
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
-
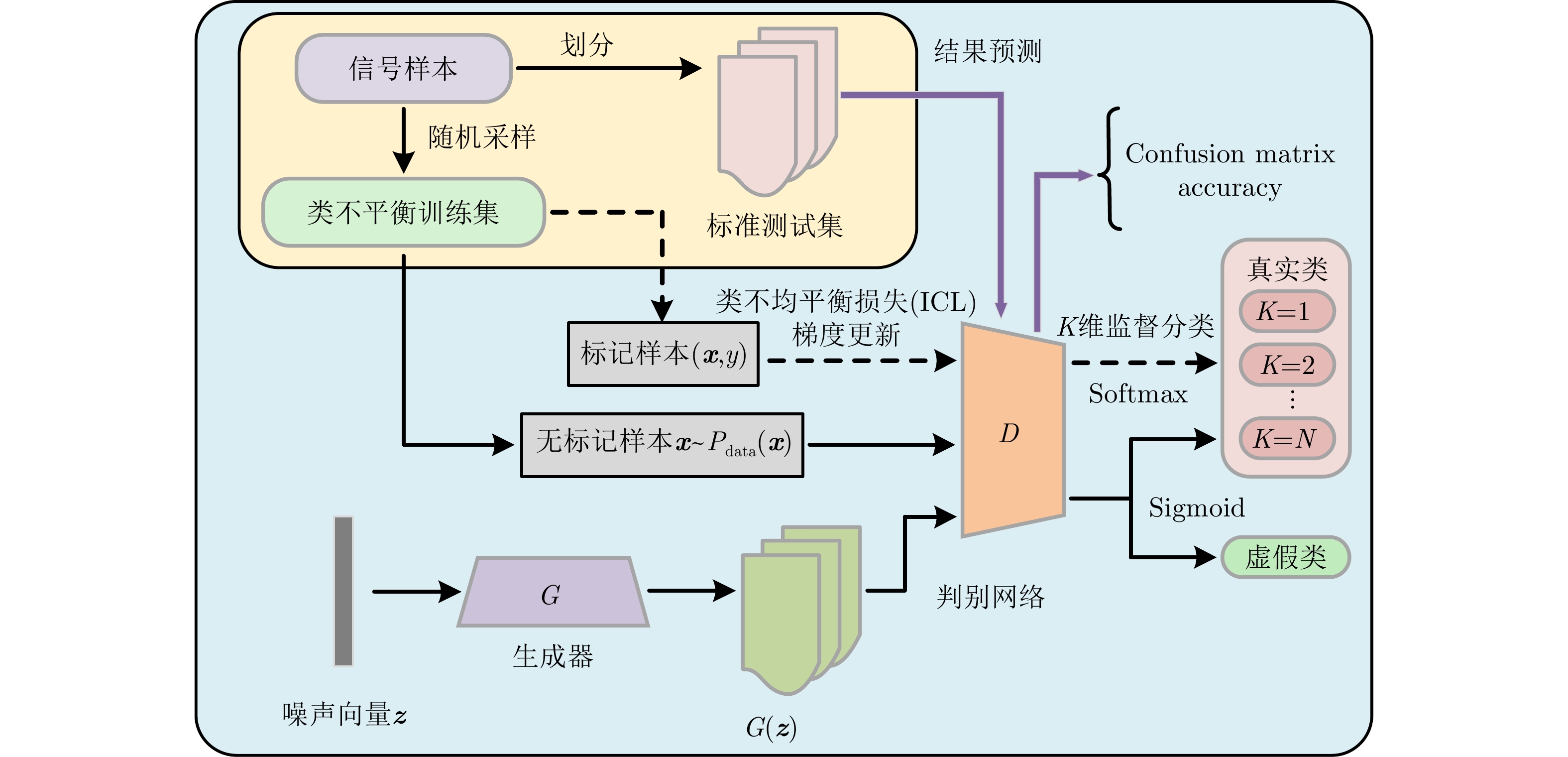
摘要: 针对辐射源个体识别(SEI)中样本标签不完整和数据类别分布不平衡导致分类准确率下降的问题,该文提出了一种基于代价敏感学习和半监督生成式对抗网络(GAN)的特定辐射源分类方法。该方法通过半监督训练方式优化生成器和判别器的网络参数,并向残差网络中添加多尺度拓扑模块融合时域信号的多维分辨率特征,赋予生成样本额外标签从而直接利用判别器完成分类。同时设计代价敏感损失缓解优势样本导致的梯度传播失衡,改善分类器在类不平衡数据集上的识别性能。在4类失衡仿真数据集上的实验结果表明,存在40%无标记样本的情况下,该方法对于5个辐射源的平均识别率相比于交叉熵损失和焦点损失分别提高5.34%和2.69%,为解决数据标注缺失和类别分布不均条件下的特定辐射源识别问题提供了新思路。Abstract: This paper proposes an SEI method based on cost-sensitive learning and semisupervised generative adversarial networks to address the problem of incomplete sample labels and imbalanced data category distribution in Specific Emitter Identification (SEI), which leads to a decline in inaccuracy. Through semisupervised training, the method optimizes the network parameters of the generator and discriminator, adds a multiscale topological block to ResNet to fuse the multi-dimensional resolution features of the time-domain signal, and attributes additional labels to the generated samples to directly use the discriminator to complete the classification. Simultaneously, a cost-sensitive loss is designed to alleviate the imbalance of gradient propagation caused by the dominant samples and improve the recognition performance of the classifier on the class-imbalanced dataset. The experimental results on four types of imbalanced datasets show that in the presence of 40% unlabeled samples, the average recognition accuracy for five emitters is improved by 5.34% and 2.69%, respectively, compared with the cross-entropy loss and focus loss. This provides a new idea for solving the problem of SEI under the conditions of insufficient data labels and an unbalanced distribution of data.
