
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
A Review of Radio Frequency Fingerprinting Methods Based on Raw I/Q and Deep Learning(in English)
-
摘要: 硬件差异会形成辐射源的独有指纹,并附加在无线电信号上,利用辐射源的这一独特属性可进行射频指纹识别。在非合作条件下,由于信道环境未知、信号调制方案等先验知识匮乏,基于特征工程的射频指纹识别方法面临巨大挑战,而基于深度学习的射频指纹识别方法,尤其是能够直接处理Raw I/Q的方法表现出了很大潜力,但是该方向的研究成果较为零散,妨碍了研究者对关键问题的把握。该文首先从先验知识的利用上,对基于深度学习的射频指纹识别方法进行了分类对比,将问题聚焦到基于Raw I/Q和深度学习的射频指纹识别方法。然后,该文重点对使用Raw I/Q进行射频指纹识别的深度神经网络模型进行了分类和讨论,并对射频指纹识别相关的开源数据集、数据表示方法和数据增强方法进行了整理和归纳。最后,该文讨论了基于深度学习的射频指纹识别方法所面临的难题和值得关注的研究方向,以期对射频指纹识别的研究与应用有所帮助。Abstract: The hardware imperfection can generate a unique fingerprint of the trasmitter, and it is attached to the radio signal. The unique attribute of transmitter can be used for Radio Frequency Fingerprinting (RFF). Due to the unknown channel conditional and the lack of prior information such as modulation scheme, the traditional method of RFF faces huge challenges to non-cooperative conditions. On the contrary, RFF methods based on Deep Learning (DL), especially those that can directly process raw I/Q, show great potential. However, the research results of this direction are scattered, which seriously hinders researchers from grasping the key issues. This paper first classifies and compares the RFF methods based on DL according to the utilization of prior knowledge, and focuses on the RFF methods based on raw I/Q and DL. Then, this paper focuses on the classification and discussion of the deep neural network model of RFF using raw I/Q, and summarizes the open source data sets, data representation methods and data augmentation methods related to RFF. Finally, this paper discusses the difficulties and research directions of the RFF based on DL, hoping to help the research and application of the RFF.
-
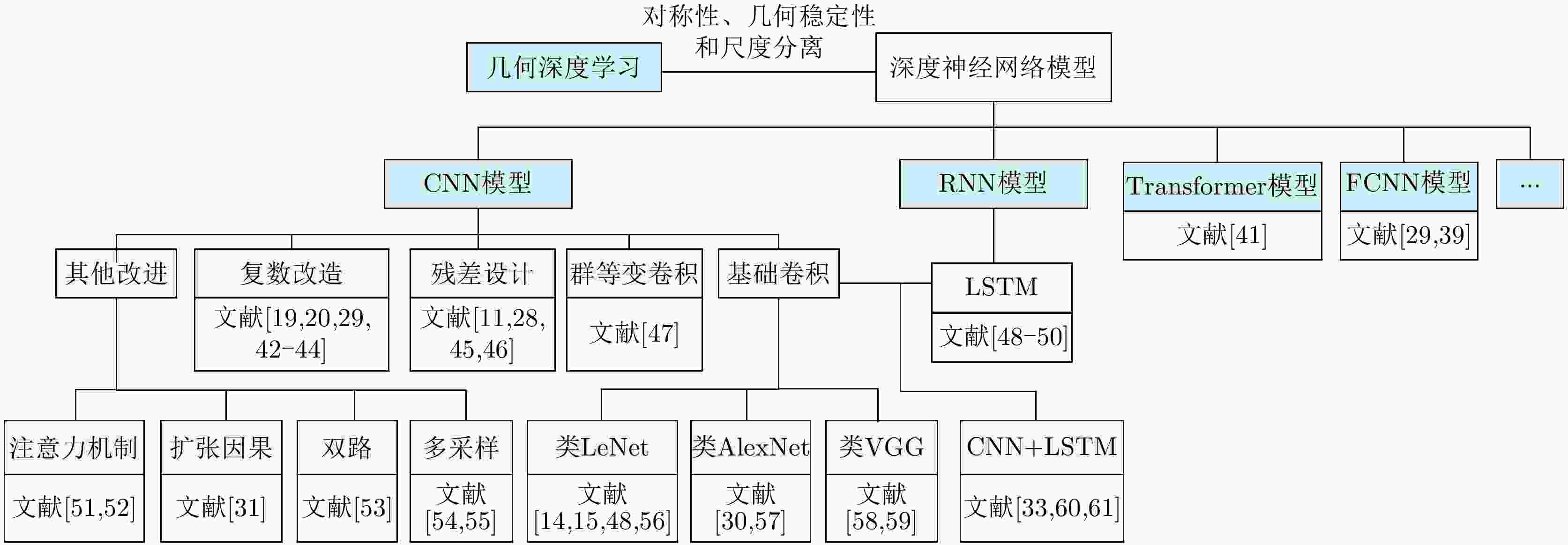
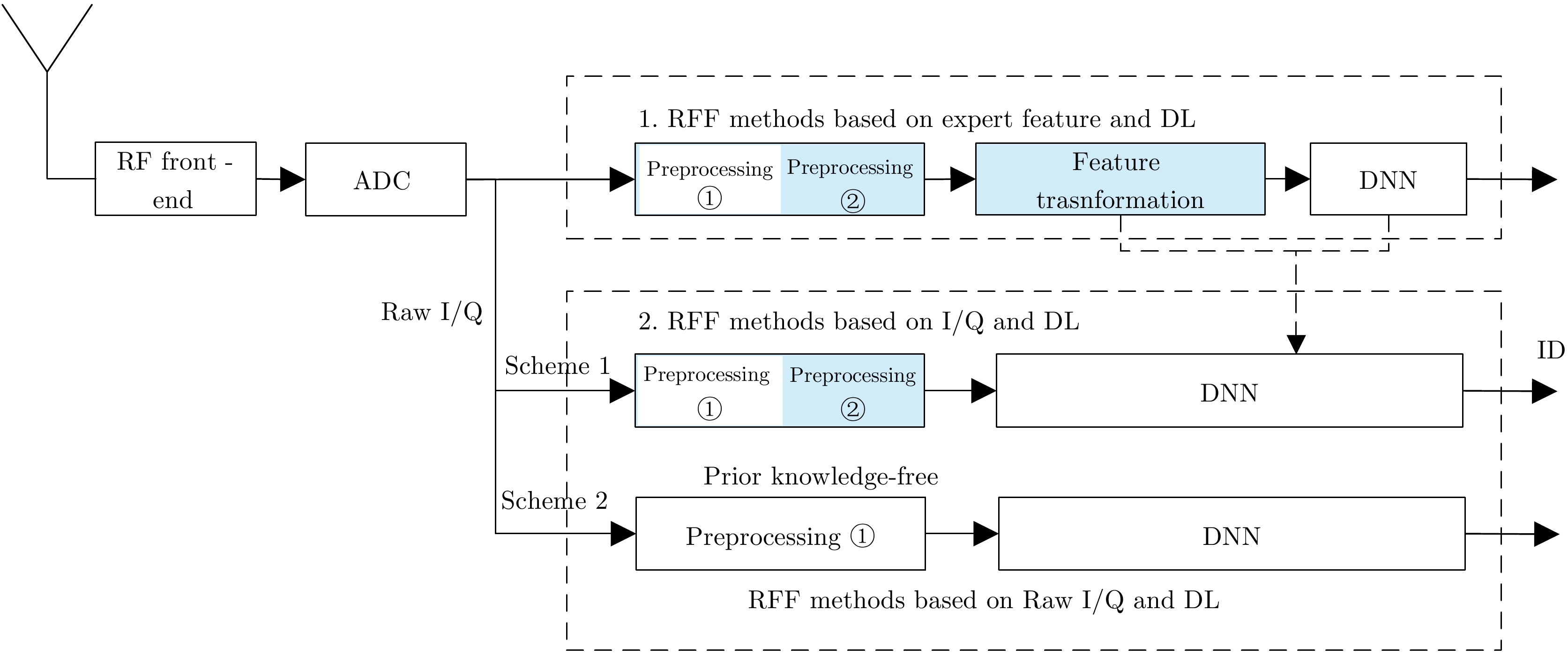
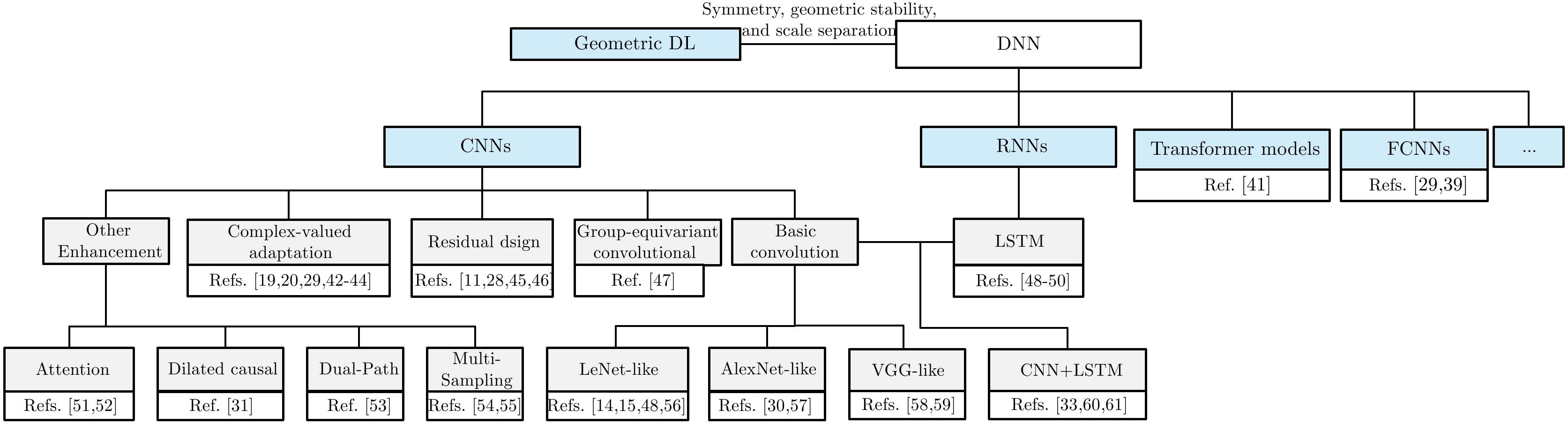
图 2 基于Raw I/Q和深度学习的射频指纹识别方法分类
Figure 2. Classification of RFF methods based on Raw I/Q and deep learning
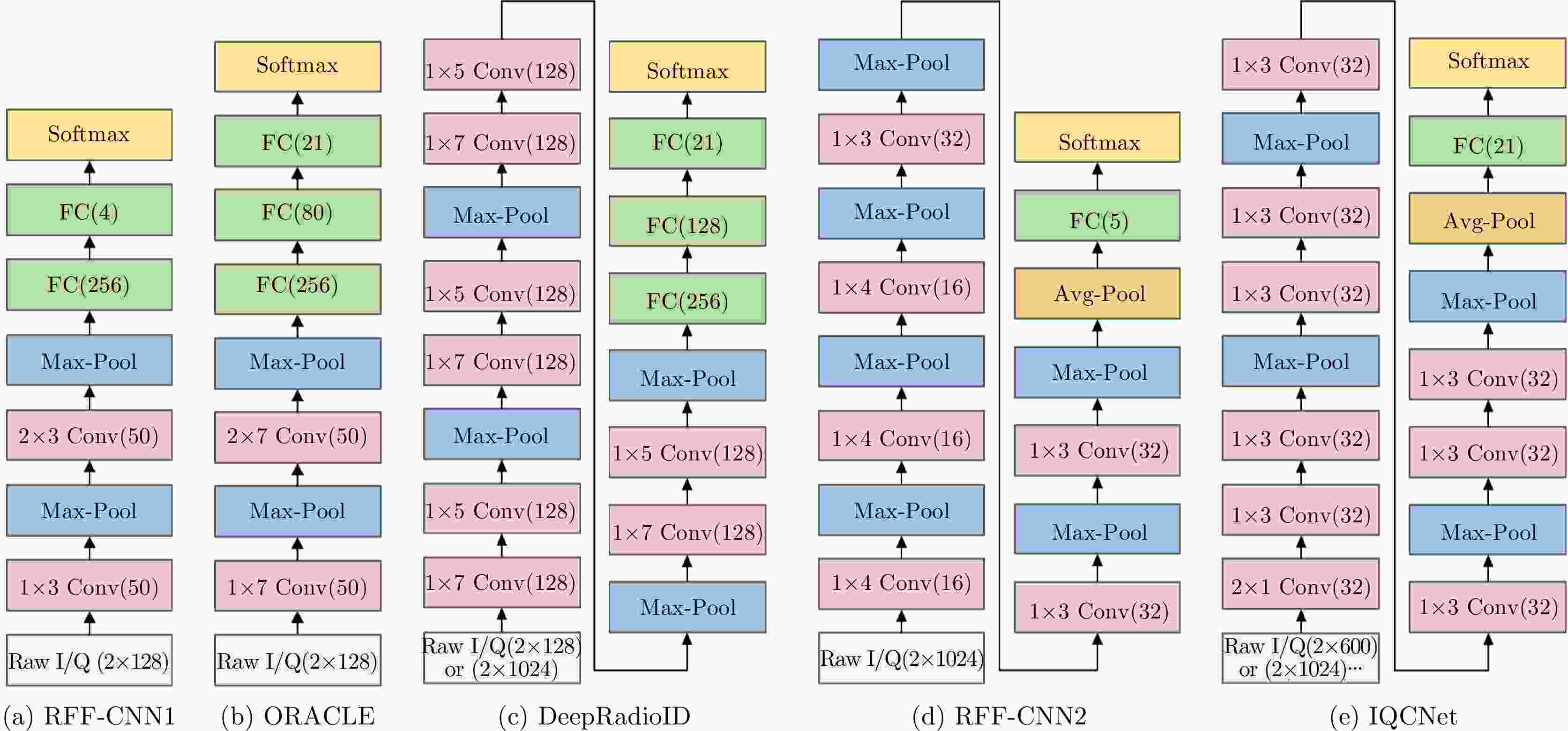
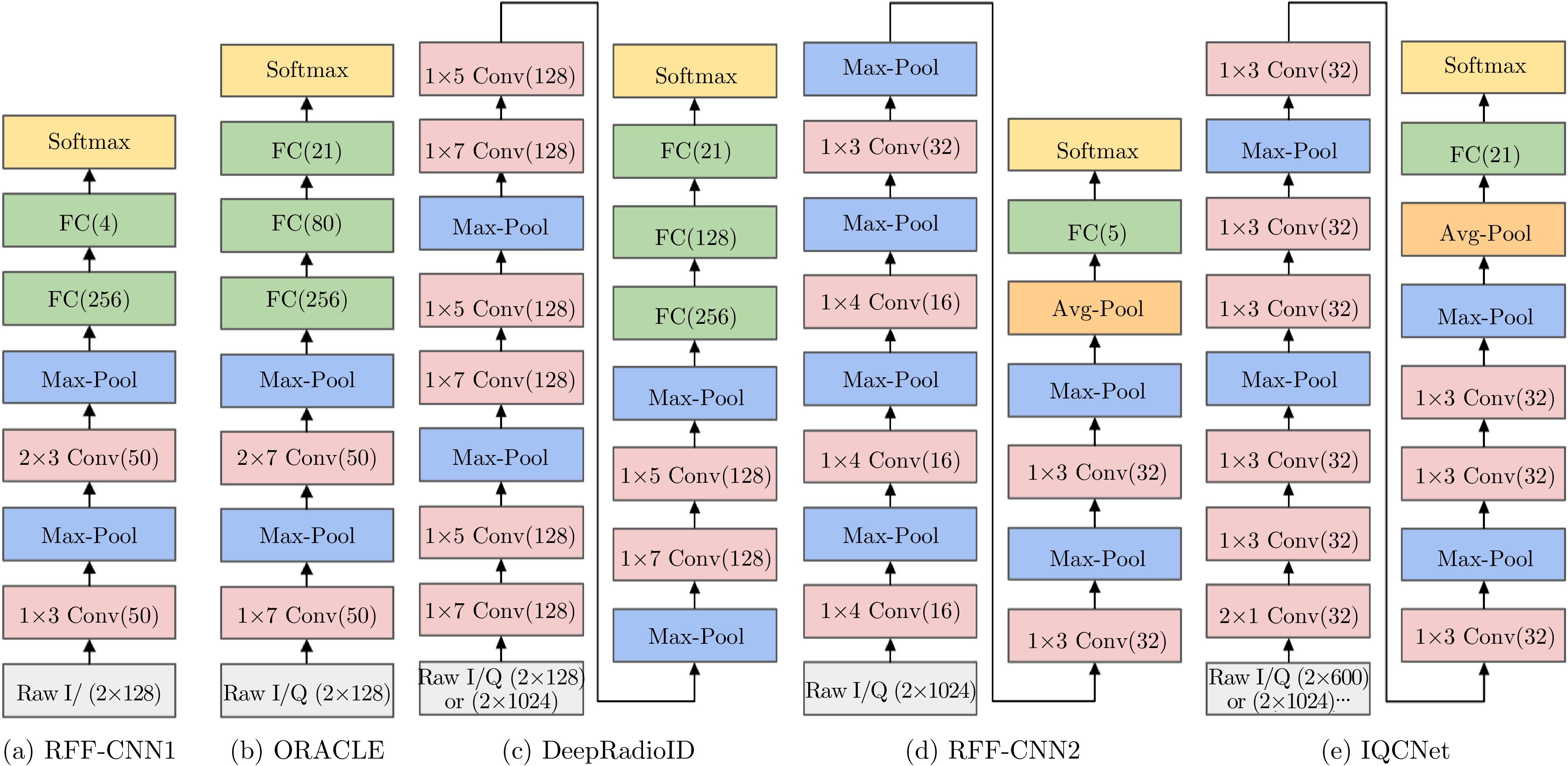
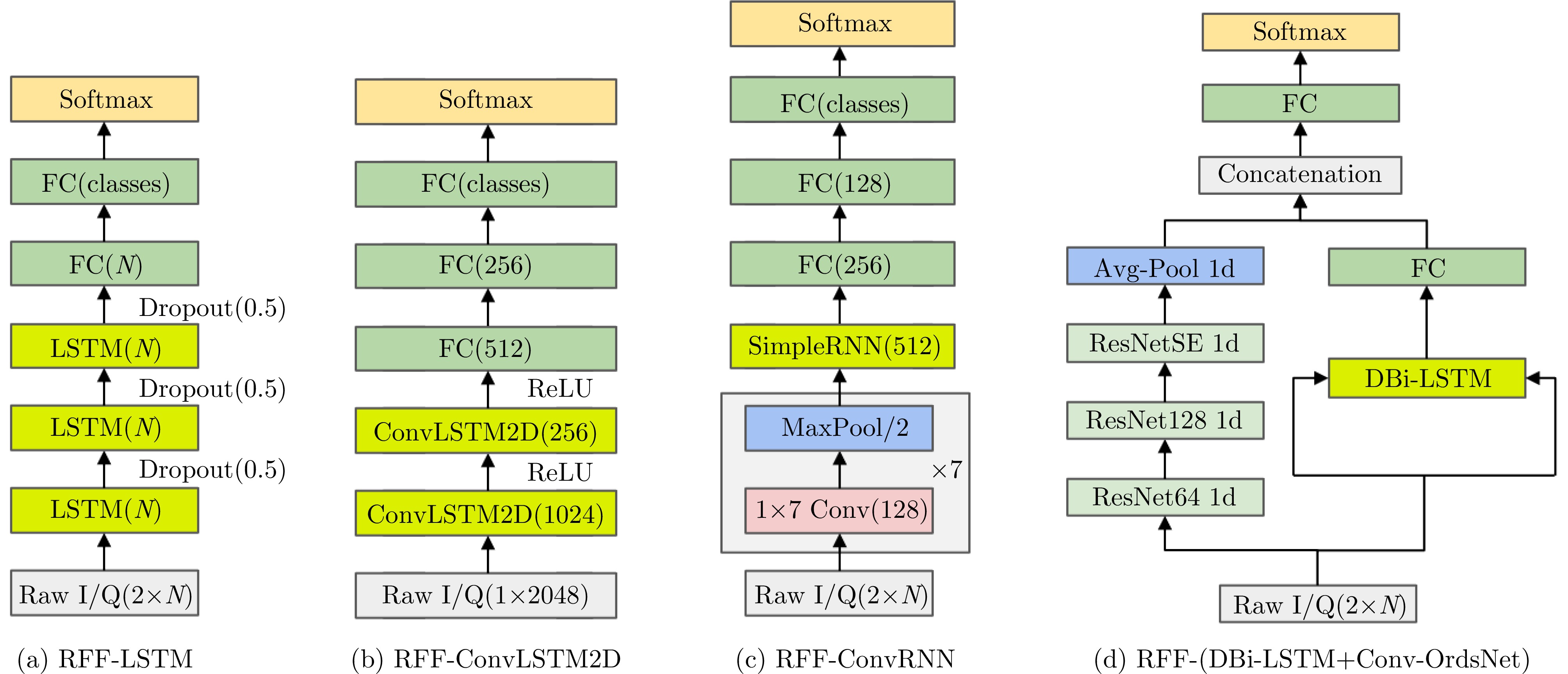
图 3 使用Raw I/Q进行射频指纹识别的基础卷积神经网络模型
Figure 3. The basis CNN model inputted with Raw I/Q for RFF
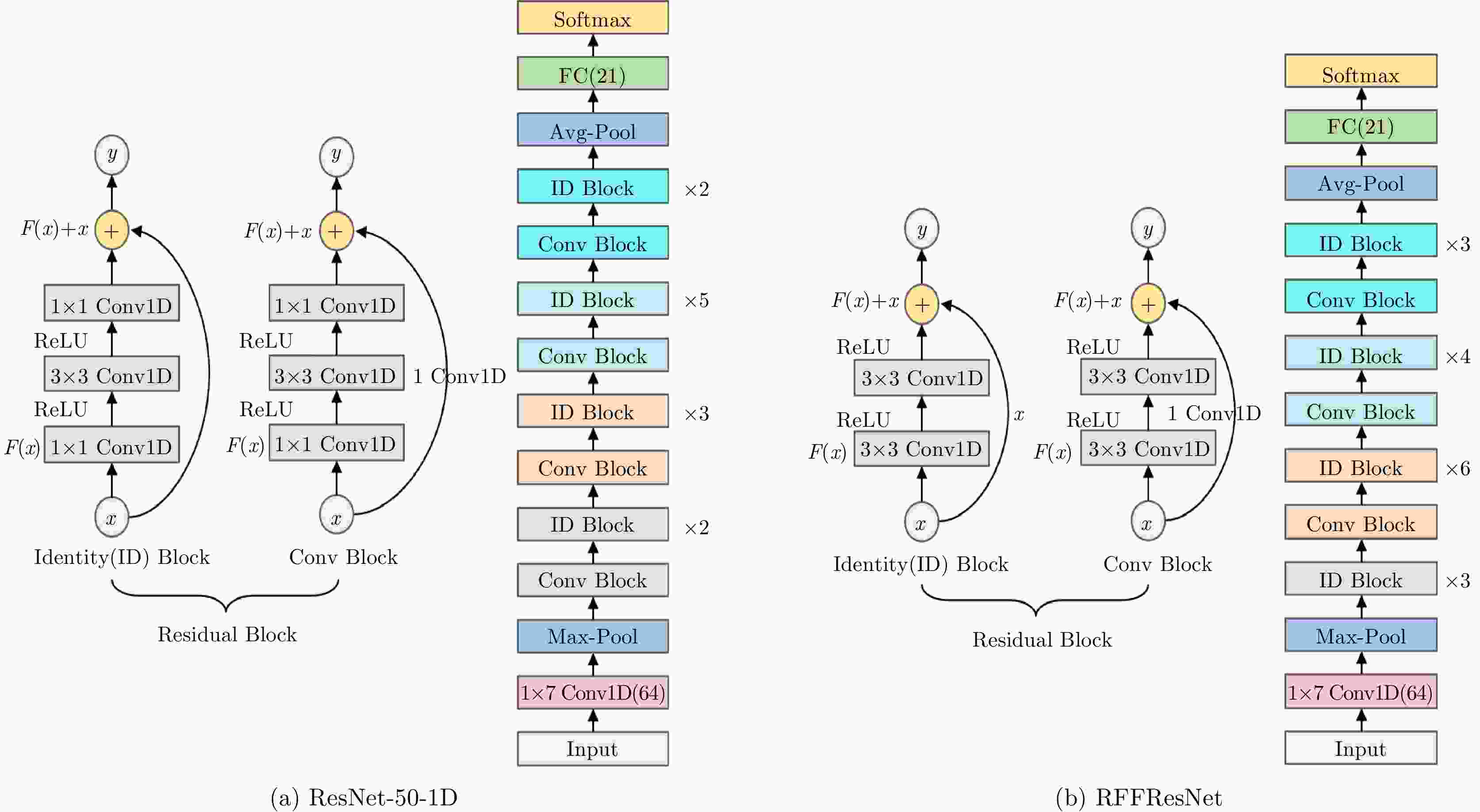
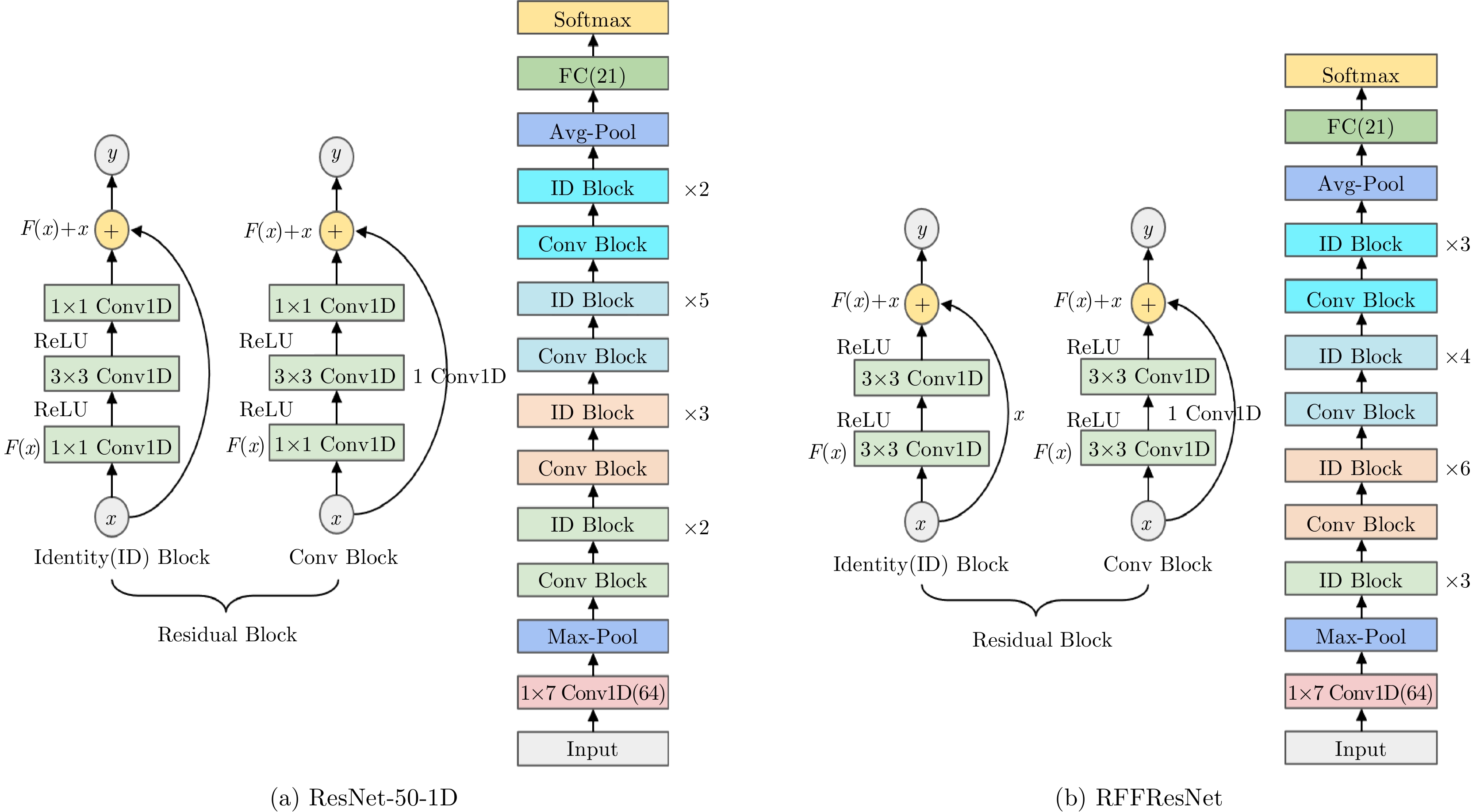
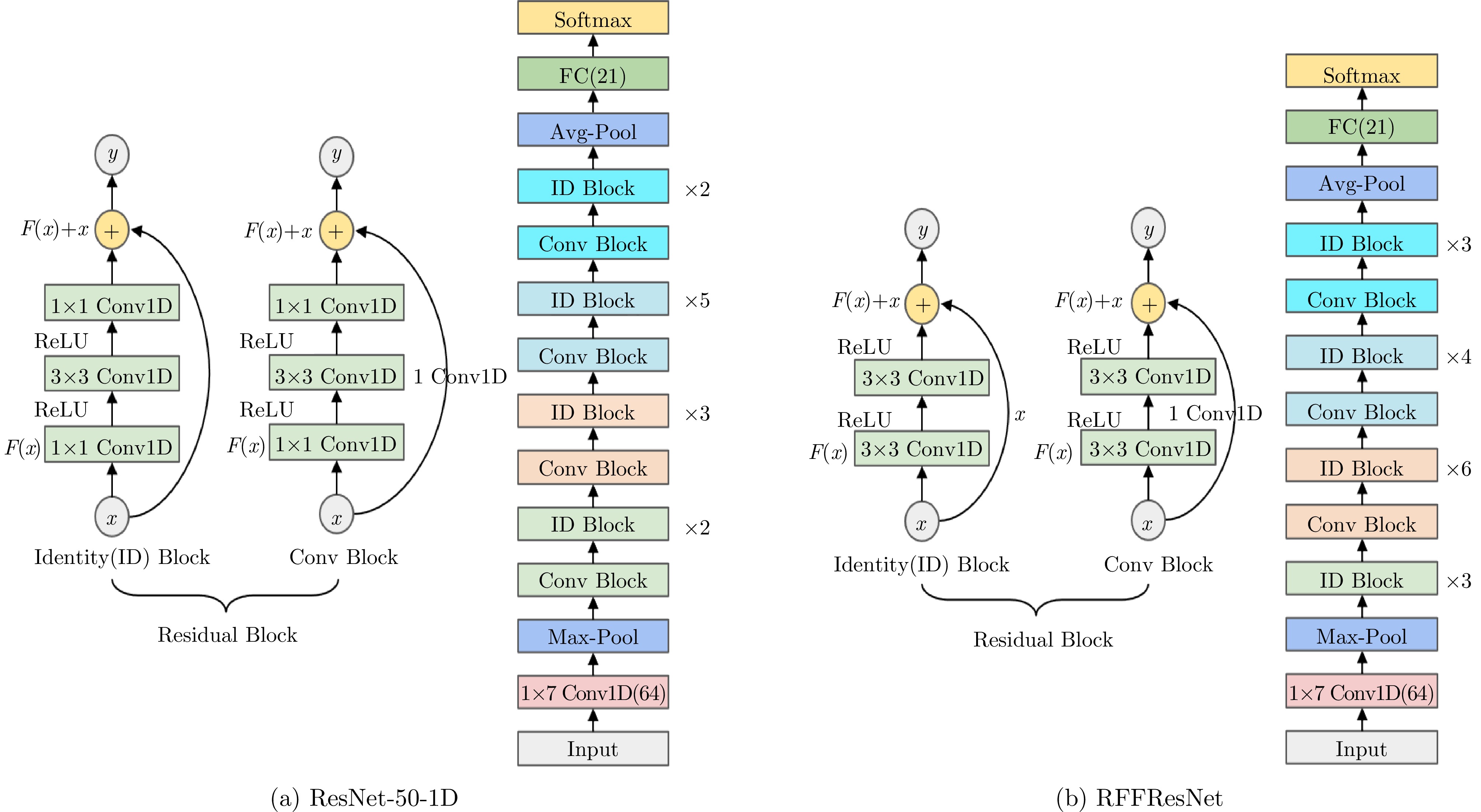
图 4 使用Raw I/Q进行射频指纹识别的ResNet模型
Figure 4. The ResNet model inputted with Raw I/Q for RFF
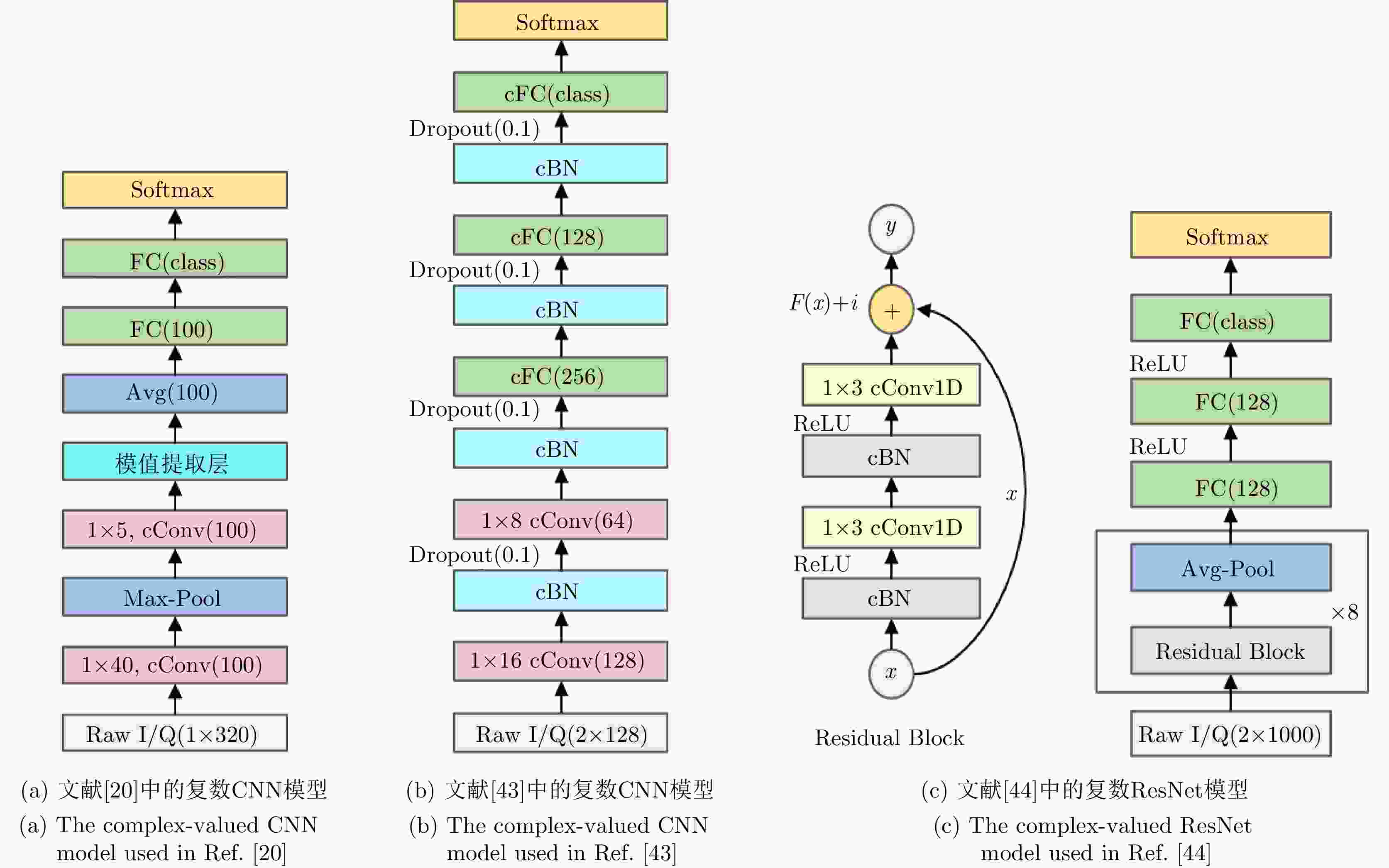
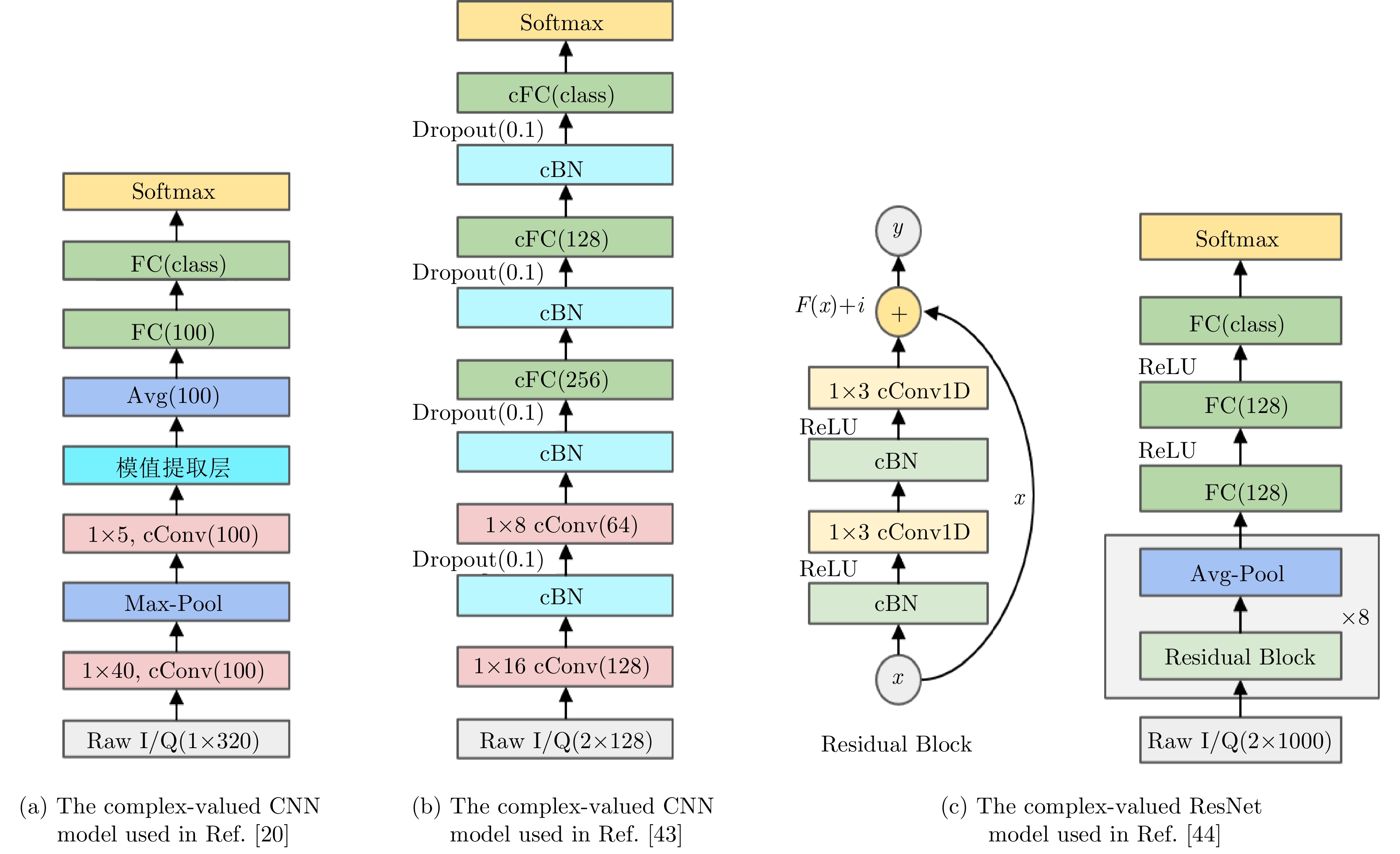
图 5 使用Raw I/Q进行射频指纹识别的复数深度神经网络模型
Figure 5. The complex-valued DNN model inputted with Raw I/Q for RFF
表 1 开源的射频指纹数据集
Table 1. Open source dataset of radio frequency fingerprint
文献 发射端 环境、信道、采集时间等配置 接收端 辐射源 数量 信号类型 接收机 采样率 其他 [63] USRP X310 16 IEEE802.11a 室内;LOS;不同距离(2~62 ft,
6 ft为步长)USRP B210 5 MS/s 2e7个I/Q采样点/个体 [57] USRP N210/X310 20 IEEE802.11a/g 线缆直连/暗室/室内;不同时间(10 d);
同一天线/不同天线USRP N210 20 MS/s 288个I/Q采样点/样本,
250条样本/个体/配置,[81] USRP X310 4 IEEE802.11a /LTE/5G-NR 室外;LOS/NLOS;不同时间(2 d);
不同距离(300~1000 m)USRP B210 5 MS/s,
7.68 MS/s512个I/Q采样点/样本,
3e6个I/Q采样点/个体[62] 无线网卡 174 IEEE802.11a/g 室内;LOS;不同时间(4 d);
不同接收机(41个)USRP B210/
N210/X31025 MS/s 全集有1e7条数据包,1.4 TB大小,裁剪为4个子集 [82] 智能手机 86 Bluetooth LOS;固定距离(30 cm) Tektronix TDS7404 250 MS/s,
5 GS/s150条样本/个体 [83] 飞行器 140 ADS-B 真实飞行数据 USRP B210 8 MS/s 总共3e4条样本 [18] 飞行器 530/
198ADS-B 真实飞行数据 Signal Hound
SM200B50 MS/s 200~600条样本/个体 [84] 物联网设备 60 LoRa 室内;LOS/NLOS;静止/移动 USRP N210 1 MS/s 8192 个I/Q采样点/样本1000 条样本/个体[85] 物联网设备 25 LoRa 室内/室外;不同时间(5 d);不同距离(5 m/10 m/15 m/20 m);不同接收机(2个) USRP B210 1 MS/s 2e8个I/Q采样点/个体/天 [86] USRP 2932 21 IEEE 802.15.4 半电波暗室内;不同功率;
受移动机器人扰动的动态信道USRP 2932 5 MS/s 600个I/Q采样点/样本
