
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Knowledge Transfer Method for Vision-language Models for Processing Synthetic Aperture Radar Images
-
摘要: 基于海量图文数据预训练的大规模视觉语言模型(VLM)在自然图像领域表现出色,但将其迁移至合成孔径雷达(SAR)图像领域面临两大挑战:一是SAR图像高质量文本标注成本高昂,限制了SAR图文配对数据集的构建;二是SAR图像与光学自然图像在图像特征上存在显著差异,增加了跨域知识迁移难度。针对上述问题,该文提出一种面向SAR图像的视觉语言大模型知识迁移方法。首先,利用配对的SAR与光学遥感图像,借助生成式视觉语言大模型为光学遥感图像自动生成文本描述,从而以较低成本间接构建了SAR图文配对数据集。其次,设计了两阶段迁移策略,将自然图像领域向SAR图像领域的大跨度迁移进行拆解,降低单次迁移难度。最后,在SAR图像零样本场景分类、检索以及目标识别任务上进行实验验证,实验结果表明所提方法能够有效实现视觉语言大模型向SAR图像领域的知识迁移。
-
关键词:
- 视觉语言模型(VLM) /
- 合成孔径雷达(SAR) /
- 知识迁移 /
- 自动文本生成 /
- 两阶段迁移策略
Abstract: A large-scale Vision-Language Model (VLM) pre-trained on massive image-text datasets performs well when processing natural images. However, there are two major challenges in applying it to Synthetic Aperture Radar (SAR) images: (1) The high cost of high-quality text annotation limits the construction of SAR image-text paired datasets, and (2) The considerable differences in image features between SAR images and optical natural images increase the difficulty of cross-domain knowledge transfer. To address these problems, this study developed a knowledge transfer method for VLM tailored to SAR images. First, this study leveraged paired SAR and optical remote sensing images and employed a generative VLM to automatically produce textual descriptions of the optical images, thereby indirectly constructing a low-cost SAR-text paired dataset. Second, a two-stage transfer strategy was designed to address the large domain discrepancy between natural and SAR images, reducing the difficulty of each transfer stage. Finally, experimental validation was conducted through the zero-shot scene classification, image retrieval, and object recognition of SAR images. The results demonstrated that the proposed method enables effective knowledge transfer from a large-scale VLM to the SAR image domain. -
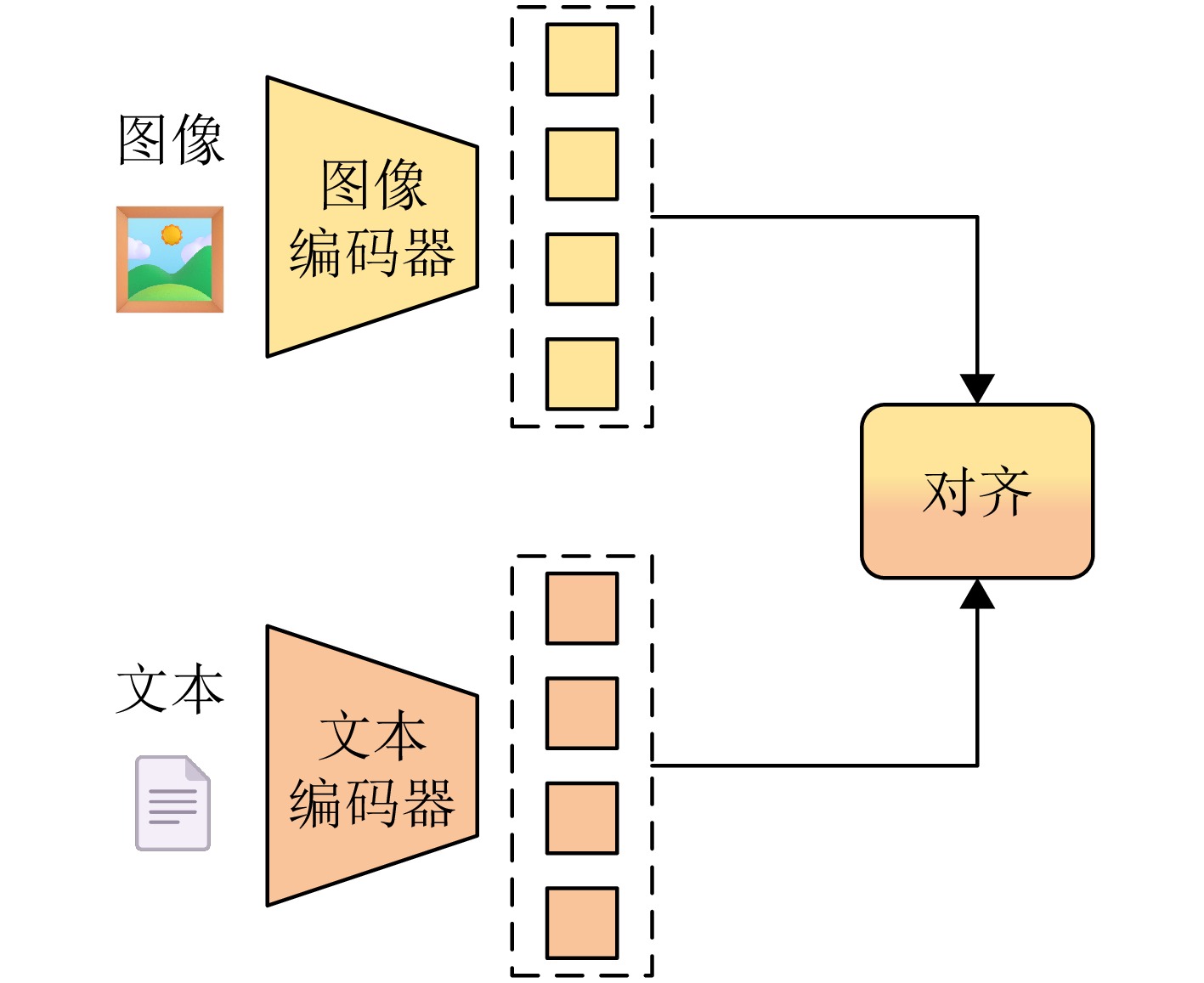
