
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Through-wall Human Pose Reconstruction and Action Recognition Using Four-dimensional Imaging Radar
-
摘要: 隔墙人体姿态重建和行为识别在智能安防和虚拟现实等领域具有广泛应用前景。然而,现有隔墙人体感知方法通常忽视了对4D时空特征的建模以及墙体对信号的影响,针对这些问题,该文创新性地提出了一种基于4D成像雷达的隔墙人体感知新架构。首先,基于时空分离的分步策略,该文设计了ST2W-AP时空融合网络,解决了由于主流深度学习库缺少4D卷积而无法充分利用多帧3D体素时空域信息的问题,实现了保留3D空域信息的同时利用长序时域信息,大幅提升姿态估计任务和行为识别任务的性能。此外,为抑制墙体对信号的干扰,该文利用深度学习强大的拟合性能和并行输出的特点设计了深度回波域补偿器,降低了传统墙体补偿方法的计算开销。大量的实验结果表明,相比于现有最佳方法,ST2W-AP将平均关节位置误差降低了33.57%,并且将行为识别的F1分数提高了0.51%。Abstract: Through-wall human pose reconstruction and behavior recognition have enormous potential in fields like intelligent security and virtual reality. However, existing methods for through-wall human sensing often fail to adequately model four-Dimensional (4D) spatiotemporal features and overlook the influence of walls on signal quality. To address these issues, this study proposes an innovative architecture for through-wall human sensing using a 4D imaging radar. The core of this approach is the ST2W-AP fusion network, which is designed using a stepwise spatiotemporal separation strategy. This network overcomes the limitations of mainstream deep learning libraries that currently lack 4D convolution capabilities, which hinders the effective use of multiframe three-Dimensional (3D) voxel spatiotemporal domain information. By preserving 3D spatial information and using long-sequence temporal information, the proposed ST2W-AP network considerably enhances the pose estimation and behavior recognition performance. Additionally, to address the influence of walls on signal quality, this paper introduces a deep echo domain compensator that leverages the powerful fitting performance and parallel output characteristics of deep learning, thereby reducing the computational overhead of traditional wall compensation methods. Extensive experimental results demonstrate that compared with the best existing methods, the ST2W-AP network reduces the average joint position error by 33.57% and improves the F1 score for behavior recognition by 0.51%.