5e4条样本/个体[87] DJI M100 7 非标准波形 暗室悬停;不同距离(6 ft/9 ft/12 ft/15 ft) USRP X310 10 MS/s 约92e3个I/Q采样点/样本 2240 条样本/个体 下载: 导出CSV
下载: 导出CSV
表 2 数据表示形式的研究
Table 2. Research of data representation
文献 网络模型 信号类型 设备数量 待比较的数据
表示形式研究结论 [42] 复数CNN WiFi/ADS-B 100/ 1000 I/Q, I/Q+FFT I/Q+FFT更好 [90] LSTM WiFi 4 I/Q, NL, I/Q+NL I/Q+NL更稳定 [51] 有注意力机制CNN WiFi 20 I/Q, FFT FFT更好 [91] 复数CNN WiFi 20 I/Q, 差分I/Q 差分I/Q更好 [85] CNN LoRa 25 I/Q, FFT, $A/\phi $ I/Q和$A/\phi $更好 [26] CNN LoRa 20 I/Q, FFT, STFT STFT更好。经频偏补偿后,3种表示形式时模型的
正确率都获得大幅提升,STFT更好[50] CNN, LSTM LoRa 100 I/Q, $A/\phi $
STFT<10个设备时,$ A/\phi $和STFT与LSTM模型配合最好;10~49个设备时,
$ A/\phi $最好;50个设备以上时,3种数据表示形式都很差[66] CNN、复数CNN Wired/WiFi/
LoRa20/10/25 I/Q, $A/\phi $ 实数CNN:LoRa数据集上,I/Q更好,Wired和WiFi数据集上,$ A/\phi $更好
复数CNN:LoRa和WiFi数据集上,I/Q更好,Wired数据集上,$ A/\phi $更好
下载: 导出CSV
表 1 Open-source datasets of RF fingerprint
Ref. Transmitter Environment/Channel/
Collection configReceiver Type Qty Signal type Type Sample rate Other details [ 63] USRP X310 16 IEEE802.11a Indoor; LOS; Varying distances
(2–62 ft, 6 ft steps)USRP B210 5 MS/s 2e7 I/Q samples per device [ 57] USRP N210/X310 20 IEEE802.11a/g Cable-connected/Anechoic/Indoor;
Multi-day (10 days);
Same/different antennasUSRP N210 20 MS/s 288 I/Q samples per capture;
250 captures per device/config[ 81] USRP X310 4 IEEE802.11a /LTE/5G-NR Outdoor; LOS/NLOS; Multi-day
(2 days); Varying distances
(300–1000 m)USRP B210 5 MS/s,
7.68 MS/s512 I/Q samples per capture;
3e6 I/Q samples per device[ 62] Wireless NIC 174 IEEE802.11a/g Indoor; LOS; Multi-day
(4 days); Multiple receivers (41 units)USRP B210/N210/X310 25 MS/s Full set: 1e7 packets (1.4 TB); Subsampled to 4 subsets [ 82] Smartphones 86 Bluetooth LOS; Fixed distance (30 cm) Tektronix TDS7404 250 MS/s,
5 GS/s150 samples per device [ 83] Aircraft 140 ADS-B Real-flight data USRP B210 8 MS/s Total 3e4 samples [ 18] Aircraft 530/
198ADS-B Real-flight data Signal Hound
SM200B50 MS/s 200-600 samples per device [ 84] IoT 60 LoRa Indoor; LOS/NLOS; Static/mobile USRP N210 1 MS/s 8192 I/Q samples per capture;1000 samples per device[ 85] IoT 25 LoRa Indoor/Outdoor; Multi-day (5 days);
Varying distances (5 m/10 m/15 m/
20 m); Multiple receivers (2 units)USRP B210 1 MS/s 2e8 I/Q samples per
device per day[ 86] USRP 2932 21 IEEE 802.15.4 Semi-anechoic chamber;
Varying power; Dynamic channel with
mobile robot interferenceUSRP 2932 5 MS/s 600 I/Q samples per capture;
5e4 samples per device[ 87] DJI M100 7 Non-standard waveform Anechoic chamber hover;
Varying distances (6 ft/9 ft/
12 ft/15 ft)USRP X310 10 MS/s ~92e3 I/Q samples per capture; 2240 samples per device
下载: 导出CSV
表 2 Research of data representation
Ref Network model Signal type Device count Data representations Research founding [ 42] Complex-valued CNN WiFi/ADS-B 100/ 1000 I/Q, I/Q+FFT I/Q+FFT perform better [ 90] LSTM WiFi 4 I/Q, NL, I/Q+NL I/Q+NL shows better stability [ 51] CNN with Attention WiFi 20 I/Q, FFT FFT performs better [ 91] Complex-Valued CNN WiFi 20 I/Q, Differential I/Q Differential I/Q performs better [ 85] CNN LoRa 25 I/Q, FFT, $ A / \phi $ I/Q and $ A / \phi $ performs better [ 26] CNN LoRa 20 I/Q, FFT, STFT STFT performs better. After frequency offset compensation, all three representations show significant accuracy improvement, with STFT being the best [ 50] CNN, LSTM LoRa 100 I/Q, $ A / \phi $, STFT With <10 devices: [Image1] and STFT work best with LSTM; 10-49 devices: [Image1] performs best; >50 devices: All three representations perform poorly [ 66] CNN, Complex-Valued CNN Wired/ WiFi/ LoRa 20/ 10/ 25 I/Q, $ A / \phi $ Real-valued CNN: I/Q better for LoRa, $ A / \phi $ better for Wired and WiFi; Complex-valued CNN: I/Q better for LoRa and WiFi, $ A / \phi $ better for Wired
下载: 导出CSV
