
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
A Lightweight Human Activity Recognition Method for Ultra-wideband Radar Based on Spatiotemporal Features of Point Clouds
-
摘要: 低频超宽带(UWB)雷达因其良好穿透性和分辨率,在人体行为识别领域具有显著的优势。针对现有的动作识别算法运算量大、网络参数多的问题,该文提出了一种基于时空点云的高效且轻量的超宽带雷达人体行为识别方法。首先通过UWB雷达采集人体的四维运动数据,然后采用离散采样的方法将雷达图像转换为点云表示,由于人体行为识别属于时间序列上的分类问题,该文结合PointNet++网络与Transformer网络提出了一种轻量化的时空网络,通过提取并分析四维点云的时空特征,实现了对人体行为的端到端识别。在模型的训练过程中,提出了一种点云数据多阈值融合的方法,进一步提高了模型的泛化性和识别能力。该文根据公开的四维雷达成像数据集对所提方法进行验证,并与现有方法进行了比较。结果表明,所提方法在人体行为识别率达到96.75%,且消耗较少的参数量和运算量,验证了其有效性。
-
关键词:
- 超宽带雷达 /
- 行为识别 /
- 点云 /
- PointNet++ /
- Transformer
Abstract: Low-frequency Ultra-WideBand (UWB) radar offers significant advantages in the field of human activity recognition owing to its excellent penetration and resolution. To address the issues of high computational complexity and extensive network parameters in existing action recognition algorithms, this study proposes an efficient and lightweight human activity recognition method using UWB radar based on spatiotemporal point clouds. First, four-dimensional motion data of the human body are collected using UWB radar. A discrete sampling method is then employed to convert the radar images into point cloud representations. Because human activity recognition is a classification problem on time series, this paper combines the PointNet++ network with the Transformer network to propose a lightweight spatiotemporal network. By extracting and analyzing the spatiotemporal features of four-dimensional point clouds, end-to-end human activity recognition is achieved. During the model training process, a multithreshold fusion method is proposed for point cloud data to further enhance the model’s generalization and recognition capabilities. The proposed method is then