-
Key words:
- Through-wall /
- Human pose estimation /
- Activity recognition /
- RF sensing /
- Deep learning
-
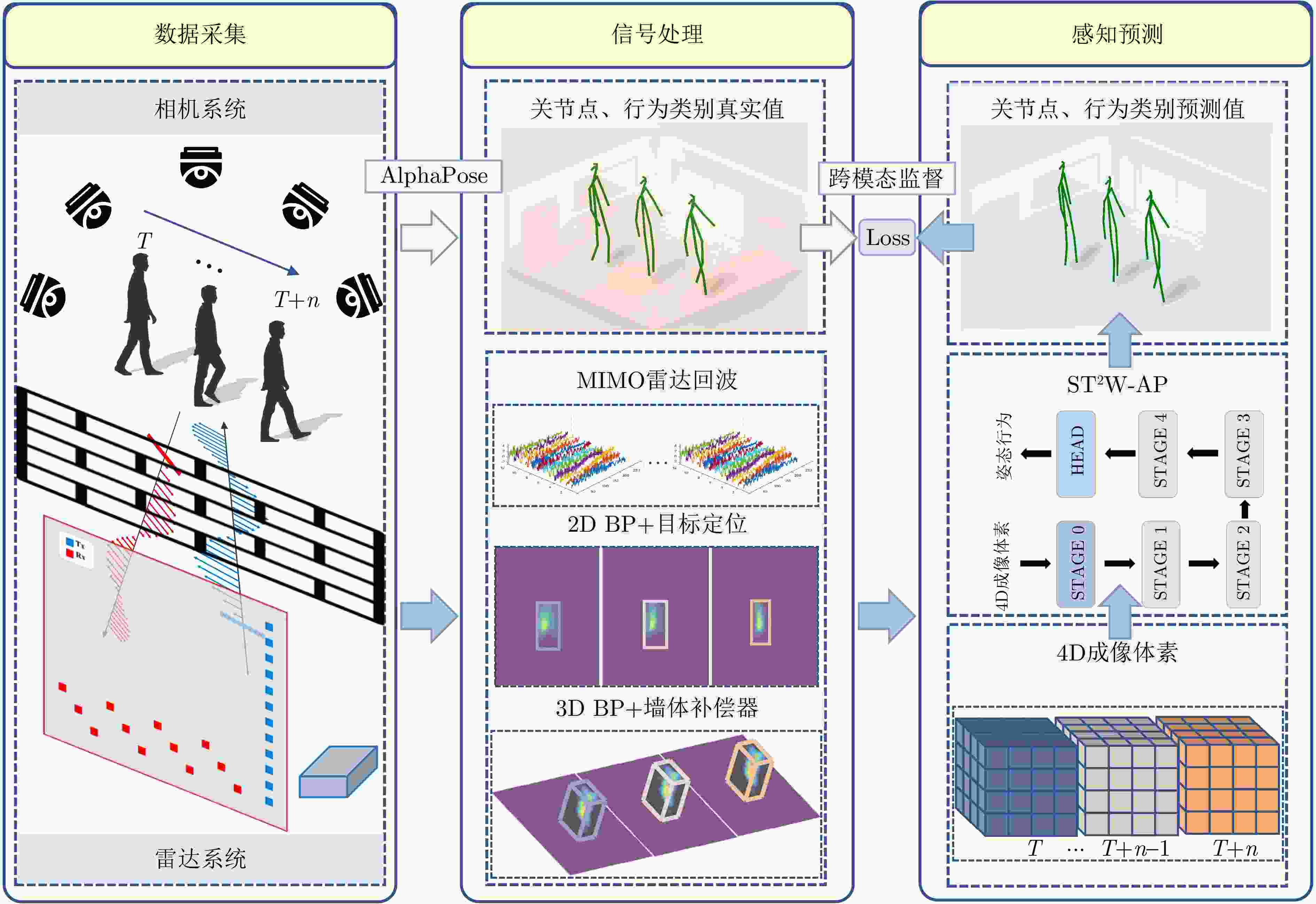
图 1 穿墙姿态估计和行为识别框架流程
Figure 1. Pipeline of the proposed through-wall pose estimation and activity recognition framework
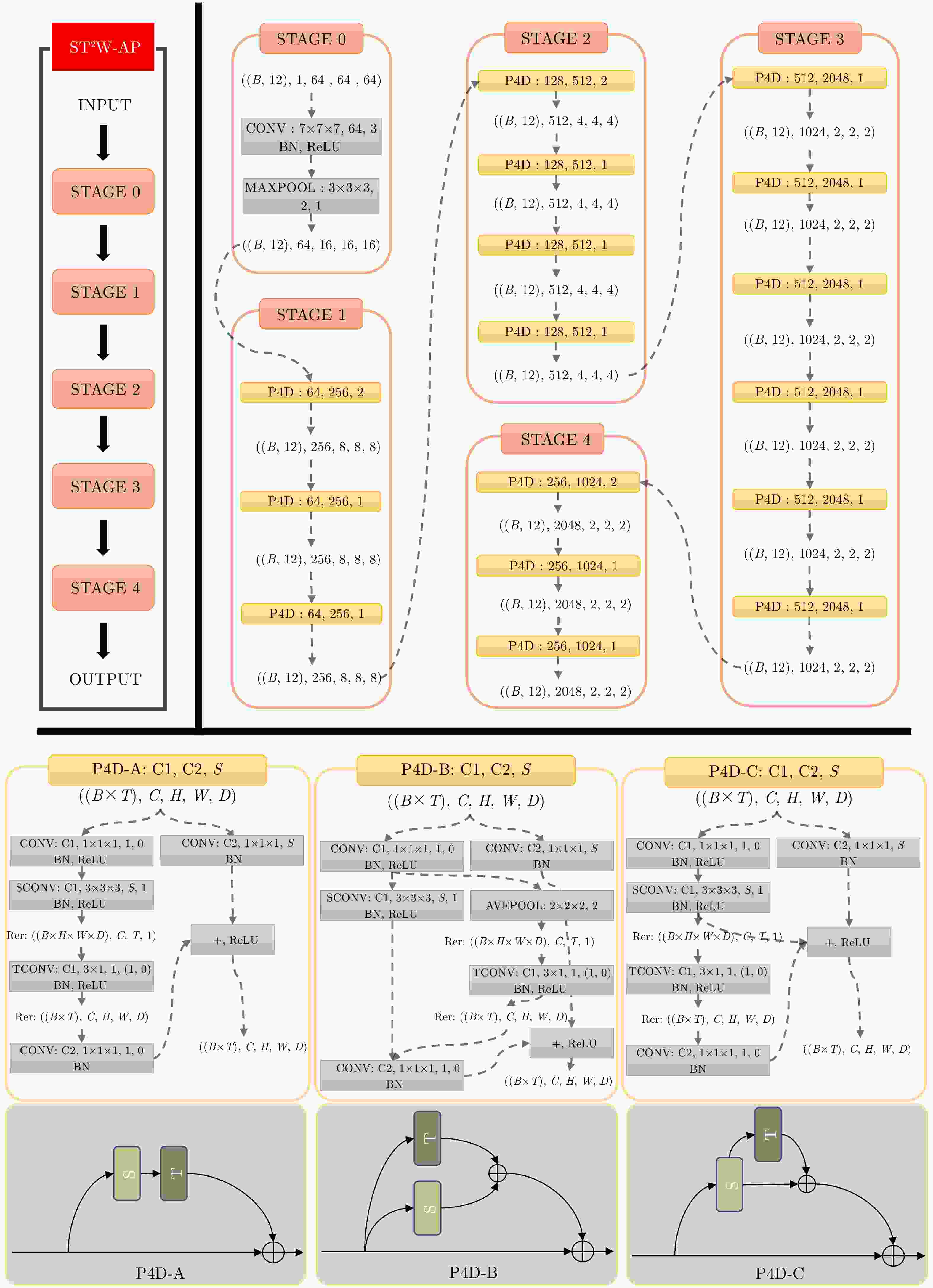
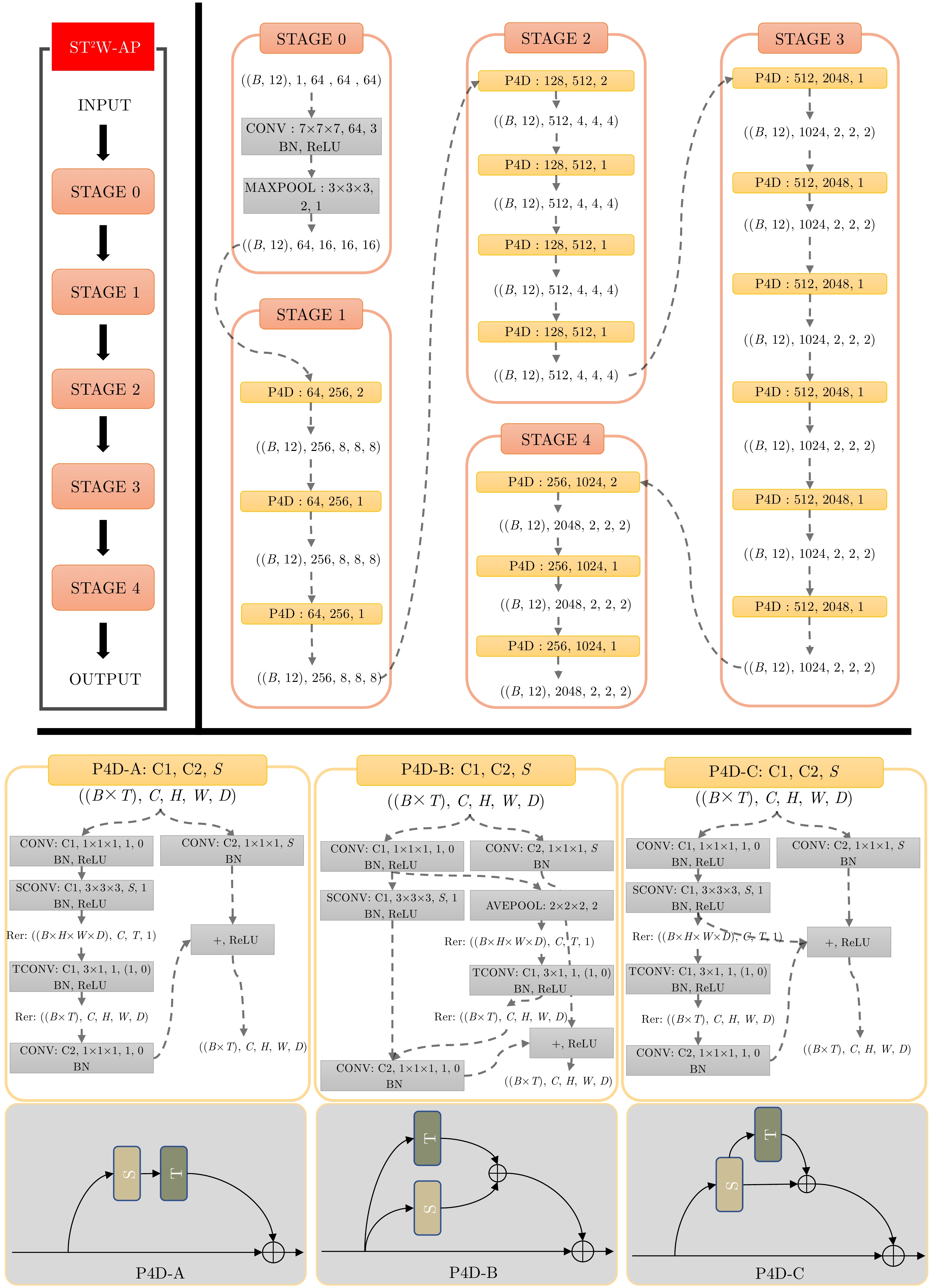
图 5 网络结构图及P4D模块的3种设计(B为批大小,T为时域序列长度,C为输入通道数,H为高度,W为宽度,以及D为深度。C1, C2为卷积输入通道,S为步长)
Figure 5. Network structure diagram and three designs of the pseudo P4D module (B represents the batch size, T denotes the length of the temporal sequence, C indicates the number of input channels, H stands for height, W denotes width, and D represents depth. C1 and C2 represent the input channels for the convolution, while S denotes the stride)
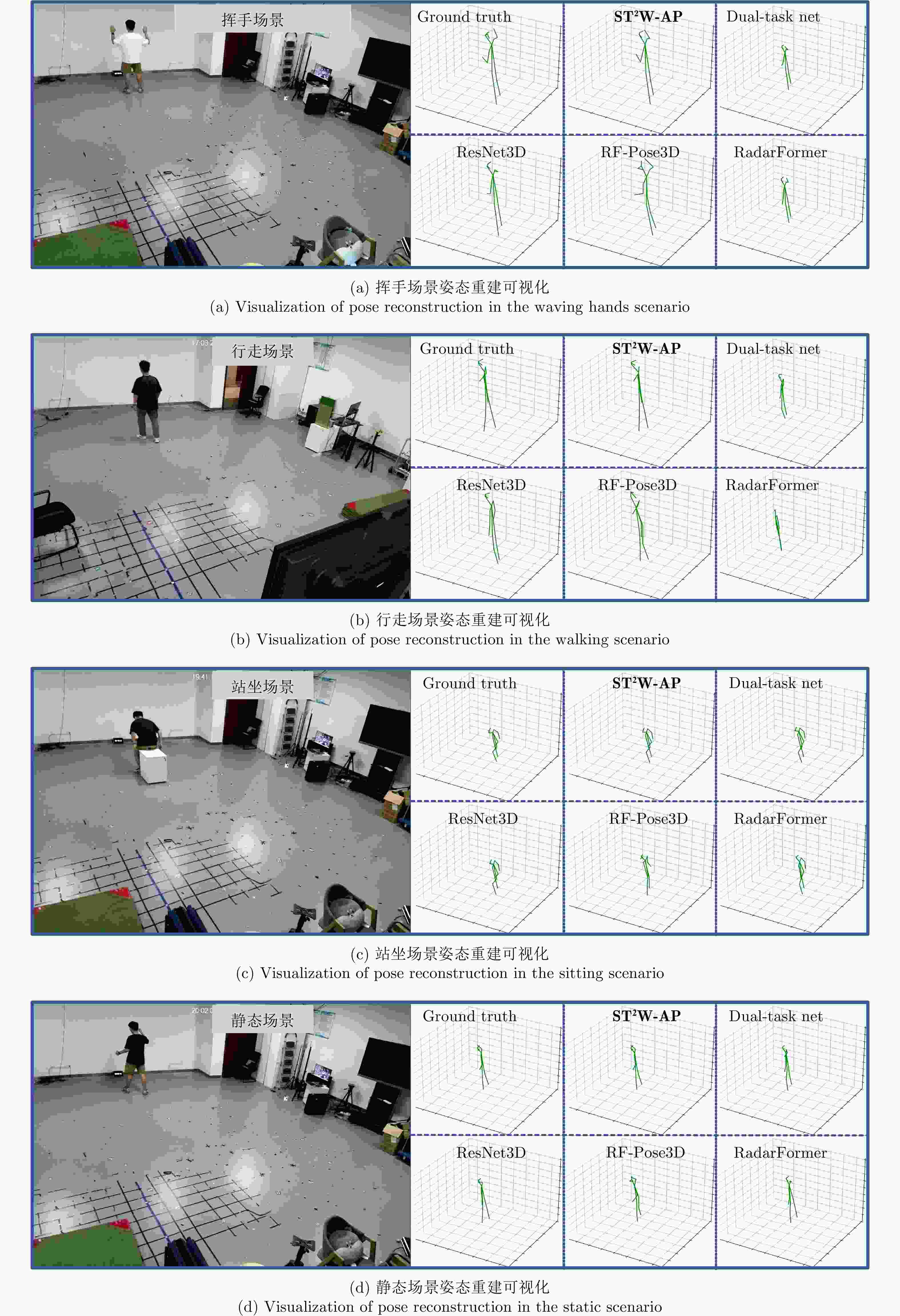
图 7 不同场景姿态重建可视化
Figure 7. Visualization of pose reconstruction across different scenarios
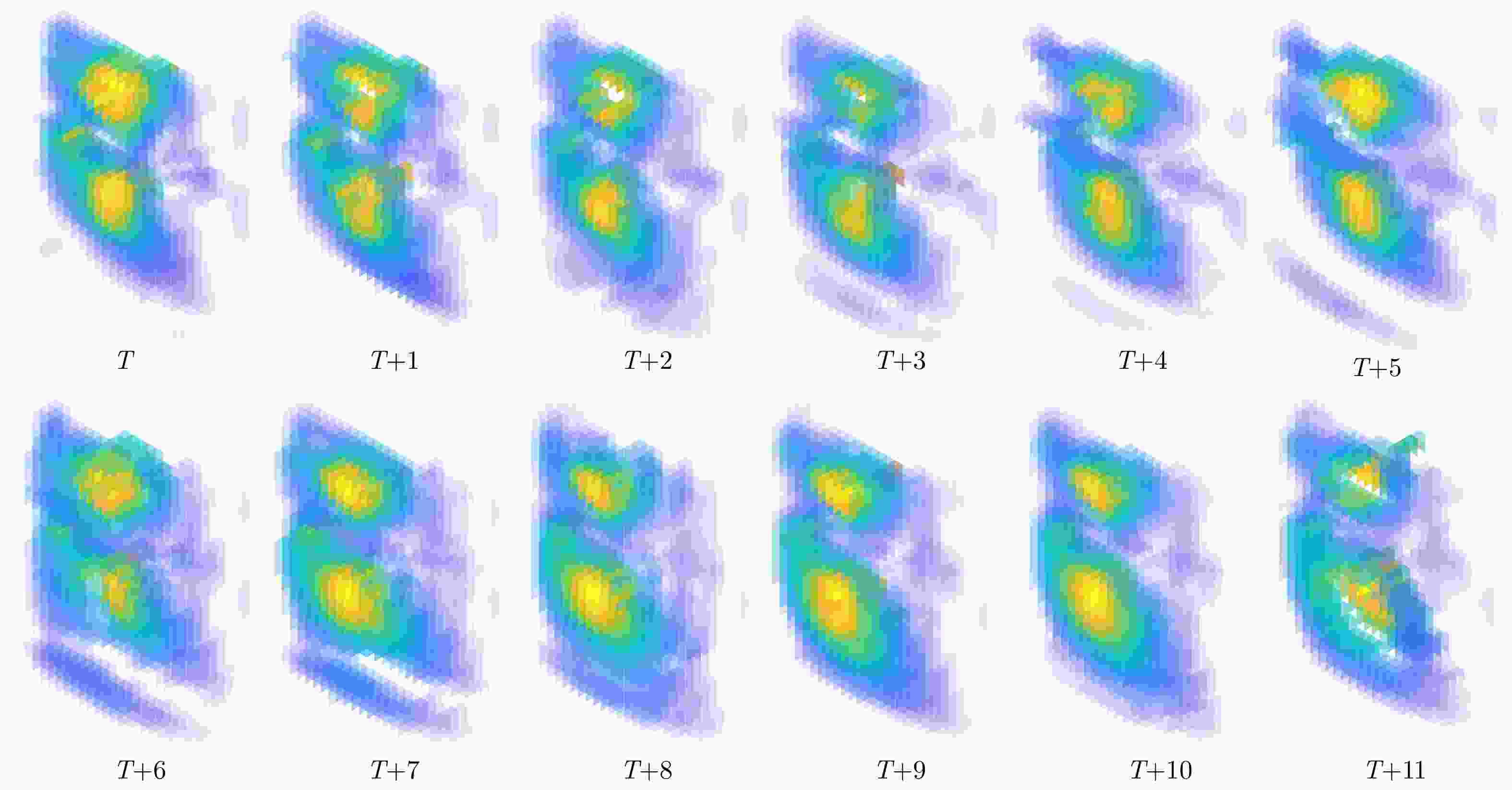
图 8 时间序列长度为12帧的4D成像结果
Figure 8. 4D imaging results with a time series length of 12 frames
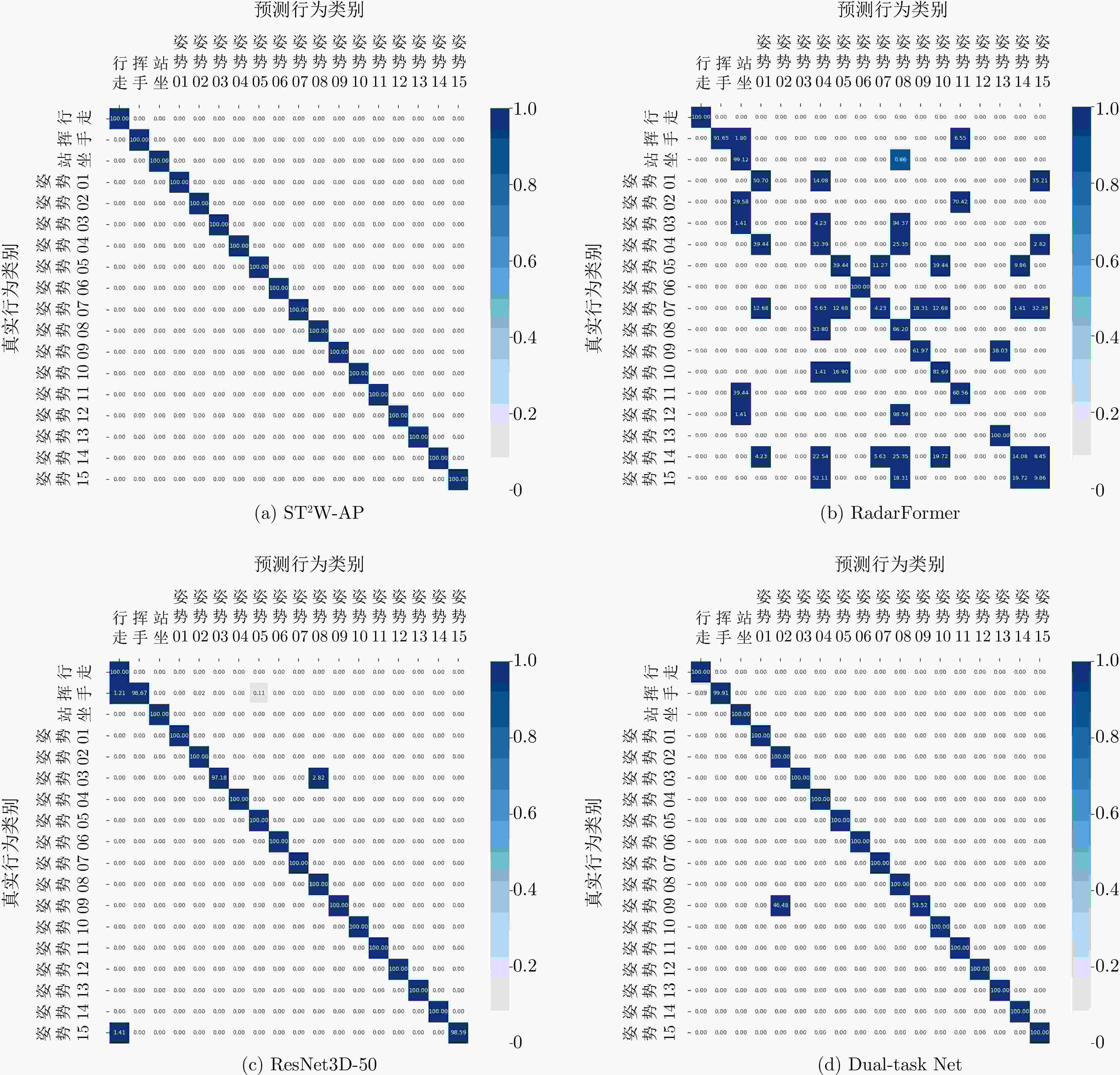
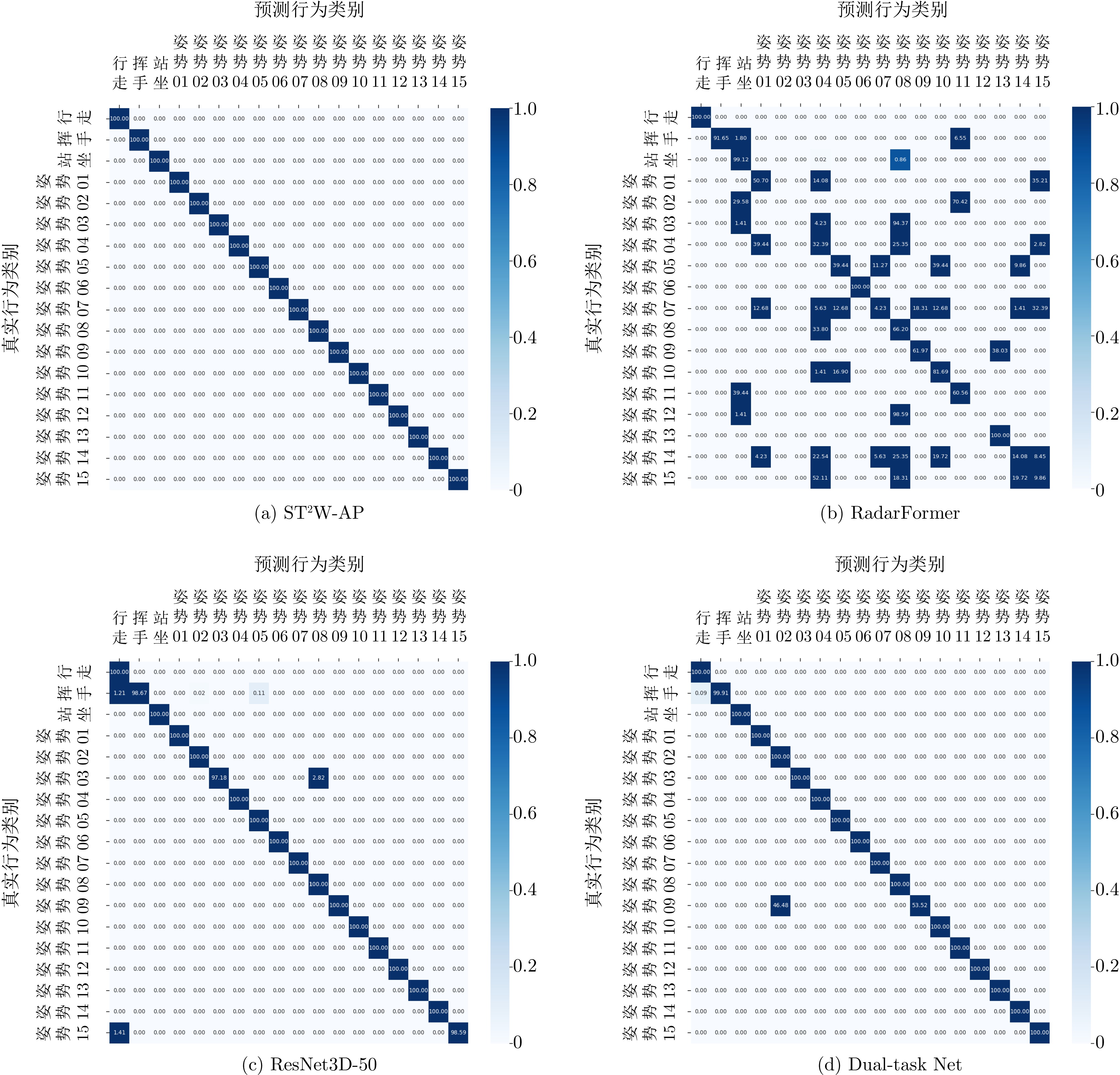
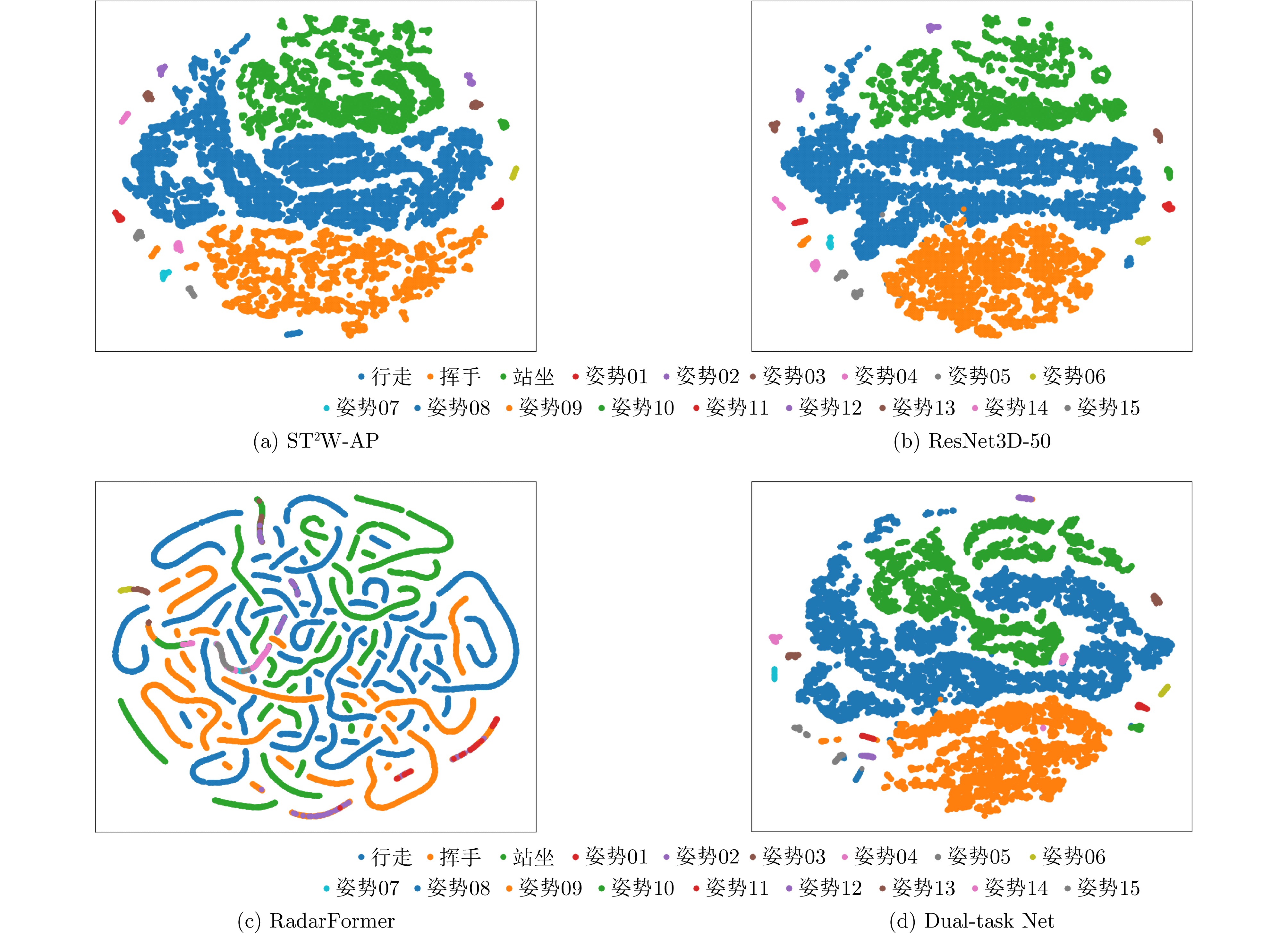
图 9 不同方法在行为识别任务的混淆矩阵
Figure 9. Confusion matrices for activity recognition task across different methods
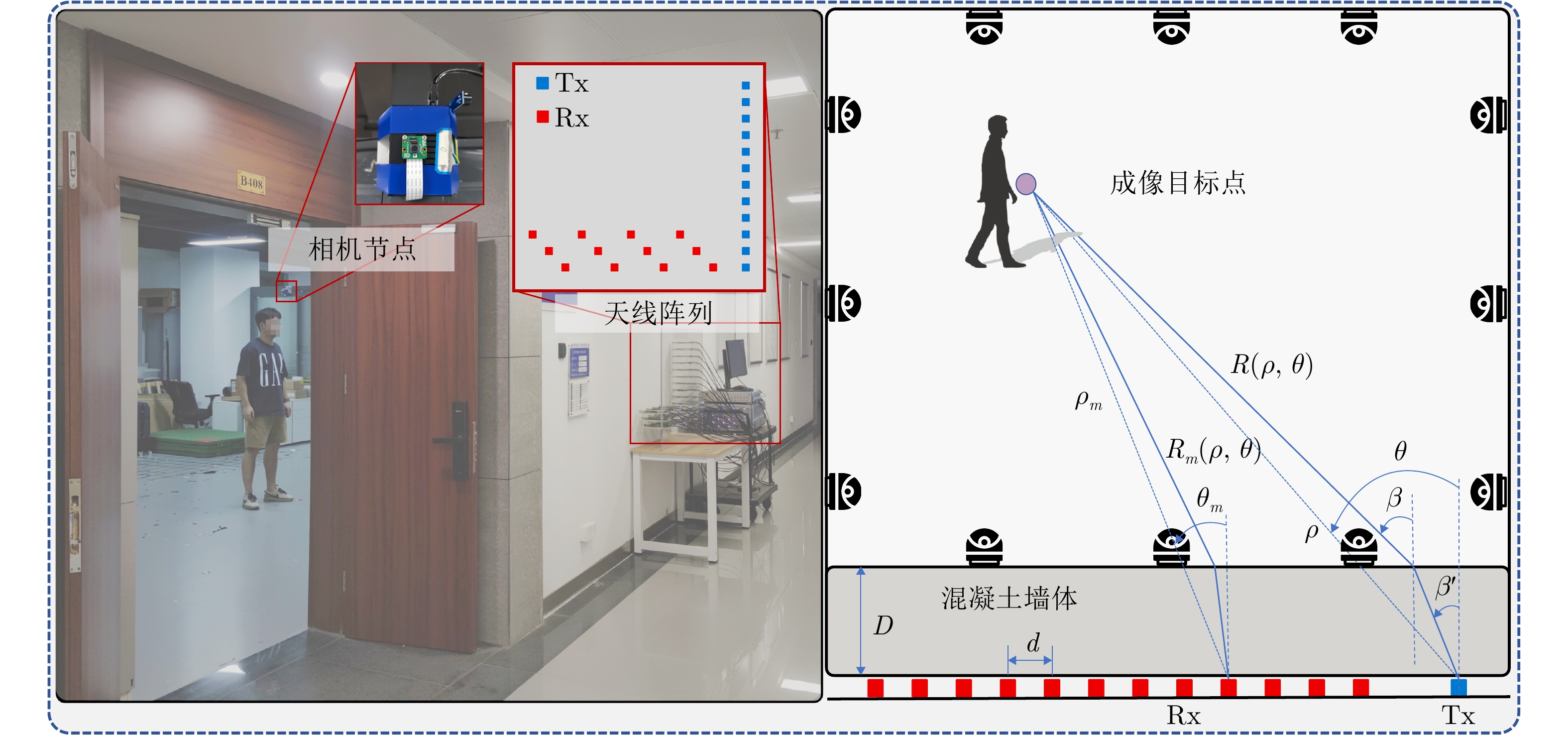
表 1 雷达系统参数
Table 1. Key parameters of radar system
参数 数值 中心频率 1.8 GHz 带宽 2.0 GHz 频点 201 帧率 12 帧/s 发射天线阵列长度 59.4 cm 接收天线阵列长度 59.4 cm  下载: 导出CSV
下载: 导出CSV
表 2 人体关节点重建误差定量评估结果(mm)
Table 2. Quantitative evaluation results of human body joint reconstruction error (mm)
方法 鼻子 脖子 肩膀 手肘 手腕 臀部 膝盖 脚踝 眼睛 耳朵 平均值 RF-Pose3D[22] 98.57 51.52 73.07 88.70 98.32 76.76 65.32 91.08 85.06 71.67 80.55 ResNet3D-50[39] 82.42 65.55 71.58 86.61 118.98 64.83 68.72 79.26 84.41 74.02 80.27 Dual-task Net[27] 136.09 104.37 109.49 129.81 175.06 100.37 98.50 113.55 126.68 117.09 121.20 RadarFormer[28] 367.52 318.65 328.37 360.11 418.66 313.13 302.99 294.66 359.07 338.58 339.85 ST2W-AP 56.39 44.93 47.26 55.41 71.16 44.74 47.68 53.79 58.86 50.34 53.32
