
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor WorkCurrent Issue
2026
Vol. 15,
No. 3
 Previous Issue
Previous Issue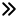
2026,
15(3):
779-796.
 Abstract
Abstract 12045KB
12045KB
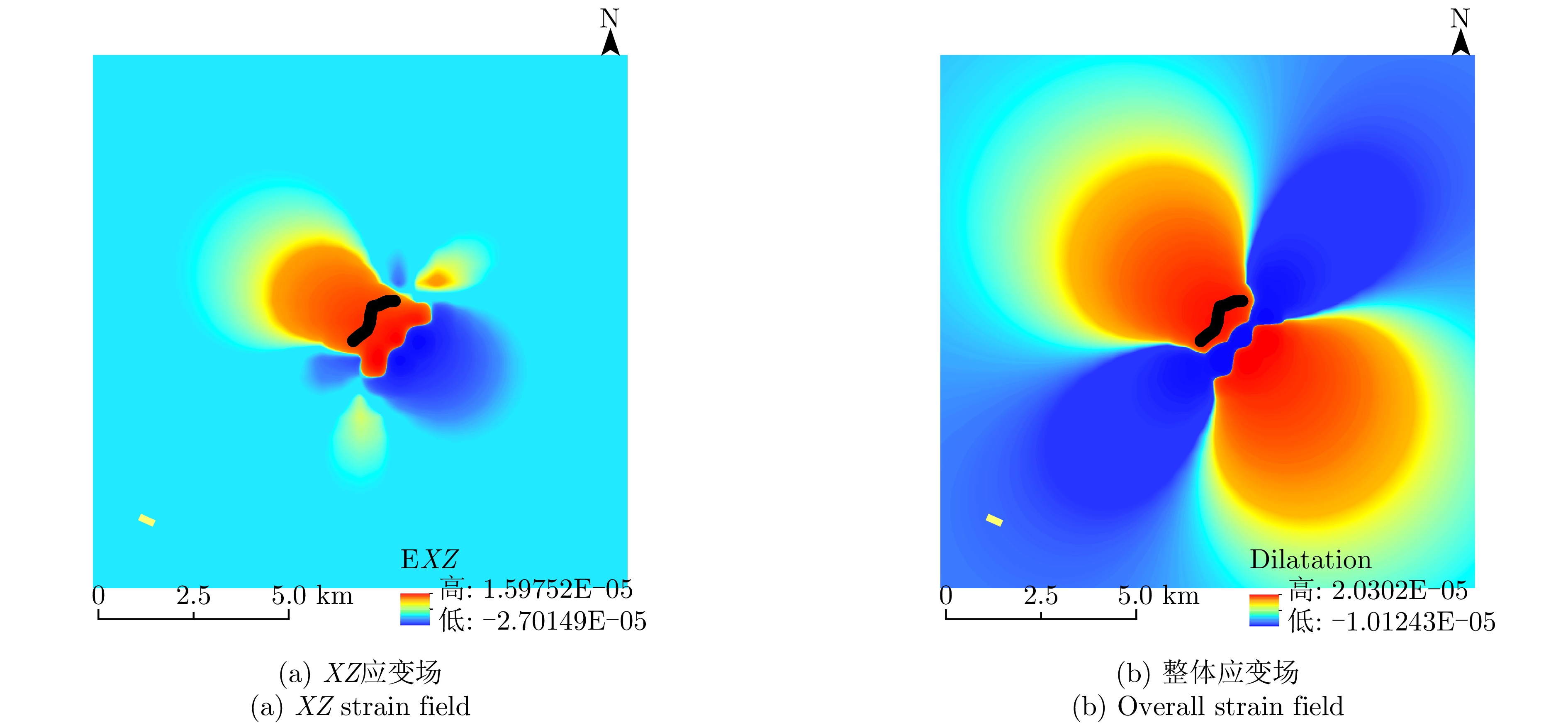
Lunar lobate scarps are small-scale linear structures formed by shallow thrust fault activity on the lunar surface, and their spatial distribution and stress characteristics provide essential clues for understanding the late-stage tectonic evolution of the Moon. At present, the correlation mechanism between the stress characteristics of lobate scarps and their radar scattering response remains unclear. In this study, lobate scarps in the Apollo Basin are considered as the research focus, and scattering characteristic parameters are extracted from Mini-RF images. Subsequently, the Coulomb software is used to invert the distribution characteristics of the regional stress field based on high-resolution digital elevation models. On this basis, the correspondence between radar scattering characteristics and stress is analyzed using statistical correlation methods, revealing the underlying relationship between tectonic activity and surface material response. The main conclusions are as follows. (1) The strain near the fault is markedly higher than that in the surrounding areas, with the maximum shear strain concentrated in the fault dip direction. Volumetric strain indicates volume expansion within the fault hanging wall, whereas volume contraction is observed at both ends and at the center of the sliding surface. (2) The scarp face and hanging wall regions exhibit stronger scattering responses in terms of the circular polarization ratio and partial polarization decomposition parameters, suggesting higher degrees of fragmentation, boulder exposure, or structural complexity in these areas. However, the scattering differences are also influenced by the combined effects of surface roughness, incidence geometry, and subsequent modification processes. (3) The regression analysis of scattering parameters and stress fields, based on multiple linear regression and random forest algorithms, indicates that the correlation between scattering characteristics and stress is likely nonlinear, governed by the combined effects of topographic conditions, surface roughness, and local structures. Overall, this study develops an exploratory radar-topography joint analysis framework for lobate scarps in the Apollo Basin to evaluate whether a quantifiable statistical correspondence exists between scattering features and stress indicators, as well as to provide supplementary evidence for studies of shallow tectonic activity under similar geological settings.
Lunar lobate scarps are small-scale linear structures formed by shallow thrust fault activity on the lunar surface, and their spatial distribution and stress characteristics provide essential clues for understanding the late-stage tectonic evolution of the Moon. At present, the correlation mechanism between the stress characteristics of lobate scarps and their radar scattering response remains unclear. In this study, lobate scarps in the Apollo Basin are considered as the research focus, and scattering characteristic parameters are extracted from Mini-RF images. Subsequently, the Coulomb software is used to invert the distribution characteristics of the regional stress field based on high-resolution digital elevation models. On this basis, the correspondence between radar scattering characteristics and stress is analyzed using statistical correlation methods, revealing the underlying relationship between tectonic activity and surface material response. The main conclusions are as follows. (1) The strain near the fault is markedly higher than that in the surrounding areas, with the maximum shear strain concentrated in the fault dip direction. Volumetric strain indicates volume expansion within the fault hanging wall, whereas volume contraction is observed at both ends and at the center of the sliding surface. (2) The scarp face and hanging wall regions exhibit stronger scattering responses in terms of the circular polarization ratio and partial polarization decomposition parameters, suggesting higher degrees of fragmentation, boulder exposure, or structural complexity in these areas. However, the scattering differences are also influenced by the combined effects of surface roughness, incidence geometry, and subsequent modification processes. (3) The regression analysis of scattering parameters and stress fields, based on multiple linear regression and random forest algorithms, indicates that the correlation between scattering characteristics and stress is likely nonlinear, governed by the combined effects of topographic conditions, surface roughness, and local structures. Overall, this study develops an exploratory radar-topography joint analysis framework for lobate scarps in the Apollo Basin to evaluate whether a quantifiable statistical correspondence exists between scattering features and stress indicators, as well as to provide supplementary evidence for studies of shallow tectonic activity under similar geological settings.












2026,
15(3):
797-813.
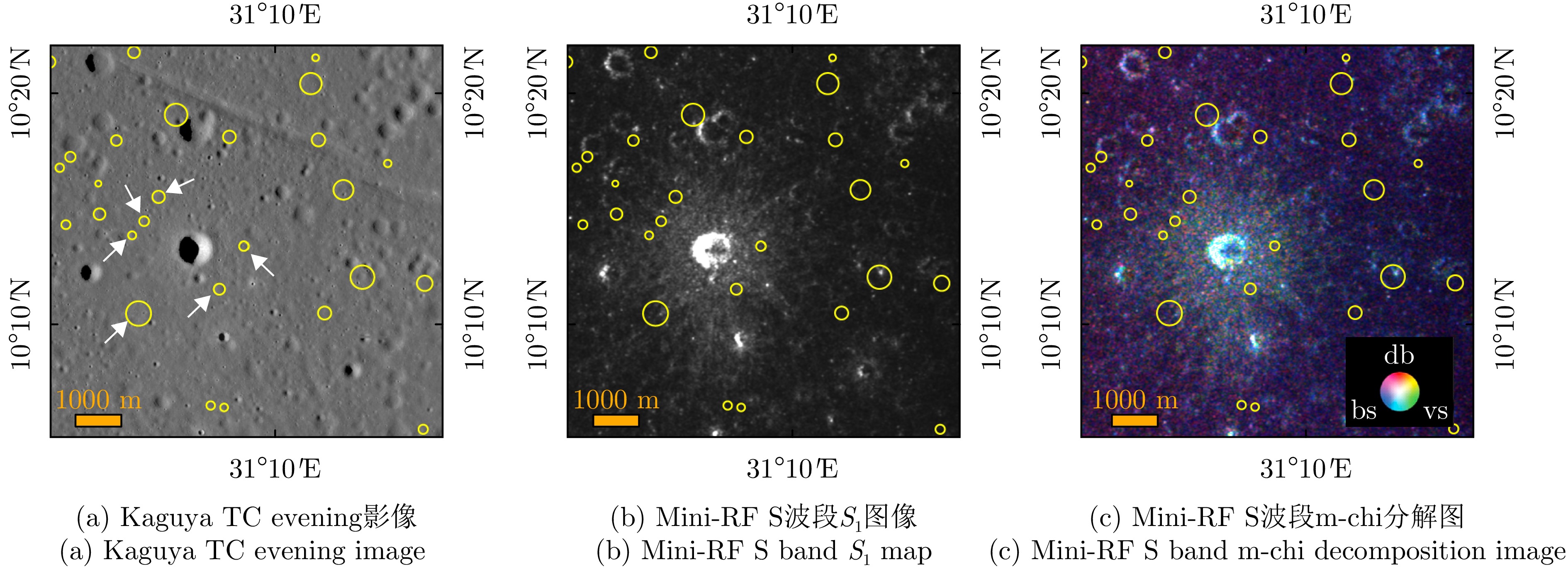
The Ring-Moat Dome Structure (RMDS) is a small-scale domical landform that develops on the lunar mare basalt surface. With an average height of only 3–4 m and a mean diameter of approximately 200 m, these features display a low-relief morphology. Owing to their abundance, RMDSs have become an important subject for understanding lunar volcanic activity and magmatic thermodynamic processes. Although optical remote sensing observations support a volcanic origin for RMDSs, alternative hypotheses have been proposed. Therefore, confirming their genesis requires further geological evidence. Microwave radar provides a distinct advantage in probing the subsurface structure and physical properties of the Moon owing to its penetrative capability. However, to date, no studies have examined the microwave radar scattering characteristics of RMDSs. This paper therefore analyzes the radar backscatter power and Circular Polarization Ratio (CPR) characteristics of RMDSs using S-band (12.6 cm wavelength) data acquired by the spaceborne Miniature Radio Frequency (Mini-RF) instrument and the ground-based Arecibo radar. The study area is a region densely populated with RMDSs on the mare surface within the Mare Tranquillitatis basin. The results indicate the following: (1) RMDSs exhibit low backscatter power, which is highly consistent with the weak radar scattering predicted by the foamy magma genetic model. According to this model, the primary cause of the low-intensity radar echo is the presence of submillimeter-scale fine-grained materials within the uppermost ~2–3 m depth range. (2) Influenced by impact cratering, topographic variations, and mass wasting, some RMDSs display localized enhancement of backscatter to varying degrees; however, prolonged space weathering diminishes this effect. (3) The mean statistical values of the radar backscatter coefficient and the CPR for RMDSs are remarkably close to those of pyroclastic deposits, indicating that their surface physical properties are analogous and that the particle size of their surface materials should be comparable to those of pyroclastic materials, which are predominantly fine-grained particles in the micrometer-to-millimeter range. These findings further confirm that multiband, high-resolution, and multipolarization radar data can yield richer geological evidence for the detailed investigation of RMDSs. This not only deepens the understanding of RMDS formation and evolutionary mechanisms but also provides a valuable reference for future microwave remote sensing exploration of lunar volcanic landforms.
The Ring-Moat Dome Structure (RMDS) is a small-scale domical landform that develops on the lunar mare basalt surface. With an average height of only 3–4 m and a mean diameter of approximately 200 m, these features display a low-relief morphology. Owing to their abundance, RMDSs have become an important subject for understanding lunar volcanic activity and magmatic thermodynamic processes. Although optical remote sensing observations support a volcanic origin for RMDSs, alternative hypotheses have been proposed. Therefore, confirming their genesis requires further geological evidence. Microwave radar provides a distinct advantage in probing the subsurface structure and physical properties of the Moon owing to its penetrative capability. However, to date, no studies have examined the microwave radar scattering characteristics of RMDSs. This paper therefore analyzes the radar backscatter power and Circular Polarization Ratio (CPR) characteristics of RMDSs using S-band (12.6 cm wavelength) data acquired by the spaceborne Miniature Radio Frequency (Mini-RF) instrument and the ground-based Arecibo radar. The study area is a region densely populated with RMDSs on the mare surface within the Mare Tranquillitatis basin. The results indicate the following: (1) RMDSs exhibit low backscatter power, which is highly consistent with the weak radar scattering predicted by the foamy magma genetic model. According to this model, the primary cause of the low-intensity radar echo is the presence of submillimeter-scale fine-grained materials within the uppermost ~2–3 m depth range. (2) Influenced by impact cratering, topographic variations, and mass wasting, some RMDSs display localized enhancement of backscatter to varying degrees; however, prolonged space weathering diminishes this effect. (3) The mean statistical values of the radar backscatter coefficient and the CPR for RMDSs are remarkably close to those of pyroclastic deposits, indicating that their surface physical properties are analogous and that the particle size of their surface materials should be comparable to those of pyroclastic materials, which are predominantly fine-grained particles in the micrometer-to-millimeter range. These findings further confirm that multiband, high-resolution, and multipolarization radar data can yield richer geological evidence for the detailed investigation of RMDSs. This not only deepens the understanding of RMDS formation and evolutionary mechanisms but also provides a valuable reference for future microwave remote sensing exploration of lunar volcanic landforms.









2026,
15(3):
814-826.
Chang’e-7 will carry a fully polarimetric Synthetic Aperture Radar (SAR) to investigate the topography and material properties of the lunar polar regions, which necessitates reliable polarimetric calibration. However, conventional ground-based calibration strategies are infeasible for lunar missions, underscoring the need for new relative polarimetric calibration methods tailored to the lunar surface. To address this challenge, we adopt a normal-incidence observation geometry and analyze how the co-polarization ratio \begin{document}$ {\sigma _{{\text{HH}}}} $\end{document} \begin{document}$ {\sigma _{{\text{VV}}}} $\end{document} \begin{document}$ \sigma $\end{document} \begin{document}$ {\sigma _{{\text{HH}}}} $\end{document} \begin{document}$ {\sigma _{{\text{VV}}}} $\end{document} \begin{document}$ \sigma $\end{document}












2026,
15(3):
827-843.
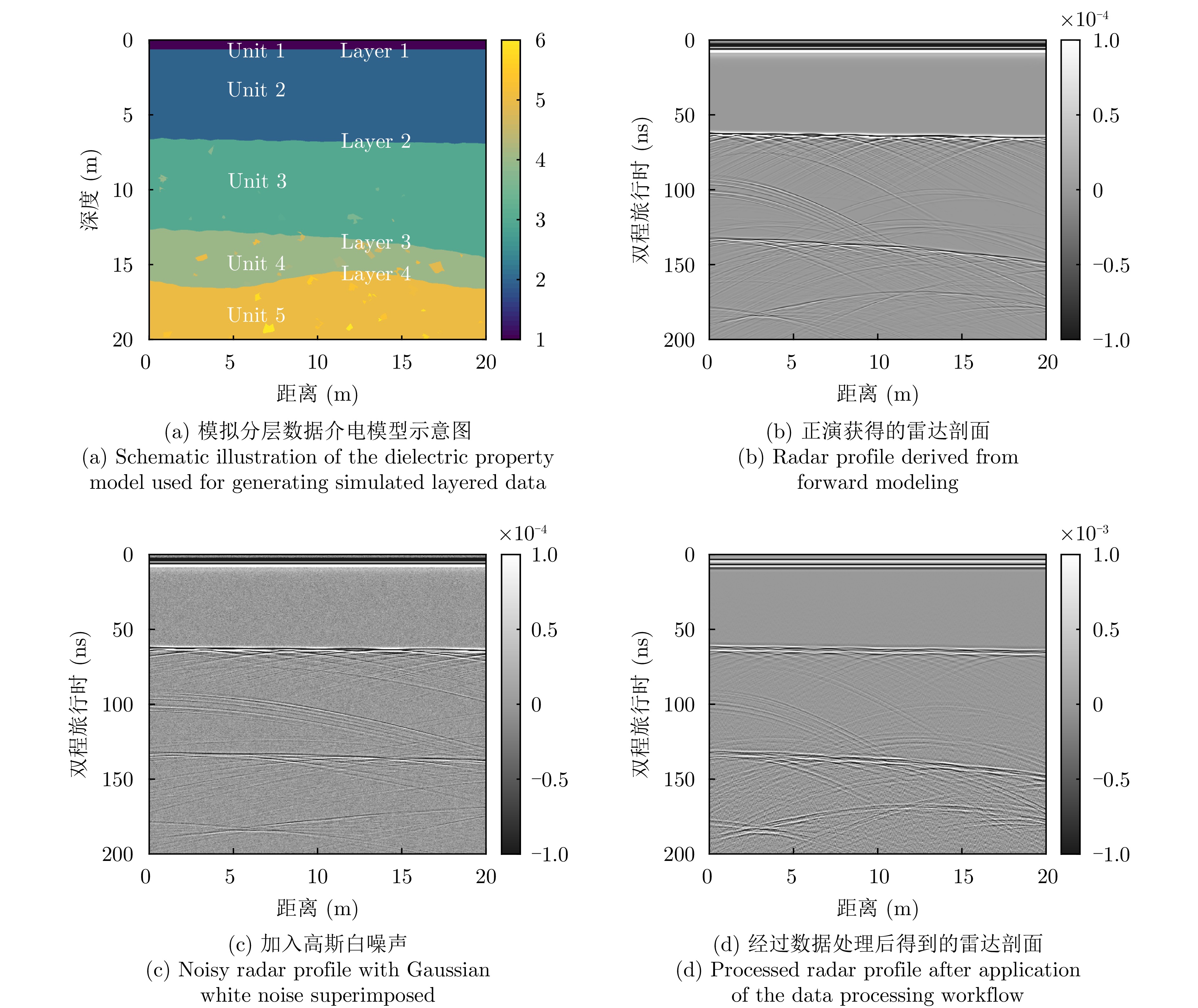
The Moon’s shallow subsurface structure provides crucial insights into its geological evolution, material composition, and space weathering processes. With the acquisition of extensive radar datasets from recent lunar exploration programs, such as the Chang’E missions, high-resolution characterization of the lunar regolith’s stratigraphic and physical properties has become a focus and challenge in lunar science. Conventional radar layer identification and tracking methods often suffer from instability in complex scattering environments, because of their sensitivity to noise and subsurface heterogeneity. To address these limitations, this study proposes an automatic layer-tracking algorithm based on a Dynamic Search Center (DSC) approach. This algorithm employs a Gaussian-weighted prediction mechanism to balance historical trajectory trends with local signal responses and uses a multifeatured fusion decision scheme to enhance tracking robustness under noisy conditions. Numerical simulations demonstrate that, with a search radius l = 20 and a historical window n = 20, the algorithm achieves a layer identification error of less than 2% for shallow strata (<140 ns). Meanwhile, for deep layers (>170 ns), with considerable signal attenuation, incorporating an edge-direction weighting term reduces the tracking error by over 30%. When applied to lunar penetrating radar data from the Chang’E-4 mission, the proposed method successfully realizes automatic stratigraphic tracing in lunar radar profiles, producing layer boundaries that are highly consistent with previous interpretations. Simulation and in-situ results confirm that the DSC-based algorithm accurately delineates real subsurface interfaces across media and structural morphologies, effectively suppressing noise, while maintaining smooth trajectories. Overall, the proposed method achieves low manual dependence, high robustness, and high precision in automatic radar layer tracking, thereby providing a valuable reference for analyzing radar data from upcoming missions such as Chang’E-7 and Martian shallow-subsurface explorations.
The Moon’s shallow subsurface structure provides crucial insights into its geological evolution, material composition, and space weathering processes. With the acquisition of extensive radar datasets from recent lunar exploration programs, such as the Chang’E missions, high-resolution characterization of the lunar regolith’s stratigraphic and physical properties has become a focus and challenge in lunar science. Conventional radar layer identification and tracking methods often suffer from instability in complex scattering environments, because of their sensitivity to noise and subsurface heterogeneity. To address these limitations, this study proposes an automatic layer-tracking algorithm based on a Dynamic Search Center (DSC) approach. This algorithm employs a Gaussian-weighted prediction mechanism to balance historical trajectory trends with local signal responses and uses a multifeatured fusion decision scheme to enhance tracking robustness under noisy conditions. Numerical simulations demonstrate that, with a search radius l = 20 and a historical window n = 20, the algorithm achieves a layer identification error of less than 2% for shallow strata (<140 ns). Meanwhile, for deep layers (>170 ns), with considerable signal attenuation, incorporating an edge-direction weighting term reduces the tracking error by over 30%. When applied to lunar penetrating radar data from the Chang’E-4 mission, the proposed method successfully realizes automatic stratigraphic tracing in lunar radar profiles, producing layer boundaries that are highly consistent with previous interpretations. Simulation and in-situ results confirm that the DSC-based algorithm accurately delineates real subsurface interfaces across media and structural morphologies, effectively suppressing noise, while maintaining smooth trajectories. Overall, the proposed method achieves low manual dependence, high robustness, and high precision in automatic radar layer tracking, thereby providing a valuable reference for analyzing radar data from upcoming missions such as Chang’E-7 and Martian shallow-subsurface explorations.









