
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Semi-supervised Video Synthetic Aperture Radar Shadow Tracking Based on Physics-aware Spectral Spatial Attention and Kinematic Constraints
-
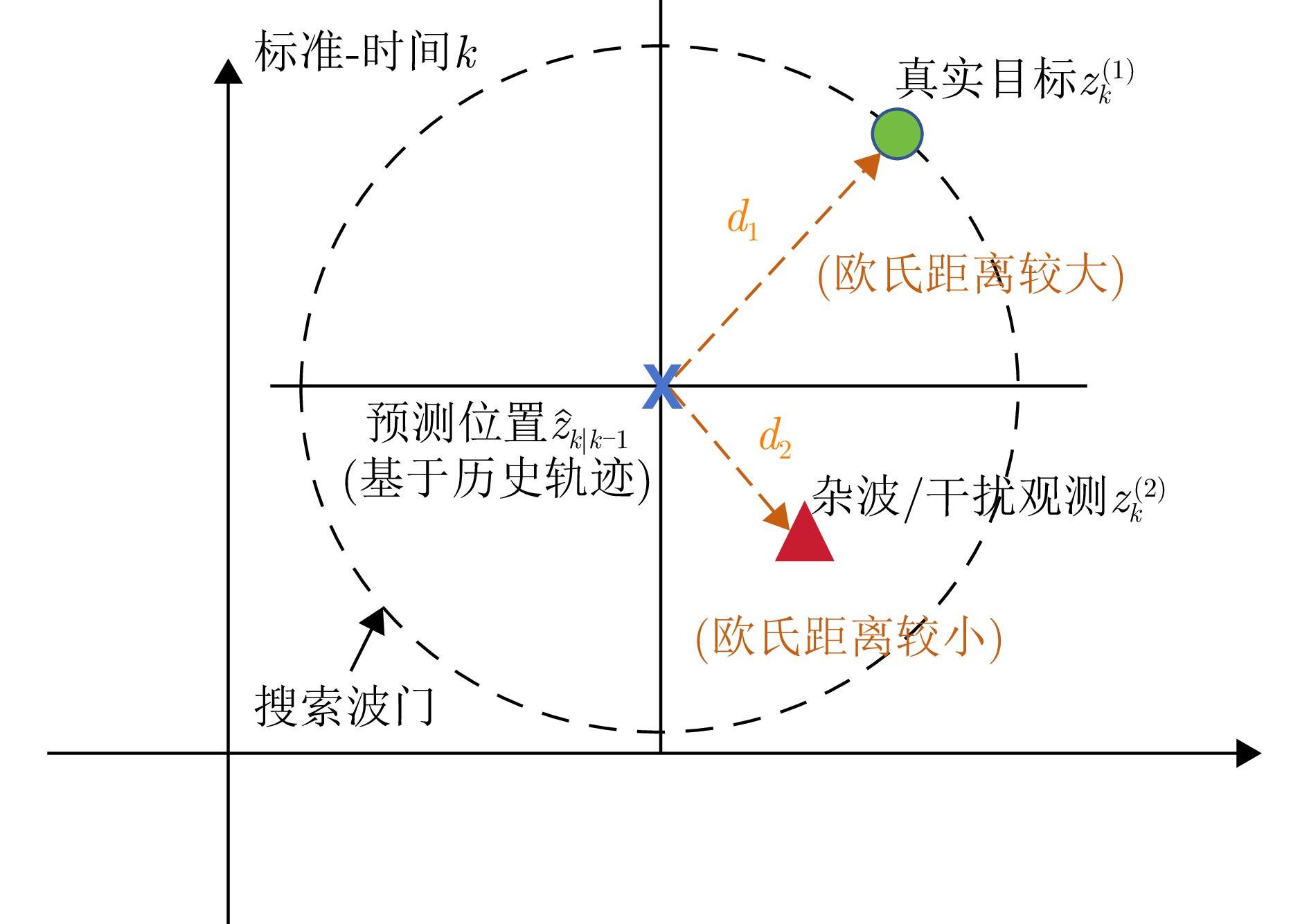
摘要: 针对视频合成孔径雷达(Video SAR)动目标阴影跟踪任务中面临的强相干斑噪声、显著非刚性形变及有监督训练样本稀缺等挑战,该文提出一种融合物理感知频空注意力与运动学约束的半监督跟踪方法。在检测阶段,构建基于UniMatchV2架构改进的半监督特征增强网络,通过在解码器高层特征嵌入所设计的物理感知混合频空注意力(PA-HSSA)模块,利用其频域分支实现对特征域宽带高频干扰的全局抑制,并借助空域分支对阴影几何结构进行局部锚定,同时引入动态权重生成器以自适应融合双域特征,从而在极低标注率条件下生成高质量的预测掩码。在跟踪阶段,提出一种面向半监督不确定性的时空关联框架,首先基于线性高斯状态空间模型(LGSSM)构建运动学先验波门以平滑检测结果的边缘抖动,进而设计融合运动学残差与几何一致性约束的多维代价矩阵,有效缓解因目标机动与形变引起的关联模糊问题。基于桑迪亚国家实验室(SNL)实测数据的实验结果表明,在仅使用1/32有标签数据的情况下,所提方法的多目标跟踪准确率(MOTA)达到64.19%,较基准方法提升6.73%,显著提升了强杂波背景下弱小阴影目标的稳健跟踪性能。Abstract: Moving target shadow tracking in Video Synthetic Aperture Radar (Video SAR) faces significant challenges, including strong speckle noise interference, substantial nonrigid target deformation, and a scarcity of supervised training samples. To address these issues, we propose a semi-supervised tracking method that integrates physics-aware spectral spatial attention and kinematic constraints. For the detection stage, we construct a semi-supervised feature enhancement network based on an improved UniMatchV2 architecture. Specifically, to account for the spectral spatial characteristics of SAR images, a Physics-Aware Hybrid Spectral Spatial Attention (PA-HSSA) module is designed and embedded into the high-level feature space of the decoder. This module utilizes its spectral branch to globally suppress wideband high-grequercy interference and its spatial branch to locally anchor the shadow’s geometric structure. A dynamic weight generator is introduced to adaptively fuse the dual-domain features, thereby generating high-quality prediction masks under extremely low annotation ratios. For the tracking stage, we propose a spatiotemporal association framework tailored for semi-supervised uncertainty. The framework includes a kinematic