
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor Work2024 Vol. 13, No. 2
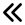 Previous Issue
Previous Issue
2024, 13(2): 285-306.
 Abstract
Abstract 4930KB
4930KB
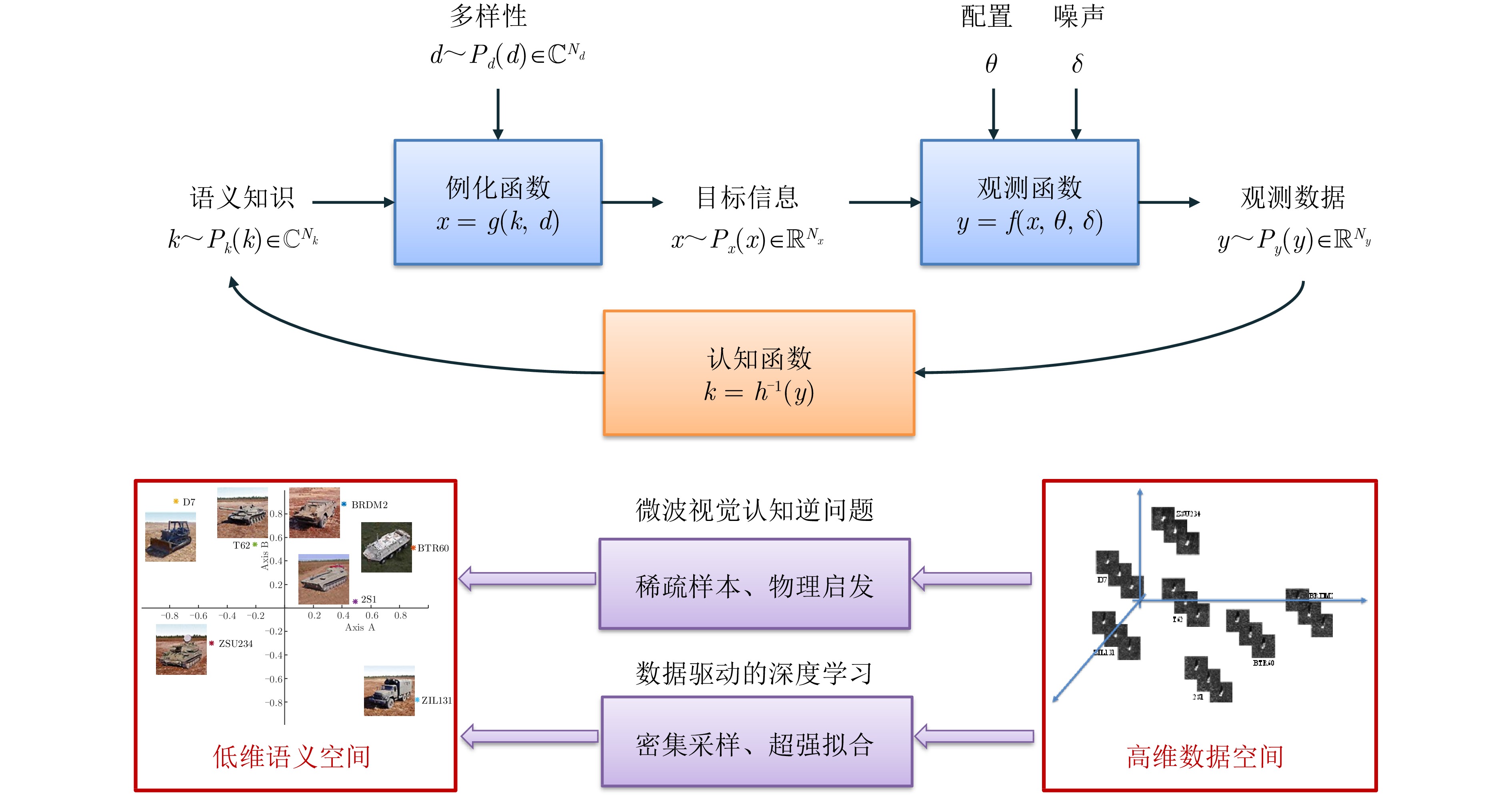
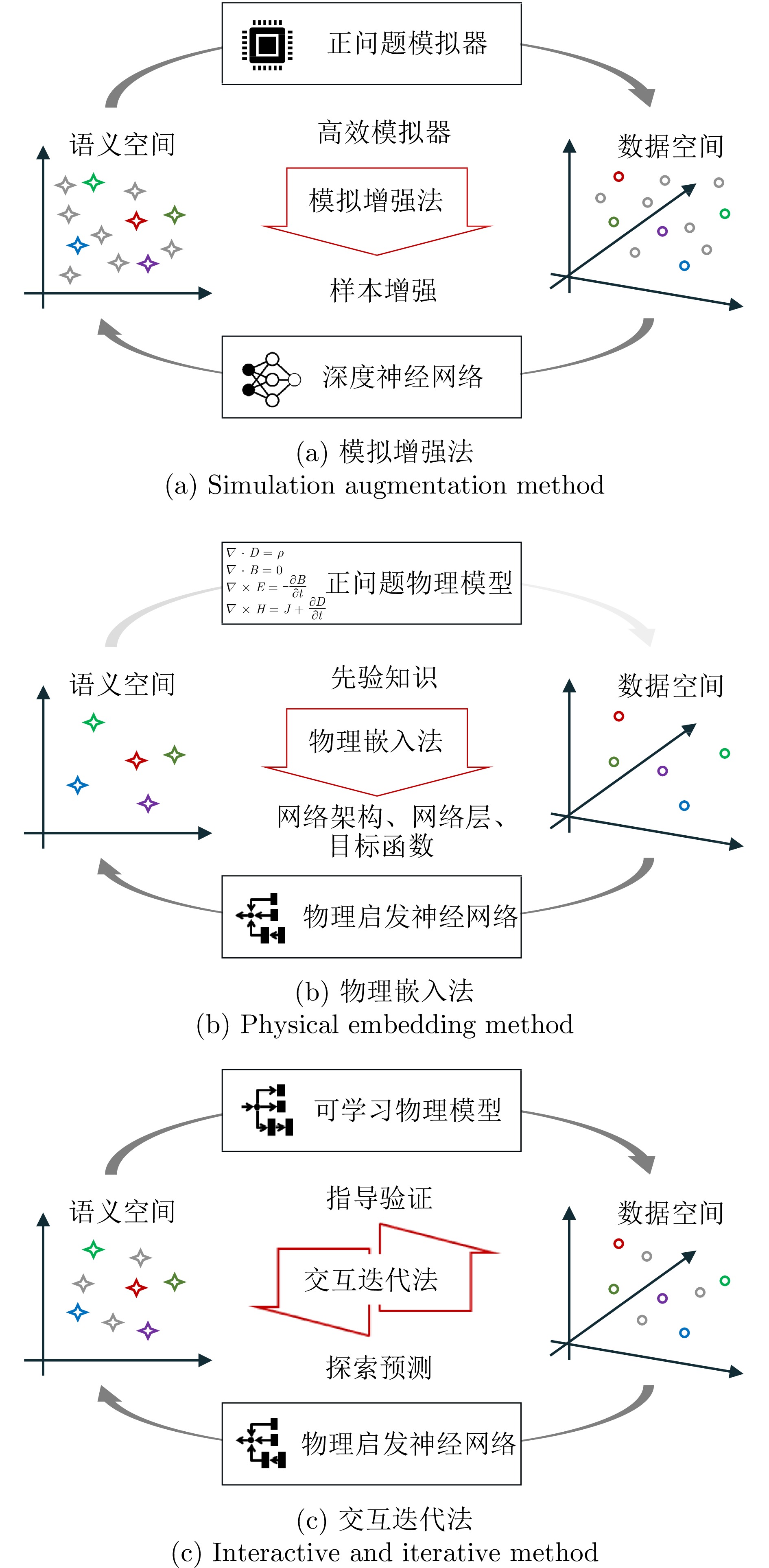
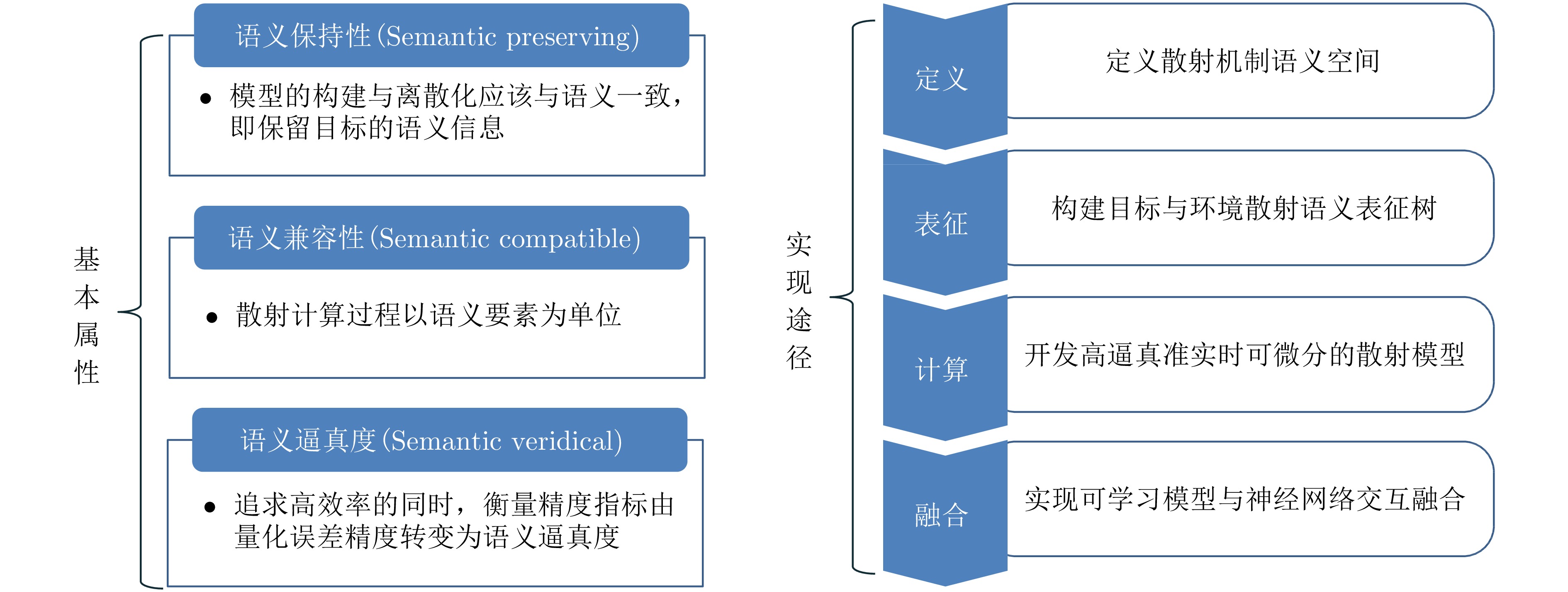
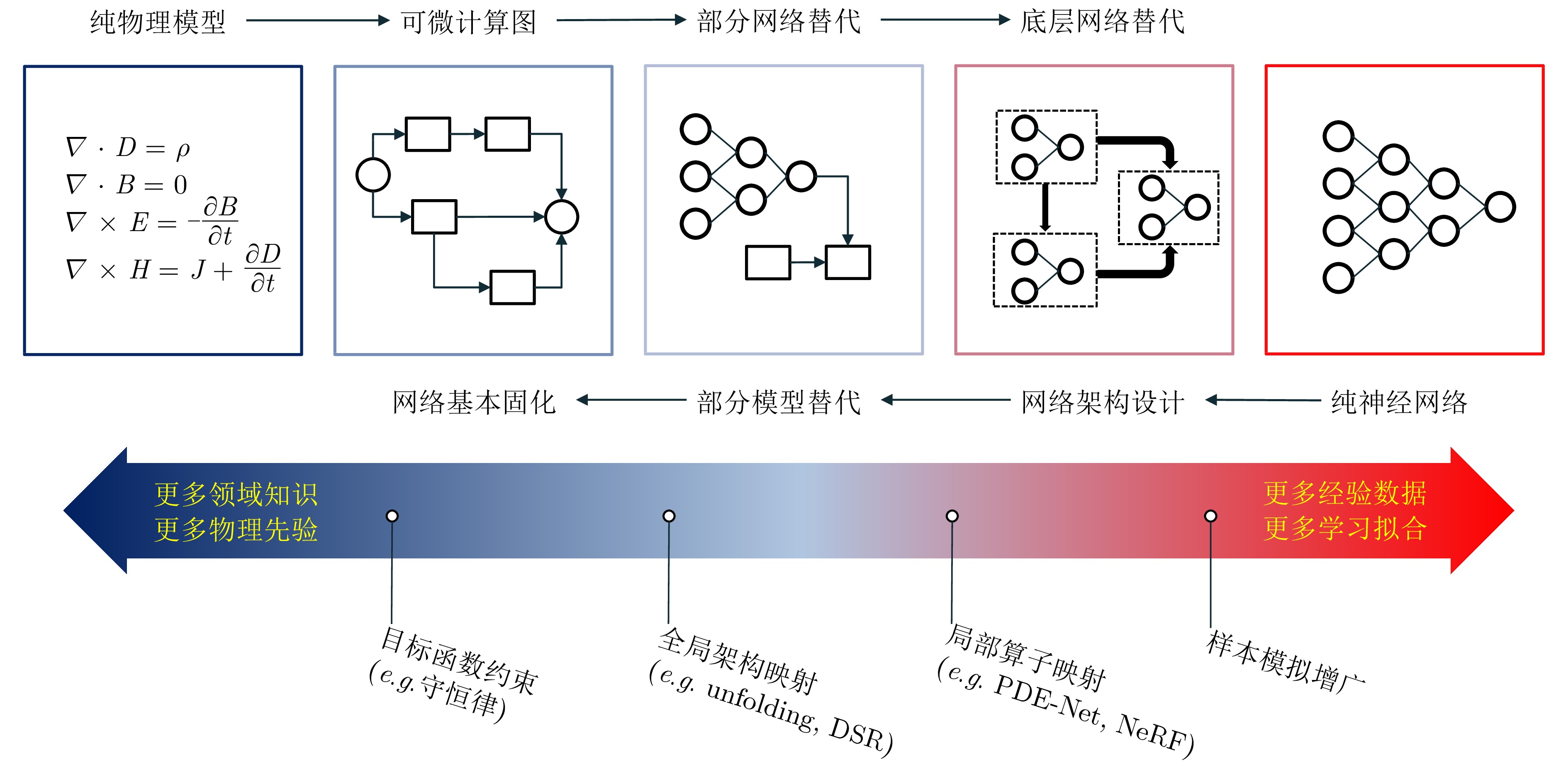
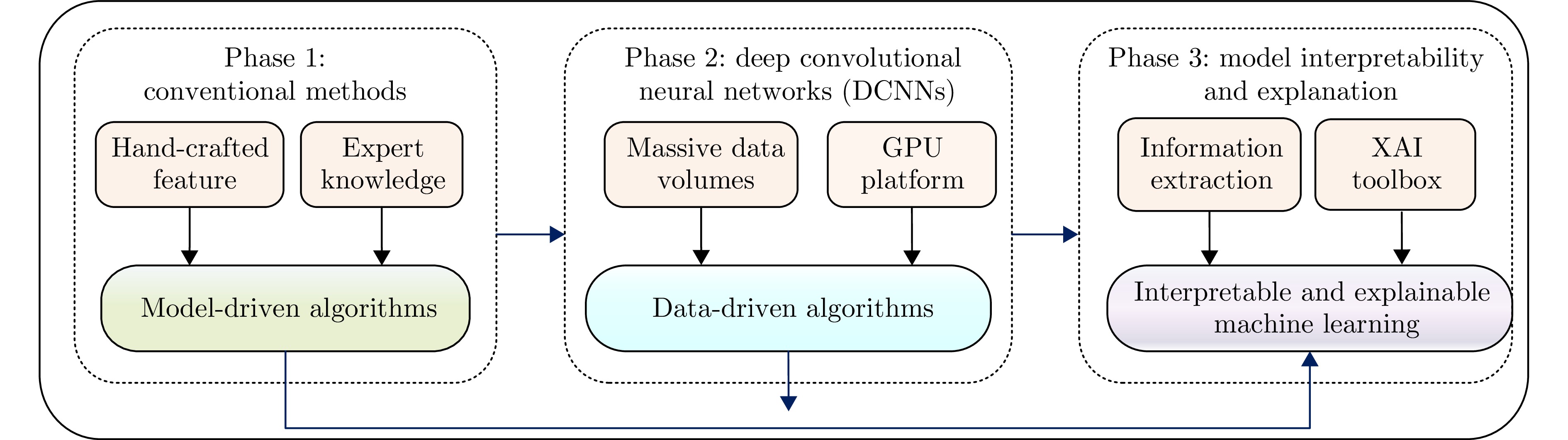
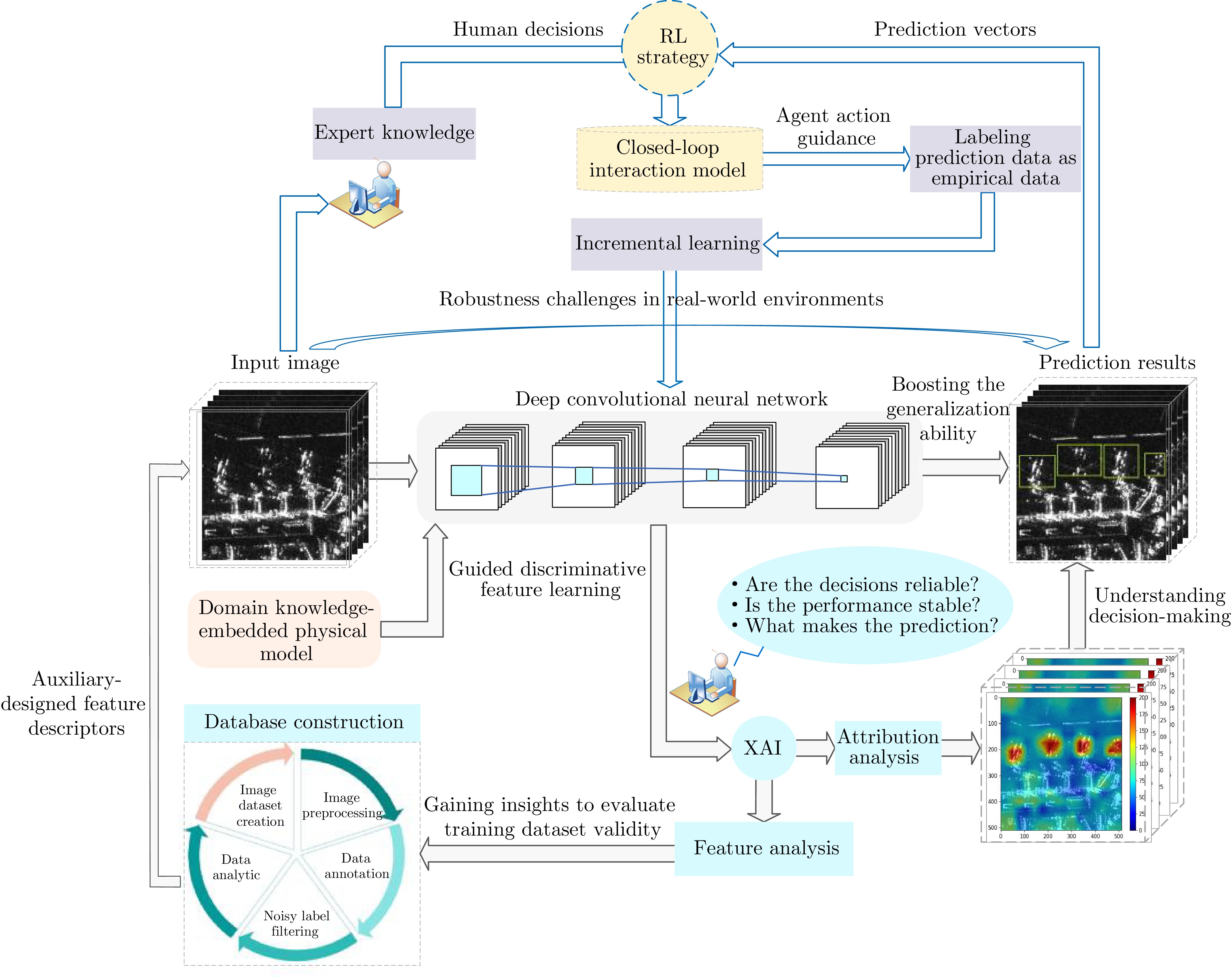
With the rapid development of high-resolution radar imaging technology, artificial intelligence, and big data technology, remarkable advancements have been made in the intelligent interpretation of radar imagery. Despite growing demands, radar image intrpretation is now facing various technical challenges mainly because of the particularity of the radar sensor itself and the complexity of electromagnetic scattering physical phenomena. To address the problem of microwave radar imagery perception, this article proposes the development of the cross-disciplinary microwave vision research, which further integrates electromagnetic physics and radar imaging mechanism with human brain visual perception principles and computer vision technologies. This article discusses the concept and implication of microwave vision, proposes a microwave vision perception model, and explains its basic scientific problems and technical roadmaps. Finally, it introduces the preliminary research progress on related issues achieved by the authors’ group.
With the rapid development of high-resolution radar imaging technology, artificial intelligence, and big data technology, remarkable advancements have been made in the intelligent interpretation of radar imagery. Despite growing demands, radar image intrpretation is now facing various technical challenges mainly because of the particularity of the radar sensor itself and the complexity of electromagnetic scattering physical phenomena. To address the problem of microwave radar imagery perception, this article proposes the development of the cross-disciplinary microwave vision research, which further integrates electromagnetic physics and radar imaging mechanism with human brain visual perception principles and computer vision technologies. This article discusses the concept and implication of microwave vision, proposes a microwave vision perception model, and explains its basic scientific problems and technical roadmaps. Finally, it introduces the preliminary research progress on related issues achieved by the authors’ group.




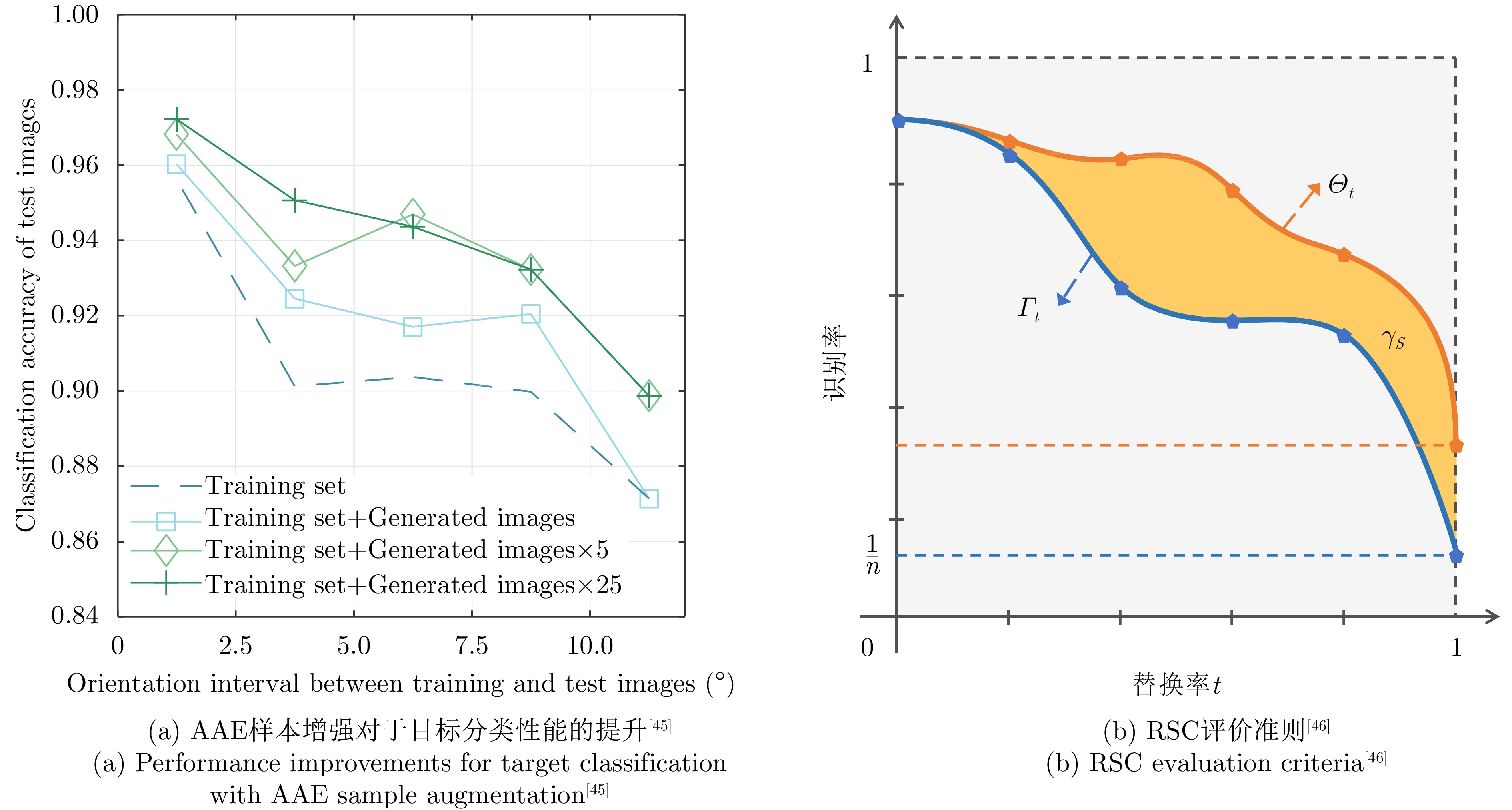
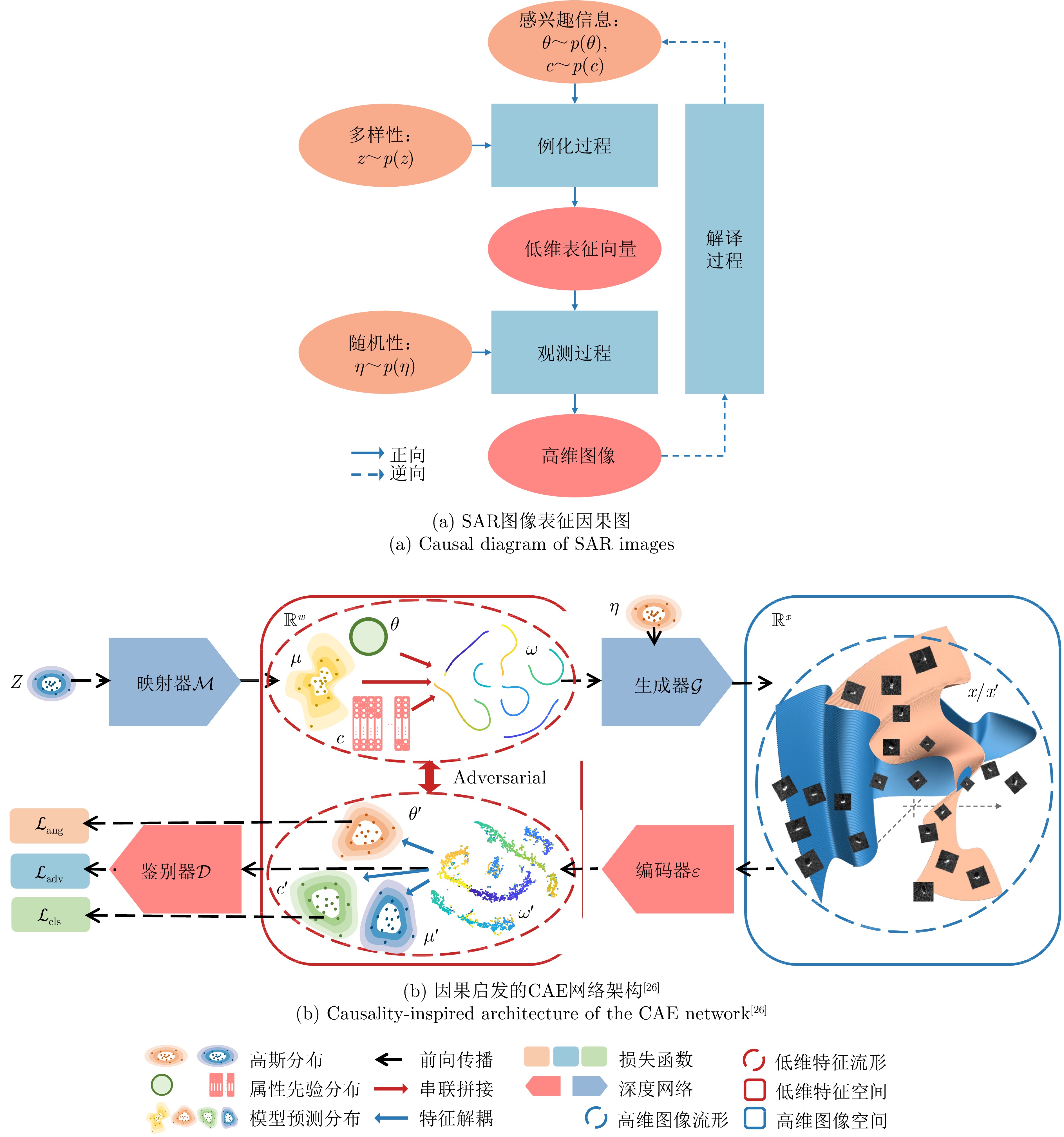
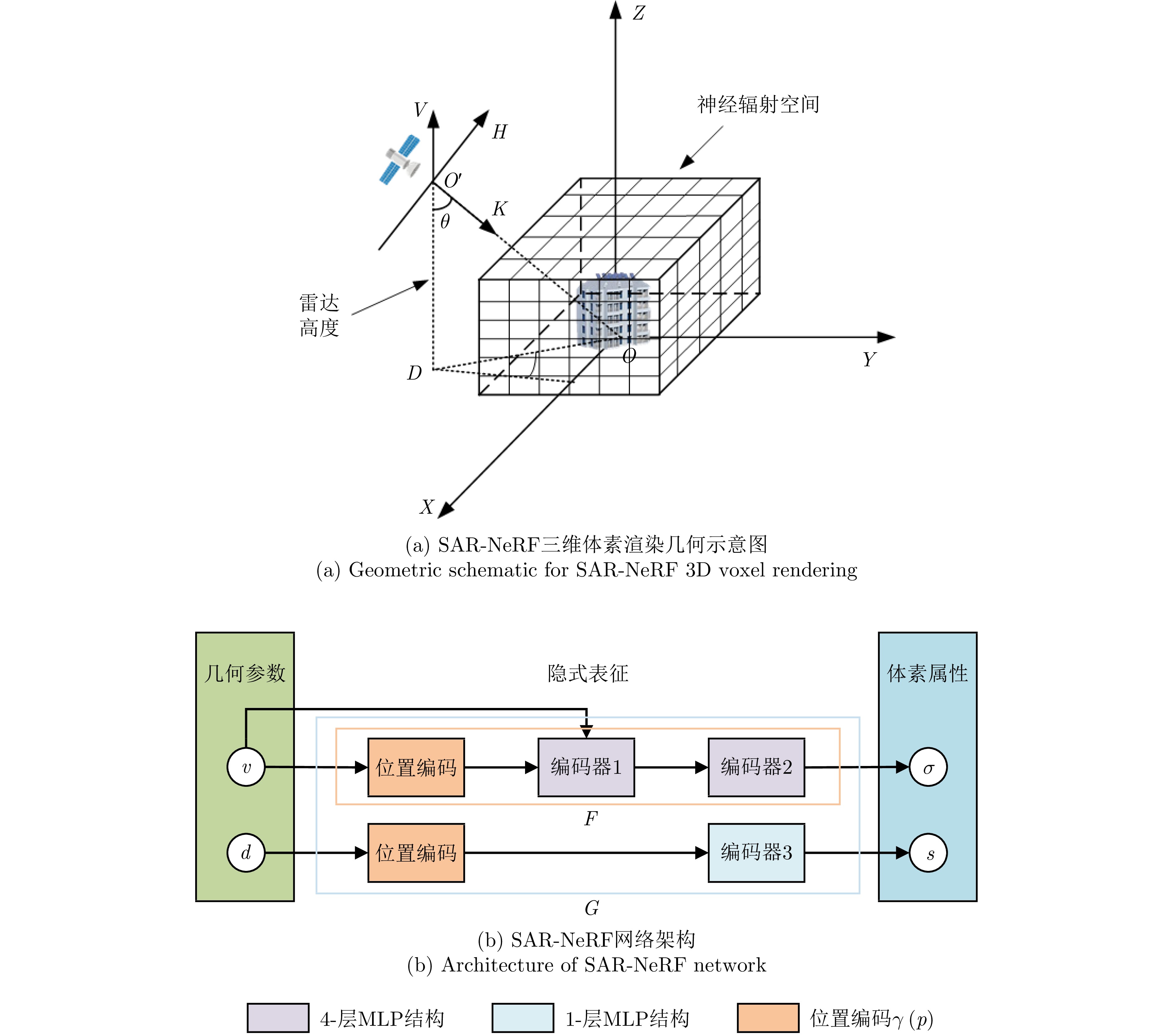


