
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Online Decision-making Method for Frequency-agile Radar Based on Multi-Armed Bandit
-
摘要: 频率捷变技术发挥了雷达在电子对抗中主动对抗优势,可以有效提升雷达的抗噪声压制式干扰性能。然而,随着干扰环境的日益复杂,在无法事先了解环境性质的情况下,设计一种具有动态适应能力的频率捷变雷达在线决策方法是一个具有挑战性的问题。该文根据干扰策略的特征,将压制式干扰场景分为3类,并以最大化检测概率为目标,设计了一种基于多臂赌博机(MAB)的频率捷变雷达在线决策方法。该方法是一种在线学习算法,无需干扰环境的先验知识和离线训练过程,在不同干扰场景下均实现了优异的学习性能。理论分析和仿真结果表明,与经典算法和随机捷变策略相比,所提方法具有更强的灵活性,在多种干扰场景下均能够有效提升频率捷变雷达的抗干扰和目标检测性能。
-
关键词:
- 频率捷变 /
- 噪声压制式干扰 /
- 检测概率 /
- 多臂赌博机(MAB) /
- 在线学习
Abstract: Frequency agile technology provides full play to the advantage of radars for adopting electronic countermeasures actively, which can effectively enhance the antinoise suppression jamming performance of radars. However, with the increasing complexity of the interference environment, developing an online decision-making method for frequency-agile radar with dynamic adaptability and without foresight of the nature of the environment is a demanding task. According to the features of the jamming strategy, suppression jamming scenarios are divided into three categories, and an online decision-making method for frequency-agile radar based on Multi-Armed Bandit (MAB) is developed to maximize the radar’s detection probability. This approach is an online learning algorithm that does not need to interfere with the foresight of the environment and offline training process and realizes remarkable learning performance from noninterference scenarios to adaptive interference scenarios. The simulation results and theoretical analysis demonstrate that compared with the classical algorithm and stochastic agile strategy, the proposed method has stronger flexibility and can effectively improve the antijamming and target detection performances of the frequency-agile radar for various jamming scenarios. -
