
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Adversarial Robustness of Deep Convolutional Neural Network-based Image Recognition Models: A Review
-
摘要: 近年来,以卷积神经网络为代表的深度识别模型取得重要突破,不断刷新光学和SAR图像场景分类、目标检测、语义分割与变化检测等多项任务性能水平。然而深度识别模型以统计学习为主要特征,依赖大规模高质量训练数据,只能提供有限的可靠性能保证。深度卷积神经网络图像识别模型很容易被视觉不可感知的微小对抗扰动欺骗,给其在医疗、安防、自动驾驶和军事等安全敏感领域的广泛部署带来巨大隐患。该文首先从信息安全角度分析了基于深度卷积神经网络的图像识别系统潜在安全风险,并重点讨论了投毒攻击和逃避攻击特性及对抗脆弱性成因;其次给出了对抗鲁棒性的基本定义,分别建立对抗学习攻击与防御敌手模型,系统总结了对抗样本攻击、主被动对抗防御、对抗鲁棒性评估技术的研究进展,并结合SAR图像目标识别对抗攻击实例分析了典型方法特性;最后结合团队研究工作,指出存在的开放性问题,为提升深度卷积神经网络图像识别模型在开放、动态、对抗环境中的鲁棒性提供参考。Abstract: Deep convolutional neural networks have achieved great success in recent years. They have been widely used in various applications such as optical and SAR image scene classification, object detection and recognition, semantic segmentation, and change detection. However, deep neural networks rely on large-scale high-quality training data, and can only guarantee good performance when the training and test data are independently sampled from the same distribution. Deep convolutional neural networks are found to be vulnerable to subtle adversarial perturbations. This adversarial vulnerability prevents the deployment of deep neural networks in security-sensitive applications such as medical, surveillance, autonomous driving and military scenarios. This paper first presents a holistic view of security issues for deep convolutional neural network-based image recognition systems. The entire information processing chain is analyzed regarding safety and security risks. In particular, poisoning attacks and evasion attacks on deep convolutional neural networks are analyzed in detail. The root causes of adversarial vulnerabilities of deep recognition models are also discussed. Then, we give a formal definition of adversarial robustness and present a comprehensive review of adversarial attacks, adversarial defense, and adversarial robustness evaluation. Rather than listing existing research, we focus on the threat models for the adversarial attack and defense arms race. We perform a detailed analysis of several representative adversarial attacks on SAR image recognition models and provide an example of adversarial robustness evaluation. Finally, several open questions are discussed regarding recent research progress from our workgroup. This paper can be further used as a reference to develop more robust deep neural network-based image recognition models in dynamic adversarial scenarios.
-
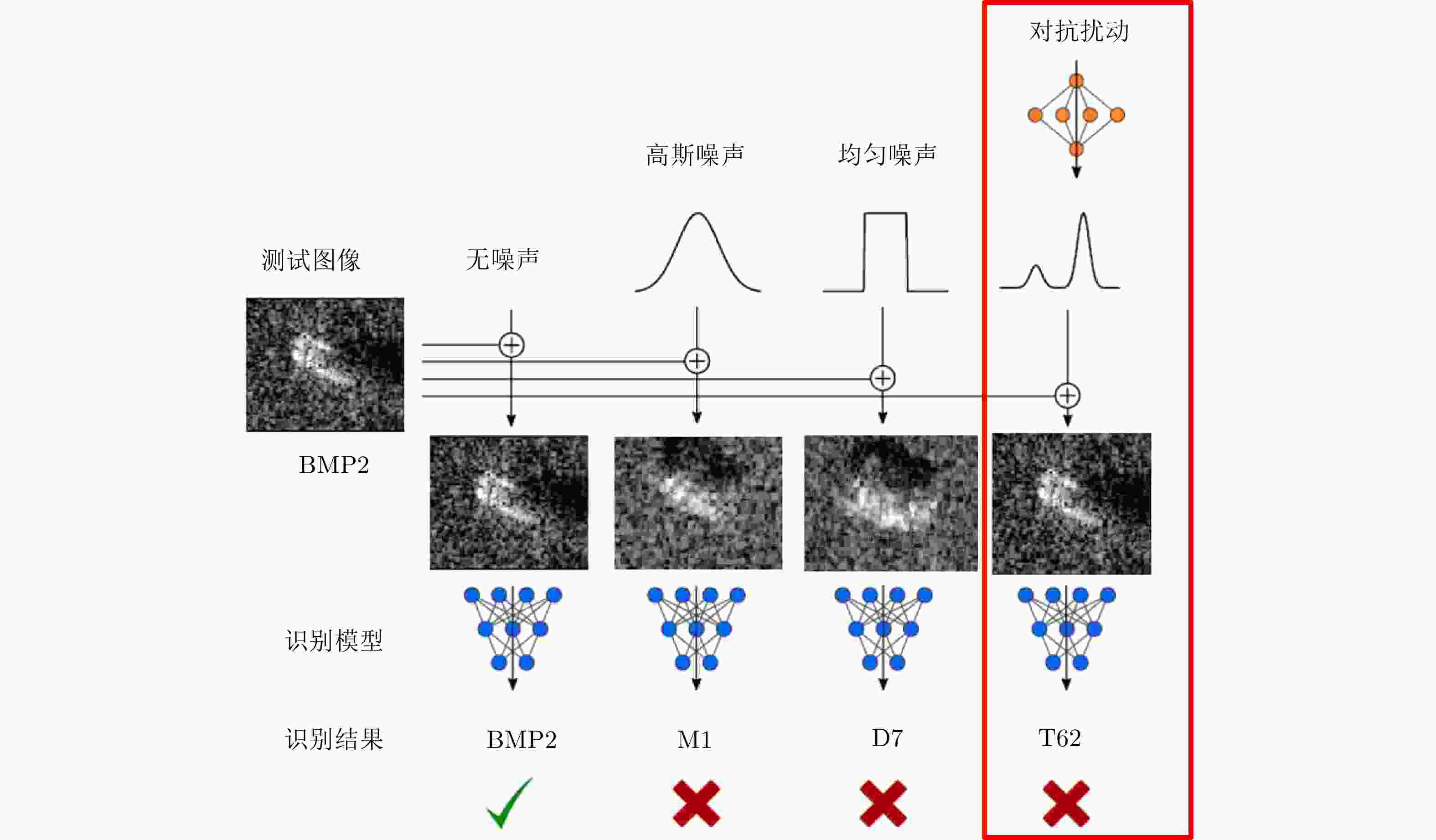
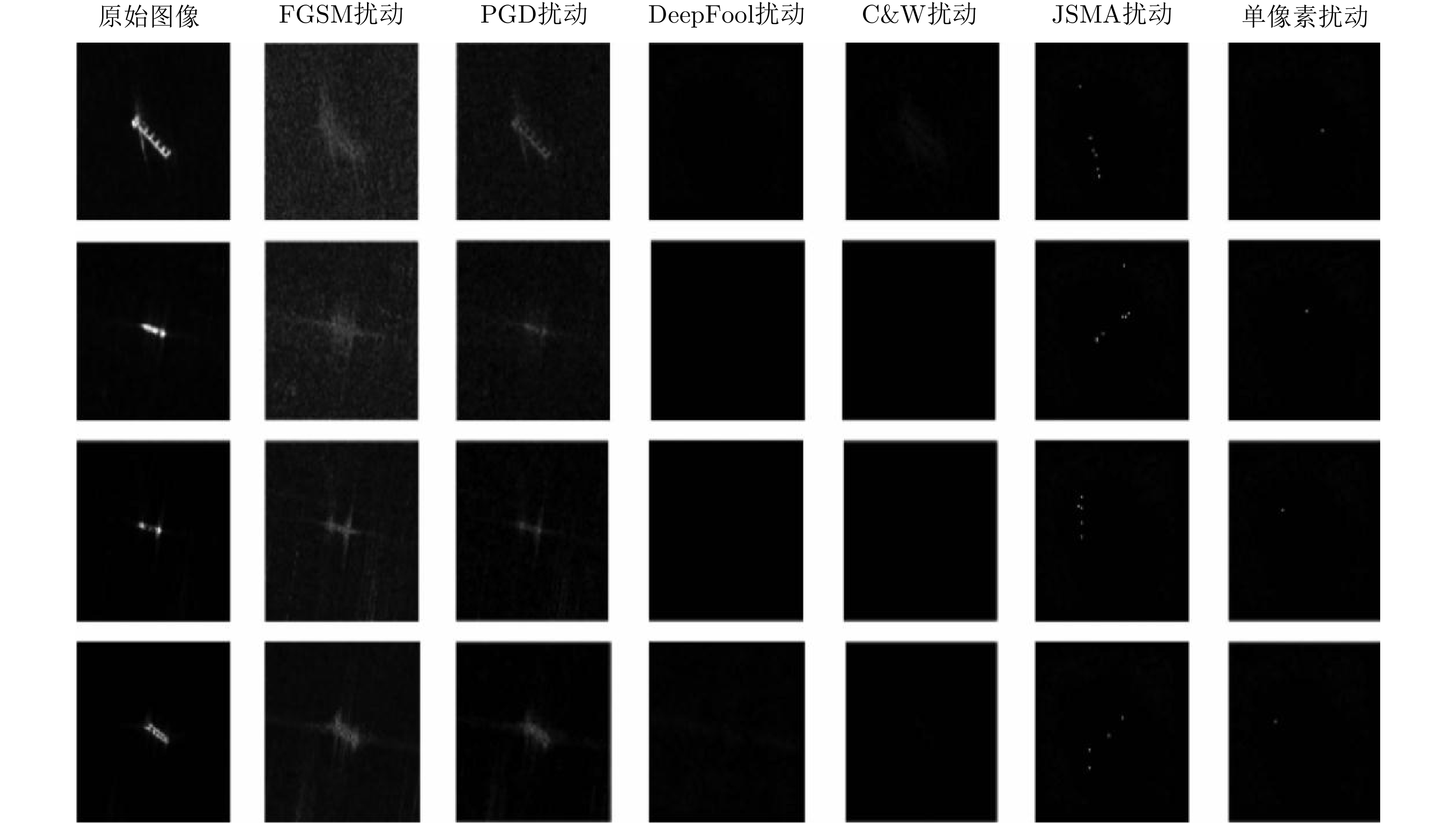
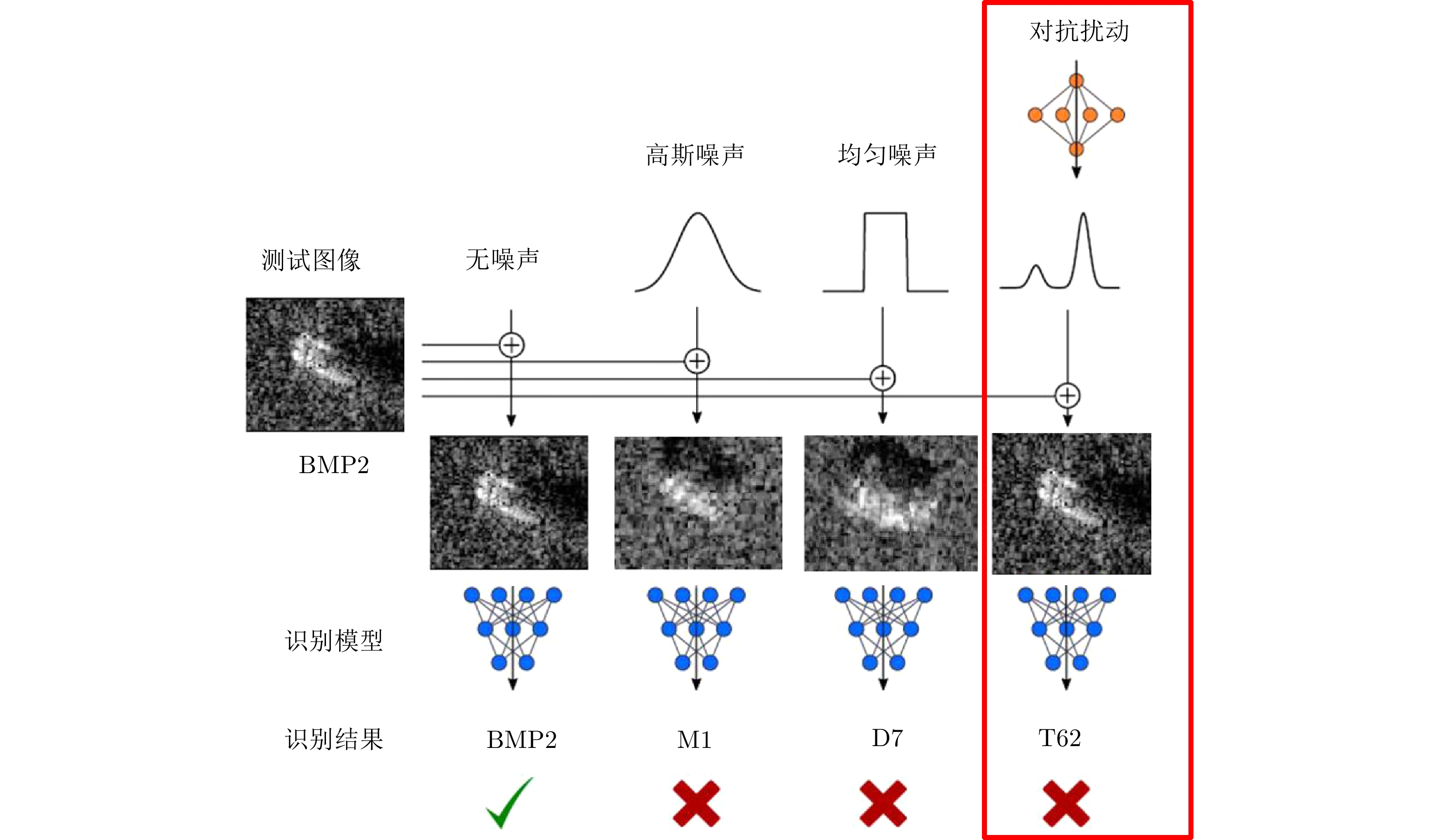
图 1 SAR图像深度神经网络识别模型典型扰动对比示例
Figure 1. Different perturbations for deep neural networks based SAR image recognition models

图 2 深度学习图像识别系统潜在安全风险
Figure 2. Security risks for deep learning based image recognition system
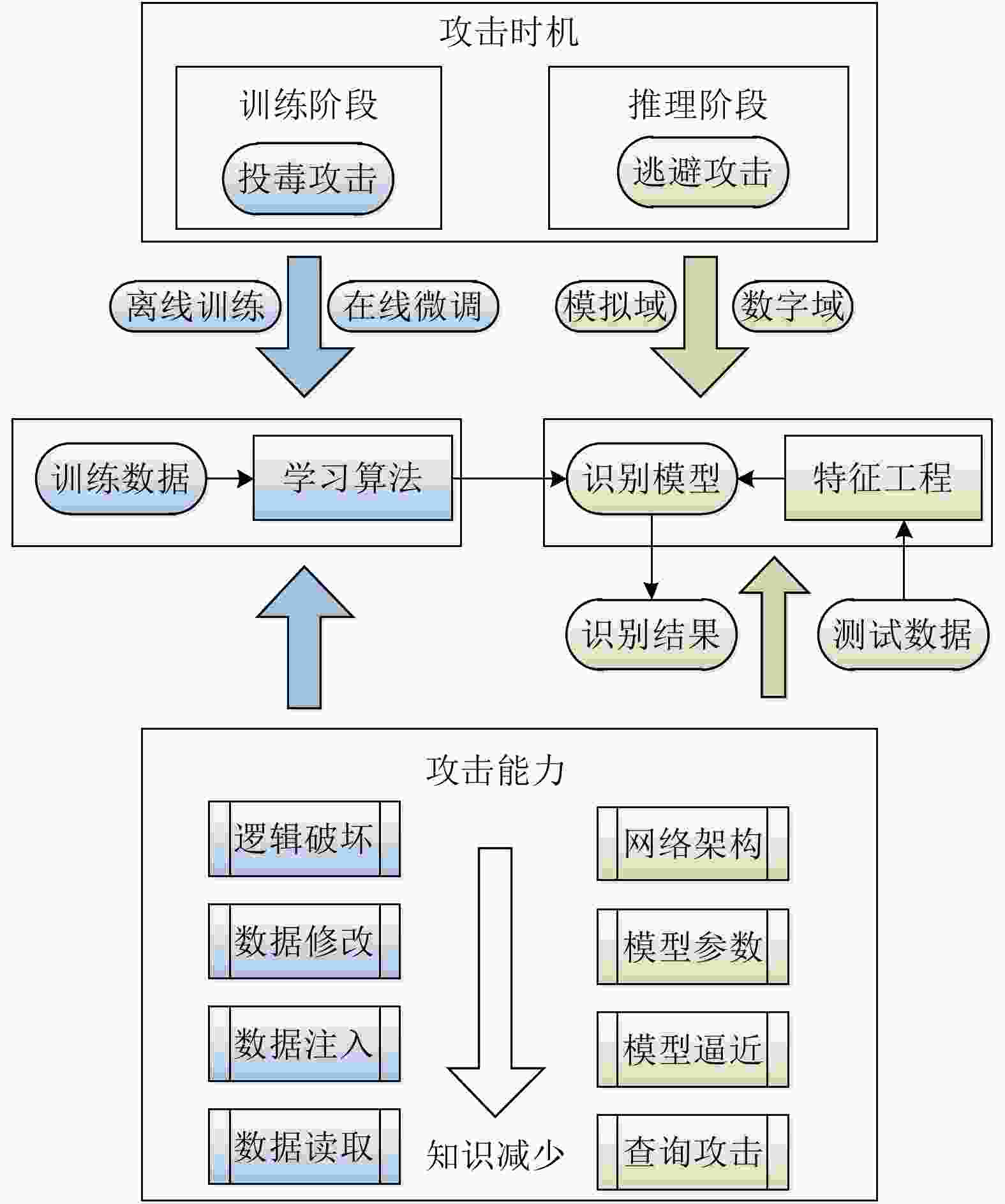
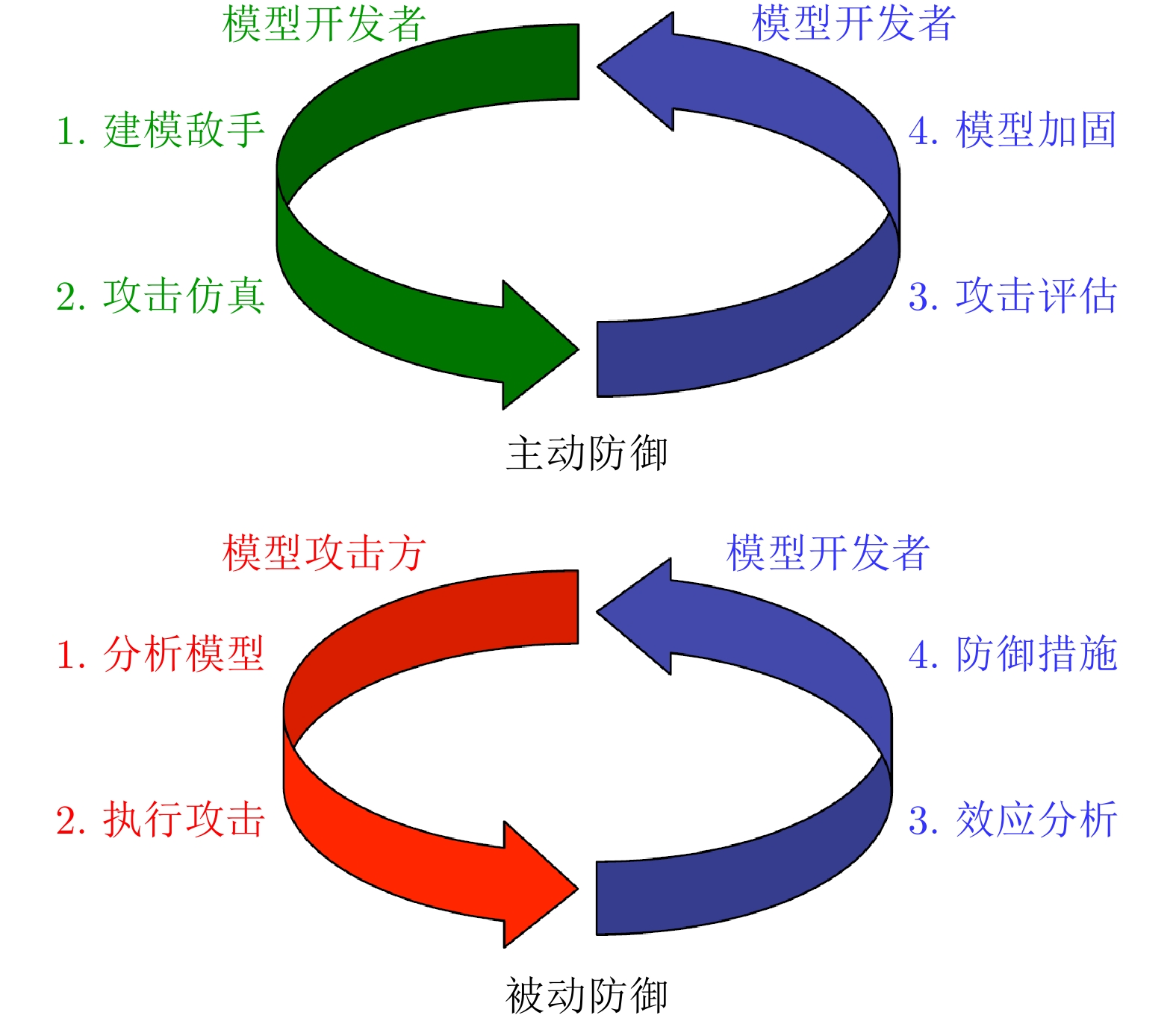
图 3 深度学习训练阶段和测试阶段攻击对比
Figure 3. Comparison of training stage attacks and testing stage attacks for deep learning

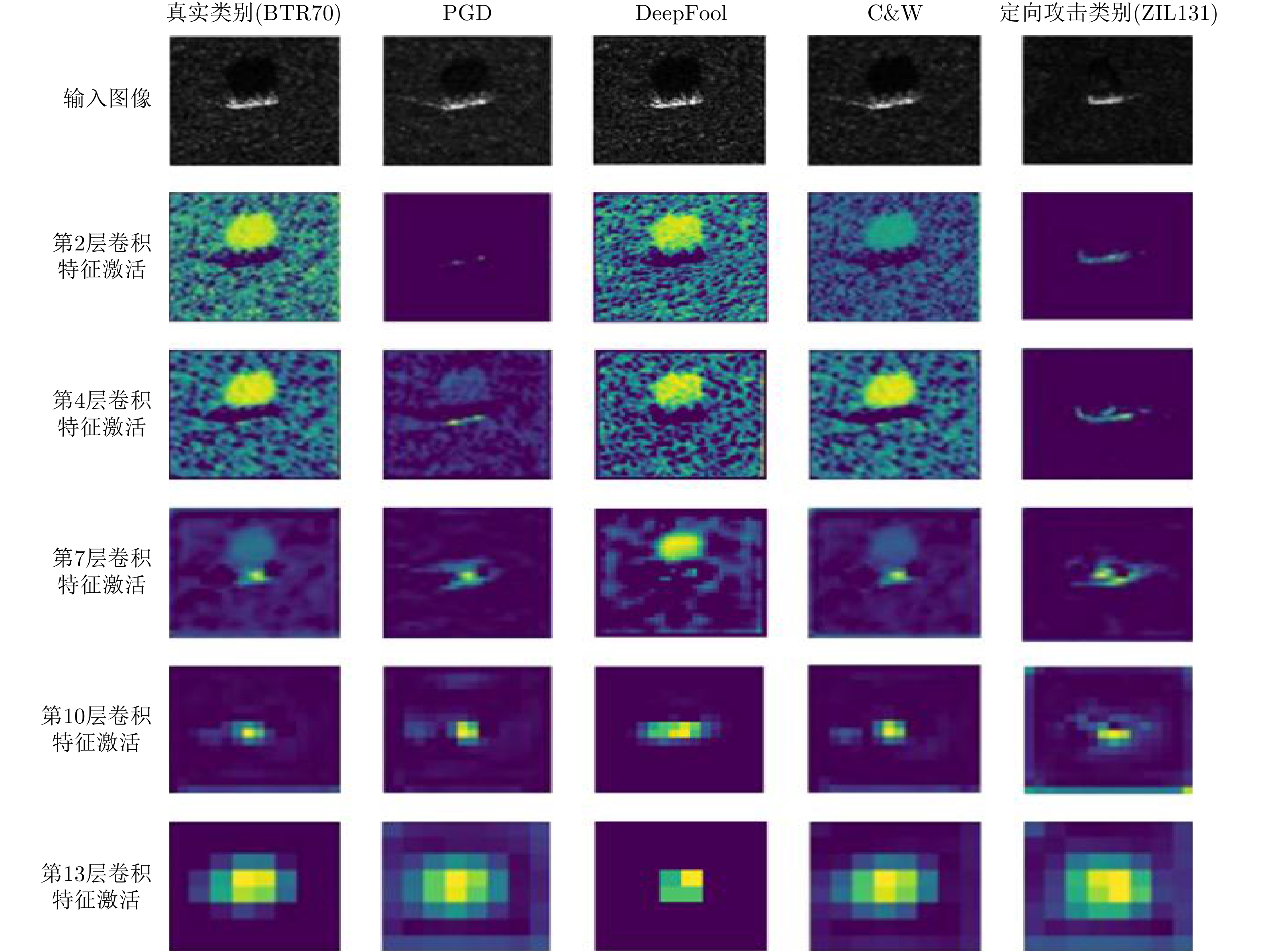
图 9 SAR图像目标识别定向对抗攻击举例
Figure 9. Targeted adversarial attacks for SAR image target recognition

表 1 对抗攻击典型方法
Table 1. Summarization of adversarial attacks
攻击方法 攻击知识 攻击目标 攻击策略 扰动度量 扰动范围 L-BFGS[7] 白盒 定向 约束优化 Linf 个体扰动 FGSM/FGV[8] 白盒 非定向 梯度优化 Linf 个体扰动 BIM/ILCM[28] 白盒 非定向 梯度优化 Linf 个体扰动 JSMA[29] 白盒 定向 敏感性分析 L0 个体扰动 DeepFool-DF[30] 白盒 非定向 梯度优化 L0, L2, Linf 个体扰动/通用扰动 LaVAN[31] 白盒 定向 梯度优化 L2 个体扰动/通用扰动 UAN[32] 白盒 定向 生成模型 L2, Linf 通用扰动 EOT[33] 白盒 定向 梯度优化 L2 个体扰动 C&W[34] 白盒 定向/非定向 约束优化 L0, L2, Linf 个体扰动 Hot-Cold[35] 白盒 定向 梯度优化 L2 个体扰动 PGD[36] 白盒 定向/非定向 梯度优化 L1, Linf 个体扰动 EAD[37] 白盒 定向/非定向 梯度优化 L1 个体扰动 RP2[38] 白盒 定向 梯度优化 L1, L2 个体扰动 GTA[39] 白盒 定向 梯度优化 L1, Linf 个体扰动 OptMargin[40] 白盒 定向 梯度优化 L1, L2, Linf 个体扰动 ATNs[41] 白盒 定向 生成模型 Linf 个体扰动 M-BIM[42] 白盒/黑盒 非定向 梯度优近似 Linf 个体扰动 POBA-GA[43] 黑盒 定向/非定向 估计决策边界 自定义 个体扰动 AutoZoom[44] 黑盒 定向/非定向 估计决策边界 L2 个体扰动 LSA attack[45] 黑盒 定向/非定向 梯度近似 L0 个体扰动 NES attack[46] 黑盒 定向 梯度近似 Linf 个体扰动 BA attack[47] 黑盒 定向 估计决策边界 L2 个体扰动 GenAttack[48] 黑盒 定向 估计决策边界 L2, Linf 个体扰动 ZOO[49] 黑盒 定向/非定向 迁移机制 L2 个体扰动 UPSET[50] 黑盒 定向 梯度近似 L2 通用扰动 ANGRI[50] 黑盒 定向 梯度近似 L2 个体扰动 HSJA[51] 黑盒 定向/非定向 决策近似 L2, Linf 个体扰动 单像素[52] 黑盒 定向/非定向 估计决策边界 L0 个体扰动 BPDA[53] 黑盒 定向/非定向 梯度近似 L2, Linf 个体扰动 SPSA[54] 黑盒 非定向 梯度近似 Linf 个体扰动 AdvGAN[55] 黑盒 定向 生成模型 L2 个体扰动 Houdini[56] 黑盒 定向 约束优化 L2, Linf 个体扰动  下载: 导出CSV
下载: 导出CSV
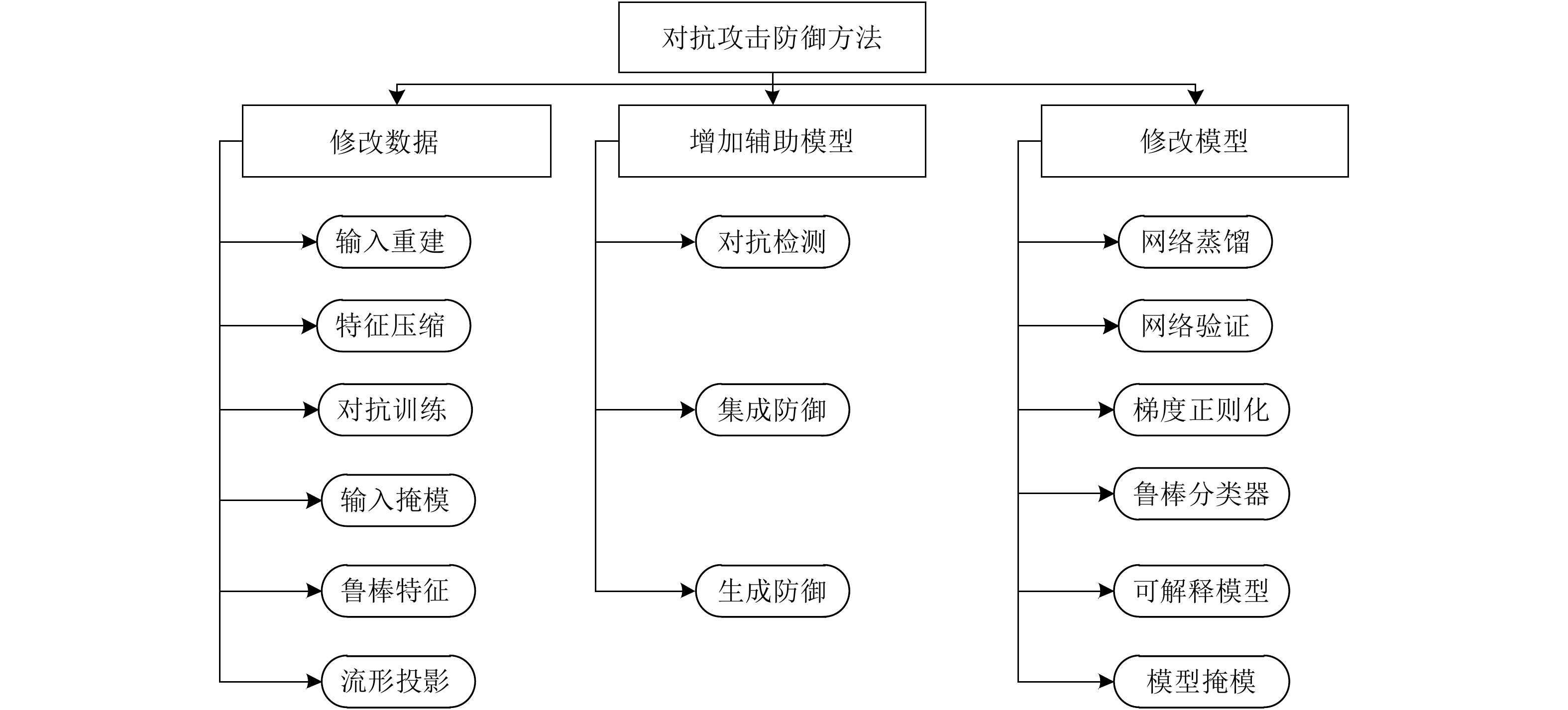
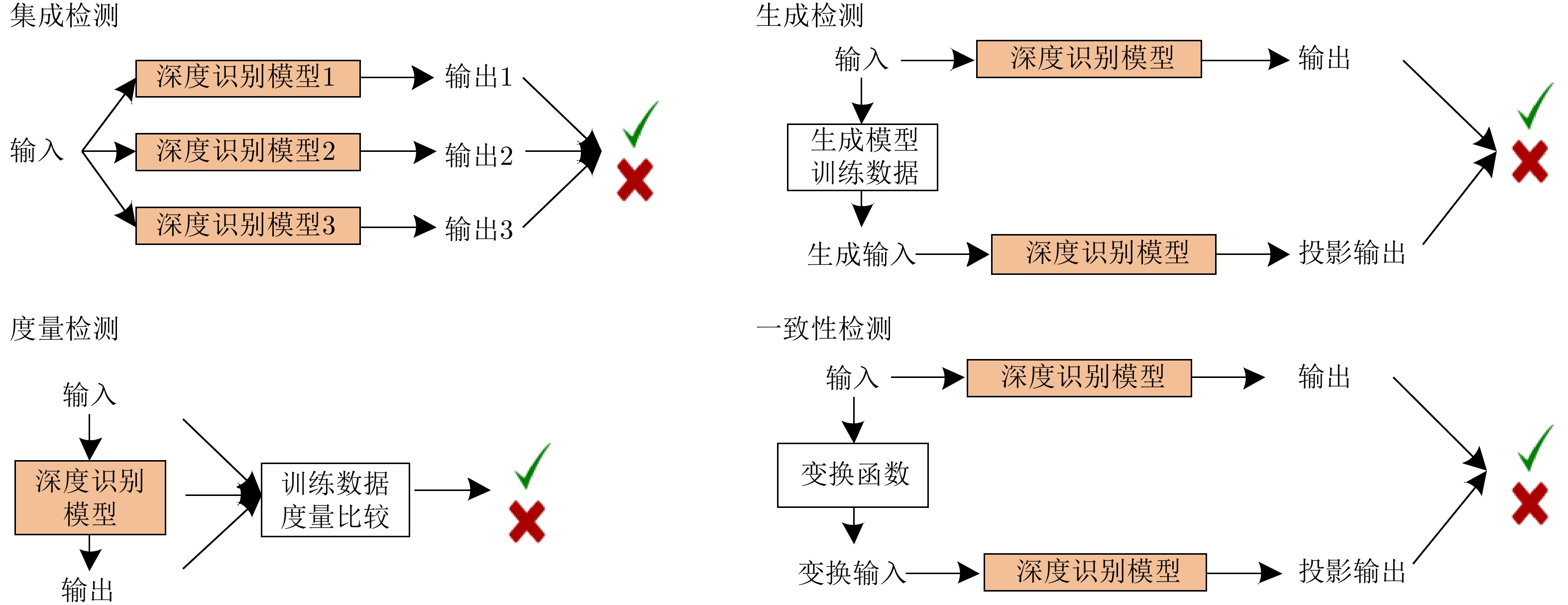
表 2 对抗攻击防御方法
Table 2. Defense methods for adversarial attack