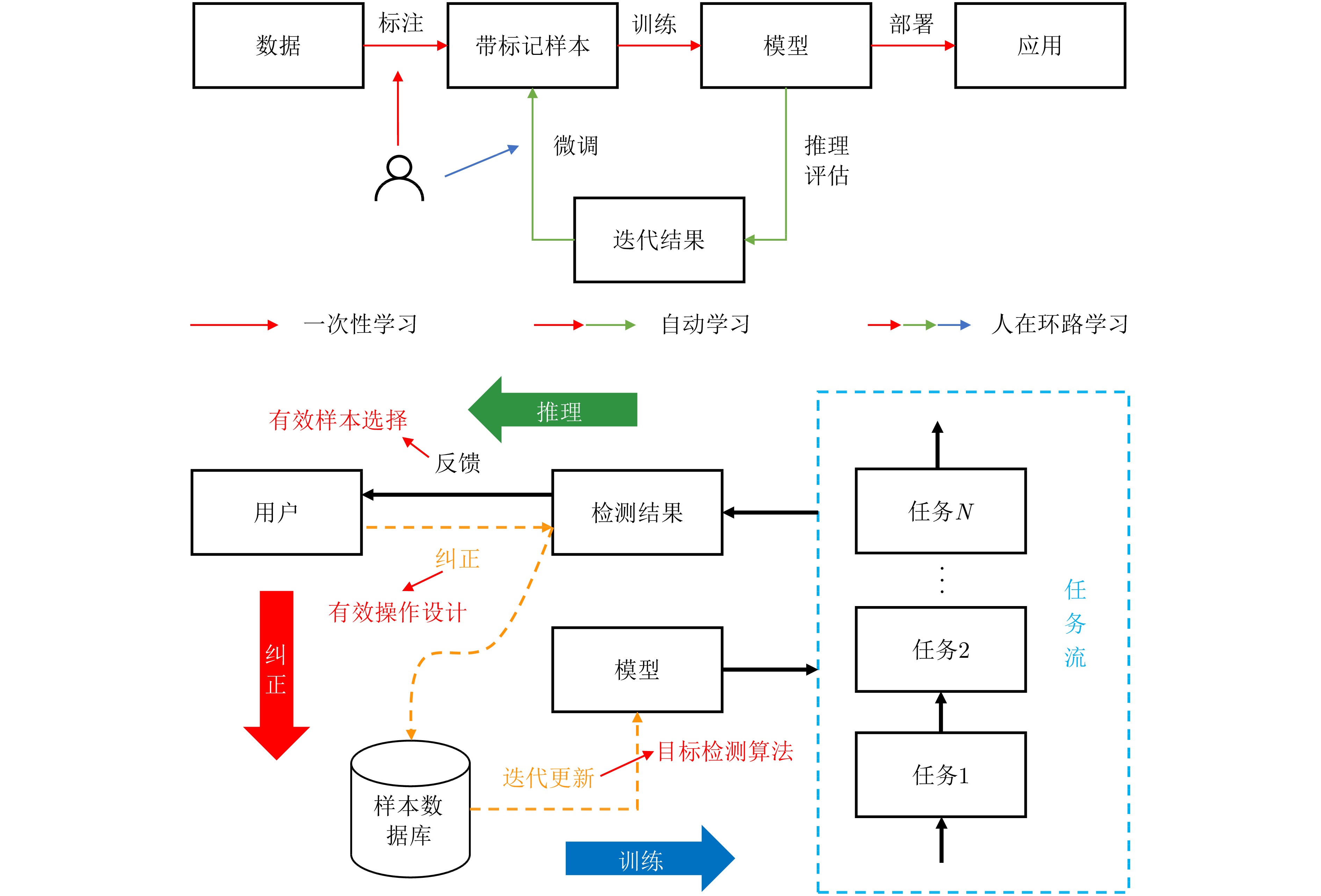
2024, 13(2): 307-330.
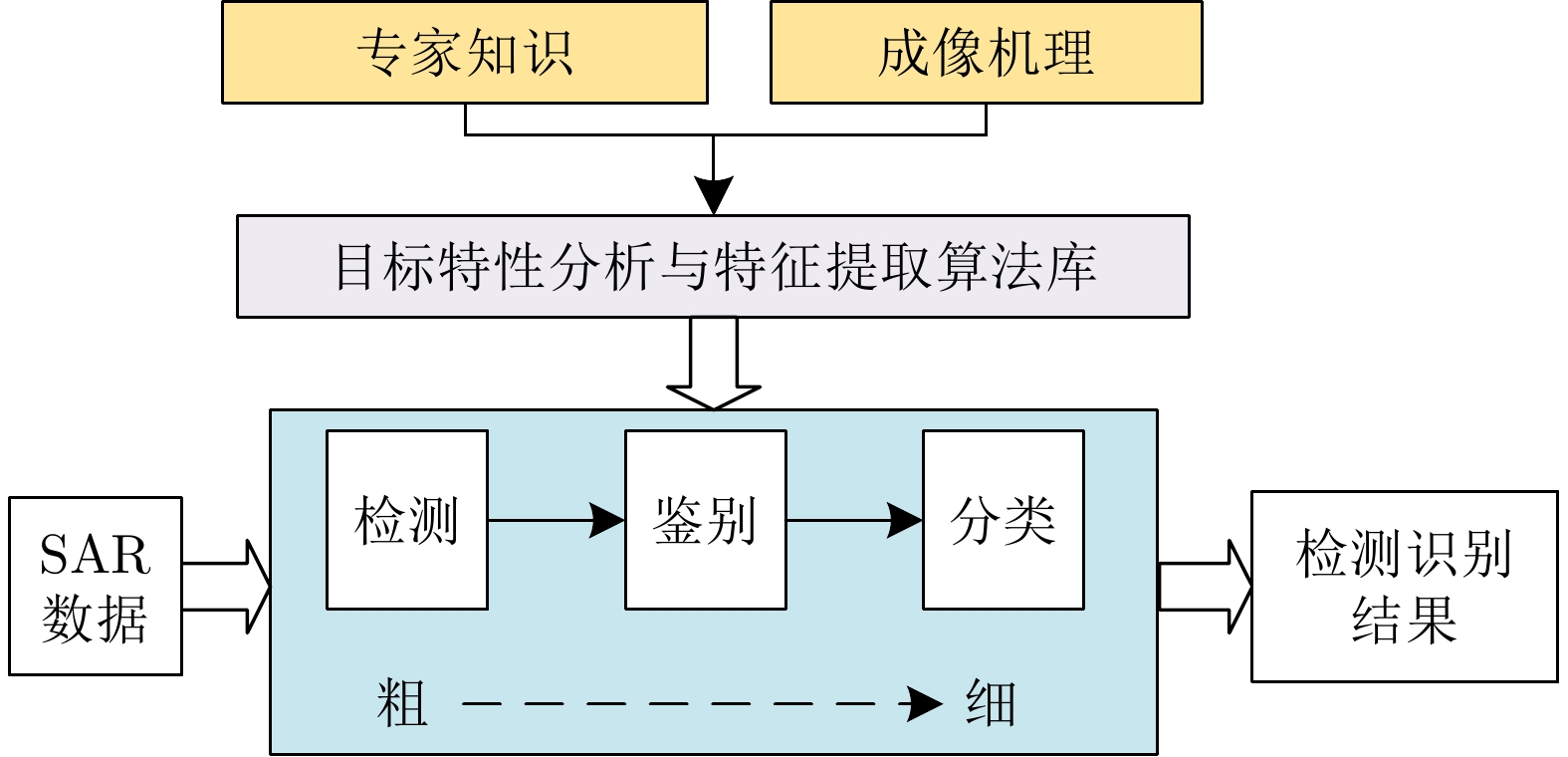
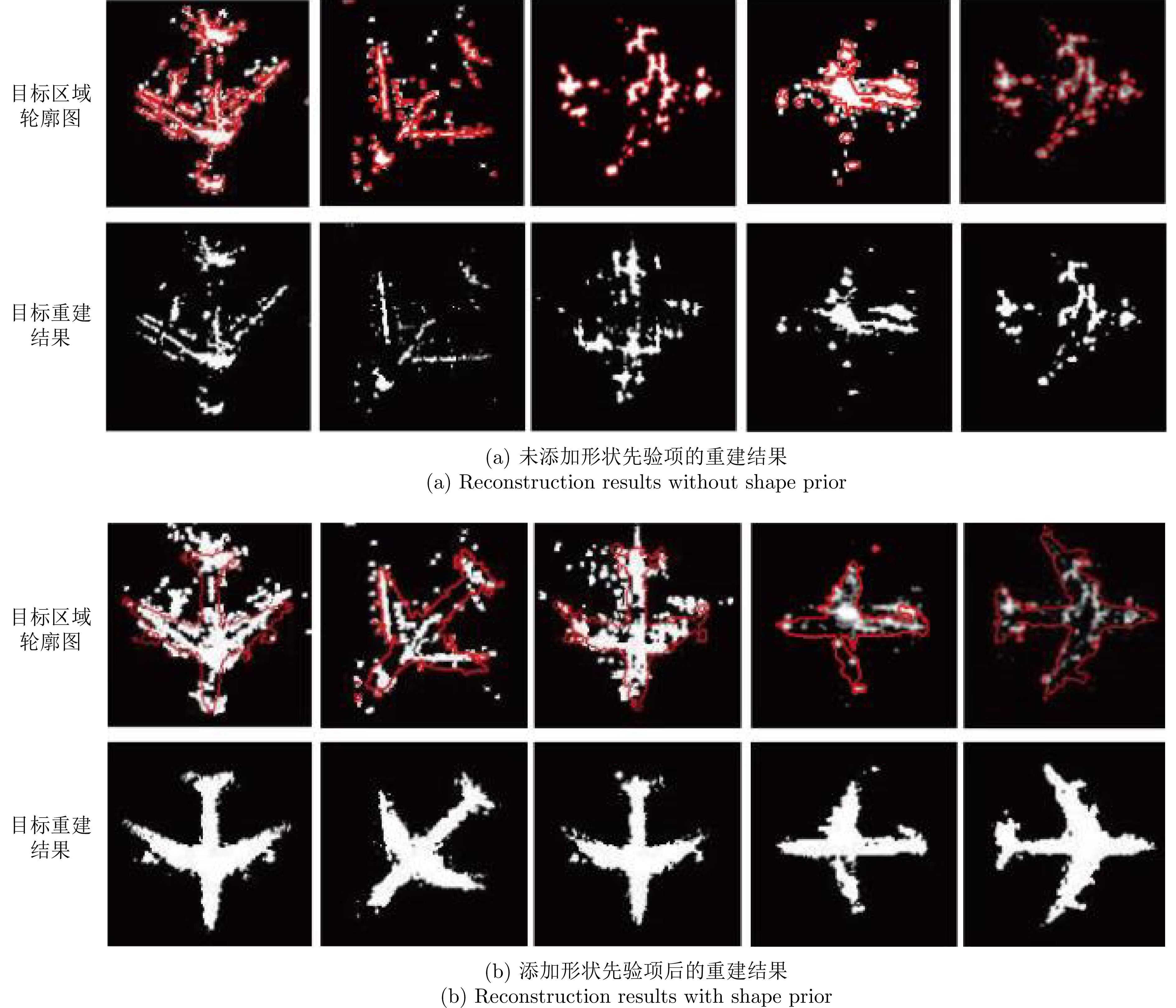
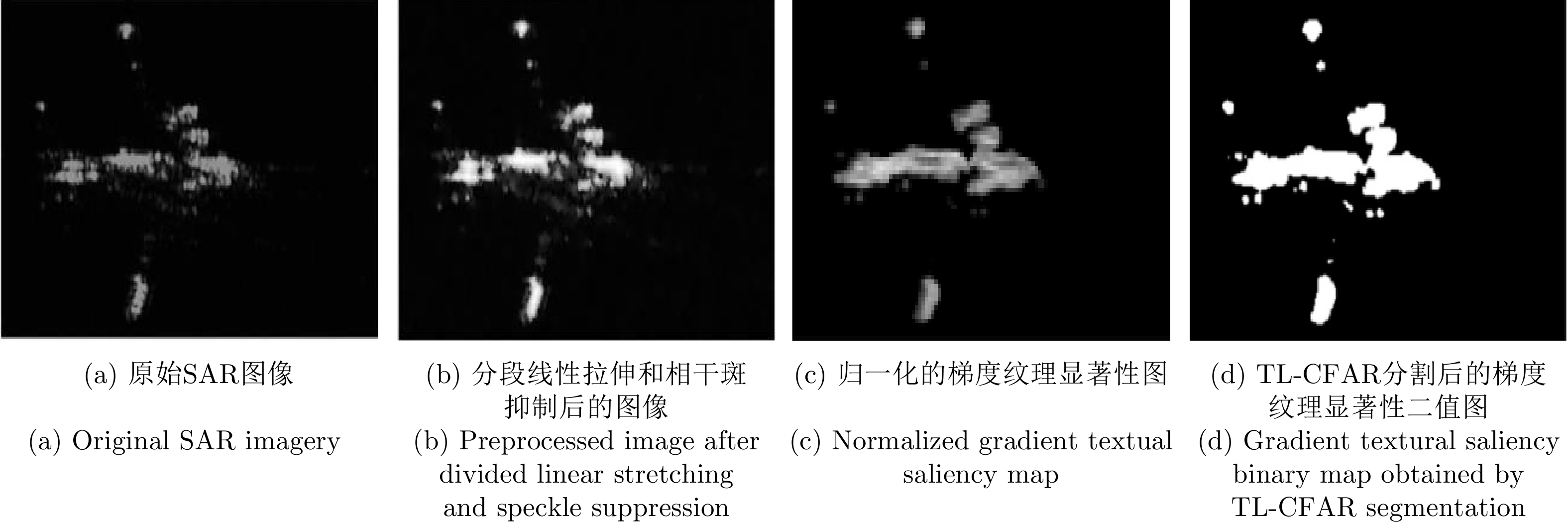
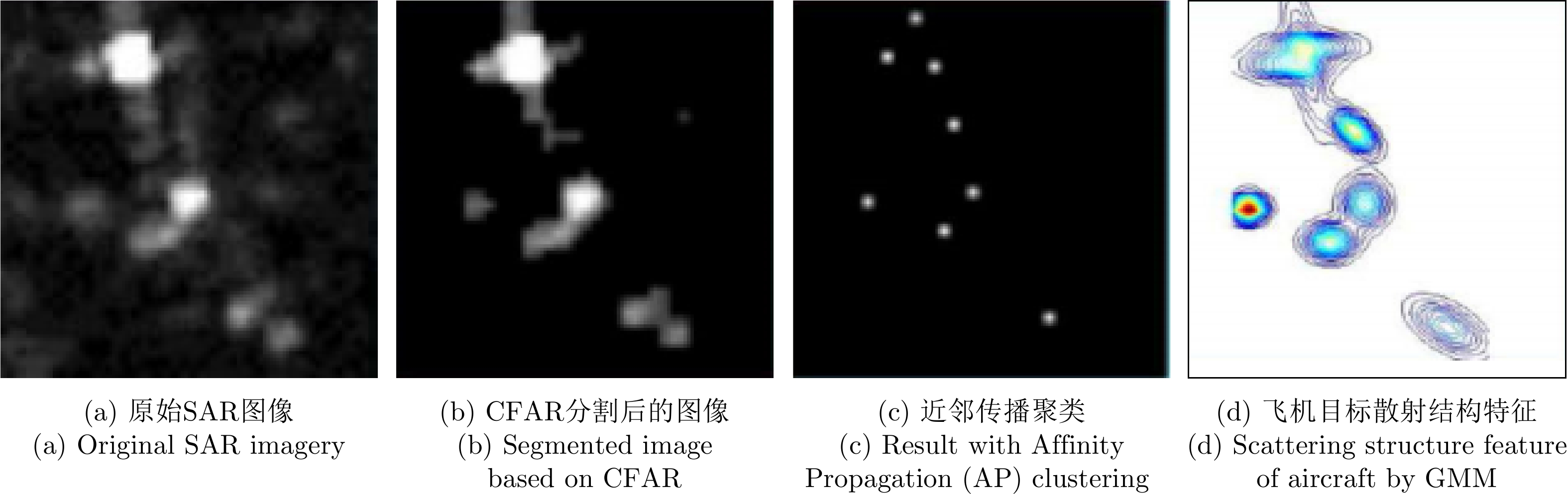
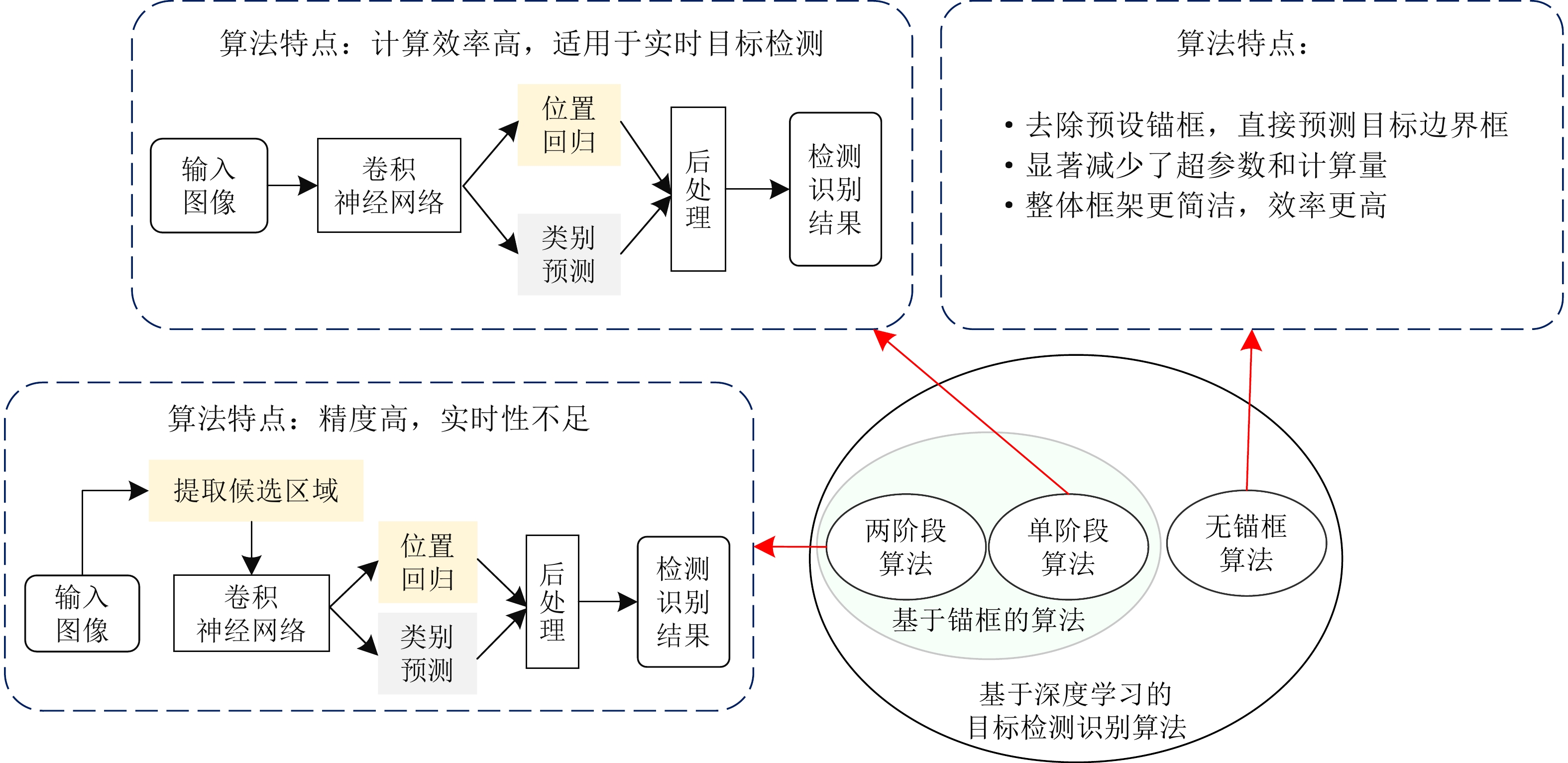
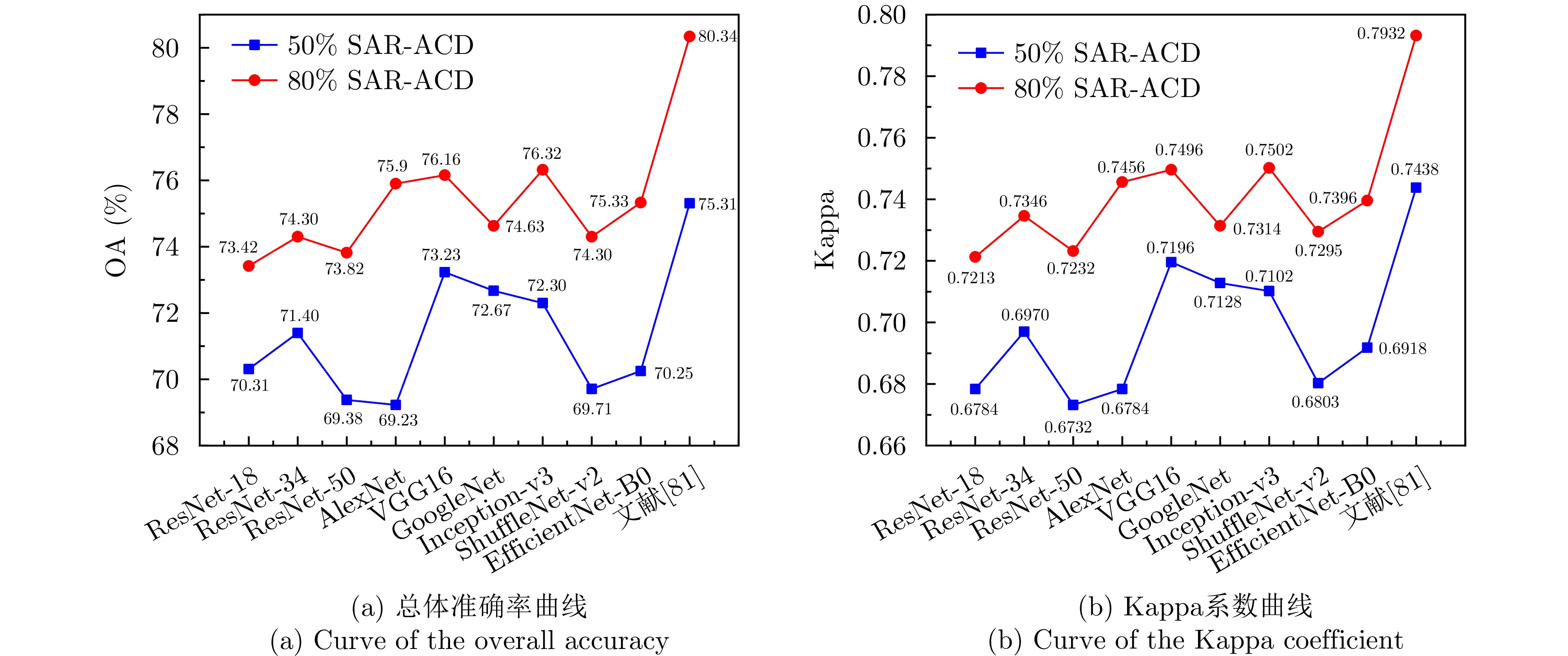
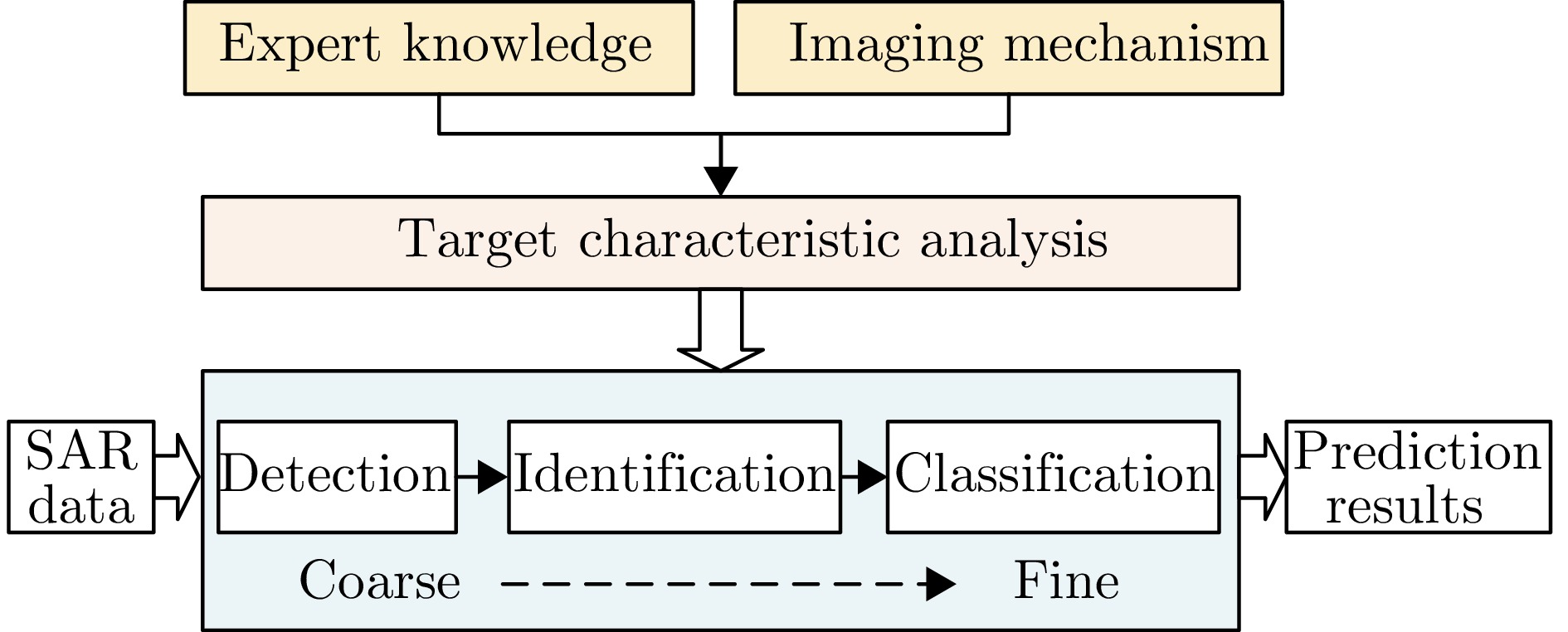
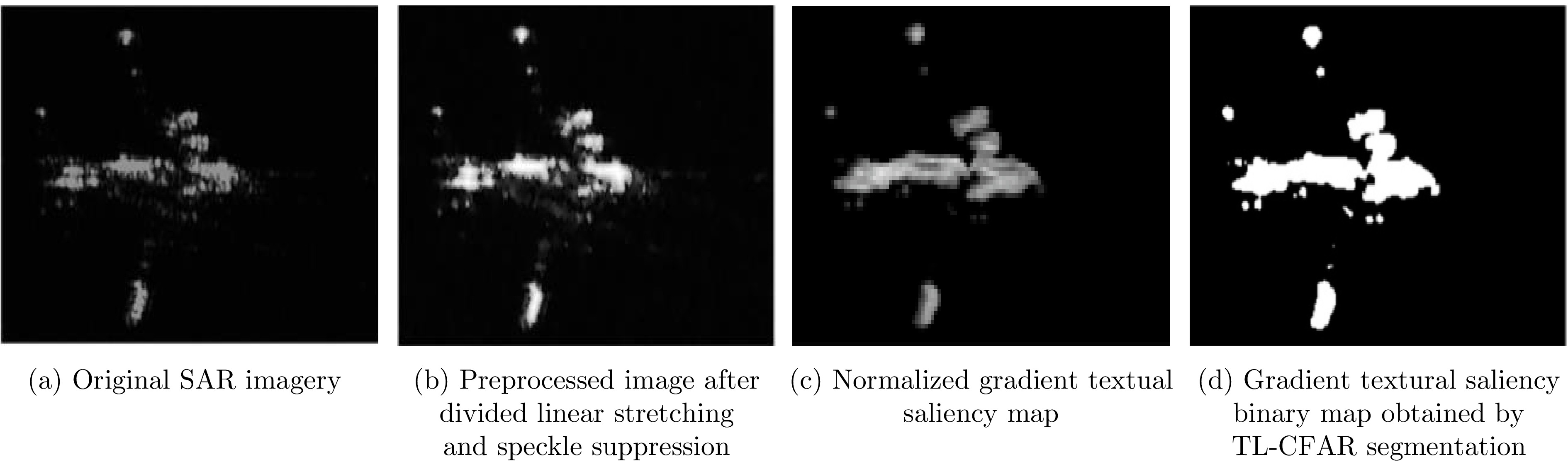
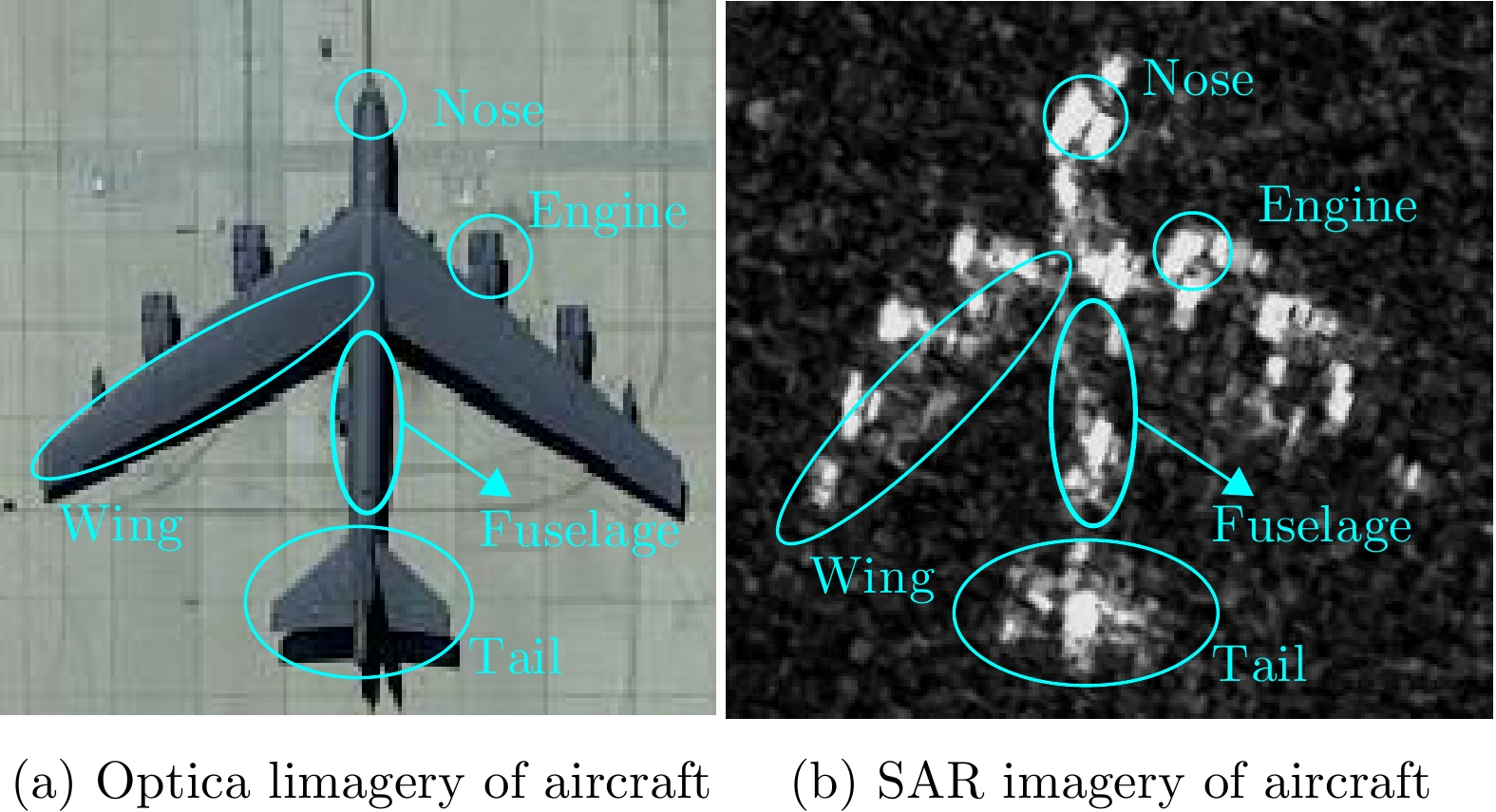
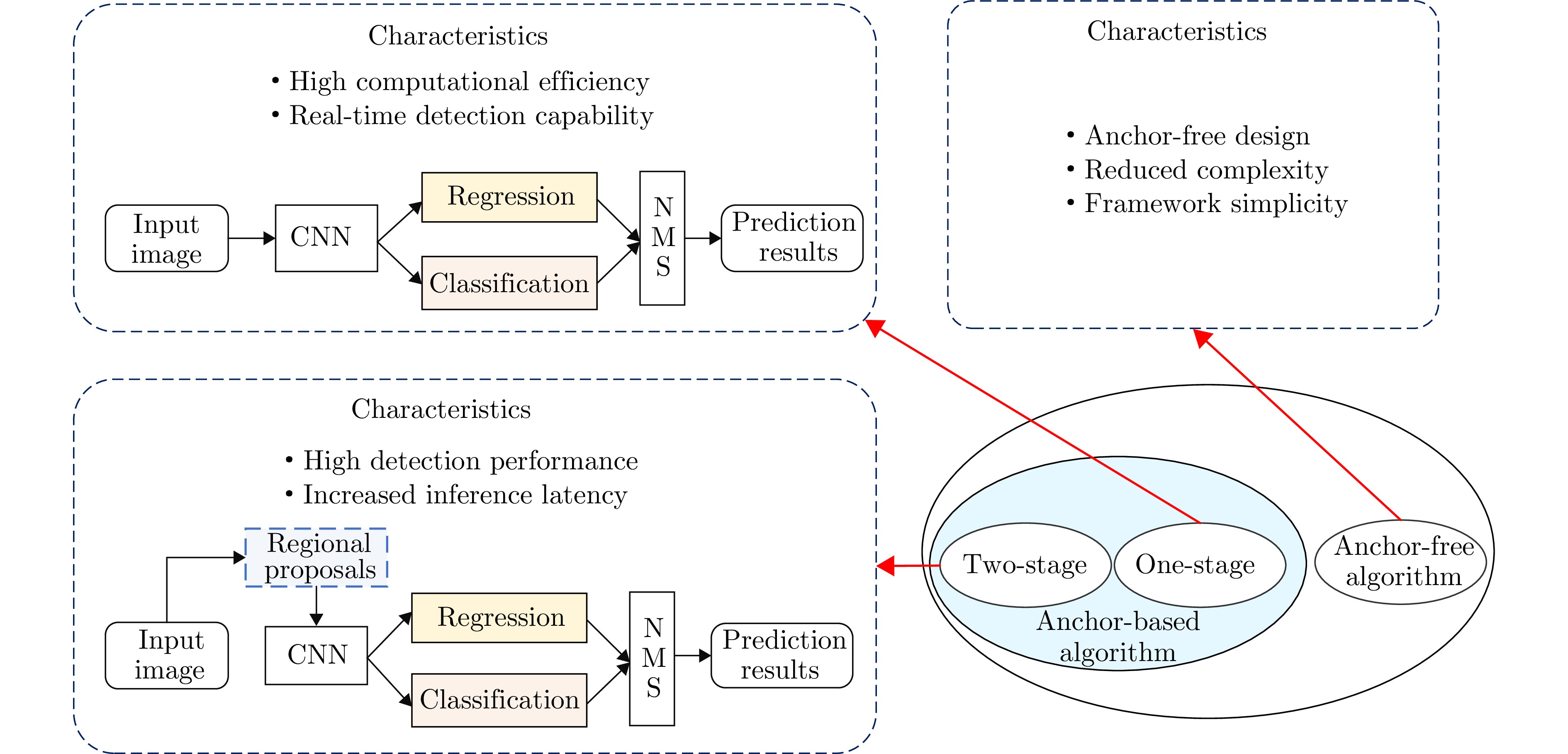
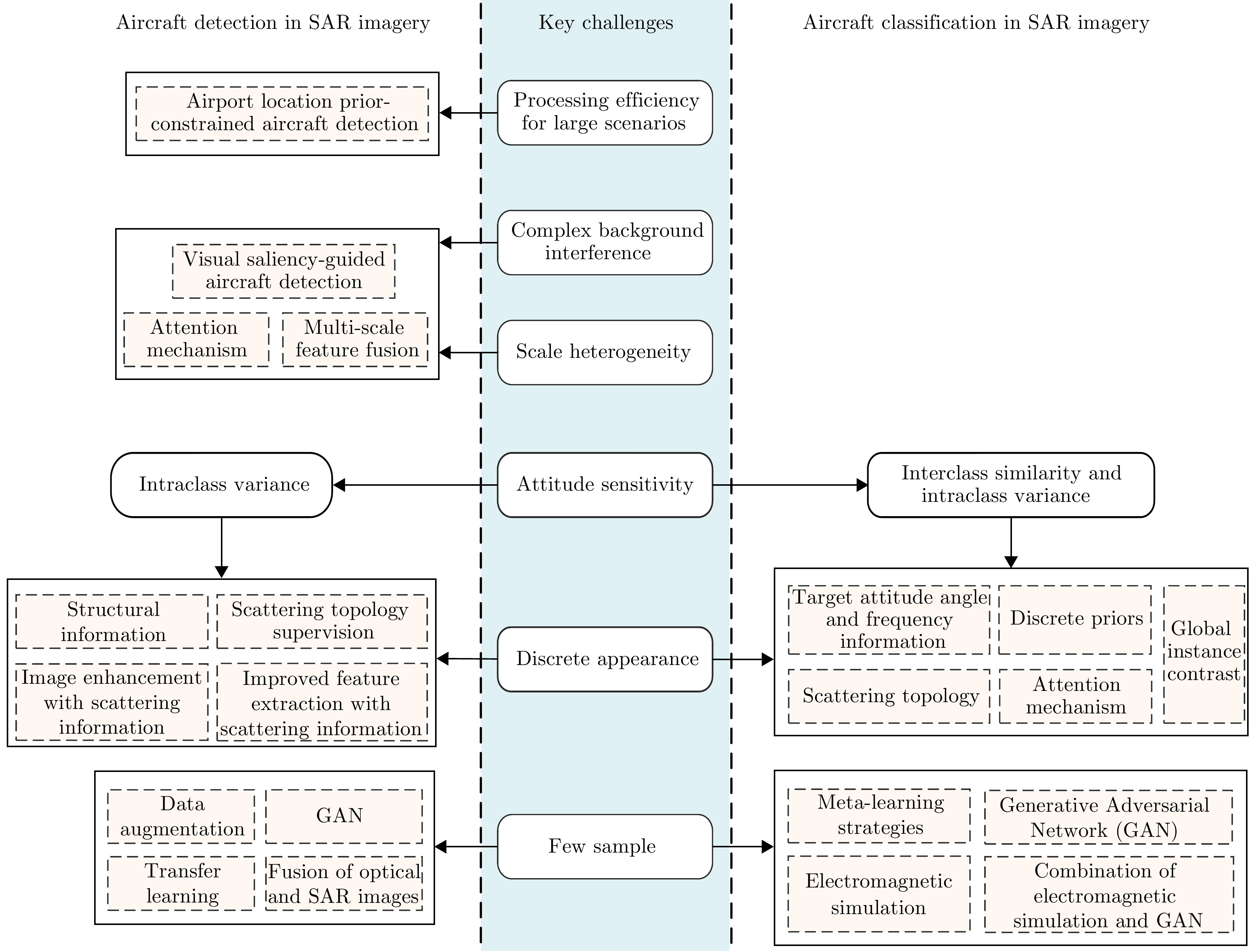
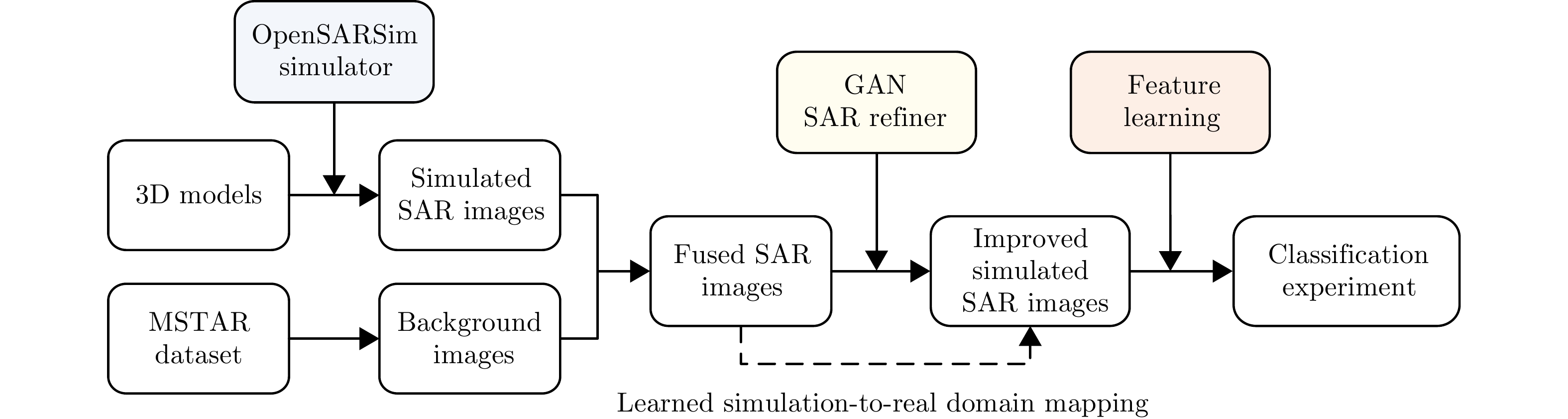
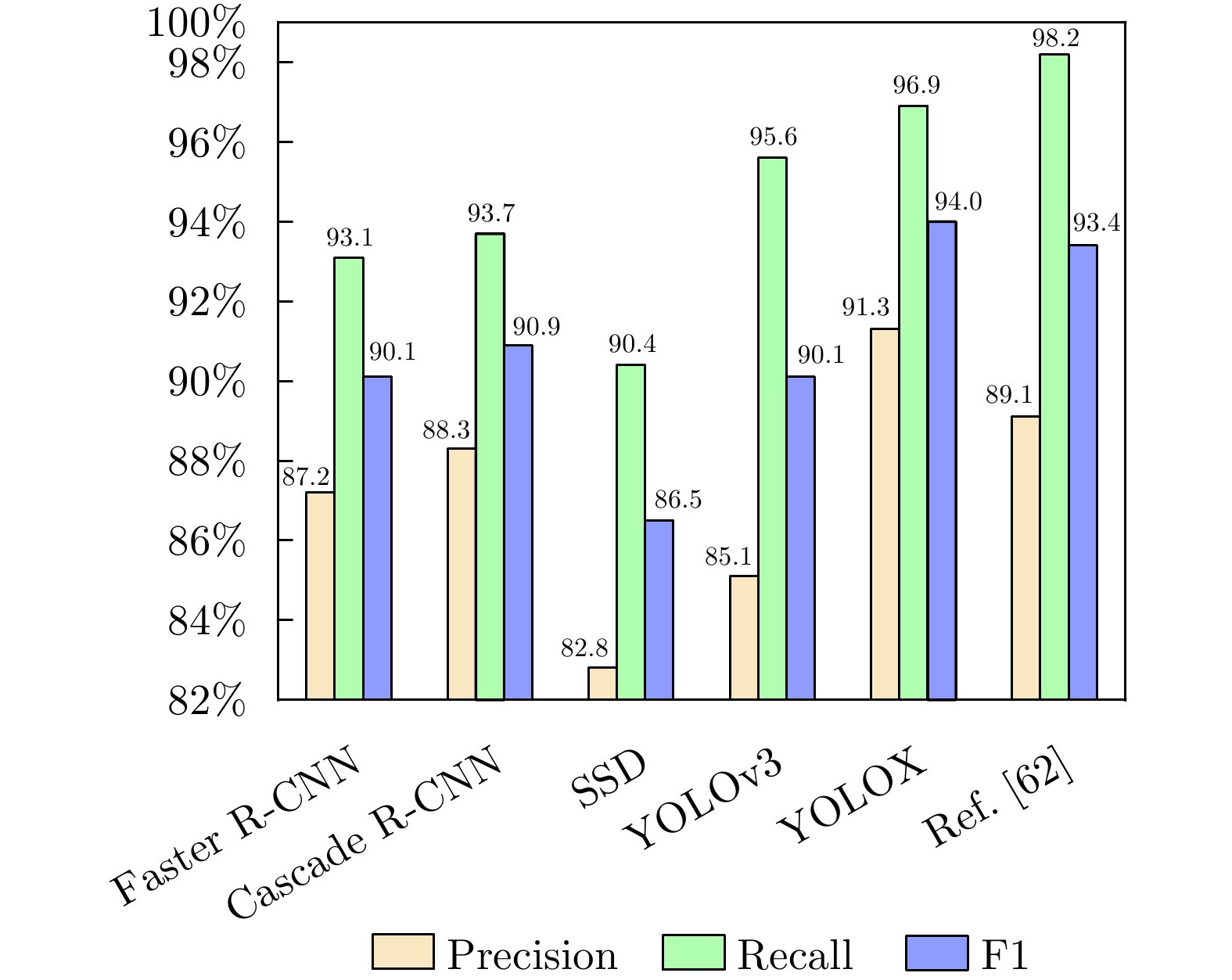
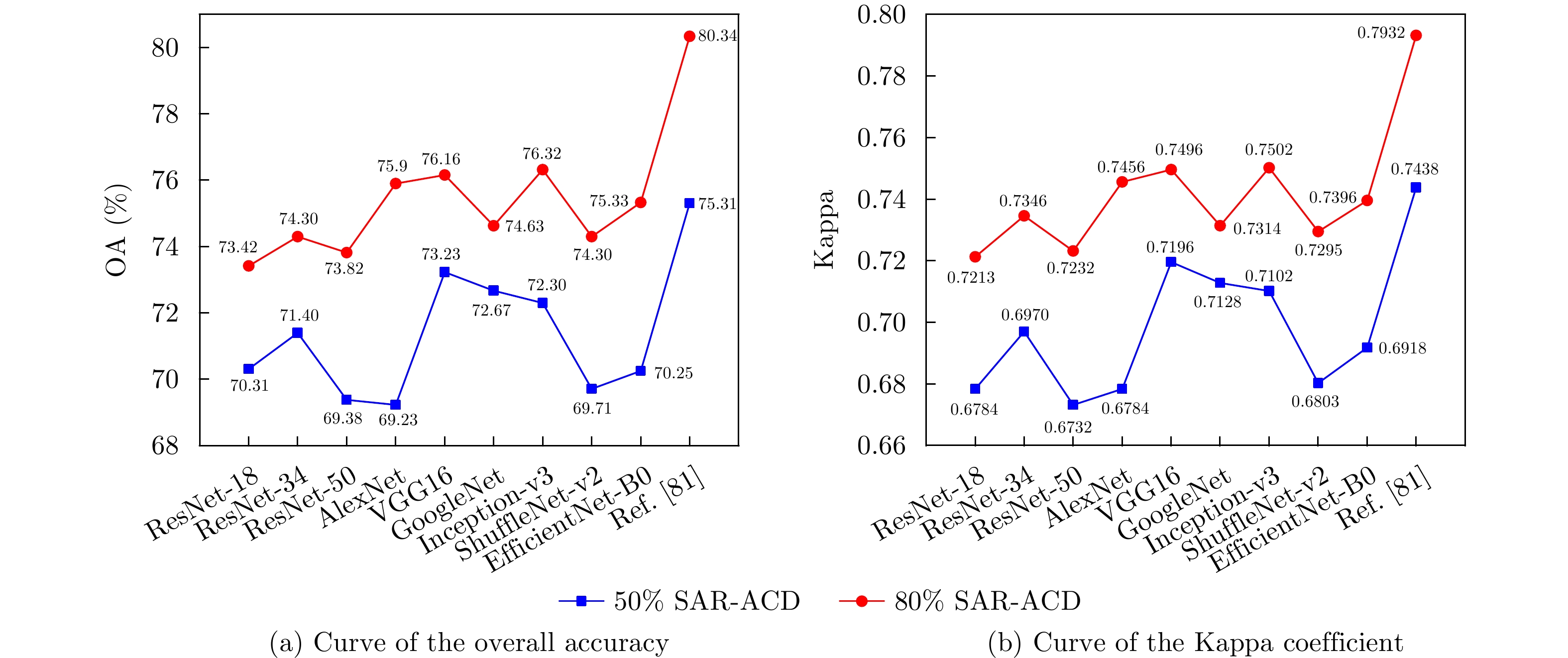
Synthetic Aperture Radar (SAR), with its coherent imaging mechanism, has the unique advantage of all-day and all-weather imaging. As a typical and important topic, aircraft detection and recognition have been widely studied in the field of SAR image interpretation. With the introduction of deep learning, the performance of aircraft detection and recognition, which is based on SAR imagery, has considerably improved. This paper combines the expertise gathered by our research team on the theory, algorithms, and applications of SAR image-based target detection and recognition, particularly aircraft. Additionally, this paper presents a comprehensive review of deep learning-powered aircraft detection and recognition based on SAR imagery. This review includes a detailed analysis of the aircraft target characteristics and current challenges associated with SAR image-based detection and recognition. Furthermore, the review summarizes the latest research advancements, characteristics, and application scenarios of various technologies and collates public datasets and performance evaluation metrics. Finally, several challenges and potential research prospects are discussed.
Synthetic Aperture Radar (SAR), with its coherent imaging mechanism, has the unique advantage of all-day and all-weather imaging. As a typical and important topic, aircraft detection and recognition have been widely studied in the field of SAR image interpretation. With the introduction of deep learning, the performance of aircraft detection and recognition, which is based on SAR imagery, has considerably improved. This paper combines the expertise gathered by our research team on the theory, algorithms, and applications of SAR image-based target detection and recognition, particularly aircraft. Additionally, this paper presents a comprehensive review of deep learning-powered aircraft detection and recognition based on SAR imagery. This review includes a detailed analysis of the aircraft target characteristics and current challenges associated with SAR image-based detection and recognition. Furthermore, the review summarizes the latest research advancements, characteristics, and application scenarios of various technologies and collates public datasets and performance evaluation metrics. Finally, several challenges and potential research prospects are discussed.






















