
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
A Survey on Earth Observation Multimodal Large Language Models: Framework, Core Technologies, and Future Perspectives
-
摘要: 近年来,人工智能技术和对地观测领域的结合已成为领域发展的前沿热点,多模态大语言模型(MLLM)的快速发展为智能解译带来新的机遇和挑战。多模态对地观测大模型通过构建大语言模型与视觉模型之间的桥接机制并采用联合训练方式,深度融合光学影像、合成孔径雷达影像与文本等多模态信息,有效推动对地观测智能解译由浅层语义匹配向高层的世界知识理解跃迁。该文系统性回顾了多模态对地观测大模型的相关研究成果,以期为新的研究方向提供依据。具体而言,该文首先明确了多模态对地观测大模型(EO-MLLM)的概念定义,并梳理了多模态对地观测大模型的发展脉络。随后,详细阐述了多模态对地观测大模型的模型架构、训练方法、适用任务及其对应的基准数据集,并介绍了对地观测智能体。最后,探讨了多模态对地观测大模型的研究现状和未来发展方向。
-
关键词:
- 大语言模型 /
- 多模态大语言模型 /
- 多模态对地观测大模型 /
- 视觉语言模型 /
- 对地观测智能体
Abstract: In recent years, the rapid development of Multimodal Large Language Models (MLLMs) and their applications in earth observation have garnered significant attention. Earth observation MLLMs achieve deep integration of multimodal information, including optical imagery, Synthetic Aperture Radar (SAR) imagery, and textual data, through the design of bridging mechanisms between large language models and vision models, combined with joint training strategies. This integration facilitates a paradigm shift in intelligent earth observation interpretation—from shallow semantic matching to higher-level understanding based on world knowledge. In this study, we systematically review the research progress in the applications of MLLMs in earth observation, specifically examining the development of Earth Observation MLLMs (EO-MLLMs), which provides a foundation for future research directions. Initially, we discuss the concept of EO-MLLMs and review their development in chronological order. Subsequently, we provide a detailed analysis and statistical summary of the proposed architectures, training methods, applications, and corresponding benchmark datasets, along with an introduction to Earth Observation Agents (EO-Agent). Finally, we summarize the research status of EO-MLLMs and discuss future research directions. -
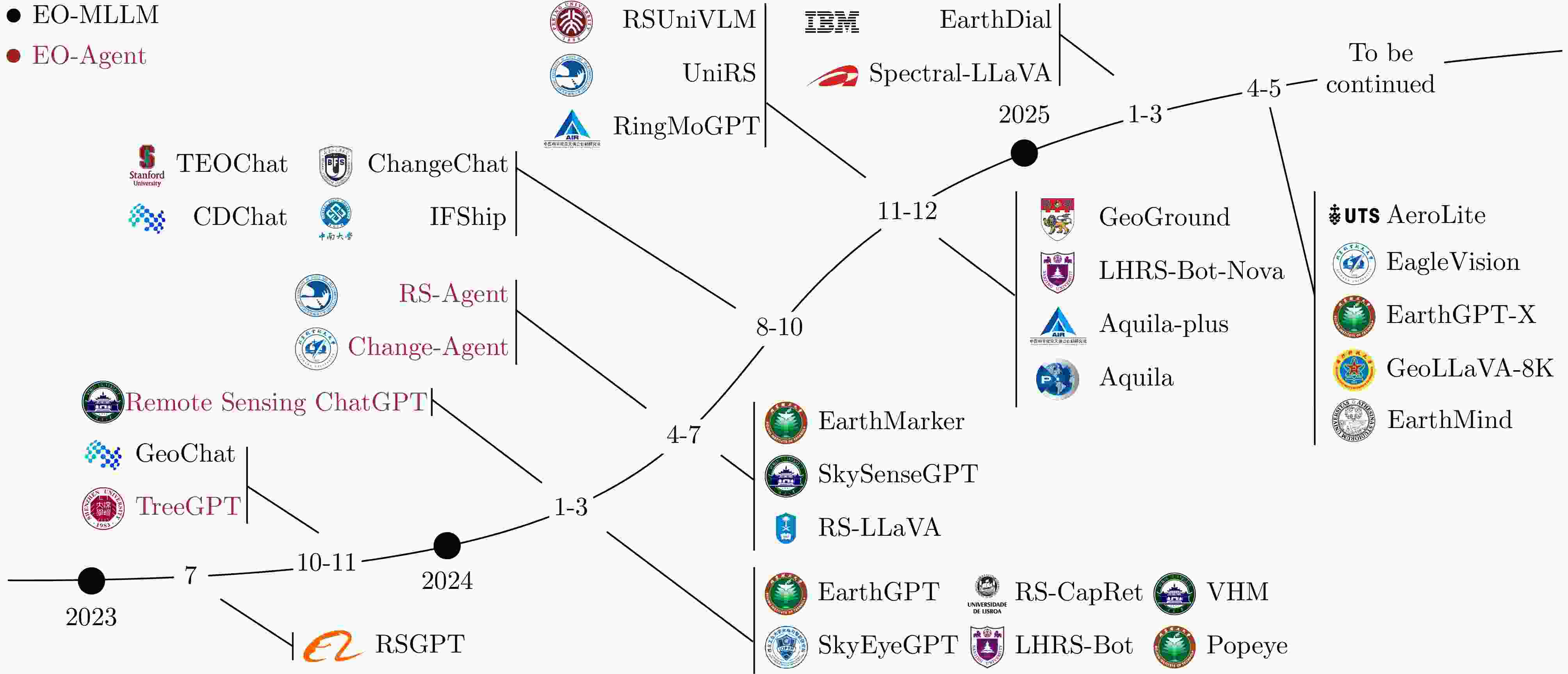
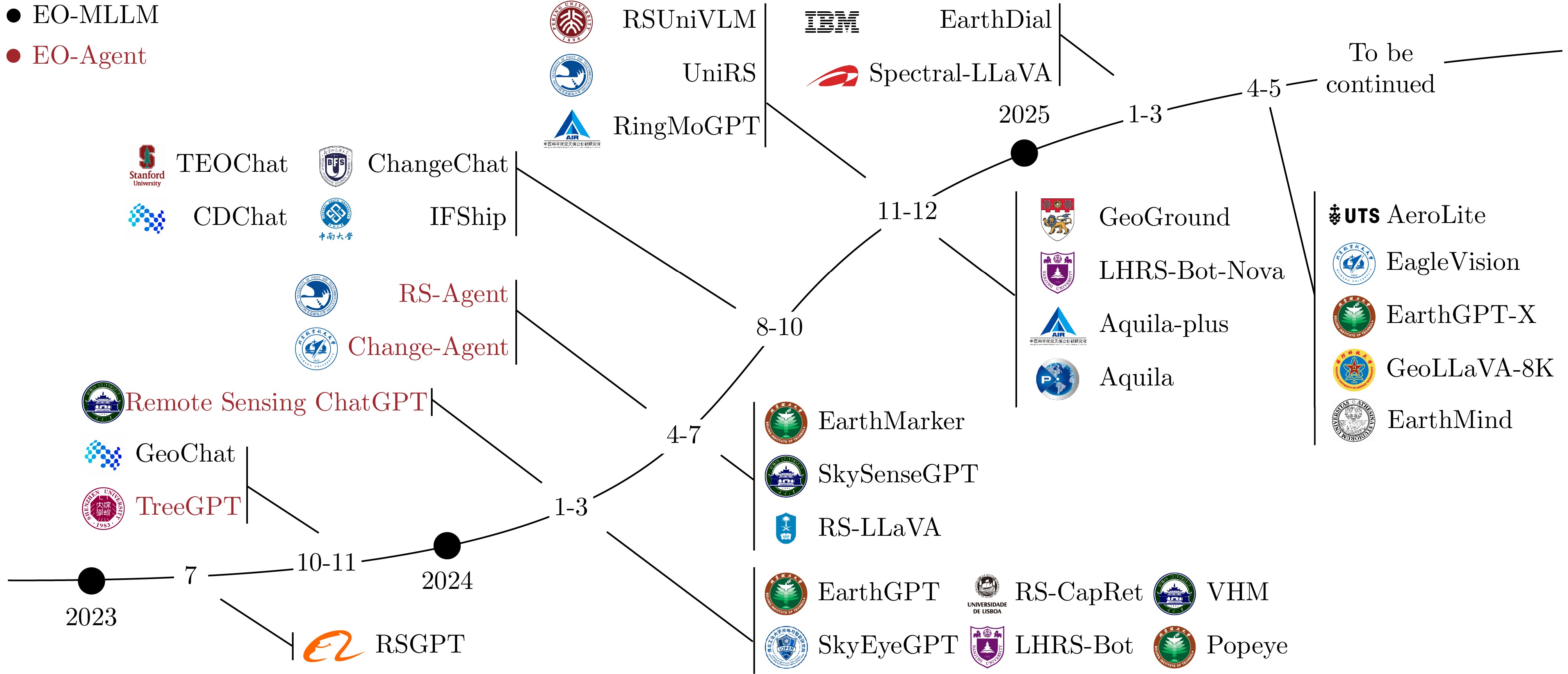
图 2 代表性多模态对地观测大模型和对地观测智能体的发展时间线
Figure 2. Timeline of representative Earth Observation MLLMs (EO-MLLM) and Earth Observation Agents (EO-Agent)
表 1 多模态对地观测大模型具体结构
Table 1. The specific structure of EO-MLLM
EO-MLLM 多模态编码器 多模态特征投影器 预训练大语言模型 训练硬件 AeroLite[58] CLIP ViT-L/14 A two-layer MLP LLaMA3.2-3B 4090 Aquila[59] Aquila-CLIPConvNext (A-CCN) SFI (MDA)-LLM(基于LLaMA3) 4$* $A800 Aquila-plus[60] CLIP ConvNeXt-L Mask spatial feature extractor Vicuna - CDChat[50] CLIP ViT-L/14 A two-layer MLP (GELU) Vicuna-v1.5-7B 3$* $A100 ChangeChat[49] CLIP ViT/14 A two-layer MLP Vicuna-v1.5 L20 (48 GB) EagleVision[61] Baseline detector Attribute disentangle InternLM2.5-7B-Chat等 8$* $A100 EarthDial[52] Adaptive high resolution +
Data fusion +InternViT-300MA simple MLP Phi-3-mini 8$* $A100 (80 GB) EarthGPT[12] DINOv2 ViT-L/14 + CLIP ConvNeXt-L A linear layer LLaMA2-13B 16$* $A100 EarthGPT-X[53] DINOv2 ViT-L/14 + CLIP ConvNeXt-L + Hybrid signals mutual understanding Vision-to-language
Modality-align projectionLLaMA2-13B 8$* $A100 (80 GB) EarthMarker[62] DINOv2 ViT-L/14 + CLIP ConvNeXt-L A linear layer LLaMA2-13B 8$* $A100 (80 GB) GeoChat[43] CLIP ViT-L/14 A two-layer MLP (GELU) Vicuna-v1.5-7B - GeoGround[29] CLIP ViT A two-layer MLP Vicuna-v1.5 8$* $V100 (32 GB) GeoLLaVA-8K[63] CLIP ViT-L/14 + A two-step tokens compression module A linear layer Vicuna-v1.5-7B - IFShip[47] CLIP ViT-L/14 A four-layer MLP (GELU) Vicuna-13B - LHRS-Bot[11] CLIP ViT-L/14 Vision perceiver LLaMA2-7B 8$* $V100 (32 GB) LHRS-Bot-Nova[64] SigLIP-L/14 Vision perceiver LLaMA3-8B 8$* $H100 Popeye[48] DINOv2 ViT-L/14 + CLIP ConvNeXt-L Alignment projection LLaMA-7B - RingMoGPT[30] EVA-CLIP ViT-g/14 A Q-Former + A linear layer Vicuna-13B 8$* $A100 (80 GB) RS-CapRet[46] CLIP ViT-L/14 Three linear layers LLaMA2-7B - RSGPT[10] EVA-G A Q-Former + A linear layer Vicuna-7B· Vicuna-13B 8$* $A100 RS-LLaVA[65] CLIP ViT-L A two-layer MLP (GELU) Vicuna-v1.5-7B
Vicuna-v1.5-13B2$* $A6000 (48 GB) RSUniVLM[66] SigLIP-400M A two-layer MLP QWen2-0.5B 4$* $A40 (40 GB) SkyEyeGPT[31] EVA-CLIP A linear layer LLaMA2 4$* $ 3090 SkySenseGPT[45] CLIP ViT-L/14 A two-layer MLP Vicuna-v1.5 4$* $A100 (40 GB) Spectral-LLaVA[67] SpectralGPT[34] (encoder only) A linear layer LLaMA3 - TEOChat[51] CLIP ViT-L/14 A two-layer MLP LLaMA2 A4000 (16 GB) UniRS[13] SigLIP + A change extraction module A downsampling module +
A MLPSheared-LLaMA (3B) 4$* $ 4090 (24 GB)VHM[44] CLIP ViT-L/14 A two-layer MLP Vicuna-v1.5-7B 16$* $A100 (80 GB) 注:斜体表示该模型在论文中并未给出正式名称或缩写。  下载: 导出CSV
下载: 导出CSV
表 2 多模态对地观测大模型训练时使用的数据集
Table 2. Datasets used for train in EO-MLLMs
