
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Wi-Fi-based Indoor Human Pose Estimation Using a Pyramid Dilated Convolutional Residual Network
-
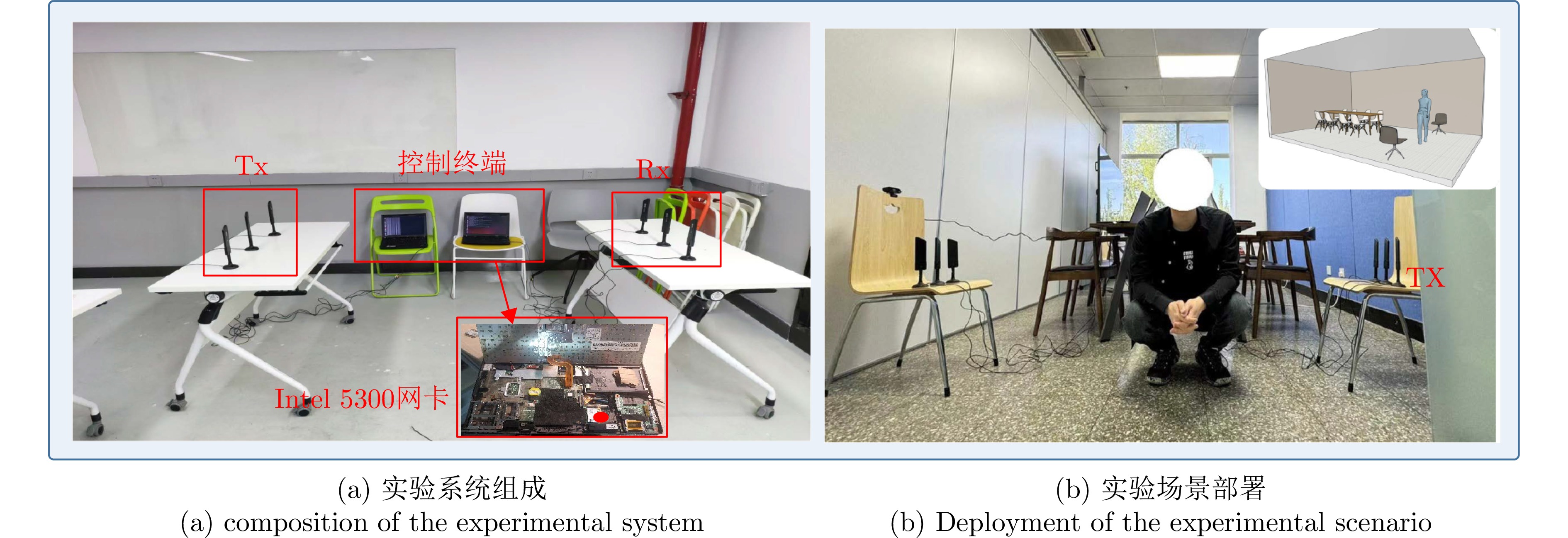
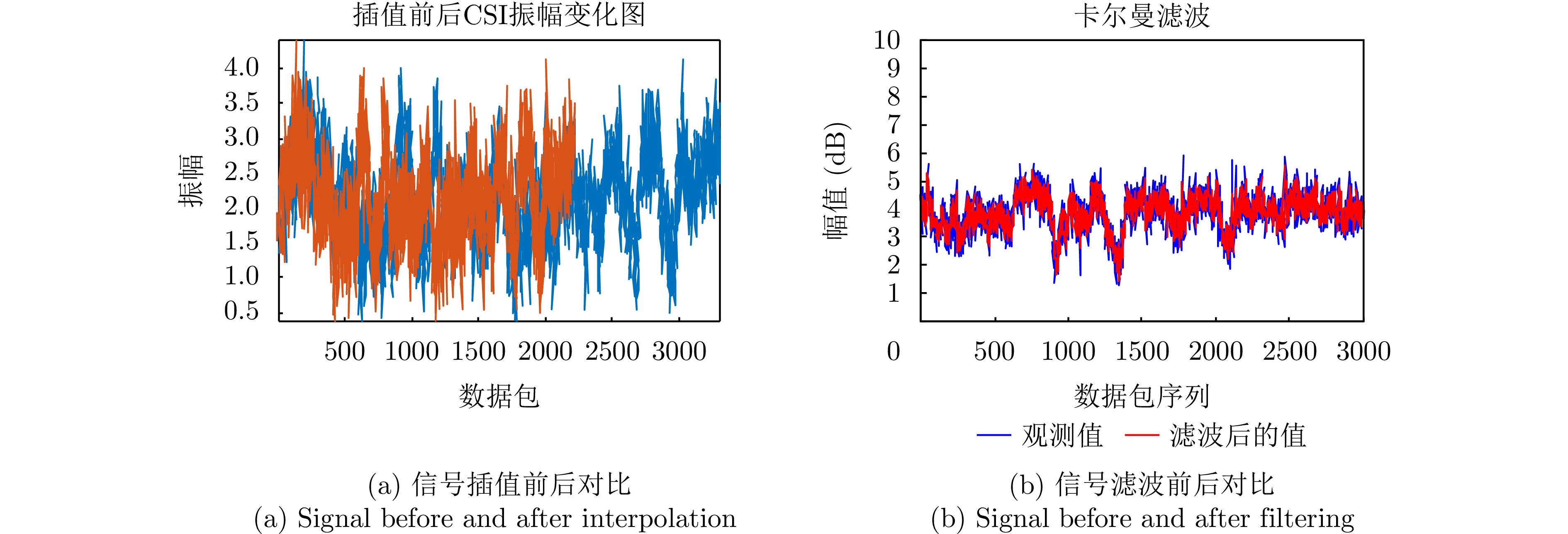
摘要: 人体姿态估计技术能支撑准确获取人体动作与行为特征,在智能监测、人机交互及健康感知等领域展现出广泛的应用潜力。Wi-Fi感知技术因其普遍性、低成本、非接触感知等优势,成为当前人体姿态非接触式感知技术的研究热点。然而,人体活动具有多尺度、非线性及动态变化复杂等特征,不同肢体部位在时间、空间上运动幅度存在显著差异,对姿态估计算法的多尺度特征建模能力提出了更高要求。现有Wi-Fi人体姿态估计算法普遍存在模型参数量大、特征提取不充分的问题,难以在保证计算效率的同时兼顾估计精度,从而限制了其在复杂场景下的应用潜力。针对上述问题,该文设计并优化了一种基于金字塔型空洞卷积的残差网络架构。针对多尺度人体运动特征设计了金字塔型空洞卷积结构单元,该结构能够在保持空间分辨率的同时显著扩大卷积层的感受野,从而有效捕捉多尺度空间与动态变化信息。同时,空洞卷积结构设计能够在一定程度上减少计算量,提升计算效率。为缓解深层网络训练中的梯度消失与模型退化问题,该文进一步设计了残差结构网络,确保模型在深层结构下的特征表达能力与稳定性。为了验证所提方法的有效性,论文设计搭建了完整的多源数据采集系统,可高效获取Wi-Fi姿态估计数据与对应真值数据。实验结果表明,所提方法在人体姿态估计任务中表现优异,MPCK@0.10 指标达到94.96%,优于现有算法,验证了方法的有效性与优越性。Abstract: Human pose estimation allows for precise capture of movement and behavioral traits, holding significant potential for applications such as intelligent surveillance, human-computer interaction, and health monitoring. Among emerging approaches, Wi-Fi sensing has gained increasing research interest for contactless human pose detection because of its widespread availability, affordability, and privacy-preserving qualities. However, human activities are multiscale, nonlinear, and highly dynamic, with notable spatiotemporal variations in motion amplitude across different body parts. These characteristics pose high demands on the ability of algorithms to model multiscale features effectively. Current Wi-Fi-based techniques often struggle with excessive parameter complexity and limited feature extraction, which makes it hard to balance computational speed with accuracy in complex situations. To address these issues, this paper introduces a pyramid dilated