validated using a public four-dimensional radar imaging dataset and compared with existing methods. The results show that the proposed method achieves a human activity recognition rate of 96.75% while consuming fewer parameters and computational resources, thereby verifying its effectiveness.-
Key words:
- Ultra-WideBand (UWB) radar /
- Action recognition /
- Point clouds /
- PointNet++ /
- Transformer
-

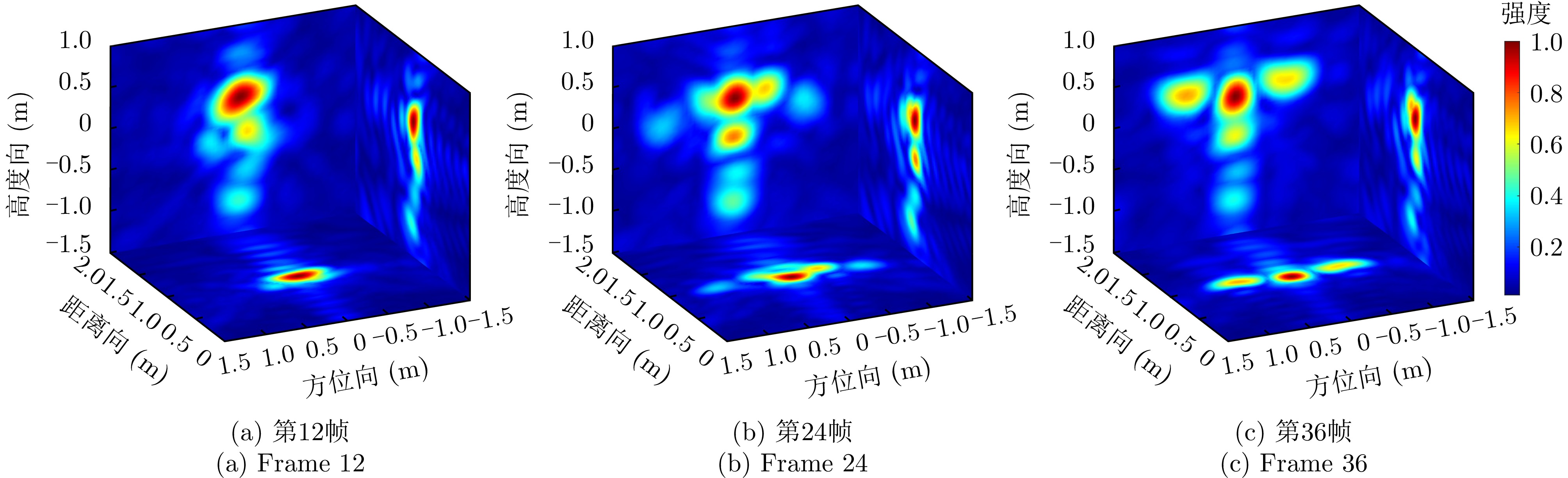
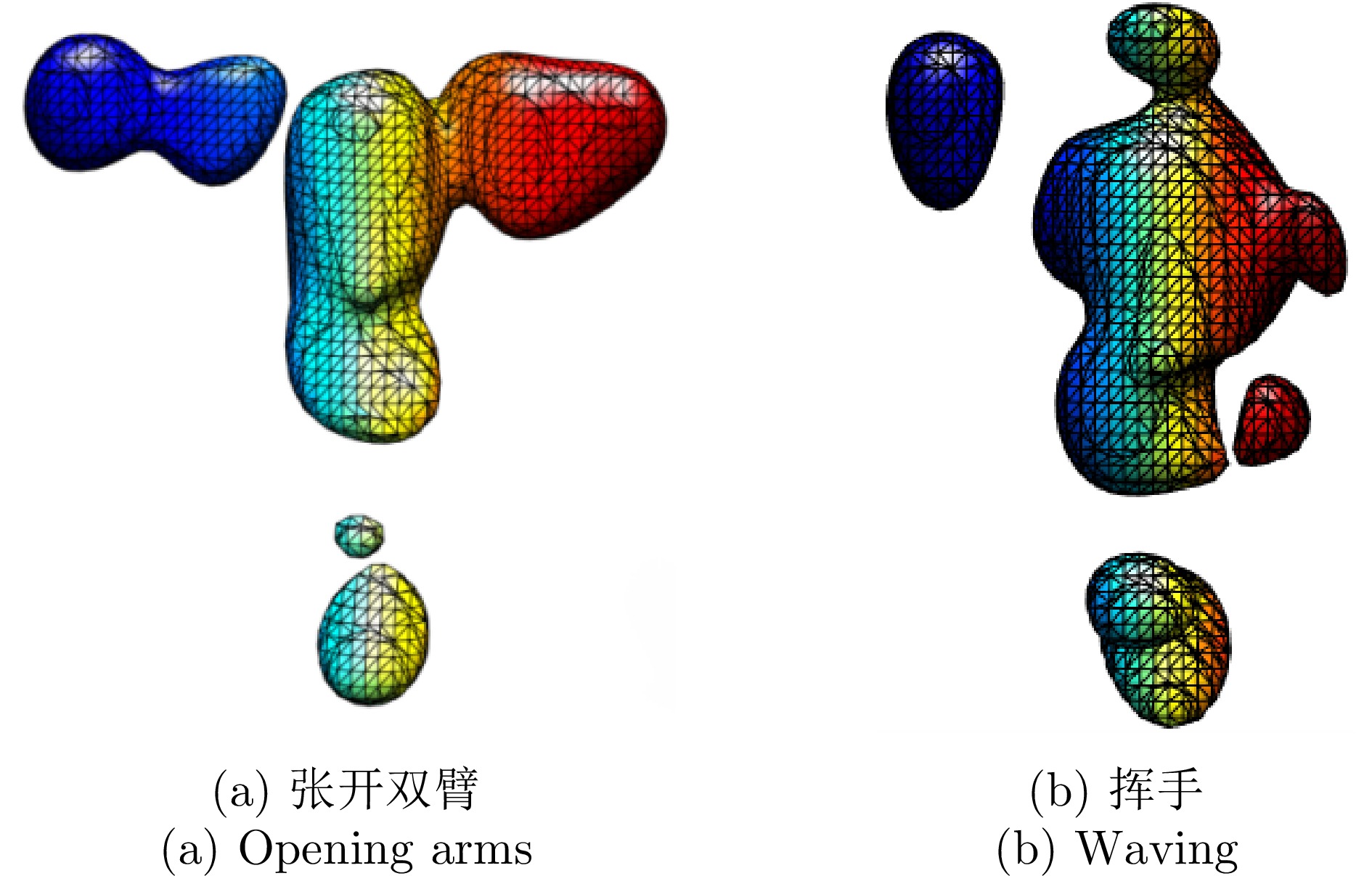
图 4 不同动作经雷达回波转换后的三维等值面图
Figure 4. Three-dimensional isosurface diagrams of different actions converted from radar echo data

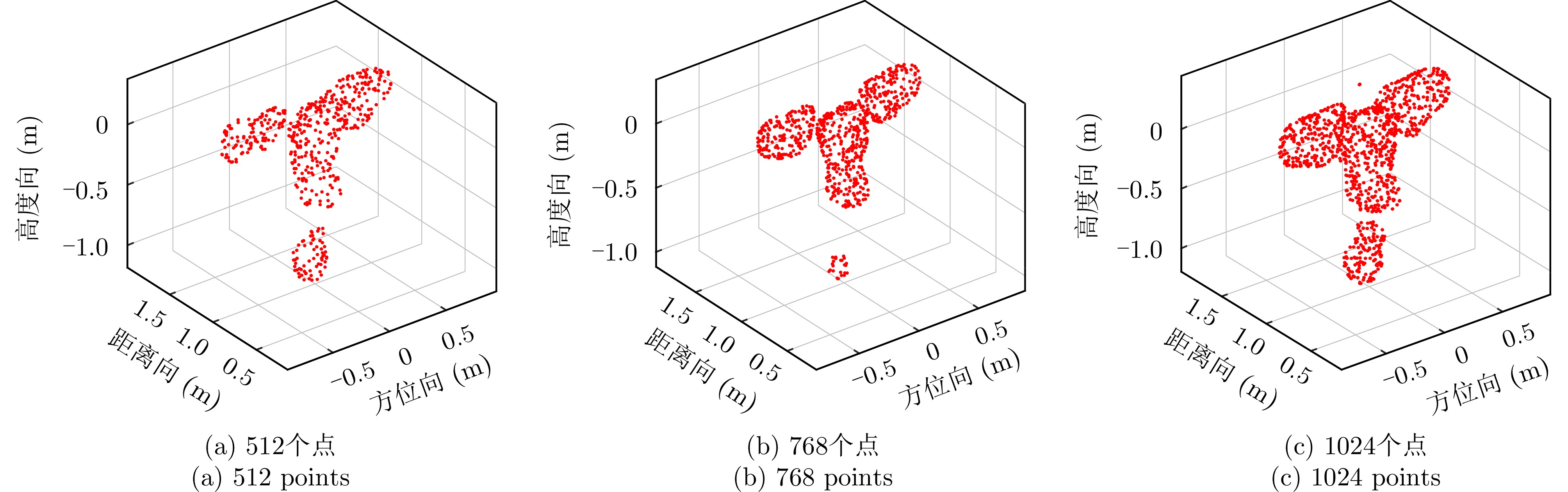
图 5 不同点云数目所构建的人体模型
Figure 5. Human body models constructed from point clouds of varying quantities

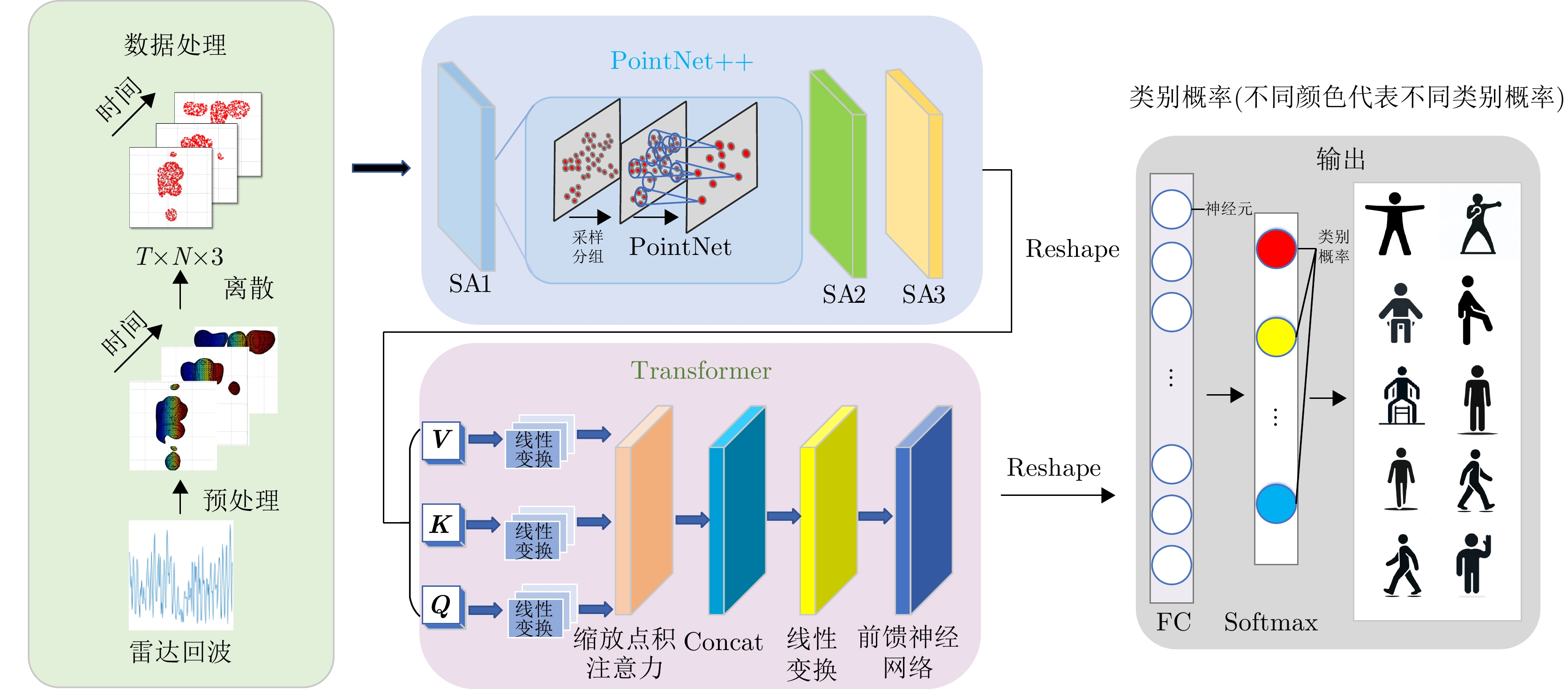
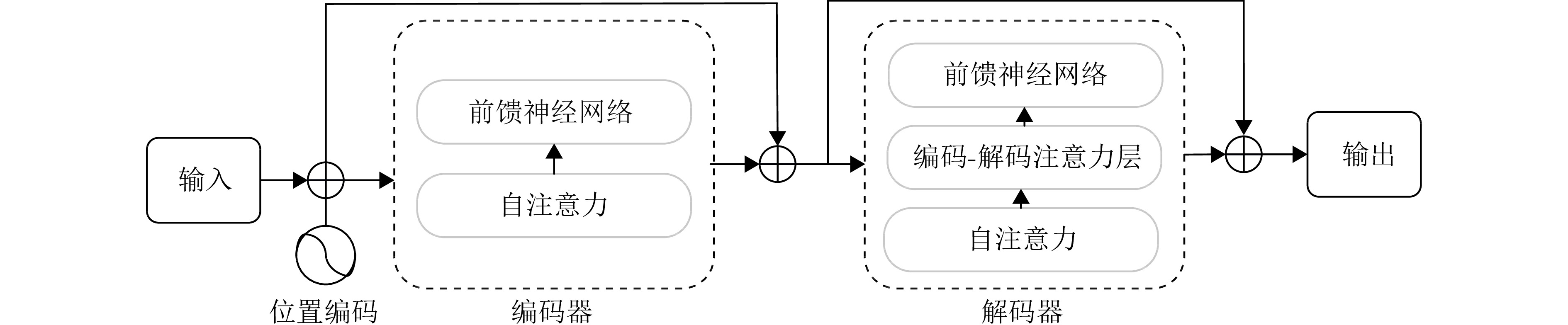
图 6 UWB-PointTransformer网络结构图
Figure 6. Schematic diagram of the UWB-PointTransformer network architecture

图 8 数据采集使用的MIMO超宽带雷达阵列
Figure 8. Ultra-wideband MIMO radar array used for data acquisition

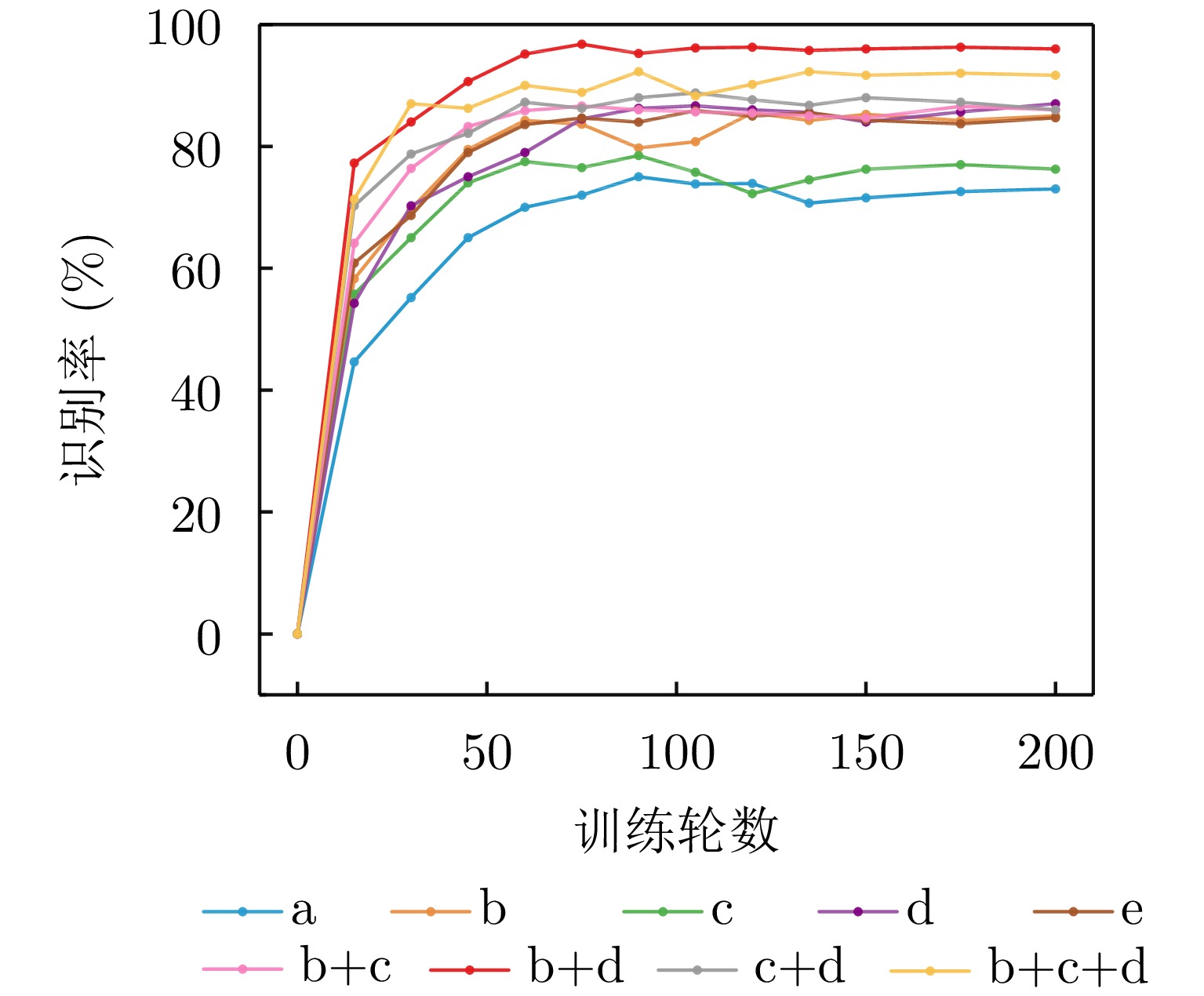
图 9 不同训练集随训练轮数的识别率变化
Figure 9. Recognition rate variation with training epochs for different training sets

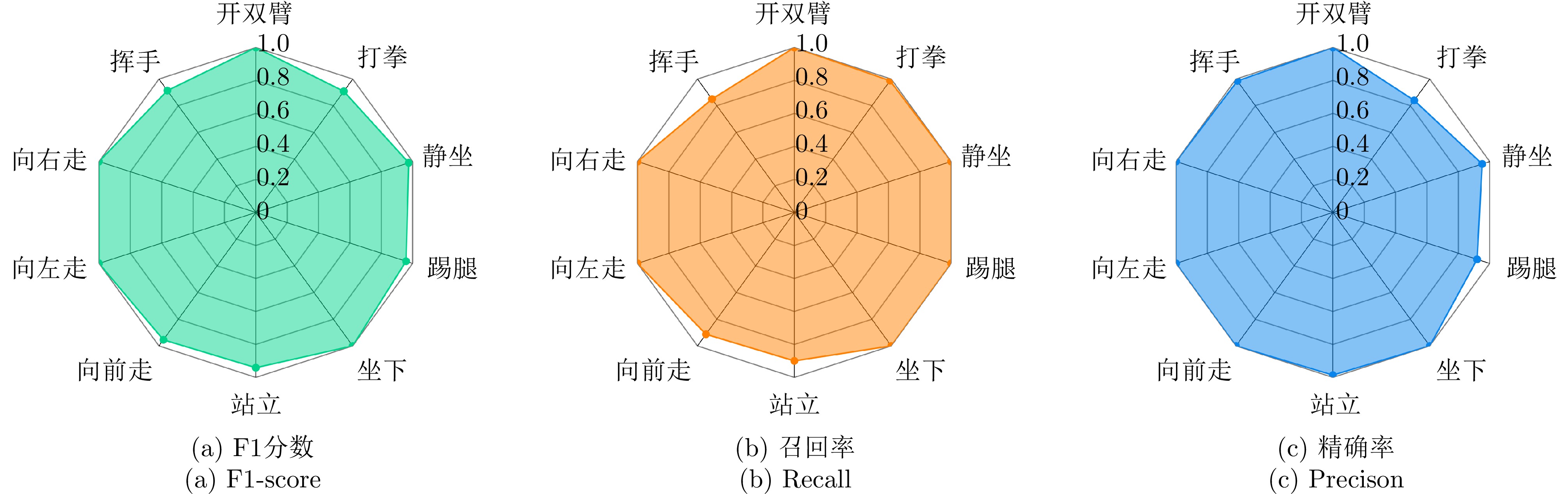
图 11 模型的F1, Recall, Precision参数雷达图
Figure 11. Radar charts for model’s F1, Recall, Precision parameters
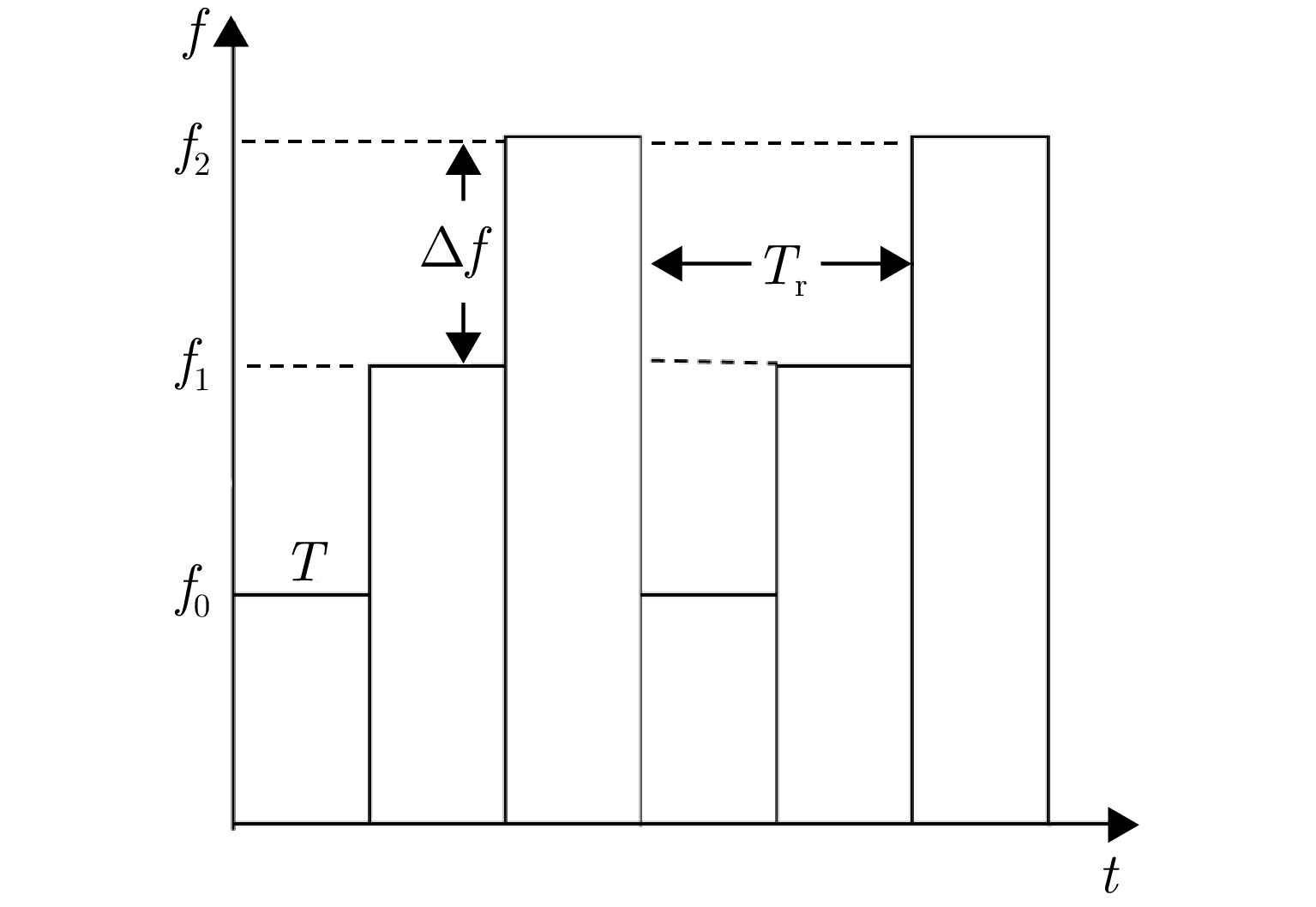
表 1 MIMO超宽带雷达参数表
Table 1. Parameter table for ultra-wideband MIMO radar
参数 指标 信号体制 步进频信号 信号带宽 1 GHz 工作频段 1.78~2.78 GHz 信号重复频率 10 Hz 信号步进带宽 4 MHz 信号发射功率 20 dBm (100 mW) 系统尺寸 60 cm×88 cm 天线阵元数 10发10收 可穿透介质 塑料、木板、砖墙等  下载: 导出CSV
下载: 导出CSV
表 2 不同数据集在模型中的识别率
Table 2. Recognition rates of different datasets within the model
