
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
MMRGait-1.0: A Radar Time-frequency Spectrogram Dataset for Gait Recognition under Multi-view and Multi-wearing Conditions
-
摘要: 步态识别作为一种生物识别技术,在实际生活中通常被认为是一项检索任务。然而,受限于现有雷达步态识别数据集的规模,目前的研究主要针对分类任务且局限于单一行走视角和相同穿着条件,这限制了基于雷达的步态识别在实际场景中的应用。该文公开了一个多视角多穿着条件下的雷达步态识别数据集,该数据集使用毫米波雷达采集了121位受试者在多种穿着条件下沿不同视角行走的时频谱图数据,每位受试者共采集8个视角,每个视角采集10组,其中6组为正常穿着,2组为穿大衣,2组为挎包。同时,该文提出一种基于检索任务的雷达步态识别方法,并在公布数据集上进行了实验,实验结果可以作为基准性能指标,方便更多学者在此数据集上开展进一步研究。Abstract: As a biometric technology, gait recognition is usually considered a retrieval task in real life. However, because of the small scale of the existing radar gait recognition dataset, the current studies mainly focus on classification tasks and only consider the situation of a single walking view and the same wearing condition, limiting the practical application of radar-based gait recognition. This paper provides a radar gait recognition dataset under multi-view and multi-wearing conditions; the dataset uses millimeter-wave radar as a sensor to collect the time-frequency spectrogram data of 121 subjects walking along views under multiple wearing conditions. Eight views were collected for each subject, and ten sets were collected for each view. Six of the ten sets are dressed normally, two are dressed in coats, and the last two are carrying bags. Meanwhile, this paper proposes