prior gate based on a Linear Gaussian State Space Model (LGSSM) to smooth and correct jittery detection edges. Subsequently, a multidimensional cost matrix integrating kinematic residuals and geometric consistency is built to resolve association ambiguities caused by target maneuverability and deformation. Experimental results on measured data from Sandia National Laboratories (SNL) demonstrate that the proposed method achieves a Multiple Object Tracking Accuracy (MOTA) of 64.19% using only 1/32 of the labeled data, outperforming baseline methods by 6.73%. This method effectively addresses the challenge of robustly tracking weak and small shadows in heavily cluttered backgrounds.
-
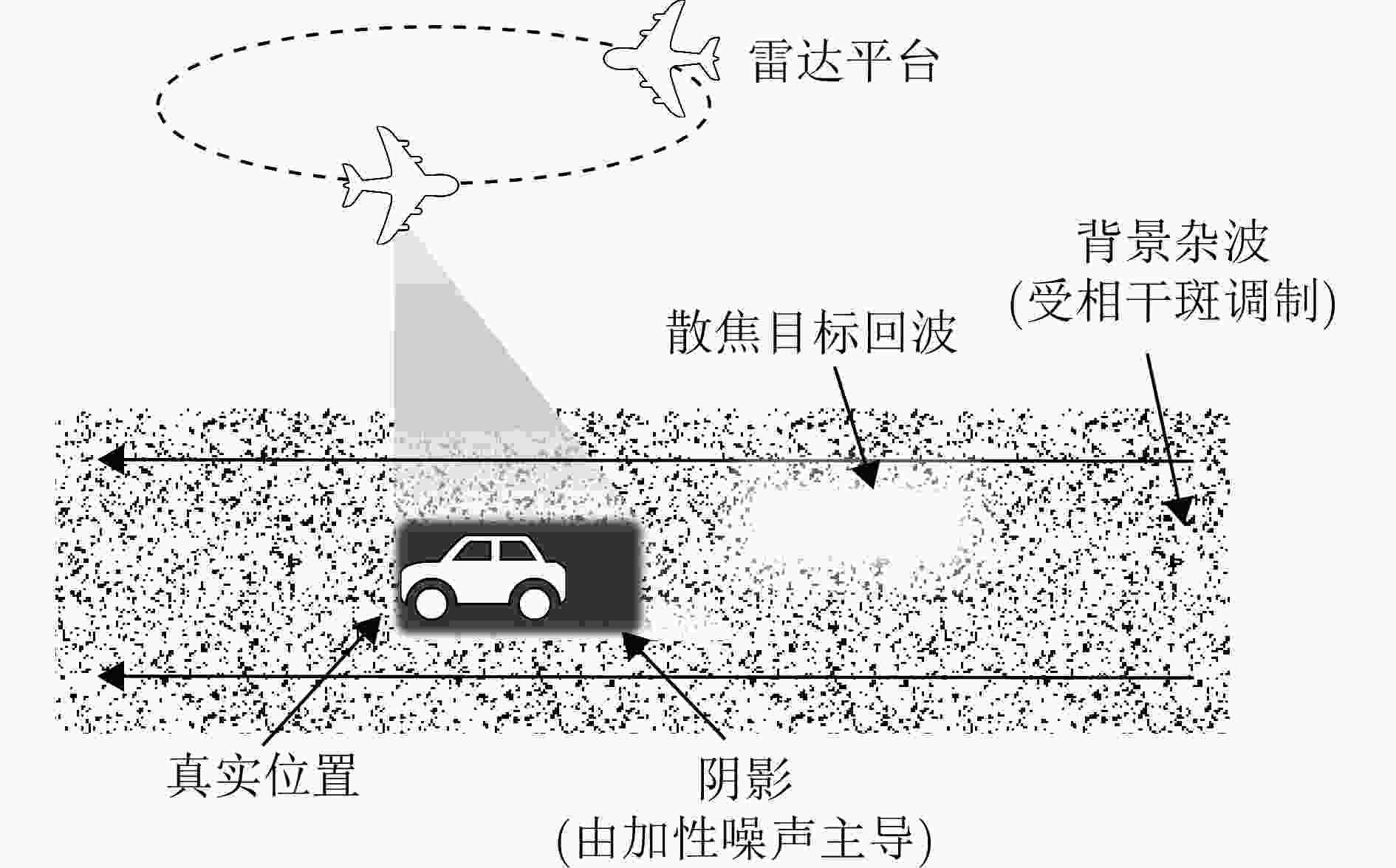
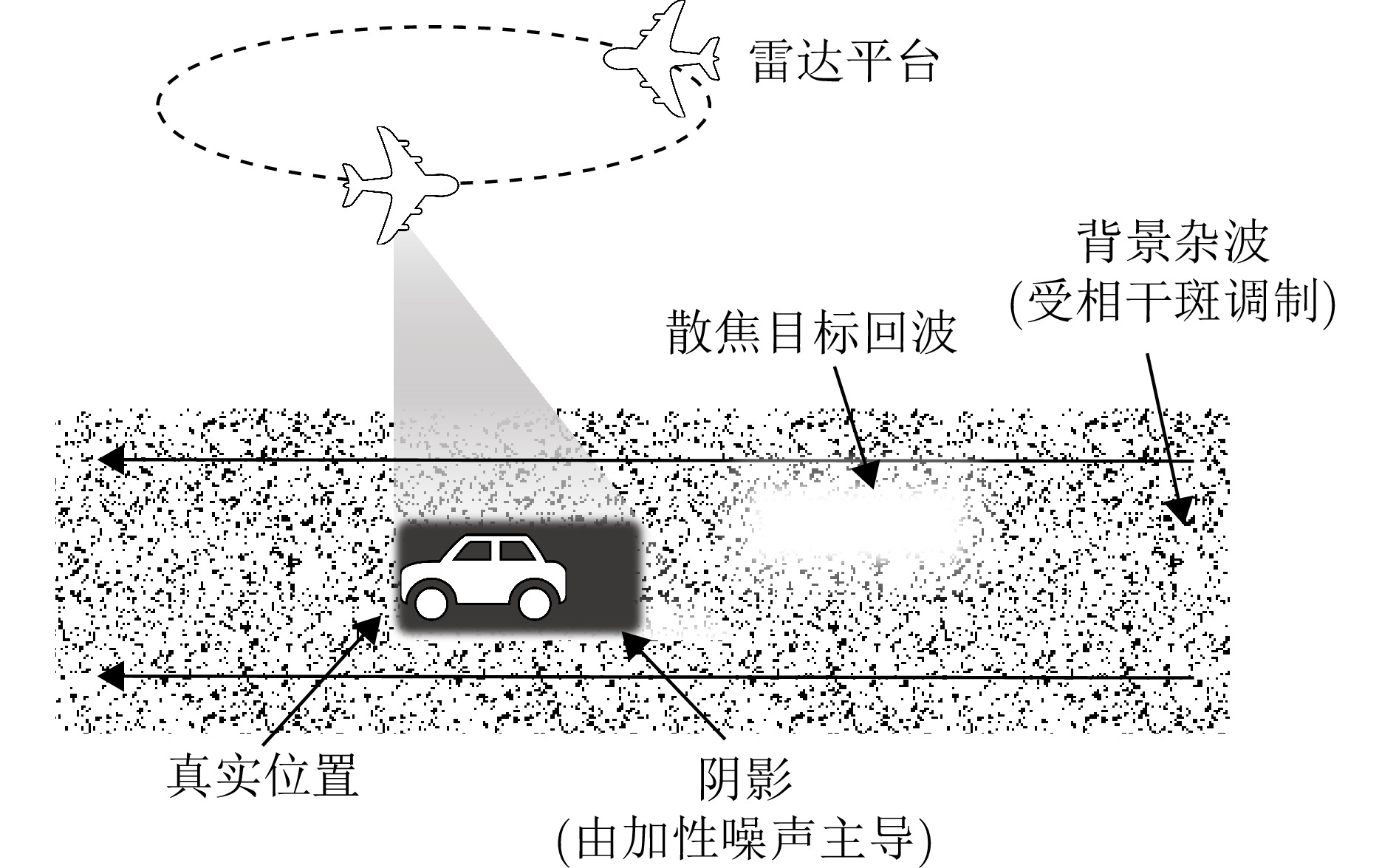
图 1 视频SAR动目标多普勒散焦与阴影成像几何示意图
Figure 1. Geometric schematic of Doppler defocusing and shadow imaging for moving targets in Video SAR

图 2 典型视频SAR场景下弱阴影目标与频空域干扰要素的视觉特性分析
Figure 2. Visual characteristics analysis of weak shadow targets and spatio-frequency interference elements in typical Video SAR scenes
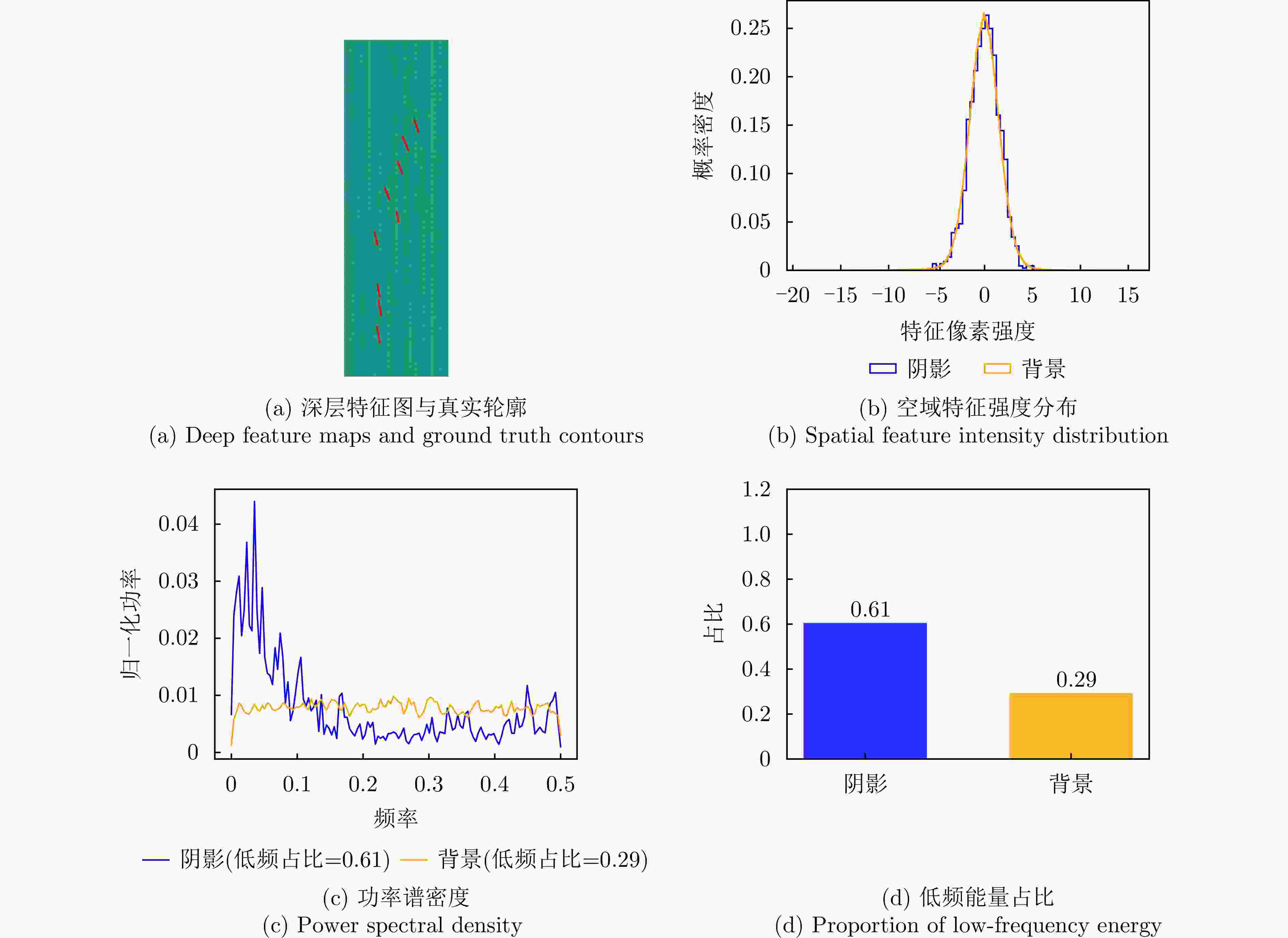
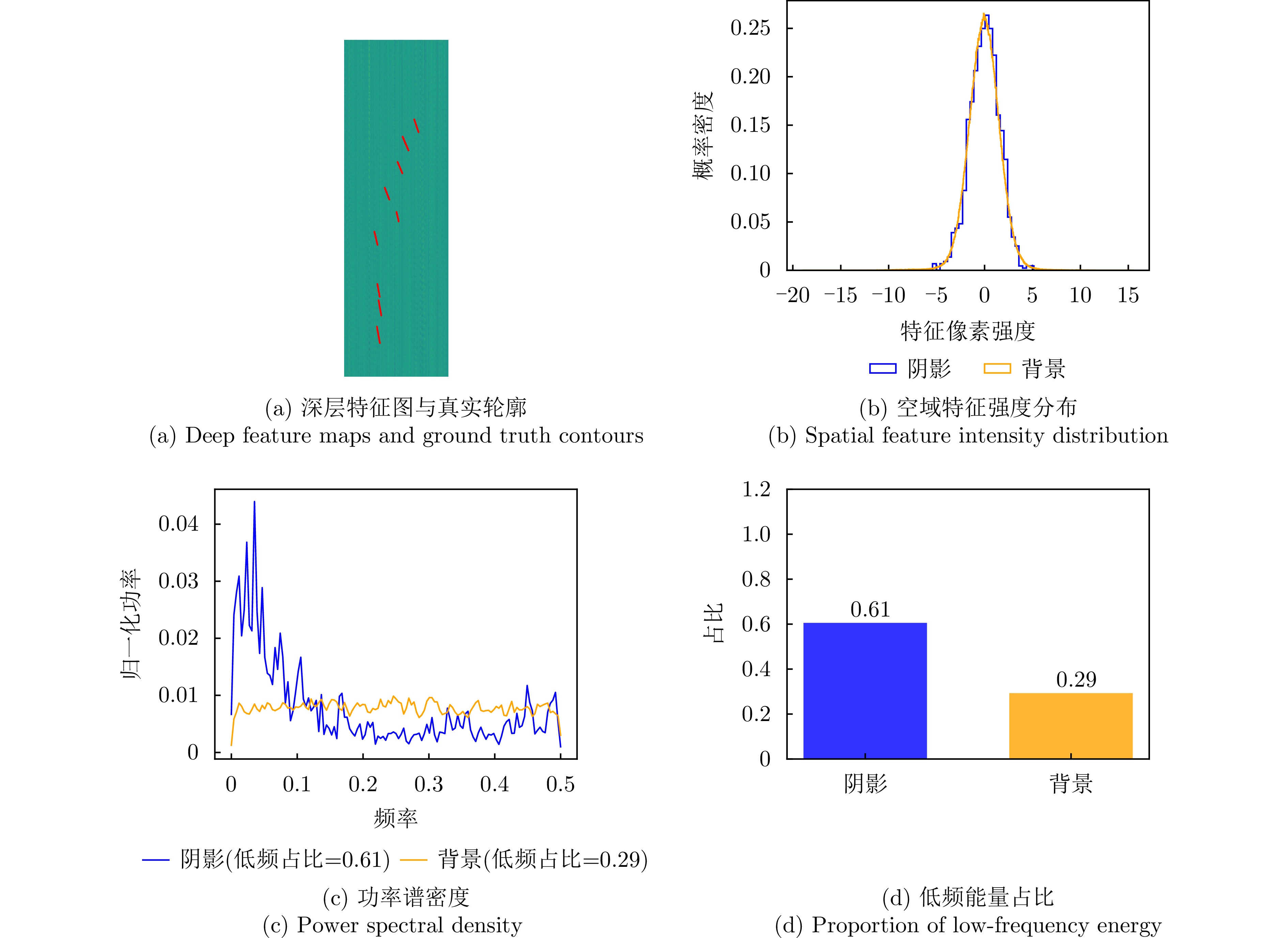
图 3 基于真实标签的阴影与杂波特征定量频谱分析
Figure 3. Quantitative spectral analysis of shadow and clutter features based on ground truth
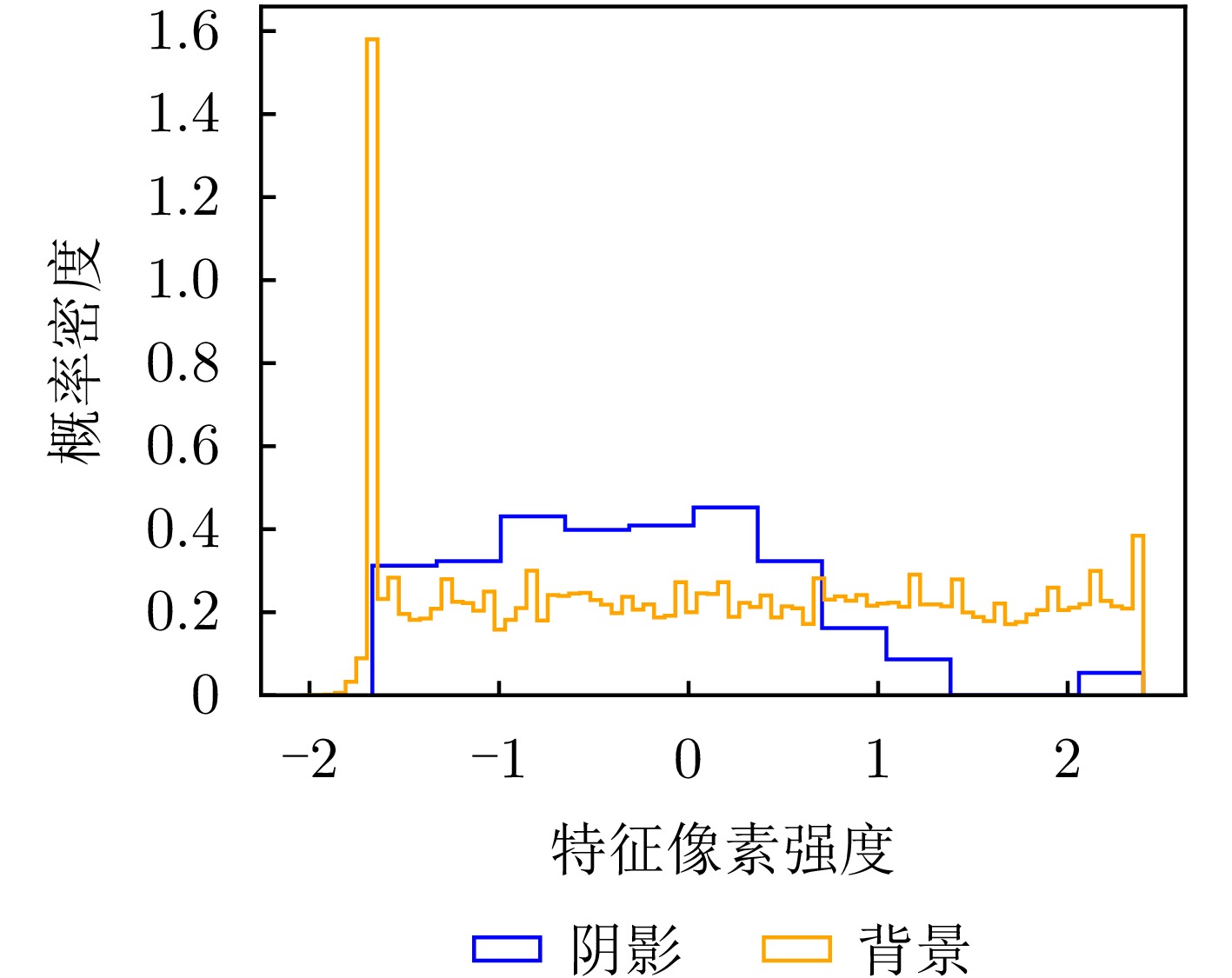
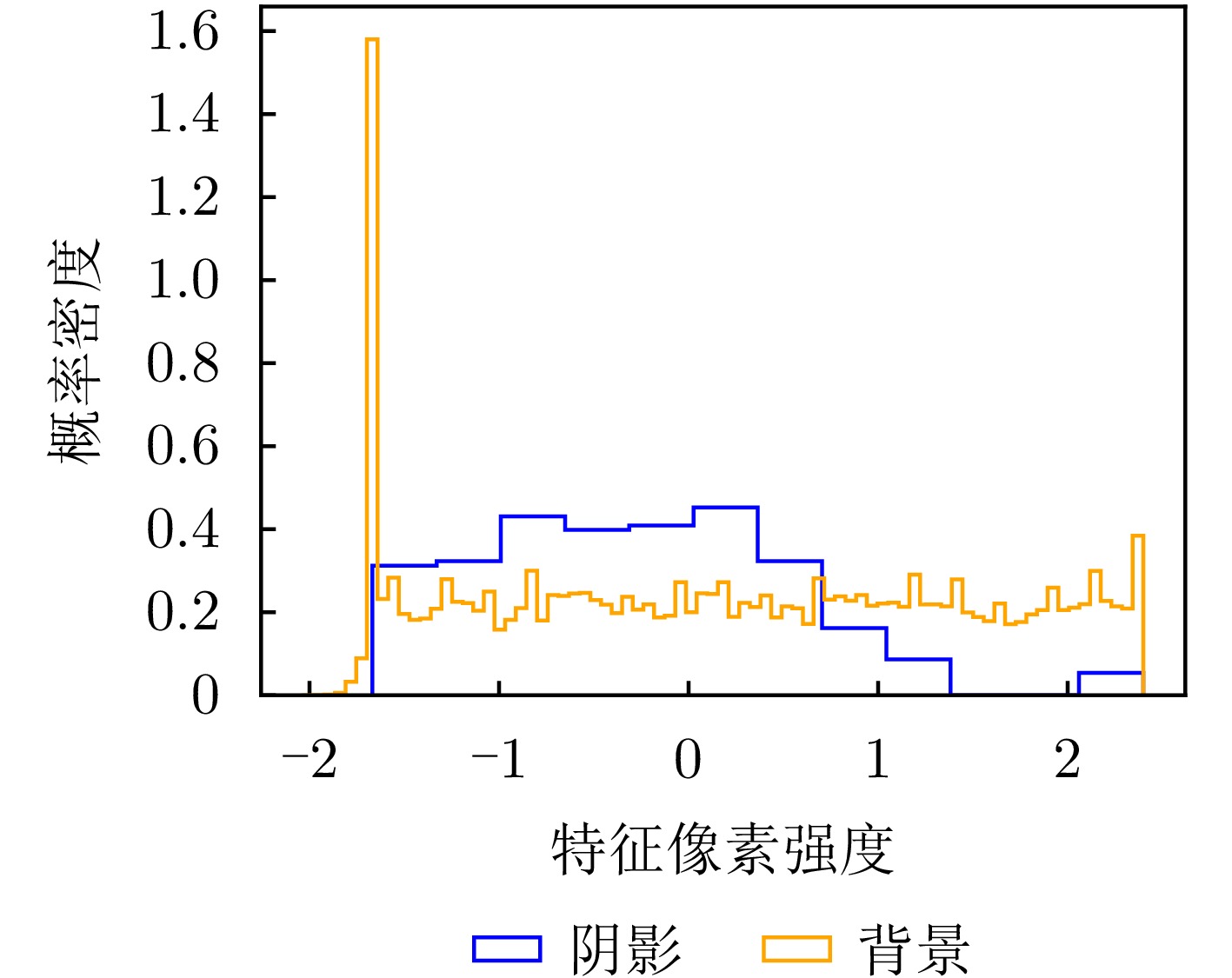
图 4 原始视频SAR图像空域特征强度分布直方图
Figure 4. Histogram of spatial feature intensity distribution in original Video SAR images
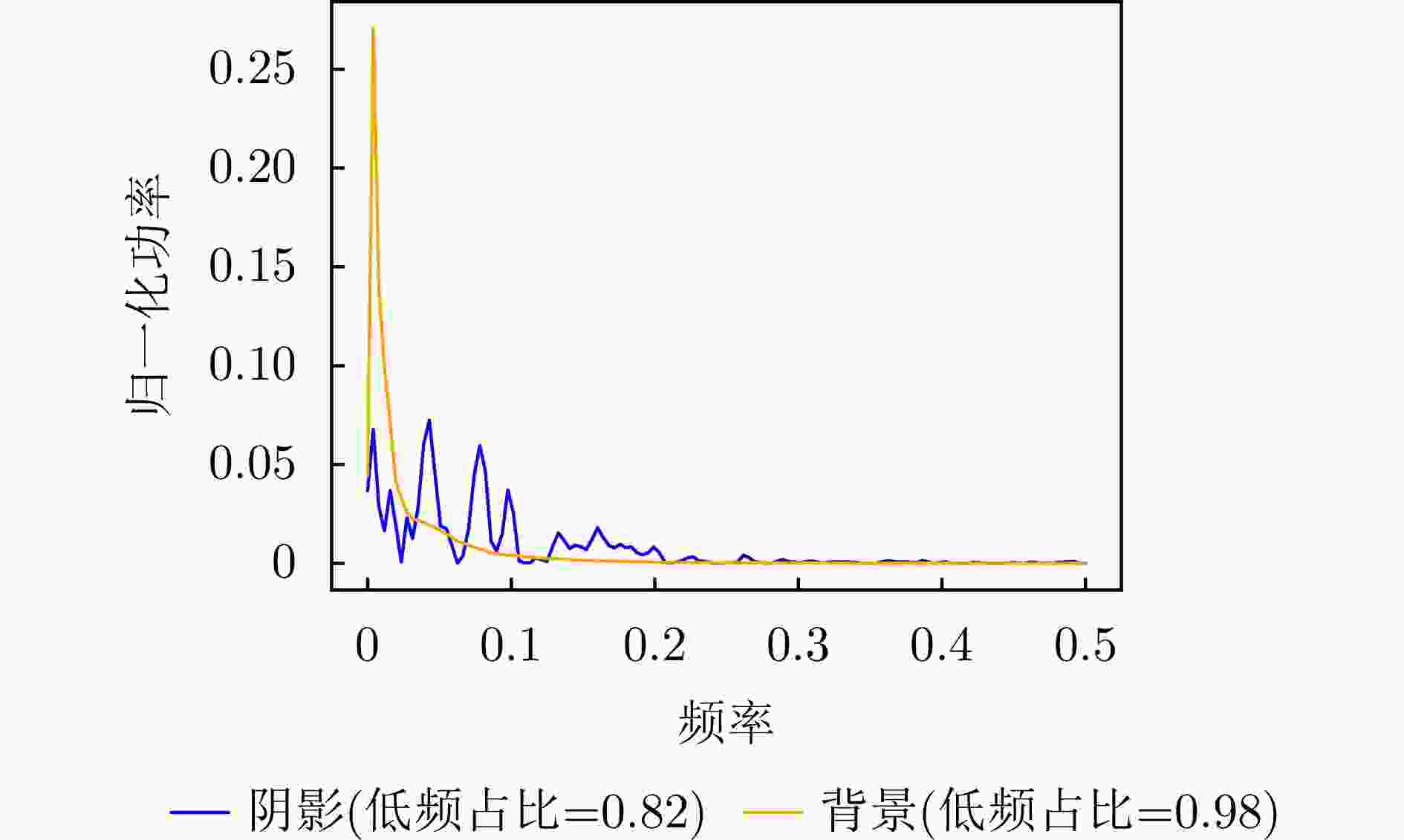
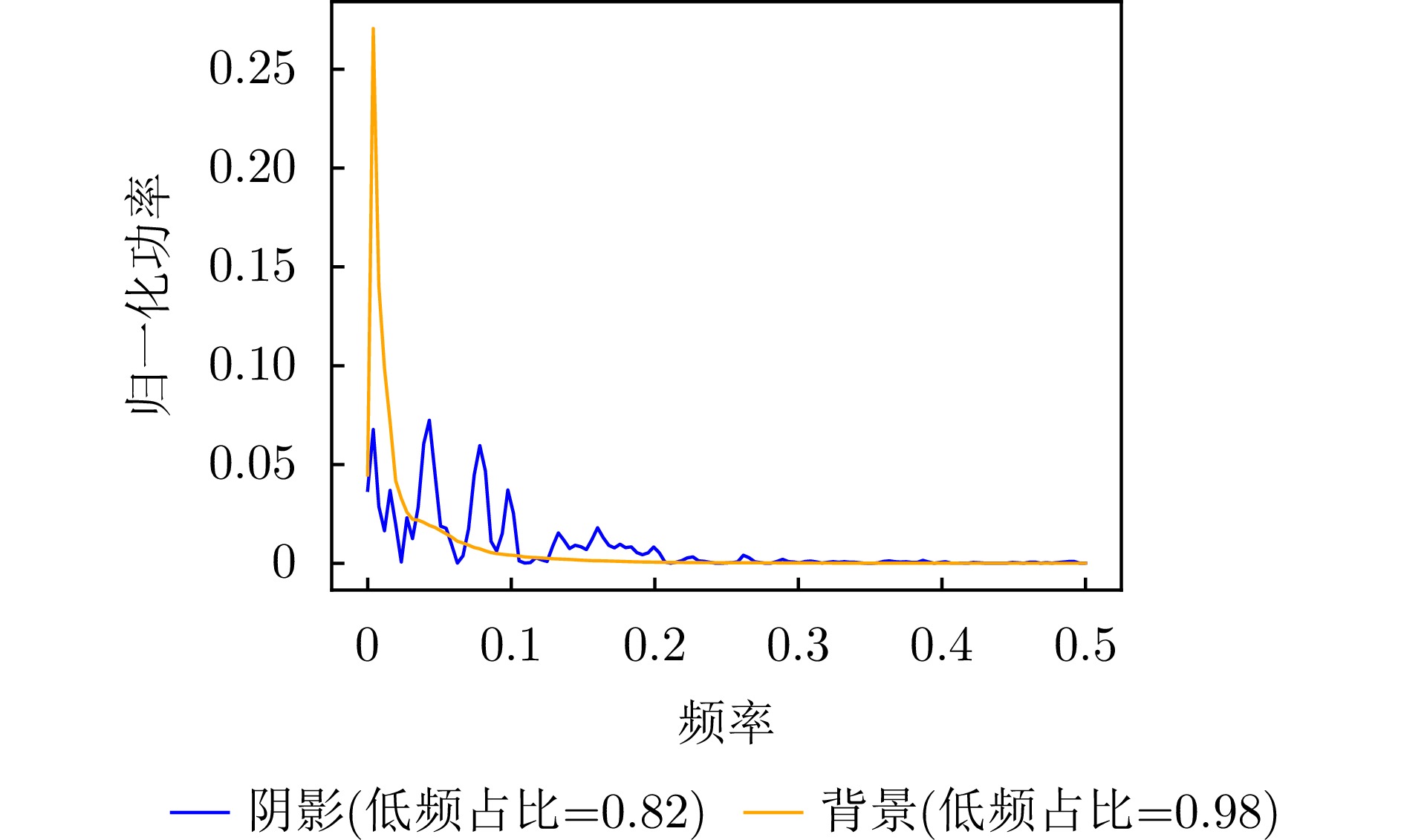
图 5 原始视频SAR图像功率谱密度分析
Figure 5. Power spectral density analysis of original Video SAR images
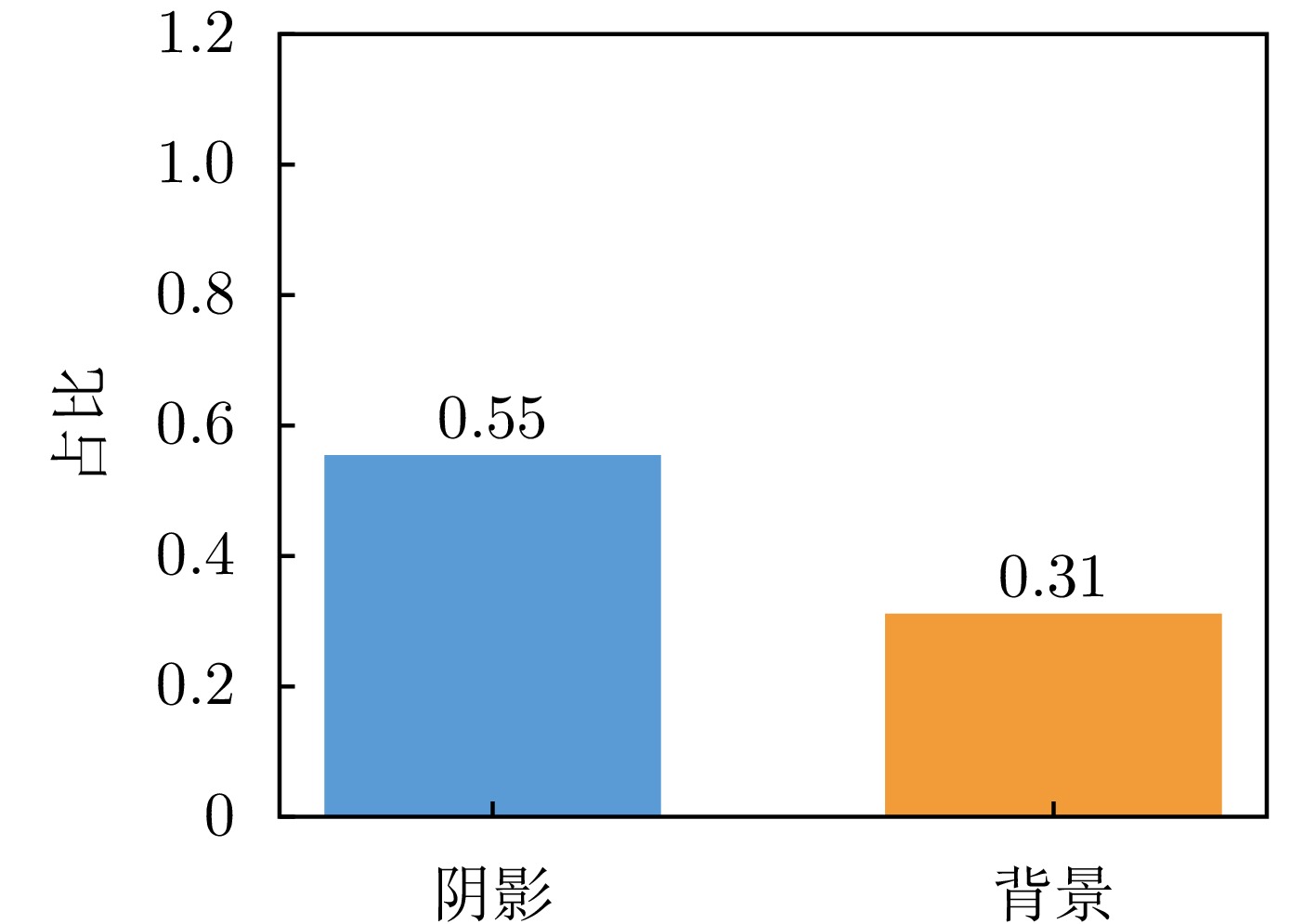
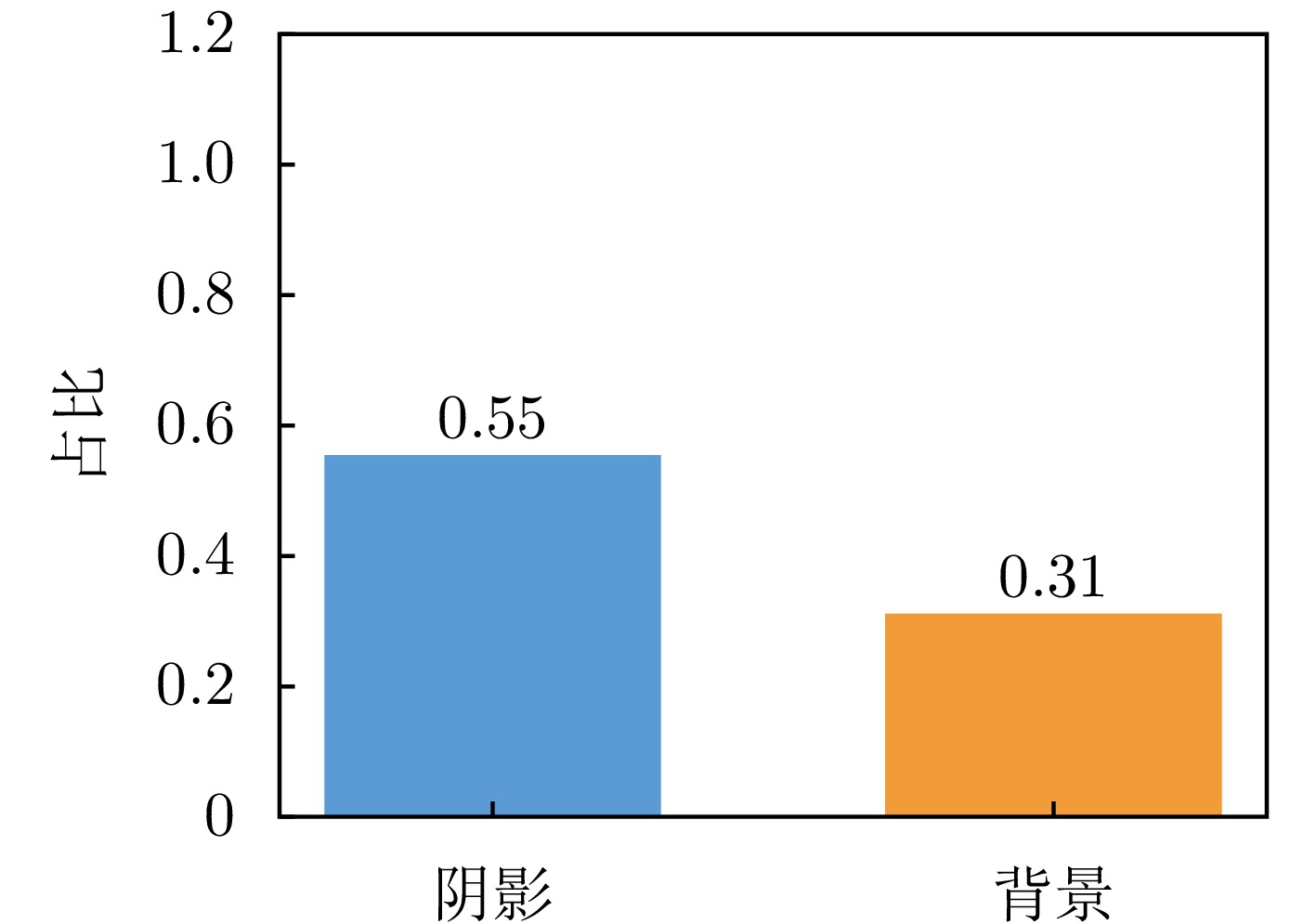
图 6 序列尺度低频能量占比统计
Figure 6. Sequence-level statistics of low-frequency energy proportion
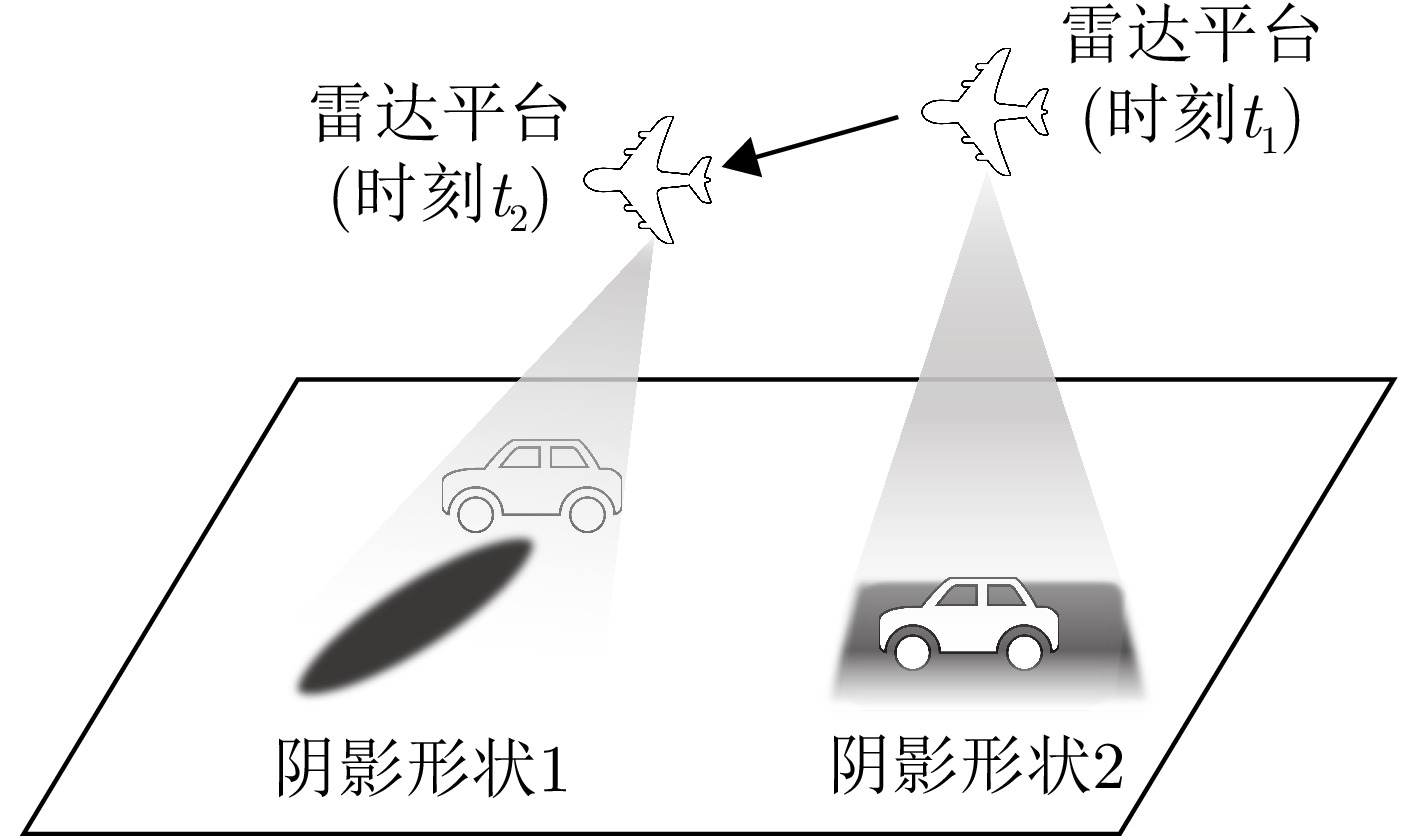
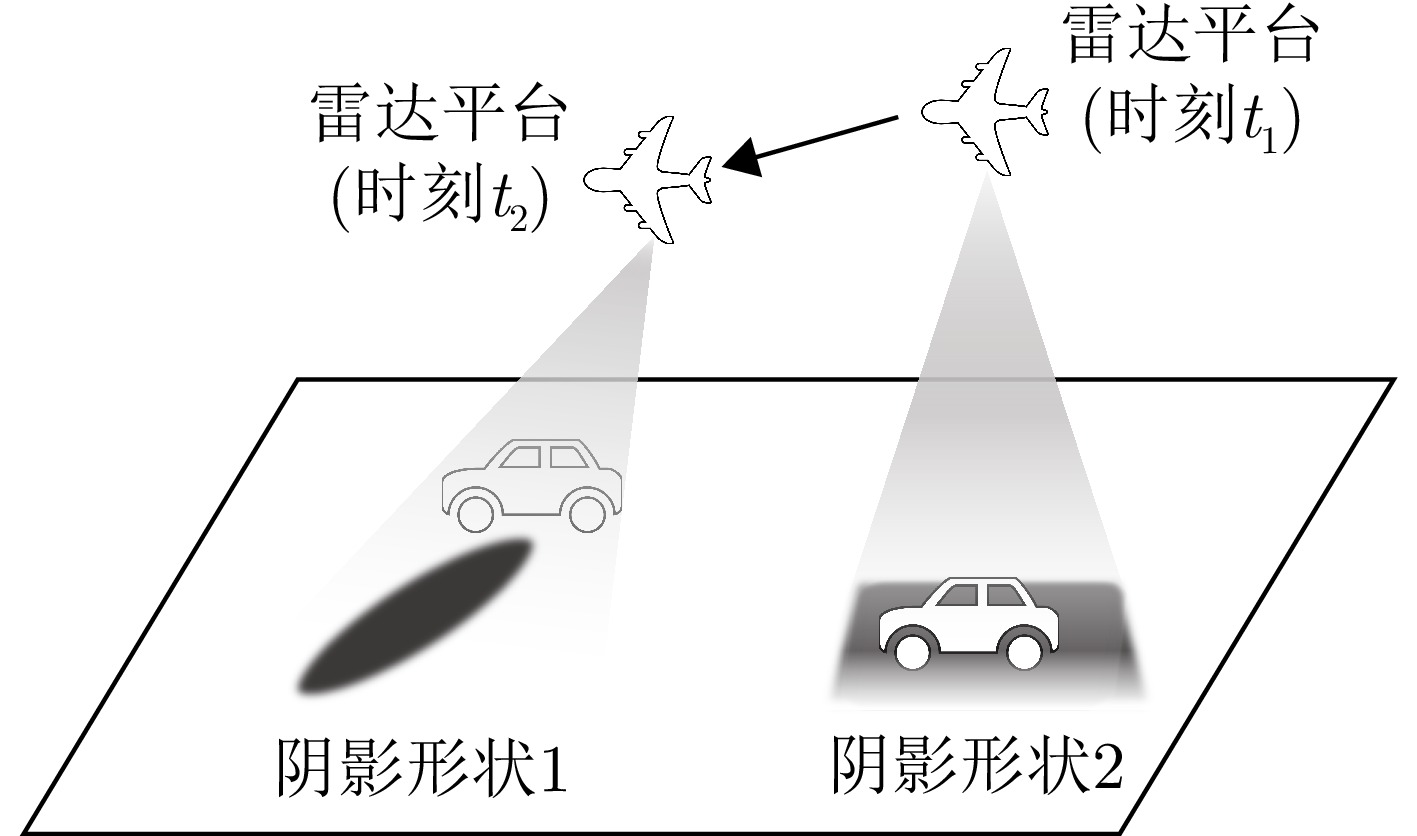
图 8 雷达视角变化下的阴影形状变化
Figure 8. Shadow shape variation under changing radar viewing angles
