
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
-
摘要: “合成孔径雷达微波视觉三维成像”,从概念上说,旨在将“视觉语义”引入到合成孔径雷达的成像模型中,以期提高三维成像的质量。对层析合成孔径雷达(TomoSAR)来说, “视觉语义”的引入可望有效减少TomoSAR所需的观测次数。然而,什么是“视觉语义”?从视觉感知的途径看, “单眼”和“双眼”均可以从场景感知三维结构信息;从场景内容看,不同的人对同一幅图像会有不同感受;从视觉神经加工机理看,三维信息加工和二维信息加工也存在一些本质差异。另外,人类视觉感知普遍存在错觉(illusion)现象。那么,到底什么类型的“视觉语义信息”可望在计算的层次上有助于微波三维成像呢?如何借鉴计算机视觉的理论和方法来提取微波三维成像中有用的“视觉语义”信息呢?该文对这些问题进行了一些初步探讨。Abstract: Conceptually speaking, Synthetic Aperture Radar (SAR) microwave vision 3D imaging refers to fusing visual semantics into the SAR 3D imaging process to enhance the 3D imaging quality. For SAR Tomography (TomoSAR), it specifically means to reduce the needed observations by fully exploiting SAR visual semantics. However, what does it mean by visual semantics? From the viewpoint of visual perception, 3D structural information could be perceived from either monocular image or binocular images and the same scene could be perceived differently by different people. From the viewpoint of neurophysiology, depth perception from binocular or monocular vision has fundamentally different mechanism. Besides visual illusion phenomenon is omnipresent in daily life. Hence what kinds of visual semantics could be helpful for SAR 3D imaging from the computational point of view? What could be learnt from computer vision community to extract useful visual semantics from SAR images? This short note presents some preliminary discussions on such issues, a purely personal view on such vast topics.
-
Key words:
- Visual pathway /
- Microwave vision /
- TomoSAR
-
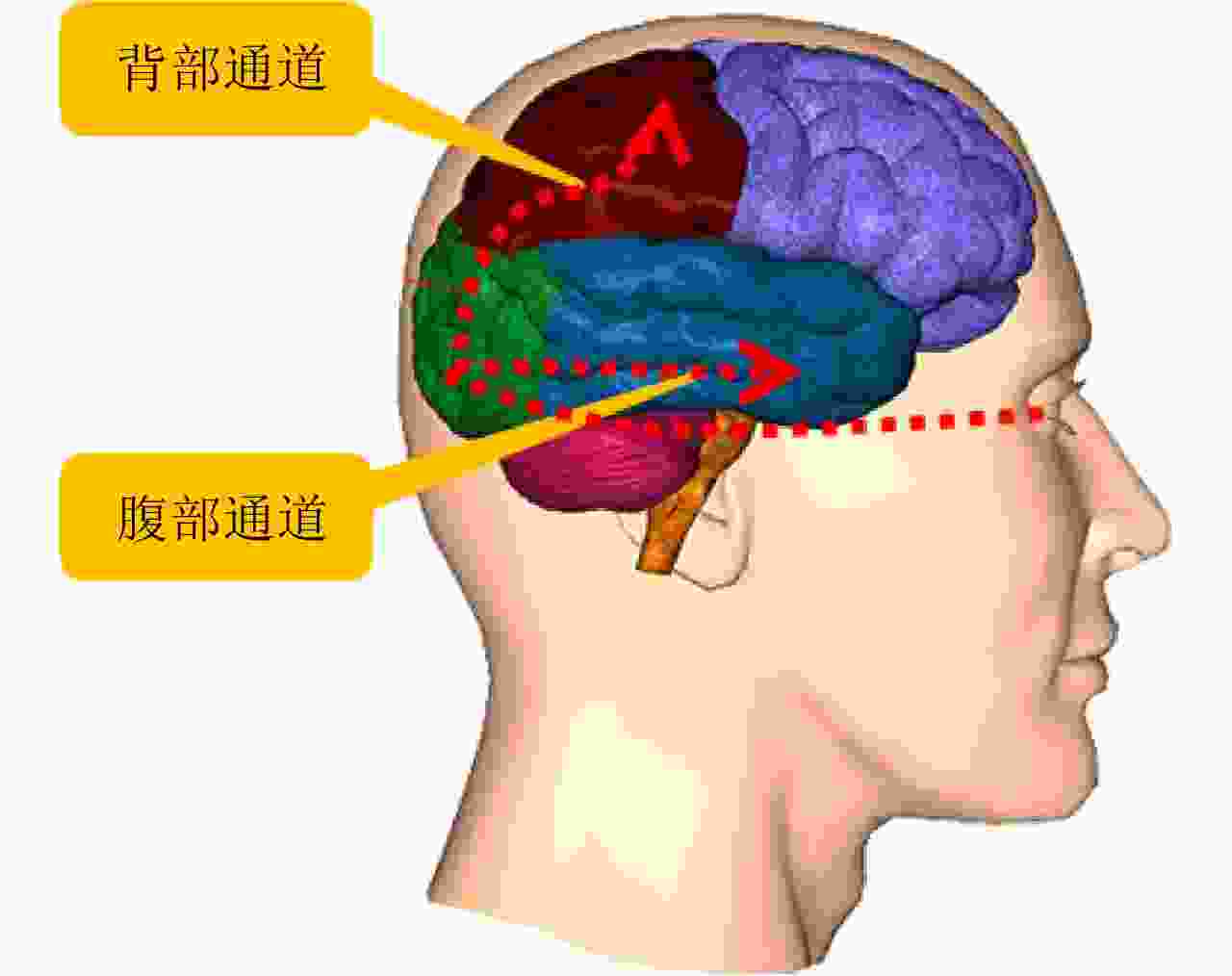
图 1 视觉腹部通道和背部通道。腹部通道主要负责物体视觉,背部通道主要负责空间视觉
Figure 1. Visual ventral pathway and dorsal pathway: Ventral pathway is mainly for object vision, dorsal pathway for spatial vision

图 3 图中两个人身高感觉存在明显差异
Figure 3. The Ames room illusion. Two women in the picture have similar heights, but perceived very differently

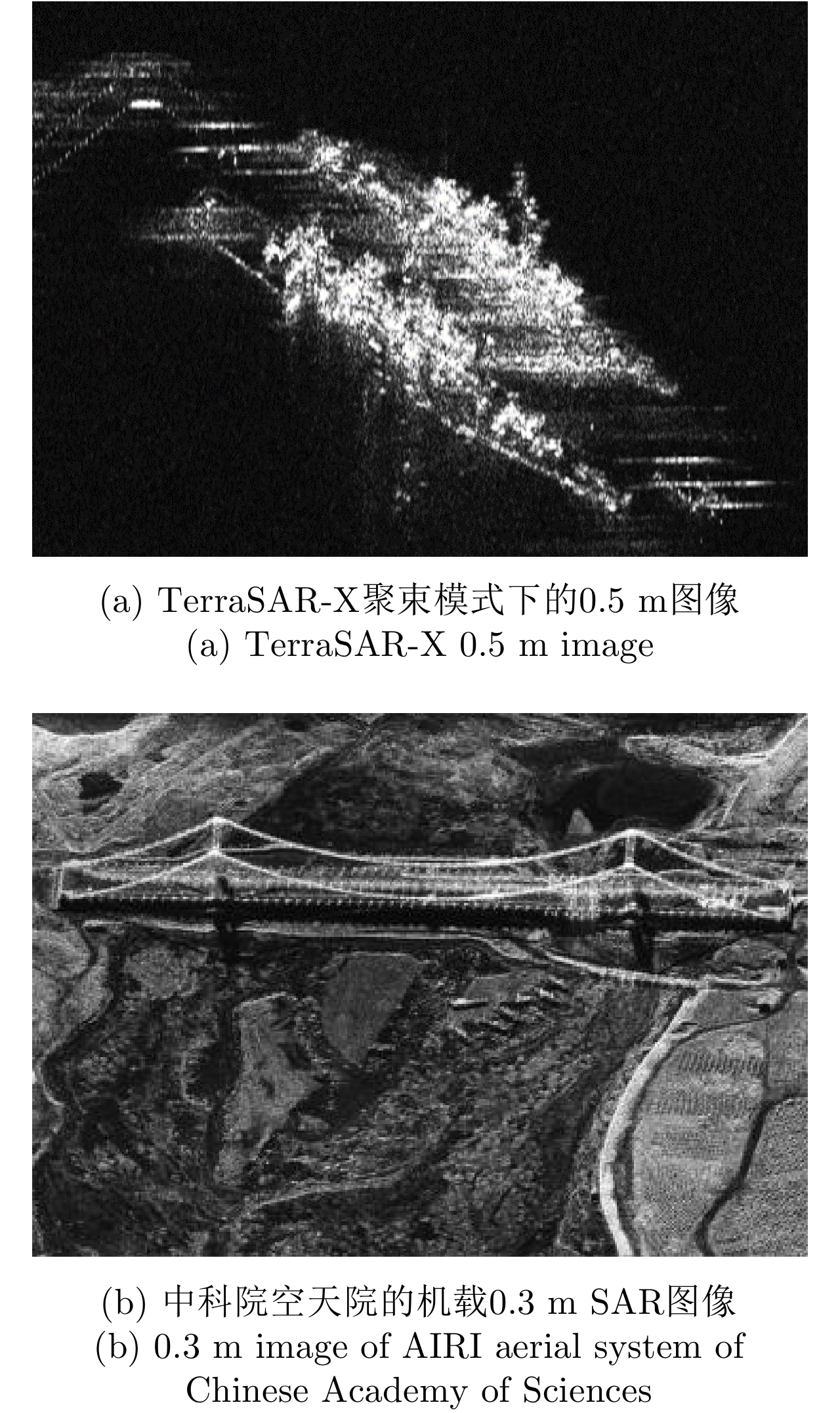
图 4 从图(a)可以感知到船的一些三维结构信息;图(b)可以感知到桥的一些三维结构
Figure 4. 3D ship structural information could be perceived from (a); Bridge 3D shape could be clearly perceived from (b)
-
