
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Offline Reward Backfilling-based Intelligent Cooperative Jamming Strategy Learning Method
-
摘要: 针对复杂电磁环境下多干扰机协同对抗组网雷达存在的局部可观测、奖励稀疏以及信用分配失真等难题,该文提出一种基于离线奖励回填机制的智能协同干扰策略学习方法。所提方法将多干扰机的协同干扰过程建模为部分可观测马尔可夫决策过程,构建即时奖励与离线奖励回填相结合的双层奖励结构,以实现对干扰效果的精准评估。具体而言,多干扰机通过周期性信息汇总弥补局部可观测带来的信息缺失:在周期内,各干扰机利用局部观测对截获节奏和发射行为进行在线引导;在周期末,通过多机交互数据联合回溯评估与奖励回填,修正策略梯度信号,提升策略对真实干扰效果的表征与学习能力。在此基础上,该文结合集中训练、分散执行框架,提出基于离线奖励回填的多智能体近端策略优化算法ORB-MAPPO,实现多干扰机协同时频干扰策略学习。仿真结果表明,所提方法能够稳定学习有效的时频协同干扰策略,干扰遮盖率可达95%以上,信息截获率接近100%,相较典型多智能体策略优化方法,所提方法的干扰遮盖率提升约20%,表现出更优的协同干扰性能与训练稳定性。Abstract: To address partial observability, reward sparsity, and distorted credit assignment in cooperative jamming against networked radars in complex electromagnetic environments, this paper proposes an intelligent cooperative jamming strategy learning method with an offline reward backfilling mechanism. The multi-jammer cooperative jamming process is formulated as a partially observable Markov decision process. A two-level reward design is introduced, integrating immediate rewards with offline reward backfilling to improve the evaluation of jamming effectiveness and policy learning. Specifically, within each aggregation period, each jammer performs online adaptations of interception rhythm and transmission behavior based on local observations. At the end of the period, multi-jammer interaction data are aggregated to retrospectively assess the effectiveness of joint jamming actions. The resulting evaluation is backfilled into policy optimization to refine the policy gradient signal. This design enhances the policy’s ability to capture the actual jamming effectiveness. Accordingly, under the centralized training and decentralized execution framework, an offline reward backfilling-based multi-agent