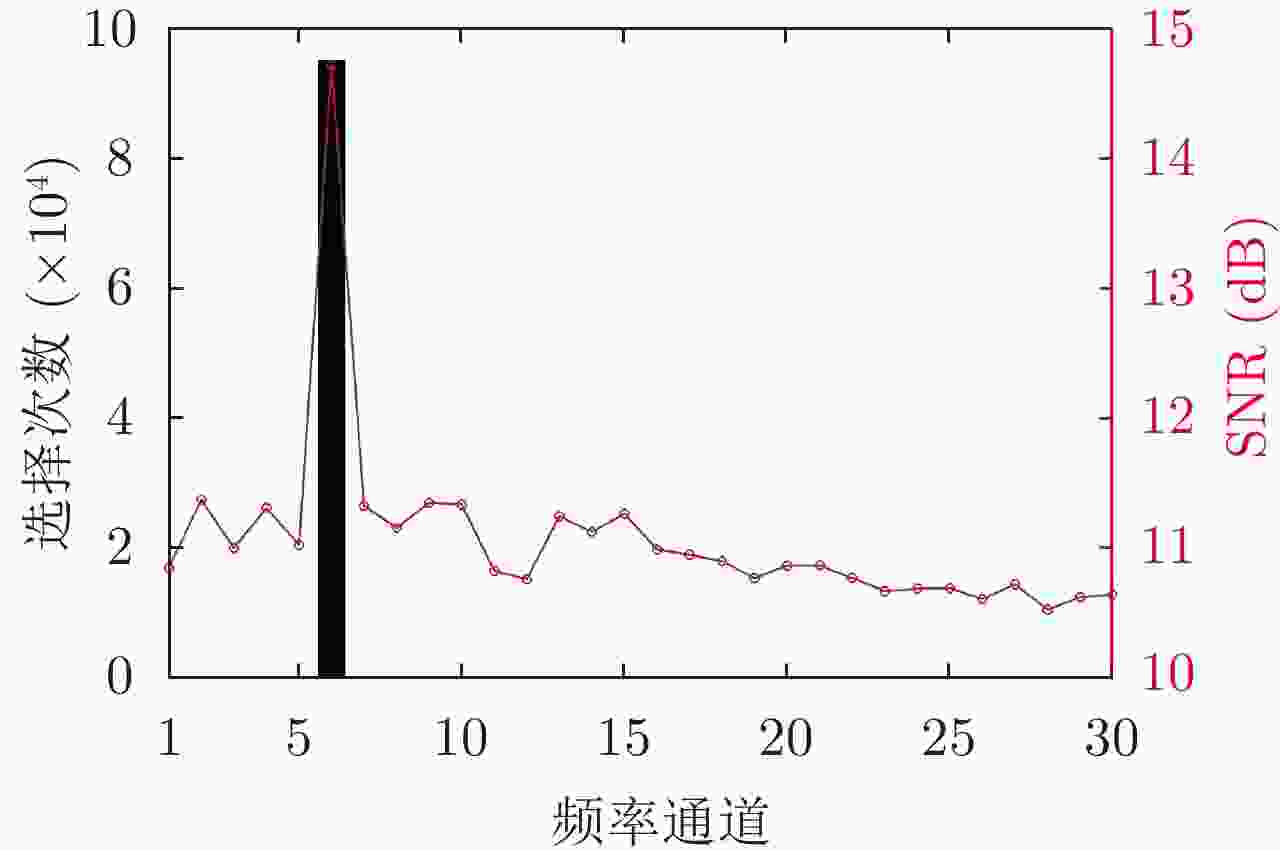
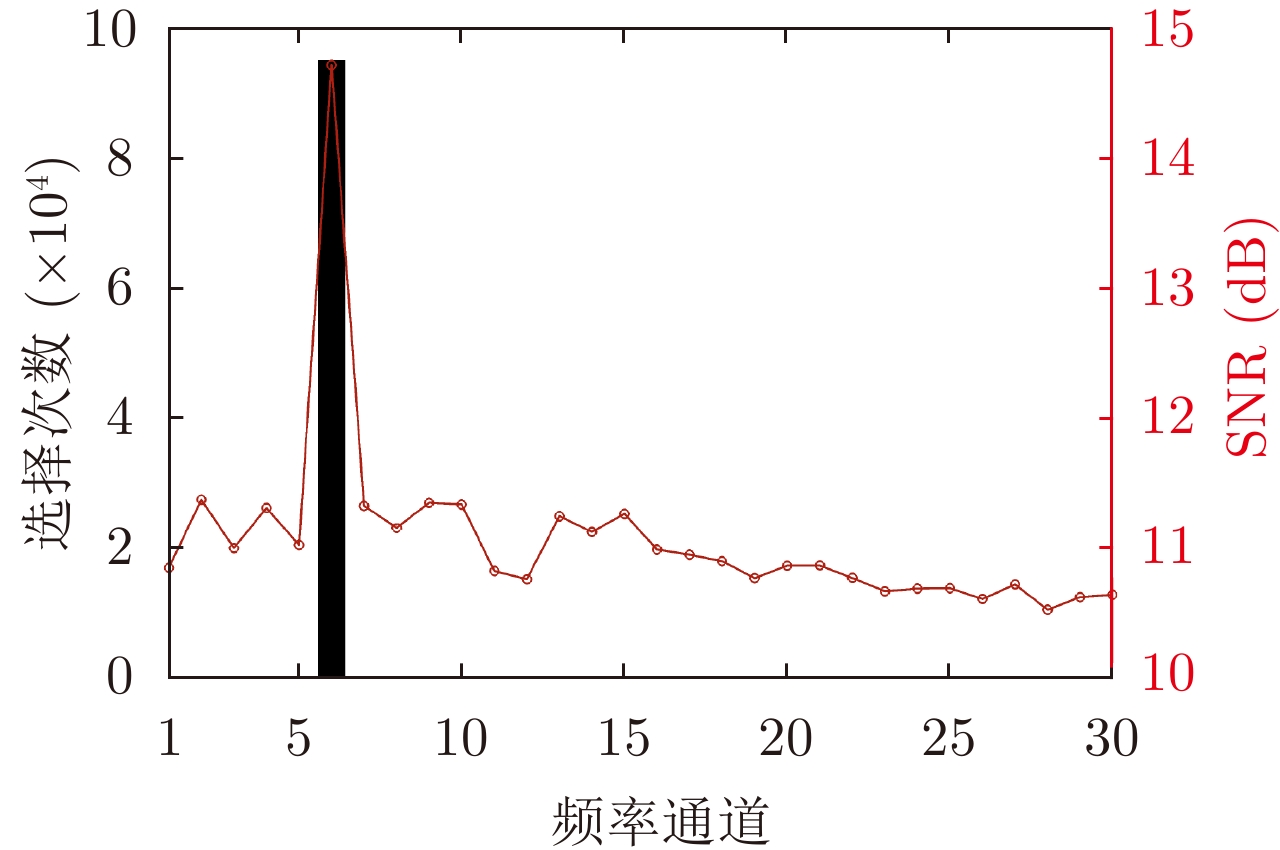
图 3 无干扰环境下频率通道选择次数与SNR
Figure 3. Frequency channel selection times and SNR in the no jamming environment
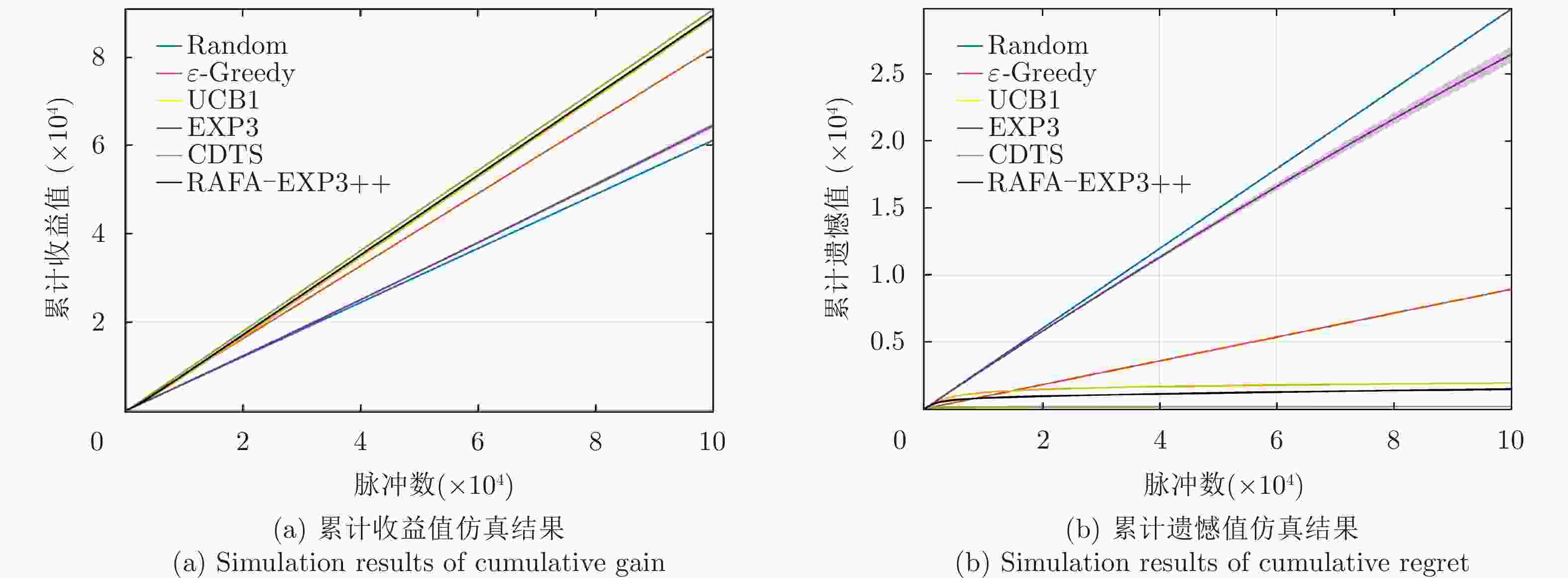
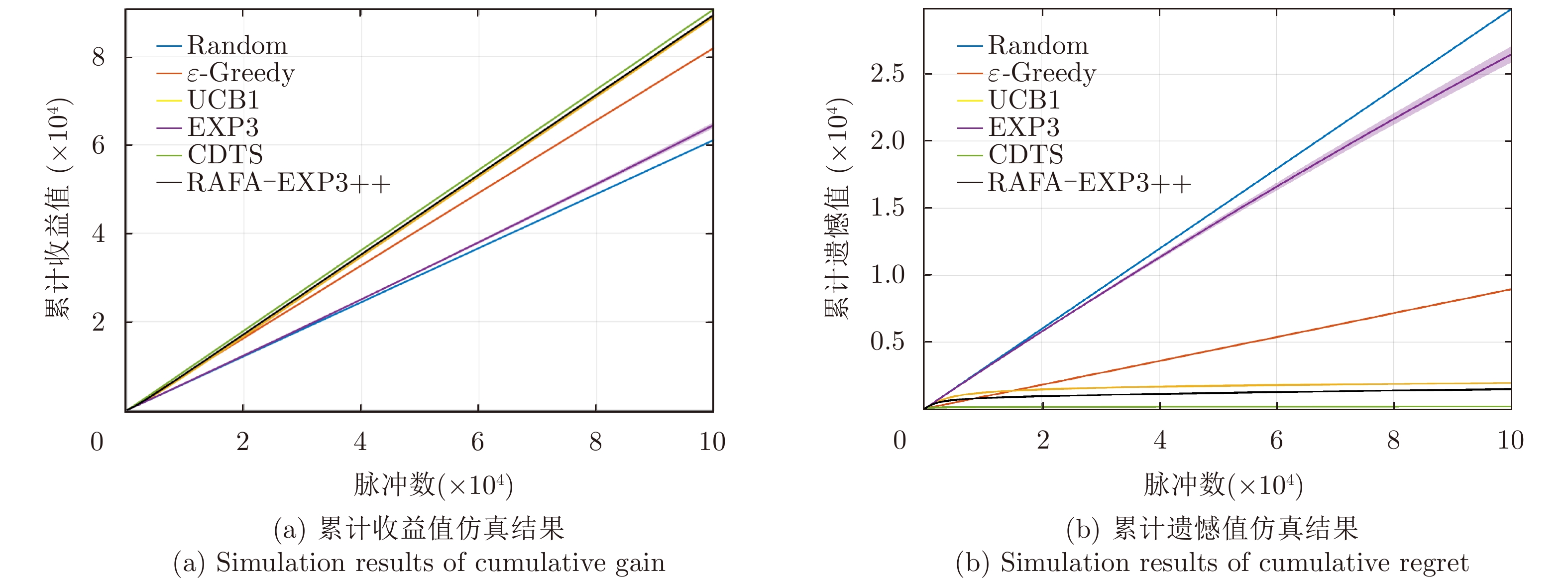
图 4 无干扰环境下所提算法的性能对比图
Figure 4. Comparison plots of the performance of the proposed algorithm in no jamming environment

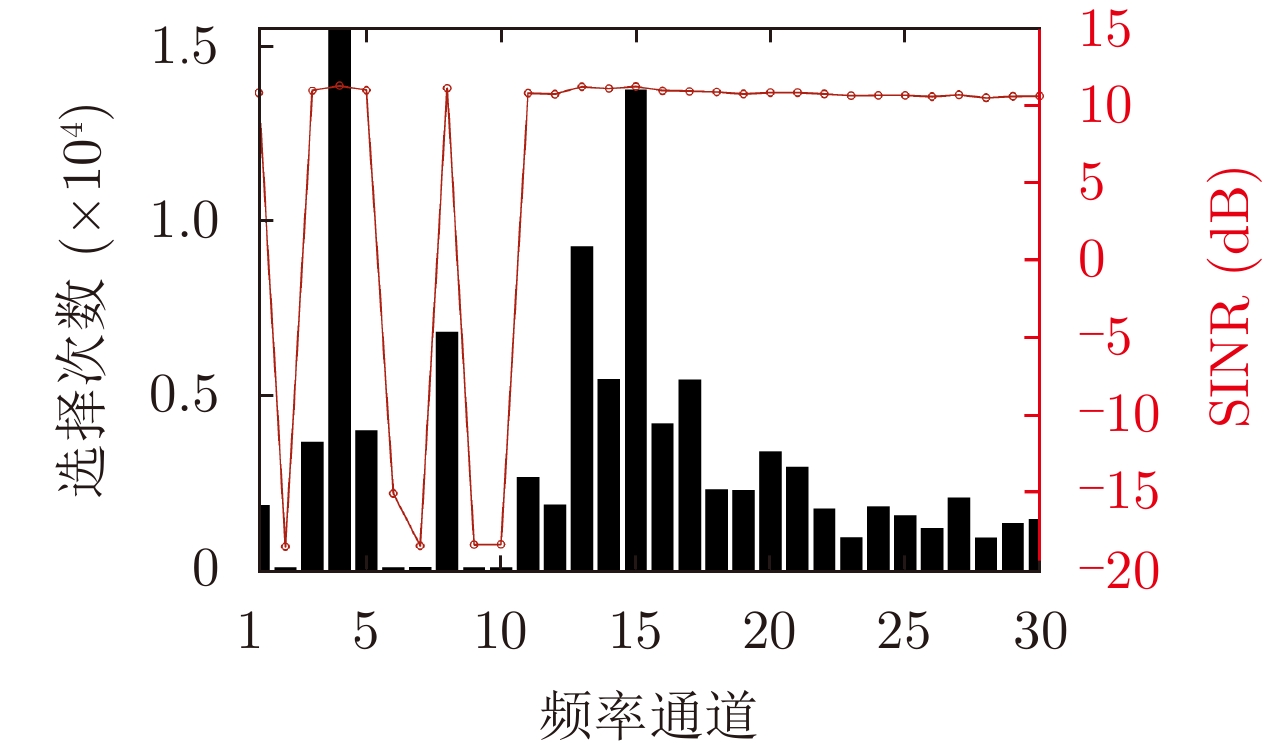
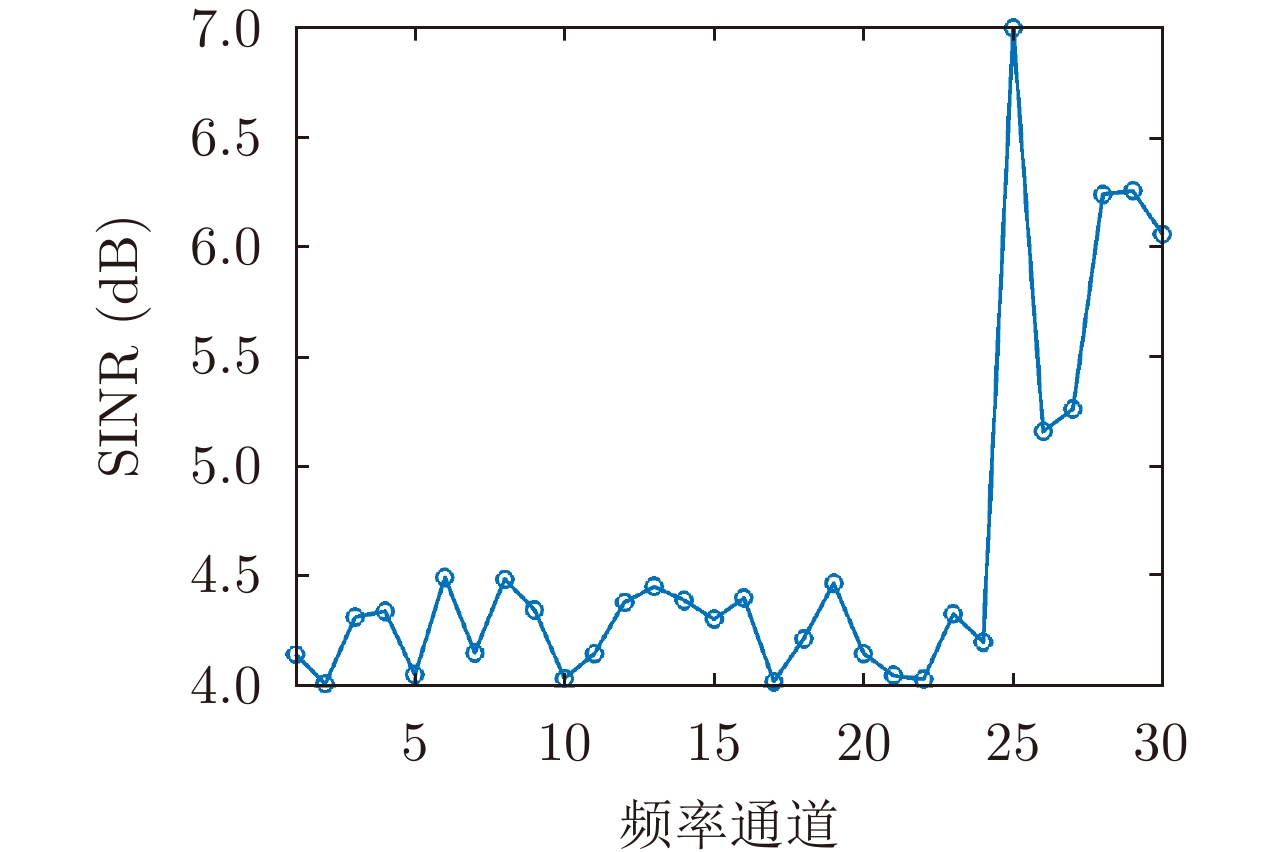
图 5 固定干扰策略环境下频率通道选择次数与SINR
Figure 5. Frequency channel selection times and SINR in the fixed jamming strategy environment
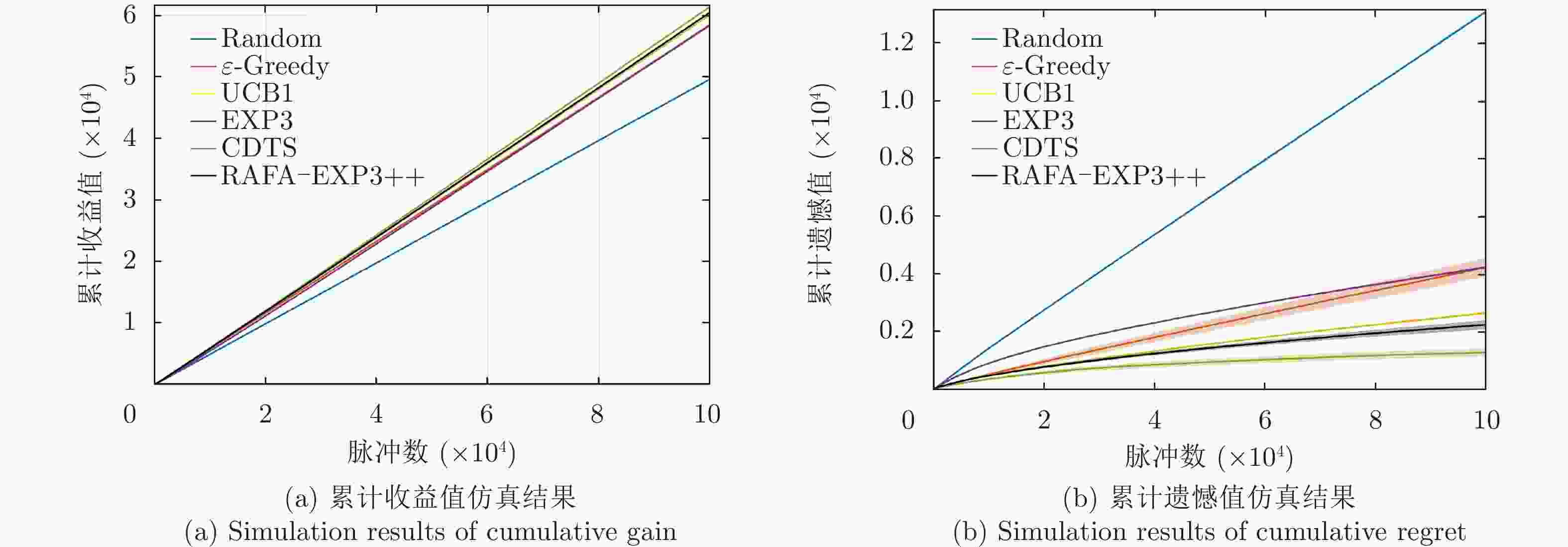
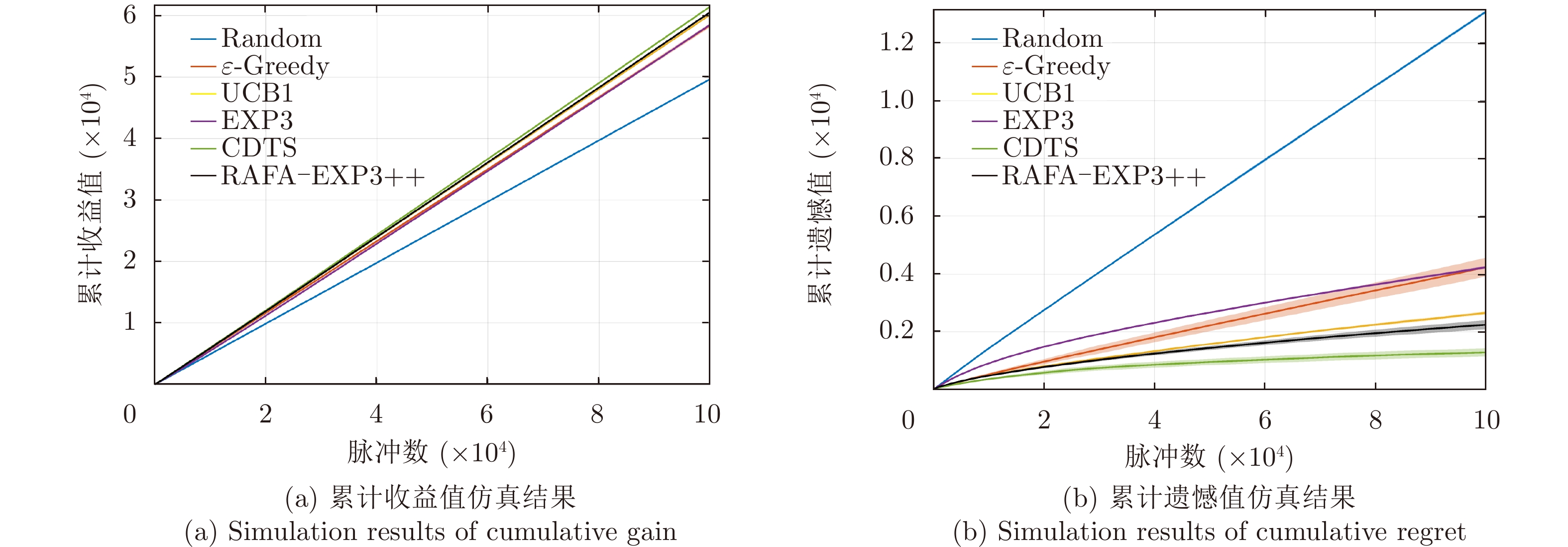
图 6 固定干扰策略场景下所提算法的性能对比图
Figure 6. Comparison plots of the performance of the proposed algorithm in fixed jamming strategy environment

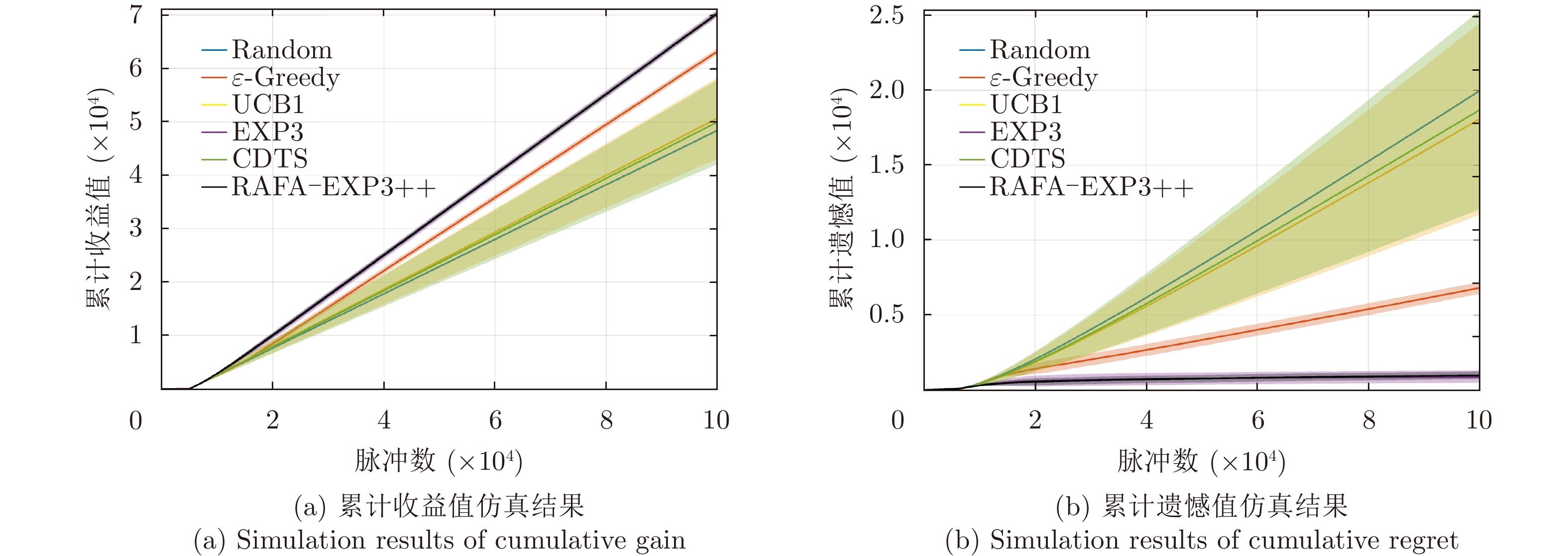
图 8 非自适应干扰场景中所提算法的性能对比图
Figure 8. Comparison plots of the performance of the proposed algorithm in non-adaptive jamming scene

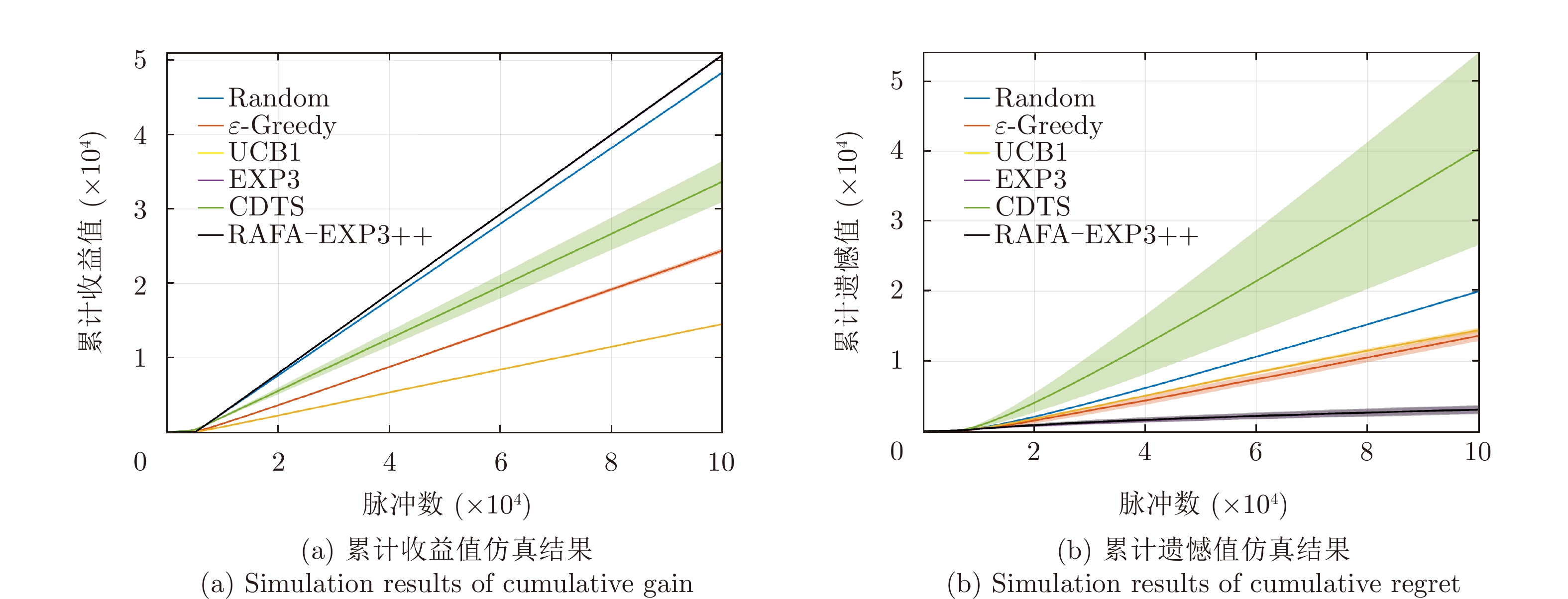
图 9 自适应干扰场景下所提算法的性能对比图
Figure 9. Comparison plots of the performance of the proposed algorithm in adaptive jamming scene
1 RAFA-EXP3++算法
1. RAFA-EXP3++ algorithm
初始化:频率通道数N, $\forall {f_i} \in \mathcal{F}$,初始损失估计值 ${\tilde L_0}({f_i}) = 0$,权重 ${w_0}({f_i}) = 1$,损失期望差估计值 $ {\hat \varDelta _0}({f_i}) $=1 对于每一个脉冲重复周期 $t = 1,2, \cdots ,T$ 1. 设置参数: ${\beta _{t}} = \dfrac{1}{2}\sqrt {\dfrac{{\ln N}}{{tN}}} $; ${\eta _{t}} = 2{\beta _{t}}$; $c = 20$; $\forall {f_i} \in \mathcal{F}$: $ {\xi _{t}}({f_i}) = \dfrac{{c{{(\ln t)}^2}}}{{t{{\hat \varDelta }_{t - 1}}{{({f_i})}^2}}} $; ${\varepsilon _{t}}({f_i}) = \min \left\{ \dfrac{1}{{2N}},{\beta _{t}},{\xi _{t}}({f_i})\right\} $ 2. $\forall {f_i} \in \mathcal{F}$,计算各频率通道选择概率 ${p_{t}}({f_i})$: ${p_{t}}({f_i}) = \left(1 - \displaystyle\sum\limits_{j = 1}^N {{\varepsilon _{t}}({f_j})} \right)\dfrac{{{w_{t - 1}}({f_i})}}{{\displaystyle\sum\limits_{j = 1}^N {{w_{t - 1}}({f_j})} }} + {\varepsilon _{t}}({f_i})$ (11) 3. 依概率 ${p_{t}}$从可用频率通道集 $\mathcal{F}$中选择发射频率通道 ${f_a}$,接收回波信号并利用式(5)计算损失值 ${l_{t}}({f_a})$。 4. $\forall {f_i} \in \mathcal{F}$,更新各频率通道权重值 $ {w_{t}}({f_i}) $和损失期望差估计值 $ {\hat \varDelta _{t}}({f_i}) $: $ {\tilde{L}}_{t}({f}_{i})=\left\{\begin{array}{cc}{\tilde{L}}_{t-1}({f}_{i})+\dfrac{{l}_{t}({f}_{i})}{{p}_{t}({f}_{i})},& 当{f}_{i}={f}_{a}时\\ {\tilde{L}}_{t-1}({f}_{i}),& 当{f}_{i}\ne {f}_{a}时\end{array} \right. $ (12) $ {w_{t}}({f_i}) = \exp \left( - {\eta _{t}}{\tilde L_{t}}({f_i})\right) $ (13) $ {\hat \varDelta _{t}}({f_i}) = \min \left\{ {1,\dfrac{1}{t}\left( {{{\tilde L}_{t}}({f_i}) - \mathop {\min }\limits_{{f_j} \in \mathcal{F}} {{\tilde L}_{t}}({f_j})} \right)} \right\} $ (14)  下载: 导出CSV
下载: 导出CSV
表 1 仿真实验雷达参数
Table 1. Radar parameters of simulation experiment
参数 数值 工作频段 Ku频段 信号带宽B 40 MHz 频率通道数N 30 脉冲重复周期 ${T_{\mathrm{r}}}$ 20 μs 发射功率 ${P_{t}}$ 1000 W 发射天线增益G 40 dB 雷达系统损耗 ${L_{s}}$ 4 dB 接收机带宽 ${B_{\rm n}}$ 40 MHz 接收机噪声系数 ${F_{\rm n}}$ 3 dB 虚警率 ${P_{{\mathrm{fa}}}}$ ${10^{ - 4}}$ 目标的径向距离R 10 km
下载: 导出CSV
表 2 仿真实验中目标RCS均值(m2)
Table 2. The mean RCS of target in the simulation experiment (m2)
频率通道 RCS均值 1~5 $U(8.5,9.5)$ 6 $14$ 7~15 $U(8.5,10.0)$ 16~30 $U(9.0,9.5)$
下载: 导出CSV
表 3 仿真实验干扰机部分参数
Table 3. Jammer parameters of simulation experiment