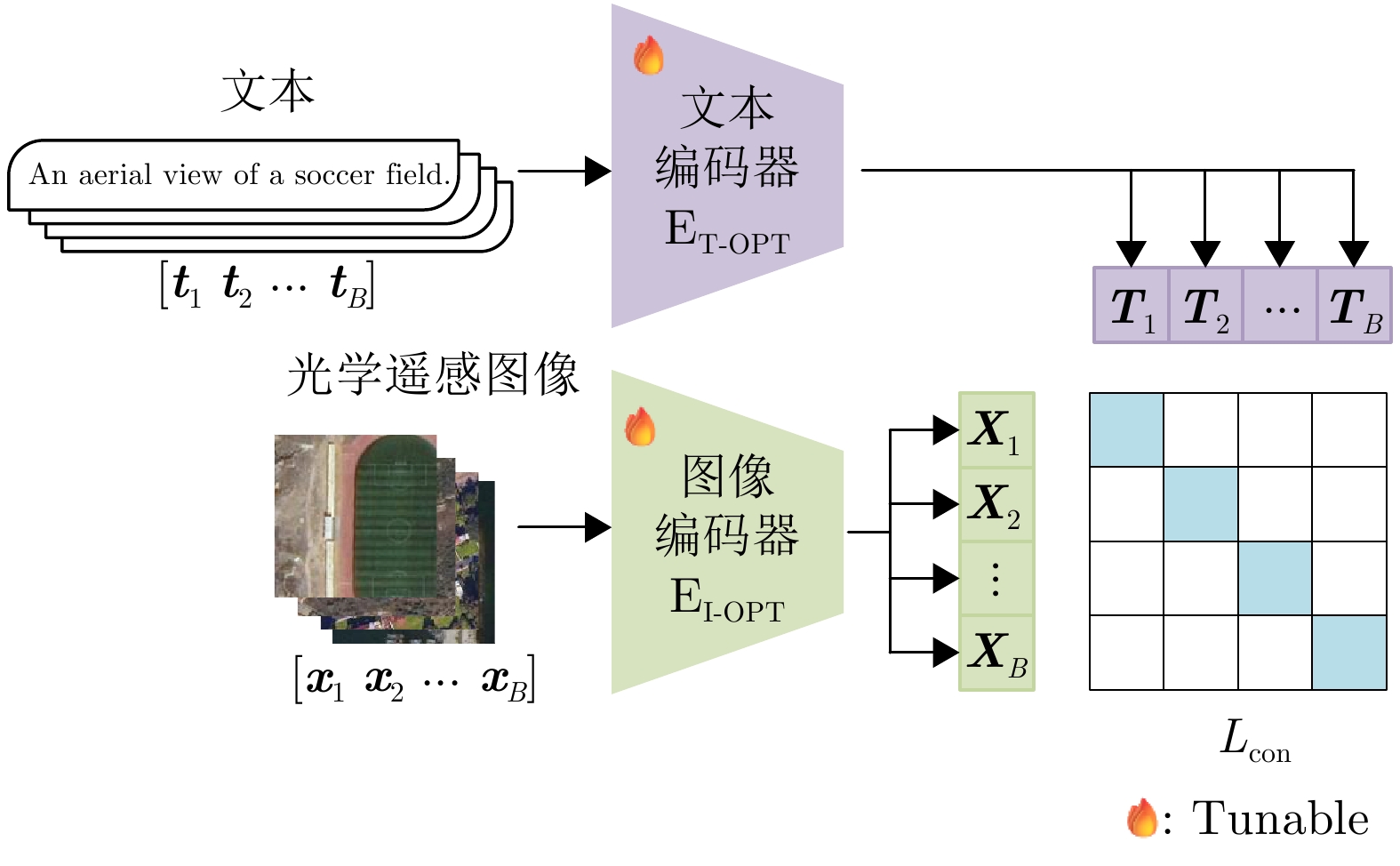
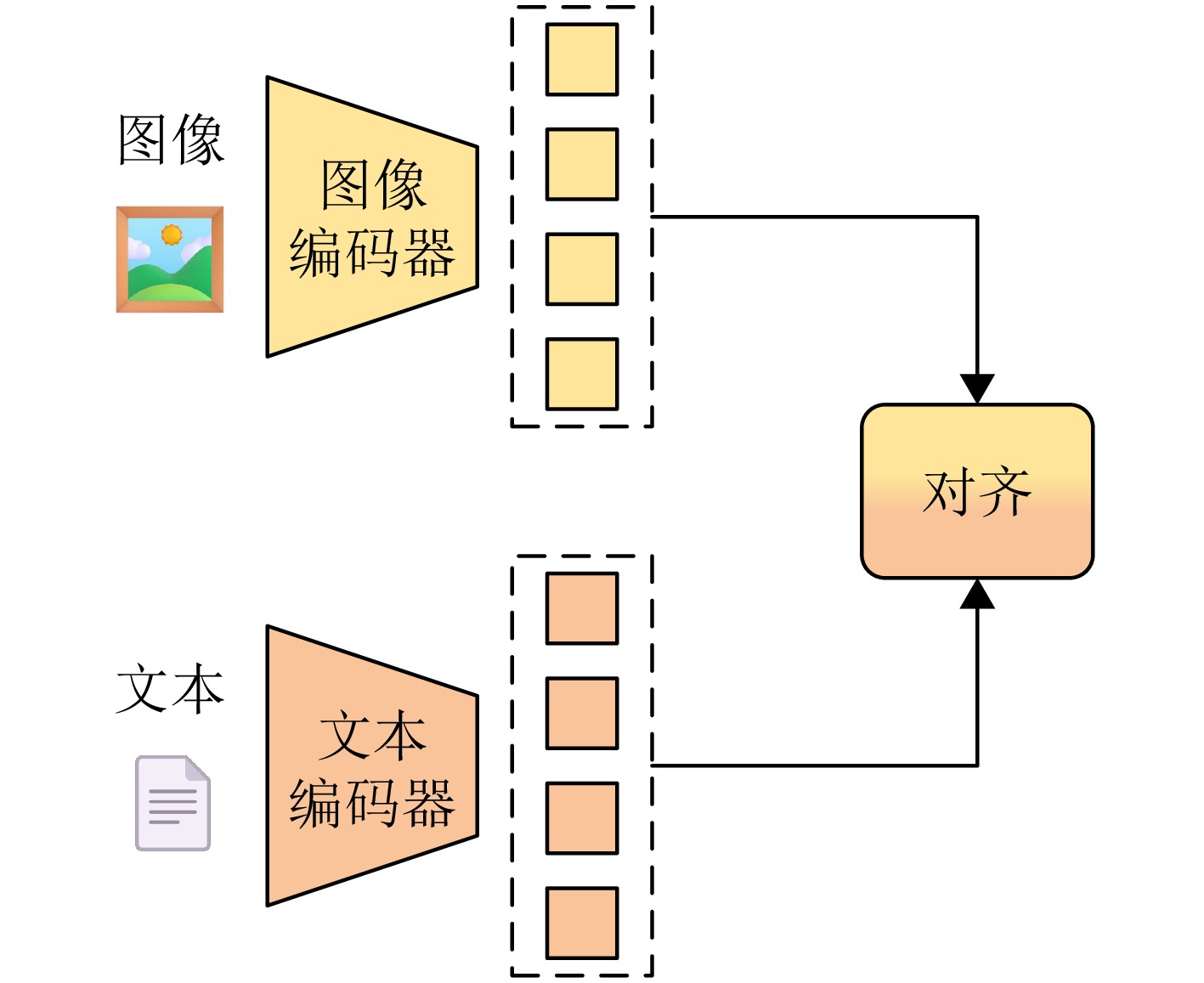
图 1 图像编码器-文本编码器的双塔结构图
Figure 1. The dual-tower structure of the visual encoder and the text encoder
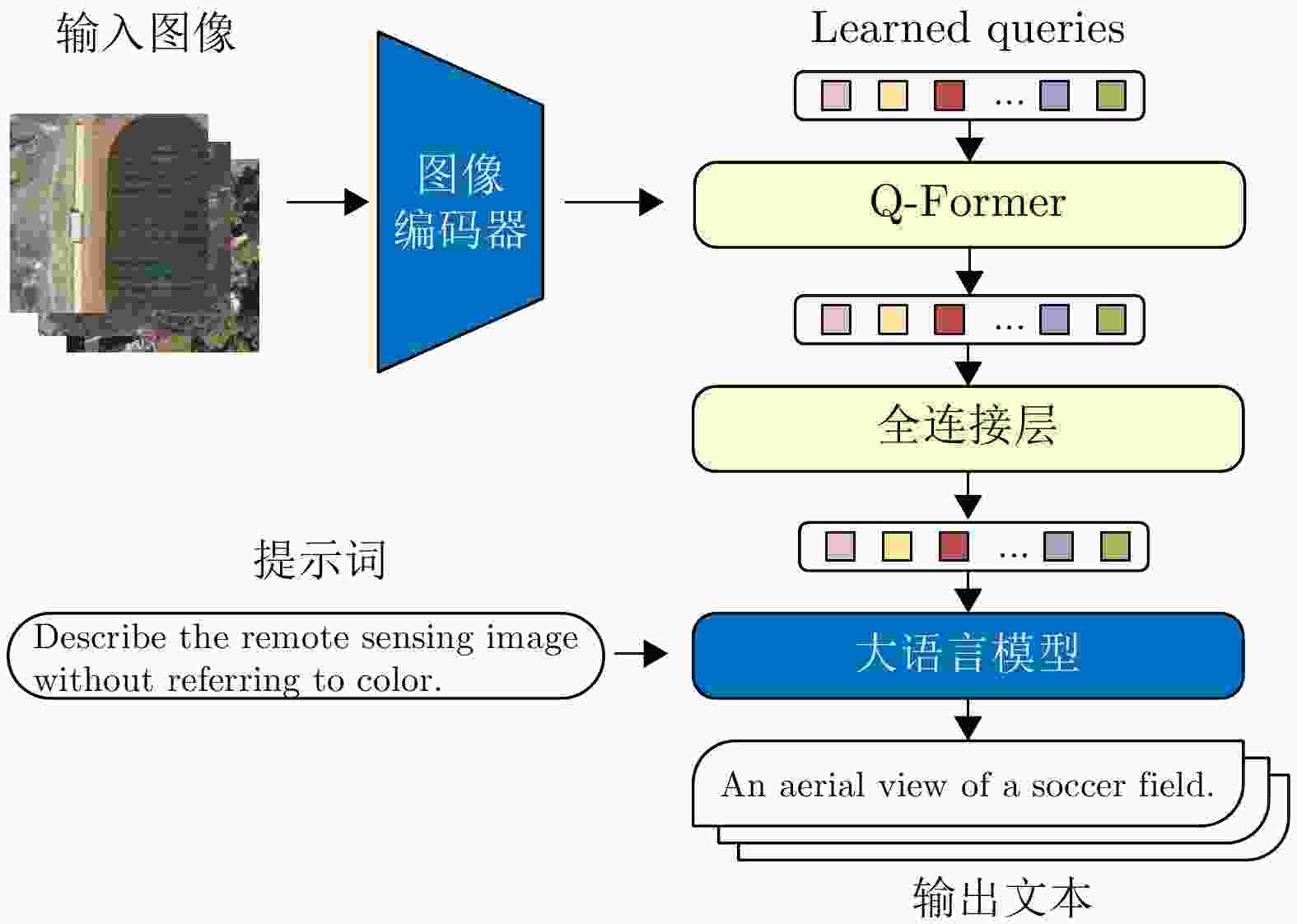
图 3 BLIP-2模型生成文本描述的具体过程
Figure 3. The specific workflow of the BLIP-2 model for generating text descriptions
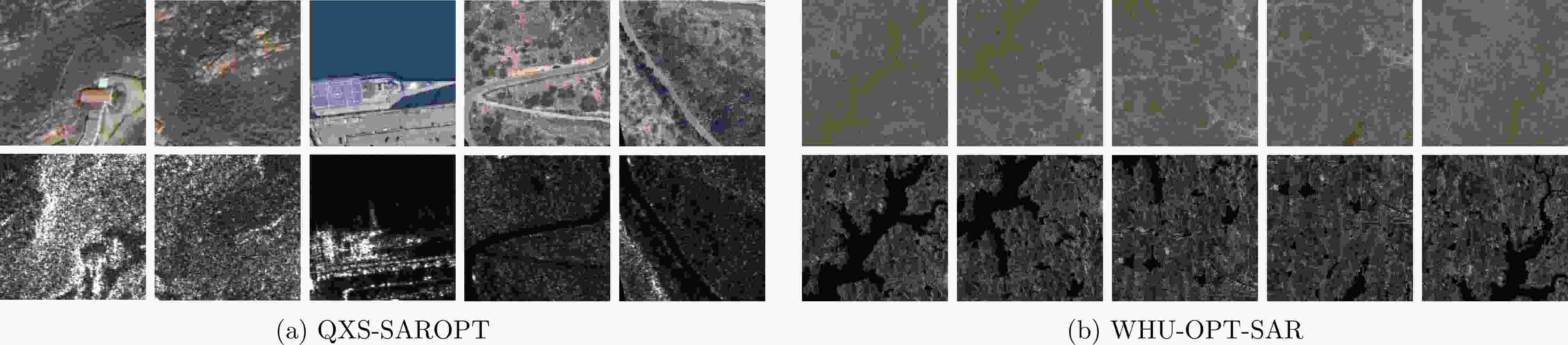
图 6 QXS-SAROPT数据集和WHU-OPT-SAR数据集中的光学遥感图像及其对应的SAR图像示例
Figure 6. Examples of optical remote sensing images and corresponding SAR images of QXS-SAROPT dataset and WHU-OPT-SAR dataset
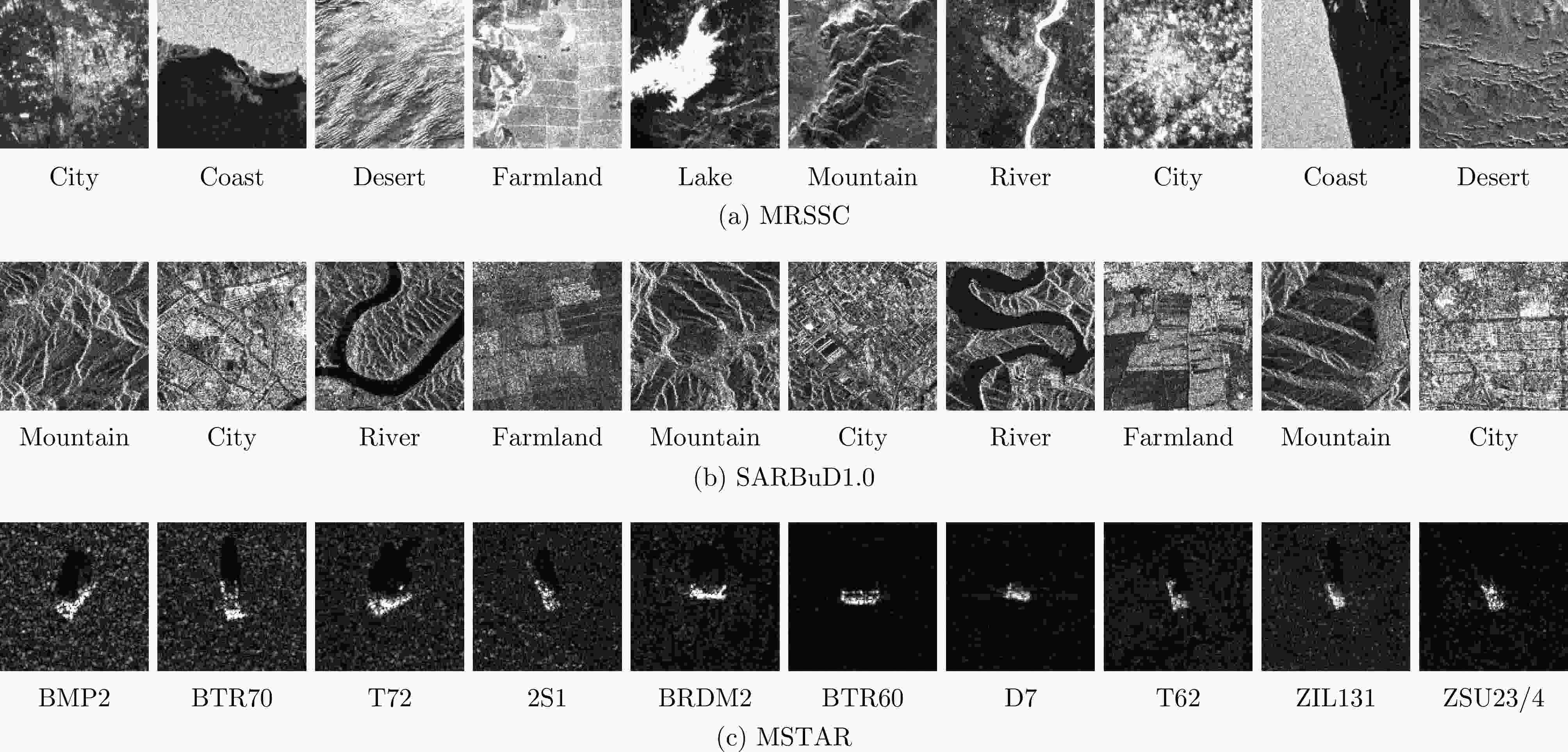
图 7 MRSSC数据集、SARBuD1.0数据集和MSTAR数据集的SAR图像示例
Figure 7. Examples of SAR images of MRSSC dataset, SARBuD1.0 dataset and MSTAR dataset
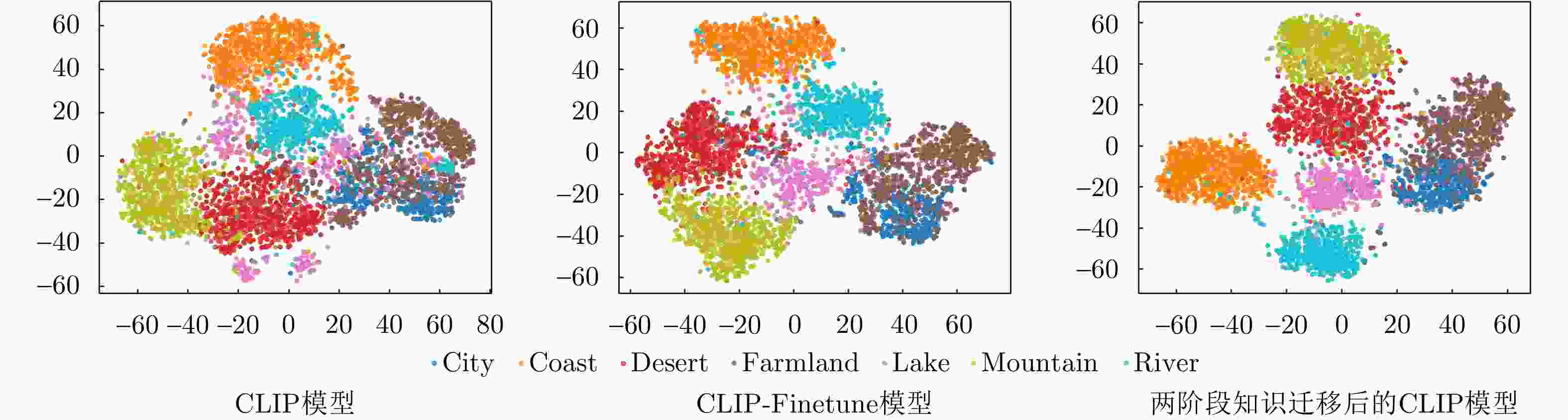
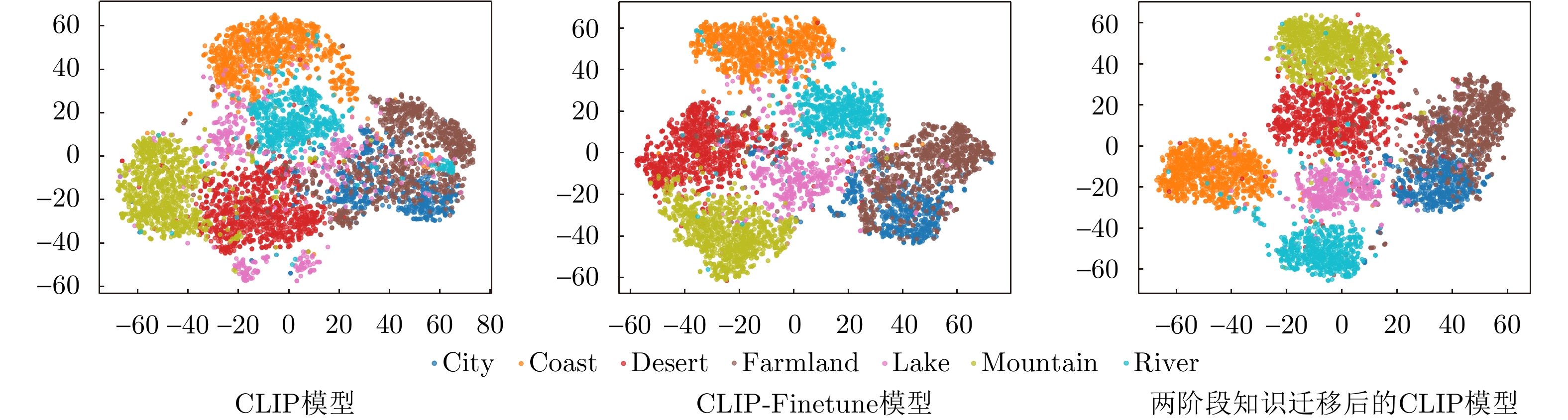
图 10 MRSSC数据集在不同模型上的特征可视化图
Figure 10. Feature visualization of MRSSC dataset on different models
表 1 用于知识迁移的QXS-SAROPT数据集和WHU-OPT-SAR数据集的具体信息
Table 1. The detailed information of QXS-SAROPT dataset and WHU-OPT-SAR dataset used for knowledge transfer
数据集名称 图像模态 图像尺寸(像素) 空间分辨率(m) 图像数量 获取平台 波段 QXS-SAROPT 光学遥感图像 $ 256\times 256 $ 1 20000 Google Earth - SAR图像 $ 256\times 256 $ 1 20000 Ganfen-3 C WHU-OPT-SAR 光学遥感图像 $ 5556\times 3704 $ 5 100 Gaofen-1 - SAR图像 $ 5556\times 3704 $ 5 100 Gaofen-3 C  下载: 导出CSV
下载: 导出CSV
表 2 用于实验验证的MRSSC数据集、SARBuD1.0数据集和MSTAR数据集的具体信息
Table 2. The detailed information of MRSSC dataset, SARBuD1.0 dataset and MSTAR dataset used for experimental verification
数据集名称 图像模态 图像尺寸(像素) 空间分辨率(m) 类别数量 图像数量 获取平台 波段 MRSSC SAR图像 $ 256\times 256 $ 40 7 5199 Tiangong-2 Ku SARBuD1.0 SAR图像 $ 256\times 256 $ 10 4 1150 Gaofen-3 C MSTAR SAR图像 $ 128\times 128 $ 0.3 10 2425 - X
下载: 导出CSV
表 3 SAR图像零样本场景分类实验结果(%)
Table 3. Experimental results of zero-shot scene classification for SAR images (%)
模型 零样本场景分类PCC MRSSC (SAR) SARBuD1.0 (SAR) CLIP 36.66 49.62 CLIP-Finetune 71.35 76.48 RemoteCLIP 61.16 74.56 GeoRSCLIP 64.95 72.38 两阶段知识迁移后的CLIP模型 75.80 82.60 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 4 SAR图像检索实验结果(%)
