time-frequency cooperative jamming strategies, achieving a jamming coverage rate of over 95% and an information interception rate close to 100%. Compared with typical multi-agent policy optimization methods, the proposed method improves the jamming coverage rate by approximately 20%, demonstrating superior cooperative jamming performance and training stability.
To address partial observability, reward sparsity, and distorted credit assignment in cooperative jamming against networked radars in complex electromagnetic environments, this paper proposes an intelligent cooperative jamming strategy learning method with an offline reward backfilling mechanism. The multi-jammer cooperative jamming process is formulated as a partially observable Markov decision process. A two-level reward design is introduced, integrating immediate rewards with offline reward backfilling to improve the evaluation of jamming effectiveness and policy learning. Specifically, within each aggregation period, each jammer performs online adaptations of interception rhythm and transmission behavior based on local observations. At the end of the period, multi-jammer interaction data are aggregated to retrospectively assess the effectiveness of joint jamming actions. The resulting evaluation is backfilled into policy optimization to refine the policy gradient signal. This design enhances the policy’s ability to capture the actual jamming effectiveness. Accordingly, under the centralized training and decentralized execution framework, an offline reward backfilling-based multi-agent proximal policy optimization algorithm, termed ORB-MAPPO, is developed to realize collaborative time-frequency jamming strategy learning for multiple jammers. Simulation results demonstrate that the proposed method stably learns effective time-frequency cooperative jamming strategies, achieving a jamming coverage rate of over 95% and an information interception rate close to 100%. Compared with typical multi-agent policy optimization methods, the proposed method improves the jamming coverage rate by approximately 20%, demonstrating superior cooperative jamming performance and training stability.
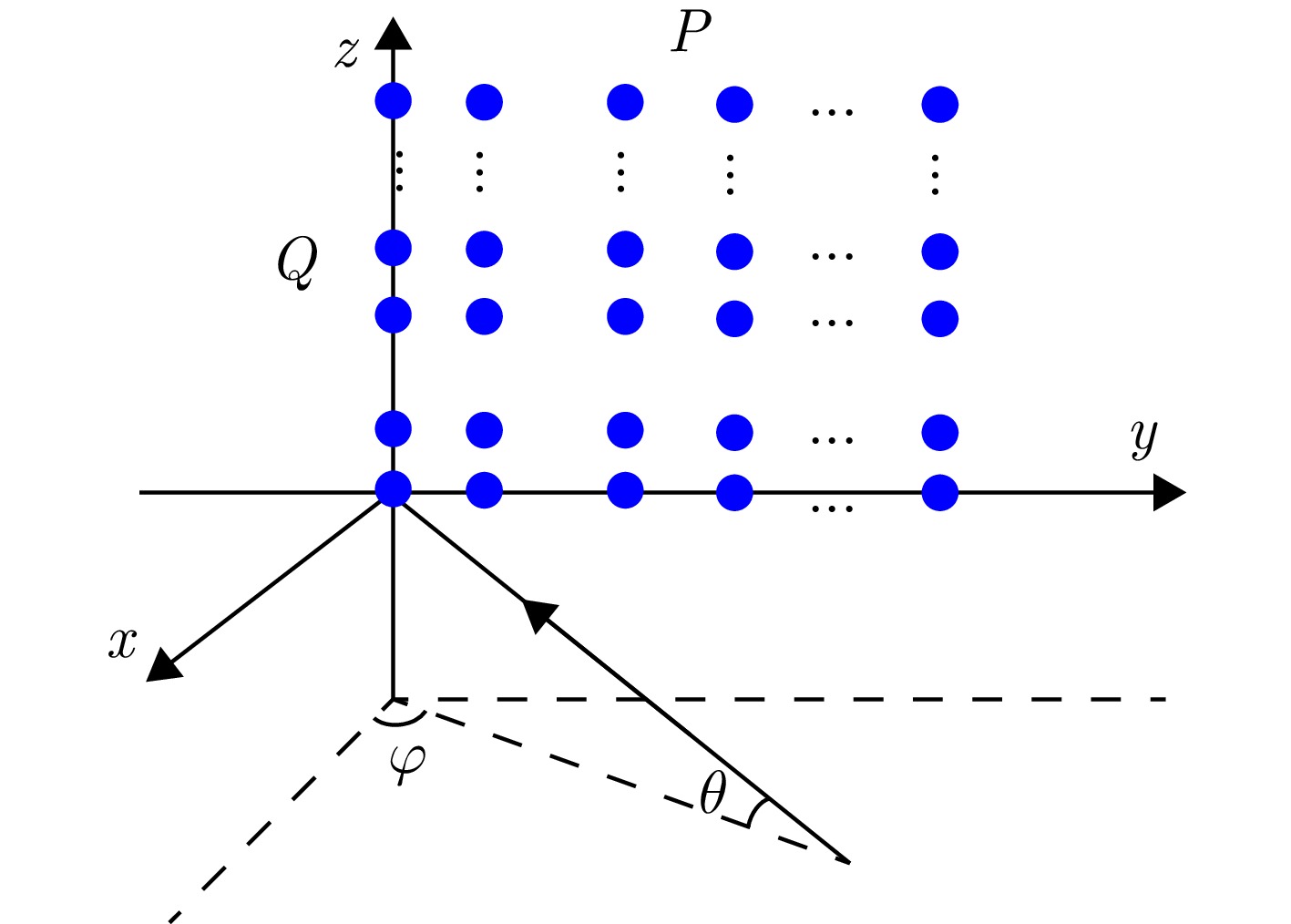
Multimodal orbital angular momentum imaging, which uses sparse recovery models, is a form of computational imaging where target reconstruction can be formulated as a linear inverse problem defined by an imaging equation. However, solving this problem using the least squares method can lead to substantial degradation in reconstruction quality, even with minor noise perturbations. Moreover, because the imaging equation is often underdetermined and has multiple solutions, the least squares method, which prioritizes data fitting accuracy, frequently produces results that deviate considerably from the actual target. Given that solution errors caused by noise are inversely proportional to the singular values of the reference matrix, this study first introduces an array design method that uses nonuniform element placement. This method, when compared to traditional uniform circular array designs, increases the number of array elements, reduces the correlation among the column vectors of the reference matrix, and decreases the number of small singular values. On this basis, a regional focusing least squares algorithm based on subspace projection is proposed. This algorithm first uses a basic correlation method to identify the target region. The echo vector is then projected onto the linear subspace of this target region. This projection transforms the underdetermined imaging equation into an overdetermined one within the focused target region. Concurrently, it effectively reduces noise power by exploiting the low correlation between noise and the target region’s linear subspace. The proposed algorithm’s effectiveness is subsequently validated through simulation experiments.
Multimodal orbital angular momentum imaging, which uses sparse recovery models, is a form of computational imaging where target reconstruction can be formulated as a linear inverse problem defined by an imaging equation. However, solving this problem using the least squares method can lead to substantial degradation in reconstruction quality, even with minor noise perturbations. Moreover, because the imaging equation is often underdetermined and has multiple solutions, the least squares method, which prioritizes data fitting accuracy, frequently produces results that deviate considerably from the actual target. Given that solution errors caused by noise are inversely proportional to the singular values of the reference matrix, this study first introduces an array design method that uses nonuniform element placement. This method, when compared to traditional uniform circular array designs, increases the number of array elements, reduces the correlation among the column vectors of the reference matrix, and decreases the number of small singular values. On this basis, a regional focusing least squares algorithm based on subspace projection is proposed. This algorithm first uses a basic correlation method to identify the target region. The echo vector is then projected onto the linear subspace of this target region. This projection transforms the underdetermined imaging equation into an overdetermined one within the focused target region. Concurrently, it effectively reduces noise power by exploiting the low correlation between noise and the target region’s linear subspace. The proposed algorithm’s effectiveness is subsequently validated through simulation experiments.
As a noninvasive and contactless sensing technology, millimeter-wave radar has attracted considerable attention because of its broad application potential in human-computer interaction, smart homes, and virtual reality. Existing deep learning models achieve strong performance in recognizing gestures from trained users owing to their powerful feature extraction capabilities; however, their recognition accuracy degrades significantly when applied to new users with different gesture habits and hand sizes. To improve model generalization in cross-user scenarios, this paper proposes a millimeter-wave radar gesture recognition network that integrates end-to-end learning with a state space model. The proposed method directly processes raw radar data cubes and incorporates a Mamba module to capture long-range spatiotemporal dependencies. This enables the adaptive extraction and robust representation of user-independent gesture features. Experimental results show that the proposed end-to-end architecture effectively captures discriminative gesture patterns that are invariant across users. On the cross-user test set, the proposed method achieved an average recognition accuracy of 94.28% with a standard deviation of 2.55% across 11 folds, while the highest single-fold accuracy reached 97.50%. These results substantially outperform those of conventional deep learning methods and validate the generalization capability of the proposed method in cross-user application scenarios.
As a noninvasive and contactless sensing technology, millimeter-wave radar has attracted considerable attention because of its broad application potential in human-computer interaction, smart homes, and virtual reality. Existing deep learning models achieve strong performance in recognizing gestures from trained users owing to their powerful feature extraction capabilities; however, their recognition accuracy degrades significantly when applied to new users with different gesture habits and hand sizes. To improve model generalization in cross-user scenarios, this paper proposes a millimeter-wave radar gesture recognition network that integrates end-to-end learning with a state space model. The proposed method directly processes raw radar data cubes and incorporates a Mamba module to capture long-range spatiotemporal dependencies. This enables the adaptive extraction and robust representation of user-independent gesture features. Experimental results show that the proposed end-to-end architecture effectively captures discriminative gesture patterns that are invariant across users. On the cross-user test set, the proposed method achieved an average recognition accuracy of 94.28% with a standard deviation of 2.55% across 11 folds, while the highest single-fold accuracy reached 97.50%. These results substantially outperform those of conventional deep learning methods and validate the generalization capability of the proposed method in cross-user application scenarios.
Current airborne platforms rely primarily on passive stealth techniques, such as shape optimization and radar-absorbing material coatings, to reduce their radar signatures. However, due to several technical bottlenecks, their stealth performance remains constrained in terms of multidirectional and wideband effectiveness. As a complementary approach, active stealth has gradually become a research focus. To enhance the stealth performance of airborne platforms against distributed radar network detection systems, this paper proposes an active stealth method based on a self-defense/escort intelligent electromagnetic jamming strategy inspired by the principles of cognitive electronic warfare. The proposed method aims to reduce radar receivers’ perception of both electromagnetic interference and airborne targets. Through flexible jamming beam steering and multiband jamming coverage, it achieves an equivalent reduction of the target Radar Cross Section (RCS) over multiple directions and wide frequency bands via an adaptive electromagnetic jamming strategy. Specifically, a reinforcement learning mechanism is introduced to construct an electronic warfare strategy generation framework. First, the platform’s onboard or escort cognitive electronic warfare system is used to sense, in real time, the electromagnetic radiation signals of external radar networked detection systems, and a comprehensive observation space is established by integrating prior intelligence and other relevant data. Then, an action space is formulated based on jamming parameters, such as bandwidth, power, and radiation direction. In addition, a multilevel reward function is designed to influence radar working states and reduce the risk of electromagnetic jamming exposure. Finally, a reinforcement learning algorithm is employed to train the agent and optimize the intelligent jamming strategies. Simulation results show that, compared with conventional passive stealth techniques and fixed jamming strategies, the proposed method effectively reduces both the detection range of radar networks and their perception of electromagnetic interference. The maximum average equivalent RCS reduction achieved for multiband radar stations is 9.40 dB, while the concealment rate of electromagnetic interference remains above 97.83%. Moreover, the general jamming parameters can be dynamically adjusted in response to changes in the external electromagnetic environment, substantially improving the radar stealth performance of airborne platforms and providing a reference for the development of future active stealth technologies.
Current airborne platforms rely primarily on passive stealth techniques, such as shape optimization and radar-absorbing material coatings, to reduce their radar signatures. However, due to several technical bottlenecks, their stealth performance remains constrained in terms of multidirectional and wideband effectiveness. As a complementary approach, active stealth has gradually become a research focus. To enhance the stealth performance of airborne platforms against distributed radar network detection systems, this paper proposes an active stealth method based on a self-defense/escort intelligent electromagnetic jamming strategy inspired by the principles of cognitive electronic warfare. The proposed method aims to reduce radar receivers’ perception of both electromagnetic interference and airborne targets. Through flexible jamming beam steering and multiband jamming coverage, it achieves an equivalent reduction of the target Radar Cross Section (RCS) over multiple directions and wide frequency bands via an adaptive electromagnetic jamming strategy. Specifically, a reinforcement learning mechanism is introduced to construct an electronic warfare strategy generation framework. First, the platform’s onboard or escort cognitive electronic warfare system is used to sense, in real time, the electromagnetic radiation signals of external radar networked detection systems, and a comprehensive observation space is established by integrating prior intelligence and other relevant data. Then, an action space is formulated based on jamming parameters, such as bandwidth, power, and radiation direction. In addition, a multilevel reward function is designed to influence radar working states and reduce the risk of electromagnetic jamming exposure. Finally, a reinforcement learning algorithm is employed to train the agent and optimize the intelligent jamming strategies. Simulation results show that, compared with conventional passive stealth techniques and fixed jamming strategies, the proposed method effectively reduces both the detection range of radar networks and their perception of electromagnetic interference. The maximum average equivalent RCS reduction achieved for multiband radar stations is 9.40 dB, while the concealment rate of electromagnetic interference remains above 97.83%. Moreover, the general jamming parameters can be dynamically adjusted in response to changes in the external electromagnetic environment, substantially improving the radar stealth performance of airborne platforms and providing a reference for the development of future active stealth technologies.
Synthetic Aperture Radar (SAR) enables round-the-clock high-resolution imaging under all weather conditions, thereby playing a vital role in both military domains (e.g., surveillance, reconnaissance, air defense, and missile defense) and civilian domains (e.g., disaster monitoring). However, advancements in electronic countermeasure technologies have led to the development of radar jammers that generate deceptive jamming with false targets in SAR imagery. This seriously undermines the interpretation of SAR images and real-time decision-making. To tackle these issues, this study proposes a Scattering Feature-enhanced Vision Transformer-based network (SF-ViT) to discriminate deceptive jamming using SAR false targets, which leverages the electromagnetic scattering mechanisms of targets. By targeting the azimuth distribution disparity of echoes caused by the fixed spatial positions of jammers and the scattering feature discrepancy induced by variations in template configurations and signal parameters, the network first highlights the differences between real and false targets in the image domain using a shallow feature enhancement module. Subsequently, it extracts and classifies high-dimensional semantic features through a lightweight hybrid convolutional-ViT network. Experimental validation on the SAR false-target deceptive jamming dataset built in this study indicates that the proposed network attains an average discrimination accuracy of 94.97% under diverse signal-to-noise ratio conditions and requires fewer parameters, making it easy to deploy on edge devices. In addition, ablation experiments demonstrate that the proposed scattering feature enhancement module can be integrated with traditional models, further enhancing the discrimination accuracy of SAR false-target deceptive jamming.
Synthetic Aperture Radar (SAR) enables round-the-clock high-resolution imaging under all weather conditions, thereby playing a vital role in both military domains (e.g., surveillance, reconnaissance, air defense, and missile defense) and civilian domains (e.g., disaster monitoring). However, advancements in electronic countermeasure technologies have led to the development of radar jammers that generate deceptive jamming with false targets in SAR imagery. This seriously undermines the interpretation of SAR images and real-time decision-making. To tackle these issues, this study proposes a Scattering Feature-enhanced Vision Transformer-based network (SF-ViT) to discriminate deceptive jamming using SAR false targets, which leverages the electromagnetic scattering mechanisms of targets. By targeting the azimuth distribution disparity of echoes caused by the fixed spatial positions of jammers and the scattering feature discrepancy induced by variations in template configurations and signal parameters, the network first highlights the differences between real and false targets in the image domain using a shallow feature enhancement module. Subsequently, it extracts and classifies high-dimensional semantic features through a lightweight hybrid convolutional-ViT network. Experimental validation on the SAR false-target deceptive jamming dataset built in this study indicates that the proposed network attains an average discrimination accuracy of 94.97% under diverse signal-to-noise ratio conditions and requires fewer parameters, making it easy to deploy on edge devices. In addition, ablation experiments demonstrate that the proposed scattering feature enhancement module can be integrated with traditional models, further enhancing the discrimination accuracy of SAR false-target deceptive jamming.
Synthetic Aperture Radar (SAR) image interpretation has a wide range of applications, with SAR aircraft detection and recognition being a significant branch. However, collecting and annotating SAR aircraft samples is inherently difficult, leading to a scarcity of training data. Thus, developing few-shot methods for SAR aircraft detection and recognition is urgently needed. The complex SAR imaging environment results in unstable target feature representation, making it difficult for detection networks to adaptively manage disturbances from intricate SAR backgrounds. These factors limit the accuracy of aircraft detection and recognition under few-shot conditions. To address these challenges, this study proposes a few-shot SAR fine-grained aircraft detection and recognition method guided by strong scattering dynamic prototypes. This approach integrates strong scattering physical priors into a meta-metric learning framework. Detection and recognition performance are enhanced through two key aspects: Target feature enhancement and task-adaptive network adjustment. A dynamic prototype generation module is introduced to extract strong scattering points from SAR images and create physical attention masks. High-level semantic features are anchored to the physical geometric structure of targets, enabling robust feature representation. These features are then adaptively fused with prototypes to produce dynamic prototypes. A dynamic prototype guidance module, which maps dynamic prototypes from semantic space to parameter space, is also proposed. This enables adaptive adjustments to network weight updates, feature inputs, and prediction outputs, thereby improving the model’s rapid adaptation capability for novel categories. The proposed method enhances the stability of SAR target feature representation and reduces background clutter interference. Experiments conducted on the CSAR-AC dataset demonstrate that the proposed method outperforms mainstream few-shot object detection algorithms under both 1- and 5-shot settings, significantly improving few-shot SAR aircraft detection and recognition performance in complex scenes.
Synthetic Aperture Radar (SAR) image interpretation has a wide range of applications, with SAR aircraft detection and recognition being a significant branch. However, collecting and annotating SAR aircraft samples is inherently difficult, leading to a scarcity of training data. Thus, developing few-shot methods for SAR aircraft detection and recognition is urgently needed. The complex SAR imaging environment results in unstable target feature representation, making it difficult for detection networks to adaptively manage disturbances from intricate SAR backgrounds. These factors limit the accuracy of aircraft detection and recognition under few-shot conditions. To address these challenges, this study proposes a few-shot SAR fine-grained aircraft detection and recognition method guided by strong scattering dynamic prototypes. This approach integrates strong scattering physical priors into a meta-metric learning framework. Detection and recognition performance are enhanced through two key aspects: Target feature enhancement and task-adaptive network adjustment. A dynamic prototype generation module is introduced to extract strong scattering points from SAR images and create physical attention masks. High-level semantic features are anchored to the physical geometric structure of targets, enabling robust feature representation. These features are then adaptively fused with prototypes to produce dynamic prototypes. A dynamic prototype guidance module, which maps dynamic prototypes from semantic space to parameter space, is also proposed. This enables adaptive adjustments to network weight updates, feature inputs, and prediction outputs, thereby improving the model’s rapid adaptation capability for novel categories. The proposed method enhances the stability of SAR target feature representation and reduces background clutter interference. Experiments conducted on the CSAR-AC dataset demonstrate that the proposed method outperforms mainstream few-shot object detection algorithms under both 1- and 5-shot settings, significantly improving few-shot SAR aircraft detection and recognition performance in complex scenes.
Due to their fixed baselines, traditional single-baseline spaceborne along-track interferometric Synthetic Aperture Radar (SAR) systems struggle to meet the measurement requirements for ocean surface current, particularly under complex sea conditions. To overcome this limitation and optimize multi-baseline designs for distributed SAR satellite systems, this study introduces a multi-baseline optimization method for ocean current measurements. The method operates under the dual constraints of interferometric coherence and current measurement sensitivity. The study also derives the theoretical upper bound of accuracy for multi-baseline weighted least squares fusion inversion of ocean surface current. Results show that this method significantly reduces radial current velocity error, with accuracy approaching the theoretical upper limit as the number of baselines increases. Under various sea conditions, the fusion error meets the required velocity measurement accuracy of 0.1 m/s. Notably, the X and C-band require longer baselines than the Ku-band. This method effectively supports the design of distributed interferometric SAR satellite systems for ocean current measurements.
Due to their fixed baselines, traditional single-baseline spaceborne along-track interferometric Synthetic Aperture Radar (SAR) systems struggle to meet the measurement requirements for ocean surface current, particularly under complex sea conditions. To overcome this limitation and optimize multi-baseline designs for distributed SAR satellite systems, this study introduces a multi-baseline optimization method for ocean current measurements. The method operates under the dual constraints of interferometric coherence and current measurement sensitivity. The study also derives the theoretical upper bound of accuracy for multi-baseline weighted least squares fusion inversion of ocean surface current. Results show that this method significantly reduces radial current velocity error, with accuracy approaching the theoretical upper limit as the number of baselines increases. Under various sea conditions, the fusion error meets the required velocity measurement accuracy of 0.1 m/s. Notably, the X and C-band require longer baselines than the Ku-band. This method effectively supports the design of distributed interferometric SAR satellite systems for ocean current measurements.
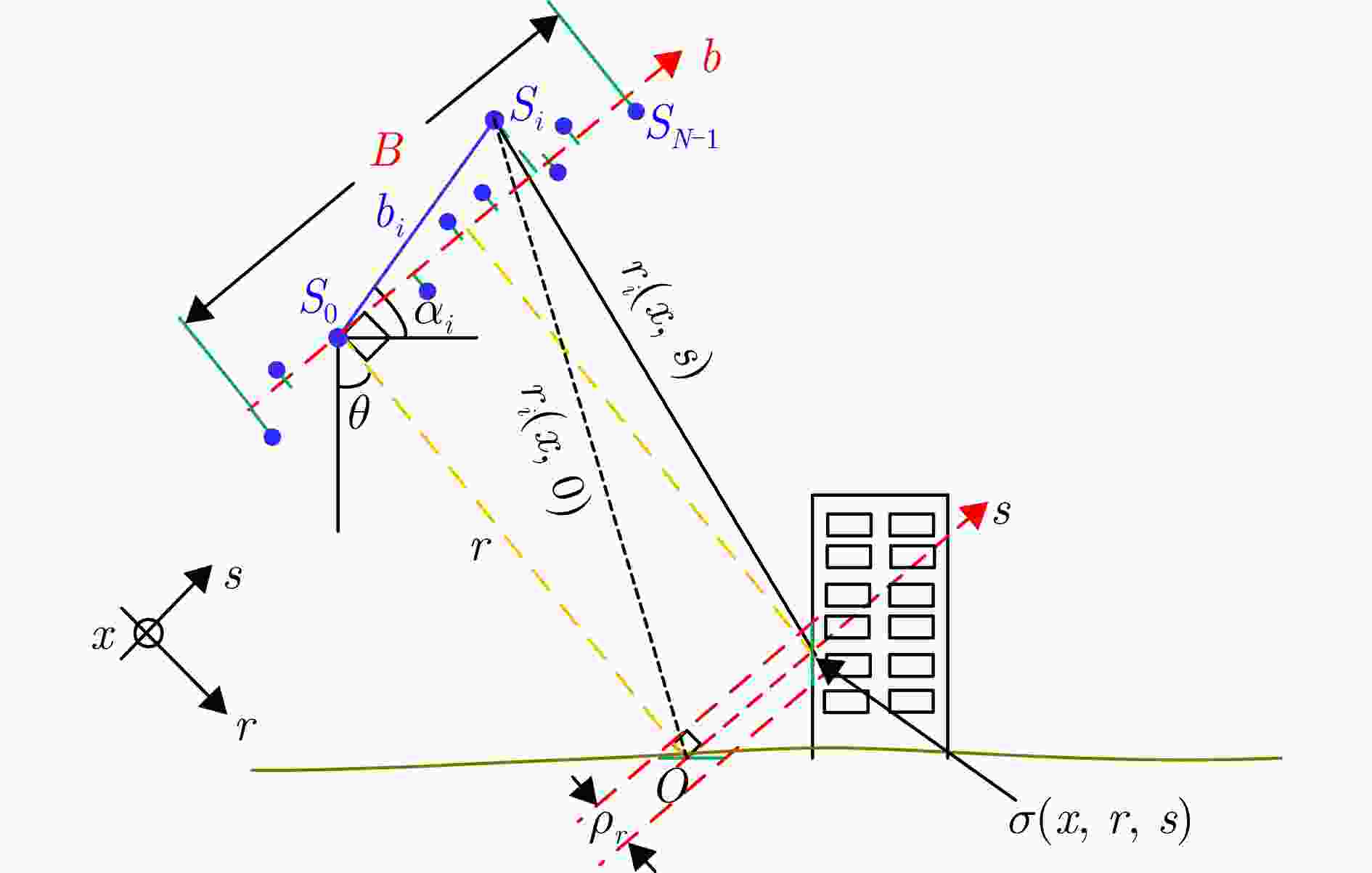
This study proposes an algorithm focused on Radio Frequency (RF) stealth-oriented energy management and beam-position task scheduling for regional search in constellation radar systems. First, the search airspace is discretized into a set of beam positions using a recursive beam-position generation method. The detection data from individual beam positions are then combined to create regional composite detection information. Based on prior target threat distribution, geometric link gains, and radiation energy allocation, an analytical expression for the regional weighted detection probability is derived to serve as the performance metric for the regional search. On this basis, an RF stealth-oriented energy management optimization model is established, in which the total radiation energy of the constellation radar system is minimized while adhering to a specified threshold for the regional weighted detection probability and ensuring full coverage of all beam positions. In this model, the radiation energy for each beam position is treated as a continuous decision variable. The optimized beam-position search tasks are then assigned to specific space-based radars using a quota-aware polling and blind-compensation strategy to form a practical task scheduling scheme. To solve the formulated problem, a regional search performance function based on a fixed total radiation energy is constructed, and a two-step decomposition algorithm is developed. This algorithm combines an outer monotonic bisection search with an inner marginal-gain allocation based on the Karush-Kuhn-Tucker theorem. Simulation results show that the proposed algorithm effectively reduces the total radiation energy of the constellation radar system compared to benchmark methods, thereby lowering the cumulative RF exposure level.