2026,
15(3):
844-859.
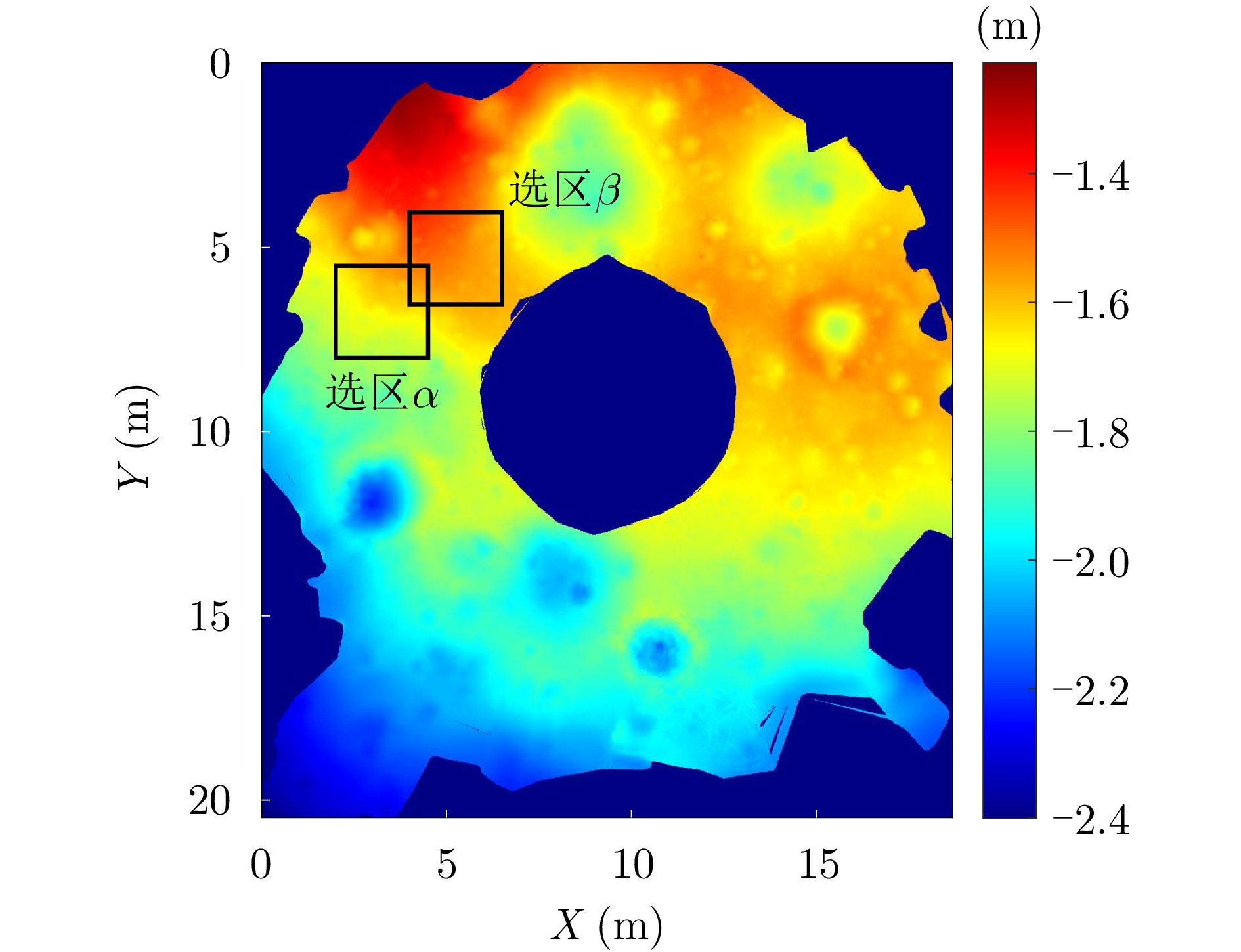
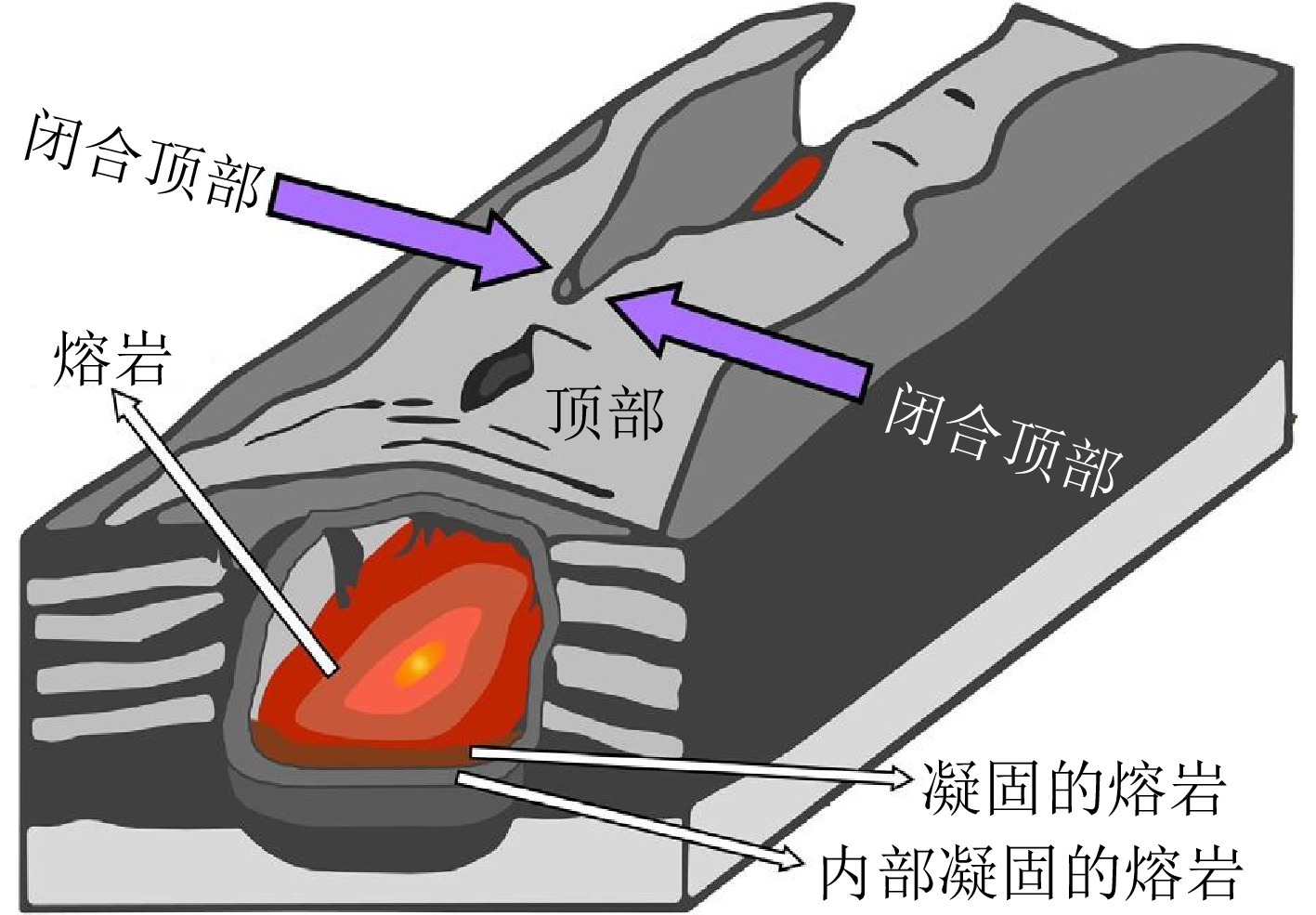
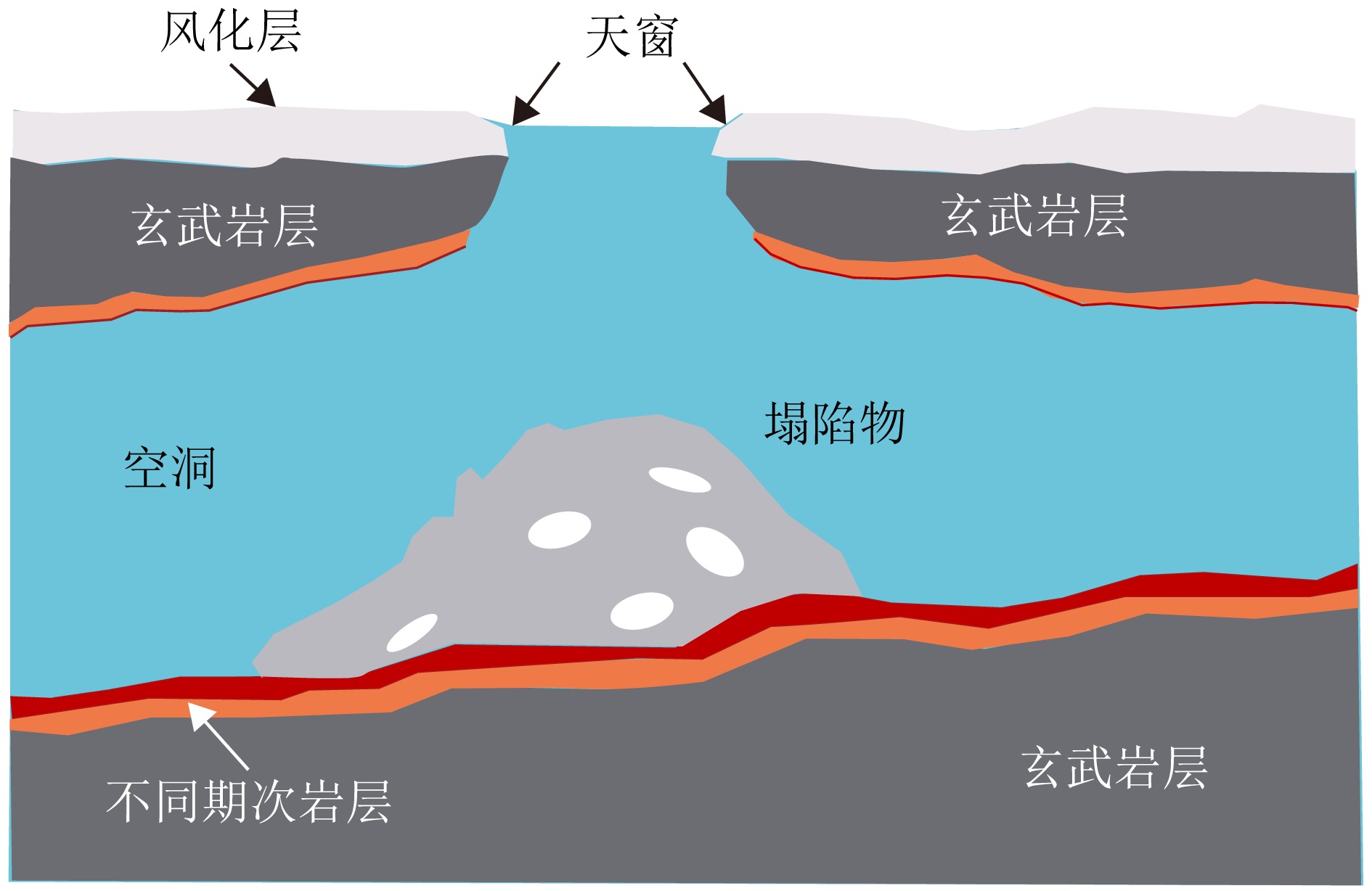
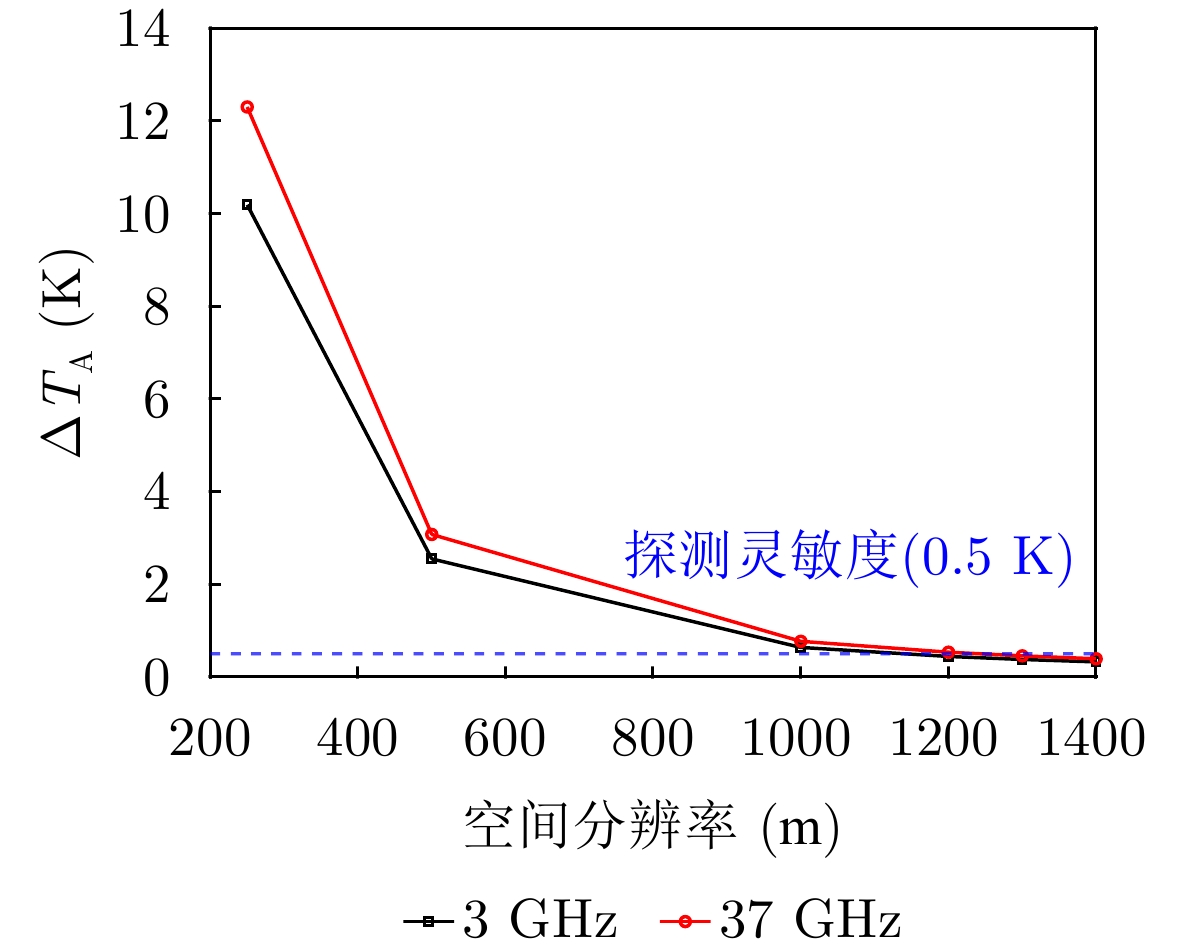
Formed by the cooling and solidification of flowing lava during volcanic activity, lunar lava tubes are considered promising candidates for future lunar bases due to their stable and protective roofs. However, these tubes are typically buried hundreds of meters to kilometers beneath the surface, making direct detection extremely difficult. Current detection methods mainly rely on radar and gravity anomaly analysis. However, the resolution of orbital radar is insufficient to distinguish similar subsurface structures, whereas in situ lunar penetrating radar is limited by a small detection range and vulnerability to near-field interference. Gravity anomaly detection also performs poorly when identifying tubes oriented north-south or with roofs narrower than a kilometer. Skylights serve as critical indicators for locating subsurface tubes and can be identified through optical imagery and infrared radiation thermal anomalies. However, optical images are constrained by illumination conditions, making full three-dimensional reconstruction of skylights difficult. Infrared data are further limited by penetration depth and spatial resolution (320 m×160 m), which hinders the detection of subsurface thermal anomalies and the assessment of the thermophysical properties of materials at the pit floor. To address these challenges, this paper explores the feasibility of detecting skylight thermal anomalies using microwave radiation. Owing to its penetration capability and sensitivity to dielectric properties, this approach can probe subsurface thermal features and effectively determine the material composition of the pit floor. However, a significant scale disparity exists between the kilometer-scale resolution of current data and the relatively small size of skylights. Therefore, enhancing the detection capability of passive microwave methods for 100-m-scale skylights remains a critical issue that requires immediate attention.
Formed by the cooling and solidification of flowing lava during volcanic activity, lunar lava tubes are considered promising candidates for future lunar bases due to their stable and protective roofs. However, these tubes are typically buried hundreds of meters to kilometers beneath the surface, making direct detection extremely difficult. Current detection methods mainly rely on radar and gravity anomaly analysis. However, the resolution of orbital radar is insufficient to distinguish similar subsurface structures, whereas in situ lunar penetrating radar is limited by a small detection range and vulnerability to near-field interference. Gravity anomaly detection also performs poorly when identifying tubes oriented north-south or with roofs narrower than a kilometer. Skylights serve as critical indicators for locating subsurface tubes and can be identified through optical imagery and infrared radiation thermal anomalies. However, optical images are constrained by illumination conditions, making full three-dimensional reconstruction of skylights difficult. Infrared data are further limited by penetration depth and spatial resolution (320 m×160 m), which hinders the detection of subsurface thermal anomalies and the assessment of the thermophysical properties of materials at the pit floor. To address these challenges, this paper explores the feasibility of detecting skylight thermal anomalies using microwave radiation. Owing to its penetration capability and sensitivity to dielectric properties, this approach can probe subsurface thermal features and effectively determine the material composition of the pit floor. However, a significant scale disparity exists between the kilometer-scale resolution of current data and the relatively small size of skylights. Therefore, enhancing the detection capability of passive microwave methods for 100-m-scale skylights remains a critical issue that requires immediate attention.






2026,
15(3):
860-875.
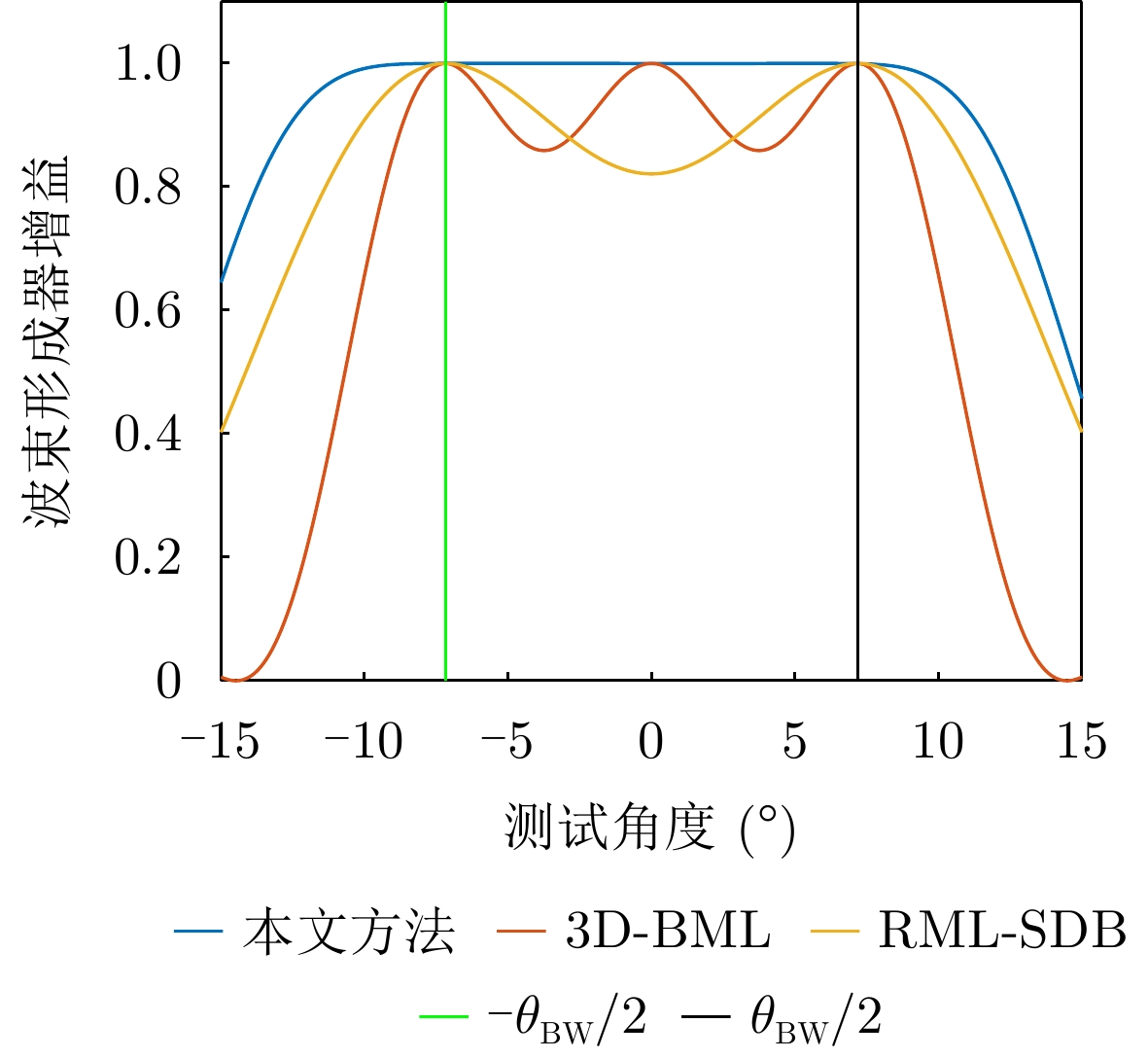
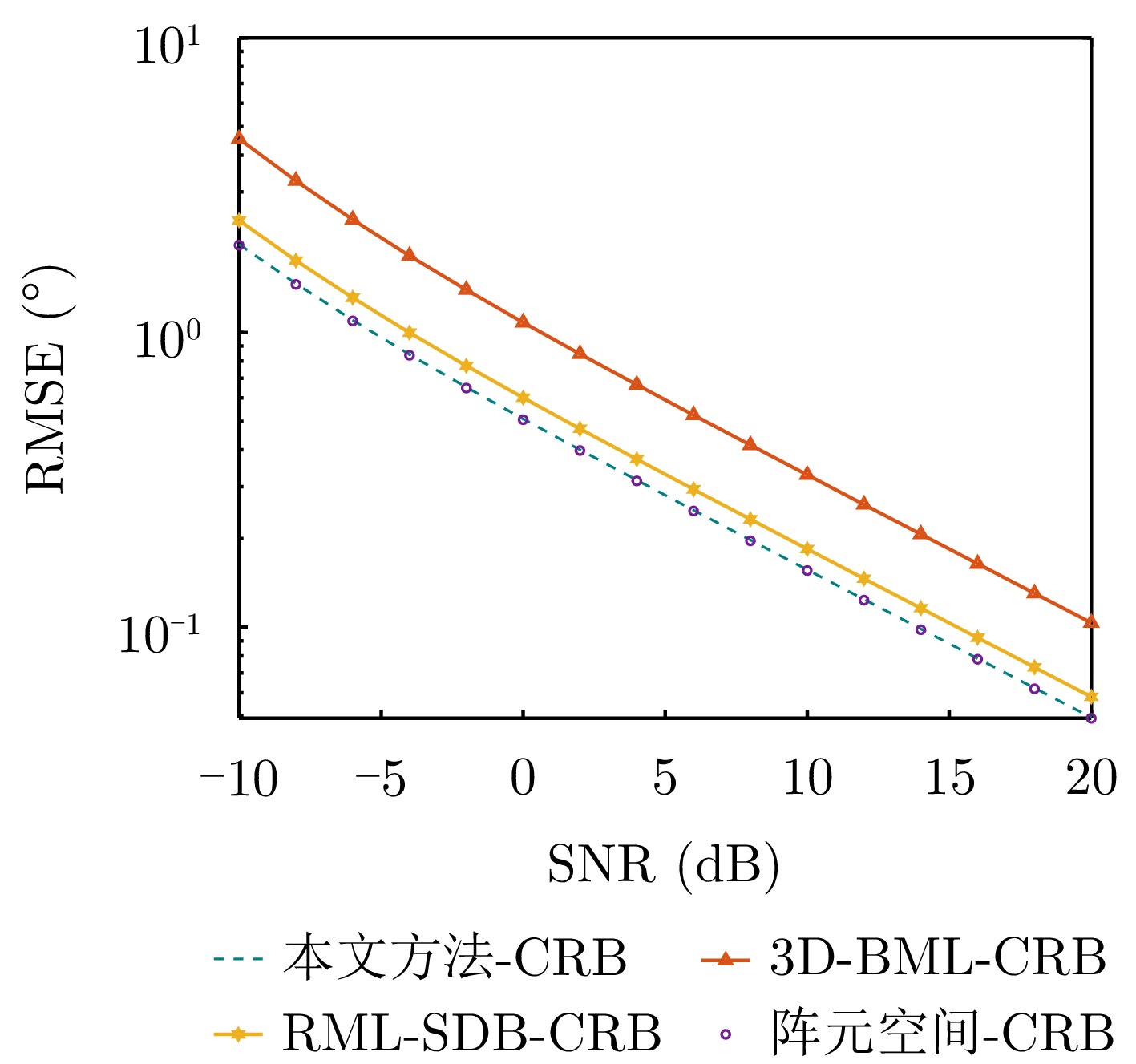
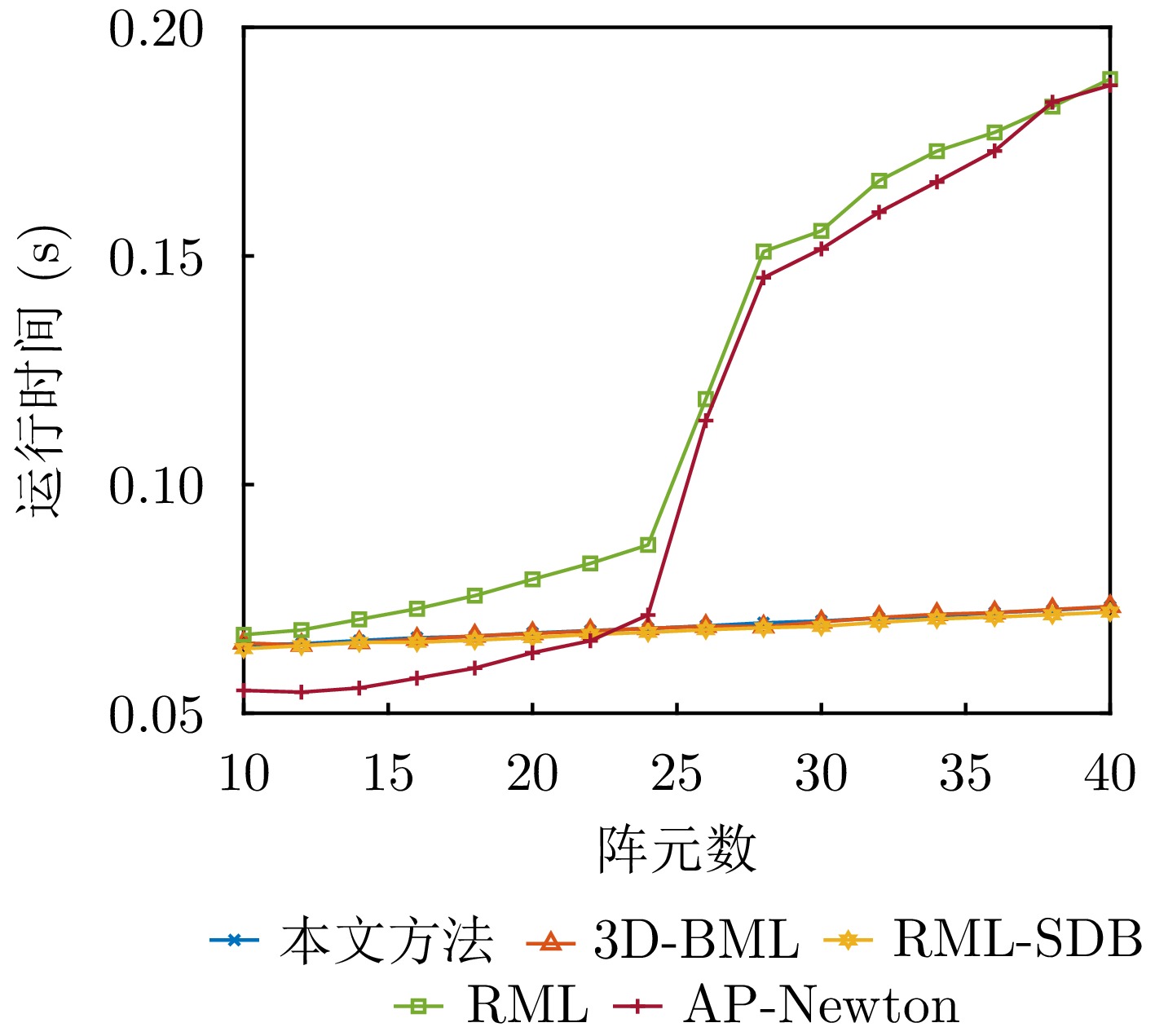
Direction of Arrival (DOA) estimation for low-elevation angle targets is a critical challenge in meter-wave and holographic staring radar systems, as its accuracy directly affects target height measurement performance. Traditional beamspace methods reduce computational complexity by projecting high-dimensional element-space data onto a low-dimensional beamspace using a beamformer. However, this lossy mapping leads to partial information loss, resulting in degraded elevation-angle estimation accuracy compared to that of element-space methods. To address this issue, this study proposes a high-accuracy beamspace DOA estimation method for low-elevation angle targets. First, the Cramér-Rao Bound (CRB) for both element-space and beamspace DOA estimation is derived, and the conditions under which these bounds are equal are analyzed. Since these conditions are difficult to satisfy in practical scenarios, an approximate-condition-based beamformer design strategy is developed to reduce data dimensionality while preserving effective target information. Finally, precise elevation-angle estimation is achieved using the maximum likelihood criterion. Simulation and experimental results show that the proposed method significantly reduces data dimensionality while maintaining estimation accuracy comparable to that of element-space methods at low-elevation angles, clearly outperforming existing beamspace algorithms.
Direction of Arrival (DOA) estimation for low-elevation angle targets is a critical challenge in meter-wave and holographic staring radar systems, as its accuracy directly affects target height measurement performance. Traditional beamspace methods reduce computational complexity by projecting high-dimensional element-space data onto a low-dimensional beamspace using a beamformer. However, this lossy mapping leads to partial information loss, resulting in degraded elevation-angle estimation accuracy compared to that of element-space methods. To address this issue, this study proposes a high-accuracy beamspace DOA estimation method for low-elevation angle targets. First, the Cramér-Rao Bound (CRB) for both element-space and beamspace DOA estimation is derived, and the conditions under which these bounds are equal are analyzed. Since these conditions are difficult to satisfy in practical scenarios, an approximate-condition-based beamformer design strategy is developed to reduce data dimensionality while preserving effective target information. Finally, precise elevation-angle estimation is achieved using the maximum likelihood criterion. Simulation and experimental results show that the proposed method significantly reduces data dimensionality while maintaining estimation accuracy comparable to that of element-space methods at low-elevation angles, clearly outperforming existing beamspace algorithms.












