
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor Work- Home
- Articles & Issues
-
Data
- Dataset of Radar Detecting Sea
- SAR Dataset
- SARGroundObjectsTypes
- SARMV3D
- AIRSAT Constellation SAR Land Cover Classification Dataset
- 3DRIED
- UWB-HA4D
- LLS-LFMCWR
- FAIR-CSAR
- MSAR
- SDD-SAR
- FUSAR
- SpaceborneSAR3Dimaging
- Sea-land Segmentation
- SAR Multi-domain Ship Detection Dataset
- SAR-Airport
- Hilly and mountainous farmland time-series SAR and ground quadrat dataset
- SAR images for interference detection and suppression
- HP-SAR Evaluation & Analytical Dataset
- GDHuiYan-ATRNet
- Multi-System Maritime Low Observable Target Dataset
- DatasetinthePaper
- DatasetintheCompetition
- Report
- Course
- About
- Publish
- Editorial Board
- Chinese
| Citation: | ZOU Kun, LAI Lei, LUO Yanbo, et al. Suppression of non-Gaussian clutter from subspace interference[J]. Journal of Radars, 2020, 9(4): 715–722. doi: 10.12000/JR19050

|
Suppression of Non-Gaussian Clutter from Subspace Interference
DOI: 10.12000/JR19050 CSTR: 32380.14.JR19050
More Information-
Abstract
In complex electromagnetic environments, a clutter covariance matrix is required to estimate in the on-line manner, so as to adaptively adjust the filter weight to effectively suppress clutter, thereby improving target estimation, detection, location, and tracking. In this paper, a non-Gaussian clutter model is considered, while apart of the clutter data maybe contaminated by subspace interference, wherein the signal of interest is located in the subspace. To this end, we propose a knowledge-aided hierarchical Bayesian model and obtain the approximated posterior