
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
-
摘要: 合成孔径雷达(SAR)因其全天候、全天时的监测能力在民用和军事领域得到广泛应用。近年来,深度学习已被广泛应用于SAR图像自动解译。然而,由于卫星轨道和观测角度的限制,SAR目标样本面临视角覆盖率不全的问题,这为学习型SAR目标检测识别算法带来了挑战。该文提出一种融合可微分渲染的SAR多视角样本生成方法,结合逆向三维重建和正向渲染技术,通过卷积神经网络(CNN)从少量SAR视角图像中反演目标三维表征,然后利用可微分SAR渲染器(DSR)渲染出更多视角样本,实现样本在角度维的插值。另外,方法的训练过程使用DSR构建目标函数,无需三维真值监督。根据仿真数据的实验结果,该方法能够有效地增加多视角SAR目标图像,并提高小样本条件下典型SAR目标识别率。
-
关键词:
- 合成孔径雷达(SAR) /
- 可微分SAR渲染器(DSR) /
- 卷积神经网络(CNN) /
- 三维重建 /
- 多视角样本生成
Abstract: Synthetic Aperture Radar (SAR) is extensively utilized in civilian and military domains due to its all-weather, all-time monitoring capabilities. In recent years, deep learning has been widely employed to automatically interpret SAR images. However, due to the constraints of satellite orbit and incident angle, SAR target samples face the issue of incomplete view coverage, which poses challenges for learning-based SAR target detection and recognition algorithms. This paper proposes a method for generating multi-view samples of SAR targets by integrating differentiable rendering, combining inverse Three-Dimensional (3D) reconstruction, and forward rendering techniques. By designing a Convolutional Neural Network (CNN), the proposed method inversely infers the 3D representation of targets from limited views of SAR target images and then utilizes a Differentiable SAR