下载: 导出CSV
表 3 不同场景关节点重建误差定量评估结果(mm)
Table 3. Quantitative evaluation results of joint reconstruction error in different scenarios (mm)
下载: 导出CSV
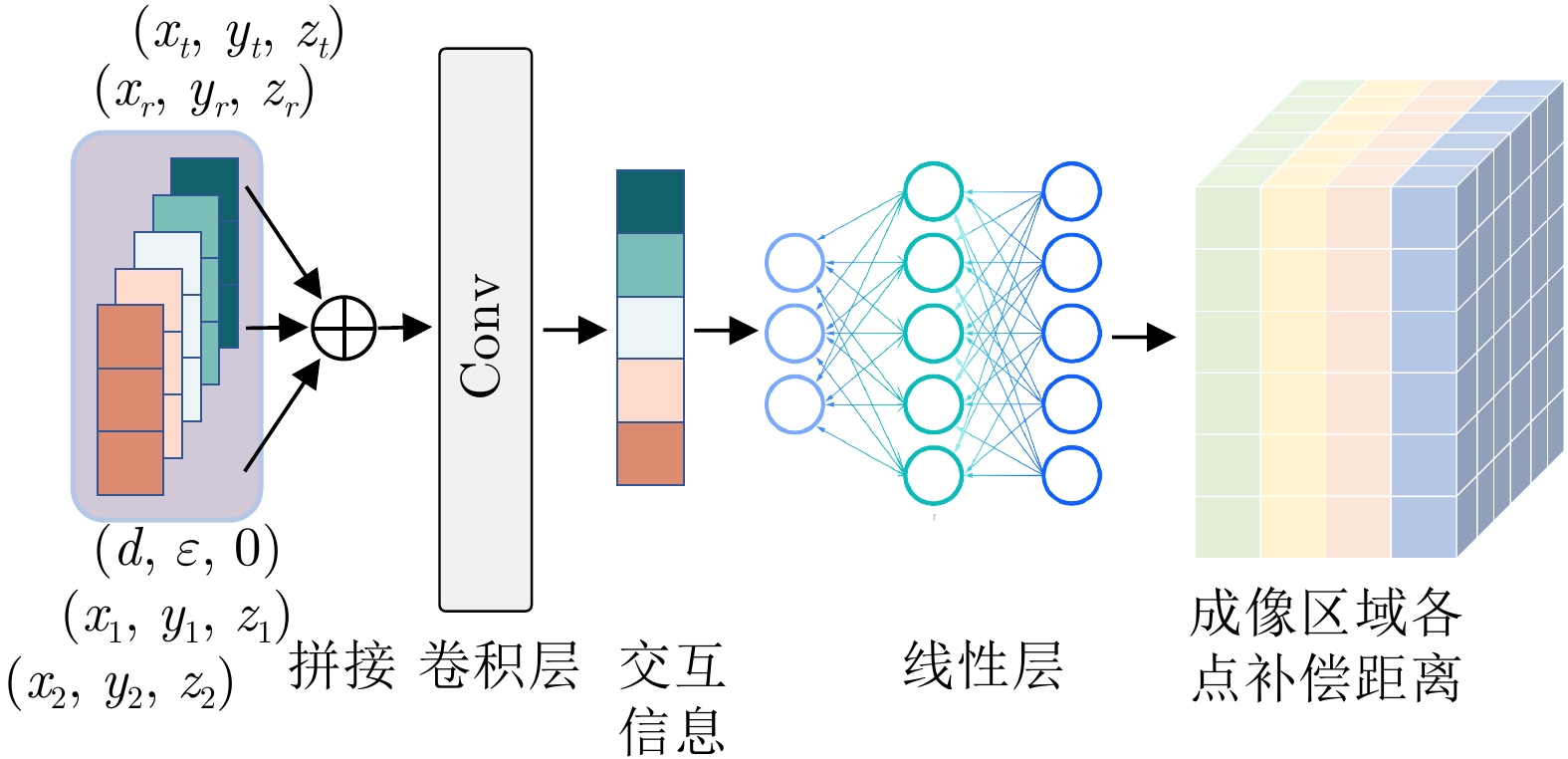
表 5 选择路径1下的补偿器RMSPE相对误差分布
Table 5. Distribution of compensator accuracy under selection path 1
折次 12 24 30 40 60 120 无补偿 第1折 0.00427 0.00476 0.00422 0.00399 0.00302 0.00235 0.01399 第2折 0.00405 0.00385 0.00238 0.00211 0.00158 0.00127 0.01382 第3折 0.00373 0.00362 0.00210 0.00194 0.00225 0.00124 0.01363 第4折 0.00332 0.00290 0.00183 0.00181 0.00218 0.00125 0.01335 第5折 0.00370 0.00332 0.00224 0.00180 0.00161 0.00151 0.01315 第6折 0.00473 0.00398 0.00342 0.00344 0.00258 0.00225 0.01294 平均 0.00397 0.00374 0.00270 0.00252 0.00220 0.00165 0.01348
下载: 导出CSV
表 6 选择路径2下的补偿器RMSPE相对误差分布
Table 6. Distribution of compensator accuracy under selection path 2
折次 12 24 30 40 60 120 无补偿 第1折 0.00455 0.00492 0.00273 0.00315 0.00267 0.00201 0.01413 第2折 0.00386 0.00492 0.00241 0.00225 0.00260 0.00149 0.01378 第3折 0.00370 0.00305 0.00202 0.00283 0.00155 0.00130 0.01352 第4折 0.00336 0.00347 0.00192 0.00209 0.00236 0.00137 0.01348 第5折 0.00365 0.00333 0.00336 0.00349 0.00273 0.00188 0.01312 第6折 0.00479 0.00507 0.00292 0.00312 0.00293 0.00215 0.01284 平均 0.00399 0.00413 0.00256 0.00282 0.00247 0.00170 0.01348
下载: 导出CSV
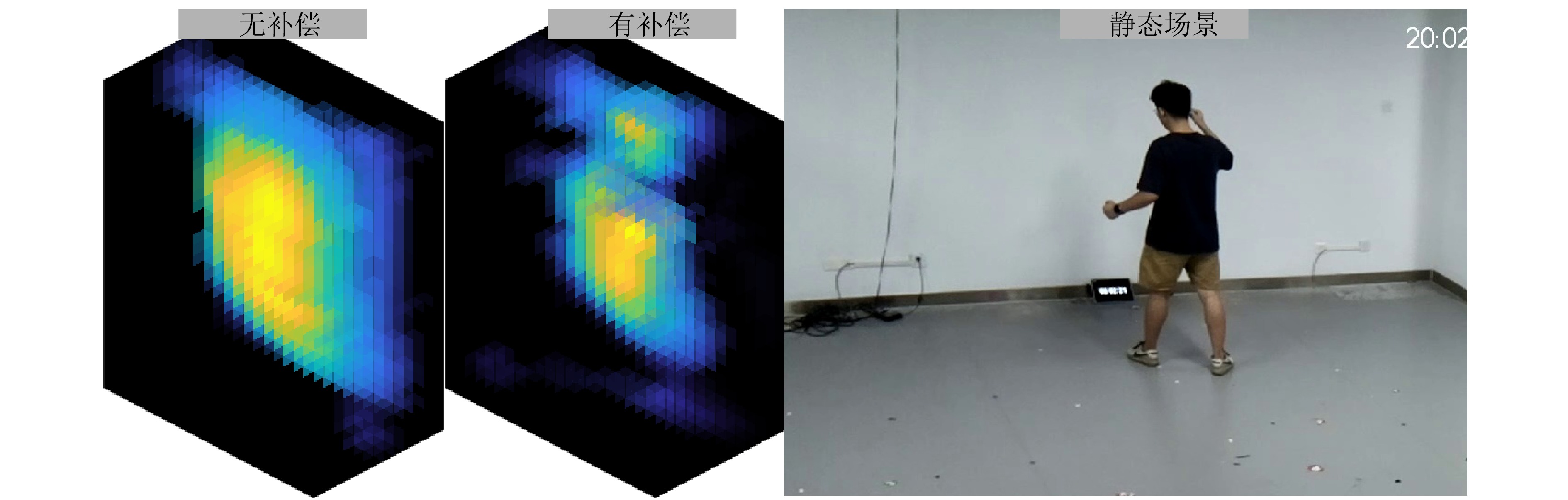
表 7 计算时间开销对比
Table 7. Comparison of time overheads
墙体补偿方法 推理时间(s) 传统补偿方法[29] 15914.359 深度回波域补偿器 9.066
下载: 导出CSV
表 8 自由空间行为识别和姿态重建定量评估结果
Table 8. Quantitative evaluation results of free-space behavior recognition and pose estimation
指标 数值 准确率
召回率
精确率
F1分数
MPJPE (mm)0.9990 0.9997 0.9831 0.9905
42.68
下载: 导出CSV
表 9 行为识别和姿态重建定量评估结果
Table 9. Quantitative evaluation results of behavior recognition and pose estimation
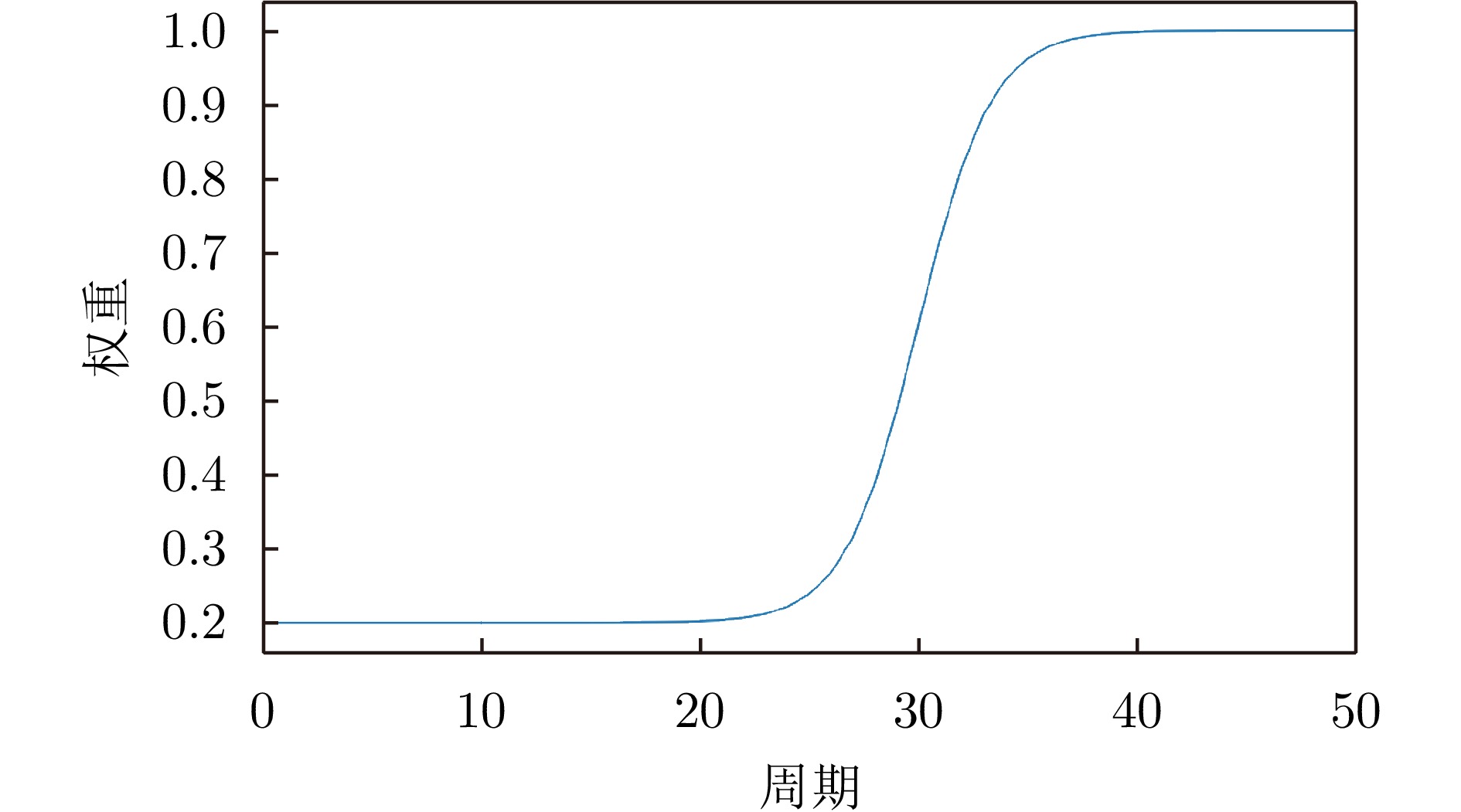