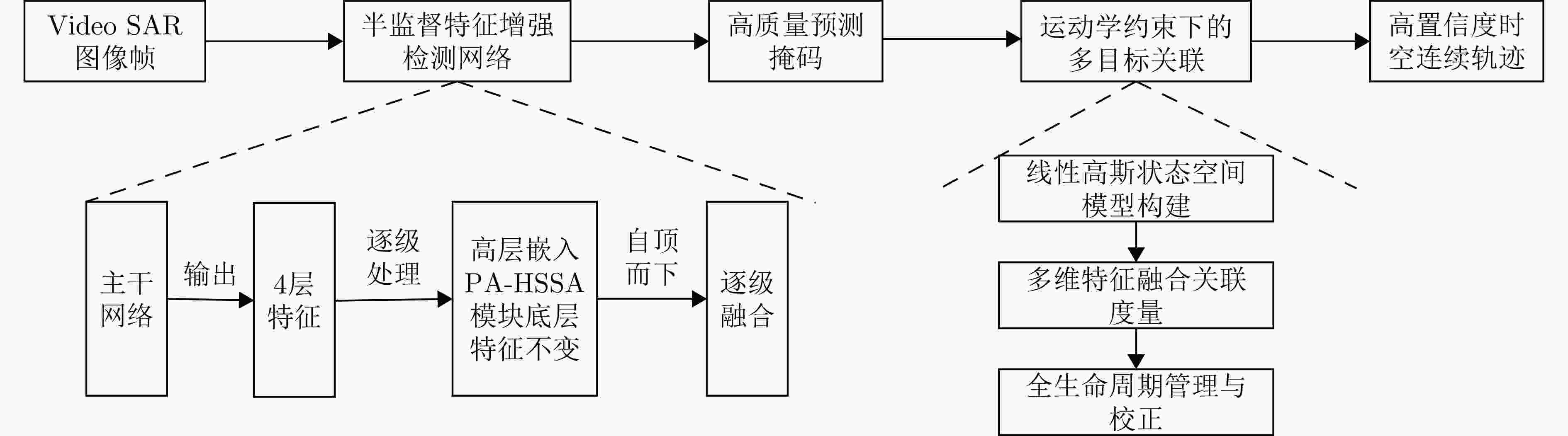
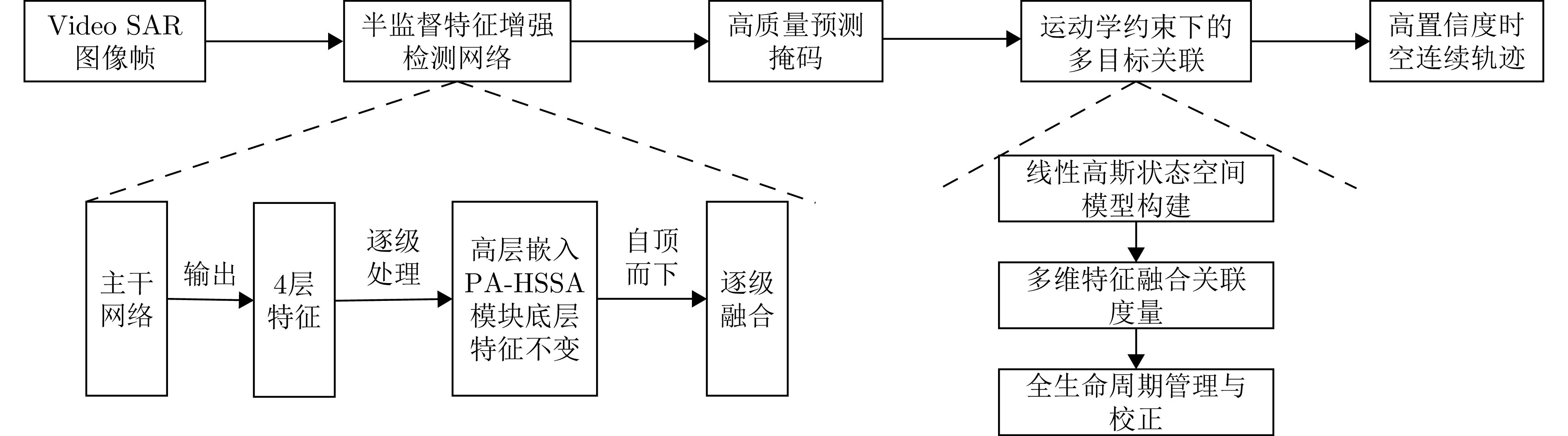
图 9 物理感知驱动的半监督检测与跟踪框架
Figure 9. Physics-aware semi-supervised detection and tracking framework
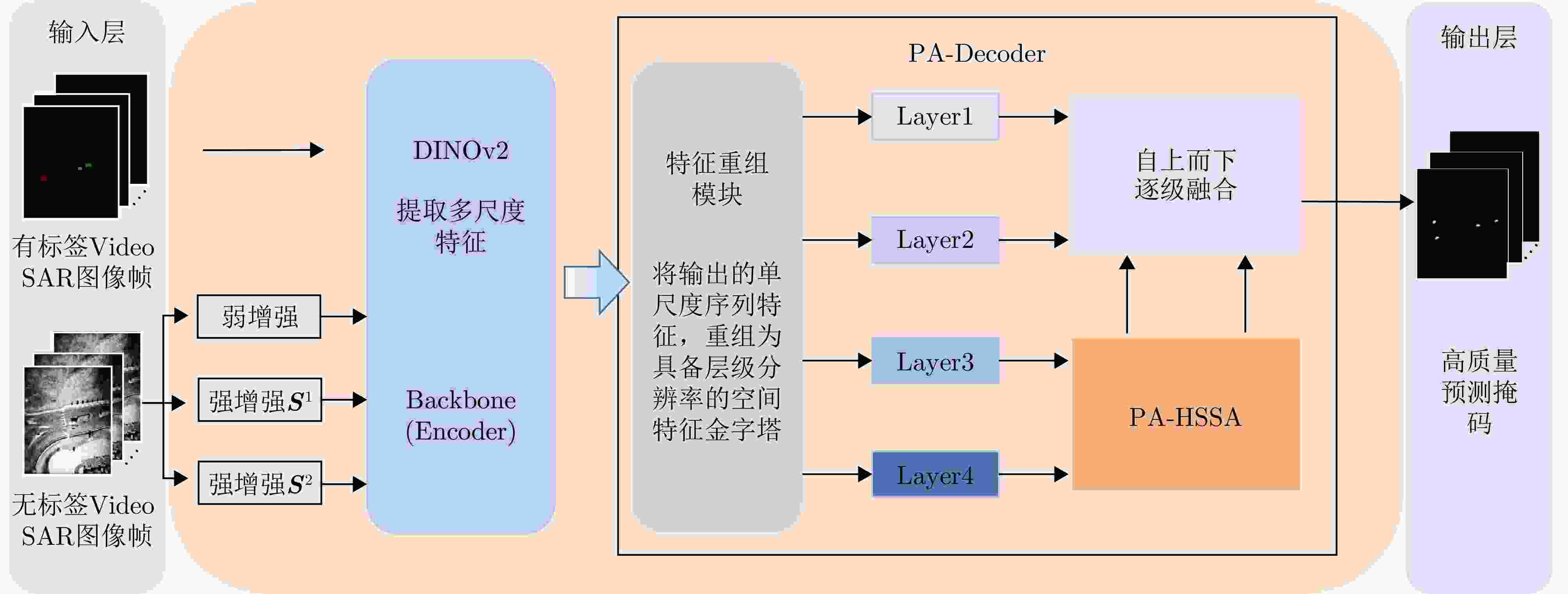
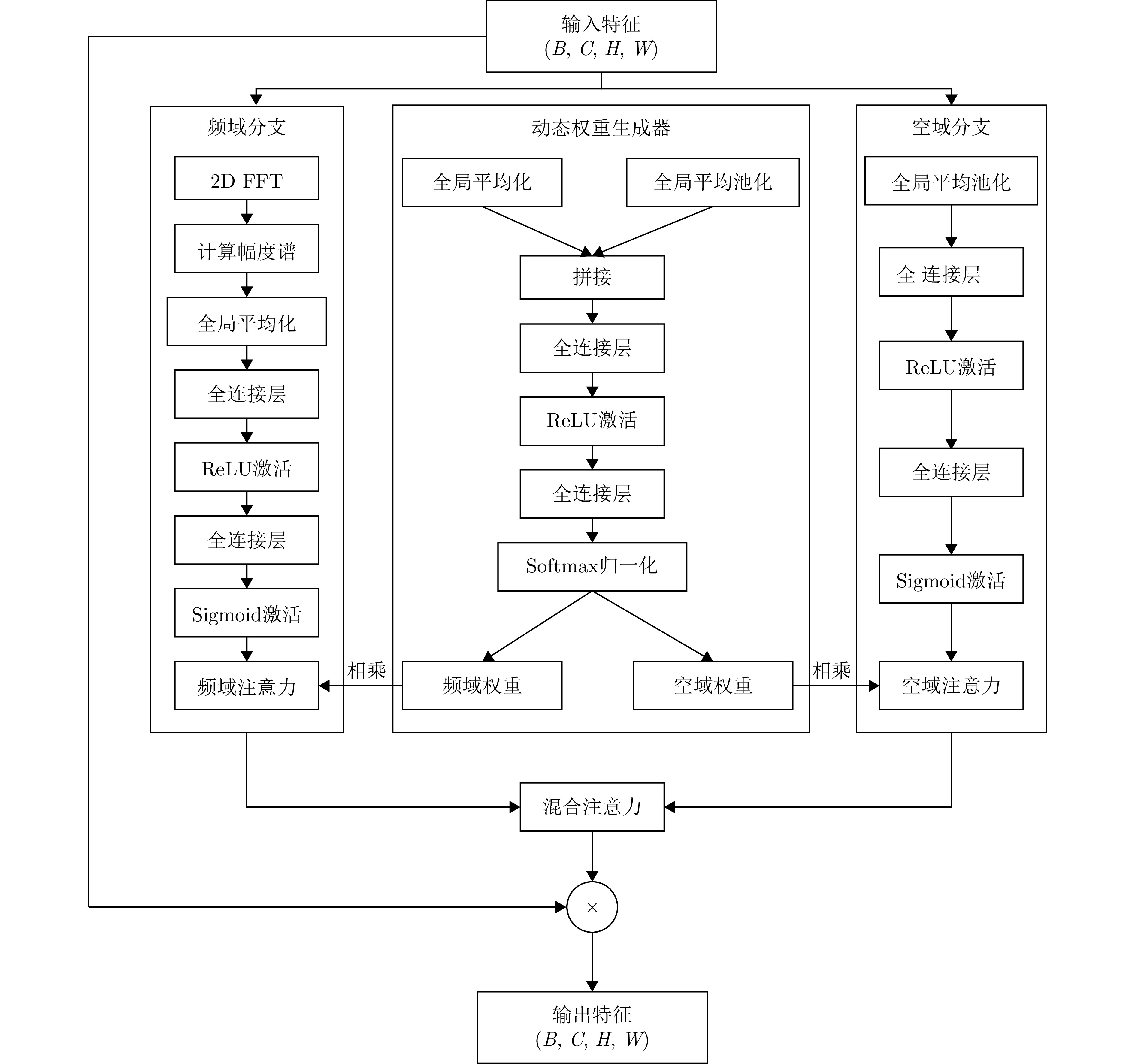
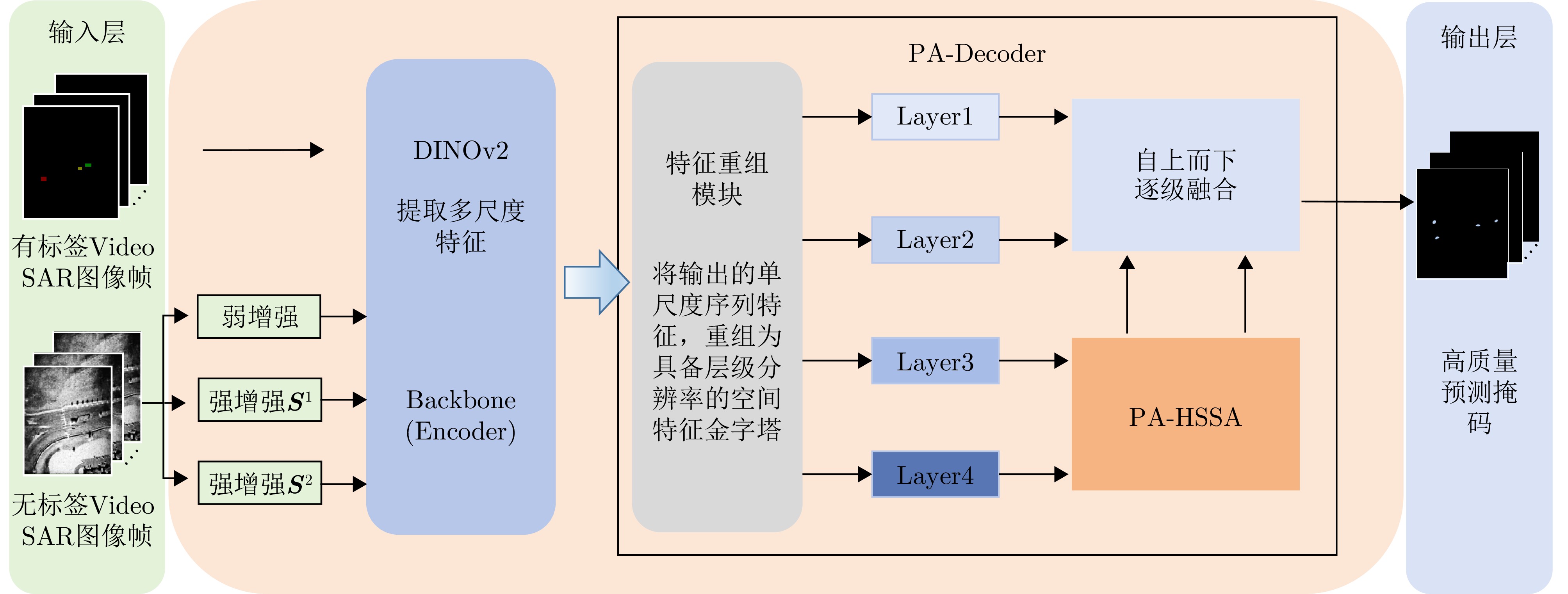
图 11 半监督特征增强检测网络结构与PA-Decoder细节
Figure 11. Architecture of semi-supervised feature-enhanced detection network and details of PA-Decoder
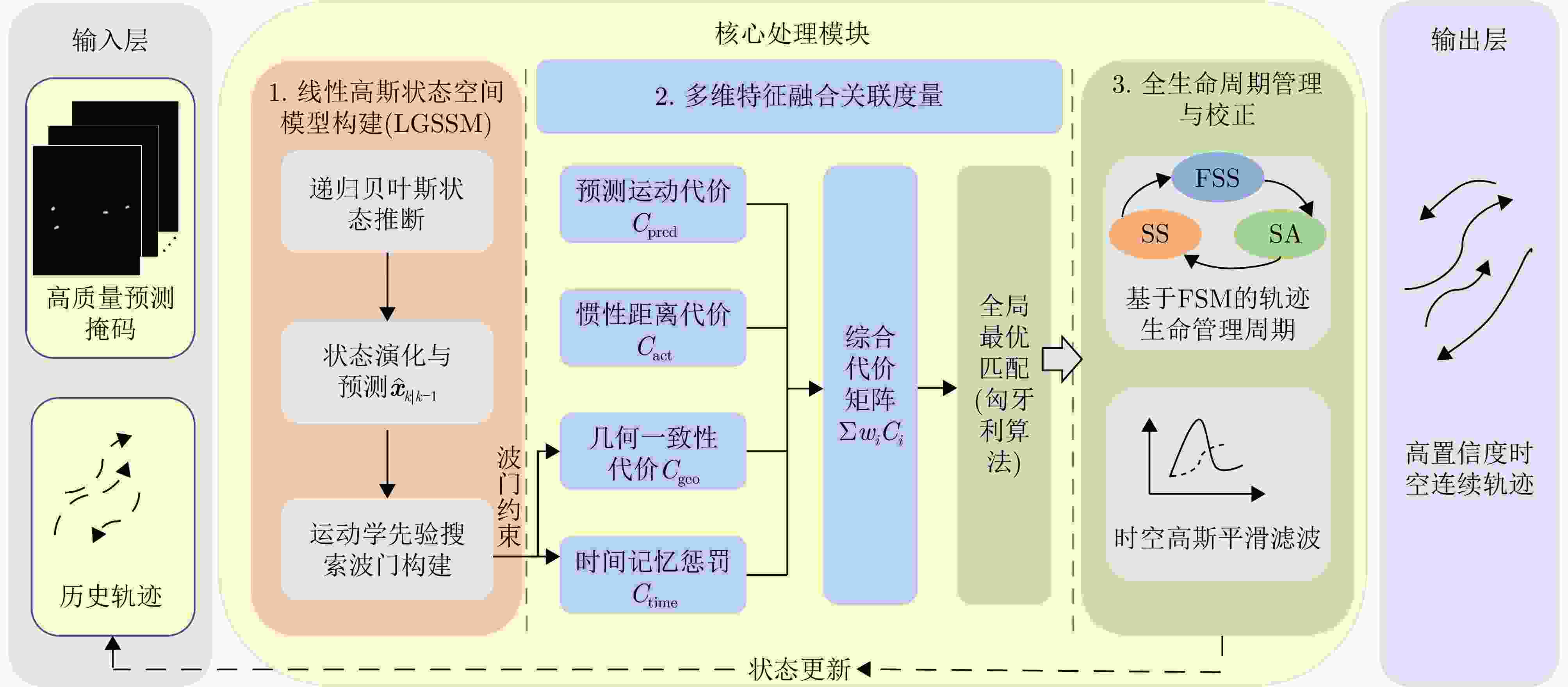
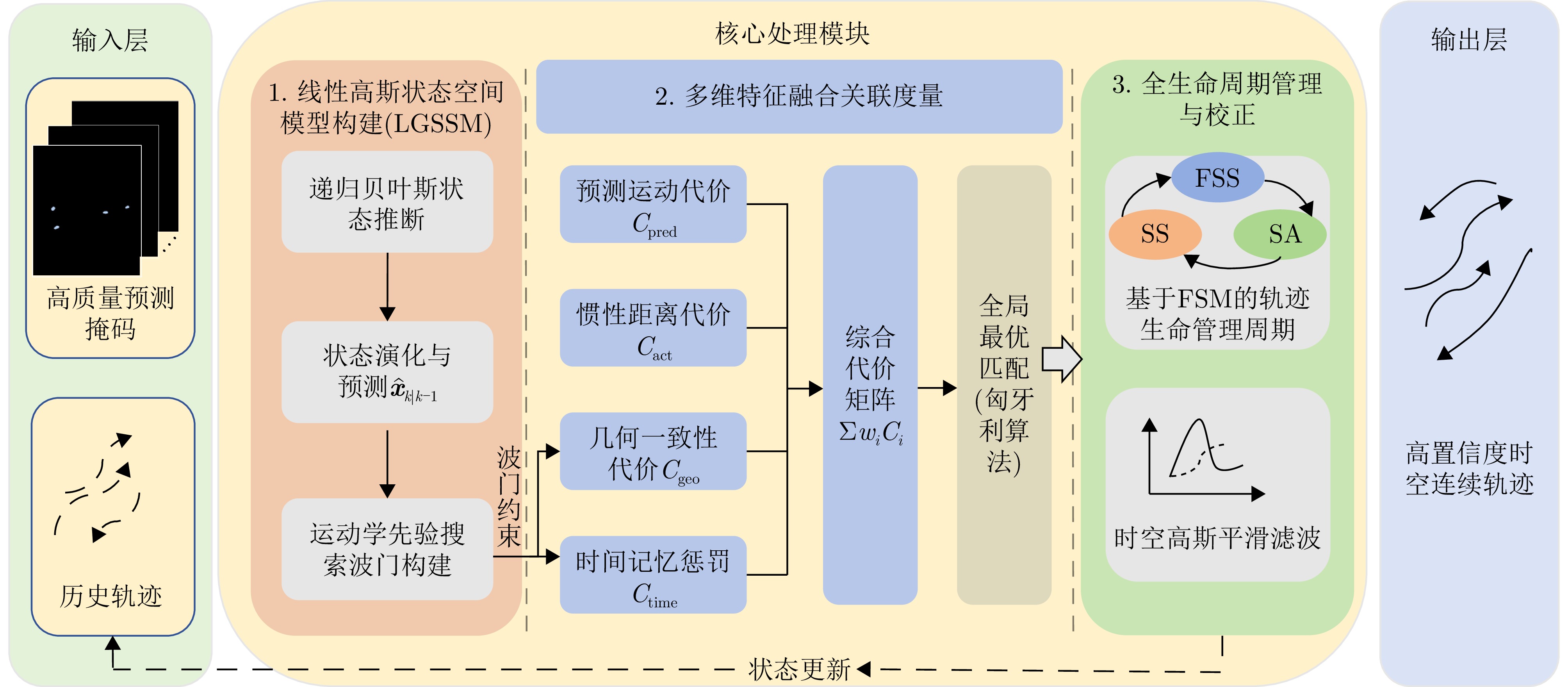
图 12 面向半监督增强的改进型时空关联框架
Figure 12. Improved spatiotemporal association framework oriented toward semi-supervised enhancement
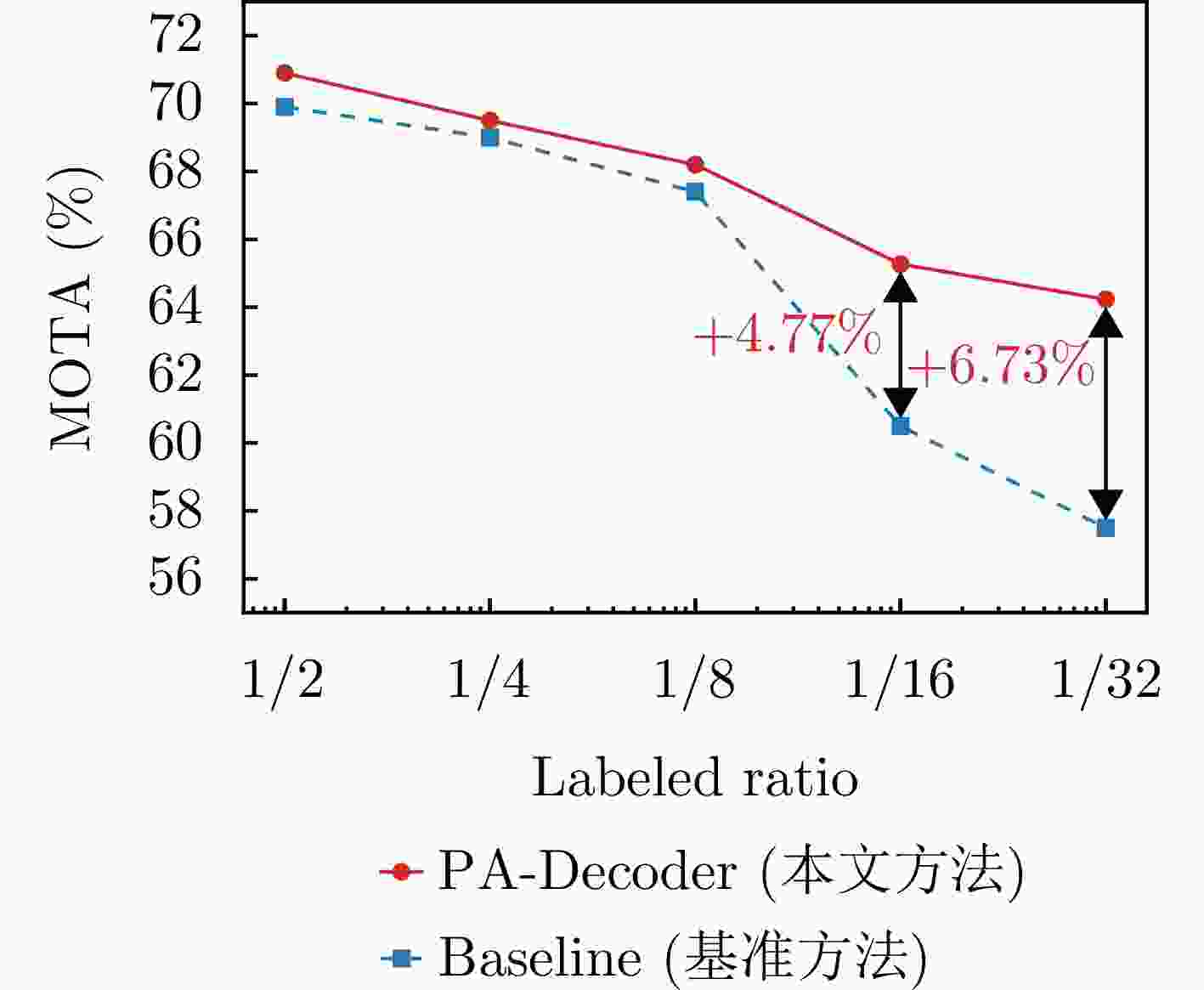
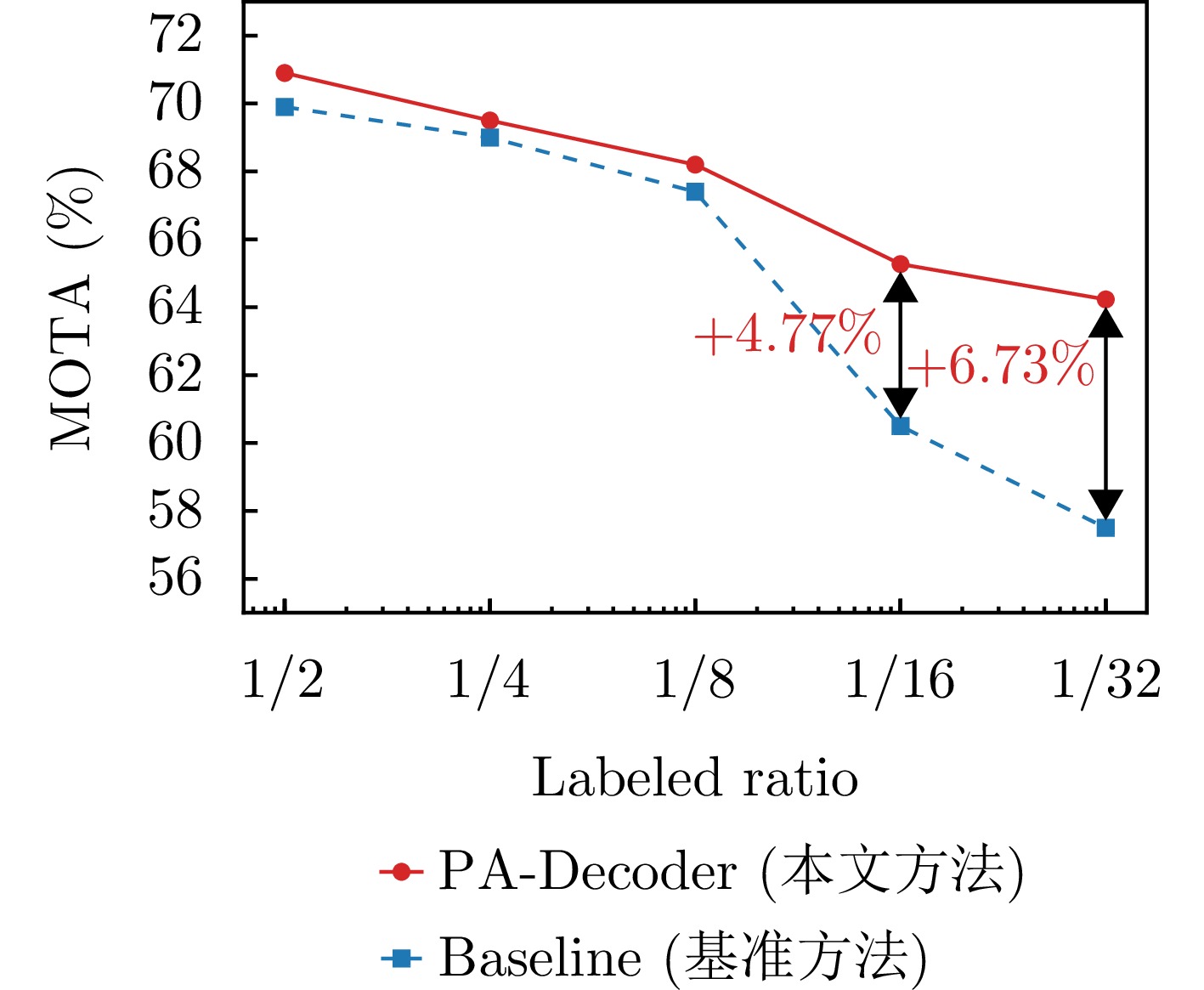
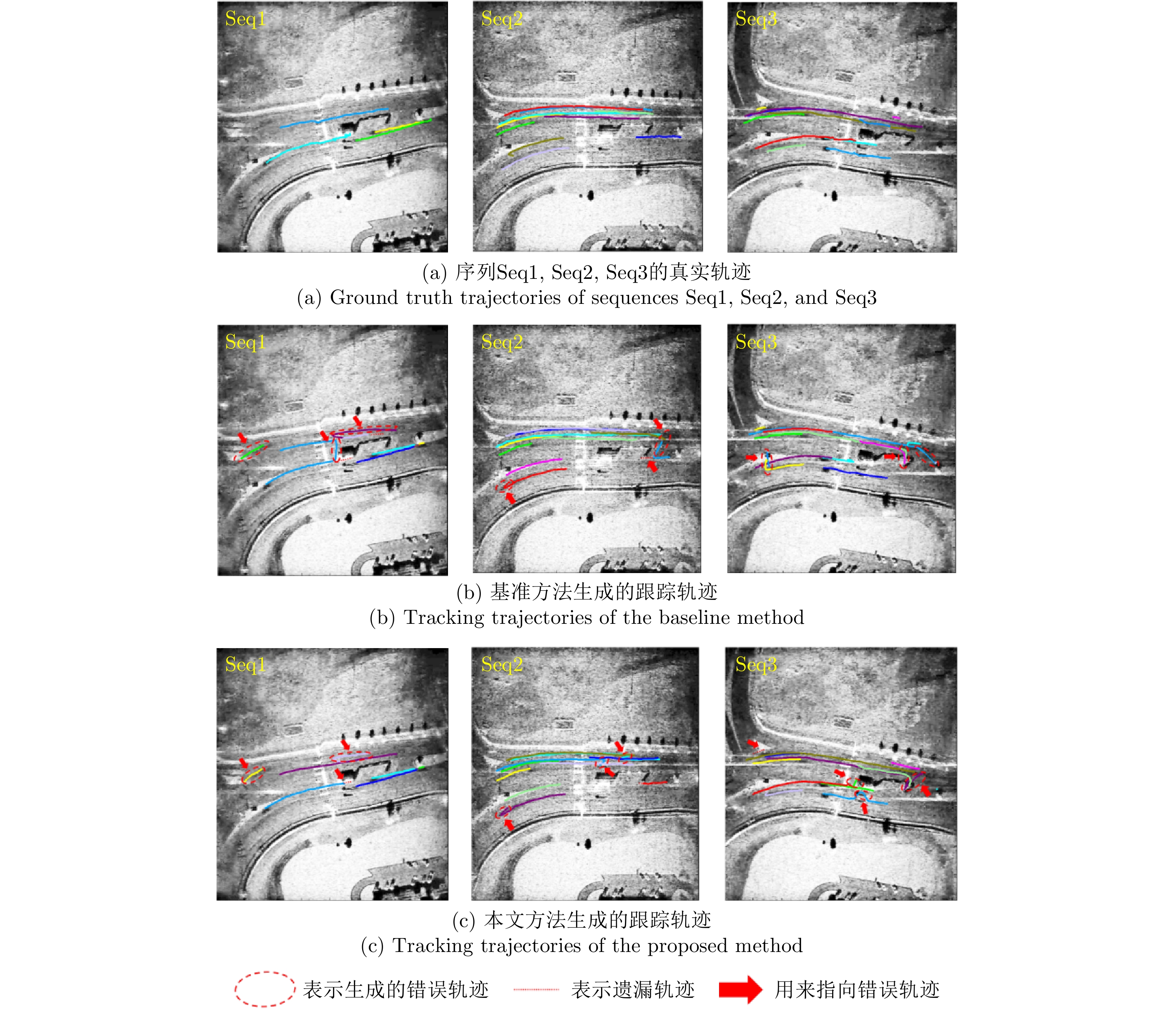
图 13 低资源半监督设定下的跟踪鲁棒性评估
Figure 13. Robustness evaluation of tracking under low-resource semi-supervised settings
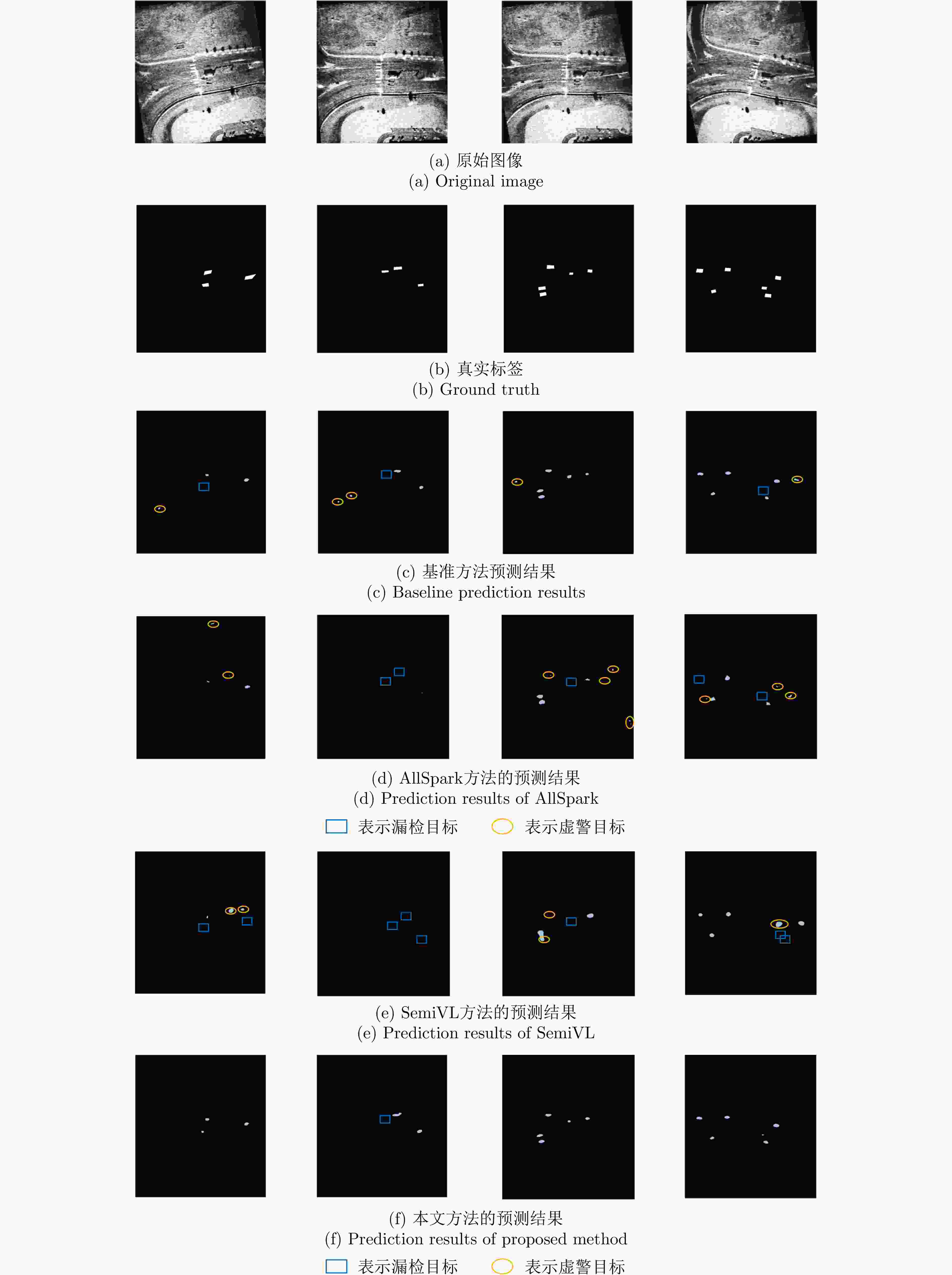
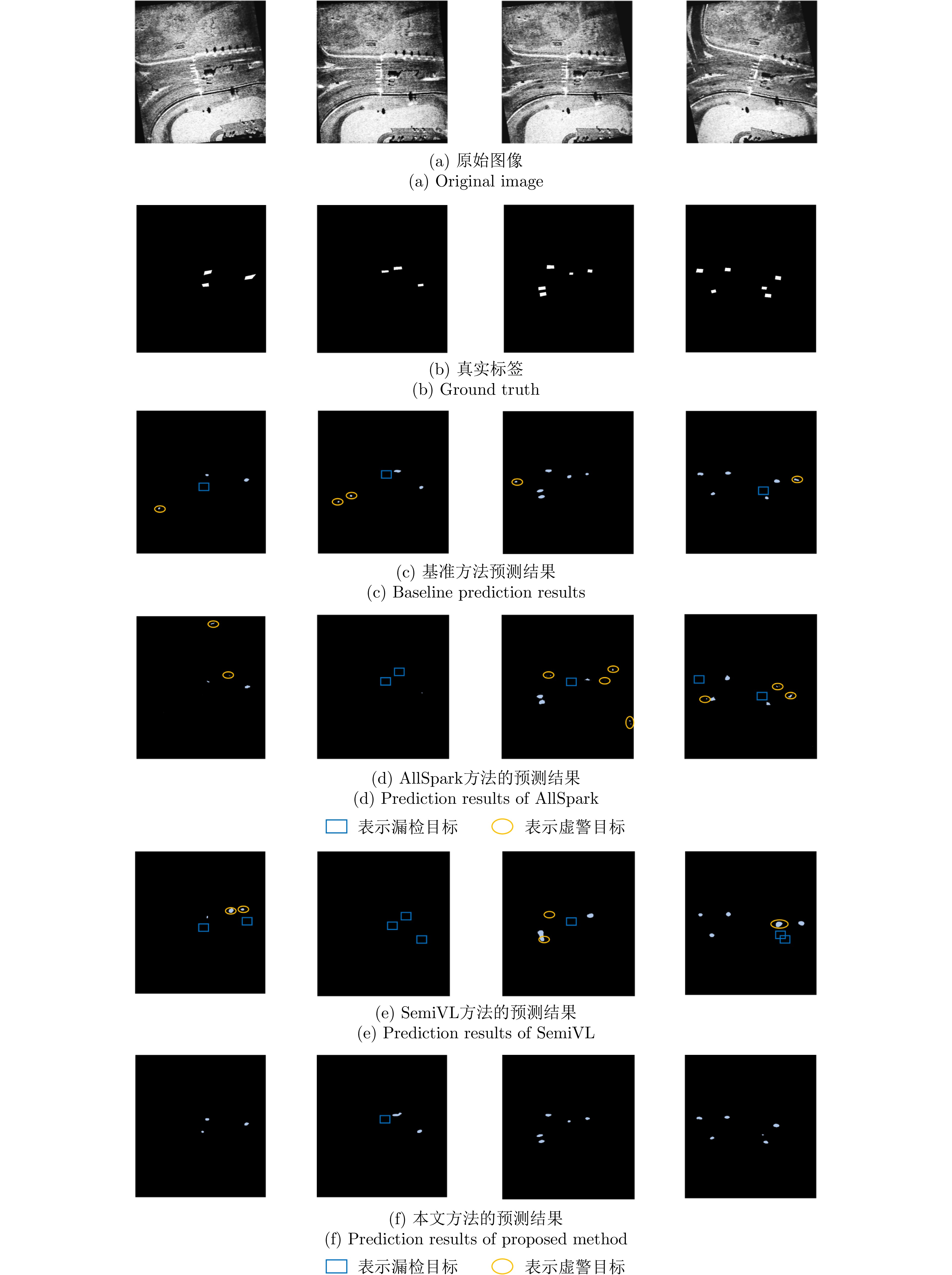
图 14 基于1/2有标签数据训练下的弱阴影检测可视化对比
Figure 14. Visual comparison of weak shadow detection trained with 1/2 labeled data
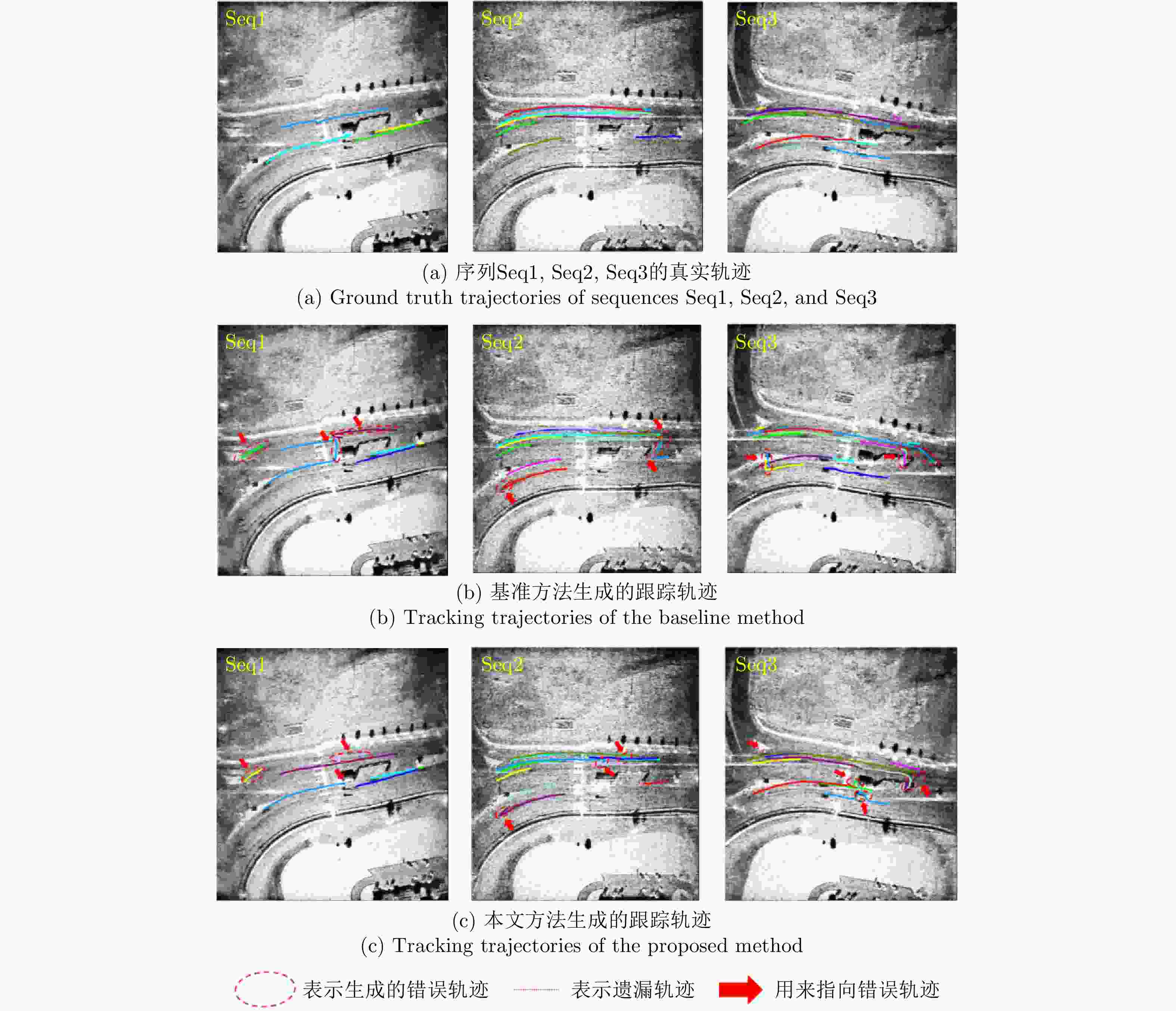
图 15 基于1/2有标签数据训练下的复杂运动场景轨迹连续性可视化对比
Figure 15. Visual comparison of trajectory continuity in complex motion scenarios trained with 1/2 labeled data

图 16 在CASIC数据集中基于1/2有标签数据训练下的弱阴影检测可视化对比
Figure 16. Visual comparison of weak shadow detection trained with 1/2 labeled data on the CASIC dataset
表 1 不同标注比例下物理感知解码器与基准方法的跟踪性能对比
Table 1. Tracking performance comparison between PA-Decoder and baseline under different labeled ratios
解码器 标签 MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ PA-Decoder 1/2 70.93 75.55 12 102 227 1/4 69.48 74.82 10 101 247 1/8 68.20 68.57 11 109 253 1/16 65.30 65.36 16 98 293 1/32 64.19 68.13 10 149 261 基准方法 1/2 69.91 75.91 6 115 232 1/4 69.05 70.56 11 83 269 1/8 67.43 69.80 14 84 284 1/16 60.53 67.09 8 83 372 1/32 57.46 69.18 22 261 216  下载: 导出CSV
下载: 导出CSV
表 2 不同半监督学习框架在SNL数据集上的跟踪性能
