
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
-
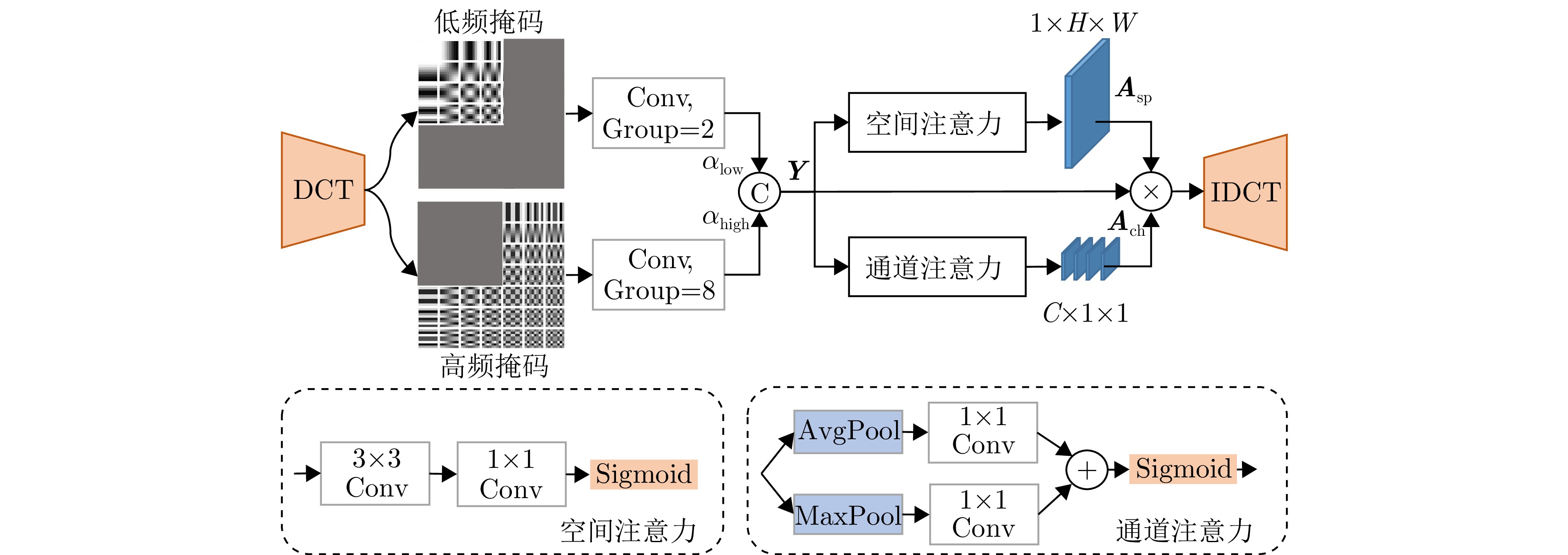
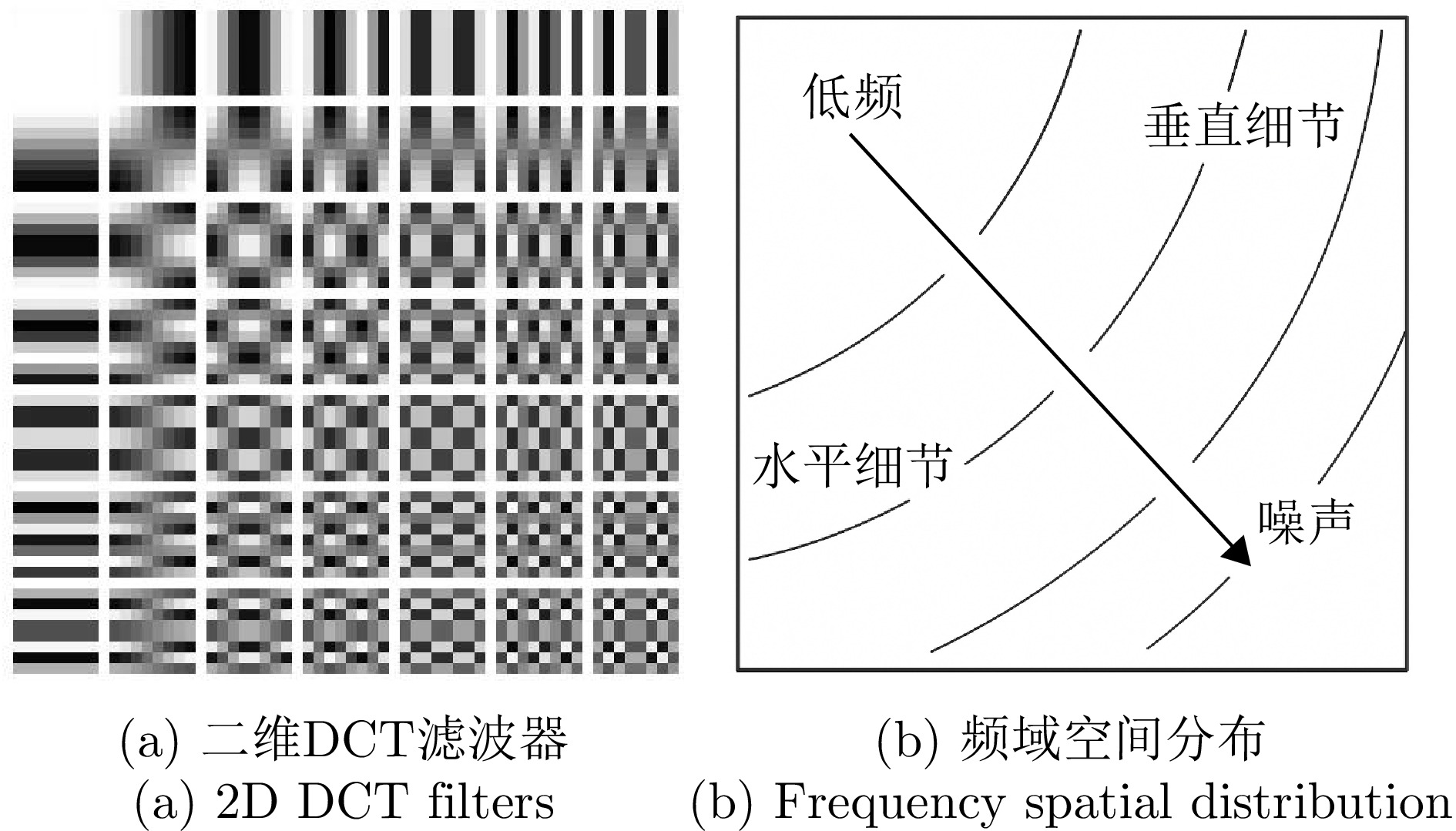
摘要: 合成孔径雷达(SAR)作为一种主动微波遥感系统,具有“全天时、全天候”的观测能力,在灾害监测、城市管理及军事侦察等领域发挥着重要应用价值。尽管深度学习技术已推动SAR图像解译取得了显著进展,但现有目标识别与检测方法多聚焦于局部特征提取与单一目标判别,难以全面刻画复杂场景的整体语义结构与多目标关系,且解译流程仍高度依赖专业人员,自动化水平有限。SAR图像描述旨在将视觉信息转化为自然语言,是从“感知目标”向“认知场景”跨越的关键技术,对于提升SAR图像解译的自动化与智能化水平具有重要意义。然而,SAR图像固有的相干斑噪声干扰、纹理细节匮乏、语义鸿沟显著进一步加剧了跨模态理解的难度。针对上述问题,该文提出一种基于空间-频率感知的SAR图像描述方法(DGS-CapNet)。首先,构建空间-频域感知模块,利用离散余弦变换(DCT)掩码注意力机制对频谱成分加权以抑制噪声并强化结构特征,同时结合Gabor多尺度纹理增强模块提升对方向与边缘细节的感知能力;其次,设计跨模态语义增强损失函数,通过双向对比损失与最大互信息损失,有效缩减视觉特征与自然语言间的语义鸿沟。此外,我们还构建了包含
72400 条高质量图文对的大规模细粒度SAR图像描述数据集FSAR-Cap。实验结果表明,该方法在SARLANG和FSAR-Cap数据集上的CIDEr指标分别达到151.00和95.14。定性分析表明,该模型有效抑制了幻觉,并准确捕捉了细粒度的空间纹理细节,显著优于主流方法。Abstract: Synthetic Aperture Radar (SAR), as an active microwave remote sensing system, offers all-weather, all-day observation capabilities and has considerable application value in disaster monitoring, urban management, and military reconnaissance. Although deep learning techniques have achieved remarkable progress in interpreting SAR images, existing methods for target recognition and detection primarily focus on local feature extraction and single-target discrimination. They struggle to comprehensively characterize the global semantic structure and multitarget relationships in complex scenes, and the interpretation process remains highly dependent on human expertise with limited automation. SAR image captioning aims to translate visual information into natural language, serving as a key technology to bridge the gap between “perceiving targets” and “cognizing scenes,” which is of great importance for enhancing the automation and intelligence of SAR image interpretation. However, the inherent speckle noise, the scarcity of textural details, and the substantial semantic gap in SAR images further exacerbate the difficulty of cross-modal understanding. To address these challenges, this paper proposes a spatial-frequency aware model for SAR image captioning. First, a spatial-frequency aware module is constructed. It employs a Discrete Cosine Transform (DCT) mask attention mechanism to reweight spectral components for noise suppression and structure enhancement, combined with a Gabor multiscale texture enhancement submodule to improve sensitivity to directional and edge details. Second, a cross-modal semantic