2024, 13(2): 331-344.
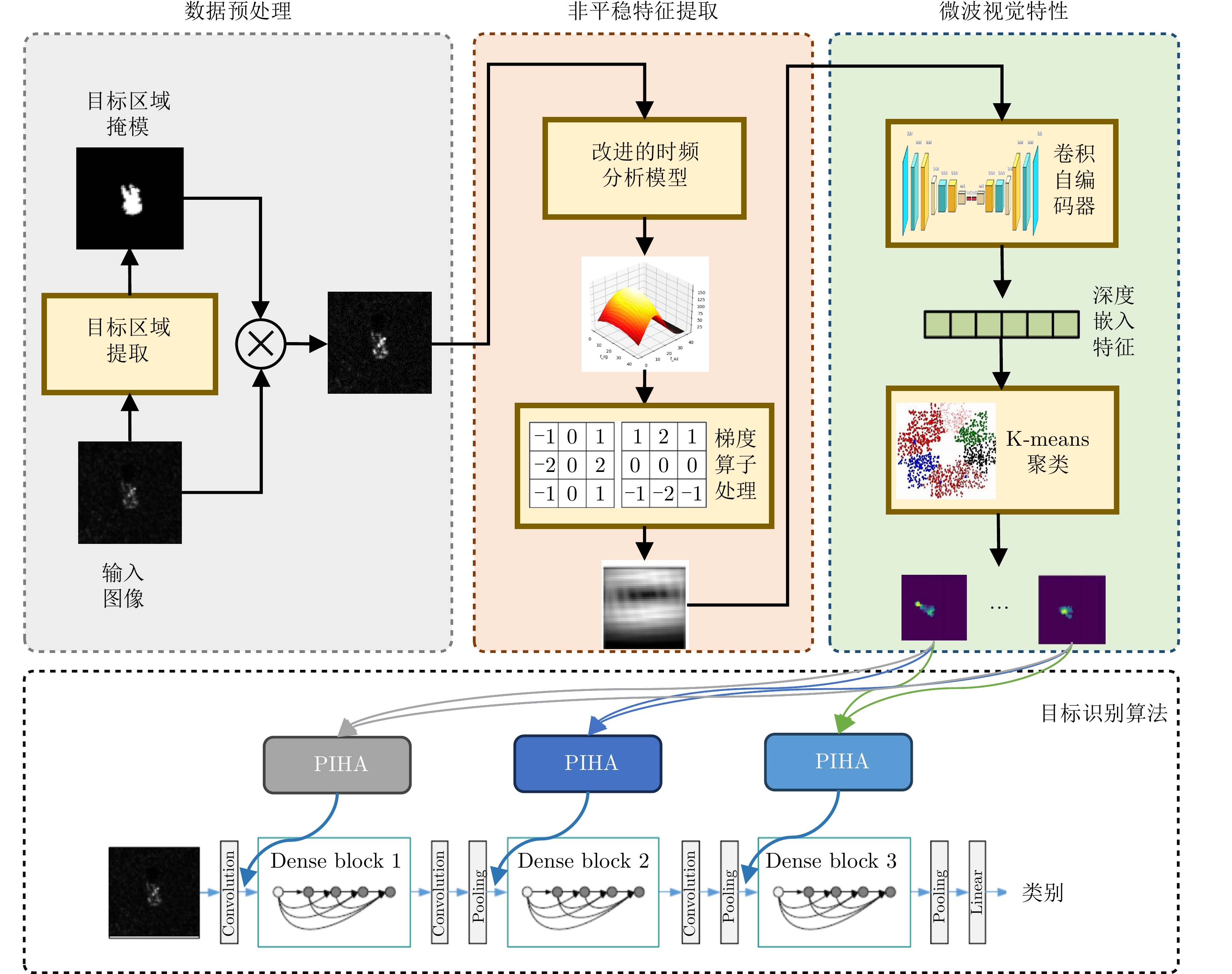
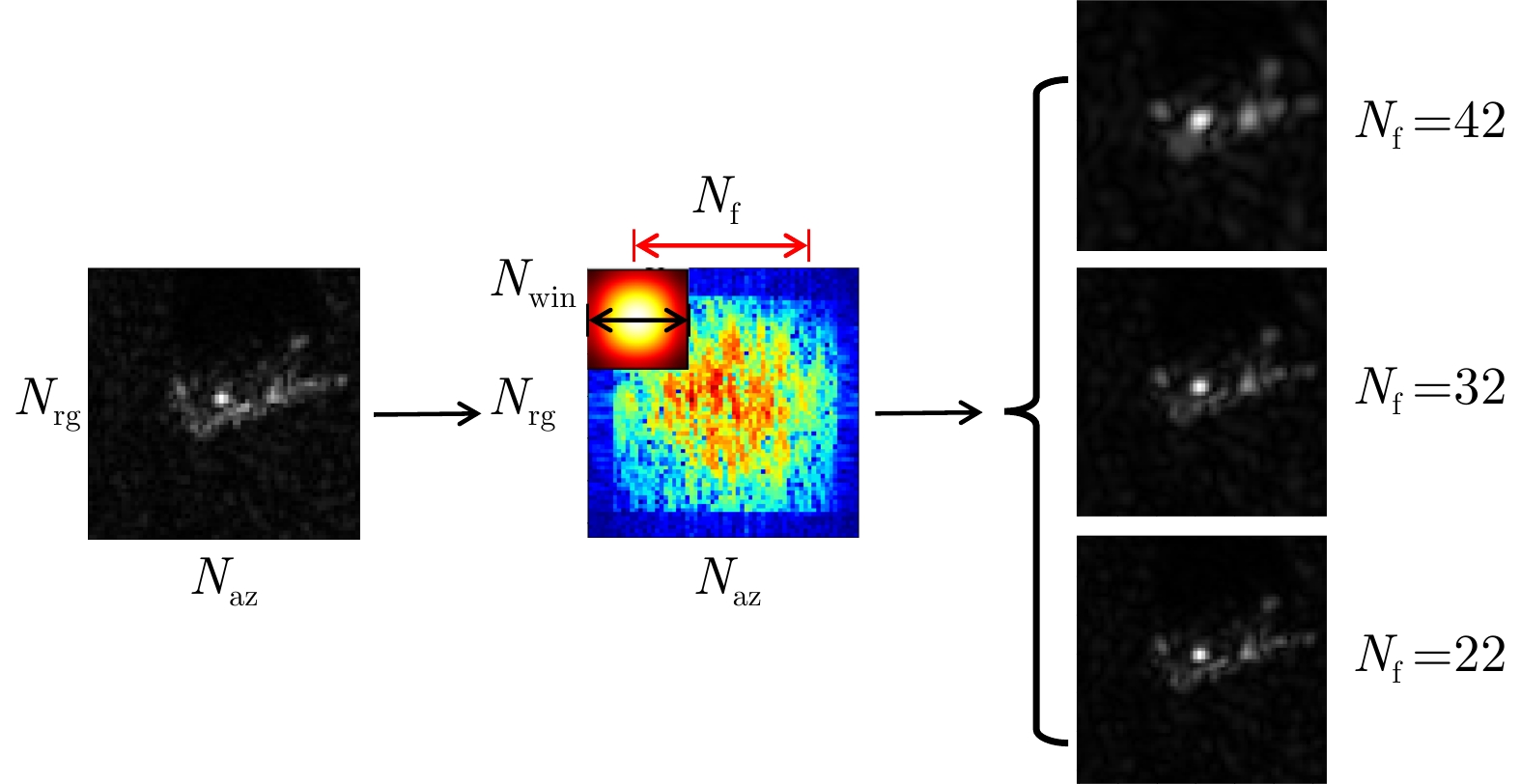
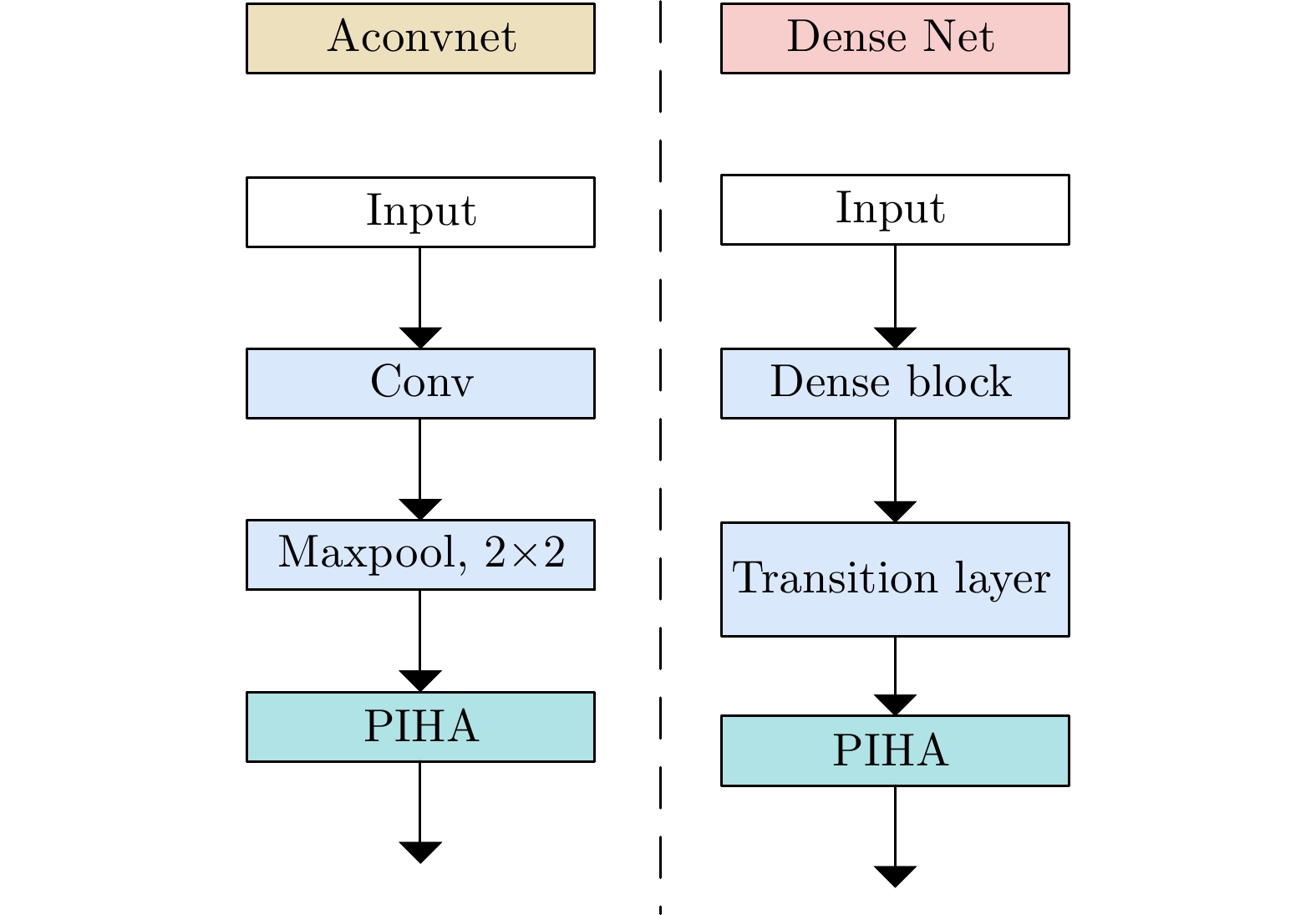
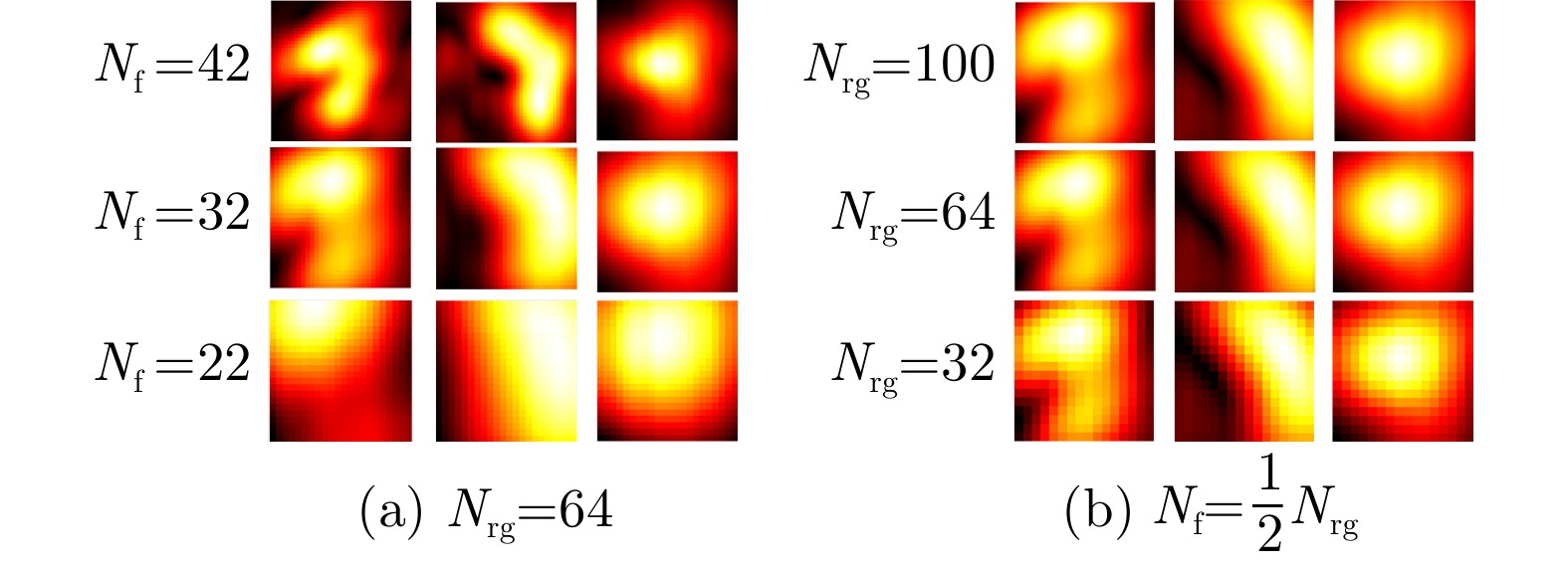
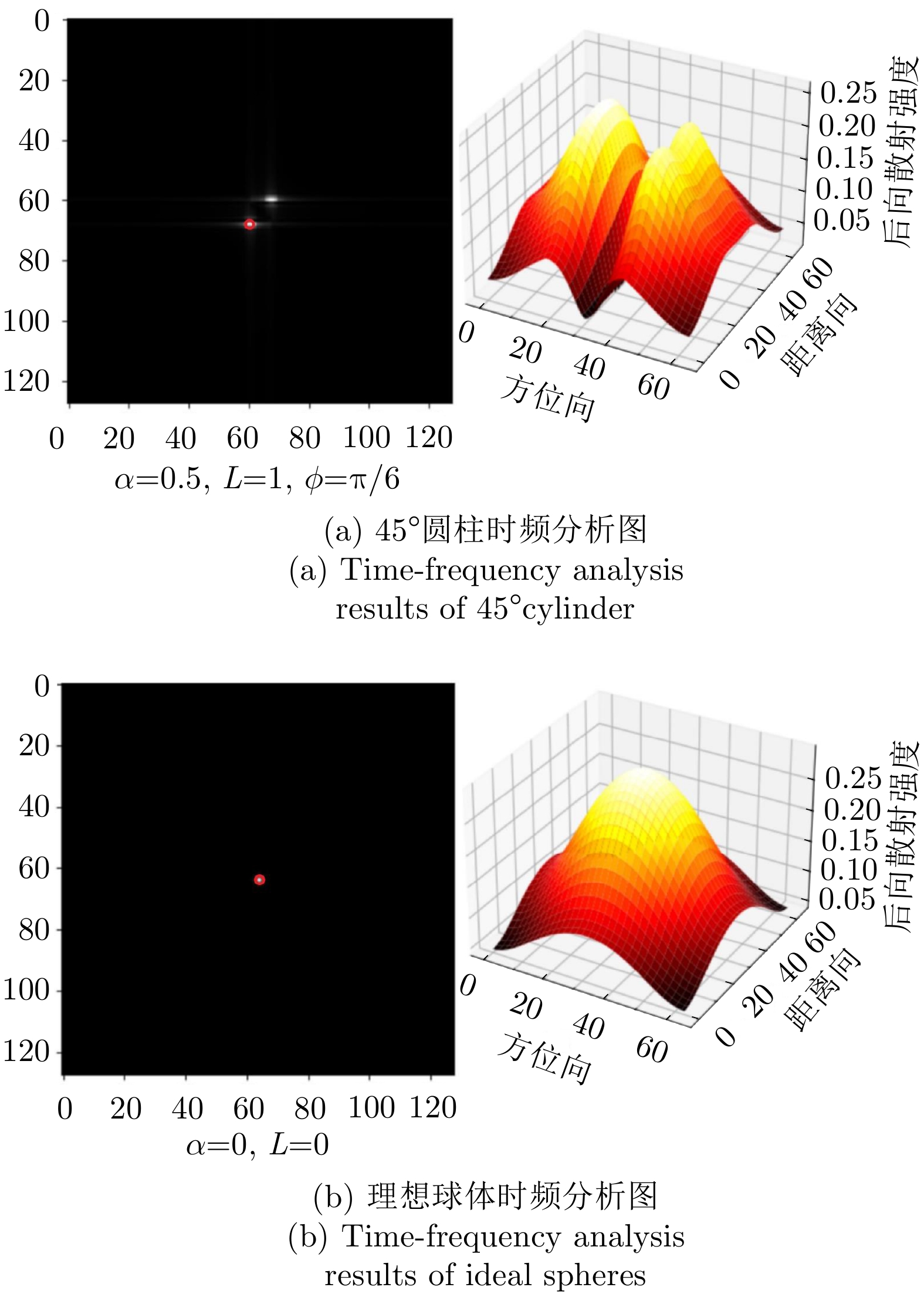
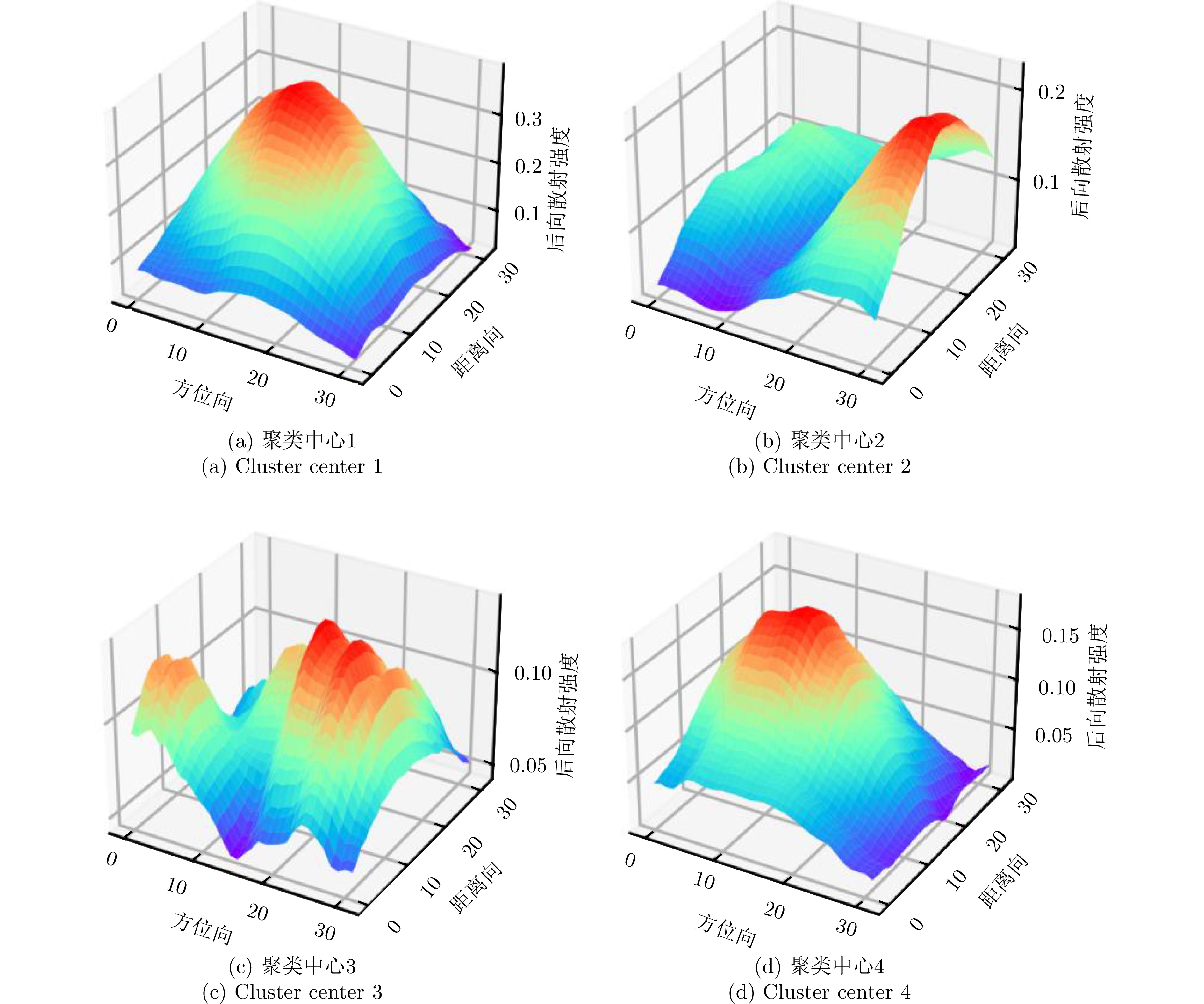
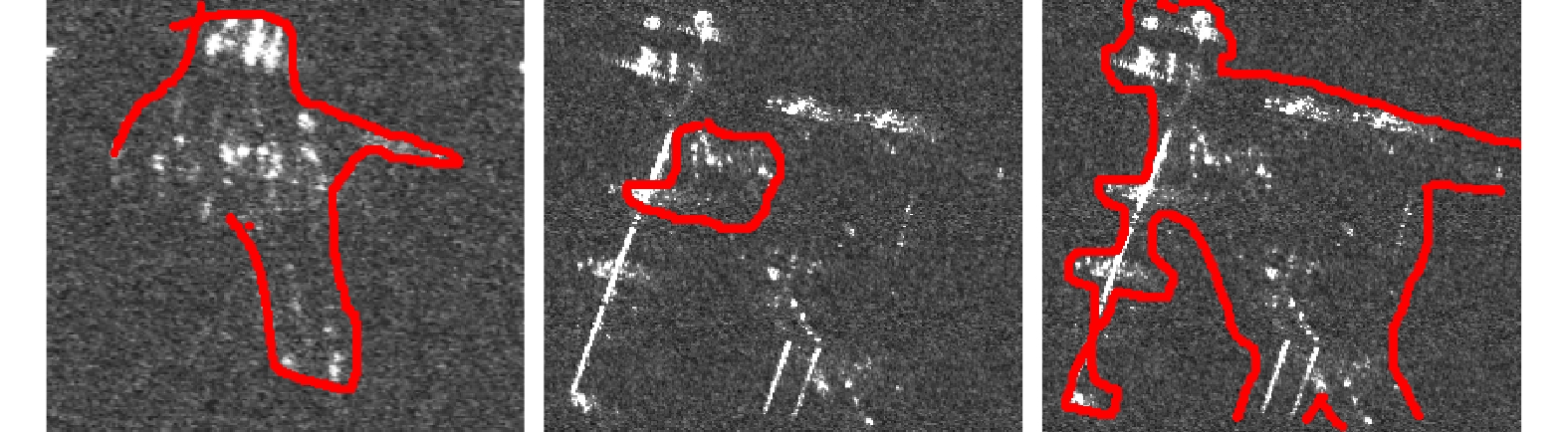
The current state of intelligent target recognition approaches for Synthetic Aperture Radar (SAR) continues to experience challenges owing to their limited robustness, generalizability, and interpretability. Currently, research focuses on comprehending the microwave properties of SAR targets and integrating them with advanced deep learning algorithms to achieve effective and resilient SAR target recognition. The computational complexity of SAR target characteristic-inversion approaches is often considerable, rendering their integration with deep neural networks for achieving real-time predictions in an end-to-end manner challenging. To facilitate the utilization of the physical properties of SAR targets in intelligent recognition tasks, advancing the development of microwave physical property sensing technologies that are efficient, intelligent, and interpretable is imperative. This paper focuses on the nonstationary nature of high-resolution SAR targets and proposes an improved intelligent approach for analyzing target characteristics using time-frequency analysis. This method enhances the processing flow and calculation efficiency, making it more suitable for SAR targets. It is integrated with a deep neural network for SAR target recognition to achieve consistent performance improvement. The proposed approach exhibits robust generalization capabilities and notable computing efficiency, enabling the acquisition of classification outcomes of the SAR target characteristics that are readily interpretable from a physical standpoint. The enhancement in the performance of the target recognition algorithm is comparable to that achieved by the attribute scattering center model.
The current state of intelligent target recognition approaches for Synthetic Aperture Radar (SAR) continues to experience challenges owing to their limited robustness, generalizability, and interpretability. Currently, research focuses on comprehending the microwave properties of SAR targets and integrating them with advanced deep learning algorithms to achieve effective and resilient SAR target recognition. The computational complexity of SAR target characteristic-inversion approaches is often considerable, rendering their integration with deep neural networks for achieving real-time predictions in an end-to-end manner challenging. To facilitate the utilization of the physical properties of SAR targets in intelligent recognition tasks, advancing the development of microwave physical property sensing technologies that are efficient, intelligent, and interpretable is imperative. This paper focuses on the nonstationary nature of high-resolution SAR targets and proposes an improved intelligent approach for analyzing target characteristics using time-frequency analysis. This method enhances the processing flow and calculation efficiency, making it more suitable for SAR targets. It is integrated with a deep neural network for SAR target recognition to achieve consistent performance improvement. The proposed approach exhibits robust generalization capabilities and notable computing efficiency, enabling the acquisition of classification outcomes of the SAR target characteristics that are readily interpretable from a physical standpoint. The enhancement in the performance of the target recognition algorithm is comparable to that achieved by the attribute scattering center model.







2024, 13(2): 345-358.
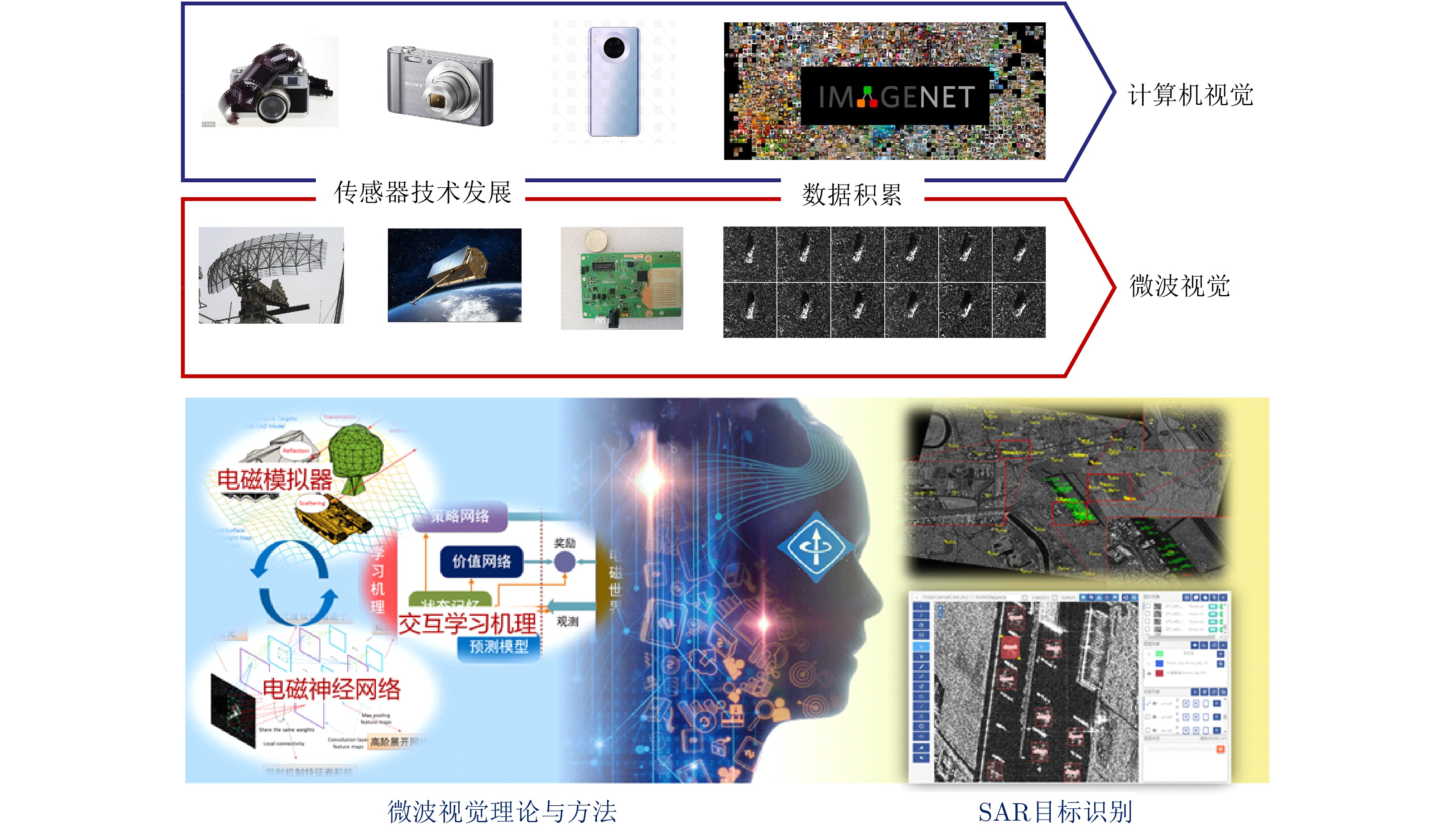
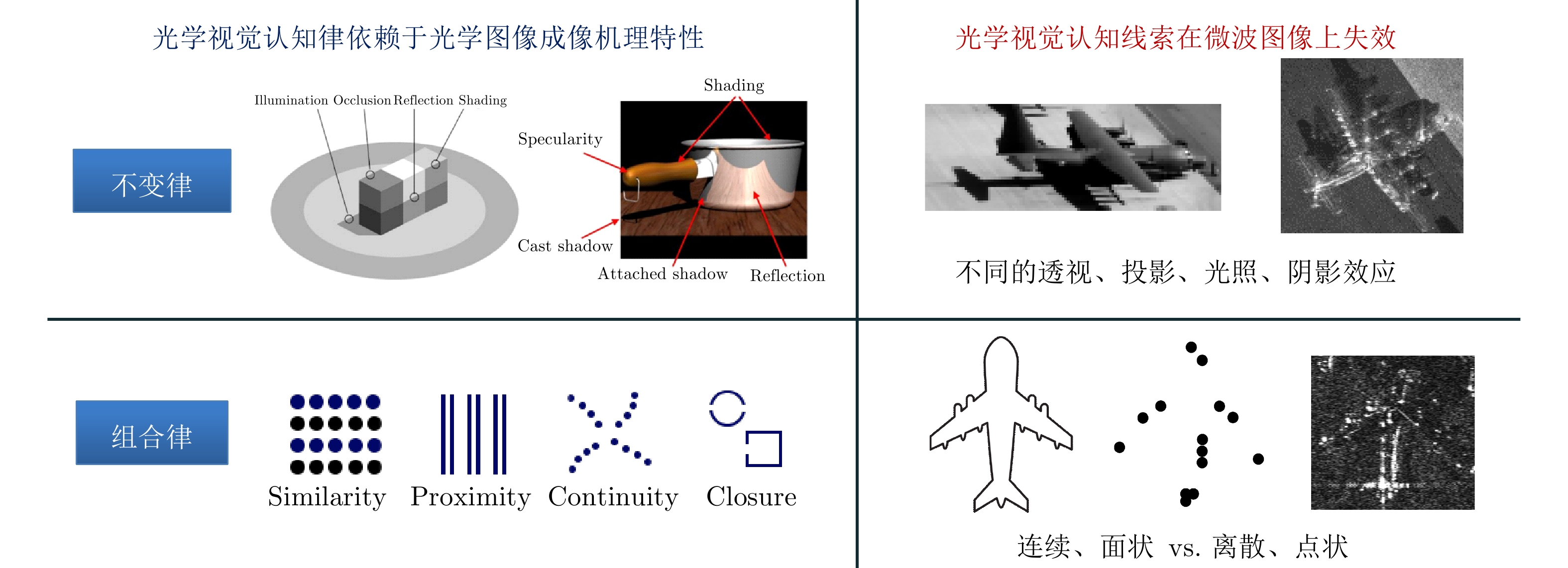
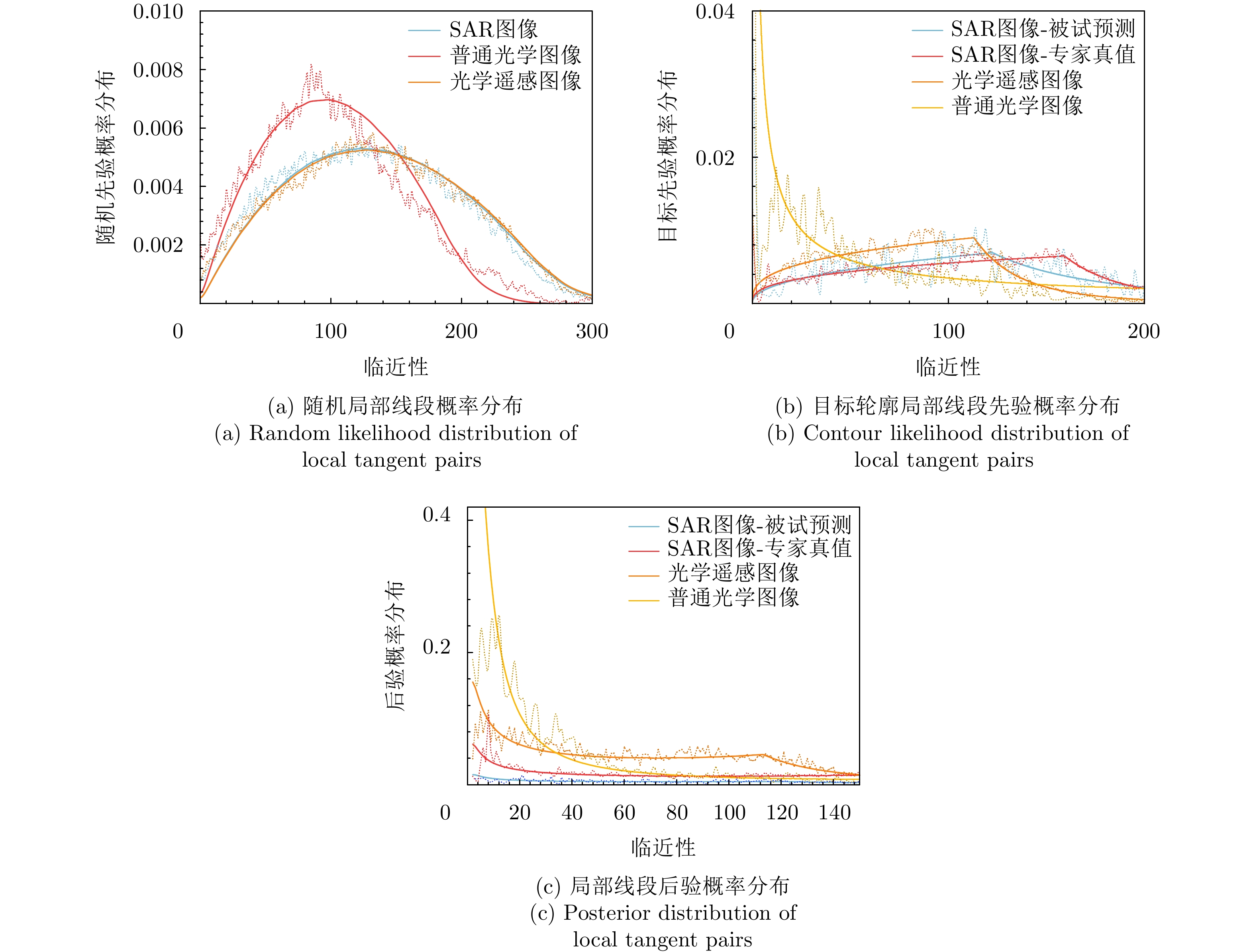
Synthetic Aperture Radar (SAR) images are an important data source in microwave vision research; however, computer vision cannot interpret these images effectively based on optical perceptual principles. Therefore, microwave vision, which draws inspiration from human visual perception principles and combines computer vision techniques with electromagnetic physical principles, has become an important research direction in microwave remote sensing. Exploring the cognitive basis for microwave vision is crucial for improving the theoretical system of microwave vision. Therefore, as a preliminary attempt to enhance the theoretical understanding of microwave vision, this paper examines the effectiveness of optical perceptual principles for microwave vision. As a classical visual theory, Gestalt perceptual principles are commonly used for describing the perceptual principles of the human visual system for the external optical world and are a cognitive theoretical foundation of computer vision. In this context, this paper uses SAR images as the research object, focuses on the design process of cognitive psychology experiments, and preliminarily studies the effectiveness of Gestalt perceptual principles for SAR images, including the principles of perceptual grouping and perceptual invariance, exploring the cognitive basis of microwave vision. The experimental results indicate that the Gestalt perceptual principles cannot be directly applied to the algorithm design for SAR images, and the knowledge concepts and visual principles derived from the optical world using the human visual system do not perform well in SAR images. In the future, it will be necessary to summarize the corresponding visual cognitive principles based on the characteristics of microwave images, such as SAR images.
Synthetic Aperture Radar (SAR) images are an important data source in microwave vision research; however, computer vision cannot interpret these images effectively based on optical perceptual principles. Therefore, microwave vision, which draws inspiration from human visual perception principles and combines computer vision techniques with electromagnetic physical principles, has become an important research direction in microwave remote sensing. Exploring the cognitive basis for microwave vision is crucial for improving the theoretical system of microwave vision. Therefore, as a preliminary attempt to enhance the theoretical understanding of microwave vision, this paper examines the effectiveness of optical perceptual principles for microwave vision. As a classical visual theory, Gestalt perceptual principles are commonly used for describing the perceptual principles of the human visual system for the external optical world and are a cognitive theoretical foundation of computer vision. In this context, this paper uses SAR images as the research object, focuses on the design process of cognitive psychology experiments, and preliminarily studies the effectiveness of Gestalt perceptual principles for SAR images, including the principles of perceptual grouping and perceptual invariance, exploring the cognitive basis of microwave vision. The experimental results indicate that the Gestalt perceptual principles cannot be directly applied to the algorithm design for SAR images, and the knowledge concepts and visual principles derived from the optical world using the human visual system do not perform well in SAR images. In the future, it will be necessary to summarize the corresponding visual cognitive principles based on the characteristics of microwave images, such as SAR images.







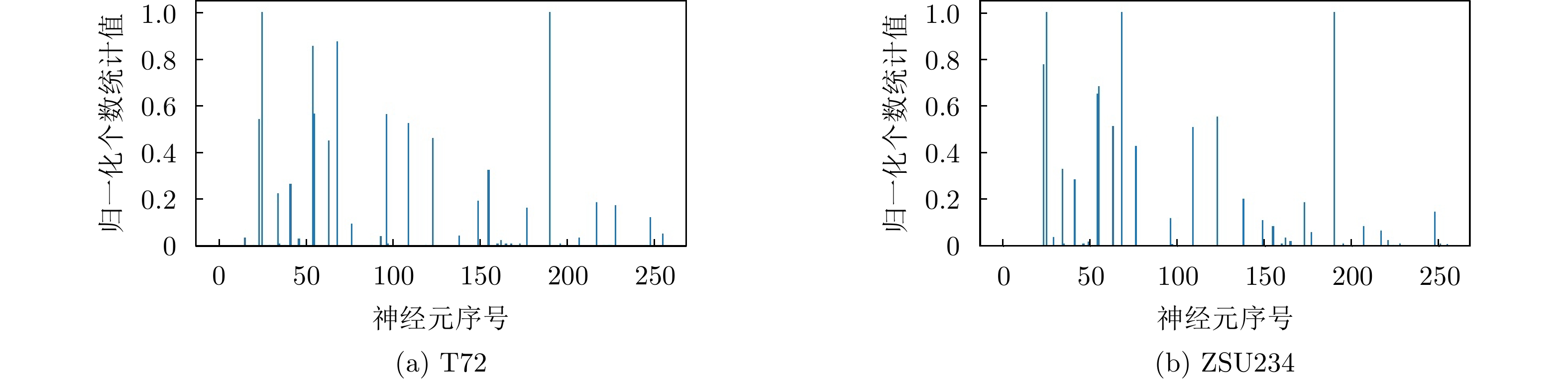
2024, 13(2): 359-373.
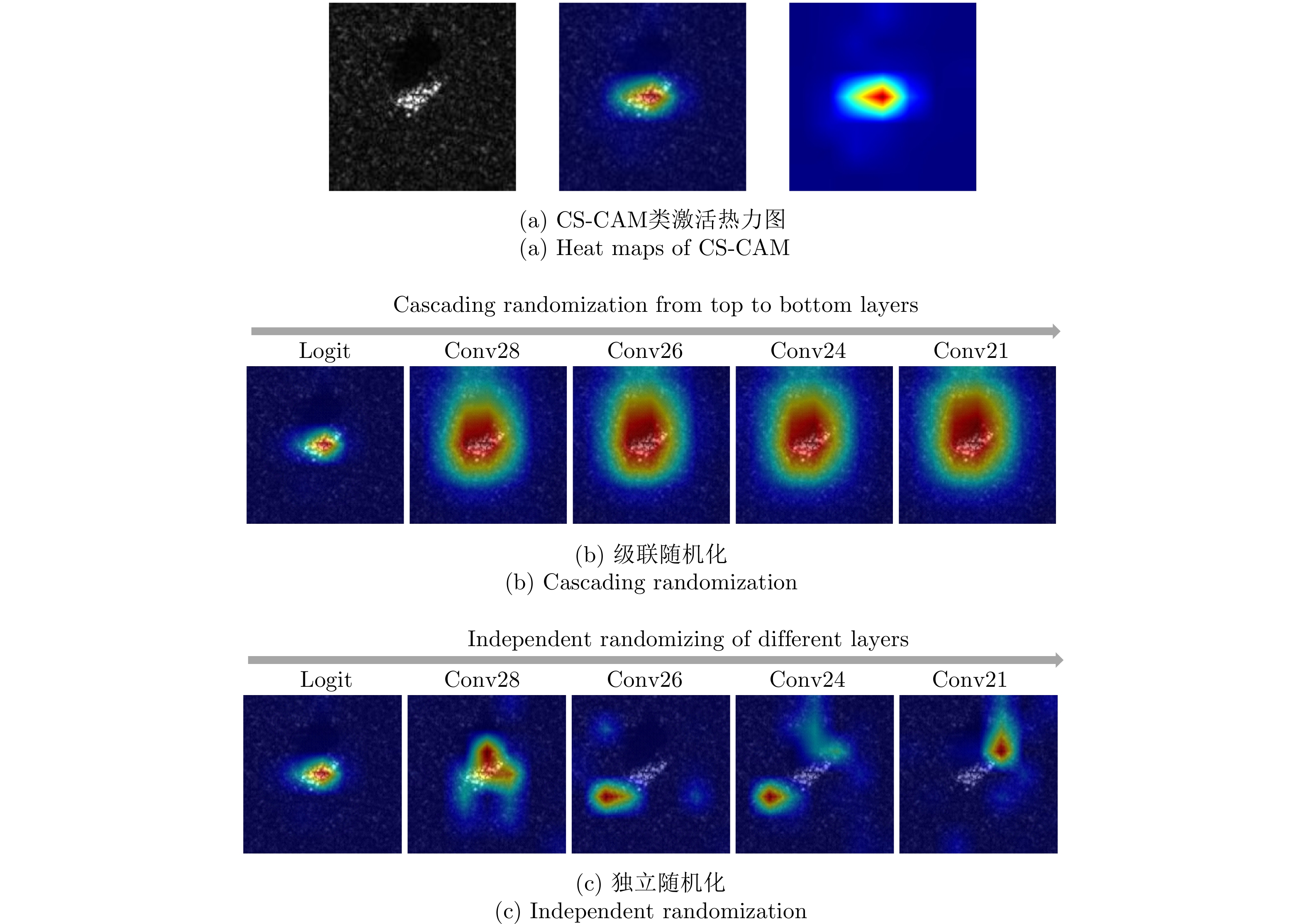
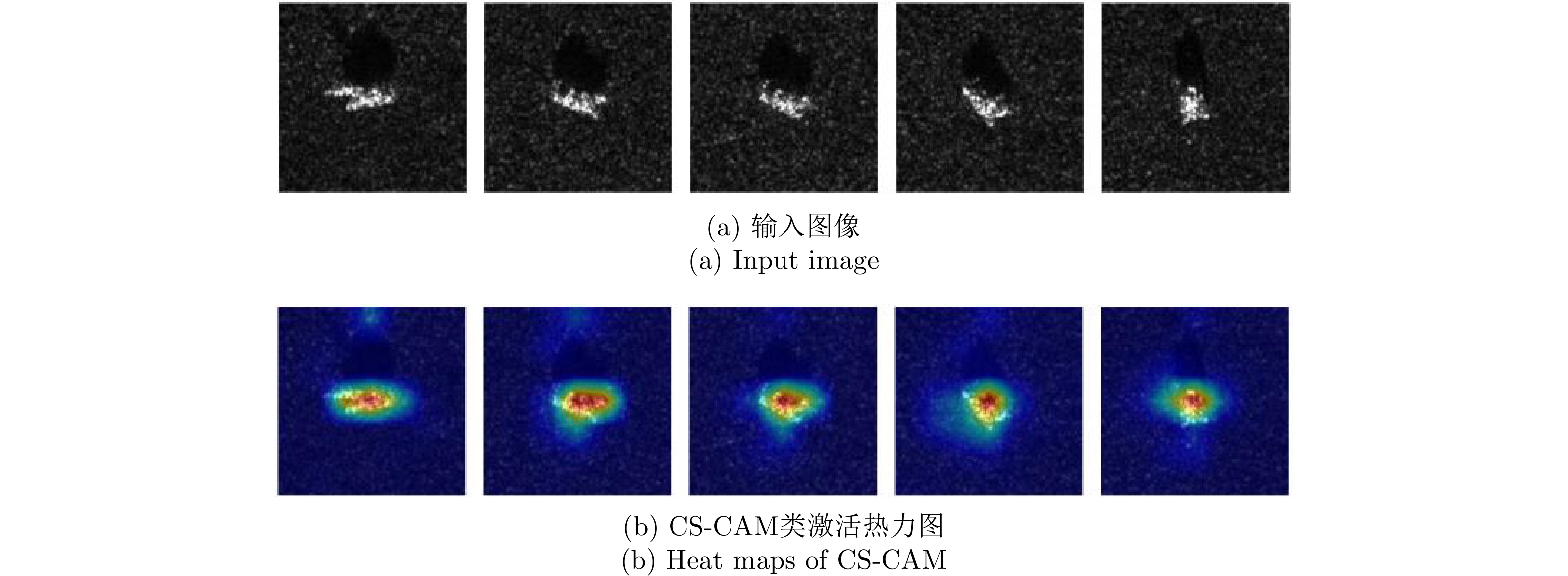
Convolutional Neural Network (CNN) is widely used for image target classifications in Synthetic Aperture Radar (SAR), but the lack of mechanism transparency prevents it from meeting the practical application requirements, such as high reliability and trustworthiness. The Class Activation Mapping (CAM) method is often used to visualize the decision region of the CNN model. However, existing methods are primarily based on either channel-level or space-level class activation weights, and their research progress is still in its infancy regarding more complex SAR image datasets. Based on this, this paper proposes a CNN model visualization method for SAR images, considering the feature extraction ability of neurons and their current network decisions. Initially, neuronal activation values are used to visualize the capability of neurons to learn a target structure in its corresponding receptive field. Further, a novel CAM-based method combined with channel-wise and spatial-wise weights is proposed, which can provide the foundation for the decision-making process of the trained CNN models by detecting the crucial areas in SAR images. Experimental results showed that this method provides interpretability analysis of the model under different settings and effectively expands the application of CNNs for SAR image visualization.
Convolutional Neural Network (CNN) is widely used for image target classifications in Synthetic Aperture Radar (SAR), but the lack of mechanism transparency prevents it from meeting the practical application requirements, such as high reliability and trustworthiness. The Class Activation Mapping (CAM) method is often used to visualize the decision region of the CNN model. However, existing methods are primarily based on either channel-level or space-level class activation weights, and their research progress is still in its infancy regarding more complex SAR image datasets. Based on this, this paper proposes a CNN model visualization method for SAR images, considering the feature extraction ability of neurons and their current network decisions. Initially, neuronal activation values are used to visualize the capability of neurons to learn a target structure in its corresponding receptive field. Further, a novel CAM-based method combined with channel-wise and spatial-wise weights is proposed, which can provide the foundation for the decision-making process of the trained CNN models by detecting the crucial areas in SAR images. Experimental results showed that this method provides interpretability analysis of the model under different settings and effectively expands the application of CNNs for SAR image visualization.