Table 2. Tracking performance of different semi-supervised learning frameworks on the SNL dataset
方法 MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ AllSpark 25.83 53.43 28 371 471 SemiVL 41.77 54.33 27 149 507 UniMatchV2 69.91 75.91 6 115 232 Ours 70.93 75.55 12 102 227 注:加粗数值表示最优。
下载: 导出CSV
表 3 本文方法与主流全监督跟踪算法在SNL数据集上的性能对比
Table 3. Performance comparison between the proposed method and mainstream fully-supervised tracking algorithms on the SNL dataset
方法 标签(%) MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ FairMOT 100 30.19 33.60 202 55 460 ByteTrack 100 54.94 48.78 2 96 431 OC-SORT 100 53.24 48.98 4 103 442 GNN-JFL 100 60.70 63.60 43 237 385 Graph-based Tracker 100 63.50 64.20 46 292 220 Ours 50 70.93 75.55 12 102 227 注:加粗数值表示最优。
下载: 导出CSV
表 4 频空域特征融合的消融实验
Table 4. Ablation study on spatial frequency feature fusion
方法 MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ 基准实验 69.91 75.91 6 115 232 频域注意力 68.46 72.60 11 107 252 空域注意力 68.63 69.90 13 149 206 频空动态融合 70.93 75.55 12 102 227 注:加粗数值表示最优。
下载: 导出CSV
表 5 传统单一度量与本文多维关联策略的跟踪性能对比
Table 5. Tracking performance comparison between the traditional single metric and the proposed multi-dimensional association strategy
方法 MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ 单一度量关联 69.39 52.45 28 104 227 多维关联策略 70.93 75.55 12 102 227 注:加粗数值表示最优。
下载: 导出CSV
表 6 在特征空间中不同去噪机制的对比
Table 6. Comparison of different denoising mechanisms in the feature space
方法 MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ 高斯平滑滤波 63.77 69.86 17 139 269 PA-HSSA 70.93 75.55 12 102 227 注:加粗数值表示最优。
下载: 导出CSV
表 7 在CASIC数据集中不同标注比例下物理感知解码器与基准方法的跟踪性能对比
Table 7. Tracking performance comparison between PA-Decoder and Baseline under different labeled ratios on the CASIC dataset
解码器 标签 MOTA (%)↑ IDF1 (%)↑ IDSW↓ FP↓ FN↓ PA-Decoder 1/2 51.41 71.74 0 36 153 1/4 47.04 69.06 1 61 144 1/8 43.96 68.31 0 64 154 1/16 42.42 67.72 1 71 152 1/32 39.33 63.12 0 49 187 基准方法 1/2 48.84 70.25 2 54 145 1/4 44.73 58.08 4 66 145 1/8 40.62 60.97 4 105 122 1/16 39.07 65.01 1 72 164 1/32 30.59 62.38 1 103 166
