
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Wideband Radar Echo Frequency-domain Simulation and Analysis for High Speed Moving Targets
-
摘要: 该文提出了一种高速运动目标宽带雷达回波频域模拟方法。根据雷达波与运动目标相互作用的物理过程建立了运动目标宽带雷达回波的频谱模型,提出了一种雷达回波的频域建模流程,分析了目标径向距离和径向速度对LFM 信号匹配滤波结果的影响,推导了高分辨率距离像(HRRP)平移和扩展的定量结论。仿真结果验证了该方法的正确性和有效性。
-
关键词:
- 雷达信号处理 /
- 宽带雷达 /
- 运动目标 /
- 雷达散射截面(RCS) /
- 线性调频(LFM)波形
Abstract: A frequency-domain method is proposed for wideband radar echo simulation of high-speed moving targets. Based on the physical process of electromagnetic waves observing a moving target, a frequency-domain echo model of wideband radar is constructed, and the block diagram of the radar echo simulation in frequency-domain is presented. Then, the impacts of radial velocity and slant range on the matching filtering of LFM radar are analyzed, and some quantitative conclusions on the shift and expansion of the radar profiles are obtained. Simulation results illustrate the correctness and efficiency of the proposed method.-
Key words:
- Radar signal processing /
- Wideband radar /
- Moving target /
- Radar Cross Section (RCS) /
- LFM waveform
-
1. 引言
多目标跟踪(Multitarget Tracking, MTT)是现代雷达系统的一项关键任务,旨在根据雷达的观测信息,实时估计多个目标的运动状态(如位置、速度等),并对它们的运动轨迹进行持续而准确的跟踪[1]。作为雷达信号处理领域的核心问题之一,MTT在军事[2,3]、自动驾驶[4]、智慧城市[5]等诸多领域有着广泛而重要的应用。然而,由于雷达探测环境的复杂多变性,如低信噪比、高杂波密度、频繁的目标出现和消失等,MTT一直面临着严峻的技术挑战。
传统的MTT方法主要有基于数据关联(Data Association, DA)的方法[6−8]和基于随机有限集(Random Finite Set, RFS)统计理论的方法两大类。DA-MTT受限于复杂环境下的关联决策问题以及随量测和目标数目增长关联假设组合爆炸的问题。而RFS-MTT在给出具有“工程友好”特性的同时提出了一种严密的多目标跟踪问题研究的统计学理论框架,在近些年备受关注。该方法通过将多目标状态和观测建模为随机集合,并利用贝叶斯滤波机制实现状态的递归估计[9]。在RFS理论的指导下,研究者先后发展了多种MTT滤波器,包括概率假设密度(Probability Hypothesis Density, PHD)滤波器[10]、势PHD (Cardinalized PHD, CPHD)滤波器[11],多目标多伯努利(Multitarget Multi-Bernoulli, MeMBer)滤波器[12]。以上滤波算法虽然有效避免了数据关联中组合爆炸的问题,但无法获得目标的轨迹信息,且均为近似的后验结果。在此背景下,Vo等人[13]提出的广义标签多伯努利(Generalized Labelled Multi-Bernoulli, GLMB)滤波器通过给目标分配唯一标签实现了轨迹的生成。Garcia-fernandez等人[14]提出的泊松多伯努利混合(Poisson Multi-Bernoulli Mixture, PMBM)滤波器输出结果虽然不包含显式的轨迹信息,但在理论上达到了无损近似。尽管这些方法在多种场景下取得了一定的成果,但它们普遍依赖于目标运动和观测噪声的先验模型,如高斯假设、泊松分布等,仍难以适应复杂动态环境下的模型失配问题。此外,这些滤波器在实时性和计算效率方面也存在一定局限。
2014年—2024年,深度学习凭借其特征提取和函数拟合能力,为解决MTT难题带来了新的契机[15]。通过深度神经网络,从海量数据中自动挖掘目标运动和观测的内在模式,降低对先验假设的依赖,并提高算法的泛化性能。已有的工作主要分为两类:一类代表性工作致力于将深度学习与经典MTT滤波器相结合,在原有滤波框架下,利用神经网络改进滤波器的关键模块,如滤波器的初始化[16]、杂波抑制[17]、状态估计[18,19]等。另一类则尝试探索深度网络模型的MTT范式,通过时空信息的联合优化实现多目标状态和轨迹的同时估计[20−22]。由于需要学习数据的长期依赖关系,LSTM网络的应用尤其广泛,文献[23,24]基于LSTM网络提出了多目标跟踪模型MTF和DeepMTT,以数据驱动的方式解决复杂场景下的数据关联和机动目标跟踪的问题。尽管这些方法在特定场景下取得了优于传统方法的性能,但在面对雷达数据所固有的稀疏性、数据关联复杂性等挑战时,依然难以实现对目标运动的精准刻画和长时追踪。
近些年,Transformer[25]以其注意力机制和时序建模能力[26],为进一步突破MTT瓶颈提供了全新思路。Pinto等人[27]基于Transformer网络提出了用于多目标跟踪的模型框架(Multitarget Tracking Transformer, MT3),凭借Transformer独特的自注意力(Self-attention)和交叉注意力(Cross-attention)机制,MT3能够从量测数据中学习目标运动模式并且建立目标序列的长程依赖,隐式地执行数据关联,实现了端到端的多目标跟踪,在多种复杂任务上的性能表现超越传统的基于模型的MTT方法[28]。但MT3模型的设计是利用一个时间段内所有的雷达量测数据,去预测最后一个时间步下所有目标的状态及存在概率,仅是一个单一时间步的预测算法,无法刻画多目标长时间跟踪过程,生成跟踪轨迹。
鉴于此,受Transformer在时序建模中成功案例[29,30]的启发,本文在MT3模型的基础上,提出了一种新颖的MTT模型Track-MT3。主要创新点在于:在编码器-解码器结构的基础上引入了跟踪查询(Track query)机制,用于对已知目标的状态更新。并且创新性地提出了跨帧目标对齐(Cross-frame Target Alignment, CTA)策略,在相邻帧间传递匹配信息,实现了跟踪查询与真实轨迹的长时段关联,增强了跟踪过程的时间连续性和一致性。同时,查询变换与时间编码模块(Query Transformation and Temporal Feature Encoding Mechanism, QTM)的设计进一步增强了跟踪查询对目标运动的刻画能力,在不同时间尺度上自适应地聚合目标运动信息,提高了跟踪器的鲁棒性。此外,Track-MT3还采用了集体平均损失(Collective Average Loss, CAL)实现模型性能的全局优化。经过多种任务场景下的仿真验证,Track-MT3继承了MT3单一时间步下的预测能力,并且实现了多目标长时跟踪,生成预测轨迹。
2. 多目标模型
本节将从目标模型和量测模型两个方面建立MTT问题的数学模型,较为全面地刻画MTT问题中的各个要素。
2.1 目标模型
在二维平面(x,y)∈R2内,假设共有N个运动目标。对于第i个目标(i=1,2,⋯,N),其在k时刻的状态可以用一个向量xik∈R4表示:
xik=[pix,k,piy,k,vix,k,viy,k]T (1) 其中,(pix,k,piy,k)表示目标在二维平面上的位置坐标,(vix,k,viy,k)表示目标的速度分量。
本文将目标运动建模为单一运动模型,其运动方程可以表示为
xik=Fxik−1+wik−1 (2) 其中,F为状态转移矩阵,w(i)k−1∼N(0,Q)为过程噪声,服从均值为零、协方差矩阵为Q的多元高斯分布。
假设不存在目标的衍生,在k时刻,新目标出生的个数nbirth(k)服从参数为λbirth的泊松分布:
nbirth(k)∼Poisson(λbirth) (3) 其中,λbirth=ˉnbirth是每个时刻预期的新目标数量。新生成目标的初始状态从预定义的高斯分布中采样:
xbirth∼N(μbirth,Vbirth) (4) 其中,μbirth和Vbirth分别是新生目标状态的均值和协方差。
每个现有目标以概率PS在下一个时刻存活,即存活概率为PS,目标消亡概率为1−PS。在k时刻目标i的存活情况可通过伯努利试验来决定:
Iisurvive(k)∼Bernoulli(PS) (5) 其中,Iisurvive(k)是一个指示变量,表示目标i在k时刻是否存活。
2.2 量测模型
在实际应用中,目标的真实状态往往难以直接观测,需要依赖传感器获取含有噪声的量测数据。遵循每个目标在每一个传感器扫描时刻最多仅产生一个量测数据的假设,在k时刻,目标i以检测概率PD被探测到,如果被检测到,其对应的量测zik∈Rm可建模为
zik=Hxik+vik (6) 其中,H是量测矩阵,vik∼N(0,R)是量测噪声,服从均值为零、协方差矩阵为R的高斯分布。
另外,受限于传感器本身的性能和特性,我们接收到的量测数据不仅包含来自目标的真实的量测,还包含杂波的干扰信息。为了刻画杂波的数量分布和空间分布,假设在时间步k下,杂波量测的个数nc(k)服从参数为λc的泊松分布:
nc(k)∼Poission(λc) (7) 其中,λc=ˉnc为杂波量测的平均值。
杂波量测的位置(xc,yc)在传感器的视场(FOVx,FOVy)∈R2内服从均匀分布:
xc∼U(xlb,xub) (8) yc∼U(ylb,yub) (9) 其中,xlb, xub和ylb, yub分别是视场x轴、y轴的下界和上界。
最终在k时刻所有的量测值集合Zk为
Zk=Nk⋃i=1zik∪Ck (10) 其中,zik表示第k时刻第i个真实目标产生的量测集合,Nk表示第k时刻的真实目标总数,Ck为该时刻下所有的杂波量测。
3. 基于Transformer的新型多目标跟踪算法:Track-MT3
3.1 Transformer目标跟踪算法
Transformer模型最初是为了解决自然语言处理中的序列转换问题而提出的,例如机器翻译[31],采用了编码器-解码器架构来映射输入序列与输出序列之间的复杂关系。随着人们对Transformer的关注,发现其在集合预测问题中也表现出卓越的性能,所有被广泛运用在计算机视觉图像处理[32]领域中。从建模的抽象角度来看,多目标跟踪(MTT)问题与两者都有着相似之处,可以将多目标跟踪看作一个时间序列集合的预测问题:将观测序列转换为目标轨迹序列。因此,Transformer模型天然适合用于多目标跟踪任务。
假设一个时间段τ内获得的量测数据表示为z1:n=[ZT−τ,ZT−(τ−1),⋯,ZT],即
z1:n=[zT−τ1,zT−τ2,⋯,zT−τnT−τ,⋯,zT1,⋯,zTnT] (11) 其中,nt=|Zt|为时间步t下获得的量测数据样本数量,n=∑Tt=T−τniz为时间段τ内所有的量测数据的样本数量,z1:n中的数据以随机的顺序排列。
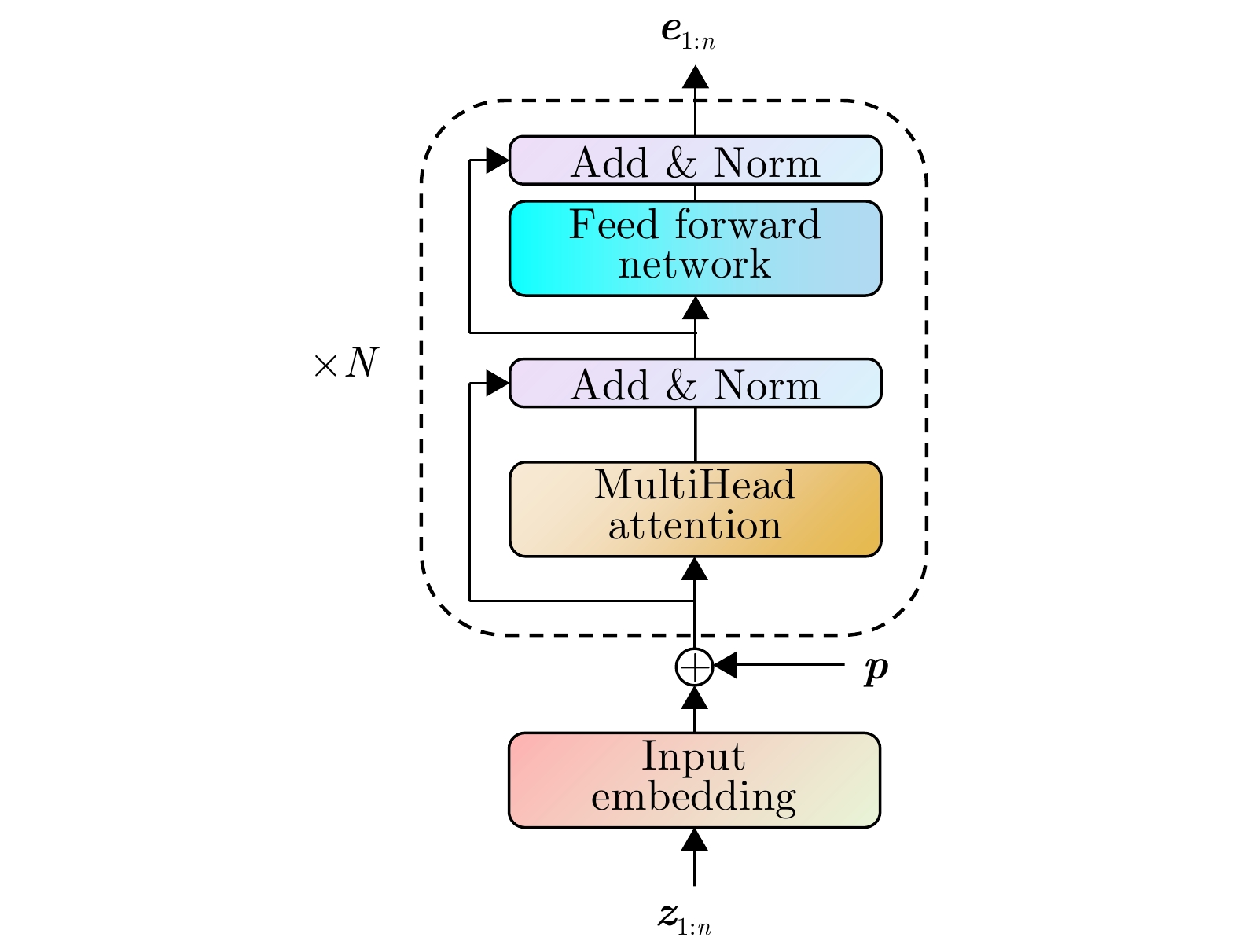
如图1所示,在多目标跟踪应用中。设输入的量测序列为z1:n=(z1,z2,⋯,zn),其中,zi∈Rdz表示第i个量测向量,n为总的量测数。Transformer编码器将其映射为一个新的表示序列e1:n=(e1,e2,⋯,en),其中,ei∈Rdmodel。编码器将低维的量测数据映射到高维的特征空间中:
Encoder:Rdz→Rdmodelzi↦Encoder(zi)=ei (12) 这种映射过程可以看作一种特征提取或特征学习,旨在从原始输入数据中提取出更加抽象、高层次的特征表示,以便后续的任务能够更好地利用这些高维特征。故而编码后的表示ei蕴含了量测数据丰富的上下文信息即所有目标的空间特征和时间特征。
编码器由N个函数相同的编码器层fenci(⋅),i=1,2,⋯,N堆叠而成,每层都包含两个子层:多头自注意力层MultiHead(⋅)和前馈层FFN(⋅),以及在两个子层间的残差连接和层归一化LayerNorm(⋅)。设第l层编码器的输入为x(l−1),输出为x(l),则编码器的计算过程可表示为
a(l)=MultiHead(x(l−1)) (13) ˜x(l)=LayerNorm(x(l−1)+a(l)) (14) b(l)=FFN(˜x(l)) (15) x(l)=LayerNorm(˜x(l)+b(l)) (16) 其中,x(0)=Ez+p, E∈Rdmodel×dz为量测嵌入矩阵,p∈Rn×dmodel为位置编码,e1:n=x(N)为编码器输出。
如图2所示,这是一个改进后的Transformer解码器,基于编码表示e1:n,在该解码器中首先需要经过解码计算得到ˆypre1:n。解码器堆叠了M个函数相同的解码器层fdeci(⋅),i=1,2,⋯,M,除了编码器中的两个子层外,每层还引入了第3个子层交叉注意力机制CrossMultiHead(⋅)用于同编码器输出做交互,预测器和分类器分别由一个多层感知机和线性层组成,a[k]n表示第k层第n个神经元。设对象查询矩阵为O∈Rk×dmodel,第l层解码器的输入为y(l−1),解码器的计算过程为
q(l)=MultiHead(y(l−1)) (17) ˜y(l)=LayerNorm(y(l−1)+q(l)) (18) r(l)=CrossMultiHead(˜y(l),ei) (19) ˉy(l)=LayerNorm(˜y(l)+r(l)) (20) s(l)=FFN(ˉy(l)) (21) y(l)=LayerNorm(ˉy(l)+s(l)) (22) 其中,y(0)=O,解码输出ˆypre1:n=y(M)。然后将解码输出ˆypre1:n输入预测器和分类器,经过处理后,输出状态预测序列ˆy1:n={y1,y2,⋯,yn},其中yi=(ˆxi,ˆpi)表示第i个目标的状态预测ˆxi和存在概率预测ˆpi,n为潜在目标的最大数量。解码过程利用了编码器提供的信息丰富的量测表示,通过交叉注意力机制聚焦于与当前目标最相关的量测,实现隐式的软数据关联,并通过解码器自注意力机制建模目标之间的交互,最终得到准确的状态估计。
在编码、解码过程中,核心是利用多头注意力机制计MultiHead(⋅)将查询Q、键K、值V投影到h个不同的子空间中,即产生h个注意力通道,每个通道都会得到维度为dmodel/h的新的表示Qi,Ki,Vi,i=1,2,⋯,h。然后在这h个投影子空间中并行计算注意力函数Attention(⋅):
MultiHead(X)=Concat(H1,H2,⋯,Hh)WO (23) Hi=Attention(Qi,Ki,Vi)=softmax(QiKTi√dk)Vi (24) 其中,Hi为注意力通道,WO∈Rhdv×dmodel为注意力通道投影的权重矩阵,dk=dv=dmodel/h。多头注意力允许模型在不同的表示子空间联合关注来自不同位置的信息,这使得每一层都能获取输入序列的不同方面的信息,丰富了特征表示的能力。
将以上观测序列z1:n的处理过程看作一个编码-解码问题。设xit表示在t时刻第i个目标的状态,编码器产生的观测表示为ht,则解码器的目标是学习条件概率分布p(xit|h≤t,x<t)。假设各个目标之间条件独立,则多目标的联合分布可分解为
p(Xt∣z≤t)=Nt∏t=1p(xit∣h≤txi<t) (25) 其中,Xt={xit}Nti=1为t时刻所有目标的状态集合,Nt为目标总数。在训练阶段,每个目标对应一个查询qi,通过交替优化以下编码器和解码器损失函数,可以端到端地学习跟踪模型:
Lenc(ϕ)=−E(z≤T,X≤T)T∑t=1lnp(zt∣h<t,ϕ) (26) Ldec (θ)=−E(z≤T,X≤T)T∑t=1Nt∑i=1lnp(xit|h≤t,qi,xi<t,θ) (27) 其中,ϕ和θ分别为编码器和解码器的参数。可见,观测序列的似然和目标轨迹序列的似然可以联合优化,使得模型自适应地学习提取跟踪所需的状态表示,而不依赖于手工设计的特征工程。
需要指出的是,得益于Transformer架构并行计算的特点,在推理阶段能够通过一次前向传播同时估计出所有目标的状态。与逐帧滤波方法相比[33],简化了跟踪流程,有望带来计算效率的提升。
3.2 Track-MT3模型结构
MT3是一种基于Transformer架构的深度学习多目标跟踪模型。凭借Transformer架构处理整个量测序列的强大能力,将量测的时间信息编码融入特征,能够有效地学习如何利用输入序列中的时间相关性来直接预测目标状态。这使得MT3能够绕过传统方法中复杂的后验计算,从而实现更优越的性能。然而,MT3仅是一种单帧预测算法,只能预测一段时间内的最后一个时刻T下每个目标的状态估计ˆxT1:k和存在概率p1:k,无法长时间关联目标生成目标轨迹。
Track-MT3延续了MT3基于Transformer架构的编码器-解码器设计,并引入了“轨迹查询”对整个跟踪过程中的目标轨迹进行建模,实现了连续时间下的MTT任务。与传统的基于滤波和数据关联的跟踪范式相比,这种端到端的方法主要面临3个挑战:
(1) 如何自适应地处理运动过程中新出现的目标(Newborn)和消亡的目标(Dead);
(2) 如何建立预测轨迹与目标之间稳定的一一对应关系,做到一个轨迹只跟踪一个目标;
(3) 如何在时间维度上建模目标间的交互和运动的长期依赖。
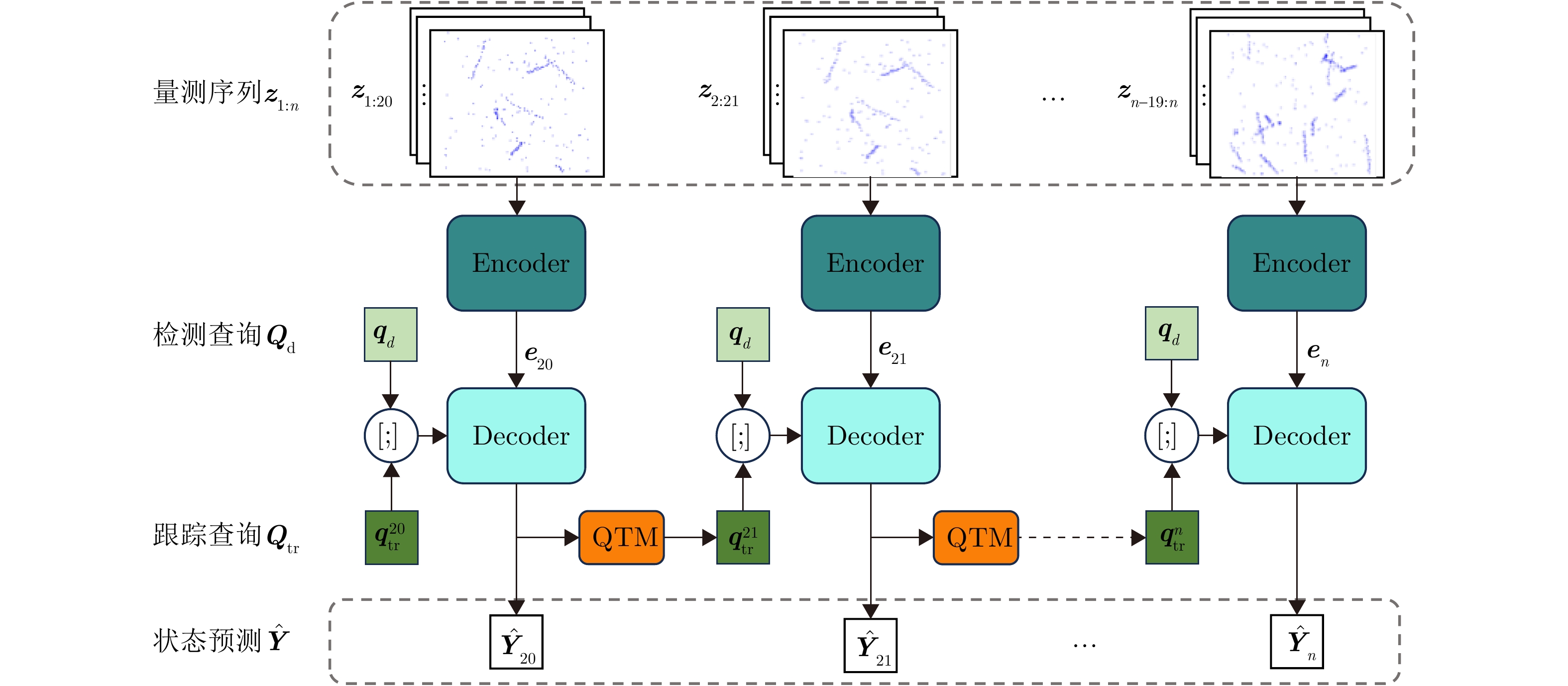
对此,本文在检测查询的基础上引入了轨迹查询,并且通过CTA机制和QTM模块进一步强化模型表达能力。通过设计以上模块并与MT3架构深度融合,Track-MT3在多目标精准长时跟踪和时序建模两方面实现了全面优化。如图3所示,Track-MT3的整体架构包含3个主要组件:特征提取、预测生成和查询更新。和MT3不同,对于输入的量测序列z1:n={z1,z2,⋯,zn},其中zi∈Rdz表示i时刻的量测数据,首先,根据注意力机制刻画目标运动以及处理量测数据的能力,以大小为20的时间滑动窗口将量测数据经由编码器处理后映射为一组高维特征表示e20:n={e20,e21,⋯,en},ei∈Rde:
e20:n=Encoder(z1:n) (28) 编码后的特征序列e20:n汇总了量测序列的空间和时间信息,为后续的跟踪预测提供了较为完备的表示。在预测阶段,Track-MT3引入两类查询:检测查询qd∈RNd×dq和跟踪查询qtr∈RNtr×dq,分别用于检测新出现的目标和预测已有目标的状态。其中Nd,Ntr分别为检测查询和跟踪查询的个数,dq为查询的嵌入维度。在每一时刻,跟踪查询qtr和检测查询qd被级联输入到解码器中,与编码器的输出ei进行交互,生成当前帧的目标预测。解码过程表示为
ˆYi=Decoder([qtr;qd],ei) (29) 其中,[;]表示级联操作。ˆYi={yi1,yi2,⋯,yiNtr+Nd}为第i帧的预测结果,其中,yij=(ˆbij,ˆpij)包含预测位置坐标ˆbij∈R2和类别置信度ˆpij∈[0,1]。在训练阶段,Track-MT3采用跨帧目标对齐策略为每个查询分配监督信息,具体方法将在3.4节介绍。通过随机梯度下降优化算法最小化损失函数,从数据中学习表示目标状态的特征。推理时,Track-MT3以大小为20的滑动窗口在线处理输入的量测序列,并生成逐帧的目标预测结果。
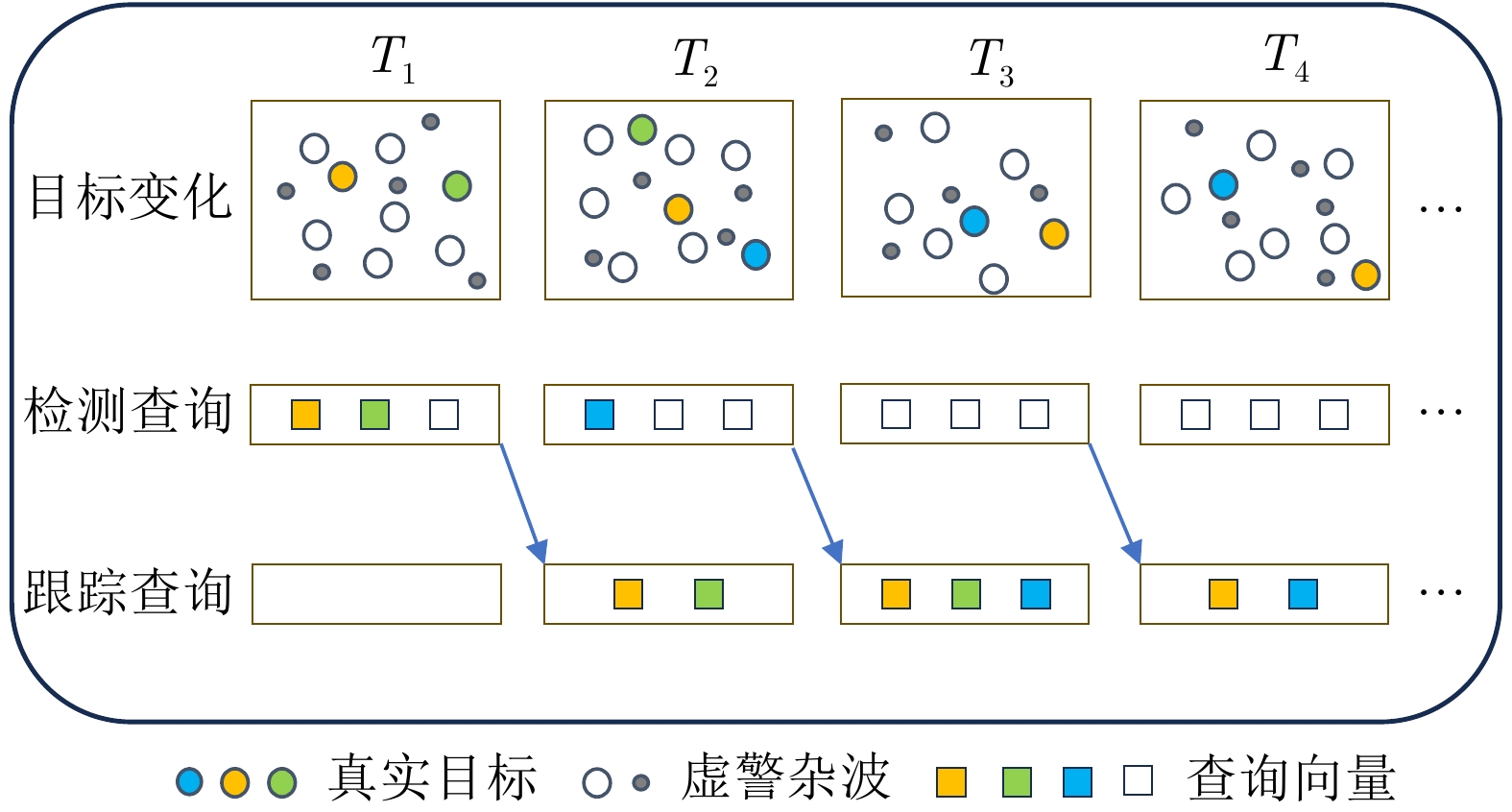
3.3 检测查询和跟踪查询
为了适应MTT任务中目标数量的变化,如图4所示,Track-MT3引入了两类查询:检测查询qd和跟踪查询qtr,分别负责检测新出现的目标和预测已有目标的状态。检测查询集合大小是固定的,跟踪查询集合是动态更新的,大小可变。
检测查询qd∈RNd×dq是一组固定的可学习参数,用于从输入序列中发现新目标。Nd为检测查询的数量,dq为查询嵌入的维度。在每个时刻,检测查询与编码器输出的特征ei交互,生成Nd个候选预测。这一过程可表示为
ˆYidet=Decoder(qd,ei) (30) 其中,ˆYidet={yidet,1,yidet,2,⋯,yidet,Nd}为i时刻的检测查询预测结果。每个预测yidet,j=(ˆbidet,j,ˆpidet,j)包含目标位置坐标和置信度。
与检测查询不同,跟踪查询qtr∈RNtr×dq是一个动态更新的集合,用于跟踪已出现的目标。其中Ntr为跟踪查询的数量,初始为0,后续根据检测结果自适应调整。Qitr={qitr,1,qitr,2,⋯,qitr,Ntr}表示i时刻的跟踪查询,是由上一帧的状态预测ˆYi−1tr生成,具体在3.5节介绍,并与编码器输出ei交互生成跟踪预测:
ˆYitr=Decoder(qitr,ei) (31) 其中,ˆYitr={yitr,1,yitr,2,⋯,yitr,Ntr}为第i帧Ntr个已有目标的状态估计。
3.4 跨帧目标对齐
为确保跟踪查询与目标之间的一致对应关系,即每个跟踪查询专注于跟踪一个特定目标,Track-MT3引入了CTA机制。CTA通过在相邻帧之间传递匹配信息,实现跟踪查询与真实轨迹的长时段关联。具体而言,CTA包含两个关键策略:针对跟踪查询的“目标一致性匹配”,以及针对检测查询的“新生目标匹配”。
对于跟踪查询,CTA直接延续上一帧的匹配结果,以保持跟踪目标的一致性。若ˆYitr={ˆyitr,j}Jij=1为第i帧中Ji个跟踪查询的预测结果,witr∈{0,1}Ji×Mi为跟踪查询与真值的二分匹配矩阵,其中Mi为真值目标的数量。当i>1时,跟踪查询的标签分配遵循以下原则:
witr=wi−1tr∪widet (32) 即跟踪查询的监督信息来自上一帧(i−1)的匹配结果wi−1tr以及新检测到的目标匹配widet。这一策略隐式地调整了跟踪查询的数量,使其能够适应目标数的变化,即Ji=Ji−1+|widet|。对于第1帧(i=1),由于缺乏先验的跟踪信息,w1tr为空集。
与跟踪查询不同,检测查询负责探测新出现的目标。因此,CTA需要将检测查询的预测结果与真值中的新生目标进行匹配。设ˆYidet={ˆyidet,k}Kk=1为第i帧中K个检测查询的预测,Yinew={yinew,m}Minewm=1为新出现的真值目标集合,则最优的检测匹配widet应满足:
widet=argminw∈ΩC(ˆYidet,Yinew|w) (33) 其中,C(⋅)为匹配代价函数,Ω为所有可行的二分匹配矩阵集合。在Track-MT3中,我们设计了一种综合考虑状态一致性和类别一致性的代价函数:
C(ˆYidet,Yinew|w)=K∑k=1Minew∑m=1wk,m⋅L(ˆyidet,k,yinew,m) (34) 其中,L(ˆyidet,k,yinew,m)为第k个检测结果与第m个新生目标之间的代价,定义为
L(ˆyidet,k,yinew,m)=Lstat(ˆxidet,k,xinew,m)+Lcls(ˆcidet,k,cinew,m) (35) 其中,Lstat(ˆxidet,k,xinew,m)为检测状态ˆxidet,k与真值状态xinew,m之间的绝对距离,Lcls(ˆcidet,k,cinew,m)为检测类别ˆcidet,k与真值类别cinew,m之间的交叉熵损失。两项分别衡量了检测结果与真值目标在状态和类别上的差异:
Lstat(ˆxidet,k,xinew,m)=‖ (36) {\mathcal{L}}_{\text{cls}}\left({\hat{c}}_{\text{det},k}^{i},{c}_{\text{new},m}^{i}\right)=-\sum _{j=1}^{{N}_{{\mathrm{c}}}}{{1}} \left[{c}_{\text{new},m}^{i},\,j \right]\cdot \mathrm{ln}\left({\hat{p}}_{\text{det},k,j}^{i}\right) (37) 其中,{N_{\mathrm{c}}} = 2为类别数,1为指示函数,\hat p_{{\text{det}},k,j}^i为第k个检测结果属于第j类的预测概率。基于该代价函数的二分匹配问题可通过匈牙利算法进行求解。