2026,
15(3):
876-890.
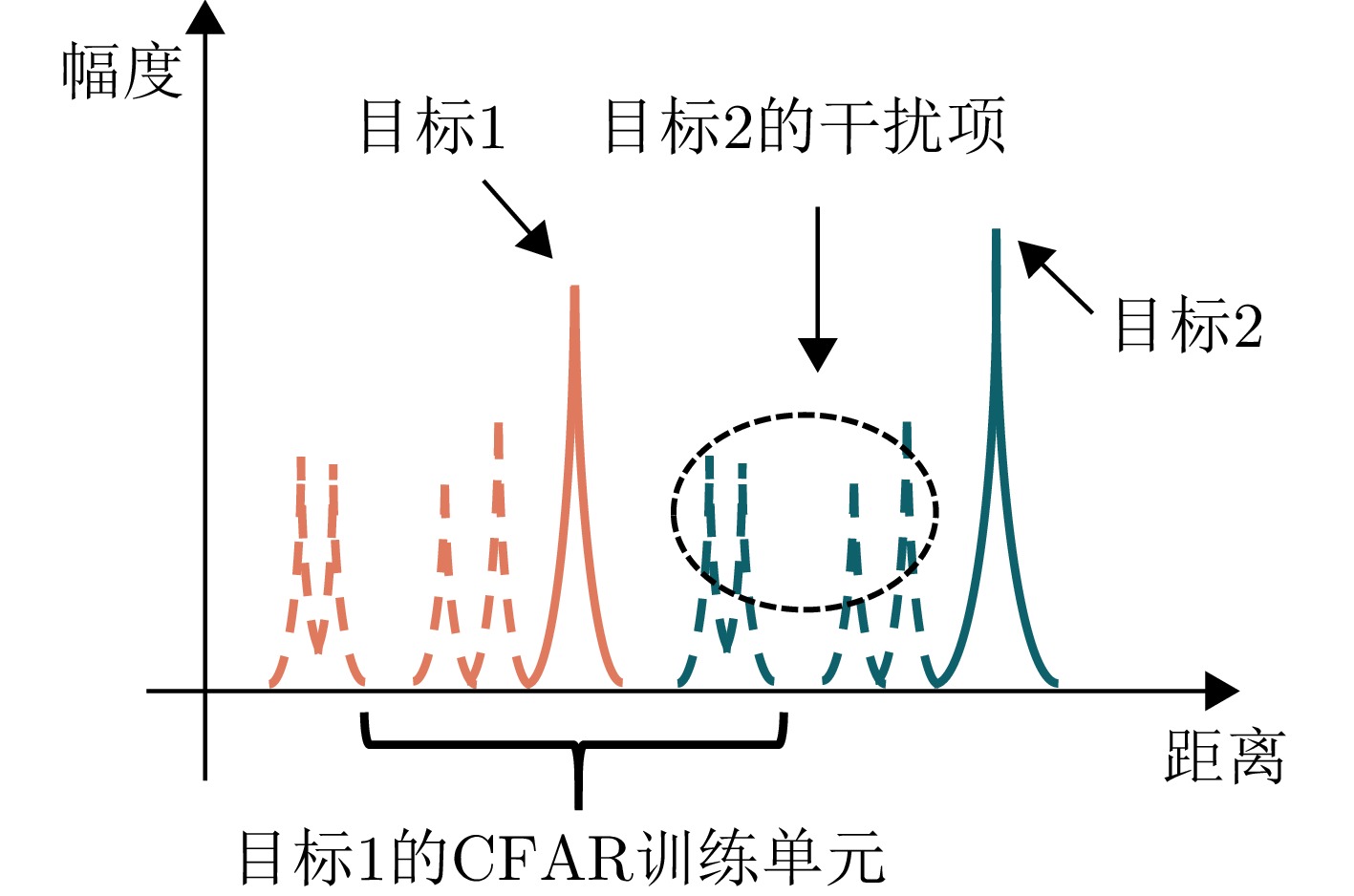
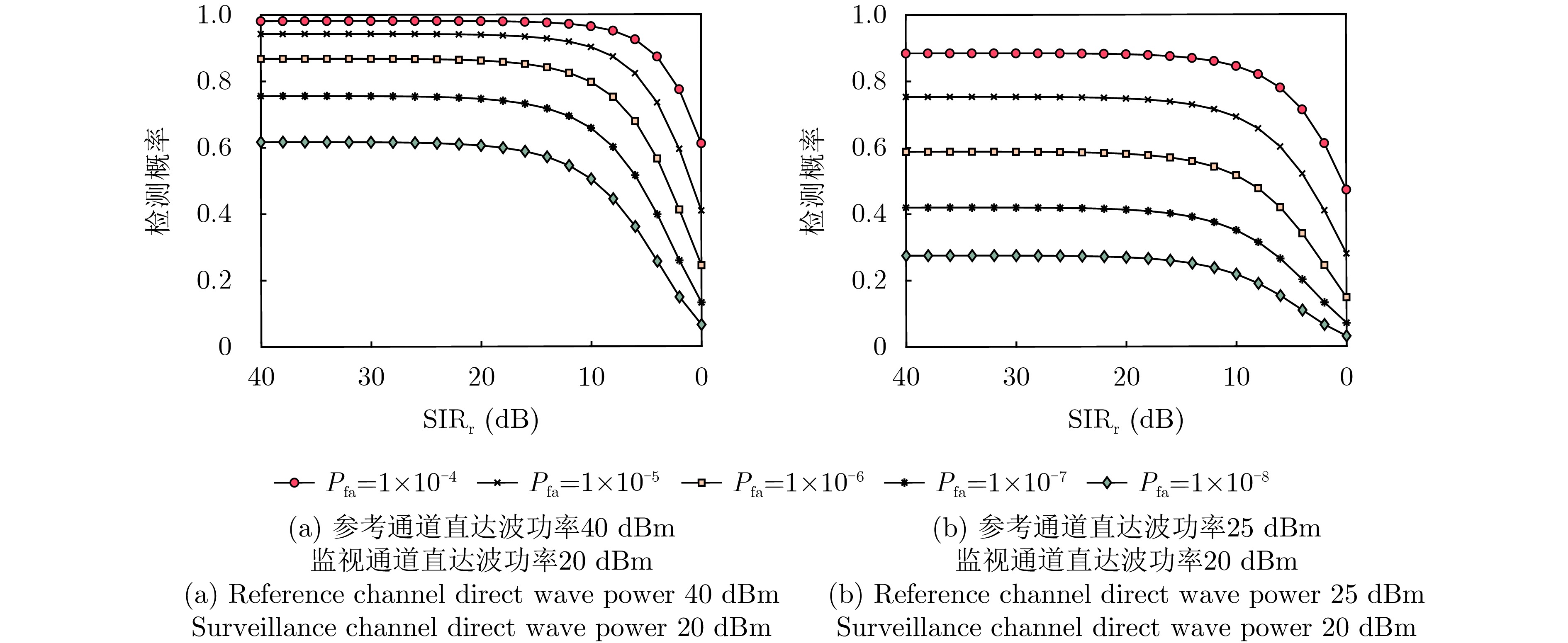
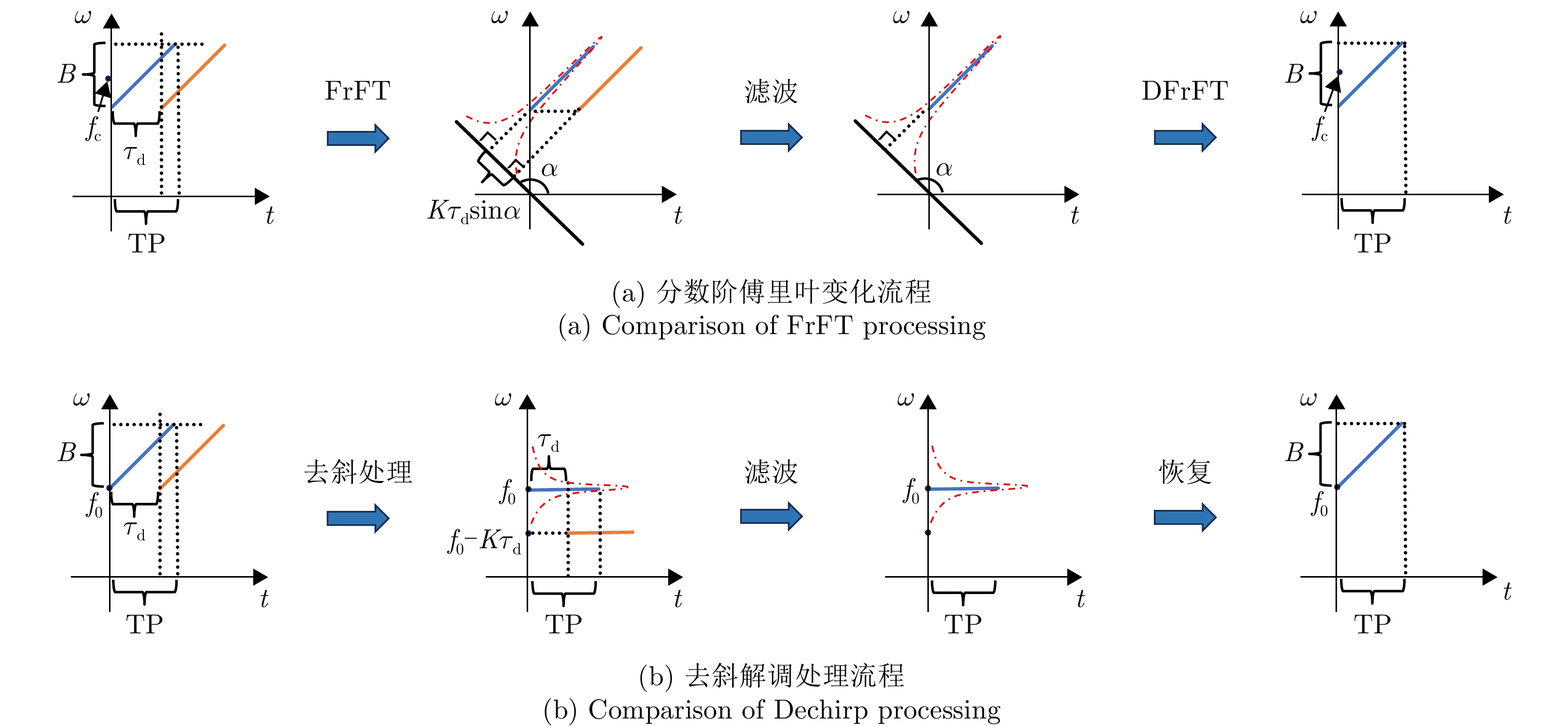
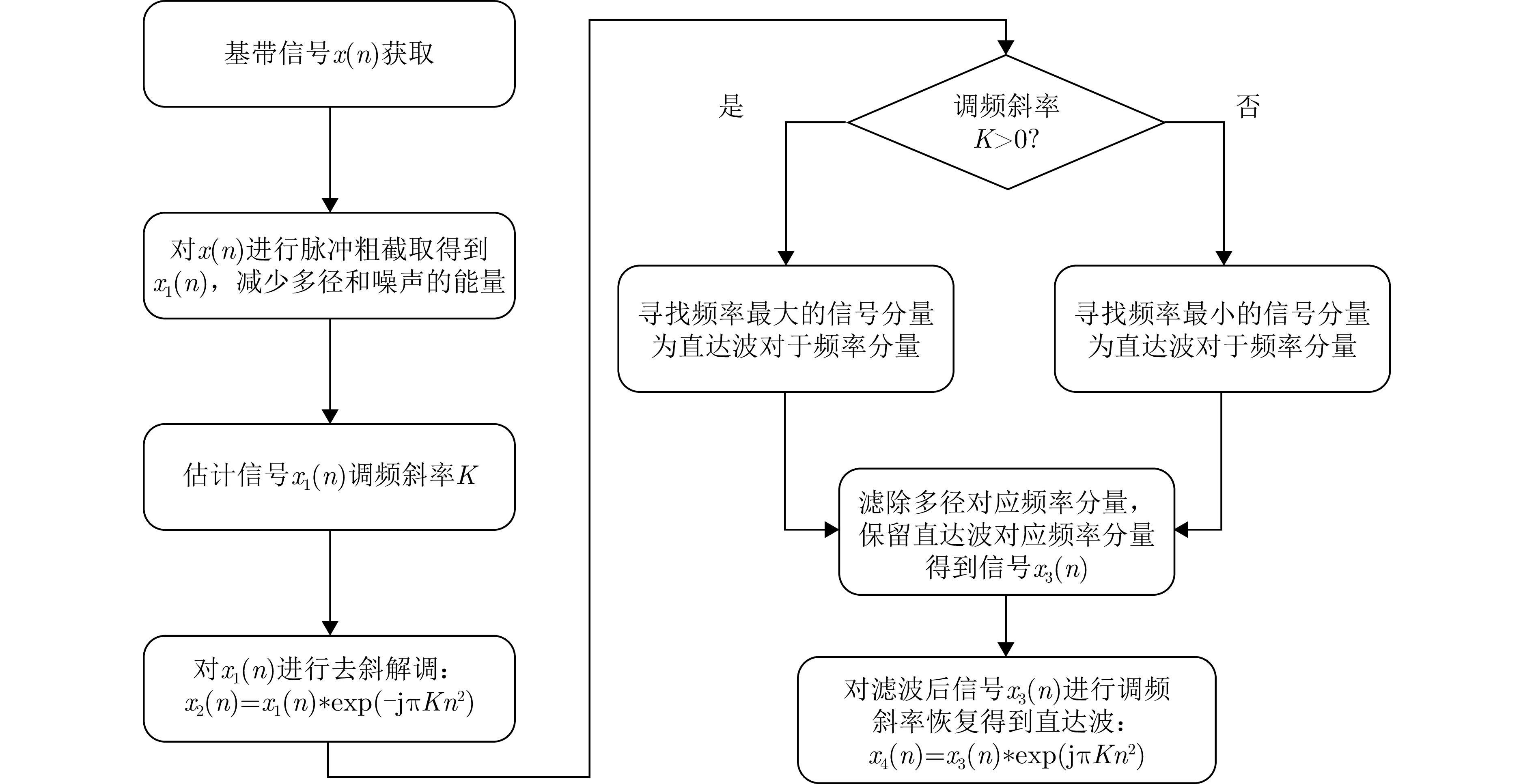
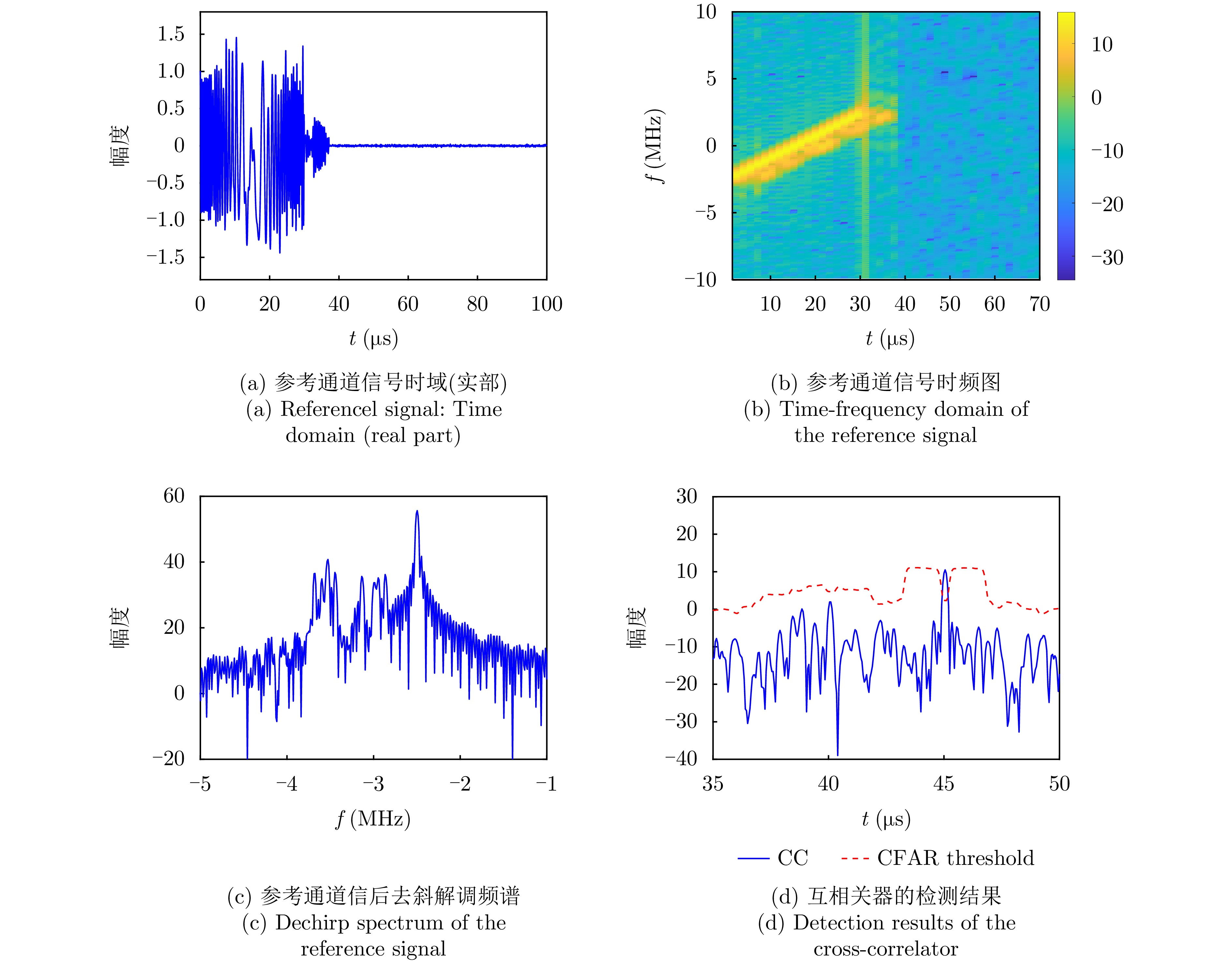
Non-cooperative bistatic radar exhibits significant application value for both civilian and military applications due to its anti-stealth and anti-jamming capabilities. However, its practical implementation faces challenges from unavoidable multipath interference and noise contamination in reference signals, stemming from uncontrollable radar illuminators and complex geographical environments. These effects substantially degrade the performance of cross-correlation processing between reference and echo signals compared with the ideal matched filter, resulting in stationary false targets. Such issues remain a critical bottleneck to operational deployment. This study systematically addresses these challenges by analyzing cross-correlation degradation under multipath and noise in the reference channel, and by establishing a quantitative mapping between multipath intensity, noise power, and detection probability. For Linear Frequency Modulated (LFM) signals, a dechirp-based multipath suppression algorithm is proposed. The algorithm exploits the inherent properties of LFM signals, transforming multipath components with different delays into distinct frequency offsets. Compared with mainstream Fractional Fourier Transform (FrFT) methods, this approach exhibits greater frequency separation among multipath components, enabling effective suppression with significantly reduced filter orders. The algorithm outperforms conventional methods in improving overall detection probability. Measured data processing in practical field-test scenarios (direct-path signals overwhelmed by strong multipath interference) validates the method’s efficacy in eliminating false targets, correcting range offsets, and enhancing detection probability.
Non-cooperative bistatic radar exhibits significant application value for both civilian and military applications due to its anti-stealth and anti-jamming capabilities. However, its practical implementation faces challenges from unavoidable multipath interference and noise contamination in reference signals, stemming from uncontrollable radar illuminators and complex geographical environments. These effects substantially degrade the performance of cross-correlation processing between reference and echo signals compared with the ideal matched filter, resulting in stationary false targets. Such issues remain a critical bottleneck to operational deployment. This study systematically addresses these challenges by analyzing cross-correlation degradation under multipath and noise in the reference channel, and by establishing a quantitative mapping between multipath intensity, noise power, and detection probability. For Linear Frequency Modulated (LFM) signals, a dechirp-based multipath suppression algorithm is proposed. The algorithm exploits the inherent properties of LFM signals, transforming multipath components with different delays into distinct frequency offsets. Compared with mainstream Fractional Fourier Transform (FrFT) methods, this approach exhibits greater frequency separation among multipath components, enabling effective suppression with significantly reduced filter orders. The algorithm outperforms conventional methods in improving overall detection probability. Measured data processing in practical field-test scenarios (direct-path signals overwhelmed by strong multipath interference) validates the method’s efficacy in eliminating false targets, correcting range offsets, and enhancing detection probability.









2026,
15(3):
891-908.
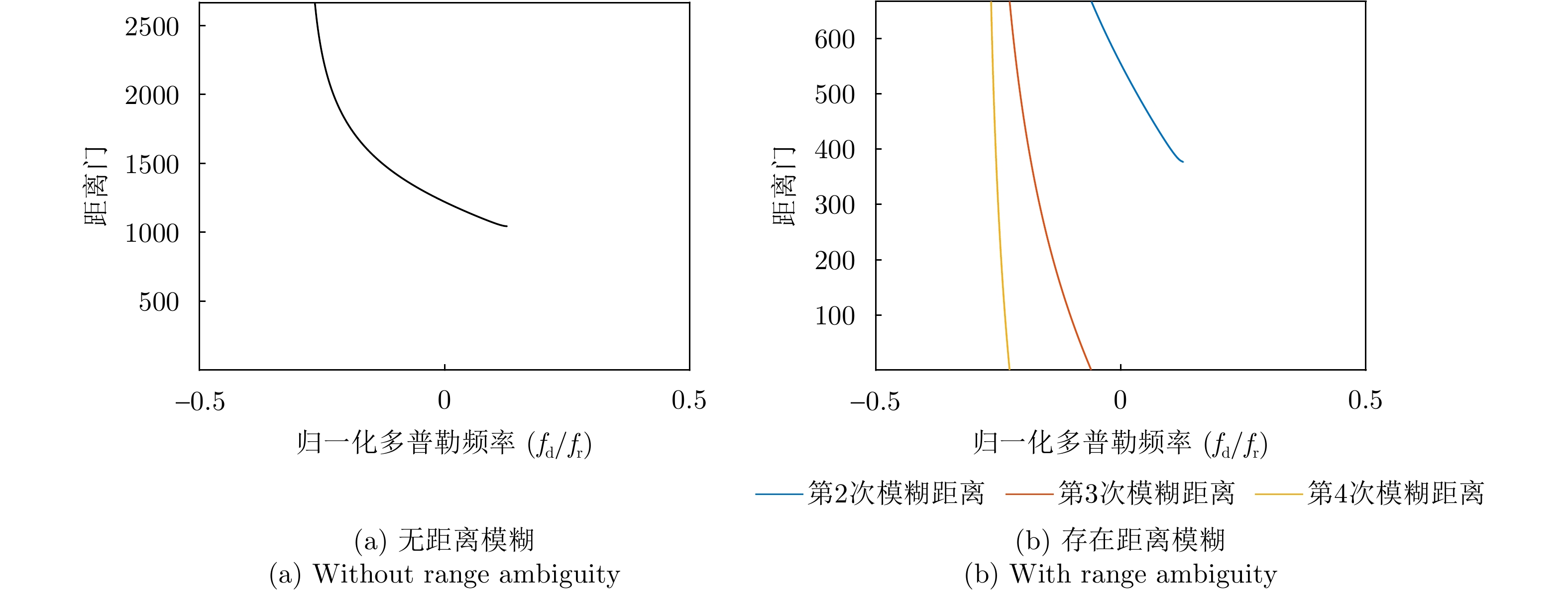
Space-Time Adaptive Processing (STAP) is a key technique used for ground/sea clutter suppression and moving target detection in airborne radar. However, under range ambiguity conditions, the inherent clutter nonstationarity in airborne bistatic radar violates the independent and identically distributed assumption required for training samples, significantly degrading the performance of conventional STAP methods. To address this issue, this study first analyzed the limitations of the Conventional Beamforming (CBF)-based disambiguation approach, which exhibits a trade-off between mainlobe gain loss and sidelobe suppression. A method based on a cascaded blocking matrix and adaptive beamforming is proposed for separating range-ambiguous clutter. Although this method improves upon the CBF-based approach, it introduces noise distortion, which limits further improvements in clutter separation and suppression accuracy. Hence, a novel method based on beam pattern reconstruction is proposed to overcome this drawback. This method formulates an optimization problem incorporating beam-maintenance and sidelobe-control terms to design spatial filter weights, effectively separating range-ambiguous clutter while preserving the mainlobe target gain and suppressing sidelobe clutter. Subsequently, angle-Doppler compensation is applied to the separated clutter, followed by final suppression using a subarray-based STAP method incorporating a joint three-channel Doppler transform. Simulation results revealed that compared with typical methods, the proposed approach more effectively separated clutter, significantly narrowed the mainlobe notch width, and limited the output signal-to-clutter-plus-noise ratio loss to <3 dB, thereby markedly enhancing clutter suppression performance and target detection capability under range ambiguity conditions.
Space-Time Adaptive Processing (STAP) is a key technique used for ground/sea clutter suppression and moving target detection in airborne radar. However, under range ambiguity conditions, the inherent clutter nonstationarity in airborne bistatic radar violates the independent and identically distributed assumption required for training samples, significantly degrading the performance of conventional STAP methods. To address this issue, this study first analyzed the limitations of the Conventional Beamforming (CBF)-based disambiguation approach, which exhibits a trade-off between mainlobe gain loss and sidelobe suppression. A method based on a cascaded blocking matrix and adaptive beamforming is proposed for separating range-ambiguous clutter. Although this method improves upon the CBF-based approach, it introduces noise distortion, which limits further improvements in clutter separation and suppression accuracy. Hence, a novel method based on beam pattern reconstruction is proposed to overcome this drawback. This method formulates an optimization problem incorporating beam-maintenance and sidelobe-control terms to design spatial filter weights, effectively separating range-ambiguous clutter while preserving the mainlobe target gain and suppressing sidelobe clutter. Subsequently, angle-Doppler compensation is applied to the separated clutter, followed by final suppression using a subarray-based STAP method incorporating a joint three-channel Doppler transform. Simulation results revealed that compared with typical methods, the proposed approach more effectively separated clutter, significantly narrowed the mainlobe notch width, and limited the output signal-to-clutter-plus-noise ratio loss to <3 dB, thereby markedly enhancing clutter suppression performance and target detection capability under range ambiguity conditions.











2026,
15(3):
909-918.
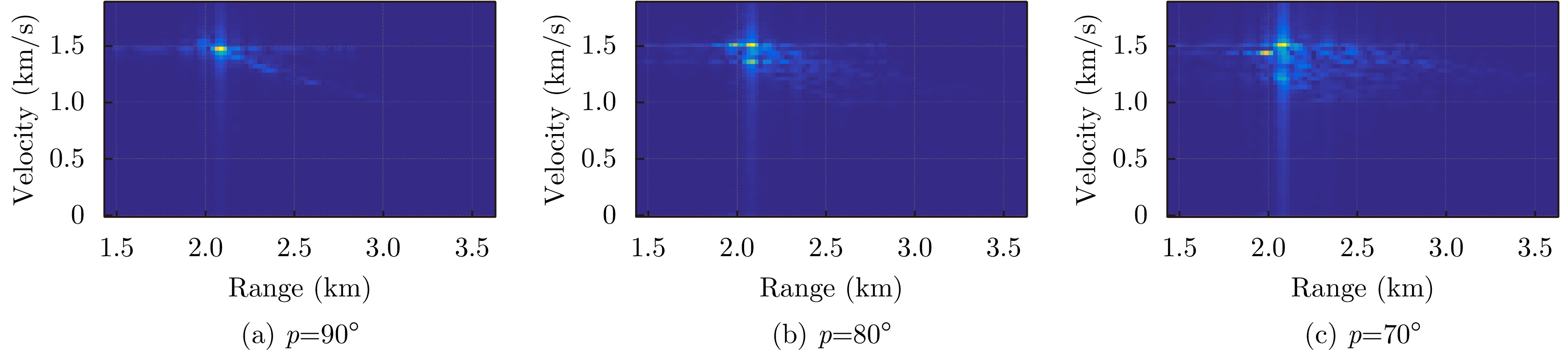
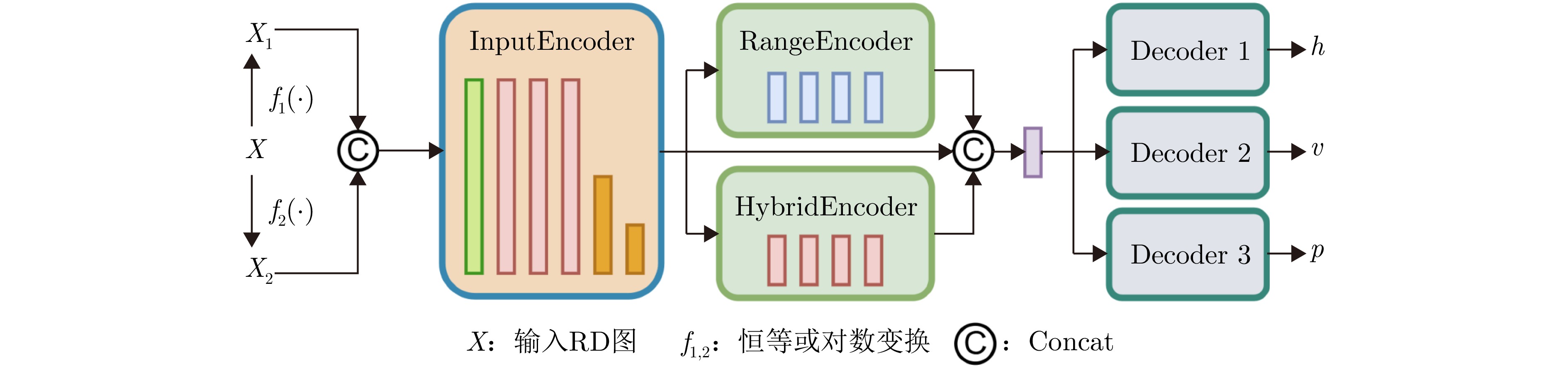
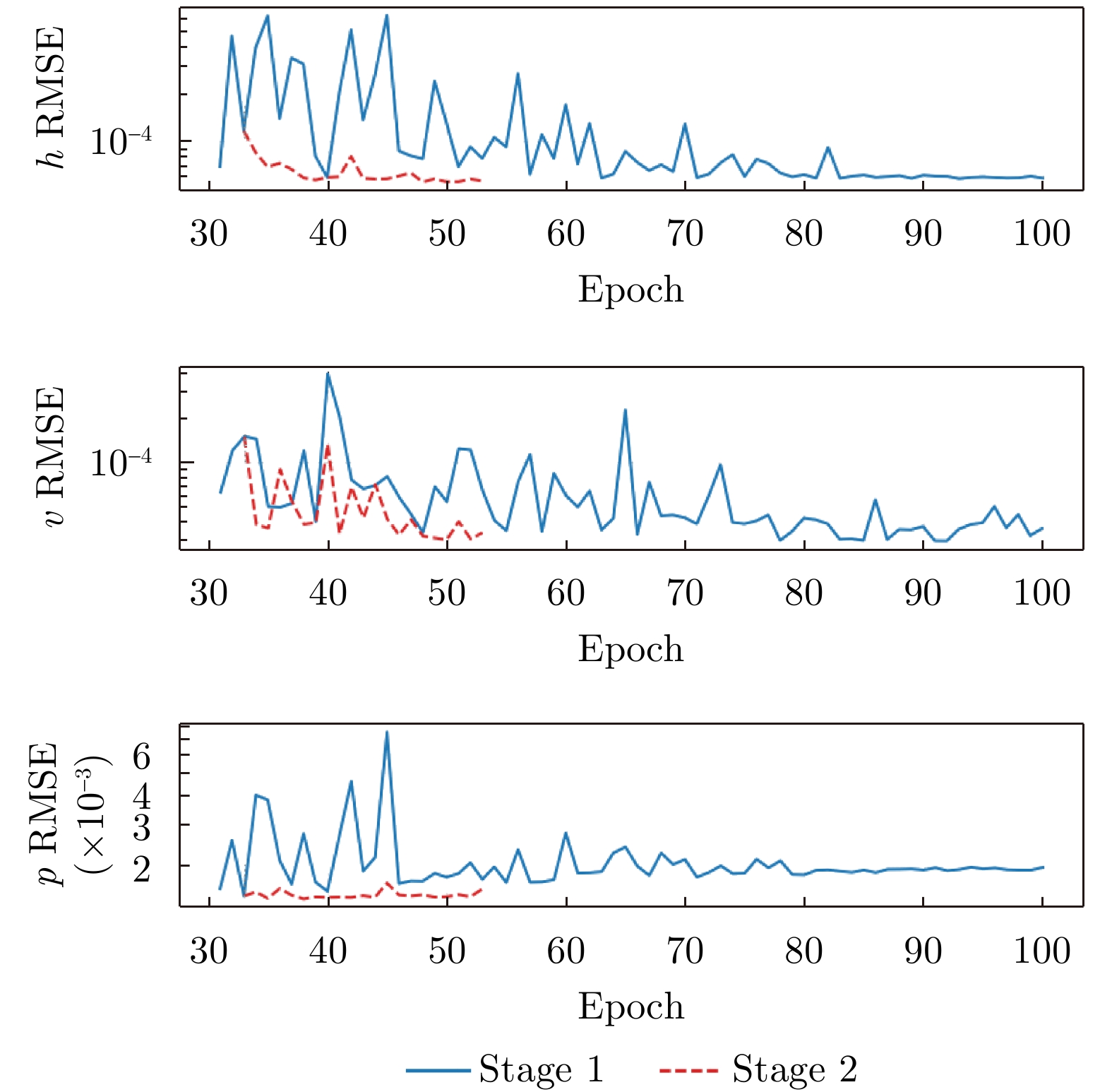
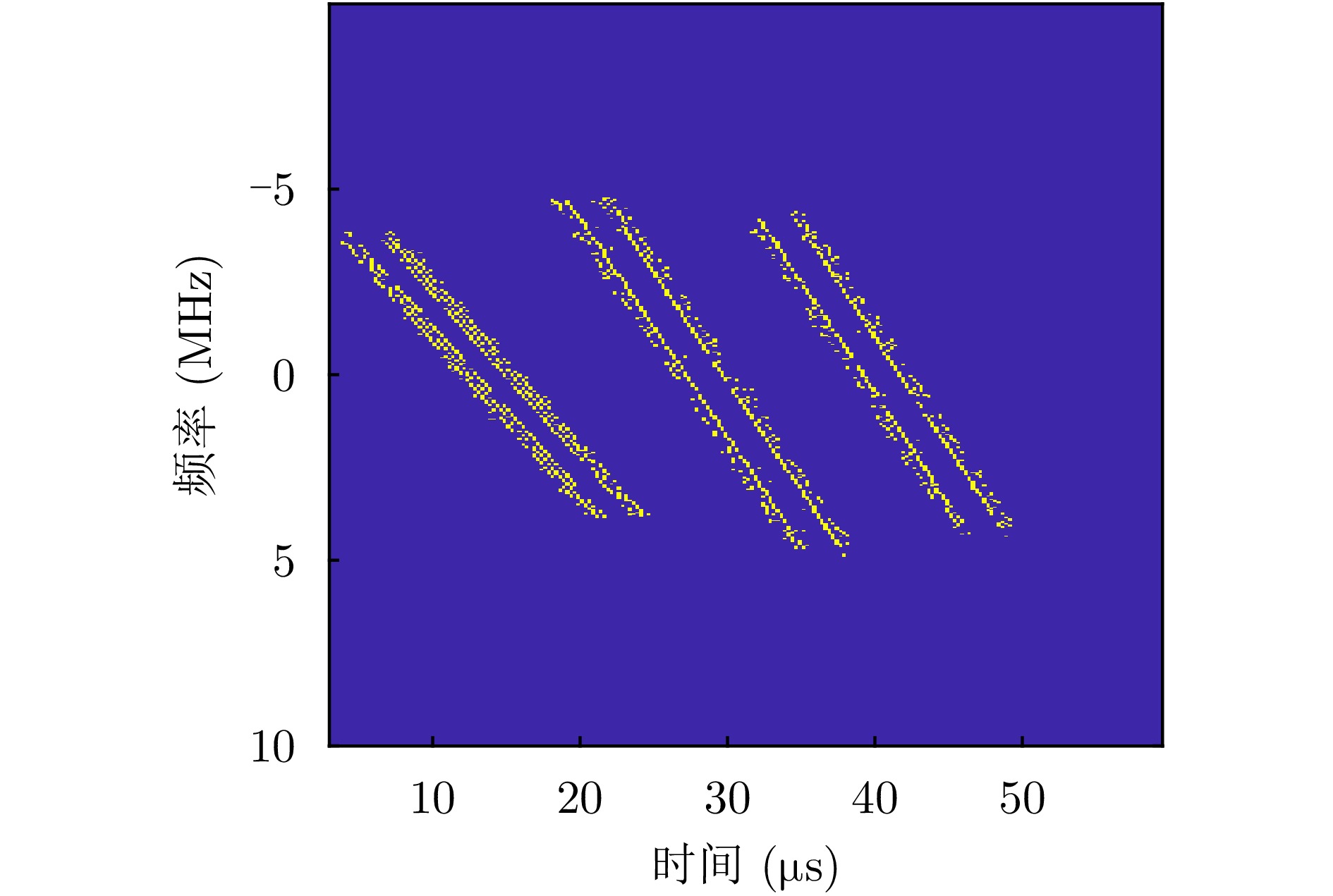
Pulse Doppler radar provides all-weather operational capability and enables simultaneous acquisition of target range and velocity through Range-Doppler (RD) maps. In near-vertical flight scenarios, the geometric structure of RD maps implicitly encodes key platform motion parameters, including altitude, velocity, and pitch angle. However, these parameters are strongly coupled in the RD domain, making effective decoupling difficult for traditional signal-processing-based inversion methods, particularly under complex terrain and near-vertical incidence conditions. Although recent advances in deep learning have shown strong potential for motion information sensing, multitask learning in this context still faces challenges in achieving both real-time performance and high estimation accuracy. To address these issues, this study proposes a novel network architecture, termed Range-Doppler Map Fusion Network (RDMFNet), that performs multirepresentation information fusion via shared encoders and parallel decoders, along with a two-stage progressive training strategy to enhance parameter estimation accuracy. Experimental results show that RDMFNet achieves estimation errors of 14.447 m for altitude, 4.635 m/s for velocity, and 0.755° for pitch angle, demonstrating its effectiveness for high-precision, real-time perception.
Pulse Doppler radar provides all-weather operational capability and enables simultaneous acquisition of target range and velocity through Range-Doppler (RD) maps. In near-vertical flight scenarios, the geometric structure of RD maps implicitly encodes key platform motion parameters, including altitude, velocity, and pitch angle. However, these parameters are strongly coupled in the RD domain, making effective decoupling difficult for traditional signal-processing-based inversion methods, particularly under complex terrain and near-vertical incidence conditions. Although recent advances in deep learning have shown strong potential for motion information sensing, multitask learning in this context still faces challenges in achieving both real-time performance and high estimation accuracy. To address these issues, this study proposes a novel network architecture, termed Range-Doppler Map Fusion Network (RDMFNet), that performs multirepresentation information fusion via shared encoders and parallel decoders, along with a two-stage progressive training strategy to enhance parameter estimation accuracy. Experimental results show that RDMFNet achieves estimation errors of 14.447 m for altitude, 4.635 m/s for velocity, and 0.755° for pitch angle, demonstrating its effectiveness for high-precision, real-time perception.