EO-MLLM 指令调优 其他训练 AeroLite[58] - RSSCN7, DLRSD, iSAID, LoveDA, WHU, UCM-Captions, Sydney-Captions Aquila[59] FIT-RS CapERA, UCM-Captions, Sydney-Captions, NWPU-Captions, RSICD, RSITMD, RSVQA-HR, RSVQA-LR, WHU_RS19 Aquila-plus[60] Aquila-plus-100K - CDChat[50] LEVIR-CD, SYSU-CD LEVIR-CD, SYSU-CD ChangeChat[49] ChangeChat-87k - EagleVision[61] EVAttrs-95K EVAttrs-95K EarthDial[52] EarthDial-Instruct EarthDial-Instruct EarthGPT[12] MMRS-1M LAION-400M, COCO Caption EarthGPT-X[53] M-RSVP - EarthMarker[62] RSVP-3M COCO Caption, RSVP-3M, RefCOCO, RefCOCO+ EarthMind[54] FusionEO large-scale natural image datasets, EO-specific multimodal data, multi-spectral data GeoChat[43] RS multimodal instruction following dataset - GeoGround[29] refGeo FAIR1M, DIOR, DOTA GeoLLaVA-8K[63] SuperRS-VQA, HighRS-VQA - IFShip[47] TITANIC-FGS - LHRS-Bot[11] LLaVA complex reasoning dataset, NWPU,
RSITMD, LHRS-InstructLHRS-Align LHRS-Bot-Nova[64] Multi-task instruction dataset LHRS-Align-Recap, LHRS-Instruct, LHRS-Instruct-Plus, LRV-Instruct Popeye[47] MMShip COCO Caption RingMoGPT[30] Instruction-tuning dataset Image-text pre-training dataset RS-CapRet[46] - RSCID, UCM-Captions, Sydney-Captions,
NWPU-CaptionsRSGPT[10] - RSICap RS-LLaVA[65] RS-Instructions - RSUniVLM[66] RSUniVLM-Instruct-1.2M RSUniVLM-Resampled SkyEyeGPT[31] SkyEye-968k SkyEye-968k SkySenseGPT[45] FIT-RS, NWPU-Captions, UCM-Captions, RSITMD, EarthVQA, Floodnet-VQA, RSVQA-LR, DOTA,
DIOR, FAIR1M- Spectral-LLaVA[67] BigEarthNet-v2 fMoW, BigEarthNet-v1 TEOChat[51] TEOChatlas - UniRS[13] GeoChat-Instruct, LEVIR-CC, EAR - VHM[44] VersaD-Instruct, VariousRS-Instruct, HnstD VersaD 注:由于主要关注指令调优阶段的数据集,因此将其他训练阶段的数据集合并至第3列。斜体表示该数据集在论文中并未给出正式名称或缩写。
下载: 导出CSV
表 3 多模态对地观测大模型的适用任务及其对应的基准数据集
Table 3. The applicable tasks of EO-MLLMs and their corresponding benchmark datasets
EO-MLLM IC VQA VG SC AeroLite[58] Sydney-Captions[81], UCM-Captions[81] – – – Aquila[59] RSICD[82], Sydney-Captions[81], UCM-Captions[81], FIT-RS[45] RSVQA-LR[83], RSVQA-HR[83], FIT-RS[45] – – EarthDial[52] NWPU-Captions[84], RSICD[82], RSITMD-Captions[85], Sydney-Captions[81], UCM-Captions[81] RSVQA-LR[83], RSVQA-HR[83] – AID[86], UCMerced[87],WHU-RS19[88], BigEarthNet[89], xBD Set 1[90], fMoW[91] EarthGPT[12] NWPU-Captions[84] CRSVQA[92], RSVQA-HR[83] DIOR-RSVG[93] NWPU-RESISC45[94], CLRS[95], NaSC-TG2[96] EarthMind[54] EarthMind-Bench EarthMind-Bench, RSVQA-HR[83], VRSBench[97] EarthMind-Bench, DIOR-RSVG[93], VRSBench[97] EarthMind-Bench, AID[86], UCMerced[87] GeoChat[43] – RSVQA-LR[83], RSVQA-HR[83] GeoChat*[43] AID[86], UCMerced[87] GeoGround[29] – – DIOR-RSVG[93], RSVG[98], GeoChat*[43], VRSBench*[97], AVVG[29] – LHRS-Bot[11] – RSVQA-LR[83], RSVQA-HR[83] DIOR-RSVG[93], RSVG[98] AID[86], WHU-RS19[88], NWPU-RESISC45[94],
SIRI-WHU[99], EuroSAT[100], METER-ML[101], fMoW[91]LHRS-Bot-Nova[64] – RSVQA-LR[83], RSVQA-HR[83] DIOR-RSVG[93], RSVG[98] AID[86], WHU-RS19[88], NWPU-RESISC45[94], SIRI-WHU[99], EuroSAT[100], METER-ML[101], fMoW[91] RingMoGPT[30] DOTA-Cap[30], DIOR-Cap[30], NWPU-Captions[84], RSICD[82], Sydney-Captions[81], UCM-Captions[81] HRVQA[102] – AID[86], NWPU-RESISC45[94], UCMerced[87], WHU-RS19[88] RS-CapRet[46] NWPU-Captions[84], RSICD[82], Sydney-Captions[81],
UCM-Captions[81]– – – RSGPT[10] RSIEval[10], UCM-Captions[81], Sydney-Captions[81], RSICD[82] RSIEval[10], RSVQA-LR[83], RSVQA-HR[83] – – RS-LLaVA[65] UCM-Captions[81], UAV[103] RSVQA-LR[83], RSIVQA-DOTA[104] – – RSUniVLM[66] – RSVQA-LR[83], RSVQA-HR[83] DIOR-RSVG[93], VRSBench[97] AID[86], WHU-RS19[88], NWPU-RESISC45[94],
SIRI-WHU[99]SkyEyeGPT[31] UCM-Captions[81], CapERA[105] RSVQA-LR[83], RSVQA-HR[83] DIOR-RSVG[93], RSVG[98] – TEOChat[51] – RSVQA-LR[83], RSVQA-HR[83] – AID[86], UCMerced[87] UniRS[13] – RSVQA-LR[83], RSVQA-HR[83], CRSVQA[92] – – VHM[44] – RSVQA-LR[83], RSVQA-HR[83] DIOR-RSVG[93] AID[86], WHU-RS19[88], NWPU-RESISC45[94], SIRI-WHU[99], METER-ML[101] 注:*表示测试集已修改。
下载: 导出CSV
表 4 多模态对地观测大模型在不同的图像描述数据集上的性能表现
Table 4. Performance of EO-MLLMs on various image captioning datasets
数据集 模型 BLEU-1↑ BLEU-2↑ BLEU-3↑ BLEU-4↑ METEOR↑ ROUGE-L↑ CIDEr↑ SPICE↑ NWPU-Captions[84] EarthDial[52] – – – – 0.806 0.400 – – EarthGPT[12] 0.871 0.787 0.716 0.655 0.445 0.782 1.926 0.322 EarthMarker[62] 0.844 0.731 0.629 0.543 0.375 0.700 1.629 0.268 RS-CapRet[46] 0.871 0.787 0.717 0.656 0.436 0.776 1.929 0.311 RSICD[82] Aquila[59] 0.746 – – – – – – – EarthDial[52] – – – – 0.562 0.276 – – RS-CapRet[46] 0.741 0.622 0.529 0.455 0.376 0.649 2.605 0.484 RSGPT[10] 0.703 0.542 0.440 0.368 0.301 0.533 1.029 – SkyEyeGPT[31] 0.867 0.767 0.673 0.600 0.354 0.626 0.837 – RingMoGPT[30] – – – – 0.343 0.616 2.758 – UCM-Captions[81] AeroLite[58] 0.934 – – 0.796 0.498 0.880 – – Aquila[59] 0.883 – – – – – – – EarthDial[52] – – – – 0.514 0.342 – – RS-CapRet[46] 0.843 0.779 0.722 0.670 0.472 0.817 3.548 0.525 RSGPT[10] 0.861 0.791 0.723 0.657 0.422 0.783 3.332 – SkyEyeGPT[31] 0.907 0.857 0.816 0.784 0.462 0.795 2.368 – RS-LLaVA[65] 0.900 0.849 0.803 0.760 0.492 0.858 3.556 – RingMoGPT[30] – – – – 0.499 0.833 3.593 – Sydney-Captions[81] AeroLite[58] 0.919 – – 0.759 0.475 0.837 – – Aquila[59] 0.834 – – – – – – – EarthDial[52] – – – – 0.573 0.410 – – RS-CapRet[46] 0.787 0.700 0.628 0.564 0.388 0.707 2.392 0.434 RSGPT[10] 0.823 0.753 0.686 0.622 0.414 0.748 2.731 – SkyEyeGPT[31] 0.919 0.856 0.809 0.774 0.466 0.777 1.811 – RingMoGPT[30] – – – – 0.421 0.734 2.888 – FIT-RS[45] Aquila[59] 0.351 – – – – – – – GeoChat[43] 0.088 – – – – – – – SkySenseGPT[45] 0.273 – – – – – – – 注:所有结果均引自对应论文原文,加粗表示最佳结果。
