
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
-
摘要: 该文针对光学与雷达传感器融合人体姿态估计研究,基于连续时间微动累积量与姿态增量的物理对应关系,提出了一种单通道超宽带雷达人体姿态增量估计方案。具体来说,通过构造空时分步增量估计网络,采用空域伪3D卷积层与时域膨胀卷积层分步提取空时微动特征,将其映射为时间段内人体姿态增量,结合光学提供的姿态初值,实现人体三维姿态估计。实测数据结果表明,融合姿态估计在原地动作集取得5.38 cm估计误差,并能够实现一段时间行走动作连续姿态估计。与其他雷达姿态估计对比和消融实验证明了该文方法的优势。Abstract: This study focuses on integrating optical and radar sensors for human pose estimation. Based on the physical correspondence between the continuous-time micromotion accumulation and pose increment, a single-channel ultra-wideband radar human pose-incremental estimation scheme is proposed. Specifically, by constructing a spatiotemporal incremental estimation network, using spatiotemporal pseudo-3D convolutional and time-domain-dilated convolutional layers to extract spatiotemporal micromotion features step by step, mapping these features to human pose increments within a time period, and combining them with the initial pose values provided by optics, we can realize a 3D pose estimation of the human body. The measured data results show that fusion attitude estimation achieves an estimation error of 5.38 cm in the original action set and can achieve continuous attitude estimation for the period of walking actions. Comparison and ablation experiments with other radar attitude estimation methods demonstrate the advantages of the proposed method.
-
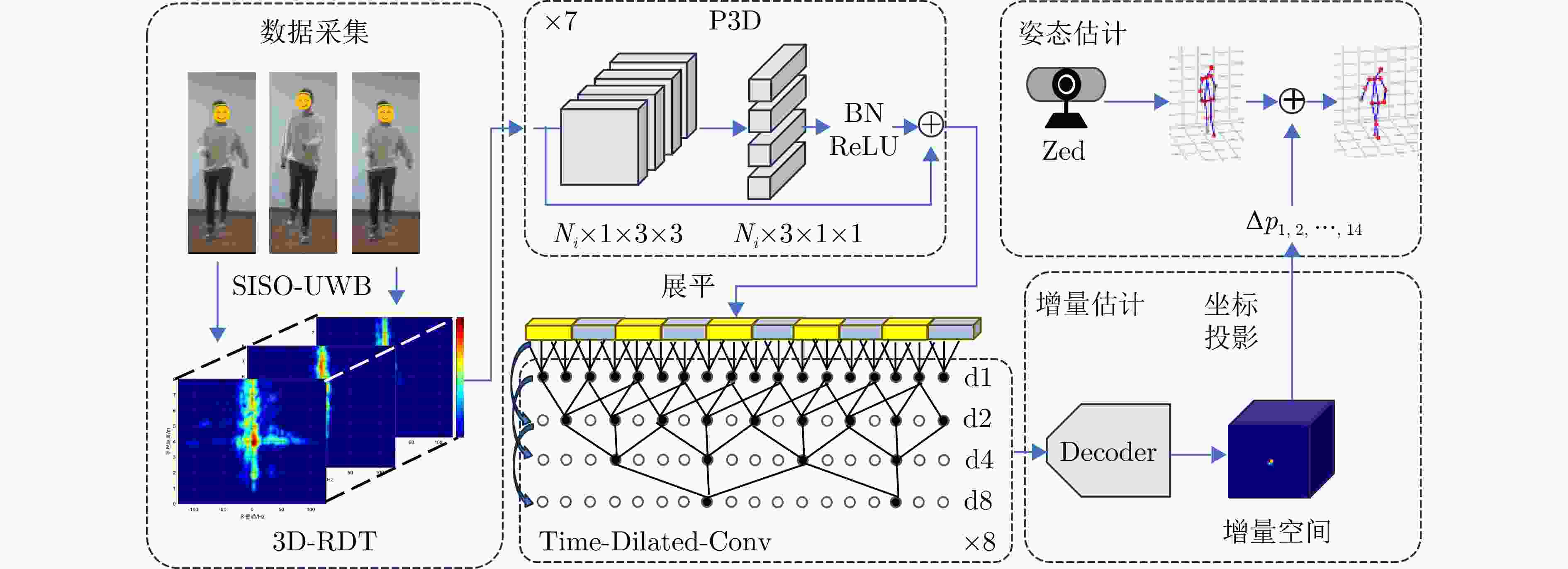
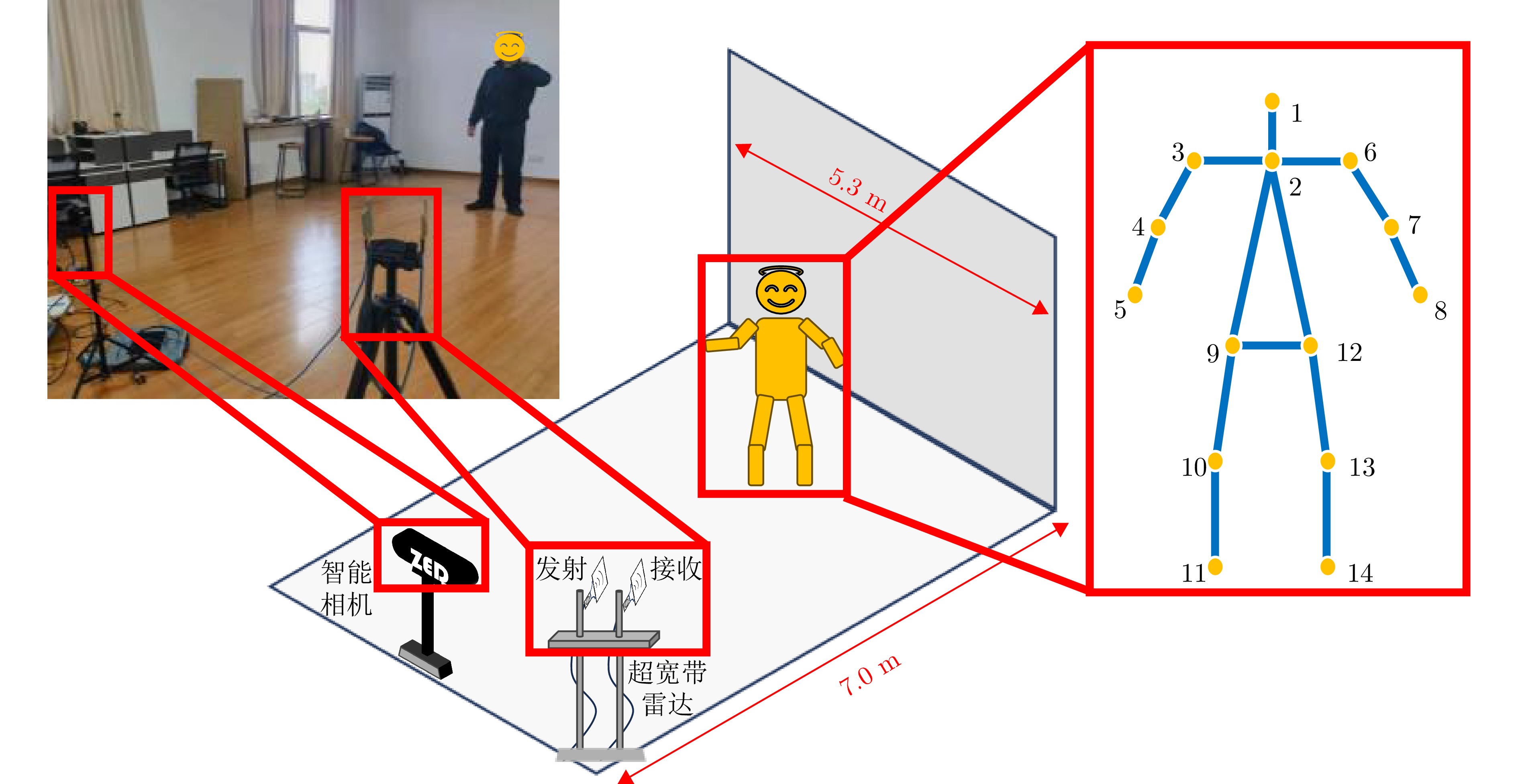
图 2 空时分步姿态增量估计框架
Figure 2. Structure of pose-increment estimation using spatiotemporal step-by-step
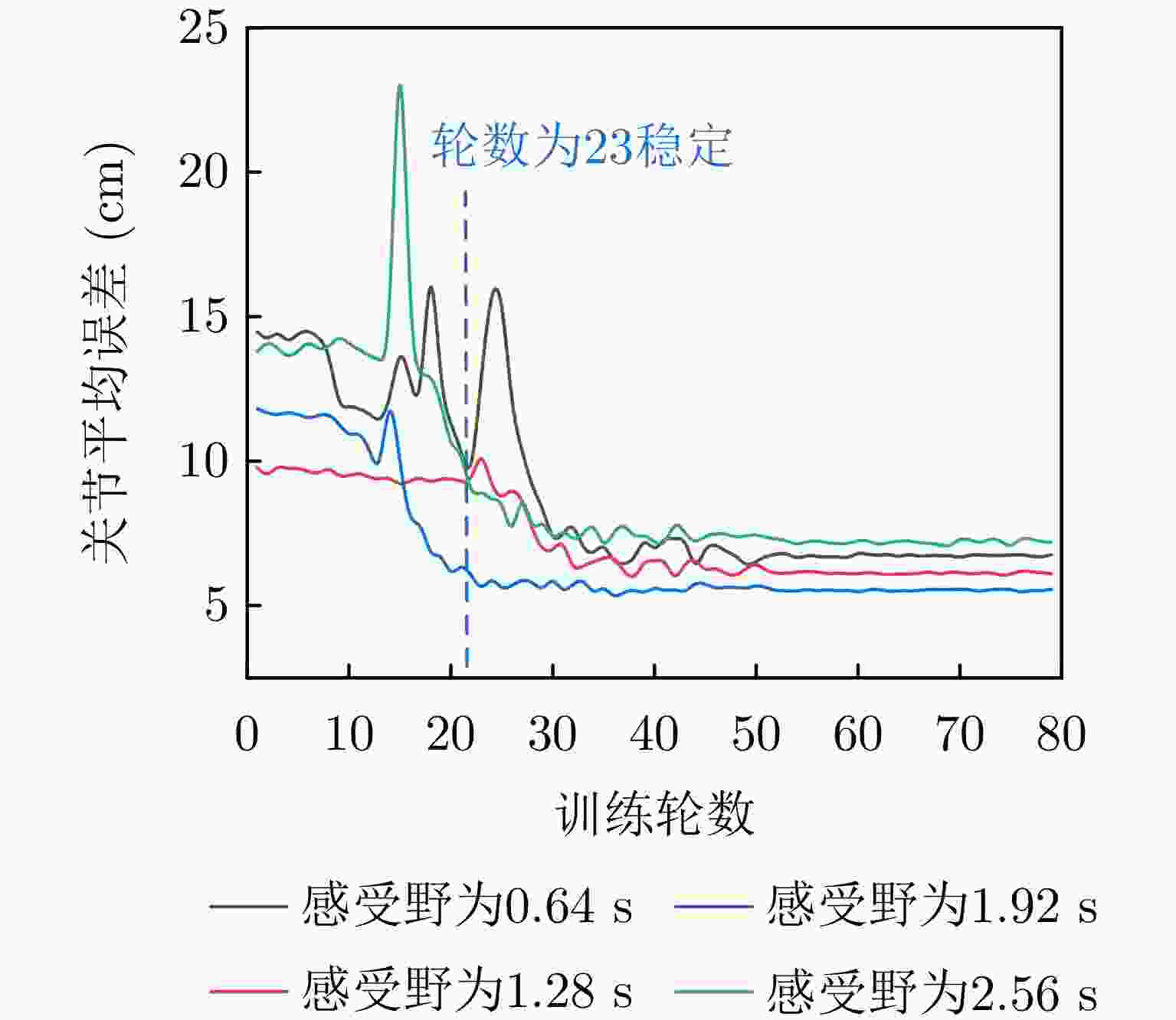
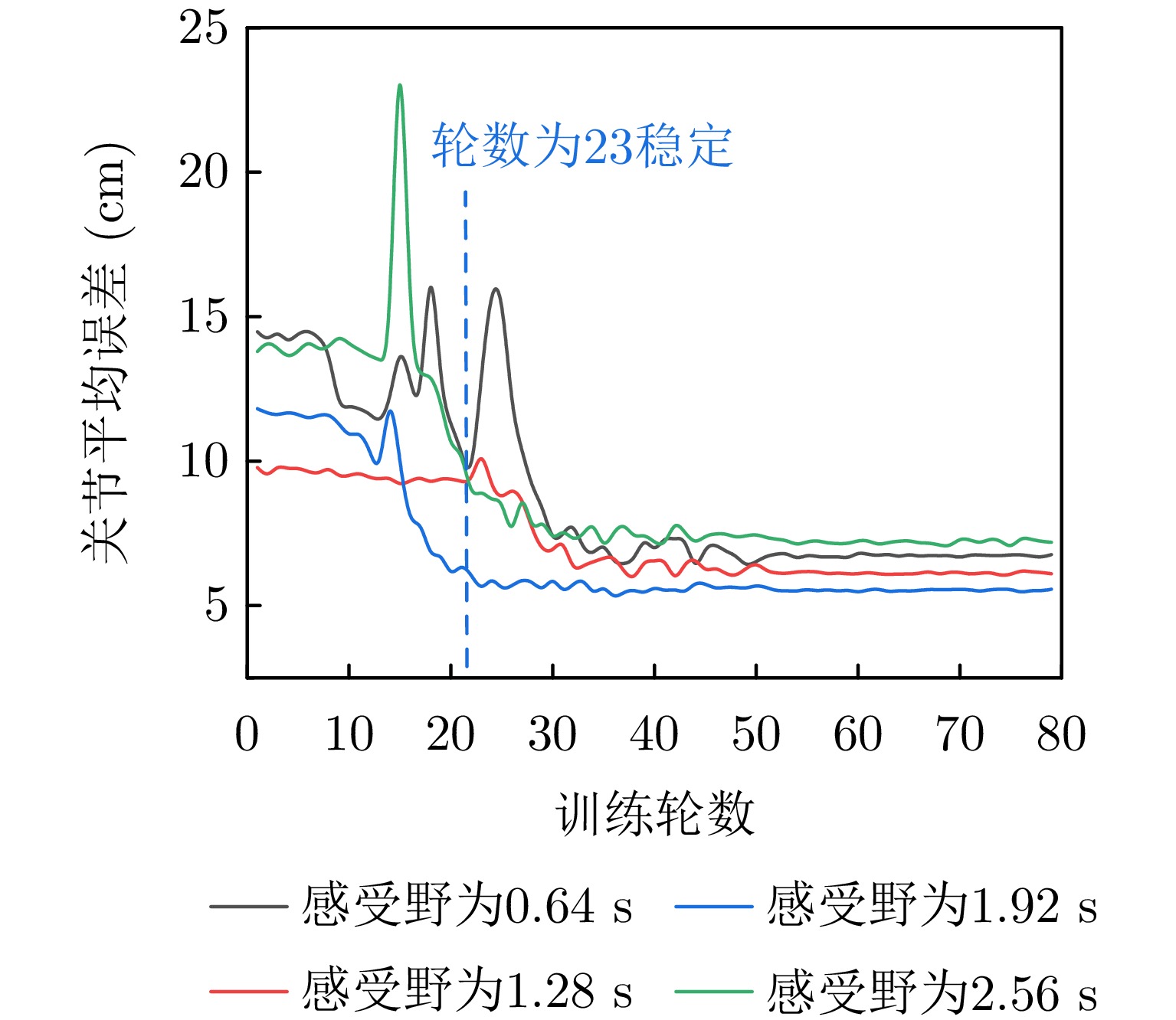
图 5 时域感受野对原地动作增量估计影响
Figure 5. Impact of time-domain receptive field on increment estimation in situ
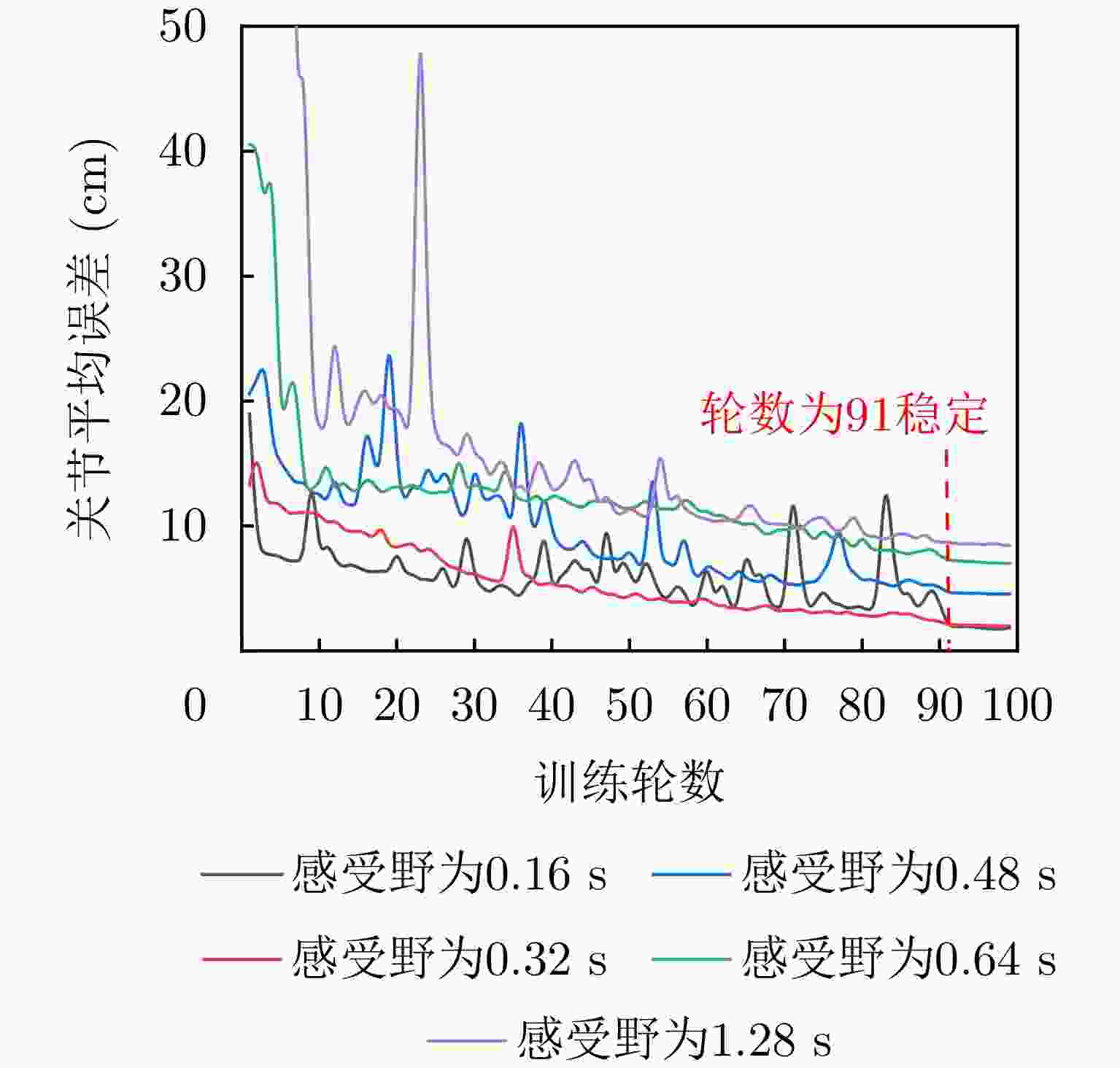
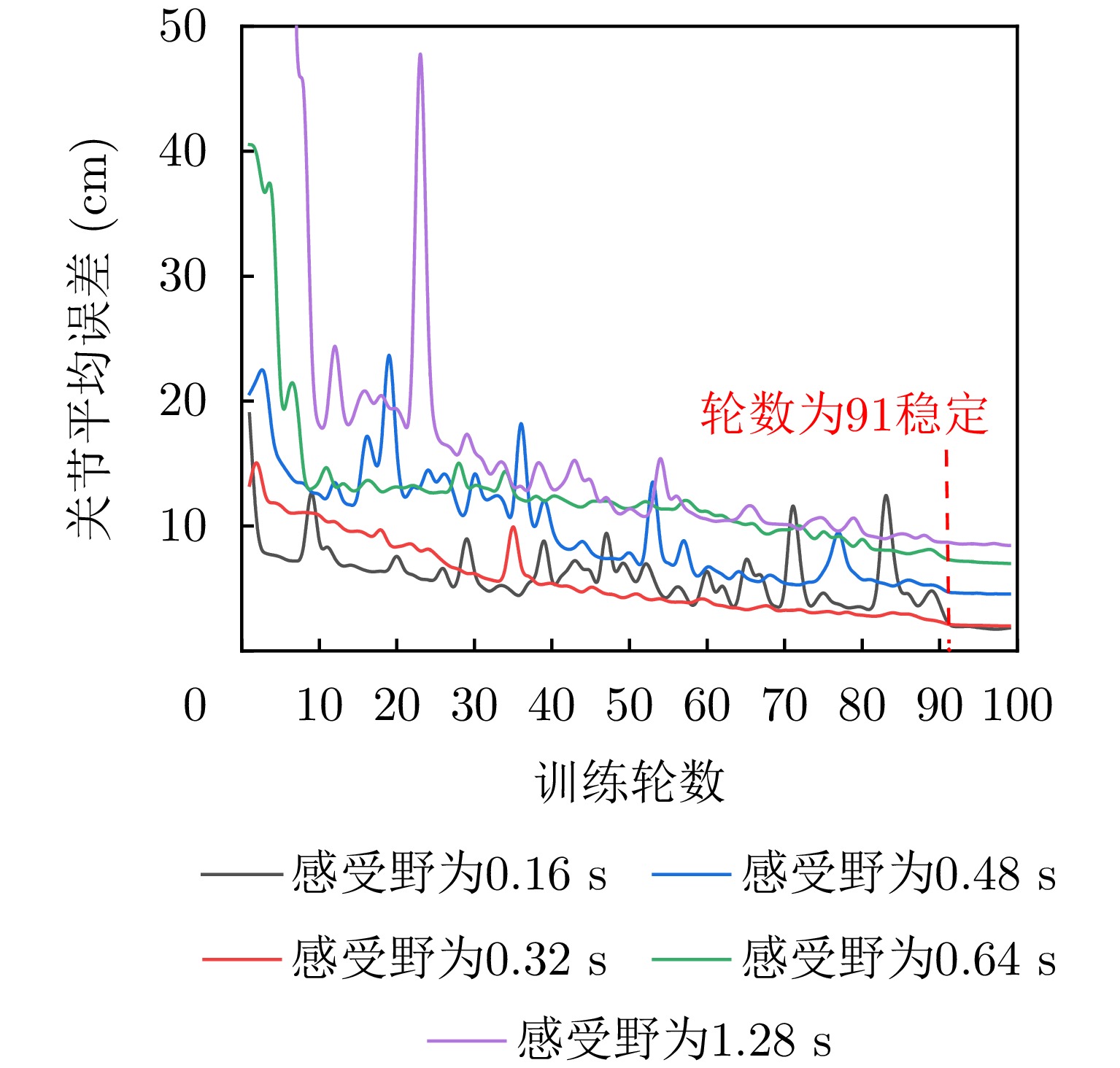
图 6 时域感受野对行走动作增量估计影响
Figure 6. Impact of time-domain receptive field on increment estimation of walking
表 1 原地动作增量估计误差(cm)
Table 1. Incremental estimation error of in situ actions (cm)
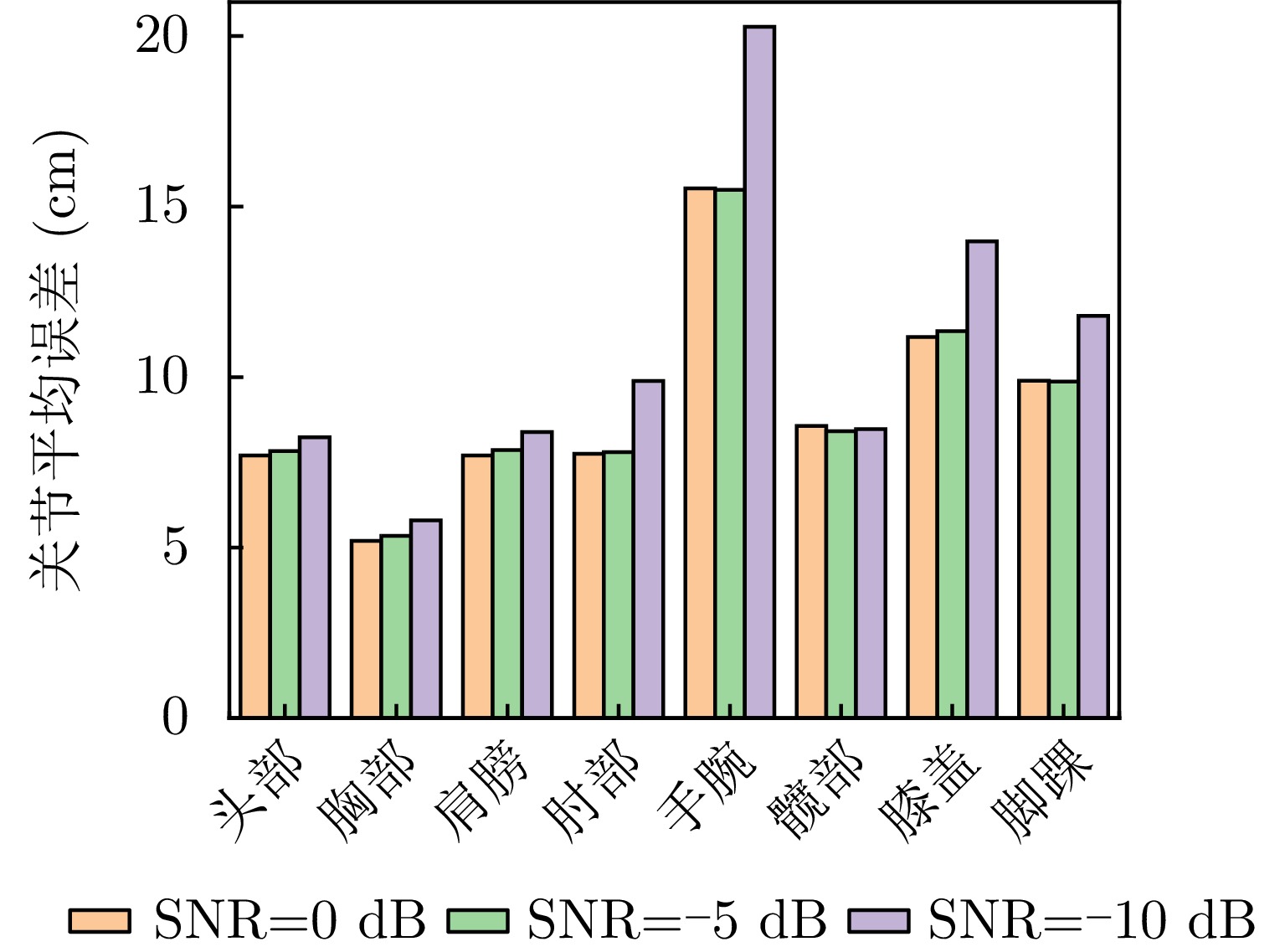