-
[1] BRIK V, BANERJEE S, GRUTESER M, et al. Wireless device identification with radiometric signatures[C]. The 14th ACM international conference on Mobile computing and networking, San Francisco, USA, 2008: 116–127. [2] KLEIN R W, TEMPLE M A, and MENDENHALL M J. Application of wavelet-based RF fingerprinting to enhance wireless network security[J]. Journal of Communications and Networks, 2009, 11(6): 544–555. doi: 10.1109/JCN.2009.6388408. [3] SOLTANIEH N, NOROUZI Y, YANG Yang, et al. A review of radio frequency fingerprinting techniques[J]. IEEE Journal of Radio Frequency Identification, 2020, 4(3): 222–233. doi: 10.1109/JRFID.2020.2968369. [4] 孙丽婷, 黄知涛, 王翔, 等. 辐射源指纹特征提取方法述评[J]. 雷达学报, 2020, 9(6): 1014–1031. doi: 10.12000/JR19115.SUN Liting, HUANG Zhitao, WANG Xiang, et al. Overview of radio frequency fingerprint extraction in specific emitter identification[J]. Journal of Radars, 2020, 9(6): 1014–1031. doi: 10.12000/JR19115. [5] 孟祥豪, 安永旺, 罗景青. 雷达信号基因形成机理与多层次建模方法研究[J]. 现代雷达, 2019, 41(2): 72–77. doi: 10.16592/j.cnki.1004-7859.2019.02.017.MENG Xianghao, AN Yongwang, and LUO Jingqing. A study on formation mechanism and multi-level modeling of the radar signal genes[J]. Modern Radar, 2019, 41(2): 72–77. doi: 10.16592/j.cnki.1004-7859.2019.02.017. [6] CHANG Zeyu. 6G, LIFI and WIFI wireless systems: Challenges, development and prospects[C]. 2021 18th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 2021: 322–325. [7] RESTUCCIA F and MELODIA T. Deep learning at the physical layer: System challenges and applications to 5G and beyond[J]. IEEE Communications Magazine, 2020, 58(10): 58–64. doi: 10.1109/MCOM.001.2000243. [8] KOŽOVIĆ D V and ĐURĐEVIĆ D Ž. Spoofing in aviation: Security threats on GPS and ADS-B systems[J]. Vojnotehnički Glasnik, 2021, 69(2): 461–485. doi: 10.5937/vojtehg69-30119. [9] WONG L J, CLARK W H, FLOWERS B, et al. An rfml ecosystem: Considerations for the application of deep learning to spectrum situational awareness[J]. IEEE Open Journal of the Communications Society, 2021, 2: 2243–2264. doi: 10.1109/OJCOMS.2021.3112939. [10] 曾勇虎, 陈翔, 林云, 等. 射频指纹识别的研究现状及趋势[J]. 电波科学学报, 2020, 35(3): 305–315. doi: 10.13443/j.cjors.2019070501.ZENG Yonghu, CHEN Xiang, LIN Yun, et al. Review of radio frequency fingerprinting identification[J]. Chinese Journal of Radio Science, 2020, 35(3): 305–315. doi: 10.13443/j.cjors.2019070501. [11] JIAN Tong, RENDON B C, OJUBA E, et al. Deep learning for RF fingerprinting: A massive experimental study[J]. IEEE Internet of Things Magazine, 2020, 3(1): 50–57. doi: 10.1109/IOTM.0001.1900065. [12] O’SHEA T J, CORGAN J, and CLANCY T C. Convolutional radio modulation recognition networks[C]. 17th International Conference on Engineering Applications of Neural Networks, Aberdeen, UK, 2016: 213–226. [13] O’SHEA T J, ROY T, and CLANCY T C. Over-the-air deep learning based radio signal classification[J]. IEEE Journal of Selected Topics in Signal Processing, 2018, 12(1): 168–179. doi: 10.1109/JSTSP.2018.2797022. [14] RIYAZ S, SANKHE K, IOANNIDIS S, et al. Deep learning convolutional neural networks for radio identification[J]. IEEE Communications Magazine, 2018, 56(9): 146–152. doi: 10.1109/MCOM.2018.1800153. [15] WONG L J, HEADLEY W C, ANDREWS S, et al. Clustering learned CNN features from raw I/Q data for emitter identification[C]. MILCOM 2018 - 2018 IEEE Military Communications Conference (MILCOM), Los Angeles, USA, 2018: 26–33. [16] WONG L J, HEADLEY W C, and MICHAELS A J. Specific emitter identification using convolutional neural network-based IQ imbalance estimators[J]. IEEE Access, 2019, 7: 33544–33555. doi: 10.1109/ACCESS.2019.2903444. [17] RESTUCCIA F, D’ORO S, AL-SHAWABKA A, et al. DeepRadioID: Real-time channel-resilient optimization of deep learning-based radio fingerprinting algorithms[C]. The Twentieth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Catania, Italy, 2019: 51–60. [18] TU Ya, LIN Yun, ZHA Haoran, et al. Large-scale real-world radio signal recognition with deep learning[J]. Chinese Journal of Aeronautics, 2022, 35(9): 35–48. doi: 10.1016/j.cja.2021.08.016. [19] CEKIC M, GOPALAKRISHNAN S, and MADHOW U. Wireless fingerprinting via deep learning: The impact of confounding factors[C]. 