Renderer (DSR) to render new samples from more views, achieving sample interpolation in the view dimension. Moreover, the training process of the proposed method constructs the objective function using DSR, eliminating the need for 3D ground-truth supervision. According to experimental results on simulated data, this method can effectively increase the number of multi-view SAR target images and improve the recognition rate of typical SAR targets under few-shot conditions. -
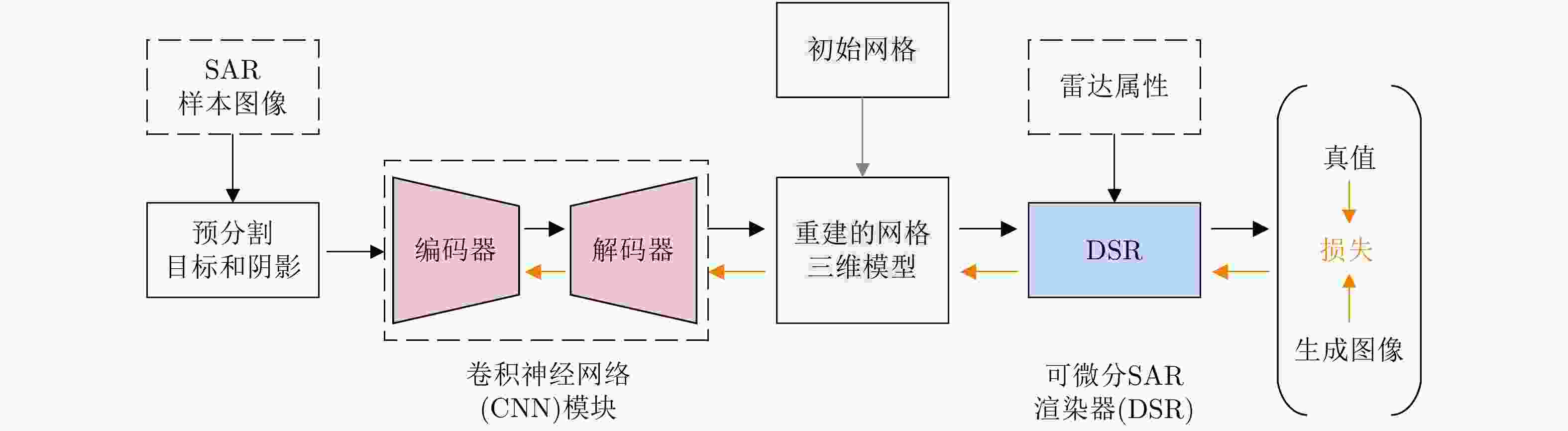
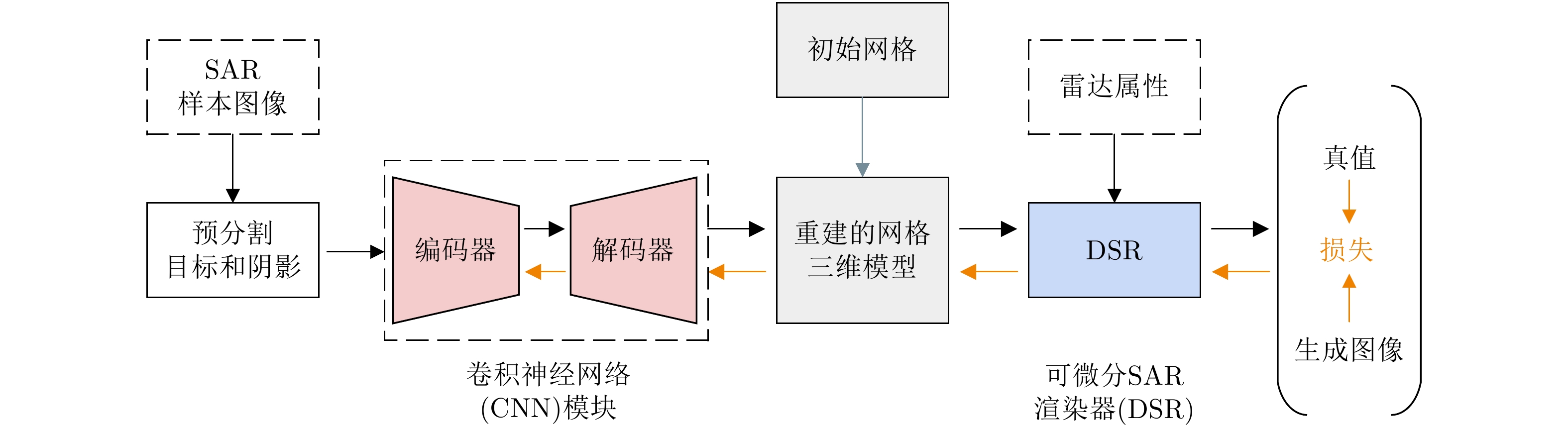
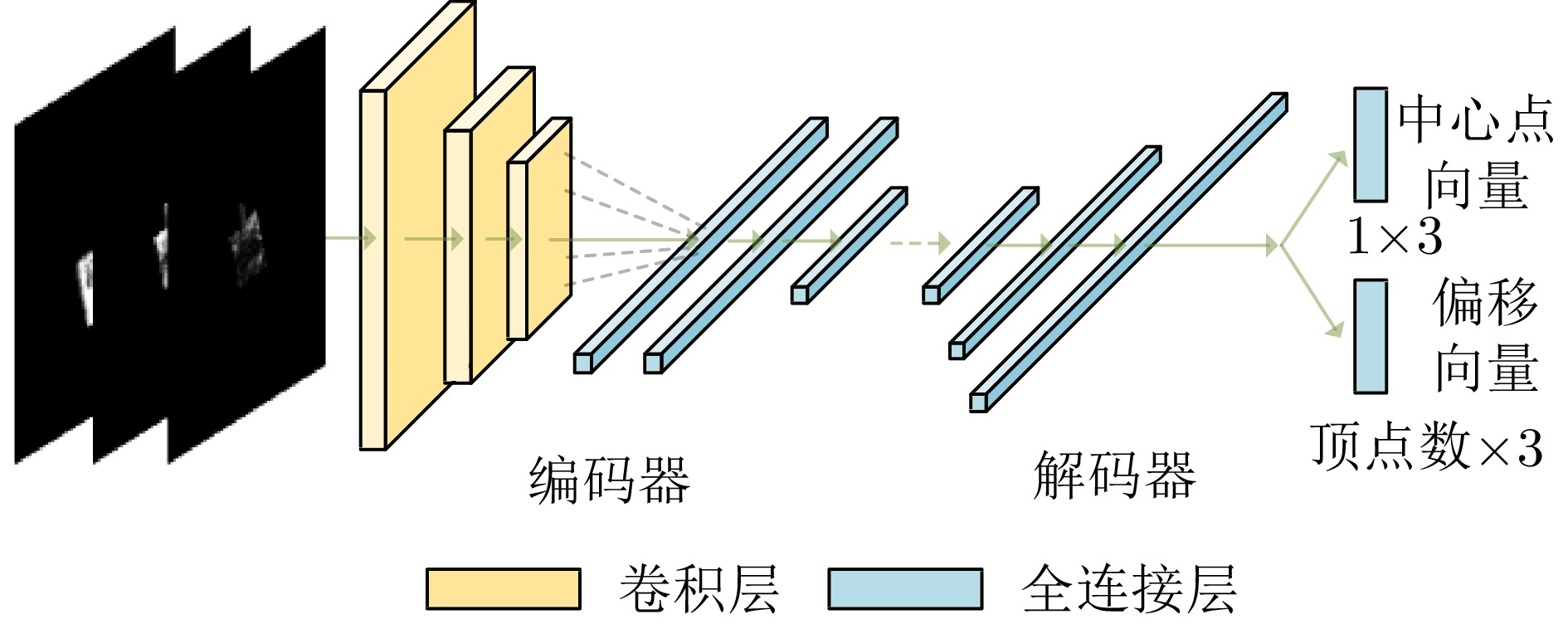
图 2 SAR多视角样本增广算法框架
Figure 2. Overall framework of multi-view sample augumentation for SAR
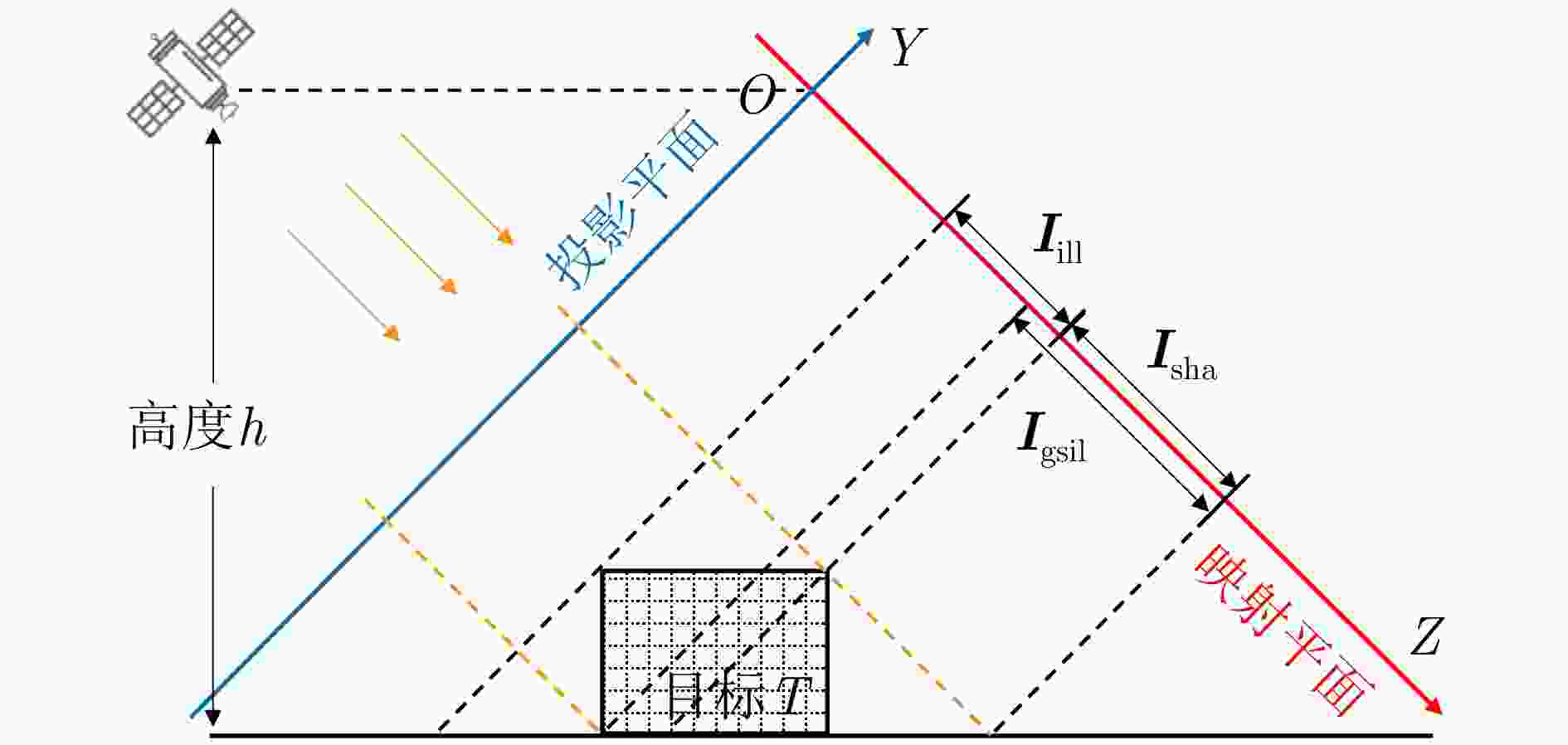
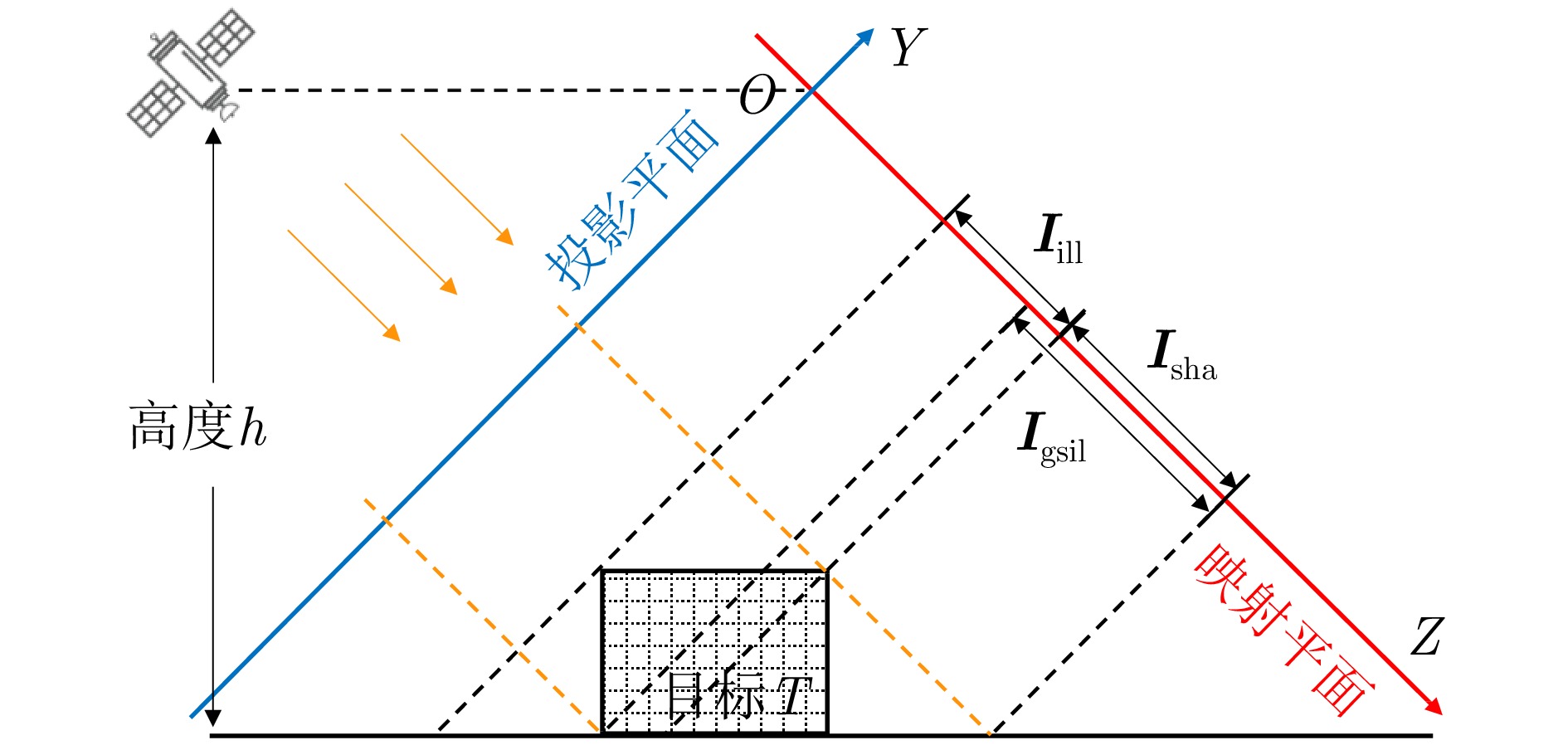
图 5 目标照射图和阴影图生成示意
Figure 5. Illustration of illumination map and shadow map generation

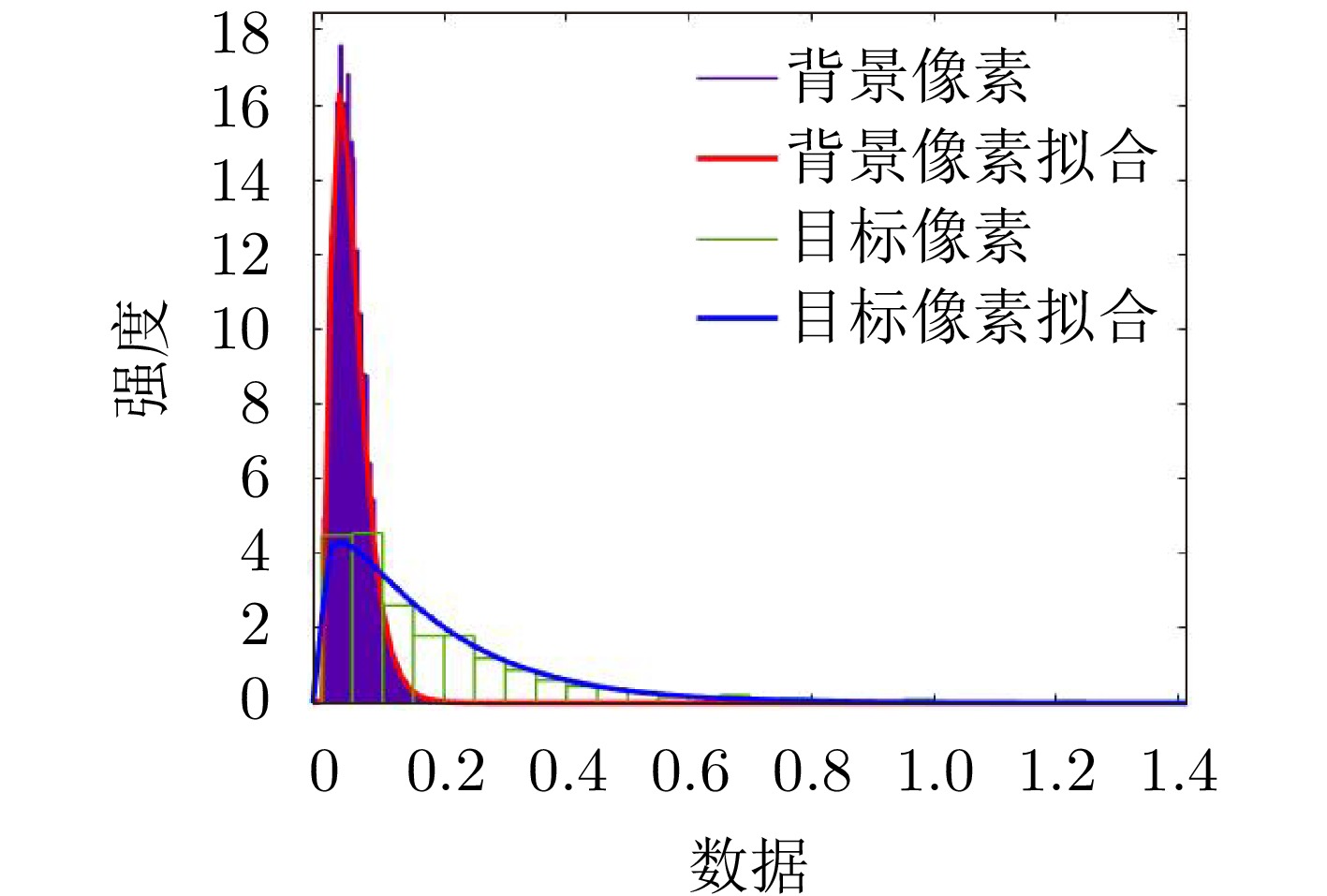
图 8 目标区域和背景区域像素的Gamma分布拟合
Figure 8. Gamma distribution fitting of pixel values in target and background regions
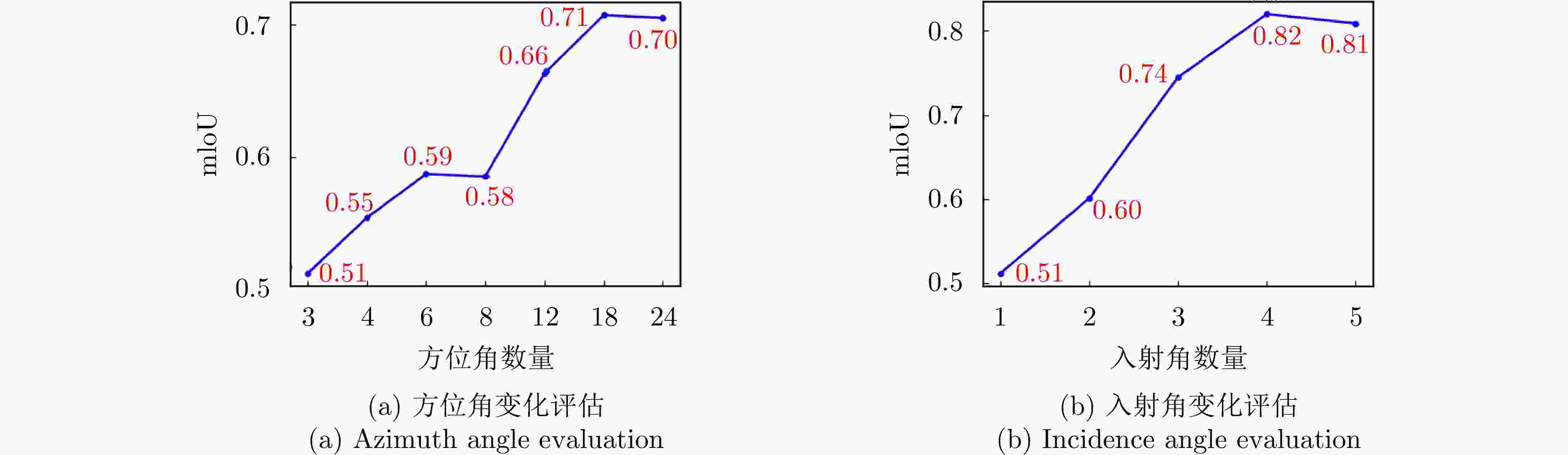
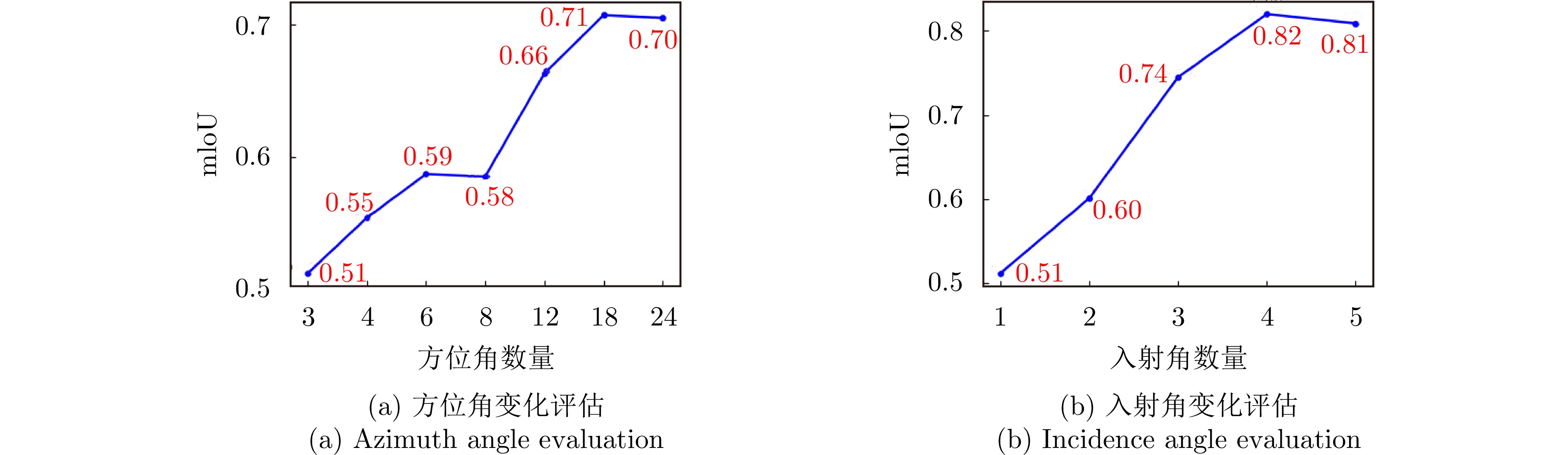
图 9 不同视角数量下的目标重建结果评估
Figure 9. Evaluation of target reconstruction results with different numbers of views

图 10 T72实测样本的目标和阴影区域分割示意
Figure 10. Illustration of target and shadow area segmentation for T72 measured samples

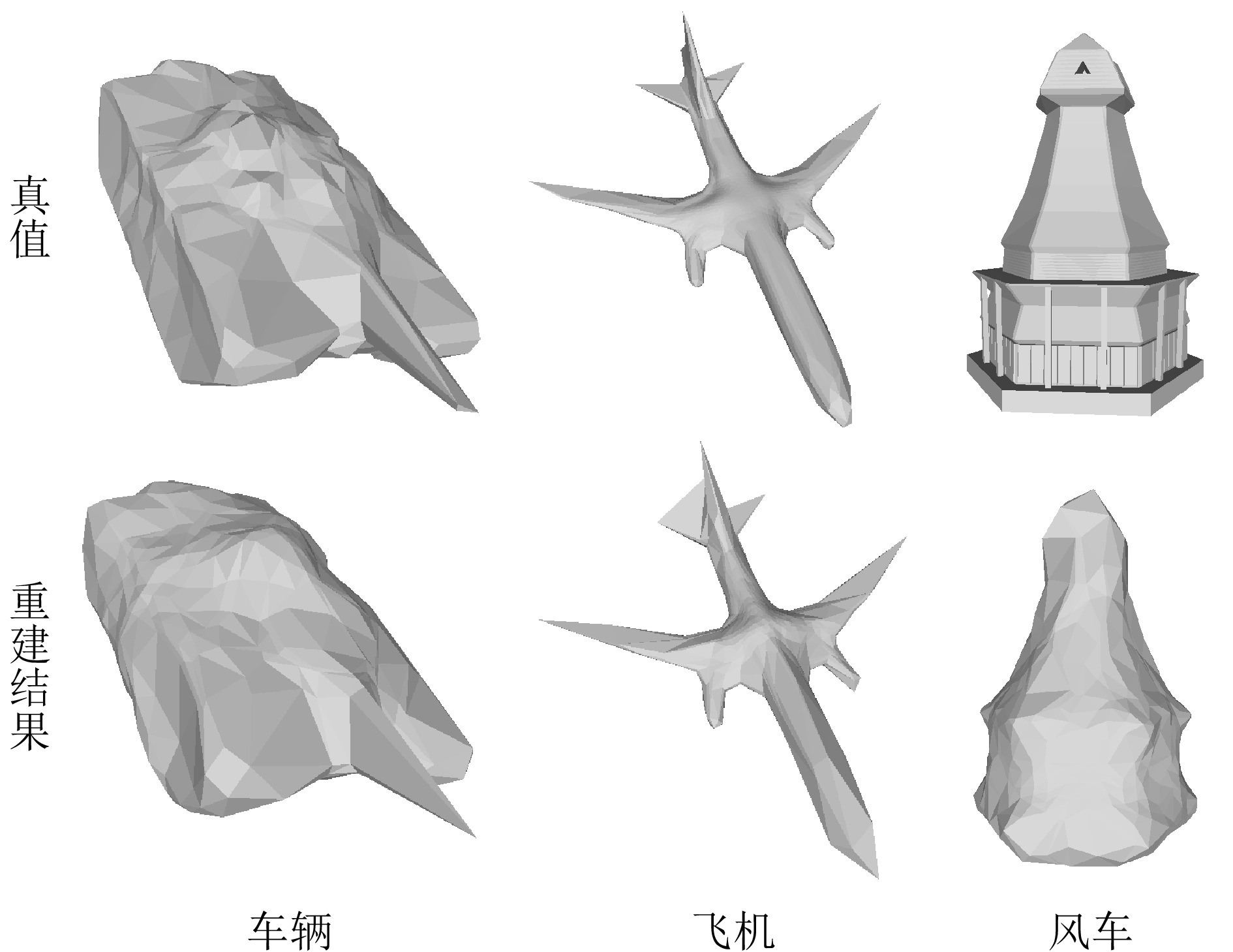