enhancement loss function is designed to bridge the semantic gap between visual features and natural language through bidirectional image-text alignment and mutual information maximization. Furthermore, a large-scale fine-grained SAR image captioning dataset, FSAR-Cap, containing 72400 high-quality image-text pairs, is constructed. The experimental results demonstrate that the proposed method achieves CIDEr scores of 151.00 and 95.14 on the SARLANG and FSAR-Cap datasets, respectively. Qualitatively, the model effectively suppresses hallucinations and accurately captures fine-grained spatial-textural details, considerably outperforming mainstream methods. -

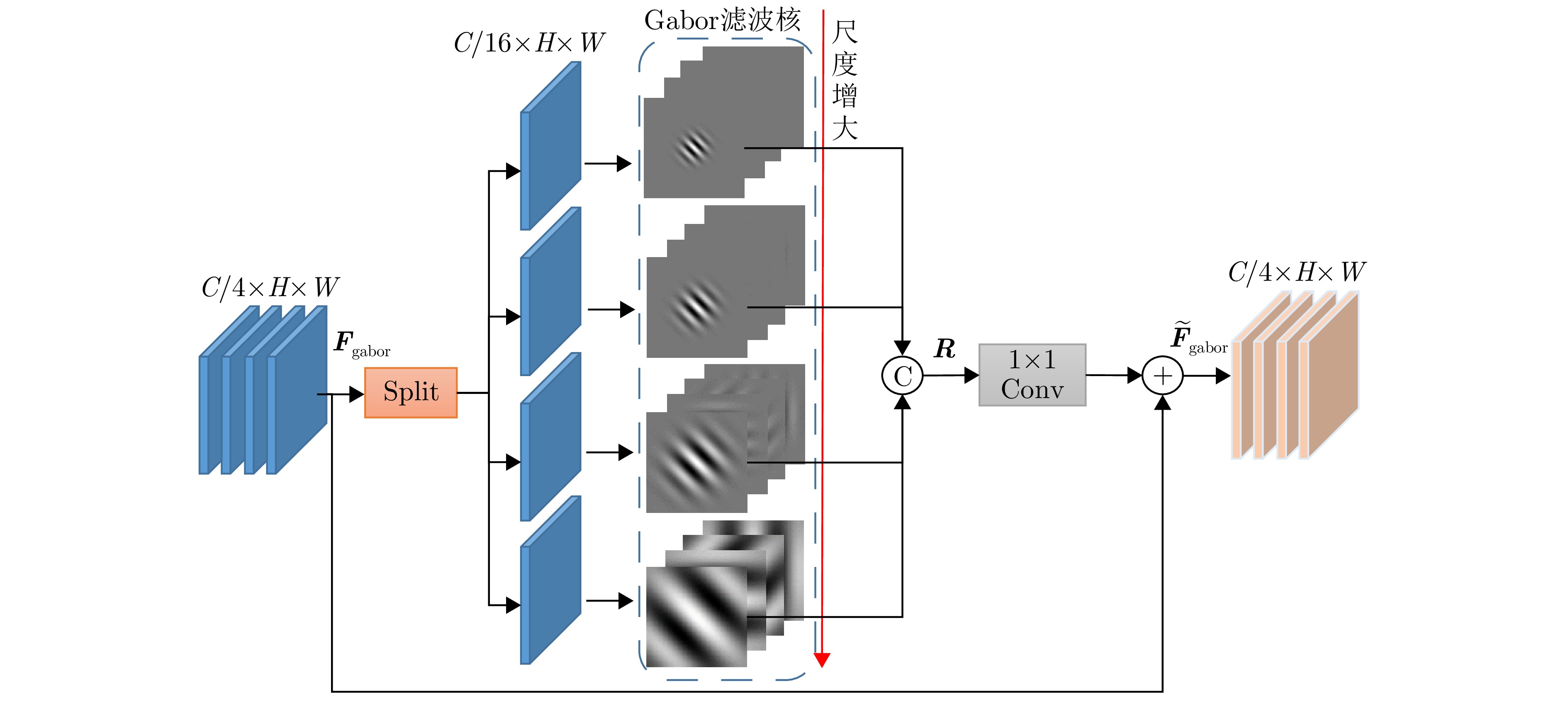
图 2 不同方向的Gabor滤波核和对应的纹理细节图
Figure 2. Gabor filter kernels in different directions and the corresponding texture detail maps

图 3 基于DCT去噪与Gabor纹理增强的结果可视化
Figure 3. Visualization of the results based on DCT denoising and Gabor texture enhancement
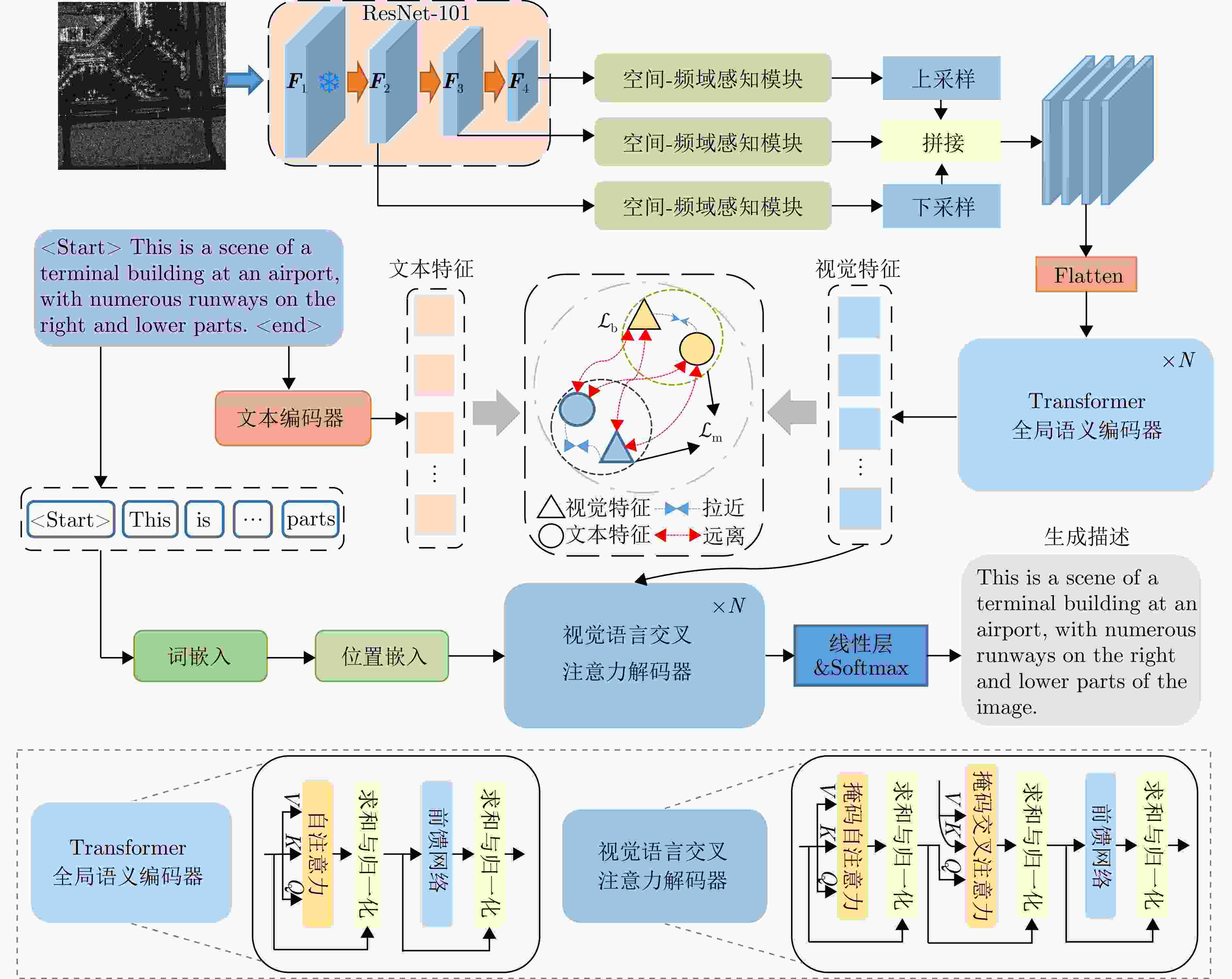
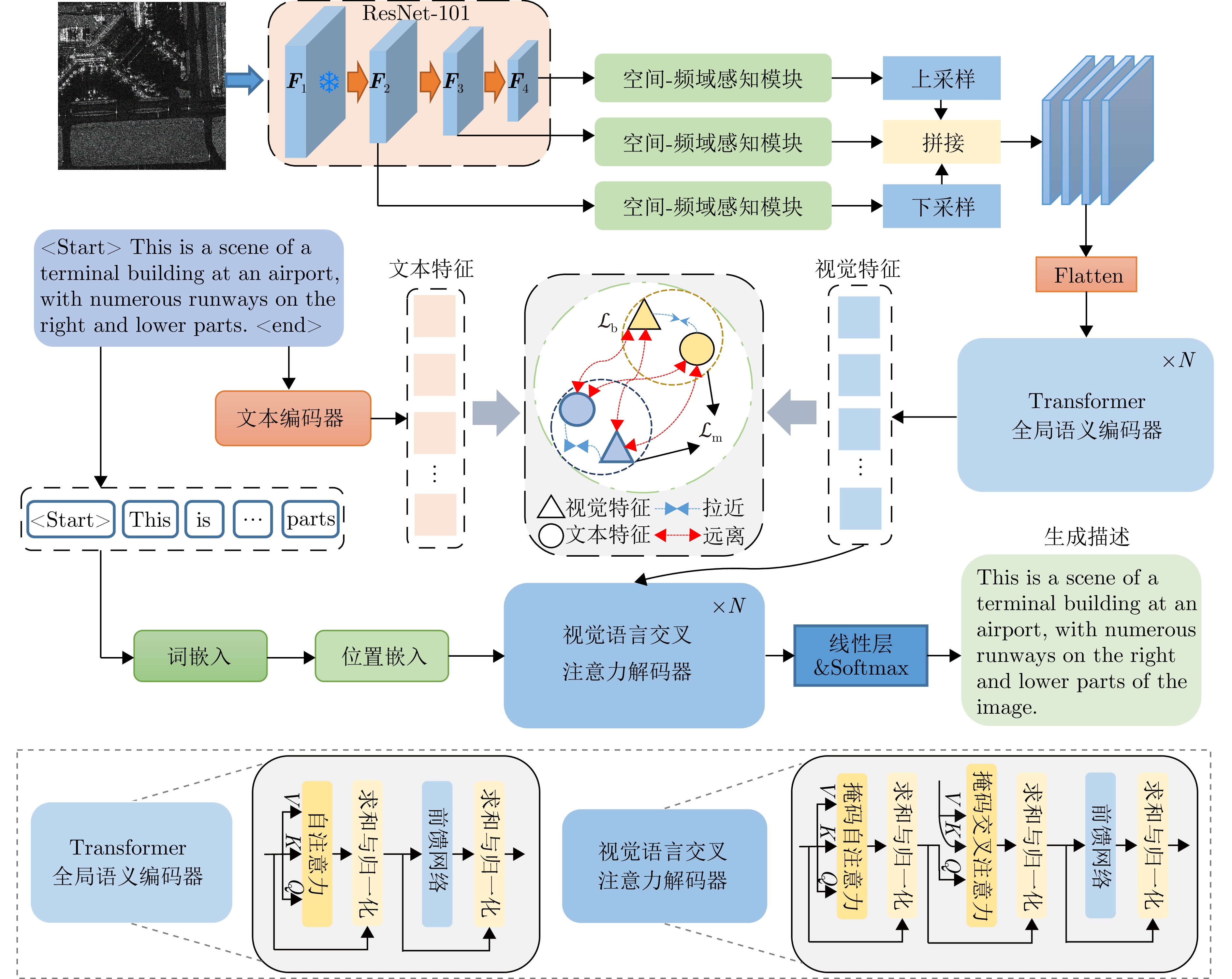
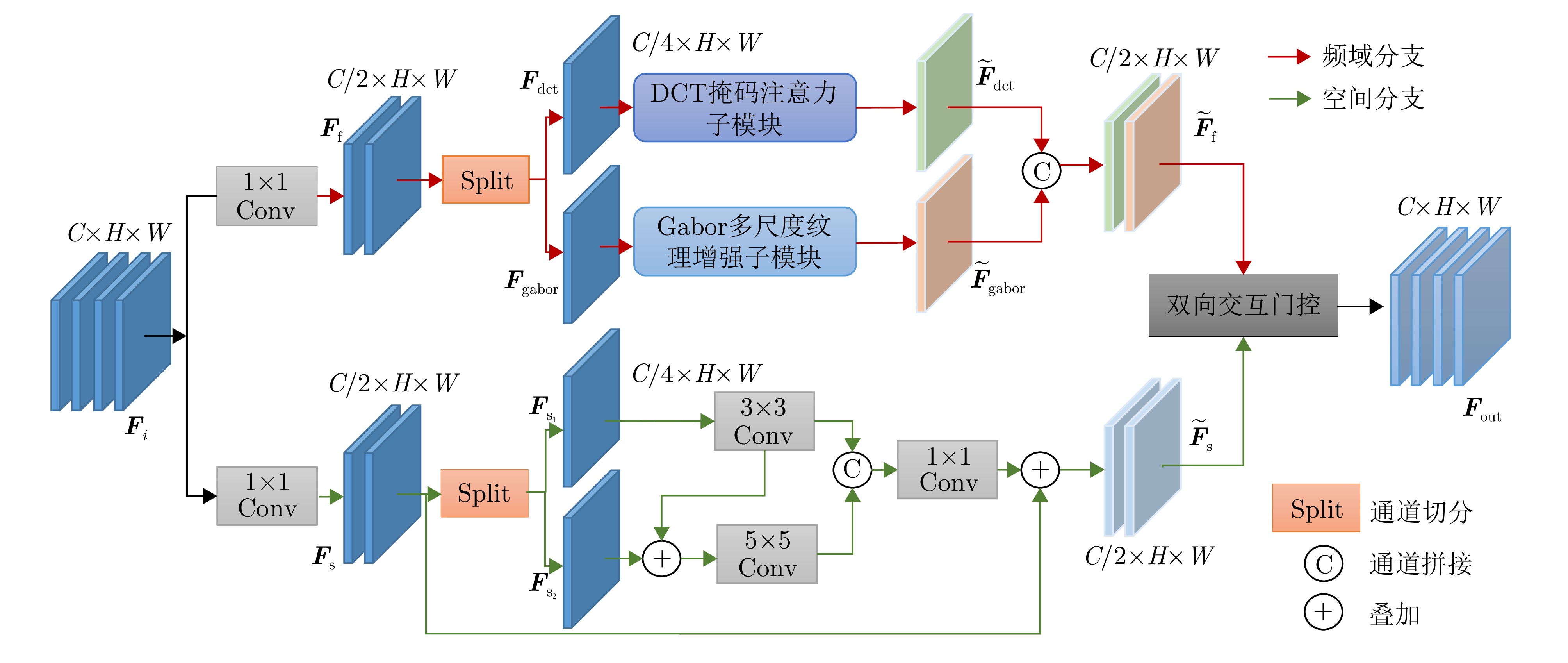
图 4 基于空间-频域感知的SAR图像描述模型整体框架
Figure 4. Overall framework of the proposed SAR image captioning model with spatial-frequency awareness
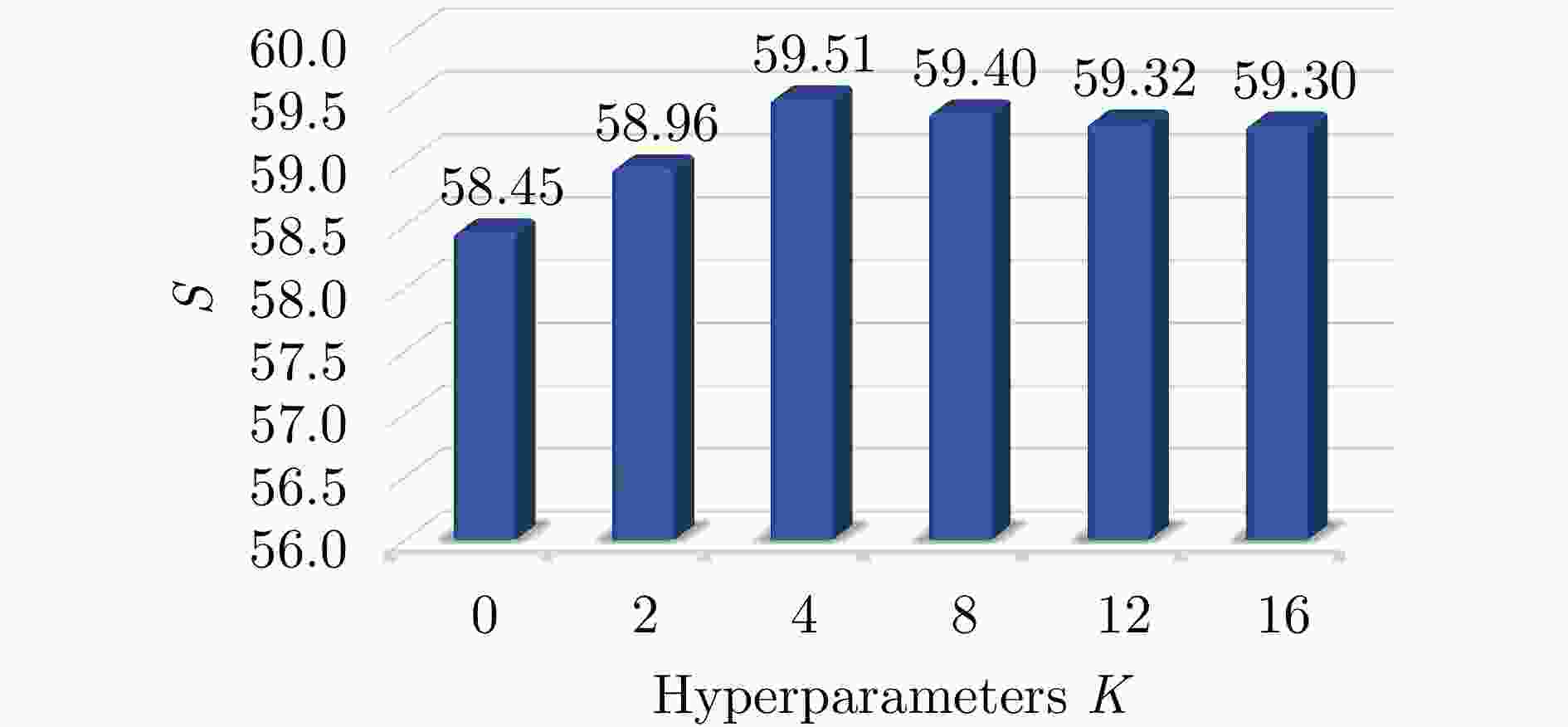
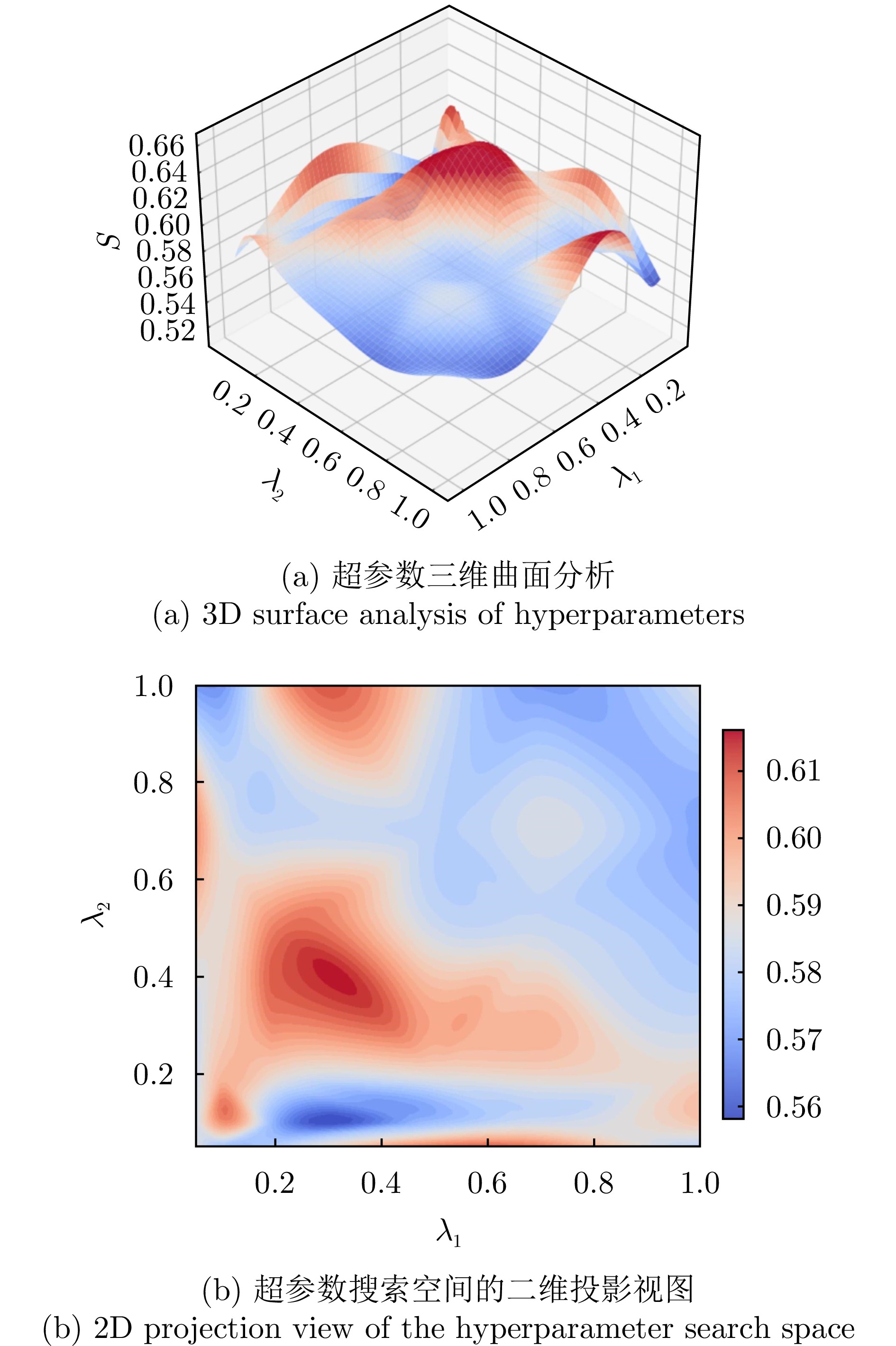
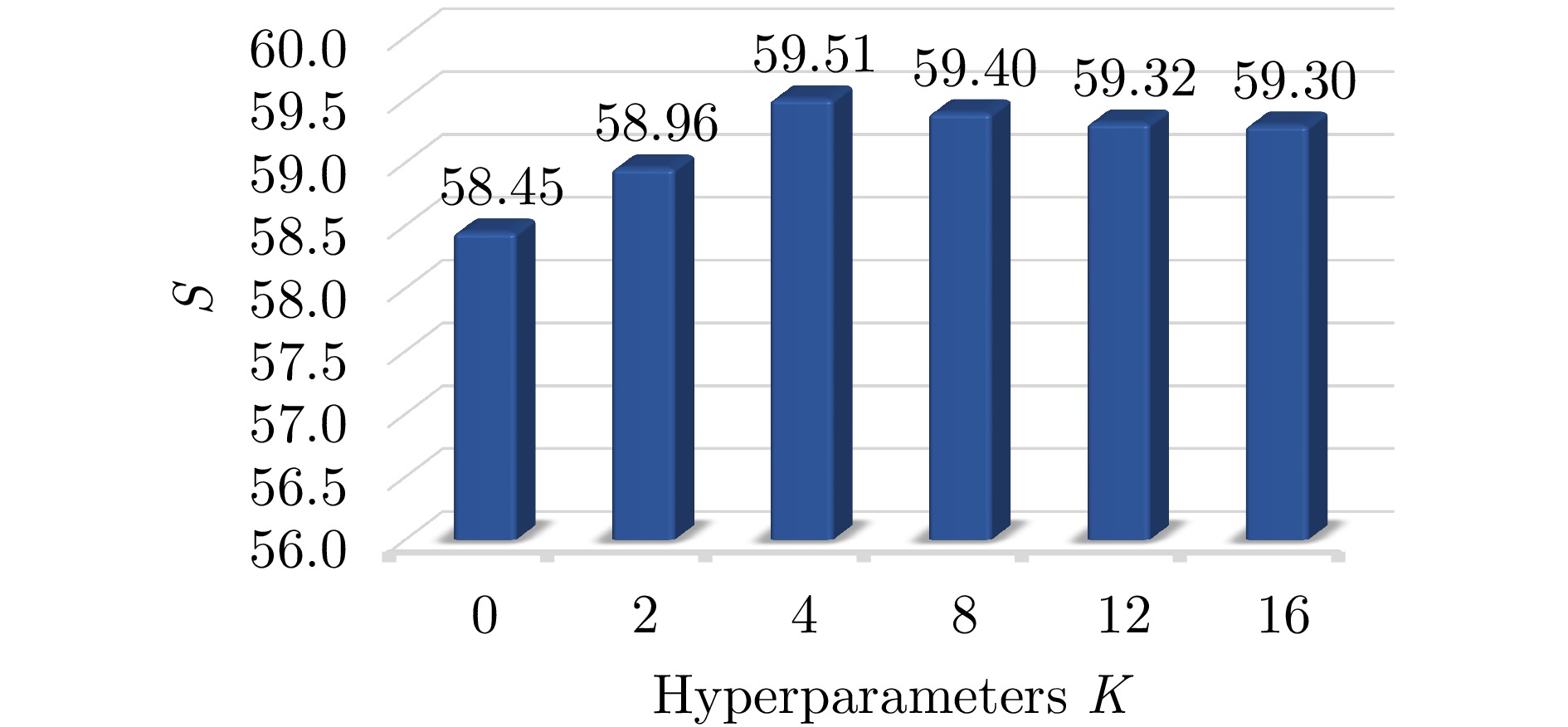
图 10 Gabor多尺度纹理增强模块超参数搜索实验
Figure 10. Experiment on hyperparameter search of Gabor multi-scale texture enhancement module

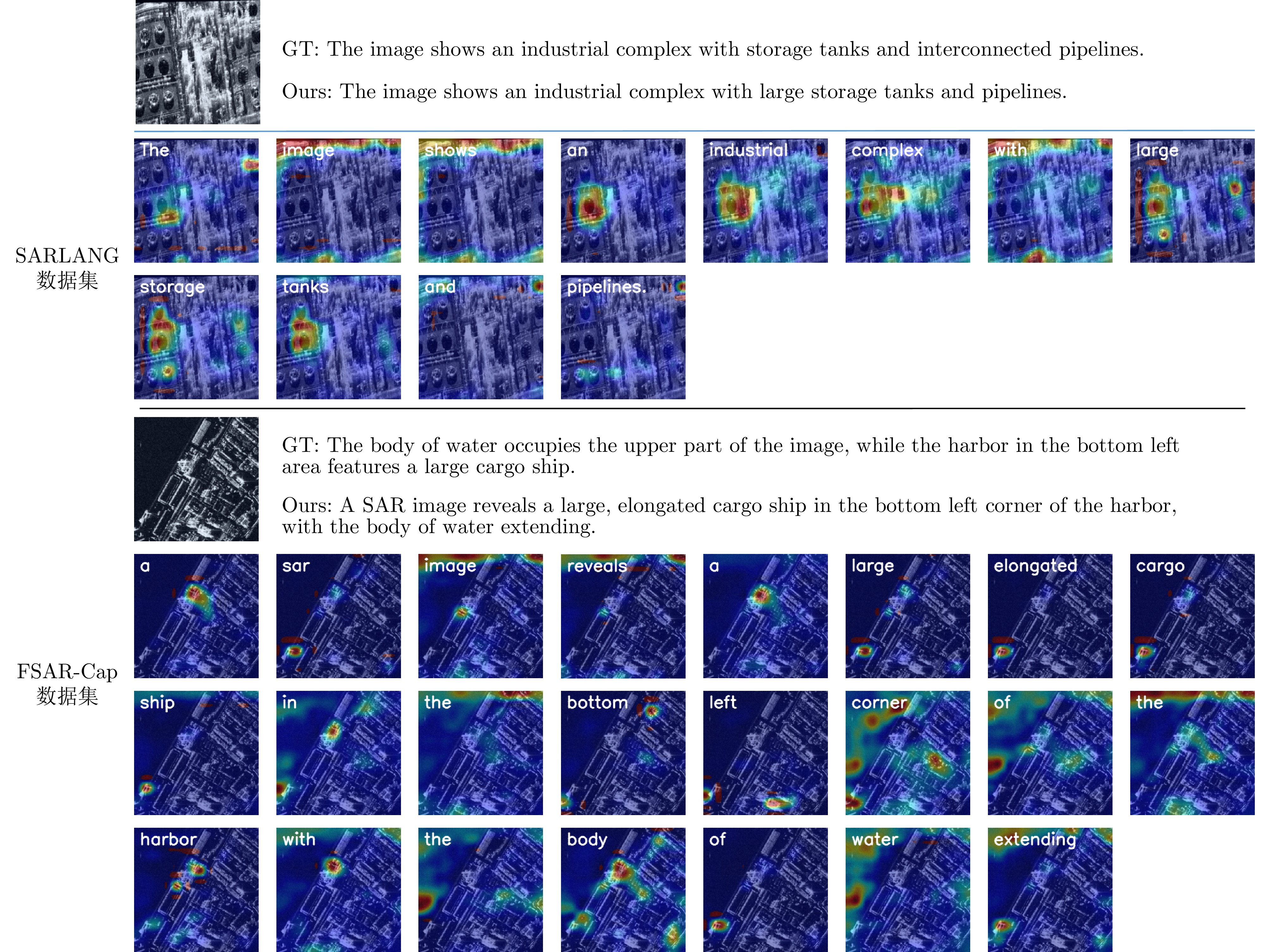
图 11 SARLANG和FSAR-Cap数据集的示例分析
Figure 11. Examples of the SARLANG and FSAR-Cap datasets
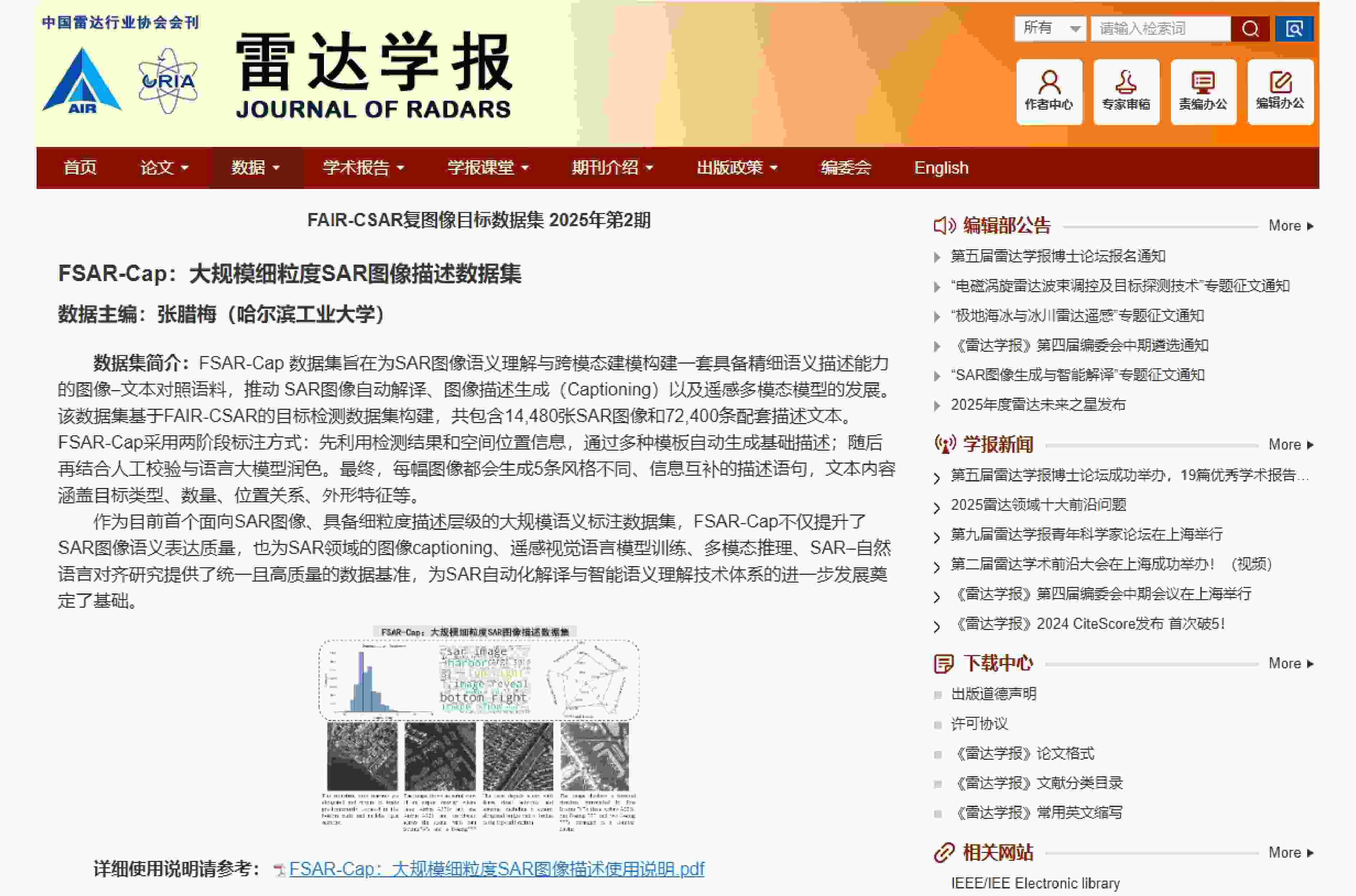
1 FSAR-Cap:大规模细粒度SAR图像描述数据集发布网页
1. Release webpage of FSAR-Cap: Large-scale fine-grained SAR image captioning dataset
表 1 SAR图像文本数据集对比
Table 1. Comparison of SAR image captioning datasets
数据集 发布时间 图像数量 配对文本数量 细粒度描述 标注方式 针对的类别 SSICD 2022年 1500 7500 × 人工标注 船 HRSSRD-Captions 2025年 1000 5000 × 人工标注 船 SARChat-Captions 2025年 – 52173 × 模版 6个类别 SARLANG-Cap 2025年 13346 45650 × 光SAR配对图片 – SAR-TEXT 2025年 – 136584 × 模版+遥感图像描述模型 – ATRNet-SARCap 2025年 5251 47259 × GPT-4V 飞机 FSAR-Cap 2025年 14480 72400 √ 25个模版+人工补充+LLM 5个主类别和22个子类别  下载: 导出CSV
下载: 导出CSV
表 2 SARLANG数据集上与主流图像描述模型的对比实验
Table 2. Comparative experiments with mainstream image captioning models on the SARLANG dataset