convolution block that expands the receptive field while maintaining spatial resolution, making it possible to capture multiscale spatial and dynamic details efficiently. The dilated design also lessens computational redundancy, improving overall efficiency. Building on this, a residual network is designed to prevent gradient vanishing and model degradation, ensuring solid feature representation in deep networks. To test the proposed method, a comprehensive multisource data system was built to synchronize Wi-Fi pose data with ground-truth labels. Experimental results show the proposed approach’s superiority, reaching a mean percentage of correct keypoints (MPCK@0.10) of 94.96%, surpassing current leading algorithms. These results confirm the method’s effectiveness for reliable and efficient human pose estimation.
-

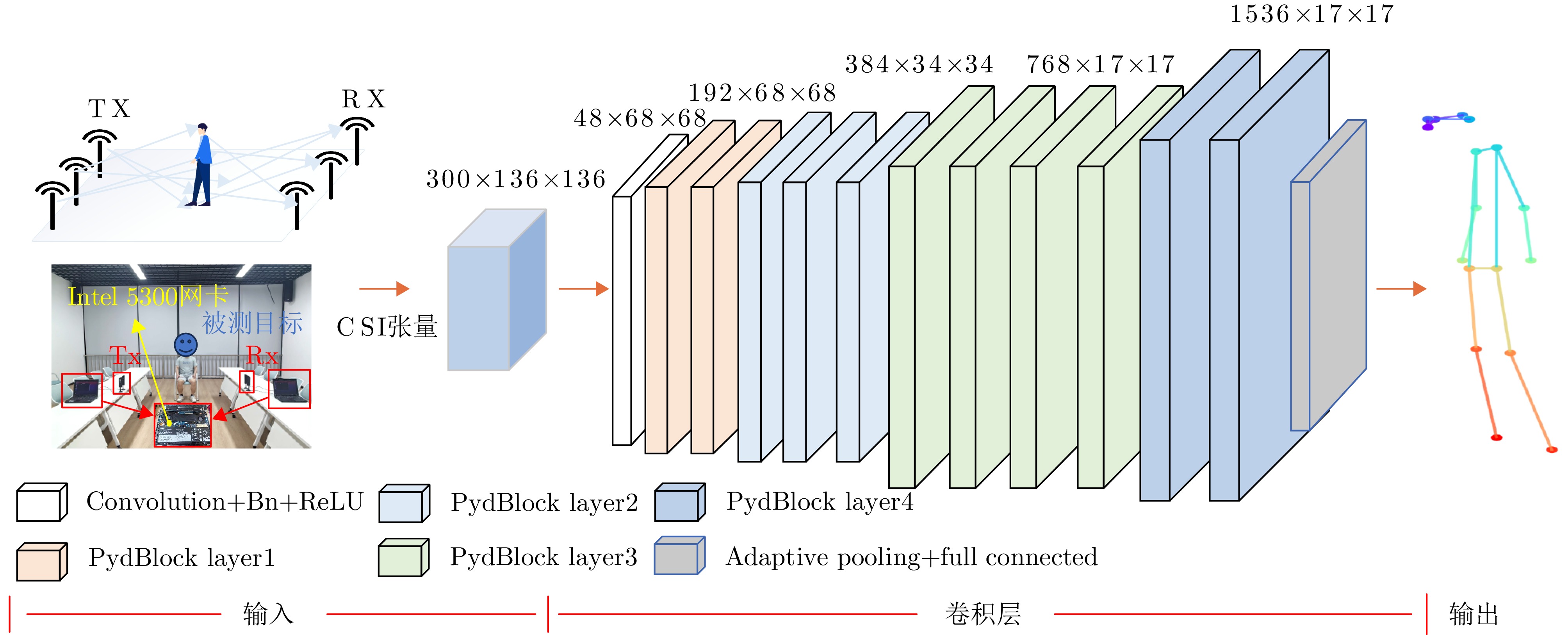
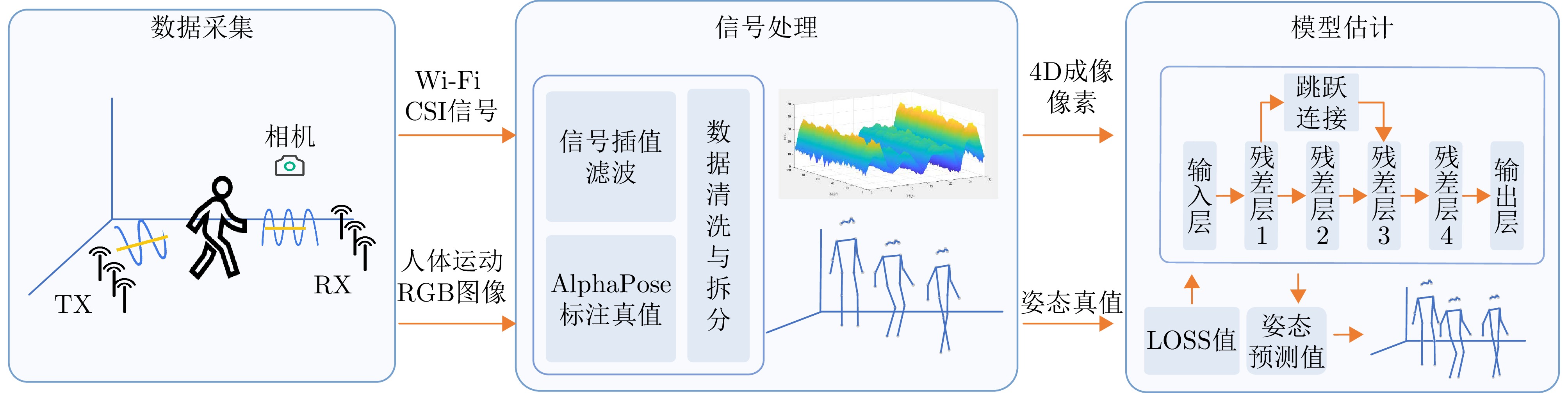
图 1 Wi-Fi人体姿态估计框架
Figure 1. Framework of the proposed Wi-Fi-based human pose estimation method
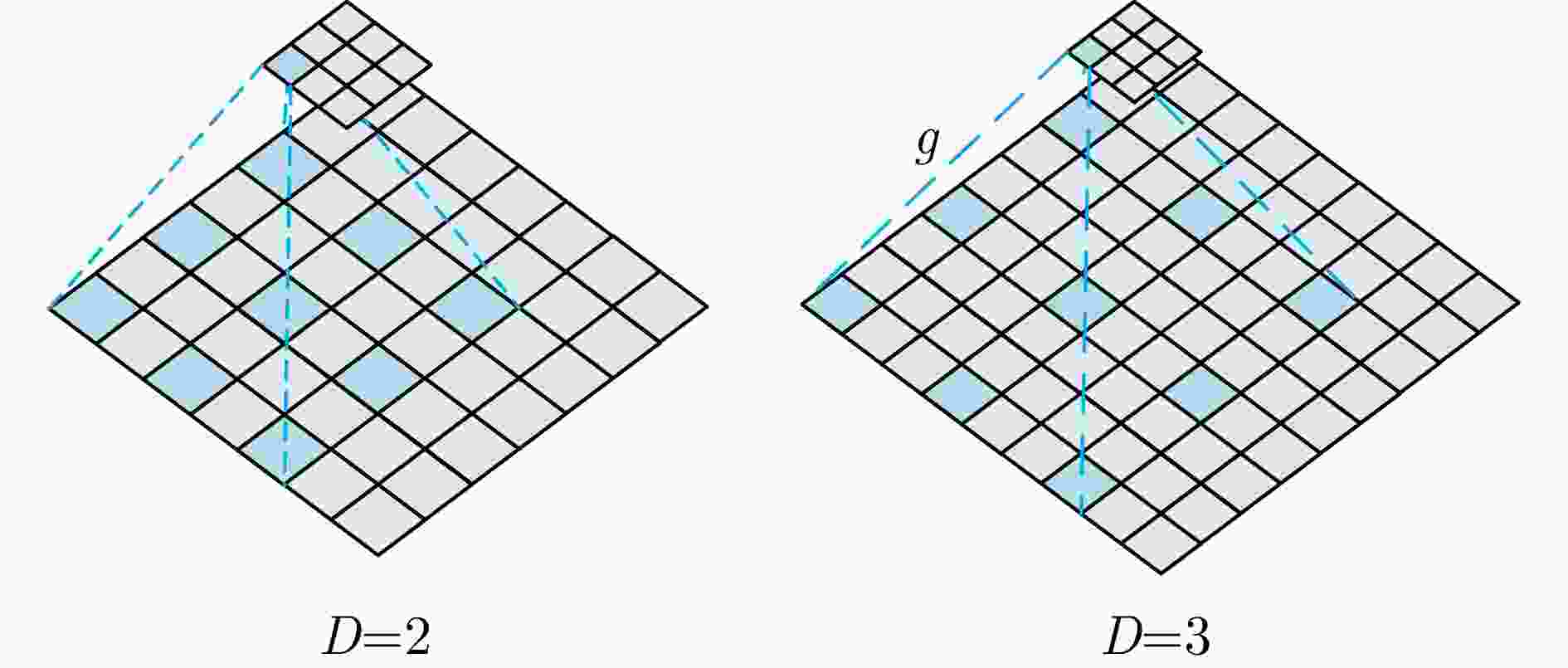
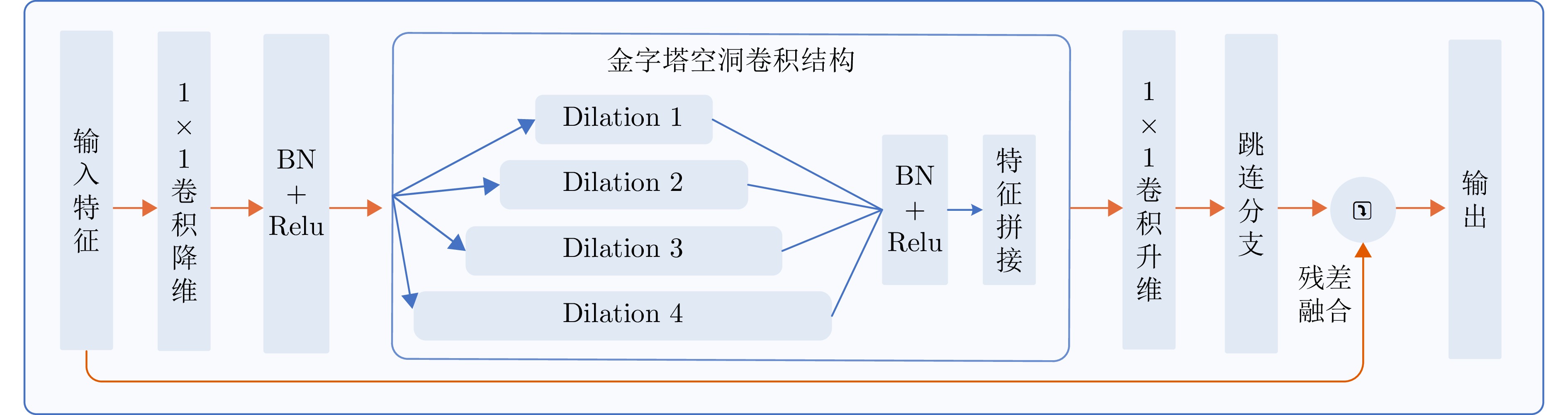
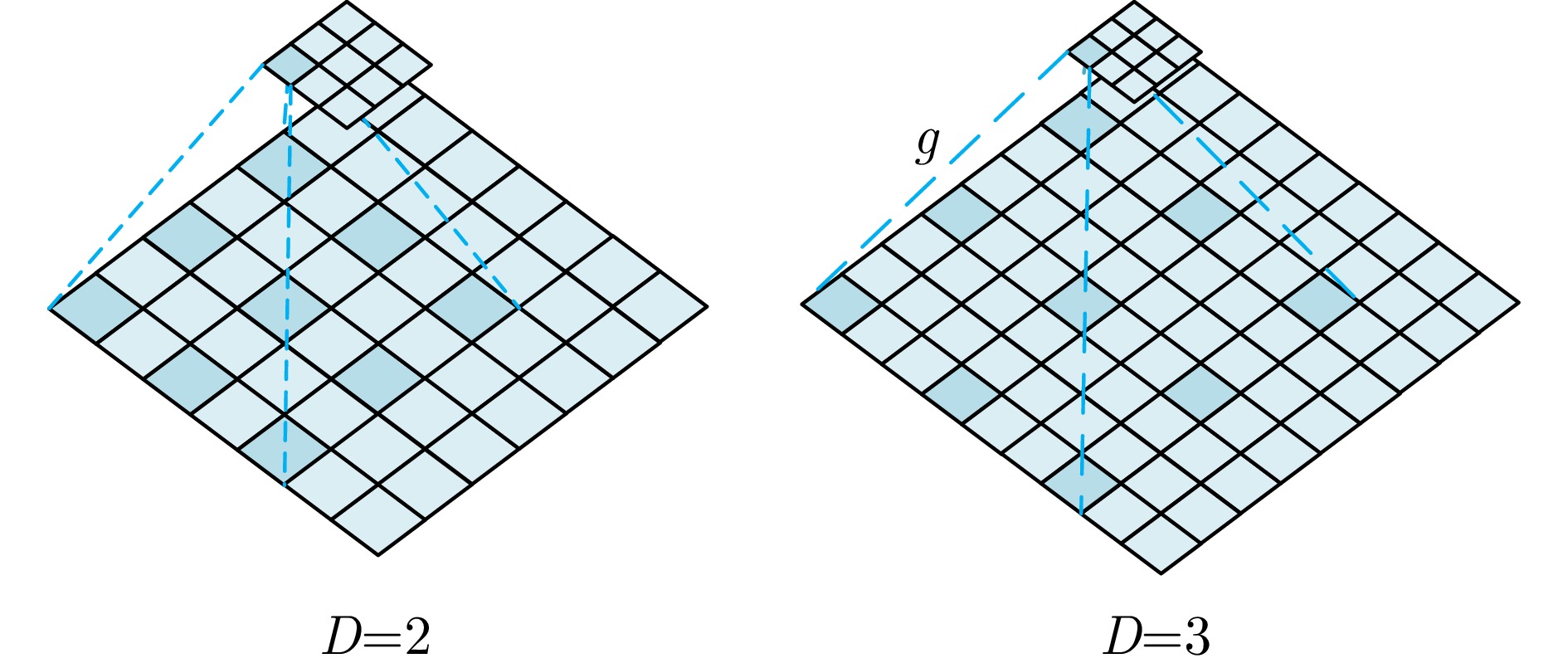
图 9 不同空洞率的空洞卷积示意图
Figure 9. Illustration of dilated convolutions with different dilation rates
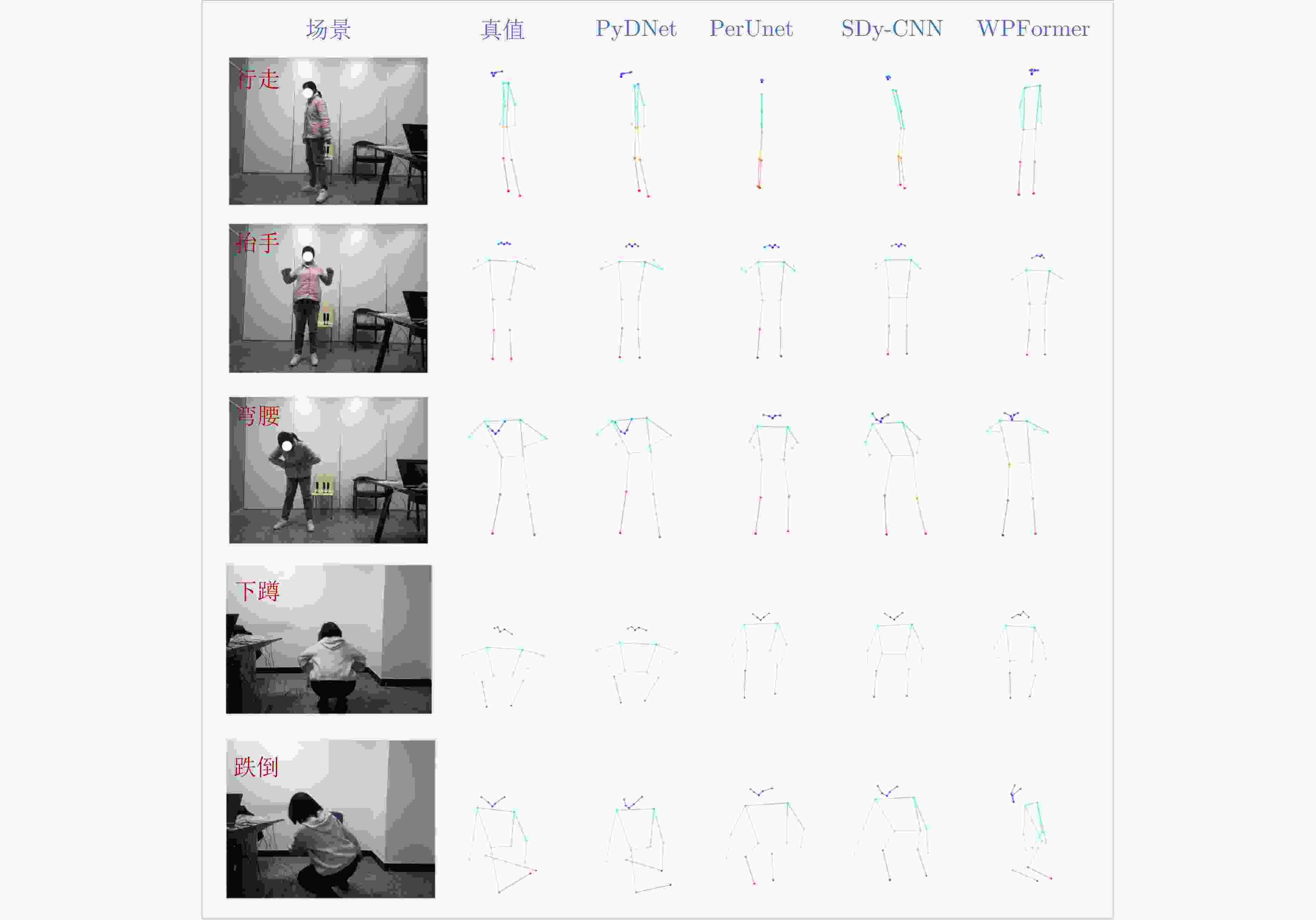
图 14 人体姿态估计效果对比图
Figure 14. Comparison of human pose estimation results across different models
表 1 网络结构参数
Table 1. Parameters of the network architecture
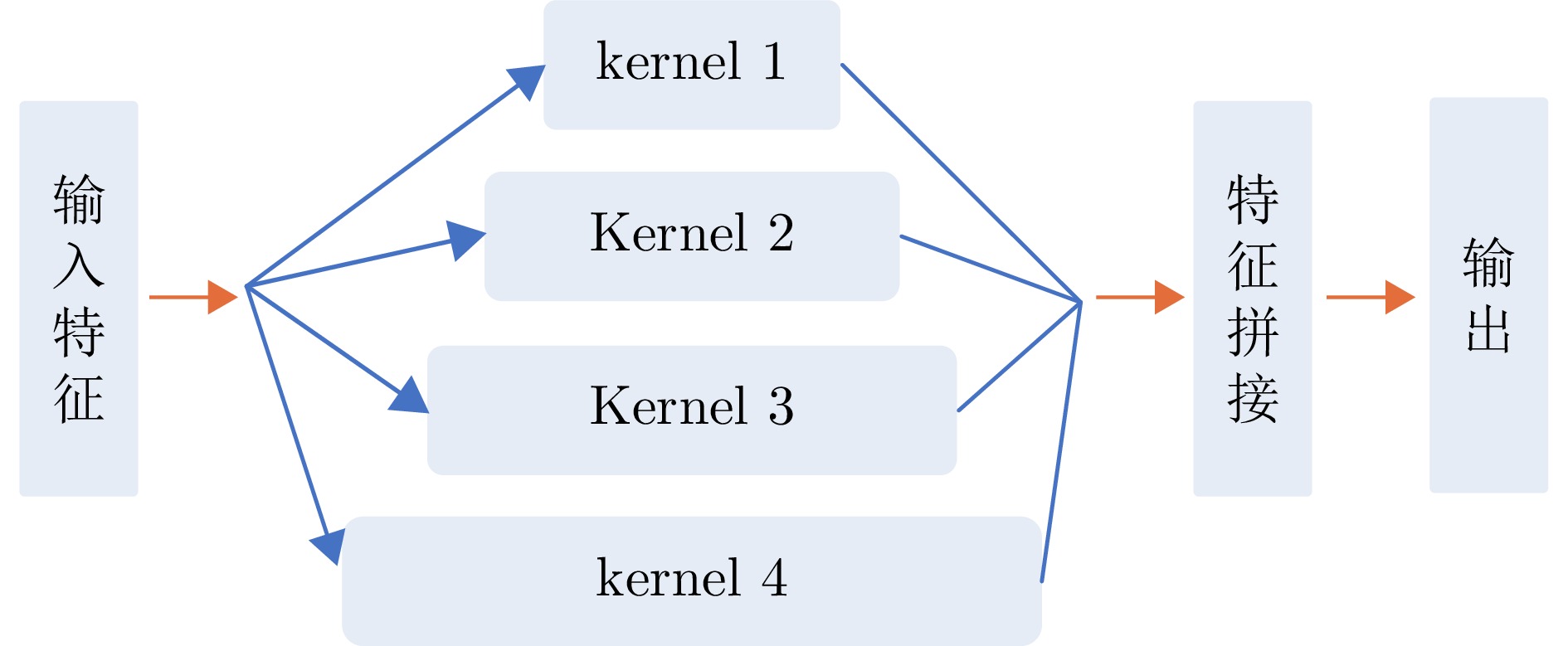
网络层 组成 输入/输出尺寸(C×H×W) 参数说明 初始卷积层 Conv7×7 + BN + ReLU 300×136×136 → 48×68×68 stride=2, padding=3 残差层 Layer1
(2×PyDBlock)48×68×68 → 192×68×68 multi-scale dilations [1,2,2,3];
grouped conv G=[3,6,6,12]Layer2
(3×PyDBlock)192×68×68 → 384×34×34 dilations [2,3];
grouped conv G=[12,16];
stride=2Layer3
(4×PyDBlock)384×34×34 → 768×17×17 dilations [1,2,3];