关节点 跌倒 挥拳 踏步 弯腰 转圈 平均 头部 7.47 2.23 2.14 10.47 5.99 5.66 胸部 3.76 3.52 2.24 4.16 4.81 3.70 右肩 4.72 2.45 2.30 6.60 10.18 5.25 右肘 8.48 3.75 2.69 6.93 9.03 6.18 右腕 6.94 3.33 2.20 6.96 13.99 6.68 左肩 6.07 3.10 5.74 5.93 8.20 5.81 左肘 6.78 1.96 3.62 6.68 8.52 5.51 左腕 6.75 1.35 5.83 9.11 11.17 6.84 右髋 10.18 3.91 2.74 4.90 8.81 6.11 右膝 3.42 2.05 2.50 8.59 8.70 5.05 右脚 13.64 1.09 2.89 1.42 8.08 5.42 左髋 6.95 1.94 1.99 3.58 6.67 4.23 左膝 4.48 2.65 3.75 3.67 8.00 4.51 左脚 5.67 1.36 2.78 1.55 10.24 4.32 平均 6.81 2.48 3.10 5.75 8.74 5.37  下载: 导出CSV
下载: 导出CSV
表 3 各组件性能与计算成本
Table 3. Performance and computational cost of each component
方法 估计性能 计算成本 平均(cm) $\varDelta $ (%) 参数量(M) 推理时间(ms) 2D 6.14 — 85.88 8.61 P3D 5.82 +5.21 35.48 6.16 2D-TDC 5.79 +5.70 84.73 9.26 P3D-TDC 5.38 +12.38 34.33 6.73
下载: 导出CSV
-
[1] LI Ming, QIN Hao, HUANG M, et al. RGB-D image-based pose estimation with Monte Carlo localization[C]. 2017 3rd International Conference on Control, Automation and Robotics, Nagoya, Japan, 2017: 109–114. DOI: 10.1109/ICCAR.2017.7942670. [2] KHAN A, GUPTA S, and GUPTA S K. Multi-hazard disaster studies: Monitoring, detection, recovery, and management, based on emerging technologies and optimal techniques[J]. International Journal of Disaster Risk Reduction, 2020, 47: 101642. doi: 10.1016/j.ijdrr.2020.101642. [3] 鲁勇, 吕绍和, 王晓东, 等. 基于WiFi信号的人体行为感知技术研究综述[J]. 计算机学报, 2019, 42(2): 231–251. doi: 10.11897/SP.J.1016.2019.00231.LU Yong, LV Shaohe, WANG Xiaodong, et al. A survey on WiFi based human behavior analysis technology[J]. Chinese Journal of Computers, 2019, 42(2): 231–251. doi: 10.11897/SP.J.1016.2019.00231. [4] VON MARCARD T, ROSENHAHN B, BLACK M J, et al. Sparse inertial poser: Automatic 3D human pose estimation from sparse IMUs[J]. Computer Graphics Forum, 2017, 36(2): 349–360. doi: 10.1111/cgf.13131. [5] DAI Yongpeng, JIN Tian, LI Haoran, et al. Imaging enhancement via CNN in MIMO virtual array-based radar[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(9): 7449–7458. doi: 10.1109/TGRS.2020.3035064. [6] 金添, 何元, 李新羽, 等. 超宽带雷达人体行为感知研究进展[J]. 