Table 4. Experimental results of SAR image retrieval (%)
模型 MRSSC SARBuD1.0 mAP mAP@5 mAP@10 mAP mAP@5 mAP@10 CLIP 40.22 56.33 53.00 40.33 29.33 29.53 CLIP-Finetune 61.41 66.19 67.89 75.84 77.50 78.15 RemoteCLIP 56.69 70.29 65.22 74.78 76.25 78.51 GeoRSCLIP 64.57 67.48 65.18 75.49 77.50 74.00 两阶段知识迁移后的CLIP模型 67.88 93.71 86.75 81.39 94.00 89.38 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 5 SAR目标识别实验结果(%)
Table 5. Experimental results of SAR target recognition (%)
模型 目标识别PCC 10%训练
样本30%训练
样本100%训练
样本CLIP-Adapter 78.42 87.84 93.86 Tip-Adapter 75.13 82.80 87.30 SAR-JEPA 81.23 94.88 96.45 CLIP 83.75 94.30 98.80 CLIP-Finetune 88.49 95.63 99.18 RemoteCLIP 88.29 95.84 99.22 GeoRSCLIP 88.70 96.16 99.46 两阶段知识迁移后的CLIP模型 90.39 96.78 99.59 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 6 批尺寸对CLIP模型迁移效果的影响
Table 6. Effects of batch size on CLIP model knowledge transfer performance
批尺寸 PCC (%) 32 73.7 64 75.2 128 75.8 256 73.3 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 7 权重$ {\boldsymbol{\lambda}} $对CLIP模型迁移效果的影响
Table 7. Effects of weighting coefficient ${\boldsymbol{ \lambda}} $ on CLIP model knowledge transfer performance
权重$ \lambda $ PCC (%) 0 69.2 0.5 74.8 1.0 75.3 1.5 75.4 2.0 75.6 2.5 75.8 3.0 74.6 注:表内加粗数值表示最优结果。
下载: 导出CSV
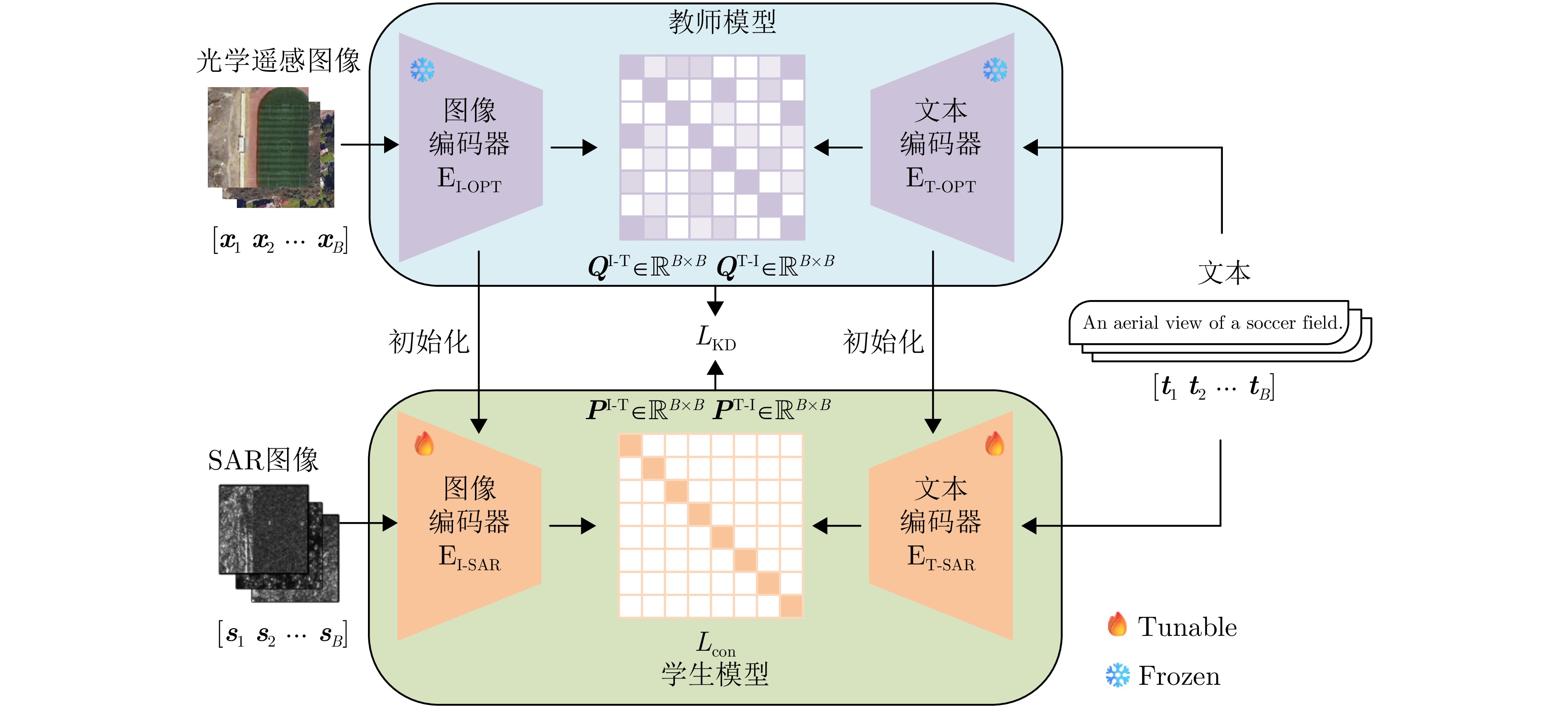
表 8 两阶段知识迁移策略的消融实验结果
Table 8. Ablation study results of the two-stage knowledge transfer
一阶段知识迁移 二阶段知识迁移 PCC (%) 36.66 √ 48.48 √ 72.31 √ √ 75.80 注:表内加粗数值表示最优结果。
下载: 导出CSV
表 9 软标签蒸馏策略的消融实验结果
Table 9. Ablation study results of the soft-label distillation
损失函数 PCC (%) $ {L}_{\mathrm{con}} $ 69.21 $ {L}_{\mathrm{con}}+\lambda \cdot {L}_{\mathrm{KD}} $ 75.80 注:表内加粗数值表示最优结果。
下载: 导出CSV
-
