
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
SARMV3D-1.0: Synthetic Aperture Radar Microwave Vision 3D Imaging Dataset(in English)
-
摘要:
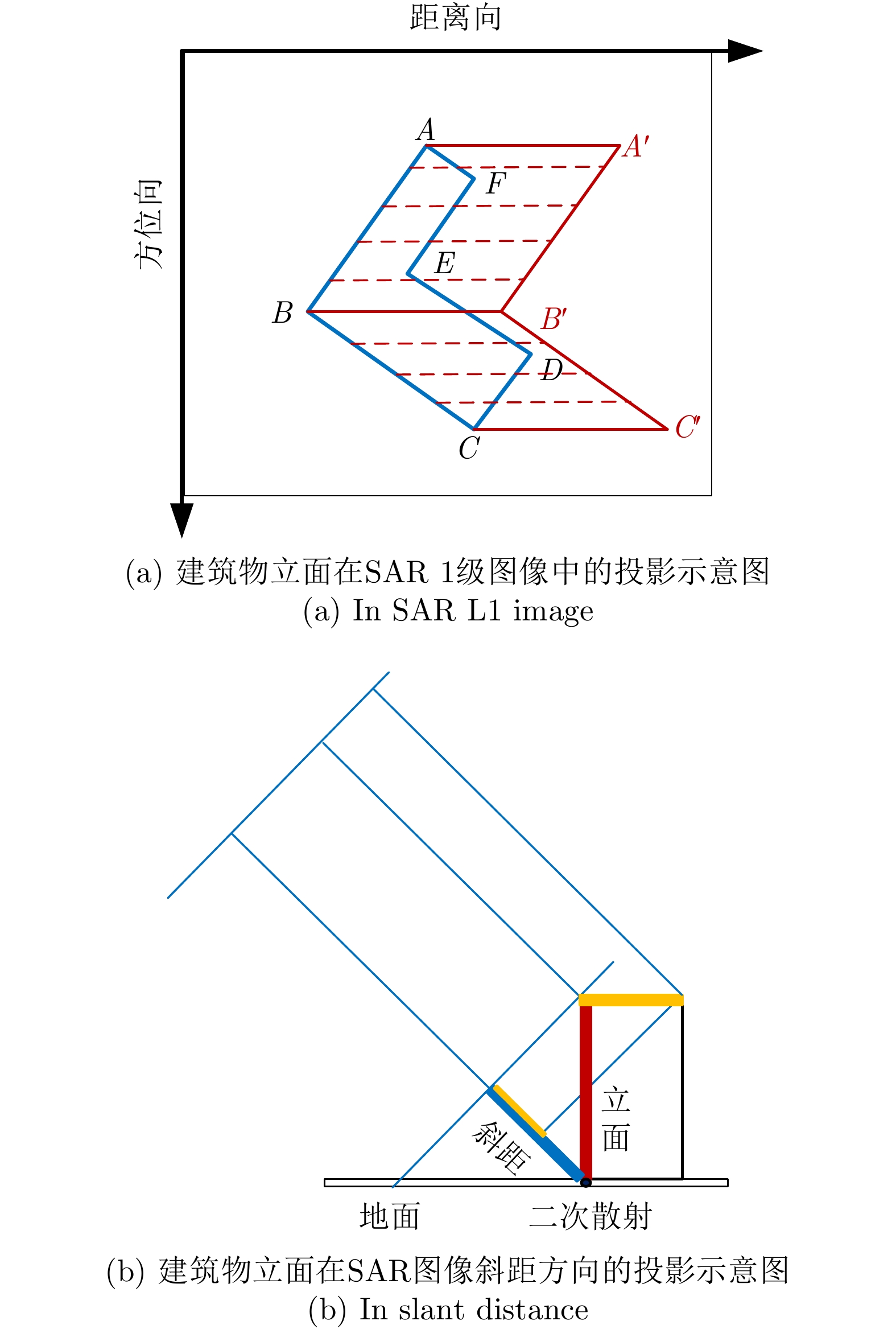
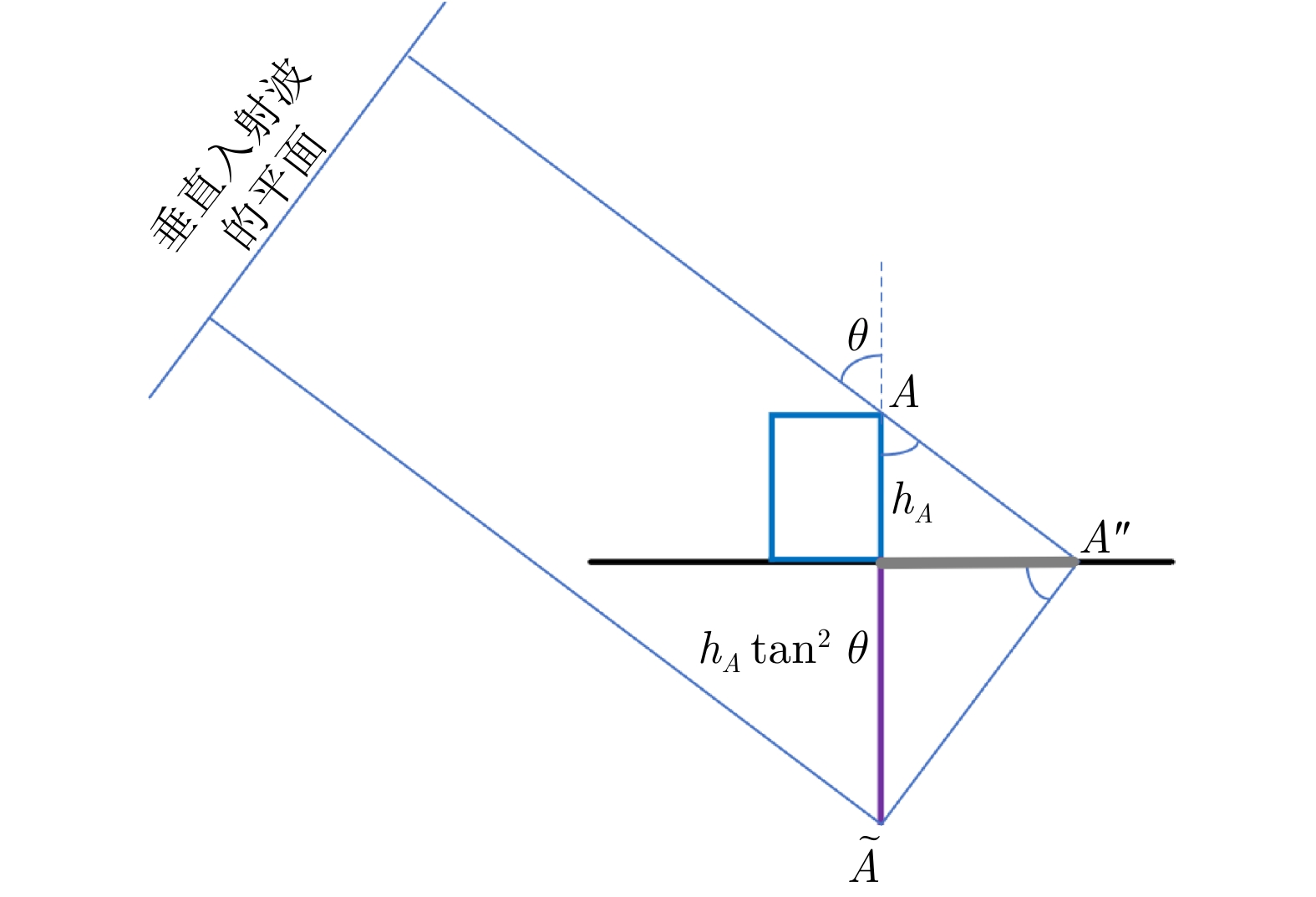
三维成像是合成孔径雷达技术发展的前沿趋势之一,目前的SAR三维成像体制主要包括层析和阵列干涉,但面临数据采集周期长或系统过于复杂的问题,为此该文提出了SAR微波视觉三维成像的新技术思路,即充分挖掘利用SAR微波散射机制和图像视觉语义中蕴含的三维线索,并将其与SAR成像模型有效结合,以显著降低SAR三维成像的系统复杂度,实现高效能、低成本的SAR三维成像。为推动SAR微波视觉三维成像理论技术的发展,在国家自然科学基金重大项目支持下,拟构建一个比较完整的SAR微波视觉三维成像数据集。该文概述了该数据集的构成和构建规划,并给出了第一批发布数据(SARMV3D-1.0)的组成和信息描述方式、数据集制作的方法,为该数据集的共享和应用提供支撑。
Abstract:Three-dimensional (3D) imaging is one of the leading trends in the development of Synthetic Aperture Radar (SAR) technology. The current SAR 3D imaging system mainly includes tomography and array interferometry, both with drawbacks of either long acquisition cycle or too much system complexity. Therefore, a novel framework of SAR microwave vision 3D imaging is proposed, which is to effectively combine the SAR imaging model with various 3D cues contained in SAR microwave scattering mechanism and the perceptual semantics in SAR images, so as to significantly reduce the system complexity, and achieve high-efficiency and low-cost SAR 3D imaging. In order to promote the development of SAR microwave vision 3D imaging theory and technology, a comprehensive SAR microwave vision 3D imaging dataset is planned to be constructed with the support of NSFC major projects. This paper outlines the composition and construction plan of the dataset, and gives detailed composition and information description of the first version of published data and the method of making the dataset, so as to provide some helpful support for SAR community.