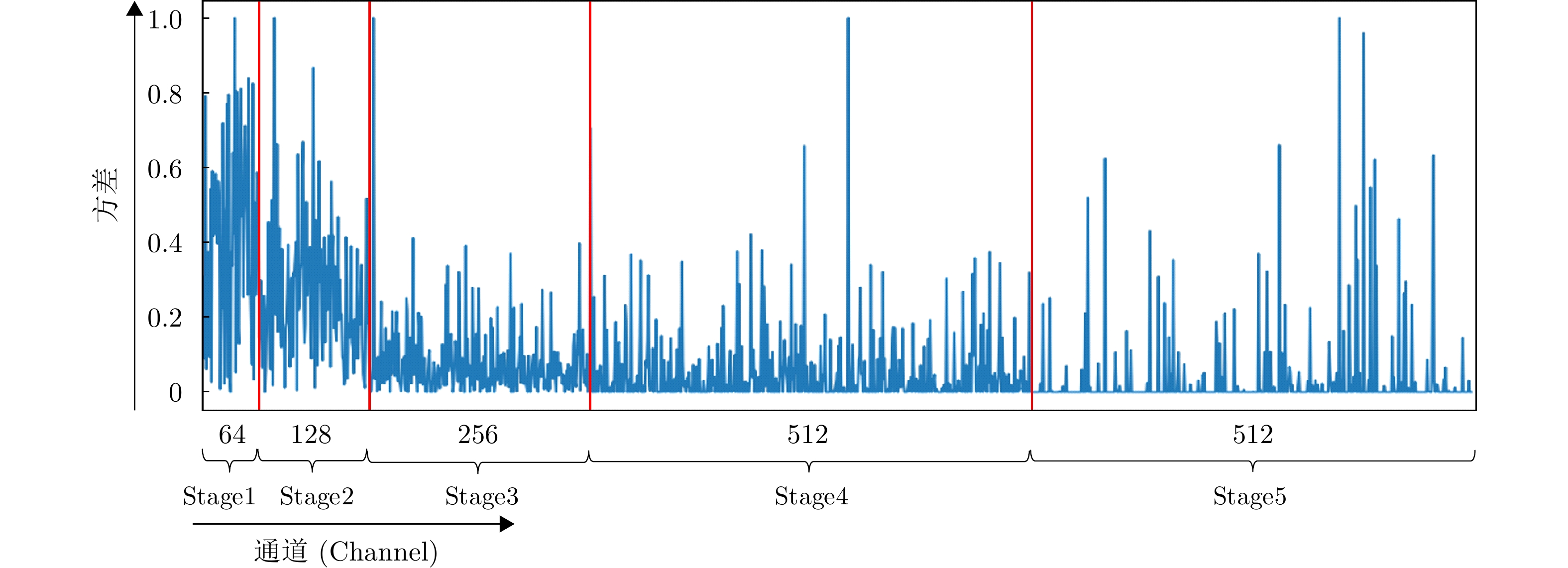



2024, 13(2): 374-395.
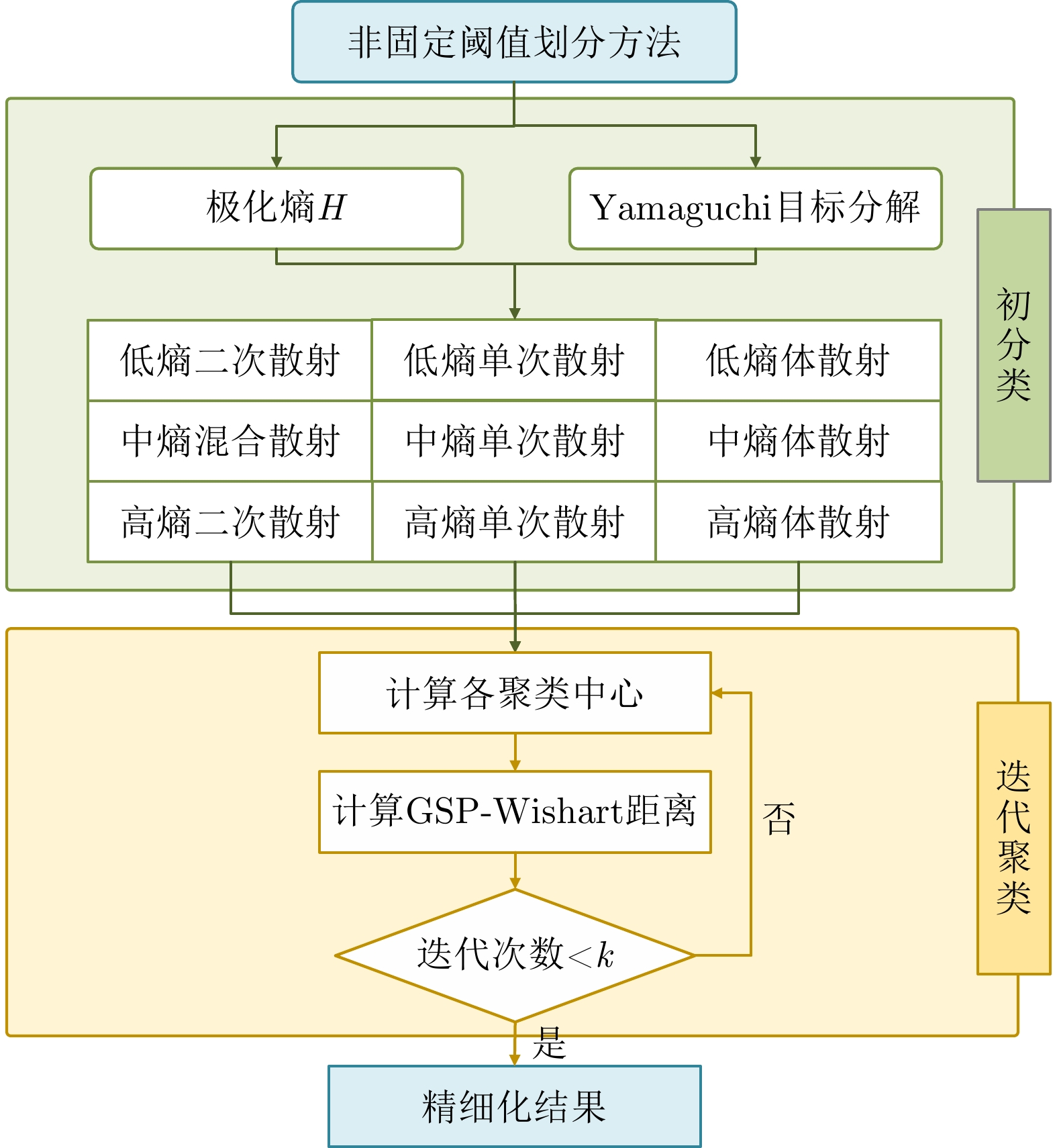
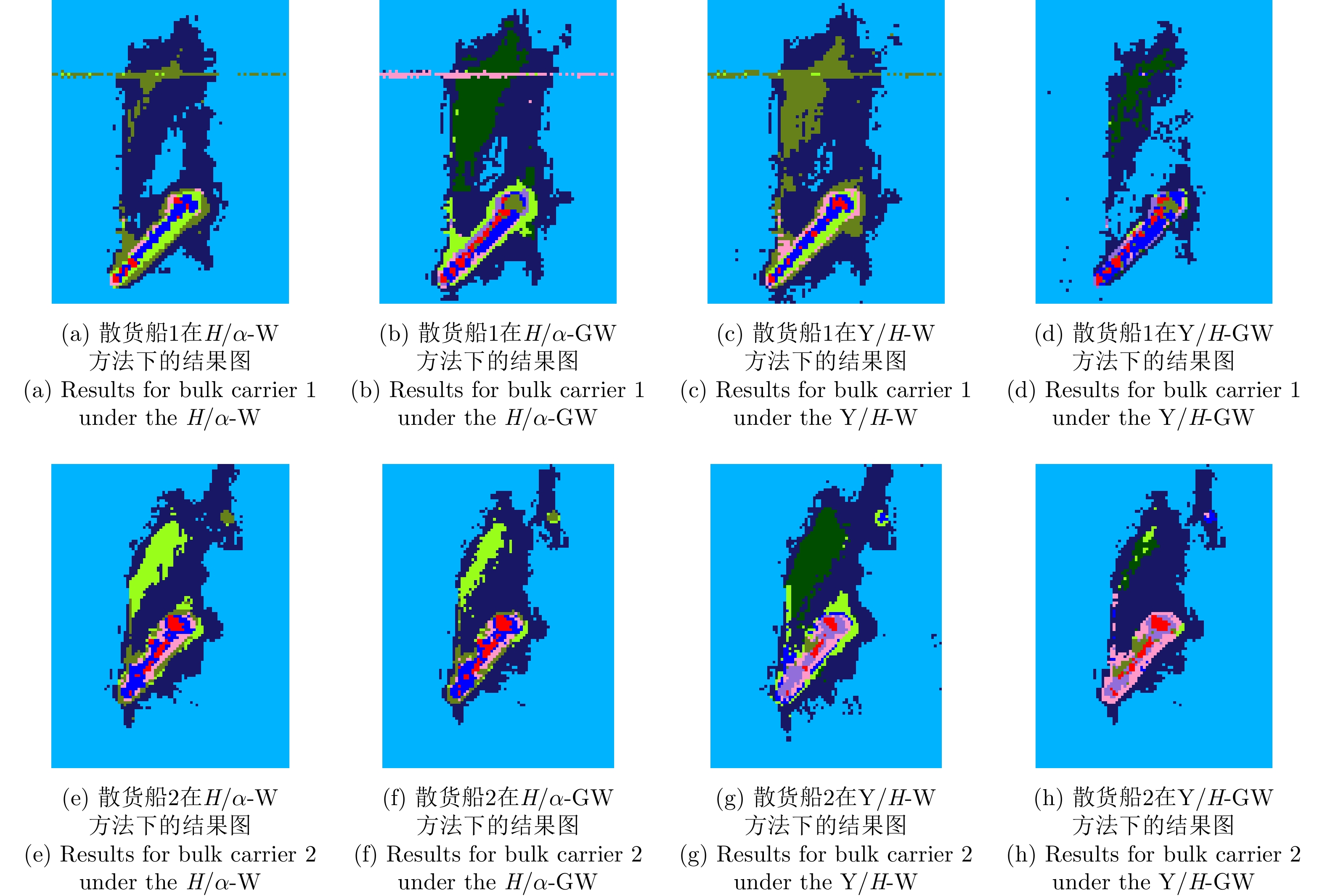
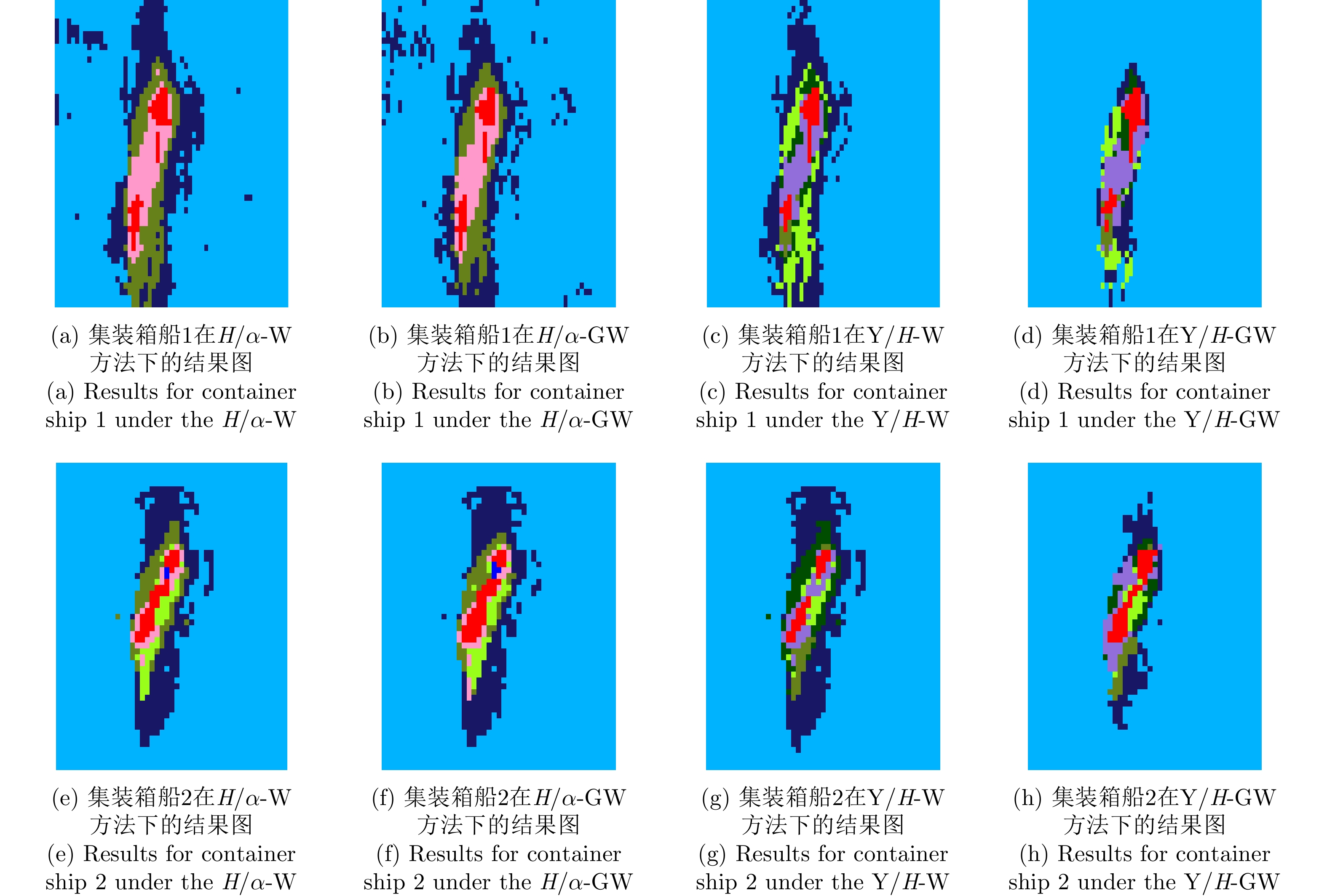
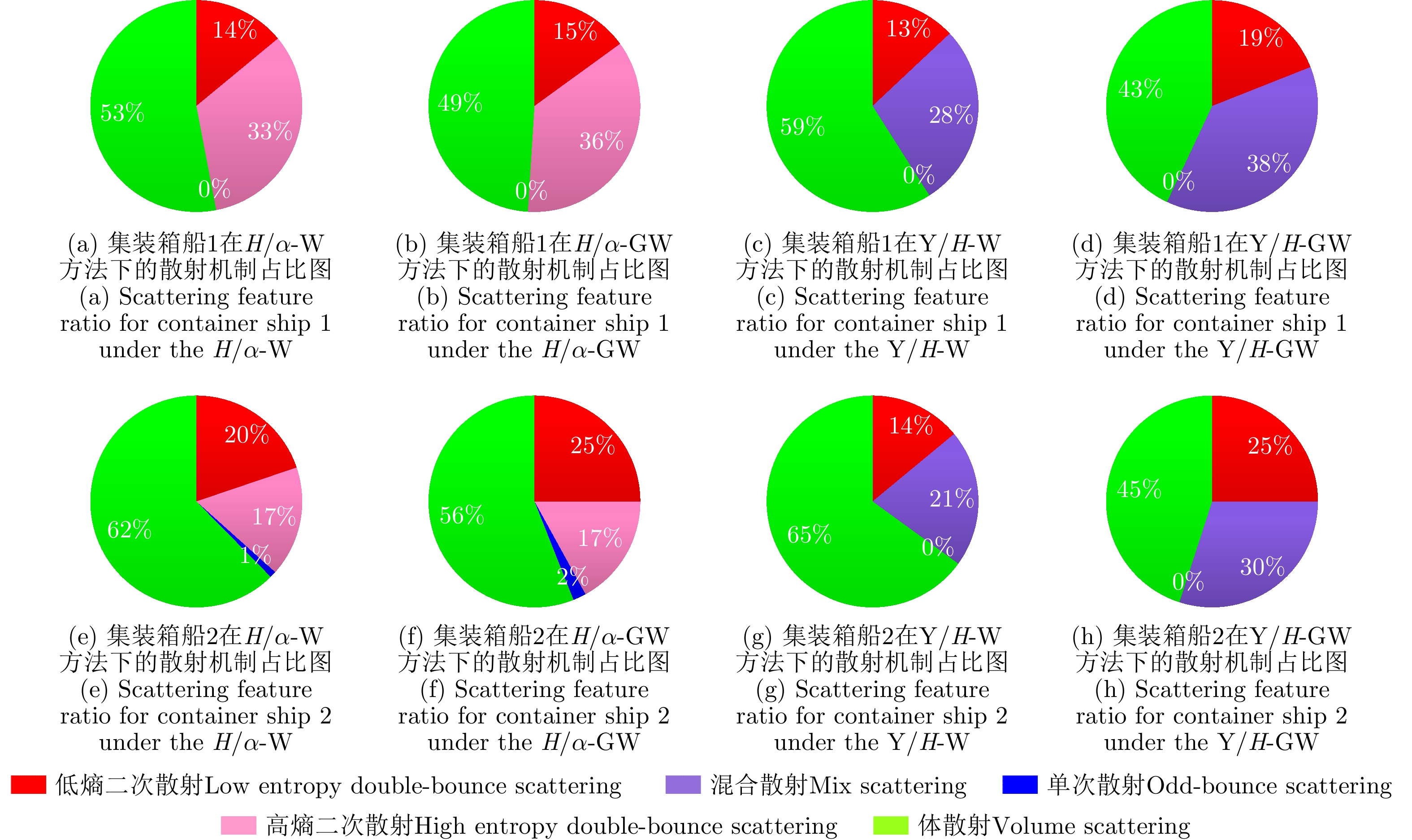
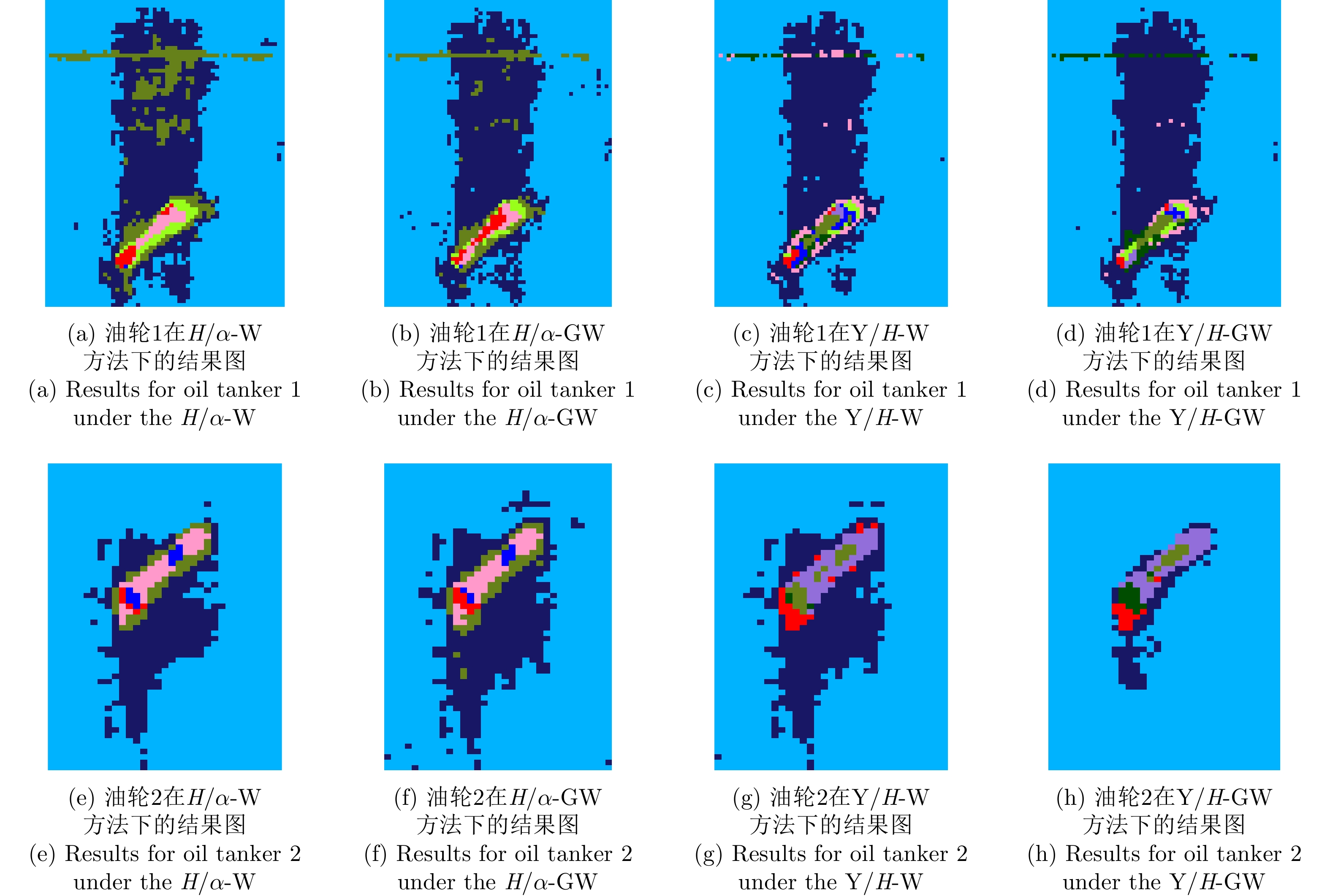
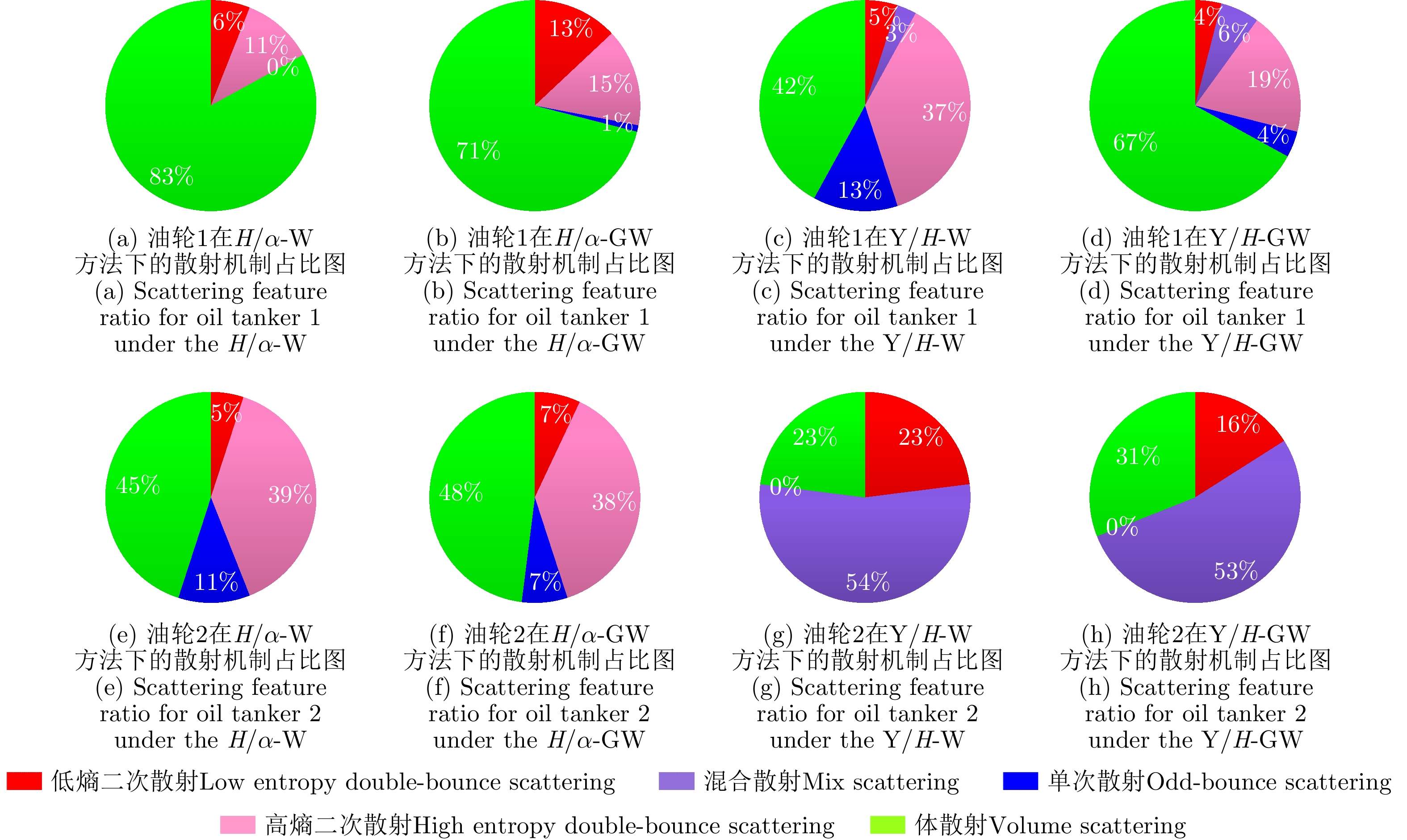
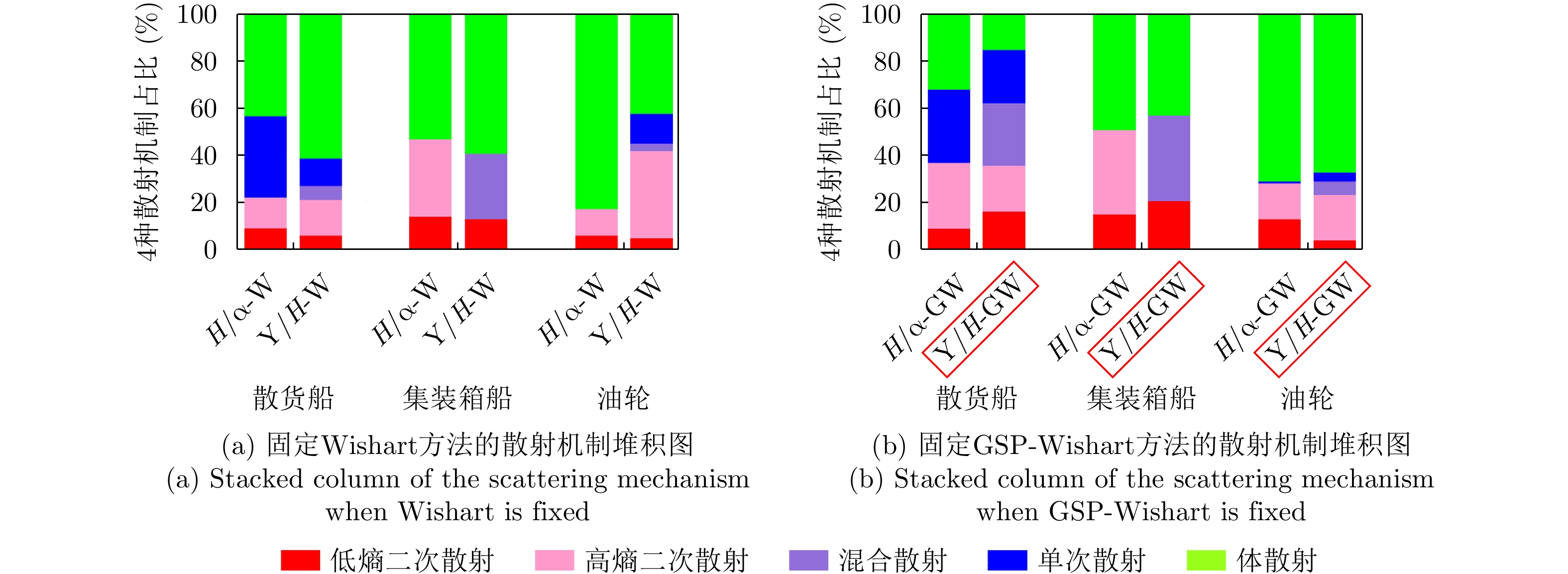
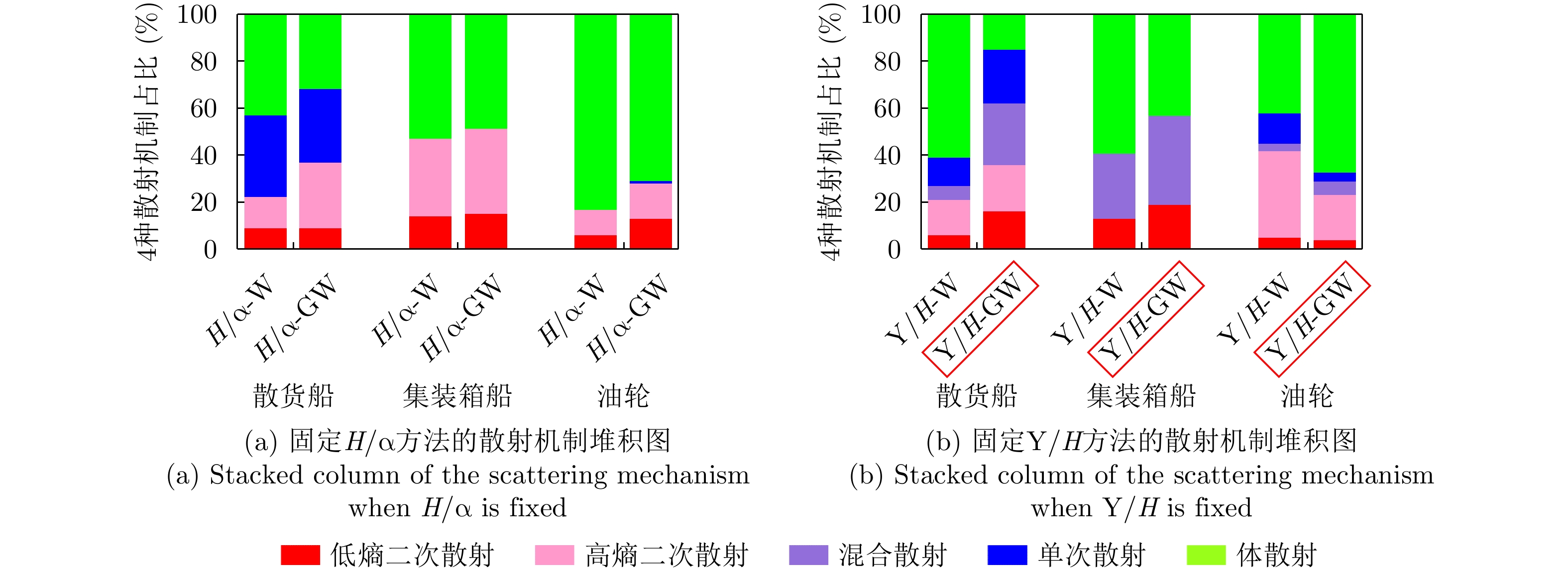
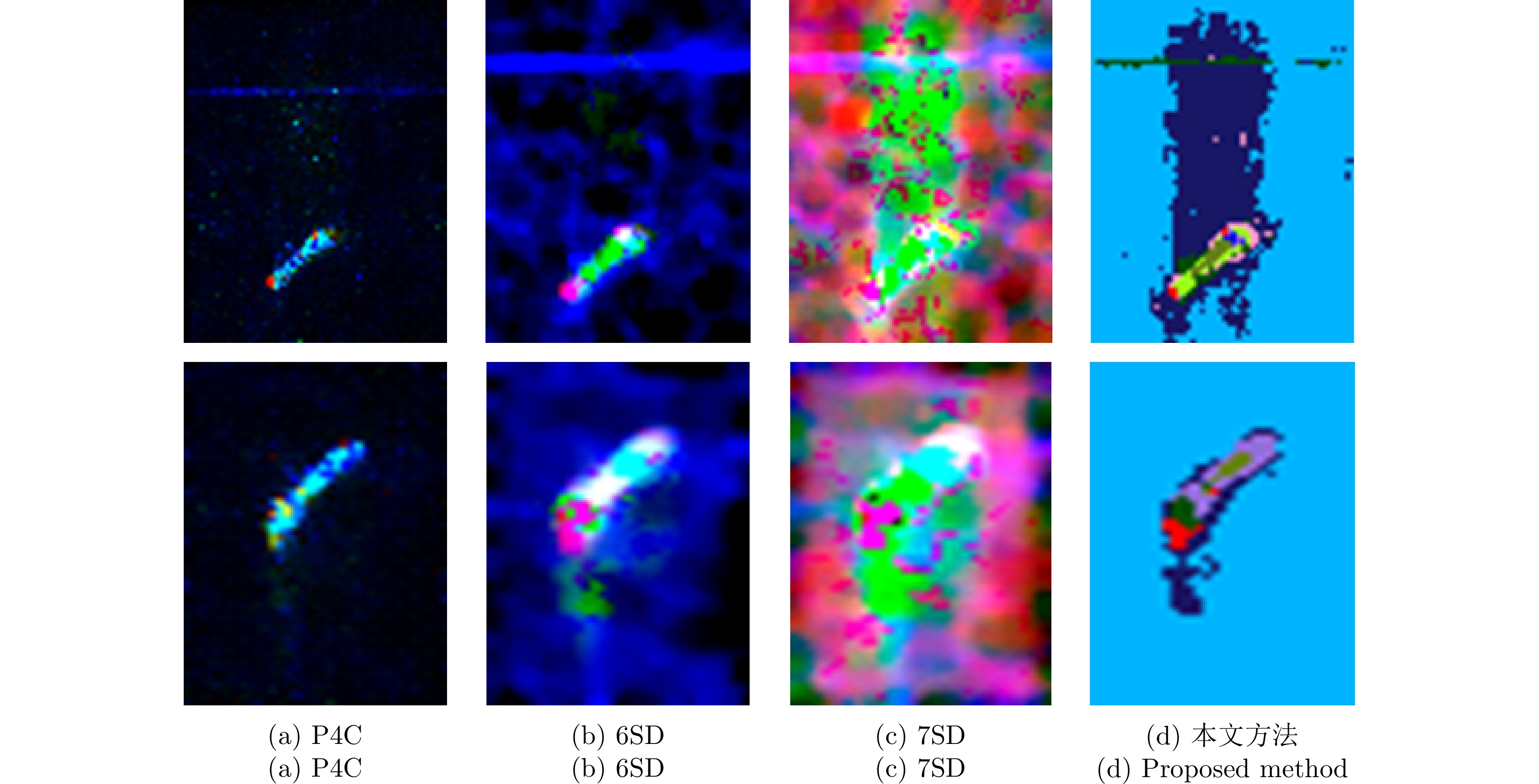
With advances in satellite technology, Polarimetric Synthetic Aperture Radar (PolSAR) now have higher resolution and better data quality, providing excellent data conditions for the refined visual interpretation of artificial targets. The primary method currently used is a multicomponent decomposition, but this method can result in pixel misdivision problems. Thus, we propose a non-fixed threshold division method for achieving advanced feature ship structure characterization in full-polarimetric SAR images. Yamaguchi decomposition can effectively identify the primary scattering mechanism and characterize artificial targets. Its modified volume scattering model is more consistent with actual data. The polarization entropy can serve as the target scattering mechanism at a specified equivalent point in the weakly depolarized state, which can effectively highlight the ship structure. This paper combines the three components of the Yamaguchi decomposition algorithm with the entropy, and divides it into a nine-classification plane with a non-fixed threshold. This method reduces category randomness generated by noise at the threshold boundary for complicated threshold treatments. Furthermore, the Mixed Scattering Mechanism (MSM) which is the region where both secondary scattering and single scattering are significant, was proposed to better match the scattering types of typical structures of vessels in the experiment. The Generalized Similarity Parameter (GSP) was used to further shorten the intra-class distance and perform iterative clustering using a modified GSP-Wishart classifier. This method improves the vessel distinguishability by enhancing the secondary and mixed scattering mechanisms. Finally, this paper uses full-polarimetric SAR data from a port in Shanghai, China, for the experiment. We collected and filtered ship information and optical data from this port through the Automatic Identification System (AIS) and matched them with the ships in full-polarimetric SAR images to verify the correct characterization of each vessel’s features. The experimental results show that the proposed method can effectively distinguish three types of vessels: bulk carriers, container ships and tankers.
With advances in satellite technology, Polarimetric Synthetic Aperture Radar (PolSAR) now have higher resolution and better data quality, providing excellent data conditions for the refined visual interpretation of artificial targets. The primary method currently used is a multicomponent decomposition, but this method can result in pixel misdivision problems. Thus, we propose a non-fixed threshold division method for achieving advanced feature ship structure characterization in full-polarimetric SAR images. Yamaguchi decomposition can effectively identify the primary scattering mechanism and characterize artificial targets. Its modified volume scattering model is more consistent with actual data. The polarization entropy can serve as the target scattering mechanism at a specified equivalent point in the weakly depolarized state, which can effectively highlight the ship structure. This paper combines the three components of the Yamaguchi decomposition algorithm with the entropy, and divides it into a nine-classification plane with a non-fixed threshold. This method reduces category randomness generated by noise at the threshold boundary for complicated threshold treatments. Furthermore, the Mixed Scattering Mechanism (MSM) which is the region where both secondary scattering and single scattering are significant, was proposed to better match the scattering types of typical structures of vessels in the experiment. The Generalized Similarity Parameter (GSP) was used to further shorten the intra-class distance and perform iterative clustering using a modified GSP-Wishart classifier. This method improves the vessel distinguishability by enhancing the secondary and mixed scattering mechanisms. Finally, this paper uses full-polarimetric SAR data from a port in Shanghai, China, for the experiment. We collected and filtered ship information and optical data from this port through the Automatic Identification System (AIS) and matched them with the ships in full-polarimetric SAR images to verify the correct characterization of each vessel’s features. The experimental results show that the proposed method can effectively distinguish three types of vessels: bulk carriers, container ships and tankers.