电子与信息学报, 2022, 44(4): 1147–1155. doi: 10.11999/JEIT211044.JIN Tian, HE Yuan, LI Xinyu, et al. Advances in human activity sensing using ultra-wide band radar[J]. Journal of Electronics & Information Technology, 2022, 44(4): 1147–1155. doi: 10.11999/JEIT211044. [7] ADIB F, HSU C Y, MAO Hongzi, et al. Capturing the human figure through a wall[J]. ACM Transactions on Graphics (TOG), 2015, 34(6): 219. doi: 10.1145/2816795.2818072. [8] ZHAO Mingmin, LI Tianhong, ALSHEIKH M A, et al. Through-wall human pose estimation using radio signals[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7356–7365. DOI: 10.1109/CVPR.2018.00768. [9] ZHAO Mingmin, TIAN Yonglong, ZHAO Hang, et al. RF-based 3D skeletons[C]. The 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 2018: 267–281. DOI: 10.1145/3230543.3230579. [10] SENGUPTA A, JIN Feng, ZHANG Renyuan, et al. mm-Pose: Real-time human skeletal posture estimation using mmWave radars and CNNs[J]. IEEE Sensors Journal, 2020, 20(17): 10032–10044. doi: 10.1109/JSEN.2020.2991741. [11] YU Cong, ZHANG Dongheng, WU Zhi, et al. RFPose-OT: RF-based 3D human pose estimation via optimal transport