下载: 导出CSV
表 5 多模态对地观测大模型在不同的视觉问答数据集上的性能表现(%)
Table 5. Performance of EO-MLLMs on various visual question answering datasets (%)
模型 RSVQA-LR[83]数据集 RSVQA-HR[83]数据集 CRSVQA[92]数据集 FIT-RS[45]数据集 Presence Compare Rural/Urban Avg Presence Compare Avg Avg Avg Aquila[59] 92.72 – – – 92.64 – – – 83.87 EarthDial[52] 92.58 92.75 94.00 92.70 58.89 83.11 72.45 – – EarthGPT[12] – – – – 62.77 79.53 72.06 82.00 – GeoChat[42] 91.09 90.33 94.00 90.70 59.02 83.16 – – 53.47 LHRS-Bot[11] 89.07 88.51 90.00 89.19 92.57 92.53 92.55 – – LHRS-Bot-Nova[64] 89.00 90.71 89.11 89.61 91.68 92.44 92.06 – – RSGPT[10] 91.17 91.70 94.00 92.29 90.92 90.02 90.47 – – RS-LLaVA[65] 92.27 91.37 95.00 88.10 – – – – – RSUniVLM[66] 92.00 91.51 92.65 92.05 90.81 90.88 90.85 – – SkyEyeGPT[31] 88.93 88.63 75.00 84.19 80.00 80.13 82.56 – – SkySenseGPT[45] 95.00 91.07 92.00 92.69 69.14 84.14 76.64 – 79.76 TEOChat[51] 91.70 92.70 94.00 – 67.50 81.10 – – – UniRS[13] 91.81 93.23 93.00 92.63 59.29 84.05 73.15 86.67 – VHM[44] 91.17 89.89 88.00 89.33 64.00 83.50 73.75 – 注:所有结果均引自对应论文原文,加粗表示最佳结果。
下载: 导出CSV
表 6 多模态对地观测大模型在不同的视觉定位数据集上的性能表现(%)
Table 6. Performance of EO-MLLMs on various visual grounding datasets (%)
下载: 导出CSV
表 7 多模态对地观测大模型在不同的场景分类数据集上的性能表现(%)
Table 7. Performance of EO-MLLMs on various scene classification datasets (%)
模型 UCMerced[87] AID[86] NWPU-
RESISC45[94]CLRS[95] NaSC-TG2[96] WHU-
RS19[88]SIRI-
WHU[99]EuroSAT[100] METER-
ML[101]fMoW[91] EarthDial[52] 92.42 88.76 – – – 96.21 – – – 70.03 EarthGPT[12] – – 93.84 77.37 74.72 – – – – – EarthMaker[62] 86.52 77.97 – – – – – – – – GeoChat[43] 84.43 72.03 – – – – – – – – LHRS-Bot[11] – 91.26 83.94 – – 93.17 62.66 51.40 69.81 56.56 LHRS-Bot-Nova[64] – 88.32 86.80 – – 95.63 74.75 63.54 70.05 57.11 RingMoGPT[30] 86.48 97.94 96.47 – – 97.71 – – – – RSUniVLM[66] – 81.18 86.86 – – 84.91 68.13 – – – SkyEyeGPT[31] 60.95 26.30 – – – – – – – – TEOChat[51] 86.30 80.90 – – – – – – – – VHM[44] – 91.70 94.54 – – 95.80 70.88 – 72.74 – 注:所有结果均引自对应论文原文,加粗表示最佳结果。
下载: 导出CSV
-
[1] 王桥, 刘思含. 国家环境遥感监测体系研究与实现[J]. 遥感学报, 2016, 20(5): 1161–1169. doi: 10.11834/jrs.20166201.WANG Qiao and LIU Sihan. Research and implementation of national environmental remote sensing monitoring system[J]. Journal of Remote Sensing, 2016, 20(5): 1161–1169. doi: 10.11834/jrs.20166201. [2] 安立强, 张景发, MONTEIRO R, 等. 地震灾害损失评估与遥感技术现状和展望[J]. 遥感学报, 2024, 28(4): 860–884. doi: 10.11834/jrs.20232093.AN Liqiang, ZHANG Jingfa, MONTEIRO R, et al. A review and prospective research of earthquake damage assessment and remote sensing[J]. National Remote Sensing Bulletin, 2024, 28(4): 860–884. doi: 10.11834/jrs.20232093. [3] 张王菲, 陈尔学, 李增元, 等. 雷达遥感农业应用综述[J]. 雷达学报, 2020, 9(3): 444–461. doi: 10.12000/JR20051.ZHANG Wangfei, CHEN Erxue, LI Zengyuan, et al. Review of applications of radar remote sensing in agriculture[J]. Journal of Radars, 2020, 9(3): 444–461. doi: 10.12000/JR20051. [4] LI Yansheng, DANG Bo, ZHANG Yongjun, et al. Water body classification from high-resolution optical remote sensing imagery: Achievements and perspectives[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 187: 306–327. doi: 10.1016/j.isprsjprs.2022.03.013. [5] LI Yansheng, WEI Fanyi, ZHANG Yongjun, et al. HS2P: Hierarchical spectral and structure-preserving fusion network for multimodal remote sensing image cloud and shadow removal[J]. Information Fusion, 2023, 94: 215–228. doi: 10.1016/j.inffus.2023.02.002. [6] CHEN Yongqi, FENG Shou, ZHAO Chunhui, et al. High-resolution remote sensing image change detection based on Fourier feature interaction and multiscale perception[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5539115. doi: 10.1109/TGRS.2024.3500073. [7] 杨桄, 刘湘南. 遥感影像解译的研究现状和发展趋势[J]. 国土资源遥感, 2004(2): 7–10, 15. doi: 10.3969/j.issn.1001-070X.2004.02.002.YANG Guang and LIU Xiangnan. The present research condition and development trend of remotely sensed imagery interpretation[J]. Remote Sensing for Land & Resources, 2004(2): 7–10, 15. doi: 10.3969/j.issn.1001-070X.2004.02.002. [8] ZHAO W X, ZHOU Kun, LI Junyi, et al. A survey of large language models[J]. arXiv preprint arXiv: 2303.18223, 2023. doi: 10.48550/arXiv.2303.18223. [9] YIN Shukang, FU Chaoyou, ZHAO Sirui, et al. A survey on multimodal large language models[J]. National Science Review, 2024, 11(12): nwae403. doi: 10.1093/nsr/nwae403. [10] HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: A remote sensing vision language model and benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 224: 272–286. doi: 10.1016/j.isprsjprs.2025.03.028. [11] MUHTAR D, LI Zhenshi, GU Feng, et al. LHRS-Bot: Empowering remote sensing with VGI-enhanced large multimodal language model[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 440–457. doi: 10.1007/978-3-031-72904-1_26. [12] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5917820. doi: 