-

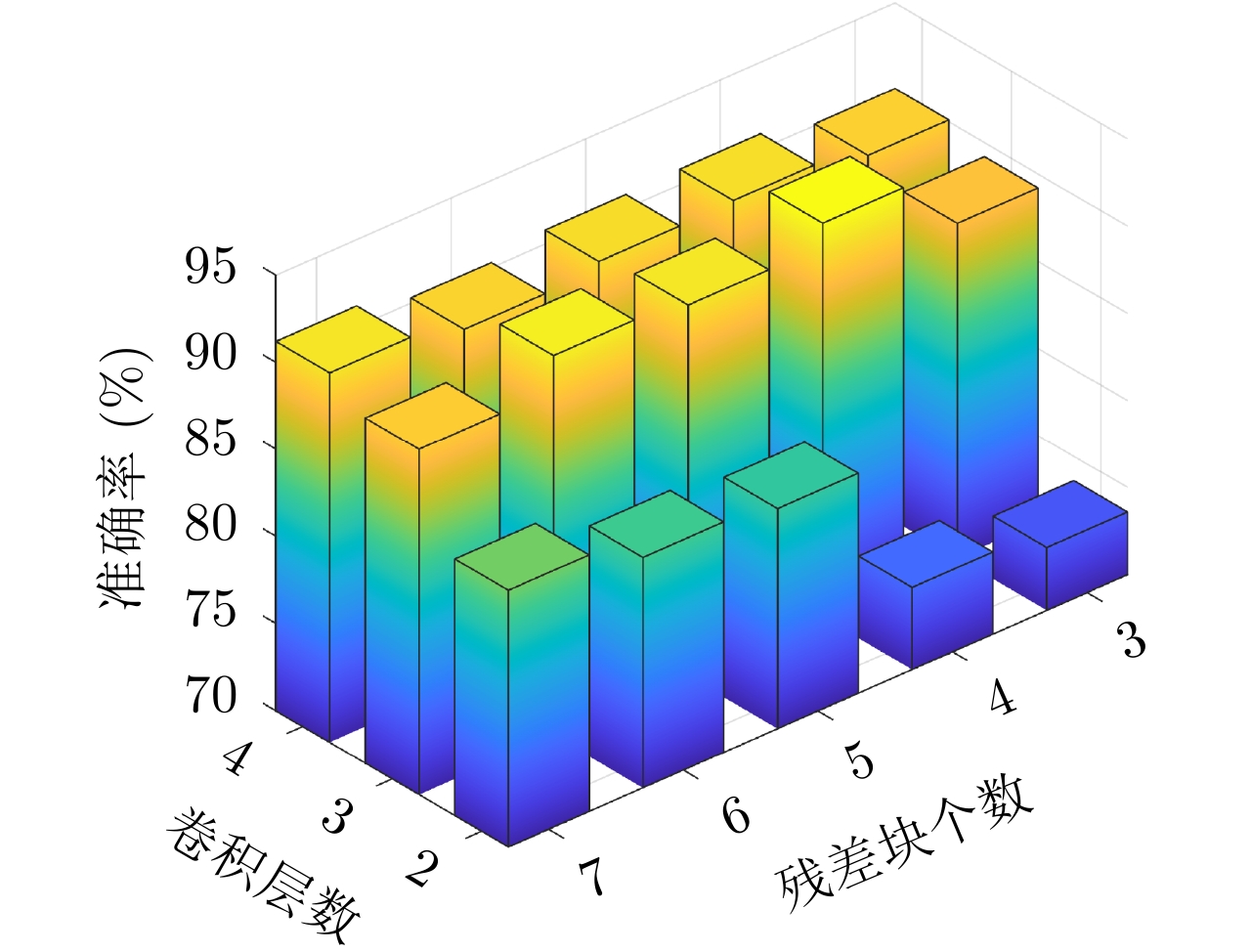
图 6 判别器结构参数对识别准确率的影响
Figure 6. The influence of discriminator structure parameters on recognition accuracy
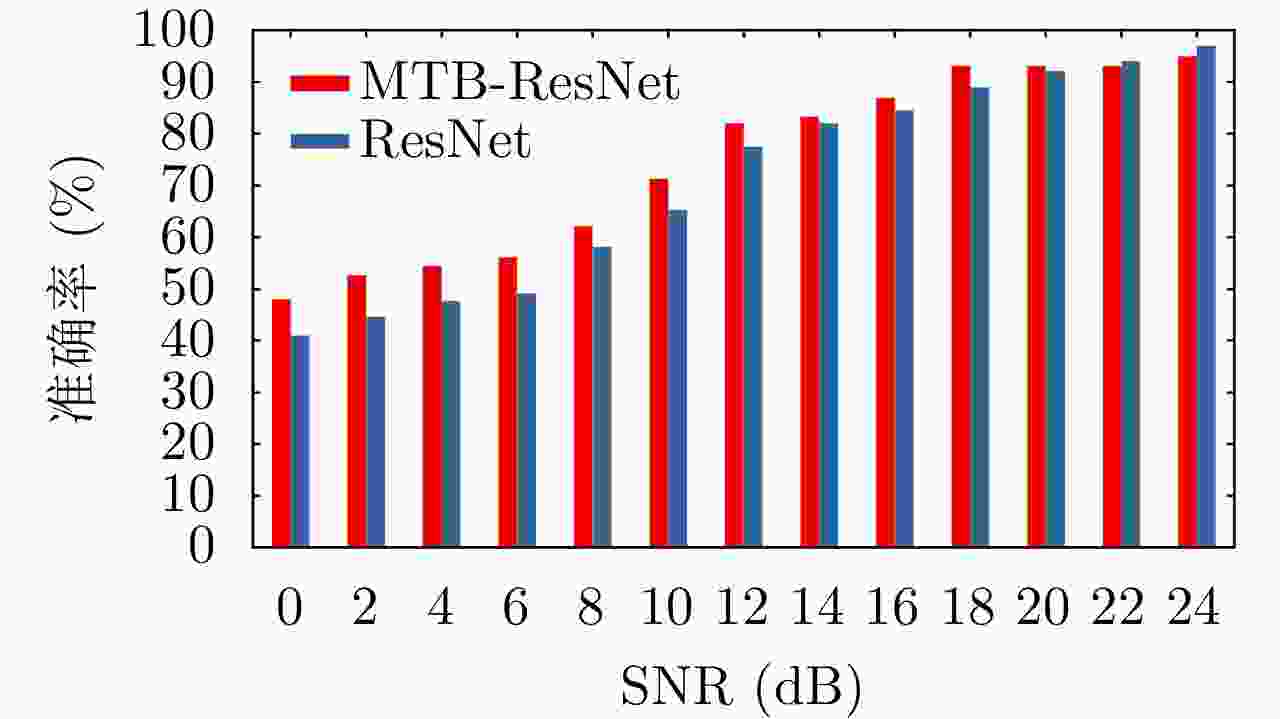
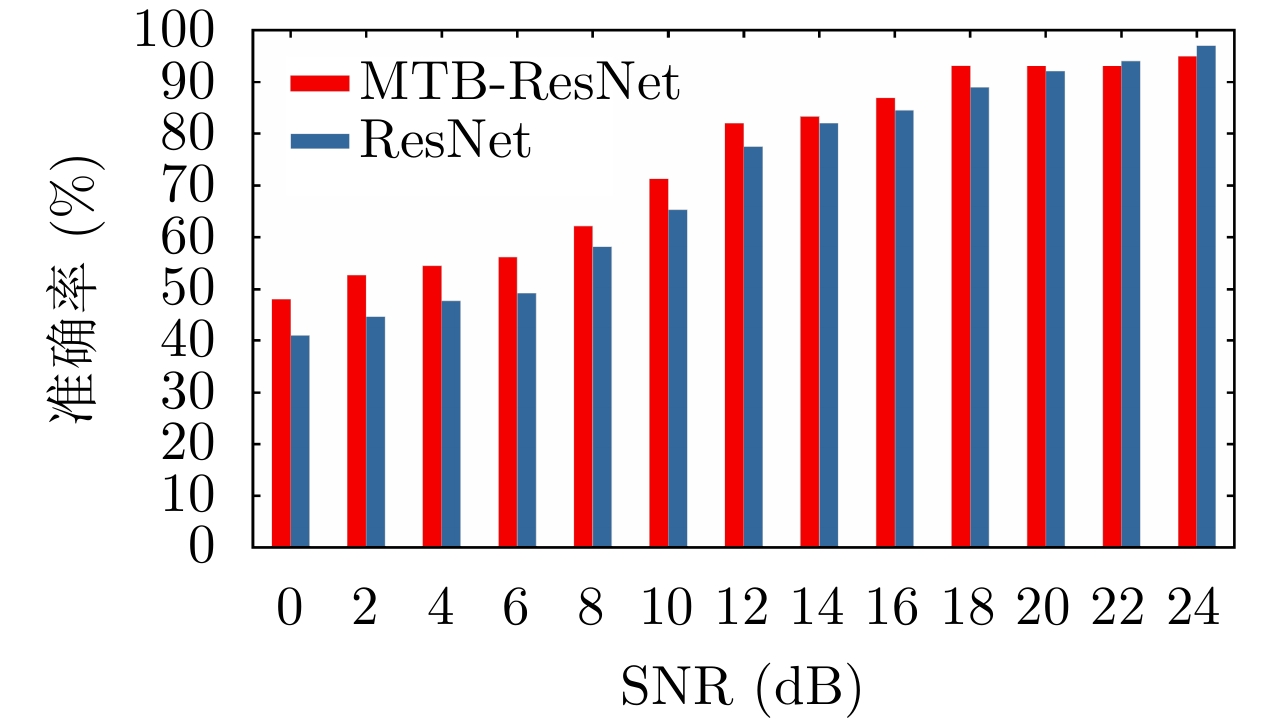
图 7 MTB-ResNet与ResNet的识别准确率对比
Figure 7. Comparison of recognition accuracy between MTB-ResNet and ResNet
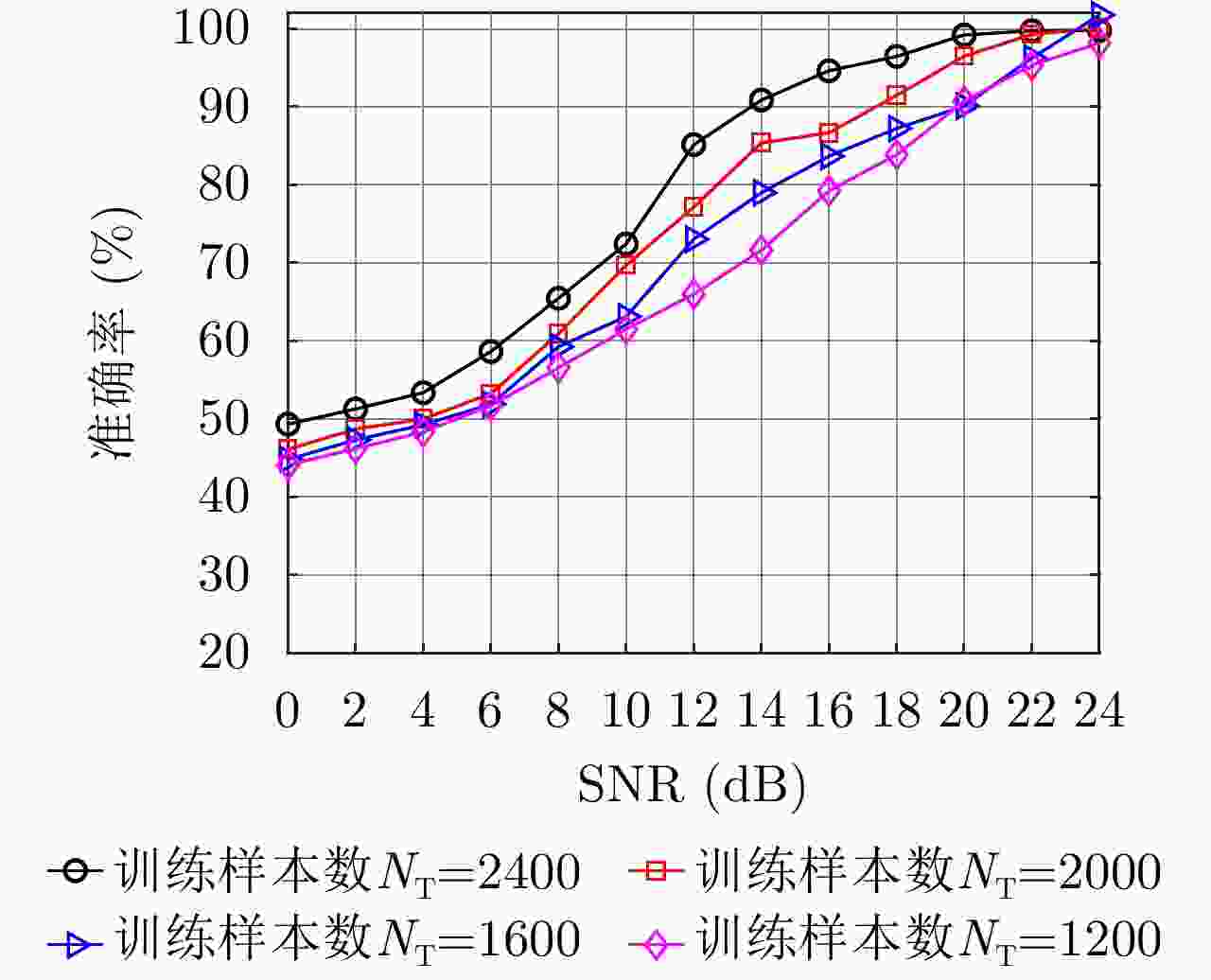
图 8 不同训练样本数下识别性能对比
Figure 8. Comparison of recognition performance under different numbers of training samples
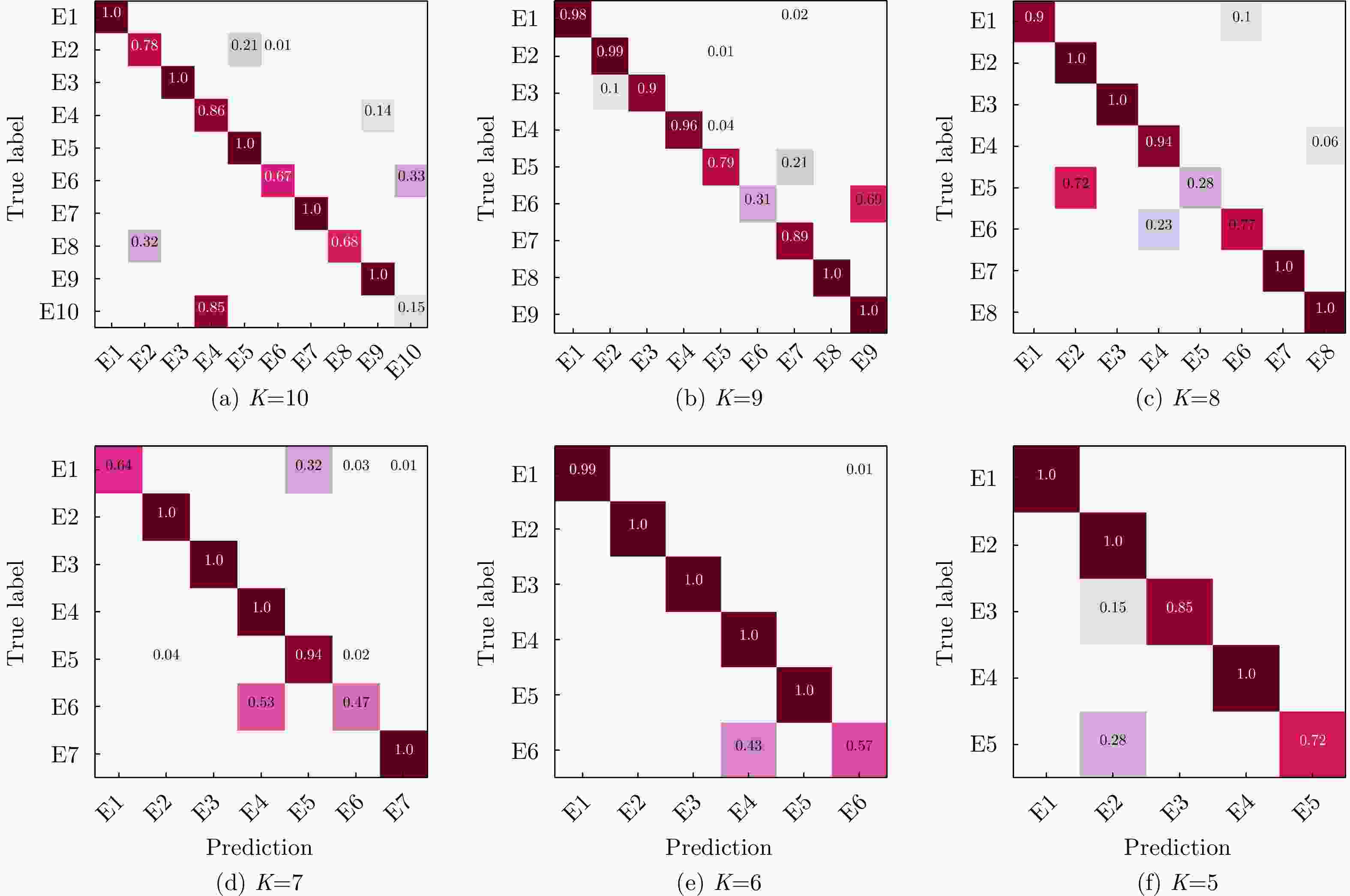
图 11 IC-SGAN对于不同辐射源数量的识别结果
Figure 11. The recognition results for different numbers of emitters
表 1 生成器结构
Table 1. The structure of generator
层名称 参数设置 输入层随机噪声 1×100 全连接层
维度变换256×64
1×256×64卷积层1,批归一化,
LeakyReLU,上采样Filters = 128, kernel_size = 1×3,
strides = 1, padding = same卷积层3 Filters = 128 卷积层4 Filters = 64 卷积层5 Filters = 32 卷积层6 Filters = 1 Flatten,全连接层
输出层1000
1×1000信号向量 下载: 导出CSV
下载: 导出CSV
表 2 仿真数据的训练集和测试集设置
Table 2. Training and test set settings for simulation data
数据集 类别 E1 E2 E3 E4 E5 标准训练集 480 480 480 480 480 标准测试集 480 480 480 480 480 训练集1 10 10 100 480 480 训练集2 10 20 200 180 480 训练集3 480 480 480 20 80 训练集4 50 50 180 480 300
下载: 导出CSV
表 3 不同损失函数在不同信噪比下的性能评估(%)
Table 3. Performance evaluation of loss functions under different SNRs (%)
训练集 损失函数 0 dB 2 dB 4 dB 6 dB 8 dB 10 dB 12 dB 14 dB 16 dB 18 dB 20 dB 22 dB 24 dB
标准训练集CE 49.33 51.17 53.36 58.64 65.47 72.44 85.16 90.88 94.64 96.48 99.23 99.76 99.80 FL 48.78 50.97 54.29 57.97 64.31 70.84 86.10 91.12 93.77 92.57 98.68 98.56 98.65 ICL 48.31 51.26 54.33 56.19 62.99 68.09 85.84 89.55 94.05 95.69 96.02 98.27 99.31 训练集1 CE 29.88 35.14 37.32 39.24 39.88 40.04 41.52 42.63 45.68 48.52 74.72 79.87 82.61 FL 30.13 33.16 36.08 38.84 40.40 42.32 41.96 43.08 45.12 48.60 74.16 80.77 84.16 ICL 30.65 36.47 35.04 