方法 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE_L CIDEr S VGG19+LSTM 38.00 28.61 22.82 18.40 19.72 39.01 77.09 38.55 ResNet-101+LSTM 40.12 29.46 22.34 18.99 20.11 39.73 86.64 41.37 ViT+LSTM 38.06 28.22 22.22 17.68 19.22 38.95 76.18 38.01 VGG19+Trans 46.26 34.87 27.86 22.43 22.51 43.46 136.76 56.29 ResNet-101+Trans 46.21 35.04 28.11 22.77 22.15 43.59 140.63 57.28 ViT+Trans 46.19 35.05 28.03 22.64 22.60 43.47 132.87 55.40 Soft-Attenition 46.58 35.03 27.57 21.79 22.64 43.82 134.94 55.80 Hard-Attenition 46.67 35.76 28.93 23.72 22.91 44.28 140.89 57.95 FC-Att 47.12 36.18 29.39 23.96 23.11 44.13 138.75 57.48 SM-Att 46.10 34.39 27.34 21.89 22.37 43.31 125.49 53.26 MLCA 47.56 35.66 28.12 21.36 23.01 44.22 130.66 54.81 MLAT 45.32 33.89 26.68 21.20 22.04 42.55 134.82 55.15 HCNet 47.26 35.92 28.66 22.92 23.14 44.58 139.75 57.60 PureT 42.31 31.49 24.96 19.83 20.62 40.62 110.51 47.90 DGS-CapNet (Ours) 48.44 37.42 30.02 24.31 23.78 45.79 151.00 61.22 注:加粗数值为最优指标数值。
下载: 导出CSV
表 3 FSAR-Cap数据集上与主流图像描述模型的对比实验
Table 3. Comparative experiments with mainstream image captioning models on the FSAR-Cap dataset
方法 BLEU-1 BLEU-2 BLEU-3 BLEU-4 METEOR ROUGE-L CIDEr S VGG19+LSTM 57.49 44.98 34.25 25.16 24.98 46.27 46.43 35.71 ResNet-101+LSTM 63.94 49.81 38.49 29.48 24.91 47.16 61.97 40.88 ViT+LSTM 60.28 46.72 36.29 27.88 23.67 46.48 53.98 38.00 VGG19+Trans 68.45 55.77 44.89 35.53 26.84 50.69 83.06 49.03 ResNet-101+Trans 69.87 57.20 46.79 37.92 28.25 52.78 90.22 52.30 ViT+Trans 69.34 56.27 45.45 36.47 27.74 51.83 83.97 50.00 Soft-Attenition 68.75 55.95 45.29 36.21 27.26 51.86 78.88 48.55 Hard-Attenition 63.61 50.92 40.60 31.97 25.10 48.46 62.57 42.03 FC-Att 66.55 52.74 41.81 32.94 26.39 49.44 75.82 46.15 SM-Att 67.21 53.10 41.70 32.38 26.35 49.18 71.33 44.81 MLCA 67.64 53.29 41.89 32.66 26.63 49.27 72.35 45.23 MLAT 68.84 55.80 45.37 36.68 27.80 51.79 84.54 50.20 HCNet 70.95 56.77 45.34 35.89 28.08 51.59 79.90 48.87 PureT 65.70 52.65 41.74 33.05 28.86 49.53 71.04 45.62 DGS-CapNet (Ours) 71.24 58.50 47.95 38.99 28.80 53.58 95.14 54.13 注:加粗数值为最优指标数值。
下载: 导出CSV
表 4 SARLANG数据集上与大模型微调的对比实验
Table 4. Comparative experiments with fine-tuning of VLMs on the SARLANG dataset
模型 模型参数 微调策略 BLEU-1 BLEU-2 BLEU-3 BLEU-4 ROUGE-L CIDEr LLaVA1.5 13 B 无微调 6.69 2.88 1.11 0.44 11.50 0.01 LLaVA1.5 7 B 无微调 7.13 3.08 1.11 0.44 12.06 0.03 QWEN2-VL 7 B 无微调 6.48 2.79 0.96 0.35 11.33 0.01 QWEN2.5-VL 7 B 无微调 24.56 13.69 8.87 5.35 24.49 9.42 LLaVA1.5 13 B LoRA微调 34.90 22.95 16.55 12.01 32.43 45.13 LLaVA1.5 7 B LoRA微调 35.24 23.63 17.28 12.70 32.72 46.35 QWEN2-VL 7 B LoRA微调 35.78 23.72 17.57 13.08 32.84 48.36 QWEN2.5-VL 7 B LoRA微调 32.79 22.29 16.44 12.25 30.24 55.64 DGS-CapNet (Ours) 123 M – 48.44 37.42 30.02 24.31 45.79 151.00 注:加粗数值为最优指标数值。