图 11 基于实测数据重建的目标三维模型可视化
Figure 11. Visualization of target 3D models reconstructed based on measured data
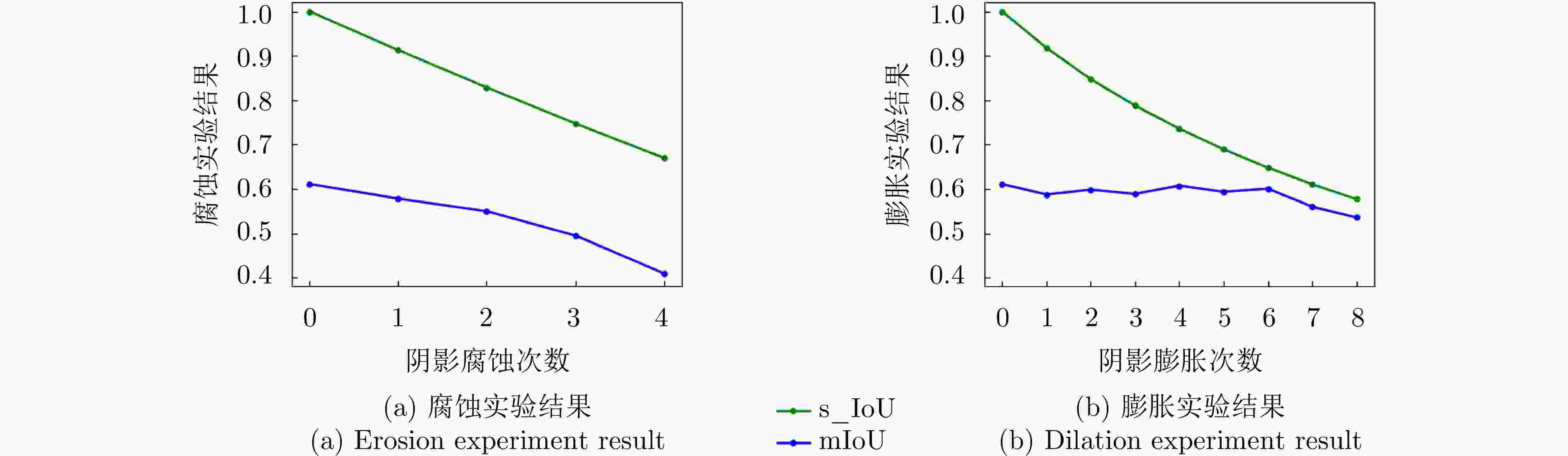
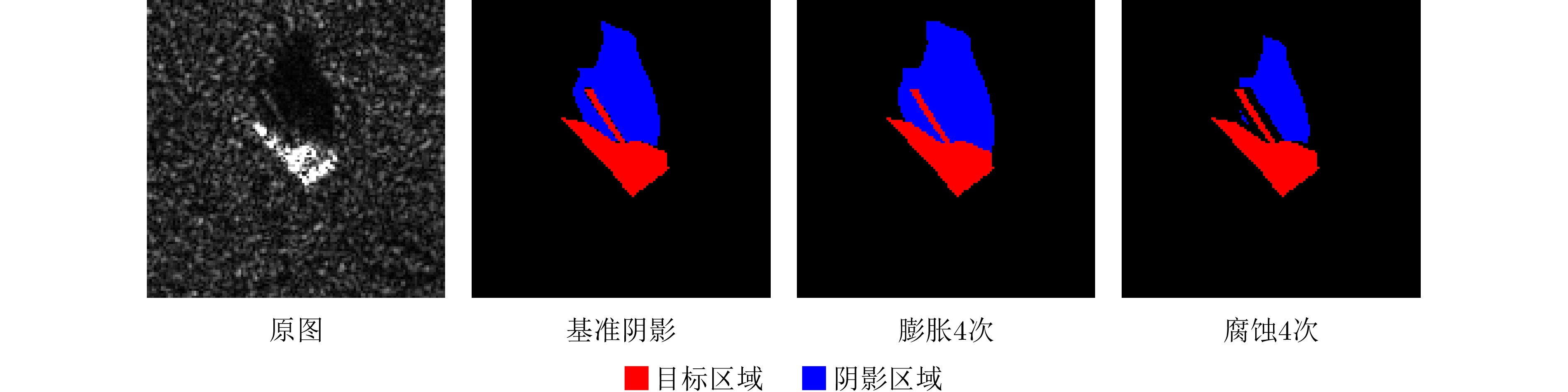
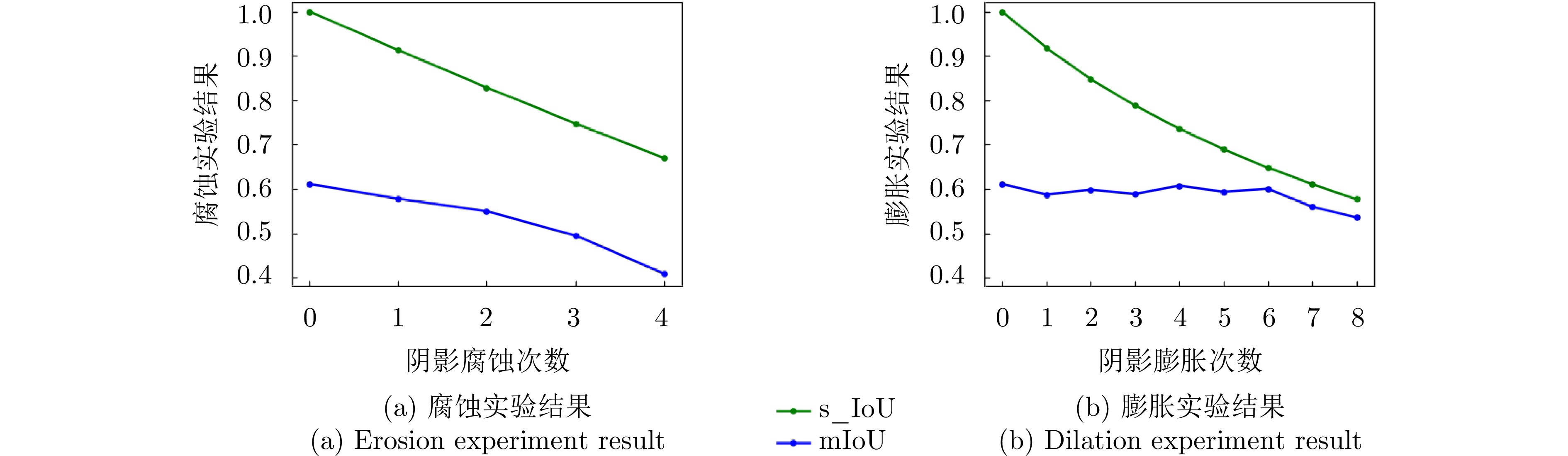
图 14 不同阴影分割准确性下的实验结果
Figure 14. Experimental results under different shadow segmentation accuracies

图 15 各类别中间结果的三维模型可视化
Figure 15. Visualization of intermediate 3D models for each category

图 16 各类别生成样本与真值可视化对比
Figure 16. Visualization comparison of generated samples and ground truth for each category
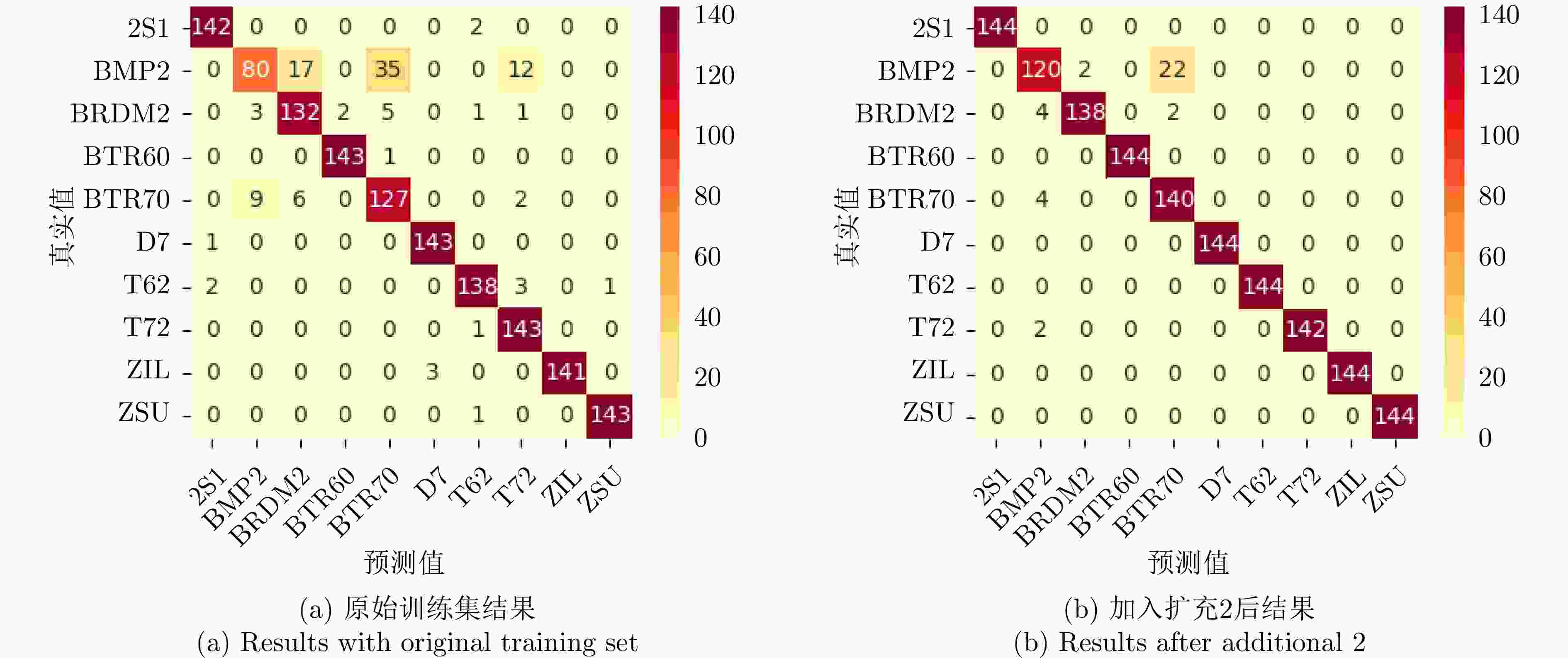
图 17 扩充前后识别结果混淆矩阵
Figure 17. Confusion matrices of recognition results before and after augmentation
表 1 仿真数据集信息
Table 1. Information of the simulated dataset
实验数据集 入射角$ \alpha $ 方位角$ \beta $ 训练集 {30°, 40°, 50°, 60°} {0°, 45°, 90°, ···, 315°} 测试集1 {30°, 40°, 50°, 60°} {30°, 75°, 120°, ···, 345°} 测试集2 {35°, 45°, 55°, 65°} {30°, 75°, 120°, ···, 345°}  下载: 导出CSV
下载: 导出CSV
表 2 各目标重建结果的mIoU
Table 2. mIoU of reconstruction results for each target
目标类型 训练集 测试集1 测试集2 车辆 0.8410 0.8375 0.8401 飞机 0.8629 0.8521 0.8554 风车 0.7860 0.7858 0.7880
下载: 导出CSV
表 3 小样本识别实验数据配置
Table 3. Configuration of experimental data for few-shot recognition
训练数据 入射角$ \alpha $ 方位角$ \beta $ 样本数量 训练集 {30°, 40°, 50°, 60°} {0°, 45°, 90°, ···, 315°} 320 测试集 {5°, 15°, 25°, ···, 355°} 1440 扩充1 {0°, 30°, 60°, ···, 330°} 480 扩充2 {0°, 20°, 40°, ···, 340°} 720 扩充3 {0°, 10°, 20°, ···, 350°} 1440