grouped conv G=[6,12,12];
stride=2Layer4
(2×PyDBlock)768×17×17 → 1536 ×17×17dilation=3; grouped conv G=16 特征融合层 Skip connection (Layer1+Layer3) 768×17×17 1×1 Conv + BN + ReLU;
adaptive pooling to 17×17输出层 Pooling + Fully connected 1536 ×17×17 → 2×17FC; output 17 keypoint coordinates  下载: 导出CSV
下载: 导出CSV
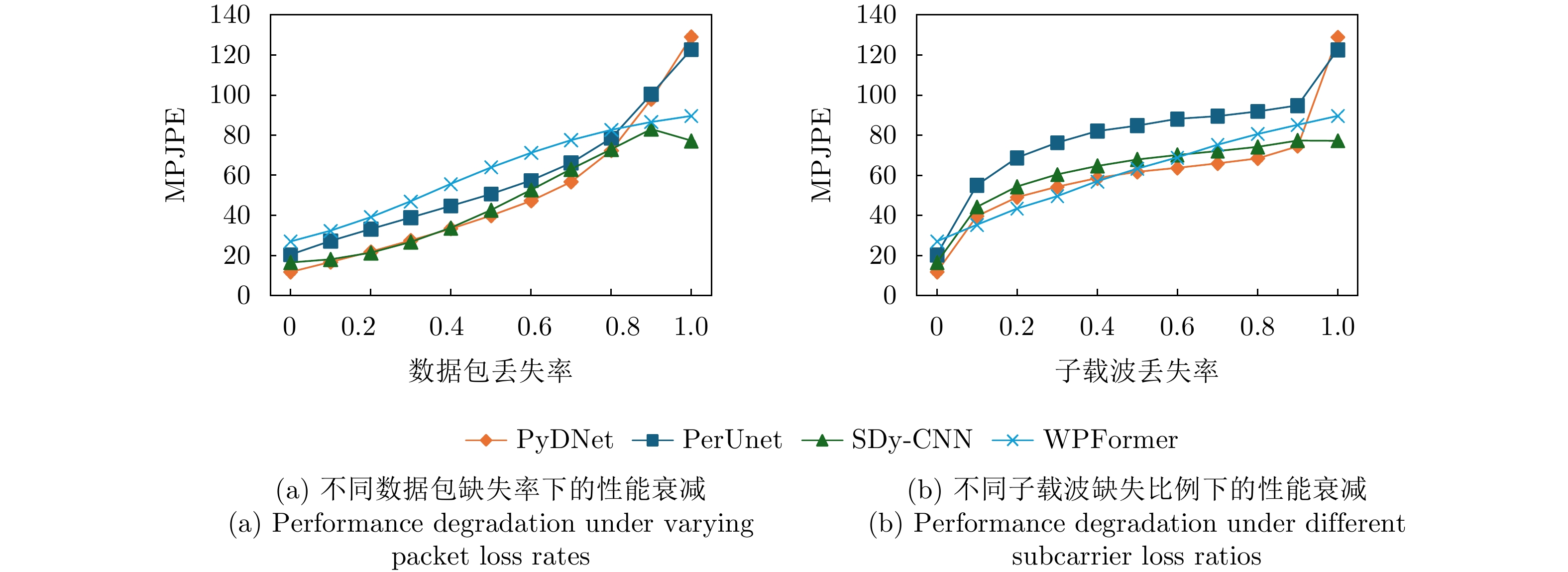
表 2 各模型PCK结果(%)
Table 2. PCK results of different models (%)
人体关键点 PCK@0.10 PCK@0.05 PCK@0.01 PyDNet PerUnet SDy-CNN WPFormer PyDNet PerUnet SDy-CNN WPFormer PyDNet PerUnet SDy-CNN WPFormer 鼻子 95.00 89.25 94.28 78.79 85.76 69.90 79.08 57.96 42.35 18.26 19.85 9.33 耳朵 94.94 88.97 94.09 78.74 85.60 70.65 79.56 58.69 43.01 18.55 20.03 11.33 眼睛 95.48 90.56 94.86 81.19 87.00 73.88 81.24 62.44 44.35 21.08 21.38 15.16 肩关节 96.33 92.44 96.01 83.74 88.40 74.64 81.74 63.75 42.38 18.92 18.81 13.66 肘关节 93.67 86.03 91.83 75.31 80.83 57.52 67.47 47.07 23.76 5.39 7.63 3.50 手腕 87.17 65.76 80.08 53.74 66.74 30.38 41.62 22.53 13.29 2.06 2.22 1.65 髋关节 98.17 95.30 97.18 90.81 92.80 81.90 86.52 71.89 48.90 24.91 25.63 11.53 膝关节 97.53 93.06 95.14 89.55 91.63 78.53 82.47 71.22 48.31 24.78 25.06 12.03 脚踝 96.34 91.08 93.90 86.67 90.13 74.22 79.26 68.03 47.07 20.32 15.33 11.84 均值 94.96 87.98 92.97 79.90 85.41 67.84 75.23 58.19 39.09 17.07 17.18 10.04 注:表内加粗数值表示各指标下的最优结果。
下载: 导出CSV
表 3 各模型PJPE结果
Table 3. PJPE results of different models
人体关键点 PyDNet PerUnet SDy-CNN WPFormer 鼻子 11.71 19.67 14.97 28.49 左耳 11.63 19.49 14.80 28.30 右耳 11.78 19.67 14.87 28.50 左眼 10.90 17.72 14.20 25.23 右眼 10.96 17.79 13.86 25.68 左肩 10.21 16.75 13.89 22.72 右肩 9.95 16.50 13.44 23.34 左肘 14.38 24.50 19.47 30.84 右肘 14.88 25.29 20.48 33.62 左腕 21.15 37.94 29.47 45.64 右腕 23.05 41.63 32.21 51.74 左髋 7.88 13.19 11.42 18.51 右髋 7.61 12.94 11.14 17.47 左膝 8.27 14.31 12.73 17.90 右膝 8.51 15.23 13.31 19.49 左脚踝 9.42 17.20 15.52 20.99 右脚踝 10.08 18.44 16.12 22.86 均值 11.90 20.49 16.58 27.14 注:表内加粗数值表示各指标下的最优结果。