a method for radar gait recognition based on retrieval tasks. Experiments are conducted on this dataset, and the experimental results can be used as a benchmark to facilitate further research by related scholars on this dataset.
-
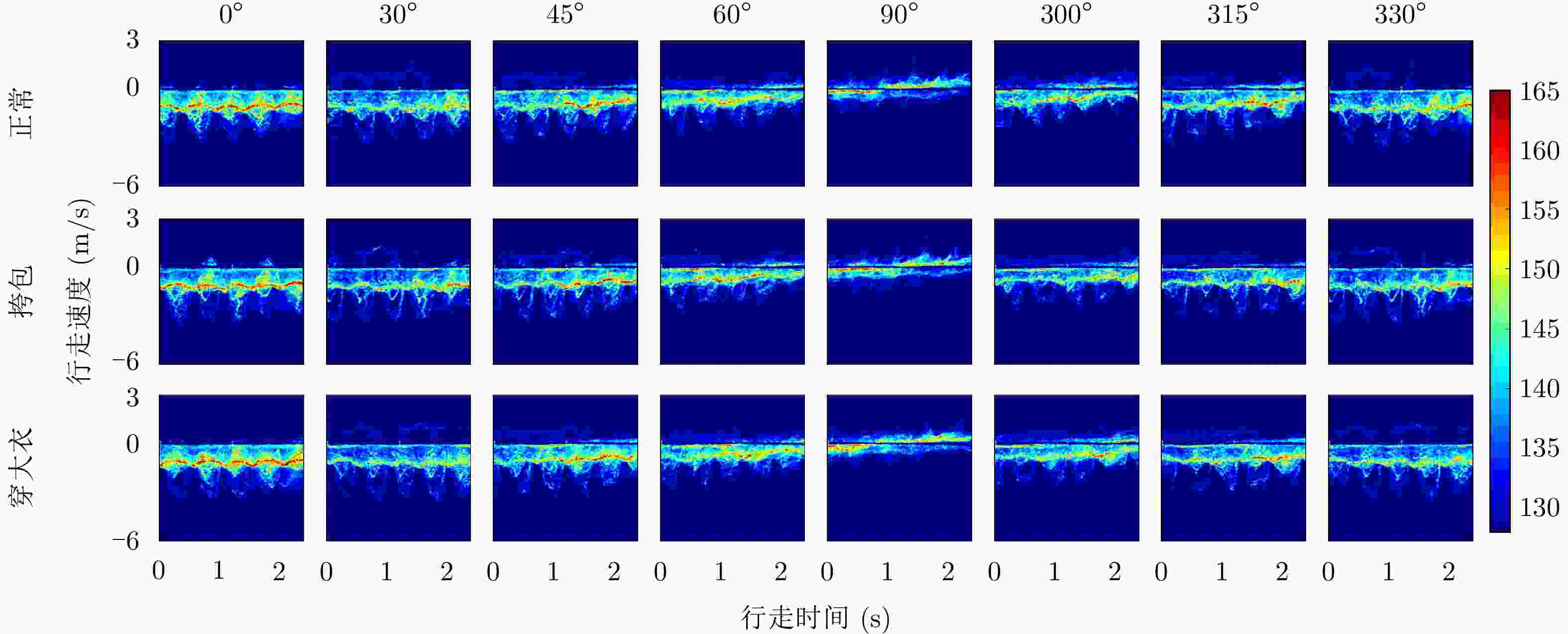
图 6 8种行走视角、3种穿着条件下的时频谱图
Figure 6. Time-frequency spectrograms for eight walking views and three wearing conditions

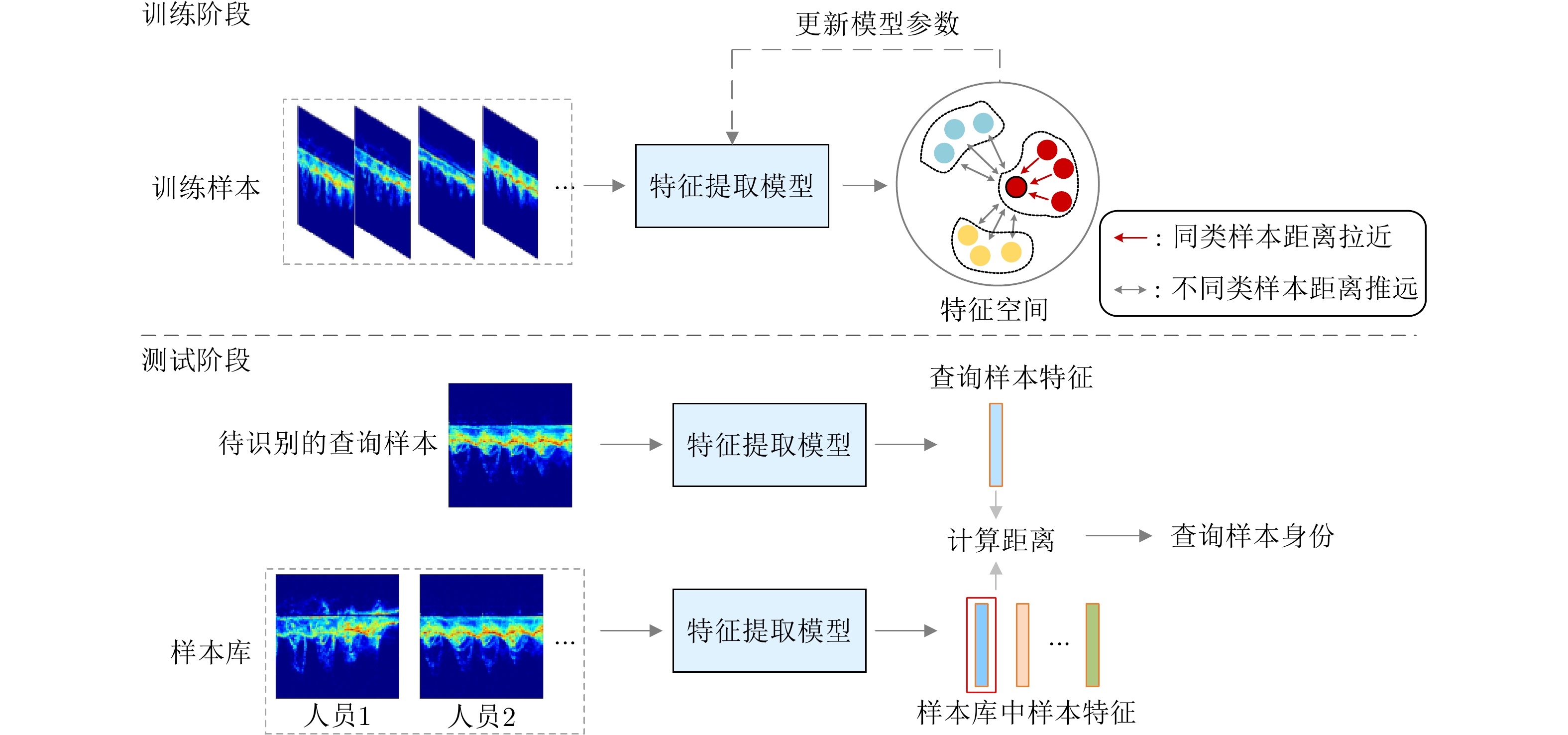
图 8 基于检索任务的雷达步态识别流程图
Figure 8. Flow chart of radar gait recognition based on retrieval task
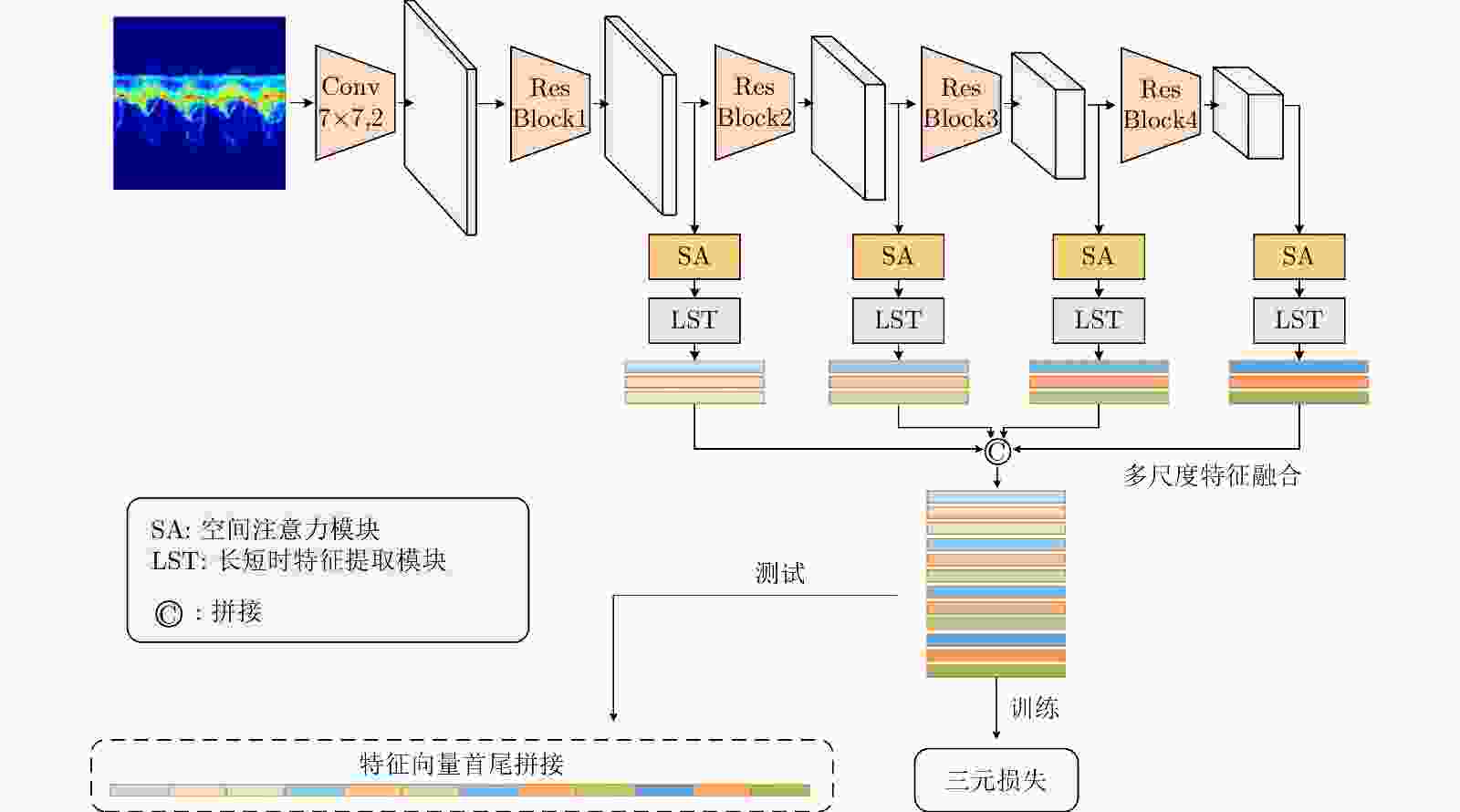
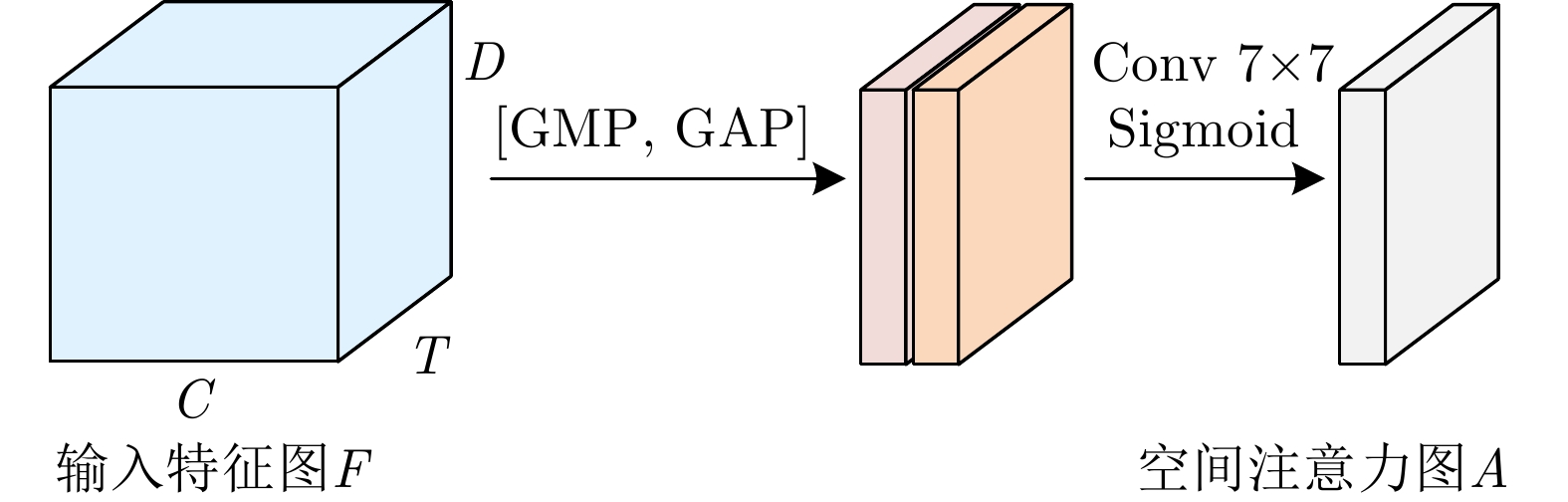
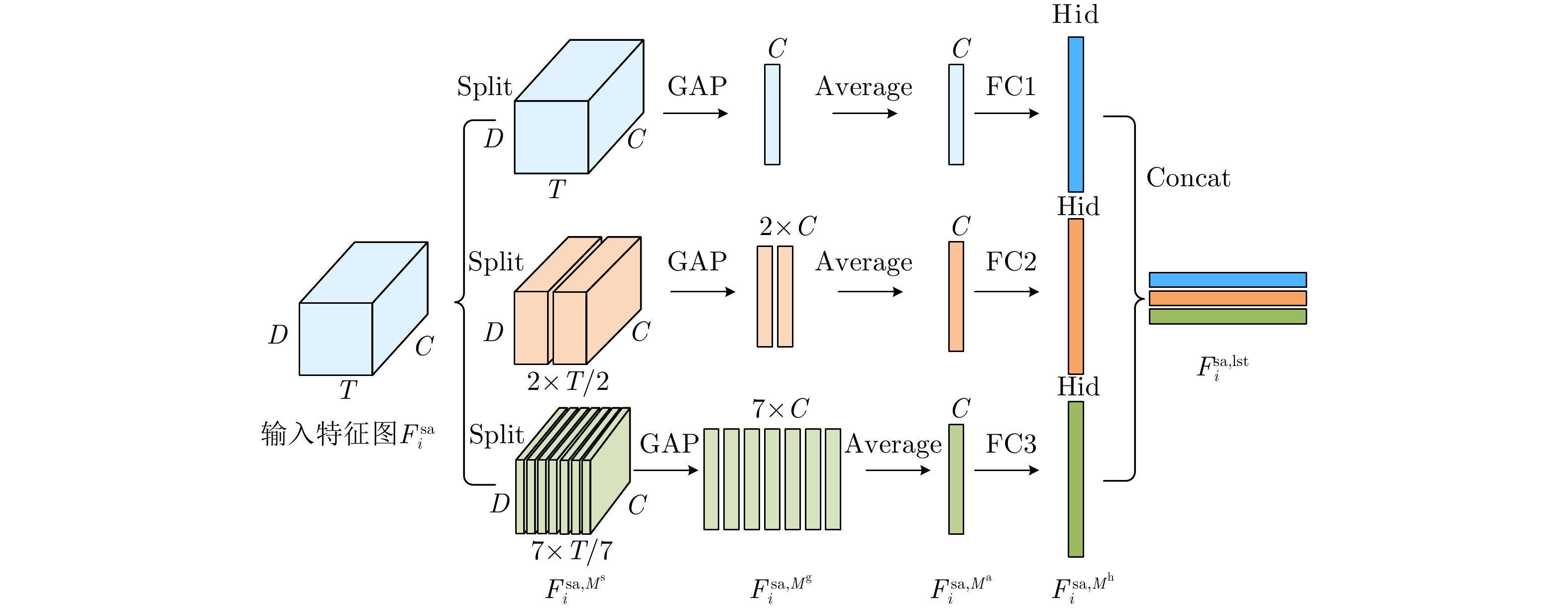
图 9 基于检索任务的特征提取网络模型结构框图
Figure 9. Framework for feature extraction network model based on retrieval task
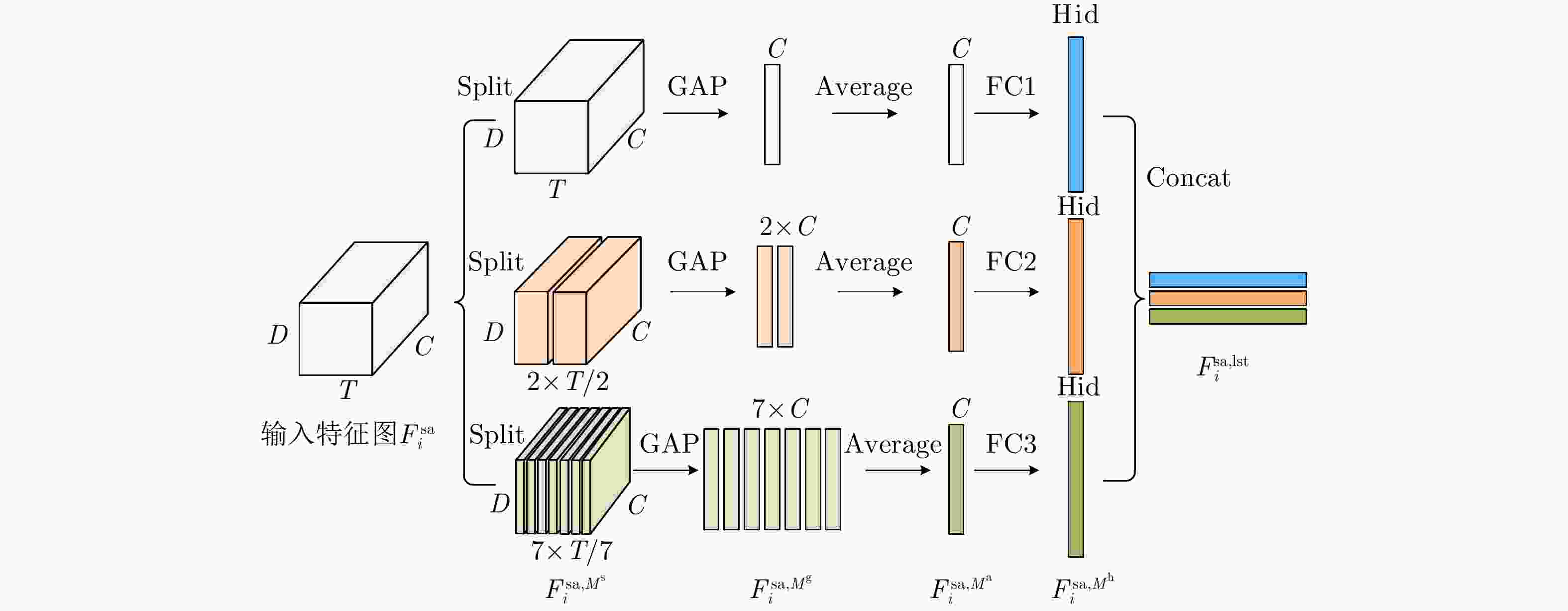
图 11 长短时特征提取模块计算流程
Figure 11. Long-short time feature extraction module calculation process
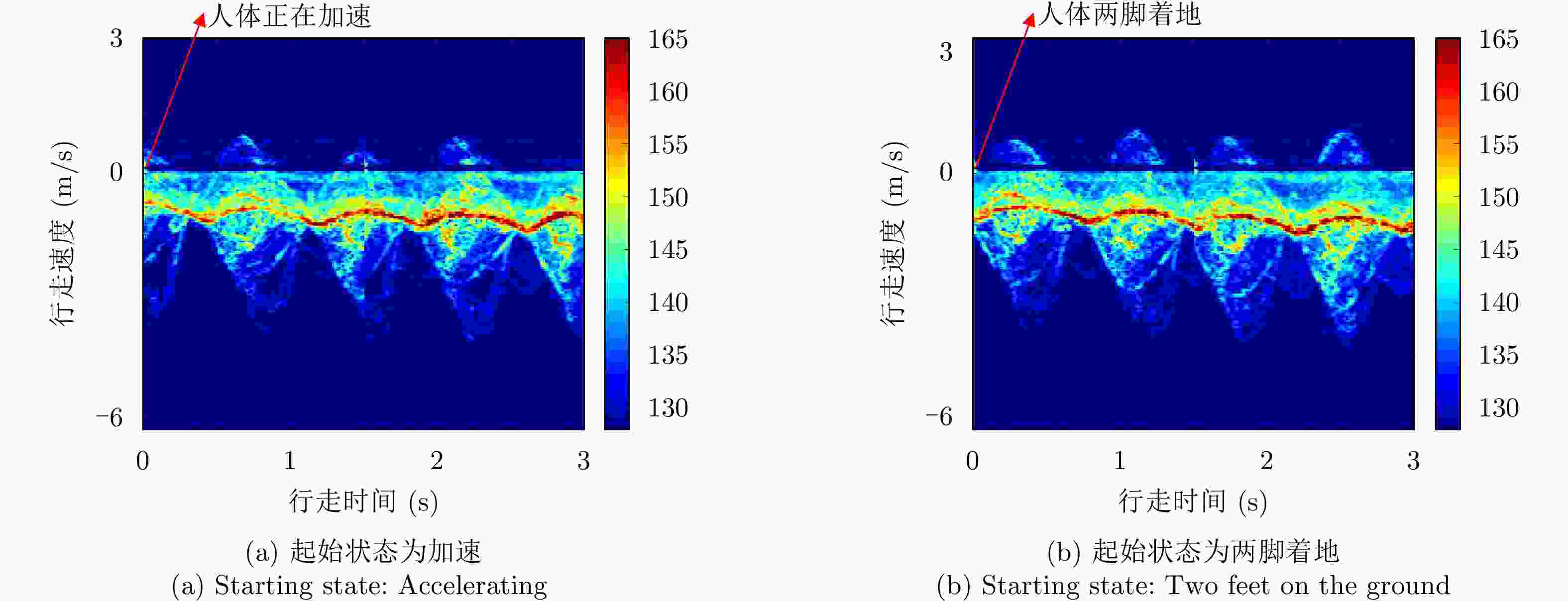
图 12 同一人不同起始状态下行走的两组时频谱图数据
Figure 12. Two sets of time-spectrogram data of walking in different starting states

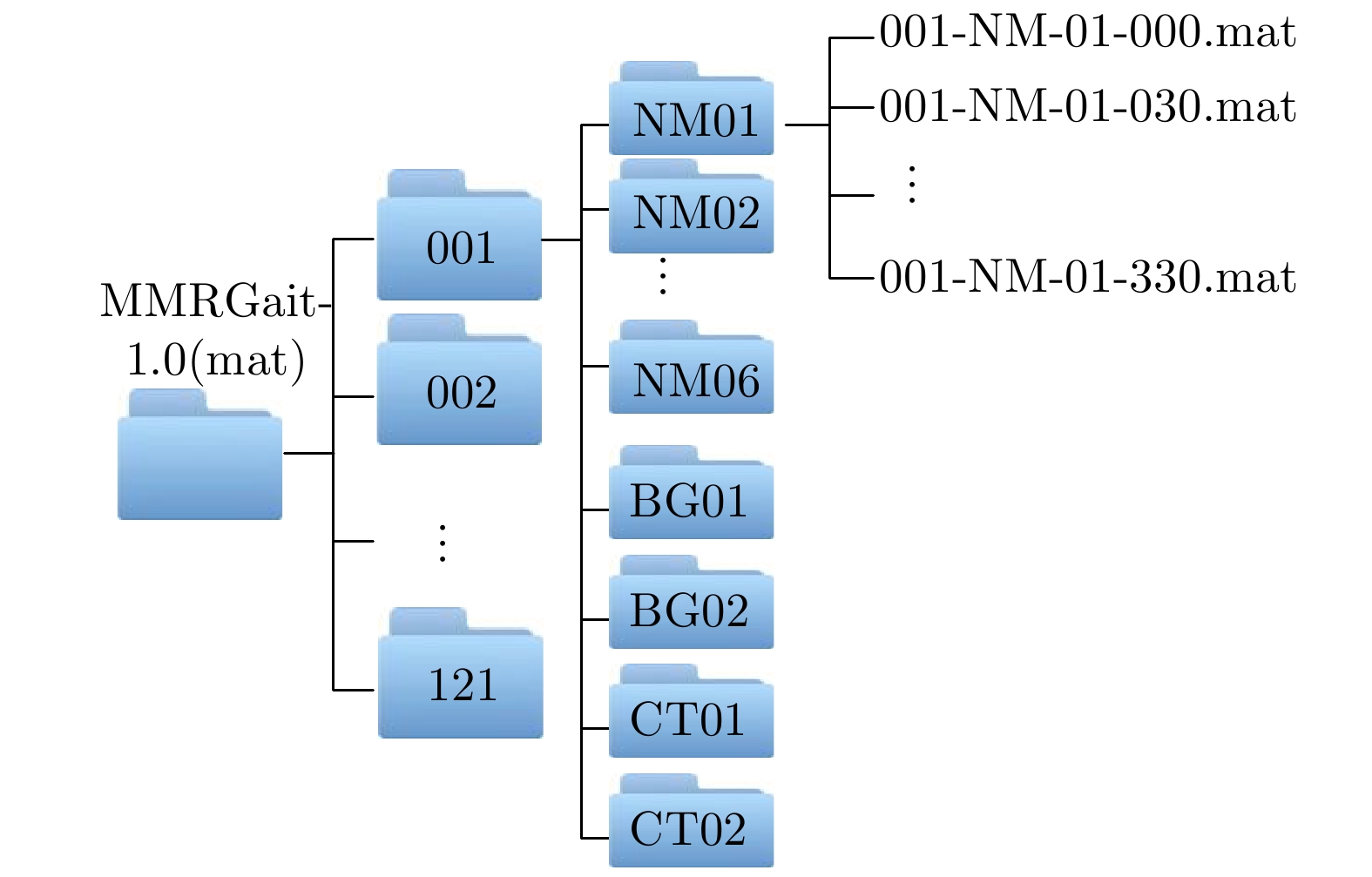
1 MMRGait-1.0:多视角多穿着条件下的雷达时频谱图步态识别数据集发布网页
1. Release webpage of MMRGait-1.0: A radar time-frequency spectrogram dataset for gait recognition under multi-view and multi-wearing conditions dataset
表 1 雷达发射波形参数配置
Table 1. Parameter configurations of the radar transmitting waveform