下载: 导出CSV
表 4 各类别重建三维模型结果评估
Table 4. Quantitative evaluation of intermediate 3D models for each category
目标 mIoU $ {{L}}_{\mathrm{f}\mathrm{l}\mathrm{a}\mathrm{t}} $ 目标 mIoU $ {{L}}_{\mathrm{f}\mathrm{l}\mathrm{a}\mathrm{t}} $ BRDM2 0.7919 0.0036 ZIL131 0.7995 0.0050 BTR60 0.7812 0.0029 ZSU234 0.6000 0.0029 D7 0.6653 0.0039 T72 0.6406 0.0032 2S1 0.8052 0.0030 BMP2 0.7982 0.0022 T62 0.7321 0.0040 BTR70 0.7781 0.0030
下载: 导出CSV
表 5 各类别散射纹理Gamma拟合参数估计
Table 5. Estimation of Gamma fitting parameters for scattering texture of each category
目标 背景区域 目标区域 参数a 参数b 参数a 参数b BRDM2 2.583 0.014 1.104 0.147 BTR60 2.125 0.022 1.094 0.185 D7 3.898 0.009 0.909 0.245 2S1 3.597 0.012 1.145 0.169 T62 3.331 0.010 1.070 0.191 ZIL131 4.076 0.008 1.080 0.157 ZSU234 3.144 0.009 0.955 0.216 T72 2.550 0.018 1.066 0.202 BMP2 2.561 0.018 1.027 0.191 BTR70 2.610 0.018 1.179 0.141
下载: 导出CSV
表 6 样本扩充与小样本识别结果
Table 6. Results of few-shot recognition with sample augmentation
训练数据 样本总数 旋转增强 准确率(%) VGG16 ResNet50 HRNet Swin-tiny 原训练集 320 – 89.65 92.50 85.35 89.79 √ 95.69 96.87 94.86 95.83 扩充1 800 – 94.24 96.94 95.76 94.24 扩充2 1040 – 96.32 97.50 95.83 94.65 扩充3 1760 – 95.90 97.29 95.69 96.39 √ 97.78 99.03 97.85 98.96
下载: 导出CSV
表 7 ResNet50的各类别识别结果准确率(%)