方法 准确率 召回率 精确率 F1分数 MPJPE (mm) ST2W-AP-PA 1.0000 1.0000 1.0000 1.0000 53.32 ST2W-AP-PB 1.0000 1.0000 1.0000 1.0000 54.36 ST2W-AP-PC 1.0000 1.0000 1.0000 1.0000 55.49 ST2W-AP18 0.9973 0.9994 0.9917 0.9952 155.30 ST2W-AP101 1.0000 1.0000 1.0000 1.0000 53.29 ST2W-AP-50 w/o com 0.8952 0.7863 0.9004 0.8370 192.14 ST2W-AP-50 w/o dw 0.9998 1.0000 1.0000 1.0000 54.46 注:w/o com 表示去除墙体补偿,w/o dw表示去除动态权重调整策略。
下载: 导出CSV
-
[1] 杨小鹏, 高炜程, 渠晓东. 基于微多普勒角点特征与Non-Local机制的穿墙雷达人体步态异常终止行为辨识技术[J]. 雷达学报(中英文), 2024, 13(1): 68–86. doi: 10.12000/JR23181.YANG Xiaopeng, GAO Weicheng, and QU Xiaodong. Human anomalous gait termination recognition via through-the-wall radar based on micro-Doppler corner features and Non-Local mechanism[J]. Journal of Radars, 2024, 13(1): 68–86. doi: 10.12000/JR23181. [2] 金添, 宋勇平, 崔国龙, 等. 低频电磁波建筑物内部结构透视技术研究进展[J]. 雷达学报, 2020, 10(3): 342–359. doi: 10.12000/JR20119.JIN Tian, SONG Yongping, CUI Guolong, et al. Advances on penetrating imaging of building layout technique using low frequency radio waves[J]. Journal of Radars, 2021, 10(3): 342–359. doi: 10.12000/JR20119. [3] 崔国龙, 余显祥, 魏文强, 等. 认知智能雷达抗干扰技术综述与展望[J]. 雷达学报, 2022, 11(6): 974–1002. doi: 10.12000/JR22191.CUI Guolong, YU Xianxiang, WEI Wenqiang, et al. An overview of antijamming methods and future works on cognitive intelligent radar[J]. Journal of Radars, 2022, 11(6): 974–1002. doi: 10.12000/JR22191. [4] 夏正欢, 张群英, 叶盛波, 等. 一种便携式伪随机编码超宽带人体感知雷达设计[J]. 雷达学报, 2015, 4(5): 527–537. doi: 10.12000/JR15027.XIA Zhenghuan, ZHANG Qunying, YE Shengbo, et al. Design of a handheld pseudo random coded UWB radar for human sensing[J]. Journal of Radars, 2015, 4(5): 527–537. doi: 10.12000/JR15027. [5] 金添, 宋勇平. 超宽带雷达建筑物结构稀疏成像[J]. 雷达学报, 2018, 7(3): 275–284. doi: 10.12000/JR18031.JIN Tian and SONG Yongping. Sparse imaging of building layouts in ultra-wideband radar[J]. Journal of Radars, 2018, 7(3): 275–284. doi: 10.12000/JR18031. [6] 丁一鹏, 厍彦龙. 穿墙雷达人体动作识别技术的研究现状与展望[J]. 