参数 数值 起始频率(GHz) 77 Chirp重复周期(μs) 78.125 调频斜率(MHz/μs) 9.753 调频时长(μs) 60 ADC采样时间(μs) 40.96 ADC采样点数 512 帧内Chirp数 255 帧周期(ms) 19.922 连续发射帧数 60 连续发射时长(s) 1.195 空闲时长(s) 0.005  下载: 导出CSV
下载: 导出CSV
表 2 不同步态识别方法在多视角条件下的识别准确度(%)
Table 2. Recognition accuracy of different gait recognition methods in multi-view conditions (%)
查询样本 方法 0º 30º 45º 60º 90º 300º 315º 330º 平均值 NM05-06 方法1 40.70 39.53 37.21 38.37 37.21 38.37 36.05 34.88 37.79 方法2 32.39 39.53 53.49 46.51 44.19 43.02 47.67 55.81 45.35 方法3 48.84 60.47 60.47 66.28 55.81 58.14 63.95 53.49 58.43 方法4 73.26 76.74 75.58 74.42 62.79 75.58 69.77 73.26 72.68 方法5 61.63 56.98 55.81 58.14 46.51 60.47 62.79 64.71 58.38 本文方法 91.86 94.19 96.51 94.19 91.86 98.84 91.86 96.51 94.48 BG01-02 方法1 20.93 29.07 29.07 23.26 32.56 38.82 39.53 30.23 30.43 方法2 36.05 36.05 43.02 44.19 39.53 47.06 43.02 32.56 40.19 方法3 41.86 34.88 46.51 37.21 39.53 49.31 53.49 44.19 43.39 方法4 46.51 54.65 63.95 51.16 43.02 60.00 60.47 59.30 54.88 方法5 52.33 41.86 48.84 53.49 43.02 50.00 47.67 45.35 47.82 本文方法 80.23 75.58 77.91 83.72 80.23 83.72 84.88 83.72 81.25 CT01-02 方法1 27.91 33.72 36.05 27.91 34.88 33.72 27.91 39.53 32.70 方法2 33.72 32.56 32.56 45.35 36.05 36.05 34.88 34.88 35.76 方法3 37.21 32.56 54.65 44.19 34.88 45.35 45.35 41.86 42.01 方法4 45.35 47.67 55.81 61.63 45.35 47.67 60.47 51.16 51.89 方法5 44.19 41.86 56.98 43.02 34.88 52.33 50.00 50.00 46.66 本文方法 74.42 76.74 83.72 84.88 80.23 76.74 82.56 74.42 79.21