[1] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C/OL]. The 38th International Conference on Machine Learning, 2021: 8748–8763. https://icml.cc/virtual/2021/oral/9194. [2] LI Junnan, LI Dongxu, SAVARESE S, et al. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 19730–19742. [3] ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10674–10685. doi: 10.1109/CVPR52688.2022.01042. [4] LIU Fan, CHEN Delong, GUAN Zhangqingyun, et al. RemoteCLIP: A vision language foundation model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5622216. doi: 10.1109/TGRS.2024.3390838. [5] HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: A remote sensing vision language model and benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 224: 272–286. doi: 10.1016/j.isprsjprs.2025.03.028. [6] KHANNA S, LIU P, Zhou Linqi, et al. DiffusionSat: A generative foundation model for satellite imagery[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024: 5586–5604. [7] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5917820. doi: 10.1109/TGRS.2024.3409624. [8] LI Weijie, YANG Wei, HOU Yuenan, et al. SARATR-X: Toward building a foundation model for SAR target recognition[J]. IEEE Transactions on Image Processing, 2025, 34: 869–884. doi: 10.1109/TIP.2025.3531988. [9] WANG Yi, ALBRECHT C M, and ZHU Xiaoxiang. Multilabel-guided soft contrastive learning for efficient earth observation pretraining[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5644516. doi: 10.1109/TGRS.2024.3466896. [10] DU Yuntao, CHEN Yushi, HUANG Lingbo, et al. SUMMIT: A SAR foundation model with multiple auxiliary tasks enhanced intrinsic characteristics[J]. International Journal of Applied Earth Observation and Geoinformation, 2025, 141: 104624. doi: 10.1016/j.jag.2025.104624. [11] WANG Mengyu, BI Hanbo, FENG Yingchao, et al. A complex-valued SAR foundation model based on physically inspired representation learning[OL]. https://arxiv.org/abs/ 2504.11999v1, 2025. [12] REN Zhongle, DING Hui, WANG Kai, et al. DI3CL: Contrastive learning with dynamic instances and contour consistency for SAR land-cover classification foundation model[OL]. https://arxiv.org/abs/2511.07808, 2025. [13] REN Zhongle, DU Zhe, HOU Biao, et al. Self-supervised learning of contrast-diffusion models for land cover classification in SAR Images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5219620. doi: 10.1109/TGRS.2025.3600895. [14] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016. 90. [15] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021: 611–631. https://iclr.cc /virtual/2021/oral/3458. [16] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [17] JIA Chao, YANG Yinfei, XIA Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C/OL]. The 38th International Conference on Machine Learning, 2021: 4904–4916. https://icml.cc/virtual /2021/oral/10658. [18] ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M and GeoRSCLIP: A large-scale vision- language dataset and a large vision-language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5642123. doi: 10.1109/TGRS.2024.3449154. [19] LI Xiang, WEN Congcong, HU Yuan, et al. RS-CLIP: Zero shot remote sensing scene classification via contrastive vision-language supervision[J]. International Journal of Applied Earth Observation and Geoinformation, 2023, 124: 103497. doi: 10.1016/j.jag.2023.103497. [20] HE Yiguo, CHENG Xinjun, ZHU Junjie, et al. SAR-TEXT: A large-scale SAR image-text dataset built with SAR-Narrator and a progressive learning strategy for downstream tasks[OL]. https://arxiv.org/abs/2507.18743, 2025. [21] JIANG Chaowei, WANG Chao, WU Fan, et al. SARCLIP: A multimodal foundation framework for SAR imagery via contrastive language-image pre-training[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2026, 231: 17–34. doi: 10.1016/j.isprsjprs.2025.10.017. [22] MA Qiwei, WANG Zhiyu, LIU Wang, et al. SARVLM: A vision language foundation model for semantic understanding and target recognition in SAR imagery[OL]. https://arxiv. org/abs/2510.22665, 2025. [23] YANG Yi, ZHANG Xiaokun, FANG Qingchen, et al. SAR-KnowLIP: Towards multimodal foundation models for remote sensing[OL]. https://arxiv.org/abs/2509.23927v1, 2025. [24] DAI Wenyuan, YANG Qiang, XUE Guirong, et al. Boosting for transfer learning[C]. The 24th International Conference on Machine Learning, Corvalis, USA, 2007: 193–200. doi: 10.1145/ 1273496.1273521. [25] HINTON G, VINYALS O, and DEAN J. Distilling the knowledge in a neural network[OL]. https://arxiv.org/abs/ 1503.02531, 2015. [26] KARIMI MAHABADI R, HENDERSON J, and RUDER S. COMPACTER: Efficient low-rank hypercomplex adapter layers[C/OL]. The 35th International Conference on Neural Information Processing Systems, 2021: 1022–1035. https://proceedings.neurips.cc/paper/2021/hash/081be9fdff07f3bc808f935906ef70c0-Abstract.html. [27] ZHOU Kaiyang, YANG Jingkang, LOY C C, et al. Learning to prompt for vision-language models[J]. International Journal of Computer Vision, 2022, 130(9): 2337–2348. doi: 10.1007/s11263-022-01653-1. [28] ZAKEN E B, GOLDBERG Y, and RAVFOGEL S. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models[C]. The 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 2022: 1–9. doi: 10.18653/v1/2022.acl-short.1. [29] HU E J, SHEN Yelong, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[C/OL]. The 10th International Conference on Learning Representations, 2022. https://iclr.cc/virtual/2022/poster/6319. [30] GAO Peng, GENG Shijie, ZHANG Renrui, et al. CLIP-adapter: Better vision-language models with feature adapters[J]. International Journal of Computer Vision, 2024, 132(2): 581–595. doi: 10.1007/s11263-023-01891-x. [31] ZHANG Renrui, ZHANG Wei, FANG Rongyao, et al. Tip-adapter: Training-free adaption of CLIP for few-shot classification[C]. The 17th European Conference on Computer Vision. Tel Aviv, Israel, 2022: 493–510. doi: 10.1007/978-3-031-19833-5_29. [32] CHENG Cheng, SONG Lin, XUE Ruoyi, et al. Meta-adapter: An online few-shot learner for vision-language model[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, Dec. 2023: 55361–55374. [33] KRISHNA R, ZHU Yuke, GROTH O, et al. Visual Genome: Connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32–73. doi: 10.1007/s11263-016-0981-7. [34] SHARMA P, DING Nan, GOODMAN S, et al. Conceptual Captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2556–2565. doi: 10.18653/v1/P18-1238. [35] CHANGPINYO S, SHARMA P, DING Nan, et al. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3557–3567. doi: 10.1109/CVPR46437. 2021.00356. [36] ORDONEZ V, KULKARNI G, and BERG T L. Im2Text: Describing images using 1 million captioned photographs[C]. The 25th International Conference on Neural Information Processing Systems, Granada, Spain, 2011: 1143–1151. [37] LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 34892–34916. [38] BAI Shuai, CHEN Keqin, LIU Xuejing, et al. Qwen2.5-VL technical report[OL]. https://arxiv.org/abs/2502.13923, 2025. [39] WEI Yimin, XIAO Aoran, REN Yexian, et al. SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding[OL]. https://arxiv.org/abs/2504.03254v1, 2025. [40] LI Junnan, LI Dongxu, XIONG Caiming, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 12888–12900. [41] OpenAI. GPT-4 technical report[OL]. https://arxiv.org/abs/2303.08774, 2024. [42] GRETTON A, BORGWARDT K M, RASCH M, et al. A Kernel Method for the Two-sample-problem[M]. SCHÖLKOPF B, PLATT J, and HOFMANN T. Advances in Neural Information Processing Systems 19. Cambridge: The MIT Press, 2007: 19. doi: 10.7551/mitpress/7503.003.0069. [43] VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[OL]. https://arxiv.org/abs/1807.03748, 2019. [44] HUANG Meiyu, XU Yao, QIAN Lixin, et al. The QXS- SAROPT dataset for deep learning in SAR-optical data fusion[OL]. https://arxiv.org/abs/2103.08259, 2021. [45] LI Xue, ZHANG Guo, CUI Hao, et al. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 106: 102638. doi: 10.1016/j.jag.2021.102638. [46] LIU Kang, WU Aodi, WAN Xue, et al. MRSSC: A benchmark dataset for multimodal remote sensing scene classification[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2021, XLIII-B2-2021: 785–792. doi: 10.5194/isprs- archives-XLIII-B2-2021-785-2021. [47] 吴樊, 张红, 王超, 等. SARBuD1.0: 面向深度学习的GF-3 精细模式SAR建筑数据集[J]. 遥感学报, 2022, 26(4): 620–631. doi: 10.11834/jrs.20220296.WU Fan, ZHANG Hong, WANG Chao, et al. SARBuD1.0: A SAR building dataset based on GF-3 FSII imageries for built-up area extraction with deep learning method[J]. National Remote Sensing Bulletin, 2022, 26(4): 620–631. doi: 10.11834/jrs.20220296. [48] ROSS T D, WORRELL S W, VELTEN V J, et al. Standard SAR ATR evaluation experiments using the MSTAR public release data set[C]. SPIE 3370, Algorithms for Synthetic Aperture Radar Imagery V, Orlando, USA, 1998: 566–573. doi: 10.1117/12.321859. [49] REIMERS N and GUREVYCH I. Sentence-BERT: Sentence embeddings using siamese BERT-networks[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 2019: 3982–3992. doi: 10.18653/v1/D19-1410. [50] LI Weijie, YANG Wei, LIU Tianpeng, et al. Predicting gradient is better: Exploring self-supervised learning for SAR ATR with a joint-embedding predictive architecture[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2024, 218: 326–338. doi: 10.1016/j.isprsjprs.2024.09.013. [51] GAO Ziyi, SUN Shuzhou, CHENG Mingming, et al. Multimodal large models driven SAR image captioning: A benchmark dataset and baselines[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 24011–24026. doi: 10.1109/JSTARS.2025.3603036. [52] XIAO Rui, KIM S, GEORGESCU M I, et al. FLAIR: VLM with fine-grained language-informed image representations[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 24884–24894. doi: 10.1109/CVPR52734.2025.02317. [53] ZHENG Kecheng, ZHANG Yifei, WU Wei, et al. DreamLIP: Language-image pre-training with long captions[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2025: 73–90. doi: 10.1007/978-3-031-72649-1_5. -








计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