2026,
15(3):
919-928.
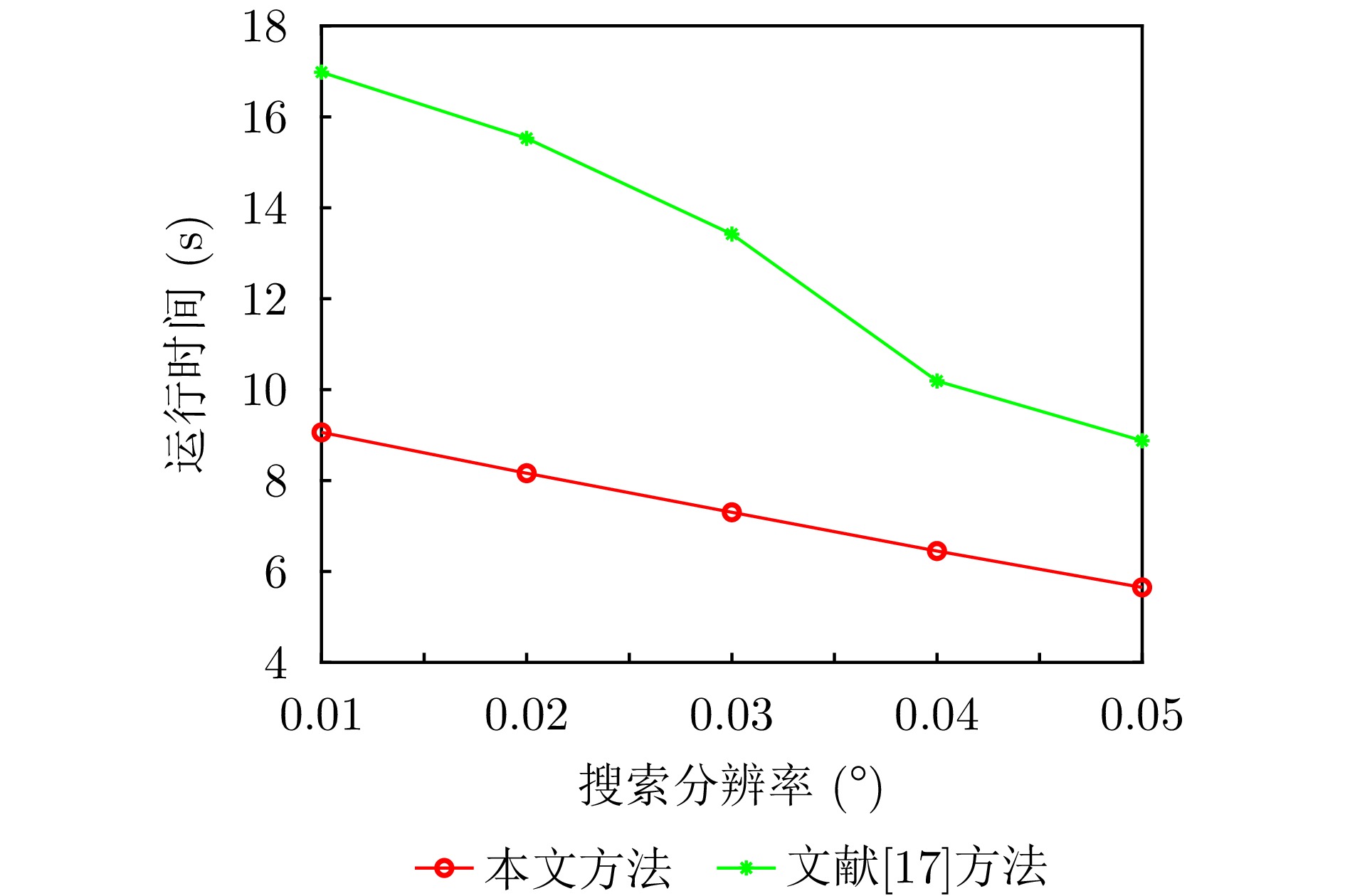
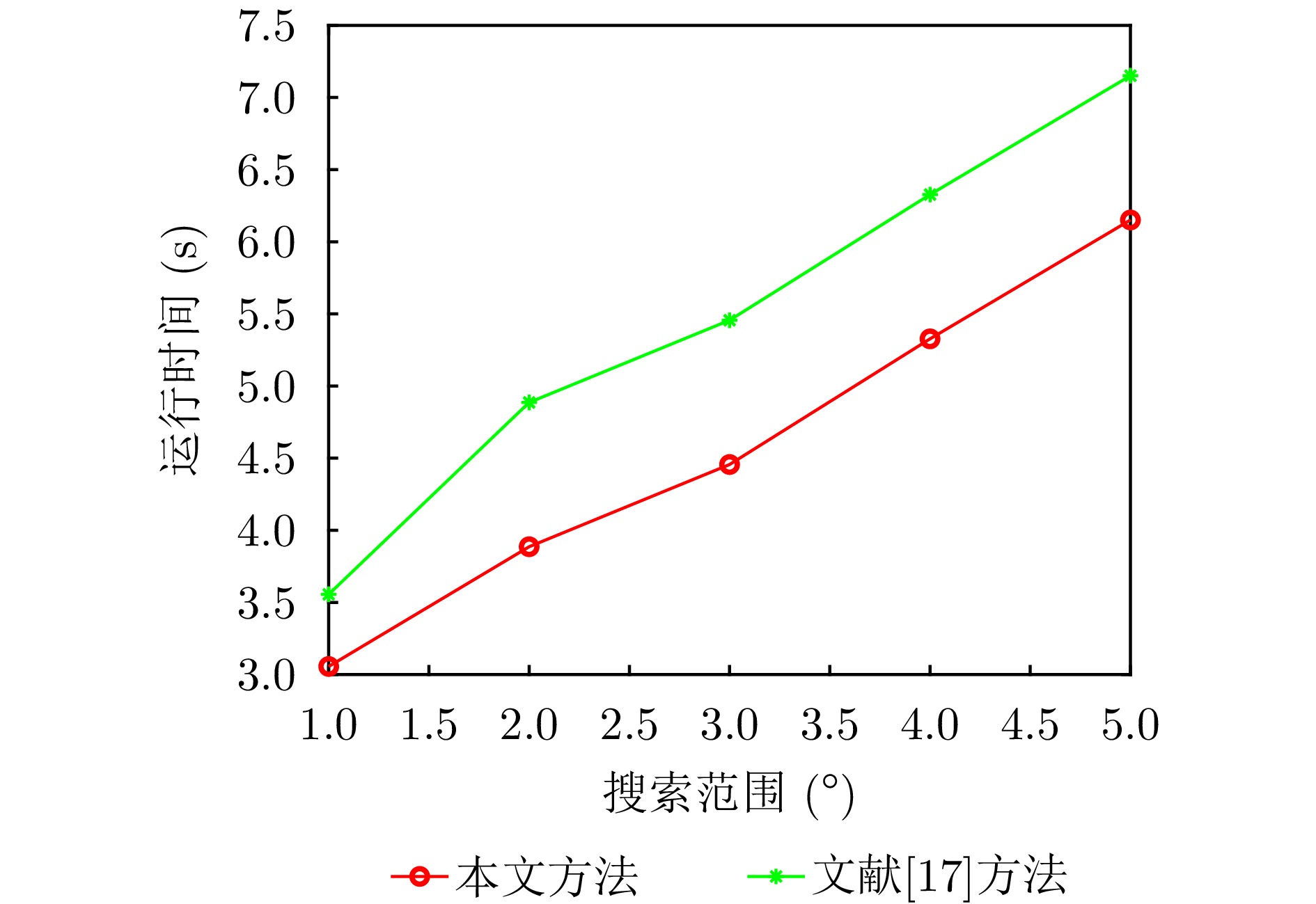
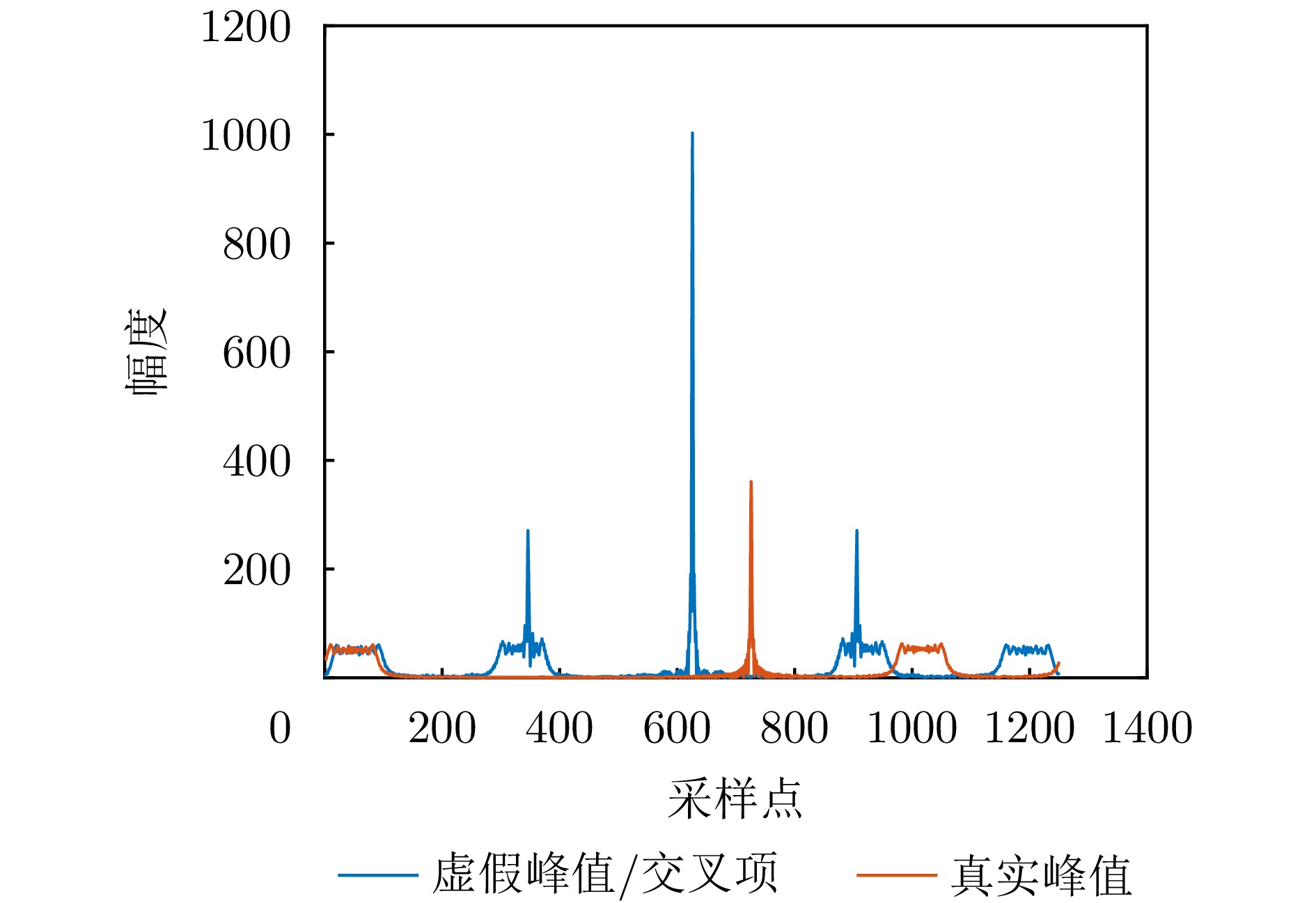
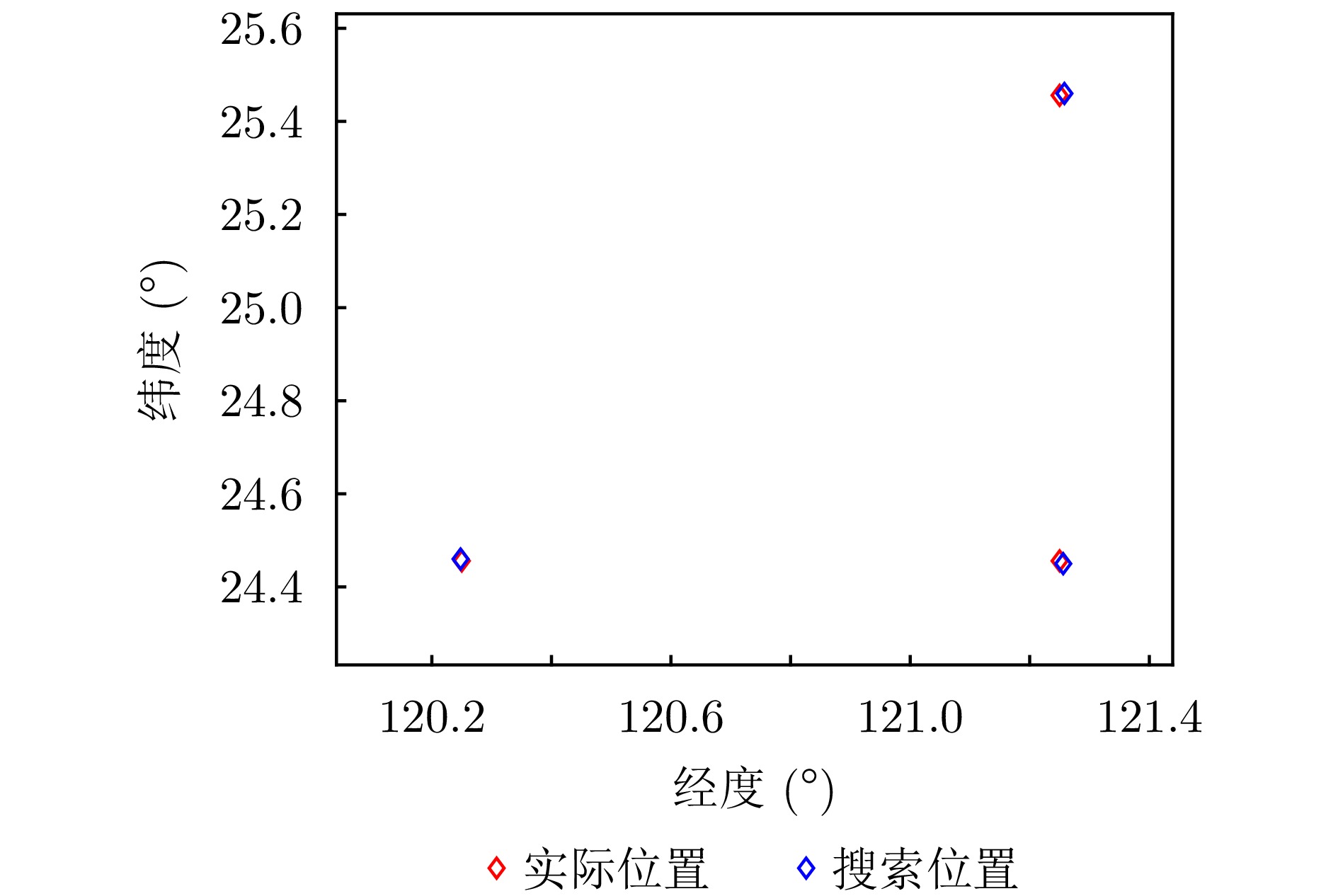
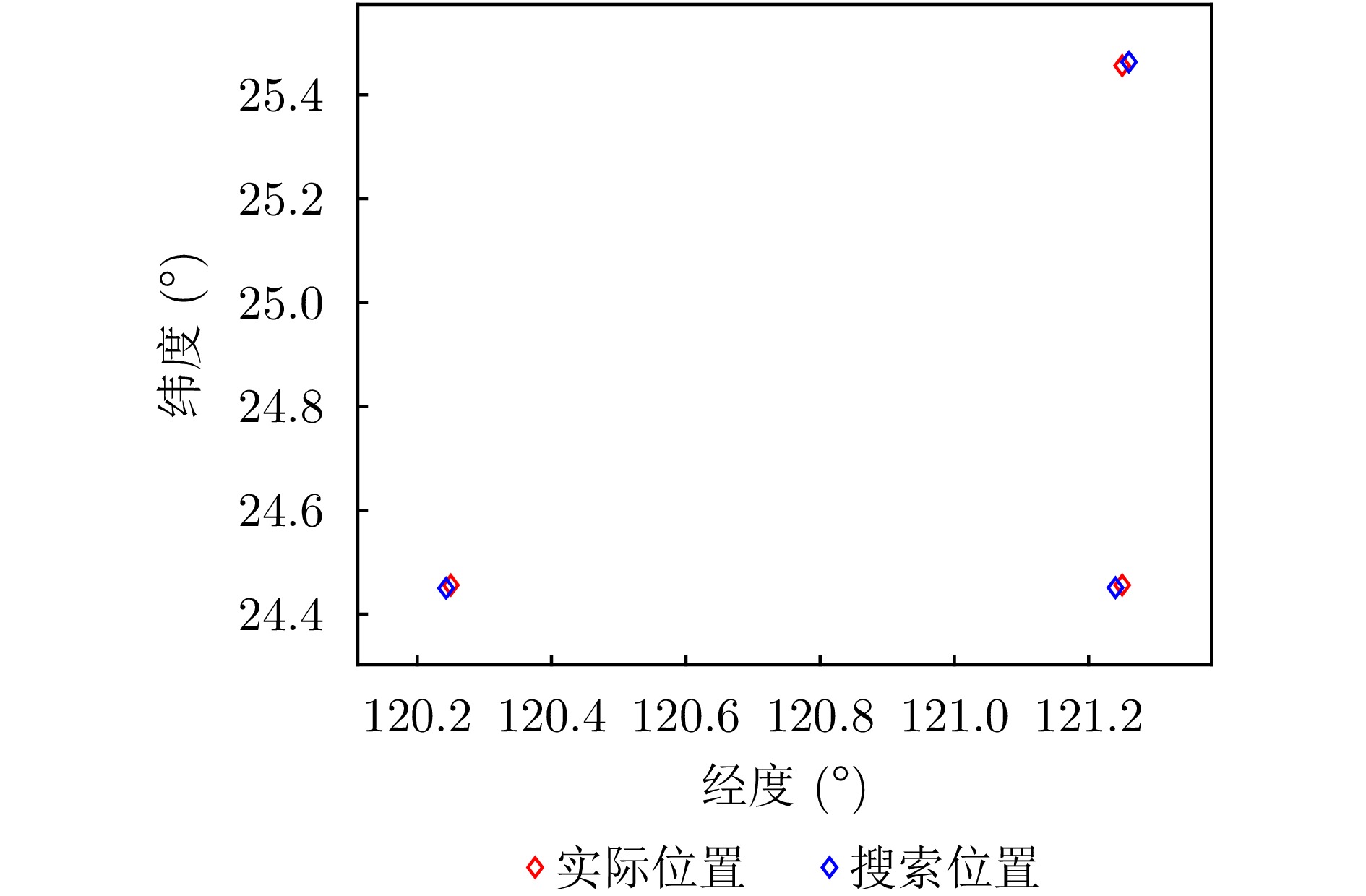
Passive localization methods based on synthetic aperture imaging offer high positioning accuracy. However, in scenarios involving multiple radar emitters transmitting Linear Frequency-Modulated (LFM) signals, distinguishing signals that are overlapped in the time and frequency domains can be challenging. This phenomenon, known as phase overlap, results in a significant degradation of localization performance. To address this issue, the present paper proposes a single-satellite multi-radar-emitter passive localization method based on synthetic aperture imaging using time-frequency parameter estimation. First, a signal model for multiple radar emitters transmitting LFM signals is constructed. The time-frequency parameters of the multiple radar emitter signals are estimated concurrently via a combination of Short-Time Fourier Transform (STFT) and DBSCAN. A rapid approximation of the azimuth chirp rate is attained through a coarse-to-fine search strategy founded upon the use of the STFT. The accurate localization of multiple radar emitters is ultimately realized through the implementation of two-dimensional focusing in the range and azimuth dimensions. The Cramer-Rao lower bound of the proposed method is derived on this basis. The experimental findings demonstrate that the proposed method enhances the localization accuracy by approximately 10 km at a signal-to-noise ratio of −10 dB, in comparison with the enhanced real-valued space-time subspace data fusion-based direct positioning method. Moreover, it reduces the computational time by half relative to the CLEAN-based synthetic aperture multi-source localization approach.
Passive localization methods based on synthetic aperture imaging offer high positioning accuracy. However, in scenarios involving multiple radar emitters transmitting Linear Frequency-Modulated (LFM) signals, distinguishing signals that are overlapped in the time and frequency domains can be challenging. This phenomenon, known as phase overlap, results in a significant degradation of localization performance. To address this issue, the present paper proposes a single-satellite multi-radar-emitter passive localization method based on synthetic aperture imaging using time-frequency parameter estimation. First, a signal model for multiple radar emitters transmitting LFM signals is constructed. The time-frequency parameters of the multiple radar emitter signals are estimated concurrently via a combination of Short-Time Fourier Transform (STFT) and DBSCAN. A rapid approximation of the azimuth chirp rate is attained through a coarse-to-fine search strategy founded upon the use of the STFT. The accurate localization of multiple radar emitters is ultimately realized through the implementation of two-dimensional focusing in the range and azimuth dimensions. The Cramer-Rao lower bound of the proposed method is derived on this basis. The experimental findings demonstrate that the proposed method enhances the localization accuracy by approximately 10 km at a signal-to-noise ratio of −10 dB, in comparison with the enhanced real-valued space-time subspace data fusion-based direct positioning method. Moreover, it reduces the computational time by half relative to the CLEAN-based synthetic aperture multi-source localization approach.








2026,
15(3):
929-943.
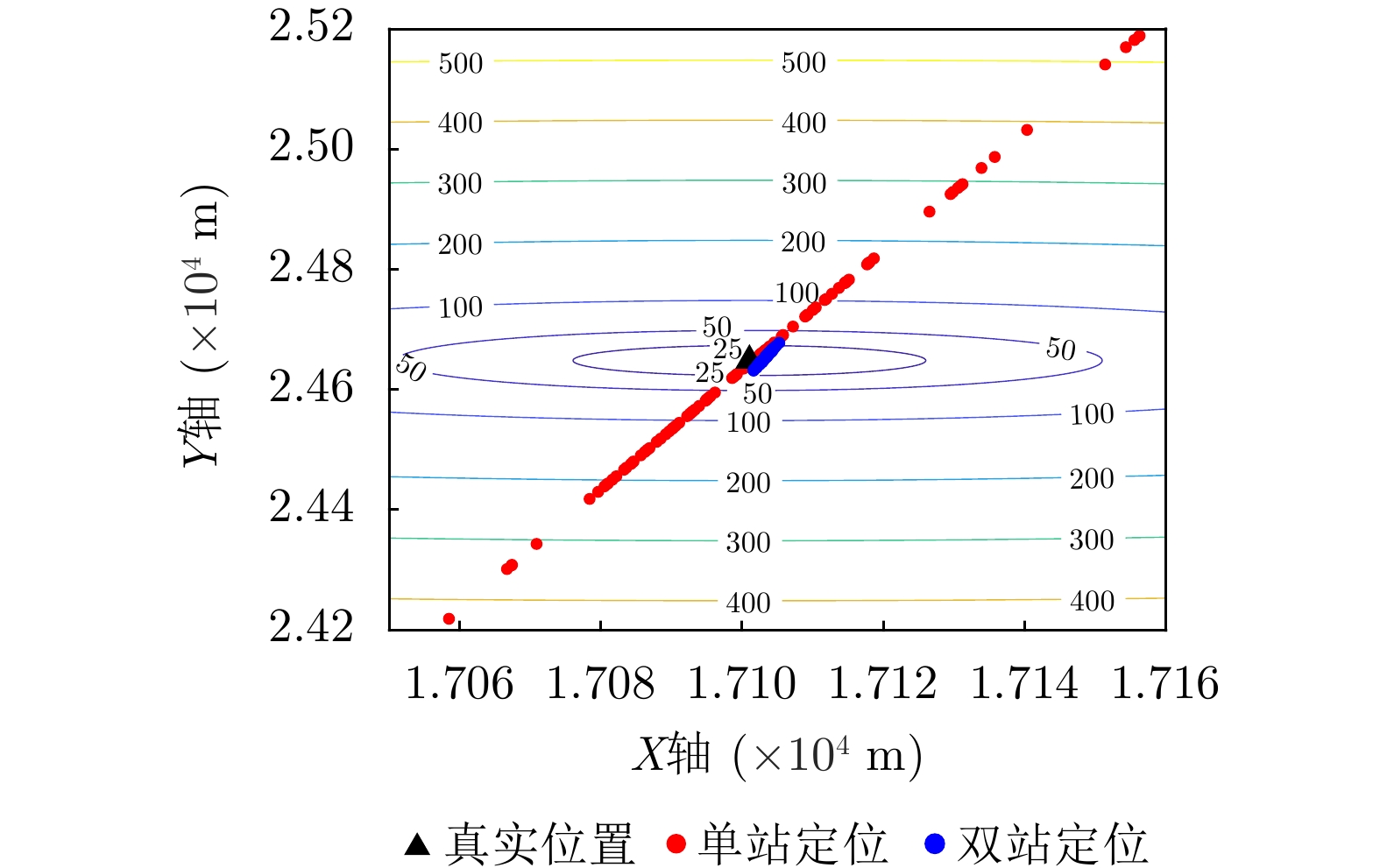
In locating ground moving radiating sources, traditional passive positioning methods, such as Direction of Arrival (DOA), often rely on long-term observation and filtering, resulting in low positioning efficiency. Existing synthetic aperture-based positioning methods are primarily designed for stationary radiating sources, making high-precision positioning of moving sources difficult. To address this limitation, this paper proposes synthetic aperture-based fast positioning and velocity estimation methods for moving radiating sources under single- and dual-station positioning systems, respectively. The proposed methods establish an instantaneous slant range model of the radiating source and derive the mapping relationship between the positioning parameters (position and velocity) and the imaging parameters. Specifically, in the single-station scenario, the traditional second-order slant range model is extended to third order, and a third-order chirp rate is introduced to supplement the degrees of freedom, thereby enabling simultaneous estimation of position and velocity. In the dual-station scenario, an additional observation station is used to introduce two new imaging parameters, thereby further improving the rapidity and accuracy of positioning. To address the multi-solution problem inherent in the positioning equations, this paper proposes true-solution determination criteria for the single- and dual-station systems and presents an initialization strategy to ensure a unique solution for dual-station positioning. Furthermore, the paper analyzes how various factors affect the positioning accuracy of single- and dual-station models, compares the performance of the proposed single- and dual-station passive positioning models, and verifies the effectiveness of the proposed algorithms through simulations.
In locating ground moving radiating sources, traditional passive positioning methods, such as Direction of Arrival (DOA), often rely on long-term observation and filtering, resulting in low positioning efficiency. Existing synthetic aperture-based positioning methods are primarily designed for stationary radiating sources, making high-precision positioning of moving sources difficult. To address this limitation, this paper proposes synthetic aperture-based fast positioning and velocity estimation methods for moving radiating sources under single- and dual-station positioning systems, respectively. The proposed methods establish an instantaneous slant range model of the radiating source and derive the mapping relationship between the positioning parameters (position and velocity) and the imaging parameters. Specifically, in the single-station scenario, the traditional second-order slant range model is extended to third order, and a third-order chirp rate is introduced to supplement the degrees of freedom, thereby enabling simultaneous estimation of position and velocity. In the dual-station scenario, an additional observation station is used to introduce two new imaging parameters, thereby further improving the rapidity and accuracy of positioning. To address the multi-solution problem inherent in the positioning equations, this paper proposes true-solution determination criteria for the single- and dual-station systems and presents an initialization strategy to ensure a unique solution for dual-station positioning. Furthermore, the paper analyzes how various factors affect the positioning accuracy of single- and dual-station models, compares the performance of the proposed single- and dual-station passive positioning models, and verifies the effectiveness of the proposed algorithms through simulations.