电子与信息学报, 2022, 44(4): 1156–1175. doi: 10.11999/JEIT211051.DING Yipeng and SHE Yanlong. Research status and prospect of human movement recognition technique using through-wall radar[J]. Journal of Electronics & Information Technology, 2022, 44(4): 1156–1175. doi: 10.11999/JEIT211051. [7] 刘天亮, 谯庆伟, 万俊伟, 等. 融合空间-时间双网络流和视觉注意的人体行为识别[J]. 电子与信息学报, 2018, 40(10): 2395–2401. doi: 10.11999/JEIT171116.LIU Tianliang, QIAO Qingwei, WAN Junwei, et al. Human action recognition via spatio-temporal dual network flow and visual attention fusion[J]. Journal of Electronics & Information Technology, 2018, 40(10): 2395–2401. doi: 10.11999/JEIT171116. [8] MOHAN R and VALADA A. EfficientPS: Efficient panoptic segmentation[J]. International Journal of Computer Vision, 2021, 129(5): 1551–1579. doi: 10.1007/s11263-021-01445-z. [9] LAZAROW J, LEE K, SHI Kunyu, et al. Learning instance occlusion for panoptic segmentation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10717–10726. doi: 10.1109/CVPR42600.2020.01073. [10] ZHANG Dongheng, HU Yang, and CHEN Yan. MTrack: Tracking multiperson moving trajectories and vital signs with radio signals[J]. IEEE Internet of Things Journal, 2021, 8(5): 3904–3914. doi: 10.1109/JIOT.2020.3025820. [11] LI Yadong, ZHANG Dongheng, CHEN Jinbo, et al. Towards domain-independent and real-time gesture recognition using mmWave signal[J]. IEEE Transactions on Mobile Computing, 2023, 22(12): 7355–7369. doi: 10.1109/TMC.2022.3207570. [12] ZHANG Binbin, ZHANG Dongheng, LI Yadong, et al. Unsupervised domain adaptation for RF-based gesture recognition[J]. IEEE Internet of Things Journal, 2023, 10(23): 21026–21038. doi: 10.1109/JIOT.2023.3284496. [13] SONG Ruiyuan, ZHANG Dongheng, WU Zhi, et al. RF-URL: Unsupervised representation learning for RF sensing[C]. The 28th Annual International Conference on Mobile Computing and Networking, Sydney, Australia, 2022: 282–295. doi: 10.1145/3495243.3560529. [14] GONG Hanqin, ZHANG Dongheng, CHEN Jinbo, et al. Enabling orientation-free mmwave-based vital sign sensing with multi-domain signal analysis[C]. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of, 2024: 8751–8755. doi: 10.1109/ICASSP48485.2024.10448323. [15] XIE Chunyang, ZHANG Dongheng, WU Zhi, et al. RPM 2.0: RF-based pose machines for multi-person 3D pose estimation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024, 34(1): 490–503. doi: 10.1109/TCSVT.2023.3287329. [16] YANG Shuai, ZHANG Dongheng, SONG Ruiyuan, et al. Multiple WiFi access points co-localization through joint AoA estimation[J]. IEEE Transactions on Mobile Computing, 2024, 23(2): 1488–1502. doi: 10.1109/TMC.2023.3239377. [17] WU Zhi, ZHANG Dongheng, XIE Chunyang, et al. RFMask: A simple baseline for human silhouette segmentation with radio signals[J]. IEEE Transactions on Multimedia, 2023, 25: 4730–4741. doi: 10.1109/TMM.2022.3181455. [18] GENG Ruixu, HU Yang, LU Zhi, et al. Passive non-line-of-sight imaging using optimal transport[J]. IEEE Transactions on Image Processing, 2022, 31: 110–124. doi: 10.1109/TIP.2021.3128312. [19] XIE Chunyang, ZHANG Dongheng, WU Zhi, et al. RPM: RF-based pose machines[J]. IEEE Transactions on Multimedia, 2024, 26: 637–649. doi: 10.1109/TMM.2023.3268376. [20] YU Cong, ZHANG Dongheng, WU Zhi, et al. MobiRFPose: Portable RF-based 3D human pose camera[J]. IEEE Transactions on Multimedia, 2024, 26: 3715–3727. doi: 10.1109/TMM.2023.3314979. [21] ZHAO Mingmin, LI Tianhong, ABU ALSHEIKH M, et al. Through-wall human pose estimation using radio signals[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7356–7365. doi: 10.1109/CVPR.2018.00768. [22] ZHAO Mingmin, TIAN Yonglong, ZHAO Hang, et al. RF-based 3D skeletons[C]. The 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 2018: 267–281. doi: 10.1145/3230543.3230579. [23] YU Cong, ZHANG Dongheng, WU Zhi, et al. Fast 3D human pose estimation using RF signals[C]. ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 2023: 1–5. doi: 10.1109/ICASSP49357.2023.10094778. [24] JIANG Wenjun, XUE Hongfei, MIAO Chenglin, et al. Towards 3D human pose construction using wifi[C]. The 26th Annual International Conference on Mobile Computing and Networking, London, UK, 2020: 23. doi: 10.1145/3372224.3380900. [25] ZHENG Zhijie, PAN Jun, NI Zhikang, et al. Recovering human pose and shape from through-the-wall radar images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5112015. doi: 10.1109/TGRS.2022.3162333. [26] ZHENG Zhijie, PAN Jun, ZHANG Diankun, et al. Through-wall human pose estimation by mutual information maximizing deeply supervised nets[J]. IEEE Internet of Things Journal, 2024, 11(2): 3190–3205. doi: 10.1109/JIOT.2023.3294955. [27] SONG Yongkun, DAI Yongpeng, JIN Tian, et al. Dual-task human activity sensing for pose reconstruction and action recognition using 4-D imaging radar[J]. IEEE Sensors Journal, 2023, 23(19): 23927–23940. doi: 10.1109/JSEN.2023.3308788. [28] ZHENG Zhijie, ZHANG Diankun, LIANG Xiao, et al. RadarFormer: End-to-end human perception with through-wall radar and transformers[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 35(10): 4319–4332. doi: 10.1109/TNNLS.2023.3314031. [29] AHMAD F, AMIN M G, and KASSAM S A. Synthetic aperture beamformer for imaging through a dielectric wall[J]. IEEE Transactions on Aerospace and Electronic Systems, 2005, 41(1): 271–283. doi: 10.1109/TAES.2005.1413761. [30] ZHANG Zhengyou. A flexible new technique for camera calibration[J]. IEEE Transactions on pattern analysis and machine intelligence, 2000, 22(11): 1330–1334. doi: 10.1109/34.888718. [31] FANG Haoshu, LI Jiefeng, TANG Hongyang, et al. AlphaPose: Whole-body regional multi-person pose estimation and tracking in real-time[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7157–7173. doi: 10.1109/TPAMI.2022.3222784. [32] HE Ying, ZHANG Dongheng, and CHEN Yan. 3D radio imaging under low-rank constraint[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(8): 3833–3847. doi: 10.1109/TCSVT.2023.3239683. [33] 刘剑刚. 