防御方法 防御目标 防御策略 攻击算法 Thermometer encoding[62] 主动防御 输入重建 PGD VectorDefense[63] 主动防御 输入重建 BIM/JSMA/C&W/PGD Super resolution[64] 主动防御 输入重建 FGSM/BIM/DF/C&W/MI-BIM Pixel deflection[65] 主动防御 输入重建 FGSM/BIM/JSMA/DF/L-BFGS D3[66] 主动防御 输入重建 FGSM/DF/C&W/UAP RRP[67] 主动防御 预处理-输入随机变换 FGSM/DF/C&W DR[68] 主动防御 特征压缩 FGSM DeT[69] 主动防御 输入重建/增加辅助模型 FGSM/BIM/DF/C&W Feature distillation[70] 主动防御 输入重建 FGSM/BIM/DF/C&W MALADE[71] 主动防御 输入重建 FGSM/BIM/JSMA/C&W JPEG compression[72] 主动防御 输入重建/集成重建 FGSM/ DF SAP[73] 主动防御 模型掩模 FGSM RSE[74] 主动防御 随机噪声层/集成预测 C&W Deep defense[75] 主动防御 正则化 DF Na et al.[76] 主动防御 正则化 FGSM/BIM/ILCM/C&W Cao et al.[77] 主动防御 区域分类器 FGSM/BIM/JSMA/DF/ C&W S2SNet[78] 主动防御 梯度掩模 FGSM/BIM /C&W Adversarial training[8,36,79] 主动防御 对抗训练 PGD Bilateral AT[80] 主动防御 改进对抗训练 FGSM/PGD TRADES[81] 主动防御 改进对抗训练 PGD SPROUT[82] 主动防御 改进对抗训练 PGD CCNs[83] 主动防御 预处理 FGSM/ DF DCNs[84] 主动防御 梯度掩模/预处理 L-BFGS WSNNS[85] 主动防御 近邻度量 FGSM/PGD/C&W ME-Net[86] 主动防御 预处理 FGSM/PGD/C&W/BA Defense distillation[87] 主动防御 梯度掩模 JSMA EDD[88] 主动防御 梯度掩模 FGSM/JSMA Strauss et al.[89] 主动防御 集成防御 FGSM/BIM Tramèr et al.[90] 主动防御 梯度掩模/集成防御 FGSM/BIM/ILCM MTDeep[91] 主动防御 集成防御 FGSM/C&W Defense-GAN[92] 主动防御 预处理 FGSM/C&W APE-GAN[93] 主动防御 预处理 FGSM/JSMA/L-BFGS/DF/C&W Zantedeschi et al.[94] 主动防御 梯度掩模 FGSM/JSMA Parseval networks[95] 主动防御 梯度掩模 FGSM/BIM HGD[96] 主动防御 预处理 FGSM/BIM ALP[97] 主动防御 梯度掩模 PGD Sinha et al.[98] 主动防御 梯度掩模 FGSM/BIM/PGD Fortified networks[99] 主动防御 预处理 FGSM/PGD DeepCloak[100] 主动防御 预处理 FGSM/JSMA/L-BFGS DDSA[101] 主动防御 预处理 FGSM/M-BIM/C&W/PGD ADV-BNN[102] 主动防御 梯度掩模 PGD PixelDefend[103] 主动防御 预处理/近邻度量 FGSM/BIM/DF/C&W Artifacts[104] 被动防御 对抗检测 FGSM/BIM/JSMA /C&W AID[105] 被动防御 对抗检测 L-BFGS/FGSM ConvFilter[106] 被动防御 预处理 L-BFGS ReabsNet[107] 被动防御 预处理/辅助模型 FGSM/DF/C&W MIP[108] 被动防御 统计对比/近邻度量 FGSM/BIM/DF RCE[109] 被动防御 梯度掩模 FGSM/BIM/JSMA/C&W NIC[110] 被动防御 辅助模型/近邻度量 FGSM/BIM/JSMA/C&W/DF LID[111] 被动防御 被动防御 FGSM/BIM/JSMA/C&W IFNN[112] 被动防御 被动防御 FGSM/BIM/DF/C&W Gong et al.[113] 被动防御 辅助模型 FGSM/ JSMA Metzen et al.[114] 被动防御 辅助模型 FGSM/BIM/DF MagNet[115] 被动防御 预处理 FGSM/BIM/DF/C&W MultiMagNet[116] 被动防御 预处理/近邻度量/集成防御 FGSM/BIM/DF/C&W SafetyNet[117] 被动防御 辅助模型 FGSM/BIM/DF/JSMA Feature squeezing[118] 被动防御 预处理 FGSM/BIM/C&W/JSMA TwinNet[119] 被动防御 辅助模型/集成防御 UAP Abbasi et al.[120] 被动防御 集成防御 FGSM/DF Liang et al.[121] 被动防御 预处理 FGSM/DF/C&W
下载: 导出CSV
评估指标 行为 架构 对抗扰动 堕化扰动 白盒 黑盒 单模型 多模型 数据 K多节神经元覆盖(KMNC)[123] √ √ √ √ 神经元边界覆盖(NBC)[123] √ √ √ √ 强神经元激活覆盖(SNAC)[123] √ √ √ √ 平均Lp失真度(ALDp)[124] √ √ √ 平均结构相似性(ASS)[125] √ √ √ 扰动敏感距离(PSD)[126] √ √ √ 模型 干净数据集正确率(CA)[127] √ √ √ 白盒对抗正确率(AAW)[127] √ √ √ √ 黑盒对抗正确率(AAB)[127] √ √ √ √ 对抗类别平均置信度(ACAC)[124] √ √ √ √ 正确类别平均置信度(ACTC)[124] √ √ √ √ √ 误分类与最大概率差(NTE)[124] √ √ √ √ 自然噪声平均差值(MCE)[132] √ √ √ √ 自然噪声相对差值(RMCE)[132] √ √ √ √ 连续噪声分类差别(mFR)[132] √ √ √ √ 分类准确率方差(CAV)[124] √ √ √ √ √ 减少/增加错误分类百分比(CRR/CSR)[124] √ √ √ √ √ 防御置信方差(CCV)[124] √ √ √ √ √ 防御前后输出概率相似性(COS)[124] √ √ √ √ √ 经验边界距离(EBD)[127] √ √ √ √ 经验边界距离2(EBD2)[127] √ √ √ √ 经验噪声敏感性(ENI)[128] √ √ √ √ 神经元敏感度(NS)[128] √ √ √ √ 神经元不确定性(NU)[128] √ √ √ √ √
下载: 导出CSV
表 4 SAR舰船目标识别深度模型对抗鲁棒性评估实例[59]
Table 4. Adversarial robustness evaluation of deep models for SAR ship recognition[59]
攻击方法 平均正确率(%) ACAC ACTC ALDpL0 ALDpL2 ALDpLinf ASS PSD NTE FGSM 62.79 3.49 0.19 0.97 6396.70 16.00 0.08 11213.42 0.39 PGD 29.07 7.52 0.09 0.93 4330.60 16.00 0.23 7129.40 0.47 DeepFool 29.07 2.12 0.27 0.39 563.79 9.43 0.90 828.41 0.25 C&W 40.70 1.39 0.37 0.24 412.92 8.80 0.96 468.21 0.12 HSJA 62.79 1.14 0.41 0.74 1892.80 7.75 0.68 3220.93 0.06 单像素 79.82 INF 0 2e-5 255.00 255.00 0.90 643.32 0.14
下载: 导出CSV
-
[1] BERGHOFF C, NEU M, and VON TWICKEL A. Vulnerabilities of connectionist AI applications: Evaluation and defense[J]. Frontiers in Big Data, 2020, 3: 23. doi: 10.3389/fdata.2020.00023 [2] 潘宗序, 安全智, 张冰尘. 基于深度学习的雷达图像目标识别研究进展[J]. 中国科学: 信息科学, 2019, 49(12): 1626–1639. doi: 10.1360/SSI-2019-0093PAN Zongxu, AN Quanzhi, and ZHANG Bingchen. Progress of deep learning-based target recognition in radar images[J]. Scientia Sinica Informationis, 2019, 49(12): 1626–1639. doi: 10.1360/SSI-2019-0093 [3] 徐丰, 王海鹏, 金亚秋. 深度学习在SAR目标识别与地物分类中的应用[J]. 雷达学报, 2017, 6(2): 136–148. doi: 10.12000/JR16130XU Feng, WANG Haipeng, and JIN Yaqiu. Deep learning as applied in SAR target recognition and terrain classification[J]. Journal of Radars, 2017, 6(2): 136–148. doi: 10.12000/JR16130 [4] CHENG Gong, XIE Xingxing, HAN Junwei, et al. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 3735–3756. doi: 10.1109/JSTARS.2020.3005403 [5] BLASCH E, MAJUMDER U, ZELNIO E, et al. Review of recent advances in AI/ML using the MSTAR data[C]. SPIE 11393, Algorithms for Synthetic Aperture Radar Imagery XXVII, Online Only, 2020. [6] SCHÖLKOPF B, LOCATELLO F, BAUER S, et al. Towards causal representation learning[EB/OL]. https://arxiv.org/abs/2102.11107v1, 2021. [7] SZEGEDY C, ZAREMBA W, SUTSKEVER I, et al. Intriguing properties of neural networks[EB/OL]. https://arxiv.org/abs/1312.6199v1, 2014. [8] GOODFELLOW I J, SHLENS J, and SZEGEDY C. Explaining and harnessing adversarial examples[EB/OL]. https://arxiv.org/abs/1412.6572v1, 2015. [9] MACHADO G R, SILVA E, and GOLDSCHMIDT R R. Adversarial machine learning in image classification: A survey towards the defender’s perspective[EB/OL]. https://arxiv.org/abs/2009.03728v1, 2020. [10] SERBAN A, POLL E, and VISSER J. Adversarial examples on object recognition: A comprehensive survey[J]. ACM Computing Surveys, 2020, 53(3): 66. doi: 10.1145/3398394 [11] OSENI A, MOUSTAFA N, JANICKE H, et al. Security and privacy for artificial intelligence: Opportunities and challenges[EB/OL]. https://arxiv.org/abs/2102.04661, 2021. [12] KEYDEL E R, LEE S W, and MOORE J T. MSTAR extended operating conditions: A tutorial[C]. SPIE 2757, Algorithms for Synthetic Aperture Radar Imagery III, Orlando, United States, 1996: 228–242. [13] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. https://arxiv.org/abs/1409.1556v4, 2015. [14] WANG Bolun, YAO Yuanshun, SHAN S, et al. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks[C]. 2019 IEEE Symposium on Security and Privacy, San Francisco, USA, 2019: 707–723. doi: 10.1109/SP.2019.00031. [15] SHEN Juncheng, ZHU Xiaolei, and MA De. TensorClog: An imperceptible poisoning attack on deep neural network applications[J]. IEEE Access, 2019, 7: 41498–41506. doi: 10.1109/ACCESS.2019.2905915 [16] QUIRING E and RIECK K. Backdooring and poisoning neural networks with image-scaling attacks[C]. 2020 IEEE Security and Privacy Workshops, San Francisco, USA, 2020: 41–47. doi: 10.1109/SPW50608.2020.00024. [17] SINGH J and SHARMILA V C. Detecting Trojan attacks on deep neural networks[C]. The 4th International Conference on Computer, Communication and Signal Processing, Chennai, India, 2020: 1–5. doi: 10.1109/ICCCSP49186.2020.9315256. [18] HE Yingzhe, MENG Guozhu, CHEN Kai, et al. Towards security threats of deep learning systems: A survey[EB/OL]. https://arxiv.org/abs/1911.12562v2, 2020. [19] DELDJOO Y, NOIA T D, and MERRA F A. Adversarial machine learning in recommender systems: State of the art and challenges[EB/OL]. https://arxiv.org/abs/2005.10322v1, 2020. [20] BIGGIO B and ROLI F. Wild patterns: Ten years after the rise of adversarial machine learning[J]. Pattern Recognition, 2018, 84: 317–331. doi: 10.1016/j.patcog.2018.07.023 [21] ROSS T D, BRADLEY J J, HUDSON L J, et al. SAR ATR: So what’s the problem? An MSTAR perspective[C]. SPIE 3721, Algorithms for Synthetic Aperture Radar Imagery VI, Orlando, USA, 1999: 606–610. [22] 成科扬, 王宁, 师文喜, 等. 深度学习可解释性研究进展[J]. 计算机研究与发展, 2020, 57(6): 1208–1217. doi: 10.7544/issn1000-1239.2020.20190485CHENG Keyang, WANG Ning, SHI Wenxi, et al. Research advances in the interpretability of deep learning[J]. Journal of Computer Research and Development, 2020, 57(6): 1208–1217. doi: 10.7544/issn1000-1239.2020.20190485 [23] 化盈盈, 张岱墀, 葛仕明. 深度学习模型可解释性的研究进展[J]. 信息安全学报, 2020, 5(3): 1–12. doi: 10.19363/J.cnki.cn10-1380/tn.2020.05.01HUA Yingying, ZHANG Daichi, and GE Shiming. Research progress in the interpretability of deep learning models[J]. Journal of Cyber Security, 2020, 5(3): 1–12. doi: 10.19363/J.cnki.cn10-1380/tn.2020.05.01 [24] 郭炜炜, 张增辉, 郁文贤, 等. SAR图像目标识别的可解释性问题探讨[J]. 雷达学报, 2020, 9(3): 462–476. doi: 10.12000/JR20059GUO Weiwei, ZHANG Zenghui, YU Wenxian, et al. Perspective on explainable SAR target recognition[J]. Journal of Radars, 2020, 9(3): 462–476. doi: 10.12000/JR20059 [25] ORTIZ-JIMENEZ G, MODAS A, MOOSAVI-DEZFOOLI S M, et al. Optimism in the face of adversity: Understanding and improving deep learning through adversarial robustness[EB/OL]. HYPERLINK "https: //arxiv. org/abs/2010.09624v2" https://arxiv.org/abs/2010.09624v2, 2021. [26] QAYYUM A, USAMA M, QADIR J, et al. Securing connected & autonomous vehicles: Challenges posed by adversarial machine learning and the way forward[J]. IEEE Communications Surveys & Tutorials, 2020, 22(2): 998–1026. doi: 10.1109/COMST.2020.2975048 [27] YUAN Xiaoyong, HE Pan, ZHU Qile, et al. Adversarial examples: Attacks and defenses for deep learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(9): 2805–2824. doi: 10.1109/TNNLS.2018.2886017 [28] KURAKIN A, GOODFELLOW I, and BENGIO S. Adversarial examples in the physical world[EB/OL]. https://arxiv.org/abs/1607.02533v4, 2017. [29] PAPERNOT N, MCDANIEL P, JHA S, et al. The limitations of deep learning in adversarial settings[C]. 