3.5 查询变换与时间特征编码
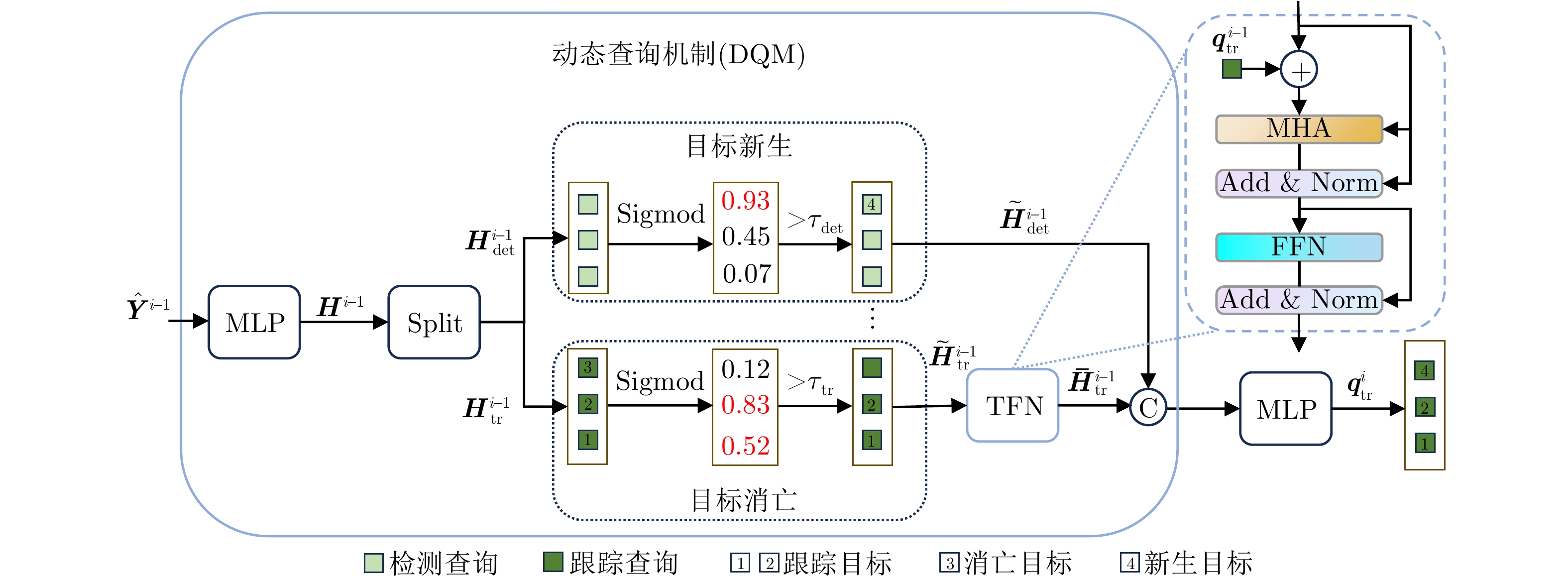
跟踪查询的有效性取决于其对目标状态的编码能力。为进一步增强跟踪查询对目标运动的建模,Track-MT3设计了QTM模块,如图5所示。通过引入动态查询机制(Dynamic Query Mechanism, DQM)和时间特征编码网络(Temporal Feature Encoding Network, TFN)实现对跟踪查询的自适应更新。
QTM将i - 1帧的状态预测 {{\boldsymbol{\hat Y}}^{i - 1}} 作为输入,输出第i帧的跟踪查询{\boldsymbol{q}}_{{\text{tr}}}^i。QTM的计算过程如下:
{{\boldsymbol{H}}^{i - 1}} = {\text{MLP}}({{\boldsymbol{\hat Y}}^{i - 1}}){{\boldsymbol{\hat p}}_t} \in {[0,1]^{{N_t}}} (38) {\boldsymbol{H}}_{{\text{det}}}^{i - 1},{\boldsymbol{H}}_{{\text{tr}}}^{i - 1} = {\text{Split}}\left({{\boldsymbol{H}}^{i - 1}}\right) (39) {\boldsymbol{\tilde H}}_{\det }^{i - 1} = \left\{ {{\boldsymbol{h}}_{\det }} \in {\boldsymbol{H}}_{{\mathrm{det}}}^{i - 1}\mid {\text{sigmod}}({{\boldsymbol{h}}_{\det }}) > {\tau _{\det }}\right\} (40) {\boldsymbol{\tilde H}}_{{\text{tr}}}^{i - 1} = \left\{ {{\boldsymbol{h}}_{{\text{tr}}}} \in {\boldsymbol{H}}_{{\text{tr}}}^{i - 1}|{\text{sigmod}}({{\boldsymbol{h}}_{{\text{tr}}}}) > {\tau _{{\text{tr}}}}\right\} (41) {\boldsymbol{\bar H}}_{{\text{tr}}}^{i - 1} = {\text{TEN}}\left({\boldsymbol{\tilde H}}_{{\text{tr}}}^{i - 1},{\boldsymbol{q}}_{{\text{tr}}}^{i - 1}\right) (42) {\boldsymbol{q}}_{{\text{tr}}}^i = {\text{MLP}}\left({\text{Concat}}\left({\boldsymbol{\bar H}}_{{\text{tr}}}^{i - 1},{\boldsymbol{\tilde H}}_{\det }^{i - 1}\right)\right) (43) 其中,{\text{MLP}}为多层感知机, {{\boldsymbol{\hat Y}}^{i - 1}} 为查询在第i - 1帧经过解码器和特征交互后的预测结果,经过零偏置多层感知机映射后得到隐藏状态 {{\boldsymbol{H}}^{i - 1}} ,{\text{Split}}操作将隐藏状态分为检测查询和轨迹查询各自的隐藏状态 {\boldsymbol{H}}_{{\mathrm{det}}}^{i - 1},{\boldsymbol{H}}_{{\mathrm{tr}}}^{i - 1} 。然后经过置信度的筛选后得到新生目标的隐藏状态剔除消亡目标的隐藏状态,得到 {\boldsymbol{\tilde H}}_{\det }^{i - 1} 和 {\boldsymbol{\tilde H}}_{{\text{tr}}}^{i - 1} ,本文中设置检测置信度阈值 {\tau _{\det }} = 0.75 ,轨迹置信度阈值 {\tau _{{\text{tr}}}} = 0.5 。{\text{TFN}}模块是一个改进的Transformer编码器,将上一帧的跟踪查询 {\boldsymbol{q}}_{{\text{tr}}}^{i - 1} 作为额外的信息和当前帧筛选后的轨迹查询隐藏状态 {\boldsymbol{\tilde H}}_{{\text{tr}}}^{i - 1} 相加作为多头自注意力的查询和键值,经过这个编码器处理后和当前帧经过筛选的检测查询隐藏状态 {\boldsymbol{\tilde H}}_{\det }^{i - 1} 拼接得到第i帧的跟踪查询{\boldsymbol{q}}_{{\text{tr}}}^i。
3.6 损失函数
为了充分利用量测序列的时序信息,指导运动建模和量测关联。Track-MT3采用CAL损失函数来优化模型在整个量测序列上的表现,对整个跟踪过程进行端到端优化。
具体而言,CAL将整个量测序列 {{\boldsymbol{z}}_{1:n}} 的预测损失求平均,作为网络的优化目标:
{\mathcal{L}_{{\text{CAL}}}} = \frac{1}{T}\sum\limits_{t = 1}^T {{\mathcal{L}_t}} ({{\boldsymbol{\hat X}}_t},{{\boldsymbol{X}}_t}|{{\boldsymbol{w}}_t}) (44) 其中, {{\boldsymbol{\hat X}}_t} = \{ {{\boldsymbol{\hat x}}_{t,i}}\} _{i = 1}^{{N_t}} 和{{\boldsymbol{X}}_t} = \{ {{\boldsymbol{x}}_{t,i}}\} _{i = 1}^{{M_t}}分别表示第t帧的预测结果和真值序列,{N_t}和{M_t}为相应的目标数量。{{\boldsymbol{w}}_t} \in {\{ 0,1\} ^{{N_t} \times {M_t}}}为预测结果与真值的匹配矩阵,其中,{{\boldsymbol{w}}_{t,ij}} = 1表示将第i个预测目标指派给第j个真实目标。对于第t帧,在匹配矩阵{{\boldsymbol{w}}_t}的约束下,预测损失{\mathcal{L}_t}可进一步分解为定位损失和置信度损失:
\begin{split} {\mathcal{L}}_{t}({\hat{{\boldsymbol{X}}}}_{t},{{\boldsymbol{X}}}_{t}|{{\boldsymbol{w}}}_{t})=\;&\frac{1}{\left|{{\boldsymbol{X}}}_{t}\right|}\Biggr(\sum _{i=1}^{{N}_{t}}\sum _{j=1}^{{M}_{t}}{\lambda }_{{l}_{1}}{{\boldsymbol{w}}}_{t,ij}{\mathcal{L}}_{\text{loc}}({\hat{{\boldsymbol{x}}}}_{t,i},{{\boldsymbol{x}}}_{t,j})\\ & +{\lambda }_{c}{\mathcal{L}}_{\text{conf}}({\hat{{\boldsymbol{p}}}}_{t},{\boldsymbol{{w}}}_{t})\Biggr)\\[-1pt] \end{split} (45) 其中, {{\boldsymbol{\hat p}}_t} 为第t帧中{N_t}个预测结果的置信度向量。
定位损失{\mathcal{L}_{{\text{loc}}}}衡量匹配目标对之间状态估计的误差,采用 {l_1} 损失:
{\mathcal{L}_{{\text{loc}}}}({{\boldsymbol{\hat x}}_{t,i}},{{\boldsymbol{x}}_{t,j}}) = {\left\| {{{{\boldsymbol{\hat x}}}_{t,i}} - {{\boldsymbol{x}}_{t,j}}} \right\|_1} (46) 置信度损失{\mathcal{L}_{{\text{conf}}}}基于交叉熵,用于区分预测结果的有效性:
\begin{split} {\mathcal{L}}_{\text{conf}}({\hat{{\boldsymbol{p}}}}_{t},{{\boldsymbol{w}}}_{t})=\,&-\displaystyle\sum\limits _{i=1}^{{N}_{t}}(\underset{j}{\mathrm{max}}{{\boldsymbol{w}}}_{t,ij}\mathrm{ln}\left({\hat{p}}_{t,i}\right)\\ \,&+ \left(1-\underset{j}{\mathrm{max}}{{\boldsymbol{w}}}_{t,ij}\right)\mathrm{ln}\left(1-{\hat{p}}_{t,i}\right)) \end{split} (47) 其中, {\lambda _{{l_1}}} 和 {\lambda _c} 为平衡系数。式中的损失项在整个序列的时间跨度内平均,使得Track-MT3能够学习到全局一致的状态估计和数据关联策略。
需要指出的是,匹配矩阵{{\boldsymbol{w}}_t}的计算通过3.4节中的CTA机制实现。CTA利用当前帧和历史帧的信息,以时序连贯性为目标优化匹配结果,这进一步增强了CAL损失的全局约束能力。基于以上设计,我们构建了完整的Track-MT3模型。接下来,将通过实验来评估其性能。
4. 实验
4.1 仿真数据和评估指标
4.1.1 仿真数据及数据的归一化
模型的训练数据和实验仿真数据根据第2节中描述的多目标模型生成。在笛卡儿坐标系下设雷达量测视场20 m×20 m,目标在视场内运动为匀速运动,状态转移矩阵为
{\boldsymbol{F}} = \left[ {\begin{array}{*{20}{c}} 1&0&{\Delta t}&0 \\ 0&1&0&{\Delta t} \\ 0&0&1&0 \\ 0&0&0&1 \end{array}} \right] (48) 过程噪声协方差矩阵为
{\boldsymbol{Q}} = {\sigma _{\text{q}}}\left[ {\begin{array}{*{20}{c}} {\dfrac{{\Delta {t^3}}}{3}}&0&{\dfrac{{\Delta {t^2}}}{2}}&0 \\ 0&{\dfrac{{\Delta {t^3}}}{3}}&0&{\dfrac{{\Delta {t^2}}}{2}} \\ {\dfrac{{\Delta {t^2}}}{2}}&0&{\Delta t}&0 \\ 0&{\dfrac{{\Delta {t^2}}}{2}}&0&{\Delta t} \end{array}} \right] (49) \Delta t = 0.1 s表示采样时间间隔,{\sigma _{\mathrm{q}}}为过程噪声强度。目标初始位置(x,y)的均值及方差为
\left\{ {\begin{array}{*{20}{c}} {{{\boldsymbol{\mu}} _{(x,y)}} = {{\left[ {\begin{array}{*{20}{c}} 0&0 \end{array}} \right]}^{\text{T}}}} \\ {{{\boldsymbol{\varSigma}} _{(x,y)}} = \left[ {\begin{array}{*{20}{c}} 3&0 \\ 0&3 \end{array}} \right]} \end{array}} \right. (50) 目标初始速度({v_x},{v_y})的均值和方差为
\left\{ {\begin{array}{*{20}{c}} {{{\boldsymbol{\mu}} _{({v_x},{v_y})}} = {{\left[ {\begin{array}{*{20}{c}} 0&0 \end{array}} \right]}^{\text{T}}}} \\ {{{\boldsymbol{\varSigma}} _{({v_x},{v_y})}} = \left[ {\begin{array}{*{20}{c}} 3&0 \\ 0&3 \end{array}} \right]} \end{array}} \right. (51) 量测方程为
{\boldsymbol{H}} = \left[ {\begin{array}{*{20}{c}} 1&0&0&0 \\ 0&1&0&0 \end{array}} \right] (52) 量测噪声协方差为
{\boldsymbol{R}} = {\sigma _{\text{r}}}\left[ {\begin{array}{*{20}{c}} 1&0 \\ 0&1 \end{array}} \right] (53) 其中,{\sigma _{\text{r}}}为量测噪声强度。
本文采取在线随机仿真的方式持续产生较大规模训练样本,在节省数据存储成本的同时为模型提供了丰富的先验知识。在模型训练的过程中,设置初始目标数量为4,最大目标数量为16,{\lambda _{{\text{birth}}}} = 0.01, {P_{\text{S}}} = 0.95, {P_{\text{D}}} = 0.9, {\sigma _{\text{q}}} = 0.5, {\sigma _{\text{r}}} = 0.1, {\lambda _{\text{c}}} = 10,在每一次梯度更新时,并行生成批次大小为32的模拟数据,即每一次迭代并行生成32个独立同分布的仿真样本,每个样本包含20个时间步的量测数据。根据实验统计,模型训练样本信息如表1所示。生成评估数据时,根据任务场景设置不同的参数生成数据。
表 1 训练样本信息Table 1. Training sample information参数 数值 总的样本数(有效量测点数) 401651991 真实目标量测点数 81664937 杂波量测点数 319987054 平均每个批次样本总数 8034 平均每个时间窗口样本总数 252 考虑到原始量测数据的尺度差异和分布非平稳性,我们在模型训练前采用一种预设边界的放缩方法对模型输入数据进行了归一化处理。设原始测量数据为 {\boldsymbol{z}} \in {\mathbb{R}^{{d_z}}} ,其中, {d_z} 为测量维度,则归一化变换为{\boldsymbol{\tilde z}} = {\boldsymbol{z}}/s,其中,s = 20为归一化缩放因子,定义为量测空间各维度的跨度。模型内部计算使用的是归一化后的特征,输出阶段使用反归一化将其还原为原始尺度的状态估计:
{\boldsymbol{\hat z}} = s \cdot ({\text{sigmoid}}({\boldsymbol{\hat y}}) - 0.5) (54) 4.1.2 评估指标
本文采用了广义最优子模式分配(Generalized Optimal Sub-Pattern Assignment, GOSPA)度量[34]作为主要评价指标。除了传统的GOSPA指标外,我们还使用了概率GOSPA (Probabilistic GOSPA, Pro-GOSPA)指标[27],以更好地评估算法输出的目标存在概率的准确性。
对于真实目标集合Y = \{ {y_1},{y_2},\cdots,{y_n}\} 和估计目标集合 X = \{ {x_1},{x_2},\cdots,{x_m}\} ,GOSPA度量定义如式(55)所示。其中,{d^{(c)}}( \cdot )表示截断距离,\varGamma 为X和Y元素的所有可能匹配,即X中的每个元素最多分配给Y中的一个元素,反之亦然。参数 c > 0 为截断阈值,s \ge 1为距离阶数,\alpha \in (0,2]用于控制基数误差的惩罚强度。本文设置截断阈值 c{\text{ = 2}}{\text{.0}} ,距离阶为 s = 1 ,惩罚系数\alpha = 2。这使得GOSPA可以较为平衡地考虑定位误差和基数误差,符合多目标跟踪任务的评估要求。