10.1109/TGRS.2024.3409624. [13] LI Yujie, XU Wenjia, LI Guangzuo, et al. UniRS: Unifying multi-temporal remote sensing tasks through vision language models[J]. arXiv preprint arXiv: 2412.20742, 2024. doi: 10.48550/arXiv.2412.20742. [14] VOUTILAINEN A. A syntax-based part-of-speech analyser[C]. The 7th Conference of the European Chapter of the Association for Computational Linguistics, Dublin, Ireland, 1995. [15] BRILL E and RESNIK P. A rule-based approach to prepositional phrase attachment disambiguation[C]. The 15th International Conference on Computational Linguistics, Kyoto, Japan, 1994. [16] HINTON G E, OSINDERO S, and TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527–1554. doi: 10.1162/neco.2006.18.7.1527. [17] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, 2019: 4171–4186. doi: 10.18653/v1/N19-1423. [18] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. https://openai.com/iadex/language-unsupervised, 2018. [19] RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[EB/OL]. https://openai.com/index/better-langaage-models/, 2019. [20] BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 159. [21] OpenAI. GPT-4 technical report[J]. arXiv preprint arXiv: 2303.08774, 2023. doi: 10.48550/arXiv.2303.08774. [22] TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: Open and efficient foundation language models[J]. arXiv preprint arXiv: 2302.13971, 2023. doi: 10.48550/arXiv.2302.13971. [23] BAI Jinze, BAI Shuai, CHU Yunfei, et al. Qwen technical report[J]. arXiv preprint arXiv: 2309.16609, 2023. doi: 10.48550/arXiv.2309.16609. [24] DeepSeek-AI. DeepSeek-V3 technical report[J]. arXiv preprint arXiv: 2412.19437, 2024. doi: 10.48550/arXiv.2412.19437. [25] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [26] LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1516. [27] LIN Bin, YE Yang, ZHU Bin, et al. Video-LLaVA: Learning united visual representation by alignment before projection[C]. 2024 Conference on Empirical Methods in Natural Language Processing, Miami, USA, 2024: 5971–5984. [28] KOH J Y, FRIED D, and SALAKHUTDINOV R R. Generating images with multimodal language models[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 939. [29] ZHOU Yue, LAN Mengcheng, LI Xiang, et al. GeoGround: A unified large vision-language model for remote sensing visual grounding[J]. arXiv preprint arXiv: 2411.11904, 2024. doi: 10.48550/arXiv.2411.11904. [30] WANG Peijin, HU Huiyang, TONG Boyuan, et al. RingMoGPT: A unified remote sensing foundation model for vision, language, and grounded tasks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5611320. doi: 10.1109/TGRS.2024.3510833. [31] ZHAN Yang, XIONG Zhitong, and YUAN Yuan. SkyEyeGPT: Unifying remote sensing vision-language tasks via instruction tuning with large language model[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 221: 64–77. doi: 10.1016/j.isprsjprs.2025.01.020. [32] 张永军, 李彦胜, 党博, 等. 多模态遥感基础大模型: 研究现状与未来展望[J]. 测绘学报, 2024, 53(10): 1942–1954. doi: 10.11947/j.AGCS.2024.20240019.ZHANG Yongjun, LI Yansheng, DANG Bo, et al. Multi-modal remote sensing large foundation models: Current research status and future prospect[J]. Acta Geodaetica et Cartographica Sinica, 2024, 53(10): 1942–1954. doi: 10.11947/j.AGCS.2024.20240019. [33] HONG Danfeng, HAN Zhu, YAO Jing, et al. SpectralFormer: Rethinking hyperspectral image classification with transformers[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5518615. doi: 10.1109/TGRS.2021.3130716. [34] HONG Danfeng, ZHANG Bing, LI Xuyang, et al. SpectralGPT: Spectral remote sensing foundation model[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5227–5244. doi: 10.1109/TPAMI.2024.3362475. [35] FULLER A, MILLARD K, and GREEN J R. CROMA: Remote sensing representations with contrastive radar-optical masked autoencoders[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 241. [36] WANG Yi, ALBRECHT C M, BRAHAM N A A, et al. Decoupling common and unique representations for multimodal self-supervised learning[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 286–303. doi: 10.1007/978-3-031-73397-0_17. [37] 张良培, 张乐飞, 袁强强. 遥感大模型: 进展与前瞻[J]. 武汉大学学报(信息科学版), 2023, 48(10): 1574–1581. doi: 10.13203/j.whugis20230341.ZHANG Liangpei, ZHANG Lefei, and YUAN Qiangqiang. Large remote sensing model: Progress and prospects[J]. Geomatics and Information Science of Wuhan University, 2023, 48(10): 1574–1581. doi: 10.13203/j.whugis20230341. [38] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, 2021: 8748–8763. [39] CHIANG W L, LI Zhuohan, LIN Zi, et al. Vicuna: An open-source Chatbot impressing GPT-4 with 90%* ChatGPT quality[EB/OL]. https://lmsys.org/blog/2023-03-30-vicuna/, 2023. [40] DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning[J]. arXiv preprint arXiv: 2501.12948, 2025. doi: 10.48550/arXiv.2501.12948. [41] ALAYRAC J B, DONAHUE J, LUC P, et al. Flamingo: A visual language model for few-shot learning[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1723. [42] LI Junnan, LI Dongxu, SAVARESE S, et al. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 814. [43] KUCKREJA K, DANISH M S, NASEER M, et al. GeoChat: Grounded large vision-language model for remote sensing[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 27831–27840. doi: 10.1109/CVPR52733.2024.02629. [44] PANG Chao, WENG Xingxing, WU Jiang, et al. VHM: Versatile and honest vision language model for remote sensing image analysis[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, USA, 2025: 6381–6388. doi: 10.1609/aaai.v39i6.32683. [45] LUO Junwei, PANG Zhen, ZHANG Yongjun, et al. SkySenseGPT: A fine-grained instruction tuning dataset and model for remote sensing vision-language understanding[J]. arXiv preprint arXiv: 2406.10100, 2024. doi: 10.48550/arXiv.2406.10100. [46] SILVA J D, MAGALHÃES J, TUIA D, et al. Large language models for captioning and retrieving remote sensing images[J]. arXiv preprint arXiv: 2402.06475, 2024. doi: 10.48550/arXiv.2402.06475. [47] GUO Mingning, WU Mengwei, SHEN Yuxiang, et al. IFShip: Interpretable fine-grained ship classification with domain knowledge-enhanced vision-language models[J]. Pattern Recognition, 2025, 166: 111672. doi: 10.1016/j.patcog.2025.111672. [48] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. Popeye: A unified visual-language model for multisource ship detection from remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 20050–20063. doi: 10.1109/JSTARS.2024.3488034. [49] DENG Pei, ZHOU Wenqian, and WU Hanlin. ChangeChat: An interactive model for remote sensing change analysis via multimodal instruction tuning[C]. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 2025: 1–5. doi: 10.1109/ICASSP49660.2025.10890620. [50] NOMAN M, AHSAN N, NASEER M, et al. CDChat: A large multimodal model for remote sensing change description[J]. arXiv preprint arXiv: 2409.16261, 2024. doi: 10.48550/arXiv.2409.16261. [51] IRVIN J A, LIU E R, CHEN J C, et al. TEOChat: A large vision-language assistant for temporal earth observation data[C]. The 13th International Conference on Learning Representations, Singapore, Singapore, 2025. [52] SONI S, DUDHANE A, DEBARY H, et al. EarthDial: Turning multi-sensory earth observations to interactive dialogues[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 14303–14313. doi: 10.1109/CVPR52734.2025.01334. [53] ZHANG Wei, CAI Miaoxin, NING Yaqian, et al. EarthGPT-X: Enabling MLLMs to flexibly and comprehensively understand multi-source remote sensing imagery[J]. arXiv preprint arXiv: 2504.12795, 2025. doi: 10.48550/arXiv.2504.12795. [54] SHU Yan, REN Bin, XIONG Zhitong, et al. EarthMind: Leveraging cross-sensor data for advanced earth observation interpretation with a unified multimodal LLM[J]. arXiv preprint arXiv: 2506.01667, 2025. doi: 10.48550/arXiv.2506.01667. [55] LIU Zhuang, MAO Hanzi, WU Chaoyuan, et al. A ConvNet for the 2020s[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11966–11976. doi: 10.1109/CVPR52688.2022.01167. [56] SUN Quan, FANG Yuxin, WU L, et al. EVA-CLIP: Improved training techniques for CLIP at scale[J]. arXiv preprint arXiv: 2303.15389, 2023. doi: 10.48550/arXiv.2303.15389. [57] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, 2021. [58] ZI Xing, NI Tengjun, FAN Xianjing, et al. AeroLite: Tag-guided lightweight generation of aerial image captions[J]. arXiv preprint arXiv: 2504.09528, 2025. doi: 10.48550/arXiv.2504.09528. [59] LU Kaixuan, ZHANG Ruiqian, HUANG Xiao, et al. Aquila: A hierarchically aligned visual-language model for enhanced remote sensing image comprehension[J]. arXiv preprint arXiv: 2411.06074, 2024. doi: 10.48550/arXiv.2411.06074. [60] LU Kaixuan. Aquila-plus: Prompt-driven visual-language models for pixel-level remote sensing image understanding[J]. arXiv preprint arXiv: 2411.06142, 2024. doi: 10.48550/arXiv.2411.06142. [61] JIANG Hongxiang, YIN Jihao, WANG Qixiong, et al. EagleVision: Object-level attribute multimodal LLM for remote sensing[J]. arXiv preprint arXiv: 2503.23330, 2025. doi: 10.48550/arXiv.2503.23330. [62] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. EarthMarker: A visual prompting multimodal large language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5604219. doi: 10.1109/TGRS.2024.3523505. [63] WANG Fengxiang, CHEN Mingshuo, LI Yueying, et al. GeoLLaVA-8K: Scaling remote-sensing multimodal large language models to 8K resolution[J]. arXiv preprint arXiv: 2505.21375, 2025. doi: 10.48550/arXiv.2505.21375. [64] LI Zhenshi, MUHTAR D, GU Feng, et al. LHRS-Bot-Nova: Improved multimodal large language model for remote sensing vision-language interpretation[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 227: 539–550. doi: 10.1016/j.isprsjprs.2025.06.003. [65] BAZI Y, BASHMAL L, AL RAHHAL M M, et al. RS-LLaVA: A large vision-language model for joint captioning and question answering in remote sensing imagery[J]. Remote Sensing, 2024, 16(9): 1477. doi: 10.3390/rs16091477. [66] LIU Xu and LIAN Zhouhui. RSUniVLM: A unified vision language model for remote sensing via granularity-oriented mixture of experts[J]. arXiv preprint arXiv: 2412.05679, 2024. doi: 10.48550/arXiv.2412.05679. [67] KARANFIL E, IMAMOGLU N, ERDEM E, et al. A vision-language framework for multispectral scene representation using language-grounded features[J]. arXiv preprint arXiv: 2501.10144, 2025. doi: 10.48550/arXiv.2501.10144. [68] ZHANG Hao, LI Feng, LIU Shilong, et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023. [69] ZHAI Xiaohua, MUSTAFA B, KOLESNIKOV A, et al. Sigmoid loss for language image pre-training[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 11941–11952. doi: 10.1109/ICCV51070.2023.01100. [70] ZHANG Jihai, QU Xiaoye, ZHU Tong, et al. CLIP-MoE: Towards building mixture of experts for CLIP with diversified multiplet upcycling[J]. arXiv preprint arXiv: 2409.19291, 2024. doi: 10.48550/arXiv.2409.19291. [71] WANG Weihan, LV Qingsong, YU Wenmeng, et al. CogVLM: Visual expert for pretrained language models[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 3860. [72] LIU Haotian, LI Chunyuan, LI Yuheng, et al. Improved baselines with visual instruction tuning[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 26286–26296. doi: 10.1109/CVPR52733.2024.02484. [73] KAUFMANN T, WENG P, BENGS V, et al. A survey of reinforcement learning from human feedback[J]. Transactions on Machine Learning Research, in press, 2025. [74] HU E J, SHEN Yelong, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[C]. The 10th International Conference on Learning Representations, 2022. [75] OUYANG Long, WU J, JIANG Xu, et al. Training language models to follow instructions with human feedback[C]. The 36th Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 27730–27744. [76] BAI Yuntao, JONES A, NDOUSSE K, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback[J]. arXiv preprint arXiv: 2204.05862, 2022. doi: 10.48550/arXiv.2204.05862. [77] ZIEGLER D M, STIENNON N, WU J, et al. Fine-tuning language models from human preferences[J]. arXiv preprint arXiv: 1909.08593, 2019. doi: 10.48550/arXiv.1909.08593. [78] ZHANG Yifan, YU Tao, TIAN Haochen, et al. MM-RLHF: The next step forward in multimodal LLM alignment[C]. The 42nd International Conference on Machine Learning, Vancouver, Canada, 2025: 1–30. [79] LI Lei, XIE Zhihui, LI Mukai, et al. VLFeedback: A large-scale AI feedback dataset for large vision-language models alignment[C]. The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), Miami, USA, 2024: 6227–6246. doi: 10.18653/v1/2024.emnlp-main.358. [80] FENG K, GONG K, LI B, et al. ideo-r1: Reinforcing video reasoning in mllms[J]. arXiv preprint arXiv: 2503.21776, 2025. doi: 10.48550/arXiv.2503.21776. [81] QU Bo, LI Xuelong, TAO Dacheng, et al. Deep semantic understanding of high resolution remote sensing image[C]. 2016 International Conference on Computer, Information and Telecommunication Systems (CITS), Kunming, China, 2016: 1–5. doi: 10.1109/CITS.2016.7546397. [82] LU Xiaoqiang, WANG Binqiang, ZHENG Xiangtao, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183–2195. doi: 10.1109/TGRS.2017.2776321. [83] LOBRY S, MARCOS D, MURRAY J, et al. RSVQA: Visual question answering for remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(12): 8555–8566. doi: 10.1109/TGRS.2020.2988782. [84] CHENG Qimin, HUANG Haiyan, XU Yuan, et al. NWPU-captions dataset and MLCA-Net for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5629419. doi: 10.1109/TGRS.2022.3201474. [85] YUAN Zhiqiang, ZHANG Wenkai, FU Kun, et al. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 4404119. doi: 10.1109/TGRS.2021.3078451. [86] XIA Guisong, HU Jingwen, HU Fan, et al. AID: A benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965–3981. doi: 10.1109/TGRS.2017.2685945. [87] YANG Yi and NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]. The 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, USA, 2010: 270–279. doi: 10.1145/1869790.1869829. [88] DAI Dengxin and YANG Wen. Satellite image classification via two-layer sparse coding with biased image representation[J]. IEEE Geoscience and Remote Sensing Letters, 2011, 8(1): 173–176. doi: 10.1109/LGRS.2010.2055033. [89] SUMBUL G, CHARFUELAN M, DEMIR B, et al. BigEarthNet: A large-scale benchmark archive for remote sensing image understanding[C]. IGARSS 2019-2019 IEEE international geoscience and remote sensing symposium, Yokohama, Japan, 2019: 5901–5904. doi: 10.1109/IGARSS.2019.8900532. [90] GUPTA R, GOODMAN B, PATEL N, et al. Creating xBD: A dataset for assessing building damage from satellite imagery[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, USA, 2019: 10–17. [91] CHRISTIE G, FENDLEY N, WILSON J, et al. Functional map of the world[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6172–6180. doi: 10.1109/CVPR.2018.00646. [92] ZHANG Meimei, CHEN Fang, and LI Bin. Multistep question-driven visual question answering for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 