2024, 13(2): 396-410.
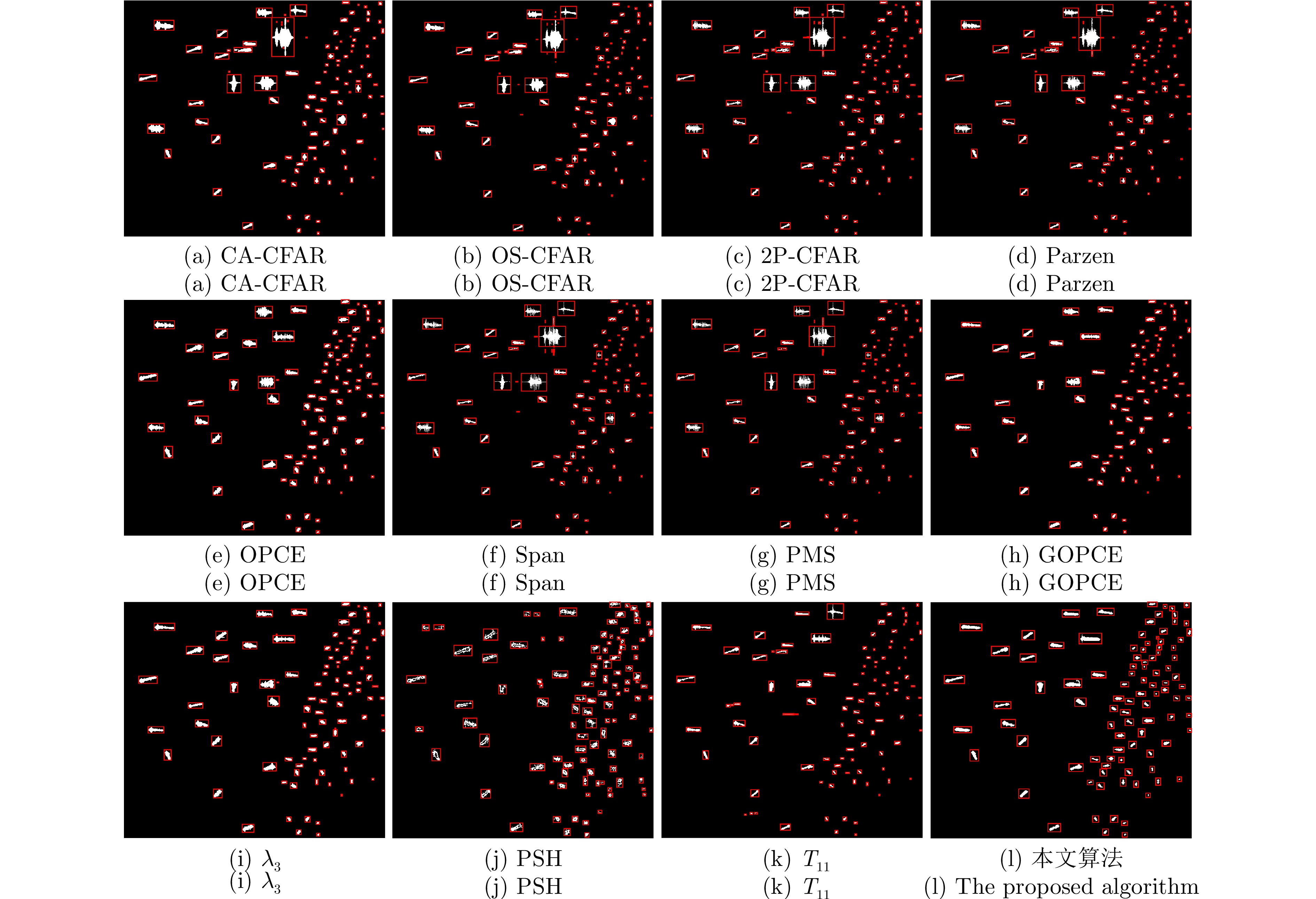
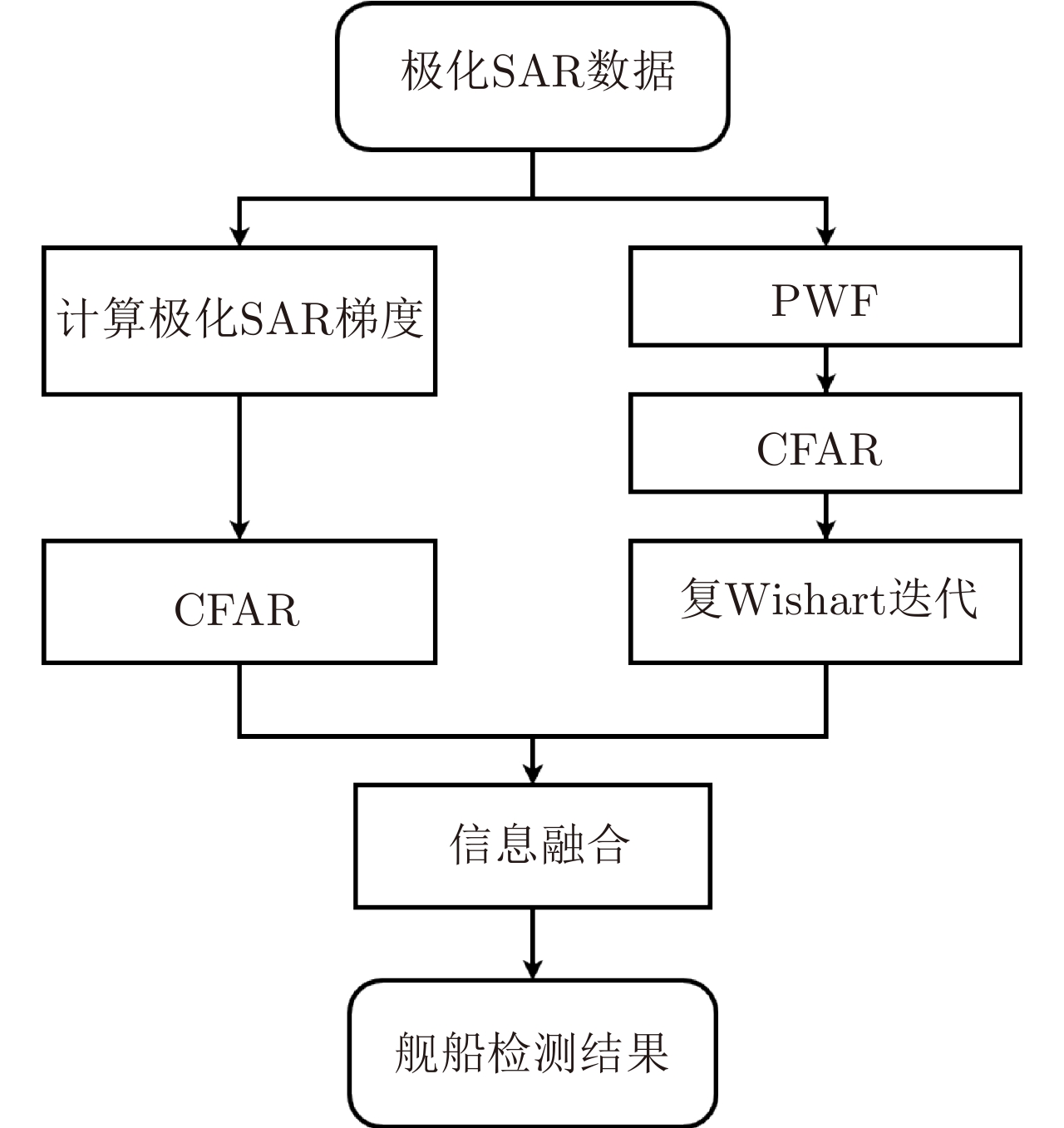
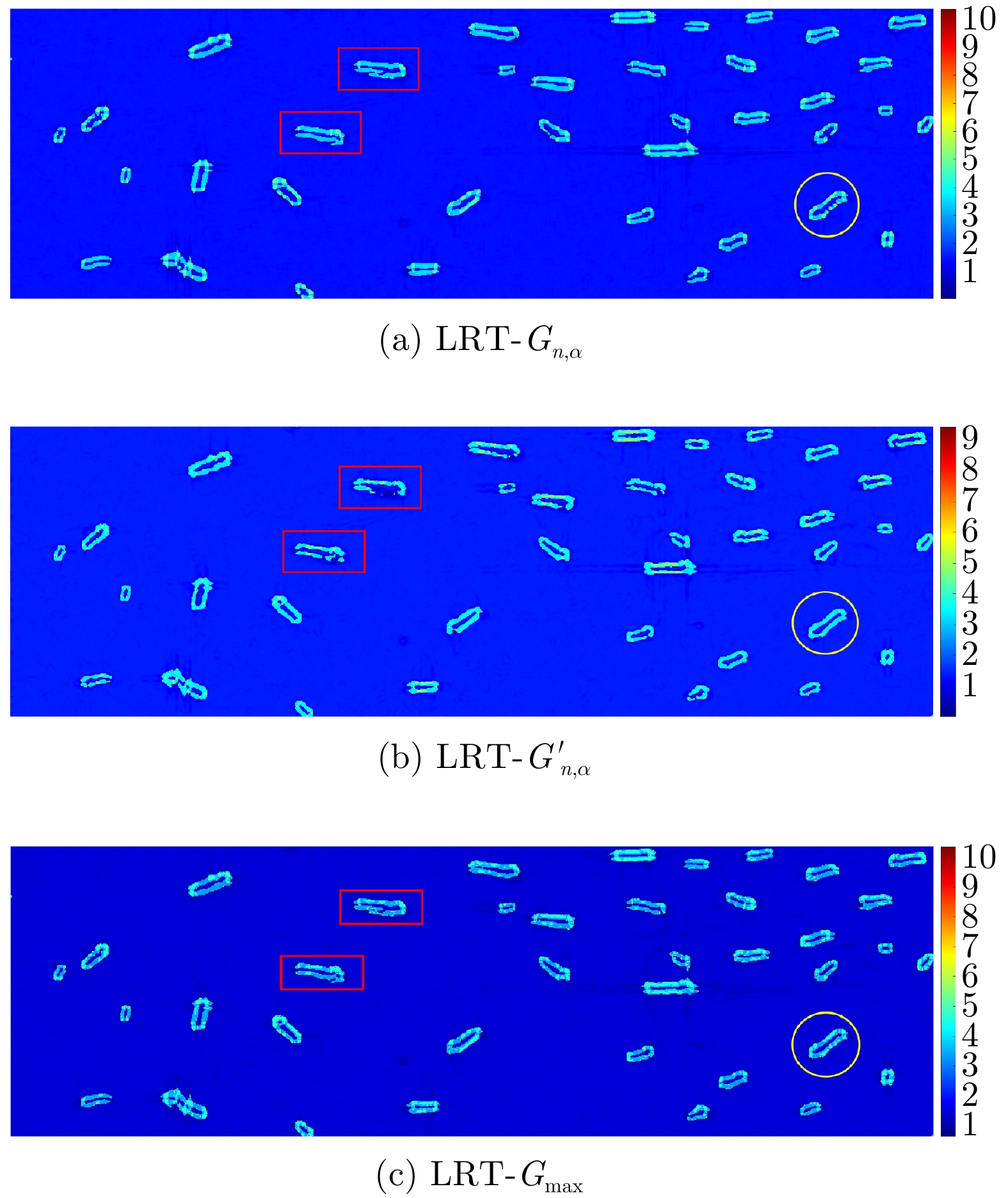
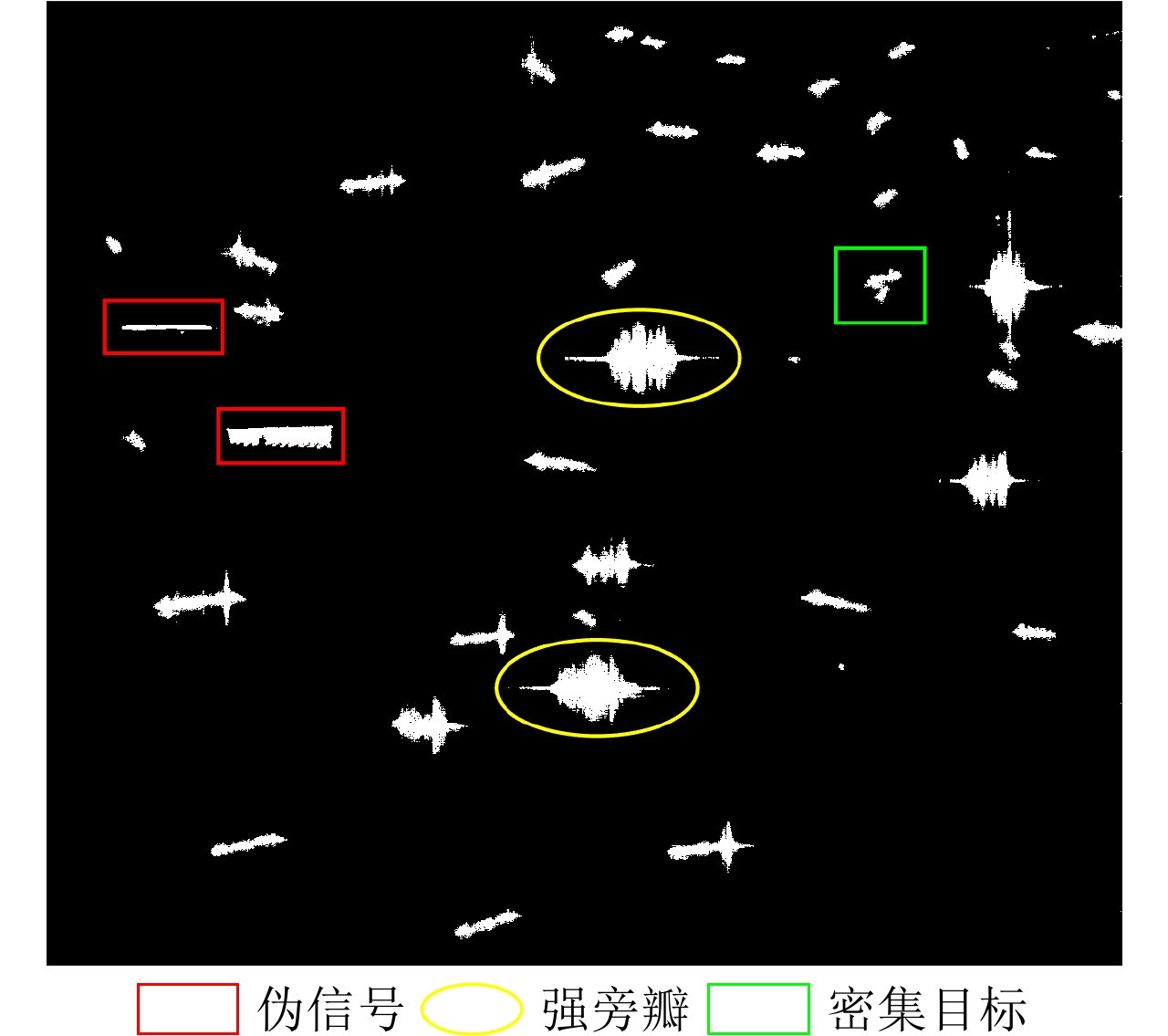
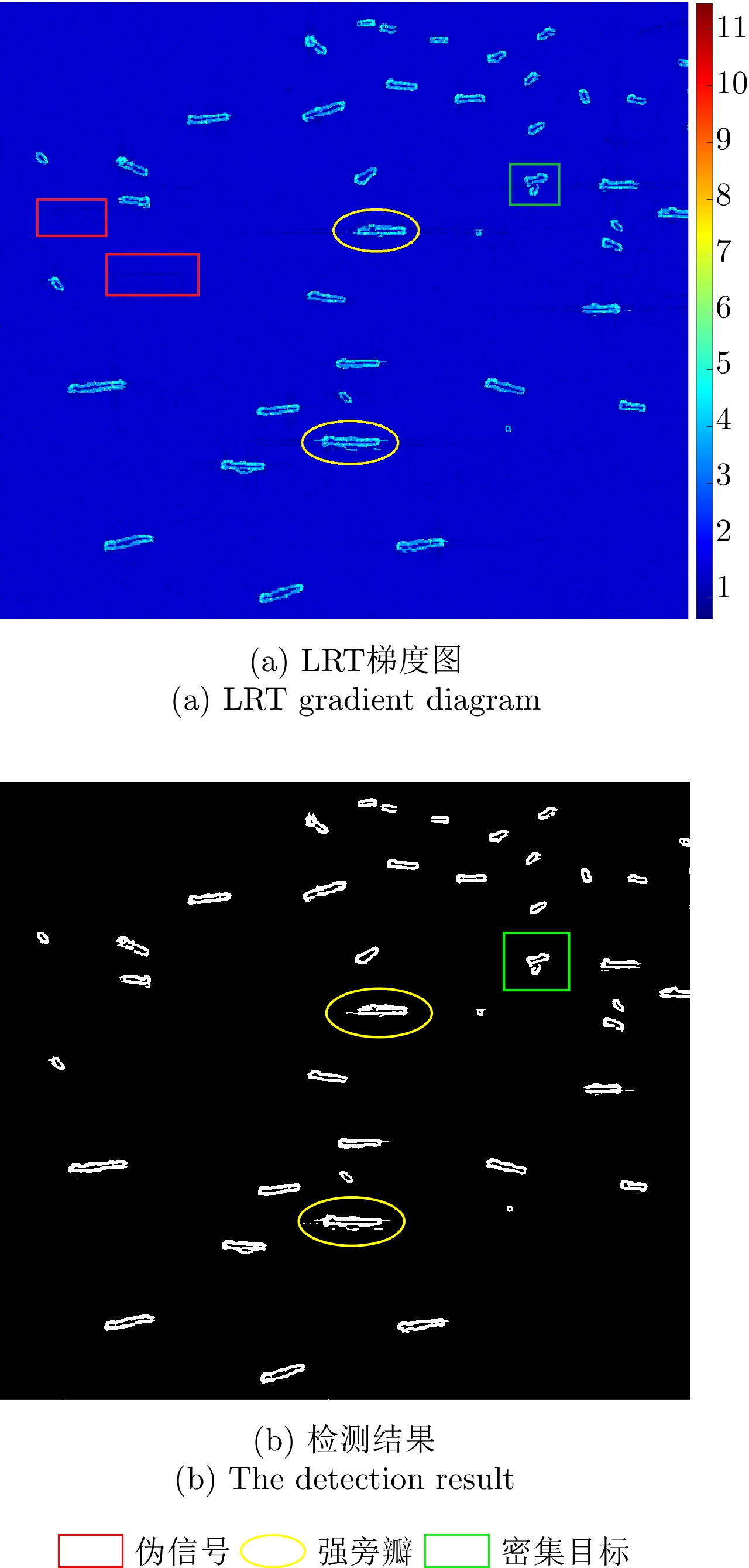
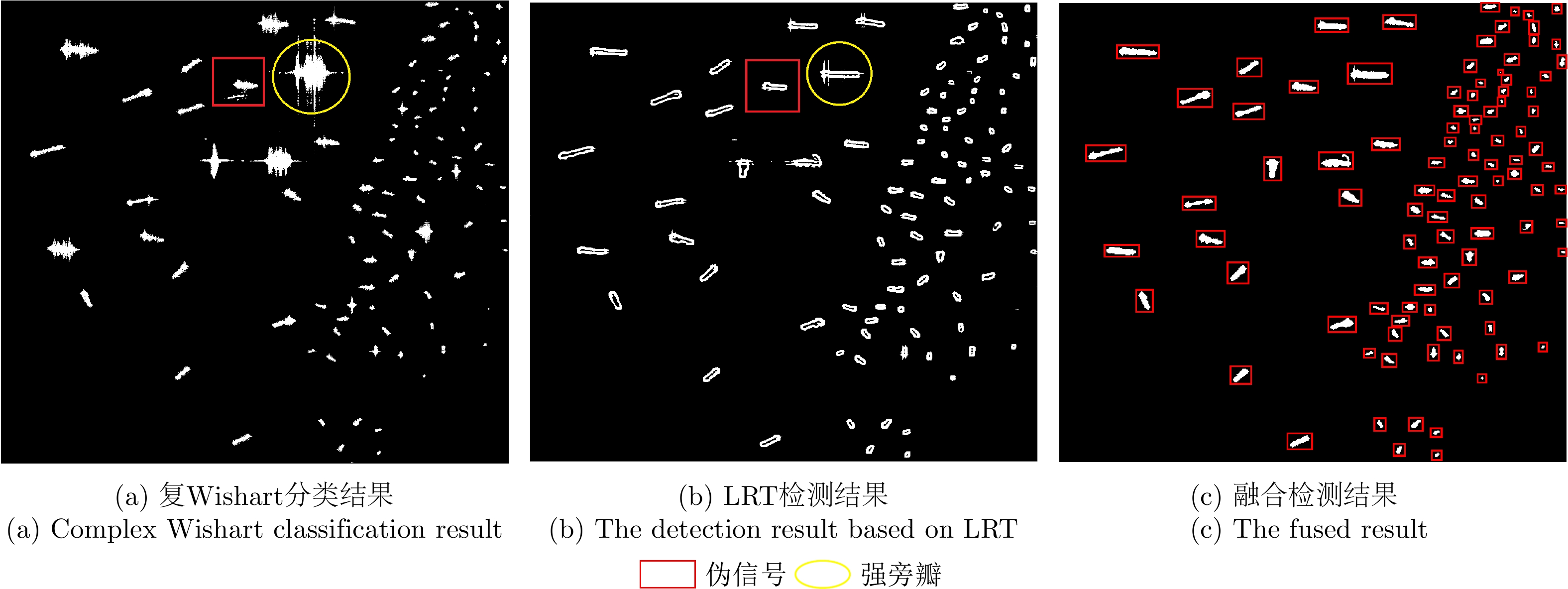
Ship detection is one of the most important applications of polarimetric Synthetic Aperture Radar (SAR) systems. Current ship detection methods are susceptible to side flap interference, making it difficult to extract the target shape correctly. In addition, when ships are exceedingly dense and have different scales, adjacent ships may be considered as a single target because of the influence of strong sidelobes, causing missed detections. To address the issues of sidelobe interference and multi-scale dense ship detection, a ship detection method based on the polarimetric SAR gradient and the complex Wishart classifier is proposed. First, the Likelihood Ratio Test (LRT) gradient is introduced into the log-ratio gradient framework to apply it to the polarimetric SAR data. Then, a Constant False Alarm Rate (CFAR) detector is applied to the gradient image to map the ship boundaries accurately. Second, the complex Wishart iterative classifier is used to detect the strong scattering part of the ship, which can eliminate most clutter interference and maintain the ship’s shape details. Finally, the LRT detection and complex Wishart classifier detection results are fused. Thus, not only the strong sidelobe interference can be greatly suppressed, but the dense targets with different scales are also distinguished and accurately located. This study performs comparative experiments on three polarimetric SAR images from the ALOS-2 satellite. Experimental results show that compared with the existing methods, the proposed algorithm has fewer false alarms and missed detections and can effectively overcome the problems of sidelobe interference while maintaining the shape details.
Ship detection is one of the most important applications of polarimetric Synthetic Aperture Radar (SAR) systems. Current ship detection methods are susceptible to side flap interference, making it difficult to extract the target shape correctly. In addition, when ships are exceedingly dense and have different scales, adjacent ships may be considered as a single target because of the influence of strong sidelobes, causing missed detections. To address the issues of sidelobe interference and multi-scale dense ship detection, a ship detection method based on the polarimetric SAR gradient and the complex Wishart classifier is proposed. First, the Likelihood Ratio Test (LRT) gradient is introduced into the log-ratio gradient framework to apply it to the polarimetric SAR data. Then, a Constant False Alarm Rate (CFAR) detector is applied to the gradient image to map the ship boundaries accurately. Second, the complex Wishart iterative classifier is used to detect the strong scattering part of the ship, which can eliminate most clutter interference and maintain the ship’s shape details. Finally, the LRT detection and complex Wishart classifier detection results are fused. Thus, not only the strong sidelobe interference can be greatly suppressed, but the dense targets with different scales are also distinguished and accurately located. This study performs comparative experiments on three polarimetric SAR images from the ALOS-2 satellite. Experimental results show that compared with the existing methods, the proposed algorithm has fewer false alarms and missed detections and can effectively overcome the problems of sidelobe interference while maintaining the shape details.












2024, 13(2): 411-427.
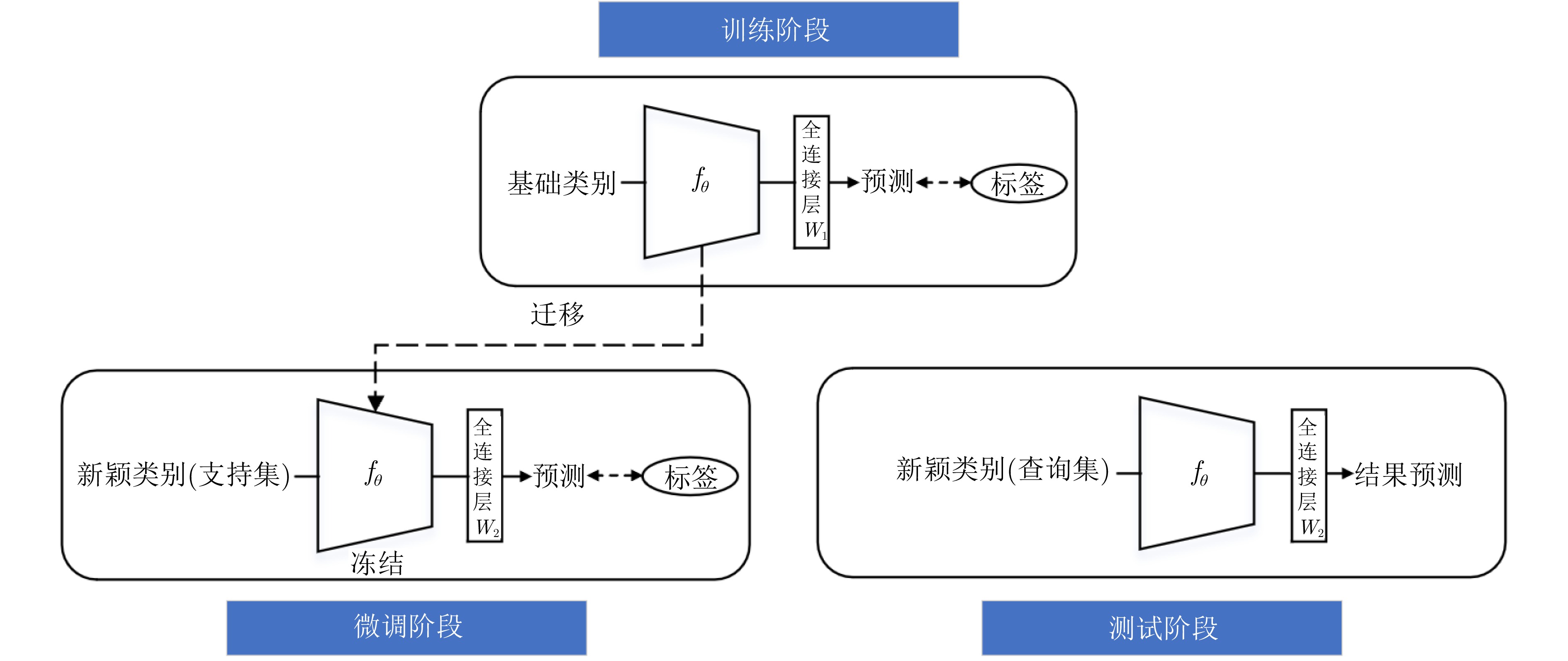
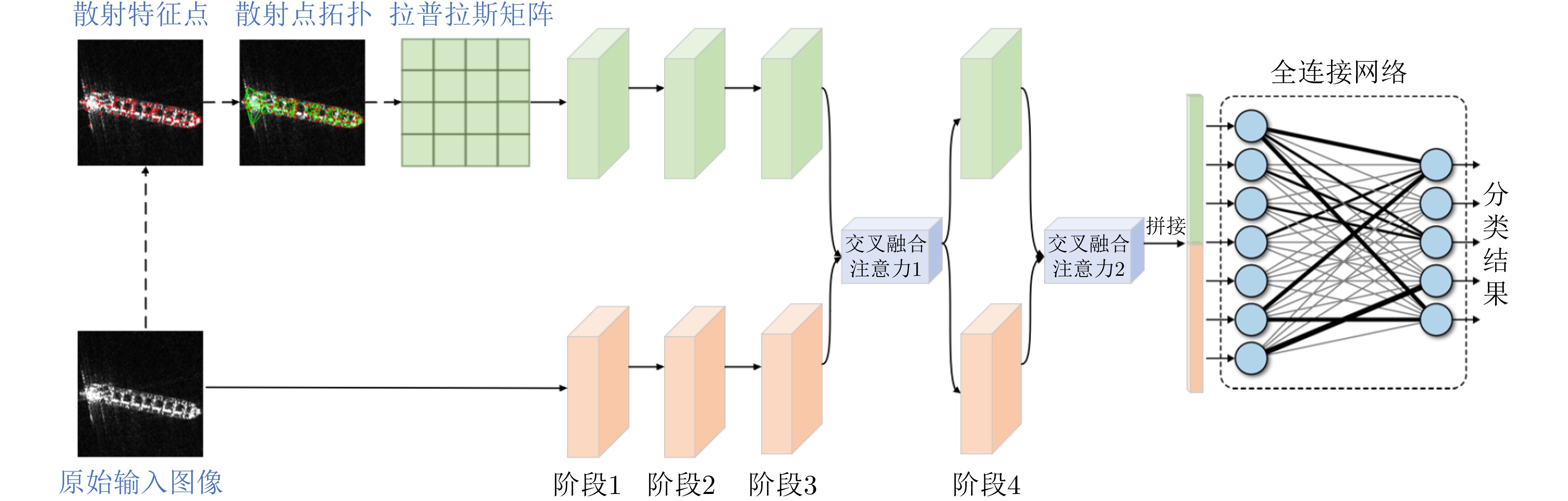
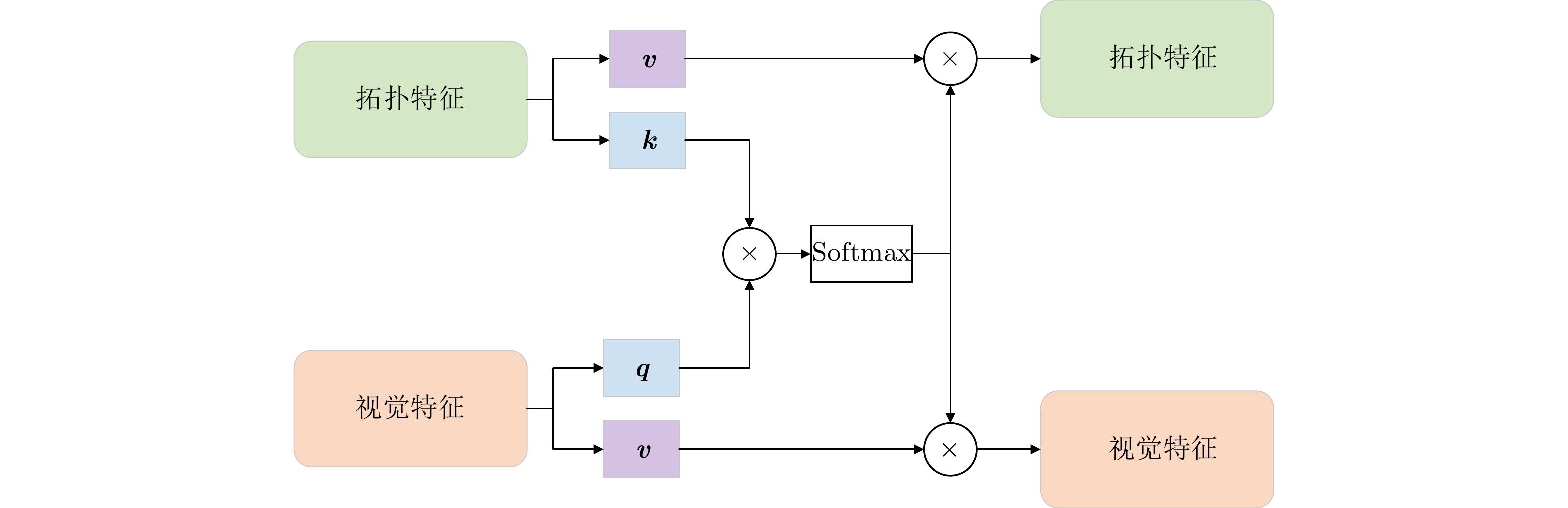
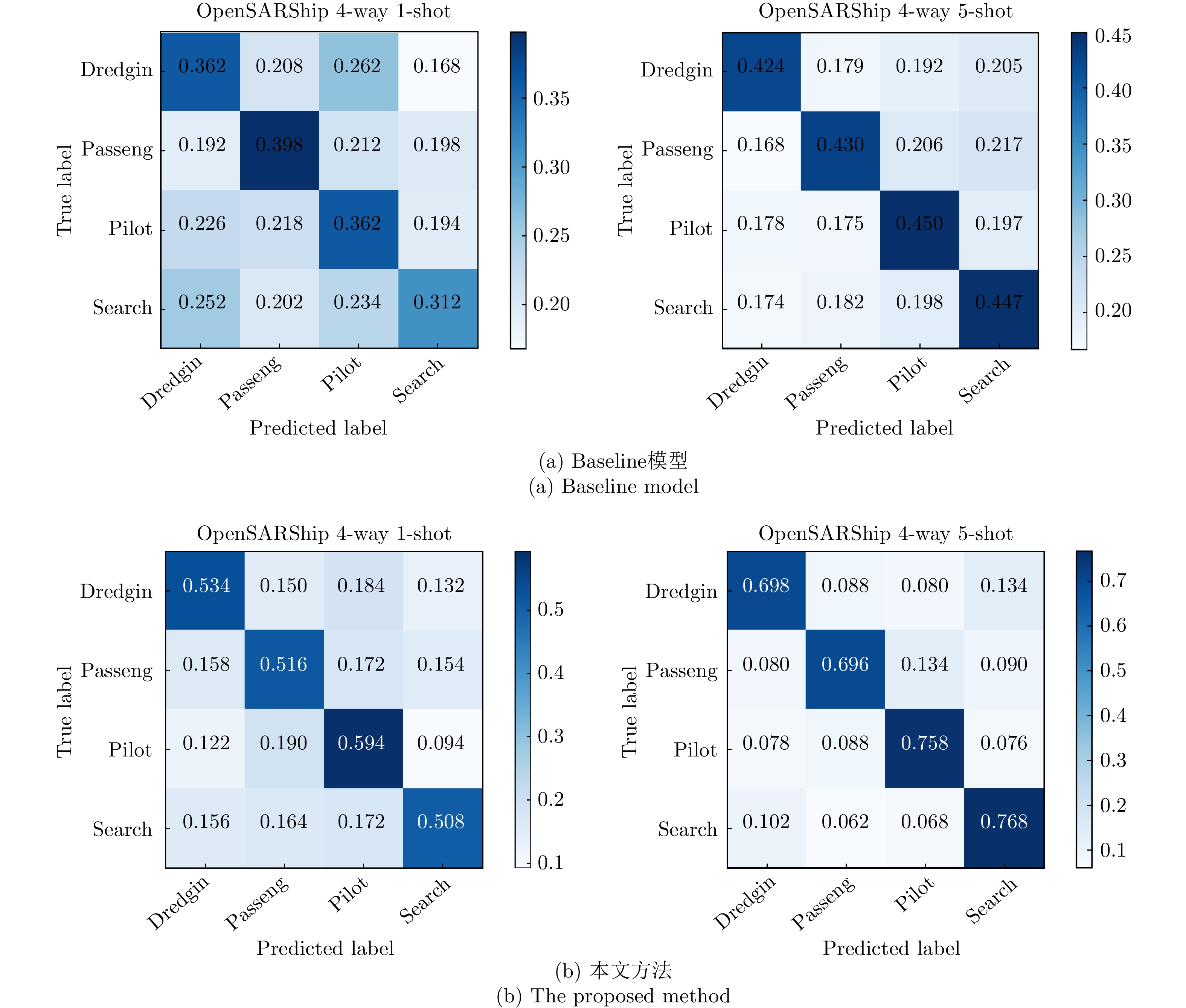
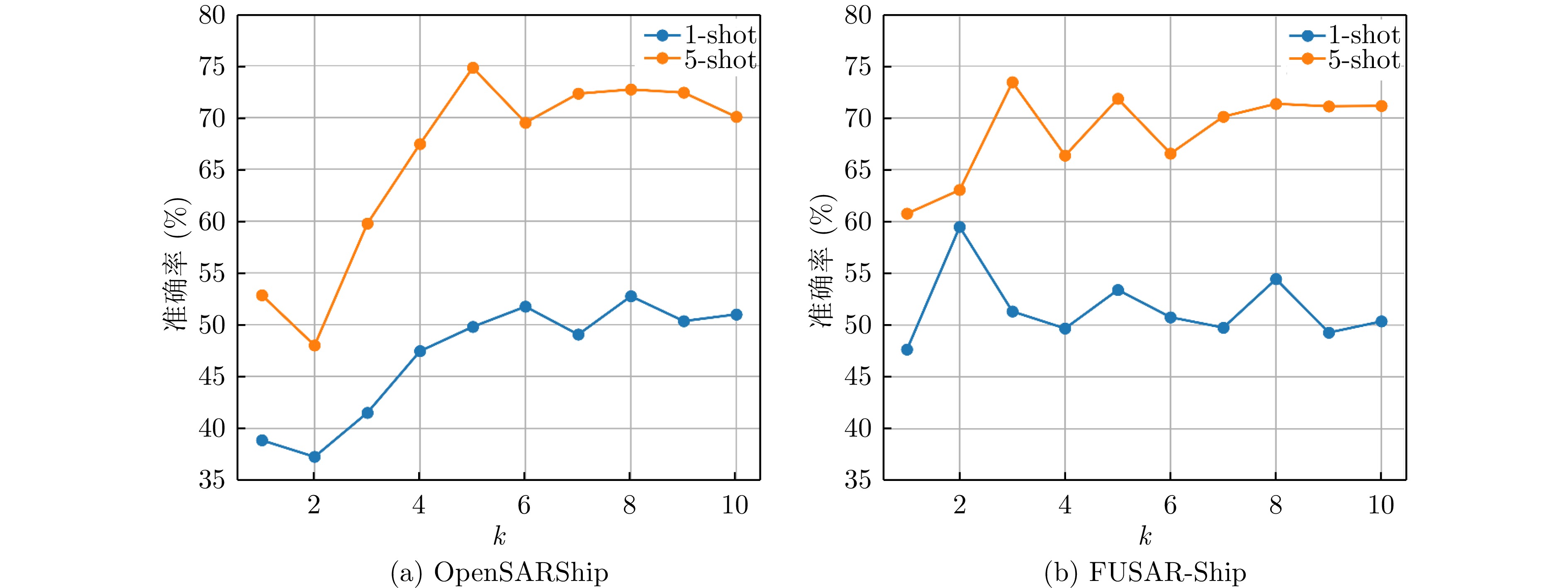
With the widespread application of Synthetic Aperture Radar (SAR) images in ship detection and recognition, accurate and efficient ship classification has become an urgent issue that needs to be addressed. In few-shot learning, conventional methods often suffer from limited generalization capabilities. Herein, additional information and features are introduced to enhance the understanding and generalization capabilities of the model for targets. To address this challenge, this study proposes a few-shot ship classification method for SAR images based on scattering point topology and Dual-Branch Convolutional Neural Network (DB-CNN). First, a topology structure was constructed using scattering key points to characterize the structural and shape features of ship targets. Second, the Laplacian matrix of the topology structure was calculated to transform the topological relations between scattering points into a matrix form. Finally, the original image and Laplacian matrix were used as inputs to the DB-CNN for feature extraction. Regarding network architecture, a DB-CNN comprising two independent convolution branches was designed. These branches were tasked with processing visual and topological features, employing two cross-fusion attention modules to collaboratively merge features from both branches. This approach effectively integrates the topological relations of target scattering points into the automated learning process of the network, enhancing the generalization capabilities and enhancing the classification accuracy of the model. Experimental results demonstrated that the proposed approach obtained average accuracies of 53.80% and 73.00% in 1-shot and 5-shot tasks, respectively, on the OpenSARShip dataset. Similarly, on the FUSAR-Ship dataset, it achieved average accuracies of 54.44% and 71.36% in 1-shot and 5-shot tasks, respectively. In the case of both 1-shot and 5-shot tasks, the proposed approach outperformed the baseline by >15% in terms of accuracy, underscoring the effectiveness of incorporating scattering point topology in few-shot ship classification of SAR images.
With the widespread application of Synthetic Aperture Radar (SAR) images in ship detection and recognition, accurate and efficient ship classification has become an urgent issue that needs to be addressed. In few-shot learning, conventional methods often suffer from limited generalization capabilities. Herein, additional information and features are introduced to enhance the understanding and generalization capabilities of the model for targets. To address this challenge, this study proposes a few-shot ship classification method for SAR images based on scattering point topology and Dual-Branch Convolutional Neural Network (DB-CNN). First, a topology structure was constructed using scattering key points to characterize the structural and shape features of ship targets. Second, the Laplacian matrix of the topology structure was calculated to transform the topological relations between scattering points into a matrix form. Finally, the original image and Laplacian matrix were used as inputs to the DB-CNN for feature extraction. Regarding network architecture, a DB-CNN comprising two independent convolution branches was designed. These branches were tasked with processing visual and topological features, employing two cross-fusion attention modules to collaboratively merge features from both branches. This approach effectively integrates the topological relations of target scattering points into the automated learning process of the network, enhancing the generalization capabilities and enhancing the classification accuracy of the model. Experimental results demonstrated that the proposed approach obtained average accuracies of 53.80% and 73.00% in 1-shot and 5-shot tasks, respectively, on the OpenSARShip dataset. Similarly, on the FUSAR-Ship dataset, it achieved average accuracies of 54.44% and 71.36% in 1-shot and 5-shot tasks, respectively. In the case of both 1-shot and 5-shot tasks, the proposed approach outperformed the baseline by >15% in terms of accuracy, underscoring the effectiveness of incorporating scattering point topology in few-shot ship classification of SAR images.