参数 数值 干扰机发射总功率 ${P_{\mathrm{J}}}$ 800 W 干扰机天线增益 ${G_{\mathrm{J}}}$ 10 dB 雷达在干扰方向增益 $G(\theta )$ 20 dB 极化失配损失 ${\gamma _{\mathrm{J}}}$ 0.5 干扰系统损耗 ${L_{\mathrm{J}}}$ 5 dB 与雷达的径向距离 ${R_{\mathrm{J}}}$ 15 km
下载: 导出CSV
表 4 扫频式干扰参数设置
Table 4. Parameter setting of sweeping frequency jamming
参数 数值 扫频带宽 1.2 GHz 干扰带宽 200 MHz 跳频带宽 200 MHz 扫频周期 120 μs
下载: 导出CSV
表 5 非自适应干扰场景中检测到目标的次数
Table 5. The number of detected targets in non-adaptive jamming scene
算法名称 次数 Random 53965 $\varepsilon {\text{-}} {\mathrm{Greedy}}$ 66838 UCB1 55951 EXP3 72825 CDTS 55345 RAFA-EXP3++ 72837
下载: 导出CSV
表 6 自适应干扰场景下检测到目标的次数
Table 6. The number of detected targets in adaptive jamming scene
算法名称 次数 Random 54048 $\varepsilon {\text{-}} {\mathrm{Greedy}}$ 27423 UCB 1 16265 EXP3 55135 CDTS 33723 RAFA-EXP3++ 55170
下载: 导出CSV
-
[1] LI Nengjing and ZHANG Yiting. A survey of radar ECM and ECCM[J]. IEEE Transactions on Aerospace and Electronic Systems, 1995, 31(3): 1110–1120. doi: 10.1109/7.395232 [2] HUANG Tianyao, LIU Yimin, MENG Huadong, et al. Cognitive random stepped frequency radar with sparse recovery[J]. IEEE Transactions on Aerospace and Electronic Systems, 2014, 50(2): 858–870. doi: 10.1109/TAES.2013.120443 [3] 全英汇, 方文, 高霞, 等. 捷变频雷达导引头技术现状与发展趋势[J]. 航空兵器, 2021, 28(3): 1–9. doi: 10.12132/ISSN.1673-5048.2020.0209QUAN Yinghui, FANG Wen, GAO Xia, et al. Review on frequency agile radar seeker[J]. Aero Weaponry, 2021, 28(3): 1–9. doi: 10.12132/ISSN.1673-5048.2020.0209 [4] 李潮, 张巨泉. 雷达电子战自适应捷变频对抗技术研究[J]. 电子对抗技术, 2004, 19(1): 30–33. doi: 10.3969/j.issn.1674-2230.2004.01.008LI Chao and ZHANG Juquan. Research on the combat technology of radar EW with self-adapted frequency agile ability[J]. Electronic Information Warfare Technology, 2004, 19(1): 30–33. doi: 10.3969/j.issn.1674-2230.2004.01.008 [5] 全英汇, 方文, 沙明辉, 等. 频率捷变雷达波形对抗技术现状与展望[J]. 