下载: 导出CSV
表 5 SARLANG和FSAR-Cap数据集上的消融实验
Table 5. Ablation studies on the SARLANG and FSAR-Cap datasets
数据集 SF DCT Gabor ${\mathcal{L}}_{\text{b}} $ ${\mathcal{L}}_{\text{m}} $ BLEU-4 METEOR ROUGE-L CIDEr S SARLANG × × × × × 22.77 22.15 43.59 140.63 57.28 √ × × × × 23.13 23.14 44.44 141.19 57.97 √ √ × × × 22.64 23.28 44.32 143.54 58.45 √ √ √ × × 23.83 23.58 45.42 145.22 59.51 √ √ √ √ × 24.19 23.86 45.76 149.87 60.92 √ √ √ √ √ 24.31 23.78 45.79 151.00 61.22 FSAR-Cap × × × × × 37.92 28.25 52.78 90.22 52.30 √ × × × × 38.60 28.69 52.94 90.19 52.61 √ √ × × × 38.56 28.49 53.60 92.20 53.21 √ √ √ × × 38.57 28.55 53.57 93.66 53.59 √ √ √ √ × 38.58 28.96 53.54 94.88 53.99 √ √ √ √ √ 38.99 28.80 53.58 95.14 54.13 注:加粗数值为最优指标数值。
下载: 导出CSV
表 6 SARLANG和FSAR-Cap数据集上不同组合的消融实验
Table 6. Ablation experiments with different combinations on the SARLANG and FSAR-Cap datasets
数据集 不同组合 BLEU-4 METEOR BOUGE_U CIDEr S SARLANG Gabor+SE 23.10 23.33 44.76 147.65 59.71 Gabor+CBAM 23.28 23.40 44.96 149.98 60.41 DCT+GLCM 23.01 23.21 44.65 145.64 59.13 Gabor+DCT 24.31 23.78 45.79 151.00 61.22 FSAR-Cap Gabor+SE 38.41 28.20 52.86 94.16 53.41 Gabor+CBAM 38.47 28.41 52.94 94.13 53.49 DCT+GLCM 38.31 28.43 52.54 93.99 53.32 Gabor+DCT 38.99 28.80 53.58 95.14 54.13
下载: 导出CSV
-
[1] WANG Kai, REN Zhongle, HOU Biao, et al. BSG-WSL: BackScatter-guided weakly supervised learning for water mapping in SAR images[J]. International Journal of Applied Earth Observation and Geoinformation, 2025, 136: 104385. doi: 10.1016/j.jag.2025.104385. [2] 郭倩, 王海鹏, 徐丰. SAR图像飞机目标检测识别进展[J]. 雷达学报, 2020, 9(3): 497–513. doi: 10.12000/JR20020.GUO Qian, WANG Haipeng, and XU Feng. Research progress on aircraft detection and recognition in SAR imagery[J]. Journal of Radars, 2020, 9(3): 497–513. doi: 10.12000/JR20020. [3] LI Weijie, YANG Wei, HOU Yuenan, et al. SARATR-X: Toward building a foundation model for SAR target recognition[J]. IEEE Transactions on Image Processing, 2025, 34: 869–884. doi: 10.1109/TIP.2025.3531988. [4] ZHANG Xinchen, ZHU Hao, LI Xiaotong, et al. Recurrent progressive fusion-based learning for multi-source remote sensing image classification[J]. Pattern Recognition, 2026, 171: 112284. doi: 