38.39 41.26 43.77 44.27 45.46 49.00 54.24 74.84 83.13 85.36 训练集2 CE 19.77 24.13 25.80 29.48 30.56 39.72 42.76 54.52 55.20 75.96 79.56 80.15 81.36 FL 23.08 25.55 24.16 25.76 33.16 36.24 36.44 55.80 57.24 73.00 80.24 81.66 83.48 ICL 24.11 26.67 26.77 28.94 35.29 40.94 42.96 53.97 59.33 77.04 79.64 81.08 84.70 训练集3 CE 28.09 32.40 33.57 36.74 42.17 46.38 49.44 50.36 55.56 64.36 73.49 77.76 79.40 FL 33.68 33.19 38.45 38.77 42.54 45.29 48.37 51.94 52.79 66.81 74.31 77.56 78.04 ICL 32.41 36.97 40.60 40.88 44.28 46.00 49.64 50.96 56.44 65.52 75.88 79.54 80.92 训练集4 CE 30.11 31.79 35.88 36.08 43.12 45.00 48.36 60.08 62.03 64.28 70.80 72.61 78.54 FL 31.25 33.57 36.40 40.36 42.96 43.84 54.56 62.36 64.40 64.88 74.16 73.77 79.76 ICL 32.97 33.22 36.42 41.32 44.04 47.52 56.24 64.76 67.04 68.24 81.60 82.77 83.84
下载: 导出CSV
表 4 不同算法识别准确率对比(%)
Table 4. Comparison of recognition accuracy of different schemes (%)
算法 0 dB 4 dB 8 dB 12 dB 16 dB 20 dB 24 dB 本文方法+CE 30.11 35.88 43.12 48.36 62.03 70.80 78.54 本文方法+ICL 32.97 36.42 44.04 56.24 67.04 81.60 83.84 方法1+CE 27.53 31.76 37.72 44.80 59.36 64.43 73.36 方法1+ICL 28.12 32.64 39.53 49.08 63.96 72.12 75.24 方法2+CE 26.46 33.18 41.07 46.08 60.47 68.00 77.36 方法2+ICL 29.16 34.56 42.28 51.32 65.23 75.16 79.00 方法3 34.82 33.46 40.61 50.92 57.77 67.18 71.49 方法4 20.96 25.10 34.64 45.69 57.14 58.06 67.18
下载: 导出CSV
表 5 网络复杂度对比
Table 5. Network complexity comparison
网络模型 空间复杂度
NO (M)迭代平均
耗时ttrain (s)平均识别
时间ttest (s)IC-SGAN 1.97+3.93 90.8 3.1 RFFE-InfoGAN 2.52+19.57 207.0 4.6 E3SGAN 4.25+4.61 110.5 2.8
下载: 导出CSV
表 6 真实数据的训练集和测试集设置
Table 6. Training set and test set settings for real data
数据集 类别 E1 E2 E3 E4 E5 E6 E7 E8 E9 E10 标准训练集 480 480 480 480 480 480 480 480 480 480 标准测试集 240 240 240 240 240 240 240 240 240 240 训练集1 48 480 48 480 48 480 48 480 48 480 训练集2 120 480 120 480 120 480 120 480 120 480 训练集3 480 48 480 48 480 48 480 48 480 48 训练集4 480 120 480 120 480 120 480 120 480 120