数据集 阈值(dB) 采样点数 识别率(%) a –4 256 73.92 b –8 512 85.75 c –10 768 78.45 d –14 1024 85.65 e –16 2048 85.86 b+c –8; –10 512; 768 86.55 b+d –8; –14 512; 1024 96.75 c+d –10; –14 768; 1024 88.75 b+c+d –8; –10; –14 512; 768; 1024 92.25 注:加粗项表示在所有数据集中表现出识别率最高的数据集。
下载: 导出CSV
表 3 不同网络骨干对网络整体的影响
Table 3. The impact of different network backbones on the overall network performance
网络模型 Acc (%) Params (MB) PointNet++, GRU 81.33 1.68 PointNet++, bi-GRU 84.65 1.68 PointNet++, LSTM
PointNet++, bi-LSTM83.38
85.652.17
2.17PointNet++, Multihead Attention, bi-GRU 93.50 2.54 PointNet++, Multihead Attention, bi-LSTM
PointNet++, Transformer94.63
96.752.54
0.37注:加粗项表示不同骨干网络组合中的最优结果。
下载: 导出CSV
表 4 不同模型的性能对比和在不同场景下的识别率
Table 4. Cross-scenario performance and recognition rates of various models
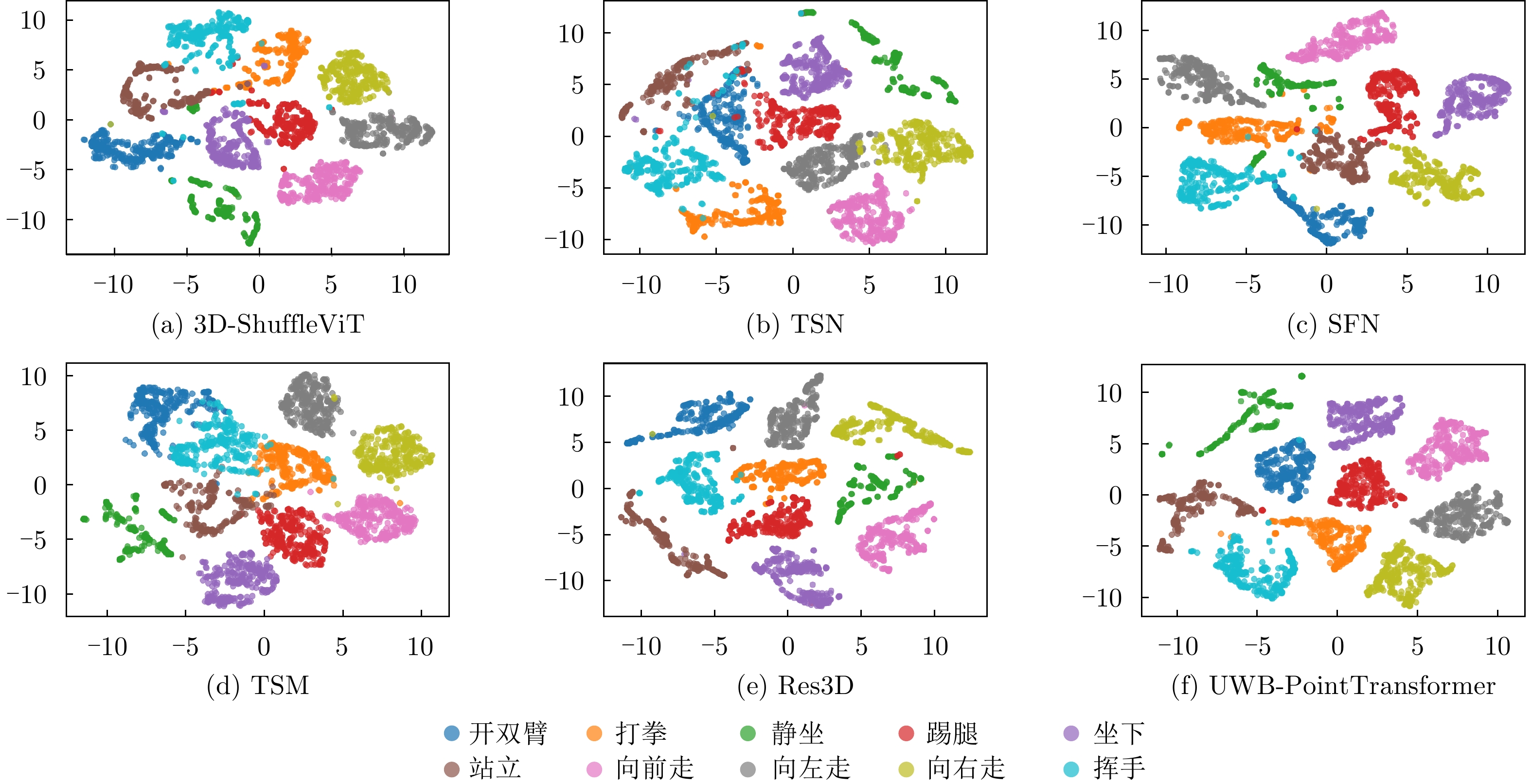
模型 S1 (%) S2 (%) S3 (%) FLOPs (GB) Params (MB) UWB-PointTransformer 96.75 93.45 82.65 1.60 0.37 Res3D[39] 92.25 90.00 77.00 3.25 31.69 SFN[40] 88.00 80.50 70.25 18.27 8.58 TSN[41] 85.75 83.50 60.75 32.28 22.34 TSM[42] 91.50 88.00 73.75 16.48 12.71 3D-ShuffleViT[21] 91.85 90.68 76.48 1.68 2.45 注:加粗项表示不同模型的性能和在不同场景识别率的最优结果。
下载: 导出CSV
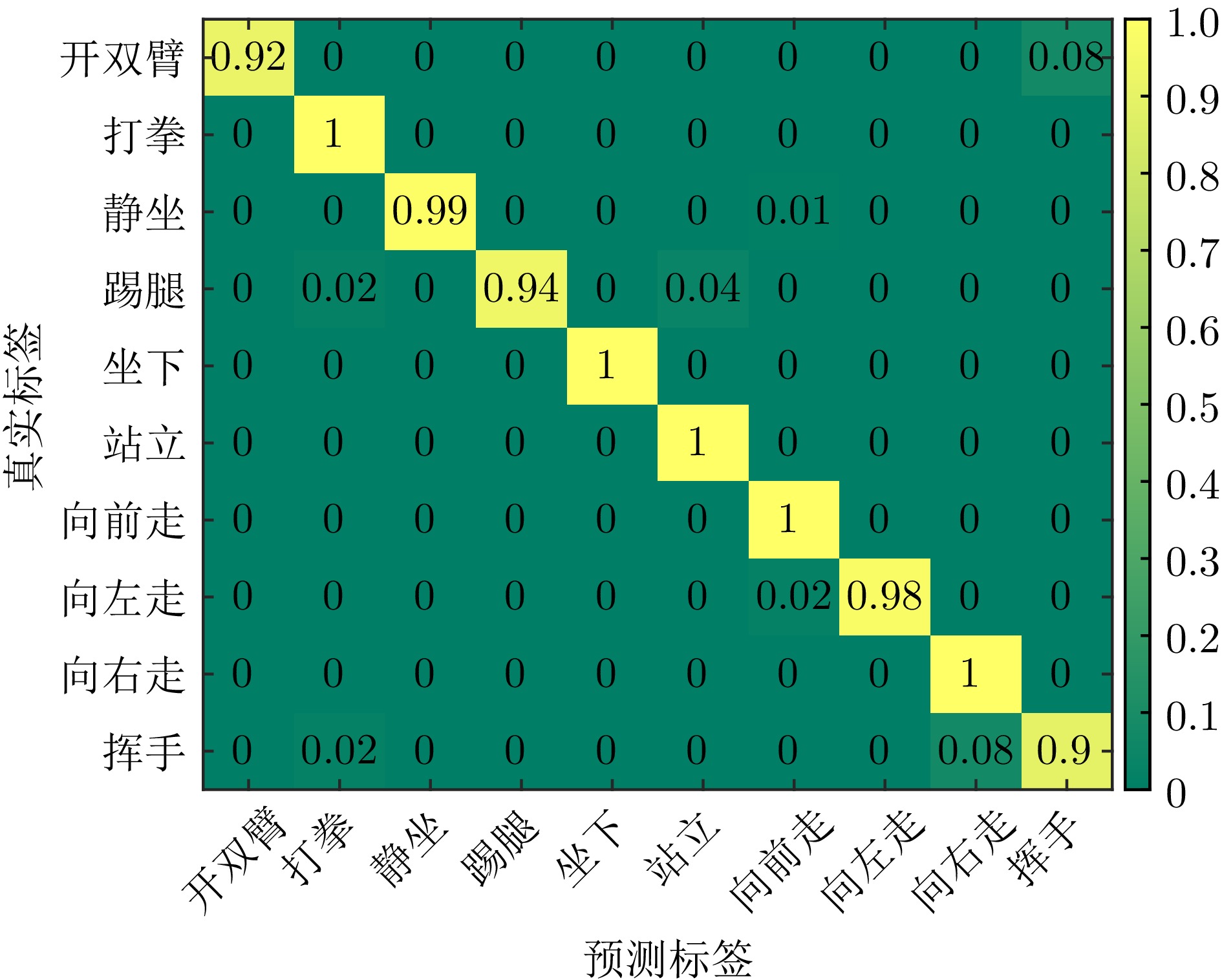
表 5 网络对不同动作的预测概率
Table 5. The network’s prediction probabilities for different actions
真实动作 预测动作 开双臂 打拳 静坐 踢腿 坐下 站立 向前走 向左走 向右走 挥手 开双臂 9.97E–1 7.78E–7 7.71E–5 1.45E–6 1.16E–5 3.43E–4 1.79E–8 3.40E–5 2.99E–5 2.60E–3 打拳 1.61E–8 9.99E–1 5.23E–9 9.07E–6 1.64E–6 1.32E–5 2.91E–8 1.04E–6 8.83E–9 2.28E–4 向前走 2.22E–5 5.29E–5 1.62E–4 1.66E–4 2.44E–5 4.05E–7 9.99E–1 7.01E–6 9.60E–9 5.47E–4 挥手 5.63E–5 4.88E–5 5.05E–8 8.70E–6 5.12E–6 1.04E–4 7.48E–7 1.86E–5 6.64E–8 9.99E–1 注:加粗项表示网络对当前动作预测概率的最高值。
下载: 导出CSV
-