Table 7. Per-category recognition accuracy using ResNet50 (%)
训练数据 BRDM2 BTR60 D7 2S1 T62 ZIL ZSU T72 BMP2 BTR70 原始数据集 85.16 98.62 97.95 97.93 96.50 100 99.31 88.82 86.96 75.60 扩充1 99.26 100 100 99.31 100 100 100 100 90.62 82.25 扩充2 98.57 100 100 100 100 100 100 100 92.31 85.37 扩充3 99.29 100 100 100 100 100 98.63 99.31 86.90 89.04
下载: 导出CSV
-
[1] ZHANG Liangpei, ZHANG Lefei, and DU Bo. Deep learning for remote sensing data: A technical tutorial on the state of the art[J]. IEEE Geoscience and Remote Sensing Magazine, 2016, 4(2): 22–40. doi: 10.1109/MGRS.2016.2540798. [2] MA Lei, LIU Yu, ZHANG Xueliang, et al. Deep learning in remote sensing applications: A meta-analysis and review[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2019, 152: 166–177. doi: 10.1016/j.isprsjprs.2019.04.015. [3] ZHU Xiaoxiang, TUIA D, MOU Lichao, et al. Deep learning in remote sensing: A comprehensive review and list of resources[J]. IEEE Geoscience and Remote Sensing Magazine, 2017, 5(4): 8–36. doi: 10.1109/MGRS.2017.2762307. [4] SUN Xian, WANG Bing, WANG Zhirui, et al. Research progress on few-shot learning for remote sensing image interpretation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 2387–2402. doi: 10.1109/JSTARS.2021.3052869. [5] HUANG Zhongling, PAN Zongxu, and LEI Bin. What, where, and how to transfer in SAR target recognition based on deep