2024, 13(2): 428-442.
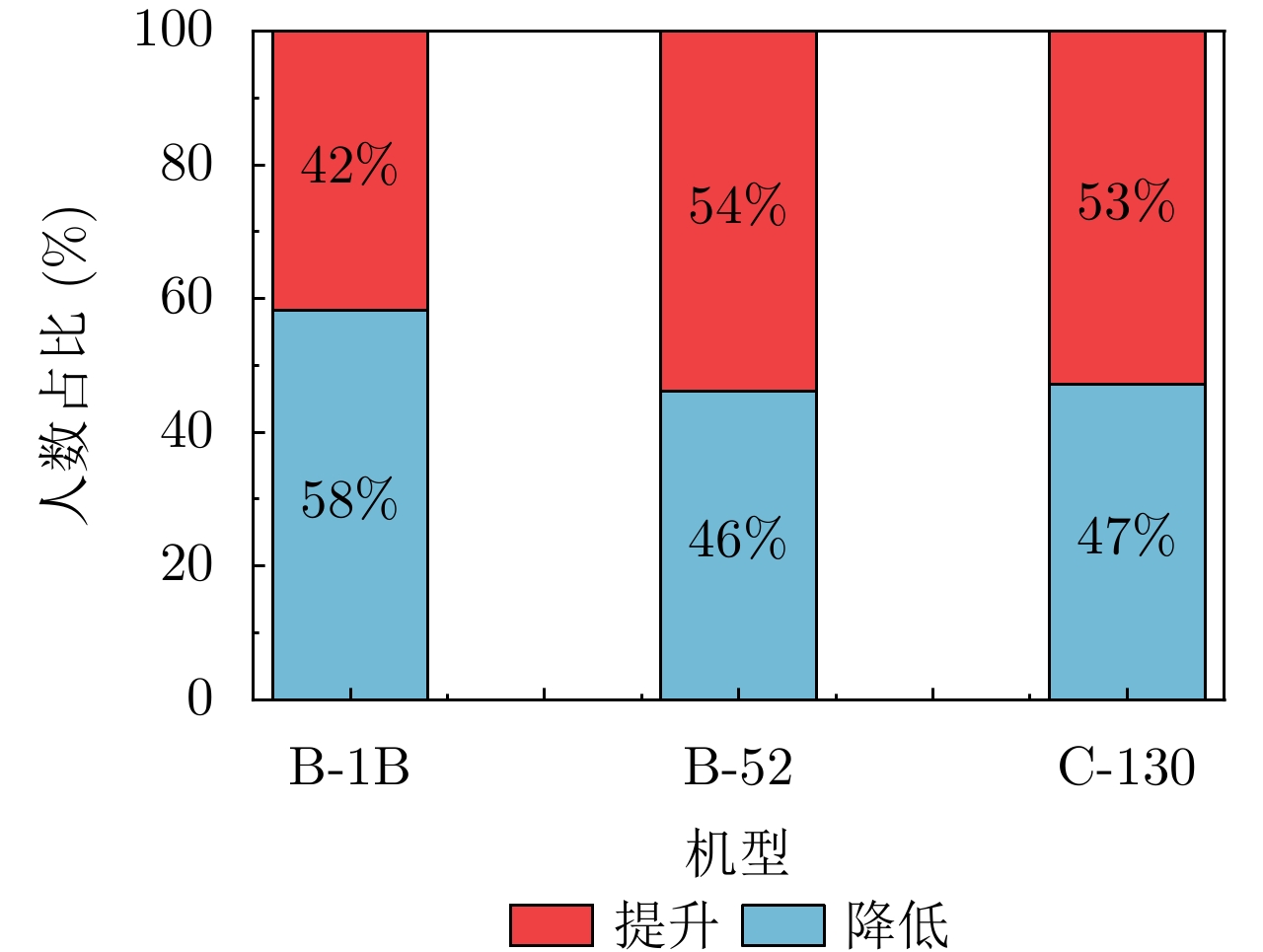
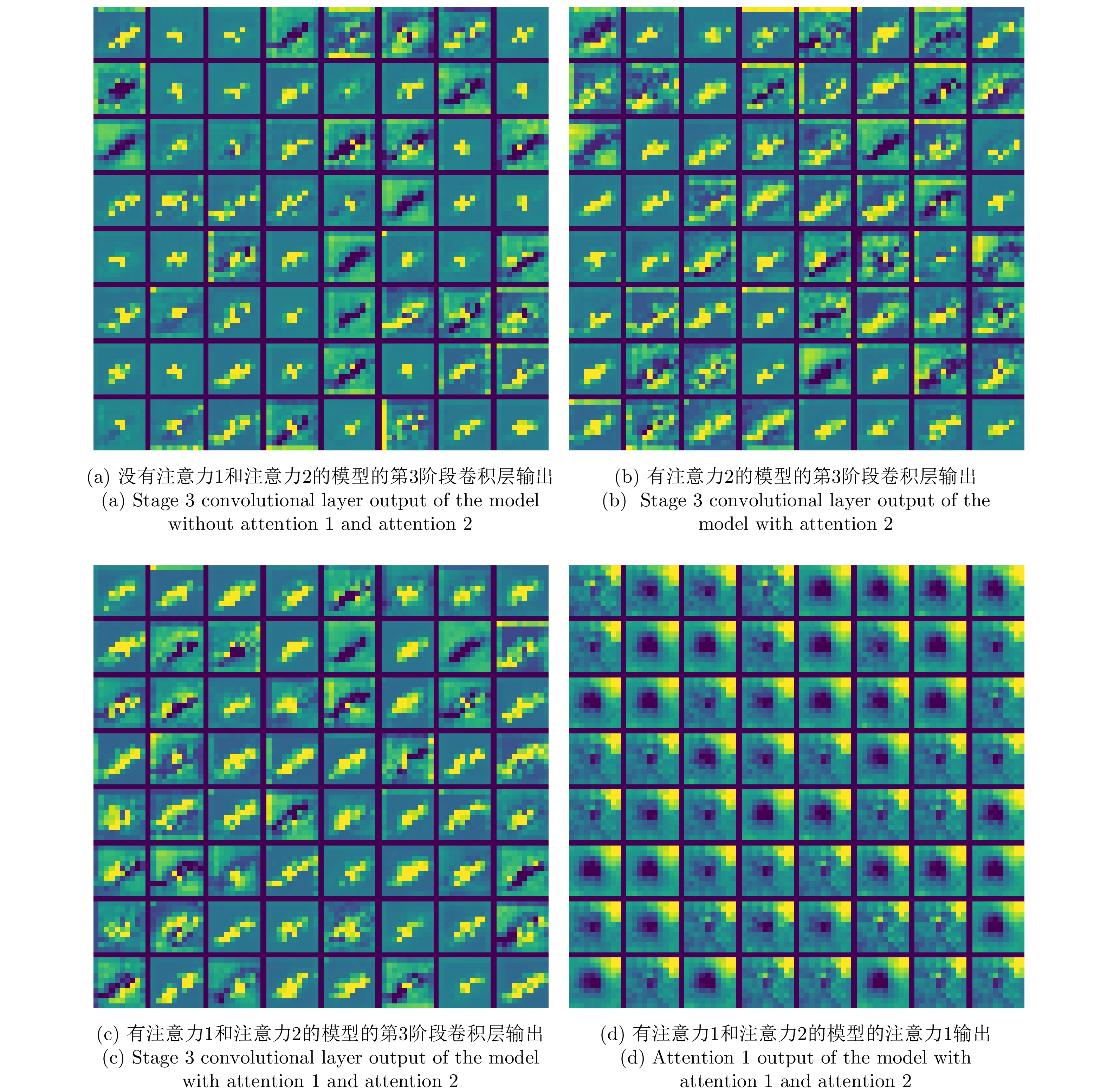
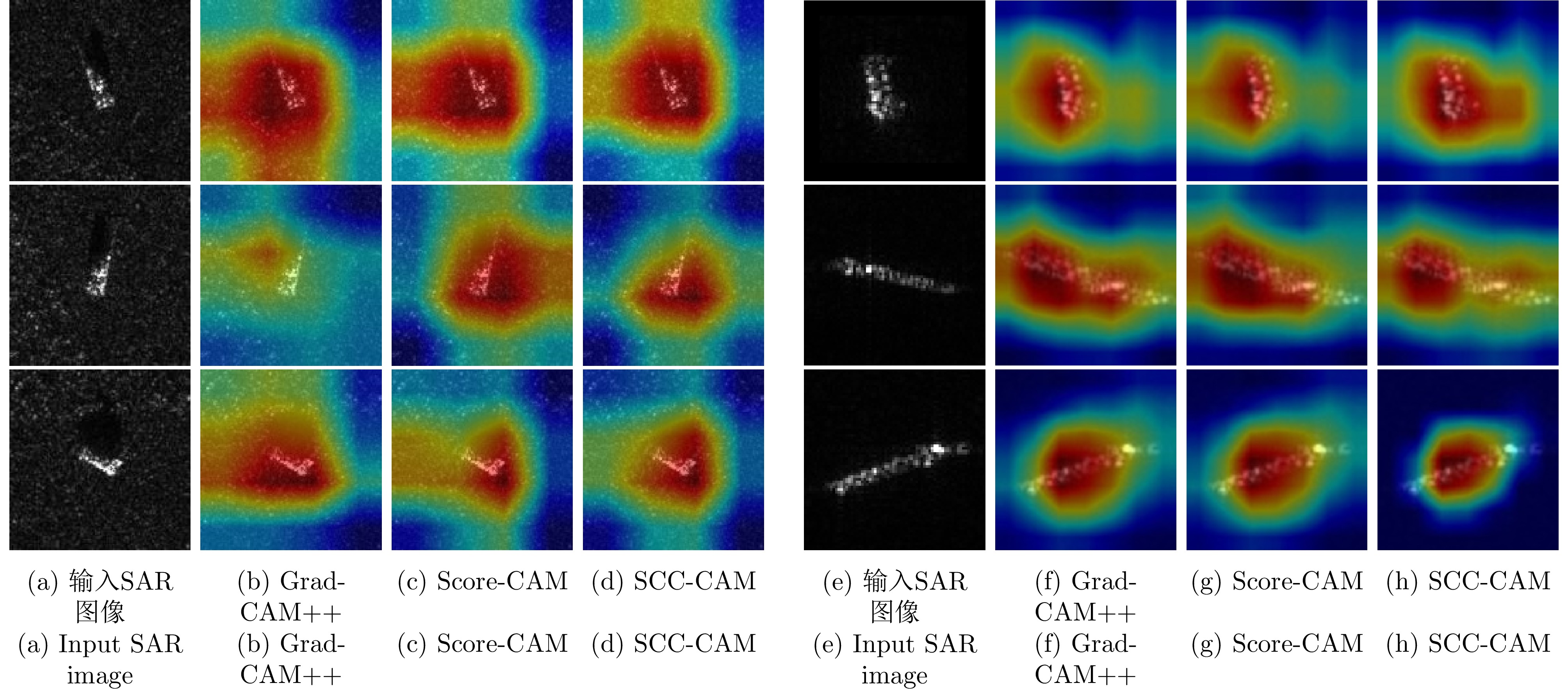
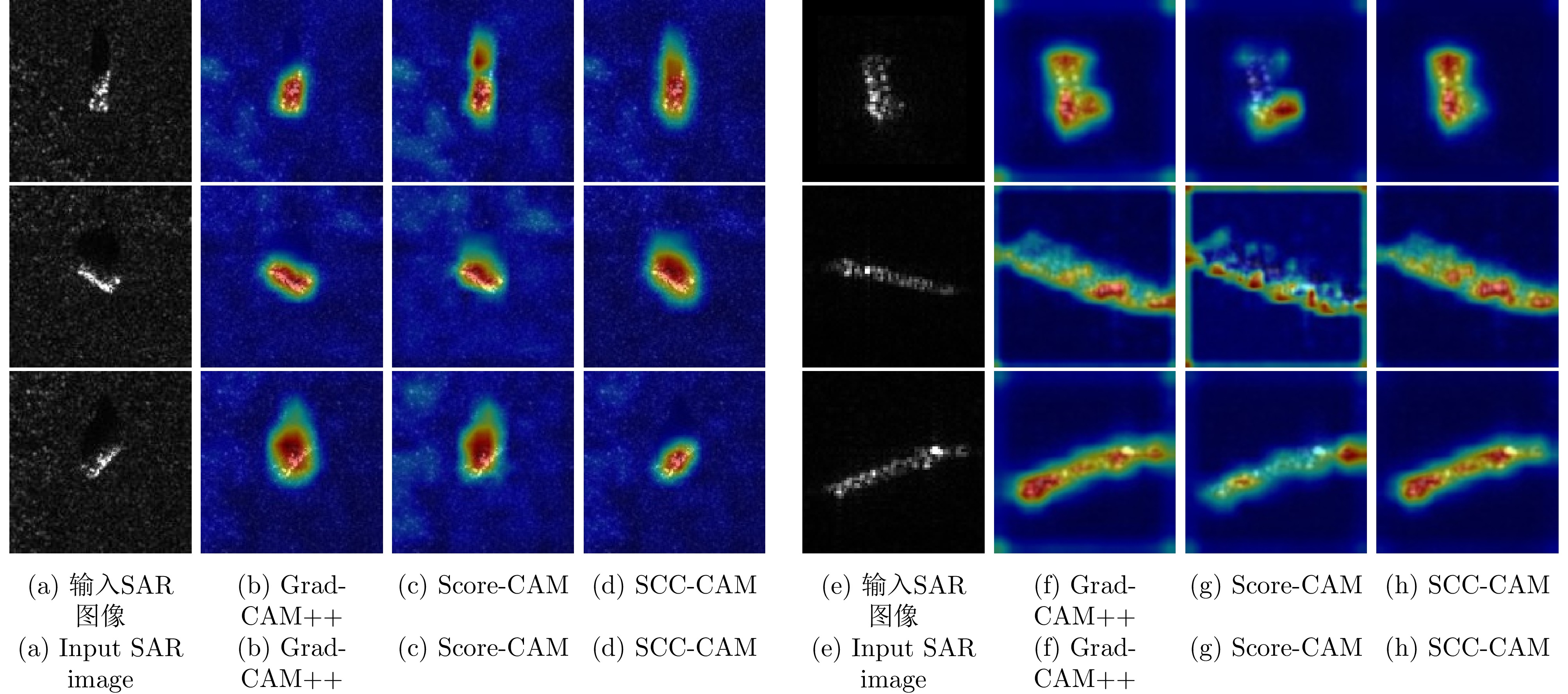
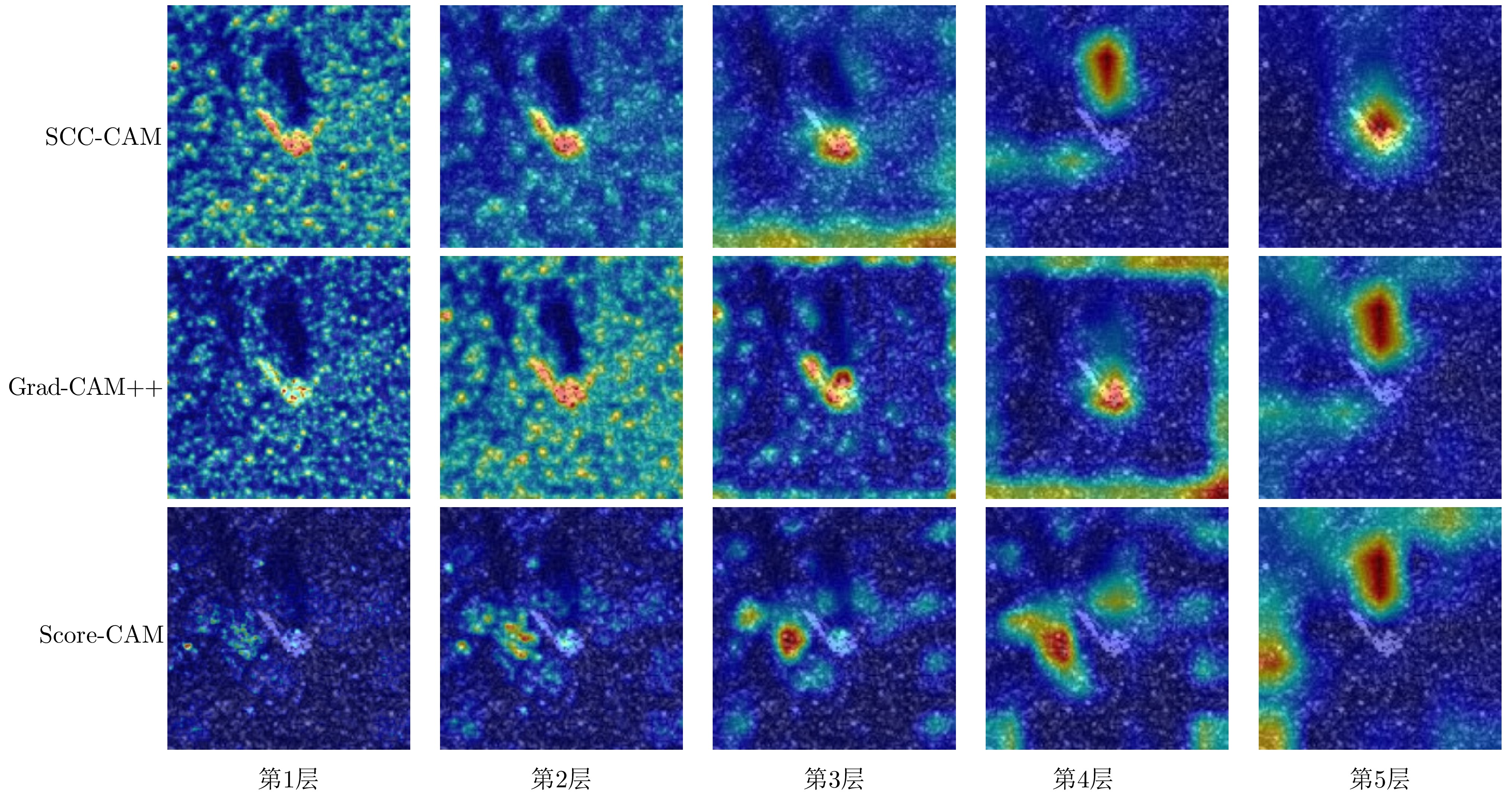
With the widespread application of deep learning methods in Synthetic Aperture Radar (SAR) image interpretation, the explainability of SAR target recognition deep networks has gradually attracted the attention of scholars. Class Activation Mapping (CAM), a commonly used explainability algorithm, can visually display the salient regions influencing the recognition task through heatmaps. However, as a post hoc explanation method, CAM can only statically display the salient regions during the current recognition process and cannot dynamically show the variation patterns of the salient regions upon changing the input. This study introduces the concept of perturbation into CAM, proposing an algorithm called SAR Clutter Characteristics CAM (SCC-CAM). By introducing globally distributed perturbations to the input image, interference is gradually applied to deep SAR recognition networks, causing decision flips. The degree of change in the activation values of network neurons is also calculated. This method addresses the issue of perturbation propagation and allows for dynamic observation and measurement of variation patterns of salient regions during the recognition process. Thus, SCC-CAM enhances the explainability of deep networks. Experiments on the MSTAR and OpenSARShip-1.0 datasets demonstrate that the proposed algorithm can more accurately locate salient regions. Compared with traditional methods, the algorithm in this study shows stronger explainability in terms of average confidence degradation rates, confidence ascent ratios, information content, and other evaluation metrics. This algorithm can serve as a universal method for enhancing the explainability of networks.
With the widespread application of deep learning methods in Synthetic Aperture Radar (SAR) image interpretation, the explainability of SAR target recognition deep networks has gradually attracted the attention of scholars. Class Activation Mapping (CAM), a commonly used explainability algorithm, can visually display the salient regions influencing the recognition task through heatmaps. However, as a post hoc explanation method, CAM can only statically display the salient regions during the current recognition process and cannot dynamically show the variation patterns of the salient regions upon changing the input. This study introduces the concept of perturbation into CAM, proposing an algorithm called SAR Clutter Characteristics CAM (SCC-CAM). By introducing globally distributed perturbations to the input image, interference is gradually applied to deep SAR recognition networks, causing decision flips. The degree of change in the activation values of network neurons is also calculated. This method addresses the issue of perturbation propagation and allows for dynamic observation and measurement of variation patterns of salient regions during the recognition process. Thus, SCC-CAM enhances the explainability of deep networks. Experiments on the MSTAR and OpenSARShip-1.0 datasets demonstrate that the proposed algorithm can more accurately locate salient regions. Compared with traditional methods, the algorithm in this study shows stronger explainability in terms of average confidence degradation rates, confidence ascent ratios, information content, and other evaluation metrics. This algorithm can serve as a universal method for enhancing the explainability of networks.






2024, 13(2): 443-456.
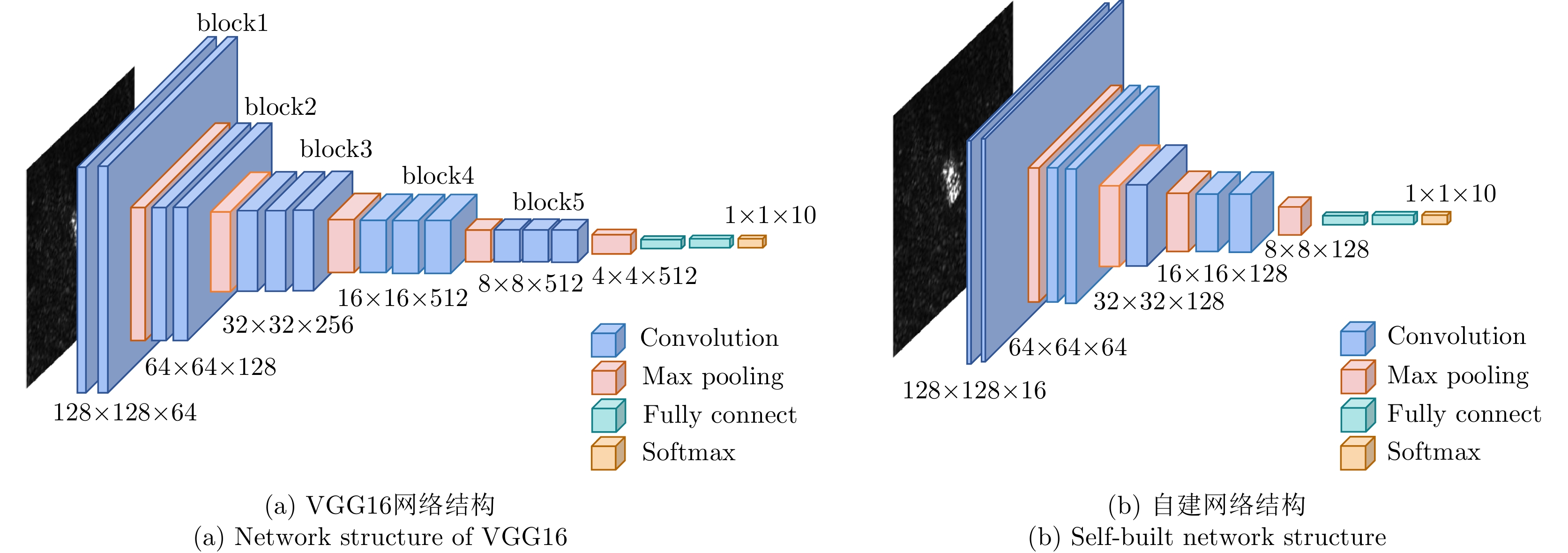
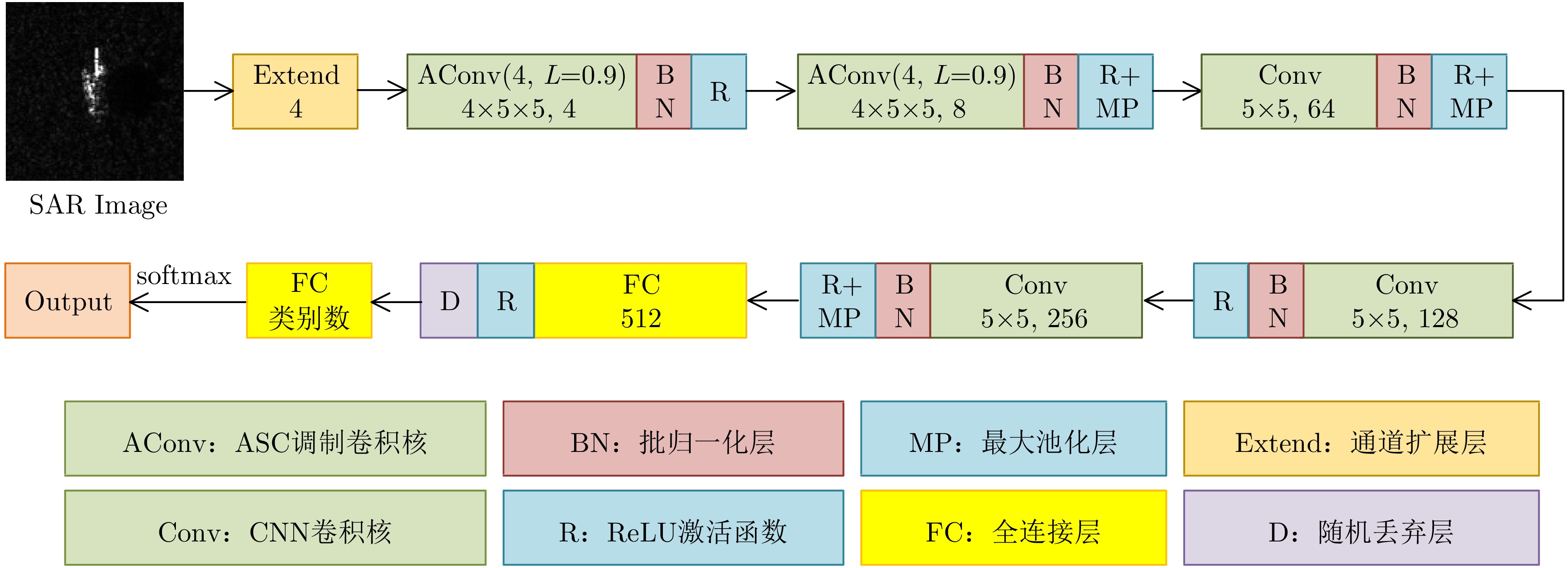
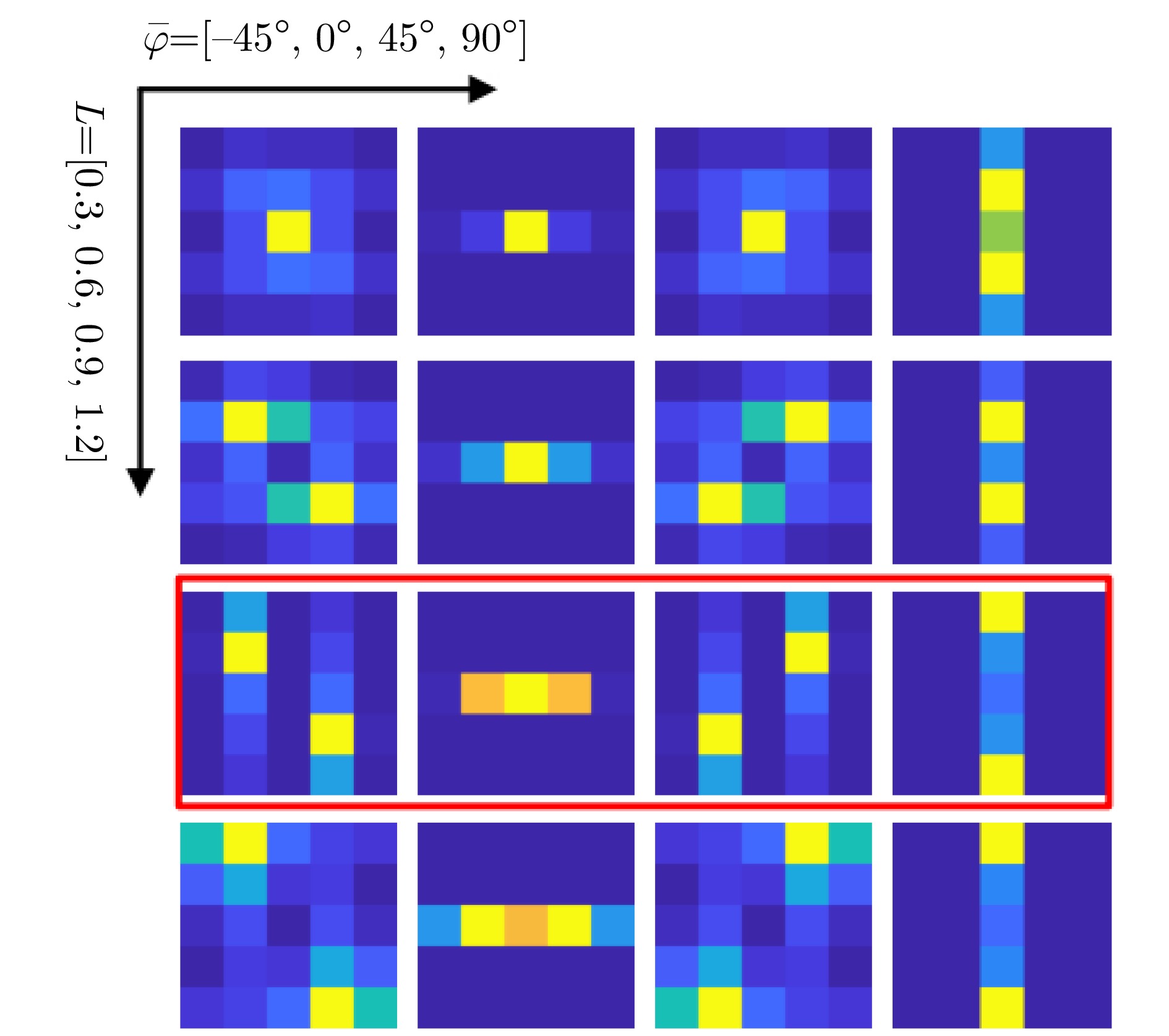
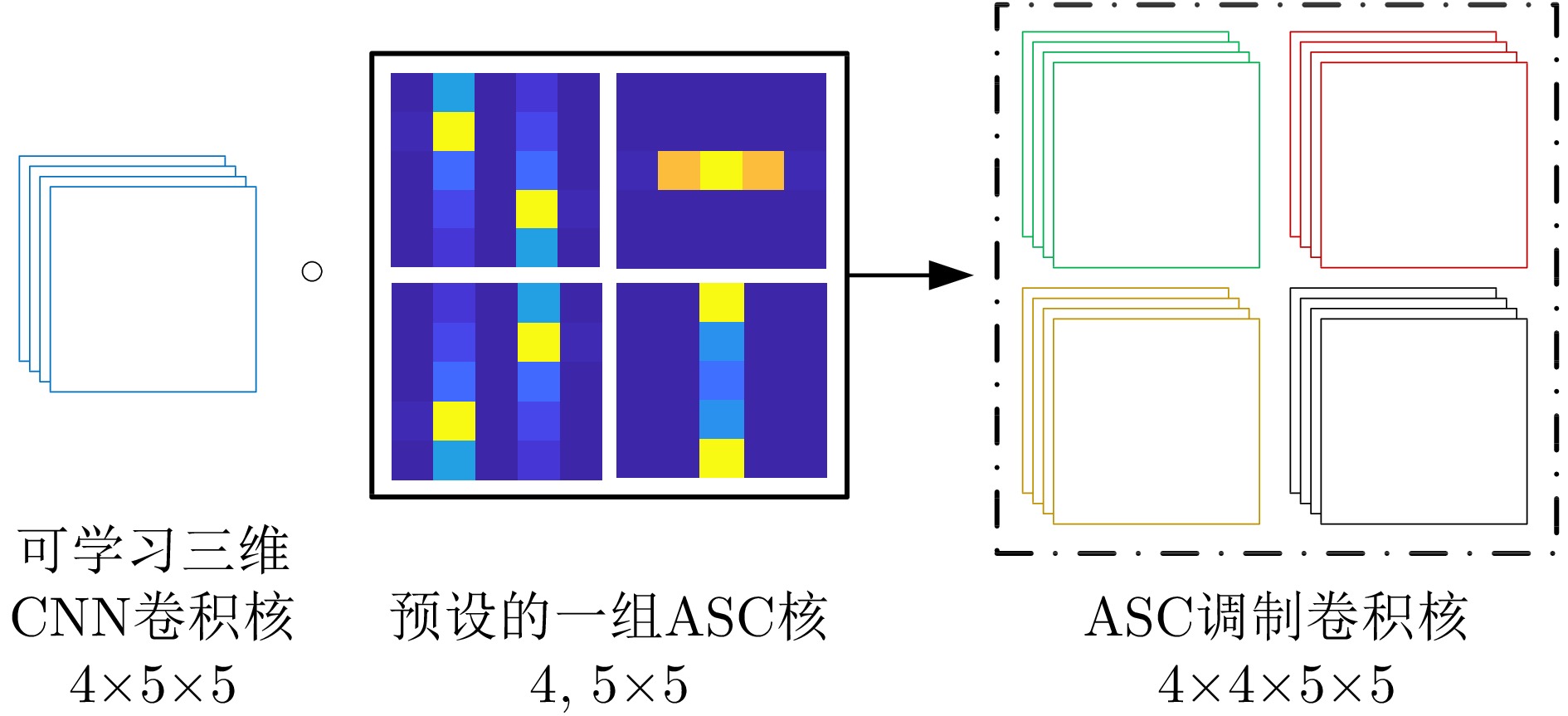
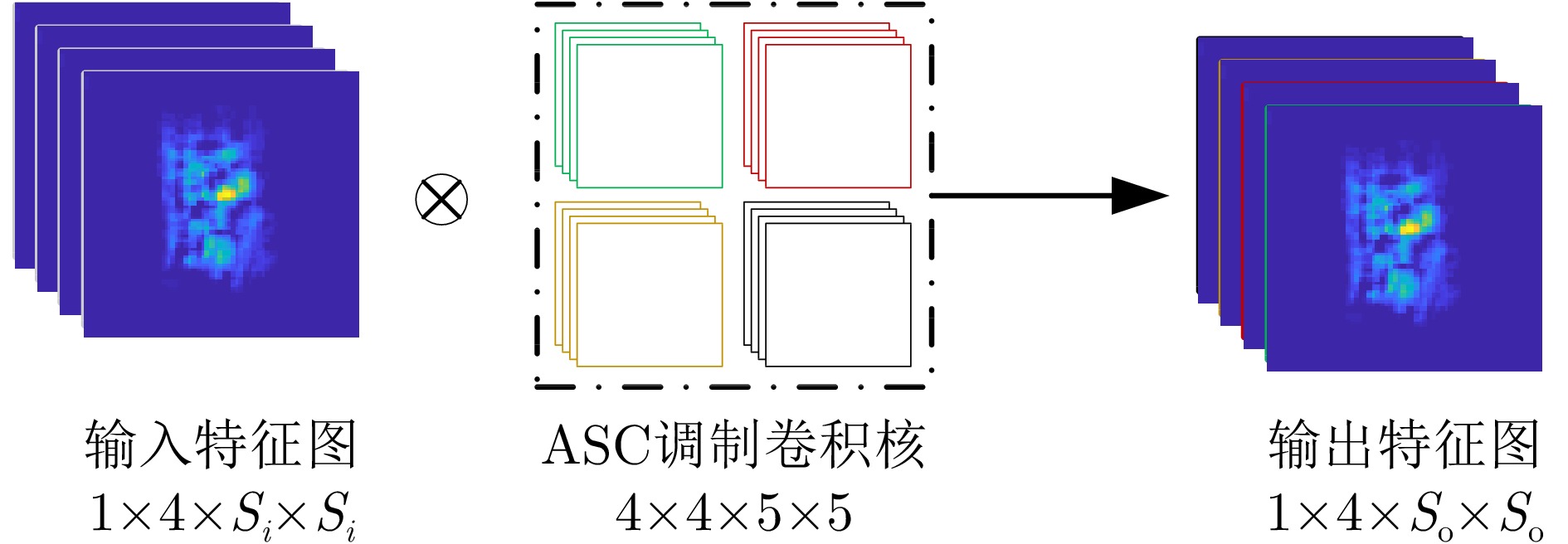
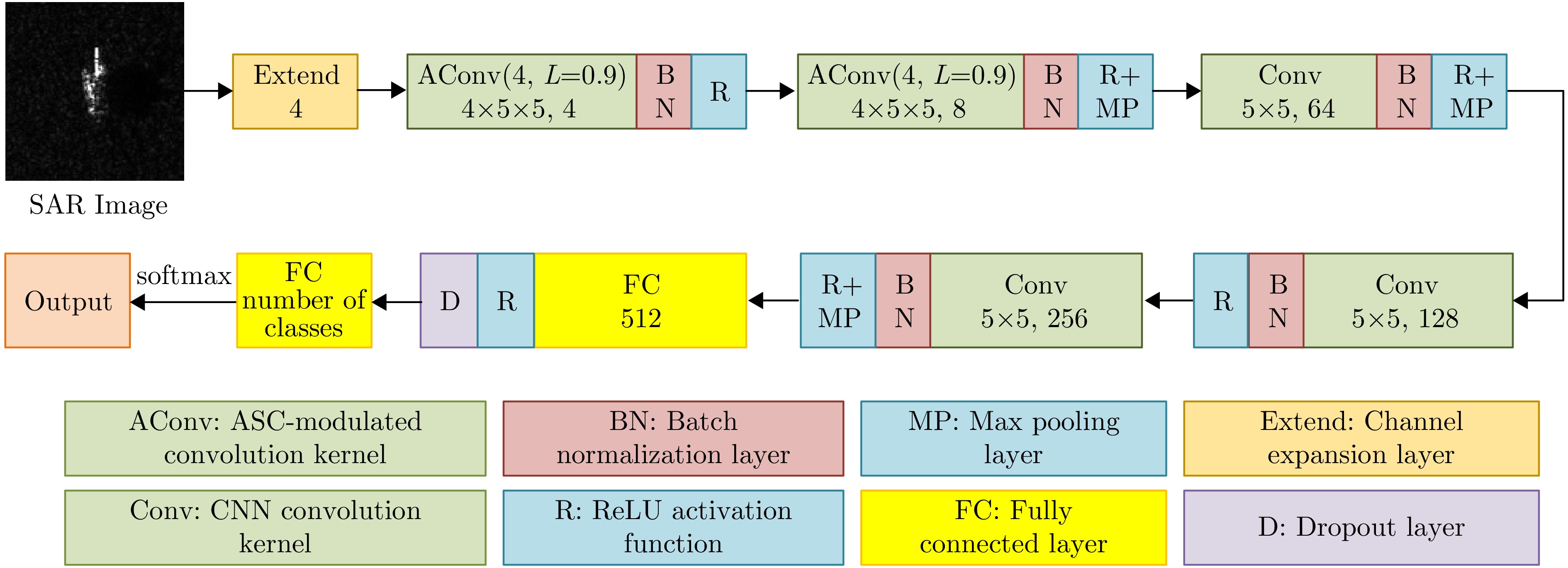
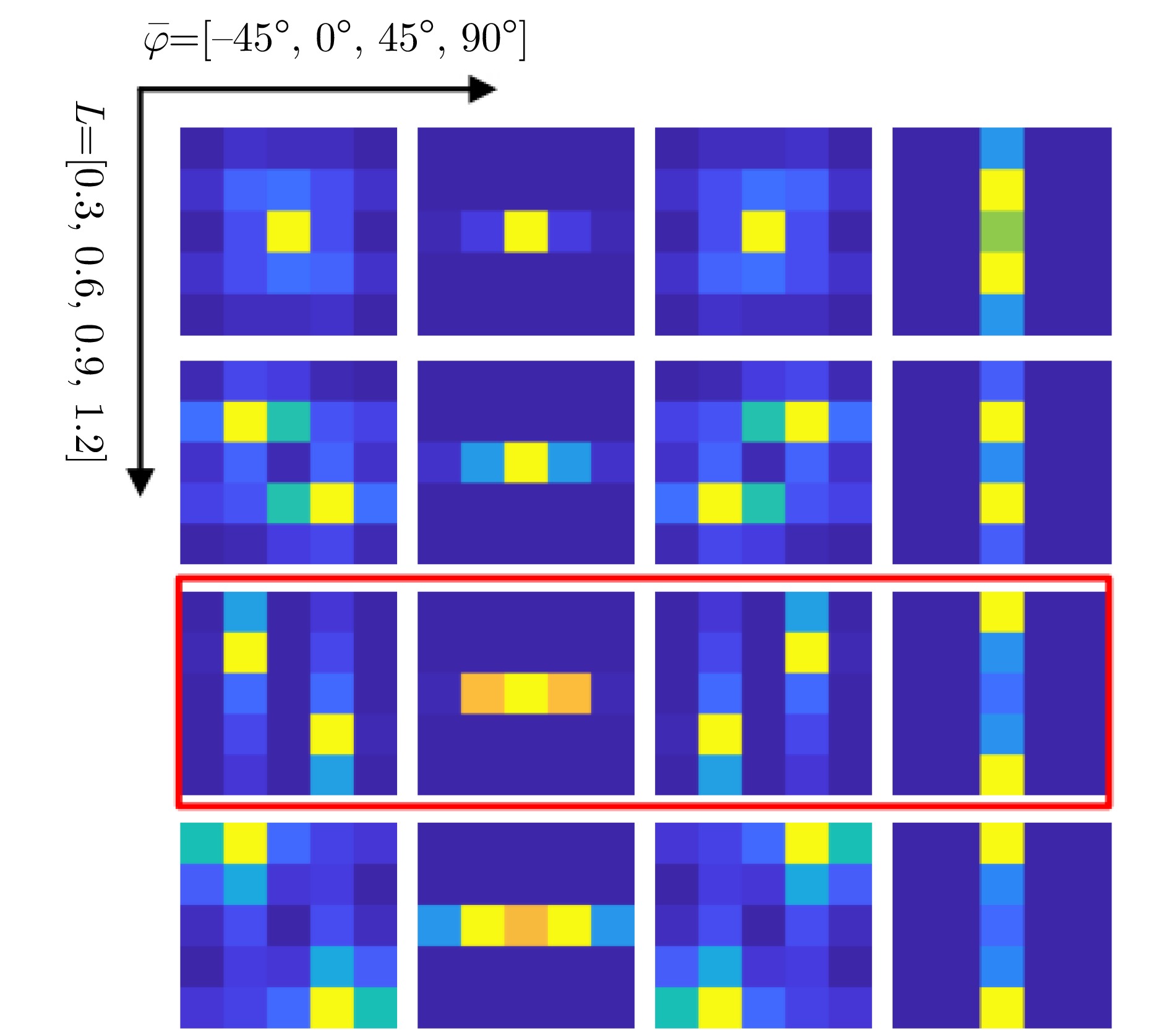
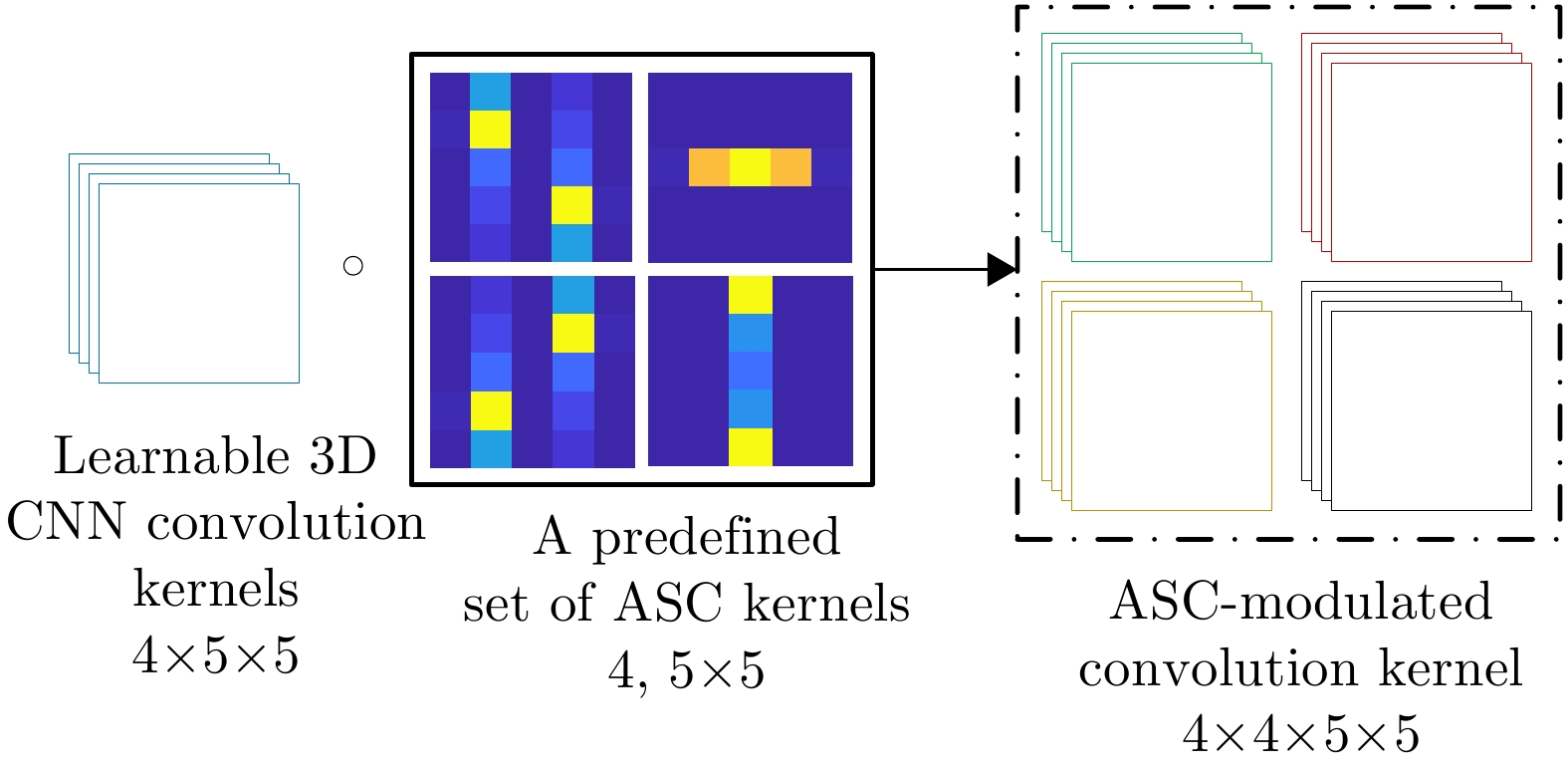
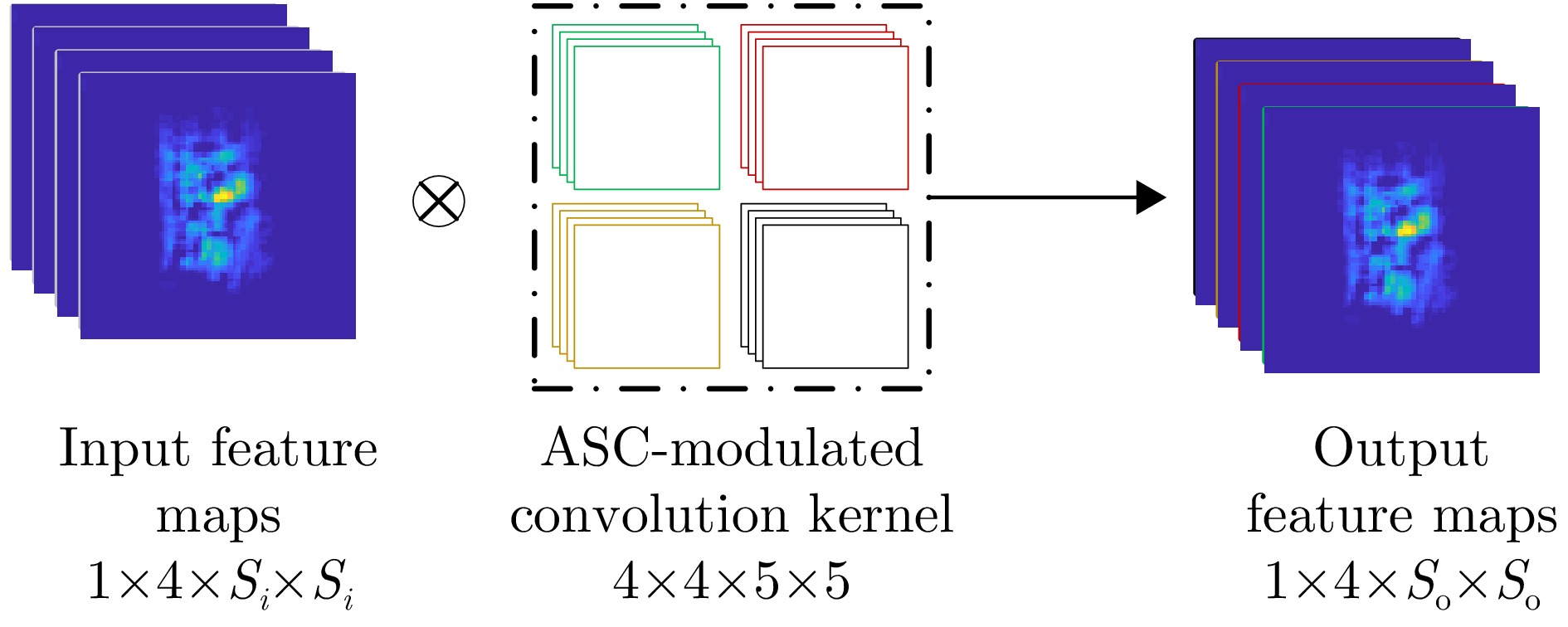
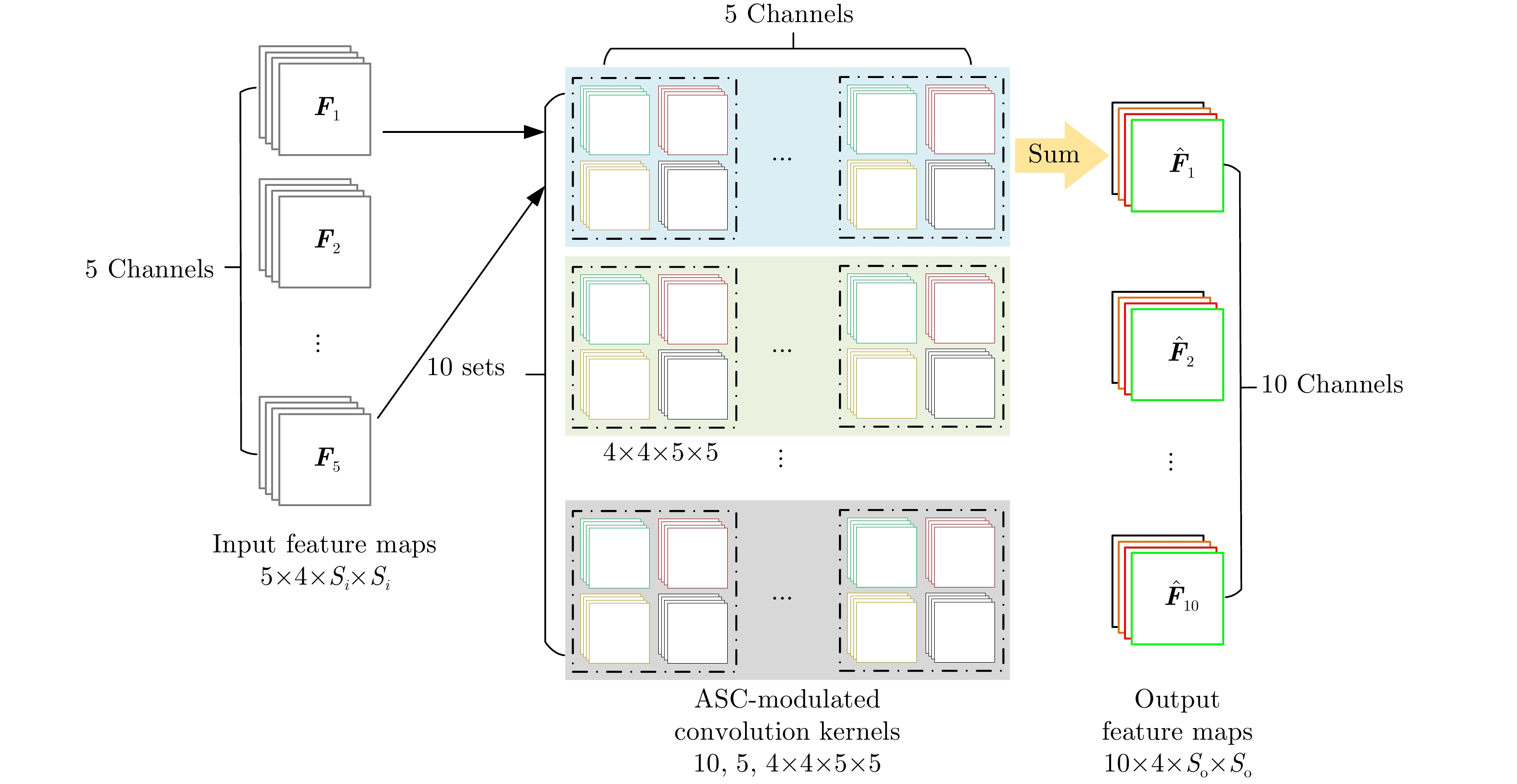
The feature extraction capability of Convolutional Neural Networks (CNNs) is related to the number of their parameters. Generally, using a large number of parameters leads to improved feature extraction capability of CNNs. However, a considerable amount of training data is required to effectively learn these parameters. In practical applications, Synthetic Aperture Radar (SAR) images available for model training are often limited. Reducing the number of parameters in a CNN can decrease the demand for training samples, but the feature expression ability of the CNN is simultaneously diminished, which affects its target recognition performance. To solve this problem, this paper proposes a deep network for SAR target recognition based on Attribute Scattering Center (ASC) convolutional kernel modulation. Given the electromagnetic scattering characteristics of SAR images, the proposed network extracts scattering structures and edge features that are more consistent with the characteristics of SAR targets by modulating a small number of CNN convolutional kernels using predefined ASC kernels with different orientations and lengths. This approach generates additional convolutional kernels, which can reduce the network parameters while ensuring feature extraction capability. In addition, the designed network uses ASC-modulated convolutional kernels at shallow layers to extract scattering structures and edge features that are more consistent with the characteristics of SAR images while utilizing CNN convolutional kernels at deeper layers to extract semantic features of SAR images. The proposed network focuses on the electromagnetic scattering characteristics of SAR targets and shows the feature extraction advantages of CNNs due to the simultaneous use of ASC-modulated and CNN convolutional kernels. Experiments based on the studied SAR images demonstrate that the proposed network can ensure excellent SAR target recognition performance while reducing the demand for training samples.
The feature extraction capability of Convolutional Neural Networks (CNNs) is related to the number of their parameters. Generally, using a large number of parameters leads to improved feature extraction capability of CNNs. However, a considerable amount of training data is required to effectively learn these parameters. In practical applications, Synthetic Aperture Radar (SAR) images available for model training are often limited. Reducing the number of parameters in a CNN can decrease the demand for training samples, but the feature expression ability of the CNN is simultaneously diminished, which affects its target recognition performance. To solve this problem, this paper proposes a deep network for SAR target recognition based on Attribute Scattering Center (ASC) convolutional kernel modulation. Given the electromagnetic scattering characteristics of SAR images, the proposed network extracts scattering structures and edge features that are more consistent with the characteristics of SAR targets by modulating a small number of CNN convolutional kernels using predefined ASC kernels with different orientations and lengths. This approach generates additional convolutional kernels, which can reduce the network parameters while ensuring feature extraction capability. In addition, the designed network uses ASC-modulated convolutional kernels at shallow layers to extract scattering structures and edge features that are more consistent with the characteristics of SAR images while utilizing CNN convolutional kernels at deeper layers to extract semantic features of SAR images. The proposed network focuses on the electromagnetic scattering characteristics of SAR targets and shows the feature extraction advantages of CNNs due to the simultaneous use of ASC-modulated and CNN convolutional kernels. Experiments based on the studied SAR images demonstrate that the proposed network can ensure excellent SAR target recognition performance while reducing the demand for training samples.





