
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Reconfigurable Mode Vortex Beam Generation Based on Transmissive Metasurfaces in the Terahertz Band
-
摘要: 太赫兹技术与轨道角动量(OAM)技术相结合在高速无线通信领域具有巨大潜力。理论上不同模态的OAM之间具备严格正交性,若能将OAM技术应用到太赫兹通信系统中,必能极大提升系统的通信容量。因此,如何产生高质量的THz-OAM波束,并给予它灵活的动态控制成为研究者们的一大研究热点。该文设计了一种双层透射型超表面,使用3D打印作为加工方式,成本低、加工难度小。超表面单元结构采用高度可变的介质单元,随着单元高度不断发生改变,透射相位覆盖0°~360°,且透射率保持在88%以上。采用WR-10标准波导喇叭天线进行馈电,在100 GHz工作频率下,通过改变双层超表面之间的相对旋转角度,产生了不同模态的OAM波束。仿真结果表明,该文设计的超表面天线能够实现
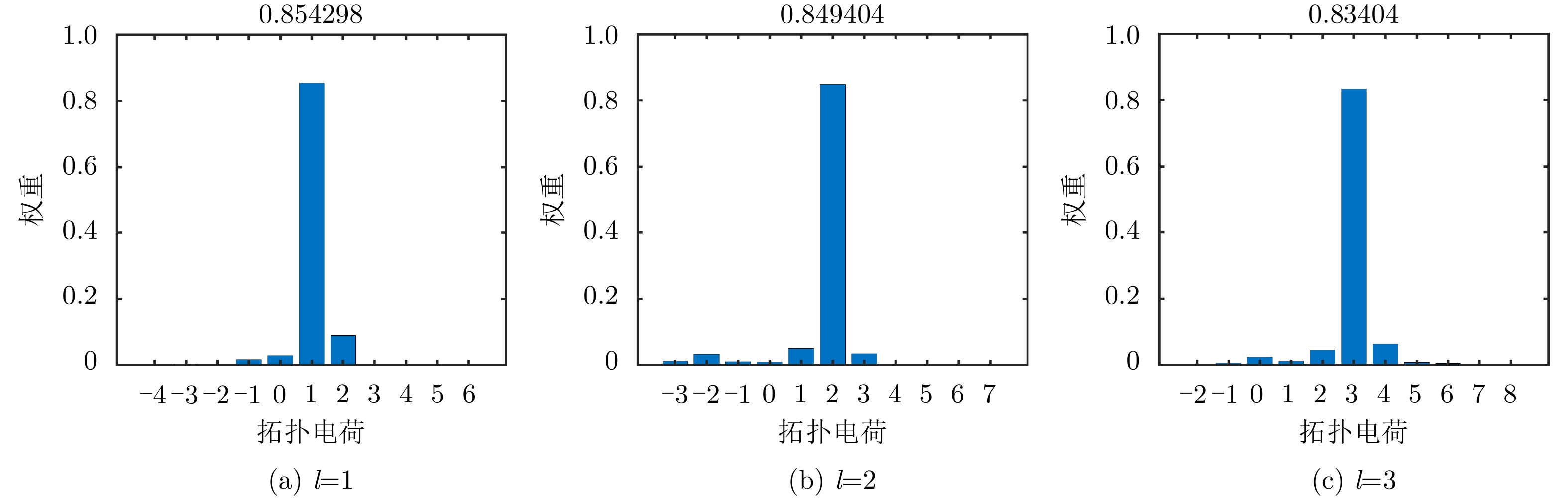
$ l=1,2,3 $ 的OAM波束,二维幅相结果符合对应模态的特征,$ l=1,2,3 $ 时,OAM波束的模态纯度分别为85.4%, 84.9%, 83.4%。 通过太赫兹扫场测试平台测试了天线在90 GHz, 100 GHz, 110 GHz频点下的电场分布。结果表明:在20 GHz带宽内,产生的OAM波束质量较好,证明该文设计的超表面天线在高频工作具有一定的工作带宽,有望应用于高频OAM通信。Abstract: Combining Terahertz (THz) and Orbital Angular Momentum (OAM) technologies has great potential in high-speed wireless communication. Theoretically, OAM with different modes has strict orthogonality. The communication capacity of the system will improve significantly if OAM technology is applied to the THz communication system. Thus, the manner to generate a high-quality and dynamically controllable THz-OAM