2016 IEEE European Symposium on Security and Privacy, Saarbruecken, Germany, 2016: 372–387. [30] MOOSAVI-DEZFOOLI S M, FAWZI A, and FROSSARD P. DeepFool: A simple and accurate method to fool deep neural networks[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 2574–2582. [31] KARMON D, ZORAN D, and GOLDBERG Y. LaVAN: Localized and visible adversarial noise[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018. [32] HAYES J and DANEZIS G. Learning universal adversarial perturbations with generative models[C]. 2018 IEEE Security and Privacy Workshops, San Francisco, USA, 2018: 43–49. [33] ATHALYE A, ENGSTROM L, ILYAS A, et al. Synthesizing robust adversarial examples[C]. The 35th International Conference on Machine Learning, Stockholm, Sweden, 2018. [34] CARLINI N and WAGNER D. Towards evaluating the robustness of neural networks[C]. 2017 IEEE Symposium on Security and Privacy, San Jose, USA, 2017: 39–57. [35] ROZSA A, RUDD E M, and BOULT T E. Adversarial diversity and hard positive generation[EB/OL]. https://arxiv.org/abs/1605.01775, 2016. [36] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks[EB/OL]. https://arxiv.org/abs/1706.06083, 2019. [37] CHEN Pinyu, SHARMA Y, ZHANG Huan, et al. EAD: Elastic-net attacks to deep neural networks via adversarial examples[EB/OL]. https://arxiv.org/abs/1709.04114, 2018. [38] EYKHOLT K, EVTIMOV I, FERNANDES E, et al. Robust physical-world attacks on deep learning models[EB/OL]. https://arxiv.org/abs/1707.08945, 2018. [39] CARLINI N, KATZ G, BARRETT C, et al. Ground-truth adversarial examples[EB/OL]. https://arxiv.org/abs/1709.10207, 2018. [40] HE W, LI Bo, and SONG D. Decision boundary analysis of adversarial examples[C]. 2018 International Conference on Learning Representations, Vancouver, Canada, 2018. [41] BALUJA S and FISCHER I. Adversarial transformation networks: Learning to generate adversarial examples[EB/OL]. https://arxiv.org/abs/1703.09387, 2017. [42] DONG Yinpeng, LIAO Fangzhou, PANG Tianyu, et al. Boosting adversarial attacks with momentum[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 9185–9193. [43] CHEN Jinyin, SU Mengmeng, SHEN Shijing, et al. POBA-GA: Perturbation optimized black-box adversarial attacks via genetic algorithm[J]. Computers & Security, 2019, 85: 89–106. doi: 10.1016/j.cose.2019.04.014 [44] TU Chunchen, TING Paishun, CHEN Pinyu, et al. AutoZOOM: Autoencoder-based zeroth order optimization method for attacking black-box neural networks[EB/OL]. https://arxiv.org/abs/1805.11770v5, 2020. [45] NARODYTSKA N and KASIVISWANATHAN S. Simple black-box adversarial attacks on deep neural networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, USA, 2017: 1310–1318. [46] ILYAS A, ENGSTROM L, ATHALYE A, et al. Black-box adversarial attacks with limited queries and information[EB/OL]. https://arxiv.org/abs/1804.08598, 2018. [47] BRENDEL W, RAUBER J, and BETHGE M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models[EB/OL]. https://arxiv.org/abs/1712.04248, 2018. [48] ALZANTOT M, SHARMA Y, CHAKRABORTY S, et al. GenAttack: Practical black-box attacks with gradient-free optimization[EB/OL]. https://arxiv.org/abs/1805.11090, 2019. [49] CHEN Pinyu, ZHANG Huan, SHARMA Y, et al. ZOO: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models[C]. The 10th ACM Workshop on Artificial Intelligence and Security, Dallas, USA, 2017: 15–26. [50] SARKAR S, BANSAL A, MAHBUB U, et al. UPSET and ANGRI: Breaking high performance image classifiers[EB/OL]. https://arxiv.org/abs/1707.01159, 2017. [51] CHEN Jianbo, JORDAN M I, and WAINWRIGHT M J. HopSkipJumpAttack: A query-efficient decision-based attack[C]. 2020 IEEE Symposium on Security and Privacy, San Francisco, USA, 2020: 1277–1294. [52] SU Jiawei, VARGAS D V, and SAKURAI K. One pixel attack for fooling deep neural networks[J]. IEEE Transactions on Evolutionary Computation, 2019, 23(5): 828–841. doi: 10.1109/TEVC.2019.2890858 [53] ATHALYE A, CARLINI N, and WAGNER D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples[EB/OL]. https://arxiv.org/abs/1802.00420, 2018. [54] UESATO J, O’DONOGHUE B, VAN DEN OORD A, et al. Adversarial risk and the dangers of evaluating against weak attacks[EB/OL]. https://arxiv.org/abs/1802.05666, 2018. [55] XIAO Chaowei, LI Bo, ZHU Junyan, et al. Generating adversarial examples with adversarial networks[EB/OL]. https://arxiv.org/abs/1801.02610, 2019. [56] CISSE M, ADI Y, NEVEROVA N, et al. Houdini: Fooling deep structured prediction models[EB/OL]. https://arxiv.org/abs/1707.05373, 2017. [57] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 618–626. doi: 10.1109/ICCV.2017.74. [58] HOU Xiyue, AO Wei, SONG Qian, et al. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition[J]. Science China Information Sciences, 2020, 63(4): 140303. doi: 10.1007/s11432-019-2772-5 [59] 徐延杰, 孙浩, 雷琳, 等. 基于对抗攻击的SAR舰船识别卷积神经网络鲁棒性研究[J]. 信号处理, 2020, 36(12): 1965–1978. doi: 10.16798/j.issn.1003-0530.2020.12.002XU Yanjie, SUN Hao, LEI Lin, et al. The research for the robustness of SAR ship identification based on adversarial example[J]. Journal of Signal Processing, 2020, 36(12): 1965–1978. doi: 10.16798/j.issn.1003-0530.2020.12.002 [60] BIGGIO B, FUMERA G, and ROLI F. Security evaluation of pattern classifiers under attack[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(4): 984–996. doi: 10.1109/TKDE.2013.57 [61] 李盼, 赵文涛, 刘强, 等. 机器学习安全性问题及其防御技术研究综述[J]. 计算机科学与探索, 2018, 12(2): 171–184. doi: 10.3778/j.issn.1673-9418.1708038LI Pan, ZHAO Wentao, LIU Qiang, et al. Security issues and their countermeasuring techniques of machine learning: A survey[J]. Journal of Frontiers of Computer Science and Technology, 2018, 12(2): 171–184. doi: 10.3778/j.issn.1673-9418.1708038 [62] BUCKMAN J, ROY A, RAFFEL C, et al. Thermometer encoding: One hot way to resist adversarial examples[C]. The ICLR 2018, Vancouver, Canada, 2018. [63] KABILAN V M, MORRIS B, and NGUYEN A. VectorDefense: Vectorization as a defense to adversarial examples[EB/OL]. https://arxiv.org/abs/1804.08529, 2018. [64] MUSTAFA A, KHAN S H, HAYAT M, et al. Image super-resolution as a defense against adversarial attacks[J]. IEEE Transactions on Image Processing, 2019, 29: 1711–1724. doi: 10.1109/TIP.2019.2940533 [65] PRAKASH A, MORAN N, GARBER S, et al. Deflecting adversarial attacks with pixel deflection[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 8571–8580. [66] MOOSAVI-DEZFOOLI S M, SHRIVASTAVA A, and TUZEL O. Divide, denoise, and defend against adversarial attacks[EB/OL]. https://arxiv.org/abs/1802.06806, 2019. [67] XIE Cihang, WANG Jianyu, ZHANG Zhishuai, et al. Mitigating adversarial effects through randomi-zation[EB/OL]. https://arxiv.org/abs/1711.01991, 2018. [68] BHAGOJI A N, CULLINA D, SITAWARIN C, et al. Enhancing robustness of machine learning systems via data transformations[EB/OL]. https://arxiv.org/abs/1704.02654, 2017. [69] LI Changjiang, WENG Haiqin, JI Shouling, et al. DeT: Defending against adversarial examples via decreasing transferability[C]. The 11th International Symposium on Cyberspace Safety and Security, Guangzhou, China, 2019: 307–322. [70] LIU Zihao, LIU Qi, LIU Tao, et al. Feature distillation: DNN-oriented JPEG compression against adversarial examples[EB/OL]. https://arxiv.org/abs/1803.05787, 2019. [71] SRINIVASAN V, MARBAN A, MULLER K R, et al. Robustifying models against adversarial attacks by langevin dynamics[EB/OL]. https://arxiv.org/abs/1805.12017, 2019. [72] DAS N, SHANBHOGUE M, CHEN S T, et al. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression[EB/OL]. https://arxiv.org/abs/1705.02900, 2017. [73] DHILLON G S, AZIZZADENESHELI K, LIPTON Z C, et al. Stochastic activation pruning for robust adversarial defense[EB/OL]. https://arxiv.org/abs/1803.01442, 2018. [74] LIU Xuanqing, CHENG Minhao, ZHANG Huan, et al. Towards robust neural networks via random self-ensemble[EB/OL]. https://arxiv.org/abs/1712.00673, 2018. [75] YAN Ziang, GUO Yiwen, and ZHANG Changshui. Deep defense: Training DNNs with improved adversarial robustness[C]. 32nd Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 419–428. [76] NA T, KO J H, and MUKHOPADHYAY S. Cascade adversarial machine learning regularized with a unified embedding[EB/OL]. https://arxiv.org/abs/1708.02582, 2018. [77] CAO Xiaoyu and GONG Zhenqiang. Mitigating evasion attacks to deep neural networks via region-based classification[C]. The 33rd Annual Computer Security Applications Conference, Orlando, USA, 2017: 278–287. [78] FOLZ J, PALACIO S, HEES J, et al. Adversarial defense based on structure-to-signal autoencoders[EB/OL]. https://arxiv.org/abs/1803.07994, 2018. [79] BAI Tao, LUO Jinqi, ZHAO Jun, et al. Recent advances in adversarial training for adversarial robustness[EB/OL]. http://arxiv.org/abs/2102.01356v4, 2021. [80] WANG Jianyu and ZHANG Haichao. Bilateral