2026,
15(3):
944-963.
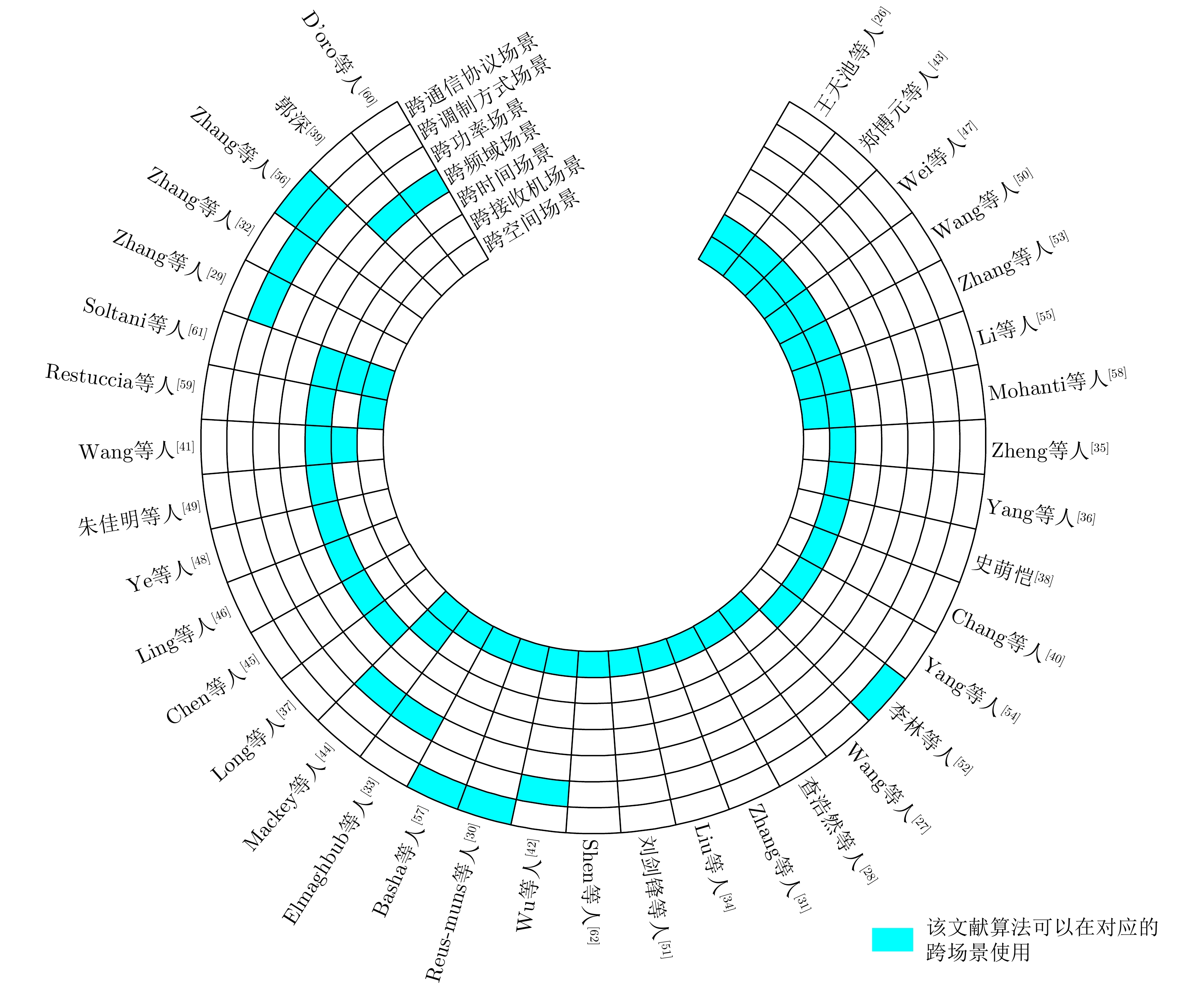
Specific Emitter Identification (SEI) relies on subtle differences in the radio frequency fingerprints of device-emitted signals to determine the emitter identity attributes. SEI plays a fundamental role in wireless security, spectrum management, and situational awareness. However, as wireless scenarios become increasingly diverse and dynamic, deep learning models trained in a single domain (where the source and target domains share the same distribution) often suffer severe performance degradation in real-world settings such as cross-receiver and cross-time scenarios. This degradation has not yet been comprehensively analyzed. To address this issue, this paper first classifies SEI according to cross-scenario types, and then systematically reviews mainstream algorithm frameworks and representative SEI methods, with a particular focus on the core ideas and key technologies underlying each method. It also summarizes the main open-source cross-scenario SEI datasets. Finally, the paper identifies current research bottlenecks and outlines potential future directions, aiming to facilitate advances in SEI theories and methodologies applicable to complex electromagnetic environments.
Specific Emitter Identification (SEI) relies on subtle differences in the radio frequency fingerprints of device-emitted signals to determine the emitter identity attributes. SEI plays a fundamental role in wireless security, spectrum management, and situational awareness. However, as wireless scenarios become increasingly diverse and dynamic, deep learning models trained in a single domain (where the source and target domains share the same distribution) often suffer severe performance degradation in real-world settings such as cross-receiver and cross-time scenarios. This degradation has not yet been comprehensively analyzed. To address this issue, this paper first classifies SEI according to cross-scenario types, and then systematically reviews mainstream algorithm frameworks and representative SEI methods, with a particular focus on the core ideas and key technologies underlying each method. It also summarizes the main open-source cross-scenario SEI datasets. Finally, the paper identifies current research bottlenecks and outlines potential future directions, aiming to facilitate advances in SEI theories and methodologies applicable to complex electromagnetic environments.

2026,
15(3):
964-982.
The spaceborne Hybrid-Polarimetric Synthetic Aperture Radar (HP-SAR) balances the acquisition of rich polarimetric information with high-performance imaging. It offers advantages such as low system complexity and reduced data acquisition costs, and has emerged as a prominent direction in multidimensional microwave remote sensing. LT-1 is China’s first radar satellite equipped with spaceborne HP imaging capability, and it is also the world’s first satellite to implement a multi-channel HP radar system. This study utilizes HP imagery from the LT-1 satellite to construct and systematically elaborate the HP-SAR Evaluation and Analytical Dataset (HEAD-1.0), thereby addressing the lack of high-quality open-source HP datasets. HEAD-1.0 aims to provide data support for the quantitative assessment of HP-SAR image quality, the development of HP-SAR technology, and the design of new satellite missions, with particular emphasis on supporting novel observational technologies for terrestrial, oceanic, and deep-space applications. It comprises three components: (1) LT-1 SAR imagery, including 30 HP-SAR images and 16 Quad-Polarimetric SAR (QP-SAR) images, covering an area of approximately 64000 km2; (2) Auxiliary data, including six optical images and Digital Elevation Model (DEM) data in the same area as SAR images; and (3) Annotation data, including 28 active/passive calibrators, approximately 17 km2 of land cover classification, and 23 polygonal/linear annotated planetary analog scenes. Based on HEAD-1.0, a preliminary qualitative and quantitative study was conducted, involving HP-SAR calibration, a comparison of terrain classification between HP-SAR and QP-SAR, and an analysis of HP characterizations of planetary analog scenes. In the future, an internationally advanced polarimetric SAR benchmark database will be constructed by integrating multi-platform, multi-band, multi-angle, and multi-temporal imaging data. In particular, the future study will focus on supporting innovative research on key technologies, including planetary surface and subsurface exploration, intelligent fusion of multisource remote sensing data, and advanced interpretation algorithms for SAR imagery.
The spaceborne Hybrid-Polarimetric Synthetic Aperture Radar (HP-SAR) balances the acquisition of rich polarimetric information with high-performance imaging. It offers advantages such as low system complexity and reduced data acquisition costs, and has emerged as a prominent direction in multidimensional microwave remote sensing. LT-1 is China’s first radar satellite equipped with spaceborne HP imaging capability, and it is also the world’s first satellite to implement a multi-channel HP radar system. This study utilizes HP imagery from the LT-1 satellite to construct and systematically elaborate the HP-SAR Evaluation and Analytical Dataset (HEAD-1.0), thereby addressing the lack of high-quality open-source HP datasets. HEAD-1.0 aims to provide data support for the quantitative assessment of HP-SAR image quality, the development of HP-SAR technology, and the design of new satellite missions, with particular emphasis on supporting novel observational technologies for terrestrial, oceanic, and deep-space applications. It comprises three components: (1) LT-1 SAR imagery, including 30 HP-SAR images and 16 Quad-Polarimetric SAR (QP-SAR) images, covering an area of approximately 64000 km2; (2) Auxiliary data, including six optical images and Digital Elevation Model (DEM) data in the same area as SAR images; and (3) Annotation data, including 28 active/passive calibrators, approximately 17 km2 of land cover classification, and 23 polygonal/linear annotated planetary analog scenes. Based on HEAD-1.0, a preliminary qualitative and quantitative study was conducted, involving HP-SAR calibration, a comparison of terrain classification between HP-SAR and QP-SAR, and an analysis of HP characterizations of planetary analog scenes. In the future, an internationally advanced polarimetric SAR benchmark database will be constructed by integrating multi-platform, multi-band, multi-angle, and multi-temporal imaging data. In particular, the future study will focus on supporting innovative research on key technologies, including planetary surface and subsurface exploration, intelligent fusion of multisource remote sensing data, and advanced interpretation algorithms for SAR imagery.
















2026,
15(3):
983-995.
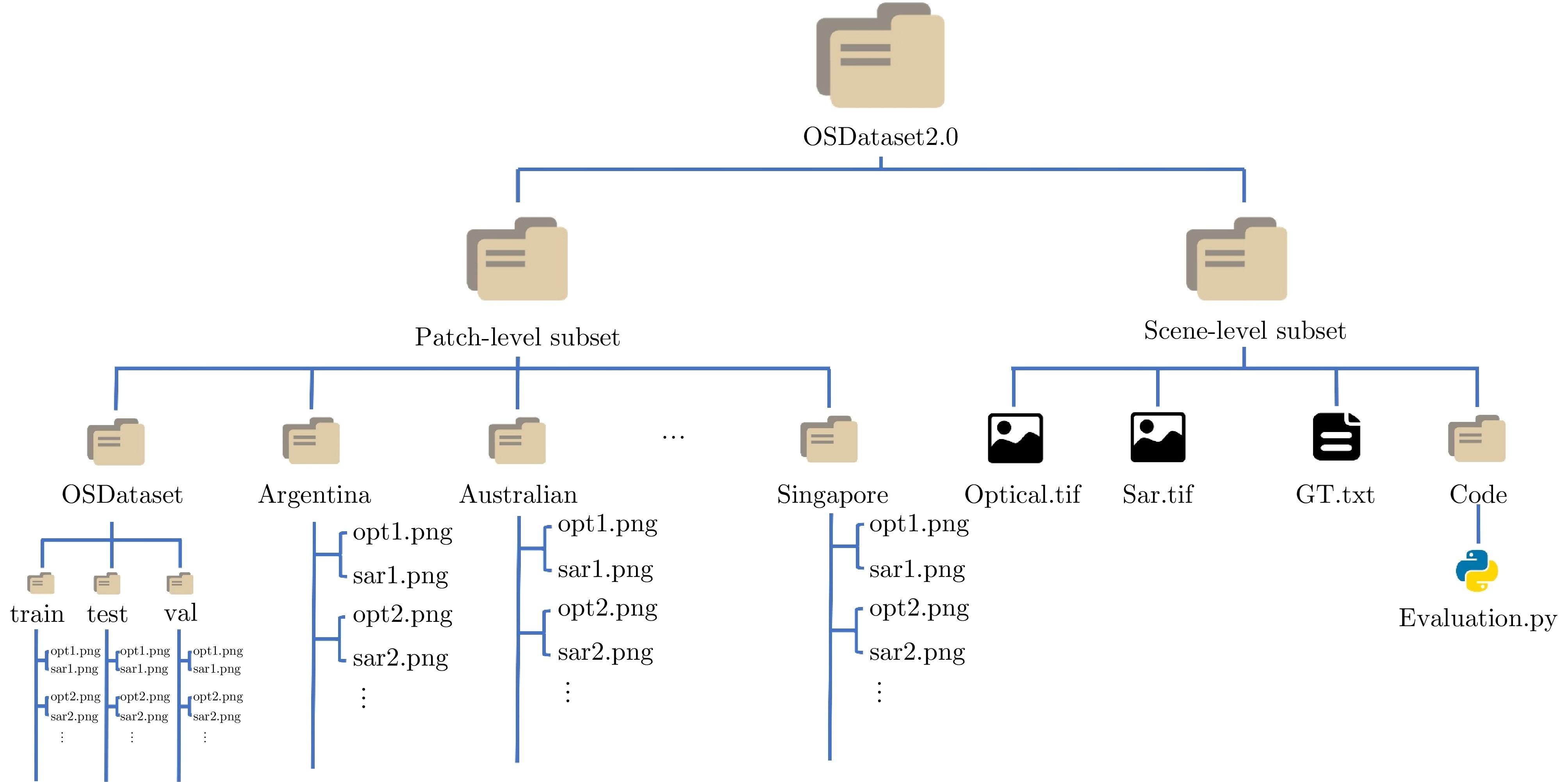
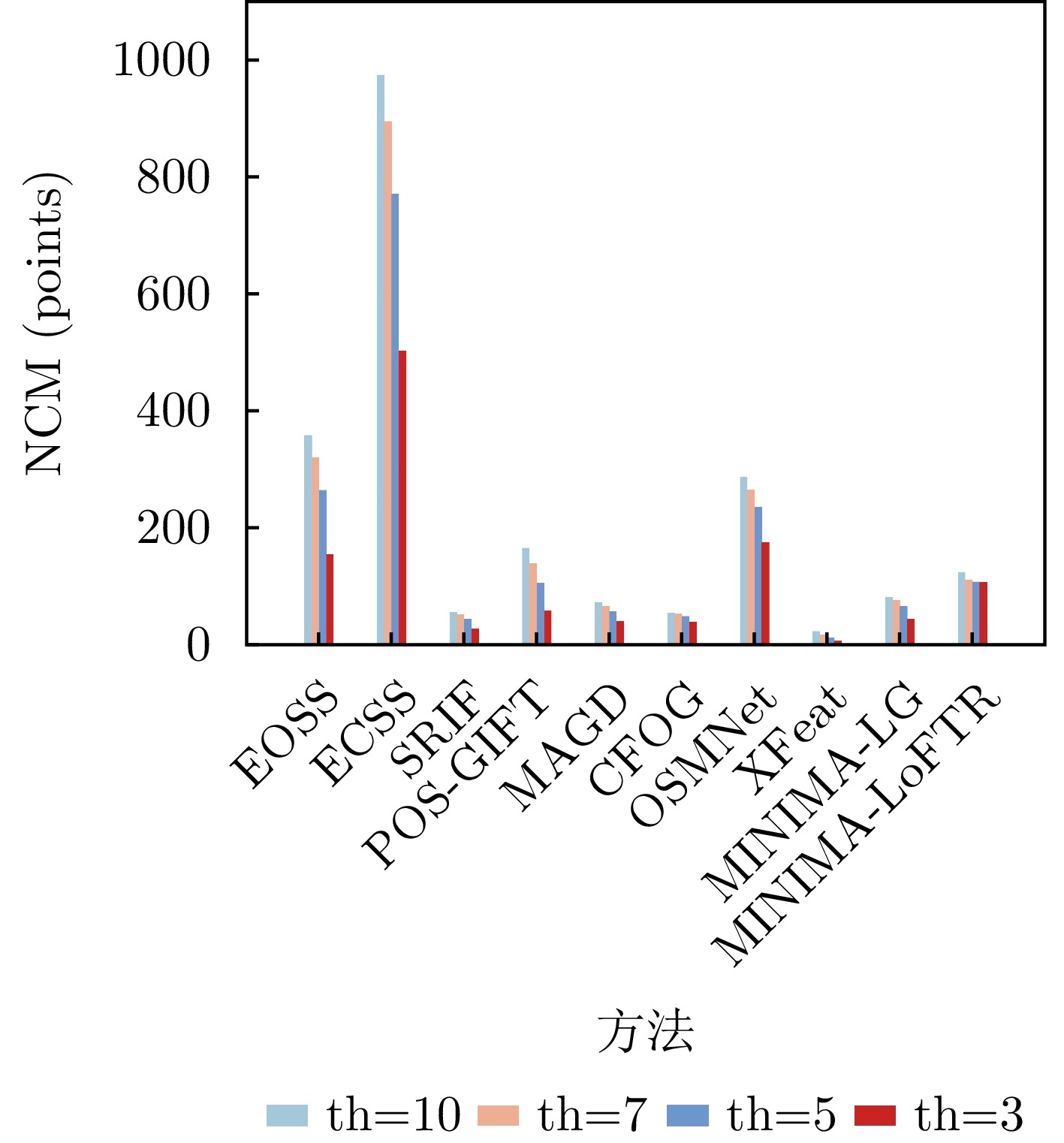
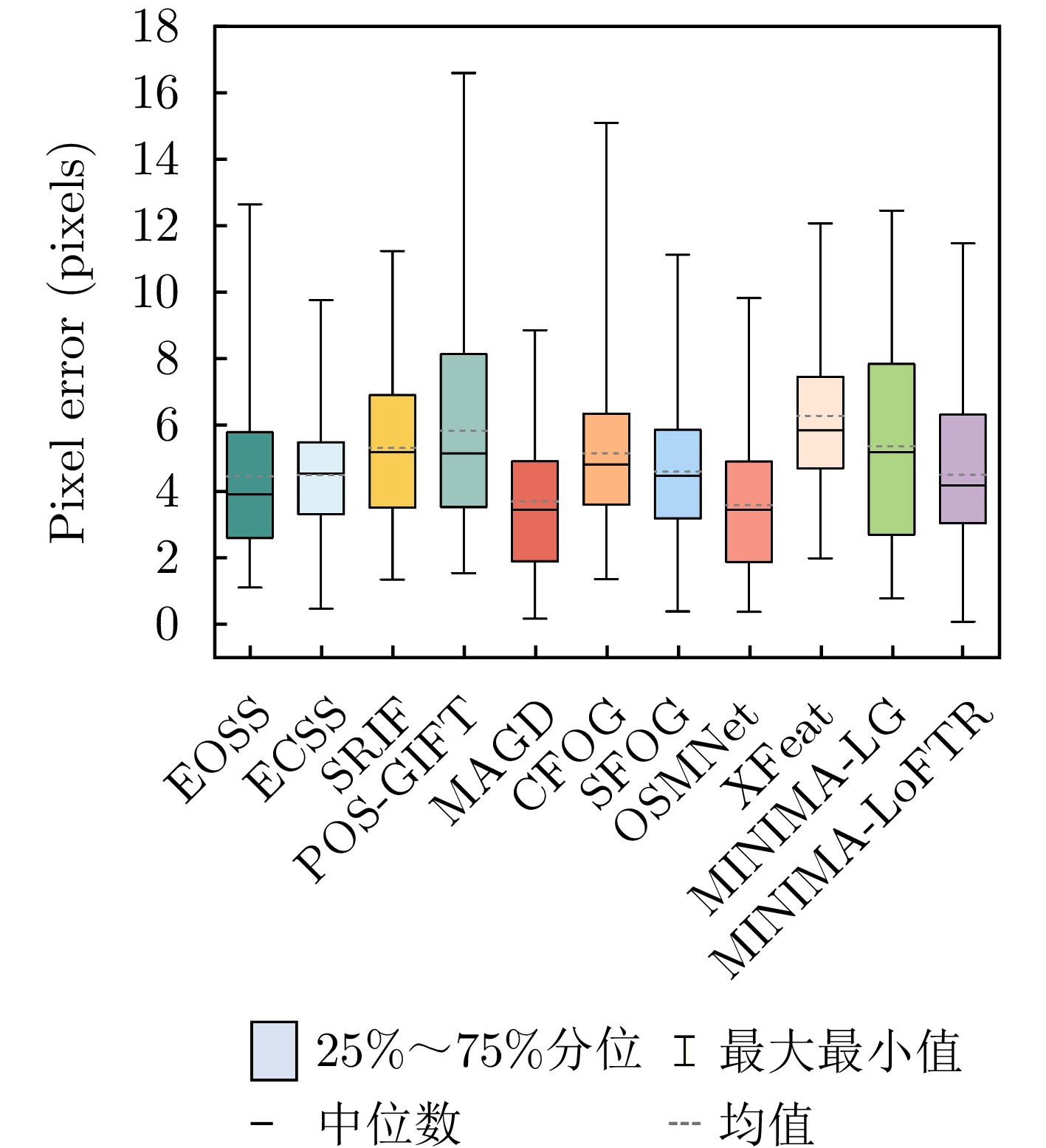
Synthetic Aperture Radar (SAR) and optical imagery are two key remote-sensing modalities in Earth observation, and cross-modal image matching between them is widely applied in tasks such as image fusion, joint interpretation, and high-precision geolocation. In recent years, with the rapid growth of Earth-observation data, the importance of cross-modal image matching between SAR and optical data has become increasingly prominent, and related studies have achieved notable progress. In particular, Deep Learning (DL)-based methods, owing to their strengths in cross-modal feature representation and high-level semantic extraction, have demonstrated excellent matching accuracy and adaptability across varying imaging conditions. However, most publicly available datasets are limited to small image patches and lack complete full-scene image pairs that cover realistic large-scale scenarios, making it difficult to comprehensively evaluate the performance of matching algorithms in practical remote-sensing settings and constraining advances in the training and generalization of DL models. To address these issues, this study develops and releases OSDataset2.0, a large-scale benchmark dataset for SAR-optical image matching. The dataset comprises two parts: A patch-level subset and a scene-level subset. The patch-level subset is composed of 6,476 registered 512 × 512 image pairs covering 14 countries (Argentina, Australia, Poland, Germany, Russia, France, Qatar, Malaysia, the United States, Japan, Türkiye, Singapore, India, and China); the scene-level subset consists of one pair of full-scene optical and SAR images. For full-scene images, high-precision, uniformly distributed ground-truth correspondences are provided, extracted under the principle of imaging-mechanism consistency, together with a general evaluation codebase that supports quantitative analysis of registration accuracy for arbitrary matching algorithms. To further assess the dataset’s effectiveness and challenge level, a systematic evaluation of 11 representative optical-SAR matching methods on OSDataset2.0 is conducted, covering traditional feature-based approaches and mainstream DL models. Experimental results show that the dataset not only supports effective algorithmic comparisons but also provides reliable training resources and a unified evaluation benchmark for subsequent research.
Synthetic Aperture Radar (SAR) and optical imagery are two key remote-sensing modalities in Earth observation, and cross-modal image matching between them is widely applied in tasks such as image fusion, joint interpretation, and high-precision geolocation. In recent years, with the rapid growth of Earth-observation data, the importance of cross-modal image matching between SAR and optical data has become increasingly prominent, and related studies have achieved notable progress. In particular, Deep Learning (DL)-based methods, owing to their strengths in cross-modal feature representation and high-level semantic extraction, have demonstrated excellent matching accuracy and adaptability across varying imaging conditions. However, most publicly available datasets are limited to small image patches and lack complete full-scene image pairs that cover realistic large-scale scenarios, making it difficult to comprehensively evaluate the performance of matching algorithms in practical remote-sensing settings and constraining advances in the training and generalization of DL models. To address these issues, this study develops and releases OSDataset2.0, a large-scale benchmark dataset for SAR-optical image matching. The dataset comprises two parts: A patch-level subset and a scene-level subset. The patch-level subset is composed of 6,476 registered 512 × 512 image pairs covering 14 countries (Argentina, Australia, Poland, Germany, Russia, France, Qatar, Malaysia, the United States, Japan, Türkiye, Singapore, India, and China); the scene-level subset consists of one pair of full-scene optical and SAR images. For full-scene images, high-precision, uniformly distributed ground-truth correspondences are provided, extracted under the principle of imaging-mechanism consistency, together with a general evaluation codebase that supports quantitative analysis of registration accuracy for arbitrary matching algorithms. To further assess the dataset’s effectiveness and challenge level, a systematic evaluation of 11 representative optical-SAR matching methods on OSDataset2.0 is conducted, covering traditional feature-based approaches and mainstream DL models. Experimental results show that the dataset not only supports effective algorithmic comparisons but also provides reliable training resources and a unified evaluation benchmark for subsequent research.