beam has been of significant interest to researchers in related fields. In this study, a double-layer transmissive metasurface that uses 3D printing as the processing method with a low cost and processing difficulty is designed. Note that the height of the unit cell for constructing the metasurface is configurable. As the height changes continuously, the phase of the transmitted wave covers 0~2${\pi }$ within 90~110 GHz, while the transmittance of the units is always higher than 88%. At 100 GHz, which is fed by a WR-10 standard waveguide horn antenna, OAM beams with different modes are generated by changing the relative rotation angle between the double-layer metasurface. The simulation results show that the metasurface antenna designed in this study can achieve OAM beams of$ l=1, \mathrm{2,3} $ , and the two-dimensional amplitude and phase results correspond with the characteristics of the corresponding modes. When$ l=1,\mathrm{ }2,\mathrm{ }3 $ , the OAM beam’s modal purity is 85.4%, 84.9%, and 83.4%, respectively. The measurement results include the results at frequency points of 90, 100, and 110 GHz. The results show that the OAM beam has a high-quality bandwidth of 20 GHz, which indicates that the metasurface antenna designed in this study has a wide working bandwidth at a high frequency and can be applied to high-frequency OAM communication.-
Key words:
- Terahertz /
- Vortex beam /
- Reconfigurable mode /
- Metasurface /
- Transmissive
-
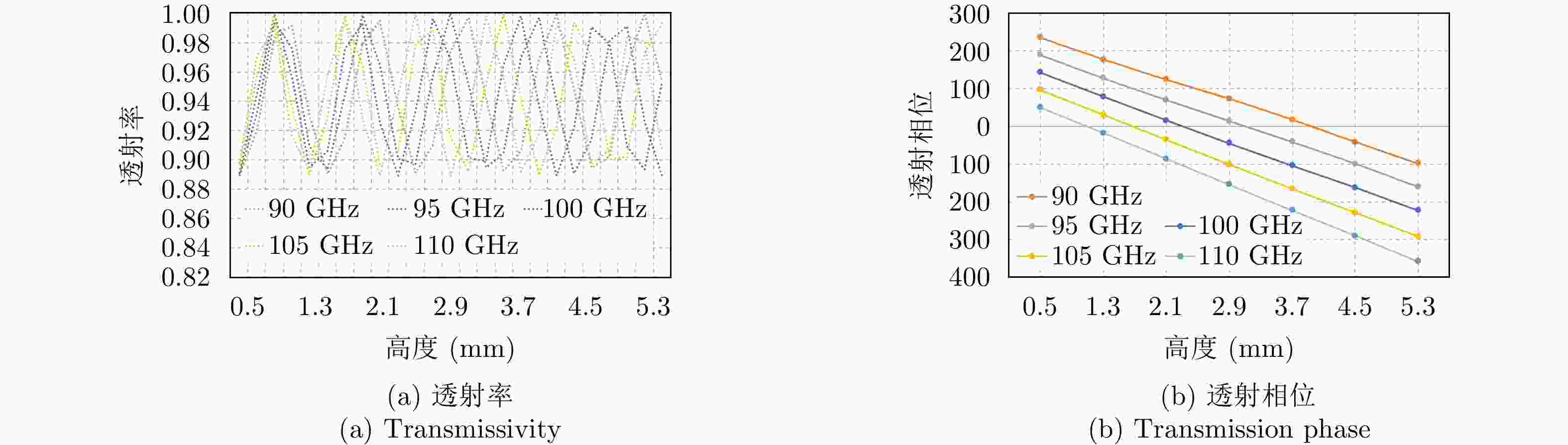
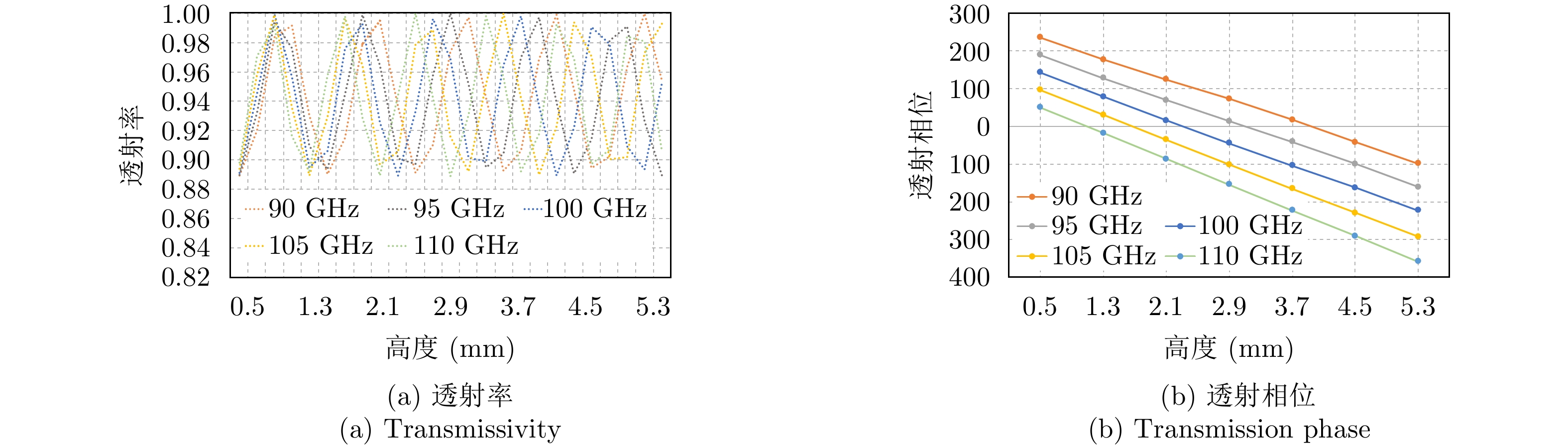
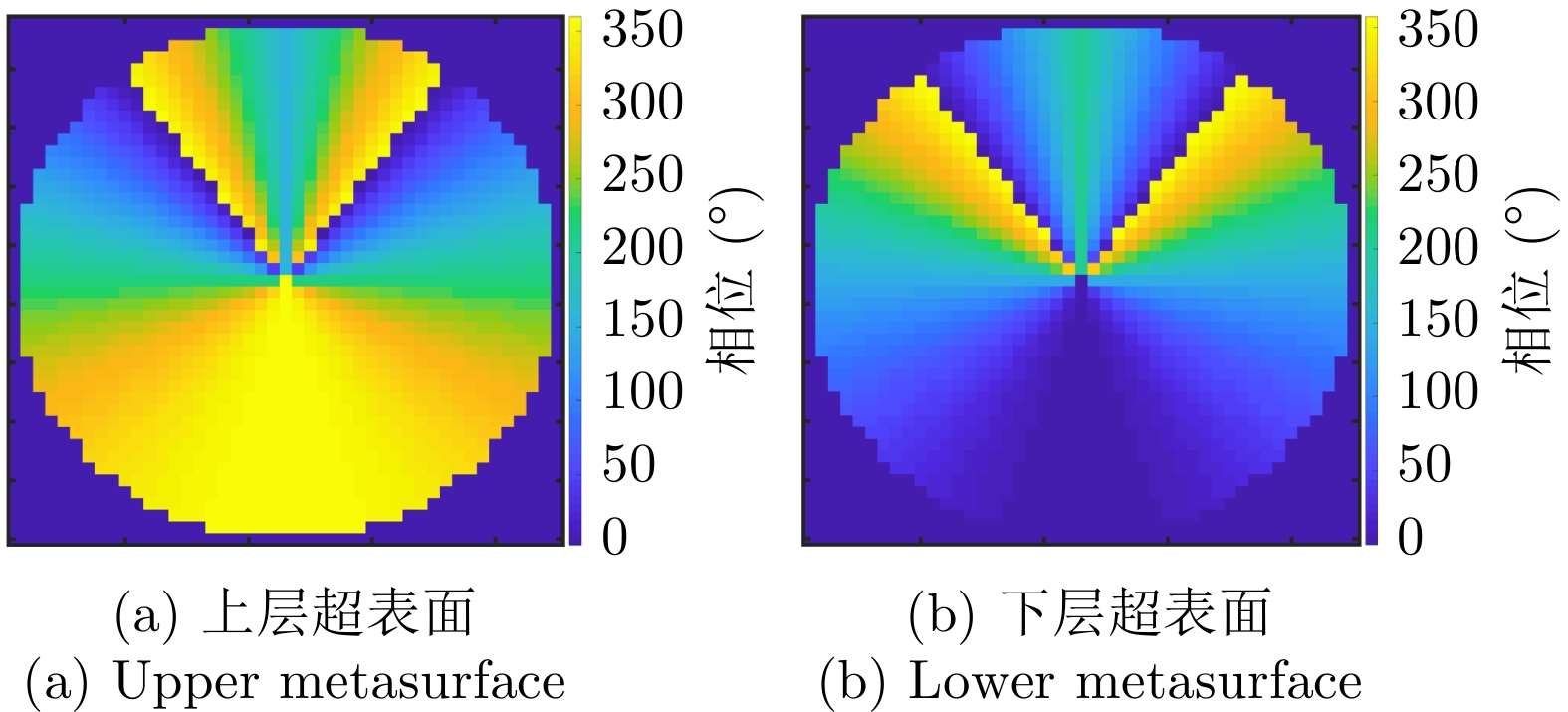
图 2 超表面单元结构透射率、透射相位仿真结果
Figure 2. Simulation results of transmissivity and transmission phase of the unit structure
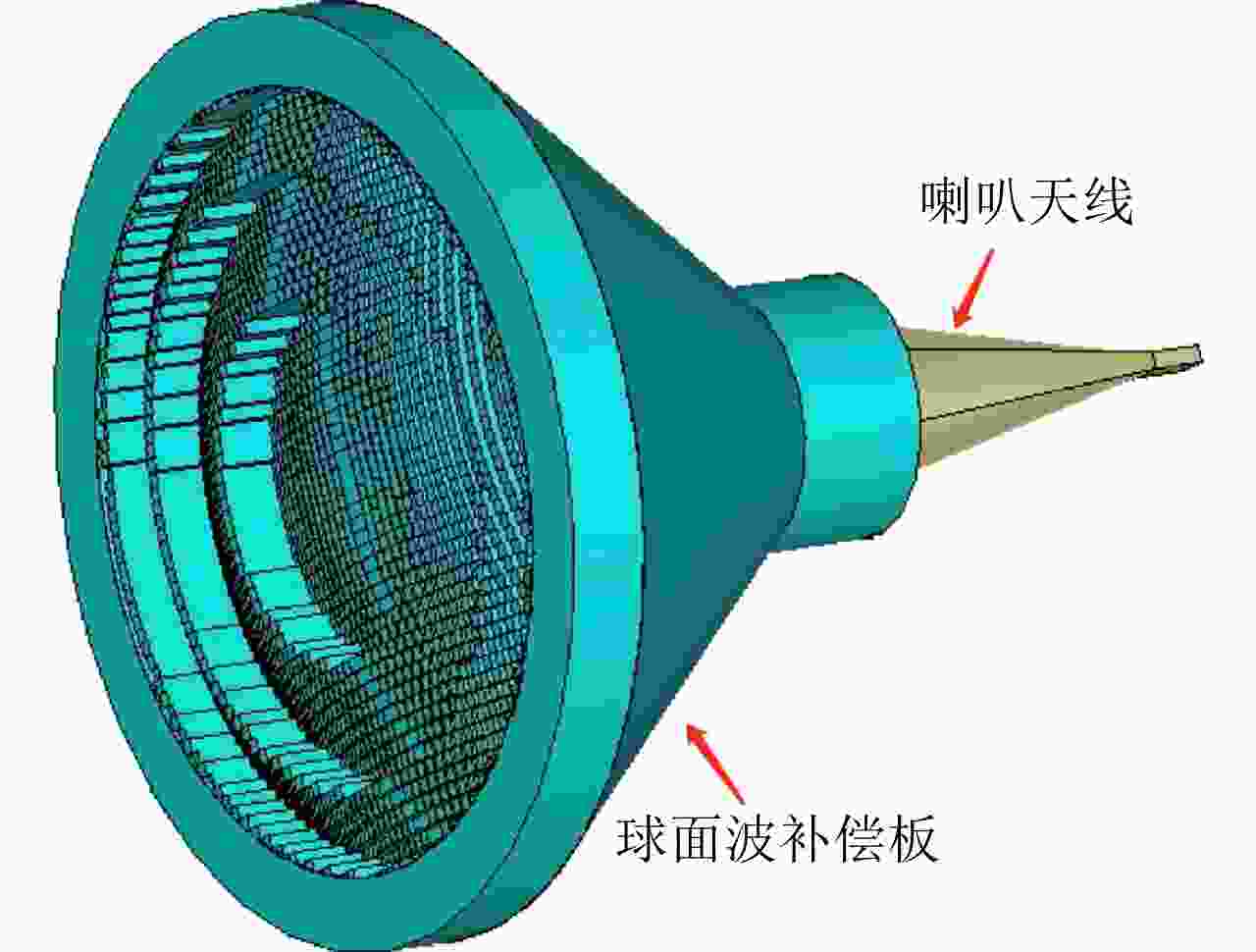
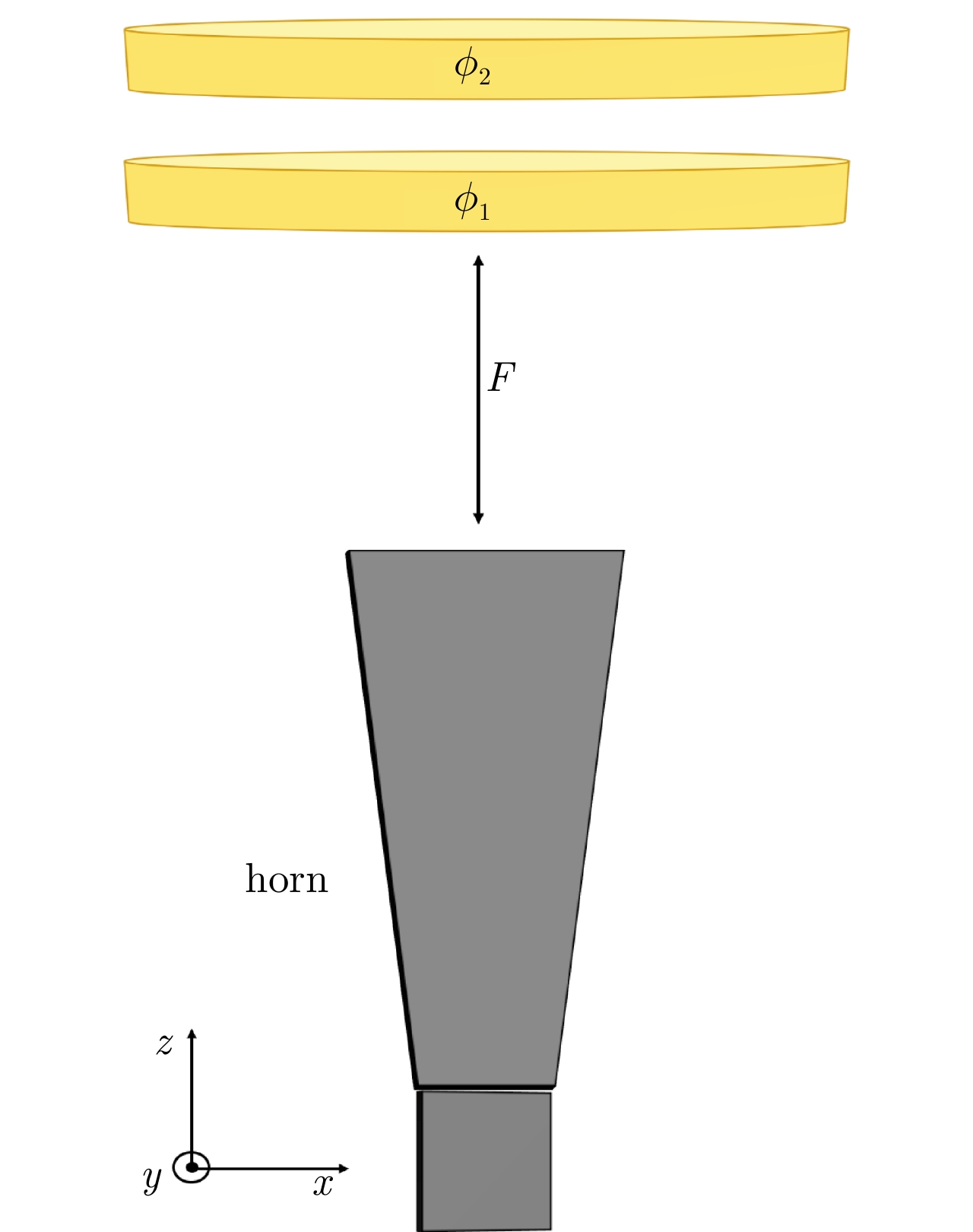
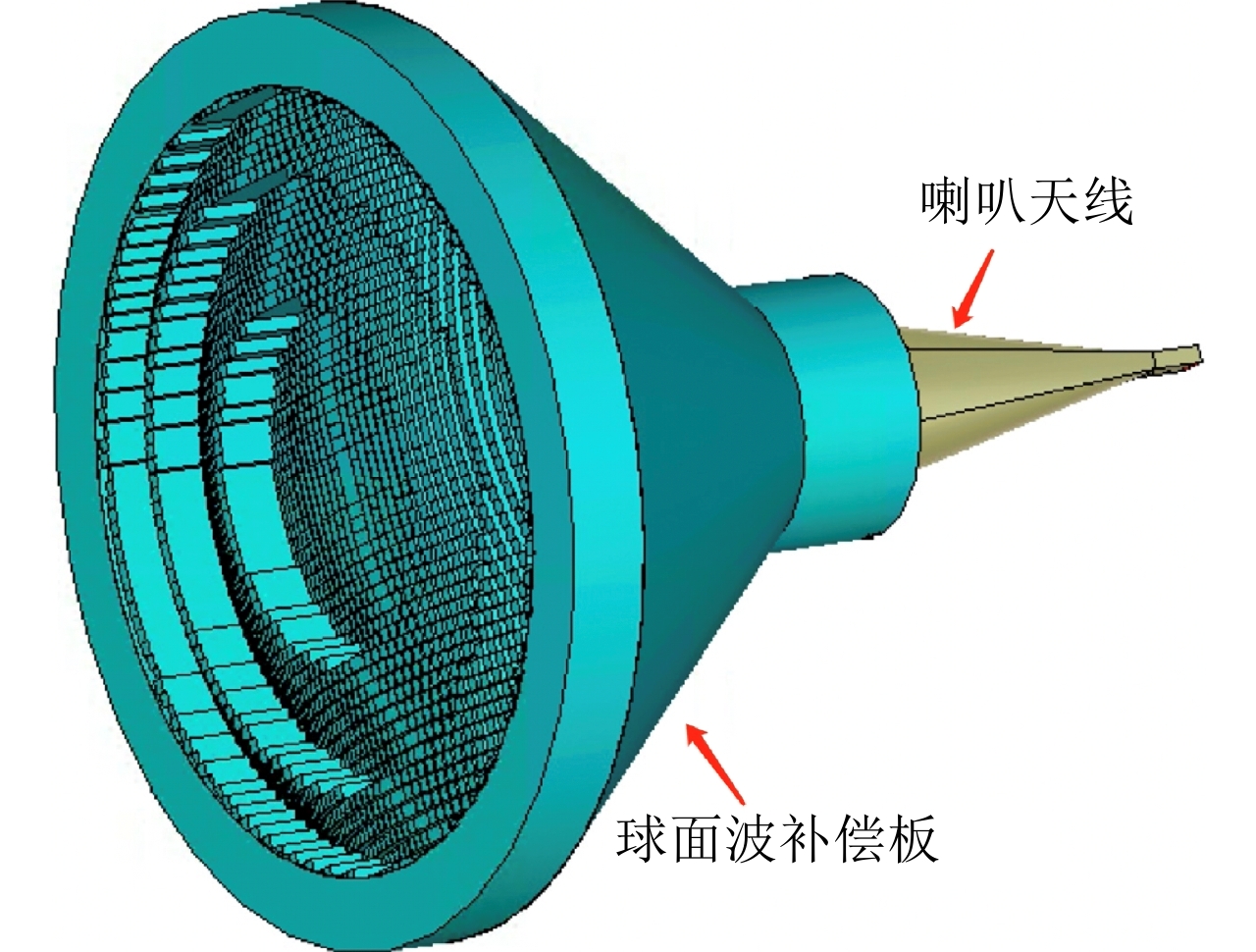
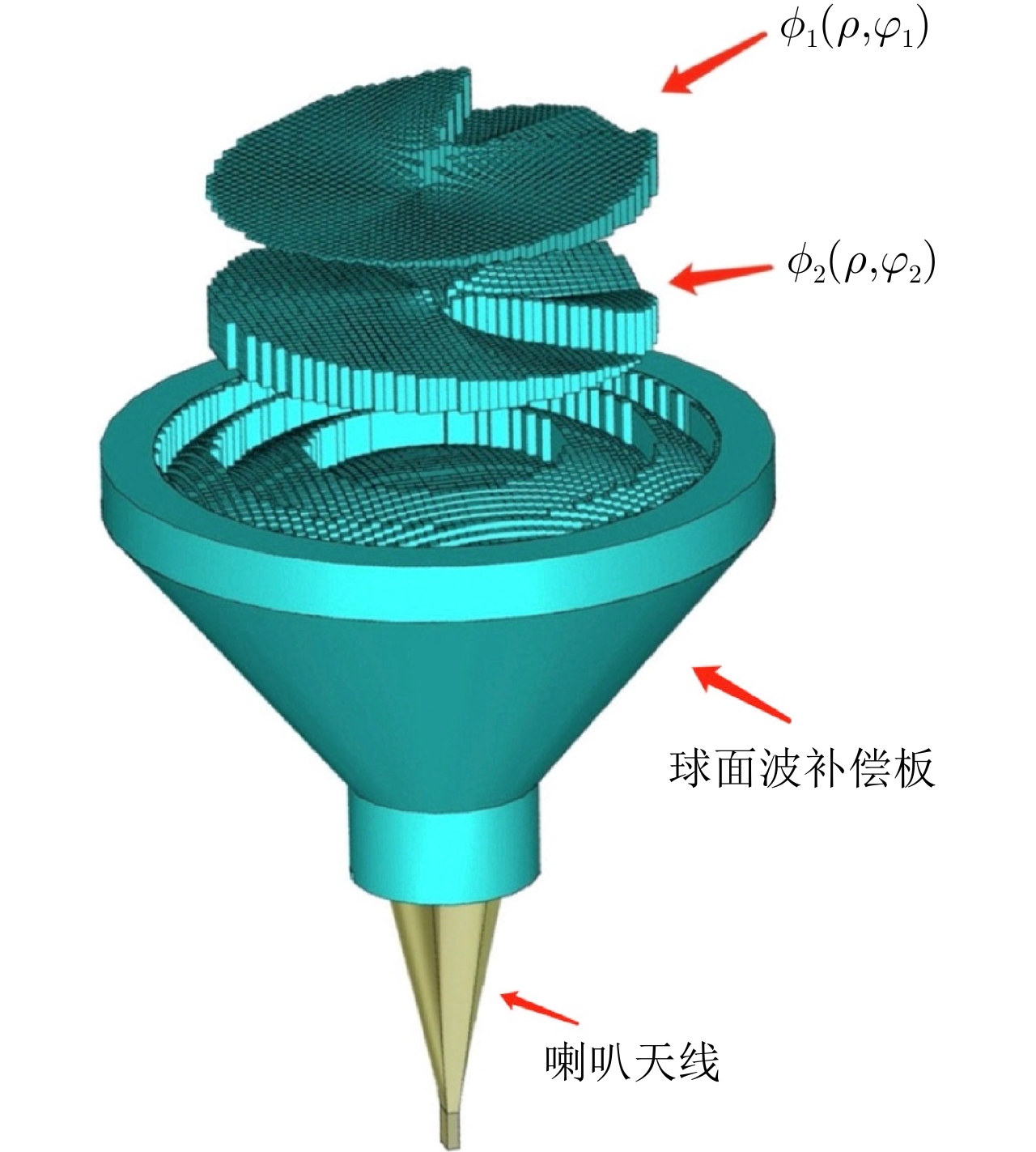
图 4 球面波补偿板-喇叭天线集成示意图
Figure 4. Integration of the compensation board and the horn antenna
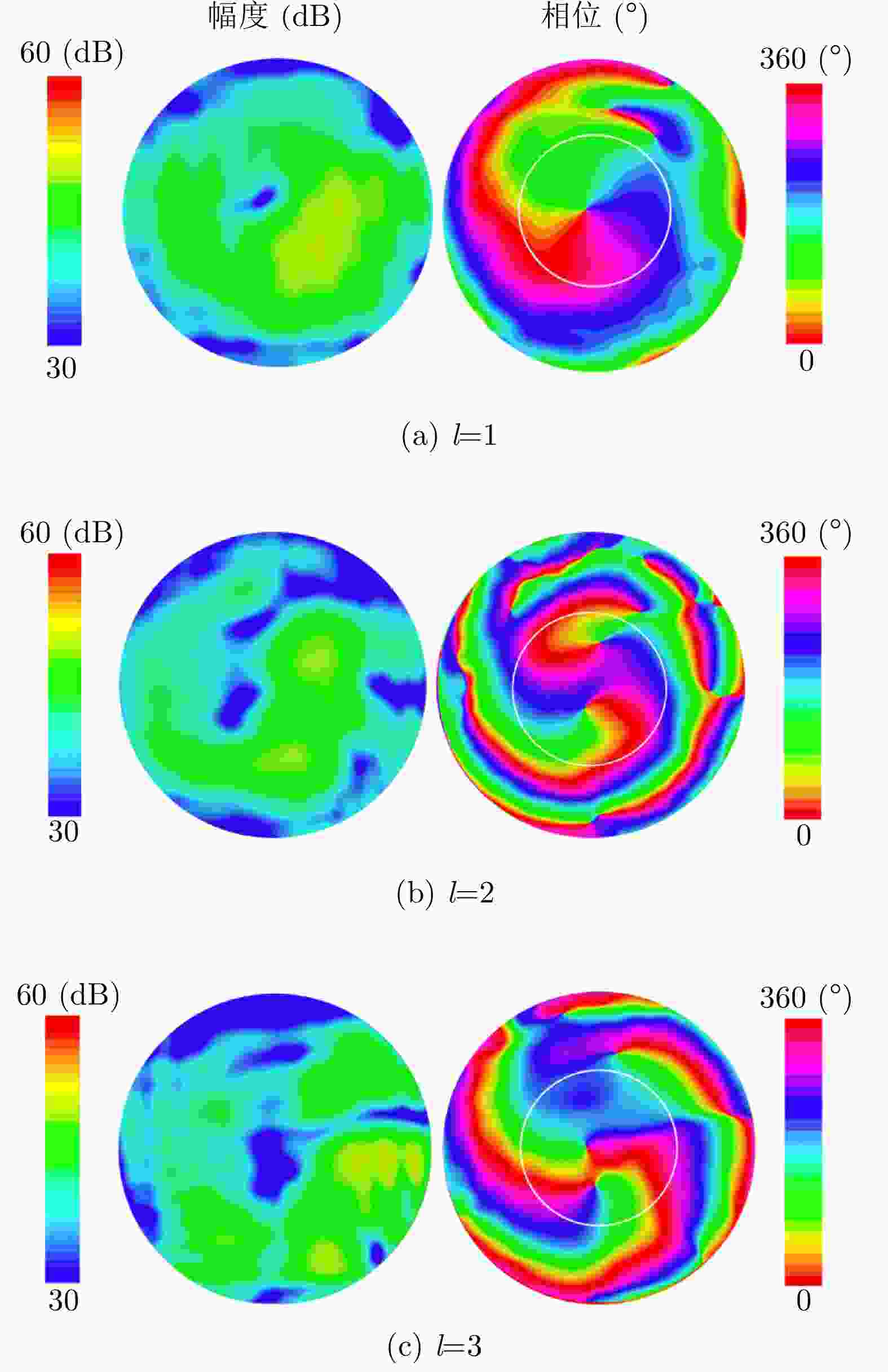
图 7 双层超表面天线不同OAM模态时仿真的幅度相位分布图
Figure 7. The simulated amplitude and phase distribution of the double-layer metasurface antenna at different OAM mode
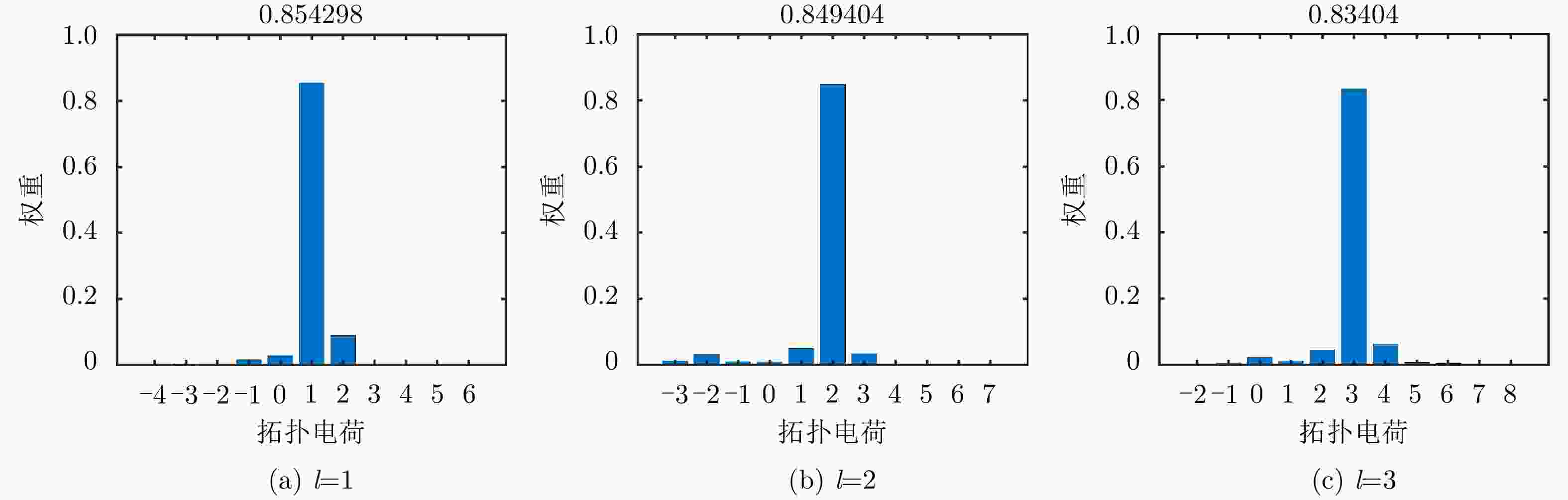
图 8 根据仿真场分布得到的不同模态OAM的纯度分析
Figure 8. The OAM purity analysis based on the simulated field distribution