[1] SUN Zehua, KE Qiuhong, RAHMANI H, et al. Human action recognition from various data modalities: A review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3200–3225. doi: 10.1109/TPAMI.2022.3183112. [2] PAREEK P and THAKKAR A. A survey on video-based human action recognition: Recent updates, datasets, challenges, and applications[J]. Artificial Intelligence Review, 2021, 54(3): 2259–2322. doi: 10.1007/s10462-020-09904-8. [3] 元志安, 周笑宇, 刘心溥, 等. 基于RDSNet的毫米波雷达人体跌倒检测方法[J]. 雷达学报, 2021, 10(4): 656–664. doi: 10.12000/JR21015.YUAN Zhian, ZHOU Xiaoyu, LIU Xinpu, et al. Human fall detection method using millimeter-wave radar based on RDSNet[J]. Journal of Radars, 2021, 10(4): 656–664. doi: 10.12000/JR21015. [4] KONG Yu and FU Yun. Human action recognition and prediction: A survey[J]. International Journal of Computer Vision, 2022, 130(5): 1366–1401. doi: 10.1007/s11263-022-01594-9. [5] LI Maosen, CHEN Siheng, CHEN Xu, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 3590–3598. doi: 10.1109/CVPR.2019.00371. [6] 杨小鹏, 高炜程, 渠晓东. 基于微多普勒角点特征与Non-Local机制的穿墙雷达人体步态异常终止行为辨识技术[J]. 雷达学报(中英文), 2024, 13(1): 68–86. doi: 10.12000/JR23181.YANG Xiaopeng, GAO Weicheng, and QU Xiaodong. Human anomalous gait termination recognition via through-the-wall radar based on micro-Doppler corner features and Non-Local mechanism[J]. Journal of Radars, 2024, 13(1): 68–86. doi: 10.12000/JR23181. [7] SONG Yongkun, DAI Yongpeng, JIN Tian, et al. Dual-task human activity sensing for pose reconstruction and action recognition using 4-D imaging radar[J]. IEEE Sensors Journal, 2023, 23(19): 23927–23940. doi: 10.1109/JSEN.2023.3308788. [8] DUAN Haodong, ZHAO Yue, CHEN Kai, et al. Revisiting skeleton-based action recognition[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 2959–2968. doi: 10.1109/CVPR52688.2022.00298. [9] JARAMILLO I E, JEONG J G, LOPEZ P R, et al. Real-time human activity recognition with IMU and encoder sensors in wearable exoskeleton robot via deep learning networks[J]. Sensors, 2022, 22(24): 9690. doi: 10.3390/s22249690. [10] PESENTI M, INVERNIZZI G, MAZZELLA J, et al. IMU-based human activity recognition and payload classification for low-back exoskeletons[J]. Scientific Reports, 2023, 13(1): 1184. doi: 10.1038/s41598-023-28195-x. [11] 王秉路, 靳杨, 张磊, 等. 