distribution of the clutter covariance matrix by exploiting variational Bayesian inference methods. The target detection performance can be enhanced using a clutter-suppression filter that is designed based on the posterior mean of the clutter covariance matrix. A comparison of the computer simulation results with real clutter data confirms that the proposed method can suppress the clutter and improve detection performance. -

-
References
[1] XU Shuwen, SHUI Penglang, and YAN Xueying. Non-coherent detection of radar target in heavy-tailed sea clutter using bi-window non-linear shrinkage map[J]. IET Signal Processing, 2016, 10(9): 1031–1039. doi: 10.1049/iet-spr.2015.0564[2] GAO Lei, JING Zhongliang, LI Minzhe, et al. Robust adaptive filtering for extended target tracking with heavy-tailed noise in clutter[J]. IET Signal Processing, 2018, 12(7): 826–835. doi: 10.1049/iet-spr.2017.0249[3] LU Shuping, YI Wei, LIU Weijian, et al. Data-dependent clustering-CFAR detector in heterogeneous environment[J]. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(1): 476–485. doi: 10.1109/TAES.2017.2740065[4] ZHANG Wei, HE Zishu, LI Huiyong, et al. Beam-space reduced-dimension space-time adaptive processing for airborne radar in sample starved heterogeneous environments[J]. IET Radar, Sonar & Navigation, 2016, 10(9): 1627–1634. doi: 10.1049/iet-rsn.2015.0592[5] SHI Sainan and SHUI Penglang. Optimum coherent detection in homogenous K-distributed clutter[J]. IET Radar, Sonar & Navigation, 2016, 10(8): 1477–1484. doi: 10.1049/iet-rsn.2015.0602[6] HAO Chengpeng, ORLANDO D, FOGLIA G, et al. Knowledge-based adaptive detection: Joint exploitation