系统工程与电子技术, 2021, 43(11): 3126–3136. doi: 10.12305/j.issn.1001-506X.2021.11.11QUAN Yinghui, FANG Wen, SHA Minghui, et al. Present situation and prospects of frequency agility radar waveform countermeasures[J]. Systems Engineering and Electronics, 2021, 43(11): 3126–3136. doi: 10.12305/j.issn.1001-506X.2021.11.11 [6] SMITH G E, CAMMENGA Z, MITCHELL A, et al. Experiments with cognitive radar[J]. IEEE Aerospace and Electronic Systems Magazine, 2016, 31(12): 34–46. doi: 10.1109/MAES.2016.150215 [7] MARTONE A F, RANNEY K I, SHERBONDY K, et al. Spectrum allocation for noncooperative radar coexistence[J]. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(1): 90–105. doi: 10.1109/TAES.2017.2735659 [8] KIRK B H, NARAYANAN R M, GALLAGHER K A, et al. Avoidance of time-varying radio frequency interference with software-defined cognitive radar[J]. IEEE Transactions on Aerospace and Electronic Systems, 2019, 55(3): 1090–1107. doi: 10.1109/TAES.2018.2886614 [9] SUTTON R S and BARTO A G. Reinforcement Learning: An Introduction[M]. 2nd ed. Cambridge: MIT Press, 2018: 32–36. [10] SELVI E, BUEHRER R M, MARTONE A, et al. Reinforcement learning for adaptable bandwidth tracking radars[J]. IEEE Transactions on Aerospace and Electronic Systems, 2020, 56(5): 3904–3921. doi: 10.1109/TAES.2020.2987443 [11] PUTERMAN M L. Chapter 8 Markov decision processes[J]. Handbooks in Operations Research and Management Science, 1990, 2: 331–434. doi: 10.1016/S0927-0507(05)80172-0 [12] THORNTON C E, KOZY M A, BUEHRER R M, et al. Deep reinforcement learning control for radar detection and tracking in congested spectral environments[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(4): 1335–1349. doi: 10.1109/TCCN.2020.3019605 [13] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529–533. doi: 10.1038/nature14236 [14] AILIYA, YI Wei, and VARSHNEY P K. Adaptation of frequency hopping interval for radar anti-jamming based on reinforcement learning[J]. IEEE Transactions on Vehicular Technology, 2022, 71(12): 12434–12449. doi: 10.1109/TVT.2022.3197425 [15] LI Kang, JIU Bo, WANG Penghui, et al. Radar active antagonism through deep reinforcement learning: A way to address the challenge of Mainlobe jamming[J]. Signal Processing, 2021, 186: 108130. doi: 10.1016/j.sigpro.2021.108130 [16] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017. [17] LEE S Y, CHOI S, and CHUNG S Y. Sample-efficient deep reinforcement learning via episodic backward update[C]. The 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2019: 2112–2121. [18] WHITE III C C and WHITE D J. Markov decision processes[J]. European Journal of Operational Research, 1989, 39(1): 1–16. [19] BUBECK S and CESA-BIANCHI N. Regret analysis of stochastic and nonstochastic multi-armed bandit problems[J]. Foundations and Trends® in Machine Learning, 2012, 5(1): 1–122. doi: 10.1561/2200000024 [20] HOI S C H, SAHOO D, LU Jing, et al. Online learning: A comprehensive survey[J]. Neurocomputing, 2021, 459: 249–289. doi: 10.1016/j.neucom.2021.04.112 [21] ZHOU Pan and JIANG Tao. Toward optimal adaptive wireless communications in unknown environments[J]. IEEE Transactions on Wireless Communications, 2016, 15(5): 3655–3667. doi: 10.1109/TWC.2016.2524638 [22] WANG Qian, XU Ping, REN Kui, et al. Towards optimal adaptive UFH-based anti-jamming wireless communication[J]. IEEE Journal on Selected Areas in Communications, 2012, 30(1): 16–30. doi: 10.1109/JSAC.2012.120103 [23] KHALEDI