下载: 导出CSV
表 4 基于蒙特卡罗仿真的不同数据划分下的实验结果
Table 4. Performance across different data partitions based on Monte Carlo simulations
实验
次数MPCK@
0.01MPCK@
0.05MPCK@
0.10MPCK@
0.20MPJPE 1 38.36 85.25 94.99 98.83 12.08 2 37.22 84.49 94.54 98.76 12.45 3 36.58 83.93 94.32 98.78 12.68 4 36.28 84.04 94.43 98.73 12.65 5 37.24 84.10 94.26 98.67 12.64 平均值 37.14 84.36 94.51 98.75 12.50 标准差 0.72 0.48 0.26 0.05 0.23
下载: 导出CSV
表 5 Wi-pose数据集下不同模型的性能对比
Table 5. Performance comparison of different models on the Wi-pose dataset
模型 MPCK@0.01 (%) MPCK@0.05 (%) MPCK@0.10 (%) MPCK@0.20 (%) MPJPE PyDNet 15.50 62.14 78.72 91.06 27.74 PerUnet 3.15 39.88 65.84 86.68 39.83 SDy-CNN 1.90 30.14 59.71 87.15 42.68 WPFormer 4.79 39.35 61.84 83.76 43.14 注:表内加粗数值表示各指标下的最优结果。
下载: 导出CSV
表 6 目标域Wi-pose上的跨域姿态估计性能对比
Table 6. Performance comparison of cross-domain pose estimation on the target domain (Wi-pose dataset)
评估指标 Baseline Proposed 性能变化 MPCK@0.1 5.41 58.70 53.29% MPCK@0.2 17.09 88.18 71.09% MPCK@0.3 30.51 97.14 66.63% MPCK@0.4 43.72 99.41 55.69% MPCK@0.5 56.03 99.90 43.87% MPJPE 210.40 42.99 –167.42
下载: 导出CSV
表 7 对比算法计算量对比
模型 参数量
(M)浮点计算数
Flops(G)单帧推理
延时(ms)吞吐量
(帧/s)数据预处理
耗时(ms)PyDNet 6.35 12.22 4.70 212.93 14.45 PerUnet 17.49 30.85 4.24 236.06 14.39 SDy-CNN 6.56 7.10 1.07 930.37 15.19 WPFormer 26.73 48.45 4.21 237.63 3.95
下载: 导出CSV
表 8 实验参数设置
Table 8. Experimental parameter settings
设置 设定值 优化器 Adam 初始学习率 1×10−3 学习率调度策略 ReduceLROnPlateau
(factor=0.1, patience=50)批处理大小 16 训练集/测试集/验证集划分比例 60%/20%/20%
下载: 导出CSV
表 9 不同卷积分支率下MPJPE
Table 9. MPJPE under different convolution branch rates
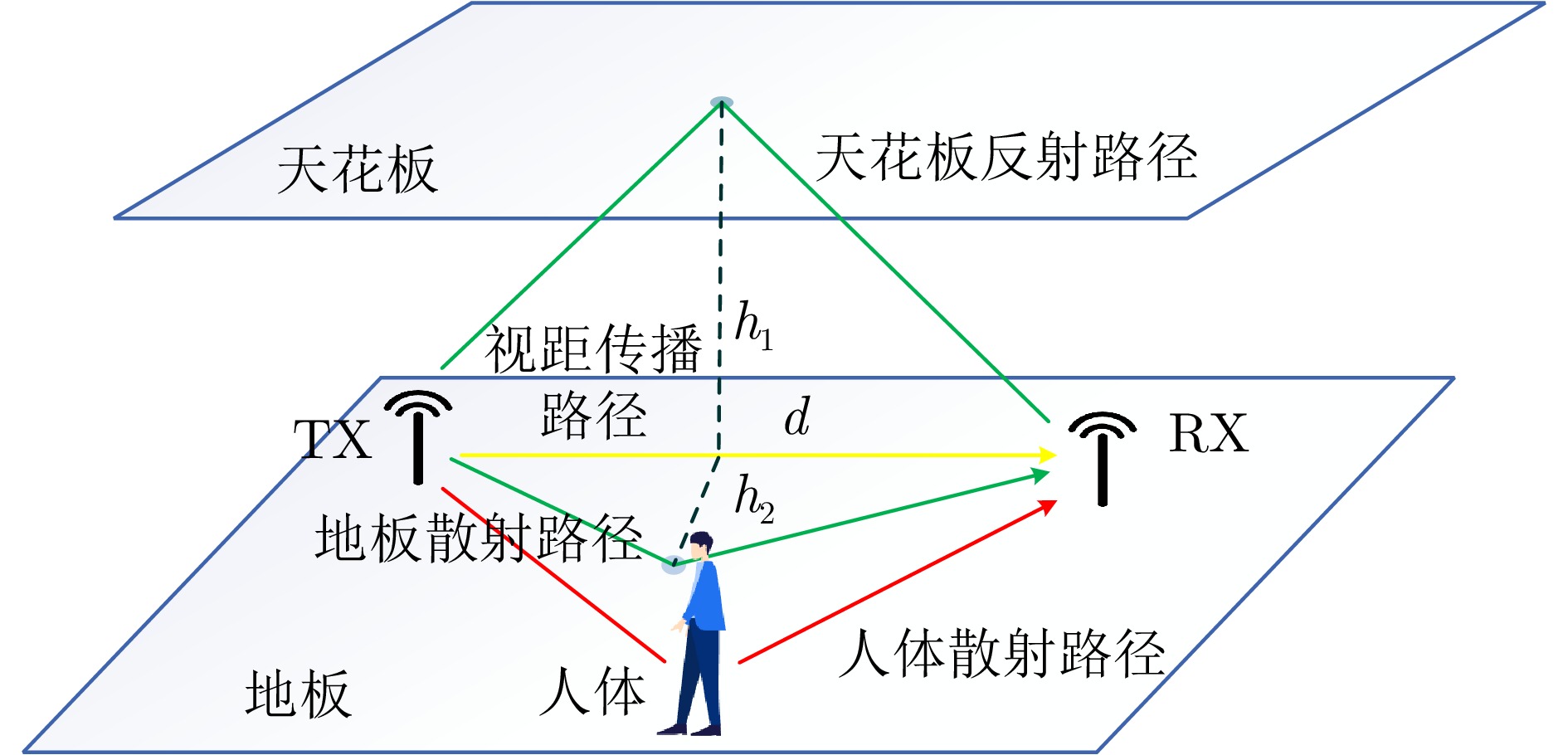