2021 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, USA, 2021: 677–684. [20] GOPALAKRISHNAN S, CEKIC M, and MADHOW U. Robust wireless fingerprinting via complex-valued neural networks[C]. 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, USA, 2019: 1–6. [21] BALDINI G, GENTILE C, GIULIANI R, et al. Comparison of techniques for radiometric identification based on deep convolutional neural networks[J]. Electronics Letters, 2019, 55(2): 90–92. doi: 10.1049/el.2018.6229. [22] PAN Yiwei, YANG Sihan, PENG Hua, et al. Specific emitter identification based on deep residual networks[J]. IEEE Access, 2019, 7: 54425–54434. doi: 10.1109/ACCESS.2019.2913759. [23] PENG Linning, ZHANG Junqing, LIU Ming, et al. Deep learning based RF fingerprint identification using differential constellation trace figure[J]. IEEE Transactions on Vehicular Technology, 2020, 69(1): 1091–1095. doi: 10.1109/TVT.2019.2950670. [24] LIN Yun, TU Ya, DOU Zheng, et al. Contour stella image and deep learning for signal recognition in the physical layer[J]. IEEE Transactions on Cognitive Communications and Networking, 2021, 7(1): 34–46. doi: 10.1109/TCCN.2020.3024610. [25] 袁泽霖. 电磁信号的射频指纹识别技术研究[D]. [硕士论文], 电子科技大学, 2021.YUAN Zelin. Research on radio frequency fingerprint recognition technology of electromagnetic signal[D]. [Master dissertation], University of Electronic Science and Technology of China, 2021. [26] SHEN Guanxiong, ZHANG Junqing, MARSHALL A, et al. Radio frequency fingerprint identification for LoRa using deep learning[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(8): 2604–2616. doi: 10.1109/JSAC.2021.3087250. [27] SHEN Guanxiong, ZHANG Junqing, MARSHALL A, et al. Radio frequency fingerprint identification for security in low-cost IoT devices[C]. 2021 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, USA, 2021: 309–313. [28] GRITSENKO A, WANG Zifeng, JIAN Tong, et al. Finding a ‘new’ needle in the haystack: Unseen radio detection in large populations using deep learning[C]. 2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, USA, 2019: 1–10. [29] AGADAKOS I, AGADAKOS N, POLAKIS J, et al. Deep complex networks for protocol-agnostic radio frequency device fingerprinting in the wild[EB/OL]. https://doi.org/10.48550/arXiv.1909.08703 , 2019.[30] SANKHE K, BELGIOVINE M, ZHOU Fan, et al. No radio left behind: Radio fingerprinting through deep learning of physical-layer hardware impairments[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(1): 165–178. doi: 10.1109/TCCN.2019.2949308. [31] ROBINSON J, KUZDEBA S, STANKOWICZ J, et al. Dilated causal convolutional model for RF fingerprinting[C]. 