proximal policy optimization algorithm, termed ORB-MAPPO, is developed to realize collaborative time-frequency jamming strategy learning for multiple jammers. Simulation results demonstrate that the proposed method stably learns effective time-frequency cooperative jamming strategies, achieving a jamming coverage rate of over 95% and an information interception rate close to 100%. Compared with typical multi-agent policy optimization methods, the proposed method improves the jamming coverage rate by approximately 20%, demonstrating superior cooperative jamming performance and training stability.
-
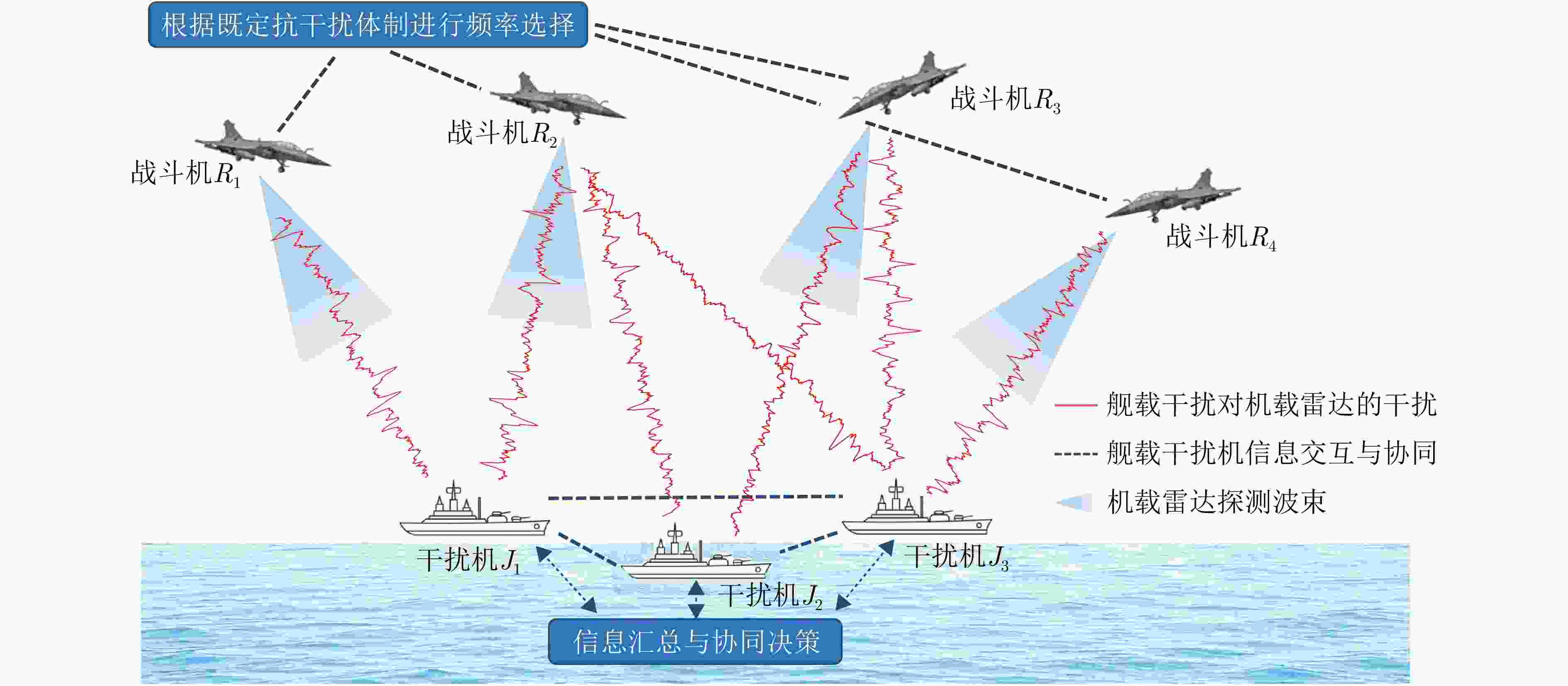
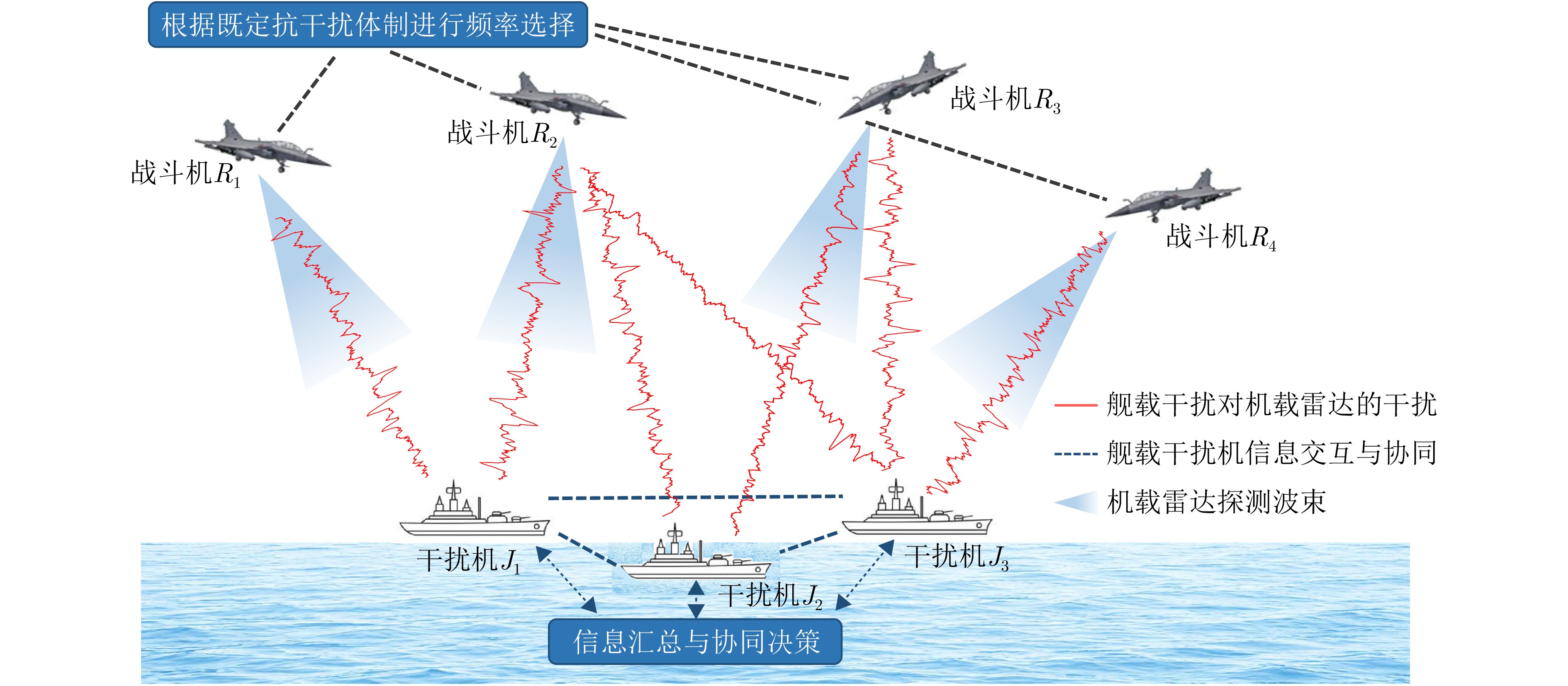
图 1 干扰资源占优条件下的海空协同对抗场景示意图
Figure 1. Schematic diagram of a sea-to-air cooperative adversarial scenario under jammer-side resource superiority
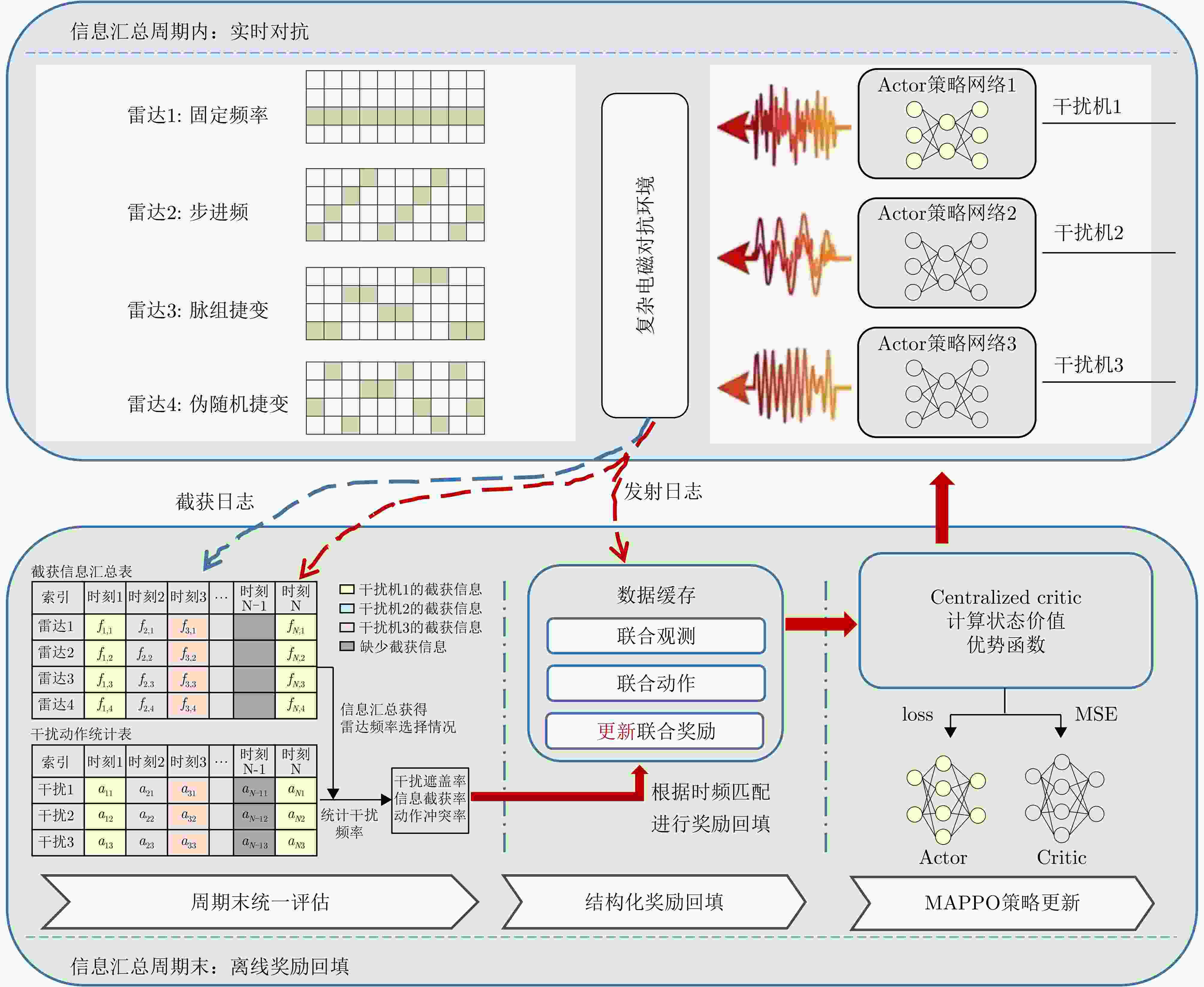
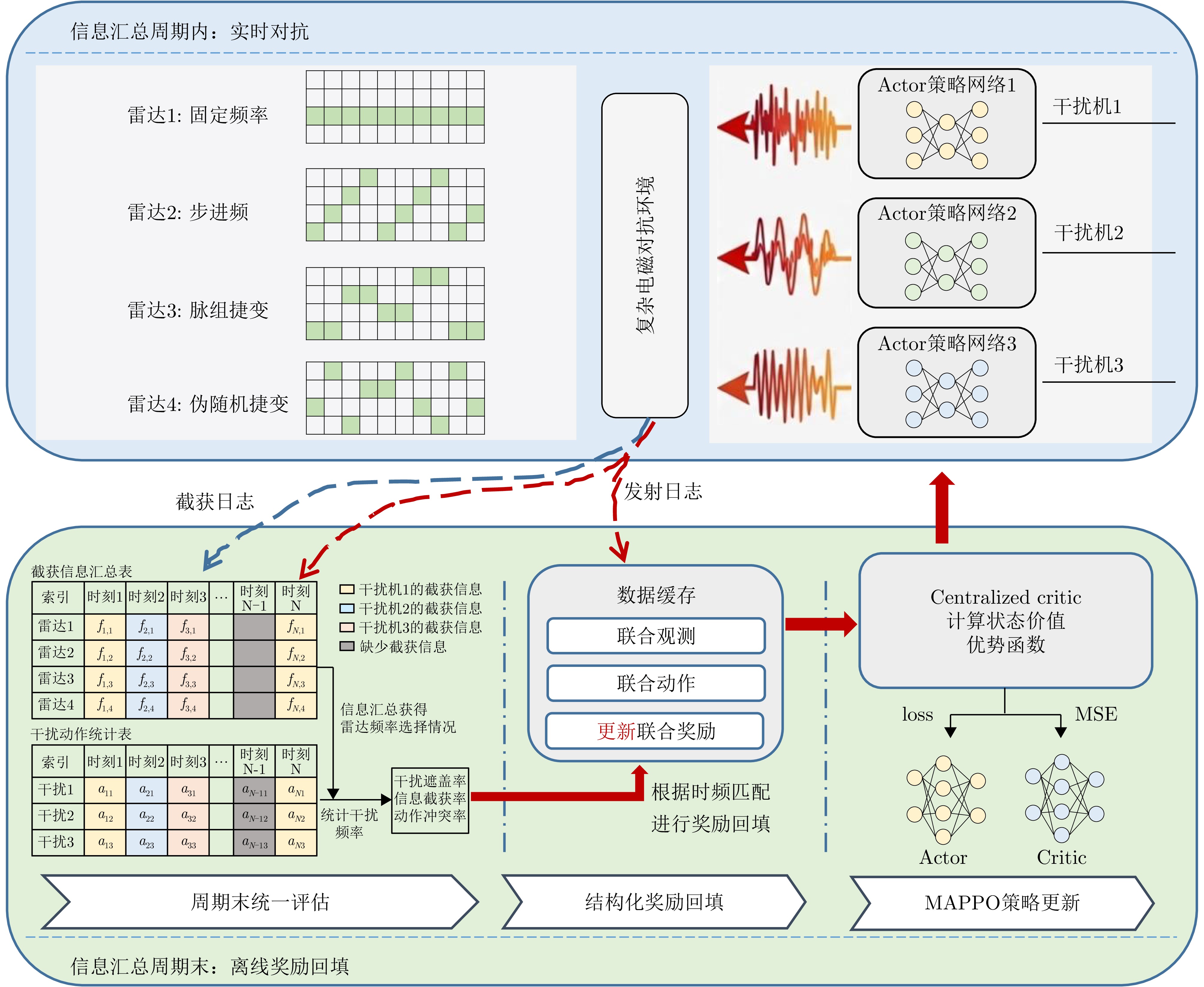
图 4 协同干扰策略学习方法流程图
Figure 4. Flowchart of collaborative interference strategy learning method
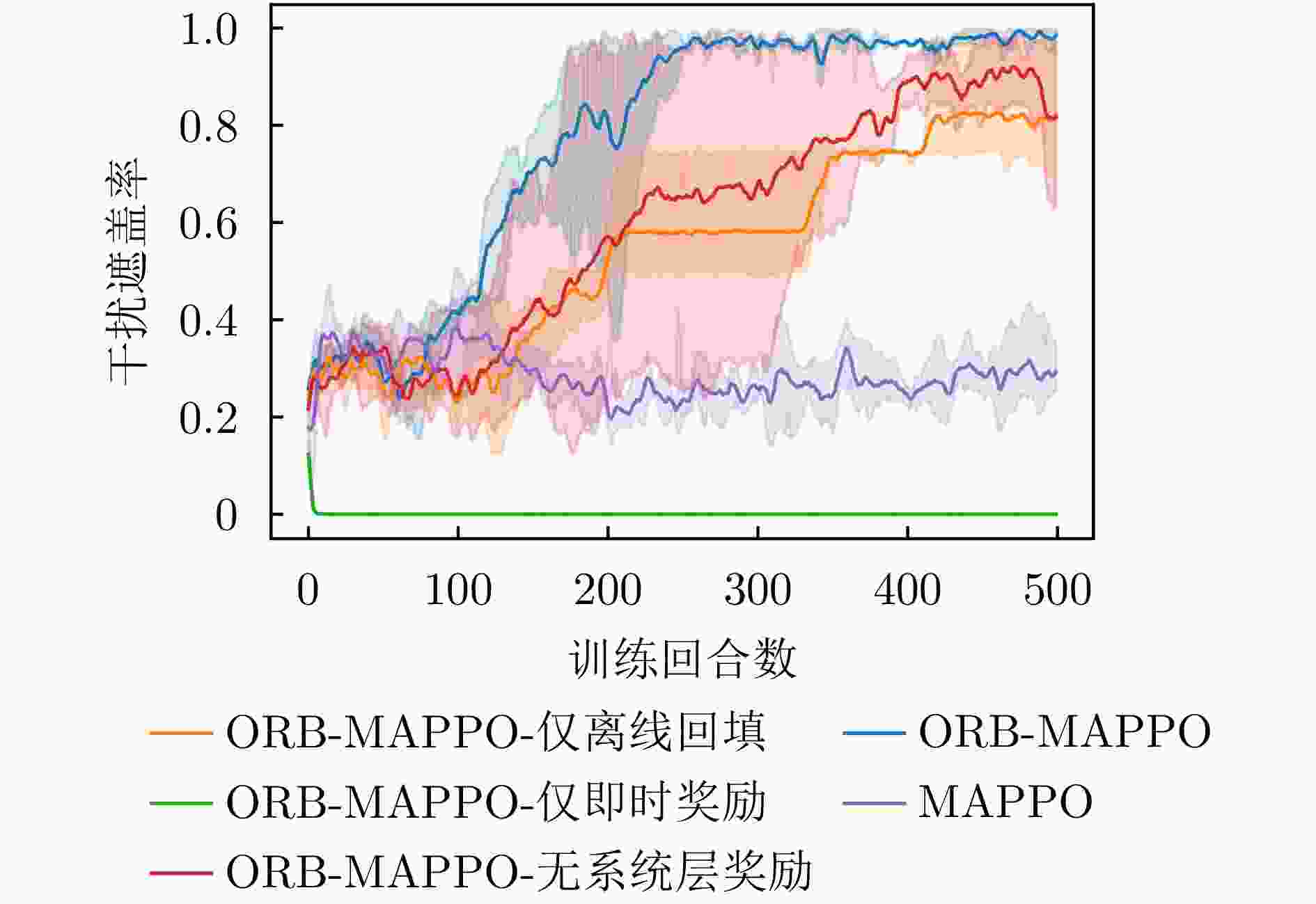
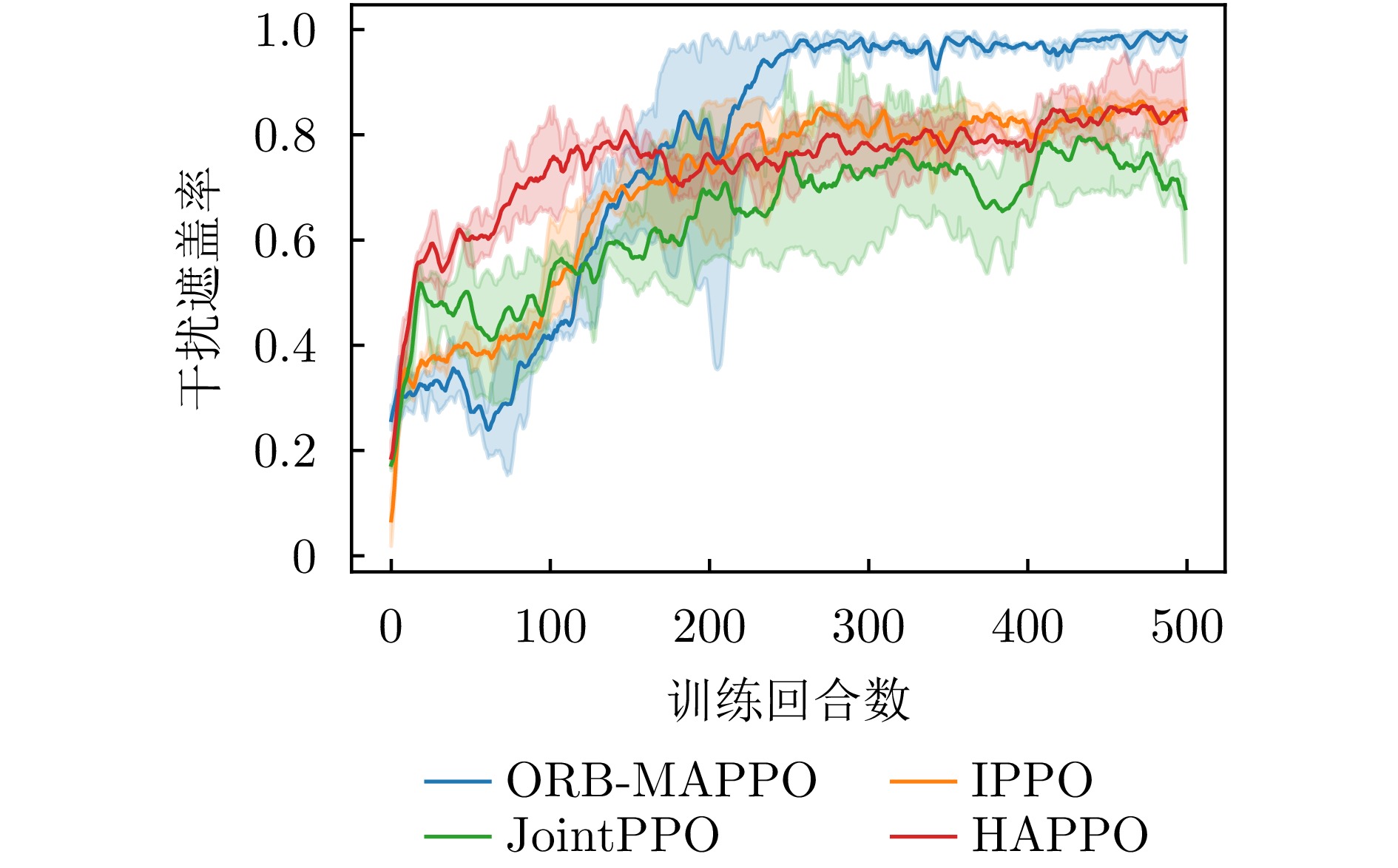
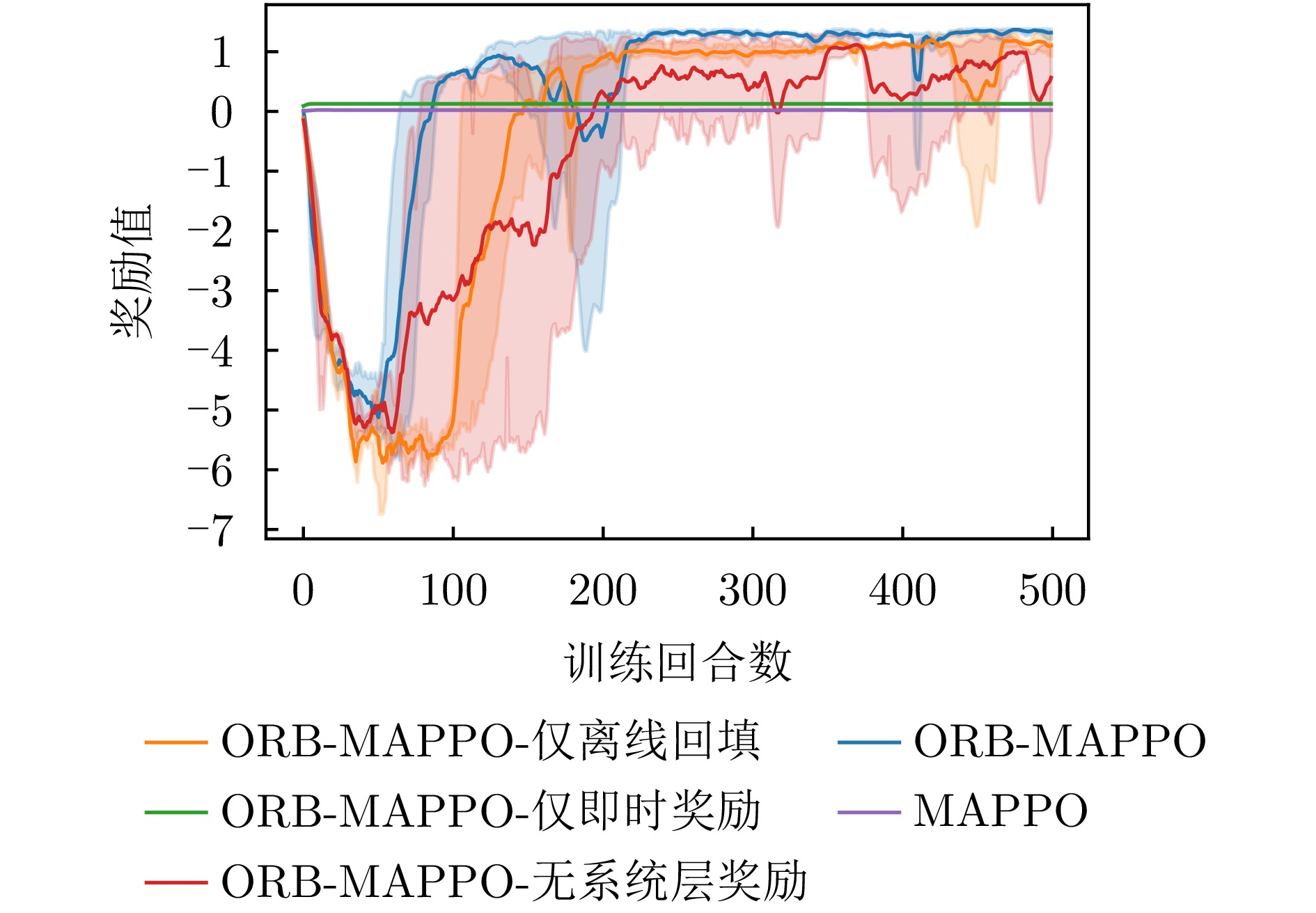
图 7 消融实验中干扰遮盖率曲线对比图
Figure 7. Comparison chart of jamming coverage rate in ablation experiment

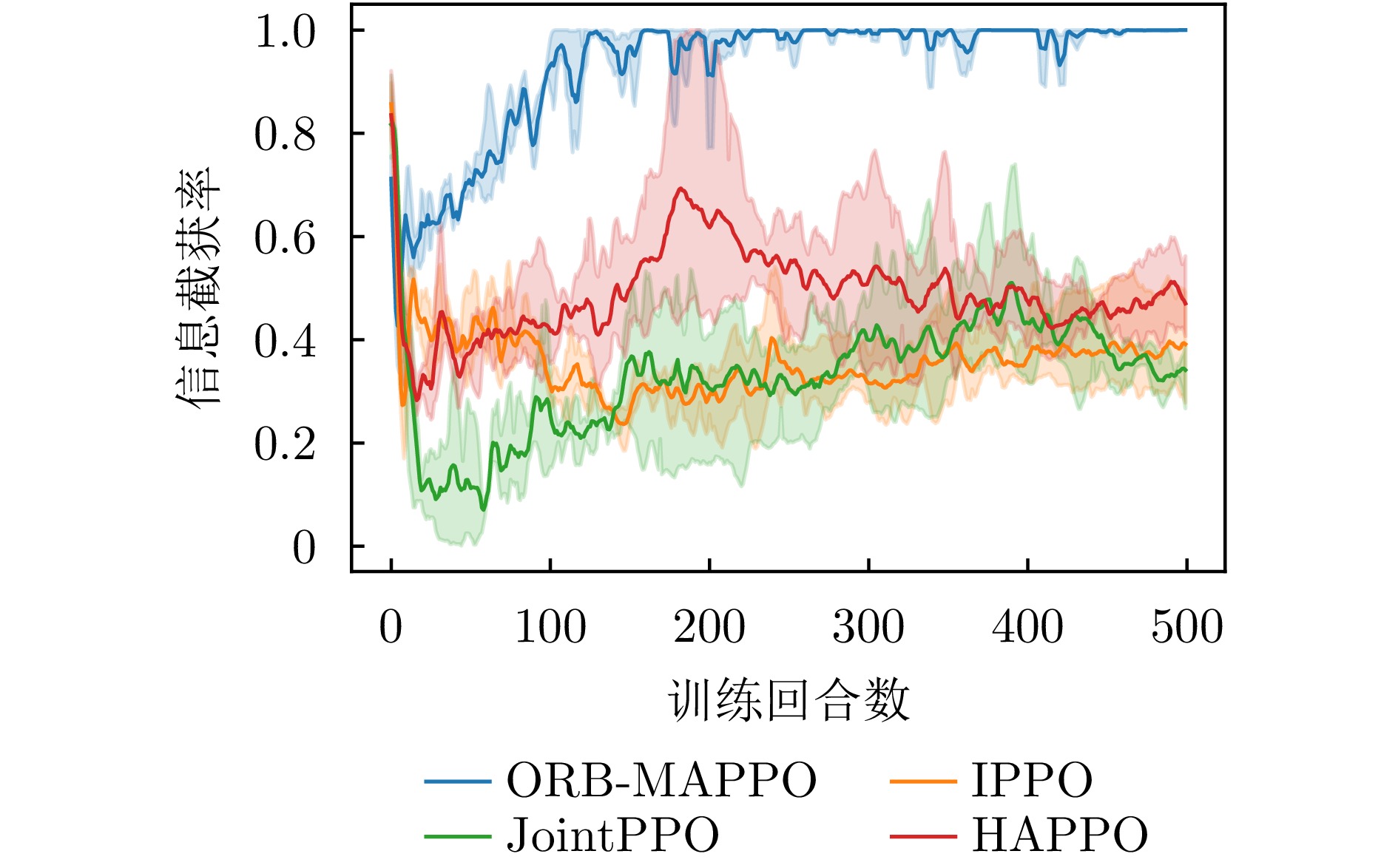
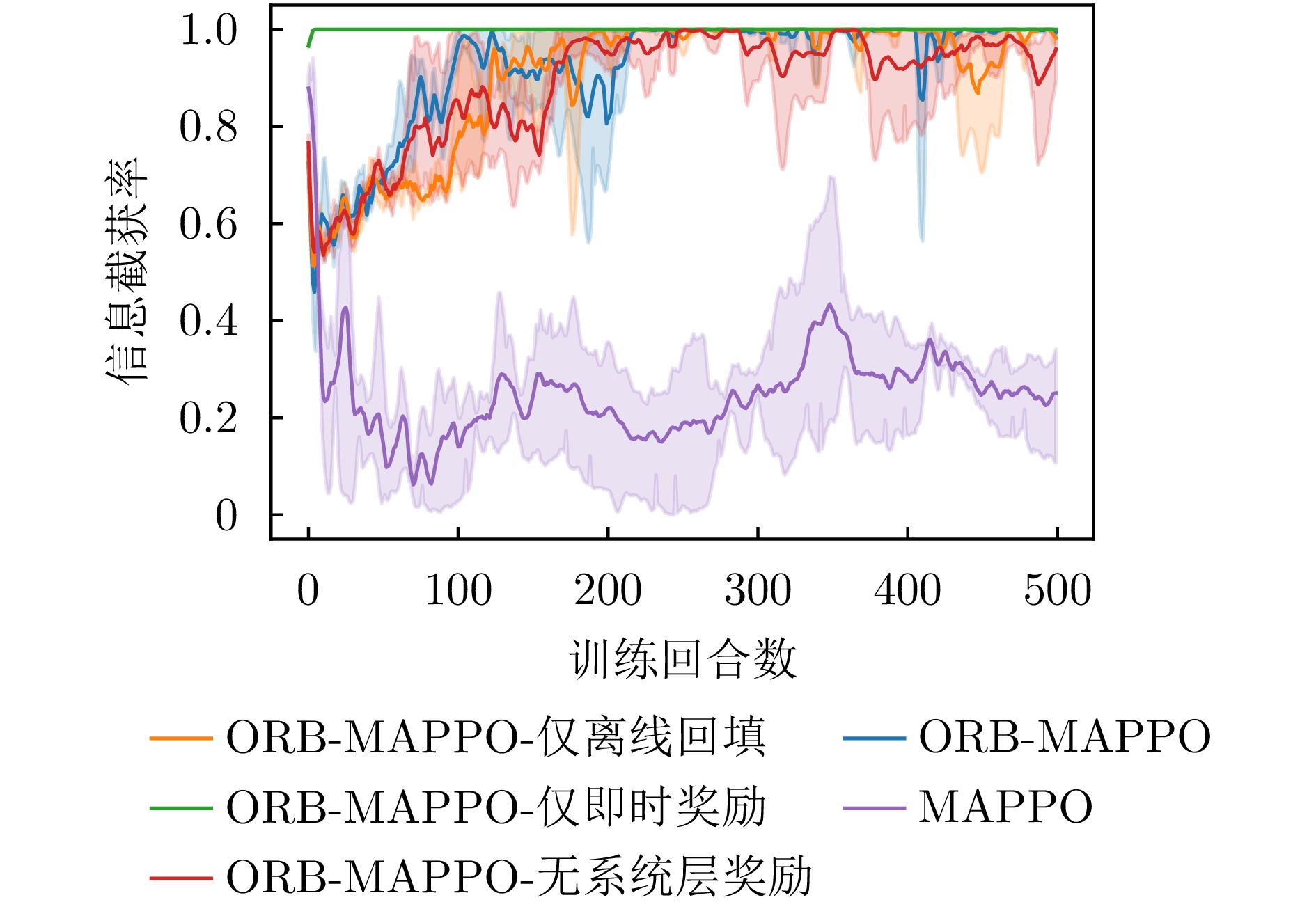
图 8 消融实验中信息截获率曲线对比图
Figure 8. Comparison of information interception rate curves in ablation experiments
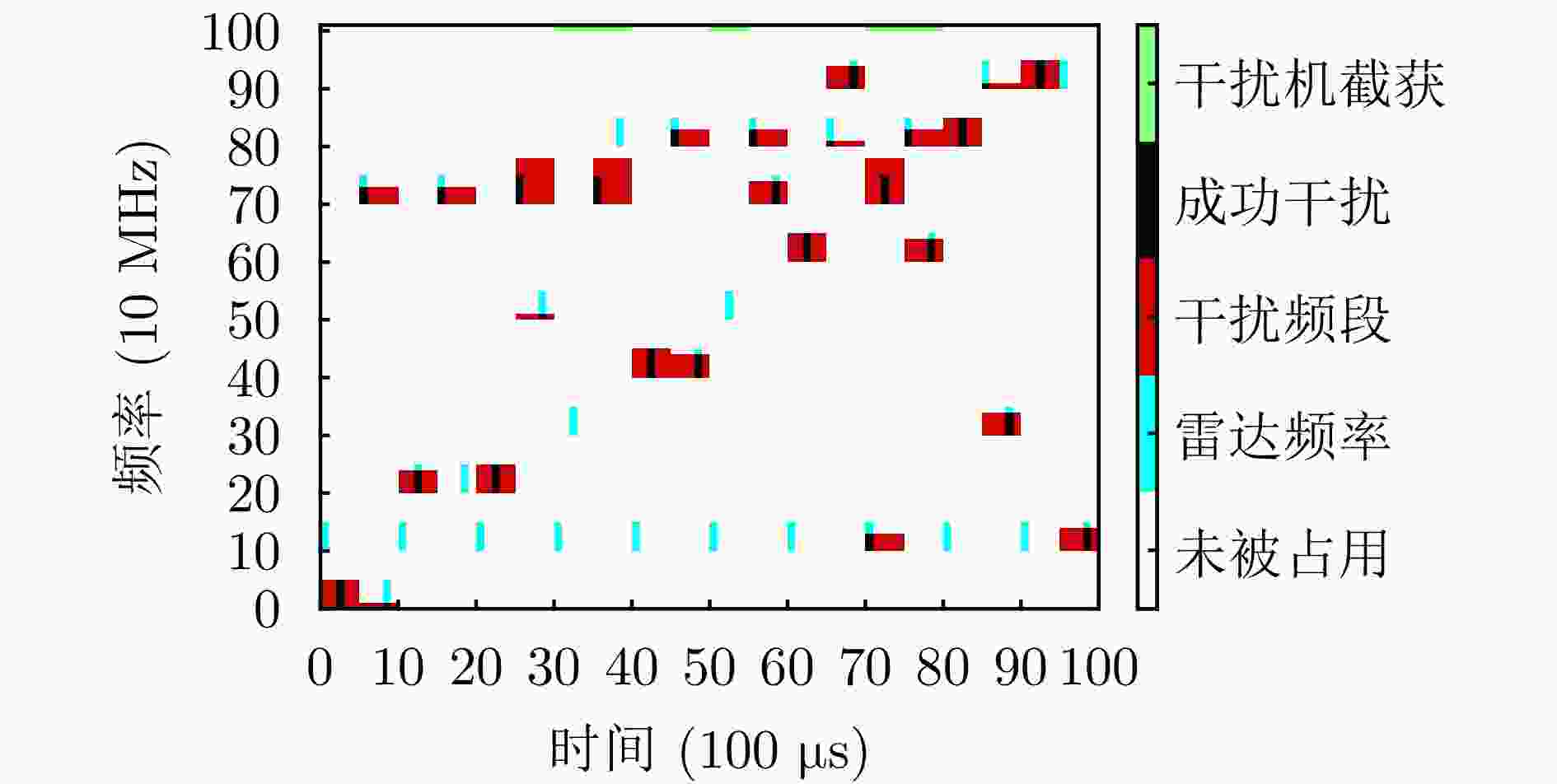
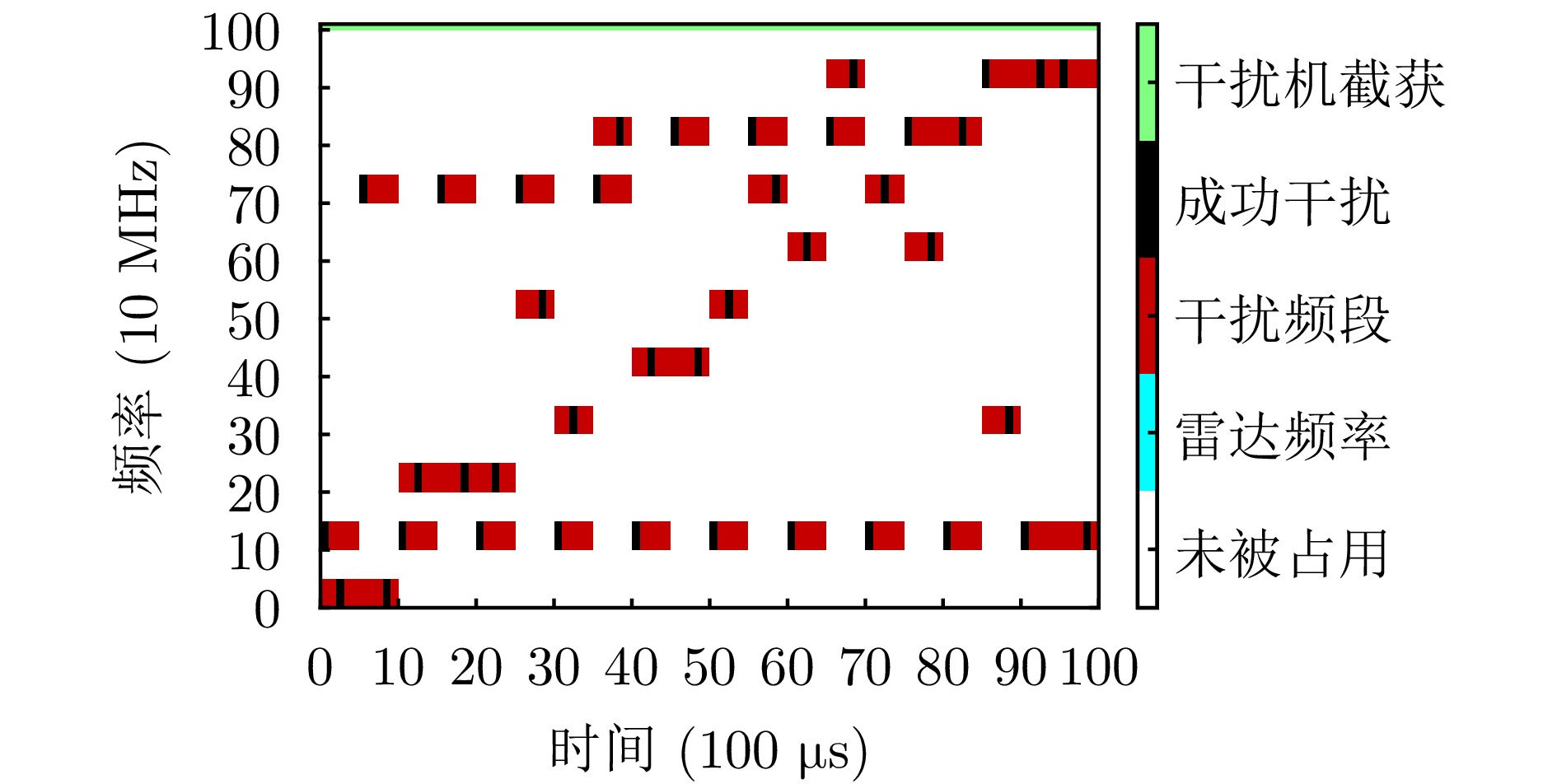
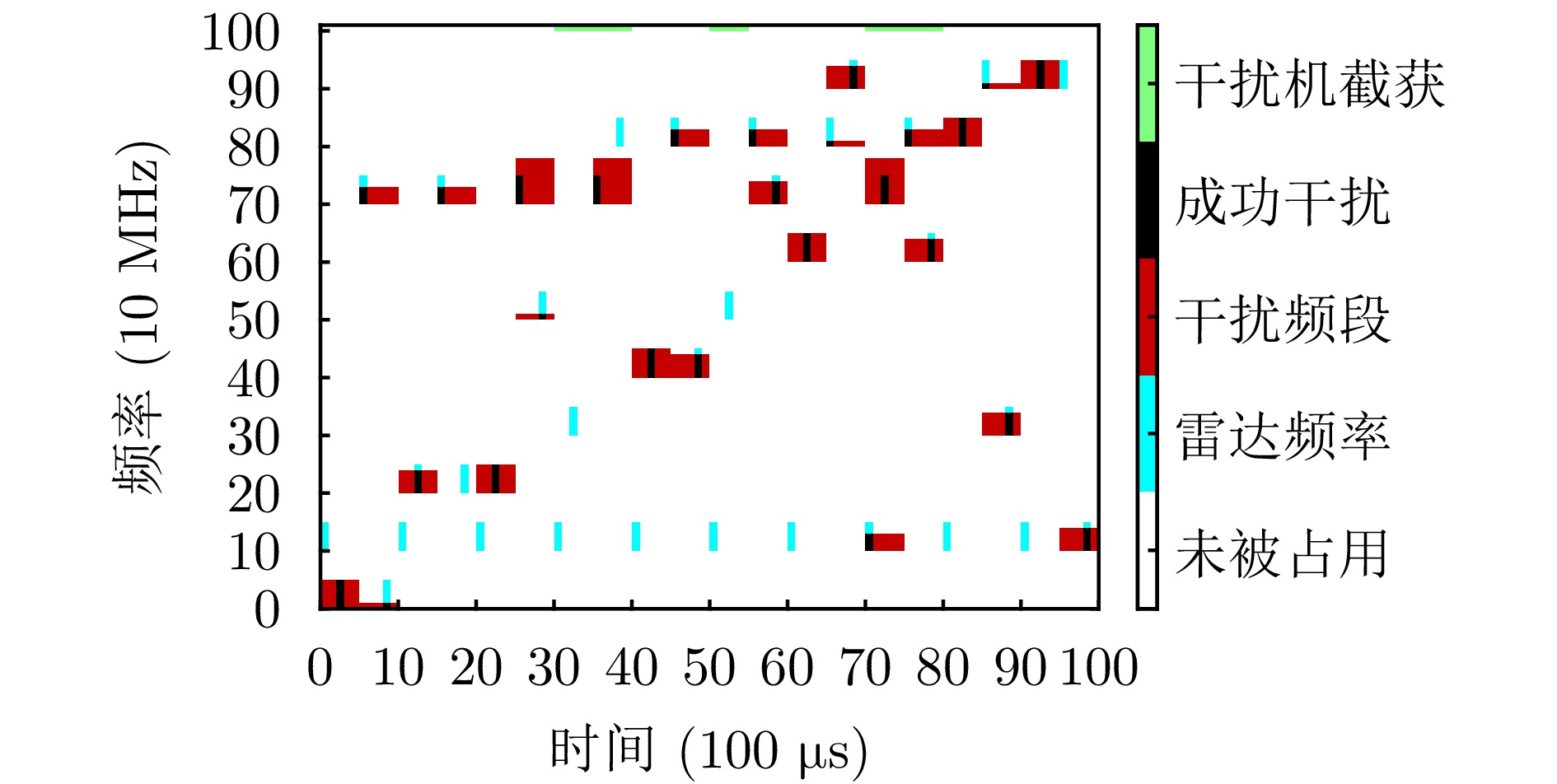
图 11 基线MAPPO算法的动作示意图
Figure 11. Schematic diagram of action of the baseline method MAPPO
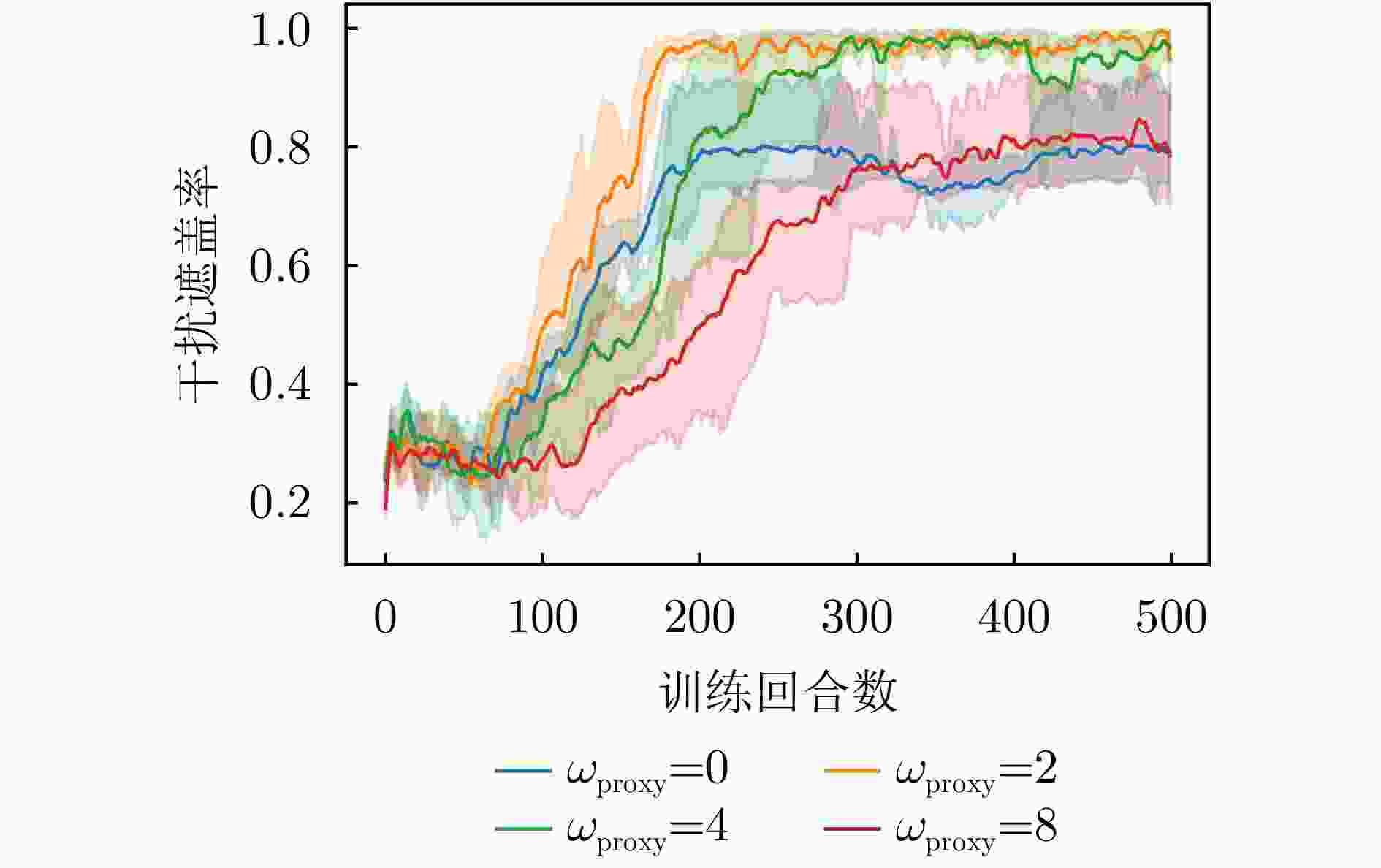
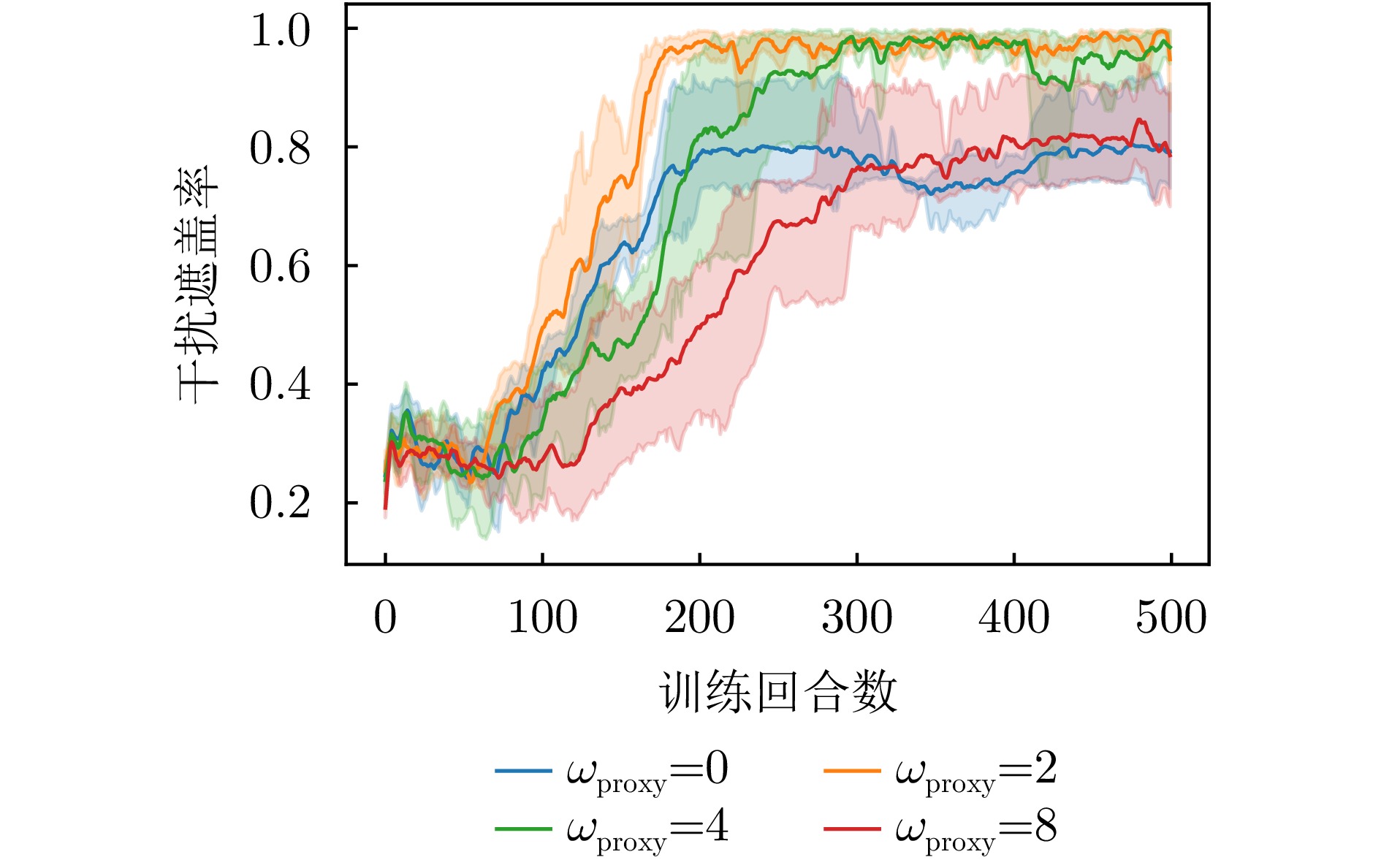
图 12 不同权重下干扰遮盖率变化曲线
Figure 12. Curve of jamming coverage rate variation under different weights