M and ABOUZEID A A. Dynamic spectrum sharing auction with time-evolving channel qualities[J]. IEEE Transactions on Wireless Communications, 2015, 14(11): 5900–5912. doi: 10.1109/TWC.2015.2443796 [24] ZHAO Qing, KRISHNAMACHARI B, and LIU Keqin. On myopic sensing for multi-channel opportunistic access: Structure, optimality, and performance[J]. IEEE Transactions on Wireless Communications, 2008, 7(12): 5431–5440. doi: 10.1109/T-WC.2008.071349 [25] PULKKINEN P, AITTOMÄKI T, and KOIVUNEN V. Reinforcement learning based transmitter-receiver selection for distributed MIMO radars[C]. 2020 IEEE International Radar Conference (RADAR), Washington, USA, 2020: 1040–1045. [26] 王俊迪, 许蕴山, 肖冰松, 等. 相控阵雷达目标搜索的MAB模型策略[J]. 现代雷达, 2019, 41(6): 45–49. doi: 10.16592/j.cnki.1004-7859.2019.06.009WANG Jundi, XU Yunshan, XIAO Bingsong, et al. A MAB mode strategy in AESA radar target searching[J]. Modern Radar, 2019, 41(6): 45–49. doi: 10.16592/j.cnki.1004-7859.2019.06.009 [27] AUER P, CESA-BIANCHI N, and FISCHER P. Finite-time analysis of the multiarmed bandit problem[J]. Machine Learning, 2002, 47(2): 235–256. doi: 10.1023/A:1013689704352 [28] THORNTON C E, BUEHRER R M, and MARTONE A F. Constrained contextual bandit learning for adaptive radar waveform selection[J]. IEEE Transactions on Aerospace and Electronic Systems, 2021, 58(2): 1133–1148. doi: 10.1109/TAES.2021.3109110 [29] THOMPSON W R. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples[J]. Biometrika, 1933, 25(3/4): 285–294. doi: 10.2307/2332286 [30] AUER P, CESA-BIANCHI N, FREUND Y, et al. The nonstochastic multiarmed bandit problem[J]. SIAM Journal on Computing, 2002, 32(1): 48–77. doi: 10.1137/S0097539701398375 [31] FANG Yuyuan, ZHANG Lei, WEI Shaopeng, et al. Online frequency-agile strategy for radar detection based on constrained combinatorial nonstationary bandit[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(2): 1693–1706. doi: 10.1109/TAES.2022.3203689 [32] 王跃东, 顾以静, 梁彦, 等. 