theory[J]. Frontiers of Information Technology & Electronic Engineering, 2023, 24(10): 1445–1457. doi: 10.1631/FITEE.2200550. [12] XIE Chunyang, ZHANG Dongheng, WU Zhi, et al. RPM: RF-based pose machines[J]. IEEE Transactions on Multimedia, 2024, 26: 637–649. doi: 10.1109/TMM.2023.3268376. [13] XIE Chunyang, ZHANG Dongheng, WU Zhi, et al. RPM 2.0: RF-based pose machines for multi-person 3D pose estimation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(1): 490–503. doi: 10.1109/TCSVT.2023.3287329. [14] SONG Yongkun, JIN Tian, DAI Yongpeng, et al. Through-wall human pose reconstruction via UWB MIMO radar and 3D CNN[J]. Remote Sensing, 2021, 13(2): 241. doi: 10.3390/rs13020241. [15] CHEN V C. The Micro-Doppler Effect in Radar[M]. Boston: Artech House, 2011. [16] ZHOU Xiaolong, JIN Tian, DAI Yongpeng, et al. MD-Pose: Human pose estimation for single-channel UWB radar[J]. IEEE Transactions on Biometrics, Behavior, and Identity Science, 2023, 5(4): 449–463. doi: 10.1109/TBIOM.2023.3265206. [17] DING Wen, CAO Zhongping, ZHANG