基于多传感器融合的协同感知方法[J]. 雷达学报(中英文), 2024, 13(1): 87–96. doi: 10.12000/JR23184.WANG Binglu, JIN Yang, ZHANG Lei, et al. Collaborative perception method based on multisensor fusion[J]. Journal of Radars, 2024, 13(1): 87–96. doi: 10.12000/JR23184. [12] 丁一鹏, 厍彦龙. 穿墙雷达人体动作识别技术的研究现状与展望[J]. 电子与信息学报, 2022, 44(4): 1156–1175. doi: 10.11999/JEIT211051.DING Yipeng and SHE Yanlong. Research status and prospect of human movement recognition technique using through-wall radar[J]. Journal of Electronics & Information Technology, 2022, 44(4): 1156–1175. doi: 10.11999/JEIT211051. [13] NIU Kai, WANG Xuanzhi, ZHANG Fusang, et al. Rethinking Doppler effect for accurate velocity estimation with commodity WiFi devices[J]. IEEE Journal on Selected Areas in Communications, 2022, 40(7): 2164–2178. doi: 10.1109/JSAC.2022.3155523. [14] LECUN Y, BOSER B, DENKER J S, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural Computation, 1989, 1(4): 541–551. doi: 10.1162/neco.1989.1.4.541. [15] SEYFIOGLU M S, EROL B, GURBUZ S Z, et al. DNN transfer learning from diversified micro-Doppler for motion classification[J]. IEEE Transactions on Aerospace and Electronic Systems, 2019, 55(5): 2164–2180. doi: 10.1109/TAES.2018.2883847. [16] RANI S, CHOWDHURY A, CHAKRAVARTY T, et al. Exploiting unique state transitions to capture micro-Doppler signatures of human actions using CW radar[J]. IEEE Sensors Journal, 2021, 21(24): 27878–27886. doi: 10.1109/JSEN.2021.3126436. [17] DING Chuanwei, ZHANG Li, CHEN Haoyu, et al. Sparsity-based human activity recognition with pointnet using a portable FMCW radar[J]. IEEE Internet of Things Journal, 2023, 10(11): 10024–10037. doi: 10.1109/JIOT.2023.3235808. [18] 何密, 平钦文, 戴然. 