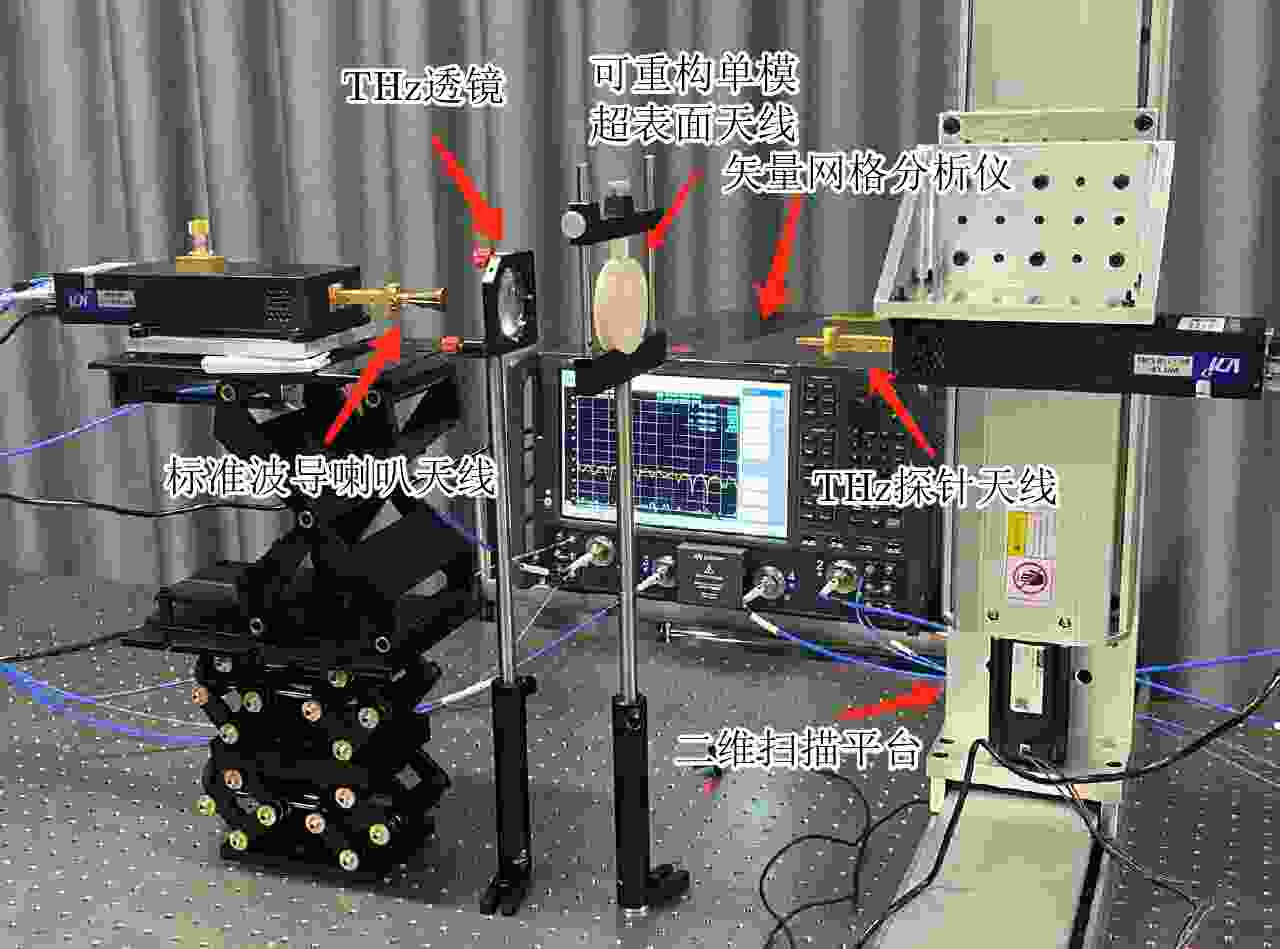
图 10 双层超表面天线实验装置
Figure 10. Experimental setup for the field scanning of the double-layer metasurface antenna
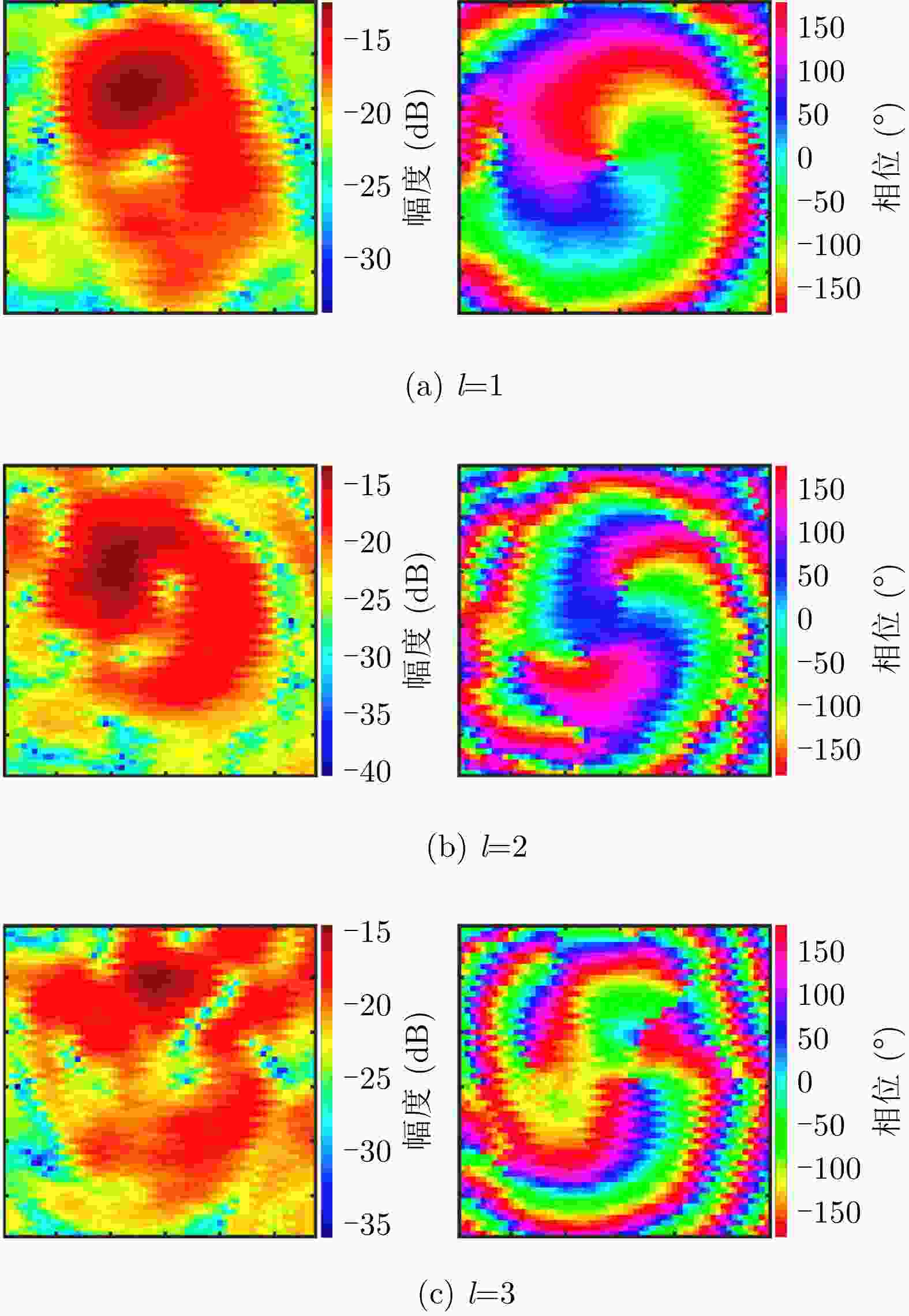
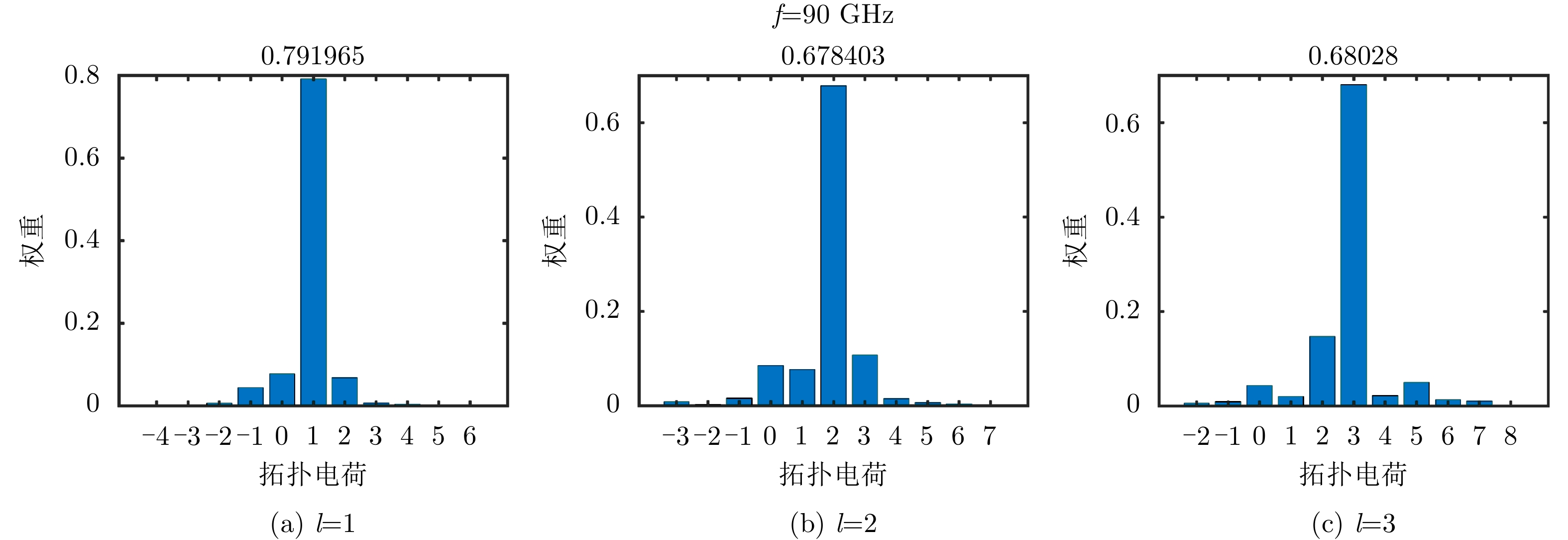
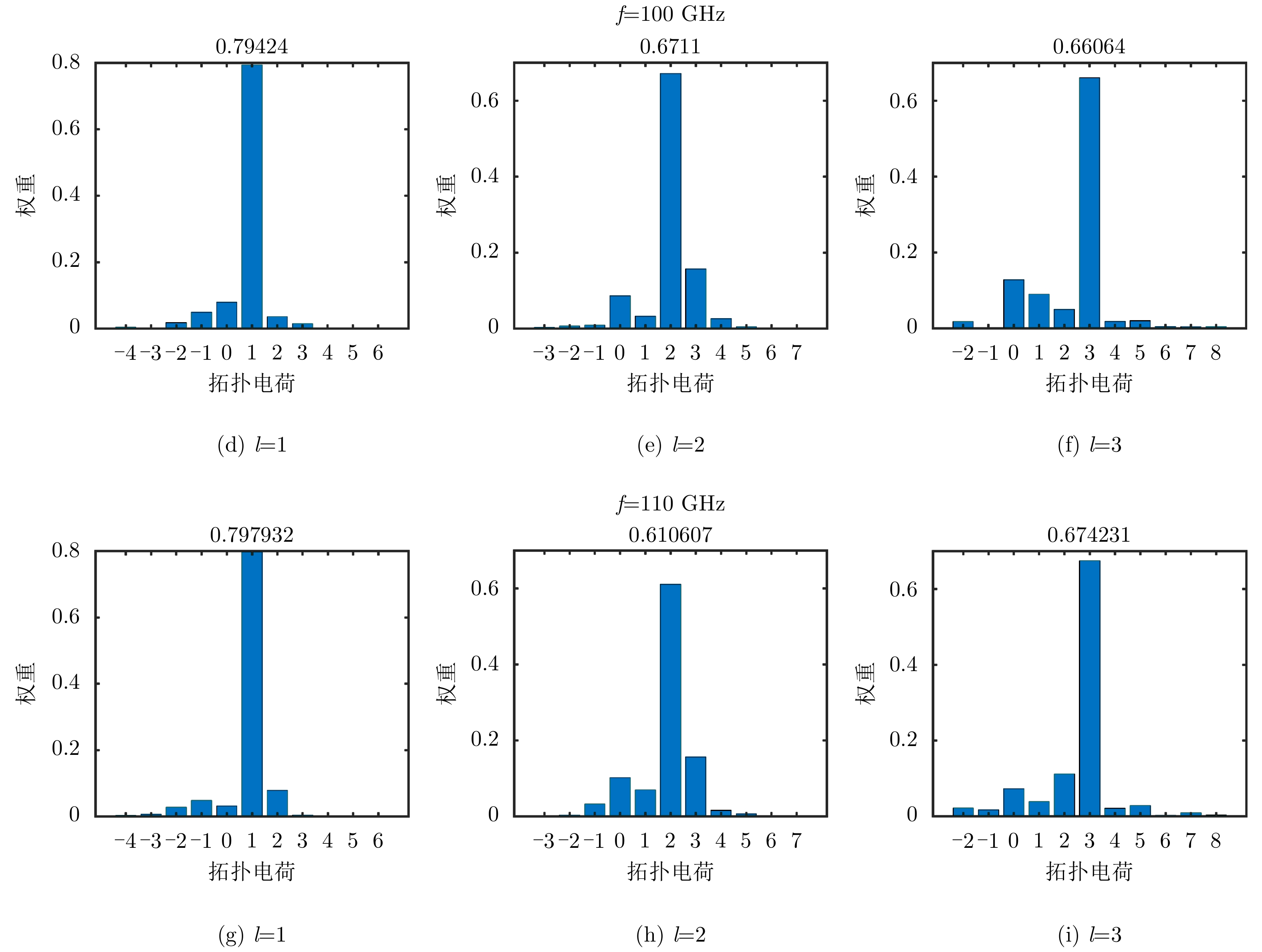
图 11 双层超表面不同重构模态时测量的幅度相位分布图
Figure 11. The measured amplitude and phase distribution of the double-layer metasurface antenna at different OAM mode
-
[1] JIA Shi, ZHANG Lu, WANG Shiwei, et al. 2 × 300 Gbit/s Line rate PS-64QAM-OFDM THz photonic-wireless transmission[J]. Journal of Lightwave Technology, 2020, 38(17): 4715–4721. doi: 10.1109/jlt.2020.2995702 [2] DING Shenghui, LI Qi, LI Yunda, et al. Continuous-wave terahertz digital holography by use of a pyroelectric array camera[J]. Optics Letters, 2011, 36(11): 1993–1995. doi: 10.1364/OL.36.001993 [3] BECK M, PLÖTZING T, MAUSSANG K, et al. High-speed THz spectroscopic imaging at ten kilohertz pixel rate with amplitude and phase contrast[J]. Optics Express, 2019, 27(8): 10866–10872. doi: 10.1364/OE.27.010866 [4] MOON S R, SUNG M, LEE J K, et al. Cost-effective photonics-based THz wireless transmission using