[1] MARR D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information[M]. New York: W. H. Freeman, 1982. [2] OHZAWA I, DEANGELIS G C, and FREEMAN R D. Stereoscopic depth discrimination in the visual cortex: Neurons ideally suited as disparity detectors[J]. Science, 1990, 249(4972): 1037–1041. doi: 10.1126/science.2396096 [3] HAEFNER R M and CUMMING B G. Adaptation to natural binocular disparities in primate V1 explained by a generalized energy model[J]. Neuron, 2008, 57(1): 147–158. doi: 10.1016/j.neuron.2007.10.042 [4] BRENNER E and SMEETS J B. Depth Perception[M]. WIXTED J. Stevens’ Handbook of Experimental Psychology and Cognitive Neuroscience: Sensation, Perception, and Attention. 4th ed. New York: John Wiley & Sons, 2018: 385–414. [5] 丁赤飚, 仇晓兰, 徐丰, 等. 合成孔径雷达三维成像——从层析、阵列到微波视觉[J]. 雷达学报, 2019, 8(6): 693–709. doi: 10.12000/JR19090DING Chibiao, QIU Xiaolan, XU Feng, et al. Synthetic aperture radar three-dimensional imaging—from TomoSAR and array InSAR to microwave vision[J]. Journal of Radars, 2019, 8(6): 693–709. doi: 10.12000/JR19090 [6] DEL CAMPO G M, NANNINI M, and REIGBER A. Statistical regularization for enhanced TomoSAR imaging[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 1567–1589. doi: 10.1109/JSTARS.2020.2970595 [7] ZHU Xiaoxiang and BAMLER R. Tomographic SAR inversion by L1-norm regularization—The compressive sensing approach[J]. IEEE Transactions on Geoscience and Remote Sensing, 2010, 48(10): 3839–3846. doi: 10.1109/TGRS.2010.2048117 [8] RAMBOUR C, DENIS L, TUPIN F, et al. Introducing spatial regularization in SAR tomography reconstruction[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(11): 8600–8617. doi: 10.1109/TGRS.2019.2921756 [9] VIOLA P and JONES M. Rapid object detection using a boosted cascade of simple features[C]. 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, USA, 2001: I–I. doi: 10.1109/CVPR.2001.990517. [10] FISCHLER M A and BOLLES R C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography[J]. Communications of the ACM, 1981, 24(6): 381–395. doi: 10.1145/358669.358692 [11] RAMBOUR C, DENIS L, TUPIN F, et al. Urban surface reconstruction in SAR tomography by graph-cuts[J]. Computer Vision and