下载: 导出CSV
表 7 3类损失函数的识别性能评估(%)
Table 7. Recognition performance evaluation of three loss functions (%)
训练集 损失函数 K = 5 K = 6 K = 7 K = 8 K = 9 K = 10 Average 标准训练集 CE 93.52 89.78 87.27 85.34 85.47 86.80 88.03 FL 97.39 87.64 88.21 89.66 87.28 85.32 89.25 ICL 94.60 88.36 90.46 88.56 86.72 86.38 89.18 训练集1 CE 90.16 78.35 76.40 72.38 70.87 62.76 75.15 FL 91.68 79.76 79.35 74.61 74.98 65.18 77.59 ICL 93.48 84.07 82.37 77.56 72.65 68.92 79.84 训练集2 CE 86.88 80.17 78.46 70.02 69.42 71.43 76.06 FL 91.54 78.12 81.98 68.33 72.13 72.16 77.37 ICL 90.53 83.41 76.29 72.21 74.87 68.59 77.65 训练集3 CE 88.57 79.44 74.67 71.62 73.51 66.94 75.79 FL 91.05 82.56 76.26 69.50 76.38 69.48 77.53 ICL 93.37 84.50 79.18 75.43 78.86 72.86 80.70 训练集4 CE 86.72 79.98 83.43 74.34 73.29 65.74 77.25 FL 84.07 82.40 77.53 77.07 75.82 68.09 77.49 ICL 83.46 84.98 79.25 77.33 79.48 71.38 79.31
下载: 导出CSV
-
[1] XING Yuexiu, HU Aiqun, ZHANG Junqing, et al. Design of a robust radio-frequency fingerprint identification scheme for multimode LFM radar[J]. IEEE Internet of Things Journal, 2020, 7(10): 10581–10593. doi: 10.1109/JIOT.2020.3003692 [2] SANKHE K, BELGIOVINE M, ZHOU Fan, et al. No radio left behind: Radio fingerprinting through deep learning of physical-layer hardware impairments[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(1): 165–178. doi: 10.1109/TCCN.2019.2949308 [3] POLAK A C, DOLATSHAHI S, and GOECKEL D L. Identifying wireless users via transmitter imperfections[J]. IEEE Journal on Selected Areas in Communications, 2011, 29(7): 1469–1479. doi: 10.1109/JSAC.2011.110812 [4] SUN Jinlong, SHI Wenjuan, YANG Zhutian, et al. Behavioral modeling and linearization of wideband RF power amplifiers using BiLSTM networks for 5G wireless systems[J]. IEEE Transactions on Vehicular Technology, 2019, 68(11): 10348–10356. doi: 10.1109/TVT.2019.2925562 [5] 潘一苇, 杨司韩, 彭华, 等. 