PAM-N signals in the 0.3 THz band[J]. Journal of Lightwave Technology, 2021, 39(2): 357–362. doi: 10.1109/JLT.2020.3032613 [5] AlLEN L, BEIJERSBERGEN M W, SPREEUW R J C, et al. Orbital angular momentum of light and the transformation of Laguerre-Gaussian Laser modes[J]. Physical Review A, 1992, 45(11): 8185–8189. doi: 10.1103/PhysRevA.45.8185 [6] YAO A M and PADGETT M J. Orbital angular momentum: Origins, behavior and applications[J]. Advances in Optics and Photonics, 2011, 3(2): 161–204. doi: 10.1364/AOP.3.000161 [7] 魏旭立. 太赫兹特殊光束的产生及其在太赫兹通信和成像中的应用[D]. [博士论文], 华中科技大学, 2016.WEI Xuli. Generation of terahertz exotic beams and their application in terahertz communication and imaging systems[D]. [Ph. D. dissertation], Huazhong University of Science & Technology, 2016. [8] BAI Qiang, TENNANT A, and ALLEN B. Experimental circular phased array for generating OAM radio beams[J]. Electronics Letters, 2014, 50(20): 1414–1415. doi: 10.1049/el.2014.2860 [9] TENNANT A and ALLEN B. Generation of OAM radio waves using circular time-switched array antenna[J]. Electronics Letters, 2012, 48(21): 1365–1366. doi: 10.1049/el.2012.2664 [10] TURNBULL G