2026,
15(3):
996-1012.
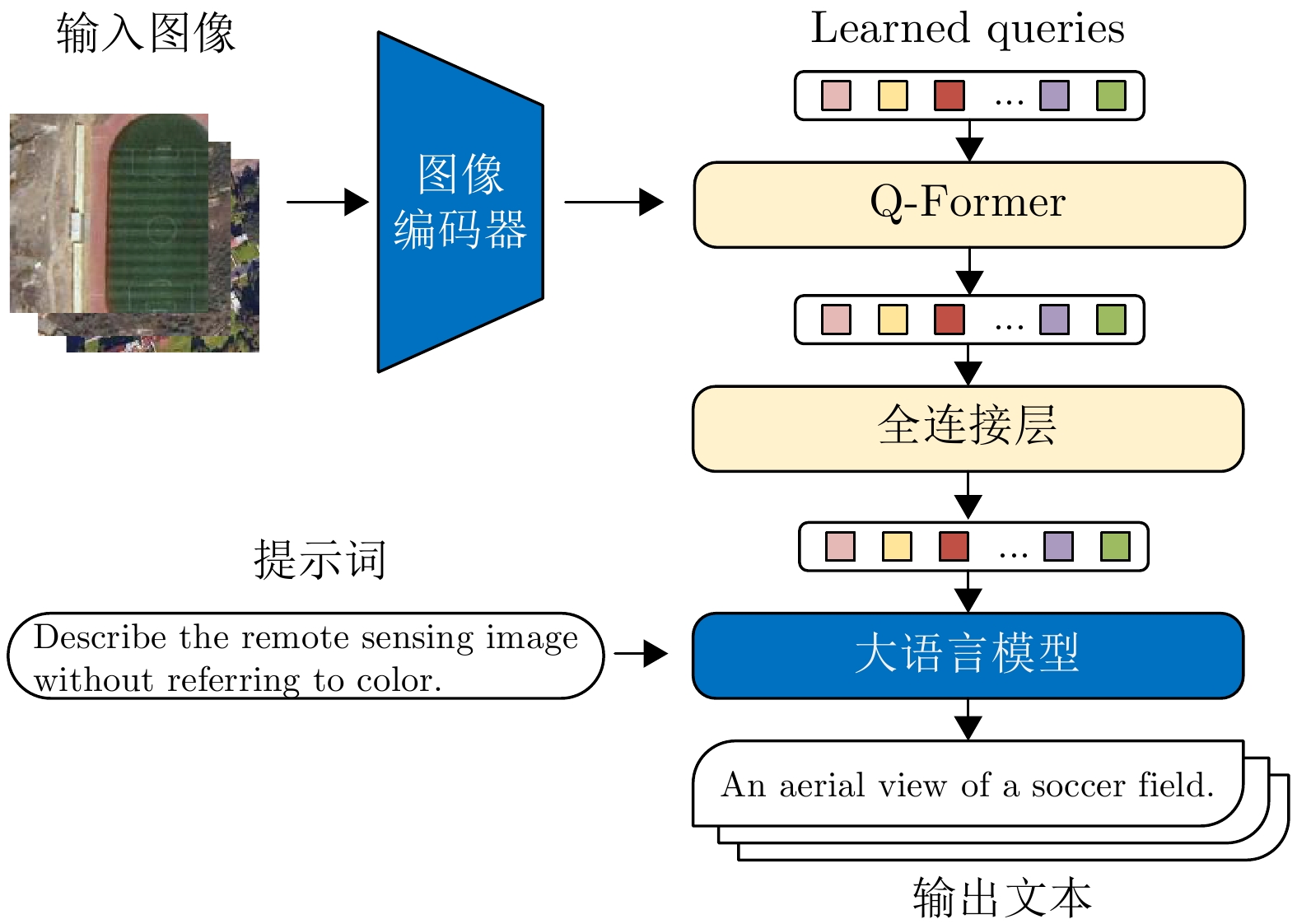
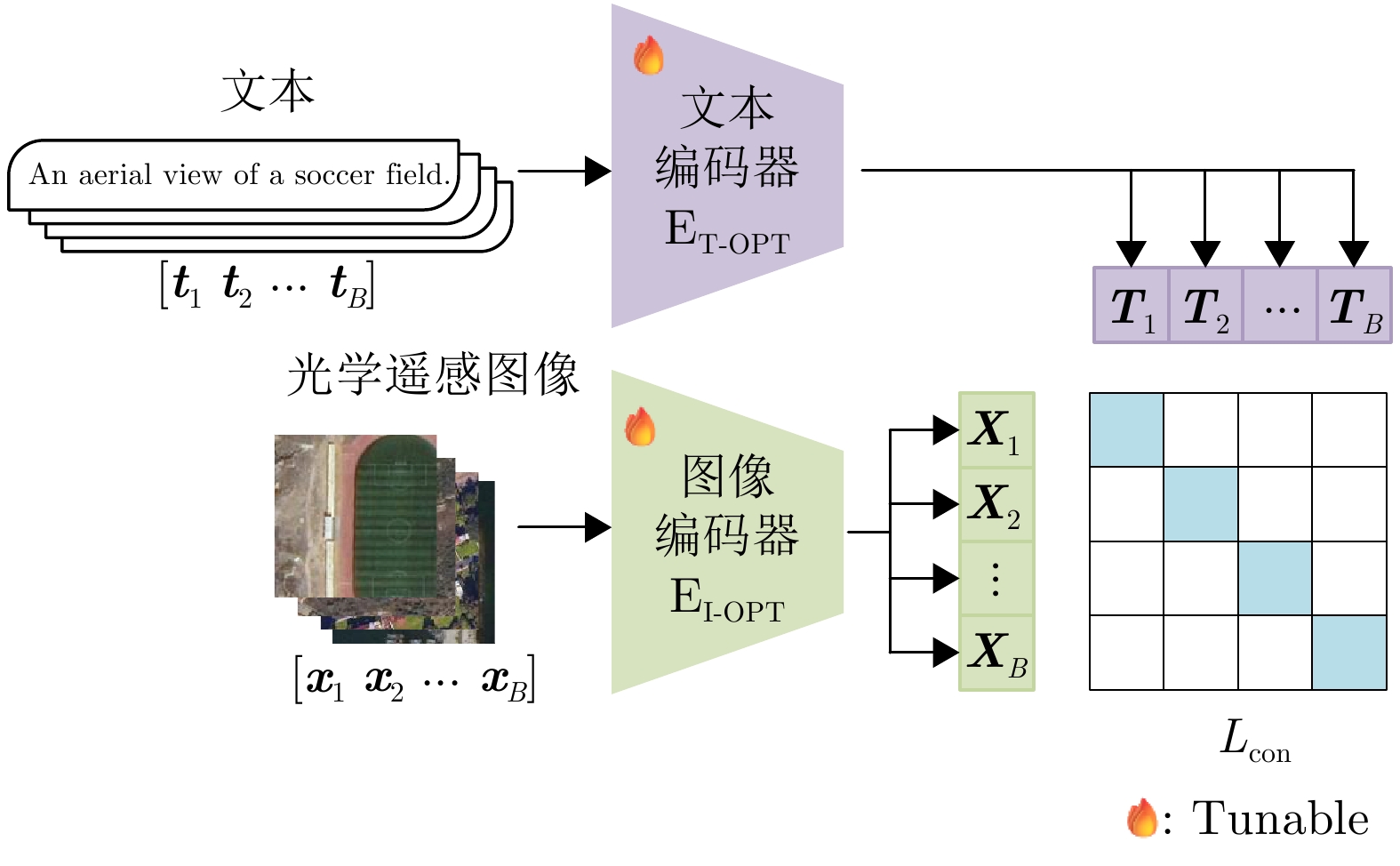
A large-scale Vision-Language Model (VLM) pre-trained on massive image-text datasets performs well when processing natural images. However, there are two major challenges in applying it to Synthetic Aperture Radar (SAR) images: (1) The high cost of high-quality text annotation limits the construction of SAR image-text paired datasets, and (2) The considerable differences in image features between SAR images and optical natural images increase the difficulty of cross-domain knowledge transfer. To address these problems, this study developed a knowledge transfer method for VLM tailored to SAR images. First, this study leveraged paired SAR and optical remote sensing images and employed a generative VLM to automatically produce textual descriptions of the optical images, thereby indirectly constructing a low-cost SAR-text paired dataset. Second, a two-stage transfer strategy was designed to address the large domain discrepancy between natural and SAR images, reducing the difficulty of each transfer stage. Finally, experimental validation was conducted through the zero-shot scene classification, image retrieval, and object recognition of SAR images. The results demonstrated that the proposed method enables effective knowledge transfer from a large-scale VLM to the SAR image domain.
A large-scale Vision-Language Model (VLM) pre-trained on massive image-text datasets performs well when processing natural images. However, there are two major challenges in applying it to Synthetic Aperture Radar (SAR) images: (1) The high cost of high-quality text annotation limits the construction of SAR image-text paired datasets, and (2) The considerable differences in image features between SAR images and optical natural images increase the difficulty of cross-domain knowledge transfer. To address these problems, this study developed a knowledge transfer method for VLM tailored to SAR images. First, this study leveraged paired SAR and optical remote sensing images and employed a generative VLM to automatically produce textual descriptions of the optical images, thereby indirectly constructing a low-cost SAR-text paired dataset. Second, a two-stage transfer strategy was designed to address the large domain discrepancy between natural and SAR images, reducing the difficulty of each transfer stage. Finally, experimental validation was conducted through the zero-shot scene classification, image retrieval, and object recognition of SAR images. The results demonstrated that the proposed method enables effective knowledge transfer from a large-scale VLM to the SAR image domain.









2026,
15(3):
1013-1026.
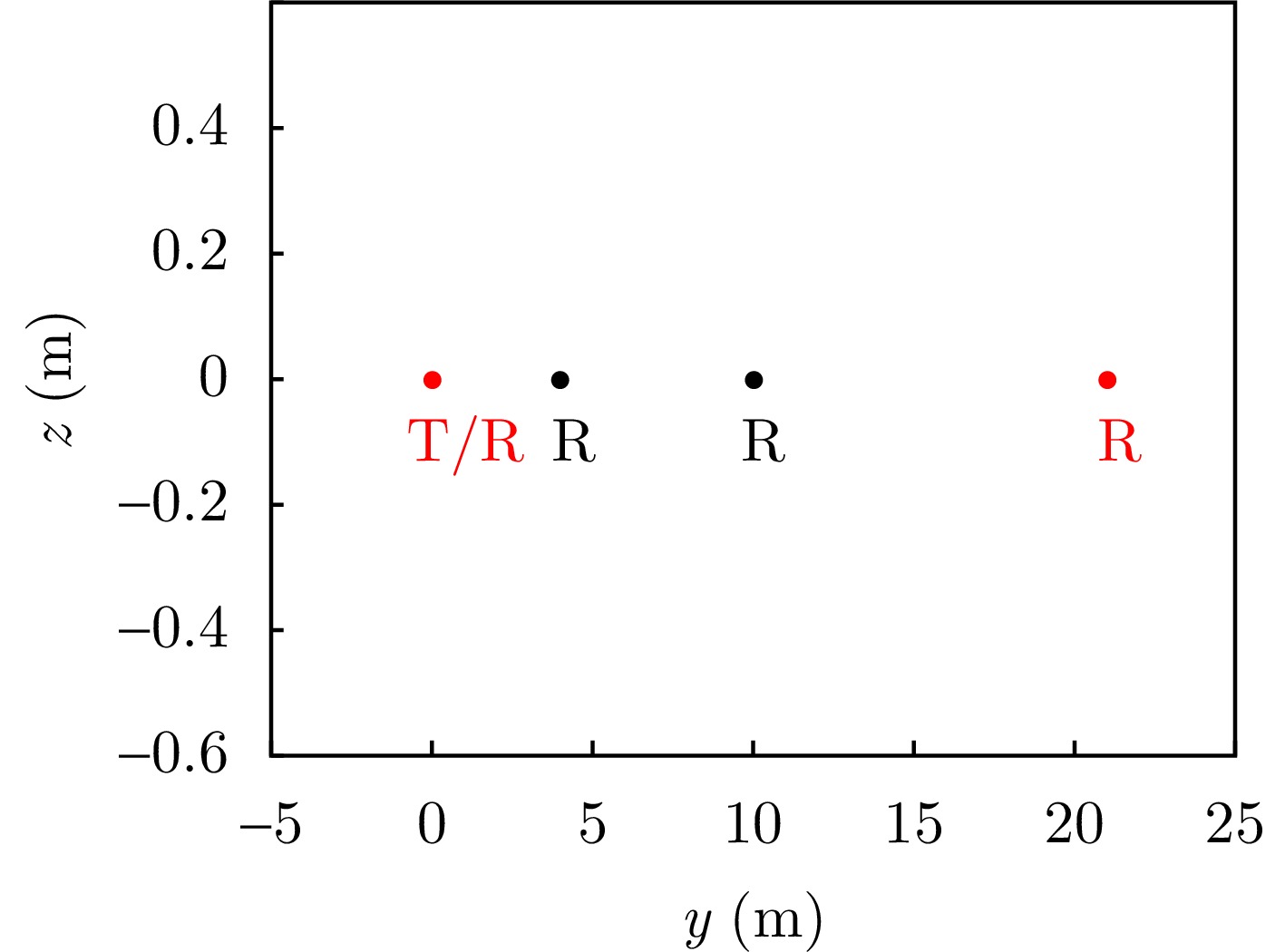
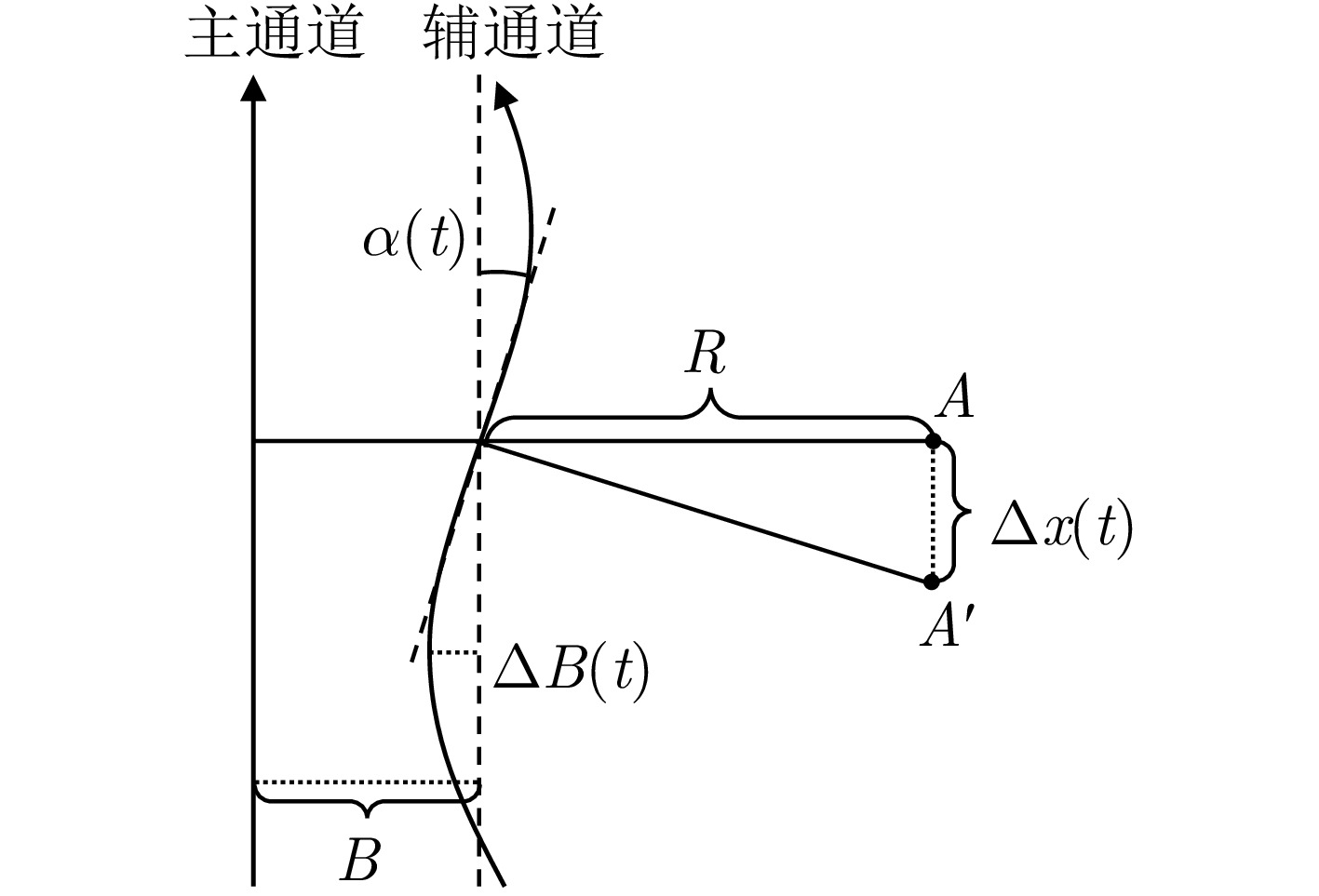
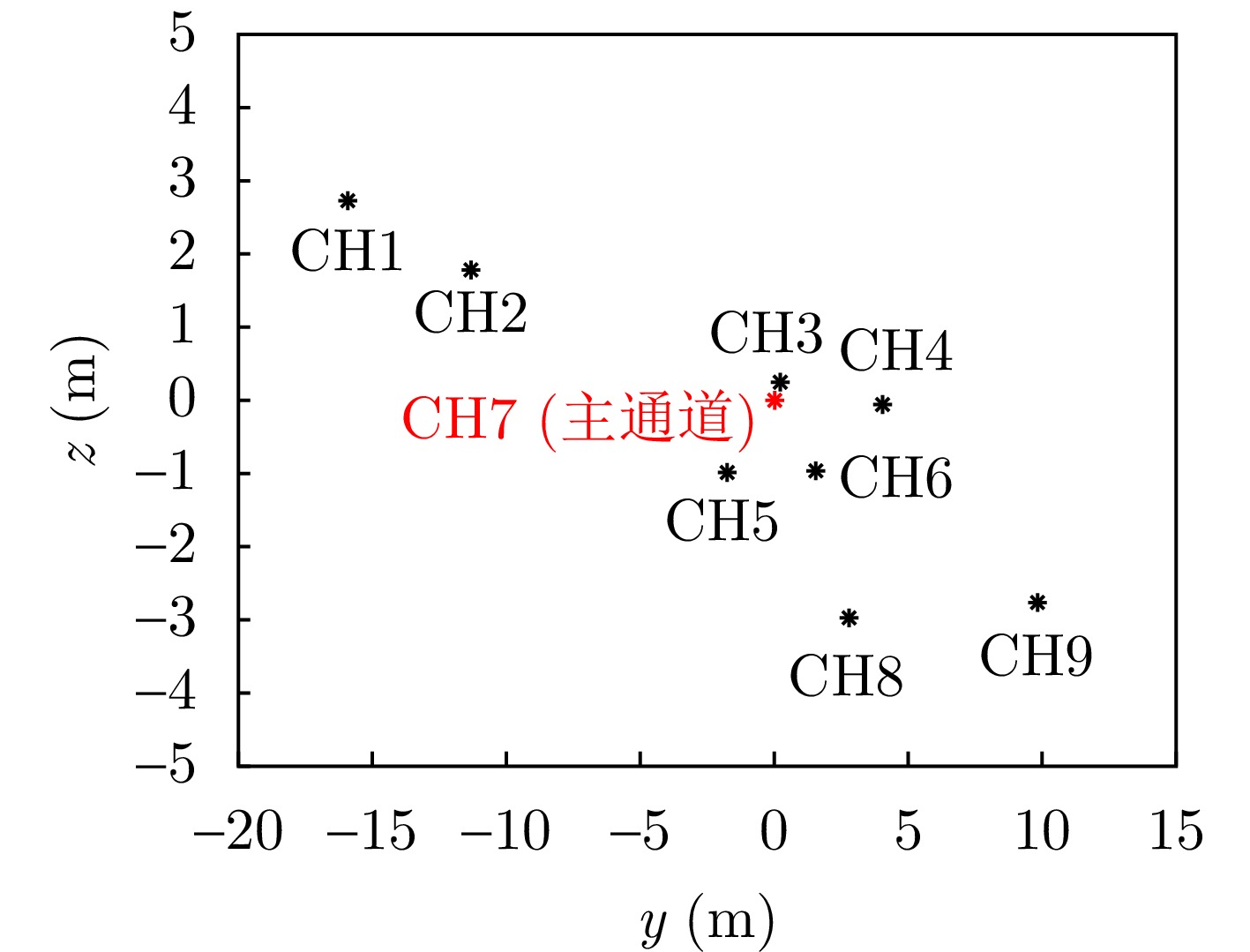
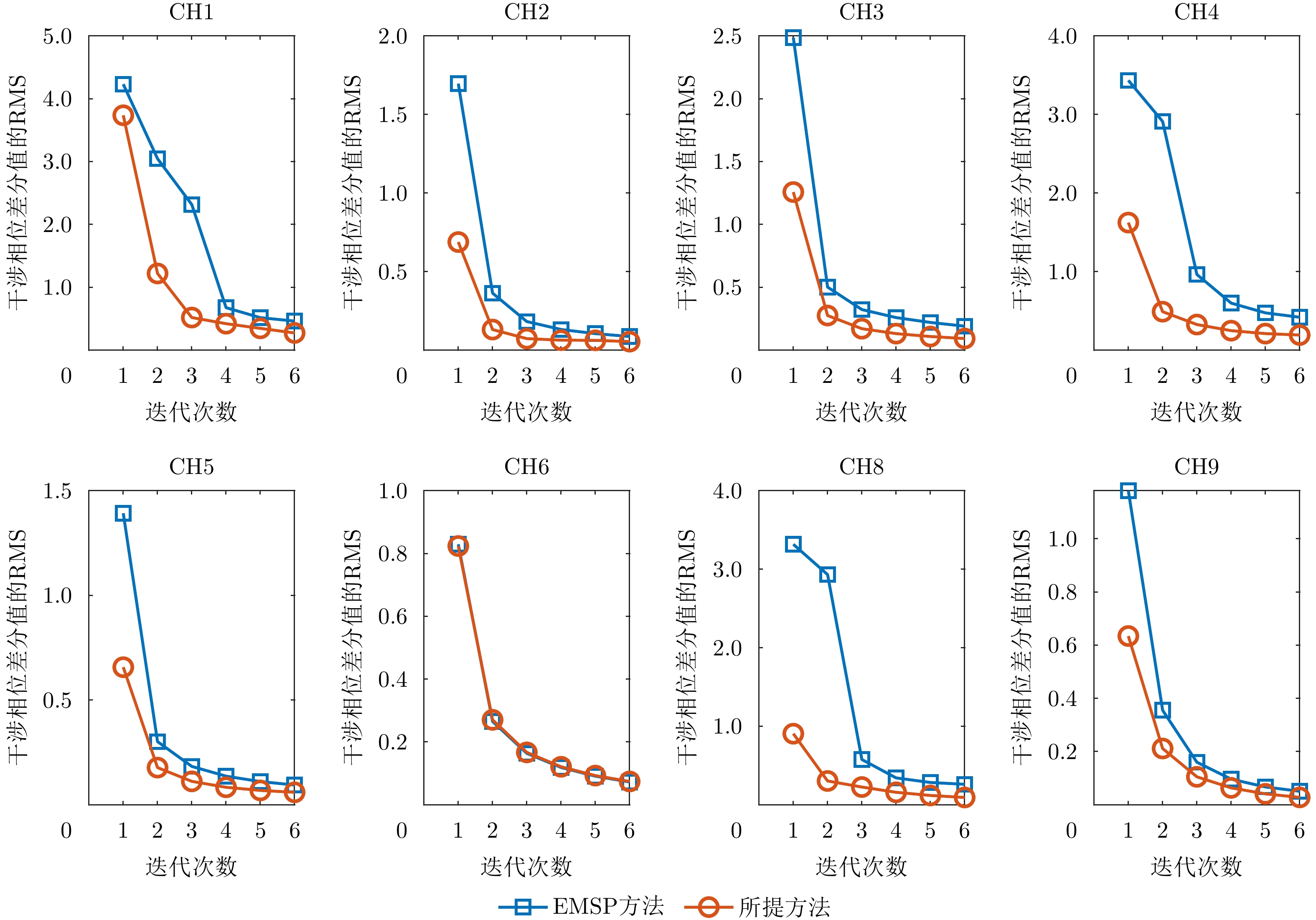
Small Unmanned Aerial Vehicle (UAV)-borne distributed Tomographic Synthetic Aperture Radar (TomoSAR) systems exhibit remarkable residual time-varying baseline errors due to the limited precision of the position and orientation system on small UAV platforms. These errors critically degrade the performance of three-Dimensional (3D) target reconstruction. Compared with airborne repeat-pass 3D Synthetic Aperture Radar (SAR), distributed TomoSAR mounted on small UAVs imposes stricter compensation accuracy requirements for time-varying baseline errors because of the altitude constraints of the carrying platform. Under the conditions of low signal-to-noise ratio and substantial time-varying baseline errors, existing estimation methods often fail to provide stable and reliable results. In this paper, a two-step time-varying baseline error estimation method based on image azimuth displacement is proposed. The method sequentially estimates the low-frequency component through the co-registration of the master and slave images and the high-frequency component using a multisquint algorithm. Iterative refinement is applied to enhance estimation accuracy. The experimental results obtained from real C-band small UAV-borne distributed TomoSAR data demonstrate that, compared with the enhanced multisquint processing method, the proposed method considerably reduces the root mean square of differential interferometric phases across most channels, thereby effectively improving interchannel coherence. In addition, the elevation-direction standard deviation of the reconstructed point cloud is reduced from 5.16 to 1.33 m, and the height reconstruction error of building targets is less than 0.5 m, validating the effectiveness and superiority of the proposed method.
Small Unmanned Aerial Vehicle (UAV)-borne distributed Tomographic Synthetic Aperture Radar (TomoSAR) systems exhibit remarkable residual time-varying baseline errors due to the limited precision of the position and orientation system on small UAV platforms. These errors critically degrade the performance of three-Dimensional (3D) target reconstruction. Compared with airborne repeat-pass 3D Synthetic Aperture Radar (SAR), distributed TomoSAR mounted on small UAVs imposes stricter compensation accuracy requirements for time-varying baseline errors because of the altitude constraints of the carrying platform. Under the conditions of low signal-to-noise ratio and substantial time-varying baseline errors, existing estimation methods often fail to provide stable and reliable results. In this paper, a two-step time-varying baseline error estimation method based on image azimuth displacement is proposed. The method sequentially estimates the low-frequency component through the co-registration of the master and slave images and the high-frequency component using a multisquint algorithm. Iterative refinement is applied to enhance estimation accuracy. The experimental results obtained from real C-band small UAV-borne distributed TomoSAR data demonstrate that, compared with the enhanced multisquint processing method, the proposed method considerably reduces the root mean square of differential interferometric phases across most channels, thereby effectively improving interchannel coherence. In addition, the elevation-direction standard deviation of the reconstructed point cloud is reduced from 5.16 to 1.33 m, and the height reconstruction error of building targets is less than 0.5 m, validating the effectiveness and superiority of the proposed method.