CNNs[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(4): 2324–2336. doi: 10.1109/TGRS.2019.2947634. [6] SHORTEN C and KHOSHGOFTAAR T M. A survey on image data augmentation for deep learning[J]. Journal of Big Data, 2019, 6(1): 60. doi: 10.1186/s40537-019-0197-0. [7] HENDRYCKS D, MU N, CUBUK E D, et al. AugMix: A simple data processing method to improve robustness and uncertainty[C]. 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 2010. [8] ALFASSY A, KARLINSKY L, AIDES A, et al. LaSO: Label-set operations networks for multi-label few-shot learning[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 6541–6550. doi: 10.1109/CVPR.2019.00671. [9] SCHWARTZ E, KARLINSKY L, SHTOK J, et al. Δ-encoder: An effective sample synthesis method for few-shot object recognition[C]. 32nd International Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 2850–2860. [10] ANTONIOU A, STORKEY A, and EDWARDS H. Data augmentation generative adversarial networks[EB/OL]. https://arxiv.org/abs/1711.04340v3, 2018. [11] MALMGREN-HANSEN D, KUSK A, DALL J, et al. Improving SAR automatic target recognition models with transfer learning from simulated data[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(9): 1484–1488. doi: 10.1109/LGRS.2017.2717486. [12] GUO Jiayi, LEI Bin, DING Chibiao, et al. Synthetic aperture radar image synthesis by using