基于矢量图的特定辐射源识别方法[J]. 电子与信息学报, 2020, 42(4): 941–949. doi: 10.11999/JEIT190329PAN Yiwei, YANG Sihan, PENG Hua, et al. Specific emitter identification using signal trajectory image[J]. Journal of Electronics &Information Technology, 2020, 42(4): 941–949. doi: 10.11999/JEIT190329 [6] DIGNE F, BAUSSARD A, KHENCHAF A, et al. Classification of radar pulses in a naval warfare context using Bézier curve modeling of the instantaneous frequency law[J]. IEEE Transactions on Aerospace and Electronic Systems, 2017, 53(3): 1469–1480. doi: 10.1109/TAES.2017.2671578 [7] GUO Shanzeng, AKHTAR S, and MELLA A. A method for radar model identification using time-domain transient signals[J]. IEEE Transactions on Aerospace and Electronic Systems, 2021, 57(5): 3132–3149. doi: 10.1109/TAES.2021.3074129 [8] URETEN O and SERINKEN N. Bayesian detection of Wi-Fi transmitter RF fingerprints[J]. Electronics Letters, 2005, 41(6): 373–374. doi: 10.1049/el:20057769 [9] GONG Jialiang, XU Xiaodong, and LEI Yingke. Unsupervised specific emitter identification method using radio-frequency fingerprint embedded InfoGAN[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 2898–2913. doi: 10.1109/TIFS.2020.2978620 [10] YAO Yanyan, YU Lu, and CHEN Yiming. Specific emitter identification based on square integral bispectrum features[C]. 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 2020: 1311–1314. [11] ZHANG Jingwen, WANG Fanggang, DOBRE O A, et al. Specific emitter identification via Hilbert-Huang transform in single-hop and relaying scenarios[J]. IEEE Transactions on Information Forensics and Security, 2016, 11(6): 1192–1205. doi: 10.1109/TIFS.2016.2520908 [12] YUAN Yingjun, HUANG Zhitao, WU Hao, et al. Specific emitter identification based on Hilbert-Huang transform-based time-frequency-energy distribution features[J]. IET Communications, 2014, 8(13): 2404–2412. doi: 10.1049/iet-com.2013.0865 [13] PAN Yiwei, YANG Sihan, PENG Hua, et al. Specific emitter identification based on deep residual networks[J]. IEEE Access, 2019, 7: 54425–54434. doi: 10.1109/ACCESS.2019.2913759 [14] 秦鑫, 黄洁, 王建涛, 等. 基于无意调相特性的雷达辐射源个体识别[J]. 通信学报, 2020, 41(5): 104–111. doi: 10.11959/j.issn.1000-436x.2020084QIN Xin, HUANG Jie, WANG Jiantao, et al. Radar emitter identification based on unintentional phase modulation on pulse characteristic[J]. Journal on Communications, 2020, 41(5): 104–111. doi: 10.11959/j.issn.1000-436x.2020084 [15] SATIJA U, TRIVEDI N, BISWAL G, et al. Specific emitter identification based on variational mode decomposition and spectral features in single hop and relaying scenarios[J]. IEEE Transactions on Information Forensics and Security, 2018, 14(3): 581–591. doi: 10.1109/TIFS.2018.2855665 [16] SA Kejin, LANG Dapeng, WANG Chenggang, et al. Specific emitter identification techniques for the internet of things[J]. IEEE Access, 2020, 8: 1644–1652. doi: 10.1109/ACCESS.2019.2962626 [17] MERCHANT K, REVAY S, STANTCHEV G, et al. Deep learning for RF device fingerprinting in cognitive communication networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2018, 12(1): 160–167. doi: 10.1109/JSTSP.2018.2796446 [18] QIAN Yunhan, QI Jie, KUAI Xiaoyan, et al. Specific emitter identification based on multi-level sparse representation in automatic identification system[J]. IEEE Transactions on Information Forensics and Security, 2021, 16: 2872–2884. doi: 10.1109/TIFS.2021.3068010 [19] WU Qingyang, FERES C, KUZMENKO D, et al. Deep learning based