-
Key words:
- SAR 3D imaging /
- Microwave vision /
- SAR dataset /
- SAR image semantic segmentation /
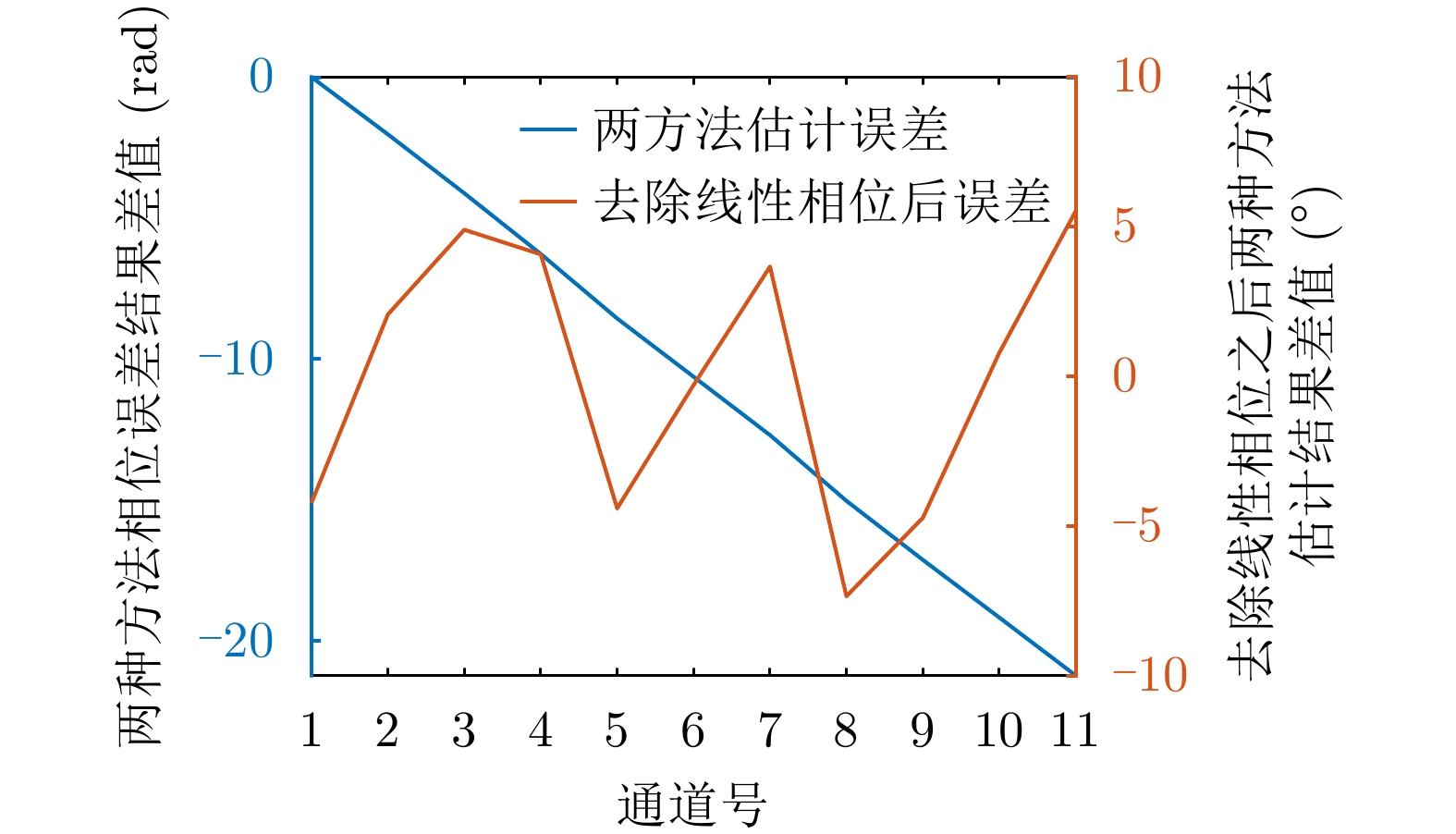
- Array InSAR
-
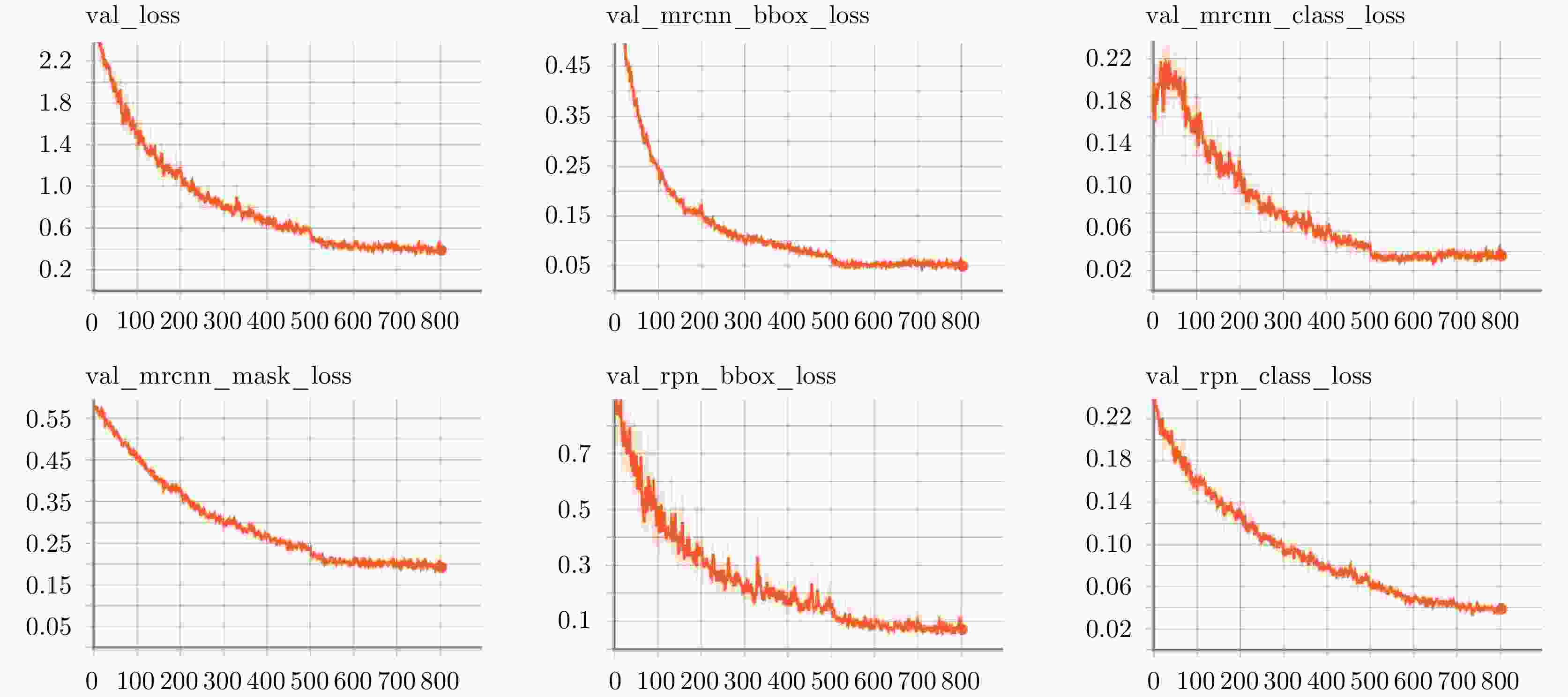