深度学习融合超宽带雷达图谱的跌倒检测研究[J]. 雷达学报, 2023, 12(2): 343–355. doi: 10.12000/JR22169.HE Mi, PING Qinwen, and DAI Ran. Fall detection based on deep learning fusing ultrawideband radar spectrograms[J]. Journal of Radars, 2023, 12(2): 343–355. doi: 10.12000/JR22169. [19] WANG Zhengwei, SHE Qi, and SMOLIC A. Action-net: Multipath excitation for action recognition[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 13209–13218. doi: 10.1109/CVPR46437.2021.01301. [20] MALIK N U R, ABU-BAKAR S A R, SHEIKH U U, et al. Cascading pose features with CNN-LSTM for multiview human action recognition[J]. Signals, 2023, 4(1): 40–55. doi: 10.3390/signals4010002. [21] WANG Yinghui, ZHU Anlei, MA Haomiao, et al. 3D-ShuffleViT: An efficient video action recognition network with deep integration of self-attention and convolution[J]. Mathematics, 2023, 11(18): 3848. doi: 10.3390/math11183848. [22] DONG Min, FANG Zhenglin, LI Yongfa, et al. AR3D: Attention residual 3D network for human action recognition[J]. Sensors, 2021, 21(5): 1656. doi: 10.3390/s21051656. [23] QI C R, SU Hao, KAICHUN M, et al. PointNet: Deep learning on point sets for 3D classification and segmentation[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 77–85. doi: 10.1109/CVPR.2017.16. [24] QI C R, YI Li, SU Hao, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5105–5114. [25] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [26] 郭帅, 陈婷, 王鹏辉, 等. 基于角度引导Transformer融合网络的多站协同目标识别方法[J]. 雷达学报, 2023, 12(3): 516–528. doi: 10.12000/JR23014.GUO Shuai, CHEN Ting, WANG Penghui, et al. Multistation cooperative radar target recognition based on an angle-guided Transformer fusion network[J]. Journal of Radars, 2023, 12(3): 516–528. doi: 10.12000/JR23014. [27] 石跃祥, 朱茂清. 