This study proposes an algorithm focused on Radio Frequency (RF) stealth-oriented energy management and beam-position task scheduling for regional search in constellation radar systems. First, the search airspace is discretized into a set of beam positions using a recursive beam-position generation method. The detection data from individual beam positions are then combined to create regional composite detection information. Based on prior target threat distribution, geometric link gains, and radiation energy allocation, an analytical expression for the regional weighted detection probability is derived to serve as the performance metric for the regional search. On this basis, an RF stealth-oriented energy management optimization model is established, in which the total radiation energy of the constellation radar system is minimized while adhering to a specified threshold for the regional weighted detection probability and ensuring full coverage of all beam positions. In this model, the radiation energy for each beam position is treated as a continuous decision variable. The optimized beam-position search tasks are then assigned to specific space-based radars using a quota-aware polling and blind-compensation strategy to form a practical task scheduling scheme. To solve the formulated problem, a regional search performance function based on a fixed total radiation energy is constructed, and a two-step decomposition algorithm is developed. This algorithm combines an outer monotonic bisection search with an inner marginal-gain allocation based on the Karush-Kuhn-Tucker theorem. Simulation results show that the proposed algorithm effectively reduces the total radiation energy of the constellation radar system compared to benchmark methods, thereby lowering the cumulative RF exposure level.
Traditional barrage jamming in single-jammer jamming of a Synthetic Aperture Radar (SAR) operating in Ground Moving Target Indication (GMTI) mode creates blind zones, increasing the risk of target exposure. Simultaneously, the motion of real targets causes azimuth energy broadening and position shifts, further increasing the requirements for jamming power and coverage. Although multi-jammer signal cooperation can alleviate these problems, it increases hardware costs and is limited to fixed SAR azimuth directions, complicating deployment. To address these issues, this paper proposes a barrage jamming signal control method based on four-phase composite modulation. This method generates false point targets with moving target defocusing and shifting characteristics through motion phase compensation. It controls the position of each barrage subregion using a subregion positioning phase and a central position control phase. Simultaneously, it adjusts the two-dimensional scale of noise points using a multi-scale noise template phase. The synergistic interaction of these four phases enables a single jammer to rapidly produce multi-region barrage jamming with controllable noise scale, moving-target-like defocus, and offset features, thereby achieving synchronous barrage jamming of multiple nearby moving targets. The generated barrage jamming region exhibits azimuth defocusing characteristics similar to those of a real moving target, ensuring that the defocus length of the noise points is highly similar to that of the real target. The azimuth offset of the barrage jamming is within the allowable error range relative to the position of the real target, ensuring that the barrage after azimuth offset effectively covers the imaging position of the moving target on the SAR image. After multi-channel Displaced Phase Center Antenna-Along Track Interferometric (DPCA-ATI) processing, both the real moving target and the barrage interference region are corrected to the same azimuth position, thus effectively protecting multiple moving targets. Theoretical analysis and simulation validation provide a quantifiable evaluation standard for the three-channel SAR-GMTI jamming techniques.
Traditional barrage jamming in single-jammer jamming of a Synthetic Aperture Radar (SAR) operating in Ground Moving Target Indication (GMTI) mode creates blind zones, increasing the risk of target exposure. Simultaneously, the motion of real targets causes azimuth energy broadening and position shifts, further increasing the requirements for jamming power and coverage. Although multi-jammer signal cooperation can alleviate these problems, it increases hardware costs and is limited to fixed SAR azimuth directions, complicating deployment. To address these issues, this paper proposes a barrage jamming signal control method based on four-phase composite modulation. This method generates false point targets with moving target defocusing and shifting characteristics through motion phase compensation. It controls the position of each barrage subregion using a subregion positioning phase and a central position control phase. Simultaneously, it adjusts the two-dimensional scale of noise points using a multi-scale noise template phase. The synergistic interaction of these four phases enables a single jammer to rapidly produce multi-region barrage jamming with controllable noise scale, moving-target-like defocus, and offset features, thereby achieving synchronous barrage jamming of multiple nearby moving targets. The generated barrage jamming region exhibits azimuth defocusing characteristics similar to those of a real moving target, ensuring that the defocus length of the noise points is highly similar to that of the real target. The azimuth offset of the barrage jamming is within the allowable error range relative to the position of the real target, ensuring that the barrage after azimuth offset effectively covers the imaging position of the moving target on the SAR image. After multi-channel Displaced Phase Center Antenna-Along Track Interferometric (DPCA-ATI) processing, both the real moving target and the barrage interference region are corrected to the same azimuth position, thus effectively protecting multiple moving targets. Theoretical analysis and simulation validation provide a quantifiable evaluation standard for the three-channel SAR-GMTI jamming techniques.
The multi-target tracking performance of phased array radar networks is fundamentally constrained by limited resources and asynchronous sampling mechanisms, especially under the Track-And-Search (TAS) mode. In this context , competition between search and tracking tasks, together with measurement uncertainty, substantially affects overall system performance. To address these challenges, this paper proposes a Task Priority-DrivenResource Scheduling (TPRS) method for asynchronous phased array radar networks (APARNs) operating in cluttered environments. The proposed method incorporates soft association probabilities and environmental parameters, including false alarm density and detection probability, into the resource scheduling model to characterize the impact of measurement uncertainty on scheduling decisions. Within the TAS framework, where target tracking is established through multiframe detection, the scheduling strategy emphasizes tracking tasks and performs priority-driven sequential allocation under resource constraints. On this basis, a closed-loop multi-target tracking framework for APARNs is developed by integrating centralized resource scheduling with distributed state estimation and fusion. Joint probabilistic data association is employed for multi-target state estimation, while covariance intersection is adopted for asynchronous measurement fusion. The posterior Cramér-Rao lower bound incorporating association uncertainty is used as the scheduling performance metric. Given that the resulting optimization problem involves coupled multidimensional decision variables and is NP-hard, a two-stage solution method combining multidimensional decoupling and sequential dynamic programming is developed to reduce computational complexity and enable adaptive scheduling of radar–target assignments and asynchronous dwell time under resource constraints. Simulation results demonstrate that, under limited resources and clutter interference, the proposed method effectively improves overall multi-target tracking accuracy and resource utilization efficiency in APARNs, thereby providing a feasible technical framework for the practical deployment of asynchronous multiradar cooperative tracking systems.
The multi-target tracking performance of phased array radar networks is fundamentally constrained by limited resources and asynchronous sampling mechanisms, especially under the Track-And-Search (TAS) mode. In this context , competition between search and tracking tasks, together with measurement uncertainty, substantially affects overall system performance. To address these challenges, this paper proposes a Task Priority-DrivenResource Scheduling (TPRS) method for asynchronous phased array radar networks (APARNs) operating in cluttered environments. The proposed method incorporates soft association probabilities and environmental parameters, including false alarm density and detection probability, into the resource scheduling model to characterize the impact of measurement uncertainty on scheduling decisions. Within the TAS framework, where target tracking is established through multiframe detection, the scheduling strategy emphasizes tracking tasks and performs priority-driven sequential allocation under resource constraints. On this basis, a closed-loop multi-target tracking framework for APARNs is developed by integrating centralized resource scheduling with distributed state estimation and fusion. Joint probabilistic data association is employed for multi-target state estimation, while covariance intersection is adopted for asynchronous measurement fusion. The posterior Cramér-Rao lower bound incorporating association uncertainty is used as the scheduling performance metric. Given that the resulting optimization problem involves coupled multidimensional decision variables and is NP-hard, a two-stage solution method combining multidimensional decoupling and sequential dynamic programming is developed to reduce computational complexity and enable adaptive scheduling of radar–target assignments and asynchronous dwell time under resource constraints. Simulation results demonstrate that, under limited resources and clutter interference, the proposed method effectively improves overall multi-target tracking accuracy and resource utilization efficiency in APARNs, thereby providing a feasible technical framework for the practical deployment of asynchronous multiradar cooperative tracking systems.
Sea ice is an important indicator of global climate change, and its accurate monitoring is essential for climate research, polar navigation, and marine resource management. Spaceborne microwave scatterometers, with their all-weather, day-and-night, and wide-swath observation capabilities, are critical remote sensing tools for monitoring polar sea ice. In this study, scatterometer observations from three Chinese satellites (HY-2B, CFOSAT, and FY-3E) were used to develop Arctic sea ice extent detection and classification models for first-year and multiyear ice using a support vector machine. All models were created using a unified projection grid, shared sample labels, and a consistent classification framework. Daily sea ice products were generated using observations from March 2022 to February 2023. The scatterometers’ performance differences were systematically evaluated by comparing them to the Ocean and Sea Ice Satellite Application Facility (OSI SAF), the National Snow and Ice Data Center (NSIDC), Moderate Resolution Imaging Spectroradiometer (MODIS) sea ice extent products, and synthetic aperture radar imagery. The findings show that the FY-3E dual-band approach performed best for ice-water discrimination, with annual mean overall accuracy and Kappa coefficient values of 99.11% and 97.39%, respectively. The results for CFOSAT, FY-3E Ku-band, and FY-3E C-band were all comparable and outperformed HY-2B. The FY-3E dual-band approach achieved the highest accuracy for sea ice type classification during the nonmelting period; using the OSI SAF sea ice type product as a reference, the mean overall accuracy and Kappa coefficient were 97.40% and 92.42%, respectively. Further cross-validation with the NSIDC sea ice age product revealed that the FY-3E dual-band approach performed the best, with an overall accuracy of 87.26% and a Kappa coefficient of 69.65%. CFOSAT, HY-2B, and FY-3E Ku-band all performed well at distinguishing sea ice types, whereas FY-3E C-band alone produced relatively low accuracy. Although different reference datasets affected the absolute accuracy of sea ice type classification, the relative performance of different methods remained consistent, indicating that the FY-3E dual-band results reflect genuine classification rather than merely fitting to the OSI SAF training labels. Overall, the FY-3E dual-band approach showed greater stability and consistency in annual sea ice extent detection and nonmelting-period sea ice type classification, highlighting the complementary benefits of dual-frequency scatterometer observations for polar sea ice monitoring. This study provides a reference for the operational application of Chinese scatterometers and multiband joint sea ice retrieval.
Sea ice is an important indicator of global climate change, and its accurate monitoring is essential for climate research, polar navigation, and marine resource management. Spaceborne microwave scatterometers, with their all-weather, day-and-night, and wide-swath observation capabilities, are critical remote sensing tools for monitoring polar sea ice. In this study, scatterometer observations from three Chinese satellites (HY-2B, CFOSAT, and FY-3E) were used to develop Arctic sea ice extent detection and classification models for first-year and multiyear ice using a support vector machine. All models were created using a unified projection grid, shared sample labels, and a consistent classification framework. Daily sea ice products were generated using observations from March 2022 to February 2023. The scatterometers’ performance differences were systematically evaluated by comparing them to the Ocean and Sea Ice Satellite Application Facility (OSI SAF), the National Snow and Ice Data Center (NSIDC), Moderate Resolution Imaging Spectroradiometer (MODIS) sea ice extent products, and synthetic aperture radar imagery. The findings show that the FY-3E dual-band approach performed best for ice-water discrimination, with annual mean overall accuracy and Kappa coefficient values of 99.11% and 97.39%, respectively. The results for CFOSAT, FY-3E Ku-band, and FY-3E C-band were all comparable and outperformed HY-2B. The FY-3E dual-band approach achieved the highest accuracy for sea ice type classification during the nonmelting period; using the OSI SAF sea ice type product as a reference, the mean overall accuracy and Kappa coefficient were 97.40% and 92.42%, respectively. Further cross-validation with the NSIDC sea ice age product revealed that the FY-3E dual-band approach performed the best, with an overall accuracy of 87.26% and a Kappa coefficient of 69.65%. CFOSAT, HY-2B, and FY-3E Ku-band all performed well at distinguishing sea ice types, whereas FY-3E C-band alone produced relatively low accuracy. Although different reference datasets affected the absolute accuracy of sea ice type classification, the relative performance of different methods remained consistent, indicating that the FY-3E dual-band results reflect genuine classification rather than merely fitting to the OSI SAF training labels. Overall, the FY-3E dual-band approach showed greater stability and consistency in annual sea ice extent detection and nonmelting-period sea ice type classification, highlighting the complementary benefits of dual-frequency scatterometer observations for polar sea ice monitoring. This study provides a reference for the operational application of Chinese scatterometers and multiband joint sea ice retrieval.
The evaluation of the security limits of radar micro-Doppler gait recognition systems under adversarial conditions is of practical significance. Current attack methods, primarily adapted from the optical image domain, do not consider the detailed feature distribution and time-frequency characteristics of micro-Doppler spectrograms. This oversight leads to limited effectiveness in cross-model black-box targeted attack scenarios. To overcome this challenge, we propose Gradient Guidance and Adaptive Cropping Radar Gait Targeted Attack (GAC-Attack), a targeted black-box attack framework for human gait micro-Doppler signatures. To reduce the number of semantic shifts caused by high inter-class similarity and closely distributed features, an inter-class relationship-guided robust gradient optimization mechanism is developed. In addition, an adaptive local cropping mechanism is designed that takes advantage of the concentration of discriminative information in local time-frequency regions, thereby increasing perturbation interference on shared discriminative features across various models. We construct two datasets, one for single-action gait recognition and the other for multi-action identity recognition, and conduct systematic comparative experiments across seven network architectures and seven black-box targeted attack methods. The experimental results show that GAC-Attack improves the targeted attack success rate by approximately 7% and 4% compared to the strongest competing baseline on the gait and identity datasets, respectively, while consistently achieving top performance across most model combinations. These results validate the effectiveness of the proposed framework in complex scenarios and its robustness in cross-model transfer settings.
The evaluation of the security limits of radar micro-Doppler gait recognition systems under adversarial conditions is of practical significance. Current attack methods, primarily adapted from the optical image domain, do not consider the detailed feature distribution and time-frequency characteristics of micro-Doppler spectrograms. This oversight leads to limited effectiveness in cross-model black-box targeted attack scenarios. To overcome this challenge, we propose Gradient Guidance and Adaptive Cropping Radar Gait Targeted Attack (GAC-Attack), a targeted black-box attack framework for human gait micro-Doppler signatures. To reduce the number of semantic shifts caused by high inter-class similarity and closely distributed features, an inter-class relationship-guided robust gradient optimization mechanism is developed. In addition, an adaptive local cropping mechanism is designed that takes advantage of the concentration of discriminative information in local time-frequency regions, thereby increasing perturbation interference on shared discriminative features across various models. We construct two datasets, one for single-action gait recognition and the other for multi-action identity recognition, and conduct systematic comparative experiments across seven network architectures and seven black-box targeted attack methods. The experimental results show that GAC-Attack improves the targeted attack success rate by approximately 7% and 4% compared to the strongest competing baseline on the gait and identity datasets, respectively, while consistently achieving top performance across most model combinations. These results validate the effectiveness of the proposed framework in complex scenarios and its robustness in cross-model transfer settings.
Monitoring of drivers’ cardiac activity enables effective assessment of their physiological and psychological states. However, existing methods such as electrocardiography and remote phontoplethysmograyhy are cumbersome and sensitive to lighting conditions, limiting their applicability in vehicular settings. Despite its high accuracy and noncontact operation, millimeter-wave radar-based heartbeat sensing is inherently vulnerable to interference. To address these issues, this paper exploits the low-frequency characteristics, long-range dynamic sensitivity, and sparsity of Radio-Frequency (RF) signals and designs a self-attention-based RF feature extractor. On this basis, a deep blind source separation network is constructed to separate the driver’s heartbeat-related RF features from in-vehicle interference. Furthermore, to reduce the burden of RF signal acquisition, we introduce a hybrid-source signal generation strategy that synthesizes a large number of mixed and ground-truth source signals using only a small number of seismocardiogram and interference signals. Finally, extensive on-road testing demonstrates that the proposed system achieves a median heart rate error of 4.92 bpm and a median interbeat interval error of 65.93 ms.
Monitoring of drivers’ cardiac activity enables effective assessment of their physiological and psychological states. However, existing methods such as electrocardiography and remote phontoplethysmograyhy are cumbersome and sensitive to lighting conditions, limiting their applicability in vehicular settings. Despite its high accuracy and noncontact operation, millimeter-wave radar-based heartbeat sensing is inherently vulnerable to interference. To address these issues, this paper exploits the low-frequency characteristics, long-range dynamic sensitivity, and sparsity of Radio-Frequency (RF) signals and designs a self-attention-based RF feature extractor. On this basis, a deep blind source separation network is constructed to separate the driver’s heartbeat-related RF features from in-vehicle interference. Furthermore, to reduce the burden of RF signal acquisition, we introduce a hybrid-source signal generation strategy that synthesizes a large number of mixed and ground-truth source signals using only a small number of seismocardiogram and interference signals. Finally, extensive on-road testing demonstrates that the proposed system achieves a median heart rate error of 4.92 bpm and a median interbeat interval error of 65.93 ms.
Through-wall human target localization has broad application prospects in fields such as target perception and rescue. However, ultra-wideband through-wall radar systems suffer from wall clutter interference, which distorts target echo features and complicates the ability of traditional methods to achieve stable detection and high-precision localization in complex environments. Although deep learning-based localization methods have shown superior performance in these environments, they often rely on distributed radar layouts, leading to difficulties in system deployment and increased algorithm complexity. To address these challenges, this study introduces a deep learning network framework that utilizes a single-view small-aperture dual-transmitter quad-receiver ultra-wideband through-wall radar. This framework combines Dual-Stream Temporal Spatial (DSTS) feature extraction with a DEtection TRansformer (DETR) to accurately locate human targets behind walls. The network processes complex-range images as input, extracts spatiotemporal features, and constructs dual streams. The phase branch captures the target’s spatial angular information, and the amplitude branch reflects the target’s radial distance, thereby fully exploiting the distance and azimuth features in the echoes. The dual streams then undergo multi-scale downsampling, and a channel attention mechanism is employed for weighted fusion, yielding low-dimensional features. These features are then enhanced with positional encoding and fed into the DETR network, which utilizes its set-prediction capabilities to deliver reliable target localization results. Validation on measured data demonstrates that the proposed method achieves an average precision of 0.79, with a threshold for accurate multi-object localization set at 0.7 m, thus outperforming several existing solutions.
Through-wall human target localization has broad application prospects in fields such as target perception and rescue. However, ultra-wideband through-wall radar systems suffer from wall clutter interference, which distorts target echo features and complicates the ability of traditional methods to achieve stable detection and high-precision localization in complex environments. Although deep learning-based localization methods have shown superior performance in these environments, they often rely on distributed radar layouts, leading to difficulties in system deployment and increased algorithm complexity. To address these challenges, this study introduces a deep learning network framework that utilizes a single-view small-aperture dual-transmitter quad-receiver ultra-wideband through-wall radar. This framework combines Dual-Stream Temporal Spatial (DSTS) feature extraction with a DEtection TRansformer (DETR) to accurately locate human targets behind walls. The network processes complex-range images as input, extracts spatiotemporal features, and constructs dual streams. The phase branch captures the target’s spatial angular information, and the amplitude branch reflects the target’s radial distance, thereby fully exploiting the distance and azimuth features in the echoes. The dual streams then undergo multi-scale downsampling, and a channel attention mechanism is employed for weighted fusion, yielding low-dimensional features. These features are then enhanced with positional encoding and fed into the DETR network, which utilizes its set-prediction capabilities to deliver reliable target localization results. Validation on measured data demonstrates that the proposed method achieves an average precision of 0.79, with a threshold for accurate multi-object localization set at 0.7 m, thus outperforming several existing solutions.
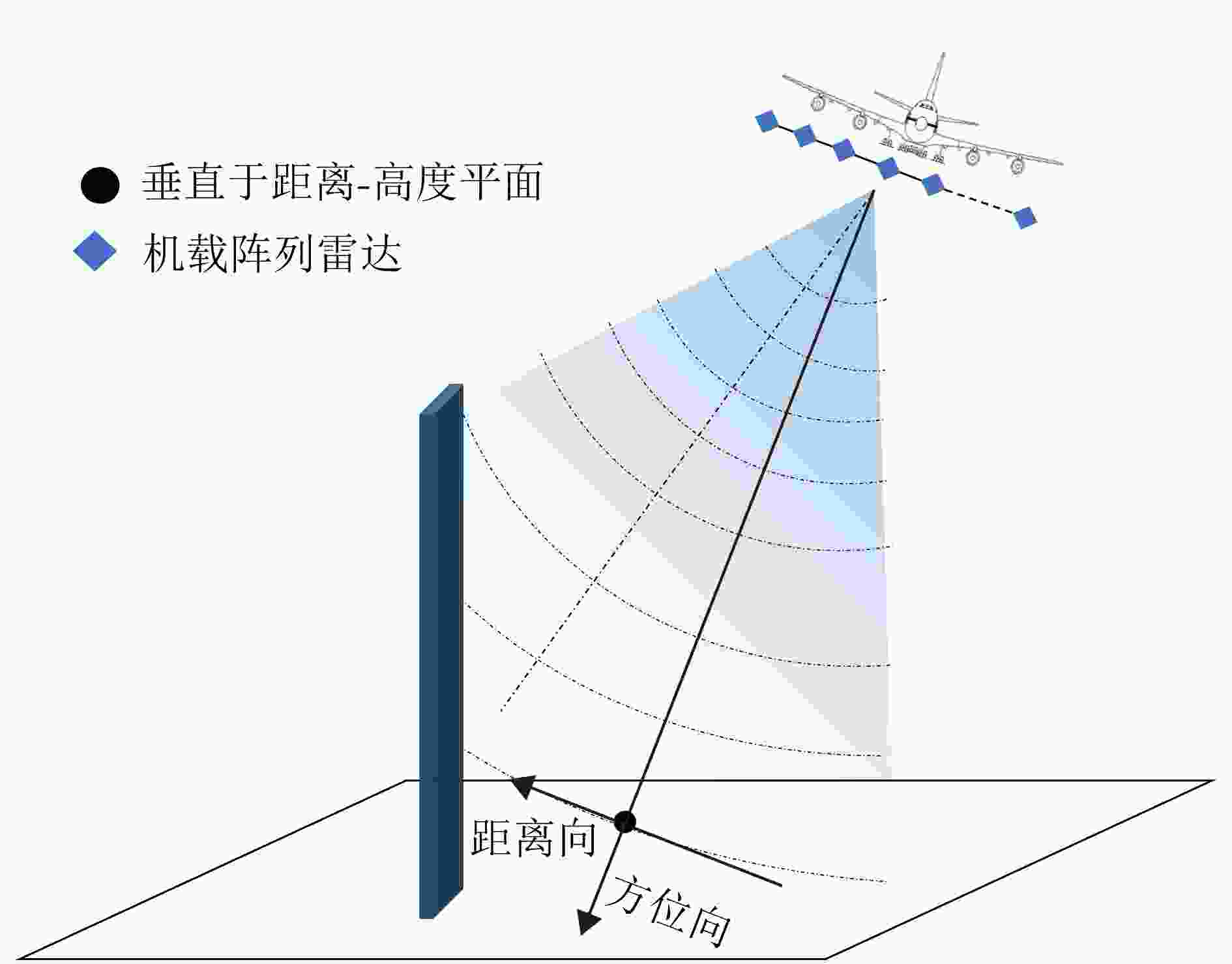
In space situational awareness systems, accurate detection of high-dynamic weak targets is critical. However, the rapid relative motion between the target and radar causes migration across range and Doppler cells. Moreover, the high computational complexity of traditional compensation algorithms hampers existing hardware platforms in meeting real-time processing demands. To address these challenges, we propose a hierarchical detection algorithm for highly dynamic weak targets paired with a corresponding field programmable gate array acceleration architecture. At the algorithmic level, we develop a cascaded processing strategy that leverages the short-term motion characteristics of the target and the parameter decoupling advantages of the Lv’s Distribution (LVD). This strategy combines coarse estimation through the reduced-dimension Radon-LVD (RLVD) with local fine-search compensation, effectively reducing computational complexity while preserving coherent integration gain. At the hardware level, an end-to-end real-time processing system is designed, centered around an 8-channel parallel RLVD computation kernel. Experimental results demonstrate that operating under a 200 MHz system clock, the system achieves real-time processing of 4-channel, single-frame 32 × 8192 echo data within an 8.41 ms full-pipeline latency. Core parameter estimation exhibits minor deviations compared to the floating-point model, with a maximum 3D positioning quantization deviation of 1.220 m. In addition, we validate the engineering feasibility of the proposed architecture in practical detection scenarios using real-measured data from a ground-based radar.
In space situational awareness systems, accurate detection of high-dynamic weak targets is critical. However, the rapid relative motion between the target and radar causes migration across range and Doppler cells. Moreover, the high computational complexity of traditional compensation algorithms hampers existing hardware platforms in meeting real-time processing demands. To address these challenges, we propose a hierarchical detection algorithm for highly dynamic weak targets paired with a corresponding field programmable gate array acceleration architecture. At the algorithmic level, we develop a cascaded processing strategy that leverages the short-term motion characteristics of the target and the parameter decoupling advantages of the Lv’s Distribution (LVD). This strategy combines coarse estimation through the reduced-dimension Radon-LVD (RLVD) with local fine-search compensation, effectively reducing computational complexity while preserving coherent integration gain. At the hardware level, an end-to-end real-time processing system is designed, centered around an 8-channel parallel RLVD computation kernel. Experimental results demonstrate that operating under a 200 MHz system clock, the system achieves real-time processing of 4-channel, single-frame 32 × 8192 echo data within an 8.41 ms full-pipeline latency. Core parameter estimation exhibits minor deviations compared to the floating-point model, with a maximum 3D positioning quantization deviation of 1.220 m. In addition, we validate the engineering feasibility of the proposed architecture in practical detection scenarios using real-measured data from a ground-based radar.