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, USA, 2020: 157–162. [32] HUA Jingyu, SUN Hongyi, SHEN Zhenyu, et al. Accurate and efficient wireless device fingerprinting using channel state information[C]. IEEE INFOCOM 2018 - IEEE Conference on Computer Communications, Honolulu, USA, 2018: 1700–1708. [33] LIU Yinghui, XU Hua, QI Zisen, et al. Specific emitter identification against unreliable features interference based on time-series classification network structure[J]. IEEE Access, 2020, 8: 200194–200208. doi: 10.1109/ACCESS.2020.3035813. [34] CHEN Shichuan, ZHENG Shilian, YANG Lifeng, et al. Deep learning for large-scale real-world ACARS and ADS-B radio signal classification[J]. IEEE Access, 2019, 7: 89256–89264. doi: 10.1109/ACCESS.2019.2925569. [35] YANG Ning, ZHANG Bangning, DING Guoru, et al. Specific emitter identification with limited samples: A model-agnostic meta-learning approach[J]. IEEE Communications Letters, 2022, 26(2): 345–349. doi: 10.1109/LCOMM.2021.3110775. [36] VO-HUU T D, VO-HUU T D, and NOUBIR G. Fingerprinting Wi-Fi devices using software defined radios[C]. The 9th ACM Conference on Security & Privacy in Wireless and Mobile Networks, Darmstadt, Germany, 2016: 3–14. [37] CHOLLET F. Deep Learning with Python[M]. 6nd ed. Manning Publications, 2017: 6. [38] ROY D, MUKHERJEE T, CHATTERJEE M, et al. RFAL: Adversarial learning for RF transmitter identification and classification[J]. IEEE Transactions on Cognitive Communications and Networking, 2020, 6(2): 783–801. doi: 10.1109/TCCN.2019.2948919. [39] ROY D, MUKHERJEE T, CHATTERJEE M, et al. Detection of rogue RF transmitters using generative adversarial nets[C]. 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 2019: 1–7. [40] BRONSTEIN M M, BRUNA J, COHEN T, et al. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges[EB/OL]. https://doi.org/10.48550/arXiv.2104.13478 , 2021.[41] XU Haifeng and XU Xiaodong. A transformer based approach for open set specific emitter identification[C]. 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 2021: 1420–1425. [42] STANKOWICZ J, ROBINSON J, CARMACK J M, et al. Complex neural networks for radio frequency fingerprinting[C]. 2019 IEEE Western New York Image and Signal Processing Workshop (WNYISPW), Rochester, USA, 2019: 1–5. [43] GU Hao, WANG Yu, GUI Guan, et al. Radio frequency fingerprinting driven drone identification based on complex-valued CNN[C]. The 13th EAI International Conference on Mobile Multimedia Communications, Harbin, China, 2020. [44] WANG Shenhua, JIANG Hongliang, FANG Xiaofang, et al. Radio frequency fingerprint identification based on deep complex residual network[J]. IEEE Access, 2020, 8: 204417–204424. doi: 10.1109/ACCESS.2020.3037206. [45] 翁琳天然, 彭进霖, 何元, 等. 基于深度残差网络的ADS-B信号辐射源个体识别[J]. 航空兵器, 2021, 28(4): 24–29. doi: 10.12132/ISSN.1673-5048.2020.0095.WENG Lintianran, PENG Jinlin, HE Yuan, et al. Specific emitter identification of ADS-B signal based on deep residual network[J]. Aero Weaponry, 2021, 28(4): 24–29. doi: 10.12132/ISSN.1673-5048.2020.0095. [46] ZHANG Tiantian, REN Pinyi, and REN Zhanyi. Deep radio fingerprint ResNet for reliable lightweight device identification[C]. 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, USA, 2021: 1–6. [47] Brown C N, Mattei E, Draganov A. ChaRRNets: Channel robust representation networks for RF fingerprinting[J]. arXiv preprint arXiv:2105.03568, 2021. [48] JAFARI H, OMOTERE O, ADESINA D, et al. IoT devices fingerprinting using deep learning[C]. MILCOM 2018 - 2018 IEEE Military Communications Conference (MILCOM), Los Angeles, USA, 2018: 1–9. [49] WU Qingyang, FERES C, KUZMENKO D, et al. Deep learning based RF fingerprinting for device identification and wireless security[J]. Electronics Letters, 2018, 54(24): 1405–1407. doi: 10.1049/el.2018.6404. [50] AL-SHAWABKA A, PIETRASKI P, PATTAR S B, et al. DeepLoRa: Fingerprinting LoRa devices at scale through deep learning and data augmentation[C]. The Twenty-Second International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Shanghai, China, 2021: 251–260. [51] PENG Yinan and ZHOU Yuan. Specific emitter identification via squeeze-and-excitation neural network in frequency domain[C]. 