伴随压制干扰与组网雷达功率分配的深度博弈研究[J]. 雷达学报, 2023, 12(3): 642–656. doi: 10.12000/JR23023WANG Yuedong, GU Yijing, LIANG Yan, et al. Deep game of escorting suppressive jamming and networked radar power allocation[J]. Journal of Radars, 2023, 12(3): 642–656. doi: 10.12000/JR23023 [33] 陈伯孝. 现代雷达系统分析与设计[M]. 西安: 西安电子科技大学出版社, 2012: 79–81.CHEN Boxiao. Mordern Radar System Analysis and Design[M]. Xi’an: Xidian University Press, 2012: 79–81. [34] 赵国庆. 雷达对抗原理[M]. 2版. 西安: 西安电子科技大学出版社, 2012: 183–186.ZHAO Guoqing. Principle of Radar Countermeasure[M]. Xi’an: Xidian University Press, 2012: 183–186. [35] AUDIBERT J Y, MUNOS R, and SZEPESVÁRI C. Exploration–exploitation tradeoff using variance estimates in multi-armed bandits[J]. Theoretical Computer Science, 2009, 410(19): 1876–1902. doi: 10.1016/j.tcs.2009.01.016 [36] ARORA R, DEKEL O, and TEWARI A. Online bandit learning against an adaptive adversary: From regret to policy regret[C]. The 29th International Conference on International Conference on Machine Learning, Edinburgh, Scotland, 2012: 1747–1754. [37] BUBECK S and SLIVKINS A. The best of both worlds: Stochastic and adversarial bandits[C]. The 25th Annual Conference on Learning Theory, Edinburgh, UK, 2012: 23. [38] SELDIN Y and SLIVKINS A. One practical algorithm for both stochastic and adversarial bandits[C]. The 31st International Conference on International Conference on Machine Learning, Beijing, China, 2014: 1287–1295. -

计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