of clutter and system symmetry properties[J]. IEEE Signal Processing Letters, 2016, 23(10): 1489–1493. doi: 10.1109/LSP.2016.2601931[7] MEHRNOUSH M and ROY S. Coexistence of WLAN network with radar: Detection and interference mitigation[J]. IEEE Transactions on Cognitive Communications and Networking, 2017, 3(4): 655–667. doi: 10.1109/TCCN.2017.2762663[8] BESSON O and BIDON S. Adaptive processing with signal contaminated training samples[J]. IEEE Transactions on Signal Processing, 2013, 61(17): 4318–4329. doi: 10.1109/TSP.2013.2269048[9] COHEN D, MISHRA K V, and ELDAR Y C. Spectrum sharing radar: Coexistence via xampling[J]. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(3): 1279–1296. doi: 10.1109/TAES.2017.2780599[10] SOERGEL U. Radar Remote Sensing of Urban Areas[M]. Dordrecht: Springer, 2010. 1–47.[11] LEFAIDA S, SOLTANI F, and MEZACHE A. Radar sea-clutter modelling using fractional generalised Pareto distribution[J]. Electronics Letters, 2018, 54(16): 999–1001. doi: 10.1049/el.2018.5233[12] SANGSTON K J and FARINA A. Coherent radar detection in compound-Gaussian clutter: Clairvoyant detectors[J]. IEEE Aerospace and Electronic Systems Magazine, 2016, 31(11): 42–63. doi: 10.1109/MAES.2016.150132[13] MITCHELL A E, SMITH G E, BELL K L, et al. Hierarchical fully adaptive radar[J]. IET Radar, Sonar & Navigation, 2018, 12(12): 1371–1379. doi: 10.1049/iet-rsn.2018.5339[14] HADAVI M, RADMARD M, and NAYEBI M M. Polynomial segment model for radar target recognition using Gibbs sampling approach[J]. IET Signal Processing, 2017, 11(3): 285–294. doi: 10.1049/iet-spr.2014.0455[15] TURLAPATY A and JIN Yuanwei. Multi-parameter