下载: 导出CSV
表 8 不同训练范式下跟踪框架的模型复杂度与运行效率对比
Table 8. Comparison of model complexity and runtime efficiency of tracking frameworks under different training paradigms
方法 训练范式 总参数量(M) 推理速度(FPS) MOTA (%)↑ FairMOT Fully-Sup. 20.35 14.31 30.19 ByteTrack Fully-Sup. 98.94 4.58 54.94 OC-SORT Fully-Sup. 98.94 4.43 53.24 AllSpark Semi-Sup. 118.18 15.70 25.83 SemiVL Semi-Sup. 89.32 14.04 41.77 UniMatchV2 Semi-Sup. 97.53 9.91 69.91 Ours Semi-Sup. 97.80 8.81 70.93
下载: 导出CSV
表 9 不同模块配置下的模型复杂度、运行效率与检测性能对比
Table 9. Comparison of model complexity, runtime efficiency and Detection Performance under different module configurations
方法 编码器(M) 解码器(M) 总参数(M) 检测(FPS) 数据关联(FPS) 端到端(FPS) MOTA (%) 频域注意力 86.58 11.04 97.62 10.24 401.73 9.91 68.46 空域注意力 86.58 11.04 97.62 10.32 379.56 9.86 68.63 PA-HSSA 86.58 11.22 97.80 9.25 340.67 8.81 70.93
下载: 导出CSV
-
[1] DING Jinshan, WEN Liwu, ZHONG Chao, et al. Video SAR moving target indication using deep neural network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(10): 7194–7204. doi: 10.1109/TGRS.2020.2980419. [2] 丁金闪, 仲超, 温利武, 等. 视频合成孔径雷达双域联合运动目标检测方法[J]. 雷达学报, 2022, 11(3): 313–323. doi: 10.12000/JR22036.DING Jinshan, ZHONG Chao, WEN Liwu, et al. Joint detection of moving target in video synthetic aperture radar[J]. Journal of Radars, 2022, 11(3): 313–323. doi: 10.12000/JR22036. [3] RAYNAL A M, BICKEL D L, and DOERRY A W. Stationary and moving target shadow characteristics in synthetic aperture radar[C]. Radar Sensor Technology XVIII, Baltimore, USA, 2014: 90771B. doi: 10.1117/12.2049729. [4] ENDER J H G, GIERULL C H, and CERUTTI-MAORI D. Improved space-based moving target indication via alternate transmission and receiver switching[J]. IEEE Transactions on Geoscience and Remote Sensing, 2008, 46(12): 3960–3974. doi: 10.1109/TGRS.2008.2002266. [5] TIAN Xiaoqing, LIU Jing, MALLICK M, et al. Simultaneous detection and tracking of moving-target shadows in ViSAR imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 