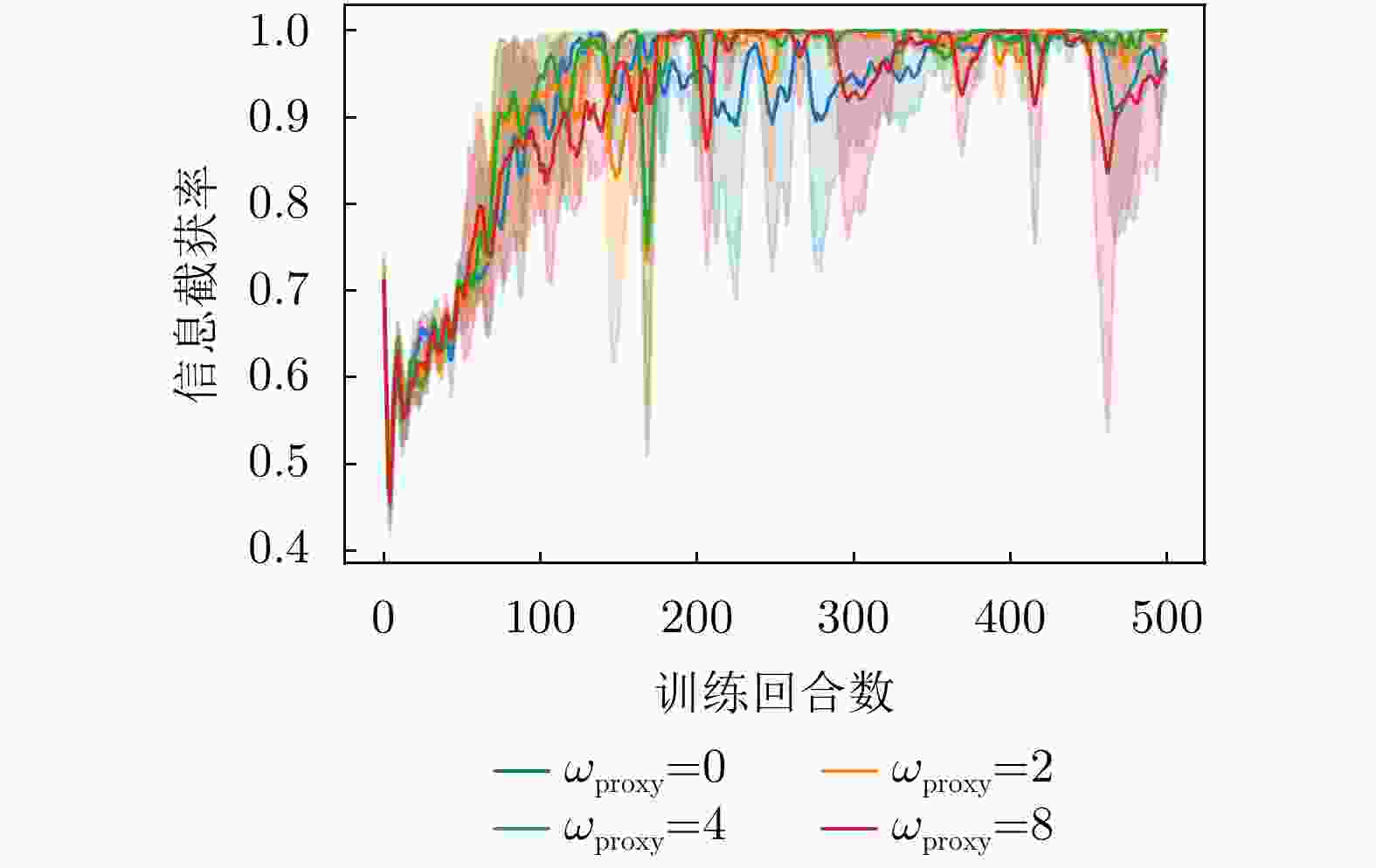
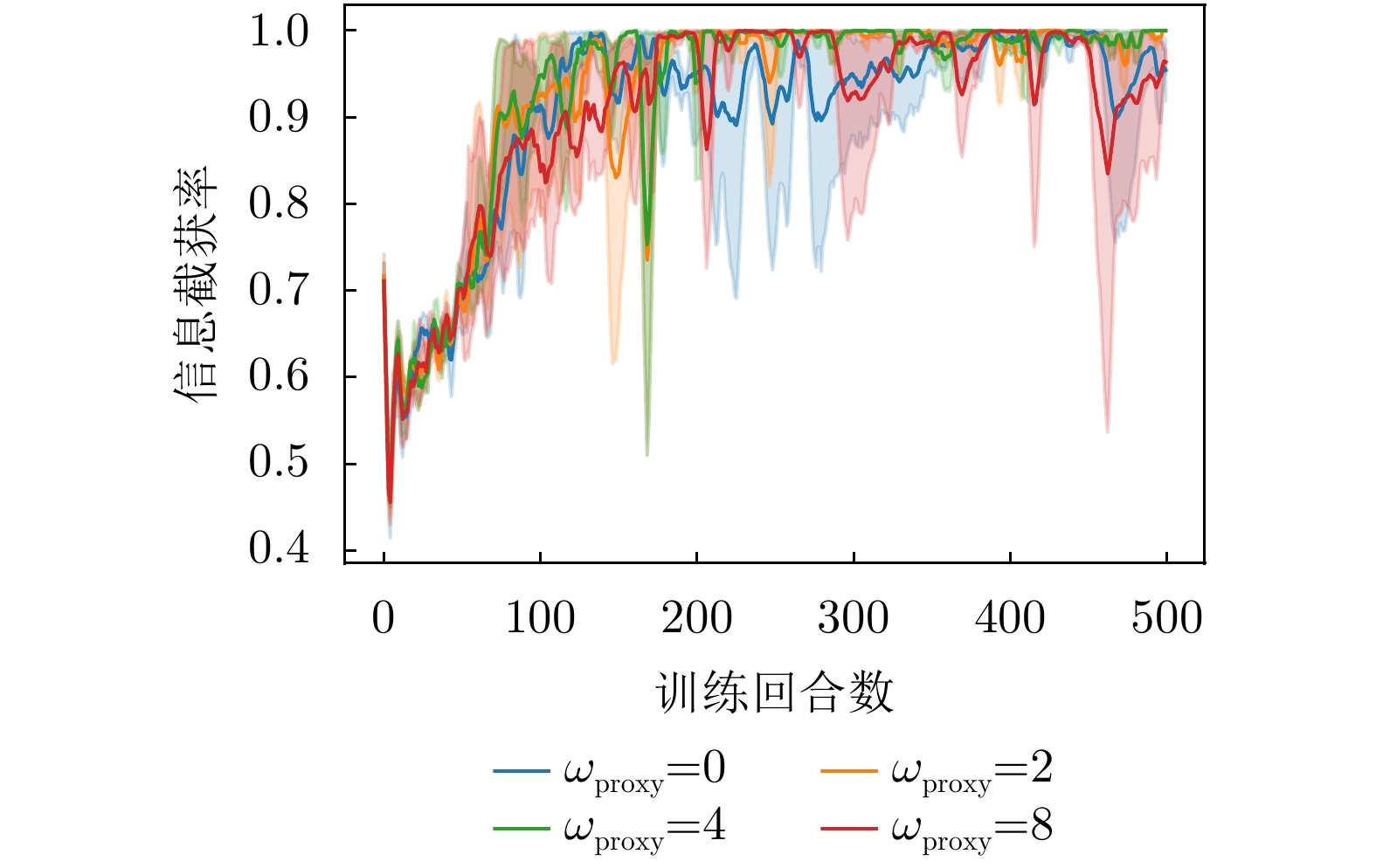
图 13 不同权重下信息截获率变化曲线
Figure 13. Curve of information interception rate variation under different weights
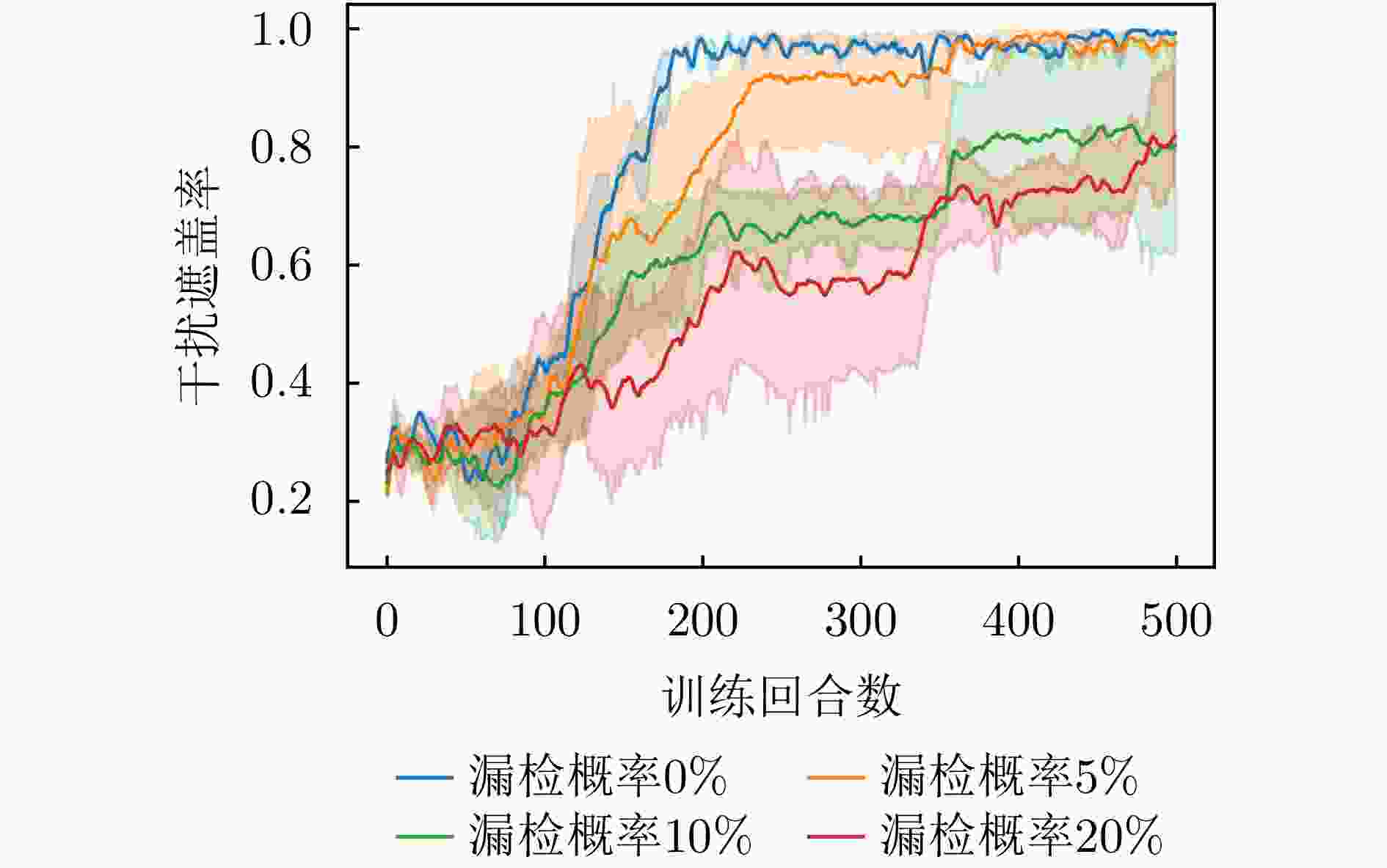
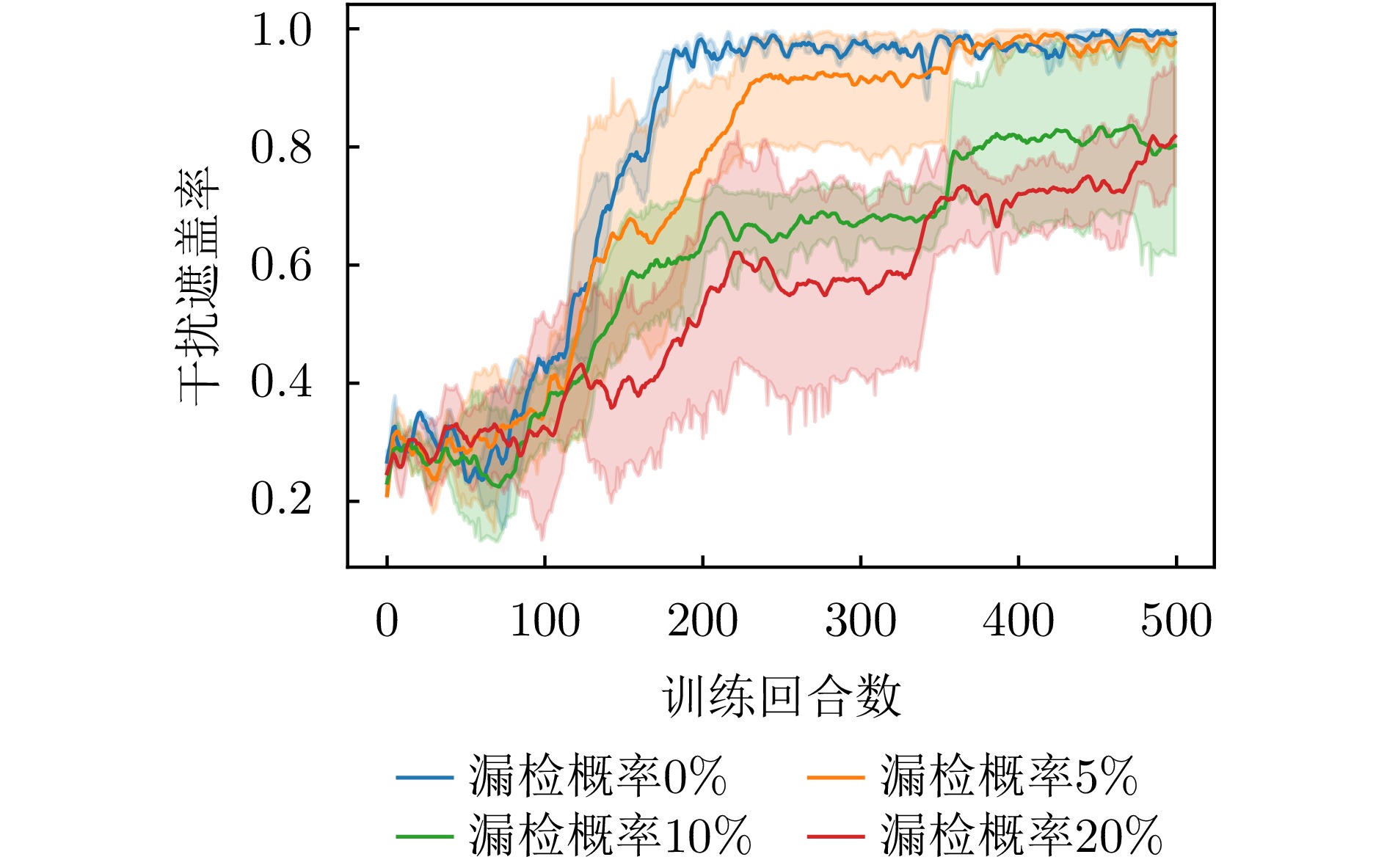
图 14 不同漏检概率下干扰遮盖率变化曲线
Figure 14. Change curve of jamming coverage rate under different missed detection probabilities
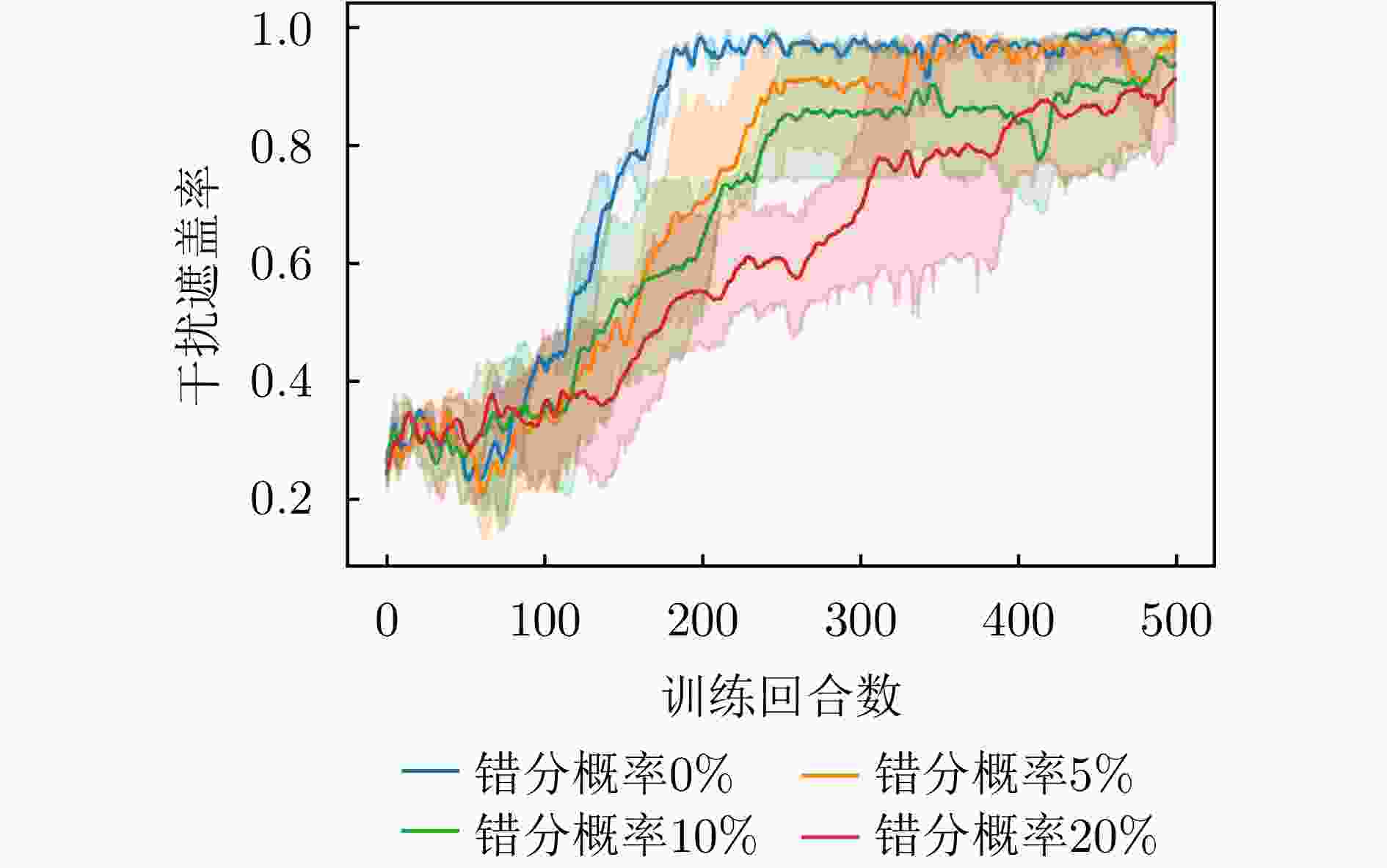
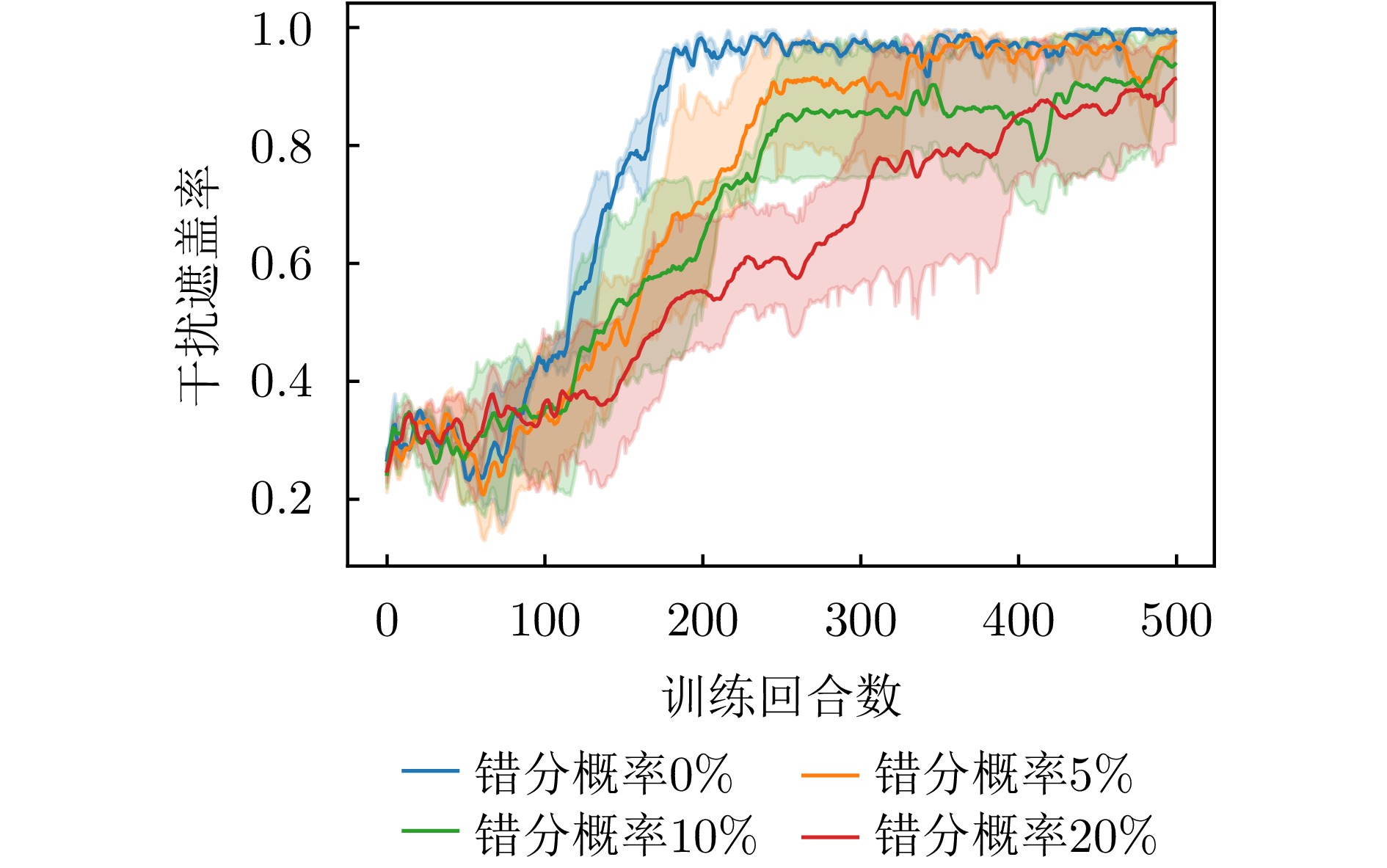
图 15 不同错分概率下干扰遮盖率变化曲线
Figure 15. Change curve of jamming coverage rate under different misclassification probabilities
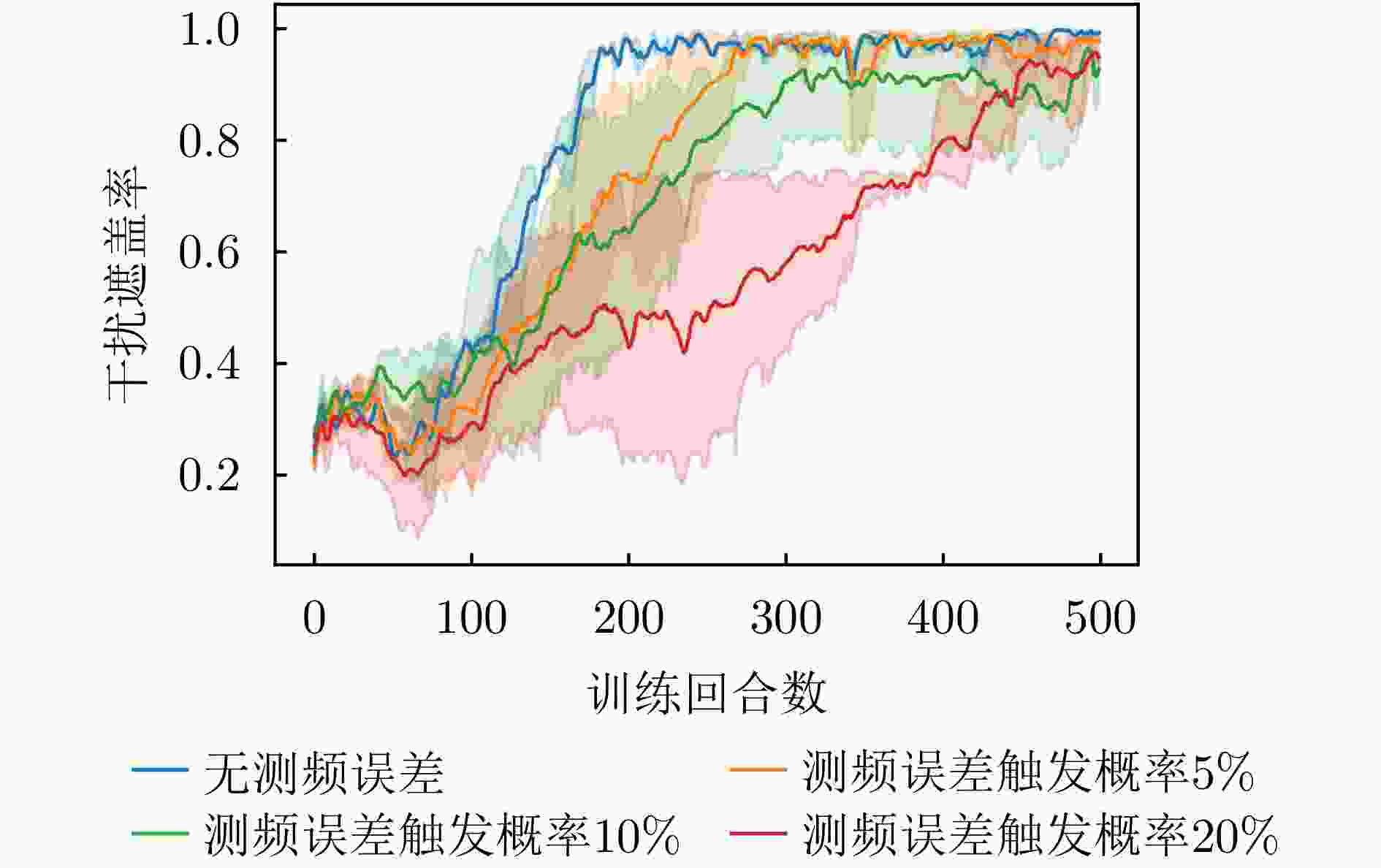
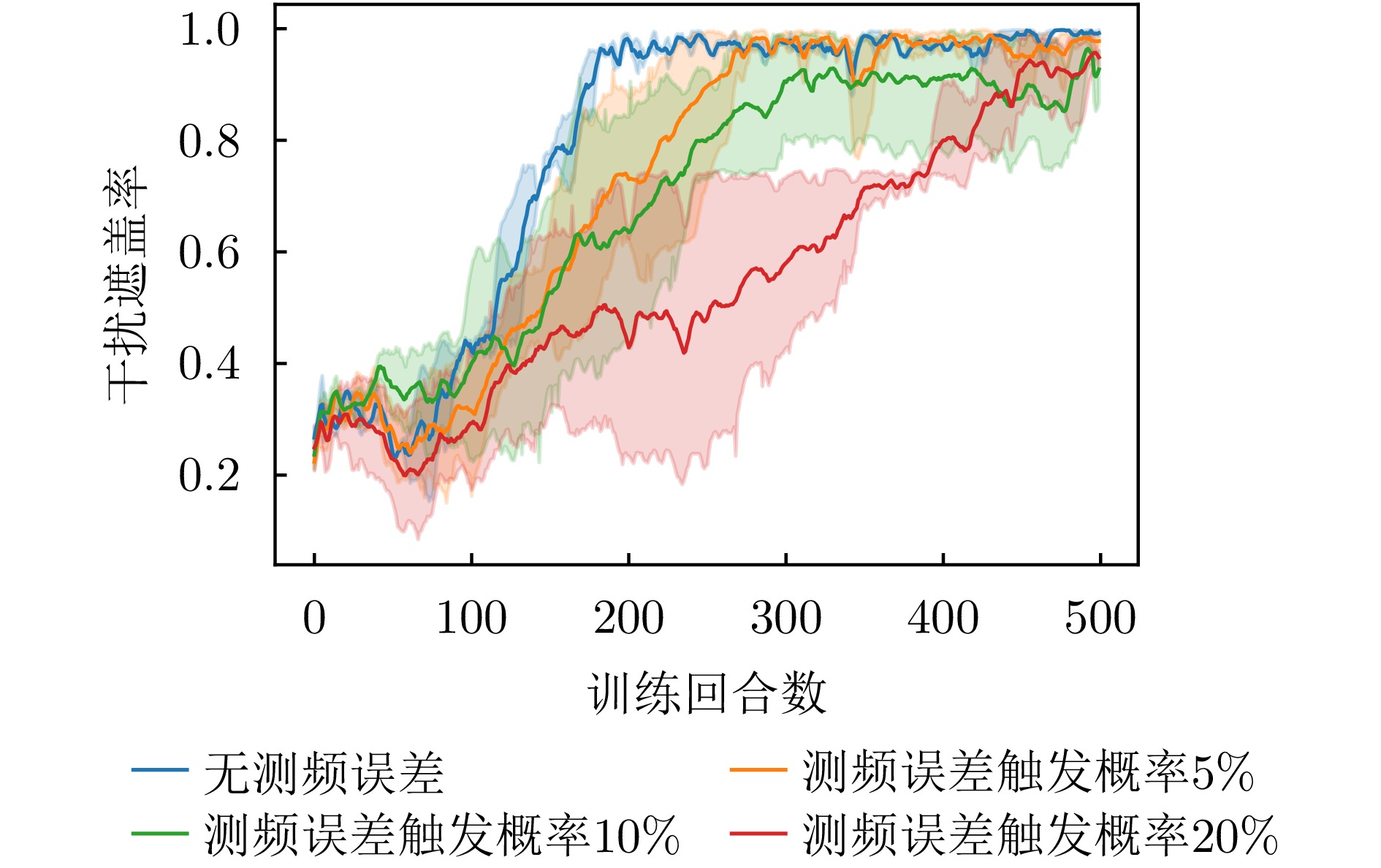
图 16 不同测频误差概率下干扰遮盖率变化曲线
Figure 16. Change curve of jamming coverage rate under different frequency measurement error probabilities
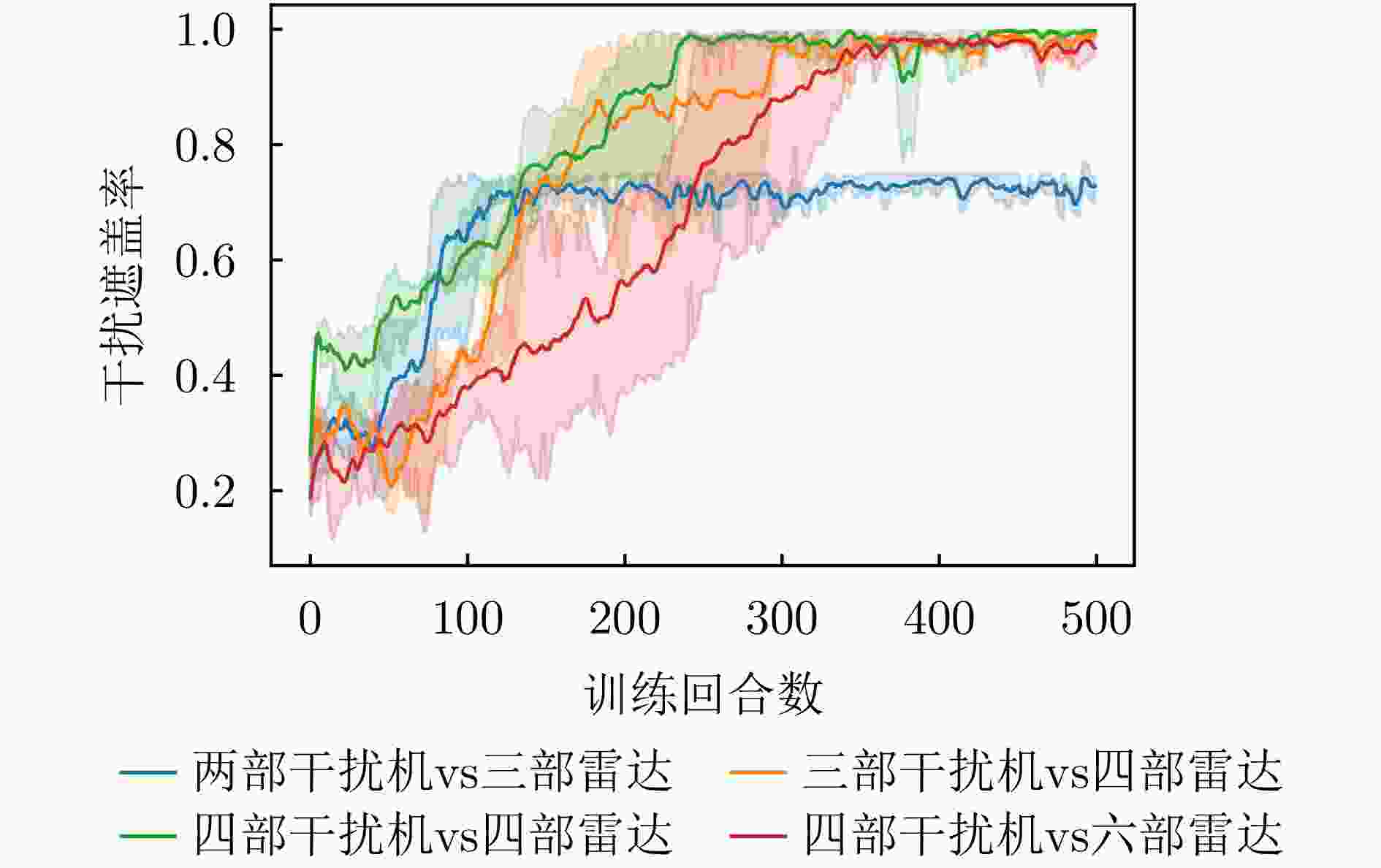
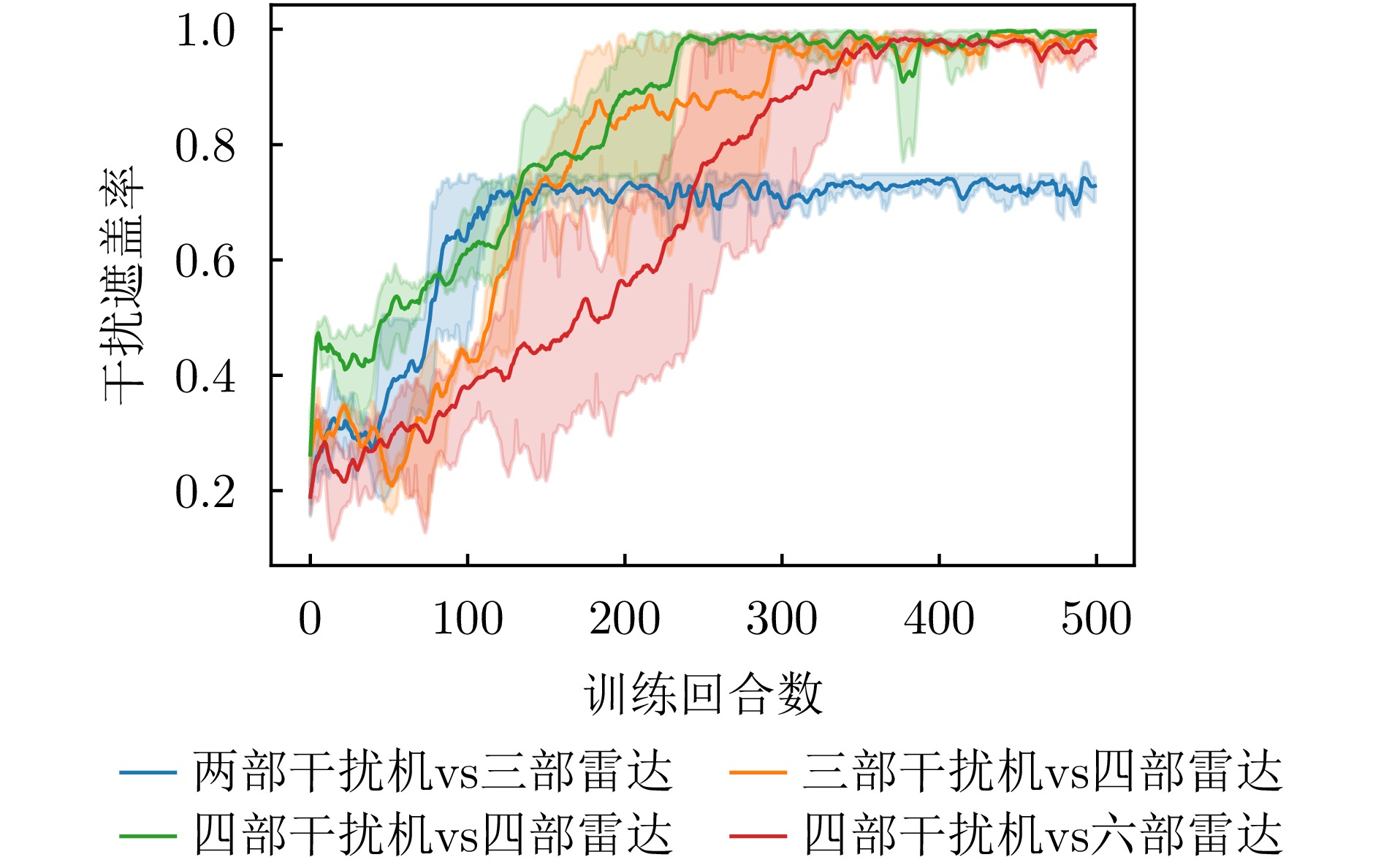
图 17 不同对抗规模下干扰遮盖率变化曲线
Figure 17. Change curve of jamming coverage rate under different adversarial scales
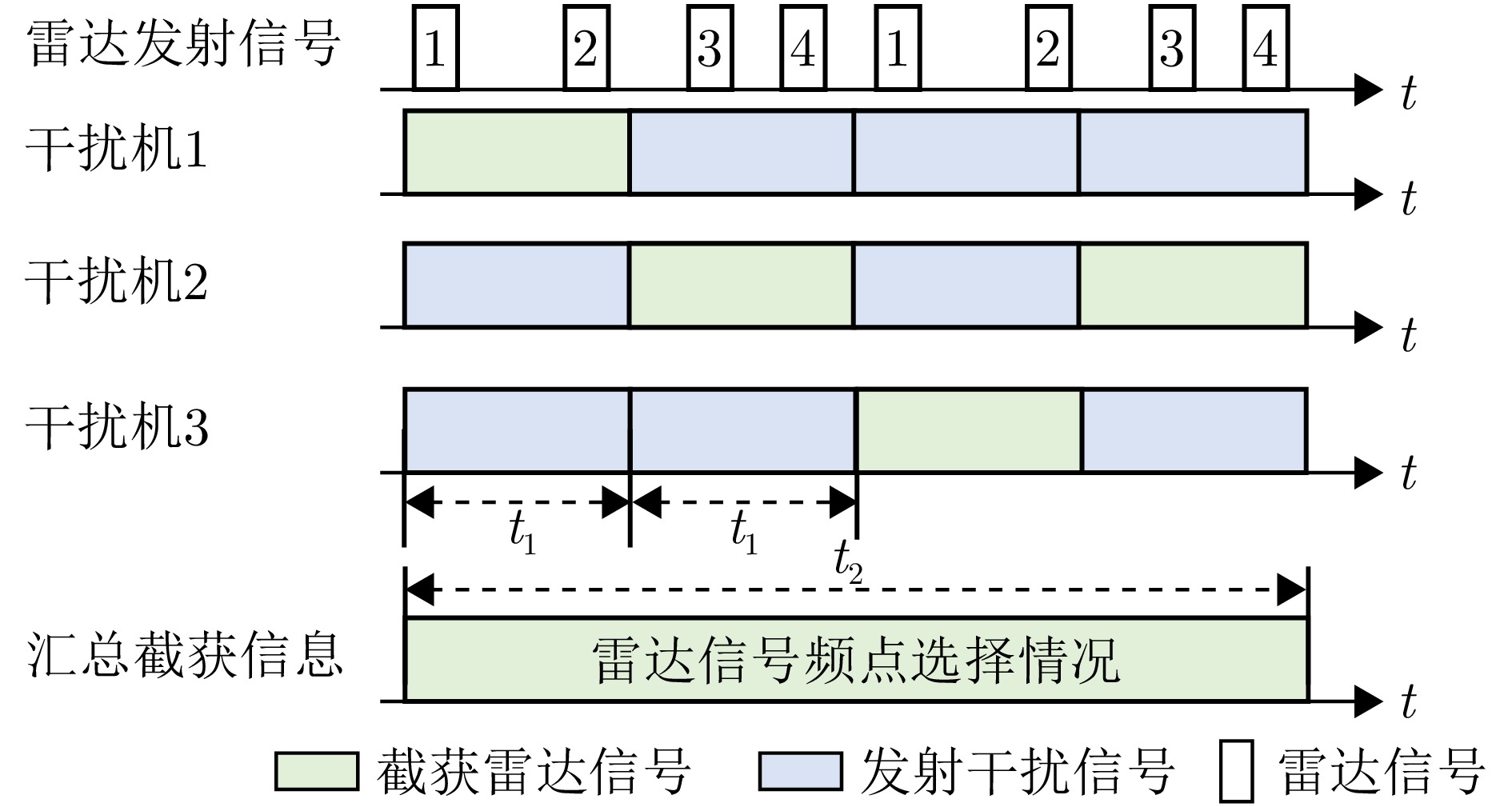
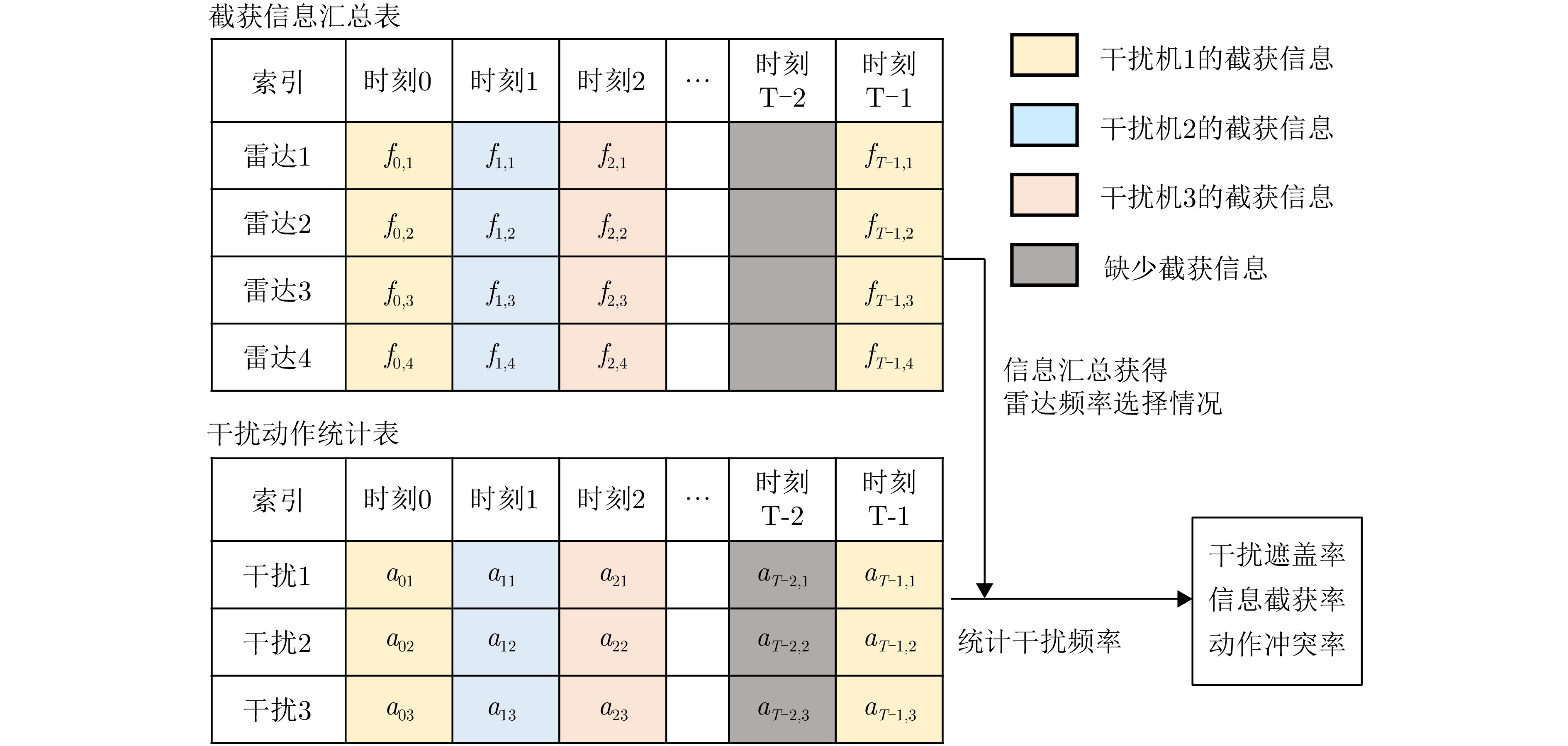
1 智能协同干扰策略学习方法算法流程
1. Algorithm flowchart of intelligent cooperative jamming strategy learning method
输入:干扰机数量N,雷达数量R,单次行动时间,信息汇总周
期长度;Actor参数$ \theta $,Critic参数$ \phi $;PPO裁剪系数$ \varepsilon $,折扣因
子$ \gamma $。输出:协同干扰策略$ {\text{π} }_{\theta } $ (1) 初始化Actor参数$ \theta $、Critic参数$ \phi $; (2) For 回合 = $ 1,2,\cdots ,M $ do (3) 重置环境,获得初始跨周期记忆$ {P}_{0} $与局部观测
$ \left\{{o}_{i}(0)\right\}i=1,2,\cdots N $;(4) 清空轨迹缓存D; (5) For k = $ 1,2,\cdots ,K $ do (6) 清空本周期截获日志、发射日志与时频占用记录 (7) For t = $ 0,1,2,\cdots ,T-1 $ do (8) For i = $ 1,2,\cdots ,N $ do (9) 将智能体id与局部观测$ {o}_{i}(t) $拼接,输入Actor; (10) 采样多头动作$ {a_i}(t) = (a_i^{{\text{mode}}}(t),{\mkern 1mu} a_i^{{\text{tar}}}(t), $