A, ROBERTSON D A, SMITH G M, et al. The generation of free-space Laguerre-Gaussian modes at millimetre-wave frequencies by use of a spiral phaseplate[J]. Optics Communications, 1996, 127(4/6): 183–188. doi: 10.1016/0030-4018(96)00070-3 [11] CHEN Yiling, ZHENG Shilie, LI Yue, et al. A Flat-lensed spiral phase plate based on phase-shifting surface for generation of millimeter-wave OAM beam[J]. IEEE Antennas and Wireless Propagation Letters, 2015, 15: 1156–1158. doi: 10.1109/LAWP.2015.2497243 [12] HUI Xiaonan, ZHENG Shilie, HU Yiping, et al. Ultralow reflectivity spiral phase plate for generation of millimeter-wave OAM beam[J]. IEEE Antennas and Wireless Propagation Letters, 2015, 14: 966–969. doi: 10.1109/LAWP.2014.2387431 [13] 李雄, 马晓亮, 罗先刚. 超表面相位调控原理及应用[J]. 光电工程, 2017, 44(3): 255–275. doi: 10.3969/j.issn.1003-501X.2017.03.001LI Xiong, MA Xiaoliang, and LUO Xiangang. Principles and applications of metasurfaces with phase modulation[J]. Opto-Electronic Engineering, 2017, 44(3): 255–275. doi: 10.3969/j.issn.1003-501X.2017.03.001 [14] WU Gengbo, CHAN Kafai, QU Shiwei, et al. Orbital angular momentum (OAM) mode-reconfigurable discrete