Image Understanding, 2019, 188: 102791. doi: 10.1016/j.cviu.2019.07.011 [12] LINDEBERG T. Scale-space[M]. WAH B W. Wiley Encyclopedia of Computer Science and Engineering. Hoboken: John Wiley & Sons, Inc. , 2008: 2495–2504. doi: 10.1002/9780470050118.ecse609. [13] CUI Hainan, GAO Xiang, SHNE Shuhan, et al. HSfM: Hybrid Structure-from-motion[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 2393–2402. doi: 10.1109/CVPR.2017.257. [14] LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91–110. doi: 10.1023/B:VISI.0000029664.99615.94 [15] KOLMOGOROV V and ZABIN R. What energy functions can be minimized via graph cuts?[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(2): 147–159. doi: 10.1109/TPAMI.2004.1262177 [16] COSTANTE G, CIARFUGLIA T A, and BIONDI F. Towards monocular digital elevation model (DEM) estimation by convolutional neural networks - Application on synthetic aperture radar images[J]. arXiv: 1803.05387, 2018: 1–6. [17] BUDILLON A, JOHNSY A C, SCHIRINZI G, et al. SAR tomography based on deep learning[C]. 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 2019: 3625–3628. doi: 10.1109/IGARSS.2019.8900616. [18] WU Chunxiao, ZHANG Zenghui, CHEN Longyong, et al. Super-resolution for MIMO array SAR 3-D imaging based on compressive sensing and deep neural network[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 3109–3124. doi: 10.1109/JSTARS.2020.3000760 [19] XU Dan, RICCI E, OUYANG Wanli, et al. Multi-scale continuous CRFs as sequential deep networks for monocular depth estimation[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 161–169. doi: 10.1109/CVPR.2017.25. [20] WANG Yuanyuan and ZHU Xiaoxiang. SAR tomography via nonlinear blind scatterer separation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(7): 5751–5763. doi: 10.1109/TGRS.2020.3022209 [21] FORNARO G, VERDE S, REALE D, et al. CAESAR: An approach based on covariance matrix decomposition to improve multibaseline-multitemporal interferometric SAR processing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(4): 2050–2065. doi: 10.1109/TGRS.2014.2352853 -

 下载:
下载:





计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