2021 40th Chinese Control Conference (CCC), Shanghai, China, 2021: 8310–8314. [52] WENG Lintianran, PENG Jianhua, LI Jinsong, et al. Message structure aided attentional convolution network for RF device fingerprinting[C]. 2020 IEEE/CIC International Conference on Communications in China (ICCC), Chongqing, China, 2020: 495–500. [53] TIAN Yinghua, WANG Sheng, and ZHANG Long. Convolutional neural network based evil twin attack detection in WiFi networks[C]. 2020 2nd International Conference on Computer Science Communication and Network Security, Sanya, China, 2021: 08006. [54] YU Jiabao, HU Aiqun, LI Guyue, et al. A robust RF fingerprinting approach using multisampling convolutional neural network[J]. IEEE Internet of Things Journal, 2019, 6(4): 6786–6799. doi: 10.1109/JIOT.2019.2911347. [55] YU Jiabao, HU Aiqun, LI Guyue, et al. A multi-sampling convolutional neural network-based RF fingerprinting approach for low-power devices[C]. IEEE INFOCOM 2019 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 2019: 1–6. [56] MERCHANT K, REVAY S, STANTCHEV G, et al. Deep learning for RF device fingerprinting in cognitive communication networks[J]. IEEE Journal of Selected Topics in Signal Processing, 2018, 12(1): 160–167. doi: 10.1109/JSTSP.2018.2796446. [57] AL-SHAWABKA A, RESTUCCIA F, D’ORO S, et al. Exposing the fingerprint: Dissecting the impact of the wireless channel on radio fingerprinting[C]. IEEE INFOCOM 2020 - IEEE Conference on Computer Communications, Toronto, Canada, 2020: 646–655. [58] Elmaghbub A, Hamdaoui B. Leveraging hardware-impaired out-of-band information through deep neural networks for robust wireless device classification[J]. arXiv preprint arXiv:2004.11126, 2020. https://doi.org/10.48550/arXiv.2004.11126 .[59] 崔天舒, 赵文杰, 黄永辉, 等. 基于射频指纹的测控地面站身份识别方法[J]. 航天电子对抗, 2021, 37(3): 6–9, 23. doi: 10.16328/j.htdz8511.2021.03.002.CUI Tianshu, ZHAO Wenjie, HUANG Yonghui, et al. Radio frequency fingerprint-based TT&C ground station identification method[J]. Aerospace Electronic Warfare, 2021, 37(3): 6–9, 23. doi: 10.16328/j.htdz8511.2021.03.002. [60] ROY D, MUKHERJEE T, CHATTERJEE M, et al. RF transmitter fingerprinting exploiting spatio-temporal properties in raw signal data[C]. 2019 18th IEEE International Conference On Machine Learning and Applications (ICMLA), Boca Raton, USA, 2019: 89–96. [61] SOLTANI N, SANKHE K, DY J, et al. More is better: Data augmentation for channel-resilient RF fingerprinting[J]. IEEE Communications Magazine, 2020, 58(10): 66–72. doi: 10.1109/MCOM.001.2000180. [62] HANNA S, KARUNARATNE S, and CABRIC D. WiSig: A large-scale WiFi signal dataset for receiver and channel agnostic RF fingerprinting[J]. IEEE Access, 2022, 10: 22808–22818. doi: 10.1109/ACCESS.2022.3154790. [63] SANKHE K, BELGIOVINE M, ZHOU Fan, et al. ORACLE: Optimized radio classification through convolutional neural networks[C]. IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, Paris, France, 2019: 370–378. [64] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Identity mappings in deep residual networks[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 630–645. [65] TRABELSI C, BILANIUK O, ZHANG Ying, et al. Deep complex networks[EB/OL]. https://doi.org/10.48550/arXiv.1705.09792 , 2017.[66] CHEN Jun, WONG W K, HAMDAOUI B, et al. An analysis of complex-valued CNNs for RF data-driven wireless device classification[C]. ICC 2022 - IEEE International Conference on Communications, Seoul, Korea, 2022: 4318–4323. [67] 李润东. 