dielectric lens operating at 300 GHz[J]. IEEE Transactions on Terahertz Science and Technology, 2020, 10(5): 480–489. doi: 10.1109/TTHZ.2020.2984451 [15] MIYAMOTO K, SUIZU K, AKIBA T, et al. Direct observation of the topological charge of a terahertz vortex beam generated by a Tsurupica spiral phase plate[J]. Applied Physics Letters, 2014, 104(26): 261104. doi: 10.1063/1.4886407 [16] YU Nanfang, GENEVET P, KATS M A, et al. Light propagation with phase discontinuities: Generalized laws of reflection and refraction[J]. Science, 2011, 334(6054): 333–337. doi: 10.1126/science.1210713 [17] MENG Zankui, SHI Yan, WEI Wenyue, et al. Graphene- based metamaterial transmitarray antenna design for the generation of tunable orbital angular momentum vortex electromagnetic waves[J]. Optical Materials Express, 2019, 9(9): 3709–3716. doi: 10.1364/OME.9.003709 [18] WANG Ling, YANG Yang, LI Shufang, et al. Terahertz reconfigurable metasurface for dynamic non-diffractive orbital angular momentum beams using vanadium dioxide[J]. IEEE Photonics Journal, 2020, 12(3): 4600712. doi: 10.1109/JPHOT.2020.3000779 [19] WANG Ling, YANG Yang, DENG Li, et al. Vanadium