Jianxiong, et al. Radar-based 3D human skeleton estimation by kinematic constrained learning[J]. IEEE Sensors Journal, 2021, 21(20): 23174–23184. doi: 10.1109/JSEN.2021.3107361. [18] CAO Zhongping, DING Wen, CHEN Rihui, et al. A joint global-local network for human pose estimation with millimeter wave radar[J]. IEEE Internet of Things Journal, 2023, 10(1): 434–446. doi: 10.1109/JIOT.2022.3201005. [19] DU Hao, JIN Tian, SONG Yongping, et al. A three-dimensional deep learning framework for human behavior analysis using range-Doppler time points[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 17(4): 611–615. doi: 10.1109/LGRS.2019.2930636. [20] BOULIC R, THALMANN N M, and THALMANN D. A global human walking model with real-time kinematic personification[J]. The Visual Computer, 1990, 6(6): 344–358. doi: 10.1007/BF01901021. [21] ZHENG Ce, ZHU Sijie, MENDIETA M, et al. 3D human pose estimation with spatial and temporal transformers[C]. The 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 11636–11645. DOI: 10.1109/ICCV48922.2021.01145. [22] FANG Yuming, DING Guanqun, LI Jia, et al. Deep3DSaliency: Deep stereoscopic video saliency detection model by 3D convolutional networks[J]. IEEE Transactions on Image Processing, 2019, 28(5): 2305–2318. doi: 10.1109/TIP.2018.2885229. [23] QIU Zhaofan, YAO Ting, and MEI Tao. Learning spatio-temporal representation with pseudo-3d residual networks[C]. The 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5534–5542. DOI: 10.1109/ICCV.2017.590. [24] PAVLLO D, FEICHTENHOFER C, GRANGIER D, et al. 3D human pose estimation in video with temporal convolutions and semi-supervised training[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA, 2020: 7745–7754. DOI: 10.1109/CVPR.2019.00794. [25] YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[J]. arXiv, 2016. [26] WANG Panqu, CHEN Pengfei, YUAN Ye, et al. Understanding convolution for semantic segmentation[C]. 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, USA, 2018: 1451–1460. DOI: 10.1109/WACV.2018.00163. -





计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