10.1016/j.patcog.2025.112284. [5] QIN Jiang, ZOU Bin, LI Haolin, et al. Cross-resolution SAR target detection using structural hierarchy adaptation and reliable adjacency alignment[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5221816. doi: 10.1109/TGRS.2025.3613170. [6] WANG Fangyi and WANG Haipeng. Scattering-aware adaptive dynamic node generation for SAR class-incremental learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5220817. doi: 10.1109/TGRS.2025.3615628. [7] YUAN Mengchao, QIN Weibo, and WANG Haipeng. SPAttack: A physically feasible adversarial patch attack against SAR target detection[J]. IEEE Geoscience and Remote Sensing Letters, 2025, 22: 4001505. doi: 10.1109/LGRS.2025.3615852. [8] 罗汝, 赵凌君, 何奇山, 等. SAR图像飞机目标智能检测识别技术研究进展与展望[J]. 雷达学报(中英文), 2024, 13(2): 307–330. doi: 10.12000/JR23056.LUO Ru, ZHAO Lingjun, HE Qishan, et al. Intelligent technology for aircraft detection and recognition through SAR imagery: Advancements and prospects[J]. Journal of Radars, 2024, 13(2): 307–330. doi: 10.12000/JR23056. [9] TAO Wenguang, WANG Xiaotian, YAN Tian, et al. EDADet: Encoder-decoder domain augmented alignment detector for tiny objects in remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5600915. doi: 10.1109/TGRS.2024.3510948. [10] CHANG Honghao, BI Haixia, LI Fan, et al. Deep symmetric fusion transformer for multimodal remote sensing data classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5644115. doi: 10.1109/TGRS.2024.3476975. [11] GAO Han, WANG Changcheng, ZHU Jianjun, et al. TVPol-Edge: An edge detection method with time-varying polarimetric characteristics for crop field edge delineation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4408917. doi: 10.1109/TGRS.2024.3403481. [12] REN Zhongle, MENG Jianhua, ZHANG Cheng, et al. HATNet: Hierarchical attention transformer with RS-CLIP patch tokens for remote sensing image captioning[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 27208–27223. doi: 10.1109/JSTARS.2025.3624411. [13] ZHANG Cheng, REN Zhongle, HOU Biao, et al. Adaptive scale-aware semantic memory network for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5653418. doi: 10.1109/TGRS.2025.3636596. [14] QIN Jiang, ZOU Bin, CHEN Yifan, et al. Scattering attribute embedded network for few-shot SAR ATR[J]. IEEE Transactions on Aerospace and Electronic Systems, 2024, 60(4): 4182–4197. doi: 10.1109/TAES.2024.3373379. [15] HAN