adversarial training: Towards fast training of more robust models against adversarial attacks[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 6629–6638. [81] ZHANG Hongyang, YU Yaodong, JIAO Jiantao, et al. Theoretically principled trade-off between robustness and accuracy[C]. The 36th International Conference on Machine Learning, Long Beach, California, 2019: 7472–7482. [82] CHENG Minhao, CHEN Pinyu, LIU Sijia, et al. Self-progressing robust training[EB/OL]. https://arxiv.org/abs/2012.11769, 2020. [83] RANJAN R, SANKARANARAYANAN S, CASTILLO C D, et al. Improving network robustness against adversarial attacks with compact convolution[EB/OL]. https://arxiv.org/abs/1712.00699, 2018. [84] GU Shixiang and RIGAZIO L. Towards deep neural network architectures robust to adversarial examples[EB/OL]. http://arxiv.org/abs/1412.5068, 2015. [85] DUBEY A, VAN DER MAATEN L, YALNIZ Z, et al. Defense against adversarial images using web-scale nearest-neighbor search[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 8767–8776. [86] YANG Yuzhe, ZHANG Guo, KATABI D, et al. ME-Net: Towards effective adversarial robustness with matrix estimation[EB/OL]. https://arxiv.org/abs/1905.11971, 2019. [87] PAPERNOT N, MCDANIEL P, WU Xi, et al. Distillation as a defense to adversarial perturbations against deep neural networks[C]. 2016 IEEE Symposium on Security and Privacy, San Jose, USA, 2016: 582–597. [88] PAPERNOT N and MCDANIEL P. Extending defensive distillation[EB/OL]. https://arxiv.org/abs/1705.05264, 2017. [89] STRAUSS T, HANSELMANN M, JUNGINGER A, et al. Ensemble methods as a defense to adversarial perturbations against deep neural networks[EB/OL]. https://arxiv.org/abs/1709.03423, 2018. [90] TRAMÈR F, KURAKIN A, PAPERNOT N, et al. Ensemble adversarial training: Attacks and defenses[EB/OL]. http://arxiv.org/abs/1705.07204, 2020. [91] SENGUPTA S, CHAKRABORTI T, and KAMBHAMPATI S. MTDeep: Boosting the security of deep neural nets against adversarial attacks with moving target defense[EB/OL]. http://arxiv.org/abs/1705.07213, 2019. [92] SAMANGOUEI P, KABKAB M, and CHELLAPPA R. Defense-GAN: Protecting classifiers against adversarial attacks using generative models[EB/OL]. http://arxiv.org/abs/1805.06605, 2018. [93] SHEN Shiwei, JIN Guoqing, GAO Ke, et al. APE-GAN: Adversarial perturbation elimination with GAN[EB/OL]. http://arxiv.org/abs/1707.05474, 2017. [94] ZANTEDESCHI V, NICOLAE M I, and RAWAT A. Efficient defenses against adversarial attacks[C]. The 10th ACM Workshop on Artificial Intelligence and Security, Dallas, USA, 2017: 39–49. [95] CISSE M, BOJANOWSKI P, GRAVE E, et al. Parseval networks: Improving robustness to adversarial examples[C]. The 34th International Conference on Machine Learning, Sydney, Australia, 2017: 854–863. [96] LIAO Fangzhou, LIANG Ming, DONG Yinpeng, et al. Defense against adversarial attacks using high-level representation guided denoiser[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 1778–1787. [97] KANNAN H, KURAKIN A, and GOODFELLOW I. Adversarial logit pairing[EB/OL]. http://arxiv.org/abs/1803.06373, 2018. [98] SINHA A, NAMKOONG H, VOLPI R, et al. Certifying some distributional robustness with principled adversarial training[EB/OL]. http://arxiv.org/abs/1710.10571, 2020. [99] LAMB A, BINAS J, GOYAL A, et al. Fortified networks: Improving the robustness of deep networks by modeling the manifold of hidden representations[EB/OL]. https://arxiv.org/abs/1804.02485, 2018. [100] GAO Ji, WANG Beilun, LIN Zeming, et al. DeepCloak: Masking deep neural network models for robustness against adversarial samples[EB/OL]. http://arxiv.org/abs/1702.06763, 2017. [101] BAKHTI Y, FEZZA S A, HAMIDOUCHE W, et al. DDSA: A defense against adversarial attacks using deep denoising sparse autoencoder[J]. IEEE Access, 2019, 7: 160397–160407. doi: 10.1109/ACCESS.2019.2951526 [102] LIU Xuanqing, LI Yao, WU Chongruo, et al. Adv-BNN: Improved adversarial defense through robust Bayesian neural network[EB/OL]. http://arxiv.org/abs/1810.01279, 2019. [103] SONG Yang, KIM T, NOWOZIN S, et al. PixelDefend: Leveraging generative models to understand and defend against adversarial examples[EB/OL]. http://arxiv.org/abs/1710.10766, 2018. [104] FEINMAN R, CURTIN R R, SHINTRE S, et al. Detecting adversarial samples from artifacts[EB/OL]. http://arxiv.org/abs/1703.00410, 2017. [105] CARRARA F, FALCHI F, CALDELLI R, et al. Adversarial image detection in deep neural networks[J]. Multimedia Tools and Applications, 2019, 78(3): 2815–2835. doi: 