${\mkern 1mu} a_i^{{\text{style}}}(t),{\mkern 1mu} a_i^{{\text{para}}}(t)) $;(11) 根据动作可行域 mask 修正非法动作概率; (12) 记录动作、对数概率$ {\log }_{{{\text{π} }_{\theta }}}\left({a}_{i}(t)|{o}_{i}(t)\right) $; (13) End for (14) 环境执行联合动作$ a(t)=\left\{{a}_{i}(t)\right\},i=1,2,\cdots ,N $; (15) 返回下一时刻局部观测$ \left\{{o}_{i}(t+1)\right\} $、即时奖励
$ \left\{r_{i}^{{\mathrm{inst}}}(t)\right\} $;(16) 记录本步局部观测、集中式观测、动作、即时奖励、
done标志;(17) 更新本周期的截获历史、发射历史、能量状态与时频
占用表;(18) End for (19) 周期末汇总所有截获日志与发射日志; (20) 计算系统指标:干扰遮盖率、信息截获率、冲突率; (21) 构造周期末奖励 $ {R}_{{\mathrm{done}}} = {\omega }_{c} * {C}_{{\mathrm{bar}}} + {\omega }_{\mathrm{cov}} * {\rm{Cov}}_{{\mathrm{int}}} - {\omega }_{c\mathrm{onf}} * \text{Conf} + {F}_{{\mathrm{fair}}}\left(\{{\mathrm{C}}_{r}\}\right) $ (22) 基于周期内时频匹配关系计算结构化离线回填奖励
$ \left\{r_{i}^{{\mathrm{off}}}(t)\right\} $;(23) 将$ r_{i}^{{\mathrm{off}}}(t) $与$ {R}_{{\mathrm{done}}} $按预定规则回填到该周期各时间步; (24) 用回填后的奖励替换缓存D中对应样本的训练奖励; (25) 生成下一周期跨周期记忆$ {P}_{k} $,并更新局部观测输入; (26) End for (27) 利用集中式Critic计算整条轨迹中各时间步状态值; 28) 依据回填后奖励计算回报与优势函数; (29) 基于PPO裁剪目标、价值损失与熵正则项更新Actor参数
$ \theta $,Critic参数$ \phi $(30) End for (31) 返回训练完成的协同干扰策略$ {\text{π} }_{\theta } $。  下载: 导出CSV
下载: 导出CSV
表 1 仿真参数表
Table 1. Simulation parameter table
参数 数值 干扰机数量N 3 雷达数量R 4 干扰机与雷达之间距离 100 km 单次行动时间$ \Delta t $ 500 μs 信息汇总周期$ {T}_{\text{sum}} $ 10 ms 阻塞干扰带宽$ {B}_{\text{blk}} $ 200 MHz 瞄频干扰带宽范围$ \left[{B}_{\text{sp,min}},{B}_{\text{sp,max}}\right] $ [10, 100] MHz 雷达脉冲重复间隔PRI 1000 μs雷达信号到达时间偏移 (0, 200, 500, 800) μs 雷达脉冲宽度$ \tau $ 100 μs 雷达频率范围$ [{f}_{\text{min}},{f}_{\text{max}}] $ [3.0, 4.0] GHz 雷达频点数 10 雷达跳频间隔$ \Delta f $ 100 MHz 雷达带宽$ {B}_{r} $ 50 MHz 步进序列长度$ {L}_{1} $ 10 脉组包含脉冲数$ {L}_{2} $ 4 伪随机序列长度$ {L}_{3} $ 10 奖励回填权重系数$ \beta $ 1 单回合交互次数 20 训练回合数 500
下载: 导出CSV
表 2 网络结构与训练超参数设置表
Table 2. Network architecture and training hyperparameter settings