基于骨架动作识别的协作卷积Transformer网络[J]. 电子与信息学报, 2023, 45(4): 1485–1493. doi: 10.11999/JEIT220270.SHI Yuexiang and ZHU Maoqing. Collaborative convolutional transformer network based on skeleton action recognition[J]. Journal of Electronics & Information Technology, 2023, 45(4): 1485–1493. doi: 10.11999/JEIT220270. [28] 韩宗旺, 杨涵, 吴世青, 等. 时空自适应图卷积与Transformer结合的动作识别网络[J]. 电子与信息学报, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.HAN Zongwang, YANG Han, WU Shiqing, et al. Action recognition network combining spatio-temporal adaptive graph convolution and Transformer[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551. [29] XIAO Zhiqiang, YE Kuntao, and CUI Guolong. PointNet-transformer fusion network for in-cabin occupancy monitoring with mm-wave radar[J]. IEEE Sensors Journal, 2024, 24(4): 5370–5382. doi: 10.1109/JSEN.2023.3347893. [30] 金添, 宋永坤, 戴永鹏, 等. UWB-HA4D-1.0: 超宽带雷达人体动作四维成像数据集[J]. 雷达学报, 2022, 11(1): 27–39. doi: 10.12000/JR22008.JIN Tian, SONG Yongkun, DAI Yongpeng, et al. UWB-HA4D-1.0: An ultra-wideband radar human activity 4D imaging dataset[J]. Journal of Radars, 2022, 11(1): 27–39. doi: 10.12000/JR22008. [31] SONG Shaoqiu, DAI Yongpeng, SUN Shilong, et al. Efficient image reconstruction methods based on structured sparsity for short-range radar[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5212615. doi: 10.1109/TGRS.2024.3404626. [32] SOUMA R, KIDERA S, and KIRIMOTO T. Fast and accurate permittivity estimation algorithm for UWB internal imaging radar[C]. 