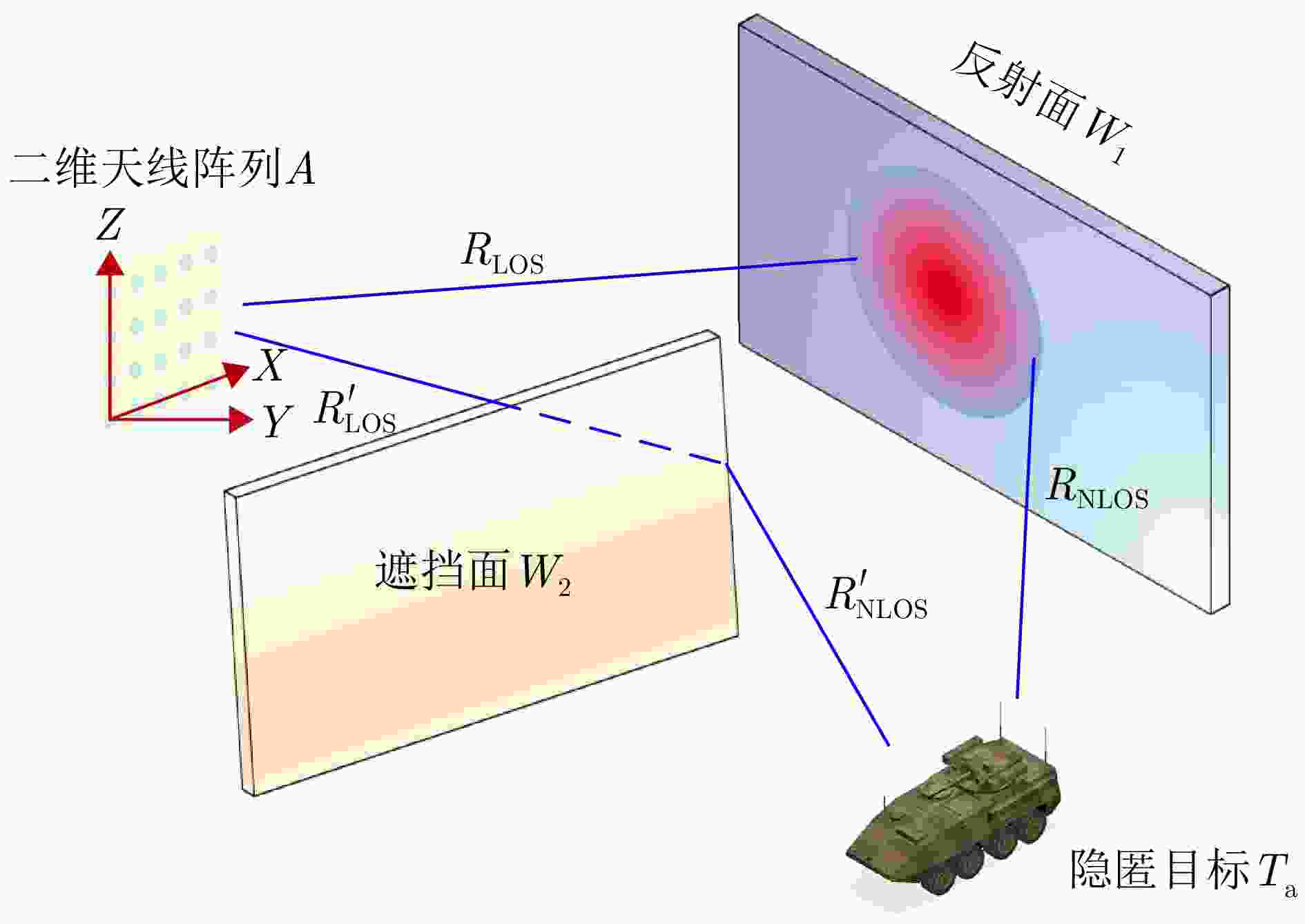
Non-Line-of-Sight (NLOS) human activity recognition using multipath-assisted radar has significant potential applications in urban warfare, autonomous driving, and emergency rescue. Existing studies typically rely on supervised deep learning frameworks, which require large labeled datasets and exhibit limited robustness to noise. To address these limitations, this study treats different propagation paths as multiview observational channels. Through path separation and Time-Frequency (T-F) analysis, we construct equivalent multiview T-F spectrograms of human activities. Furthermore, we propose a multipath physics-embedded contrastive network (MuPhyCoNet). In this framework, multiview spectrograms from different propagation paths serve as inherent positive pairs for contrastive learning, enabling the model to extract discriminative features without extensive manual labeling. Moreover, we introduce two categories of physical constraints—observational and predictive, together with a physical consistency loss. The observational constraints compute physical divergence directly from the raw spectrograms, while the predictive constraints align the physical parameters regressed by the projection head with their observed counterparts to verify the learned physical characteristics. The integration of both constraints enhances the model’s robustness to noise and modeling errors while preserving high discriminative capability. We evaluate the proposed method on a self-collected NLOS human activity dataset (comprising 6 action classes and 19,500 spectrograms) acquired using an ultrawideband stepped-frequency continuous wave radar, following a “self-supervised pretraining + downstream classifier” strategy. Experimental results demonstrate that MuPhyCoNet achieves a classification accuracy of 94.32% with only 10% labeling data, outperforming MoCo v2 (72.19%) by 22.13 percentage points while exhibiting superior noise robustness.
Non-Line-of-Sight (NLOS) human activity recognition using multipath-assisted radar has significant potential applications in urban warfare, autonomous driving, and emergency rescue. Existing studies typically rely on supervised deep learning frameworks, which require large labeled datasets and exhibit limited robustness to noise. To address these limitations, this study treats different propagation paths as multiview observational channels. Through path separation and Time-Frequency (T-F) analysis, we construct equivalent multiview T-F spectrograms of human activities. Furthermore, we propose a multipath physics-embedded contrastive network (MuPhyCoNet). In this framework, multiview spectrograms from different propagation paths serve as inherent positive pairs for contrastive learning, enabling the model to extract discriminative features without extensive manual labeling. Moreover, we introduce two categories of physical constraints—observational and predictive, together with a physical consistency loss. The observational constraints compute physical divergence directly from the raw spectrograms, while the predictive constraints align the physical parameters regressed by the projection head with their observed counterparts to verify the learned physical characteristics. The integration of both constraints enhances the model’s robustness to noise and modeling errors while preserving high discriminative capability. We evaluate the proposed method on a self-collected NLOS human activity dataset (comprising 6 action classes and 19,500 spectrograms) acquired using an ultrawideband stepped-frequency continuous wave radar, following a “self-supervised pretraining + downstream classifier” strategy. Experimental results demonstrate that MuPhyCoNet achieves a classification accuracy of 94.32% with only 10% labeling data, outperforming MoCo v2 (72.19%) by 22.13 percentage points while exhibiting superior noise robustness.
Random Frequency and Pulse interval Agile (RFPA) radars can achieve high range resolution using a synthesized wide bandwidth. However, Range Cell Migration (RCM) occurs for moving targets during long coherent integration, and the inherent randomly fluctuating high sidelobes pose a significant challenge for RFPA radars. To address these issues and enhance target detection and estimation performance, a Windowed Iterative Adaptive Approach based on the Non-Uniform Keystone Transform (NUKT-WIAA) is proposed. First, a NUKT is employed to correct the RCM caused by moving targets, effectively concentrating most of the target energy. An IAA is then applied to the NUKT results within a rectangular processing window centered on each range-Doppler cell to achieve fast sidelobe suppression of RFPA signals. A strong scatterer selection strategy is implemented during iterations to enhance the computational efficiency of the covariance matrix, thereby reducing the overall computational complexity of the proposed algorithm. Simulation results reveal that NUKT-WIAA can simultaneously achieve migration correction and sidelobe suppression for moving targets across various scenarios, multiple point targets, range-spread targets, and environments with continuous strong clutter while maintaining low computational complexity and memory usage.
Random Frequency and Pulse interval Agile (RFPA) radars can achieve high range resolution using a synthesized wide bandwidth. However, Range Cell Migration (RCM) occurs for moving targets during long coherent integration, and the inherent randomly fluctuating high sidelobes pose a significant challenge for RFPA radars. To address these issues and enhance target detection and estimation performance, a Windowed Iterative Adaptive Approach based on the Non-Uniform Keystone Transform (NUKT-WIAA) is proposed. First, a NUKT is employed to correct the RCM caused by moving targets, effectively concentrating most of the target energy. An IAA is then applied to the NUKT results within a rectangular processing window centered on each range-Doppler cell to achieve fast sidelobe suppression of RFPA signals. A strong scatterer selection strategy is implemented during iterations to enhance the computational efficiency of the covariance matrix, thereby reducing the overall computational complexity of the proposed algorithm. Simulation results reveal that NUKT-WIAA can simultaneously achieve migration correction and sidelobe suppression for moving targets across various scenarios, multiple point targets, range-spread targets, and environments with continuous strong clutter while maintaining low computational complexity and memory usage.
Low-altitude perception technology aims to transform the physical space of low-altitude targets and environments into a computable digital space, providing a foundation for the safe and organized development of low-altitude economic activities. This paper systematically examines the current progress and challenges of technologies such as large-scale visual perception, object detection, and environmental sensing in low-altitude scenarios. To address these challenges, we introduce a low-altitude active perception network based on the digital retina featuring a collaborative architecture that integrates end, edge, and cloud computing. The key mechanisms and methods are outlined across various aspects, including the overall network structure, cloud-based foundation models, and end-based object and environmental perception technologies. Early applications and experimental results confirm the effectiveness of the proposed network in enabling efficient joint perception under bandwidth limitations.
Low-altitude perception technology aims to transform the physical space of low-altitude targets and environments into a computable digital space, providing a foundation for the safe and organized development of low-altitude economic activities. This paper systematically examines the current progress and challenges of technologies such as large-scale visual perception, object detection, and environmental sensing in low-altitude scenarios. To address these challenges, we introduce a low-altitude active perception network based on the digital retina featuring a collaborative architecture that integrates end, edge, and cloud computing. The key mechanisms and methods are outlined across various aspects, including the overall network structure, cloud-based foundation models, and end-based object and environmental perception technologies. Early applications and experimental results confirm the effectiveness of the proposed network in enabling efficient joint perception under bandwidth limitations.
,
The threat from low-altitude targets to airspace security such as airport is increasing, making accurate detection and recognition essential for radar systems. High-quality measured radar datasets are crucial for advancing low-altitude target recognition. However, most existing public radar datasets for these targets consist of simulation data or short-range collected data, which have difficulty accurately reflecting and verifying radar target recognition performance in long-range scenarios. To overcome these limitations, this study creates a low-altitude target detection and recognition dataset based on Holographic Staring Radar (HSR), including measured data collection and recognition validation for typical low-altitude targets in outdoor environments. The dataset includes common targets such as multirotor unmanned aerial vehicles, sparrows, and large migratory birds, along with representative motion scenarios like hovering, circling, and radial flight. It also offers synchronized target micro-Doppler waterfall plots and radar-measured track information (including azimuth and elevation angles, radial velocity, and normalized signal-to-noise ratio), providing a data foundation for exploring the intrinsic link between target detailed features and motion states. Building on this, a multimodal adaptive feature fusion network is developed to extract and combine Doppler and kinematic features from different targets, demonstrating the dataset’s effectiveness in distinguishing various low-altitude targets.
The threat from low-altitude targets to airspace security such as airport is increasing, making accurate detection and recognition essential for radar systems. High-quality measured radar datasets are crucial for advancing low-altitude target recognition. However, most existing public radar datasets for these targets consist of simulation data or short-range collected data, which have difficulty accurately reflecting and verifying radar target recognition performance in long-range scenarios. To overcome these limitations, this study creates a low-altitude target detection and recognition dataset based on Holographic Staring Radar (HSR), including measured data collection and recognition validation for typical low-altitude targets in outdoor environments. The dataset includes common targets such as multirotor unmanned aerial vehicles, sparrows, and large migratory birds, along with representative motion scenarios like hovering, circling, and radial flight. It also offers synchronized target micro-Doppler waterfall plots and radar-measured track information (including azimuth and elevation angles, radial velocity, and normalized signal-to-noise ratio), providing a data foundation for exploring the intrinsic link between target detailed features and motion states. Building on this, a multimodal adaptive feature fusion network is developed to extract and combine Doppler and kinematic features from different targets, demonstrating the dataset’s effectiveness in distinguishing various low-altitude targets.
With the rapid aging of the population, the rising demand for home-based care and chronic disease monitoring in older adults has increased interest in radar-based technologies for indoor human trajectory tracking and vital sign detection. Existing studies mainly use Multiple-Input Multiple-Output (MIMO) systems, which face limitations such as low Signal-to-Noise Ratio (SNR) and data redundancy. In contrast, phased array radars offer better sensing reliability in complex indoor environments, thanks to higher SNR and lower data volume. However, current indoor sensing systems encounter two main challenges when applying phased array radars. First, traditional beam scheduling strategies often lose targets when tracking close-range, highly maneuverable humans. Second, achieving simultaneous trajectory tracking and real-time vital sign detection remains difficult without adaptive switching mechanisms based on target movement. To address these issues, this paper first compares MIMO and phased array radars, along with the average revisit time of different beam-scheduling strategies for tracking indoor human movements. It also proposes an adaptive real-time monitoring system for human motion states based on phased array radar. This system dynamically switches modes based on human movement: during motion, it employs a strategy combining coarse scanning, adaptive fine scanning, and sum-and-difference beam angle measurement for real-time trajectory tracking; when stationary, it shifts to a vital sign monitoring mode to capture respiration and heartbeat signals. Experimental results show that the proposed system provides stable indoor trajectory tracking and reliable vital sign monitoring, laying the groundwork for home-based smart health monitoring systems.
With the rapid aging of the population, the rising demand for home-based care and chronic disease monitoring in older adults has increased interest in radar-based technologies for indoor human trajectory tracking and vital sign detection. Existing studies mainly use Multiple-Input Multiple-Output (MIMO) systems, which face limitations such as low Signal-to-Noise Ratio (SNR) and data redundancy. In contrast, phased array radars offer better sensing reliability in complex indoor environments, thanks to higher SNR and lower data volume. However, current indoor sensing systems encounter two main challenges when applying phased array radars. First, traditional beam scheduling strategies often lose targets when tracking close-range, highly maneuverable humans. Second, achieving simultaneous trajectory tracking and real-time vital sign detection remains difficult without adaptive switching mechanisms based on target movement. To address these issues, this paper first compares MIMO and phased array radars, along with the average revisit time of different beam-scheduling strategies for tracking indoor human movements. It also proposes an adaptive real-time monitoring system for human motion states based on phased array radar. This system dynamically switches modes based on human movement: during motion, it employs a strategy combining coarse scanning, adaptive fine scanning, and sum-and-difference beam angle measurement for real-time trajectory tracking; when stationary, it shifts to a vital sign monitoring mode to capture respiration and heartbeat signals. Experimental results show that the proposed system provides stable indoor trajectory tracking and reliable vital sign monitoring, laying the groundwork for home-based smart health monitoring systems.
Time-domain digital coding metasurfaces can reconstruct electromagnetic scattering spectra by temporally modulating the scattering states of constituent elements. This study investigates the scattering-spectrum characteristics of two typical modulation schemes, namely random modulation and periodic modulation, under finite-window discrete coding conditions. For random modulation, an analytical decomposition of the average energy spectrum into coherent and background terms is derived, and the effects of the statistical moments of the coding sequence on zero-frequency suppression and spectral spreading are clarified. For periodic modulation, the mapping between the Fourier coefficients of the modulation template and the energy allocation among harmonic orders is established, revealing the mechanism of harmonic energy reconstruction. Furthermore, incorporating full-wave simulated unit parameters enables analysis of performance variations in scattering-spectrum control under nonideal conditions.
Time-domain digital coding metasurfaces can reconstruct electromagnetic scattering spectra by temporally modulating the scattering states of constituent elements. This study investigates the scattering-spectrum characteristics of two typical modulation schemes, namely random modulation and periodic modulation, under finite-window discrete coding conditions. For random modulation, an analytical decomposition of the average energy spectrum into coherent and background terms is derived, and the effects of the statistical moments of the coding sequence on zero-frequency suppression and spectral spreading are clarified. For periodic modulation, the mapping between the Fourier coefficients of the modulation template and the energy allocation among harmonic orders is established, revealing the mechanism of harmonic energy reconstruction. Furthermore, incorporating full-wave simulated unit parameters enables analysis of performance variations in scattering-spectrum control under nonideal conditions.
Human pose estimation allows for precise capture of movement and behavioral traits, holding significant potential for applications such as intelligent surveillance, human-computer interaction, and health monitoring. Among emerging approaches, Wi-Fi sensing has gained increasing research interest for contactless human pose detection because of its widespread availability, affordability, and privacy-preserving qualities. However, human activities are multiscale, nonlinear, and highly dynamic, with notable spatiotemporal variations in motion amplitude across different body parts. These characteristics pose high demands on the ability of algorithms to model multiscale features effectively. Current Wi-Fi-based techniques often struggle with excessive parameter complexity and limited feature extraction, which makes it hard to balance computational speed with accuracy in complex situations. To address these issues, this paper introduces a pyramid dilated convolution block that expands the receptive field while maintaining spatial resolution, making it possible to capture multiscale spatial and dynamic details efficiently. The dilated design also lessens computational redundancy, improving overall efficiency. Building on this, a residual network is designed to prevent gradient vanishing and model degradation, ensuring solid feature representation in deep networks. To test the proposed method, a comprehensive multisource data system was built to synchronize Wi-Fi pose data with ground-truth labels. Experimental results show the proposed approach’s superiority, reaching a mean percentage of correct keypoints (MPCK@0.10) of 94.96%, surpassing current leading algorithms. These results confirm the method’s effectiveness for reliable and efficient human pose estimation.
Human pose estimation allows for precise capture of movement and behavioral traits, holding significant potential for applications such as intelligent surveillance, human-computer interaction, and health monitoring. Among emerging approaches, Wi-Fi sensing has gained increasing research interest for contactless human pose detection because of its widespread availability, affordability, and privacy-preserving qualities. However, human activities are multiscale, nonlinear, and highly dynamic, with notable spatiotemporal variations in motion amplitude across different body parts. These characteristics pose high demands on the ability of algorithms to model multiscale features effectively. Current Wi-Fi-based techniques often struggle with excessive parameter complexity and limited feature extraction, which makes it hard to balance computational speed with accuracy in complex situations. To address these issues, this paper introduces a pyramid dilated convolution block that expands the receptive field while maintaining spatial resolution, making it possible to capture multiscale spatial and dynamic details efficiently. The dilated design also lessens computational redundancy, improving overall efficiency. Building on this, a residual network is designed to prevent gradient vanishing and model degradation, ensuring solid feature representation in deep networks. To test the proposed method, a comprehensive multisource data system was built to synchronize Wi-Fi pose data with ground-truth labels. Experimental results show the proposed approach’s superiority, reaching a mean percentage of correct keypoints (MPCK@0.10) of 94.96%, surpassing current leading algorithms. These results confirm the method’s effectiveness for reliable and efficient human pose estimation.
Synthetic Aperture Radar (SAR) is a remote sensing technology that utilizes the principle of synthetic aperture to achieve high-resolution microwave imaging. SAR image colorization is a fundamental and crucial task in remote sensing. Unlike optical imaging, SAR imaging is unaffected by clouds and fog, enabling all-weather observation of the Earth. However, owing to its imaging principle, SAR images are grayscale images; hence, they lack spectral information and have extremely low visual clarity. Therefore, numerous studies have focused on enhancing the interpretability of SAR images by incorporating color information. This paper reviews existing SAR image colorization techniques and categorizes them into three types: Traditional SAR image colorization techniques, deep-learning-based SAR-to-Optical image colorization techniques, and SAR image colorization techniques based on radiometric property preservation. Finally, we summarize the application scenarios and future development directions.
Synthetic Aperture Radar (SAR) is a remote sensing technology that utilizes the principle of synthetic aperture to achieve high-resolution microwave imaging. SAR image colorization is a fundamental and crucial task in remote sensing. Unlike optical imaging, SAR imaging is unaffected by clouds and fog, enabling all-weather observation of the Earth. However, owing to its imaging principle, SAR images are grayscale images; hence, they lack spectral information and have extremely low visual clarity. Therefore, numerous studies have focused on enhancing the interpretability of SAR images by incorporating color information. This paper reviews existing SAR image colorization techniques and categorizes them into three types: Traditional SAR image colorization techniques, deep-learning-based SAR-to-Optical image colorization techniques, and SAR image colorization techniques based on radiometric property preservation. Finally, we summarize the application scenarios and future development directions.
Here, we propose a design method for a 2-bit transmissive programmable metasurface and demonstrate the generation and dynamic control of multimode electromagnetic vortex beams. By adjusting the states of the loaded PIN diodes, the metasurface element achieves high-efficiency transmission with an insertion loss as low as 1.2 dB and precise 2-bit tunable phase control at a center frequency of 4.15 GHz. The coding schemes necessary for generating steerable vortex beams are then theoretically derived. To validate the design principle and simulation results, a metasurface prototype is fabricated. Near-field scanning measurements show that the proposed metasurface can dynamically generate vortex beams with various modes, exhibiting distinct spiral phase characteristics and annular amplitude distributions, with the mode purity of the dominant mode remaining above 0.88 for orders within ±2 at the center frequency. Far-field radiation pattern measurements further confirm that the generated vortex beams can be dynamically scanned within 0°~45°, with a scan loss of less than 3 dB. The results measured align well with the simulations. The proposed programmable metasurface for vortex beam control demonstrates strong potential for applications in radar imaging and wireless communication.
Here, we propose a design method for a 2-bit transmissive programmable metasurface and demonstrate the generation and dynamic control of multimode electromagnetic vortex beams. By adjusting the states of the loaded PIN diodes, the metasurface element achieves high-efficiency transmission with an insertion loss as low as 1.2 dB and precise 2-bit tunable phase control at a center frequency of 4.15 GHz. The coding schemes necessary for generating steerable vortex beams are then theoretically derived. To validate the design principle and simulation results, a metasurface prototype is fabricated. Near-field scanning measurements show that the proposed metasurface can dynamically generate vortex beams with various modes, exhibiting distinct spiral phase characteristics and annular amplitude distributions, with the mode purity of the dominant mode remaining above 0.88 for orders within ±2 at the center frequency. Far-field radiation pattern measurements further confirm that the generated vortex beams can be dynamically scanned within 0°~45°, with a scan loss of less than 3 dB. The results measured align well with the simulations. The proposed programmable metasurface for vortex beam control demonstrates strong potential for applications in radar imaging and wireless communication.
Current photonic-assisted Integrated Sensing And Communication (ISAC) systems face significant challenges under low Signal-to-Noise Ratio (SNR) and high-dynamic conditions, such as those in low Earth orbit satellite networks. To address these issues, this study proposes a novel photonic-assisted Doppler-robust ISAC system based on multislope division multiplexing. A Slope Division Multiplexed Frequency Shift Keying-Linear Frequency Modulation (SDM-FSK-LFM) waveform is designed by multiplexing LFM subcarriers with distinct chirp rates. This design is combined with successive interference cancellation to achieve high spreading gain while substantially increasing the communication data rate. A photonic-assisted ISAC transceiver utilizing an optical frequency comb local oscillator is developed for high-frequency signal generation and optical-domain dechirping processing. Experimental results show successful generation of a 10-subcarrier SDM-FSK-LFM signal in the Ku-band with an instantaneous bandwidth of 1.536 GHz. In sensing, the system achieved a superresolution ranging accuracy of 0.05 m. In communication, a back-to-back data rate of 95.86 Mbps was realized, with seven subcarriers maintaining a Bit Error Rate (BER) <10−4 at 0 dB SNR and five subcarriers sustaining a BER <10−5 under a Doppler shift of 200 kHz. The proposed system demonstrates good noise resistance and Doppler robustness, offering a viable solution for ISAC applications under high-dynamic scenarios.
Current photonic-assisted Integrated Sensing And Communication (ISAC) systems face significant challenges under low Signal-to-Noise Ratio (SNR) and high-dynamic conditions, such as those in low Earth orbit satellite networks. To address these issues, this study proposes a novel photonic-assisted Doppler-robust ISAC system based on multislope division multiplexing. A Slope Division Multiplexed Frequency Shift Keying-Linear Frequency Modulation (SDM-FSK-LFM) waveform is designed by multiplexing LFM subcarriers with distinct chirp rates. This design is combined with successive interference cancellation to achieve high spreading gain while substantially increasing the communication data rate. A photonic-assisted ISAC transceiver utilizing an optical frequency comb local oscillator is developed for high-frequency signal generation and optical-domain dechirping processing. Experimental results show successful generation of a 10-subcarrier SDM-FSK-LFM signal in the Ku-band with an instantaneous bandwidth of 1.536 GHz. In sensing, the system achieved a superresolution ranging accuracy of 0.05 m. In communication, a back-to-back data rate of 95.86 Mbps was realized, with seven subcarriers maintaining a Bit Error Rate (BER) <10−4 at 0 dB SNR and five subcarriers sustaining a BER <10−5 under a Doppler shift of 200 kHz. The proposed system demonstrates good noise resistance and Doppler robustness, offering a viable solution for ISAC applications under high-dynamic scenarios.
The characteristics of phased-array radars—including flexible beam scanning, rapid multimode switching, and parameter agility—pose challenges to traditional radar signal analysis methods based on parameter clustering, causing feature parameter instability and parameter space overlap. To address these issues, this paper analyzes phased-array radar signals from the perspective of beam position partitioning. In particular, we reconstruct pulse subsequences corresponding to distinct beam positions from mixed pulse streams and an innovative expert-knowledge and hybrid-reinforcement-learning framework is proposed. This framework first performs preliminary partitioning using dynamic pulse amplitude thresholds. It subsequently feeds the preliminary results into a human-in-the-loop reinforcement-learning environment by integrating expert knowledge guidance with confidence assessment to ultimately achieve fine-grained beam position partitioning. Experimental results obtained using simulated datasets demonstrate that the proposed framework achieves a partitioning precision of 92.7%, indicating excellent calibration of the confidence assessment model. This work provides an effective technical pathway for human–machine collaboration in solving complex electromagnetic signal processing problems.