2024, 13(2): 457-470.
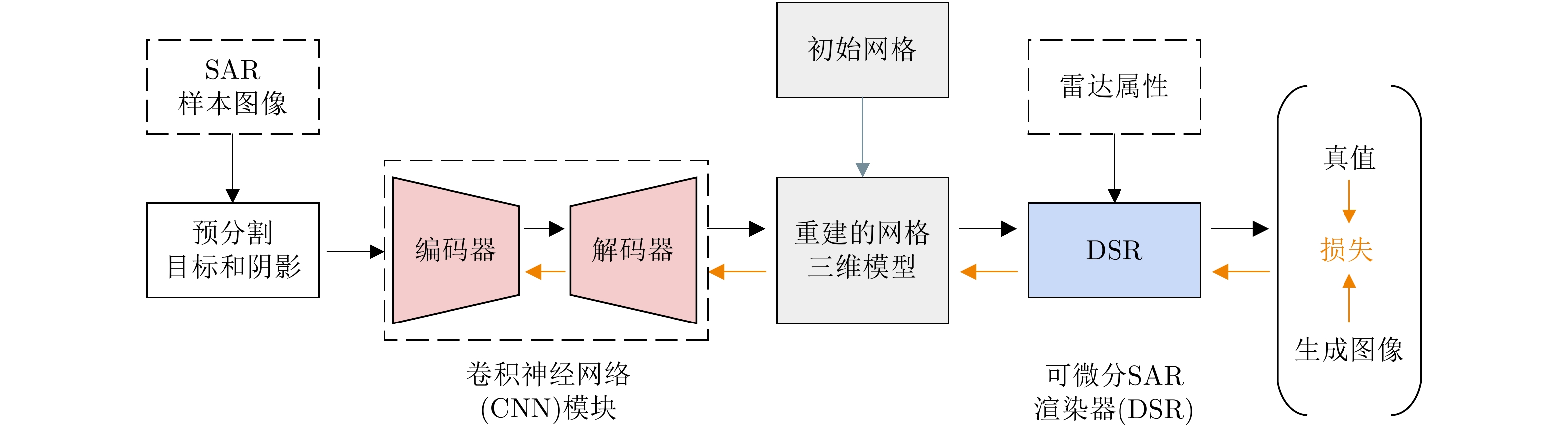
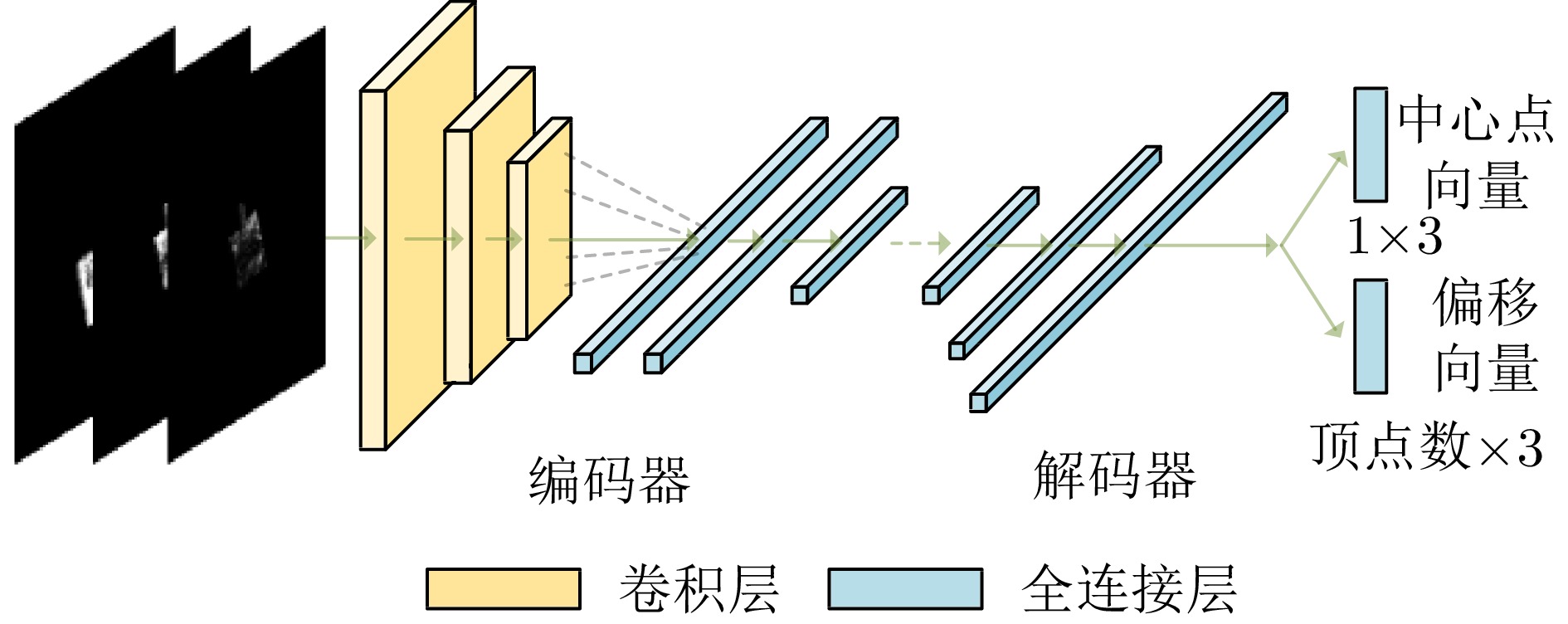
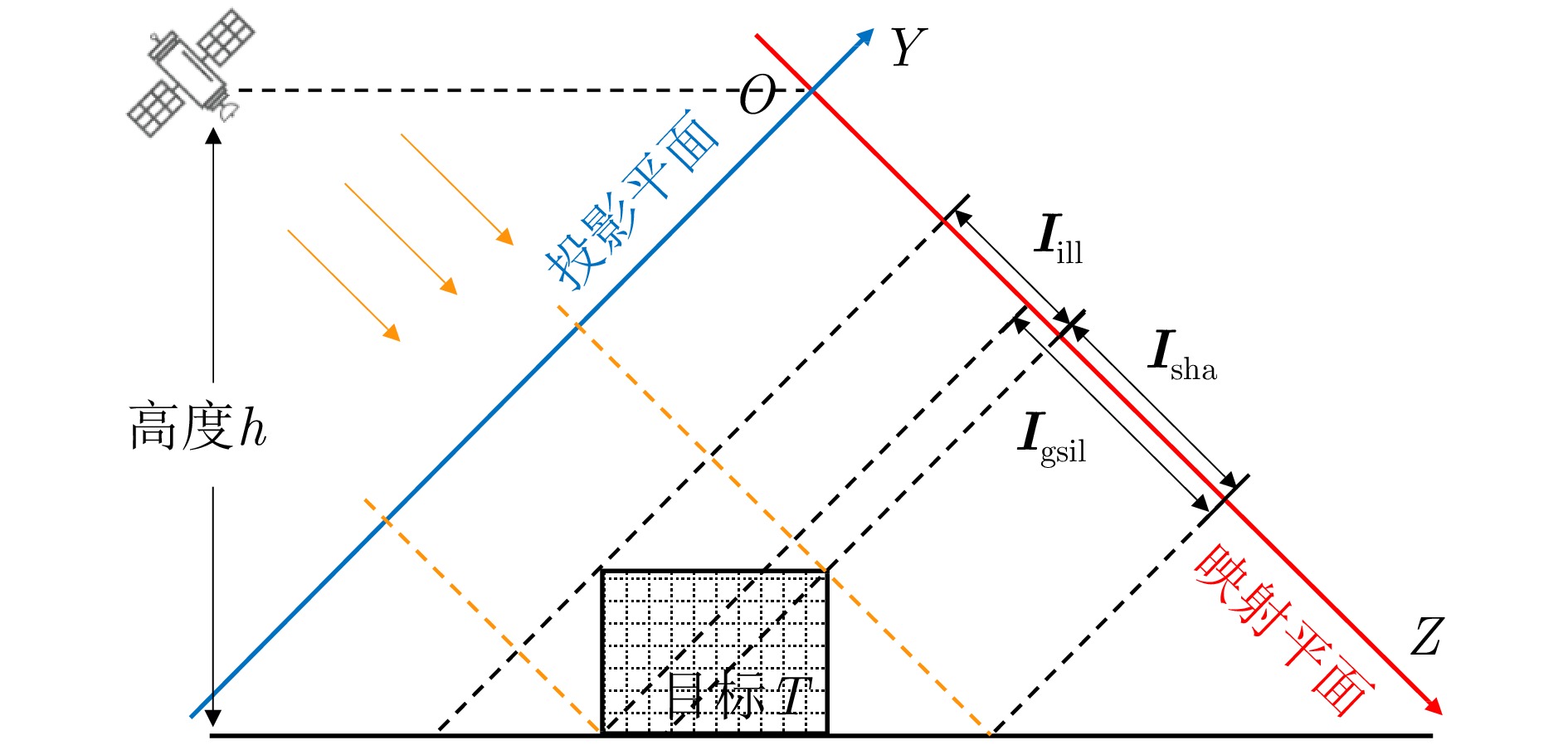
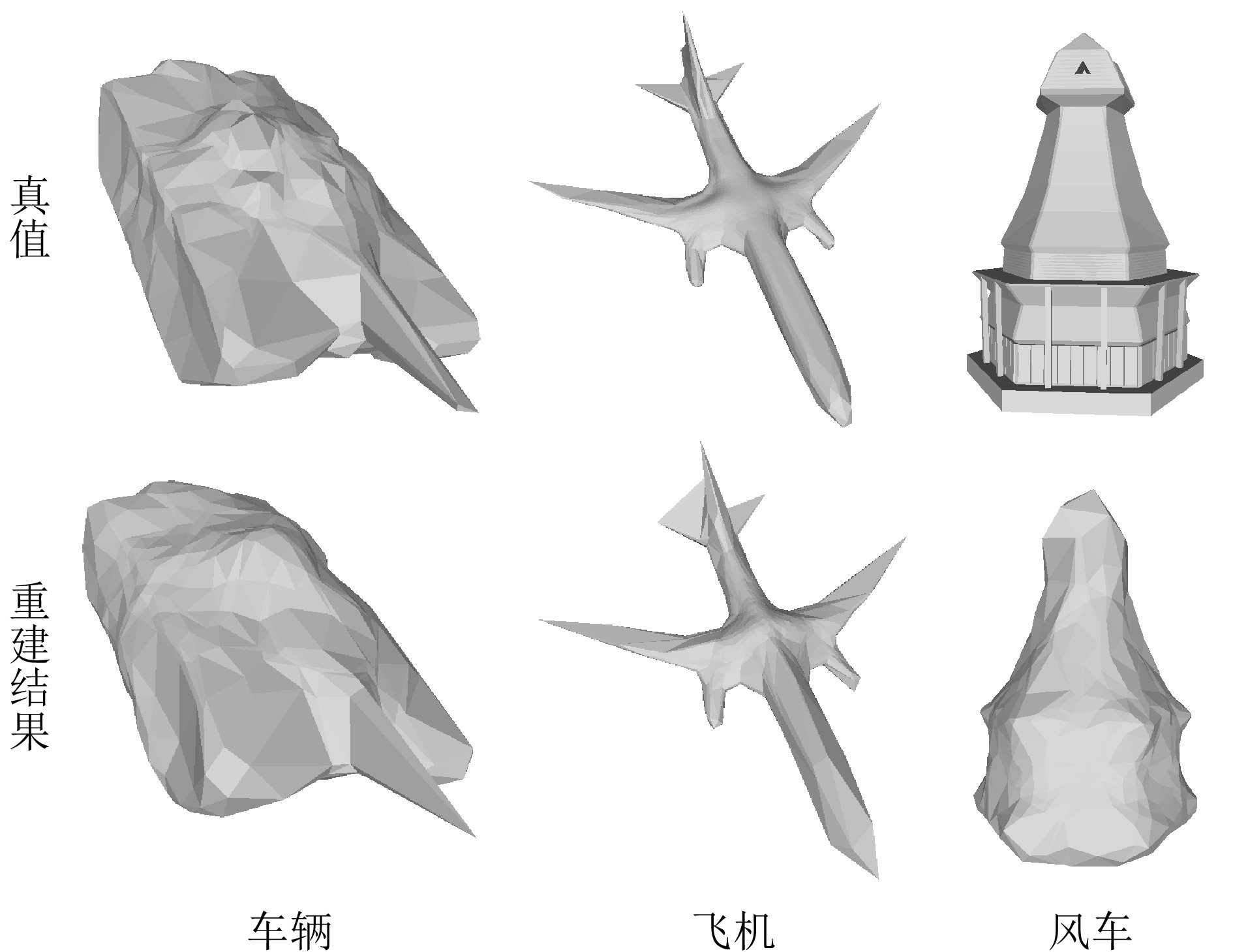
Synthetic Aperture Radar (SAR) is extensively utilized in civilian and military domains due to its all-weather, all-time monitoring capabilities. In recent years, deep learning has been widely employed to automatically interpret SAR images. However, due to the constraints of satellite orbit and incident angle, SAR target samples face the issue of incomplete view coverage, which poses challenges for learning-based SAR target detection and recognition algorithms. This paper proposes a method for generating multi-view samples of SAR targets by integrating differentiable rendering, combining inverse Three-Dimensional (3D) reconstruction, and forward rendering techniques. By designing a Convolutional Neural Network (CNN), the proposed method inversely infers the 3D representation of targets from limited views of SAR target images and then utilizes a Differentiable SAR Renderer (DSR) to render new samples from more views, achieving sample interpolation in the view dimension. Moreover, the training process of the proposed method constructs the objective function using DSR, eliminating the need for 3D ground-truth supervision. According to experimental results on simulated data, this method can effectively increase the number of multi-view SAR target images and improve the recognition rate of typical SAR targets under few-shot conditions.
Synthetic Aperture Radar (SAR) is extensively utilized in civilian and military domains due to its all-weather, all-time monitoring capabilities. In recent years, deep learning has been widely employed to automatically interpret SAR images. However, due to the constraints of satellite orbit and incident angle, SAR target samples face the issue of incomplete view coverage, which poses challenges for learning-based SAR target detection and recognition algorithms. This paper proposes a method for generating multi-view samples of SAR targets by integrating differentiable rendering, combining inverse Three-Dimensional (3D) reconstruction, and forward rendering techniques. By designing a Convolutional Neural Network (CNN), the proposed method inversely infers the 3D representation of targets from limited views of SAR target images and then utilizes a Differentiable SAR Renderer (DSR) to render new samples from more views, achieving sample interpolation in the view dimension. Moreover, the training process of the proposed method constructs the objective function using DSR, eliminating the need for 3D ground-truth supervision. According to experimental results on simulated data, this method can effectively increase the number of multi-view SAR target images and improve the recognition rate of typical SAR targets under few-shot conditions.



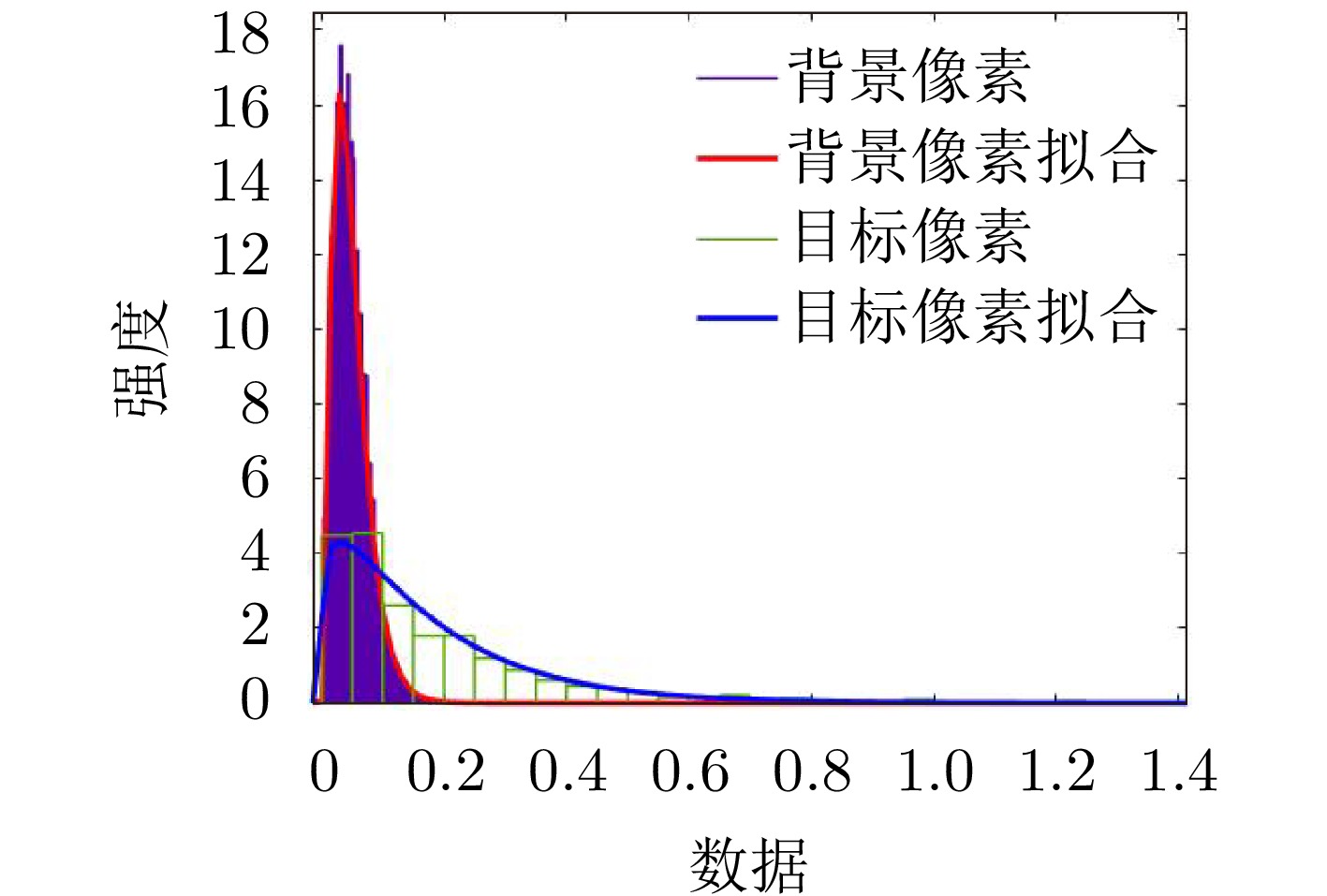




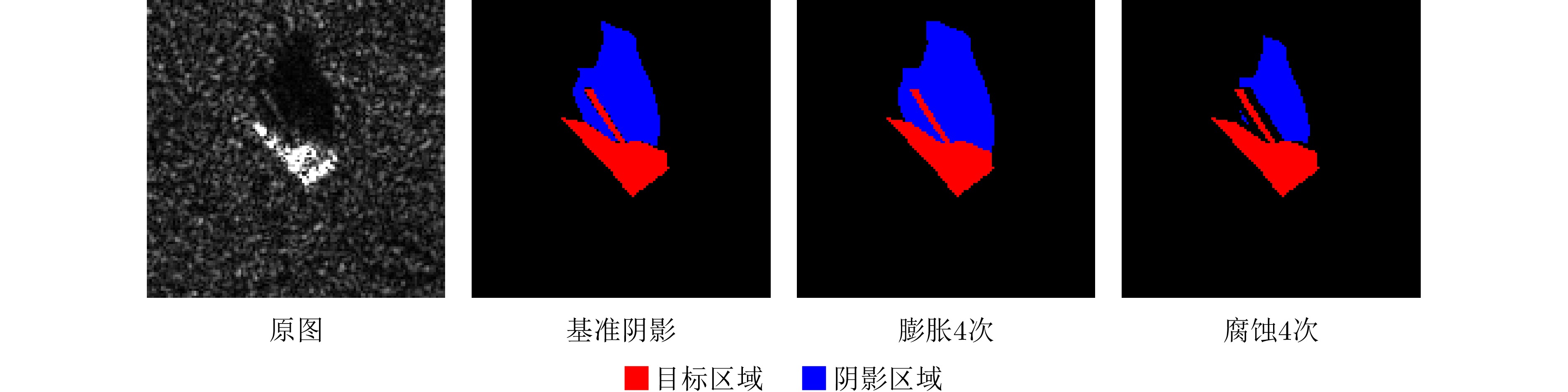



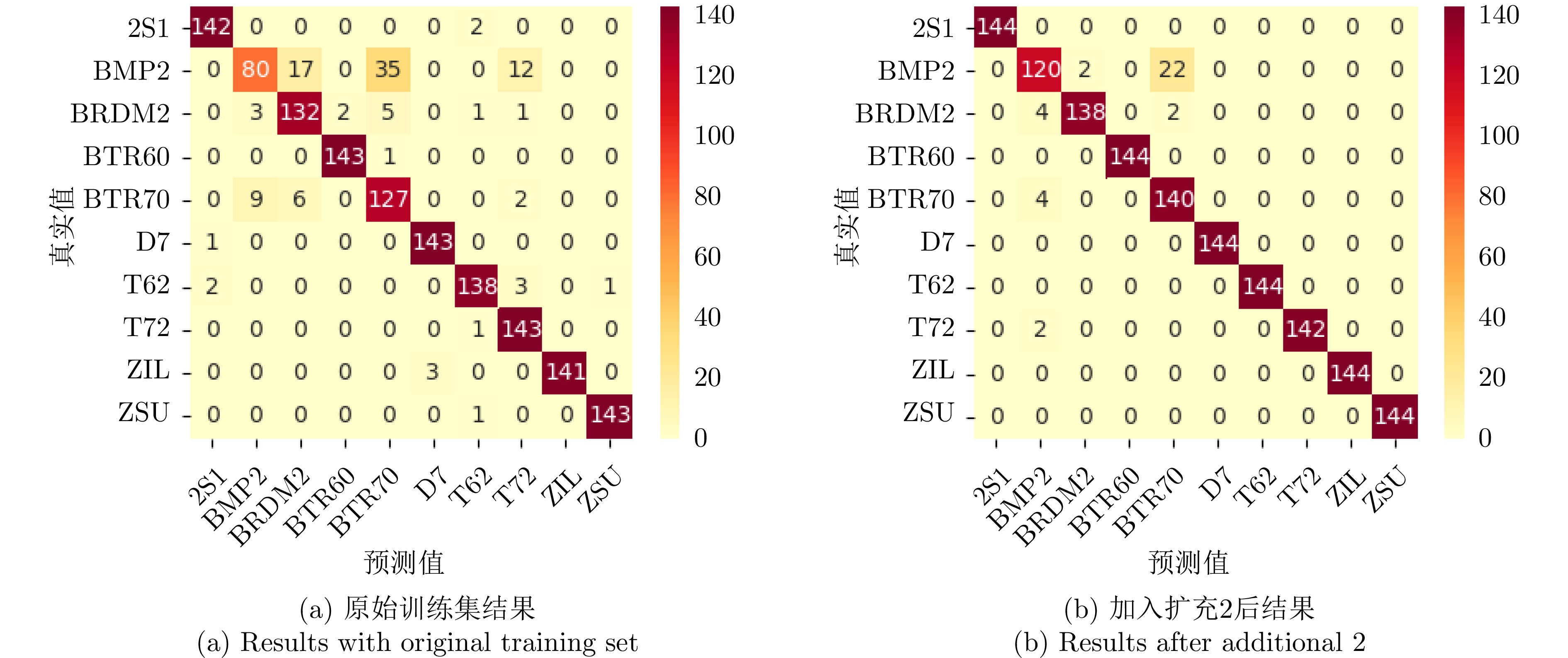
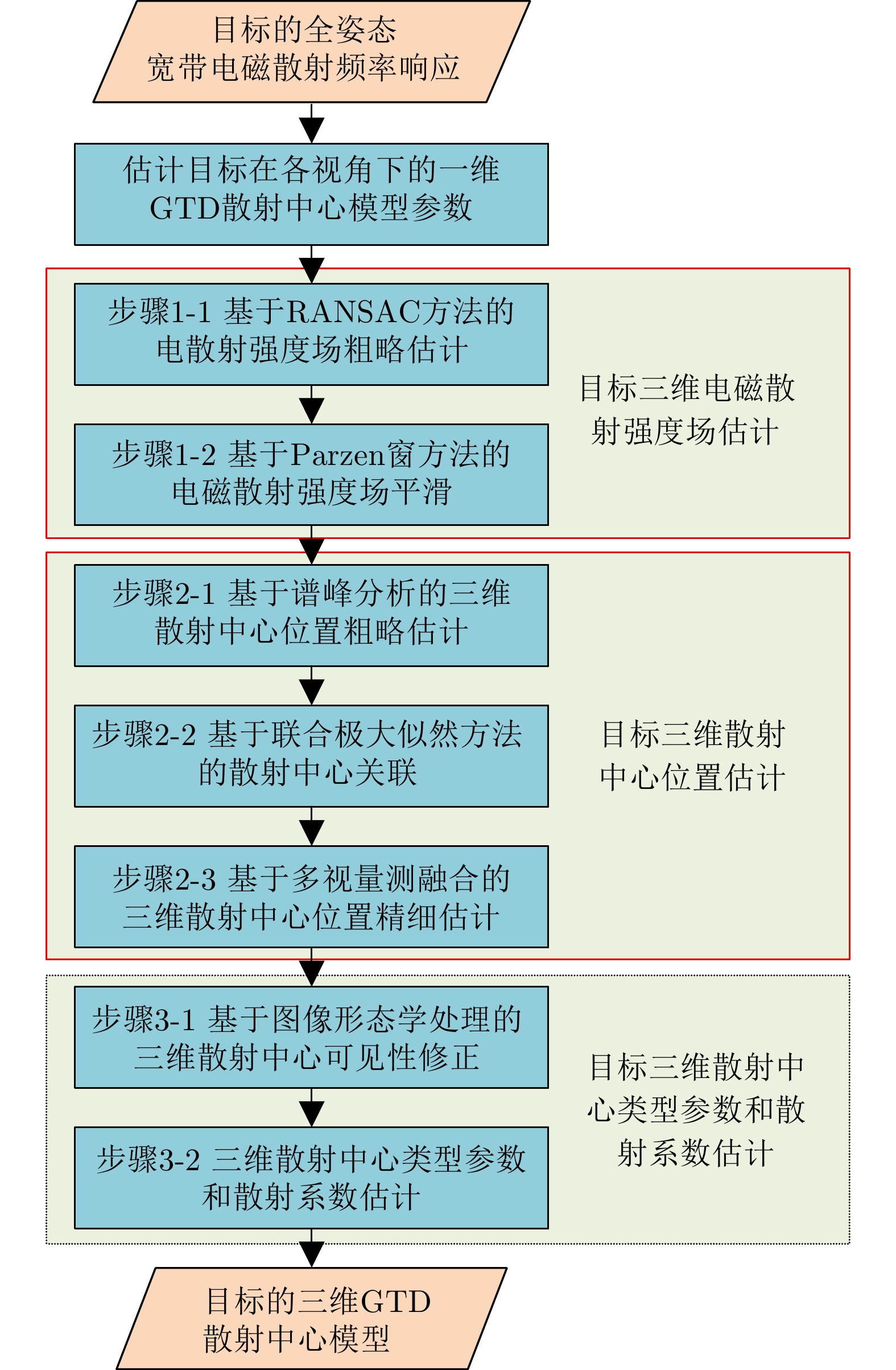
2024, 13(2): 471-484.
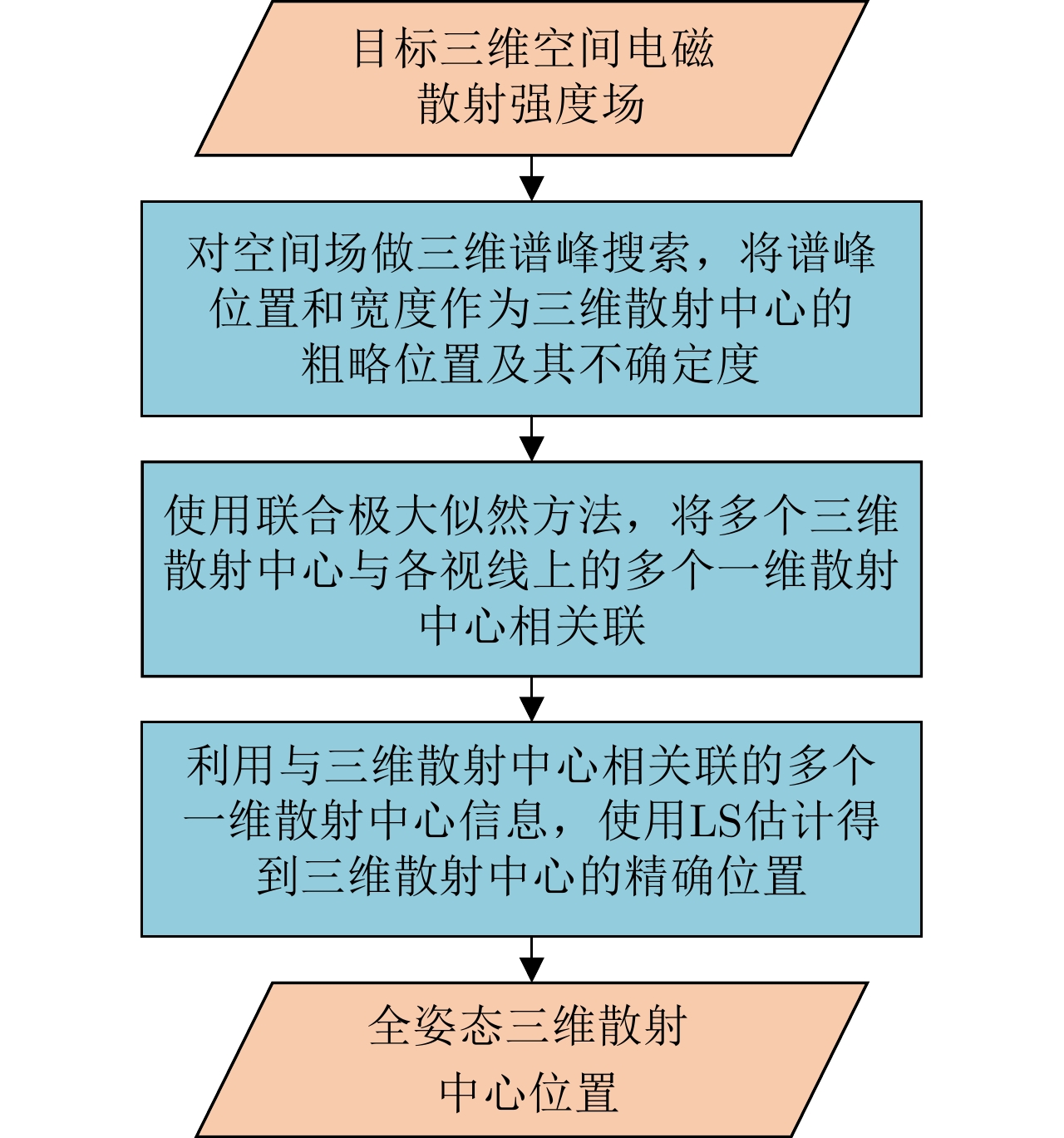
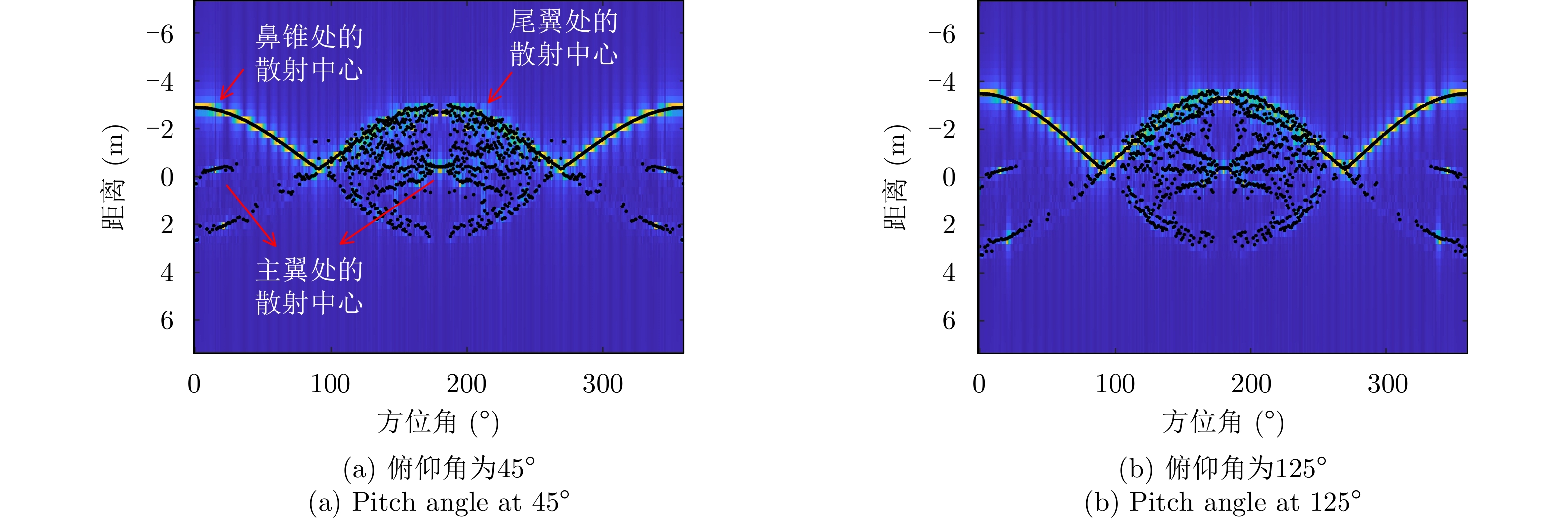
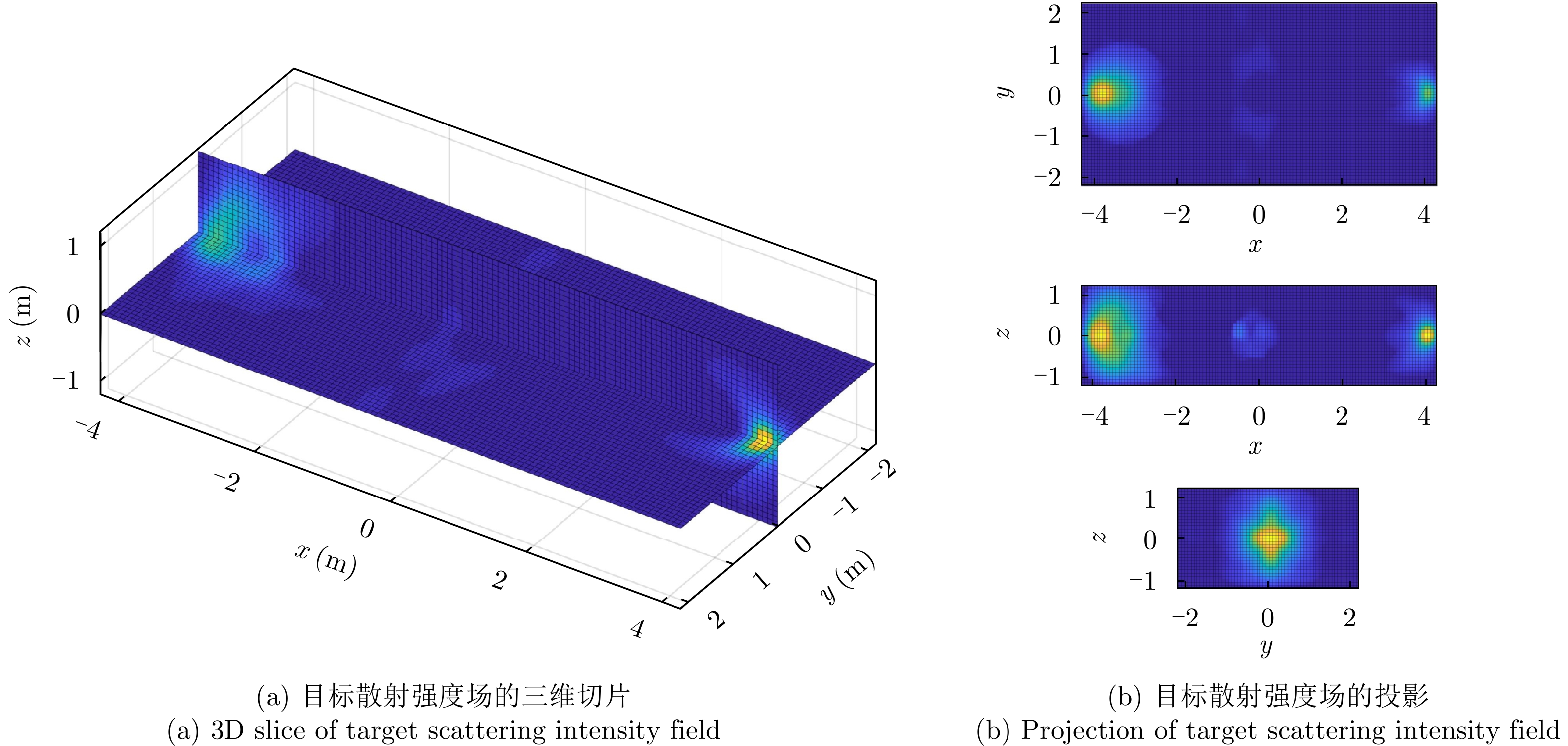
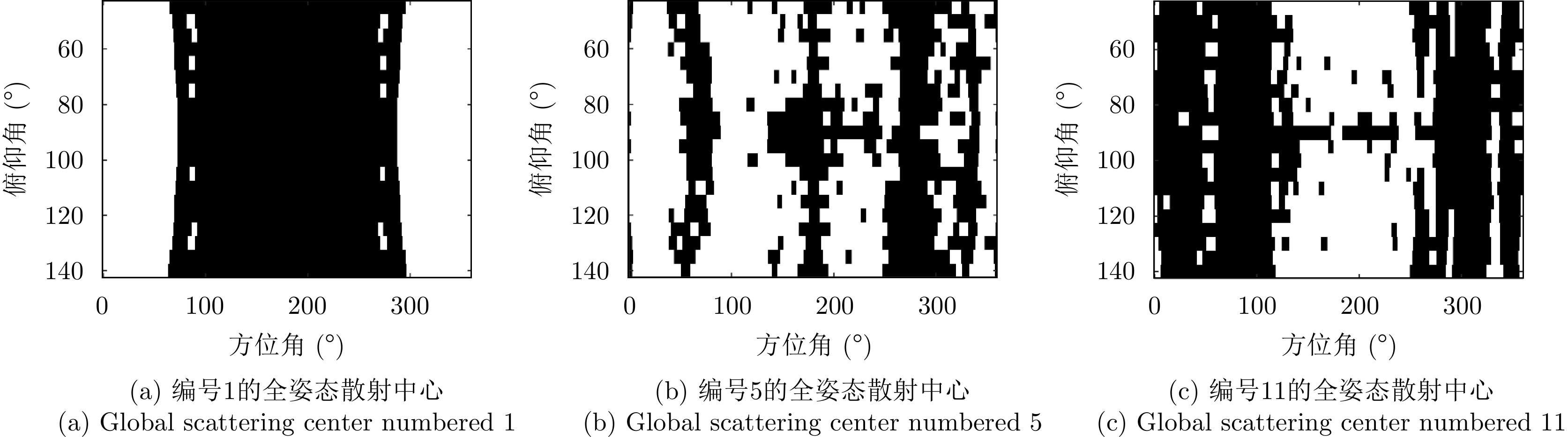
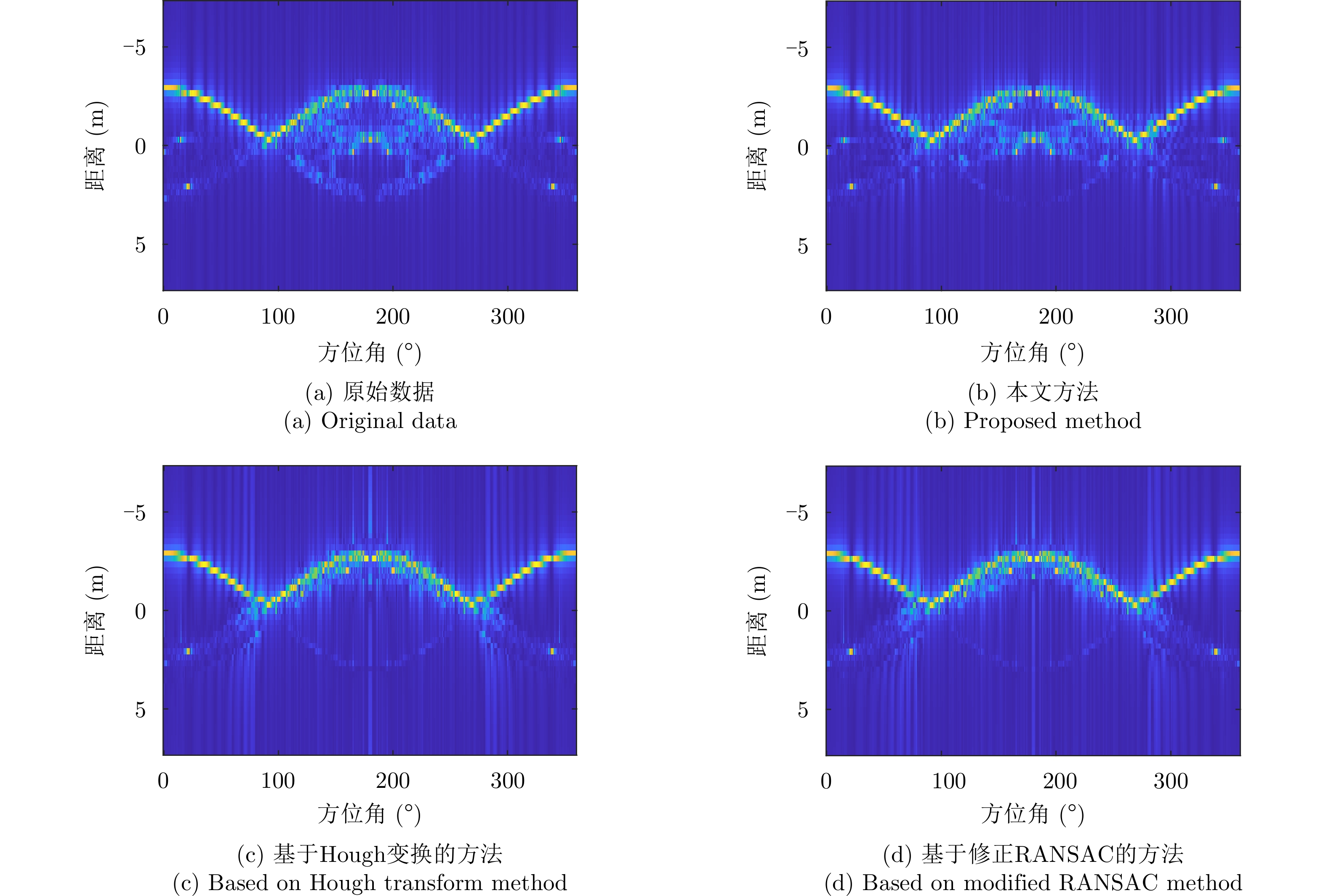
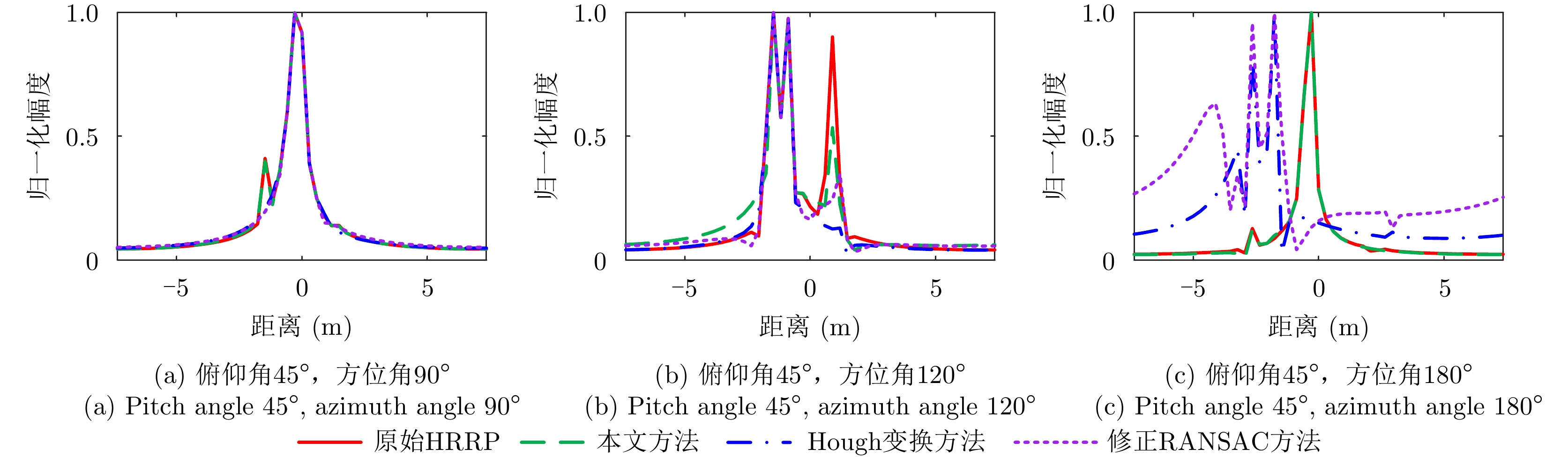
The global scattering-center model is a high-performance electromagnetic scattering parametric model for complex targets in an optical region. The traditional methods for constructing global scattering models are usually based on candidate-point screening and clustering and are prone to producing false scattering centers and ignoring actual scattering centers. To address this issue, this study proposes a novel modeling method based on the spectral peak analysis of the target electromagnetic scattering intensity field. First, the three-dimensional (3D) electromagnetic scattering intensity field of the target is estimated based on the multiperspective, one-dimensional scattering-center parameters of the target using the RANdom SAmple Consensus (RANSAC) and Parzen window methods. Next, the positions of the global 3D scattering centers are determined through spectral peak analysis, scattering-center association, and multivision measurement fusion. Finally, the scattering coefficients and type parameters of the global scattering centers are estimated after the visibility of the global scattering center is corrected through binary image morphological processing. Simulation results demonstrate that the global scattering center model extracted using this method, which is highly consistent with the geometrical structure of the target, achieves higher expression accuracy while using fewer scattering centers than those used in traditional methods.
The global scattering-center model is a high-performance electromagnetic scattering parametric model for complex targets in an optical region. The traditional methods for constructing global scattering models are usually based on candidate-point screening and clustering and are prone to producing false scattering centers and ignoring actual scattering centers. To address this issue, this study proposes a novel modeling method based on the spectral peak analysis of the target electromagnetic scattering intensity field. First, the three-dimensional (3D) electromagnetic scattering intensity field of the target is estimated based on the multiperspective, one-dimensional scattering-center parameters of the target using the RANdom SAmple Consensus (RANSAC) and Parzen window methods. Next, the positions of the global 3D scattering centers are determined through spectral peak analysis, scattering-center association, and multivision measurement fusion. Finally, the scattering coefficients and type parameters of the global scattering centers are estimated after the visibility of the global scattering center is corrected through binary image morphological processing. Simulation results demonstrate that the global scattering center model extracted using this method, which is highly consistent with the geometrical structure of the target, achieves higher expression accuracy while using fewer scattering centers than those used in traditional methods.