下载: 导出CSV
表 3 不同步态识别方法在跨视角条件下的识别准确度(%)
Table 3. Recognition accuracy of different gait recognition methods in cross-view conditions (%)
查询样本 方法 0º 30º 45º 60º 90º 300º 315º 330º 平均值 NM05-06 方法1 27.91 26.41 30.40 28.41 22.92 26.91 28.90 32.72 28.07 方法2 29.57 31.56 40.03 34.22 32.39 32.39 36.05 39.20 34.43 方法3 32.56 35.72 39.89 34.55 28.74 40.70 37.38 34.39 35.49 方法4 32.39 43.85 46.35 39.04 27.24 39.04 43.85 45.68 39.68 方法5 35.22 33.72 39.37 41.69 24.25 36.71 39.37 39.50 36.23 本文方法 50.66 64.95 68.11 64.62 50.17 63.62 70.10 66.78 62.38 BG01-02 方法1 24.09 24.25 23.75 23.42 21.10 26.55 26.74 24.09 24.25 方法2 29.90 28.57 35.21 31.56 28.41 36.47 38.54 31.39 32.51 方法3 33.22 23.59 31.39 28.24 24.09 33.61 39.04 32.23 30.68 方法4 30.07 35.55 36.88 34.55 21.93 36.30 37.87 36.71 33.73 方法5 41.53 36.88 39.04 33.72 28.24 33.39 39.37 35.71 35.98 本文方法 52.84 54.98 61.79 57.64 41.36 60.46 66.11 56.48 56.46 CT01-02 方法1 22.42 26.58 26.41 21.93 24.59 23.26 21.76 26.08 24.13 方法2 26.25 25.42 30.73 31.06 25.58 29.24 31.06 26.91 28.28 方法3 26.41 28.07 33.39 29.73 21.10 26.91 34.55 31.40 28.95 方法4 24.92 34.05 37.51 35.38 19.77 30.73 36.55 32.56 31.44 方法5 31.06 36.71 41.53 34.22 23.75 32.89 36.71 35.38 34.03 本文方法 50.50 56.15 61.79 57.97 43.86 52.66 57.64 54.15 54.34
下载: 导出CSV
表 4 不同步态识别方法的模型复杂度
Table 4. Model complexity of different gait recognition methods