对于带有存在概率的目标状态估计集合 X = \{ ({x_1}, {p_1}),({x_2},{p_2}),\cdots,({x_n},{p_n})\} ,其中{x_i}表示估计状态,{p_i} \in [0,1]表示估计存在概率,Pro-GOSPA定义为式(56)。与GOSPA相比,Pro-GOSPA在计算每个匹配对({x_i},{y_j})的代价时,不仅考虑了状态估计误差{d^{(c)}}({x_i},{y_j}),还引入了目标存在概率 {p_i} 的影响,目的是平衡状态估计和存在性估计的重要性。本文中Pro-GOSPA的参数设置与传统GOSPA保持一致。目标存在性判断阈值设为0.75,即存在概率大于0.75的估计目标才认为是有效的估计。
\begin{split} {d}_{}^{(c,\alpha )}(X,Y)=\;& \underset{\gamma \in \varGamma }{\mathrm{min}}\Biggr({\displaystyle \sum _{(i,j)\in \gamma }{d}^{(c)}{({x}_{i},{y}_{j})}^{s}} \\ & +\frac{{c}^{s}}{\alpha }(|X|+|Y|-2|\gamma |)\Biggr)^{\textstyle\frac{1}{s}} \end{split} (55) \begin{split} d_{}^{(c,\alpha )}(X,Y) =\;& \mathop {\min }\limits_{\gamma \in \varGamma } \Biggr(\sum\limits_{(i,j) \in \gamma } ({d^{(c)}}{{({x_i},{y_j})}^s}{p_i} \\ & + (1 - {p_i})\frac{{{c^s}}}{2}) + \frac{{{c^s}}}{2}(|Y| - |\gamma |)\Biggr)^{\textstyle\frac{1}{s}} \end{split} (56) 4.2 模型参数设置及训练过程分析
本文模型的训练和评估在Windows系统中基于PyTorch深度学习框架进行。实验室硬件配置如表2所示,模型参数设置如表3所示。
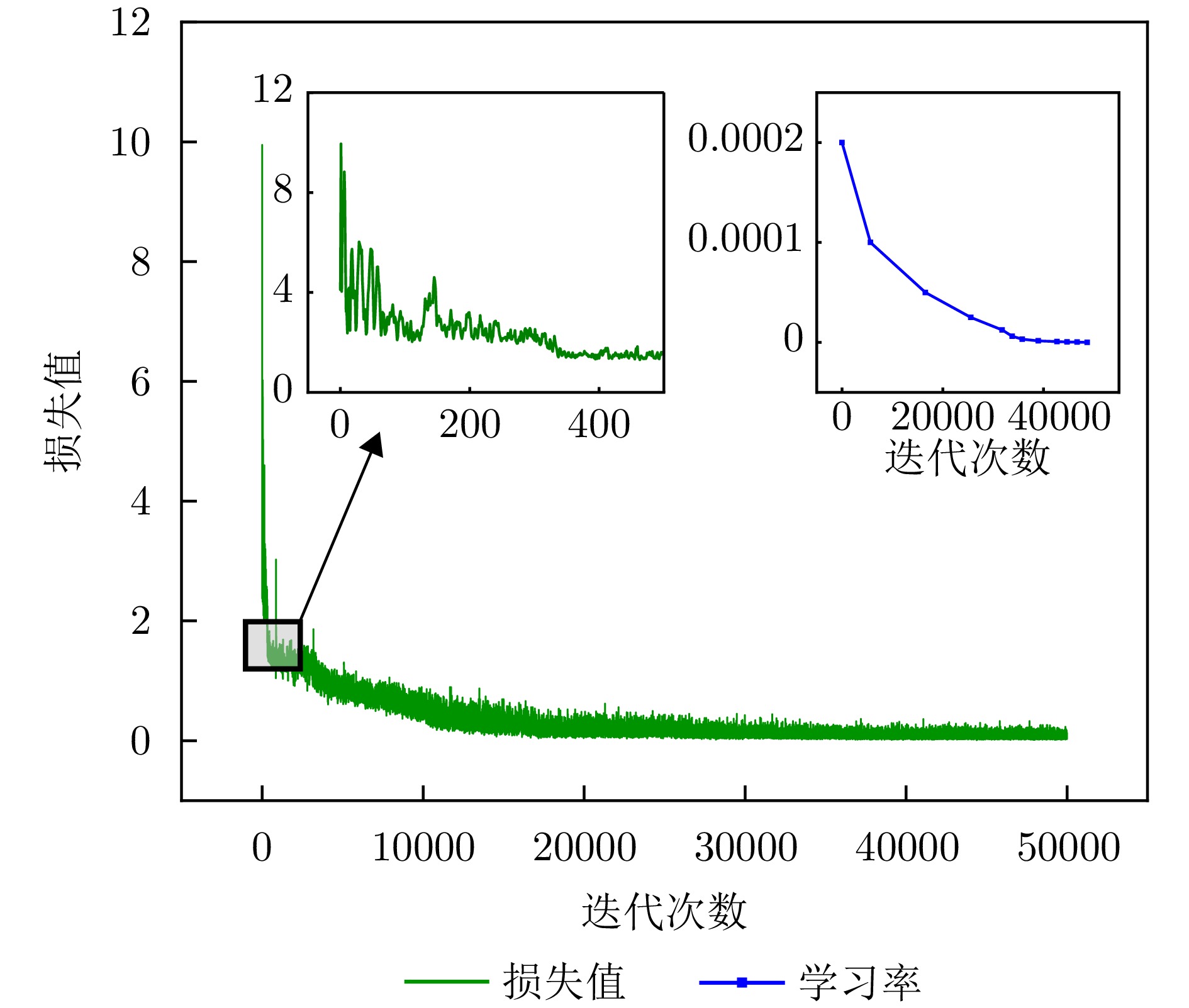
表 2 实验环境Table 2. Experimental environment项目 版本 CPU 12th Gen Intel(R) Core i5- 12400 GPU NVIDIA GeForce RTX 3090 TiPython 3.7.4 Pytorch 1.6.0 Torchvision 0.7.0 CUDA 4.14.0 表 3 Track-MT3网络参数Table 3. Track-MT3 network parameters参数 取值 编码器层数 6 解码器层数 6 编码器输入数据维度 256 解码器输入数据层数 256 多头注意力头数 8 查询向量数量 16 前馈网络隐藏层维度 2048 神经元Dropout 0.1 预测器MLP层数 3 预测器隐藏层维度 128 为了达到更好的训练效果,防止模型过拟合和落入局部最优,采用学习率衰减策略进行调整,如果在设定的epoch容忍度内没有提升,就将当前学习率乘以衰减因子作为新的学习率,训练参数设置如表4所示。图6展示了训练过程中损失函数和学习率的变化曲线。
表 4 模型训练参数Table 4. Model training parameters参数 取值 优化器 Adam Epoch数 50000 Batch Size 32 初始学习率 0.0002 学习率衰减容忍度 5000 学习率衰减因子 0.5 从图6放大的局部图可以看出,前500次的迭代尽管损失函数曲线存在轻微的振荡,但整体还是保持了稳健、快速的下降态势。从整体来看,损失函数呈现出稳定下降的趋势,表明模型在不断地学习和改进。在第
10000 ~15000 步之后,损失下降趋于平缓,但学习率的衰减机制在整个训练过程中都在作用,使得模型避免过拟合的同时性能进一步提升。经过50000 步的迭代,最终在新的数据上模型的损失稳定保持在0.1以下。4.3 单帧预测可解释性分析
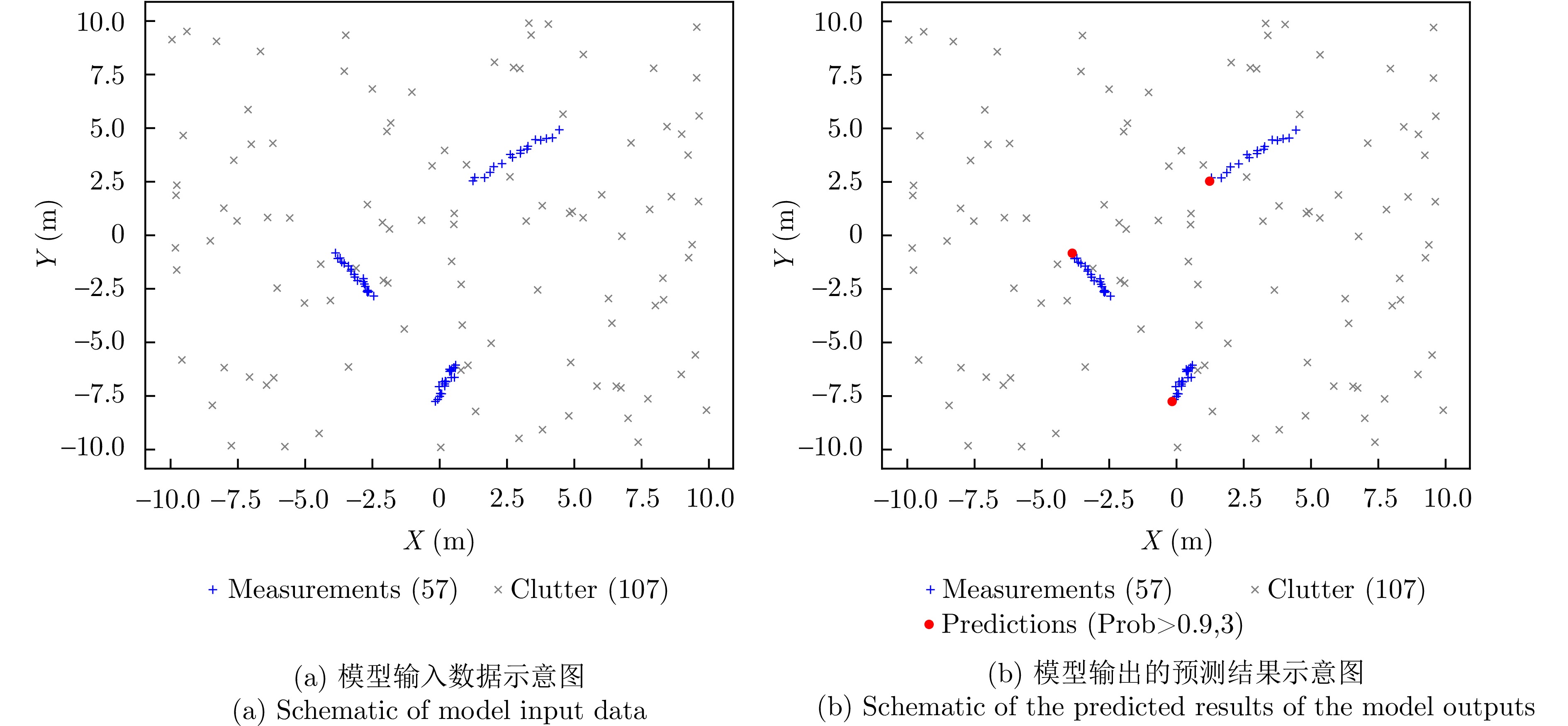
为了解释模型的单步预测过程,设置目标数量为3,平均虚假量测数量{\lambda _{\text{c}}}为5,过程噪声强度{\sigma _{\text{q}}}和量测噪声{\sigma _{\text{r}}}强度均为0.1,检测概率{P_{\text{D}}}为0.95,分析在一个大小为20的时间窗口下模型的推理过程。量测数据及模型输出如图7所示。
在该参数设置下,该时间窗口内总共产生的量测数据{{\boldsymbol{z}}_{0:19}}的数量为164,其中虚假量测(杂波)数量为107,真实目标量测数量为57,量测数据主要经由编码器、解码器这两个模型的关键模块处理,输出该时间窗口下对目标的状态预测。
首先,量测数据输入编码器,在编码器中,会将输入数据从2维映射到256维,在高维空间中,通过全局自注意力机制计算,提取所有量测数据的全局特征,生成输入数据的改进表示{{\boldsymbol{e}}_{0:19}},目的是让模型能够区分量测数据的类型。如图8所示,利用t分布随机邻域嵌入(t-distributed Stochastic Neighbor Embedding, t-SNE)方法和主成分分析(Principal Component Analysis, PCA)法将经过编码器处理后的输出数据{{\boldsymbol{e}}_{0:19}}在高维空间中分析,并投影到笛卡儿坐标系中。
在图8(a)中可以明确看出所有的量测数据被分为4类,杂波量测ID为–1,3个不同目标的量测ID分别为0, 1, 2。在图8(b)中可以清晰看出来自真实目标的量测数据在二维平面上呈近似直线状分布,这符合目标的运动规律。所以不难知道,经过编码器的处理,模型已经具备了区分量测数据的能力,不仅可以对输入数据的类别进行处理,一定程度上还能识别同一类别数据在时间上的依赖关系。
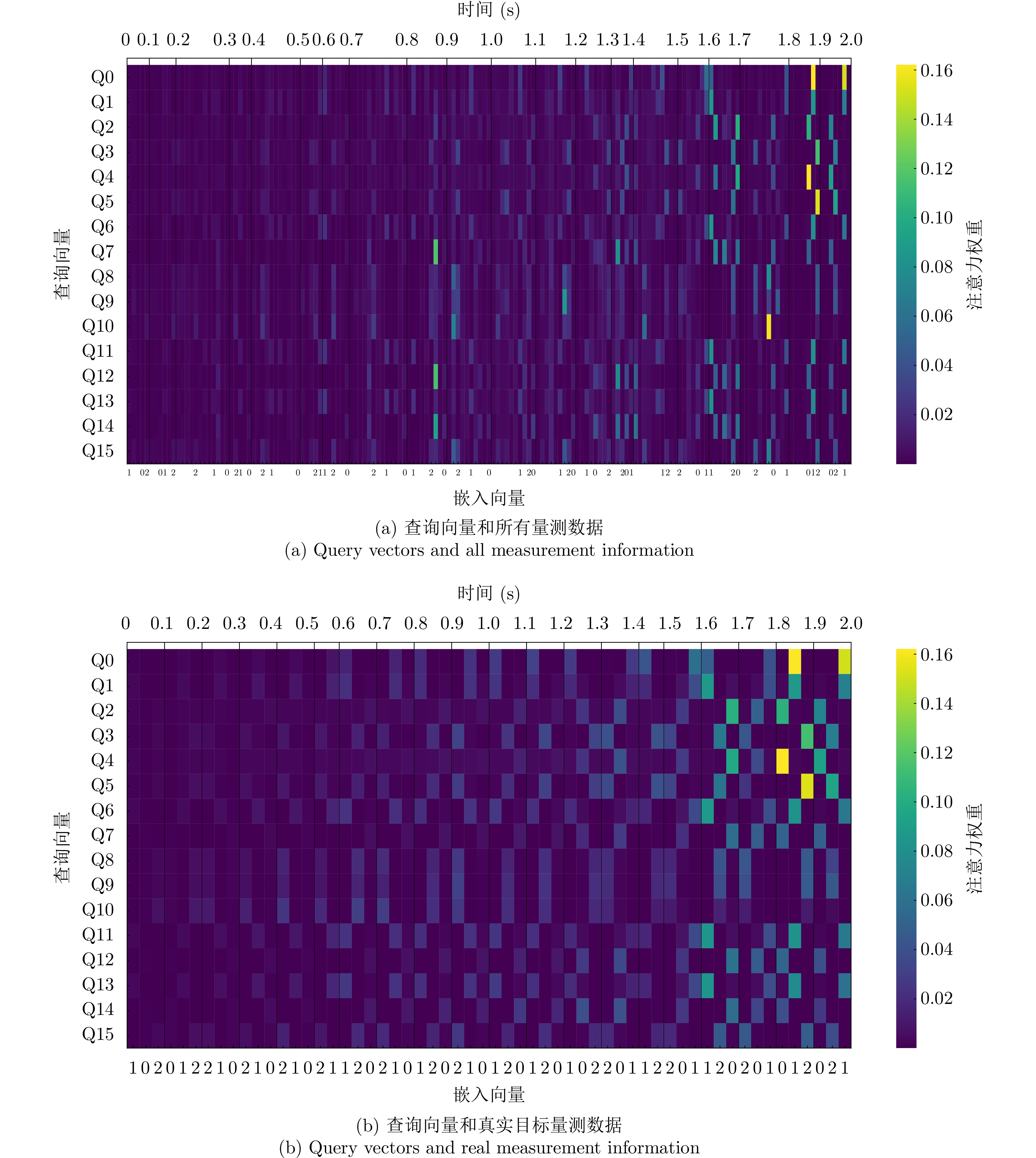
然后,在解码器中通过查询向量的自注意力机制计算,以及查询向量和编码器输出高维特征进行的交叉注意力机制计算,可以让每个查询向量特定地关注真实目标的信息,忽略虚假量测的信息。如图9所示,纵轴分别为16个检测查询向量,下方横轴为真实目标量测数据标签,上方横轴为对应量测数据的时间信息,右侧颜色条为注意力分数大小。从图9(a)中可以明确看出,查询向量和真实目标量测计算得到的注意力分数更高,说明模型更关注的是来自真实目标的量测数据,并且会忽略虚假量测数据。在图9(b)中可以清晰地看到对于所有真实目标的量测数据,查询向量对同一目标不同时间的量测注意力分数不同,模型更关注最新的量测数据,但是也没有忽略历史信息。
 图 9 查询向量和编码器输出的注意力分数可视化Figure 9. Attention score visualisation of query vectors and encoder outputs
图 9 查询向量和编码器输出的注意力分数可视化Figure 9. Attention score visualisation of query vectors and encoder outputs最后,解码器输出结果经过预测器和分类器处理得到输出在该时间窗口下的状态预测。
4.4 长时跟踪仿真验证
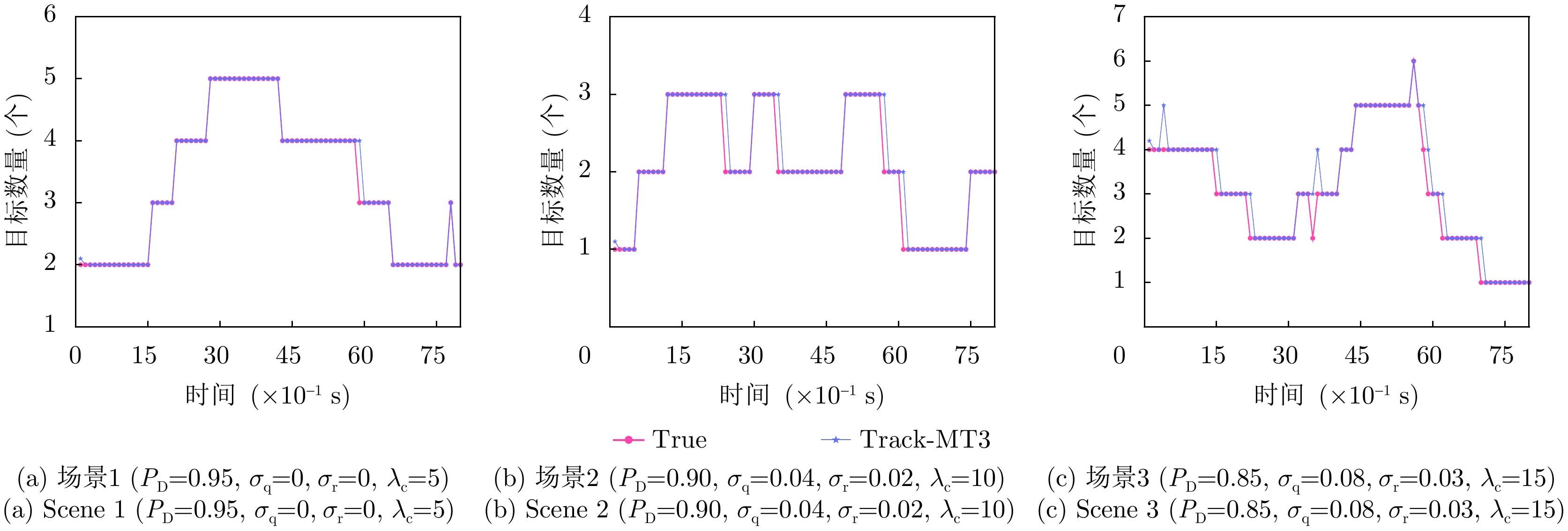
为了验证模型的长时跟踪能力,设计了3个不同的场景分别模拟10 s的目标运动,并设置传感器采样周期0.1 s,滑动窗口数量为80,大小为20。
图10给出了Track-MT3在3个场景下的目标轨迹跟踪结果,图11为对应场景下的目标数量变化图。如表5所示,场景1为简单跟踪场景,设置较少的目标数量(6个)以及较小的目标动态变化(出生率0.04,死亡率0.01),这种理想条件下,目标数量较少且运动轨迹持续时间长,考察本文所提出的Track-MT3算法的基本跟踪能力。场景2在场景1的基础上增大了目标的动态变化(出生率0.08,死亡率0.02),在此条件下目标数量不变,但目标轨迹持续时间短,考察算法对目标的检测能力。场景3进一步增大了目标数量(10个),并且目标的出生率(0.12)和死亡率(0.03)设置也高于前两个场景。总体而言,场景3的跟踪难度最大,对多目标跟踪算法有效区分真实量测并长时跟踪目标带来更大挑战。