2026,
15(3):
1027-1041.
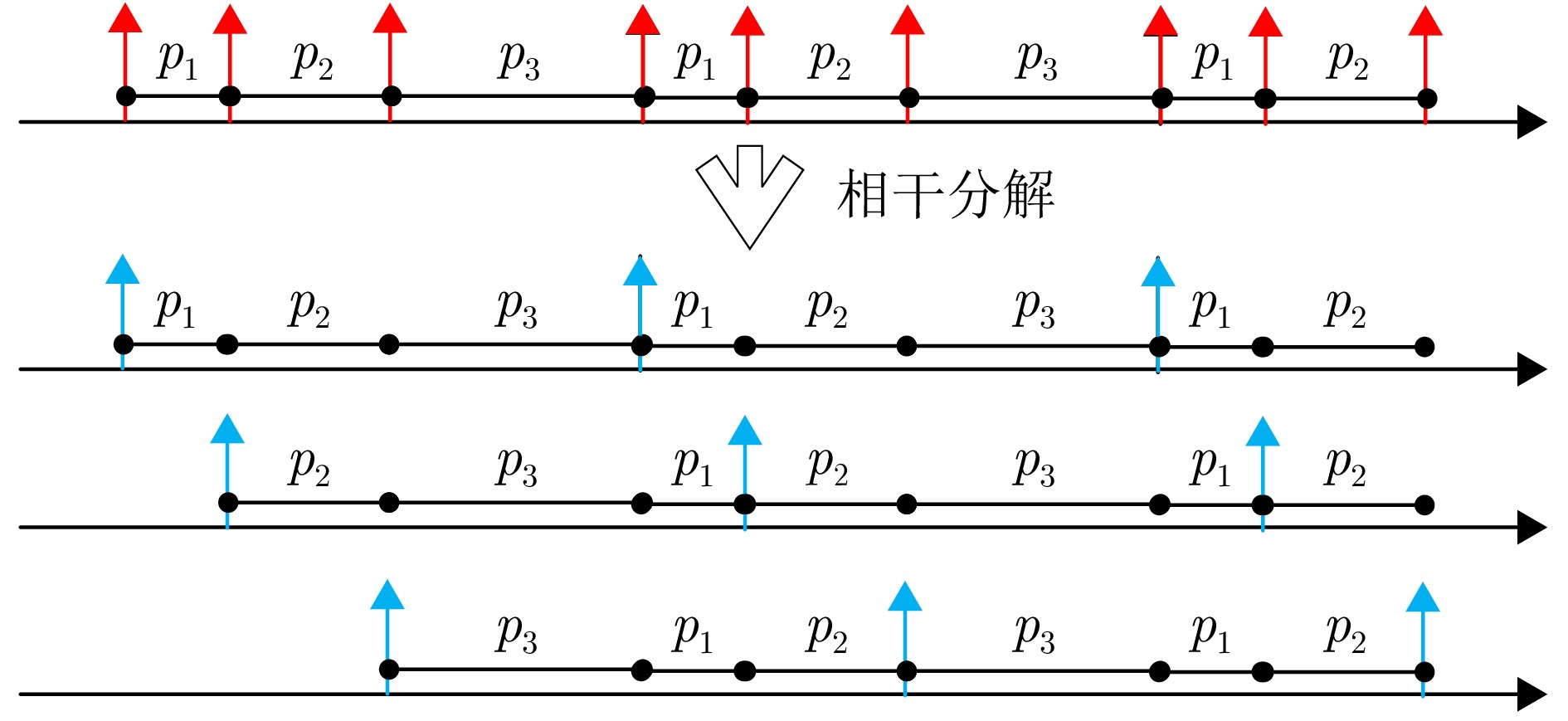
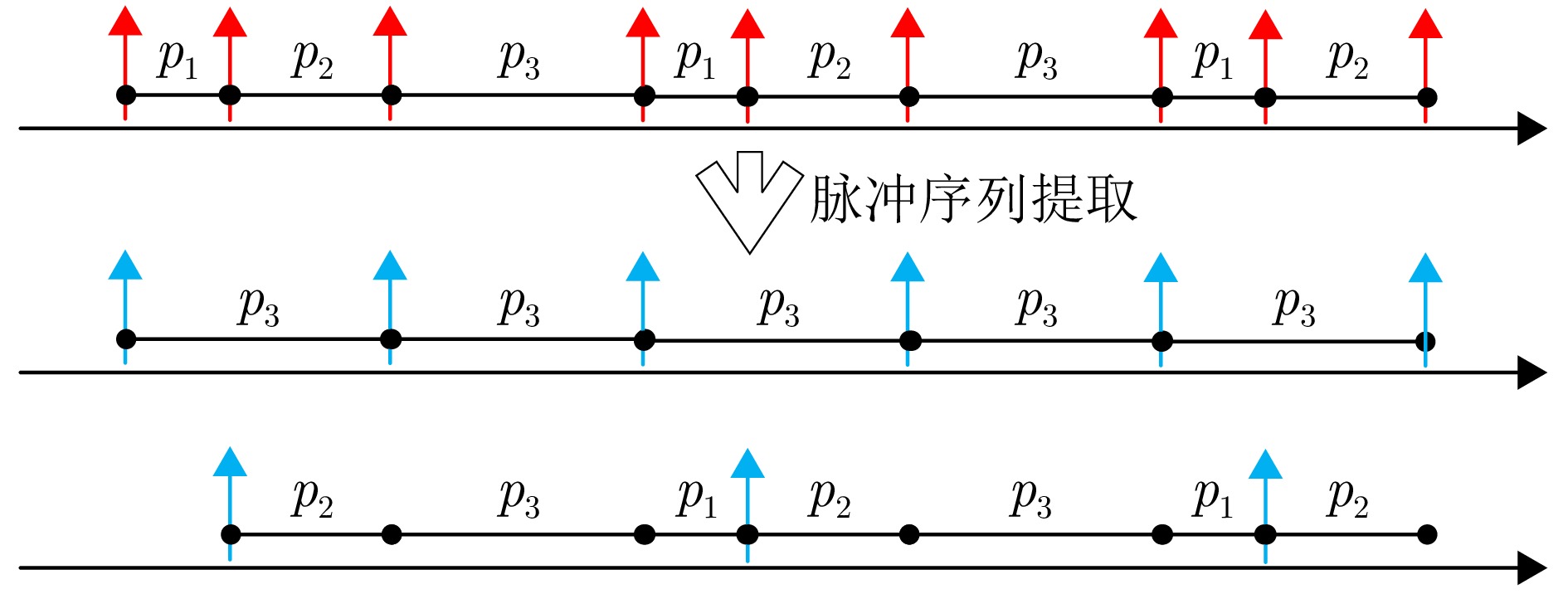
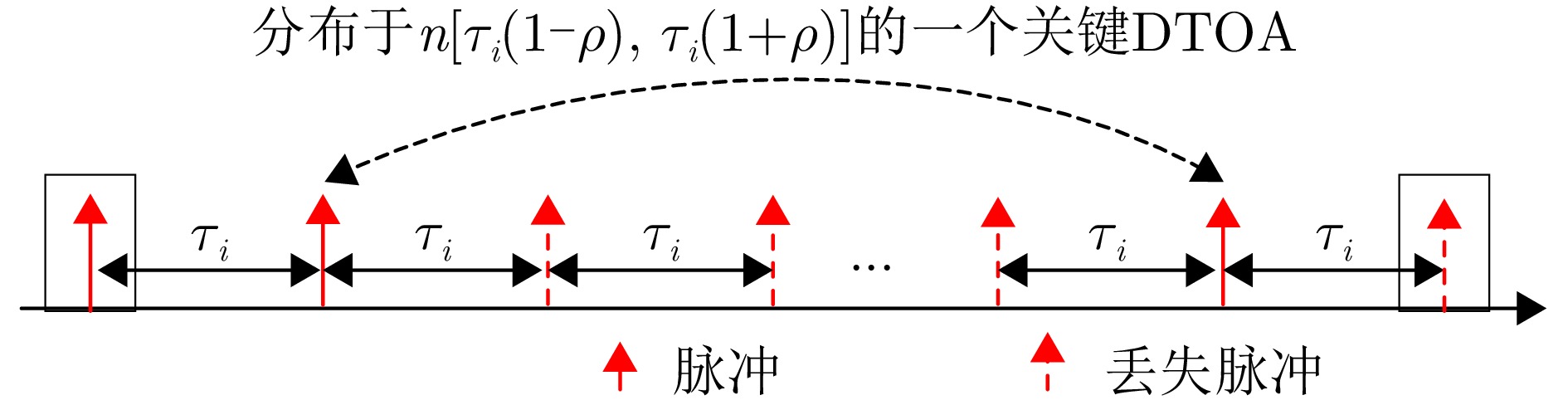
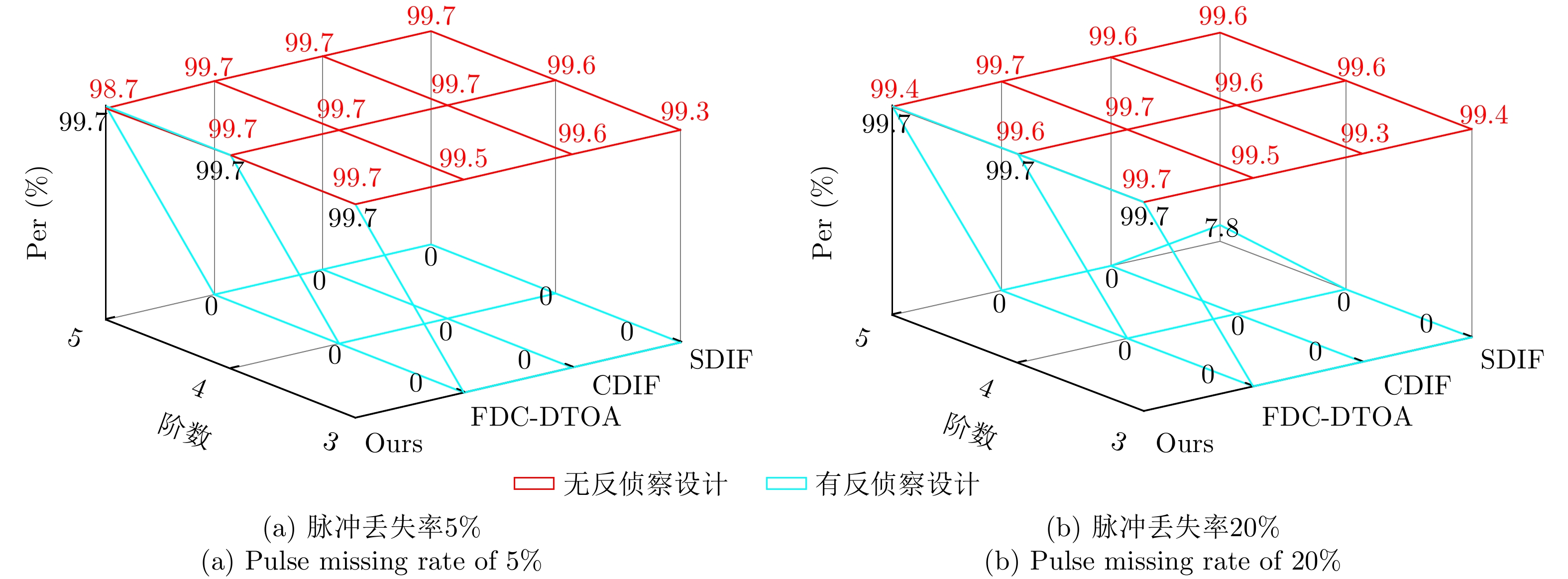
Radar signal deinterleaving is a critical technology in electronic intelligence and electronic support measures systems. The classical histogram-based method, although valued for its simplicity, is susceptible to deceptive jamming under counter-reconnaissance parameter design. This study proposes a deinterleaving method that is resistant to such deception. The main contributions are as follows: a frame period detection mechanism compatible with pulse missing rates from 0% to 50% is established through theoretical derivation; by integrating autocorrelation and the overlap rate, accurate frame period identification is achieved, which effectively distinguishes interference disguised as fixed Pulse Repetition Intervals (PRI) and prevents interference with the deinterleaving process; moreover, a coherent discrimination mechanism is introduced to handle scenarios with similar parameters and to accommodate fixed, staggered, sliding, and wobulated PRI modulation—within a unified framework. Experimental results show that the performance of histogram-based methods degrades severely in the presence of counterreconnaissance parameters, with maximum performance dropping to 0, while the proposed method maintains a minimum performance of 96.5%. Meanwhile, the proposed method reaches a minimum performance of 95.31% in parameter-similar scenarios. The proposed method remains effective against the four modulation types, whether counterreconnaissance parameters are present or not. It demonstrates antideception capability against counterreconnaissance design, strong generalization across modulation types, and reliable performance in parameter-similar scenarios, thereby greatly improving the deinterleaving reliability in complex electromagnetic environments and offering important implications for the development of electronic warfare systems.
Radar signal deinterleaving is a critical technology in electronic intelligence and electronic support measures systems. The classical histogram-based method, although valued for its simplicity, is susceptible to deceptive jamming under counter-reconnaissance parameter design. This study proposes a deinterleaving method that is resistant to such deception. The main contributions are as follows: a frame period detection mechanism compatible with pulse missing rates from 0% to 50% is established through theoretical derivation; by integrating autocorrelation and the overlap rate, accurate frame period identification is achieved, which effectively distinguishes interference disguised as fixed Pulse Repetition Intervals (PRI) and prevents interference with the deinterleaving process; moreover, a coherent discrimination mechanism is introduced to handle scenarios with similar parameters and to accommodate fixed, staggered, sliding, and wobulated PRI modulation—within a unified framework. Experimental results show that the performance of histogram-based methods degrades severely in the presence of counterreconnaissance parameters, with maximum performance dropping to 0, while the proposed method maintains a minimum performance of 96.5%. Meanwhile, the proposed method reaches a minimum performance of 95.31% in parameter-similar scenarios. The proposed method remains effective against the four modulation types, whether counterreconnaissance parameters are present or not. It demonstrates antideception capability against counterreconnaissance design, strong generalization across modulation types, and reliable performance in parameter-similar scenarios, thereby greatly improving the deinterleaving reliability in complex electromagnetic environments and offering important implications for the development of electronic warfare systems.







2026,
15(3):
1042-1058.
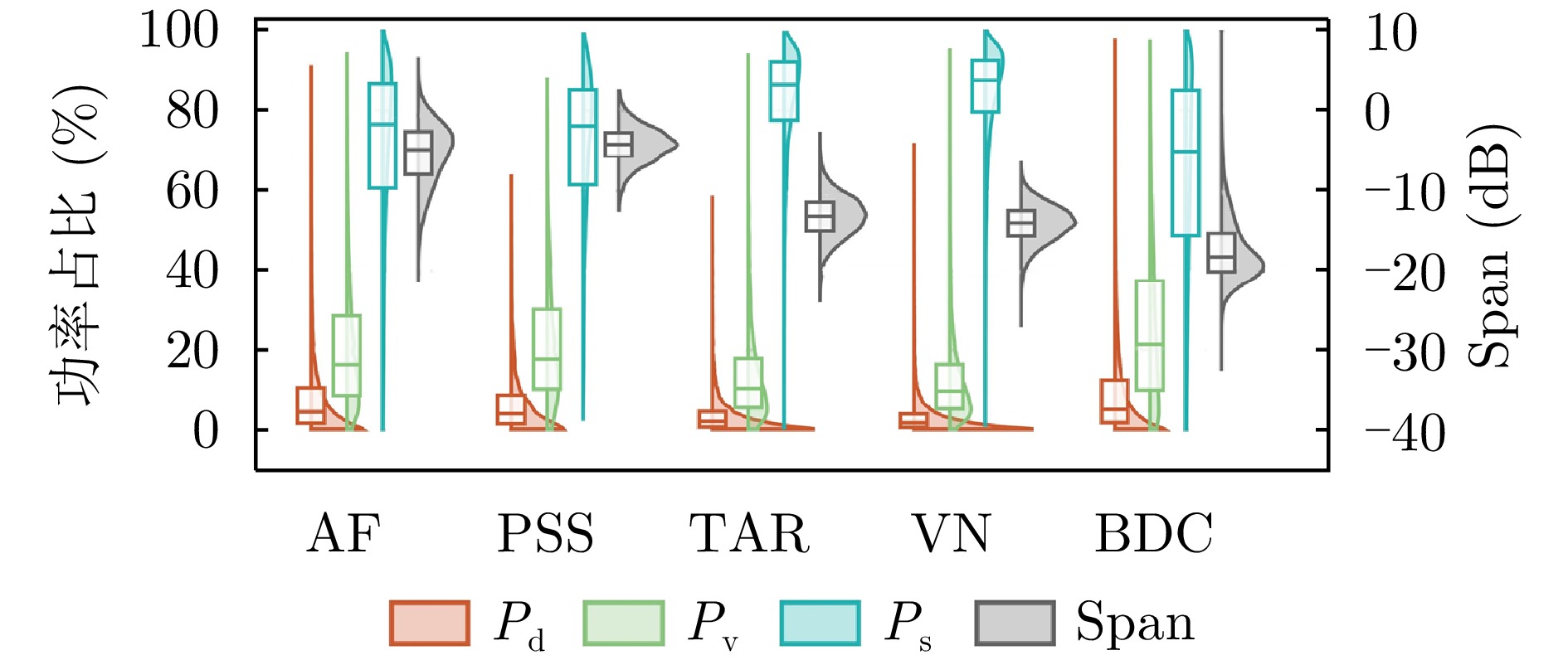
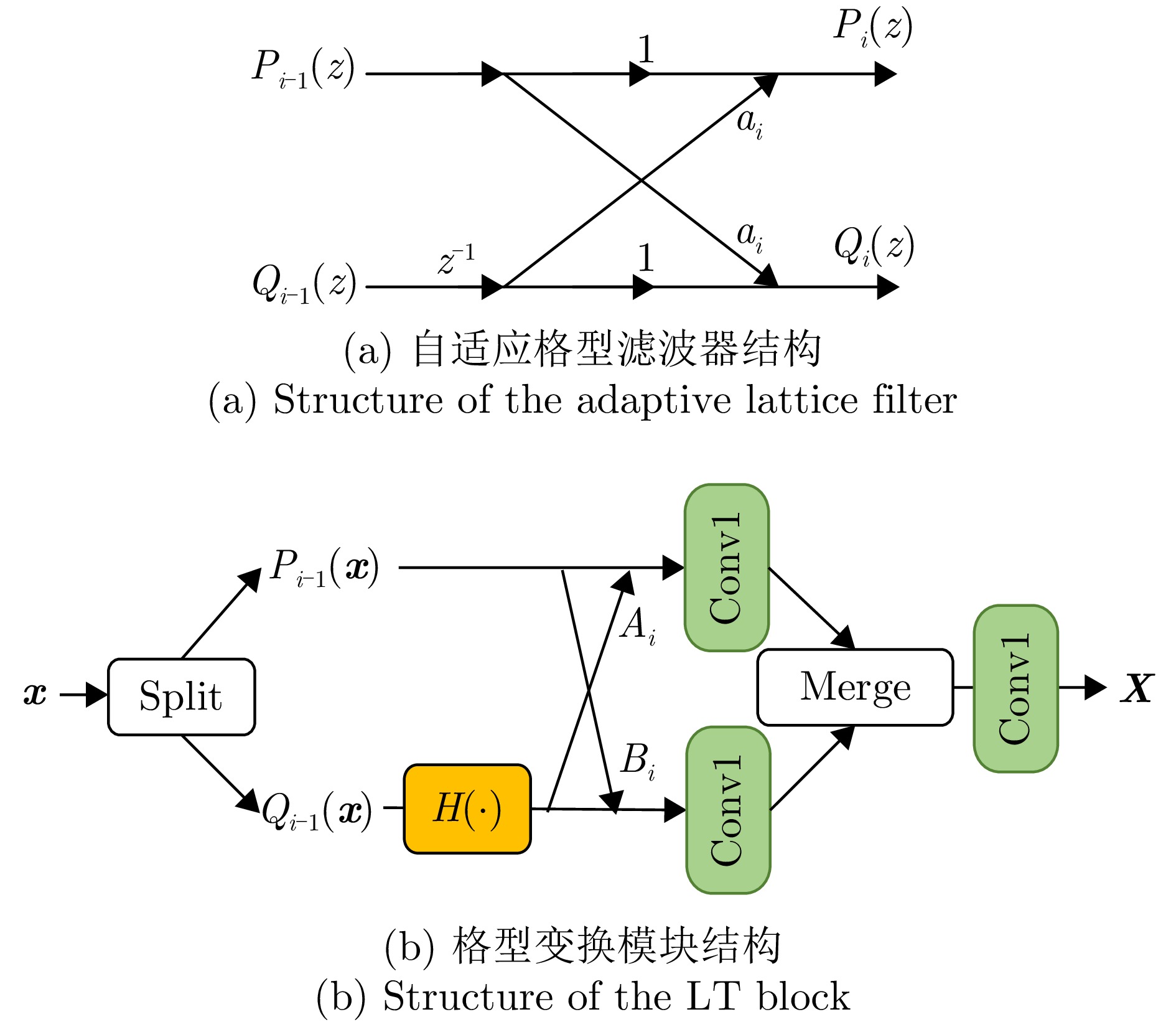
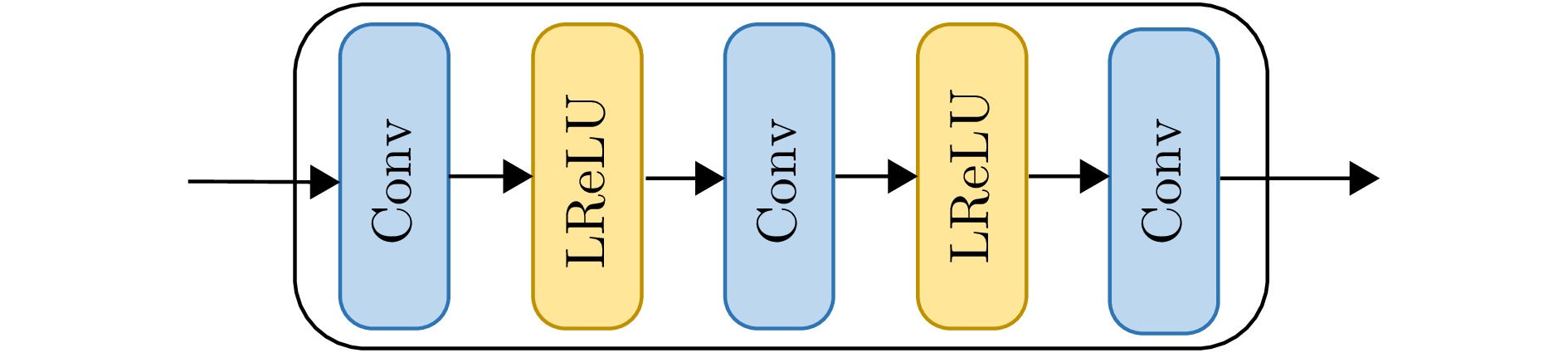
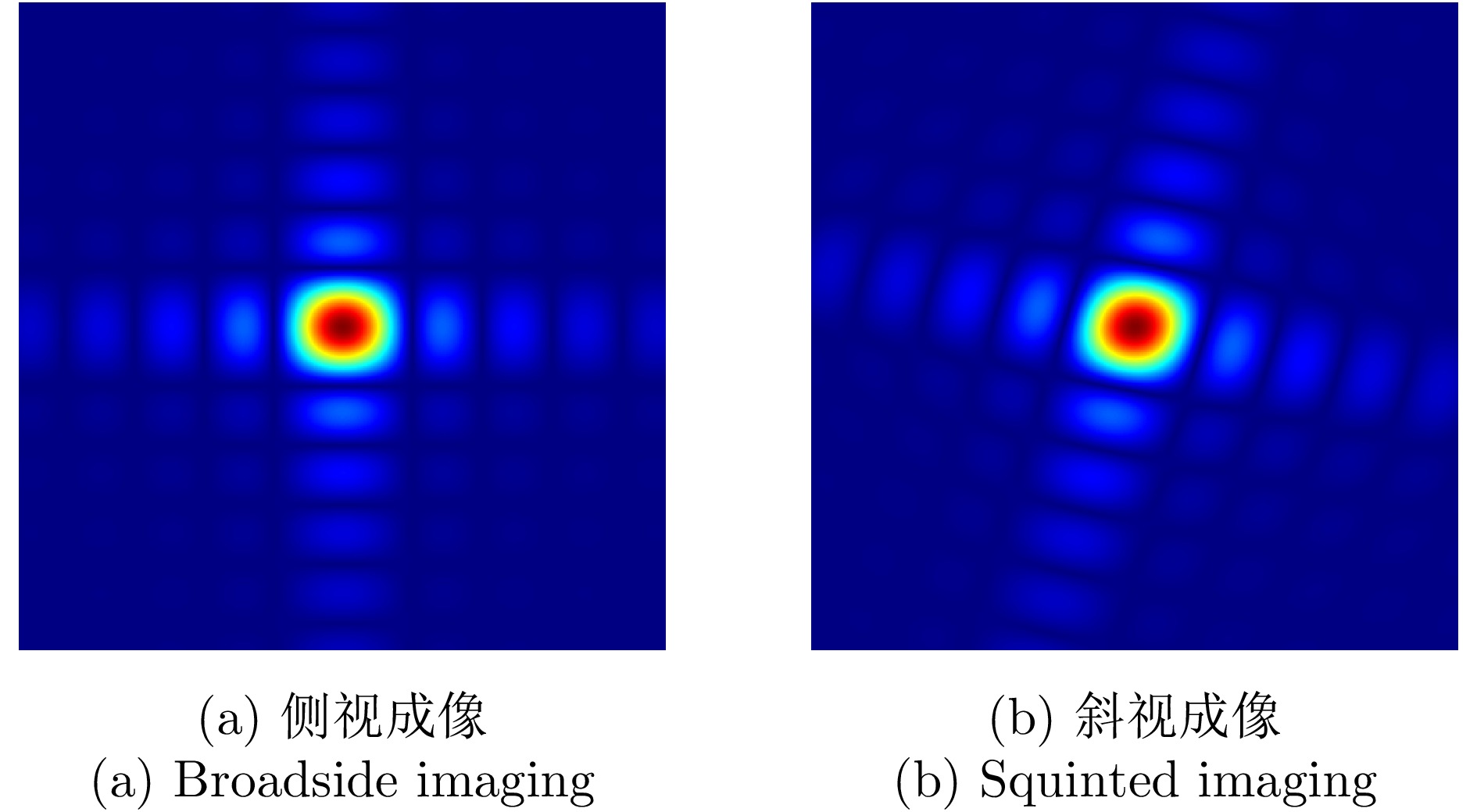
Synthetic Aperture Radar (SAR) plays a pivotal role in military reconnaissance and remote-sensing applications, given its all-weather, day-and-night operability and high-resolution imaging performance. However, diverse jamming techniques in modern complex electromagnetic environments severely distort SAR echo signals, leading to blurred or distorted imaging results and, in extreme cases, complete target unrecognizability. Given the fundamental differences in formation mechanisms and suppression strategies of different jamming types, precise jamming identification is a core prerequisite for effective counterjamming. Current SAR jamming identification methods face two major challenges. First, when the energy of the jamming signal is comparable to that of the target signal, the jamming features are easily masked, making reliable detection and identification difficult. Second, existing identification networks generally suffer from excessive complexity and poor real-time performance, limiting their practicality in engineering applications. To address these issues, this paper proposes a lightweight network-based non-spoofing active jamming identification method for SAR under low Jamming-to-Signal Ratio (JSR) conditions. This method introduces two key components: a lattice transform block that boosts interference discrimination at low JSR by refining fine-grained feature extraction and a hyperkernel-aware module that, through a custom hyperkernel block based on point target imaging, enhances context capture while ensuring algorithmic lightweighting. The superiority of the proposed method is validated through multidimensional evaluations, including effectiveness analyses of the modules, accuracy-complexity trade-off analysis of different models, and robustness testing under varying JSR conditions. The proposed method maintains high identification performance even under low JSR conditions while meeting real-time computational efficiency requirements.
Synthetic Aperture Radar (SAR) plays a pivotal role in military reconnaissance and remote-sensing applications, given its all-weather, day-and-night operability and high-resolution imaging performance. However, diverse jamming techniques in modern complex electromagnetic environments severely distort SAR echo signals, leading to blurred or distorted imaging results and, in extreme cases, complete target unrecognizability. Given the fundamental differences in formation mechanisms and suppression strategies of different jamming types, precise jamming identification is a core prerequisite for effective counterjamming. Current SAR jamming identification methods face two major challenges. First, when the energy of the jamming signal is comparable to that of the target signal, the jamming features are easily masked, making reliable detection and identification difficult. Second, existing identification networks generally suffer from excessive complexity and poor real-time performance, limiting their practicality in engineering applications. To address these issues, this paper proposes a lightweight network-based non-spoofing active jamming identification method for SAR under low Jamming-to-Signal Ratio (JSR) conditions. This method introduces two key components: a lattice transform block that boosts interference discrimination at low JSR by refining fine-grained feature extraction and a hyperkernel-aware module that, through a custom hyperkernel block based on point target imaging, enhances context capture while ensuring algorithmic lightweighting. The superiority of the proposed method is validated through multidimensional evaluations, including effectiveness analyses of the modules, accuracy-complexity trade-off analysis of different models, and robustness testing under varying JSR conditions. The proposed method maintains high identification performance even under low JSR conditions while meeting real-time computational efficiency requirements.















2026,
15(3):
1059-1090.
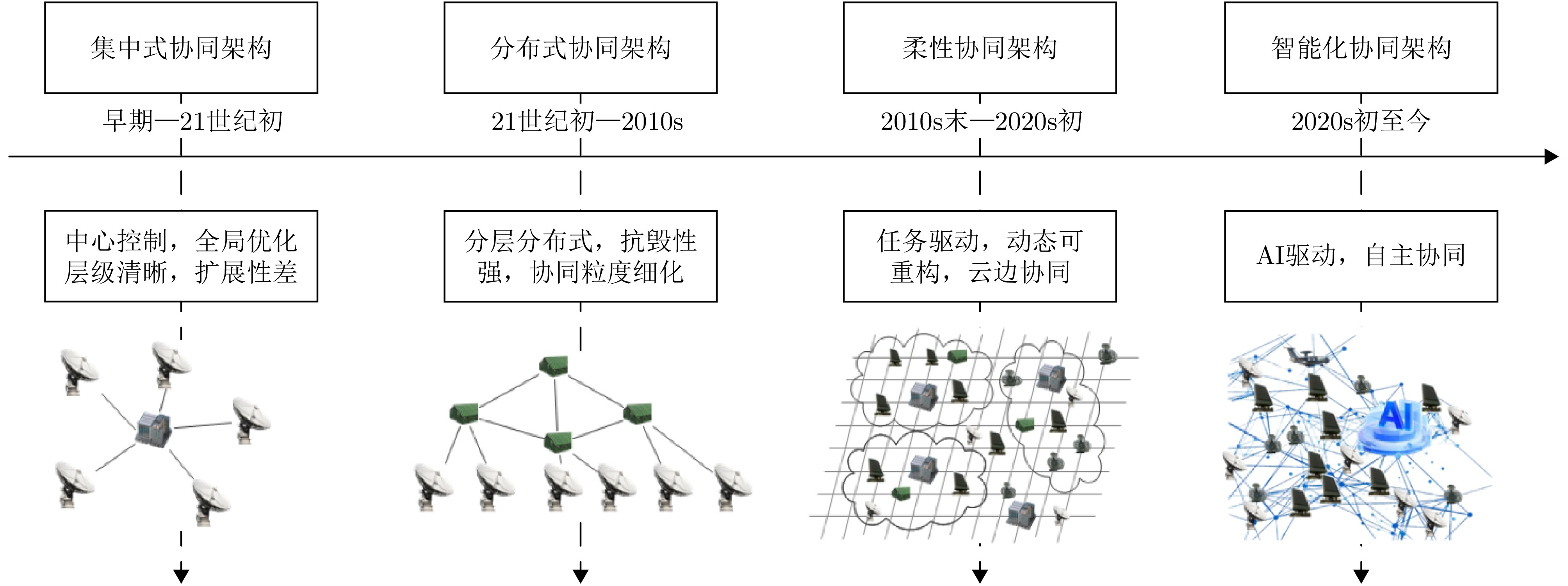
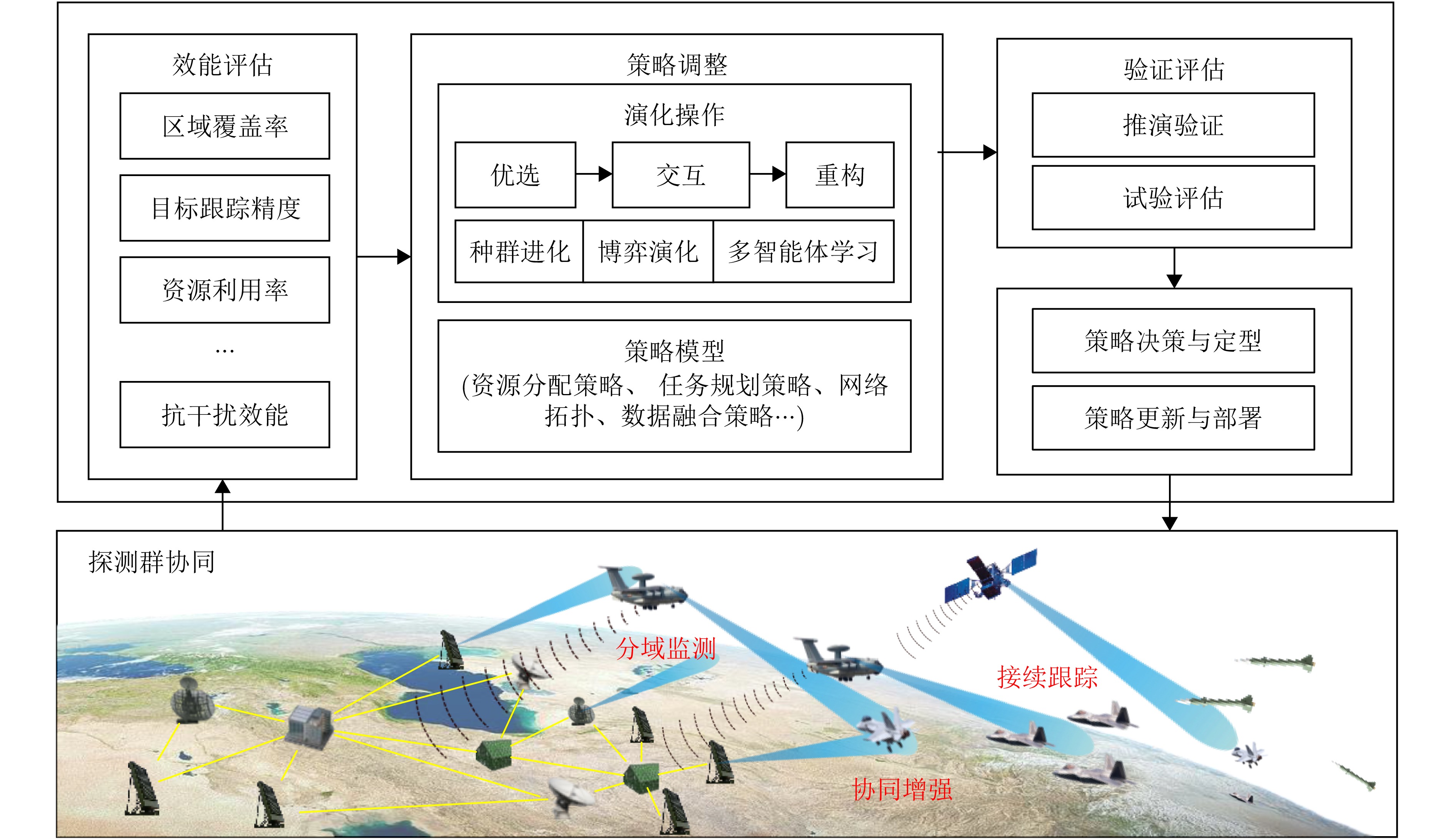
Driven by complex electromagnetic environments and multi-target collaborative detection needs, enhancing the overall effectiveness of radar networks through autonomous coordination technology has become a key research area in radar collaborative surveillance. Extensive research has been conducted worldwide, yielding substantial advances in theoretical development, technical validation, and equipment application. This paper systematically discusses the foundational concepts and main features of autonomous coordination in radar networks, examining the primary technical challenges faced during implementation and performance optimization. It also reviews recent notable research findings and technological strategies, focusing on collaborative architecture design, sensing, intelligent decision-making and control, and autonomous evolution. Finally, this paper offers an outlook on future trends in the field and provides references for related theoretical research and practical applications.
Driven by complex electromagnetic environments and multi-target collaborative detection needs, enhancing the overall effectiveness of radar networks through autonomous coordination technology has become a key research area in radar collaborative surveillance. Extensive research has been conducted worldwide, yielding substantial advances in theoretical development, technical validation, and equipment application. This paper systematically discusses the foundational concepts and main features of autonomous coordination in radar networks, examining the primary technical challenges faced during implementation and performance optimization. It also reviews recent notable research findings and technological strategies, focusing on collaborative architecture design, sensing, intelligent decision-making and control, and autonomous evolution. Finally, this paper offers an outlook on future trends in the field and provides references for related theoretical research and practical applications.