The characteristics of phased-array radars—including flexible beam scanning, rapid multimode switching, and parameter agility—pose challenges to traditional radar signal analysis methods based on parameter clustering, causing feature parameter instability and parameter space overlap. To address these issues, this paper analyzes phased-array radar signals from the perspective of beam position partitioning. In particular, we reconstruct pulse subsequences corresponding to distinct beam positions from mixed pulse streams and an innovative expert-knowledge and hybrid-reinforcement-learning framework is proposed. This framework first performs preliminary partitioning using dynamic pulse amplitude thresholds. It subsequently feeds the preliminary results into a human-in-the-loop reinforcement-learning environment by integrating expert knowledge guidance with confidence assessment to ultimately achieve fine-grained beam position partitioning. Experimental results obtained using simulated datasets demonstrate that the proposed framework achieves a partitioning precision of 92.7%, indicating excellent calibration of the confidence assessment model. This work provides an effective technical pathway for human–machine collaboration in solving complex electromagnetic signal processing problems.
Vortex electromagnetic waves have proven highly effective for moving-target detection due to their distinctive wavefront phase distribution. Accurate estimation of translational and rotational Doppler shifts is essential for high-precision measurement of motion parameters. Existing methods typically rely on transmitting multiple modes of vortex electromagnetic waves, and they often require additional prior information to resolve Doppler ambiguities for high-speed targets, and the separation accuracy of translational and rotational Doppler components is limited. To address these challenges, this work proposes a single mode vortex electromagnetic wave-based Doppler separation method combined with Adaptive Piece-Wise Sparse Representation (APWSR) for high-precision instantaneous frequency estimation. Using the Doppler compression technique, translational and rotational Doppler components can be effectively separated using only a single mode, while APWSR enables high-precision instantaneous frequency estimation. From these results, the translational velocity, rotation radius, rotational frequency, and Euler angles of the target are extracted. Simulations validate the effectiveness and robustness of the proposed method, demonstrating that it outperforms existing dual-mode approaches in Doppler frequency and motion parameter estimation.
Vortex electromagnetic waves have proven highly effective for moving-target detection due to their distinctive wavefront phase distribution. Accurate estimation of translational and rotational Doppler shifts is essential for high-precision measurement of motion parameters. Existing methods typically rely on transmitting multiple modes of vortex electromagnetic waves, and they often require additional prior information to resolve Doppler ambiguities for high-speed targets, and the separation accuracy of translational and rotational Doppler components is limited. To address these challenges, this work proposes a single mode vortex electromagnetic wave-based Doppler separation method combined with Adaptive Piece-Wise Sparse Representation (APWSR) for high-precision instantaneous frequency estimation. Using the Doppler compression technique, translational and rotational Doppler components can be effectively separated using only a single mode, while APWSR enables high-precision instantaneous frequency estimation. From these results, the translational velocity, rotation radius, rotational frequency, and Euler angles of the target are extracted. Simulations validate the effectiveness and robustness of the proposed method, demonstrating that it outperforms existing dual-mode approaches in Doppler frequency and motion parameter estimation.
Multiband fusion technology is essential for enhancing radar image resolution by overcoming the hardware bandwidth limits of radar systems. Compared with nonparametric approaches, parametric methods based on scattering models offer notable advantages in noise suppression and super-resolution imaging. However, models based on the Geometric Theory of Diffraction (GTD) are inherently limited for analyzing scatterers with continuous structures, as GTD is an asymptotic high-frequency method suited primarily for discrete scattering centers. Consequently, it fails to adequately characterize the frequency response of such continuous scatterers. To address this issue, a multiband fusion method tailored for targets that can be sparsely represented by strong scattering centers is proposed. First, a Simplified Attributed Scattering Center (SASC) model is constructed, which improves the characterization of scattering properties by incorporating the influence of the scatterer length on the frequency spectrum. Second, to address the model order estimation problem, a modified maximum singular value difference criterion is introduced to robustly estimate the model order. Building on this, a generalized RELAX-based algorithm is designed to achieve high-precision parameter estimation for the SASC model, thereby enabling effective fusion of multiband signals. Experimental results demonstrate that the proposed algorithm achieves a 6.7-fold improvement in resolution relative to the single sub-band case, while preserving the clarity and integrity of the target structure.
Multiband fusion technology is essential for enhancing radar image resolution by overcoming the hardware bandwidth limits of radar systems. Compared with nonparametric approaches, parametric methods based on scattering models offer notable advantages in noise suppression and super-resolution imaging. However, models based on the Geometric Theory of Diffraction (GTD) are inherently limited for analyzing scatterers with continuous structures, as GTD is an asymptotic high-frequency method suited primarily for discrete scattering centers. Consequently, it fails to adequately characterize the frequency response of such continuous scatterers. To address this issue, a multiband fusion method tailored for targets that can be sparsely represented by strong scattering centers is proposed. First, a Simplified Attributed Scattering Center (SASC) model is constructed, which improves the characterization of scattering properties by incorporating the influence of the scatterer length on the frequency spectrum. Second, to address the model order estimation problem, a modified maximum singular value difference criterion is introduced to robustly estimate the model order. Building on this, a generalized RELAX-based algorithm is designed to achieve high-precision parameter estimation for the SASC model, thereby enabling effective fusion of multiband signals. Experimental results demonstrate that the proposed algorithm achieves a 6.7-fold improvement in resolution relative to the single sub-band case, while preserving the clarity and integrity of the target structure.
Tropospheric delay is a major error source in Interferometric Synthetic Aperture Radar (InSAR) and significantly limits its ability to retrieve accurate surface displacements, particularly in regions with complex topography or strong atmospheric heterogeneity. Existing correction methods are constrained by either the coarse resolution of external data or their inability to model deformation-elevation coupling and complex turbulent effects. To address these challenges, this paper proposes a tropospheric correction method based on a spatially adaptive anchor network. A Comprehensive Quality Index (CQI), combining phase stability and temporal coherence, is used along with an iterative spatial selection strategy to construct a quality-driven anchor network. Within each anchor neighborhood, a local joint inversion model is developed to effectively separate deformation, topographic residuals, and tropospheric delay. Additionally, a Local Turbulence Intensity (LTI) factor is introduced to suppress error propagation from high-turbulence regions during interpolation. Validation using Sentinel-1 data from Hawaii and the Qinghai-Tibet Plateau demonstrates that the proposed method reduces the interferogram phase standard deviation by more than 73%, outperforming conventional methods. The root mean square error between InSAR and GPS time-series displacements decreases from 44.4 to 9.3 mm after correction, representing a 79% improvement in consistency. The proposed method effectively mitigates tropospheric delay, enhances the accuracy of InSAR measurements, and improves the reliability of deformation monitoring across diverse terrain conditions.
Tropospheric delay is a major error source in Interferometric Synthetic Aperture Radar (InSAR) and significantly limits its ability to retrieve accurate surface displacements, particularly in regions with complex topography or strong atmospheric heterogeneity. Existing correction methods are constrained by either the coarse resolution of external data or their inability to model deformation-elevation coupling and complex turbulent effects. To address these challenges, this paper proposes a tropospheric correction method based on a spatially adaptive anchor network. A Comprehensive Quality Index (CQI), combining phase stability and temporal coherence, is used along with an iterative spatial selection strategy to construct a quality-driven anchor network. Within each anchor neighborhood, a local joint inversion model is developed to effectively separate deformation, topographic residuals, and tropospheric delay. Additionally, a Local Turbulence Intensity (LTI) factor is introduced to suppress error propagation from high-turbulence regions during interpolation. Validation using Sentinel-1 data from Hawaii and the Qinghai-Tibet Plateau demonstrates that the proposed method reduces the interferogram phase standard deviation by more than 73%, outperforming conventional methods. The root mean square error between InSAR and GPS time-series displacements decreases from 44.4 to 9.3 mm after correction, representing a 79% improvement in consistency. The proposed method effectively mitigates tropospheric delay, enhances the accuracy of InSAR measurements, and improves the reliability of deformation monitoring across diverse terrain conditions.
Owing to their inherent Orbital Angular Momentum (OAM), vortex electromagnetic waves display a helical wavefront phase structure. Their echoes include an amplitude component modulated by Bessel functions and a phase component modulated by the azimuth angle of the target. By utilizing different OAM modes, the azimuthal scattering points of targets can be measured differentially, enabling high-resolution azimuth imaging. However, current methods require observing targets with multiple OAM modes. The inconsistency of Bessel function terms across modes causes azimuth imaging resolution to degrade. Additionally, the Bessel function term is influenced by the elevation angle of the scattering points, resulting in strong coupling between elevation and azimuth information. When the elevation angles change, compensation becomes challenging, further reducing azimuth resolution. To overcome these issues, this paper uses single-mode vortex electromagnetic waves to observe targets. By compensating the echo signals, the azimuth information of the scattering points is shifted from the phase to the amplitude, producing the desired single-mode signal. This method diminishes the effect of elevation angle variations on the amplitude component, thereby lessening their impact on azimuth imaging. At the same time, the amplitude time-delay is employed to locate the azimuth positions of the scattering points, enabling two-dimensional range-azimuth imaging based on the single-mode signal. Simulation experiments show that the proposed method achieves azimuth resolution close to the diffraction limit even with changing elevation angles, while maintaining strong imaging performance.
Owing to their inherent Orbital Angular Momentum (OAM), vortex electromagnetic waves display a helical wavefront phase structure. Their echoes include an amplitude component modulated by Bessel functions and a phase component modulated by the azimuth angle of the target. By utilizing different OAM modes, the azimuthal scattering points of targets can be measured differentially, enabling high-resolution azimuth imaging. However, current methods require observing targets with multiple OAM modes. The inconsistency of Bessel function terms across modes causes azimuth imaging resolution to degrade. Additionally, the Bessel function term is influenced by the elevation angle of the scattering points, resulting in strong coupling between elevation and azimuth information. When the elevation angles change, compensation becomes challenging, further reducing azimuth resolution. To overcome these issues, this paper uses single-mode vortex electromagnetic waves to observe targets. By compensating the echo signals, the azimuth information of the scattering points is shifted from the phase to the amplitude, producing the desired single-mode signal. This method diminishes the effect of elevation angle variations on the amplitude component, thereby lessening their impact on azimuth imaging. At the same time, the amplitude time-delay is employed to locate the azimuth positions of the scattering points, enabling two-dimensional range-azimuth imaging based on the single-mode signal. Simulation experiments show that the proposed method achieves azimuth resolution close to the diffraction limit even with changing elevation angles, while maintaining strong imaging performance.
Vortex Electromagnetic (EM) waves exhibit spiral phase fronts and have attracted considerable interest in radar forward-looking imaging. However, their Bessel-type radiation intensity pattern limits detection range, imaging field of view, and the ability of EM vortex radar to retrieve elevation information. To overcome these limitations, this study analyzes the radiation field requirements of forward-looking imaging, and proposes a novel linear wavefront modulation scheme for EM waves. Inspired by the modulation mechanism of vortex waves, a linear wavefront modulation method based on a uniform linear array is developed. Full-wave simulations and radiation field measurements demonstrate that the proposed wave not only exhibits a phase front that varies linearly with elevation angle, but also forms a focused mainlobe, effectively avoiding energy divergence and axial nulls inherent to vortex waves. Moreover, its radiation field distribution shows coupled elevation-azimuth dependence. Based on this property, a forward-looking three-Dimensional (3D) imaging model is established. An elevation-azimuth imaging method using a rotating array and back-projection algorithm is proposed, and 3D images are reconstructed by integrating range information. Simulation results show that the proposed method enables forward-looking 3D imaging with robust performance under multi-target and low signal-to-noise ratio conditions. Compared with existing vortex interferometric and array-based real-aperture 3D imaging techniques, the proposed approach achieves superior imaging performance.
Vortex Electromagnetic (EM) waves exhibit spiral phase fronts and have attracted considerable interest in radar forward-looking imaging. However, their Bessel-type radiation intensity pattern limits detection range, imaging field of view, and the ability of EM vortex radar to retrieve elevation information. To overcome these limitations, this study analyzes the radiation field requirements of forward-looking imaging, and proposes a novel linear wavefront modulation scheme for EM waves. Inspired by the modulation mechanism of vortex waves, a linear wavefront modulation method based on a uniform linear array is developed. Full-wave simulations and radiation field measurements demonstrate that the proposed wave not only exhibits a phase front that varies linearly with elevation angle, but also forms a focused mainlobe, effectively avoiding energy divergence and axial nulls inherent to vortex waves. Moreover, its radiation field distribution shows coupled elevation-azimuth dependence. Based on this property, a forward-looking three-Dimensional (3D) imaging model is established. An elevation-azimuth imaging method using a rotating array and back-projection algorithm is proposed, and 3D images are reconstructed by integrating range information. Simulation results show that the proposed method enables forward-looking 3D imaging with robust performance under multi-target and low signal-to-noise ratio conditions. Compared with existing vortex interferometric and array-based real-aperture 3D imaging techniques, the proposed approach achieves superior imaging performance.
Lunar wrinkle ridges are important linear structures that are widely distributed in the mare regions on the lunar surface and are of great importance for studying the evolution of the lunar stress field and the history of volcanic activities. Traditional lunar Wrinkle ridge recognition and cataloging mainly rely on manual interpretation, which is inefficient and subjective. In this paper, an automatic lunar wrinkle ridge extraction method based on multimodal semantic segmentation is proposed. By constructing a high-quality lunar wrinkle ridge remote sensing image annotation dataset and introducing synthetic aperture radar data, a DeepLabv3+-based multimodal semantic segmentation network WR-Net is constructed through iterative training. A dynamic fusion module and an attention mechanism were introduced into WR-Net, which effectively optimized the feature extraction and fusion process of multimodal images and markedly improved the robustness and accuracy of the model. On the multimodal lunar wrinkle ridge test set, WR-Net achieved excellent performance (Precision = 95.516%, Recall = 89.963%, F1-Score = 92.657%, and MIoU = 92.944%). Furthermore, we used WR-Net to automatically identify and extract the lunar wrinkle ridges from the 70° south latitude to the 70° north latitude of the moon and cataloged and statistically analyzed the results. The proposed method is suitable for the recognition of lunar wrinkle ridges and provides an effective paradigm for the automatic extraction of similar linear structures on the moon and other planetary bodies.
Lunar wrinkle ridges are important linear structures that are widely distributed in the mare regions on the lunar surface and are of great importance for studying the evolution of the lunar stress field and the history of volcanic activities. Traditional lunar Wrinkle ridge recognition and cataloging mainly rely on manual interpretation, which is inefficient and subjective. In this paper, an automatic lunar wrinkle ridge extraction method based on multimodal semantic segmentation is proposed. By constructing a high-quality lunar wrinkle ridge remote sensing image annotation dataset and introducing synthetic aperture radar data, a DeepLabv3+-based multimodal semantic segmentation network WR-Net is constructed through iterative training. A dynamic fusion module and an attention mechanism were introduced into WR-Net, which effectively optimized the feature extraction and fusion process of multimodal images and markedly improved the robustness and accuracy of the model. On the multimodal lunar wrinkle ridge test set, WR-Net achieved excellent performance (Precision = 95.516%, Recall = 89.963%, F1-Score = 92.657%, and MIoU = 92.944%). Furthermore, we used WR-Net to automatically identify and extract the lunar wrinkle ridges from the 70° south latitude to the 70° north latitude of the moon and cataloged and statistically analyzed the results. The proposed method is suitable for the recognition of lunar wrinkle ridges and provides an effective paradigm for the automatic extraction of similar linear structures on the moon and other planetary bodies.
This paper addresses the multi-target direct localization problem for moving single stations using the coprime difference co-array. Existing methods based on matrix norm minimization often suffer from underutilization of redundant data from virtual array elements and high computational complexity. To overcome these limitations, we propose a multi-target direct localization approach that combines redundant-data averaging for virtual array elements with fast completion of missing covariance matrix entries. First, redundant-data averaging is applied to construct the difference co-array. Missing elements are then filled through zeroinitialization followed by Toeplitz matrix reconstruction, which restores the rank structure of the covariance matrix. An alternating projection iterative algorithm is subsequently developed to minimize the ratio of the nuclear norm to the Frobenius norm. By incorporating an adaptive threshold strategy and Toeplitz constraints, the algorithm efficiently completes the missing elements in the virtual array covariance matrix. Finally, a data fusion scheme is employed to obtain the localization results. Numerical simulations demonstrate that the proposed method reduces computational complexity while improving localization accuracy, particularly under low signal-to-noise ratios and limited observation data. The results indicate that the method effectively balances localization accuracy with real-time performance requirements.
This paper addresses the multi-target direct localization problem for moving single stations using the coprime difference co-array. Existing methods based on matrix norm minimization often suffer from underutilization of redundant data from virtual array elements and high computational complexity. To overcome these limitations, we propose a multi-target direct localization approach that combines redundant-data averaging for virtual array elements with fast completion of missing covariance matrix entries. First, redundant-data averaging is applied to construct the difference co-array. Missing elements are then filled through zeroinitialization followed by Toeplitz matrix reconstruction, which restores the rank structure of the covariance matrix. An alternating projection iterative algorithm is subsequently developed to minimize the ratio of the nuclear norm to the Frobenius norm. By incorporating an adaptive threshold strategy and Toeplitz constraints, the algorithm efficiently completes the missing elements in the virtual array covariance matrix. Finally, a data fusion scheme is employed to obtain the localization results. Numerical simulations demonstrate that the proposed method reduces computational complexity while improving localization accuracy, particularly under low signal-to-noise ratios and limited observation data. The results indicate that the method effectively balances localization accuracy with real-time performance requirements.
To address the problem of insufficient labeled data in radar-based human action recognition, a semisupervised learning method based on multidomain co-training is proposed herein. This method fuses action features from the slow time-range, slow time-Doppler frequency, and range-Doppler frequency domains to construct a decision-level ensemble framework. An interdomain consistency evaluation mechanism is employed to dynamically adjust the contribution of each domain in ensemble prediction. Furthermore, a stratified confidence dynamic pseudo-labeling strategy is designed to balance pseudo-label quality and utilization rate through multilevel quality assessment and dynamic threshold calibration. In addition, a feature alignment constraint mechanism is introduced, where fast principal component analysis is utilized to extract the principal components of multidomain features. This mechanism guides the network model to learn compact feature representations and enhances model discriminability. On the through-wall human action dataset based on a random code radar, an average recognition accuracy of (93.6±1.6)% is achieved with 5% labeled data; meanwhile, the corresponding accuracy on the indoor human action dataset based on a Frequency Modulated Continuous-Wave (FMCW) radar is (91.3±1.9)%. The proposed method outperforms supervised learning methods, including the use of Bi-LSTM, LH-ViT, and MFAFN, as well as semisupervised learning methods, including the use of FixMatch, C-TGAN, MF-Match, and LW-HGR. Experimental results demonstrate that the proposed method exhibits stable performance across two different radar systems (random code and FMCW radars) and two detection scenarios (through-wall and indoor scenarios), validating its cross-system and cross-scenario adaptability. Finally, the semisupervised learning model based on multidomain co-training has 1.30 M parameters, requires 26.16 M floating-point operations, and exhibits a size of 5.01 MB, demonstrating high computational efficiency.
To address the problem of insufficient labeled data in radar-based human action recognition, a semisupervised learning method based on multidomain co-training is proposed herein. This method fuses action features from the slow time-range, slow time-Doppler frequency, and range-Doppler frequency domains to construct a decision-level ensemble framework. An interdomain consistency evaluation mechanism is employed to dynamically adjust the contribution of each domain in ensemble prediction. Furthermore, a stratified confidence dynamic pseudo-labeling strategy is designed to balance pseudo-label quality and utilization rate through multilevel quality assessment and dynamic threshold calibration. In addition, a feature alignment constraint mechanism is introduced, where fast principal component analysis is utilized to extract the principal components of multidomain features. This mechanism guides the network model to learn compact feature representations and enhances model discriminability. On the through-wall human action dataset based on a random code radar, an average recognition accuracy of (93.6±1.6)% is achieved with 5% labeled data; meanwhile, the corresponding accuracy on the indoor human action dataset based on a Frequency Modulated Continuous-Wave (FMCW) radar is (91.3±1.9)%. The proposed method outperforms supervised learning methods, including the use of Bi-LSTM, LH-ViT, and MFAFN, as well as semisupervised learning methods, including the use of FixMatch, C-TGAN, MF-Match, and LW-HGR. Experimental results demonstrate that the proposed method exhibits stable performance across two different radar systems (random code and FMCW radars) and two detection scenarios (through-wall and indoor scenarios), validating its cross-system and cross-scenario adaptability. Finally, the semisupervised learning model based on multidomain co-training has 1.30 M parameters, requires 26.16 M floating-point operations, and exhibits a size of 5.01 MB, demonstrating high computational efficiency.
,
Interference identification is a critical component in enhancing the anti-jamming capability of radar target recognition systems. Compared with single-type interference, composite interference poses substantially greater identification challenges due to its structural complexity and flexible combination patterns. However, most existing identification methods are purely data-driven and fail to incorporate interference prior knowledge, resulting in performance bottlenecks in complex scenarios and limited interpretability. Moreover, many approaches lack effective noise suppression mechanisms and are prone to noise overfitting under low Signal-to-Noise Ratio (SNR) conditions. To address these limitations, this study proposes a prior-guided, noise-robust multi-label recognition network for radar composite interference, which exploits time-domain symmetry priors in different interference types. First, a coarse-to-fine denoising strategy is employed to suppress noise while preserving and enhancing their prior structural characteristics, thereby alleviating noise-induced overfitting during the recognition process. Second, an autocorrelation-based symmetry score is introduced to quantify the strength of the interference prior. The score is then mapped into a gating mechanism via a symmetry encoder to guide interference feature fusion and temporal representation learning. Finally, noise intensity and temporal features are jointly embedded into the recognition network, further enhancing the robustness of the proposed method across varying SNR conditions. Experimental results demonstrate that, under low-SNR conditions, the proposed method achieves average recognition accuracies exceeding 90% for 15 types of intermittent sampling repeater composite interference and 30 types of complex composite interference. Moreover, the proposed approach outperforms the strongest baseline model while significantly reducing model parameters.
Interference identification is a critical component in enhancing the anti-jamming capability of radar target recognition systems. Compared with single-type interference, composite interference poses substantially greater identification challenges due to its structural complexity and flexible combination patterns. However, most existing identification methods are purely data-driven and fail to incorporate interference prior knowledge, resulting in performance bottlenecks in complex scenarios and limited interpretability. Moreover, many approaches lack effective noise suppression mechanisms and are prone to noise overfitting under low Signal-to-Noise Ratio (SNR) conditions. To address these limitations, this study proposes a prior-guided, noise-robust multi-label recognition network for radar composite interference, which exploits time-domain symmetry priors in different interference types. First, a coarse-to-fine denoising strategy is employed to suppress noise while preserving and enhancing their prior structural characteristics, thereby alleviating noise-induced overfitting during the recognition process. Second, an autocorrelation-based symmetry score is introduced to quantify the strength of the interference prior. The score is then mapped into a gating mechanism via a symmetry encoder to guide interference feature fusion and temporal representation learning. Finally, noise intensity and temporal features are jointly embedded into the recognition network, further enhancing the robustness of the proposed method across varying SNR conditions. Experimental results demonstrate that, under low-SNR conditions, the proposed method achieves average recognition accuracies exceeding 90% for 15 types of intermittent sampling repeater composite interference and 30 types of complex composite interference. Moreover, the proposed approach outperforms the strongest baseline model while significantly reducing model parameters.
Vortex waves carrying Orbital Angular Momentum (OAM) theoretically support an infinite set of orthogonal modes and exhibit distinctive helical phase-front gradients, thus enhancing spectral efficiency and sensing capability in wireless communication and radar sensing applications. However, the practical implementation of multimode OAM generation is constrained by mode interference and imbalances in mode purity, severely degrading system performance. To address these challenges, this paper conducts a rigorous mathematical analysis and develops a novel method for generating multimode OAM waves with an optimized mode purity. Requiring only 1-bit quantized phase manipulation, the proposed approach enables the simultaneous generation of multimode OAM waves (l = ±1, ±2, ···, ±n, n ∈ N+), effectively suppresses mode interference, and achieves synchronous improvement in mode purity. To verify the proposed method, numerical simulations were performed to generate and optimize multimode vortex waves with 16 OAM modes (l = ±1, ±2, ±3, ±4, ±5, ±6, ±7, ±8). A representative eight-mode OAM multiplexing case was then selected, and a transmission metasurface antenna capable of simultaneously multiplexing eight OAM modes (l = ±1, ±2, ±3, ±4) was designed, fabricated, and experimentally characterized. Both simulated and measured results demonstrate the effective suppression of mode interference and consistent mode purity across all generated OAM modes. As such, this work presents a flexible and general solution for multimode OAM generation and optimization, featuring low-complexity phase control. It also provides a practical implementation path for high-capacity communication and high-resolution radar systems.
Vortex waves carrying Orbital Angular Momentum (OAM) theoretically support an infinite set of orthogonal modes and exhibit distinctive helical phase-front gradients, thus enhancing spectral efficiency and sensing capability in wireless communication and radar sensing applications. However, the practical implementation of multimode OAM generation is constrained by mode interference and imbalances in mode purity, severely degrading system performance. To address these challenges, this paper conducts a rigorous mathematical analysis and develops a novel method for generating multimode OAM waves with an optimized mode purity. Requiring only 1-bit quantized phase manipulation, the proposed approach enables the simultaneous generation of multimode OAM waves (l = ±1, ±2, ···, ±n, n ∈ N+), effectively suppresses mode interference, and achieves synchronous improvement in mode purity. To verify the proposed method, numerical simulations were performed to generate and optimize multimode vortex waves with 16 OAM modes (l = ±1, ±2, ±3, ±4, ±5, ±6, ±7, ±8). A representative eight-mode OAM multiplexing case was then selected, and a transmission metasurface antenna capable of simultaneously multiplexing eight OAM modes (l = ±1, ±2, ±3, ±4) was designed, fabricated, and experimentally characterized. Both simulated and measured results demonstrate the effective suppression of mode interference and consistent mode purity across all generated OAM modes. As such, this work presents a flexible and general solution for multimode OAM generation and optimization, featuring low-complexity phase control. It also provides a practical implementation path for high-capacity communication and high-resolution radar systems.