 图 10 不同实验场景下的轨迹跟踪图Figure 10. Trajectory tracking plots for different experimental scenarios
图 10 不同实验场景下的轨迹跟踪图Figure 10. Trajectory tracking plots for different experimental scenarios 图 11 不同实验场景下目标数量变化图Figure 11. Variation of the number of targets in different experimental scenarios表 5 不同仿真场景参数设置Table 5. Parameter settings for different simulation scenarios
图 11 不同实验场景下目标数量变化图Figure 11. Variation of the number of targets in different experimental scenarios表 5 不同仿真场景参数设置Table 5. Parameter settings for different simulation scenarios场景 目标数量(个) 出生率 死亡率 场景1 6 0.04 0.01 场景2 6 0.08 0.02 场景3 10 0.12 0.03 图10中圆点实线连接表示各个时刻的目标真实轨迹,叉形符号虚线连接表示估计的目标轨迹,三角形表示目标起点,四边形表示目标终点,灰色的叉形符号表示杂波和虚假量测。结合图10(a)、图10(b)以及图11(a)、图11(b),可以看出,场景1中Track-MT3能够准确、稳定地跟踪所有目标;场景2中无虚警轨迹,总体跟踪效果依然较好。由图11(c)可见,在第4和第35个时间步下,Track-MT3算法由于没有准确检测到目标而在该时刻产生了虚警轨迹和漏检现象,但都在1到2个时间步之内调整到正确的目标数量上,另外由于设置了跟踪查询的休眠状态,目标消亡时预测通常会存在一个时间步的延时。在这种高噪声、高虚警、高目标密度的复杂环境下,虽然出现了少量虚警轨迹,但Track-MT3仍能较好地完成量测-目标关联并生成运动轨迹,体现了其在复杂环境下稳定的长时跟踪能力。
如图12所示,通过50次蒙特卡罗实验模拟计算了这80个时间窗口对应的GOSPA和Pro-GOSPA评价指标,并与3种基准方法进行了对比。随机预测(Random prediction)根据给定的参数随机生成目标状态和存在概率,作为模型性能的下界参考。如果模型的性能低于随机预测,那么模型的有效性就值得怀疑。第2个基准方法使用当前时刻真实目标量测值(True measurement),排除杂波和虚假目标量测值,并且设置较高的存在概率作为当前时刻的预测,作为一种理想情况下的性能上界,如果模型能够完美地区分真实目标和虚假目标,并准确估计目标状态,则可以达到这个性能水平。第3种基准是直接使用MT3模型对每个时间窗口量测数据的推理结果作为参考。
 图 12 不同场景下评价指标对比Figure 12. Comparison of evaluation indicators in different scenarios
图 12 不同场景下评价指标对比Figure 12. Comparison of evaluation indicators in different scenarios如图12(a)所示,从GOSPA指标来看,MT3算法在初始时刻性能最优,在第10~20个时间步之间指标会有发散并高于随机预测,随时间收敛的趋势不明显,这是因为MT3无法关联目标长时间的历史信息。Track-MT3算法在初始时间指标数值略高于MT3,但能很快随时间收敛,在第5~10时间步后优于MT3,并且收敛趋势明显。随着跟踪场景复杂度的提高,两个算法的性能都有所降低,但Track-MT3最后都优于MT3算法,表明其长时跟踪的稳定性,且有不输于MT3算法的单帧预测能力。
如图12(b)所示,总体来看Pro-GOSPA略低于GOSPA,且Pro-GOSPA指标的变化趋势与GOSPA不同,在初始时间内MT3优于Track-MT3,但随时间趋向于发散,这是由于MT3无法提取目标历史状态信息的特征提取、刻画长时间目标运动,导致目标存在概率预测的置信度随时间降低。Track-MT3在3个场景中的Pro-GOSPA指标均明显优于MT3,且收敛趋势明显,尤其在场景1中优势明显。表明Track-MT3能够更准确地判别目标的真实性,降低虚警的影响。
值得注意的是,Track-MT3模型在跟踪初期(尤其前10个时刻)的性能明显低于MT3,在较复杂的场景中甚至接近随机预测的水平。这主要由3个因素导致:(1)跟踪查询机制在第1帧缺乏先验目标信息,难以准确关联真实目标;(2)场景复杂度的提高对模型的学习和适应能力提出了更高要求;(3)跟踪初期较大的定位误差主导了GOSPA指标值。随着时间步的推进,Track-MT3通过跨帧信息融合逐步提升了预测精度,最终实现了优于MT3的长时跟踪性能。未来可进一步探索Track-MT3的快速适应机制,缩短其学习曲线,提升其在复杂场景下的初始表现。
综合跟踪结果和性能指标分析,本文所提出的Track-MT3算法展现了较强的多目标跟踪能力。相比MT3模型,Track-MT3能够更有效地挖掘时序信息,在复杂动态环境下实现稳定的多目标跟踪。
4.5 性能评估
4.5.1 模型计算复杂度
一般来说,模型的计算复杂度和其跟踪精度及计算效率之间存在一种微妙的平衡。Track-MT3模型的计算复杂度主要来自以下几个方面:编码器和解码器、预测器和分类器、CTA机制、QTM模块以及集体平均损失CAL。
设输入观测序列长度为T,特征维度为d,编码器和解码器的层数分别为{L_{\text{e}}}和{L_{\text{d}}},前馈网络的隐藏层维度为{d_{\text{f}}},编码器和解码器的总计算复杂度为
O({L_{\text{e}}} \cdot ({T^2} \cdot d + T \cdot d \cdot {d_{\text{f}}}) + {L_{\text{d}}} \cdot (2{T^2} \cdot d + T \cdot d \cdot {d_{\text{f}}})) (57) 预测器和分类器分别由多层感知机(输入层维度{d_{\text{i}}},隐藏层维度为{d_{\text{m}}},输出层维度{d_{\text{o}}})和线性层(输入维度为{d_{\text{c}}},输入维度为1)组成,它们的总计算复杂度为
O(T \cdot {d_{\text{i}}} \cdot {d_{\text{m}}} \cdot {d_{\text{o}}} + T \cdot {d_{\text{c}}}) (58) CTA机制中,对于跟踪查询,直接延续上一帧的匹配结果以保持跟踪目标的一致性,复杂度为O(1)。对于检测查询,需要将其与真值中的新生目标进行匈牙利匹配。设相邻两帧的目标数量最大值为{N_{{\text{max}}}},则匈牙利算法的复杂度为O(N_{{\text{max}}}^3)。QTM模块接收上一帧的目标状态预测,生成当前帧的跟踪查询,它主要包括一些矩阵运算和注意力计算。设隐藏层维度为{d_{\text{q}}},则复杂度为O(T \cdot d_{\text{q}}^2)。对于训练过程中使用的集体平均损失(CAL),在整个观测序列上计算损失,将每帧的预测损失求平均。假设每个时间步的最大目标数为{M_{\max }},损失计算中的匈牙利算法复杂度为O(M_{{\text{max}}}^3),则CAL的计算复杂度为O(T \cdot M_{\max }^3)。
综上所述,Track-MT3模型在一个观测序列上的前向计算复杂度为