方法 计算量FLOPs (G) 参数量(M) 方法1 13.68 40.47 方法2 2.98 9.96 方法3 0.14 0.90 方法4 2.35 0.72 方法5 2.26 4.33 本文方法 14.01 21.29
下载: 导出CSV
表 5 消融实验识别准确度(%)
Table 5. Recognition accuracy of ablation studies (%)
方法 NM BG CT 平均值 Base+HPM 66.28 53.64 55.67 58.53 Base+LST 80.96 65.99 64.24 70.40 Base+LST+MSF 90.70 76.60 75.44 80.91 Base+LST+MSF+SA 94.48 81.25 79.21 84.98
下载: 导出CSV
-
[1] DELIGIANNI F, GUO Yao, and YANG Guangzhong. From emotions to mood disorders: A survey on gait analysis methodology[J]. IEEE Journal of Biomedical and Health Informatics, 2019, 23(6): 2302–2316. doi: 10.1109/JBHI.2019.2938111 [2] SEPAS-MOGHADDAM A and ETEMAD A. Deep gait recognition: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(1): 264–284. doi: 10.1109/TPAMI.2022.3151865 [3] LI Haobo, MEHUL A, LE KERNEC J, et al. Sequential human gait classification with distributed radar sensor fusion[J]. IEEE Sensors Journal, 2021, 21(6): 7590–7603. doi: 10.1109/JSEN.2020.3046991 [4] CAO Peibei, XIA Weijie, YE Ming, et al. Radar-ID: Human identification based on radar micro-Doppler signatures using deep convolutional neural networks[J]. IET Radar, Sonar & Navigation, 2018, 12(7): 729–734. doi: 10.1049/iet-rsn.2017.0511 [5] LANG Yue, WANG Qing, YANG Yang, et al. Joint motion classification and person identification via multitask learning for smart homes[J]. IEEE Internet of Things Journal, 2019, 6(6): 9596–9605. doi: 