Multimode vortex electromagnetic waves, which carry mutually orthogonal Orbital Angular Momentum (OAM), have attracted extensive research interest in communications and radar systems due to their unique amplitude and phase characteristics. This study investigates the near-field scattering characteristics of metallic plate targets under the incidence of multimode vortex electromagnetic waves. First, an incidence model for multimode vortex waves is constructed based on annular aperture radiation theory, and the near-field scattering field of a perfect electric conductor circular plate is derived using the Physical Optics (PO) method. Subsequently, the effects of target longitudinal distance, transverse displacement, geometric features, and mode combination parameters (initial mode, mode interval, and number of modes) on the scattering characteristics are quantitatively analyzed, and the multimode Near-field OAM Radar Cross Section (NORCS) is calculated. The research results demonstrate that compared to plane wave incidence, the coherent superposition of multimode beams provides richer spatial feature information. The target’s efficiency in intercepting high-order mode energy significantly decreases with increasing propagation distance. Although the transverse displacement of the target induces substantial mode spectrum crosstalk, the original scattering features can be effectively reconstructed through vector superposition of scattering fields at symmetrical positions by exploiting spatial complementarity. Furthermore, the geometric shape of the target produces fine modulation on the scattering field when its size is comparable to that of the main lobe, and this modulation effect gradually diminishes as the target size increases. The theoretical calculations closely align with the simulation results, showing a main mode purity deviation of less than 0.0207 and a root mean square error of 0.054 in the scattering field amplitude distribution, thus verifying the accuracy of the theory. This study reveals the interaction mechanism between multimode vortex waves and targets, providing theoretical support for target recognition and imaging system design in future multimode vortex radar systems.
Multimode vortex electromagnetic waves, which carry mutually orthogonal Orbital Angular Momentum (OAM), have attracted extensive research interest in communications and radar systems due to their unique amplitude and phase characteristics. This study investigates the near-field scattering characteristics of metallic plate targets under the incidence of multimode vortex electromagnetic waves. First, an incidence model for multimode vortex waves is constructed based on annular aperture radiation theory, and the near-field scattering field of a perfect electric conductor circular plate is derived using the Physical Optics (PO) method. Subsequently, the effects of target longitudinal distance, transverse displacement, geometric features, and mode combination parameters (initial mode, mode interval, and number of modes) on the scattering characteristics are quantitatively analyzed, and the multimode Near-field OAM Radar Cross Section (NORCS) is calculated. The research results demonstrate that compared to plane wave incidence, the coherent superposition of multimode beams provides richer spatial feature information. The target’s efficiency in intercepting high-order mode energy significantly decreases with increasing propagation distance. Although the transverse displacement of the target induces substantial mode spectrum crosstalk, the original scattering features can be effectively reconstructed through vector superposition of scattering fields at symmetrical positions by exploiting spatial complementarity. Furthermore, the geometric shape of the target produces fine modulation on the scattering field when its size is comparable to that of the main lobe, and this modulation effect gradually diminishes as the target size increases. The theoretical calculations closely align with the simulation results, showing a main mode purity deviation of less than 0.0207 and a root mean square error of 0.054 in the scattering field amplitude distribution, thus verifying the accuracy of the theory. This study reveals the interaction mechanism between multimode vortex waves and targets, providing theoretical support for target recognition and imaging system design in future multimode vortex radar systems.
Vortex Electromagnetic (EM) wave radars utilize EM waves carrying orbital angular momentum to enrich target scattering information, thereby providing intrinsic in-beam azimuth resolution. Hence, this technology holds significant potential for advanced target detection and imaging. However, as sensing scenarios become more complex, conventional electronic vortex EM wave radars are increasingly limited by device bandwidth. Specifically, they encounter substantial challenges in broadband signal generation and control, making it difficult to achieve high range and azimuth resolutions simultaneously. Microwave photonics technology, with its inherent advantages of wide bandwidth, low transmission loss, and robustness against electromagnetic interference, is an effectivesolution to overcome these limitations. This paper reviews recent progress in microwave photonic broadband vortex EM wave radars, addressing the requirements for forward-looking imaging. The fundamental system architectures and imaging mechanisms are elucidated, followed by a critical analysis of the frequency-dependent characteristics of broadband vortex waves and their implications for imaging performance. Key microwave photonic enabling technologies, including broadband phase shifting, optical beamforming, and broadband signal generation, are summarized, and their advantages over traditional electronic schemes in terms of performance are highlighted. Based on these insights, typical system implementation schemes are described, and their high-resolution forward-looking imaging capabilities are demonstrated through proof-of-concept experiments. Finally, future development trends and research directions are discussed.
Vortex Electromagnetic (EM) wave radars utilize EM waves carrying orbital angular momentum to enrich target scattering information, thereby providing intrinsic in-beam azimuth resolution. Hence, this technology holds significant potential for advanced target detection and imaging. However, as sensing scenarios become more complex, conventional electronic vortex EM wave radars are increasingly limited by device bandwidth. Specifically, they encounter substantial challenges in broadband signal generation and control, making it difficult to achieve high range and azimuth resolutions simultaneously. Microwave photonics technology, with its inherent advantages of wide bandwidth, low transmission loss, and robustness against electromagnetic interference, is an effectivesolution to overcome these limitations. This paper reviews recent progress in microwave photonic broadband vortex EM wave radars, addressing the requirements for forward-looking imaging. The fundamental system architectures and imaging mechanisms are elucidated, followed by a critical analysis of the frequency-dependent characteristics of broadband vortex waves and their implications for imaging performance. Key microwave photonic enabling technologies, including broadband phase shifting, optical beamforming, and broadband signal generation, are summarized, and their advantages over traditional electronic schemes in terms of performance are highlighted. Based on these insights, typical system implementation schemes are described, and their high-resolution forward-looking imaging capabilities are demonstrated through proof-of-concept experiments. Finally, future development trends and research directions are discussed.
To address the urgent need to identify birds and rotary-wing Unmanned Aerial Vehicles (UAVs), this paper proposes a vortex radar-based method for extracting micromotion parameters of targets. The study focused on target parameter acquisition and systematically extended target modeling and parameter extraction strategies. First, mathematical models were developed for the body motion and wing flapping behavior of birds as well as for the rotor movement characteristics and body structure of rotary-wing UAVs. Further, analytical expressions for the radial and rotational Doppler frequency shifts at scattering points were derived, and micro-Doppler features were extracted from radar echo signals to enable target parameter inversion. For bird targets, the radial Doppler frequency was estimated by extracting the spectral peak of the echo signal to obtain the flight velocity. In addition, by combining the rotational Doppler frequency shifts of the scattering points and analyzing the variations of the rotational Doppler frequency using the Short-Time Fourier Transform (STFT), the wing-flapping length was estimated. Even under low Signal-to-Noise Ratio (SNR) conditions, the estimation error of the wing-flapping length remained within 0.03 m. For rotary-wing UAV targets, an echo signal model was first constructed, and the analytical relationship between the radial and rotational components of the micro-Doppler frequency shift was derived. Using the reconstructed Doppler information and through range-time domain analysis, six structural and motion parameters were retrieved, including the Euler angles rotor rotational speed, rotor length, and the distance between the UAV body and rotor. The estimation errors for all parameters were significantly lower than those obtained with conventional approaches based on individual Doppler features, with all parameters remaining within 2%. Simulation results demonstrated that the proposed vortex radar-based parameter extraction method enables accurate multiparameter estimation for birds and rotary-wing UAVs. The method also exhibits stable and reliable performance under low SNR conditions, confirming its effectiveness and applicability in practical engineering scenarios.
To address the urgent need to identify birds and rotary-wing Unmanned Aerial Vehicles (UAVs), this paper proposes a vortex radar-based method for extracting micromotion parameters of targets. The study focused on target parameter acquisition and systematically extended target modeling and parameter extraction strategies. First, mathematical models were developed for the body motion and wing flapping behavior of birds as well as for the rotor movement characteristics and body structure of rotary-wing UAVs. Further, analytical expressions for the radial and rotational Doppler frequency shifts at scattering points were derived, and micro-Doppler features were extracted from radar echo signals to enable target parameter inversion. For bird targets, the radial Doppler frequency was estimated by extracting the spectral peak of the echo signal to obtain the flight velocity. In addition, by combining the rotational Doppler frequency shifts of the scattering points and analyzing the variations of the rotational Doppler frequency using the Short-Time Fourier Transform (STFT), the wing-flapping length was estimated. Even under low Signal-to-Noise Ratio (SNR) conditions, the estimation error of the wing-flapping length remained within 0.03 m. For rotary-wing UAV targets, an echo signal model was first constructed, and the analytical relationship between the radial and rotational components of the micro-Doppler frequency shift was derived. Using the reconstructed Doppler information and through range-time domain analysis, six structural and motion parameters were retrieved, including the Euler angles rotor rotational speed, rotor length, and the distance between the UAV body and rotor. The estimation errors for all parameters were significantly lower than those obtained with conventional approaches based on individual Doppler features, with all parameters remaining within 2%. Simulation results demonstrated that the proposed vortex radar-based parameter extraction method enables accurate multiparameter estimation for birds and rotary-wing UAVs. The method also exhibits stable and reliable performance under low SNR conditions, confirming its effectiveness and applicability in practical engineering scenarios.
Radar systems acquire target information by transmitting waveforms, receiving echoes, and processing signals; thus, waveform performance is a critical determinant of radar system performance. Compared with other radar systems, Synthetic Aperture Radar (SAR) operates under unique conditions, including distributed target scenes, waveforms with large time-bandwidth products, wide-swath and long-range imaging, and range-azimuth coupling. These characteristics impose additional stringent requirements on SAR waveform design. Drawing on the authors’ research and expertise in SAR waveform coding, this paper reviews recent domestic and international advances in SAR waveform design, discusses key technical challenges, and highlights the role of waveform design in enhancing system imaging performance. Finally, this study outlines future trends and potential directions for SAR waveform design methodologies.
Radar systems acquire target information by transmitting waveforms, receiving echoes, and processing signals; thus, waveform performance is a critical determinant of radar system performance. Compared with other radar systems, Synthetic Aperture Radar (SAR) operates under unique conditions, including distributed target scenes, waveforms with large time-bandwidth products, wide-swath and long-range imaging, and range-azimuth coupling. These characteristics impose additional stringent requirements on SAR waveform design. Drawing on the authors’ research and expertise in SAR waveform coding, this paper reviews recent domestic and international advances in SAR waveform design, discusses key technical challenges, and highlights the role of waveform design in enhancing system imaging performance. Finally, this study outlines future trends and potential directions for SAR waveform design methodologies.
Heart Rate (HR), a core physiological indicator of human health, is of substantial clinical importance when accurately monitored in applications such as arrhythmia screening, early warning of coronary heart disease, and chronic heart failure management. However, cardiac echo signals are susceptible to coupled disturbances, including respiratory motion artifacts and environmental electromagnetic interference, which degrade the signal-to-noise ratio and compromise HR estimation accuracy. To address these challenges, we propose a multi-channel joint HR estimation method based on Multivariate Variational Mode Decomposition (MVMD) that exploits shared cardiac information across different channels. Specifically, the proposed method first constructs a multi-channel joint optimization model that minimizes the total modal bandwidth under reconstruction residual constraints. It then adaptively initialize the center frequency by leveraging the cumulative effect of multi-channel spectral peaks, enabling robust separation of heartbeat modes with consistent frequencies across channels. Finally, the HR mode is selected from the decomposed modes using a maximum energy criterion to complete HR estimation. Validation on real-world data from six subjects demonstrated that the proposed method achieves a median HR error of 1.53 bpm, outperforming conventional single-channel approaches and existing multi-channel fusion-based HR estimation methods.
Heart Rate (HR), a core physiological indicator of human health, is of substantial clinical importance when accurately monitored in applications such as arrhythmia screening, early warning of coronary heart disease, and chronic heart failure management. However, cardiac echo signals are susceptible to coupled disturbances, including respiratory motion artifacts and environmental electromagnetic interference, which degrade the signal-to-noise ratio and compromise HR estimation accuracy. To address these challenges, we propose a multi-channel joint HR estimation method based on Multivariate Variational Mode Decomposition (MVMD) that exploits shared cardiac information across different channels. Specifically, the proposed method first constructs a multi-channel joint optimization model that minimizes the total modal bandwidth under reconstruction residual constraints. It then adaptively initialize the center frequency by leveraging the cumulative effect of multi-channel spectral peaks, enabling robust separation of heartbeat modes with consistent frequencies across channels. Finally, the HR mode is selected from the decomposed modes using a maximum energy criterion to complete HR estimation. Validation on real-world data from six subjects demonstrated that the proposed method achieves a median HR error of 1.53 bpm, outperforming conventional single-channel approaches and existing multi-channel fusion-based HR estimation methods.
With the widespread use of millimeter-wave radar technology in indoor target detection and tracking, multipath effects have become a key factor affecting tracking accuracy. Indoor millimeter-wave radar target tracking is highly susceptible to multipath interference, and conventional point-target tracking methods, which ignore the extended characteristics of targets and the multipath propagation mechanism, struggle to effectively suppress ghost targets caused by multipath reflections. To address this issue, this paper proposes an Extension Mapping-based Extended Target Tracking (EM-ETT) method for indoor target tracking using millimeter-wave radar. First, a random matrix model is used to characterize the target’s geometric shape, with the extension modeled as an inverse Wishart distribution. Next, an extended projection framework is constructed by integrating a Monte Carlo-based statistical propagation mechanism. Through nonlinear multipath mapping of scattering points from the true target, ghost point clouds are generated, and their extended state priors are estimated. Furthermore, a target-path association method is introduced to establish path associations in multipath propagation based on geometric consistency and likelihood evaluation, enhancing state discrimination capability. Experimental results demonstrate that in multitarget scenarios with multipath interference, the proposed method significantly improves state estimation accuracy and effectively prevents the generation of false trajectories. Compared with conventional point-target tracking algorithms, the proposed method exhibits significant advantages in both tracking accuracy and robustness.
With the widespread use of millimeter-wave radar technology in indoor target detection and tracking, multipath effects have become a key factor affecting tracking accuracy. Indoor millimeter-wave radar target tracking is highly susceptible to multipath interference, and conventional point-target tracking methods, which ignore the extended characteristics of targets and the multipath propagation mechanism, struggle to effectively suppress ghost targets caused by multipath reflections. To address this issue, this paper proposes an Extension Mapping-based Extended Target Tracking (EM-ETT) method for indoor target tracking using millimeter-wave radar. First, a random matrix model is used to characterize the target’s geometric shape, with the extension modeled as an inverse Wishart distribution. Next, an extended projection framework is constructed by integrating a Monte Carlo-based statistical propagation mechanism. Through nonlinear multipath mapping of scattering points from the true target, ghost point clouds are generated, and their extended state priors are estimated. Furthermore, a target-path association method is introduced to establish path associations in multipath propagation based on geometric consistency and likelihood evaluation, enhancing state discrimination capability. Experimental results demonstrate that in multitarget scenarios with multipath interference, the proposed method significantly improves state estimation accuracy and effectively prevents the generation of false trajectories. Compared with conventional point-target tracking algorithms, the proposed method exhibits significant advantages in both tracking accuracy and robustness.
To address issues such as insufficient feature extraction, limited spatiotemporal correlation modeling, and poor classification performance in radar classification of Low, Slow, and Small (LSS) targets, this paper investigates on graph network-based feature extraction and classification methods. First, focusing on digital array ubiquitous radar, a radar detection dataset for LSS targets, named LSS-DAUR-1.0, is constructed; it contains Doppler and track data for six types of targets: Passenger ships, speedboats, helicopters, rotor drones, birds, and fixed-wing drones. Second, based on this dataset, the multidomain and multidimensional characteristics of the targets are analyzed, and the complementarity between Doppler and physical motion features is verified through correlation and cosine similarity analyses. On this basis, a Graph Convolutional Network with Dynamic Graph Construction (DG-GCN) classification method fusing dual features is proposed. An adaptive window adjustment, a hybrid attenuation function, and a dynamic threshold mechanism are designed to construct an adaptive dynamic graph based on spatiotemporal correlation. Combined with graph convolution-based feature learning and classification modules, this approach achieves refined classification of low, slow, and small targets. Validation on the LSS-DAUR-1.0 dataset shows that the DG-GCN achieves 99.66% classification accuracy, which is 6.78% and 17.97% higher than that of ResNet and Transformer models, respectively. The total processing time is only 4.98 ms, which is more than 80% lower than that of the aforementioned comparison models. Hence, the DG-GCN achieves both high accuracy and efficiency. In addition, noise environment tests show good robustness. Ablation experiments verify that the dynamic edge weight mechanism compensates for the lack of spatial feature correlation in purely temporal connections and improves the model’s generalizability.
To address issues such as insufficient feature extraction, limited spatiotemporal correlation modeling, and poor classification performance in radar classification of Low, Slow, and Small (LSS) targets, this paper investigates on graph network-based feature extraction and classification methods. First, focusing on digital array ubiquitous radar, a radar detection dataset for LSS targets, named LSS-DAUR-1.0, is constructed; it contains Doppler and track data for six types of targets: Passenger ships, speedboats, helicopters, rotor drones, birds, and fixed-wing drones. Second, based on this dataset, the multidomain and multidimensional characteristics of the targets are analyzed, and the complementarity between Doppler and physical motion features is verified through correlation and cosine similarity analyses. On this basis, a Graph Convolutional Network with Dynamic Graph Construction (DG-GCN) classification method fusing dual features is proposed. An adaptive window adjustment, a hybrid attenuation function, and a dynamic threshold mechanism are designed to construct an adaptive dynamic graph based on spatiotemporal correlation. Combined with graph convolution-based feature learning and classification modules, this approach achieves refined classification of low, slow, and small targets. Validation on the LSS-DAUR-1.0 dataset shows that the DG-GCN achieves 99.66% classification accuracy, which is 6.78% and 17.97% higher than that of ResNet and Transformer models, respectively. The total processing time is only 4.98 ms, which is more than 80% lower than that of the aforementioned comparison models. Hence, the DG-GCN achieves both high accuracy and efficiency. In addition, noise environment tests show good robustness. Ablation experiments verify that the dynamic edge weight mechanism compensates for the lack of spatial feature correlation in purely temporal connections and improves the model’s generalizability.
The automatic target recognition performance of radar is critically dependent on the quality of features extracted from target echo signals. As the information carrier that actively shapes echo signals, the transmitted waveform substantially affects the target classification performance. However, conventional waveform design is often decoupled from classifier optimization, thereby ignoring the critical synergy between the two. This disconnect, combined with the lack of a direct link between waveform optimization criteria and task-specific classification metrics, limits the target classification performance. Most existing approaches are confined to monostatic radar models. Further, they fail to establish relationships between the target’s aspect angle, the transmitted waveform, and classification performance, and lack a cooperative waveform design mechanism among nodes. Hence, they are unable to achieve spatial and waveform diversity gains. To overcome these limitations, this paper proposes an end-to-end “waveform aspect matching” optimization framework for target classification in distributed radar systems. This framework parameterizes the waveform as a trainable waveform generation module, cascaded with a downstream classification network. This transforms the isolated waveform design problem into a joint optimization of the waveform and classifier, directly guided by the classification task. Leveraging prior target information, the model is trained to jointly optimize and produce aspect-matched waveforms along with the corresponding classification network. Furthermore, to enhance the classification performance in distributed radar systems, a dual-branch network based on noncausal state-space duality modules is proposed to extract and fuse multiview information. Experimental results demonstrate that the proposed method can synergistically utilize waveform and spatial diversity to improve the target classification performance. It demonstrates robustness against node failures, offering a novel solution for intelligent waveform design in distributed radar systems.
The automatic target recognition performance of radar is critically dependent on the quality of features extracted from target echo signals. As the information carrier that actively shapes echo signals, the transmitted waveform substantially affects the target classification performance. However, conventional waveform design is often decoupled from classifier optimization, thereby ignoring the critical synergy between the two. This disconnect, combined with the lack of a direct link between waveform optimization criteria and task-specific classification metrics, limits the target classification performance. Most existing approaches are confined to monostatic radar models. Further, they fail to establish relationships between the target’s aspect angle, the transmitted waveform, and classification performance, and lack a cooperative waveform design mechanism among nodes. Hence, they are unable to achieve spatial and waveform diversity gains. To overcome these limitations, this paper proposes an end-to-end “waveform aspect matching” optimization framework for target classification in distributed radar systems. This framework parameterizes the waveform as a trainable waveform generation module, cascaded with a downstream classification network. This transforms the isolated waveform design problem into a joint optimization of the waveform and classifier, directly guided by the classification task. Leveraging prior target information, the model is trained to jointly optimize and produce aspect-matched waveforms along with the corresponding classification network. Furthermore, to enhance the classification performance in distributed radar systems, a dual-branch network based on noncausal state-space duality modules is proposed to extract and fuse multiview information. Experimental results demonstrate that the proposed method can synergistically utilize waveform and spatial diversity to improve the target classification performance. It demonstrates robustness against node failures, offering a novel solution for intelligent waveform design in distributed radar systems.
,
Crevasse detection using Ground Penetrating Radar (GPR) is crucial for glacier and climate studies and for ensuring safety in glacial regions. To address challenges including large texture variability in crevasses in polar environments, high false-alarm rates, limited real-time performance, and poor generalization, this study proposes a domain-adversarial learning-based automatic crevasse detection method that balances high accuracy and real-time efficiency. Using GPR data acquired from diverse regions and complex scenarios, an adversarial learning mechanism is established between a feature extractor and a domain discriminator, enabling the method to maintain discriminative feature extraction while effectively reducing interdomain distribution discrepancies. This leads to cross-domain feature alignment, enhancing robustness and generalization across heterogeneous data sources. In the feature extraction stage, a wavelet-residual-network-based crevasse feature extractor is designed. By introducing a learnable multiscale wavelet convolution module into the first layer of the residual network, the model adaptively extracts multiscale crevasse features from GPR data, significantly enhancing the separability between crevasse regions and continuous snow layers in the feature space. Experiments were conducted on two GPR datasets: The 2015 McMurdo Shear Zone dataset from Antarctica and a Greenland dataset from the Arctic region. The experimental results demonstrate that the proposed model achieves an average detection accuracy of 95.70%, an F1-score of 95.50%, and a false-alarm rate of 1.87%, with an average inference time of 5.26 ms per sample, thereby meeting the requirements for real-time crevasse warning during field GPR acquisition. Overall, the proposed method achieves a favorable balance among high accuracy, low false-alarm rate, and real-time performance across multiscene and cross-regional GPR data, demonstrating its suitability for safety assurance during Antarctic expeditions and for glacier crevasse detection in polar research.
Crevasse detection using Ground Penetrating Radar (GPR) is crucial for glacier and climate studies and for ensuring safety in glacial regions. To address challenges including large texture variability in crevasses in polar environments, high false-alarm rates, limited real-time performance, and poor generalization, this study proposes a domain-adversarial learning-based automatic crevasse detection method that balances high accuracy and real-time efficiency. Using GPR data acquired from diverse regions and complex scenarios, an adversarial learning mechanism is established between a feature extractor and a domain discriminator, enabling the method to maintain discriminative feature extraction while effectively reducing interdomain distribution discrepancies. This leads to cross-domain feature alignment, enhancing robustness and generalization across heterogeneous data sources. In the feature extraction stage, a wavelet-residual-network-based crevasse feature extractor is designed. By introducing a learnable multiscale wavelet convolution module into the first layer of the residual network, the model adaptively extracts multiscale crevasse features from GPR data, significantly enhancing the separability between crevasse regions and continuous snow layers in the feature space. Experiments were conducted on two GPR datasets: The 2015 McMurdo Shear Zone dataset from Antarctica and a Greenland dataset from the Arctic region. The experimental results demonstrate that the proposed model achieves an average detection accuracy of 95.70%, an F1-score of 95.50%, and a false-alarm rate of 1.87%, with an average inference time of 5.26 ms per sample, thereby meeting the requirements for real-time crevasse warning during field GPR acquisition. Overall, the proposed method achieves a favorable balance among high accuracy, low false-alarm rate, and real-time performance across multiscene and cross-regional GPR data, demonstrating its suitability for safety assurance during Antarctic expeditions and for glacier crevasse detection in polar research.
The millimeter-Wave (mmWave) radar is widely used in security screening, nondestructive testing, and through-the-wall imaging due to its compact size, high resolution, and strong penetration capability. High-resolution mmWave radar imaging typically requires synthetic aperture emulation, which involves dense two-dimensional spatial sampling via structured scanning on a mechanical platform. However, this process is time-consuming in practical applications. Therefore, many existing studies have focused on reconstructing echo data under sparse sampling conditions for imaging. However, most existing sparse recovery methods assume uniformly random sparse sampling or involve high computational complexity, making them difficult to apply in practical Synthetic Aperture Radar (SAR) imaging systems. This paper proposes a fast, structured sparse, mmWave three-Dimensional (3D) SAR imaging algorithm based on low-rank and smooth Matrix Completion (MC) to address this problem. First, the global low-rank property and local smoothness prior of echo data are analyzed within the framework of near-field mmWave SAR imaging theory. Our analysis demonstrated that structured sparse SAR data arising from missing entire rows or columns in practical scanning can be recovered. Building on this, an MC model incorporating low-rank and smoothness constraints was constructed. This MC model jointly regularizes with nuclear norm and total variation and can be solved efficiently using the Alternating Direction Method of Multipliers (ADMM). Finally, the performance of the proposed algorithm was validated through multiple simulation runs and real-world experiments. Experimental results showed that, using only 20%–30% of randomly sampled rows or columns of echo data, the proposed algorithm can achieve fast data recovery and high-resolution 3D imaging within tens of seconds.