4704912. doi: 10.1109/TGRS.2023.3312479. [93] ZHAN Yang, XIONG Zhitong, and YUAN Yuan. RSVG: Exploring data and models for visual grounding on remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5604513. doi: 10.1109/TGRS.2023.3250471. [94] CHENG Gong, HAN Junwei, and LU Xiaoqiang. Remote sensing image scene classification: Benchmark and state of the art[J]. Proceedings of the IEEE, 2017, 105(10): 1865–1883. doi: 10.1109/JPROC.2017.2675998. [95] LI Haifeng, JIANG Hao, GU Xin, et al. CLRS: Continual learning benchmark for remote sensing image scene classification[J]. Sensors, 2020, 20(4): 1226. doi: 10.3390/s20041226. [96] ZHOU Zhuang, LI Shengyang, WU Wei, et al. NaSC-TG2: Natural scene classification with Tiangong-2 remotely sensed imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 3228–3242. doi: 10.1109/JSTARS.2021.3063096. [97] LI Xiang, DING Jian, and ELHOSEINY M. VRSBench: A versatile vision-language benchmark dataset for remote sensing image understanding[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 106. [98] SUN Yuxi, FENG Shanshan, LI Xutao, et al. Visual grounding in remote sensing images[C]. The 30th ACM International Conference on Multimedia, Lisboa, Portugal, 2022: 404–412. doi: 10.1145/3503161.3548316. [99] ZHU Qiqi, ZHONG Yanfei, ZHAO Bei, et al. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(6): 747–751. doi: 10.1109/LGRS.2015.2513443. [100] HELBER P, BISCHKE B, DENGEL A, et al. EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019, 12(7): 2217–2226. doi: 10.1109/JSTARS.2019.2918242. [101] ZHU B, LUI N, IRVIN J, et al. METER-ML: A multi-sensor earth observation benchmark for automated methane source mapping[C]. The 2nd Workshop on Complex Data Challenges in Earth Observation (CDCEO 2022) Co-Located with 31st International Joint Conference on Artificial Intelligence and the 25th European Conference on Artificial Intelligence (IJCAI-ECAI 2022), Vienna, Austria, 2022: 33–43. [102] LI Kun, VOSSELMAN G, and YANG M Y. HRVQA: A visual question answering benchmark for high-resolution aerial images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2024, 214: 65–81. doi: 10.1016/j.isprsjprs.2024.06.002. [103] HOXHA G and MELGANI F. A novel SVM-based decoder for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5404514. doi: 10.1109/TGRS.2021.3105004. [104] ZHENG Xiangtao, WANG Binqiang, DU Xingqian, et al. Mutual attention inception network for remote sensing visual question answering[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5606514. doi: 10.1109/TGRS.2021.3079918. [105] BASHMAL L, BAZI Y, AL RAHHAL M M, et al. CapERA: Captioning events in aerial videos[J]. Remote Sensing, 2023, 15(8): 2139. doi: 10.3390/rs15082139. [106] SUN Xian, WANG Peijin, LU Wanxuan, et al. RingMo: A remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5612822. doi: 10.1109/TGRS.2022.3194732. [107] BI Hanbo, FENG Yingchao, TONG Boyuan, et al. RingMoE: Mixture-of-modality-experts multi-modal foundation models for universal remote sensing image interpretation[J]. arXiv preprint arXiv: 2504.03166, 2025. doi: 10.48550/arXiv.2504.03166. [108] CHEN Hao and SHI Zhenwei. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection[J]. Remote Sensing, 2020, 12(10): 1662. doi: 10.3390/rs12101662. [109] SHI Qian, LIU Mengxi, LI Shengchen, et al. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5604816. doi: 10.1109/TGRS.2021.3085870. [110] LIU Chenyang, ZHAO Rui, CHEN Hao, et al. Remote sensing image change captioning with dual-branch transformers: A new method and a large scale dataset[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5633520. doi: 10.1109/TGRS.2022.3218921. [111] XIA Guisong, BAI Xiang, DING Jian, et al. DOTA: A large-scale dataset for object detection in aerial images[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 3974–3983. doi: 10.1109/CVPR.2018.00418. [112] LI Ke, WAN Gang, CHENG Gong, et al. Object detection in optical remote sensing images: A survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296–307. doi: 10.1016/j.isprsjprs.2019.11.023. [113] SUMBUL G, DE WALL A, KREUZIGER T, et al. BigEarthNet-MM: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets][J]. IEEE Geoscience and Remote Sensing Magazine, 2021, 9(3): 174–180. doi: 10.1109/MGRS.2021.3089174. [114] XIA Junshi, CHEN Hongruixuan, BRONI-BEDIAKO C, et al. OpenEarthMap-SAR: A benchmark synthetic aperture radar dataset for global high-resolution land cover mapping [software and data sets][J]. IEEE Geoscience and Remote Sensing Magazine, 2025, 13(4): 476–487. doi: 10.1109/MGRS.2025.3599512. [115] PERSELLO C, HÄNSCH R, VIVONE G, et al. 2023 IEEE GRSS data fusion contest: Large-scale fine-grained building classification for semantic urban reconstruction [technical committees][J]. IEEE Geoscience and Remote Sensing Magazine, 2023, 11(1): 94–97. doi: 10.1109/MGRS.2023.3240233. [116] LI Xue, ZHANG Guo, CUI Hao, et al. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 106: 102638. doi: 10.1016/j.jag.2021.102638. [117] SHERMEYER J, HOGAN D, BROWN J, et al. SpaceNet 6: Multi-sensor all weather mapping dataset[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2020: 768–777. doi: 10.1109/CVPRW50498.2020.00106. [118] ZHANG Wenfei, ZHAO Ruipeng, YAO Yongxiang, et al. Multi-resolution SAR and optical remote sensing image registration methods: A review, datasets, and future perspectives[J]. arXiv preprint arXiv: 2502.01002, 2025. doi: 10.48550/arXiv.2502.01002. [119] LI Tianyang, WANG Chao, TIAN Sirui, et al. TACMT: Text-aware cross-modal transformer for visual grounding on high-resolution SAR images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 222: 152–166. doi: 10.1016/j.isprsjprs.2025.02.022. [120] CHEN Yaxiong, ZHAN Liwen, ZHAO Yichen, et al. VGRSS: Datasets and models for visual grounding in remote sensing ship images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 4703411. doi: 10.1109/TGRS.2025.3562717. [121] MA Zhiming, XIAO Xiayang, DONG Sihao, et al. SARChat-Bench-2M: A multi-task vision-language benchmark for SAR image interpretation[J]. arXiv preprint arXiv: 2502.08168, 2025. doi: 10.48550/arXiv.2502.08168. [122] LI Yuxuan, LI Xiang, LI Weijie, et al. SARDet-100K: Towards open-source benchmark and toolkit for large-scale SAR object detection[C]. The 38th Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 128430–128461. doi: 10.52202/079017-4079. [123] WEI Yimin, XIAO Aoran, REN Yexian, et al. SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding[J]. arXiv preprint arXiv: 2504.03254, 2025. doi: 10.48550/arXiv.2504.03254. [124] HE Yiguo, CHENG Xinjun, ZHU Junjie, et al. SAR-TEXT: A large-scale SAR image-text dataset built with SAR-narrator and a progressive learning strategy for downstream tasks[J]. arXiv preprint arXiv: 2507.18743, 2025. doi: 10.48550/arXiv.2507.18743. [125] YANG Yi, ZHANG Xiaokun, FANG Qingchen, et al. SAR-KnowLIP: Towards multimodal foundation models for remote sensing[J]. arXiv preprint arXiv: 2509.23927, 2025. doi: 10.48550/arXiv.2509.23927. [126] ZHAO Yuanxin, ZHANG Mi, YANG Bingnan, et al. LuoJiaHOG: A hierarchy oriented geo-aware image caption dataset for remote sensing image-text retrieval[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 222: 130–151. doi: 10.1016/j.isprsjprs.2025.02.009. [127] YUAN Zhenghang, XIONG Zhitong, MOU Lichao, et al. ChatEarthNet: A global-scale image-text dataset empowering vision-language geo-foundation models[J]. Earth System Science Data, 2025, 17(3): 1245–1263. doi: 10.5194/essd-17-1245-2025. [128] LI Haodong, ZHANG Xiaofeng, and QU Haicheng. DDFAV: Remote sensing large vision language models dataset and evaluation benchmark[J]. Remote Sensing, 2025, 17(4): 719. doi: 10.3390/rs17040719. [129] AN Xiao, SUN Jiaxing, GUI Zihan, et al. COREval: A comprehensive and objective benchmark for evaluating the remote sensing capabilities of large vision-language models[J]. arXiv preprint arXiv: 2411.18145, 2024. doi: 10.48550/arXiv.2411.18145. [130] ZHOU Yue, FENG Litong, LAN Mengcheng, et al. GeoMath: A benchmark for multimodal mathematical reasoning in remote sensing[C]. The 13th International Conference on Representation Learning, Singapore, Singapore, 2025. [131] GE Junyao, ZHANG Xu, ZHENG Yang, et al. RSTeller: Scaling up visual language modeling in remote sensing with rich linguistic semantics from openly available data and large language models[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 226: 146–163. doi: 10.1016/j.isprsjprs.2025.05.002. [132] DU Siqi, TANG Shengjun, WANG Weixi, et al. Tree-GPT: Modular large language model expert system for forest remote sensing image understanding and interactive analysis[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2023, XLVIII-1-W2-2023: 1729–1736. doi: 10.5194/isprs-archives-XLVIII-1-W2-2023-1729-2023. [133] GUO Haonan, SU Xin, WU Chen, et al. Remote sensing ChatGPT: Solving remote sensing tasks with ChatGPT and visual models[C]. IGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 2024: 11474–11478. doi: 10.1109/IGARSS53475.2024.10640736. [134] LIU Chenyang, CHEN Keyan, ZHANG Haotian, et al. Change-Agent: Towards interactive comprehensive remote sensing change interpretation and analysis[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5635616. doi: 10.1109/TGRS.2024.3425815. [135] XU Wenjia, YU Zijian, MU Boyang, et al. RS-Agent: Automating remote sensing tasks through intelligent agents[J]. arXiv preprint arXiv: 2406.07089, 2024. doi: 10.4850/arXiv.2406.07089. [136] SINGH S, FORE M, and STAMOULIS D. GeoLLM-Engine: A realistic environment for building geospatial copilots[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2024: 585–594. doi: 10.1109/CVPRW63382.2024.00063. [137] SINGH S, FORE M, and STAMOULIS D. Evaluating tool-augmented agents in remote sensing platforms[J]. arXiv preprint arXiv: 2405.00709, 2024. doi: 10.48550/arXiv.2405.00709. -


计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