掩蔽分支(Masked Branch) 躯干误差(MPJPE) 肢体误差(MPJPE) 躯干误差增量($\Delta $%) 肢体误差增量($\Delta $%) 小空洞率(d=1) 11.82 18.76 +32.7% +36.8% 中空洞率(d=2) 12.52 19.85 +40.5% +44.7% 大空洞率(d=3) 29.42 37.07 +230.0% +170.3% 基线模型(无掩蔽) 8.91 13.72 — —
下载: 导出CSV
表 10 消融实验中各模型的平均关键点准确率(MPCK)对比(%)
Table 10. Comparison of Mean Percentage of Correct Keypoints (MPCK) in the ablation study (%)
模型 MPCK@0.10 MPCK@0.05 MPCK@0.01 PyDNet 94.96 85.41 39.09 PyConvNet 92.22 77.13 25.43 ResNet 84.38 62.92 10.35 SE-ResNet 92.21 76.60 23.63 NL-ResNet 79.29 55.62 9.45 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 11 消融实验中各模型的平均关节位置误差(MPJPE) 对比
Table 11. Comparison of Mean Per Joint Position Error (MPJPE) in the ablation study
模型 MPJPE PyDNet 11.90 PyConvNet 16.03 ResNet 23.58 SE-ResNet 16.28 NL-ResNet 27.70 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 12 消融实验中各模型的计算量对比
Table 12. Comparison of model parameters in the ablation study
模型 参数量(M) PyDNet 6.35 PyConvNet 6.44 SE-ResNet 28.04 NL-ResNet 38.23 ResNet 29.13
下载: 导出CSV
-
[1] CAO Zhe, HIDALGO G, SIMON T, et al. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1): 172–186. doi: 10.1109/TPAMI.2019.2929257. [2] TOSHEV A and SZEGEDY C. DeepPose: Human pose estimation via deep neural networks[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 1653–1660. doi: 10.1109/CVPR.2014.214. [3] MEHRABAN S, ADELI V, and TAATI B. MotionAGFormer: Enhancing 3D human pose estimation with a Transformer-GCNformer network[C]. The IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2024: 6905–6915. doi: 10.1109/WACV57701.2024.00677. [4] AN Xiaoqi, ZHAO Lin, GONG Chen, et al. ShaRPose: Sparse high-resolution representation for human pose estimation[C]. The AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 691–699. [5] ZHAO Mingmin, LI Tianhong, ABU ALSHEIKH M, et al. Through-wall