类别 参数 数值 单智能体观测维数/Actor输入维数 $ {d}_{o} $ 93 集中式Critic输入维数 $ 3\times {d}_{o} $ 279 Actor/Critic隐藏层神经元个数 \ 256 Actor/Critic隐藏层层数 \ 2 Actor/Critic激活函数 \ ReLU Actor输出维数 模式/目标/样式/参数 2/4/2/10 Critic输出维数 \ 3 折扣因子 $ \gamma $ 0.99 GAE参数 $ \lambda $ 0.95 PPO裁剪系数 $ \varepsilon $ 0.2 Actor学习率 lra $ 3\times {10}^{-4} $ Critic学习率 lrc $ 3\times {10}^{-4} $ Batch Batch_size 512
下载: 导出CSV
-
[1] 崔国龙, 余显祥, 魏文强, 等. 认知智能雷达抗干扰技术综述与展望[J]. 雷达学报, 2022, 11(6): 974–1002. doi: 10.12000/JR22191.CUI Guolong, YU Xianxiang, WEI Wenqiang, et al. An overview of antijamming methods and future works on cognitive intelligent radar[J]. Journal of Radars, 2022, 11(6): 974–1002. doi: 10.12000/JR22191. [2] LIU Yongxiang, YANG Wei, QIU Xiangfeng, et al. Advanced cognitive radar: Principles, systems, and essential applications[J]. IEEE Aerospace and Electronic Systems Magazine, 2026, 41(4): 68–81. doi: 10.1109/MAES.2025.3648682. [3] QIU Xiangfeng, JIANG Weidong, LIU Yongxiang, et al. Constrained riemannian manifold optimization for the simultaneous shaping of ambiguity function and transmit Beampattern[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(3): 5771–5787. doi: 10.1109/TAES.2024.3520951. [4] QIU Xiangfeng, JIANG Weidong, ZHANG Xinyu, et al. Design of complementary PCFM waveform set for smearing spectrum jamming suppression in MIMO radar systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(4): 10149–10168. doi: 10.1109/TAES.2025.3560612. [5] 张大琳, 易伟, 孔令讲. 面向组网雷达干扰任务的多干扰机资源联合优化分配方法[J]. 雷达学报, 2021, 10(4): 595–606. doi: 10.12000/JR21071.ZHANG Dalin, YI Wei, and KONG Lingjiang. Optimal joint allocation of multijammer resources for jamming netted radar system[J]. Journal of Radars, 2021, 10(4): 595–606. doi: 10.12000/JR21071. [6] 蒋雯, 贾琼, 刘真, 等. 面向主被动雷达复合探测的全脉冲多机协同干扰方法[J]. 