RF fingerprinting for device identification and wireless security[J]. Electronics Letters, 2018, 54(24): 1405–1407. doi: 10.1049/el.2018.6404 [20] WANG Xuebao, HUANG Gaoming, MA Congshan, et al. Convolutional neural network applied to specific emitter identification based on pulse waveform images[J]. IET Radar, Sonar & Navigation, 2020, 14(5): 728–735. doi: 10.1049/iet-rsn.2019.0456 [21] 何遵文, 侯帅, 张万成, 等. 通信特定辐射源识别的多特征融合分类方法[J]. 通信学报, 2021, 42(2): 103–112. doi: 10.11959/j.issn.1000-436x.2021028HE Zunwen, HOU Shuai, ZHANG Wancheng, et al. Multi-feature fusion classification method for communication specific emitter identification[J]. Journal on Communications, 2021, 42(2): 103–112. doi: 10.11959/j.issn.1000-436x.2021028 [22] ZHOU Huaji, JIAO Licheng, ZHENG Shilian, et al. Generative adversarial network-based electromagnetic signal classification: A semi-supervised learning framework[J]. China Communications, 2020, 17(10): 157–169. doi: 10.23919/JCC.2020.10.011 [23] ABDI L and HASHEMI S. To combat multi-class imbalanced problems by means of over-sampling techniques[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(1): 238–251. doi: 10.1109/TKDE.2015.2458858 [24] BUNKHUMPORNPAT C, SINAPIROMSARAN K, and LURSINSAP C. DBSMOTE: Density-based synthetic minority over-sampling technique[J]. Applied Intelligence, 2012, 36(3): 664–684. doi: 10.1007/s10489-011-0287-y [25] KANG Qi, CHEN Xiaoshuang, LI Sisi, et al. A noise-filtered under-sampling scheme for imbalanced classification[J]. IEEE Transactions on Cybernetics, 2017, 47(12): 4263–4274. doi: 10.1109/TCYB.2016.2606104 [26] HOU Yun, LI Li, LI Bailin, et al. An anti-noise ensemble algorithm for imbalance classification[J]. Intelligent Data Analysis, 2019, 23(6): 1205–1217. doi: 10.3233/IDA-184354 [27] KRAWCZYK B, WOŹNIAK M, and