2024, 13(2): 485-499.
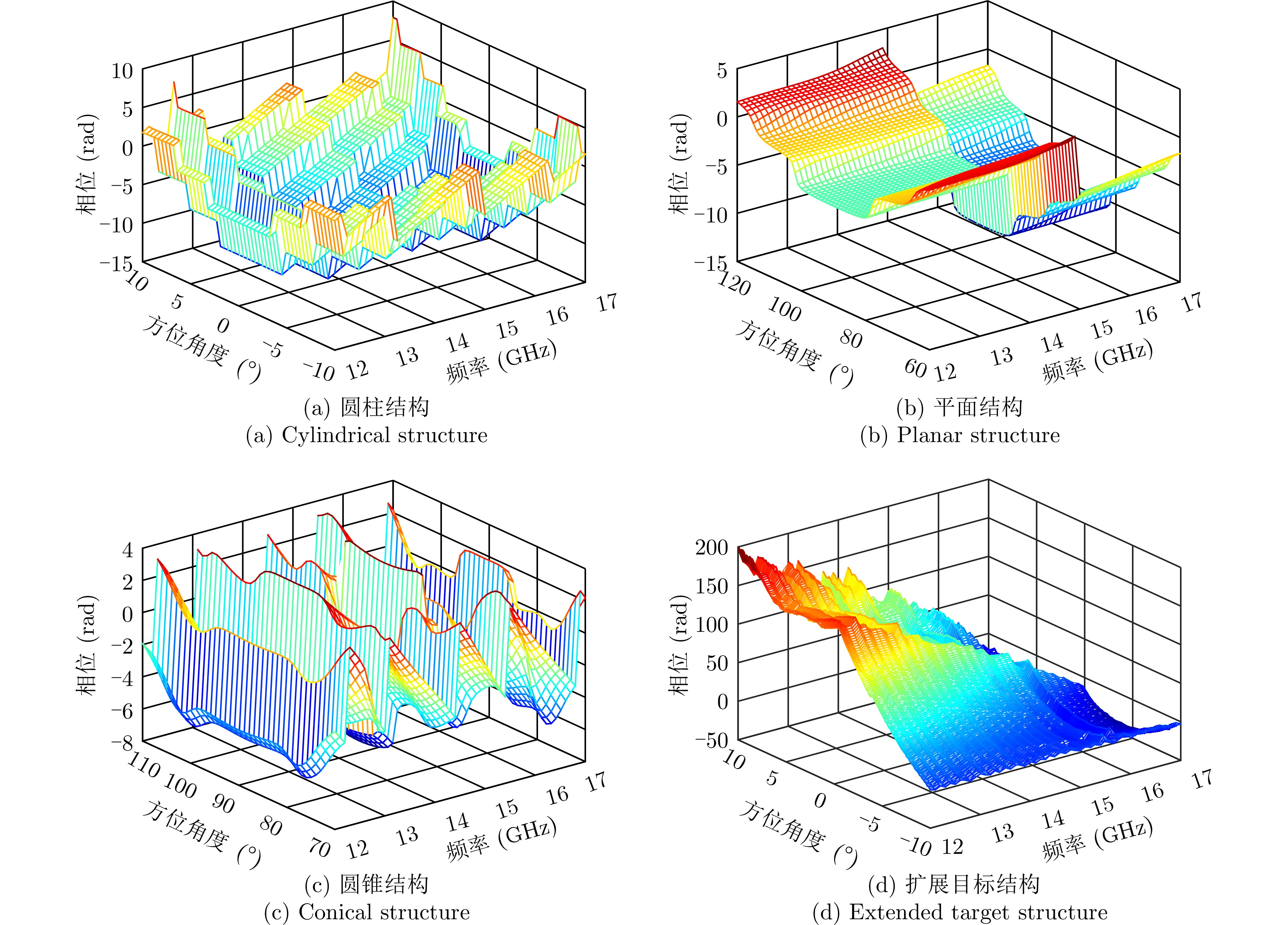
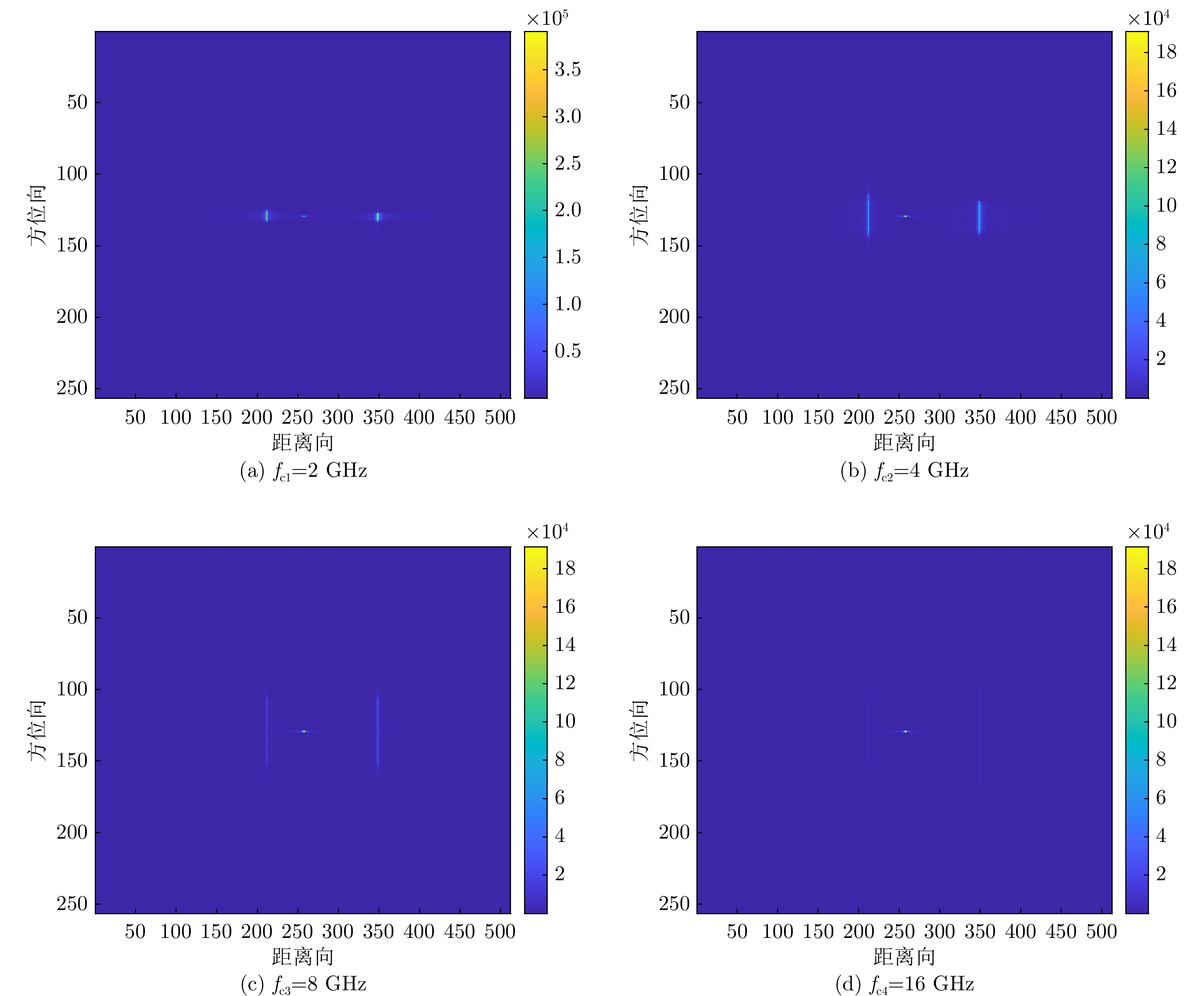
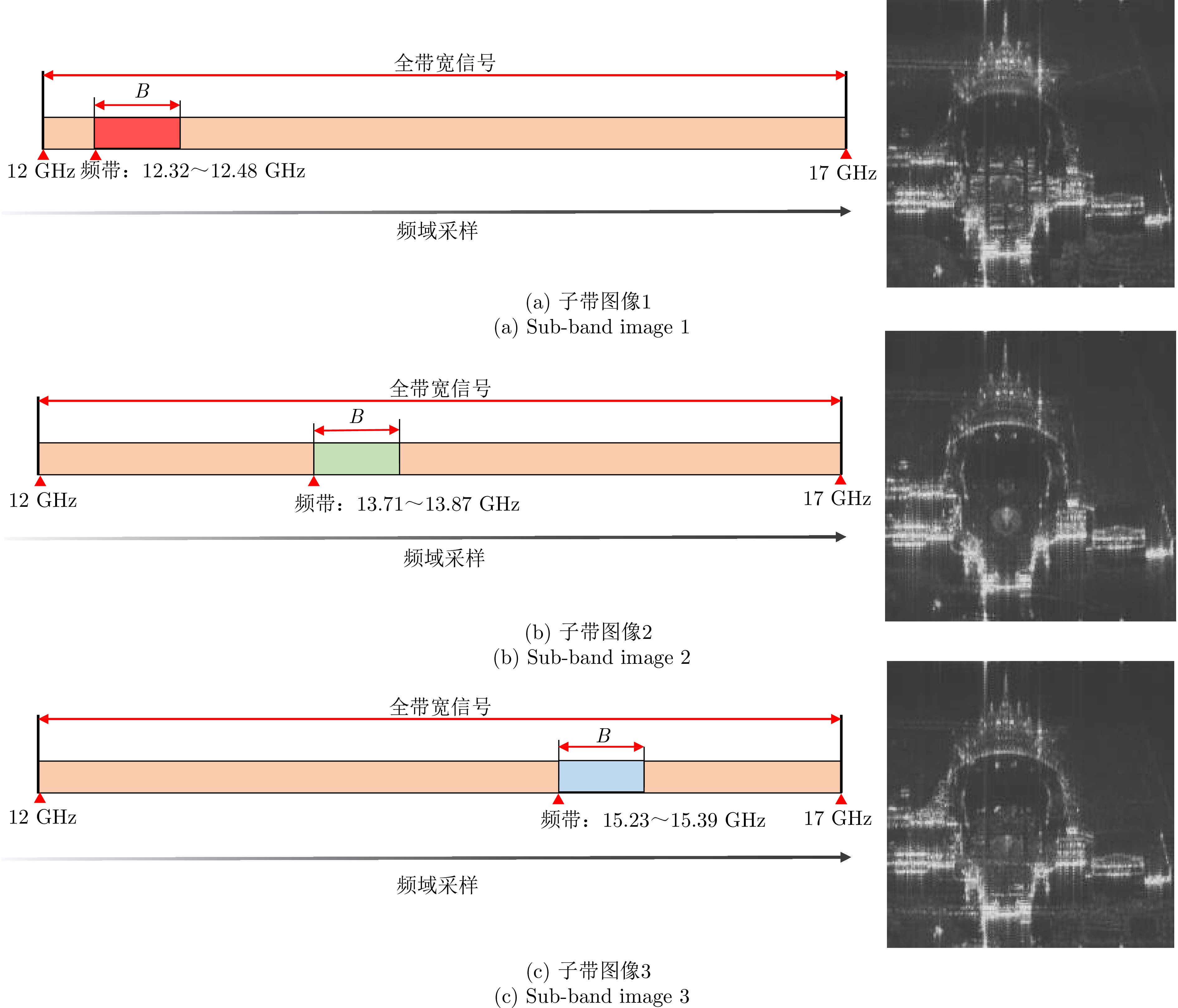
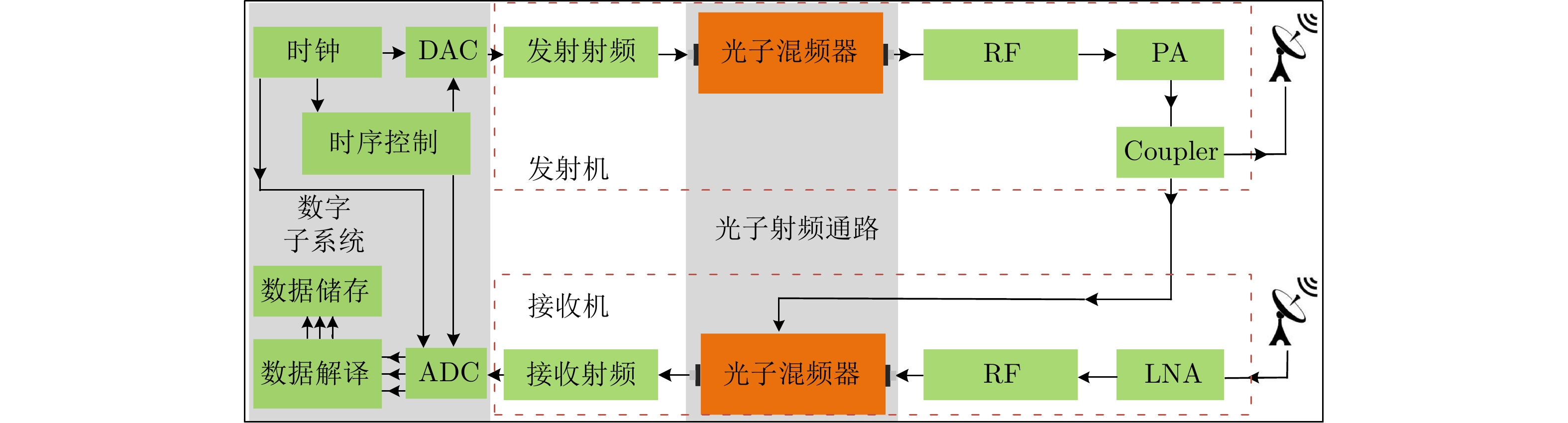
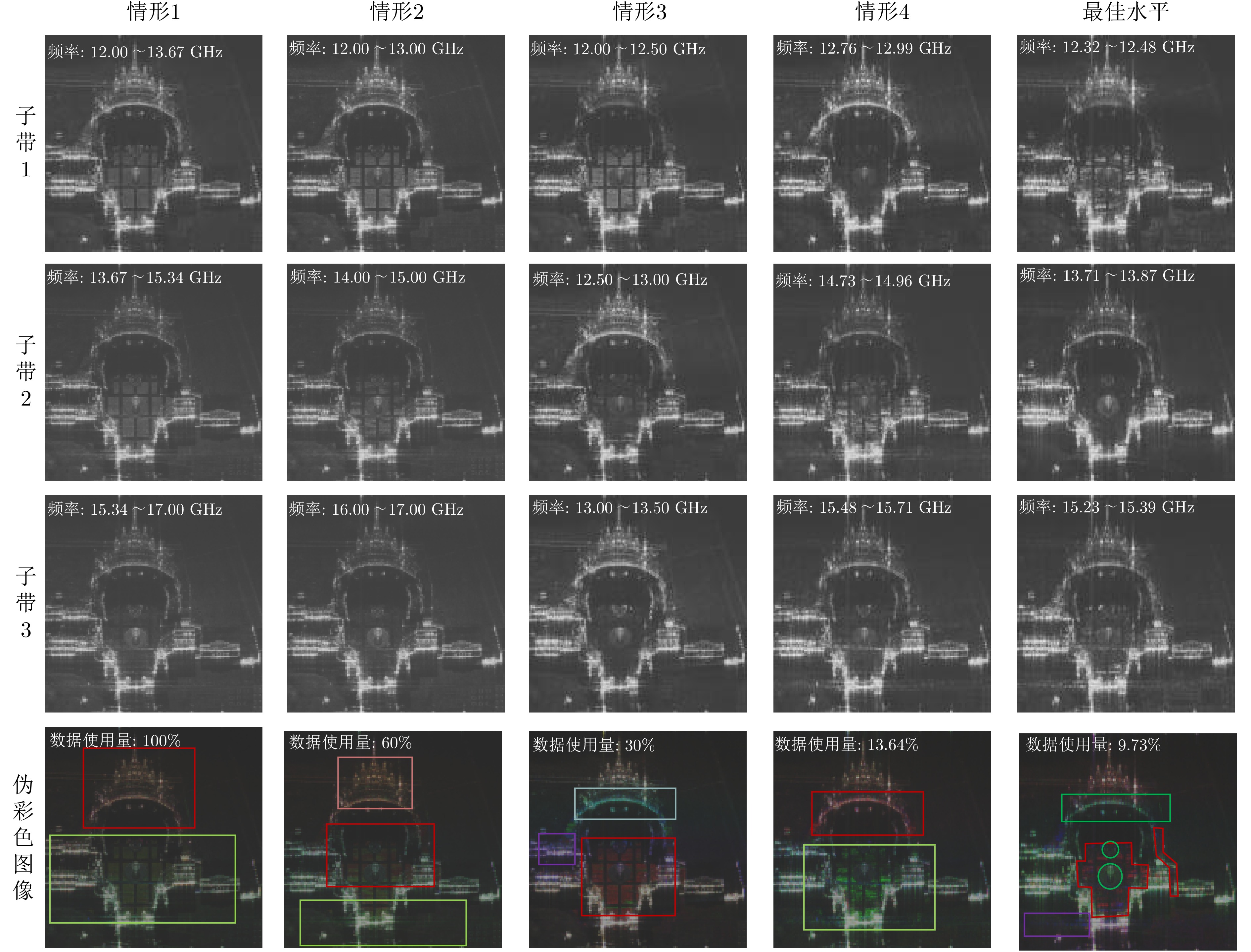
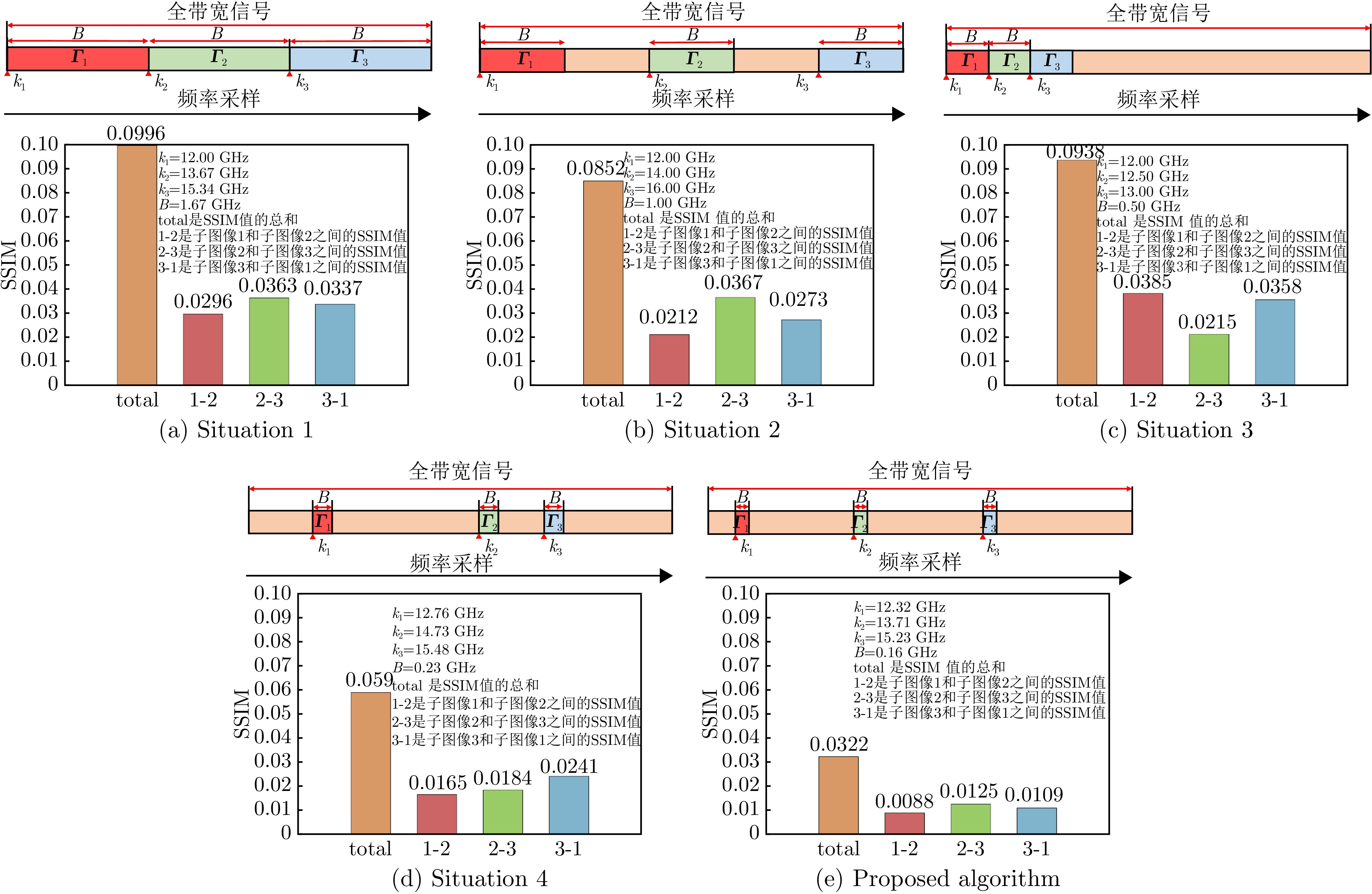
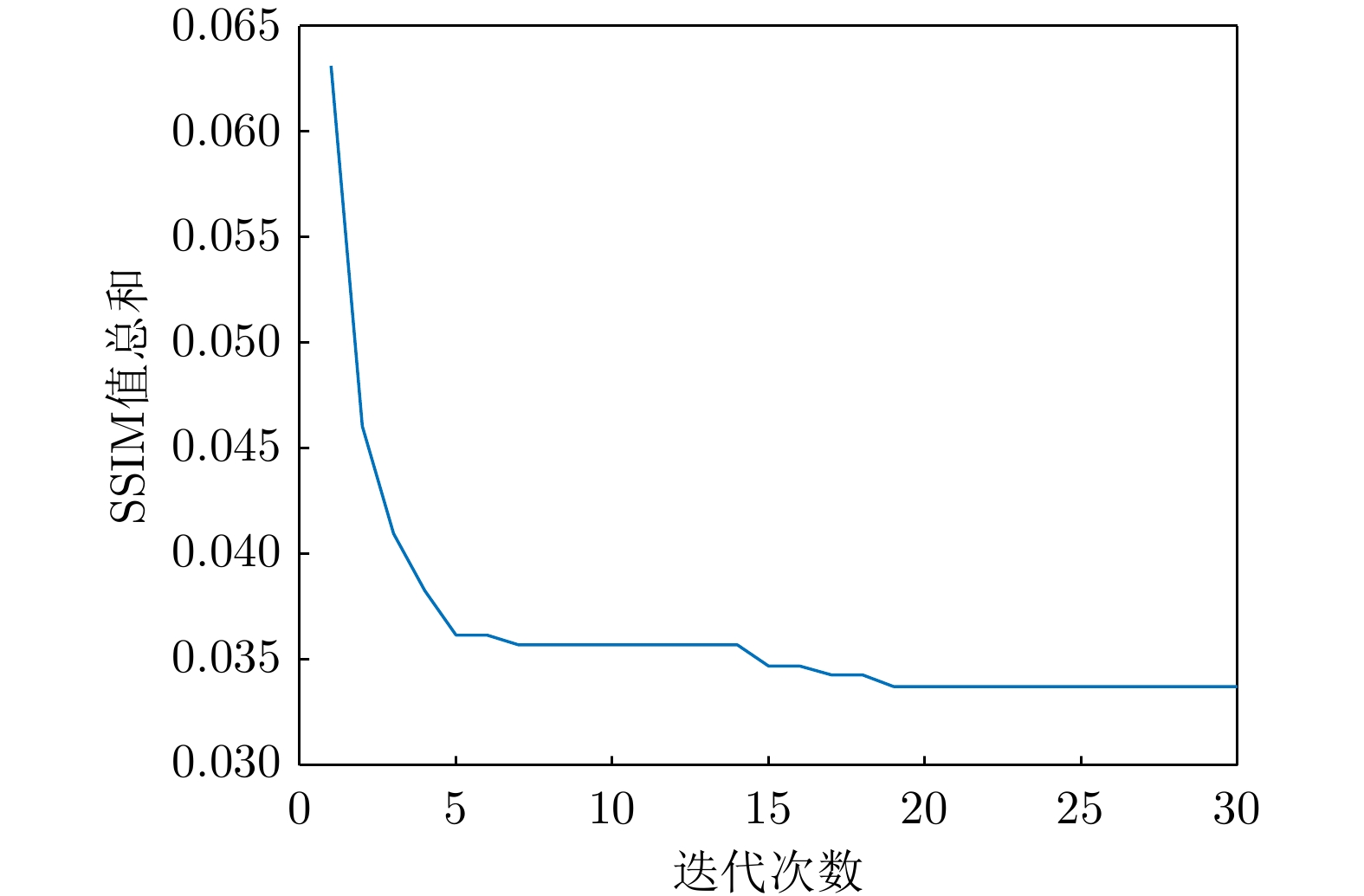
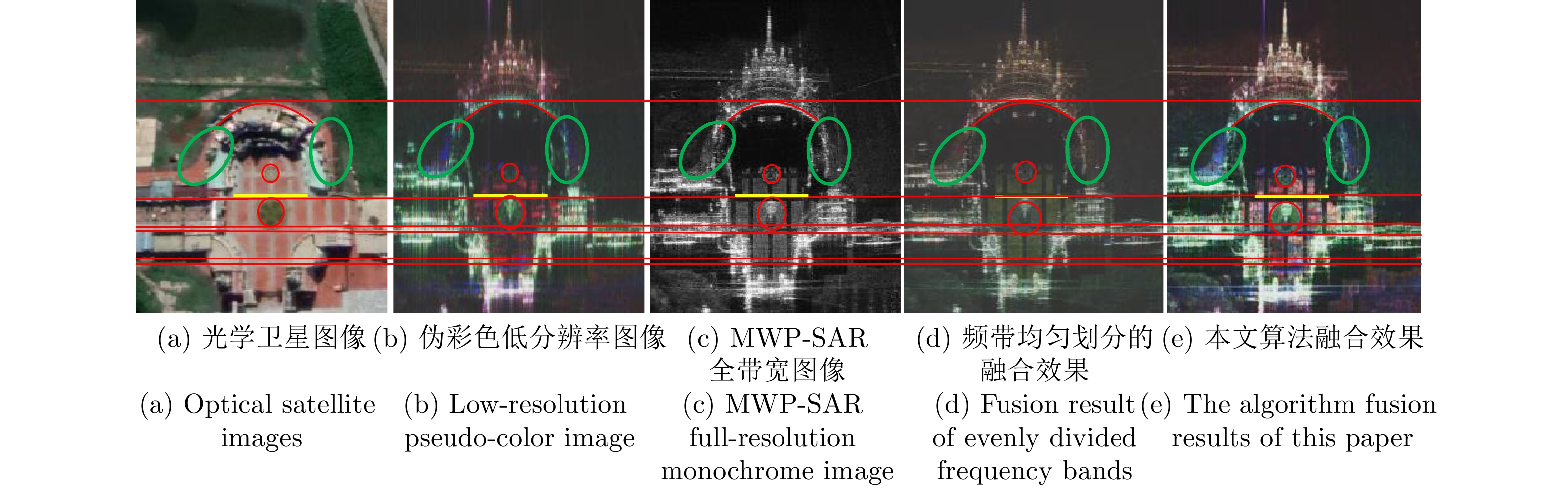
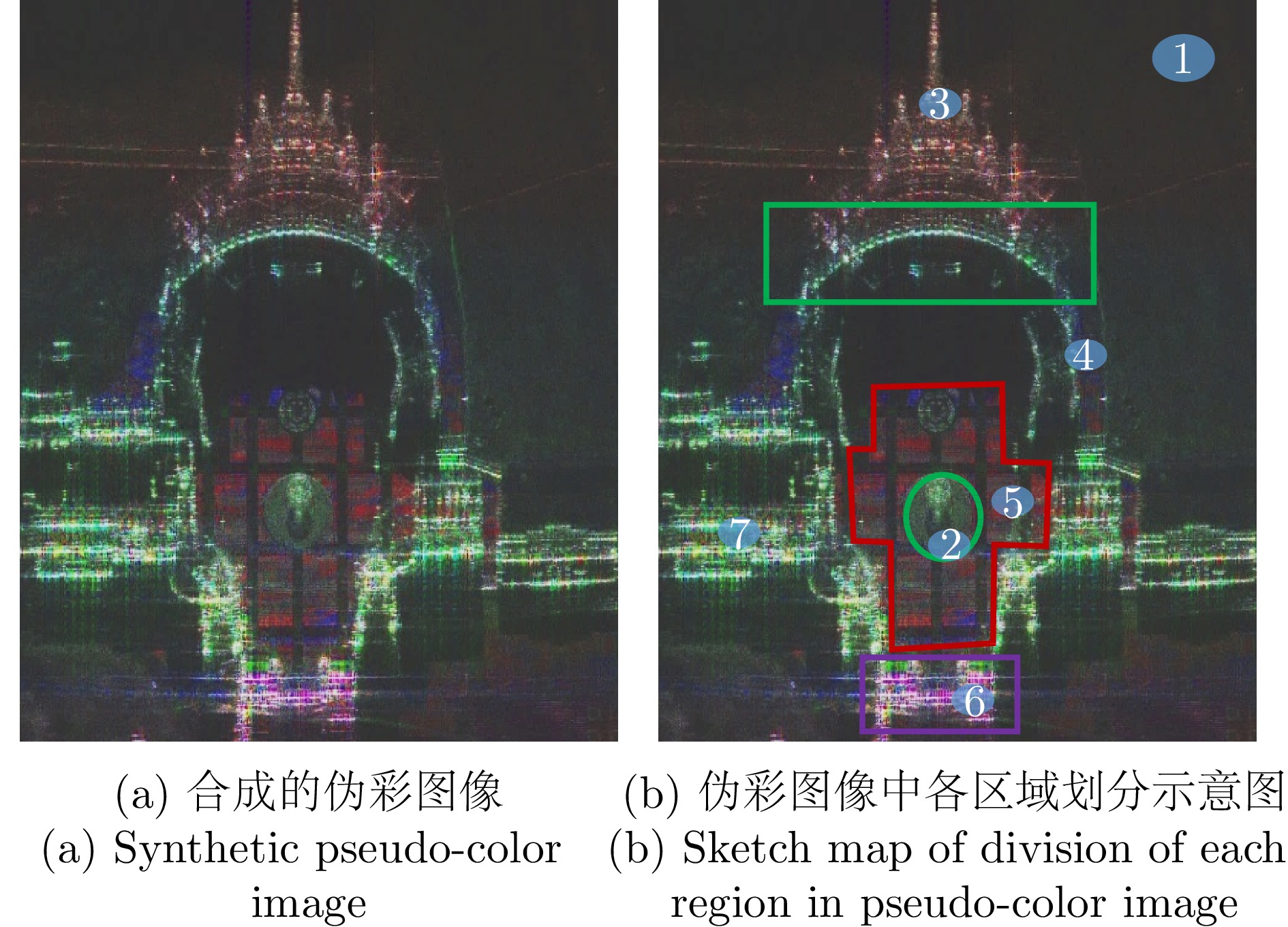
Microwave Photonic (MWP) radars have remarkably improved traditional microwave radar hardware architectures using photonics devices. With the exceptional physical properties of photonic devices, MWP radars can emit ultra-wideband, high-linearity, high-quality linear frequency modulation signals, allowing ultra-high-resolution target imaging and detection. Different target regions exhibit distinct responses to different frequency signals during target imaging and detection due to their diverse structures and characteristics. Therefore, MWP radars have the potential to generate pseudo-color images based on scattering differences, further enhancing the information retrieval capability of MWP Synthetic Aperture Radar (MWP-SAR). Pseudo-color images generated using traditional remote sensing techniques cannot achieve centimeter-level resolution. Therefore, we propose a method for generating pseudo-color images while maintaining the resolution of MWP-SAR. The algorithm first determines an optimal sub-band echo search model and subsequently employs the optimal sub-band search algorithm to process the ultra-wideband echoes to obtain sub-band echo channels with the largest scattering characteristic differences. The multi-sub-band images are then color-composited to generate pseudo-color images that best describe the target scattering characteristics. However, to ensure the high resolution of MWP-SAR, a fusion model is established to combine the full-resolution SAR image with the multi-sub-band image. Finally, full-resolution pseudo-color images are successfully synthesized using the measured airborne MWP-SAR data, validating the effectiveness of the algorithm. This algorithm enables MWP-SAR to obtain more target information during imaging, offering assistance in implementing imaging radar and microwave vision.
Microwave Photonic (MWP) radars have remarkably improved traditional microwave radar hardware architectures using photonics devices. With the exceptional physical properties of photonic devices, MWP radars can emit ultra-wideband, high-linearity, high-quality linear frequency modulation signals, allowing ultra-high-resolution target imaging and detection. Different target regions exhibit distinct responses to different frequency signals during target imaging and detection due to their diverse structures and characteristics. Therefore, MWP radars have the potential to generate pseudo-color images based on scattering differences, further enhancing the information retrieval capability of MWP Synthetic Aperture Radar (MWP-SAR). Pseudo-color images generated using traditional remote sensing techniques cannot achieve centimeter-level resolution. Therefore, we propose a method for generating pseudo-color images while maintaining the resolution of MWP-SAR. The algorithm first determines an optimal sub-band echo search model and subsequently employs the optimal sub-band search algorithm to process the ultra-wideband echoes to obtain sub-band echo channels with the largest scattering characteristic differences. The multi-sub-band images are then color-composited to generate pseudo-color images that best describe the target scattering characteristics. However, to ensure the high resolution of MWP-SAR, a fusion model is established to combine the full-resolution SAR image with the multi-sub-band image. Finally, full-resolution pseudo-color images are successfully synthesized using the measured airborne MWP-SAR data, validating the effectiveness of the algorithm. This algorithm enables MWP-SAR to obtain more target information during imaging, offering assistance in implementing imaging radar and microwave vision.






 微信 | 公众平台
微信 | 公众平台 