human pose estimation using radio signals[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7356–7365. doi: 10.1109/CVPR.2018.00768. [6] ZHENG Zhijie, ZHANG Diankun, LIANG Xiao, et al. RadarFormer: End-to-end human perception with through-wall radar and transformers[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(12): 18285–18299. doi: 10.1109/TNNLS.2023.3314031. [7] ZHANG Rui, GENG Ruixu, LI Yadong, et al. RFMamba: Frequency-aware state space model for RF-based human-centric perception[C]. The Thirteenth International Conference on Learning Representations, Singapore, Singapore, 2025. [8] SENGUPTA A and CAO Siyang. mmPose-NLP: A natural language processing approach to precise skeletal pose estimation using mmWave radars[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(11): 8418–8429. doi: 10.1109/TNNLS.2022.3151101. [9] SENGUPTA A, JIN Feng, ZHANG Renyuan, et al. mm-Pose: Real-time human skeletal posture estimation using mmWave radars and CNNs[J]. IEEE Sensors Journal, 2020, 20(17): 10032–10044. doi: 10.1109/JSEN.2020.2991741. [10] 陈彦, 张锐, 李亚东. 等. 基于无线信号的人体姿态估计综述[J]. 雷达学报(中英文), 2025, 14(1): 229–247. doi: 10.12000/JR24189.CHEN Yan, ZHANG Rui, LI Yadong, et al. An overview of human pose estimation based on wireless signals[J]. Journal of Radars, 2025, 14(1): 229–247. doi: 10.12000/JR24189. [11] MA Yongsen, ZHOU Gang, and WANG Shuangquan. WiFi sensing with channel state information: A survey[J]. ACM Computing Surveys (CSUR), 2020, 52(3): 46. doi: 10.1145/3310194. [12] WEI Bo, SONG Hang, KATTO J, et al. RSSI-CSI measurement and variation mitigation with commodity Wi-Fi device[J]. IEEE Internet of Things Journal, 2023, 10(7): 6249–6258. doi: 10.1109/JIOT.2022.3223525. [13] HALPERIN D, HU Wenjun, SHETH A, et al. Tool release: Gathering 802.11n traces