基于深度学习的通信信号智能盲检测与识别技术研究[D]. [博士论文], 电子科技大学, 2021.LI Rundong. Research on intelligent blind detection and recognition of communication signals based on deep learning[D]. [Ph. D. dissertation], University of Electronic Science and Technology of China, 2021. [68] RAMASUBRAMANIAN M, BANERJEE C, ROY D, et al. Exploiting spatio-temporal properties of I/Q signal data using 3D convolution for RF transmitter identification[J]. IEEE Journal of Radio Frequency Identification, 2021, 5(2): 113–127. doi: 10.1109/JRFID.2021.3051901. [69] YU Jiabao, HU Aiqun, ZHOU Fen, et al. Radio frequency fingerprint identification based on denoising autoencoders[C]. 2019 International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Barcelona, Spain, 2019: 1–6. [70] XIE Feiyi, WEN Hong, WU Jinsong, et al. Convolution based feature extraction for edge computing access authentication[J]. IEEE Transactions on Network Science and Engineering, 2020, 7(4): 2336–2346. doi: 10.1109/TNSE.2019.2957323. [71] GOYAL A and BENGIO Y. Inductive biases for deep learning of higher-level cognition[EB/OL]. https://doi.org/10.48550/arXiv.2011.15091 , 2020.[72] AZULAY A and WEISS Y. Why do deep convolutional networks generalize so poorly to small image transformations?[J]. Journal of Machine Learning Research, 2019, 20(184): 1–25. [73] LIU Xiaoyu, YANG Diyu, and EL GAMAL A. Deep neural network architectures for modulation classification[C]. 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, USA, 2017: 915–919. [74] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010. [75] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. 9th International Conference on Learning Representations, 2021. https://iclr.cc/Conferences/2021 .[76] COHEN T and WELLING M. Group equivariant convolutional networks[C]. The 33rd International Conference on Machine Learning, New York City, USA, 2016: 2990–2999. [77] CHAKRABORTY R, XING Yifei, amd YU S X. SurReal: Complex-valued learning as principled transformations on a scaling and rotation manifold[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(3): 940–951. doi: 10.1109/TNNLS.2020.3030565. [78] HILBURN B, WEST N, O’SHEA T, et al. SigMF: The signal metadata format[C]. The GNU Radio Conference, Henderson, USA, 2018. [79] ELMAGHBUB A and HAMDAOUI B. Comprehensive RF dataset collection and release: A deep learning-based device fingerprinting use case[C]. 2021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 2021: 1–7. [80] 乐波, 王桂良, 黄渊凌, 等. 接收机畸变对辐射源指纹识别的影响[J]. 电讯技术, 2020, 60(3): 273–278. doi: 10.3969/j.issn.1001-893x.2020.03.005.LE Bo, WANG Guiliang, HUANG Yuanling, et al. Influence of receiver distortion characteristics on specific emitter identification[J]. Telecommunication Engineering, 2020, 60(3): 273–278. doi: 10.3969/j.issn.1001-893x.2020.03.005. [81] REUS-MUNS G, JAISINGHANI D, SANKHE K, et al. Trust in 5G open RANs through machine learning: RF fingerprinting on the POWDER PAWR platform[C]. GLOBECOM 2020 - 2020 IEEE Global Communications Conference, Taipei, China, 2020: 1–6. [82] UZUNDURUKAN E, DALVEREN Y, and KARA A. A database for the radio frequency fingerprinting of Bluetooth devices[J]. Data, 2020, 5(2): 55. doi: 10.3390/data5020055. [83] LIU Yongxin, WANG Jian, LI Jianqiang, et al. Zero-bias deep learning for accurate identification of internet-of-things (IoT) devices[J]. IEEE Internet of Things Journal, 2021, 8(4): 2627–2634. doi: 10.1109/JIOT.2020.3018677. [84] SHEN Guanxiong, ZHANG Junqing, MARSHALL A, et al. Towards scalable and channel-robust radio frequency fingerprint identification for LoRa[J]. IEEE Transactions on Information Forensics and Security, 2022, 17: 774–787. doi: 10.1109/TIFS.2022.3152404. [85] ELMAGHBUB A and HAMDAOUI B. LoRa device fingerprinting in the wild: Disclosing RF data-driven fingerprint sensitivity to deployment variability[J]. IEEE Access, 2021, 9: 142893–142909. doi: 10.1109/ACCESS.2021.3121606. [86] MORIN C, CARDOSO L S, HOYDIS J, et al. Transmitter classification with supervised deep learning[C]. 