59(2): 1182–1199. doi: 10.1109/TGRS.2020.2998782. [6] ARGENTI F, LAPINI A, BIANCHI T, et al. A tutorial on speckle reduction in synthetic aperture radar images[J]. IEEE Geoscience and Remote Sensing Magazine, 2013, 1(3): 6–35. doi: 10.1109/MGRS.2013.2277512. [7] SOHN K, ZHANG Zizhao, LI Chunliang, et al. A simple semi-supervised learning framework for object detection[OL]. arXiv preprint arXiv: 2005.04757, 2020. doi: 10.48550/arXiv.2005.04757. [8] LIU Yencheng, MA C Y, HE Zijian, et al. Unbiased teacher for semi-supervised object detection[C]. 9th International Conference on Learning Representations (ICLR), Virtual, Austria, May 2021. doi: 10.48550/arXiv.2102.09480. [9] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. 15th European Conference on Computer Vision – ECCV 2018, Munich, Germany, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1. [10] QIN Zequn, ZHANG Pengyi, WU Fei, et al. FcaNet: Frequency channel attention networks[C]. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 763–772. doi: 10.1109/ICCV48922.2021.00082. [11] ZHANG Peng, CHEN Lifu, LI Zhenhong, et al. Automatic extraction of water and shadow from SAR images based on a multi-resolution dense encoder and decoder network[J]. Sensors, 2019, 19(16): 3576. doi: 10.3390/s19163576. [12] LI Qiupeng and KONG Yingying. An improved SAR image semantic segmentation Deeplabv3+ network based on the feature post-processing module[J]. Remote Sensing, 2023, 15(8): 2153. doi: 10.3390/rs15082153. [13] WANG Wei, ZHOU Yuanyuan, XIE Zhikun, et al. Moving target shadow detection using transformer in video sar[C]. IGARSS 2022 - 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 2022: 2614–2617. doi: 10.1109/IGARSS46834.2022.9884510. [14] BAO Jinyu, ZHANG Xiaoling, ZHANG Tianwen, et al. ShadowDeNet: A moving target shadow detection network for video SAR[J]. Remote Sensing, 2022, 14(2): 320. doi: 10.3390/rs14020320. [15] FANG Hui, LIAO Guisheng, LIU Yongjun, et