The millimeter-Wave (mmWave) radar is widely used in security screening, nondestructive testing, and through-the-wall imaging due to its compact size, high resolution, and strong penetration capability. High-resolution mmWave radar imaging typically requires synthetic aperture emulation, which involves dense two-dimensional spatial sampling via structured scanning on a mechanical platform. However, this process is time-consuming in practical applications. Therefore, many existing studies have focused on reconstructing echo data under sparse sampling conditions for imaging. However, most existing sparse recovery methods assume uniformly random sparse sampling or involve high computational complexity, making them difficult to apply in practical Synthetic Aperture Radar (SAR) imaging systems. This paper proposes a fast, structured sparse, mmWave three-Dimensional (3D) SAR imaging algorithm based on low-rank and smooth Matrix Completion (MC) to address this problem. First, the global low-rank property and local smoothness prior of echo data are analyzed within the framework of near-field mmWave SAR imaging theory. Our analysis demonstrated that structured sparse SAR data arising from missing entire rows or columns in practical scanning can be recovered. Building on this, an MC model incorporating low-rank and smoothness constraints was constructed. This MC model jointly regularizes with nuclear norm and total variation and can be solved efficiently using the Alternating Direction Method of Multipliers (ADMM). Finally, the performance of the proposed algorithm was validated through multiple simulation runs and real-world experiments. Experimental results showed that, using only 20%–30% of randomly sampled rows or columns of echo data, the proposed algorithm can achieve fast data recovery and high-resolution 3D imaging within tens of seconds.
Reinforcement Learning (RL) is a critical approach for enabling cognitive radar target detection. Existing studies primarily focus on detection methods for centralized Multiple-Input Multiple-Output (MIMO) radar, which are limited to a single observation perspective. To address this issue, this paper proposes an RL-based multi-target detection method for a distributed MIMO radar system that possesses waveform and spatial diversity. The proposed method exploits spatial diversity to ensure robust target detection, while waveform diversity is used to construct a Markov decision process. Specifically, the radar first perceives target attributes through statistical signal detection techniques, then optimizes the transmit waveform accordingly, and iteratively updates its understanding of the environmental context using accumulated experience. This cyclic process gradually converges, yielding radar waveforms focused on target directions and achieving improved detection performance. To facilitate target localization, a maximization grid-based generalized likelihood ratio test detector for multi-antenna configurations is derived, using regularly shaped grids as the cell under test. For waveform optimization, two types of optimization problems, namely conventional and strong-target-limited formulations, are developed, and their solutions are obtained using continuous convex approximation. Simulation results across static and dynamic scenarios demonstrate that the proposed method can autonomously perceive environmental context and achieve superior detection performance compared with benchmark methods, particularly in weak target detection.
Reinforcement Learning (RL) is a critical approach for enabling cognitive radar target detection. Existing studies primarily focus on detection methods for centralized Multiple-Input Multiple-Output (MIMO) radar, which are limited to a single observation perspective. To address this issue, this paper proposes an RL-based multi-target detection method for a distributed MIMO radar system that possesses waveform and spatial diversity. The proposed method exploits spatial diversity to ensure robust target detection, while waveform diversity is used to construct a Markov decision process. Specifically, the radar first perceives target attributes through statistical signal detection techniques, then optimizes the transmit waveform accordingly, and iteratively updates its understanding of the environmental context using accumulated experience. This cyclic process gradually converges, yielding radar waveforms focused on target directions and achieving improved detection performance. To facilitate target localization, a maximization grid-based generalized likelihood ratio test detector for multi-antenna configurations is derived, using regularly shaped grids as the cell under test. For waveform optimization, two types of optimization problems, namely conventional and strong-target-limited formulations, are developed, and their solutions are obtained using continuous convex approximation. Simulation results across static and dynamic scenarios demonstrate that the proposed method can autonomously perceive environmental context and achieve superior detection performance compared with benchmark methods, particularly in weak target detection.
Ultra-Wideband (UWB) Multiple-Input Multiple-Output (MIMO) radar has demonstrated enormous potential in the field of human intelligent perception due to its excellent resolution, strong penetration capability, strong privacy protection, and insensitivity to illumination conditions. However, its low image resolution results in blurred contours and indistinguishable actions. To address this issue, this study developes a joint framework, Spatiotemporal Wavelet Transformer network (STWTnet), for human contour restoration and action recognition by integrating spatiotemporal features. By adopting a multi-task network architecture, the proposed framework leverages Res2Net and wavelet downsampling to extract spatial detail features from radar images and employs a Transformer to establish spatiotemporal dependencies. Through multi-task learning, it shares the common features of human contour restoration and action recognition, enabling mutual complementarity between the two tasks while avoiding feature conflicts. Experiments conducted on a self-built, synchronized UWB optical dataset demonstrate that STWTnet achieves high action recognition accuracy and significantly outperforms existing techniques in contour restoration precision, providing a new approach for privacy-preserving, all-weather human behavior understanding.
Ultra-Wideband (UWB) Multiple-Input Multiple-Output (MIMO) radar has demonstrated enormous potential in the field of human intelligent perception due to its excellent resolution, strong penetration capability, strong privacy protection, and insensitivity to illumination conditions. However, its low image resolution results in blurred contours and indistinguishable actions. To address this issue, this study developes a joint framework, Spatiotemporal Wavelet Transformer network (STWTnet), for human contour restoration and action recognition by integrating spatiotemporal features. By adopting a multi-task network architecture, the proposed framework leverages Res2Net and wavelet downsampling to extract spatial detail features from radar images and employs a Transformer to establish spatiotemporal dependencies. Through multi-task learning, it shares the common features of human contour restoration and action recognition, enabling mutual complementarity between the two tasks while avoiding feature conflicts. Experiments conducted on a self-built, synchronized UWB optical dataset demonstrate that STWTnet achieves high action recognition accuracy and significantly outperforms existing techniques in contour restoration precision, providing a new approach for privacy-preserving, all-weather human behavior understanding.
Vortex electromagnetic waves carrying Orbital Angular Momentum (OAM) can meet the requirements of modern radar detection systems for high resolution and precision. However, existing OAM beam generation methods suffer from limitations, such as insufficient multimodal purity and strong mutual coupling between array elements. To overcome these challenges, this paper designs and optimizes pyramidal horn antenna elements based on a uniform concentric circular array, thereby establishing a multimodal OAM array model. A double-layer metal ground plane structure is introduced to effectively suppress mutual coupling between array elements. Furthermore, the array configuration is optimized to generate high-purity, co-directional multimodal OAM beams. On this basis, a genetic algorithm is used to further optimize the design for generating multimodal OAM beams with low sidelobes. Full-wave simulations show that the optimized array achieves an active reflection coefficient below −10 dB, indicating substantially suppression of the mutual coupling between elements. The proposed array exhibits a stable structure suitable for engineering applications and supports the generation of 14 co-directional OAM beams with modal purity exceeding 0.92 and sidelobes below −13 dB. Finally, the performance of the designed array is validated through fabrication, testing, and super-resolution imaging experiments.
Vortex electromagnetic waves carrying Orbital Angular Momentum (OAM) can meet the requirements of modern radar detection systems for high resolution and precision. However, existing OAM beam generation methods suffer from limitations, such as insufficient multimodal purity and strong mutual coupling between array elements. To overcome these challenges, this paper designs and optimizes pyramidal horn antenna elements based on a uniform concentric circular array, thereby establishing a multimodal OAM array model. A double-layer metal ground plane structure is introduced to effectively suppress mutual coupling between array elements. Furthermore, the array configuration is optimized to generate high-purity, co-directional multimodal OAM beams. On this basis, a genetic algorithm is used to further optimize the design for generating multimodal OAM beams with low sidelobes. Full-wave simulations show that the optimized array achieves an active reflection coefficient below −10 dB, indicating substantially suppression of the mutual coupling between elements. The proposed array exhibits a stable structure suitable for engineering applications and supports the generation of 14 co-directional OAM beams with modal purity exceeding 0.92 and sidelobes below −13 dB. Finally, the performance of the designed array is validated through fabrication, testing, and super-resolution imaging experiments.
Coherent Frequency Diverse Array (FDA) radar demonstrates significant potential for wide-area search tasks due to its simple system architecture, flexible beam scanning, and high transmit Degrees of Freedom (DOF). However, its inherent beam-scanning mechanism reduces dwell time in specific directions, thereby limiting the imaging range resolution when a conventional wideband waveform is used. To resolve the intrinsic contradiction between wide-area search and high-resolution imaging, this paper proposes a deep learning-based integrated search-imaging waveform design method. By leveraging the multi-DoF flexible transmission capability of coherent FDA, the proposed method customizes multidimensional transmit resources, including waveform, bandwidth, and transmit gain, for multiple Regions of Interest (ROIs) while preserving wide-coverage search performance. To address the nonconvex optimization problem with dual constraints of constant modulus and low correlation in baseband waveform design, a residual autoencoder-based optimizer is developed. This network directly learns and establishes a high-dimensional nonlinear mapping from the initial phase space to the optimized phase space that satisfies predefined performance criteria. The network efficiently generates a set of phase-coded subwaveforms exhibiting low autocorrelation sidelobes and low cross-correlation levels for multiple ROIs. Simulation results validate the effectiveness of this method, demonstrating that the designed waveforms achieve higher processing gain (compared with the narrowband searching mode) and improved imaging resolution in the designated ROIs during simultaneous search and multitarget imaging. Moreover, the autocorrelation and cross-correlation performance of the proposed method significantly outperforms that of conventional approaches, indicating that it provides an effective solution for enhancing the multitask capabilities of modern radar systems.
Coherent Frequency Diverse Array (FDA) radar demonstrates significant potential for wide-area search tasks due to its simple system architecture, flexible beam scanning, and high transmit Degrees of Freedom (DOF). However, its inherent beam-scanning mechanism reduces dwell time in specific directions, thereby limiting the imaging range resolution when a conventional wideband waveform is used. To resolve the intrinsic contradiction between wide-area search and high-resolution imaging, this paper proposes a deep learning-based integrated search-imaging waveform design method. By leveraging the multi-DoF flexible transmission capability of coherent FDA, the proposed method customizes multidimensional transmit resources, including waveform, bandwidth, and transmit gain, for multiple Regions of Interest (ROIs) while preserving wide-coverage search performance. To address the nonconvex optimization problem with dual constraints of constant modulus and low correlation in baseband waveform design, a residual autoencoder-based optimizer is developed. This network directly learns and establishes a high-dimensional nonlinear mapping from the initial phase space to the optimized phase space that satisfies predefined performance criteria. The network efficiently generates a set of phase-coded subwaveforms exhibiting low autocorrelation sidelobes and low cross-correlation levels for multiple ROIs. Simulation results validate the effectiveness of this method, demonstrating that the designed waveforms achieve higher processing gain (compared with the narrowband searching mode) and improved imaging resolution in the designated ROIs during simultaneous search and multitarget imaging. Moreover, the autocorrelation and cross-correlation performance of the proposed method significantly outperforms that of conventional approaches, indicating that it provides an effective solution for enhancing the multitask capabilities of modern radar systems.
This study addresses time-frequency synchronization errors in distributed Multiple-Input Multiple-Output (MIMO) radar systems and proposes a joint estimation method for target parameters and system time-frequency biases based on multitemporal measurement data. The method overcomes the limitations of traditional approaches that rely on singletemporal measurement data and direct-path signals, enabling high-accuracy joint parameter estimation through multiepoch data fusion without requiring direct-path information. The proposed method adopts a two-step strategy that combines a closed-form solution with iterative optimization. First, a closed-form solution is derived within a two-stage weighted least-squares framework using only the first- and last-epoch observations to obtain initial estimates of the target position, velocity, and auxiliary variables. This stage explicitly models second-order error terms and optimizes the construction of the weighting matrix, significantly improving accuracy and robustness under high-error conditions. Second, using the closed-form estimates as initialization, a maximum likelihood-maximum a posteriori objective function is formulated based on the full multi-epoch measurement data, and a trust-region iterative optimization method is applied to refine the estimates and recover the time-frequency bias parameters. Simulation results show that the proposed method outperforms existing approaches across various error levels and geometric configurations, significantly enhancing the accuracy and robustness of target localization, velocity estimation, and time-frequency bias estimation. These results demonstrate strong theoretical significance and promising practical application potential.
This study addresses time-frequency synchronization errors in distributed Multiple-Input Multiple-Output (MIMO) radar systems and proposes a joint estimation method for target parameters and system time-frequency biases based on multitemporal measurement data. The method overcomes the limitations of traditional approaches that rely on singletemporal measurement data and direct-path signals, enabling high-accuracy joint parameter estimation through multiepoch data fusion without requiring direct-path information. The proposed method adopts a two-step strategy that combines a closed-form solution with iterative optimization. First, a closed-form solution is derived within a two-stage weighted least-squares framework using only the first- and last-epoch observations to obtain initial estimates of the target position, velocity, and auxiliary variables. This stage explicitly models second-order error terms and optimizes the construction of the weighting matrix, significantly improving accuracy and robustness under high-error conditions. Second, using the closed-form estimates as initialization, a maximum likelihood-maximum a posteriori objective function is formulated based on the full multi-epoch measurement data, and a trust-region iterative optimization method is applied to refine the estimates and recover the time-frequency bias parameters. Simulation results show that the proposed method outperforms existing approaches across various error levels and geometric configurations, significantly enhancing the accuracy and robustness of target localization, velocity estimation, and time-frequency bias estimation. These results demonstrate strong theoretical significance and promising practical application potential.
High-speed squint-forward-looking Synthetic Aperture Radar (SAR) imaging (squint angle: >70°) is challenged by severe range-Doppler coupling and Doppler space variance. Traditional Nonlinear Chirp Scaling (NCS) algorithms can effectively mitigate Doppler space variance under high-squint conditions (squint angle: >30°), but they rely on approximate treatments and exhibit rapidly increasing derivation complexity at high scaling orders. This makes high-order generalization difficult and limits their application in high-speed squint-forward-looking SAR systems. To address this issue, this study demonstrates that Fourier Transform (FT) and Inverse FT (IFT) implementations, based on the Principle of Stationary Phase (POSP) and the Method of Series Reversion (MSR) for azimuth data domain transformation, exhibit regular structural patterns. Building on this insight, a fifth-order NCS algorithm with low derivation complexity is proposed, along with a dedicated geometric correction method. For a given predefined slant range model and NCS order, the proposed algorithm requires only a single FT/IFT derivation to obtain the analytical expression of the signal after NCS processing, thereby simplifying both the construction of the Doppler parameter linear equation system and the solution of NCS parameters. This significantly reduces the complexity of the algorithm derivation. Furthermore, an instantaneous projection geometric model is established based on the high-speed squint-forward-looking SAR imaging geometry, enabling the development of a tailored geometric correction method. Compared with traditional NCS algorithms, the proposed fifth-order NCS algorithm achieves superior imaging performance while maintaining computational efficiency. Simulated and real data processing validate its effectiveness and advantages in high-speed squint-forward-looking scenarios.
High-speed squint-forward-looking Synthetic Aperture Radar (SAR) imaging (squint angle: >70°) is challenged by severe range-Doppler coupling and Doppler space variance. Traditional Nonlinear Chirp Scaling (NCS) algorithms can effectively mitigate Doppler space variance under high-squint conditions (squint angle: >30°), but they rely on approximate treatments and exhibit rapidly increasing derivation complexity at high scaling orders. This makes high-order generalization difficult and limits their application in high-speed squint-forward-looking SAR systems. To address this issue, this study demonstrates that Fourier Transform (FT) and Inverse FT (IFT) implementations, based on the Principle of Stationary Phase (POSP) and the Method of Series Reversion (MSR) for azimuth data domain transformation, exhibit regular structural patterns. Building on this insight, a fifth-order NCS algorithm with low derivation complexity is proposed, along with a dedicated geometric correction method. For a given predefined slant range model and NCS order, the proposed algorithm requires only a single FT/IFT derivation to obtain the analytical expression of the signal after NCS processing, thereby simplifying both the construction of the Doppler parameter linear equation system and the solution of NCS parameters. This significantly reduces the complexity of the algorithm derivation. Furthermore, an instantaneous projection geometric model is established based on the high-speed squint-forward-looking SAR imaging geometry, enabling the development of a tailored geometric correction method. Compared with traditional NCS algorithms, the proposed fifth-order NCS algorithm achieves superior imaging performance while maintaining computational efficiency. Simulated and real data processing validate its effectiveness and advantages in high-speed squint-forward-looking scenarios.
High-Resolution Wide-Swath (HRWS) imaging is a key development direction for next-generation spaceborne Synthetic Aperture Radar (SAR) systems. Multiple-Input Multiple-Output (MIMO) SAR systems offer high spatial degrees of freedom, enabling enhanced system performance. However, effectively separating echoes from different transmit channels in MIMO-SAR systems is key to unlocking their advantages in spatial degrees of freedom. In this regard, a novel Space-Time Phase-Coded (STPC) waveform for MIMO-SAR systems is proposed based on the phase characteristics of SAR signals and the space-time properties of the “stop-and-go” model. This waveform modulates transmitted signals in the range dimension via phase coding and emits them at distinct spatial positions within each pulse repetition period, following a preset coding sequence. Upon reception, demodulating aliased echoes using receiver timing matched to the transmitter enables the efficient separation of echoes from different transmit channels. The proposed scheme can be integrated with existing classical azimuth multichannel reconstruction methods, effectively mitigating the trade-off between Pulse Repetition Frequency (PRF) and echo separability. Compared with the Alamouti, Short-Term Shift-Orthogonal (STSO), and Segmented Phase Code (SPC) waveforms in current MIMO-SAR systems, the STPC approach reduces antenna requirements by nearly 50%, thereby lowering the cost and complexity of hardware implementation. Simulation experiments on point targets and distributed scenes verify that the proposed waveform and processing scheme effectively suppress interwaveform interference and deliver strong imaging performance.
High-Resolution Wide-Swath (HRWS) imaging is a key development direction for next-generation spaceborne Synthetic Aperture Radar (SAR) systems. Multiple-Input Multiple-Output (MIMO) SAR systems offer high spatial degrees of freedom, enabling enhanced system performance. However, effectively separating echoes from different transmit channels in MIMO-SAR systems is key to unlocking their advantages in spatial degrees of freedom. In this regard, a novel Space-Time Phase-Coded (STPC) waveform for MIMO-SAR systems is proposed based on the phase characteristics of SAR signals and the space-time properties of the “stop-and-go” model. This waveform modulates transmitted signals in the range dimension via phase coding and emits them at distinct spatial positions within each pulse repetition period, following a preset coding sequence. Upon reception, demodulating aliased echoes using receiver timing matched to the transmitter enables the efficient separation of echoes from different transmit channels. The proposed scheme can be integrated with existing classical azimuth multichannel reconstruction methods, effectively mitigating the trade-off between Pulse Repetition Frequency (PRF) and echo separability. Compared with the Alamouti, Short-Term Shift-Orthogonal (STSO), and Segmented Phase Code (SPC) waveforms in current MIMO-SAR systems, the STPC approach reduces antenna requirements by nearly 50%, thereby lowering the cost and complexity of hardware implementation. Simulation experiments on point targets and distributed scenes verify that the proposed waveform and processing scheme effectively suppress interwaveform interference and deliver strong imaging performance.
To enhance the jamming recognition capabilities of radars in complex electromagnetic environments, this study proposes YOLO-S3, a lightweight network for recognizing composite jamming signals. YOLO-S3 is characterized by three core attributes: Smartness, slimness, and high speed. Initially, a technical approach based on visual detection algorithms is introduced to identify 2D time-frequency representations of jamming signals. An image dataset of composite jamming signals is constructed using signal modeling, simulation technology, and the short-time Fourier transform. Next, the backbone and neck networks of YOLOv8n are restructured by integrating StarNet and SlimNeck, and a Self-Attention Detect Head (SADH) is designed to enhance feature extraction. These modifications result in a lightweight network without compromising recognition accuracy. Finally, the network’s performance is validated through ablation and comparative experiments. Results show that YOLO-S3 features a highly lightweight network design. When the signal-to-jamming ratio varies from −10 to 0 dB and the Signal-to-Noise Ratio (SNR) is ≥0 dB, the network achieves an impressive average recognition accuracy of 99.5%. Even when the SNR decreases to −10 dB, it maintains a robust average recognition accuracy of 95.5%, exhibiting strong performance under low SNR conditions. These findings provide a promising solution for the real-time recognition of composite jamming signals on resource-constrained platforms such as airborne radar signal processors and portable electronic devices.
To enhance the jamming recognition capabilities of radars in complex electromagnetic environments, this study proposes YOLO-S3, a lightweight network for recognizing composite jamming signals. YOLO-S3 is characterized by three core attributes: Smartness, slimness, and high speed. Initially, a technical approach based on visual detection algorithms is introduced to identify 2D time-frequency representations of jamming signals. An image dataset of composite jamming signals is constructed using signal modeling, simulation technology, and the short-time Fourier transform. Next, the backbone and neck networks of YOLOv8n are restructured by integrating StarNet and SlimNeck, and a Self-Attention Detect Head (SADH) is designed to enhance feature extraction. These modifications result in a lightweight network without compromising recognition accuracy. Finally, the network’s performance is validated through ablation and comparative experiments. Results show that YOLO-S3 features a highly lightweight network design. When the signal-to-jamming ratio varies from −10 to 0 dB and the Signal-to-Noise Ratio (SNR) is ≥0 dB, the network achieves an impressive average recognition accuracy of 99.5%. Even when the SNR decreases to −10 dB, it maintains a robust average recognition accuracy of 95.5%, exhibiting strong performance under low SNR conditions. These findings provide a promising solution for the real-time recognition of composite jamming signals on resource-constrained platforms such as airborne radar signal processors and portable electronic devices.
Display Method:
2026, 15(3): 779-796.
Lunar lobate scarps are small-scale linear structures formed by shallow thrust fault activity on the lunar surface, and their spatial distribution and stress characteristics provide essential clues for understanding the late-stage tectonic evolution of the Moon. At present, the correlation mechanism between the stress characteristics of lobate scarps and their radar scattering response remains unclear. In this study, lobate scarps in the Apollo Basin are considered as the research focus, and scattering characteristic parameters are extracted from Mini-RF images. Subsequently, the Coulomb software is used to invert the distribution characteristics of the regional stress field based on high-resolution digital elevation models. On this basis, the correspondence between radar scattering characteristics and stress is analyzed using statistical correlation methods, revealing the underlying relationship between tectonic activity and surface material response. The main conclusions are as follows. (1) The strain near the fault is markedly higher than that in the surrounding areas, with the maximum shear strain concentrated in the fault dip direction. Volumetric strain indicates volume expansion within the fault hanging wall, whereas volume contraction is observed at both ends and at the center of the sliding surface. (2) The scarp face and hanging wall regions exhibit stronger scattering responses in terms of the circular polarization ratio and partial polarization decomposition parameters, suggesting higher degrees of fragmentation, boulder exposure, or structural complexity in these areas. However, the scattering differences are also influenced by the combined effects of surface roughness, incidence geometry, and subsequent modification processes. (3) The regression analysis of scattering parameters and stress fields, based on multiple linear regression and random forest algorithms, indicates that the correlation between scattering characteristics and stress is likely nonlinear, governed by the combined effects of topographic conditions, surface roughness, and local structures. Overall, this study develops an exploratory radar-topography joint analysis framework for lobate scarps in the Apollo Basin to evaluate whether a quantifiable statistical correspondence exists between scattering features and stress indicators, as well as to provide supplementary evidence for studies of shallow tectonic activity under similar geological settings.
Lunar lobate scarps are small-scale linear structures formed by shallow thrust fault activity on the lunar surface, and their spatial distribution and stress characteristics provide essential clues for understanding the late-stage tectonic evolution of the Moon. At present, the correlation mechanism between the stress characteristics of lobate scarps and their radar scattering response remains unclear. In this study, lobate scarps in the Apollo Basin are considered as the research focus, and scattering characteristic parameters are extracted from Mini-RF images. Subsequently, the Coulomb software is used to invert the distribution characteristics of the regional stress field based on high-resolution digital elevation models. On this basis, the correspondence between radar scattering characteristics and stress is analyzed using statistical correlation methods, revealing the underlying relationship between tectonic activity and surface material response. The main conclusions are as follows. (1) The strain near the fault is markedly higher than that in the surrounding areas, with the maximum shear strain concentrated in the fault dip direction. Volumetric strain indicates volume expansion within the fault hanging wall, whereas volume contraction is observed at both ends and at the center of the sliding surface. (2) The scarp face and hanging wall regions exhibit stronger scattering responses in terms of the circular polarization ratio and partial polarization decomposition parameters, suggesting higher degrees of fragmentation, boulder exposure, or structural complexity in these areas. However, the scattering differences are also influenced by the combined effects of surface roughness, incidence geometry, and subsequent modification processes. (3) The regression analysis of scattering parameters and stress fields, based on multiple linear regression and random forest algorithms, indicates that the correlation between scattering characteristics and stress is likely nonlinear, governed by the combined effects of topographic conditions, surface roughness, and local structures. Overall, this study develops an exploratory radar-topography joint analysis framework for lobate scarps in the Apollo Basin to evaluate whether a quantifiable statistical correspondence exists between scattering features and stress indicators, as well as to provide supplementary evidence for studies of shallow tectonic activity under similar geological settings.
2026, 15(3): 797-813.