10.1109/JIOT.2019.2929833 [6] PAPANASTASIOU V S, TROMMEL R P, HARMANNY R I A, et al. Deep learning-based identification of human gait by radar micro-Doppler measurements[C]. The 17th European Radar Conference (EuRAD), Utrecht, Netherlands, 2021: 49–52. [7] DONG Shiqi, XIA Weijie, LI Yi, et al. Radar-based human identification using deep neural network for long-term stability[J]. IET Radar, Sonar & Navigation, 2020, 14(10): 1521–1527. doi: 10.1049/iet-rsn.2019.0618 [8] NIAZI U, HAZRA S, SANTRA A, et al. Radar-based efficient gait classification using Gaussian prototypical networks[C]. 2021 IEEE Radar Conference (RadarConf21), Atlanta, USA, 2021: 1–5. [9] CHEN V C, LI F, HO S S, et al. Micro-Doppler effect in radar: Phenomenon, model, and simulation study[J]. IEEE Transactions on Aerospace and Electronic Systems, 2006, 42(1): 2–21. doi: 10.1109/TAES.2006.1603402 [10] BAI Xueru, HUI Ye, WANG Li, et al. Radar-based human gait recognition using dual-channel deep convolutional neural network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(12): 9767–9778. doi: 10.1109/TGRS.2019.2929096 [11] ADDABBO P, BERNARDI M L, BIONDI F, et al. Gait recognition using FMCW radar and temporal convolutional deep neural networks[C]. 