2011 3rd International Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Seoul, Korea (South), 2011: 1–4. [33] ANDERSSON L E. On the determination of a function from spherical averages[J]. SIAM Journal on Mathematical Analysis, 1988, 19(1): 214–232. doi: 10.1137/0519016. [34] CHEN Jiahui, LI Nian, GUO Shisheng, et al. Enhanced 3-D building layout tomographic imaging via tensor approach[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5105614. doi: 10.1109/TGRS.2024.3391282. [35] ASH M, RITCHIE M, and CHETTY K. On the application of digital moving target indication techniques to short-range FMCW radar data[J]. IEEE Sensors Journal, 2018, 18(10): 4167–4175. doi: 10.1109/JSEN.2018.2823588. [36] LORENSEN W E and CLINE H E. Marching cubes: A high resolution 3D surface construction algorithm[J]. ACM SIGGRAPH Computer Graphics, 1987, 21(4): 163–169. doi: 10.1145/37402.37422. [37] HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735. [38] CHUNG J, GÜLÇEHRE Ç, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL]. https://arxiv.org/abs/1412.3555, 2014. [39] TRAN D, RAY J, SHOU Zheng, et al. ConvNet architecture search for spatiotemporal feature learning[EB/OL]. https://arxiv.org/abs/1708.05038, 2017. [40] FEICHTENHOFER C, FAN Haoqi, MALIK J, et al. SlowFast networks for video recognition[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 6202–6211. doi: 10.1109/ICCV.2019.00630. [41] WANG Limin, XIONG Yuanjun, WANG Zhe, et al. Temporal segment networks: Towards good practices for deep action recognition[C]. 14th European Conference on European Conference, Amsterdam, The Netherlands, 2016: 20–36. doi: 10.1007/978-3-319-46484-8_2. [42] LIN Ji, GAN Chuang, and HAN Song. TSM: Temporal shift module for efficient video understanding[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 7082–7092. doi: 10.1109/ICCV.2019.00718. [43] VAN DER MAATEN L and HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(86): 2579–2605. -



计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