Fangzhou, DONG Hongwei, SI Lingyu, et al. Improving SAR automatic target recognition via trusted knowledge distillation from simulated data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5204314. doi: 10.1109/TGRS.2024.3360470. [16] LU Xiaoqiang, WANG Binqiang, ZHENG Xiangtao, et al. Exploring models and data for remote sensing image caption generation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2183–2195. doi: 10.1109/TGRS.2017.2776321. [17] ZHANG Ke, LI Peijie, and WANG Jianqiang. A review of deep learning-based remote sensing image caption: Methods, models, comparisons and future directions[J]. Remote Sensing, 2024, 16(21): 4113. doi: 10.3390/rs16214113. [18] VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: A neural image caption generator[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3156–3164. doi: 10.1109/CVPR.2015.7298935. [19] HUANG Lun, WANG Wenmin, CHEN Jie, et al. Attention on attention for image captioning[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 2019: 4634–4643. doi: 10.1109/ICCV.2019.00473. [20] PAN Yingwei, YAO Ting, LI Yehao, et al. X-linear attention networks for image captioning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10971–10980. doi: 10.1109/CVPR42600.2020.01098. [21] CORNIA M, STEFANINI M, BARALDI L, et al. Meshed-memory transformer for image captioning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10575–10584. doi: 10.1109/CVPR42600.2020.01059. [22] CHEN Long, ZHANG Hanwang, XIAO Jun, et al. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 5659–5667. doi: 10.1109/CVPR.2017.667. [23] WANG Yiyu, XU Jungang, and SUN Yingfei. End-to-end transformer based model for image captioning[C]. The 36th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2022: 2585–2594. doi: 10.1609/aaai.v36i3.20160. [24] GUO Longteng, LIU Jing, ZHU Xinxin, et al. Normalized and geometry-aware self-attention network for image captioning[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 10327–10336. doi: 10.1109/CVPR42600.2020.01034. [25] RENNIE S J, MARCHERET E, MROUEH Y, et al. Self-critical sequence training for image captioning[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 7008–7024. doi: 10.1109/CVPR.2017.131. [26] LIU Chenyang, ZHAO Rui, and SHI Zhenwei. Remote-sensing image captioning based on multilayer aggregated transformer[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 