The Ring-Moat Dome Structure (RMDS) is a small-scale domical landform that develops on the lunar mare basalt surface. With an average height of only 3–4 m and a mean diameter of approximately 200 m, these features display a low-relief morphology. Owing to their abundance, RMDSs have become an important subject for understanding lunar volcanic activity and magmatic thermodynamic processes. Although optical remote sensing observations support a volcanic origin for RMDSs, alternative hypotheses have been proposed. Therefore, confirming their genesis requires further geological evidence. Microwave radar provides a distinct advantage in probing the subsurface structure and physical properties of the Moon owing to its penetrative capability. However, to date, no studies have examined the microwave radar scattering characteristics of RMDSs. This paper therefore analyzes the radar backscatter power and Circular Polarization Ratio (CPR) characteristics of RMDSs using S-band (12.6 cm wavelength) data acquired by the spaceborne Miniature Radio Frequency (Mini-RF) instrument and the ground-based Arecibo radar. The study area is a region densely populated with RMDSs on the mare surface within the Mare Tranquillitatis basin. The results indicate the following: (1) RMDSs exhibit low backscatter power, which is highly consistent with the weak radar scattering predicted by the foamy magma genetic model. According to this model, the primary cause of the low-intensity radar echo is the presence of submillimeter-scale fine-grained materials within the uppermost ~2–3 m depth range. (2) Influenced by impact cratering, topographic variations, and mass wasting, some RMDSs display localized enhancement of backscatter to varying degrees; however, prolonged space weathering diminishes this effect. (3) The mean statistical values of the radar backscatter coefficient and the CPR for RMDSs are remarkably close to those of pyroclastic deposits, indicating that their surface physical properties are analogous and that the particle size of their surface materials should be comparable to those of pyroclastic materials, which are predominantly fine-grained particles in the micrometer-to-millimeter range. These findings further confirm that multiband, high-resolution, and multipolarization radar data can yield richer geological evidence for the detailed investigation of RMDSs. This not only deepens the understanding of RMDS formation and evolutionary mechanisms but also provides a valuable reference for future microwave remote sensing exploration of lunar volcanic landforms.
The Ring-Moat Dome Structure (RMDS) is a small-scale domical landform that develops on the lunar mare basalt surface. With an average height of only 3–4 m and a mean diameter of approximately 200 m, these features display a low-relief morphology. Owing to their abundance, RMDSs have become an important subject for understanding lunar volcanic activity and magmatic thermodynamic processes. Although optical remote sensing observations support a volcanic origin for RMDSs, alternative hypotheses have been proposed. Therefore, confirming their genesis requires further geological evidence. Microwave radar provides a distinct advantage in probing the subsurface structure and physical properties of the Moon owing to its penetrative capability. However, to date, no studies have examined the microwave radar scattering characteristics of RMDSs. This paper therefore analyzes the radar backscatter power and Circular Polarization Ratio (CPR) characteristics of RMDSs using S-band (12.6 cm wavelength) data acquired by the spaceborne Miniature Radio Frequency (Mini-RF) instrument and the ground-based Arecibo radar. The study area is a region densely populated with RMDSs on the mare surface within the Mare Tranquillitatis basin. The results indicate the following: (1) RMDSs exhibit low backscatter power, which is highly consistent with the weak radar scattering predicted by the foamy magma genetic model. According to this model, the primary cause of the low-intensity radar echo is the presence of submillimeter-scale fine-grained materials within the uppermost ~2–3 m depth range. (2) Influenced by impact cratering, topographic variations, and mass wasting, some RMDSs display localized enhancement of backscatter to varying degrees; however, prolonged space weathering diminishes this effect. (3) The mean statistical values of the radar backscatter coefficient and the CPR for RMDSs are remarkably close to those of pyroclastic deposits, indicating that their surface physical properties are analogous and that the particle size of their surface materials should be comparable to those of pyroclastic materials, which are predominantly fine-grained particles in the micrometer-to-millimeter range. These findings further confirm that multiband, high-resolution, and multipolarization radar data can yield richer geological evidence for the detailed investigation of RMDSs. This not only deepens the understanding of RMDS formation and evolutionary mechanisms but also provides a valuable reference for future microwave remote sensing exploration of lunar volcanic landforms.
2026, 15(3): 814-826.
Chang’e-7 will carry a fully polarimetric Synthetic Aperture Radar (SAR) to investigate the topography and material properties of the lunar polar regions, which necessitates reliable polarimetric calibration. However, conventional ground-based calibration strategies are infeasible for lunar missions, underscoring the need for new relative polarimetric calibration methods tailored to the lunar surface. To address this challenge, we adopt a normal-incidence observation geometry and analyze how the co-polarization ratio \begin{document}$ {\sigma _{{\text{HH}}}} $\end{document} \begin{document}$ {\sigma _{{\text{VV}}}} $\end{document} \begin{document}$ \sigma $\end{document} \begin{document}$ {\sigma _{{\text{HH}}}} $\end{document} \begin{document}$ {\sigma _{{\text{VV}}}} $\end{document} \begin{document}$ \sigma $\end{document}
2026, 15(3): 827-843.
The Moon’s shallow subsurface structure provides crucial insights into its geological evolution, material composition, and space weathering processes. With the acquisition of extensive radar datasets from recent lunar exploration programs, such as the Chang’E missions, high-resolution characterization of the lunar regolith’s stratigraphic and physical properties has become a focus and challenge in lunar science. Conventional radar layer identification and tracking methods often suffer from instability in complex scattering environments, because of their sensitivity to noise and subsurface heterogeneity. To address these limitations, this study proposes an automatic layer-tracking algorithm based on a Dynamic Search Center (DSC) approach. This algorithm employs a Gaussian-weighted prediction mechanism to balance historical trajectory trends with local signal responses and uses a multifeatured fusion decision scheme to enhance tracking robustness under noisy conditions. Numerical simulations demonstrate that, with a search radius l = 20 and a historical window n = 20, the algorithm achieves a layer identification error of less than 2% for shallow strata (<140 ns). Meanwhile, for deep layers (>170 ns), with considerable signal attenuation, incorporating an edge-direction weighting term reduces the tracking error by over 30%. When applied to lunar penetrating radar data from the Chang’E-4 mission, the proposed method successfully realizes automatic stratigraphic tracing in lunar radar profiles, producing layer boundaries that are highly consistent with previous interpretations. Simulation and in-situ results confirm that the DSC-based algorithm accurately delineates real subsurface interfaces across media and structural morphologies, effectively suppressing noise, while maintaining smooth trajectories. Overall, the proposed method achieves low manual dependence, high robustness, and high precision in automatic radar layer tracking, thereby providing a valuable reference for analyzing radar data from upcoming missions such as Chang’E-7 and Martian shallow-subsurface explorations.
The Moon’s shallow subsurface structure provides crucial insights into its geological evolution, material composition, and space weathering processes. With the acquisition of extensive radar datasets from recent lunar exploration programs, such as the Chang’E missions, high-resolution characterization of the lunar regolith’s stratigraphic and physical properties has become a focus and challenge in lunar science. Conventional radar layer identification and tracking methods often suffer from instability in complex scattering environments, because of their sensitivity to noise and subsurface heterogeneity. To address these limitations, this study proposes an automatic layer-tracking algorithm based on a Dynamic Search Center (DSC) approach. This algorithm employs a Gaussian-weighted prediction mechanism to balance historical trajectory trends with local signal responses and uses a multifeatured fusion decision scheme to enhance tracking robustness under noisy conditions. Numerical simulations demonstrate that, with a search radius l = 20 and a historical window n = 20, the algorithm achieves a layer identification error of less than 2% for shallow strata (<140 ns). Meanwhile, for deep layers (>170 ns), with considerable signal attenuation, incorporating an edge-direction weighting term reduces the tracking error by over 30%. When applied to lunar penetrating radar data from the Chang’E-4 mission, the proposed method successfully realizes automatic stratigraphic tracing in lunar radar profiles, producing layer boundaries that are highly consistent with previous interpretations. Simulation and in-situ results confirm that the DSC-based algorithm accurately delineates real subsurface interfaces across media and structural morphologies, effectively suppressing noise, while maintaining smooth trajectories. Overall, the proposed method achieves low manual dependence, high robustness, and high precision in automatic radar layer tracking, thereby providing a valuable reference for analyzing radar data from upcoming missions such as Chang’E-7 and Martian shallow-subsurface explorations.
2026, 15(3): 844-859.
Formed by the cooling and solidification of flowing lava during volcanic activity, lunar lava tubes are considered promising candidates for future lunar bases due to their stable and protective roofs. However, these tubes are typically buried hundreds of meters to kilometers beneath the surface, making direct detection extremely difficult. Current detection methods mainly rely on radar and gravity anomaly analysis. However, the resolution of orbital radar is insufficient to distinguish similar subsurface structures, whereas in situ lunar penetrating radar is limited by a small detection range and vulnerability to near-field interference. Gravity anomaly detection also performs poorly when identifying tubes oriented north-south or with roofs narrower than a kilometer. Skylights serve as critical indicators for locating subsurface tubes and can be identified through optical imagery and infrared radiation thermal anomalies. However, optical images are constrained by illumination conditions, making full three-dimensional reconstruction of skylights difficult. Infrared data are further limited by penetration depth and spatial resolution (320 m×160 m), which hinders the detection of subsurface thermal anomalies and the assessment of the thermophysical properties of materials at the pit floor. To address these challenges, this paper explores the feasibility of detecting skylight thermal anomalies using microwave radiation. Owing to its penetration capability and sensitivity to dielectric properties, this approach can probe subsurface thermal features and effectively determine the material composition of the pit floor. However, a significant scale disparity exists between the kilometer-scale resolution of current data and the relatively small size of skylights. Therefore, enhancing the detection capability of passive microwave methods for 100-m-scale skylights remains a critical issue that requires immediate attention.
Formed by the cooling and solidification of flowing lava during volcanic activity, lunar lava tubes are considered promising candidates for future lunar bases due to their stable and protective roofs. However, these tubes are typically buried hundreds of meters to kilometers beneath the surface, making direct detection extremely difficult. Current detection methods mainly rely on radar and gravity anomaly analysis. However, the resolution of orbital radar is insufficient to distinguish similar subsurface structures, whereas in situ lunar penetrating radar is limited by a small detection range and vulnerability to near-field interference. Gravity anomaly detection also performs poorly when identifying tubes oriented north-south or with roofs narrower than a kilometer. Skylights serve as critical indicators for locating subsurface tubes and can be identified through optical imagery and infrared radiation thermal anomalies. However, optical images are constrained by illumination conditions, making full three-dimensional reconstruction of skylights difficult. Infrared data are further limited by penetration depth and spatial resolution (320 m×160 m), which hinders the detection of subsurface thermal anomalies and the assessment of the thermophysical properties of materials at the pit floor. To address these challenges, this paper explores the feasibility of detecting skylight thermal anomalies using microwave radiation. Owing to its penetration capability and sensitivity to dielectric properties, this approach can probe subsurface thermal features and effectively determine the material composition of the pit floor. However, a significant scale disparity exists between the kilometer-scale resolution of current data and the relatively small size of skylights. Therefore, enhancing the detection capability of passive microwave methods for 100-m-scale skylights remains a critical issue that requires immediate attention.
2026, 15(3): 860-875.
Direction of Arrival (DOA) estimation for low-elevation angle targets is a critical challenge in meter-wave and holographic staring radar systems, as its accuracy directly affects target height measurement performance. Traditional beamspace methods reduce computational complexity by projecting high-dimensional element-space data onto a low-dimensional beamspace using a beamformer. However, this lossy mapping leads to partial information loss, resulting in degraded elevation-angle estimation accuracy compared to that of element-space methods. To address this issue, this study proposes a high-accuracy beamspace DOA estimation method for low-elevation angle targets. First, the Cramér-Rao Bound (CRB) for both element-space and beamspace DOA estimation is derived, and the conditions under which these bounds are equal are analyzed. Since these conditions are difficult to satisfy in practical scenarios, an approximate-condition-based beamformer design strategy is developed to reduce data dimensionality while preserving effective target information. Finally, precise elevation-angle estimation is achieved using the maximum likelihood criterion. Simulation and experimental results show that the proposed method significantly reduces data dimensionality while maintaining estimation accuracy comparable to that of element-space methods at low-elevation angles, clearly outperforming existing beamspace algorithms.
Direction of Arrival (DOA) estimation for low-elevation angle targets is a critical challenge in meter-wave and holographic staring radar systems, as its accuracy directly affects target height measurement performance. Traditional beamspace methods reduce computational complexity by projecting high-dimensional element-space data onto a low-dimensional beamspace using a beamformer. However, this lossy mapping leads to partial information loss, resulting in degraded elevation-angle estimation accuracy compared to that of element-space methods. To address this issue, this study proposes a high-accuracy beamspace DOA estimation method for low-elevation angle targets. First, the Cramér-Rao Bound (CRB) for both element-space and beamspace DOA estimation is derived, and the conditions under which these bounds are equal are analyzed. Since these conditions are difficult to satisfy in practical scenarios, an approximate-condition-based beamformer design strategy is developed to reduce data dimensionality while preserving effective target information. Finally, precise elevation-angle estimation is achieved using the maximum likelihood criterion. Simulation and experimental results show that the proposed method significantly reduces data dimensionality while maintaining estimation accuracy comparable to that of element-space methods at low-elevation angles, clearly outperforming existing beamspace algorithms.
2026, 15(3): 876-890.
Non-cooperative bistatic radar exhibits significant application value for both civilian and military applications due to its anti-stealth and anti-jamming capabilities. However, its practical implementation faces challenges from unavoidable multipath interference and noise contamination in reference signals, stemming from uncontrollable radar illuminators and complex geographical environments. These effects substantially degrade the performance of cross-correlation processing between reference and echo signals compared with the ideal matched filter, resulting in stationary false targets. Such issues remain a critical bottleneck to operational deployment. This study systematically addresses these challenges by analyzing cross-correlation degradation under multipath and noise in the reference channel, and by establishing a quantitative mapping between multipath intensity, noise power, and detection probability. For Linear Frequency Modulated (LFM) signals, a dechirp-based multipath suppression algorithm is proposed. The algorithm exploits the inherent properties of LFM signals, transforming multipath components with different delays into distinct frequency offsets. Compared with mainstream Fractional Fourier Transform (FrFT) methods, this approach exhibits greater frequency separation among multipath components, enabling effective suppression with significantly reduced filter orders. The algorithm outperforms conventional methods in improving overall detection probability. Measured data processing in practical field-test scenarios (direct-path signals overwhelmed by strong multipath interference) validates the method’s efficacy in eliminating false targets, correcting range offsets, and enhancing detection probability.
Non-cooperative bistatic radar exhibits significant application value for both civilian and military applications due to its anti-stealth and anti-jamming capabilities. However, its practical implementation faces challenges from unavoidable multipath interference and noise contamination in reference signals, stemming from uncontrollable radar illuminators and complex geographical environments. These effects substantially degrade the performance of cross-correlation processing between reference and echo signals compared with the ideal matched filter, resulting in stationary false targets. Such issues remain a critical bottleneck to operational deployment. This study systematically addresses these challenges by analyzing cross-correlation degradation under multipath and noise in the reference channel, and by establishing a quantitative mapping between multipath intensity, noise power, and detection probability. For Linear Frequency Modulated (LFM) signals, a dechirp-based multipath suppression algorithm is proposed. The algorithm exploits the inherent properties of LFM signals, transforming multipath components with different delays into distinct frequency offsets. Compared with mainstream Fractional Fourier Transform (FrFT) methods, this approach exhibits greater frequency separation among multipath components, enabling effective suppression with significantly reduced filter orders. The algorithm outperforms conventional methods in improving overall detection probability. Measured data processing in practical field-test scenarios (direct-path signals overwhelmed by strong multipath interference) validates the method’s efficacy in eliminating false targets, correcting range offsets, and enhancing detection probability.
2026, 15(3): 891-908.
Space-Time Adaptive Processing (STAP) is a key technique used for ground/sea clutter suppression and moving target detection in airborne radar. However, under range ambiguity conditions, the inherent clutter nonstationarity in airborne bistatic radar violates the independent and identically distributed assumption required for training samples, significantly degrading the performance of conventional STAP methods. To address this issue, this study first analyzed the limitations of the Conventional Beamforming (CBF)-based disambiguation approach, which exhibits a trade-off between mainlobe gain loss and sidelobe suppression. A method based on a cascaded blocking matrix and adaptive beamforming is proposed for separating range-ambiguous clutter. Although this method improves upon the CBF-based approach, it introduces noise distortion, which limits further improvements in clutter separation and suppression accuracy. Hence, a novel method based on beam pattern reconstruction is proposed to overcome this drawback. This method formulates an optimization problem incorporating beam-maintenance and sidelobe-control terms to design spatial filter weights, effectively separating range-ambiguous clutter while preserving the mainlobe target gain and suppressing sidelobe clutter. Subsequently, angle-Doppler compensation is applied to the separated clutter, followed by final suppression using a subarray-based STAP method incorporating a joint three-channel Doppler transform. Simulation results revealed that compared with typical methods, the proposed approach more effectively separated clutter, significantly narrowed the mainlobe notch width, and limited the output signal-to-clutter-plus-noise ratio loss to <3 dB, thereby markedly enhancing clutter suppression performance and target detection capability under range ambiguity conditions.
Space-Time Adaptive Processing (STAP) is a key technique used for ground/sea clutter suppression and moving target detection in airborne radar. However, under range ambiguity conditions, the inherent clutter nonstationarity in airborne bistatic radar violates the independent and identically distributed assumption required for training samples, significantly degrading the performance of conventional STAP methods. To address this issue, this study first analyzed the limitations of the Conventional Beamforming (CBF)-based disambiguation approach, which exhibits a trade-off between mainlobe gain loss and sidelobe suppression. A method based on a cascaded blocking matrix and adaptive beamforming is proposed for separating range-ambiguous clutter. Although this method improves upon the CBF-based approach, it introduces noise distortion, which limits further improvements in clutter separation and suppression accuracy. Hence, a novel method based on beam pattern reconstruction is proposed to overcome this drawback. This method formulates an optimization problem incorporating beam-maintenance and sidelobe-control terms to design spatial filter weights, effectively separating range-ambiguous clutter while preserving the mainlobe target gain and suppressing sidelobe clutter. Subsequently, angle-Doppler compensation is applied to the separated clutter, followed by final suppression using a subarray-based STAP method incorporating a joint three-channel Doppler transform. Simulation results revealed that compared with typical methods, the proposed approach more effectively separated clutter, significantly narrowed the mainlobe notch width, and limited the output signal-to-clutter-plus-noise ratio loss to <3 dB, thereby markedly enhancing clutter suppression performance and target detection capability under range ambiguity conditions.
2026, 15(3): 909-918.
Pulse Doppler radar provides all-weather operational capability and enables simultaneous acquisition of target range and velocity through Range-Doppler (RD) maps. In near-vertical flight scenarios, the geometric structure of RD maps implicitly encodes key platform motion parameters, including altitude, velocity, and pitch angle. However, these parameters are strongly coupled in the RD domain, making effective decoupling difficult for traditional signal-processing-based inversion methods, particularly under complex terrain and near-vertical incidence conditions. Although recent advances in deep learning have shown strong potential for motion information sensing, multitask learning in this context still faces challenges in achieving both real-time performance and high estimation accuracy. To address these issues, this study proposes a novel network architecture, termed Range-Doppler Map Fusion Network (RDMFNet), that performs multirepresentation information fusion via shared encoders and parallel decoders, along with a two-stage progressive training strategy to enhance parameter estimation accuracy. Experimental results show that RDMFNet achieves estimation errors of 14.447 m for altitude, 4.635 m/s for velocity, and 0.755° for pitch angle, demonstrating its effectiveness for high-precision, real-time perception.
Pulse Doppler radar provides all-weather operational capability and enables simultaneous acquisition of target range and velocity through Range-Doppler (RD) maps. In near-vertical flight scenarios, the geometric structure of RD maps implicitly encodes key platform motion parameters, including altitude, velocity, and pitch angle. However, these parameters are strongly coupled in the RD domain, making effective decoupling difficult for traditional signal-processing-based inversion methods, particularly under complex terrain and near-vertical incidence conditions. Although recent advances in deep learning have shown strong potential for motion information sensing, multitask learning in this context still faces challenges in achieving both real-time performance and high estimation accuracy. To address these issues, this study proposes a novel network architecture, termed Range-Doppler Map Fusion Network (RDMFNet), that performs multirepresentation information fusion via shared encoders and parallel decoders, along with a two-stage progressive training strategy to enhance parameter estimation accuracy. Experimental results show that RDMFNet achieves estimation errors of 14.447 m for altitude, 4.635 m/s for velocity, and 0.755° for pitch angle, demonstrating its effectiveness for high-precision, real-time perception.
2026, 15(3): 919-928.
Passive localization methods based on synthetic aperture imaging offer high positioning accuracy. However, in scenarios involving multiple radar emitters transmitting Linear Frequency-Modulated (LFM) signals, distinguishing signals that are overlapped in the time and frequency domains can be challenging. This phenomenon, known as phase overlap, results in a significant degradation of localization performance. To address this issue, the present paper proposes a single-satellite multi-radar-emitter passive localization method based on synthetic aperture imaging using time-frequency parameter estimation. First, a signal model for multiple radar emitters transmitting LFM signals is constructed. The time-frequency parameters of the multiple radar emitter signals are estimated concurrently via a combination of Short-Time Fourier Transform (STFT) and DBSCAN. A rapid approximation of the azimuth chirp rate is attained through a coarse-to-fine search strategy founded upon the use of the STFT. The accurate localization of multiple radar emitters is ultimately realized through the implementation of two-dimensional focusing in the range and azimuth dimensions. The Cramer-Rao lower bound of the proposed method is derived on this basis. The experimental findings demonstrate that the proposed method enhances the localization accuracy by approximately 10 km at a signal-to-noise ratio of −10 dB, in comparison with the enhanced real-valued space-time subspace data fusion-based direct positioning method. Moreover, it reduces the computational time by half relative to the CLEAN-based synthetic aperture multi-source localization approach.
Passive localization methods based on synthetic aperture imaging offer high positioning accuracy. However, in scenarios involving multiple radar emitters transmitting Linear Frequency-Modulated (LFM) signals, distinguishing signals that are overlapped in the time and frequency domains can be challenging. This phenomenon, known as phase overlap, results in a significant degradation of localization performance. To address this issue, the present paper proposes a single-satellite multi-radar-emitter passive localization method based on synthetic aperture imaging using time-frequency parameter estimation. First, a signal model for multiple radar emitters transmitting LFM signals is constructed. The time-frequency parameters of the multiple radar emitter signals are estimated concurrently via a combination of Short-Time Fourier Transform (STFT) and DBSCAN. A rapid approximation of the azimuth chirp rate is attained through a coarse-to-fine search strategy founded upon the use of the STFT. The accurate localization of multiple radar emitters is ultimately realized through the implementation of two-dimensional focusing in the range and azimuth dimensions. The Cramer-Rao lower bound of the proposed method is derived on this basis. The experimental findings demonstrate that the proposed method enhances the localization accuracy by approximately 10 km at a signal-to-noise ratio of −10 dB, in comparison with the enhanced real-valued space-time subspace data fusion-based direct positioning method. Moreover, it reduces the computational time by half relative to the CLEAN-based synthetic aperture multi-source localization approach.
2026, 15(3): 929-943.
In locating ground moving radiating sources, traditional passive positioning methods, such as Direction of Arrival (DOA), often rely on long-term observation and filtering, resulting in low positioning efficiency. Existing synthetic aperture-based positioning methods are primarily designed for stationary radiating sources, making high-precision positioning of moving sources difficult. To address this limitation, this paper proposes synthetic aperture-based fast positioning and velocity estimation methods for moving radiating sources under single- and dual-station positioning systems, respectively. The proposed methods establish an instantaneous slant range model of the radiating source and derive the mapping relationship between the positioning parameters (position and velocity) and the imaging parameters. Specifically, in the single-station scenario, the traditional second-order slant range model is extended to third order, and a third-order chirp rate is introduced to supplement the degrees of freedom, thereby enabling simultaneous estimation of position and velocity. In the dual-station scenario, an additional observation station is used to introduce two new imaging parameters, thereby further improving the rapidity and accuracy of positioning. To address the multi-solution problem inherent in the positioning equations, this paper proposes true-solution determination criteria for the single- and dual-station systems and presents an initialization strategy to ensure a unique solution for dual-station positioning. Furthermore, the paper analyzes how various factors affect the positioning accuracy of single- and dual-station models, compares the performance of the proposed single- and dual-station passive positioning models, and verifies the effectiveness of the proposed algorithms through simulations.
In locating ground moving radiating sources, traditional passive positioning methods, such as Direction of Arrival (DOA), often rely on long-term observation and filtering, resulting in low positioning efficiency. Existing synthetic aperture-based positioning methods are primarily designed for stationary radiating sources, making high-precision positioning of moving sources difficult. To address this limitation, this paper proposes synthetic aperture-based fast positioning and velocity estimation methods for moving radiating sources under single- and dual-station positioning systems, respectively. The proposed methods establish an instantaneous slant range model of the radiating source and derive the mapping relationship between the positioning parameters (position and velocity) and the imaging parameters. Specifically, in the single-station scenario, the traditional second-order slant range model is extended to third order, and a third-order chirp rate is introduced to supplement the degrees of freedom, thereby enabling simultaneous estimation of position and velocity. In the dual-station scenario, an additional observation station is used to introduce two new imaging parameters, thereby further improving the rapidity and accuracy of positioning. To address the multi-solution problem inherent in the positioning equations, this paper proposes true-solution determination criteria for the single- and dual-station systems and presents an initialization strategy to ensure a unique solution for dual-station positioning. Furthermore, the paper analyzes how various factors affect the positioning accuracy of single- and dual-station models, compares the performance of the proposed single- and dual-station passive positioning models, and verifies the effectiveness of the proposed algorithms through simulations.
2026, 15(3): 944-963.