estimation in compound Gaussian clutter by Variational Bayesian[J]. IEEE Transactions on Signal Processing, 2016, 64(18): 4663–4678. doi: 10.1109/TSP.2016.2573760[16] CONTE E, DE MAIO A, and GALDI C. Statistical analysis of real clutter at different range resolutions[J]. IEEE Transactions on Aerospace and Electronic Systems, 2004, 40(3): 903–918. doi: 10.1109/TAES.2004.1337463 -
Proportional views

- Publishing Ethics
- Journal Insights
- Abstracting & Indexing
- Peer Review Policies
- Guide for Authors
- Conference
- ISSN 2095-283X (Print)ISSN 2097-339X (Online)
- CN 10-1030/TN
- CODEN LXEUAO
About Journal
- Sponsor: China Radio Detection and Ranging Industry Association (CRIA)
- Phone: 010-58887062
- Email:radars@aircas.ac.cn
- Publisher: Leida Xuebao Bianjibu (Editorial office of the Journal of Radars)
Contacts Us

京ICP备20021838号-14
Supported by: Beijing Renhe Information Technology Co. Ltd

Export File
Citation
Format
Content
 DownLoad:
DownLoad:

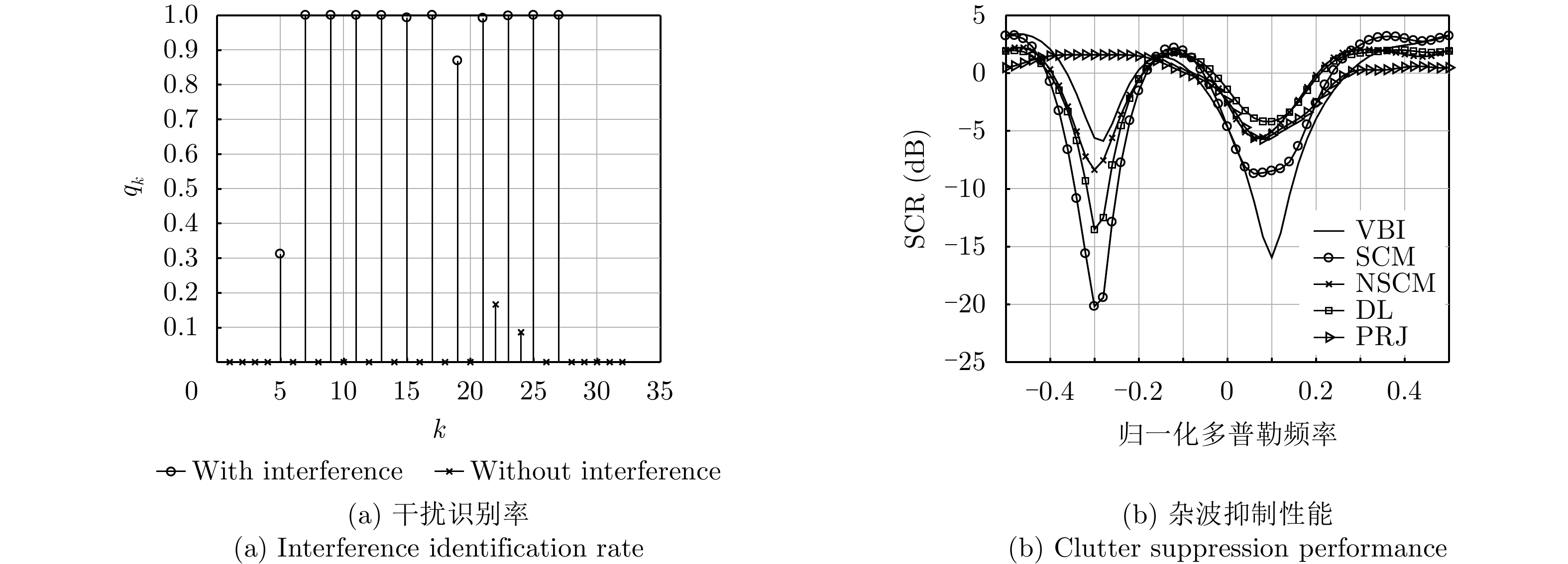
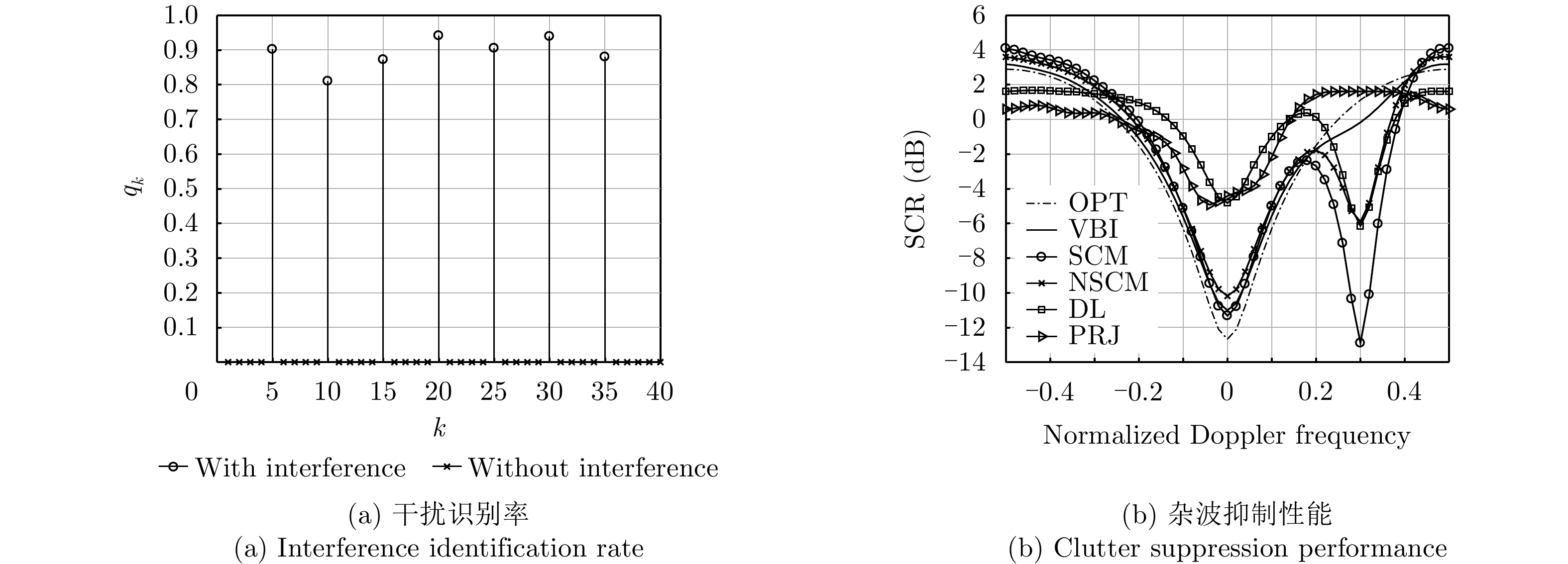
- Figure 1. Interference identification and clutter suppression with η=17.5% using simulated data
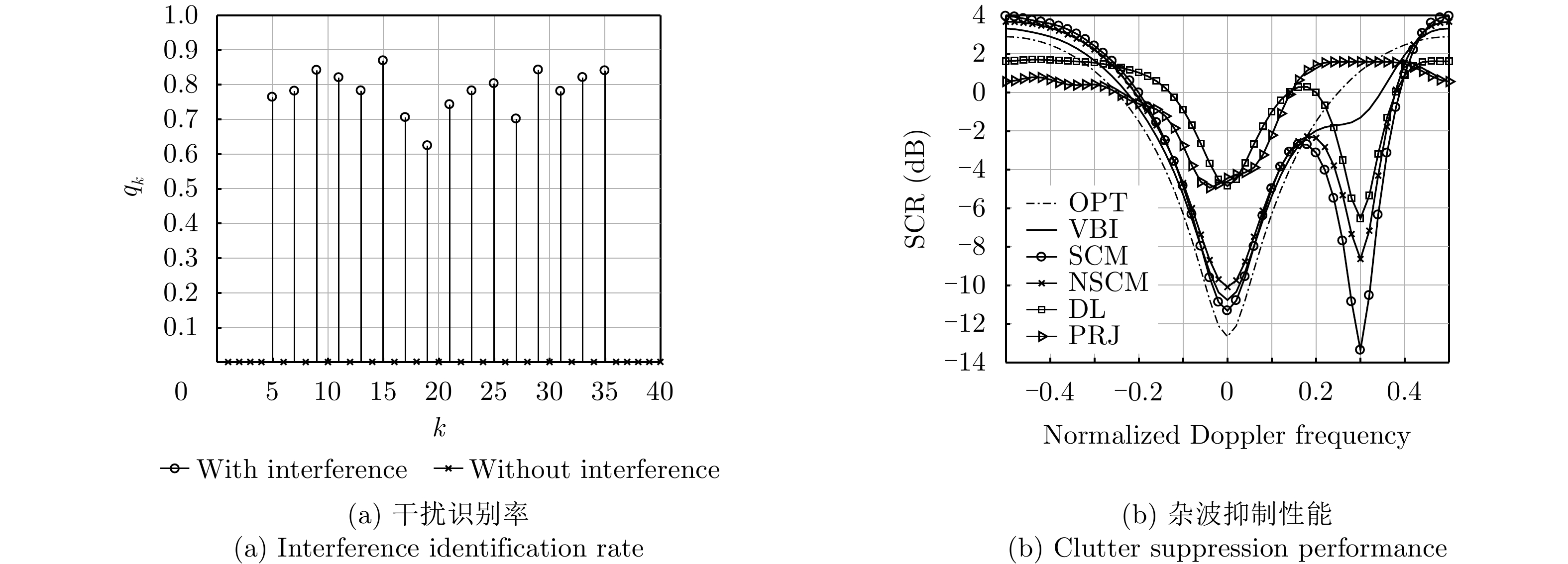
- Figure 2. Interference identification and clutter suppression with η=40.0% using simulated data
- Figure 3. Interference identification and clutter suppression with η=77.5% using simulated data
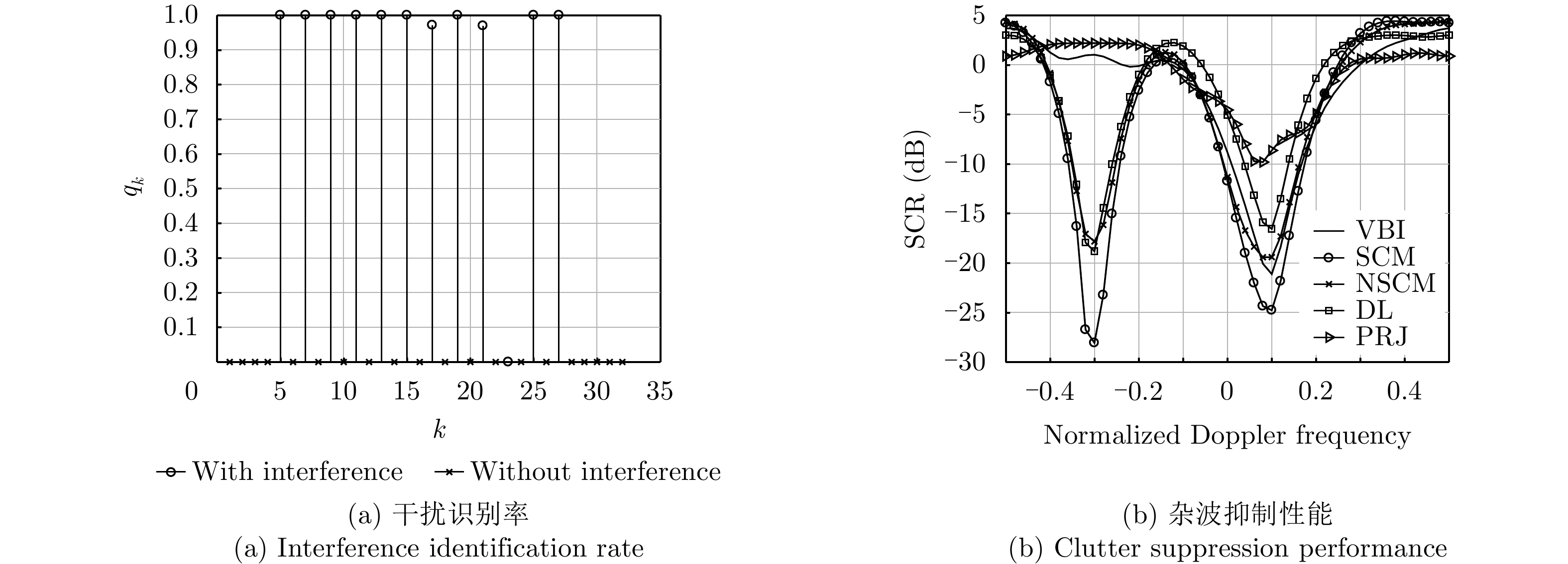
- Figure 4. Interference identification and clutter suppression with η=40.0% using IPIX dataset (30 m resolution)
- Figure 5. Interference identification and clutter suppression with η=40.0% using IPIX dataset (15 m resolution)