14th EAI International Conference on Cognitive Radio-Oriented Wireless Networks, Poznan, Poland, 2019: 73–86. [87] Soltani N, Reus-Muns G, Salehi B, et al. RF fingerprinting unmanned aerial vehicles with non-standard transmitter waveforms[J]. IEEE Transactions on Vehicular Technology, 2020, 69(12): 15518–15531. doi: 10.1109/TVT.2020.3042128. [88] O’SHEA T and HOYDIS J. An introduction to deep learning for the physical layer[J]. IEEE Transactions on Cognitive Communications and Networking, 2017, 3(4): 563–575. doi: 10.1109/TCCN.2017.2758370. [89] KULIN M, KAZAZ T, MOERMAN I, et al. End-to-end learning from spectrum data: A deep learning approach for wireless signal identification in spectrum monitoring applications[J]. IEEE Access, 2018, 6: 18484–18501. doi: 10.1109/ACCESS.2018.2818794. [90] TYLER J H, FADUL M K, REISING D R, et al. Simplified denoising for robust specific emitter identification of preamble-based waveforms[C]. 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 2021: 1–7. [91] YING Long, LI Jingchao, and ZHANG Bin. Differential complex-valued convolutional neural network-based individual recognition of communication radiation sources[J]. IEEE Access, 2021, 9: 132533–132540. doi: 10.1109/ACCESS.2021.3114191. [92] HERNÁNDEZ-GARCÍA A and KÖNIG P. Further advantages of data augmentation on convolutional neural networks[C]. 27th International Conference on Artificial Neural Networks and Machine Learning, Rhodes, Greece, 2018: 95–103. [93] HUANG Liang, PAN Weijian, ZHANG You, et al. Data augmentation for deep learning-based radio modulation classification[J]. IEEE Access, 2020, 8: 1498–1506. doi: 10.1109/ACCESS.2019.2960775. [94] MERCHANT K and NOUSAIN B. Enhanced RF fingerprinting for IoT devices with recurrent neural networks[C]. MILCOM 2019 - 2019 IEEE Military Communications Conference (MILCOM), Norfolk, USA, 2019: 590–597. [95] KARUNARATNE S, HANNA S, and CABRIC D. Open set RF fingerprinting using generative outlier augmentation[C]. 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 2021: 1–7. [96] XIE Feiyi, WEN Hong, WU Jinsong, et al. Data augmentation for radio frequency fingerprinting via pseudo-random integration[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2020, 4(3): 276–286. doi: 10.1109/TETCI.2019.2907740. [97] WONG L J and MICHAELS A J. Transfer learning for radio frequency machine learning: A taxonomy and survey[J]. Sensors, 2022, 22(4): 1416. doi: 10.3390/s22041416. [98] 张怡如. 多通信设备指纹识别技术研究[D]. [硕士论文], 电子科技大学, 2021.ZHANG Yiru. Research on Technologies for fingerprint identification of multiple communication devices[D]. [Master dissertation], University of Electronic Science and Technology of China, 2021. [99] REUS-MUNS G and CHOWDHURY K R. Classifying UAVs with proprietary waveforms via preamble feature extraction and federated learning[J]. IEEE Transactions on Vehicular Technology, 2021, 70(7): 6279–6290. doi: 10.1109/TVT.2021.3081049. [100] MORGE-ROLLET L, LE ROY F, LE JEUNE D, et al. Siamese network on I/Q signal for RF fingerprinting[C]. Conference on Artificial Intelligence for Defense (CAID) 2020, En ligne, France, 2020: 152–158. [101] JIAN Tong, GONG Yifan, ZHAN Zheng, et al. Radio frequency fingerprinting on the edge[J]. IEEE Transactions on Mobile Computing, 2022, 21(11): 4078–4093. doi: 10.1109/TMC.2021.3064466. [102] WANG Yu, GUI Guan, GACANIN H, et al. An efficient specific emitter identification method based on complex-valued neural networks and network compression[J]. IEEE Journal on Selected Areas in Communications, 2021, 39(8): 2305–2317. doi: 10.1109/JSAC.2021.3087243. -






计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