SCHAEFER G. Cost-sensitive decision tree ensembles for effective imbalanced classification[J]. Applied Soft Computing, 2014, 14: 554–562. doi: 10.1016/j.asoc.2013.08.014 [28] DUAN Wei, JING Liang, and LU Xiangyang. Imbalanced data classification using cost-sensitive support vector machine based on information entropy[J]. Advanced Materials Research, 2014, 989/994: 1756–1761. doi: 10.4028/www.scientific.net/AMR.989-994.1756 [29] ZHANG Zhongliang, LUO Xinggang, GARCÍA S, et al. Cost-sensitive back-propagation neural networks with binarization techniques in addressing multi-class problems and non-competent classifiers[J]. Applied Soft Computing, 2017, 56: 357–367. doi: 10.1016/j.asoc.2017.03.016 [30] DHAR S and CHERKASSKY V. Development and evaluation of cost-sensitive universum-SVM[J]. IEEE Transactions on Cybernetics, 2015, 45(4): 806–818. doi: 10.1109/TCYB.2014.2336876 [31] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]. The 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 2672–2680. [32] RADFORD A, METZ L, and CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. arXiv: 1511.06434[cs.LG], 2015. https://arxiv.org/abs/1511.06434. [33] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [34] ZHANG Linbin, ZHANG Caiguang, QUAN Sinong, et al. A class imbalance loss for imbalanced object recognition[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 2778–2792. doi: 10.1109/JSTARS.2020.2995703 [35] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318–327. doi: 10.1109/TPAMI.2018.2858826 [36] KHAN S H, HAYAT M, BENNAMOUN M, et al. Cost-sensitive learning of deep feature representations from imbalanced data[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(8): 3573–3587. doi: 10.1109/TNNLS.2017.2732482 -





计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