穿墙雷达隐蔽目标成像跟踪方法研究[D]. [博士学位论文], 电子科技大学, 2017.LIU Jiangang. Imaging-tracking technology for hidden targets of a through-the-wall radar[D]. [Ph.D. dissertation], University of Electronic Science and Technology of China, 2017. [34] AHMAD F, ZHANG Yimin, and AMIN M G. Three-dimensional wideband beamforming for imaging through a single wall[J]. IEEE Geoscience and Remote Sensing Letters, 2008, 5(2): 176–179. doi: 10.1109/LGRS.2008.915742. [35] CYBENKO G. Approximation by superpositions of a sigmoidal function[J]. Mathematics of Control, Signals and Systems, 1989, 2(4): 303–314. doi: 10.1007/BF02551274. [36] KARNIADAKIS G E, KEVREKIDIS I G, LU Lu, et al. Physics-informed machine learning[J]. Nature Reviews Physics, 2021, 3(6): 422–440. doi: 10.1038/s42254-021-00314-5. [37] ADIB F, HSU C Y, MAO Hongzi, et al. Capturing the human figure through a wall[J]. ACM Transactions on Graphics (TOG), 2015, 34(6): 219. doi: 10.1145/2816795.2818072. [38] QIU Zhaofan, YAO Ting, and MEI Tao. Learning spatio-temporal representation with pseudo-3D residual networks[C]. The IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5534–5542. doi: 10.1109/ICCV.2017.590. [39] HARA K, KATAOKA H, and SATOH Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet?[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 6546–6555. doi: 10.1109/CVPR.2018.00685. [40] KATAOKA H, HARA K, HAYASHI R, et al. Spatiotemporal initialization for 3D CNNs with generated motion patterns[C]. The IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2022: 737–746. doi: 10.1109/WACV51458.2022.00081. [41] JI Shuiwang, XU Wei, YANG Ming, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(1): 221–231. doi: 10.1109/TPAMI.2012.59. [42] IONESCU C, PAPAVA D, OLARU V, et al. Human3. 6M: Large scale datasets and predictive methods for 3D human sensing in natural environments[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 36(7): 1325–1339. doi: 10.1109/TPAMI.2013.248. [43] VAN DER MAATEN L and HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(86): 2579–2605. -




计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