generative adversarial nets[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(7): 1111–1115. doi: 10.1109/LGRS.2017.2699196. [13] SONG Qian, XU Feng, ZHU Xiaoxiang, et al. Learning to generate SAR images with adversarial autoencoder[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5210015. doi: 10.1109/TGRS.2021.3086817. [14] GUO Qian and XU Feng. Learning low-dimensional SAR target representations from few samples[C]. 2022 International Applied Computational Electromagnetics Society Symposium, Xuzhou, China, 2022: 1–2. doi: 10.1109/ACES-China56081.2022.10065101. [15] LIU Shichen, CHEN Weikai, LI Tianye, et al. Soft rasterizer: A differentiable renderer for image-based 3D reasoning[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 7708–7717. doi: 10.1109/ICCV.2019.00780. [16] WANG Nanyang, ZHANG Yinda, LI Zhuwen, et al. Pixel2Mesh: Generating 3D mesh models from single RGB images[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 52–67. doi: 10.1007/978-3-030-01252-6_4. [17] WEN Chao, ZHANG Yinda, LI Zhuwen, et al. Pixel2Mesh++: Multi-view 3D mesh generation via deformation[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 1042–1051. doi: 10.1109/ICCV.2019.00113. [18] FU Shilei and XU Feng. Differentiable SAR renderer and image-based target reconstruction[J]. IEEE Transactions on Image Processing, 2022, 31: 6679–6693. doi: 10.1109/TIP.2022.3215069. [19] KATO H, USHIKU Y, and HARADA T. Neural 3D mesh renderer[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3907–3916. doi: 10.1109/CVPR.2018.00411. [20] XU Feng and JIN Yaqiu. Imaging simulation of polarimetric SAR for a comprehensive terrain scene using the mapping and projection algorithm[J]. IEEE Transactions on Geoscience and Remote Sensing, 2006, 44(11): 3219–3234. doi: 10.1109/TGRS.2006.879544. [21] FU Shilei, JIA Hecheng, PU Xinyang, et al. Extension of differentiable SAR renderer for ground target reconstruction from multiview images and shadows[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5217013. doi: 10.1109/TGRS.2023.3320515. [22] Moving and stationary target acquisition and recognition (MSTAR) public release data[EB/OL]. https://www.sdms.afrl.af.mil/index.php?collection=mstar. [23] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. [24] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [25] SUN Ke, XIAO Bin, LIU Dong, et al. Deep high-resolution representation learning for human pose estimation[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5693–5703. doi: 10.1109/CVPR.2019.00584. [26] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 10012–10022. DOi: 10.1109/ICCV48922.2021.00986. -










计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