2020 IEEE 7th International Workshop on Metrology for AeroSpace (MetroAeroSpace), Pisa, Italy, 2020: 171–175. [12] DOHERTY H G, BURGUEÑO R A, TROMMEL R P, et al. Attention-based deep learning networks for identification of human gait using radar micro-Doppler spectrograms[J]. International Journal of Microwave and Wireless Technologies, 2021, 13(7): 734–739. doi: 10.1017/S1759078721000830 [13] YANG Yang, HOU Chunping, LANG Yue, et al. Person identification using micro-Doppler signatures of human motions and UWB radar[J]. IEEE Microwave and Wireless Components Letters, 2019, 29(5): 366–368. doi: 10.1109/LMWC.2019.2907547 [14] XIA Zhaoyang, DING Genming, WANG Hui, et al. Person identification with millimeter-wave radar in realistic smart home scenarios[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 19: 3509405. doi: 10.1109/LGRS.2021.3117001 [15] CHENG Yuwei and LIU Yimin. Person reidentification based on automotive radar point clouds[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5101913. doi: 10.1109/TGRS.2021.3073664 [16] TAHMOUSH D and SILVIOUS J. Angle, elevation, PRF, and illumination in radar microDoppler for security applications[C]. 2009 IEEE Antennas and Propagation Society International Symposium, North Charleston, USA, 2009: 1–4. [17] YANG Yang, YANG Xiaoyi, SAKAMOTO T, et al. Unsupervised domain adaptation for disguised-gait-based person identification on micro-Doppler signatures[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(9): 6448–6460. doi: 10.1109/TCSVT.2022.3161515 [18] AWR1843 single-chip 76-GHz to 81-GHz automotive radar sensor evaluation module[EB/OL]. https://www.ti.com/tool/AWR1843BOOST, 2022. [19] CHEN V C and LING Hao. Time-Frequency Transforms for Radar Imaging and Signal Analysis[M]. Boston: Artech House, 2002, 28–31. [20] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. [21] HERMANS A, BEYER L, and LEIBE B. In defense of the triplet loss for person re-identification[J]. arXiv preprint arXiv: 1703.07737, 2017. [22] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 3–19. [23] WANG Guanshuo, YUAN Yufeng, CHEN Xiong, et al. Learning discriminative features with multiple granularities for person re-identification[C]. 26th ACM International Conference on Multimedia, Seoul, Korea, 2018: 274–282. [24] FU Yang, WEI Yunchao, ZHOU Yuqian, et al. Horizontal pyramid matching for person re-identification[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8295–8302. doi: 10.1609/aaai.v33i01.33018295 [25] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. 3rd International Conference on Learning Representations, San Diego, USA, 2015. [26] CHAO Hanqing, HE Yiwei, ZHANG Junping, et al. GaitSet: Regarding gait as a set for cross-view gait recognition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8126–8133. doi: 10.1609/aaai.v33i01.33018126 -









计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