with channel state information[J]. ACM SIGCOMM Computer Communication Review, 2011, 41(1): 53. doi: 10.1145/1925861.1925870. [14] WANG Fei, ZHOU Sanping, PANEV S, et al. Person-in-WiFi: Fine-grained person perception using WiFi[C]. The IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 5451–5460. doi: 10.1109/ICCV.2019.00555. [15] HE Kaiming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. The IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2980–2988. doi: 10.1109/ICCV.2017.322. [16] RONNEBERGER O, FISCHER P, and BROX T. U-Net: Convolutional networks for biomedical image segmentation[C]. The 18th International Conference on Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Munich, Germany, 2015: 234–241. doi: 10.1007/978-3-319-24574-4_28. [17] YANG Jianfei, ZHOU Yunjiao, HUANG He, et al. MetaFi: Device-free pose estimation via commodity WiFi for metaverse avatar simulation[C]. The IEEE 8th World Forum on Internet of Things, Yokohama, Japan, 2022: 1–6. doi: 10.1109/WF-IoT54382.2022.10152057. [18] ZHOU Yue, ZHU Aichun, XU Caojie, et al. PerUnet: Deep signal channel attention in UNet for WiFi-based human pose estimation[J]. IEEE Sensors Journal, 2022, 22(20): 19750–19760. doi: 10.1109/JSEN.2022.3204607. [19] DENG Jie, CHEN Kaiqi, JING Pengsen, et al. CSI-channel spatial decomposition for WiFi-based human pose estimation[J]. Electronics, 2025, 14(4): 756. doi: 10.3390/electronics14040756. [20] ZHOU Yunjiao, HUANG He, YUAN Shenghai, et al. MetaFi++: WiFi-enabled transformer-based human pose estimation for metaverse avatar simulation[J]. IEEE Internet of Things Journal, 2023, 10(16): 14128–14136. doi: 10.1109/JIOT.2023.3262940. [21] JIANG Wenjun, XUE Hongfei, MIAO Chenglin, et al. Towards 3D human pose construction using WiFi[C]. The 26th