dioxide embedded frequency reconfigurable metasurface for multi-dimensional multiplexing of terahertz communication[J]. Journal of Physics D:Applied Physics, 2021, 54(25): 255003. doi: 10.1088/1361-6463/abf166 [20] YANG Qili, WANG Yan, LIANG Lanju, et al. Broadband transparent terahertz vortex beam generator based on thermally tunable geometric metasurface[J]. Optical Materials, 2021, 121: 111574. doi: 10.1016/j.optmat.2021.111574 [21] FORMLABS[EB/OL]. https://formlabs.com, 2020. [22] MAHMOULI F E and WALKER S. Orbital angular momentum generation in a 60 GHz wireless radio channel[C]. 2012 20th Telecommunications Forum (TELFOR). Belgrade, Serbia, 2012: 315–318. [23] WANG Yicheng, ZHANG Huajin, YU Haohai, et al. Light propagation in an optically active plate with topological charge[J]. Applied Physics Letters, 2012, 101(17): 171114. doi: 10.1063/1.4764546 [24] SUN Changzheng, ZHANG Juan, XIONG Bing, et al. Analysis of OAM mode purity of integrated optical vortex beam emitters[J]. IEEE Photonics Journal, 2017, 9(1): 1–7. doi: 10.1109/JPHOT.2017.265272 -





 下载:
下载:





计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