雷达学报(中英文), 2025, 14(6): 1515–1530. doi: 10.12000/JR25016.JIANG Wen, JIA Qiong, LIU Zhen, et al. Full-pulse multi-jammer cooperative jamming method for active-passive radar composite detection[J]. Journal of Radars, 2025, 14(6): 1515–1530. doi: 10.12000/JR25016. [7] GONG Liangliang, WU Shilong, and LV Tao. A radar emitter identification method based on pulse match template sequence[C]. 2010 2nd International Conference on Signal Processing Systems, Dalian, China, 2010: V3-153–V3-156. doi: 10.1109/ICSPS.2010.5555410. [8] SONG Xiufeng, WILLETT P, ZHOU Shengli, et al. The MIMO radar and jammer games[J]. IEEE Transactions on Signal Processing, 2012, 60(2): 687–699. doi: 10.1109/TSP.2011.2169251. [9] ZHANG Chudi, WANG Lei, JIANG Rundong, et al. Radar jamming decision-making in cognitive electronic warfare: A review[J]. IEEE Sensors Journal, 2023, 23(11): 11383–11403. doi: 10.1109/JSEN.2023.3267068. [10] 王俊, 郑彤, 雷鹏, 等. 深度学习在雷达中的研究综述[J]. 雷达学报, 2018, 7(4): 395–411. doi: 10.12000/JR18040.WANG Jun, ZHENG Tong, LEI Peng, et al. Study on deep learning in radar[J]. Journal of Radars, 2018, 7(4): 395–411. doi: 10.12000/JR18040. [11] 解烽, 刘环宇, 胡锡坤, 等. 基于复数域深度强化学习的多干扰场景雷达抗干扰方法[J]. 雷达学报, 2023, 12(6): 1290–1304. doi: 10.12000/JR23139.XIE Feng, LIU Huanyu, HU Xikun, et al. A radar anti-jamming method under multi-jamming scenarios based on deep reinforcement learning in complex domains[J]. Journal of Radars, 2023, 12(6): 1290–1304. doi: 10.12000/JR23139. [12] 杜兰, 王梓霖, 郭昱辰, 等. 结合强化学习自适应候选框挑选的SAR目标检测方法[J]. 雷达学报, 2022, 11(5): 884–896. doi: 10.12000/JR22121.DU Lan, WANG Zilin, GUO Yuchen, et al. Adaptive region proposal selection for SAR target detection using reinforcement learning[J]. Journal of Radars, 2022, 11(5): 884–896. doi: 10.12000/JR22121. [13] ZHANG Yujie, HUO Weibo, HUANG Yulin, et al. Jamming policy generation via heuristic programming reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(6): 