10.1007/s11042-018-5853-4 [106] LI Xin and LI Fuxin. Adversarial examples detection in deep networks with convolutional filter statistics[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5775–5783. [107] CHEN Jiefeng, MENG Zihang, SUN Changtian, et al. ReabsNet: Detecting and revising adversarial examples[EB/OL]. http://arxiv.org/abs/1712.08250, 2017. [108] ZHENG Zhihao and HONG Pengyu. Robust detection of adversarial attacks by modeling the intrinsic properties of deep neural networks[C]. The 32nd Conference on Neural Information Processing Systems, Montréal, Canada, 2018: 7913–7922. [109] PANG Tianyu, DU Chao, and ZHU Jun. Robust deep learning via reverse cross-entropy training and thresholding test[EB/OL]. https://arxiv.org/abs/1706.00633v1, 2018. [110] MA Shiqing, LIU Yingqi, TAO Guanhong, et al. NIC: Detecting adversarial samples with neural network invariant checking[C]. 2019 Network and Distributed Systems Security Symposium, San Diego, USA, 2019: 1–15. [111] MA Xingjun, LI Bo, WANG Yisen, et al. Characterizing adversarial subspaces using local intrinsic dimension-ality[EB/OL]. http://arxiv.org/abs/1801.02613, 2018. [112] COHEN G, SAPIRO G, and GIRYES R. Detecting adversarial samples using influence functions and nearest neighbors[EB/OL]. http://arxiv.org/abs/1909.06872, 2020. [113] GONG Zhitao, WANG Wenlu, and KU W S. Adversarial and clean data are not twins[EB/OL]. http://arxiv.org/abs/1704.04960, 2017. [114] METZEN J H, GENEWEIN T, FISCHER V, et al. On detecting adversarial perturbations[EB/OL]. http://arxiv.org/abs/1702.04267, 2017. [115] MENG Dongyu and CHEN Hao. MagNet: A two-pronged defense against adversarial examples[C]. The 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, USA, 2017: 135–147. [116] MACHADO G R, GOLDSCHMIDT R R, and SILVA E. MultiMagNet: A non-deterministic approach based on the formation of ensembles for defending against adversarial images[C]. The 21st International Conference on Enterprise Information Systems, Heraklion, Greece, 2019: 307–318. [117] LU Jiajun, ISSARANON T, and FORSYTH D. SafetyNet: Detecting and rejecting adversarial examples robustly[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 446–454. [118] XU Weilin, EVANS D, and Qi Yanjun. Feature squeezing: Detecting adversarial examples in deep neural networks[EB/OL]. https://arxiv.org/abs/1704.01155, 2017. [119] RUAN Yibin and DAI Jiazhu. TwinNet: A double sub-network framework for detecting universal adversarial perturbations[J]. Future Internet, 2018, 10(3): 26. doi: 10.3390/fi10030026 [120] ABBASI M and GAGNÉ C. Robustness to adversarial examples through an ensemble of specialists[EB/OL]. http://arxiv.org/abs/1702.06856, 2017. [121] LIANG Bin, LI Hongcheng, SU Miaoqiang, et al. Detecting adversarial image examples in deep networks with adaptive noise reduction[EB/OL]. http://arxiv.org/abs/1705.08378, 2019. [122] LUST J and CONDURACHE A P. A survey on assessing the generalization envelope of deep neural networks at inference time for image classification[EB/OL]. http://arxiv.org/abs/2008.09381v2, 2020. [123] MA Lei, JUEFEI-XU F, ZHANG Fuyuan, et al. DeepGauge: Multi-granularity testing criteria for deep learning systems[C]. The 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 2018: 120–131. [124] LING Xiang, JI Shouling, ZOU Jiaxu, et al. DEEPSEC: A uniform platform for security analysis of deep learning model[C]. 2019 IEEE Symposium on Security and Privacy, San Francisco, USA, 2019: 673–690. [125] WANG Zhou, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600–612. doi: 10.1109/TIP.2003.819861 [126] LUO Bo, LIU Yannan, WEI Lingxiao, et al. Towards imperceptible and robust adversarial example attacks against neural networks[EB/OL]. https://arxiv.org/abs/1801.04693, 2018. [127] LIU Aishan, LIU Xianglong, GUO Jun, et al. A comprehensive evaluation framework for deep model robustness[EB/OL]. https://arxiv.org/abs/2101.09617v1, 2021. [128] ZHANG Chongzhi, LIU Aishan, LIU Xianglong, et al. Interpreting and improving adversarial robustness of deep neural networks with neuron sensitivity[J]. IEEE Transactions on Image Processing, 2020, 30: 1291–1304. doi: 10.1109/TIP.2020.3042083 [129] VARGAS D V and KOTYAN S. Robustness assessment for adversarial machine learning: Problems, solutions and a survey of current neural networks and defenses[EB/OL]. https://arxiv.org/abs/1906.06026v2, 2020. [130] CARLINI N, ATHALYE A, PAPERNOT N, et al. On evaluating adversarial robustness[EB/OL]. https://arxiv.org/abs/1902.06705, 2019. [131] DONG