Annual International Conference on Mobile Computing and Networking, London, UK, 2020: 23. doi: 10.1145/3372224.3380900. [22] GIAN T D, TRAN D T, PHAM Q V, et al. Multi-modal human pose estimation: A Wi-Fi-driven approach with adaptive kernel selection[J]. IEEE Transactions on Artificial Intelligence, 2025. doi: 10.1109/TAI.2025.3631005. [23] GIAN T D, NGUYEN T H, NGUYEN N T, et al. WiLHPE: WiFi-enabled lightweight channel frequency dynamic convolution for HPE tasks[C]. The Tenth International Conference on Communications and Electronics, Danang, Vietnam, 2024: 516–521. doi: 10.1109/ICCE62051.2024.10634628. [24] NGUYEN X H, NGUYEN V D, LUU Q T, et al. Robust WiFi sensing-based human pose estimation using denoising autoencoder and CNN with dynamic subcarrier attention[J]. IEEE Internet of Things Journal, 2025, 12(11): 17066–17079. doi: 10.1109/JIOT.2025.3535156. [25] FANG Haoshu, LI Jiefeng, TANG Hongyang, et al. AlphaPose: Whole-body regional multi-person pose estimation and tracking in real-time[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7157–7173. [26] ZHOU Yue, XU Caojie, ZHAO Lu, et al. CSI-Former: Pay more attention to pose estimation with WiFi[J]. Entropy, 2023, 25(1): 20. doi: 10.3390/e25010020. [27] HUANG Jinyang, FENG Yuanhao, CUI Fengqi, et al. Identifying who you are no matter what you write through abstracting handwriting style[J]. IEEE Transactions on Dependable and Secure Computing, 2026. doi: 10.1109/TDSC.2026.3668275. [28] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. [29] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. doi: 10.1109/CVPR.2018.00745. [30] WANG Xiaolong, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7794–7803. doi: 10.1109/CVPR.2018.00813. -



计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