al. Siam-Sort: Multi-target tracking in video SAR based on tracking by detection and Siamese network[J]. Remote Sensing, 2023, 15(1): 146. doi: 10.3390/rs15010146. [16] ZHONG Chao, DING Jinshan, and ZHANG Yuhong. Video SAR moving target tracking using joint kernelized correlation filter[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 1481–1493. doi: 10.1109/JSTARS.2022.3146035. [17] KUHN H W. The Hungarian method for the assignment problem[J]. Naval Research Logistics Quarterly, 1955, 2(1/2): 83–97. doi: 10.1002/nav.3800020109. [18] KALMAN R E. A new approach to linear filtering and prediction problems[J]. Journal of Basic Engineering, 1960, 82(1): 35–45. doi: 10.1115/1.3662552. [19] BEWLEY A, GE Zongyuan, OTT L, et al. Simple online and realtime tracking[C]. 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, USA, 2016: 3464–3468. doi: 10.1109/ICIP.2016.7533003. [20] ZHANG Yifu, SUN Peize, JIANG Yi, et al. ByteTrack: Multi-object tracking by associating every detection box[C]. 17th European Conference on Computer Vision – ECCV 2022, Tel Aviv, Israel, 2022: 1–21. doi: 10.1007/978-3-031-20047-2_1. [21] YANG Lihe, ZHAO Zhen, and ZHAO Hengshuang. UniMatch V2: Pushing the limit of semi-supervised semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(4): 3031–3048. doi: 10.1109/TPAMI.2025.3528453. [22] GOODMAN J W. Some fundamental properties of speckle[J]. Journal of the Optical Society of America, 1976, 66(11): 1145–1150. doi: 10.1364/JOSA.66.001145. [23] GOODMAN J W. Speckle Phenomena in Optics: Theory and Applications[M]. Englewood, Roberts & Company Publishers, 2007 : 73-82. [24] GOODFELLOW I J, SHLENS J, and SZEGEDY C. Explaining and harnessing adversarial examples[C]. International Conference on Learning Representations (ICLR), San Diego, USA, 2015. doi: 10.48550/arXiv.1412.6572. [25] OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: Learning robust visual features without supervision[OL]. arXiv preprint arXiv: 2304.07193, 2023. doi: 