6506605. doi: 10.1109/LGRS.2022.3150957. [27] YANG Zhigang, LI Qiang, YUAN Yuan, et al. HCNet: Hierarchical feature aggregation and cross-modal feature alignment for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5624711. doi: 10.1109/TGRS.2024.3401576. [28] MA Xiaofeng, ZHAO Rui, and SHI Zhenwei. Multiscale methods for optical remote-sensing image captioning[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(11): 2001–2005. doi: 10.1109/LGRS.2020.3009243. [29] ZHANG Zhengyuan, ZHANG Wenkai, YAN Menglong, et al. Global visual feature and linguistic state guided attention for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5615216. doi: 10.1109/TGRS.2021.3132095. [30] ZHAO Kai and XIONG Wei. Cooperative connection transformer for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5607314. doi: 10.1109/TGRS.2024.3360089. [31] MENG Lingwu, WANG Jing, MENG Ran, et al. A multiscale grouping transformer with CLIP latents for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4703515. doi: 10.1109/TGRS.2024.3385500. [32] MENG Lingwu, WANG Jing, HUANG Yan, et al. RSIC-GMamba: A state-space model with genetic operations for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 4702216. doi: 10.1109/TGRS.2025.3548664. [33] ZHAO Kai and XIONG Wei. Exploring data and models in SAR ship image captioning[J]. IEEE Access, 2022, 10: 91150–91159. doi: 10.1109/ACCESS.2022.3202193. [34] LI Yuanli, LIU Wei, LU Wanjie, et al. Synthetic aperture radar image captioning: Building a dataset and explore models[C]. 2025 5th International Conference on Neural Networks, Information and Communication Engineering, Guangzhou, China, 2025: 465–472. doi: 10.1109/NNICE64954.2025.11063765. [35] WEI Yimin, XIAO Aoran, REN Yexian, et al. SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding[J]. arXiv preprint arXiv: 2504.03254, 2025. doi: 10.48550/arXiv.2504.03254. [36] MA Zhiming, XIAO Xiayang, DONG Shihao, et al. SARChat-Bench-2M: A multi-task vision-language benchmark for SAR image interpretation[J]. arXiv preprint arXiv: 2502.08168, 2025. doi: 10.48550/arXiv.2502.08168. [37] GAO Ziyi, SUN Shuzhou, CHENG Mingming, et al. Multimodal large models driven SAR image captioning: A benchmark dataset and baselines[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 24011–24026. doi: 10.1109/JSTARS.2025.3603036. [38] HE Yiguo, CHENG Xinjun, ZHU Junjie, et al. SAR-TEXT: A large-scale SAR