\begin{split} & O({L_{\text{e}}} \cdot ({T^2} \cdot d + T \cdot d \cdot {d_{\text{f}}}) \\ & \quad + {L_{\text{d}}} \cdot (2{T^2} \cdot d + T \cdot d \cdot {d_{\text{f}}}) \\ & \quad + T \cdot {d_{\text{i}}} \cdot {d_{\text{m}}} \cdot {d_{\text{o}}} + T \cdot {d_{\text{c}}} \\ & \quad + T \cdot N_{\max }^3 + T \cdot d_{\text{q}}^2 + T \cdot M_{\max }^3) \end{split} (59) 由于{d_{\text{i}}}, {d_{\text{m}}}, {d_{\text{o}}}, {N_{{\text{max}}}}, {M_{\max }}为常数且远远小于其他参数,总的计算复杂度可以简化为式(57)。这表明,Track-MT3模型的计算复杂度主要取决于观测序列的长度T(一个滑动窗口产生的量测数据点总数)以及编码器和解码器的参数,在实际应用中,可以通过调整滑动窗口的大小来控制T,从而在跟踪精度和计算效率之间进行权衡。
4.5.2 准确性和计算效率
在4.4节的3个实验场景中,经实验统计,场景1中总的目标数量为6,观测序列长度平均为T = 160,相邻两帧最大目标数量为{N_{\max }} = 5,每帧最大目标数为{M_{\max }} = 5;场景2中总的目标数量为6,观测序列长度平均为T = 249,相邻两帧最大目标数量为{N_{\max }} = 3,每帧最大目标数为{M_{\max }} = 3;场景3中总的目标数量为10,观测序列长度平均为T = 380,相邻两帧最大目标数量为{N_{\max }} = 5,每帧最大目标数为{M_{\max }} = 5。根据模型参数设置,将以上参数代入式(59),可以得到模型在场景1的计算复杂度约为O(1.15 \times {10^9}),场景2的计算复杂度约为O(1.89 \times {10^9}),场景3的计算复杂度约为O(3.11 \times {10^9})。
为了更好地量化Track-MT3模型的优势和局限性,我们在跟踪复杂度更高的场景3中进行了50次蒙特卡罗模拟实验,与JPDA算法和MHT算法进行了比较,采用分解GOSPA指标评估准确性,结果如表6所示,采用单帧运行时间和内存占用衡量计算效率,结果如表7所示。
表 6 跟踪准确性对比Table 6. Tracking accuracy comparison跟踪方法 定位误差 漏检误差 虚警误差 JPDA 0.1629 0.6208 4.2812 MHT 0.6006 1.5921 3.8717 Track-MT3 0.0588 2.3683 2.3708 表 7 计算效率对比Table 7. Computational efficiency comparison跟踪方法 单帧运行时间(s) 平均内存占用(MB) JPDA 0.0041 169.6641 MHT 0.1714 209.8398 Track-MT3 0.0123 253.6656 从表6和表7的实验结果不难看出,Track-MT3 在跟踪准确性和计算效率方面表现出了明显的优势和特点。在跟踪准确性方面,Track-MT3总体性能相比JPDA和MHT分别提高了6%和20%,定位误差最小,仅为
0.0588 ,显著优于其他两种方法,说明其在估计目标状态方面更加准确,对目标运动的刻画更加精细。虚警误差在3种方法中最小,漏检误差相对更大,说明其更倾向于保守地判别目标的存在性,以降低虚警风险。在计算效率方面,Track-MT3的单帧运行时间为0.0123 s,略高于JPDA,但远低于MHT,内存占用相对较高。考虑到Track-MT3在跟踪准确性方面的优势,这一时间开销和内存开销是可以接受的。4.5.3 消融实验及鲁棒性测试
QTM模块通过动态查询机制(DQM)和时间特征编码网络(TFN)增强了查询对目标运动的建模能力。为验证其有效性,我们移除QTM模块,直接将上一帧的跟踪查询结果及当前帧的检测查询结果经过阈值 {\tau _{{\text{det}}}} , {\tau _{{\text{tr}}}} 筛选,生成新一帧的跟踪查询,记为TrackMT3(No-QTM)。如表8所示,引入QTM后,Track-MT3的跟踪性能获得了显著提升。具体而言,GOSPA和Pro-GOSPA性能相对提升幅度分别为25.5%和30.4%。
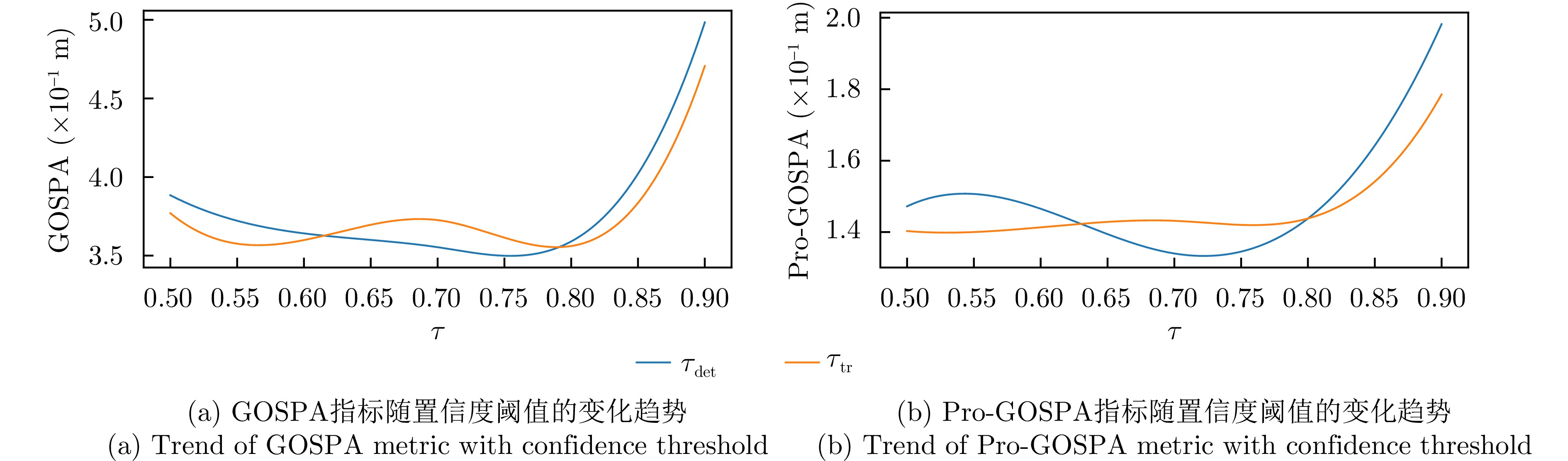
表 8 QTM消融实验Table 8. QTM ablation experiment评价指标 Full No-QTM GOSPA (×10–1 m) 3.546362 4.760920 Pro-GOSPA (×10–1 m) 1.340019 1.925471 为验证检测查询置信度阈值 {\tau _{\det }} 和轨迹查询置信度阈值 {\tau _{{\text{tr}}}} 的稳健性。我们固定其他参数分别让 {\tau _{\det }} 和 {\tau _{{\text{tr}}}} 在置信度较高的范围0.5~0.9内以步长0.05递增,记录所有时间步GOSPA和Pro-GOSPA的平均值,并用插值的方式绘制为平滑曲线,观察跟踪性能的变化趋势。如图13所示, {\tau _{\det }} 和 {\tau _{{\text{tr}}}} 对模型性能都有影响,但这两个参数在小于0.9的较大范围内具有较好的稳健性,减轻了参数调优的负担。
在实际应用中,跟踪环境可能更加复杂,因此对算法的鲁棒性有很高的要求。为了探究Track-MT3算法的鲁棒性,在4.4节中的仿真场景3下设置不同检测概率{P_{\text{D}}}、过程噪声强度{\sigma _{\text{q}}}、量测噪声强度{\sigma _{\text{r}}}以及杂波数量{\lambda _{\text{c}}}以增加数据关联难度和跟踪复杂度,验证模型跟踪的鲁棒性,实验参数设置如表9所示。
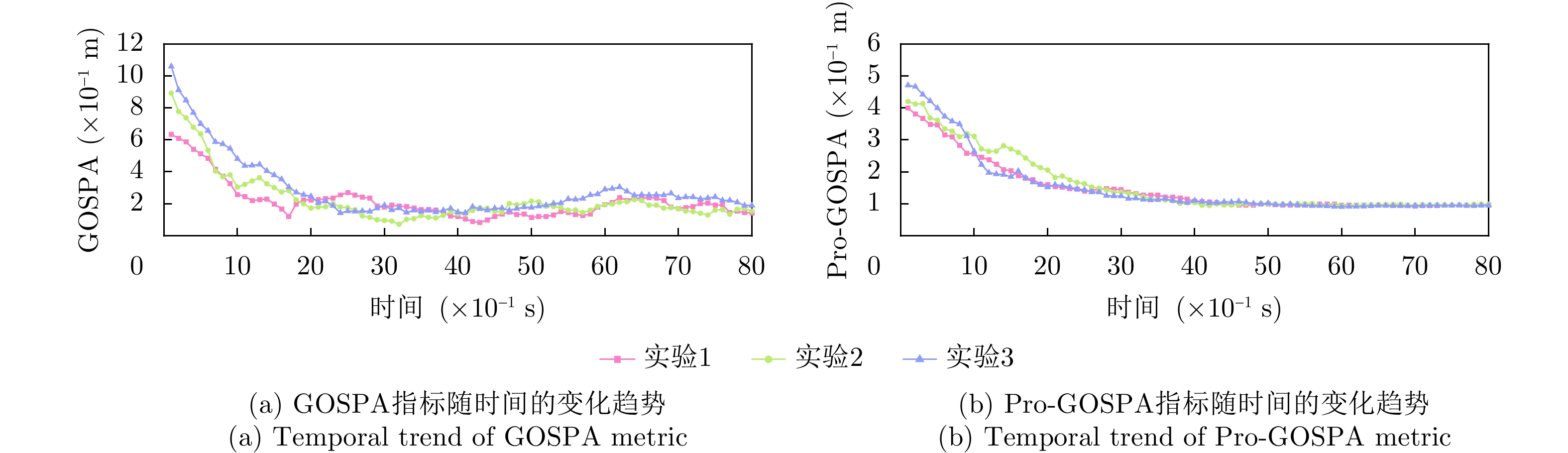
表 9 实验参数设置Table 9. Experimental parameter settings实验组 {P_{\mathrm{D}}} {\sigma _{\mathrm{q}}} {\sigma _{\mathrm{r}}} {\lambda _{\mathrm{c}}} 实验1 0.95 0.01 0.1 5 实验2 0.90 0.02 0.9 10 实验3 0.85 0.03 2.0 15 以表9的参数设置进行3组不同的实验,通过50次蒙特卡罗模拟实验模拟计算其评价指标,结果如图14所示。显然,随着跟踪复杂度的提高,跟踪性能有所下降,尤其是跟踪的初始时刻,但均随时间收敛,可以证明算法在复杂环境中具有稳定、鲁棒的跟踪能力。
5. 结语
本文针对深度学习算法在多目标跟踪领域的挑战,提出了一种创新的基于Transformer网络的多目标跟踪算法Track-MT3。该算法继承了MT3的优秀设计,较好地解决了MT3算法存在的缺陷,实现了对多目标的长时精确跟踪,生成了目标完整的预测轨迹。Track-MT3是一种高效、鲁棒的Transformer多目标跟踪算法,拓展了Transformer结构在多目标跟踪领域的应用。相比MT3算法的单帧预测,Track-MT3实现了多目标的长时跟踪,并生成目标轨迹。这不仅丰富了多目标跟踪的技术手段,也为Transformer在时序数据挖掘方面的应用提供了新的思路。未来可以进一步探索Track-MT3与图神经网络等其他先进结构的结合,以建模更复杂的目标交互行为。此外,将Track-MT3拓展到基于视觉、激光雷达等其他传感器的多目标跟踪任务也是一个有价值的研究方向。
期刊类型引用(2)
1. 周翔,潘洁,吴一戎. 透视地球——新一代对地观测技术. 遥感学报. 2024(03): 529-540 .  百度学术
百度学术2. 明星辰,王朝栋,毛馨玉,李中余,武俊杰,杨建宇. 分布式无人机载InSAR混合多基线相位解缠与高程反演技术. 信号处理. 2024(09): 1685-1695 . 百度学术其他类型引用(0)
-

 下载:
下载:




 百度学术
百度学术计量
- 文章访问数: 3435
- HTML全文浏览量: 255
- PDF下载量: 1973
- 被引次数: 2
 下载:
下载:

