
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Detection of Common Underground Targets in Ground Penetrating Radar Images Using the GDS-YOLOv8n Model
-
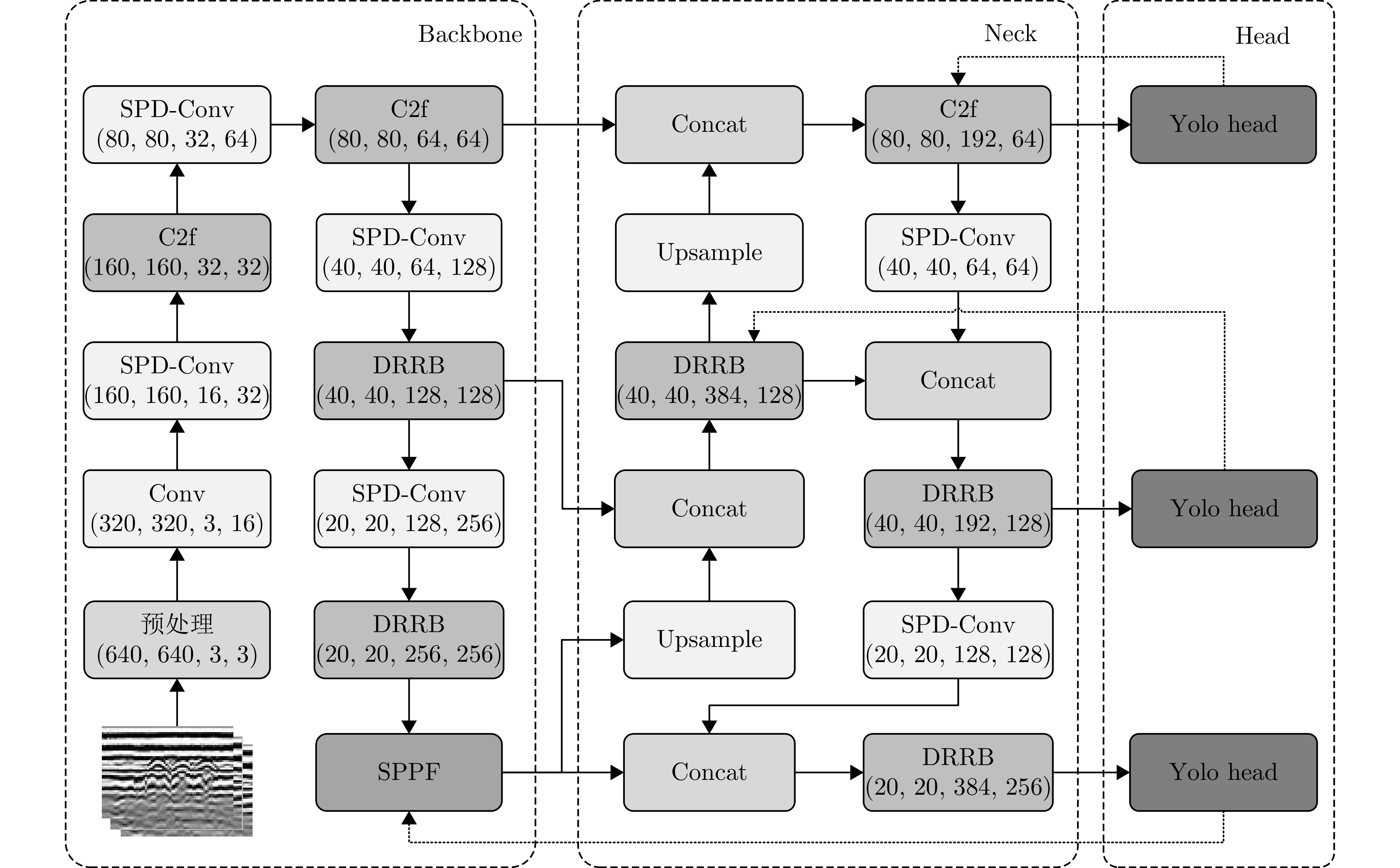
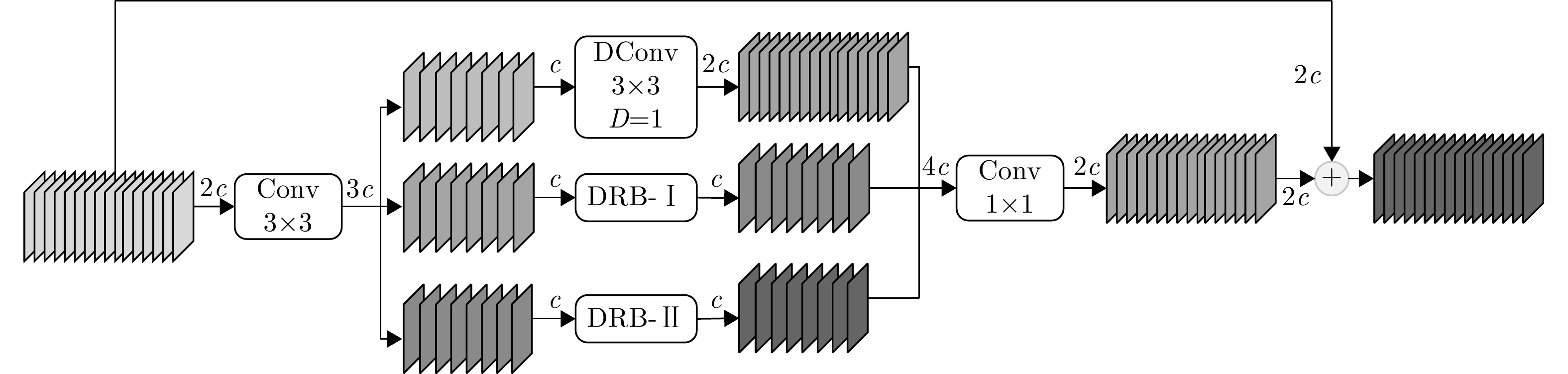
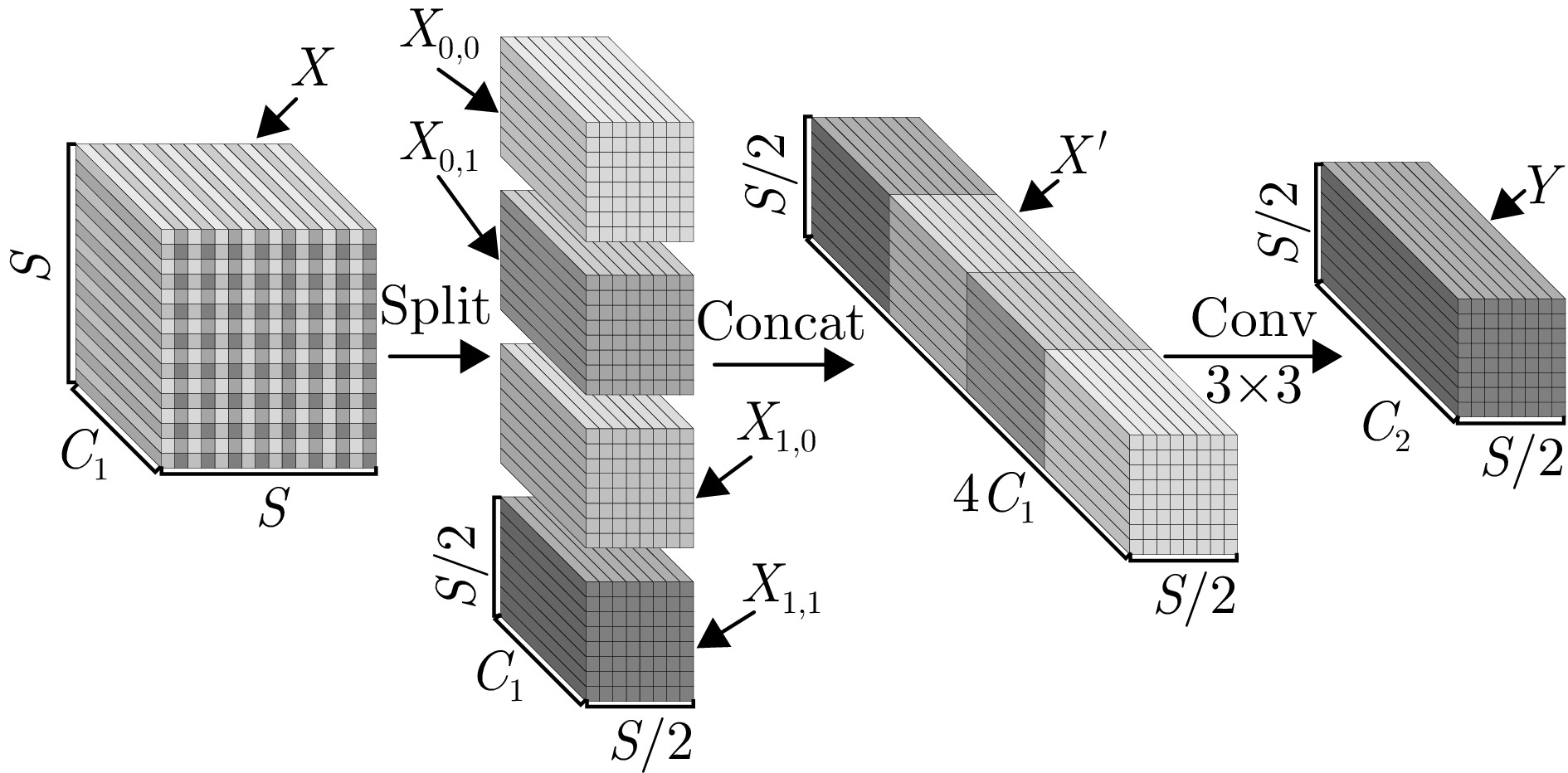
摘要: 针对当前探地雷达(GPR)图像检测中存在准确率低、误检和漏检等问题,该文提出了一种GPR常见地下目标检测模型GDS-YOLOv8n。该模型首先使用DRRB特征提取模块替换YOLOv8n模型中的部分C2f模块,旨在增强模型对多尺度特征的提取能力。其次使用SPD-Conv下采样模块替换像素为320×320及以下特征图所对应的Conv模块,有效克服分辨率受限以及存在小目标的GPR图像在下采样过程中的信息损失问题;同时利用辅助训练模块,在不增加检测阶段模型复杂度的前提下提升GPR图像的检测性能。最后,引入Inner-SIoU损失函数,在添加新约束条件的基础上,通过比例因子生成适合于当前GPR图像的辅助边界框,以提高预测框的准确性。实验结果表明,GDS-YOLOv8n模型对金属管、PVC管和电缆线等6类常见地下目标在实测GPR图像数据集上的P, R和mAP50分别为97.1%, 96.2%和96.9%,较YOLOv8n模型分别提高了4.0%, 6.1%和4.1%,尤其对PVC管和电缆线目标的检测效果提升更明显。与YOLOv5n, YOLOv7-tiny和SSD等模型相比,其mAP50分别提高了7.20%, 5.70%和14.48%。此外,将GDS-YOLOv8n模型部署到NVIDIA Jetson Orin NX嵌入式设备上,并使用TensorRT进行优化。经FP16量化后,模型的检测速度由22.0 FPS提高到40.6 FPS,能够满足移动场景下GPR地下目标实时探测任务的需求。Abstract: Ground Penetrating Radar (GPR) image detection currently faces challenges such as low accuracy, false detections, and missed detections. To overcome these challenges, we propose a novel model referred to as GDS-YOLOv8n for detecting common underground targets in GPR images. The model incorporates the DRRB (Dilated Residual Reparam Block) feature extraction module to achieve enhanced multiscale feature extraction, with certain C2f modules in the YOLOv8n architecture being effectively replaced. In addition, the space-to-depth Conv downsampling module is used to replace the Conv modules corresponding to feature maps with a resolution of 320×320 pixels and less. This replacement assists in mitigating information loss during the downsampling of GPR images, particularly for images with limited resolution and small targets. Furthermore, the detection performance is enhanced using an auxiliary training module, ensuring performance improvement without increasing inference complexity. The introduction of the Inner-SIoU loss function refines bounding box predictions by imposing new constraints tailored to GPR image characteristics. Experimental results on real-world GPR datasets demonstrate the effectiveness of the GDS-YOLOv8n model. For six classes of common underground targets, including metal pipes, PVC pipes, and cables, the model achieves a precision of 97.1%, recall of 96.2%, and mean average precision at 50% IoU (mAP50) of 96.9%. These results indicate improvements of 4.0%, 6.1%, and 4.1%, respectively, compared to corresponding values of the YOLOv8n model, with notable improvements observed when detecting PVC pipes and cables. Compared with those of models such as YOLOv5n, YOLOv7-tiny, and SSD (Single Shot multibox Detector), our model’s mAP50 is improved by 7.20%, 5.70%, and 14.48%, respectively. Finally, the application of our model on a NVIDIA Jetson Orin NX embedded system results in an increase in the detection speed from 22 to 40.6 FPS after optimization via TensorRT and FP16 quantization, meeting the demands for the real-time detection of underground targets in mobile scenarios.
-

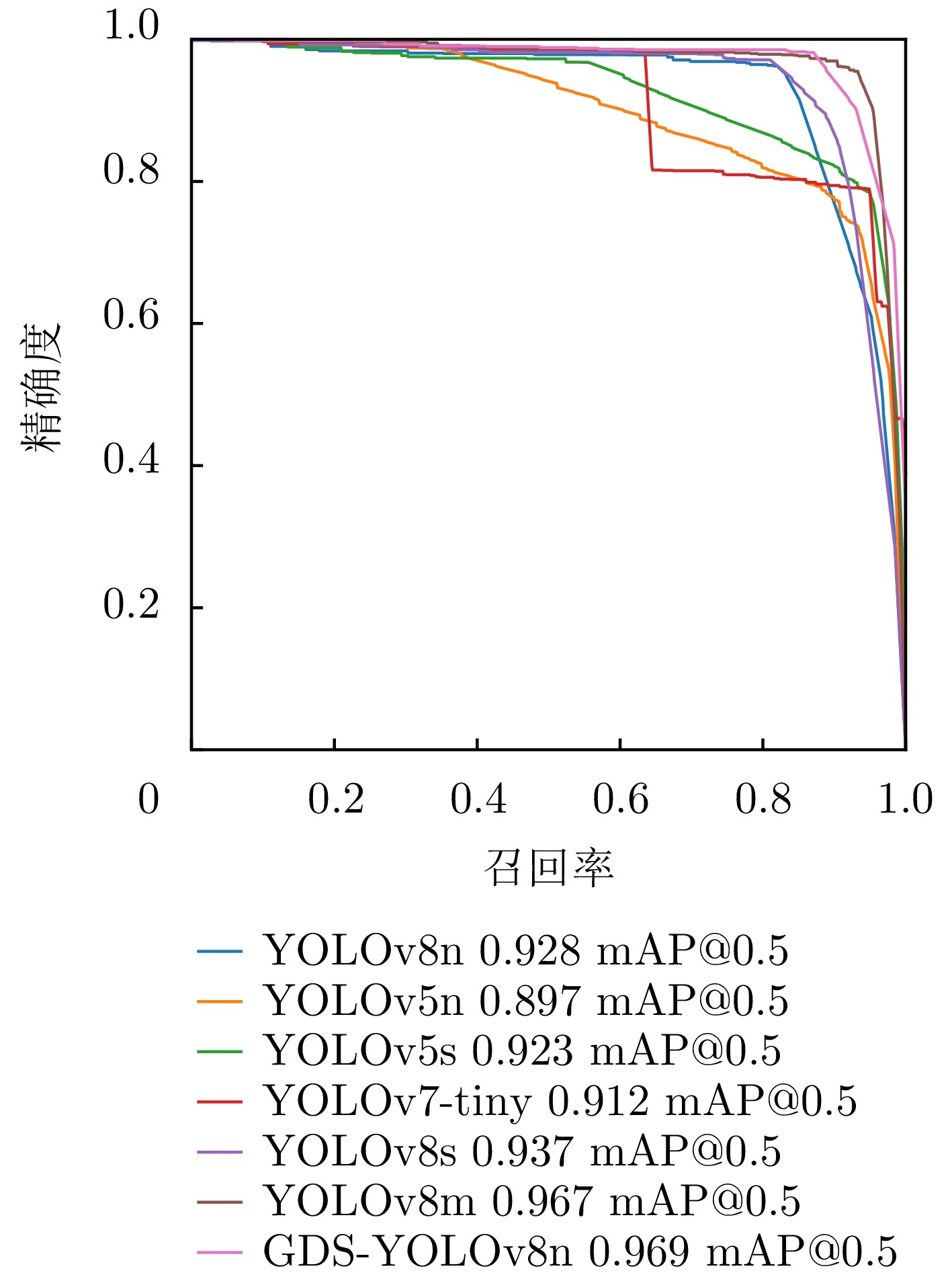
图 12 测试集上YOLOv8n模型的精确度-召回率曲线
Figure 12. P-R curve of YOLOv8n model on the test dataset

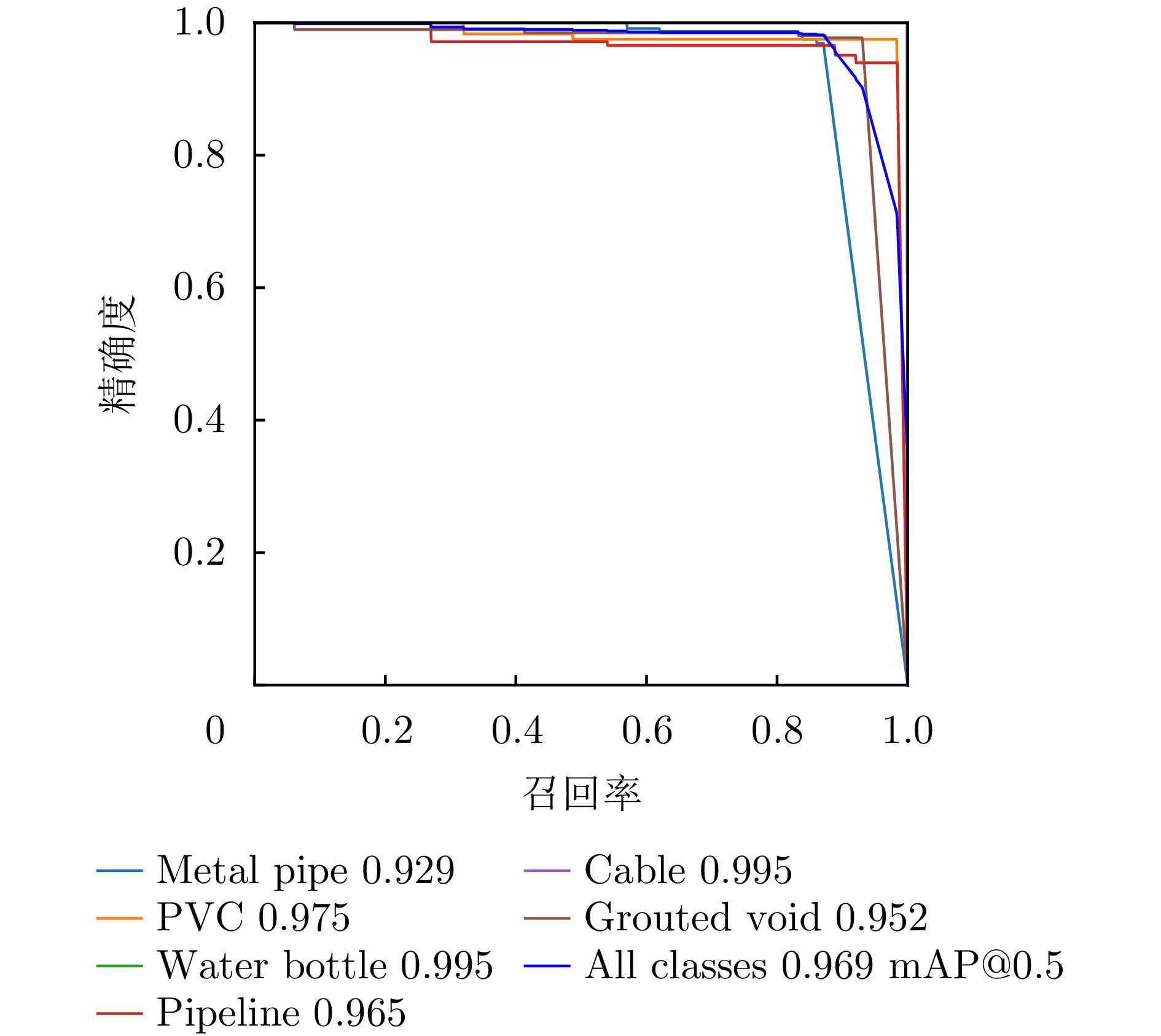
图 13 测试集上GSD-YOLOv8n模型的精确度-召回率曲线
Figure 13. P-R curve of GSD-YOLOv8n model on the test dataset
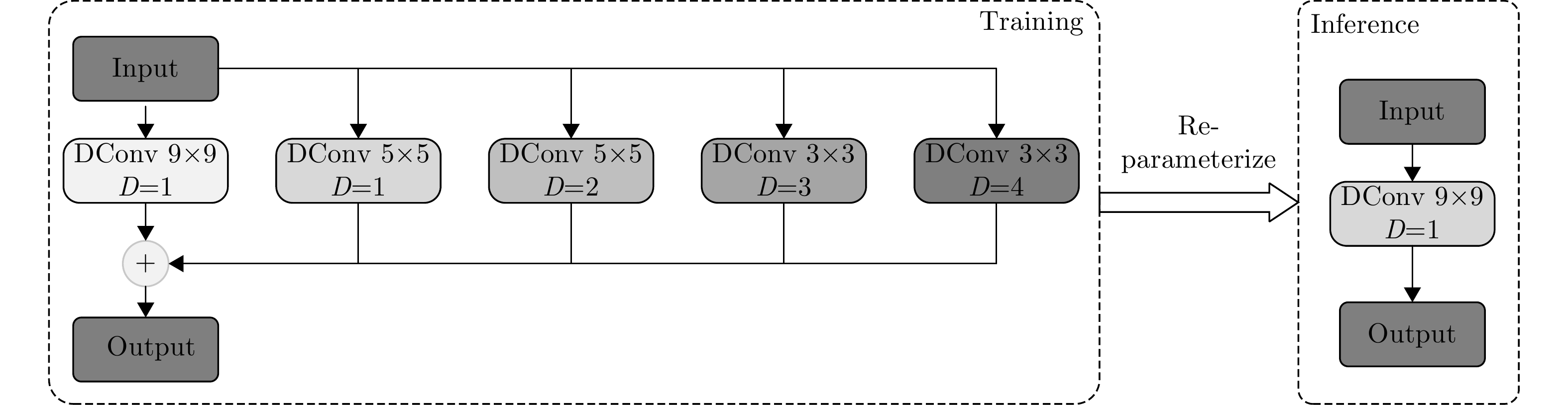
表 1 DRB模块参数
Table 1. DRB module parameter
Size k d 5 3, 3 1, 2 7 5, 5, 3 1, 2, 3 9 5, 5, 3, 3 1, 2, 3, 4 11 5, 5, 3, 3, 3 1, 2, 3, 4, 5 13 5, 7, 3, 3, 3 1, 2, 3, 4, 5  下载: 导出CSV
下载: 导出CSV
表 2 DRRB模块性能对比
Table 2. DRRB module performance comparison
20×20 40×40 Params (million) mAP50 (%) (5, 7) (7, 9) 2.690 93.9 (5, 7) (9, 11) 2.699 94.0 (7, 9) (9, 11) 2.706 95.3 (7, 9) (11, 13) 2.717 94.8 (9, 11) (11, 13) 2.727 94.1 注:(x, y)表示使用尺寸为x和y的DRB模块。
下载: 导出CSV
表 3 模型训练参数设置
Table 3. Model training parameter settings
参数名称 参数设置 迭代次数 300 批大小 16 早停机制 50 初始学习率 0.01 最终学习率 0.0001 动量 0.937 优化器权重衰减 0.0005 优化器 auto 注:优化器参数设置auto时,自动选择AdamW优化器。
下载: 导出CSV
表 4 算法改进前后P, R值对比(%)
Table 4. Comparison of P and R values before and after algorithm improvement (%)
模型 金属管 PVC 电缆线 含水塑料瓶 注浆不密实
加固体空洞管网 总计 P R P R P R P R P R P R P R YOLOv8n 95.5 82.1 93.4 83.2 100 85.1 93.2 95.3 97.4 96.5 79.5 98.4 93.1 90.1 GDS-YOLOv8n 96.3 87.2 97.5 98.3 100 100 100 100 97.7 93.0 91.2 98.4 97.1 96.2 注:加粗数字表示最优值。
下载: 导出CSV
表 5 消融实验结果(%)
Table 5. Results of ablation experiments (%)
实验 模型 P R mAP50 mAP50:95 1 YOLOv8n 93.1 90.1 92.8 60.7 2 YOLOv8n+A 95.1 93.2 95.3 63.4 3 YOLOv8n+B 94.6 92.6 94.4 61.3 4 YOLOv8n+C 96.5 91.3 94.7 61.9 5 YOLOv8n+L (ratio=1.29) 95.2 92.0 94.3 61.8 6 YOLOv8n+A+B 96.4 94.5 96.0 64.0 7 YOLOv8n+A+B+C 96.8 94.4 96.5 64.2 8 YOLOv8n+A+B+C+L (ratio=1.28) 97.1 96.2 96.9 64.3 注:加粗数字表示最优值,ratio是Inner-SIoU中的比例因子。
下载: 导出CSV
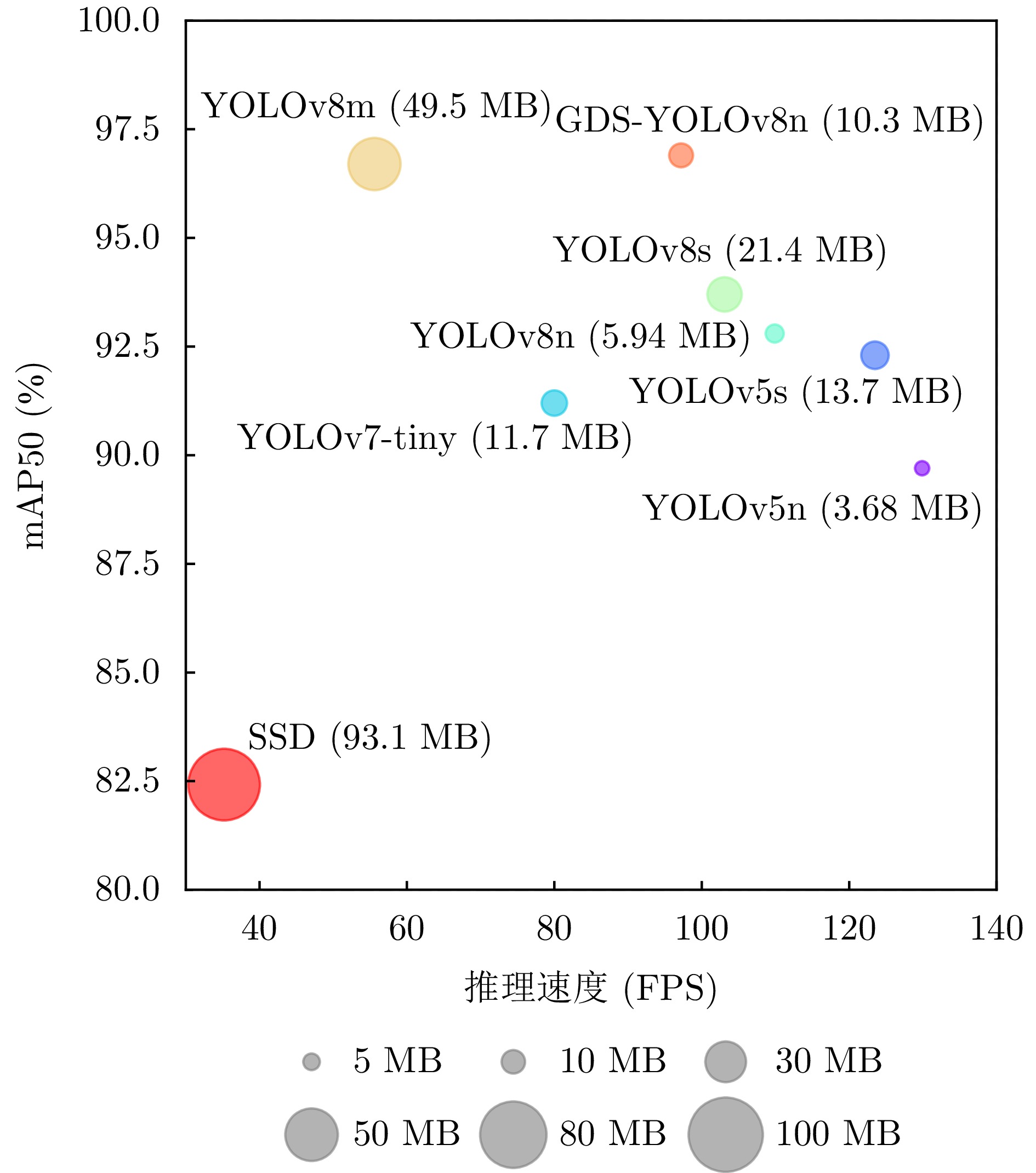
表 6 对比实验结果
Table 6. Results of comparison experiments
模型 Params (Million) GFLOPs Model size (MB) P (%) R (%) mAP50 (%) mAP50:90 (%) FPS (bs=1) SSD* 24.28 176.23 93.10 84.03 81.86 82.42 48.30 35.20 YOLOv5n 1.77 4.20 3.68 89.30 86.00 89.70 61.10 129.90 YOLOv5s 7.03 15.80 13.70 90.70 90.40 92.30 62.80 123.50 YOLOv7-tiny 6.03 13.10 11.70 91.90 92.60 91.20 57.60 80.00 YOLOv8n 3.01 8.10 5.94 93.10 90.10 92.80 60.70 109.90 YOLOv8s 11.13 28.40 21.40 94.70 90.70 93.70 62.00 103.10 YOLOv8m 25.80 78.70 49.50 94.10 96.30 96.70 63.30 55.60 GDS-YOLOv8n 4.43 11.20 10.30 97.10 96.20 96.90 64.30 97.20 注:加粗数字表示最优值;bs=1表示 batch size取1时的值;$* $表示输入图片尺寸是512×512。
下载: 导出CSV
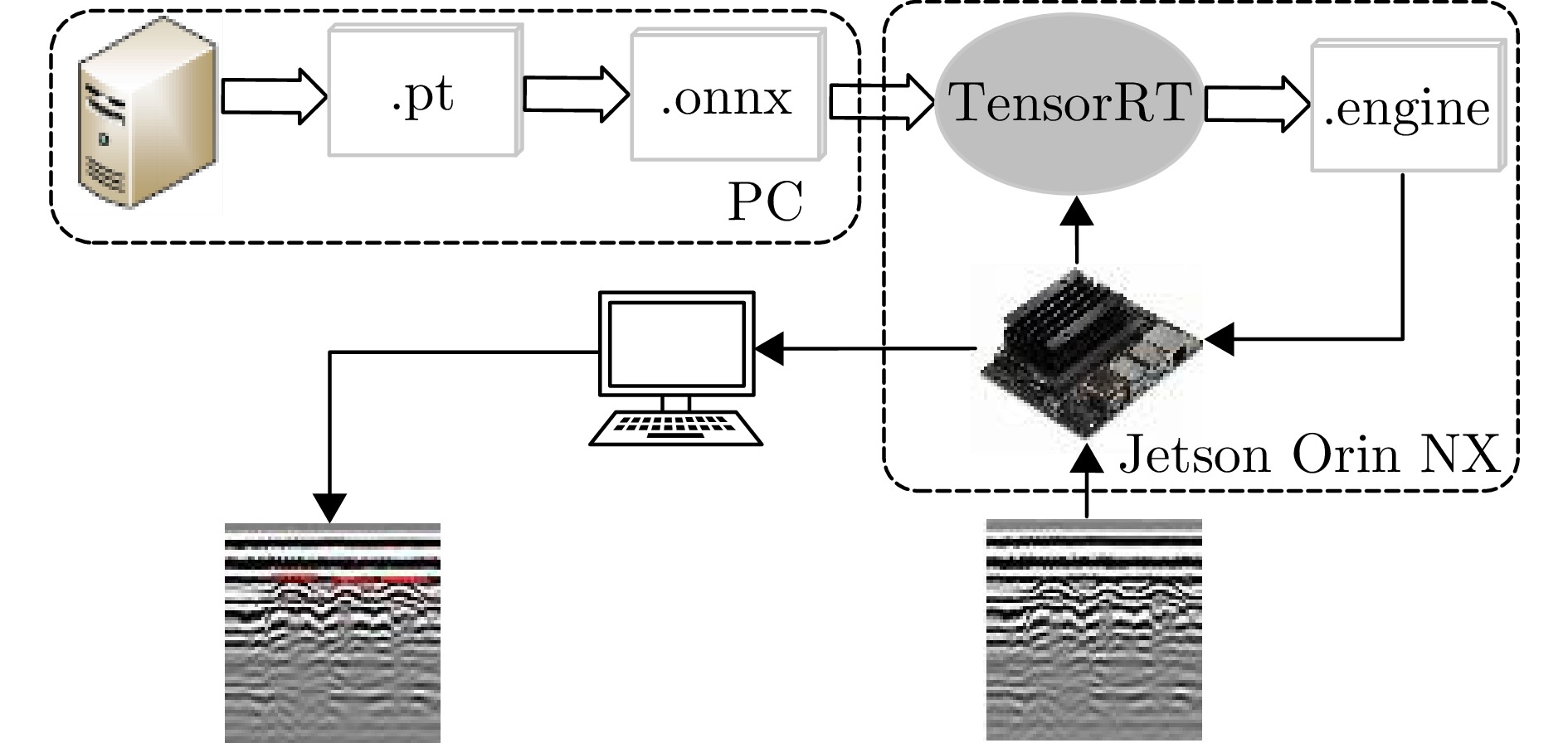
表 7 GDS-YOLOv8n模型部署格式性能对比
Table 7. Performance comparison of GDS-YOLOv8n model deployment formats
模型 Model size
(MB)mAP50
(%)FPS
(bs=1)GDS-YOLOv8n.pt 10.3 96.9 22.0 GDS-YOLOv8n.onnx 17.1 96.9 6.5 GDS-YOLOv8n.engine (FP32) 19.1 96.9 31.4 GDS-YOLOv8n.engine (FP16) 10.7 96.9 40.6 GDS-YOLOv8n.engine (INT8) 5.6 84.1 46.0 注:FP32, FP16和INT8分别表示以32位、16位浮点数和8位整数量化模型。
下载: 导出CSV
-
[1] LIU Wenchao, LUO Rong, XIAO Manzhe, et al. Intelligent detection of hidden distresses in asphalt pavement based on GPR and deep learning algorithm[J]. Construction and Building Materials, 2024, 416: 135089. doi: 10.1016/j.conbuildmat.2024.135089. [2] ZHU Jiasong, ZHAO Dingyi, and LUO Xianghuan. Evaluating the optimised YOLO-based defect detection method for subsurface diagnosis with ground penetrating radar[J]. Road Materials and Pavement Design, 2024, 25(1): 186–203. doi: 10.1080/14680629.2023.2199880. [3] RICHARDS E, STUEFER S, RANGEL R C, et al. An evaluation of GPR monitoring methods on varying river ice conditions: A case study in Alaska[J]. Cold Regions Science and Technology, 2023, 210: 103819. doi: 10.1016/j.coldregions.2023.103819. [4] WANG Xiaofen, WANG Peng, ZHANG Xiaotong, et al. Target electromagnetic detection method in underground environment: A review[J]. IEEE Sensors Journal, 2022, 22(14): 13835–13852. doi: 10.1109/JSEN.2022.3175502. [5] KAUR P, DANA K J, ROMERO F A, et al. Automated GPR rebar analysis for robotic bridge deck evaluation[J]. IEEE Transactions on Cybernetics, 2016, 46(10): 2265–2276. doi: 10.1109/TCYB.2015.2474747. [6] SARKAR M, SR N, HEMANI M, et al. Parameter efficient local implicit image function network for face segmentation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 20970–20980. doi: 10.1109/CVPR52729.2023.02009. [7] TONG Zheng, GAO Jie, and YUAN Dongdong. Advances of deep learning applications in ground-penetrating radar: A survey[J]. Construction and Building Materials, 2020, 258: 120371. doi: 10.1016/j.conbuildmat.2020.120371. [8] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. doi: 10.1109/TPAMI.2016.2577031. [9] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]. The 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 21–37. doi: 10.1007/978-3-319-46448-0_2. [10] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 779–788. doi: 10.1109/CVPR.2016.91. [11] 杨必胜, 宗泽亮, 陈驰, 等. 车载探地雷达地下目标实时探测法[J]. 测绘学报, 2020, 49(7): 874–882. doi: 10.11947/j.AGCS.2020.20190293.YANG Bisheng, ZONG Zeliang, CHEN Chi, et al. Real time approach for underground objects detection from vehicle-borne ground penetrating radar[J]. Acta Geodaetica et Cartographica Sinica, 2020, 49(7): 874–882. doi: 10.11947/j.AGCS.2020.20190293. [12] XIONG Xuetang and TAN Yiqiu. Deep learning-based detection of tie bars in concrete pavement using ground penetrating radar[J]. International Journal of Pavement Engineering, 2023, 24(2): 2155648. doi: 10.1080/10298436.2022.2155648. [13] HU Haobang, FANG Hongyuan, WANG Niannian, et al. Defects identification and location of underground space for ground penetrating radar based on deep learning[J]. Tunnelling and Underground Space Technology, 2023, 140: 105278. doi: 10.1016/j.tust.2023.105278. [14] 王惠琴, 罗佳, 何永强, 等. 改进YOLOv5的探地雷达常见地下管线识别[J]. 地球物理学报, 2024, 67(9): 3588–3604. doi: 10.6038/cjg2023R0431.WANG Huiqin, LUO Jia, HE Yongqiang, et al. Identification of common underground pipelines by ground penetrating radar based on improved YOLOv5[J]. Chinese Journal of Geophysics, 2024, 67(9): 3588–3604. doi: 10.6038/cjg2023R0431. [15] 刘震, 顾兴宇, 李骏, 等. 探地雷达数值模拟与道路裂缝图像检测的深度学习增强方法[J]. 地球物理学报, 2024, 67(6): 2455–2471. doi: 10.6038/cjg2023R0090.LIU Zhen, GU Xingyu, LI Jun, et al. Deep learning-enhanced numerical simulation of ground penetrating radar and image detection of road cracks[J]. Chinese Journal of Geophysics, 2024, 67(6): 2455–2471. doi: 10.6038/cjg2023R0090. [16] DING Xiaohan, ZHANG Xiangyu, HAN Jungong, et al. Scaling up your kernels to 31×31: Revisiting large kernel design in CNNs[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11953–11965. doi: 10.1109/CVPR52688.2022.01166. [17] WEI Haoran, LIU Xu, Xu Shouchun, et al. DWRSeg: Rethinking efficient acquisition of multi-scale contextual information for real-time semantic segmentation[J]. arXiv: 2212.01173, 2022. doi: 10.48550/arXiv.2212.01173. [18] DING Xiaohan, ZHANG Yiyuan, GE Yixiao, et al. UniRepLKNet: A universal perception large-kernel convnet for audio, video, point cloud, time-series and image recognition[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 5513–5524. doi: 10.1109/CVPR52733.2024.00527. [19] SUNKARA R and LUO Tie. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects[C]. Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Grenoble, France, 2023: 443–459. doi: 10.1007/978-3-031-26409-2_27. [20] WANG C Y, BOCHKOVSKIY A, and LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 7464–7475. doi: 10.1109/CVPR52729.2023.00721. [21] ZHANG Hao, XU Cong, and ZHANG Shuaijie. Inner-IoU: More effective intersection over union loss with auxiliary bounding box[J]. arXiv: 2311.02877, 2023. doi: 10.48550/arXiv.2311.02877. -






计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