image-text dataset built with SAR-Narrator and a progressive learning strategy for downstream tasks[J]. arXiv preprint arXiv: 2507.18743, 2025. doi: 10.48550/arXiv.2507.18743. [39] JIANG Chaowei, WANG Chao, WU Fan, et al. SARCLIP: A multimodal foundation framework for SAR imagery via contrastive language-image pre-training[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2026, 231: 17–34. doi: 10.1016/j.isprsjprs.2025.10.017. [40] DAI Yimian, ZOU Minrui, LI Yuxuan, et al. DenoDet: Attention as deformable multisubspace feature denoising for target detection in SAR images[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(2): 4729–4743. doi: 10.1109/TAES.2024.3507786. [41] LI Ke, WANG Di, HU Zhangyuan, et al. Unleashing channel potential: Space-frequency selection convolution for SAR object detection[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 17323–17332. doi: 10.1109/CVPR52733.2024.01640. [42] CHEN Zuohui, WU Hao, WU Wei, et al. ASFF-Det: Adaptive space-frequency fusion detector for object detection in SAR images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 20708–20724. doi: 10.1109/JSTARS.2025.3593313. [43] WU Youming, SUO Yuxi, MENG Qingbiao, et al. FAIR-CSAR: A benchmark dataset for fine-grained object detection and recognition based on single-look complex SAR images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5201022. doi: 10.1109/TGRS.2024.3519891. [44] ZHANG Xiangrong, WANG Xin, TANG Xu, et al. Description generation for remote sensing images using attribute attention mechanism[J]. Remote Sensing, 2019, 11(6): 612. doi: 10.3390/rs11060612. [45] CHENG Qimin, HUANG Haiyan, XU Yuan, et al. NWPU-captions dataset and MLCA-net for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5629419. doi: 10.1109/TGRS.2022.3201474. [46] HU Jie, SHEN Li, and SUN Gang. Squeeze-and-excitation networks[C]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018: 7132–7141. doi: 10.1109/CVPR.2018.00745. [47] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. doi: 10.1007/978-3-030-01234-2_1. [48] NUMBISI F N, VAN COILLIE F M B, and DE WULF R. Delineation of cocoa agroforests using multiseason sentinel-1 SAR images: A low grey level range reduces uncertainties in GLCM texture-based mapping[J]. ISPRS International Journal of Geo-Information, 2019, 8(4): 179. doi: 10.3390/ijgi8040179. -





计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