8782–8799. doi: 10.1109/TAES.2023.3312231. [14] ZHANG Chudi, YANG Biao, WANG Lei, et al. A cognitive jamming decision-making method based on heuristic improved A2C algorithm[J]. IEEE Transactions on Vehicular Technology, 2025, 74(2): 2871–2883. doi: 10.1109/TVT.2024.3470832. [15] LIU Hongdi, ZHANG Hongtao, HE Yuan, et al. Jamming strategy optimization through dual Q-learning model against adaptive radar[J]. Sensors, 2022, 22(1): 145. doi: 10.3390/s22010145. [16] PAN Zesi, LI Yunjie, WANG Shafei, et al. Joint optimization of jamming type selection and power control for countering multifunction radar based on deep reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(4): 4651–4665. doi: 10.1109/TAES.2023.3272307. [17] 王跃东, 顾以静, 梁彦, 等. 伴随压制干扰与组网雷达功率分配的深度博弈研究[J]. 雷达学报, 2023, 12(3): 642–656. doi: 10.12000/JR23023.WANG Yuedong, GU Yijing, LIANG Yan, et al. Deep game of escorting suppressive jamming and networked radar power allocation[J]. Journal of Radars, 2023, 12(3): 642–656. doi: 10.12000/JR23023. [18] YANG Boyang, LI Kang, JIU Bo, et al. Execute-evaluate two-stage framework for intelligent jamming decision-making based on reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(4): 8624–8640. doi: 10.1109/TAES.2025.3548594. [19] ZHANG Wenxu, ZHAO Tong, ZHAO Zhongkai, et al. An intelligent strategy decision method for collaborative jamming based on hierarchical multi-agent reinforcement learning[J]. IEEE Transactions on Cognitive Communications and Networking, 2024, 10(4): 1467–1480. doi: 10.1109/TCCN.2024.3373640. [20] SUN Sizhe and SHI Yanling. Joint optimization of resource utilization and jamming method selection for cluster asymmetrical multifunction radars based on deep reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(2): 5116–5131. doi: 