Yinpeng, FU Qi’an, YANG Xiao, et al. Benchmarking adversarial robustness on image classification[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 318–328. [132] HENDRYCKS T and DIETTERICH T. Benchmarking neural network robustness to common corruptions and perturbations[EB/OL]. https://arxiv.org/abs/1903.12261v1, 2019. [133] RAGHUNATHAN A, XIE S M, YANG F, et al. Understanding and mitigating the tradeoff between robustness and accuracy[EB/OL]. https://arxiv.org/abs/2002.10716v2, 2020. [134] ZHANG Xuyao, LIU Chenglin, and SUEN C Y. Towards robust pattern recognition: A review[J]. Proceedings of the IEEE, 2020, 108(6): 894–922. doi: 10.1109/JPROC.2020.2989782 [135] ABOUTALEBI H, SHAFIEE M J, KARG M, et al. Vulnerability under adversarial machine learning: Bias or variance?[EB/OL]. https://arxiv.org/abs/2008.00138v1, 2020. [136] BAI Tao, LUO Jinqi, and ZHAO Jun. Recent advances in understanding adversarial robustness of deep neural networks[EB/OL]. http://arxiv.org/abs/2011.01539v1, 2020. [137] TRAMÈR F, BEHRMANN J, CARLINI N, et al. Fundamental tradeoffs between invariance and sensitivity to adversarial perturbations[EB/OL]. https://arxiv.org/abs/2002.04599, 2020. [138] KUNHARDT O, DEZA A, and POGGIO T. The effects of image distribution and task on adversarial robustness[EB/OL]. https://arxiv.org/abs/2102.10534, 2021. [139] SERBAN A C, POLL E, and VISSER J. Adversarial examples - a complete characterisation of the phenomenon[EB/OL]. http://arxiv.org/abs/1810.01185v2, 2019. [140] CARMON Y, RAGHUNATHAN A, SCHMIDT L, et al. Unlabeled data improves adversarial robustness[C]. The 33rd Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 1–12. [141] HENDRYCKS D, MAZEIKA M, KADAVATH S, et al. Using self-supervised learning can improve model robustness and uncertainty[C]. The 33rd Conference on Neural Information Processing Systems, Vancouver, Canada, 2019. [142] CHEN Tianlong, LIU Sijia, CHANG Shiyu, et al. Adversarial robustness: From self-supervised pre-training to fine-tuning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 696–705. [143] JIANG Ziyu, CHEN Tianlong, CHEN Ting, et al. Robust pre-training by adversarial contrastive learning[EB/OL]. https://arxiv.org/abs/2010.13337, 2020. [144] KIM M, TACK J, and HWANG S J. Adversarial self-supervised contrastive learning[C]. The 34th Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1–12. [145] CHENG Gong, HAN Junwei, and LU Xiaoqiang. Remote sensing image scene classification: Benchmark and state of the art[J]. Proceedings of the IEEE, 2017, 105(10): 1865–1883. doi: 10.1109/JPROC.2017.2675998 [146] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [147] GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent a new approach to self-supervised learning[C]. The 34th Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 1–14. [148] XU Yanjie, SUN Hao, CHEN Jin, et al. Robust remote sensing scene classification by adversarial self-supervised learning[C]. 2021 International Geoscience and Remote Sensing Symposium, Brussels, Belgium, 2021: 1–4. [149] LI Haifeng, HUANG Haikuo, CHEN Li, et al. Adversarial examples for CNN-based SAR image classification: An experience study[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 1333–1347. doi: 10.1109/JSTARS.2020.3038683 [150] XU Yonghao, DU Bo, and ZHANG Liangpei. Assessing the threat of adversarial examples on deep neural networks for remote sensing scene classification: Attacks and defenses[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(2): 1604–1617. doi: 10.1109/TGRS.2020.2999962 [151] TU J, LI Huichen, YAN Xinchen, et al. Exploring adversarial robustness of multi-sensor perception systems in self driving[EB/OL]. https://arxiv.org/abs/2101.06784v1, 2021. [152] MODAS A, SANCHEZ-MATILLA R, FROSSARD P, et al. Toward robust sensing for autonomous vehicles: An adversarial perspective[J]. IEEE Signal Processing Magazine, 2020, 37(4): 14–23. doi: 10.1109/MSP.2020.2985363 [153] SUN Hao, XU Yanjie, KUANG Gangyao, et al. Adversarial robustness evaluation of deep convolutional neural network based SAR ATR algorithm[C]. 2021 International Geoscience and Remote Sensing Symposium, Brussels, Belgium, 2021: 1–4. [154] ZHU Xiaoxiang, HU Jingliang, QIU Chunping, et al. So2Sat LCZ42: A benchmark data set for the classification of global local climate zones [Software and Data Sets][J]. IEEE Geoscience and Remote Sensing Magazine, 2020, 8(3): 76–89. doi: 10.1109/MGRS.2020.2964708 -








计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