Specific Emitter Identification (SEI) relies on subtle differences in the radio frequency fingerprints of device-emitted signals to determine the emitter identity attributes. SEI plays a fundamental role in wireless security, spectrum management, and situational awareness. However, as wireless scenarios become increasingly diverse and dynamic, deep learning models trained in a single domain (where the source and target domains share the same distribution) often suffer severe performance degradation in real-world settings such as cross-receiver and cross-time scenarios. This degradation has not yet been comprehensively analyzed. To address this issue, this paper first classifies SEI according to cross-scenario types, and then systematically reviews mainstream algorithm frameworks and representative SEI methods, with a particular focus on the core ideas and key technologies underlying each method. It also summarizes the main open-source cross-scenario SEI datasets. Finally, the paper identifies current research bottlenecks and outlines potential future directions, aiming to facilitate advances in SEI theories and methodologies applicable to complex electromagnetic environments.
Specific Emitter Identification (SEI) relies on subtle differences in the radio frequency fingerprints of device-emitted signals to determine the emitter identity attributes. SEI plays a fundamental role in wireless security, spectrum management, and situational awareness. However, as wireless scenarios become increasingly diverse and dynamic, deep learning models trained in a single domain (where the source and target domains share the same distribution) often suffer severe performance degradation in real-world settings such as cross-receiver and cross-time scenarios. This degradation has not yet been comprehensively analyzed. To address this issue, this paper first classifies SEI according to cross-scenario types, and then systematically reviews mainstream algorithm frameworks and representative SEI methods, with a particular focus on the core ideas and key technologies underlying each method. It also summarizes the main open-source cross-scenario SEI datasets. Finally, the paper identifies current research bottlenecks and outlines potential future directions, aiming to facilitate advances in SEI theories and methodologies applicable to complex electromagnetic environments.
2026, 15(3): 964-982.
The spaceborne Hybrid-Polarimetric Synthetic Aperture Radar (HP-SAR) balances the acquisition of rich polarimetric information with high-performance imaging. It offers advantages such as low system complexity and reduced data acquisition costs, and has emerged as a prominent direction in multidimensional microwave remote sensing. LT-1 is China’s first radar satellite equipped with spaceborne HP imaging capability, and it is also the world’s first satellite to implement a multi-channel HP radar system. This study utilizes HP imagery from the LT-1 satellite to construct and systematically elaborate the HP-SAR Evaluation and Analytical Dataset (HEAD-1.0), thereby addressing the lack of high-quality open-source HP datasets. HEAD-1.0 aims to provide data support for the quantitative assessment of HP-SAR image quality, the development of HP-SAR technology, and the design of new satellite missions, with particular emphasis on supporting novel observational technologies for terrestrial, oceanic, and deep-space applications. It comprises three components: (1) LT-1 SAR imagery, including 30 HP-SAR images and 16 Quad-Polarimetric SAR (QP-SAR) images, covering an area of approximately 64000 km2; (2) Auxiliary data, including six optical images and Digital Elevation Model (DEM) data in the same area as SAR images; and (3) Annotation data, including 28 active/passive calibrators, approximately 17 km2 of land cover classification, and 23 polygonal/linear annotated planetary analog scenes. Based on HEAD-1.0, a preliminary qualitative and quantitative study was conducted, involving HP-SAR calibration, a comparison of terrain classification between HP-SAR and QP-SAR, and an analysis of HP characterizations of planetary analog scenes. In the future, an internationally advanced polarimetric SAR benchmark database will be constructed by integrating multi-platform, multi-band, multi-angle, and multi-temporal imaging data. In particular, the future study will focus on supporting innovative research on key technologies, including planetary surface and subsurface exploration, intelligent fusion of multisource remote sensing data, and advanced interpretation algorithms for SAR imagery.
The spaceborne Hybrid-Polarimetric Synthetic Aperture Radar (HP-SAR) balances the acquisition of rich polarimetric information with high-performance imaging. It offers advantages such as low system complexity and reduced data acquisition costs, and has emerged as a prominent direction in multidimensional microwave remote sensing. LT-1 is China’s first radar satellite equipped with spaceborne HP imaging capability, and it is also the world’s first satellite to implement a multi-channel HP radar system. This study utilizes HP imagery from the LT-1 satellite to construct and systematically elaborate the HP-SAR Evaluation and Analytical Dataset (HEAD-1.0), thereby addressing the lack of high-quality open-source HP datasets. HEAD-1.0 aims to provide data support for the quantitative assessment of HP-SAR image quality, the development of HP-SAR technology, and the design of new satellite missions, with particular emphasis on supporting novel observational technologies for terrestrial, oceanic, and deep-space applications. It comprises three components: (1) LT-1 SAR imagery, including 30 HP-SAR images and 16 Quad-Polarimetric SAR (QP-SAR) images, covering an area of approximately 64000 km2; (2) Auxiliary data, including six optical images and Digital Elevation Model (DEM) data in the same area as SAR images; and (3) Annotation data, including 28 active/passive calibrators, approximately 17 km2 of land cover classification, and 23 polygonal/linear annotated planetary analog scenes. Based on HEAD-1.0, a preliminary qualitative and quantitative study was conducted, involving HP-SAR calibration, a comparison of terrain classification between HP-SAR and QP-SAR, and an analysis of HP characterizations of planetary analog scenes. In the future, an internationally advanced polarimetric SAR benchmark database will be constructed by integrating multi-platform, multi-band, multi-angle, and multi-temporal imaging data. In particular, the future study will focus on supporting innovative research on key technologies, including planetary surface and subsurface exploration, intelligent fusion of multisource remote sensing data, and advanced interpretation algorithms for SAR imagery.
2026, 15(3): 983-995.
Synthetic Aperture Radar (SAR) and optical imagery are two key remote-sensing modalities in Earth observation, and cross-modal image matching between them is widely applied in tasks such as image fusion, joint interpretation, and high-precision geolocation. In recent years, with the rapid growth of Earth-observation data, the importance of cross-modal image matching between SAR and optical data has become increasingly prominent, and related studies have achieved notable progress. In particular, Deep Learning (DL)-based methods, owing to their strengths in cross-modal feature representation and high-level semantic extraction, have demonstrated excellent matching accuracy and adaptability across varying imaging conditions. However, most publicly available datasets are limited to small image patches and lack complete full-scene image pairs that cover realistic large-scale scenarios, making it difficult to comprehensively evaluate the performance of matching algorithms in practical remote-sensing settings and constraining advances in the training and generalization of DL models. To address these issues, this study develops and releases OSDataset2.0, a large-scale benchmark dataset for SAR-optical image matching. The dataset comprises two parts: A patch-level subset and a scene-level subset. The patch-level subset is composed of 6,476 registered 512 × 512 image pairs covering 14 countries (Argentina, Australia, Poland, Germany, Russia, France, Qatar, Malaysia, the United States, Japan, Türkiye, Singapore, India, and China); the scene-level subset consists of one pair of full-scene optical and SAR images. For full-scene images, high-precision, uniformly distributed ground-truth correspondences are provided, extracted under the principle of imaging-mechanism consistency, together with a general evaluation codebase that supports quantitative analysis of registration accuracy for arbitrary matching algorithms. To further assess the dataset’s effectiveness and challenge level, a systematic evaluation of 11 representative optical-SAR matching methods on OSDataset2.0 is conducted, covering traditional feature-based approaches and mainstream DL models. Experimental results show that the dataset not only supports effective algorithmic comparisons but also provides reliable training resources and a unified evaluation benchmark for subsequent research.
Synthetic Aperture Radar (SAR) and optical imagery are two key remote-sensing modalities in Earth observation, and cross-modal image matching between them is widely applied in tasks such as image fusion, joint interpretation, and high-precision geolocation. In recent years, with the rapid growth of Earth-observation data, the importance of cross-modal image matching between SAR and optical data has become increasingly prominent, and related studies have achieved notable progress. In particular, Deep Learning (DL)-based methods, owing to their strengths in cross-modal feature representation and high-level semantic extraction, have demonstrated excellent matching accuracy and adaptability across varying imaging conditions. However, most publicly available datasets are limited to small image patches and lack complete full-scene image pairs that cover realistic large-scale scenarios, making it difficult to comprehensively evaluate the performance of matching algorithms in practical remote-sensing settings and constraining advances in the training and generalization of DL models. To address these issues, this study develops and releases OSDataset2.0, a large-scale benchmark dataset for SAR-optical image matching. The dataset comprises two parts: A patch-level subset and a scene-level subset. The patch-level subset is composed of 6,476 registered 512 × 512 image pairs covering 14 countries (Argentina, Australia, Poland, Germany, Russia, France, Qatar, Malaysia, the United States, Japan, Türkiye, Singapore, India, and China); the scene-level subset consists of one pair of full-scene optical and SAR images. For full-scene images, high-precision, uniformly distributed ground-truth correspondences are provided, extracted under the principle of imaging-mechanism consistency, together with a general evaluation codebase that supports quantitative analysis of registration accuracy for arbitrary matching algorithms. To further assess the dataset’s effectiveness and challenge level, a systematic evaluation of 11 representative optical-SAR matching methods on OSDataset2.0 is conducted, covering traditional feature-based approaches and mainstream DL models. Experimental results show that the dataset not only supports effective algorithmic comparisons but also provides reliable training resources and a unified evaluation benchmark for subsequent research.
2026, 15(3): 996-1012.
A large-scale Vision-Language Model (VLM) pre-trained on massive image-text datasets performs well when processing natural images. However, there are two major challenges in applying it to Synthetic Aperture Radar (SAR) images: (1) The high cost of high-quality text annotation limits the construction of SAR image-text paired datasets, and (2) The considerable differences in image features between SAR images and optical natural images increase the difficulty of cross-domain knowledge transfer. To address these problems, this study developed a knowledge transfer method for VLM tailored to SAR images. First, this study leveraged paired SAR and optical remote sensing images and employed a generative VLM to automatically produce textual descriptions of the optical images, thereby indirectly constructing a low-cost SAR-text paired dataset. Second, a two-stage transfer strategy was designed to address the large domain discrepancy between natural and SAR images, reducing the difficulty of each transfer stage. Finally, experimental validation was conducted through the zero-shot scene classification, image retrieval, and object recognition of SAR images. The results demonstrated that the proposed method enables effective knowledge transfer from a large-scale VLM to the SAR image domain.
A large-scale Vision-Language Model (VLM) pre-trained on massive image-text datasets performs well when processing natural images. However, there are two major challenges in applying it to Synthetic Aperture Radar (SAR) images: (1) The high cost of high-quality text annotation limits the construction of SAR image-text paired datasets, and (2) The considerable differences in image features between SAR images and optical natural images increase the difficulty of cross-domain knowledge transfer. To address these problems, this study developed a knowledge transfer method for VLM tailored to SAR images. First, this study leveraged paired SAR and optical remote sensing images and employed a generative VLM to automatically produce textual descriptions of the optical images, thereby indirectly constructing a low-cost SAR-text paired dataset. Second, a two-stage transfer strategy was designed to address the large domain discrepancy between natural and SAR images, reducing the difficulty of each transfer stage. Finally, experimental validation was conducted through the zero-shot scene classification, image retrieval, and object recognition of SAR images. The results demonstrated that the proposed method enables effective knowledge transfer from a large-scale VLM to the SAR image domain.
2026, 15(3): 1013-1026.
Small Unmanned Aerial Vehicle (UAV)-borne distributed Tomographic Synthetic Aperture Radar (TomoSAR) systems exhibit remarkable residual time-varying baseline errors due to the limited precision of the position and orientation system on small UAV platforms. These errors critically degrade the performance of three-Dimensional (3D) target reconstruction. Compared with airborne repeat-pass 3D Synthetic Aperture Radar (SAR), distributed TomoSAR mounted on small UAVs imposes stricter compensation accuracy requirements for time-varying baseline errors because of the altitude constraints of the carrying platform. Under the conditions of low signal-to-noise ratio and substantial time-varying baseline errors, existing estimation methods often fail to provide stable and reliable results. In this paper, a two-step time-varying baseline error estimation method based on image azimuth displacement is proposed. The method sequentially estimates the low-frequency component through the co-registration of the master and slave images and the high-frequency component using a multisquint algorithm. Iterative refinement is applied to enhance estimation accuracy. The experimental results obtained from real C-band small UAV-borne distributed TomoSAR data demonstrate that, compared with the enhanced multisquint processing method, the proposed method considerably reduces the root mean square of differential interferometric phases across most channels, thereby effectively improving interchannel coherence. In addition, the elevation-direction standard deviation of the reconstructed point cloud is reduced from 5.16 to 1.33 m, and the height reconstruction error of building targets is less than 0.5 m, validating the effectiveness and superiority of the proposed method.
Small Unmanned Aerial Vehicle (UAV)-borne distributed Tomographic Synthetic Aperture Radar (TomoSAR) systems exhibit remarkable residual time-varying baseline errors due to the limited precision of the position and orientation system on small UAV platforms. These errors critically degrade the performance of three-Dimensional (3D) target reconstruction. Compared with airborne repeat-pass 3D Synthetic Aperture Radar (SAR), distributed TomoSAR mounted on small UAVs imposes stricter compensation accuracy requirements for time-varying baseline errors because of the altitude constraints of the carrying platform. Under the conditions of low signal-to-noise ratio and substantial time-varying baseline errors, existing estimation methods often fail to provide stable and reliable results. In this paper, a two-step time-varying baseline error estimation method based on image azimuth displacement is proposed. The method sequentially estimates the low-frequency component through the co-registration of the master and slave images and the high-frequency component using a multisquint algorithm. Iterative refinement is applied to enhance estimation accuracy. The experimental results obtained from real C-band small UAV-borne distributed TomoSAR data demonstrate that, compared with the enhanced multisquint processing method, the proposed method considerably reduces the root mean square of differential interferometric phases across most channels, thereby effectively improving interchannel coherence. In addition, the elevation-direction standard deviation of the reconstructed point cloud is reduced from 5.16 to 1.33 m, and the height reconstruction error of building targets is less than 0.5 m, validating the effectiveness and superiority of the proposed method.
2026, 15(3): 1027-1041.
Radar signal deinterleaving is a critical technology in electronic intelligence and electronic support measures systems. The classical histogram-based method, although valued for its simplicity, is susceptible to deceptive jamming under counter-reconnaissance parameter design. This study proposes a deinterleaving method that is resistant to such deception. The main contributions are as follows: a frame period detection mechanism compatible with pulse missing rates from 0% to 50% is established through theoretical derivation; by integrating autocorrelation and the overlap rate, accurate frame period identification is achieved, which effectively distinguishes interference disguised as fixed Pulse Repetition Intervals (PRI) and prevents interference with the deinterleaving process; moreover, a coherent discrimination mechanism is introduced to handle scenarios with similar parameters and to accommodate fixed, staggered, sliding, and wobulated PRI modulation—within a unified framework. Experimental results show that the performance of histogram-based methods degrades severely in the presence of counterreconnaissance parameters, with maximum performance dropping to 0, while the proposed method maintains a minimum performance of 96.5%. Meanwhile, the proposed method reaches a minimum performance of 95.31% in parameter-similar scenarios. The proposed method remains effective against the four modulation types, whether counterreconnaissance parameters are present or not. It demonstrates antideception capability against counterreconnaissance design, strong generalization across modulation types, and reliable performance in parameter-similar scenarios, thereby greatly improving the deinterleaving reliability in complex electromagnetic environments and offering important implications for the development of electronic warfare systems.
Radar signal deinterleaving is a critical technology in electronic intelligence and electronic support measures systems. The classical histogram-based method, although valued for its simplicity, is susceptible to deceptive jamming under counter-reconnaissance parameter design. This study proposes a deinterleaving method that is resistant to such deception. The main contributions are as follows: a frame period detection mechanism compatible with pulse missing rates from 0% to 50% is established through theoretical derivation; by integrating autocorrelation and the overlap rate, accurate frame period identification is achieved, which effectively distinguishes interference disguised as fixed Pulse Repetition Intervals (PRI) and prevents interference with the deinterleaving process; moreover, a coherent discrimination mechanism is introduced to handle scenarios with similar parameters and to accommodate fixed, staggered, sliding, and wobulated PRI modulation—within a unified framework. Experimental results show that the performance of histogram-based methods degrades severely in the presence of counterreconnaissance parameters, with maximum performance dropping to 0, while the proposed method maintains a minimum performance of 96.5%. Meanwhile, the proposed method reaches a minimum performance of 95.31% in parameter-similar scenarios. The proposed method remains effective against the four modulation types, whether counterreconnaissance parameters are present or not. It demonstrates antideception capability against counterreconnaissance design, strong generalization across modulation types, and reliable performance in parameter-similar scenarios, thereby greatly improving the deinterleaving reliability in complex electromagnetic environments and offering important implications for the development of electronic warfare systems.
2026, 15(3): 1042-1058.
Synthetic Aperture Radar (SAR) plays a pivotal role in military reconnaissance and remote-sensing applications, given its all-weather, day-and-night operability and high-resolution imaging performance. However, diverse jamming techniques in modern complex electromagnetic environments severely distort SAR echo signals, leading to blurred or distorted imaging results and, in extreme cases, complete target unrecognizability. Given the fundamental differences in formation mechanisms and suppression strategies of different jamming types, precise jamming identification is a core prerequisite for effective counterjamming. Current SAR jamming identification methods face two major challenges. First, when the energy of the jamming signal is comparable to that of the target signal, the jamming features are easily masked, making reliable detection and identification difficult. Second, existing identification networks generally suffer from excessive complexity and poor real-time performance, limiting their practicality in engineering applications. To address these issues, this paper proposes a lightweight network-based non-spoofing active jamming identification method for SAR under low Jamming-to-Signal Ratio (JSR) conditions. This method introduces two key components: a lattice transform block that boosts interference discrimination at low JSR by refining fine-grained feature extraction and a hyperkernel-aware module that, through a custom hyperkernel block based on point target imaging, enhances context capture while ensuring algorithmic lightweighting. The superiority of the proposed method is validated through multidimensional evaluations, including effectiveness analyses of the modules, accuracy-complexity trade-off analysis of different models, and robustness testing under varying JSR conditions. The proposed method maintains high identification performance even under low JSR conditions while meeting real-time computational efficiency requirements.
Synthetic Aperture Radar (SAR) plays a pivotal role in military reconnaissance and remote-sensing applications, given its all-weather, day-and-night operability and high-resolution imaging performance. However, diverse jamming techniques in modern complex electromagnetic environments severely distort SAR echo signals, leading to blurred or distorted imaging results and, in extreme cases, complete target unrecognizability. Given the fundamental differences in formation mechanisms and suppression strategies of different jamming types, precise jamming identification is a core prerequisite for effective counterjamming. Current SAR jamming identification methods face two major challenges. First, when the energy of the jamming signal is comparable to that of the target signal, the jamming features are easily masked, making reliable detection and identification difficult. Second, existing identification networks generally suffer from excessive complexity and poor real-time performance, limiting their practicality in engineering applications. To address these issues, this paper proposes a lightweight network-based non-spoofing active jamming identification method for SAR under low Jamming-to-Signal Ratio (JSR) conditions. This method introduces two key components: a lattice transform block that boosts interference discrimination at low JSR by refining fine-grained feature extraction and a hyperkernel-aware module that, through a custom hyperkernel block based on point target imaging, enhances context capture while ensuring algorithmic lightweighting. The superiority of the proposed method is validated through multidimensional evaluations, including effectiveness analyses of the modules, accuracy-complexity trade-off analysis of different models, and robustness testing under varying JSR conditions. The proposed method maintains high identification performance even under low JSR conditions while meeting real-time computational efficiency requirements.
2026, 15(3): 1059-1090.
Driven by complex electromagnetic environments and multi-target collaborative detection needs, enhancing the overall effectiveness of radar networks through autonomous coordination technology has become a key research area in radar collaborative surveillance. Extensive research has been conducted worldwide, yielding substantial advances in theoretical development, technical validation, and equipment application. This paper systematically discusses the foundational concepts and main features of autonomous coordination in radar networks, examining the primary technical challenges faced during implementation and performance optimization. It also reviews recent notable research findings and technological strategies, focusing on collaborative architecture design, sensing, intelligent decision-making and control, and autonomous evolution. Finally, this paper offers an outlook on future trends in the field and provides references for related theoretical research and practical applications.
Driven by complex electromagnetic environments and multi-target collaborative detection needs, enhancing the overall effectiveness of radar networks through autonomous coordination technology has become a key research area in radar collaborative surveillance. Extensive research has been conducted worldwide, yielding substantial advances in theoretical development, technical validation, and equipment application. This paper systematically discusses the foundational concepts and main features of autonomous coordination in radar networks, examining the primary technical challenges faced during implementation and performance optimization. It also reviews recent notable research findings and technological strategies, focusing on collaborative architecture design, sensing, intelligent decision-making and control, and autonomous evolution. Finally, this paper offers an outlook on future trends in the field and provides references for related theoretical research and practical applications.
2026, 15(3): 1091-1105.
By applying phase coding in transmit elements and pulses, the Element-Pulse Coding Multiple-Input Multiple-Output (EPC-MIMO) radar can effectively suppress mainlobe deceptive interference. However, this approach remains ineffective against mainlobe blanket interference. To address this drawback, this paper investigates the mainlobe blanket interference suppression using a Polarization Element-Pulse Coding Multiple-Input Multiple-Output (PEPC-MIMO) radar system. Specifically, within the framework of stable principal component pursuit decomposition, the interference suppression problem is formulated as a “low-rank + sparse” optimization model by exploiting the low-rank structure of the received signal in the joint time-space-polarization domain. The resulting optimization problem is solved iteratively using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno-based Alternating Optimization (L-BFGS-AO) algorithm, thereby enabling accurate separation of target echoes from mainlobe blanket interference. Furthermore, a sparse reconstruction-based parameter estimation method is proposed to estimate the target’s transmit angle, receive angle, and range ambiguity region. These estimates are then used to construct optimal receive weight vectors for the weighted summation of signals across channels. Simulation results demonstrate the effectiveness of the proposed approach in suppressing mainlobe blanket interference without requiring prior knowledge of the interference.
By applying phase coding in transmit elements and pulses, the Element-Pulse Coding Multiple-Input Multiple-Output (EPC-MIMO) radar can effectively suppress mainlobe deceptive interference. However, this approach remains ineffective against mainlobe blanket interference. To address this drawback, this paper investigates the mainlobe blanket interference suppression using a Polarization Element-Pulse Coding Multiple-Input Multiple-Output (PEPC-MIMO) radar system. Specifically, within the framework of stable principal component pursuit decomposition, the interference suppression problem is formulated as a “low-rank + sparse” optimization model by exploiting the low-rank structure of the received signal in the joint time-space-polarization domain. The resulting optimization problem is solved iteratively using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno-based Alternating Optimization (L-BFGS-AO) algorithm, thereby enabling accurate separation of target echoes from mainlobe blanket interference. Furthermore, a sparse reconstruction-based parameter estimation method is proposed to estimate the target’s transmit angle, receive angle, and range ambiguity region. These estimates are then used to construct optimal receive weight vectors for the weighted summation of signals across channels. Simulation results demonstrate the effectiveness of the proposed approach in suppressing mainlobe blanket interference without requiring prior knowledge of the interference.
2026, 15(3): 1106-1123.
To address interruptions in phantom tracks caused by platform failures or damage during Unmanned Aerial Vehicle (UAV) swarm deception operations against radar networks, this study proposes a game theory-based joint optimization algorithm for UAV swarm task allocation and trajectory planning. A decentralized swarm cooperation mechanism is designed to create a cooperative game model for UAV phantom track deception against radar networks. Based on the radar network homology test criterion, an optimization model is developed to maximize the utility function of the phantom track deception game, subject to constraints on UAV swarm kinematic performance and task allocation requirements. The existence and convergence of a Nash equilibrium are rigorously proven using exact potential game theory. To address the resulting non-convex, non-linear, mixed-integer optimization problem, an iterative algorithm is developed that combines distributed coalition game theory with a genetic algorithm. The simulation results demonstrate that, compared with existing approaches, the proposed algorithm effectively replans deception tasks and trajectories in response to platform failures or damage, thereby enhancing the continuity and effectiveness of phantom track generation against radar networks.
To address interruptions in phantom tracks caused by platform failures or damage during Unmanned Aerial Vehicle (UAV) swarm deception operations against radar networks, this study proposes a game theory-based joint optimization algorithm for UAV swarm task allocation and trajectory planning. A decentralized swarm cooperation mechanism is designed to create a cooperative game model for UAV phantom track deception against radar networks. Based on the radar network homology test criterion, an optimization model is developed to maximize the utility function of the phantom track deception game, subject to constraints on UAV swarm kinematic performance and task allocation requirements. The existence and convergence of a Nash equilibrium are rigorously proven using exact potential game theory. To address the resulting non-convex, non-linear, mixed-integer optimization problem, an iterative algorithm is developed that combines distributed coalition game theory with a genetic algorithm. The simulation results demonstrate that, compared with existing approaches, the proposed algorithm effectively replans deception tasks and trajectories in response to platform failures or damage, thereby enhancing the continuity and effectiveness of phantom track generation against radar networks.
Announcements
More- Conference Lineup | Second Round Notice of the 3rd Radar Academic Frontier Conference (RAFC 2026)
- Announcement of the 5th Journal of Radars Doctoral Forum
- Call for Papers: Special Issue on Beam Manipulation and Object Detection Technology for Electromagnetic Vortex Radar
- Call for Papers: Special Issue on Radar Remote Sensing of Polar Sea Ice and Glaciers
- Call for Papers: Special Issue on SAR Image Generation And Intelligent interpretation
- 2025 Radar Future Stars
Journal News
More-
The 2026 Radar Rising Stars Academic Forum was successfully held, with ten Radar Rising Stars standing out from the participants

- The 9th Youth Scientists Forum of *Journal of Radars* Was Held in Shanghai
- The 2nd Radar Academic Frontier Conference Was Successfully Held in Shanghai! (Video)
- The Mid-term Meeting of the 4th Editorial Board of *Journal of Radars* Was Held in Shanghai
- 2025 Radar Future Star Symposium Successfully Held!
- 4th Journal of Radars Doctoral Forum Successfully Held
Downloads
MoreLinks
More 微信 | 公众平台
微信 | 公众平台

随时查询稿件 获取最新论文 知晓行业信息
- EI
- Scopus
- DOAJ
- JST
- CSCD
- CSTPCD
- CNKI
- 中文核心期刊