10.1109/TAES.2024.3515942. [21] LI Yan, JIA Yubo, and PAN Zesi. ALI-MAPPO: Attention on local information aided MAPPO algorithm for power allocation of wireless cognitive jamming systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(5): 13759–13774. doi: 10.1109/TAES.2025.3580014. [22] FENG Cheng, FU Xiongjun, WANG Ziyi, et al. An optimization method for collaborative radar antijamming based on multi-agent reinforcement learning[J]. Remote Sensing, 2023, 15(11): 2893. doi: 10.3390/rs15112893. [23] 王子怡, 傅雄军, 董健, 等. 基于分层多智能体强化学习的雷达协同抗干扰策略优化[J]. 系统工程与电子技术, 2025, 47(4): 1108–1114. doi: 10.12305/j.issn.1001-506X.2025.04.07.WANG Ziyi, FU Xiongjun, DONG Jian, et al. Optimization of radar collaborative anti-jamming strategies based on hierarchical multi-agent reinforcement learning[J]. Systems Engineering and Electronics, 2025, 47(4): 1108–1114. doi: 10.12305/j.issn.1001-506X.2025.04.07. [24] YU C, SAHU A K, TALAKOUB S, et al. MAPPO: A PPO variant for multi-agent cooperative competition[J]. arXiv preprint arXiv: 2103.01955, 2021. [25] KRAEMER L and BANERJEE B. Multi-agent reinforcement learning as a centralized training decentralized execution problem[J]. arXiv preprint arXiv: 1604.07239. [26] FILAR J and VRIEZE K. Competitive Markov Decision Processes[M]. New York, NY, USA: Springer, 1997. [27] SONDIK E J. The optimal control of partially observable markov decision processes[D]. Stanford: Stanford University, 1971. [28] ELMAN J L. Finding structure in time[J]. Cognitive Science, 1990, 14(2): 179–211. doi: 10.1207/s15516709cog1402_1. [29] HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735. [30] CHUNG J, GULCEHRE C, CHO K H, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv: 1412.3555, 2014. doi: 10.48550/arXiv.1412.3555. -

计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