10.48550/arXiv.2304.07193. [26] BERNARDIN K and STIEFELHAGEN R. Evaluating multiple object tracking performance: The CLEAR MOT metrics[J]. EURASIP Journal on Image and Video Processing, 2008, 2008(1): 246309. doi: 10.1155/2008/246309. [27] RISTANI E, SOLERA F, ZOU R, et al. Performance measures and a data set for multi-target, multi-camera tracking[C]. Computer Vision – ECCV 2016 Workshops, Amsterdam, The Netherlands, 2016: 17–35. doi: 10.1007/978-3-319-48881-3_2. [28] WANG Haonan, ZHANG Qixiang, LI Yi, et al. AllSpark: Reborn labeled features from unlabeled in transformer for semi-supervised semantic segmentation[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 3627–3636. doi: 10.1109/CVPR52733.2024.00348. [29] HOYER L, TAN D J, NAEEM M F, et al. SemiVL: Semi-supervised semantic segmentation with vision-language guidance[C]. 18th European Conference on Computer Vision – ECCV 2024, Milan, Italy, 2025: 257–275. doi: 10.1007/978-3-031-72933-1_15. [30] ZHANG Yifu, WANG Chunyu, WANG Xinggang, et al. FairMOT: On the fairness of detection and re-identification in multiple object tracking[J]. International Journal of Computer Vision, 2021, 129(11): 3069–3087. doi: 10.1007/s11263-021-01513-4. [31] CAO Jinkun, PANG Jiangmiao, WENG Xinshuo, et al. Observation-centric SORT: Rethinking SORT for robust multi-object tracking[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 9686–9696. doi: 10.1109/CVPR52729.2023.00934. [32] ZHANG Wensi, ZHANG Xiaoling, XU Xiaowo, et al. GNN-JFL: Graph neural network for video SAR shadow tracking with joint motion-appearance feature learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5209117. doi: 10.1109/TGRS.2024.3383870. [33] SU Mingjie, NI Peishuang, PEI Hao, et al. Graph feature representation for shadow-assisted moving target tracking in video SAR[J]. IEEE Geoscience and Remote Sensing Letters, 2025, 22: 4004905. doi: 10.1109/LGRS.2025.3539748. -



计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