2026,
15(3):
1091-1105.
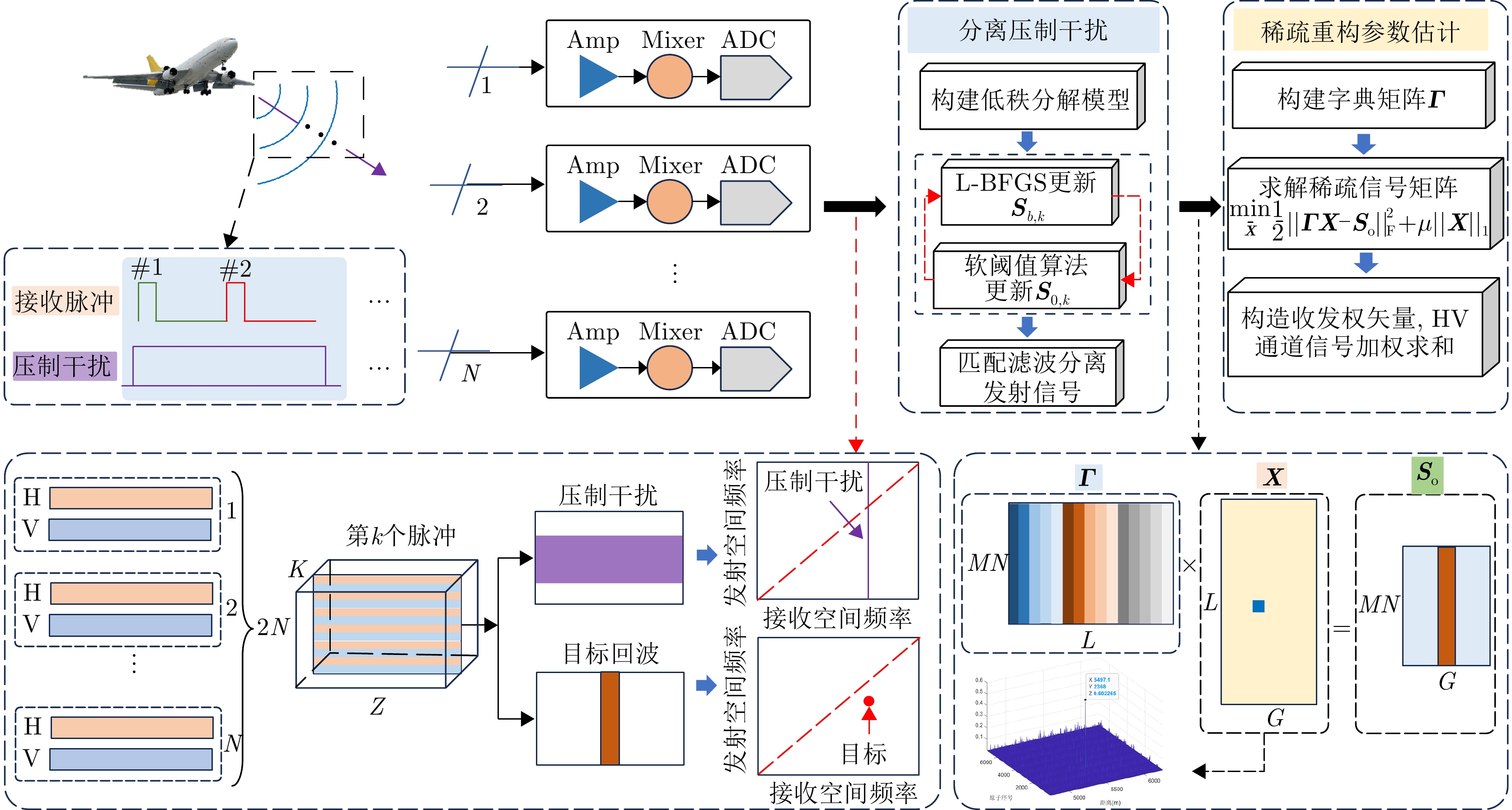
By applying phase coding in transmit elements and pulses, the Element-Pulse Coding Multiple-Input Multiple-Output (EPC-MIMO) radar can effectively suppress mainlobe deceptive interference. However, this approach remains ineffective against mainlobe blanket interference. To address this drawback, this paper investigates the mainlobe blanket interference suppression using a Polarization Element-Pulse Coding Multiple-Input Multiple-Output (PEPC-MIMO) radar system. Specifically, within the framework of stable principal component pursuit decomposition, the interference suppression problem is formulated as a “low-rank + sparse” optimization model by exploiting the low-rank structure of the received signal in the joint time-space-polarization domain. The resulting optimization problem is solved iteratively using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno-based Alternating Optimization (L-BFGS-AO) algorithm, thereby enabling accurate separation of target echoes from mainlobe blanket interference. Furthermore, a sparse reconstruction-based parameter estimation method is proposed to estimate the target’s transmit angle, receive angle, and range ambiguity region. These estimates are then used to construct optimal receive weight vectors for the weighted summation of signals across channels. Simulation results demonstrate the effectiveness of the proposed approach in suppressing mainlobe blanket interference without requiring prior knowledge of the interference.
By applying phase coding in transmit elements and pulses, the Element-Pulse Coding Multiple-Input Multiple-Output (EPC-MIMO) radar can effectively suppress mainlobe deceptive interference. However, this approach remains ineffective against mainlobe blanket interference. To address this drawback, this paper investigates the mainlobe blanket interference suppression using a Polarization Element-Pulse Coding Multiple-Input Multiple-Output (PEPC-MIMO) radar system. Specifically, within the framework of stable principal component pursuit decomposition, the interference suppression problem is formulated as a “low-rank + sparse” optimization model by exploiting the low-rank structure of the received signal in the joint time-space-polarization domain. The resulting optimization problem is solved iteratively using a Limited-memory Broyden-Fletcher-Goldfarb-Shanno-based Alternating Optimization (L-BFGS-AO) algorithm, thereby enabling accurate separation of target echoes from mainlobe blanket interference. Furthermore, a sparse reconstruction-based parameter estimation method is proposed to estimate the target’s transmit angle, receive angle, and range ambiguity region. These estimates are then used to construct optimal receive weight vectors for the weighted summation of signals across channels. Simulation results demonstrate the effectiveness of the proposed approach in suppressing mainlobe blanket interference without requiring prior knowledge of the interference.








2026,
15(3):
1106-1123.
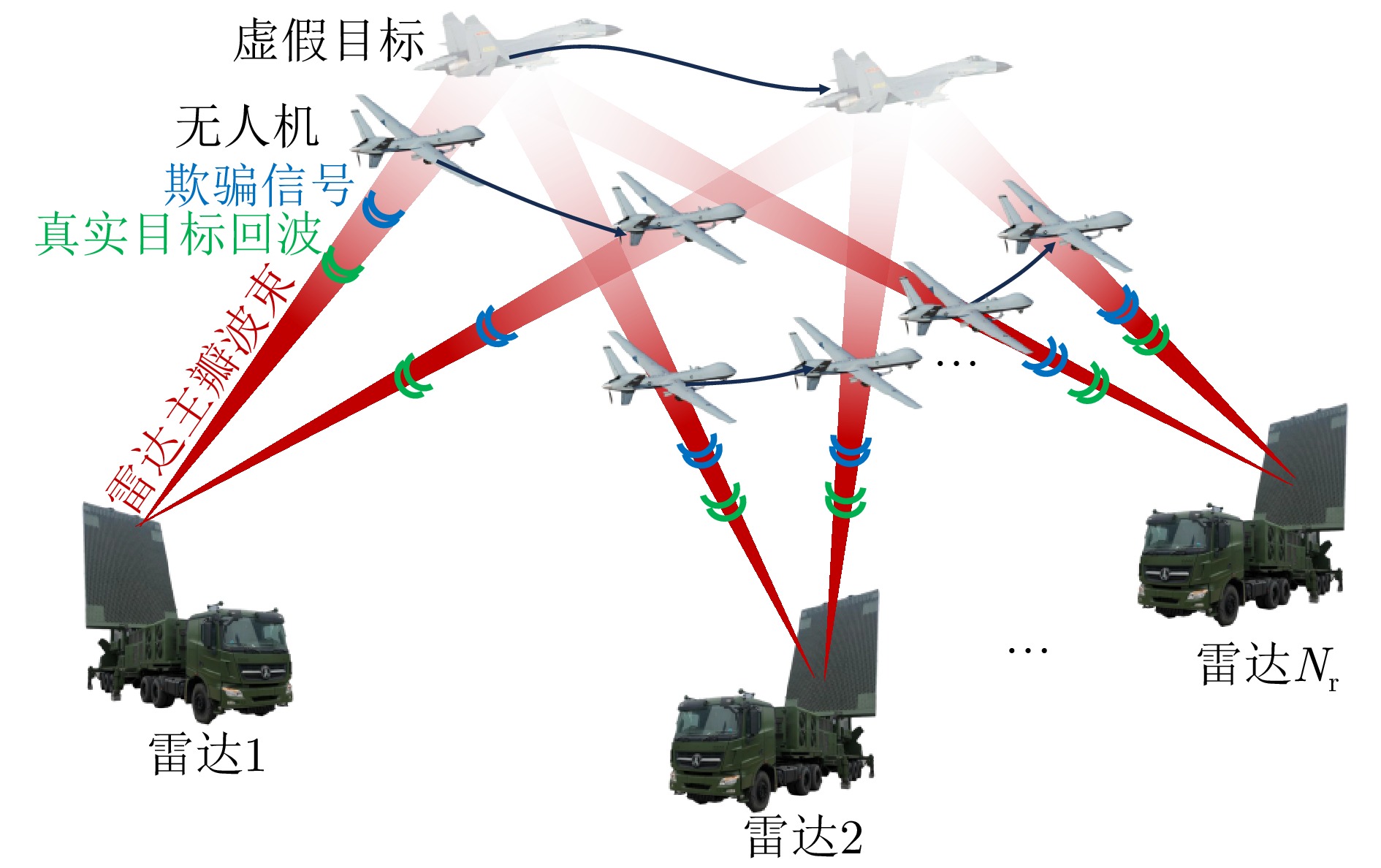
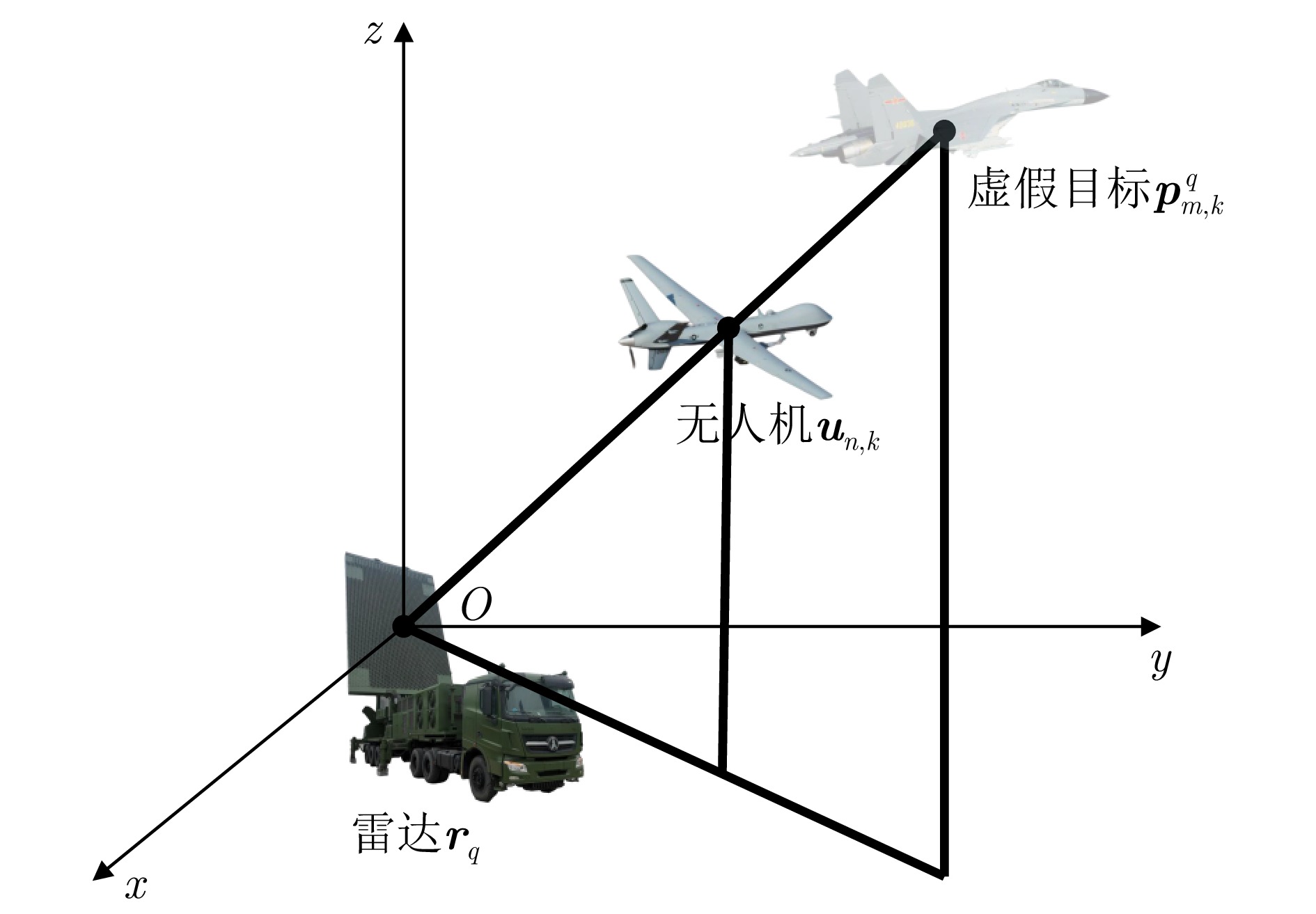
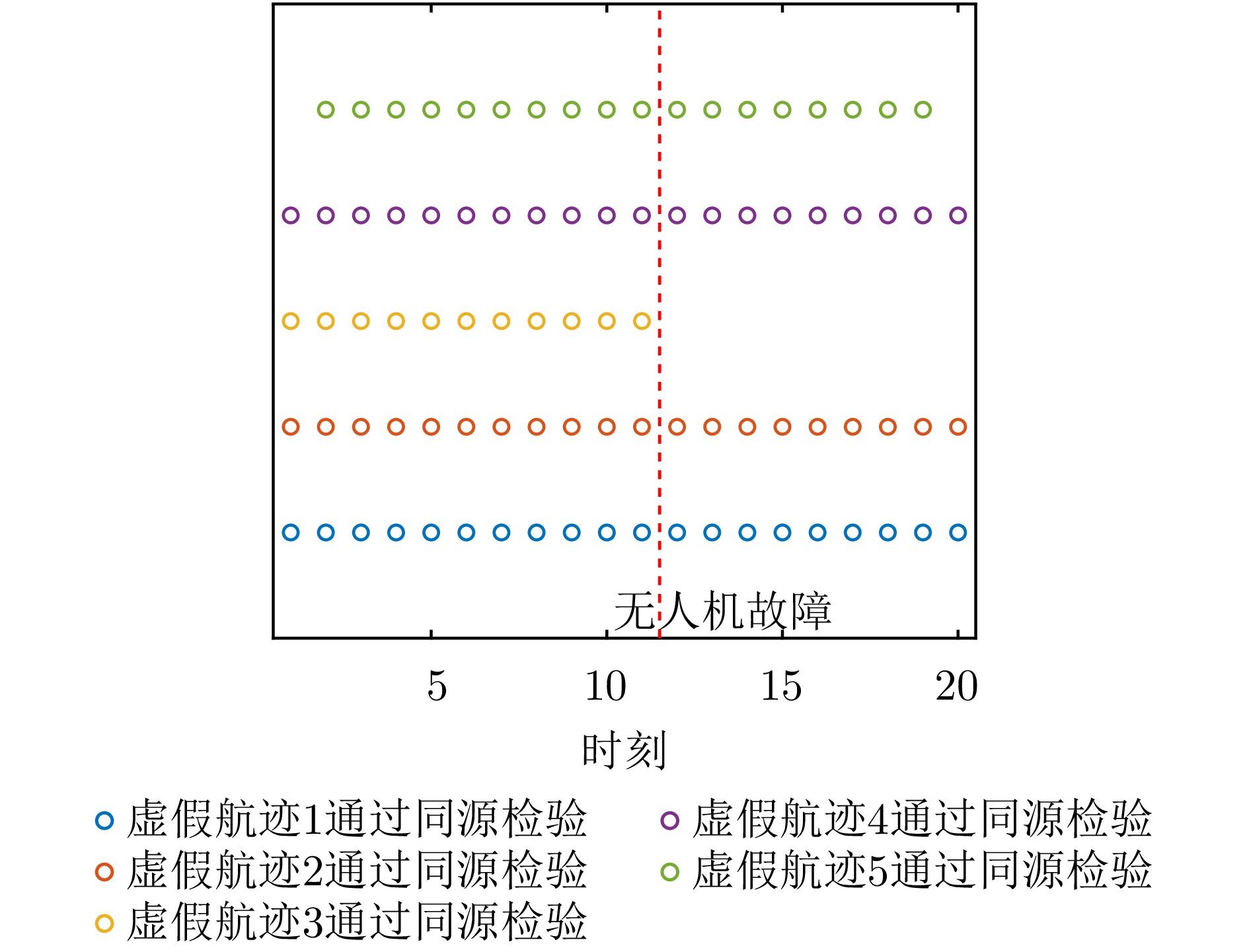
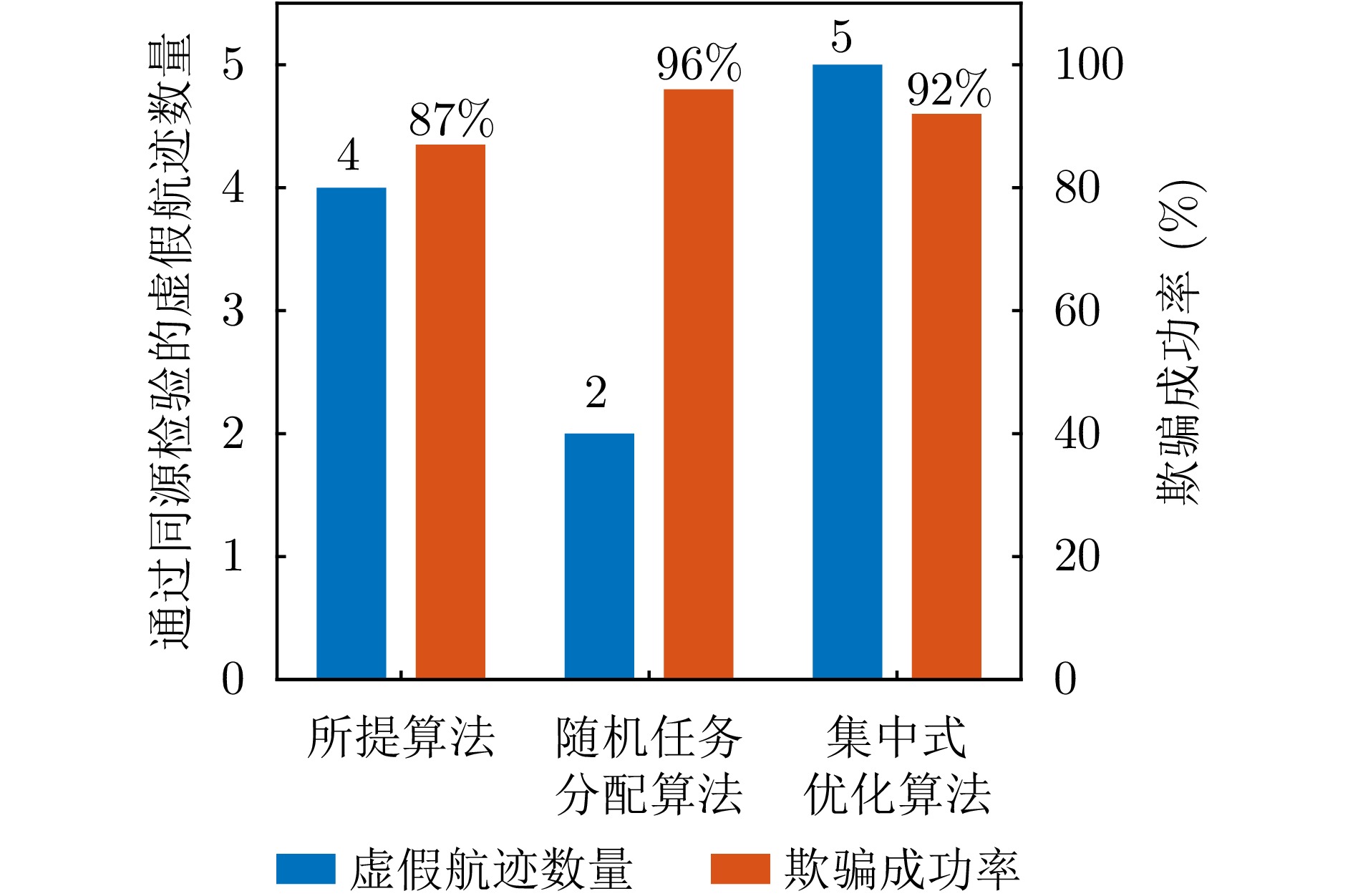
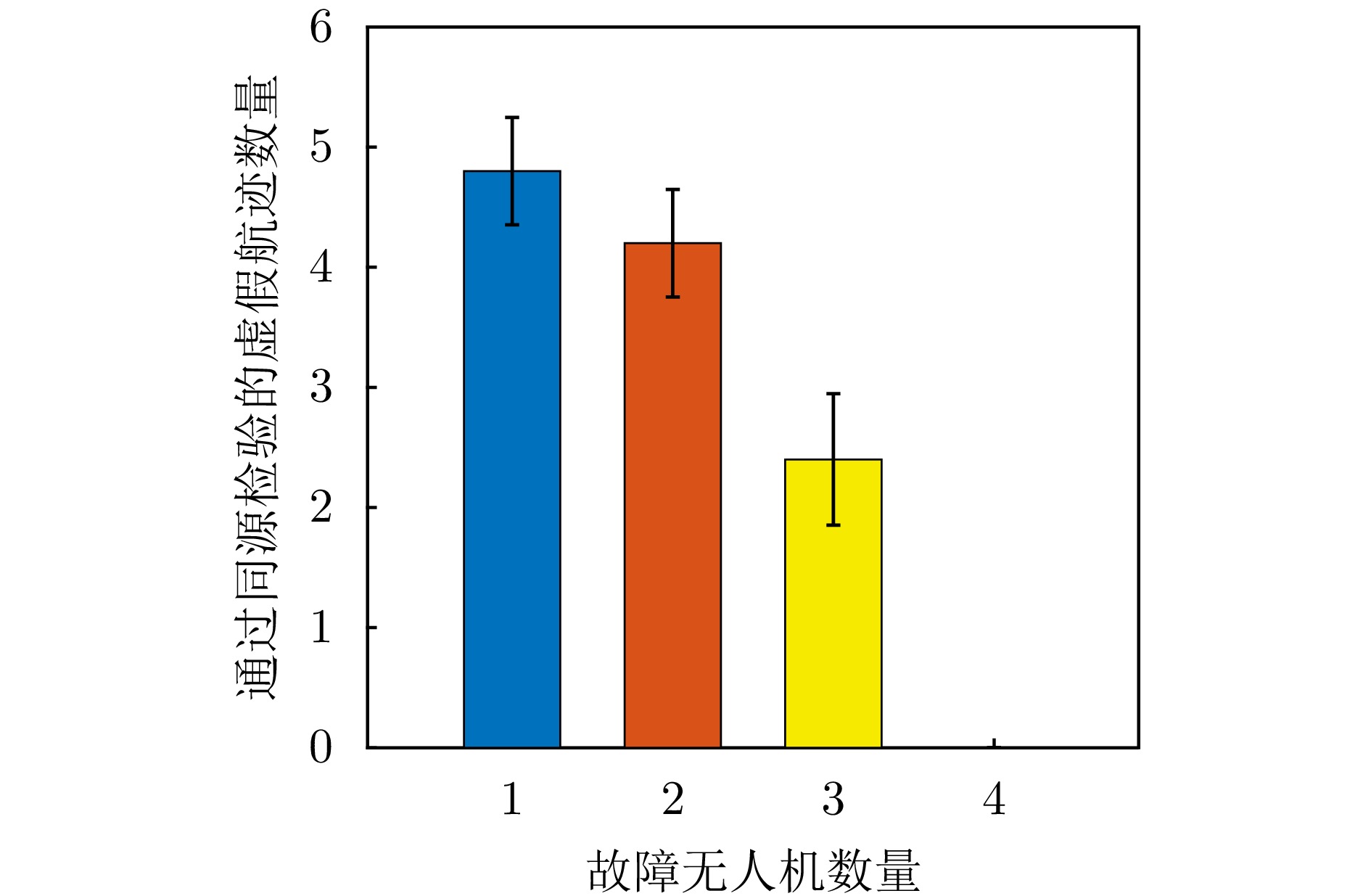
To address interruptions in phantom tracks caused by platform failures or damage during Unmanned Aerial Vehicle (UAV) swarm deception operations against radar networks, this study proposes a game theory-based joint optimization algorithm for UAV swarm task allocation and trajectory planning. A decentralized swarm cooperation mechanism is designed to create a cooperative game model for UAV phantom track deception against radar networks. Based on the radar network homology test criterion, an optimization model is developed to maximize the utility function of the phantom track deception game, subject to constraints on UAV swarm kinematic performance and task allocation requirements. The existence and convergence of a Nash equilibrium are rigorously proven using exact potential game theory. To address the resulting non-convex, non-linear, mixed-integer optimization problem, an iterative algorithm is developed that combines distributed coalition game theory with a genetic algorithm. The simulation results demonstrate that, compared with existing approaches, the proposed algorithm effectively replans deception tasks and trajectories in response to platform failures or damage, thereby enhancing the continuity and effectiveness of phantom track generation against radar networks.
To address interruptions in phantom tracks caused by platform failures or damage during Unmanned Aerial Vehicle (UAV) swarm deception operations against radar networks, this study proposes a game theory-based joint optimization algorithm for UAV swarm task allocation and trajectory planning. A decentralized swarm cooperation mechanism is designed to create a cooperative game model for UAV phantom track deception against radar networks. Based on the radar network homology test criterion, an optimization model is developed to maximize the utility function of the phantom track deception game, subject to constraints on UAV swarm kinematic performance and task allocation requirements. The existence and convergence of a Nash equilibrium are rigorously proven using exact potential game theory. To address the resulting non-convex, non-linear, mixed-integer optimization problem, an iterative algorithm is developed that combines distributed coalition game theory with a genetic algorithm. The simulation results demonstrate that, compared with existing approaches, the proposed algorithm effectively replans deception tasks and trajectories in response to platform failures or damage, thereby enhancing the continuity and effectiveness of phantom track generation against radar networks.

















 微信 | 公众平台
微信 | 公众平台 