图 10 使用Mask RCNN在SARMV3D-BIS 1.0(S)上的训练过程中验证集损失变化曲线
Figure 10. Loss curve in the train process on the SARMV3D-BIS 1.0(S) validation set by using Mask RCNN

图 11 使用Mask RCNN在SARMV3D-BIS 1.0(S)验证集上的实例分割结果
Figure 11. Results of instance segmentation on the SARMV3D-BIS 1.0(S) validation set by using Mask RCNN
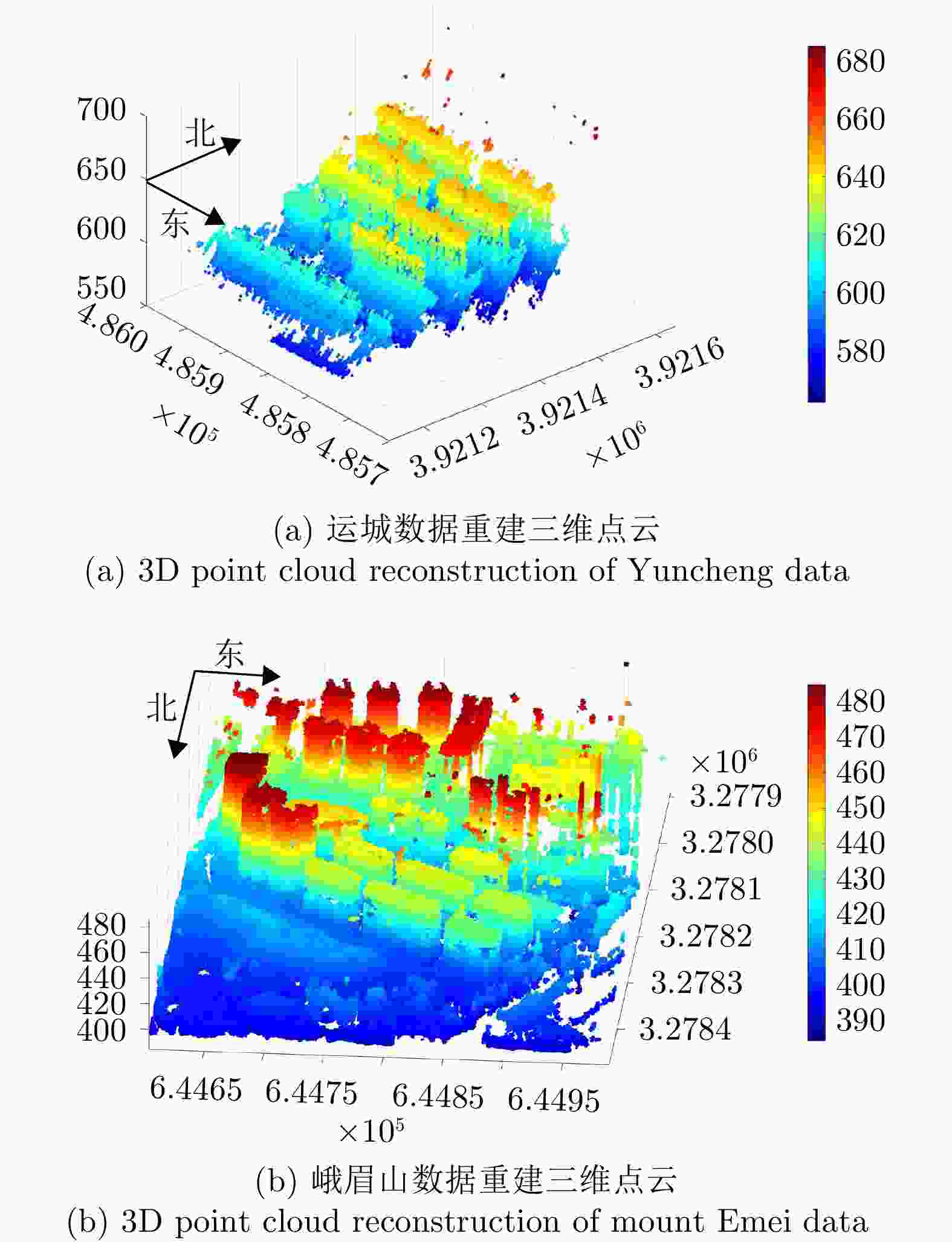
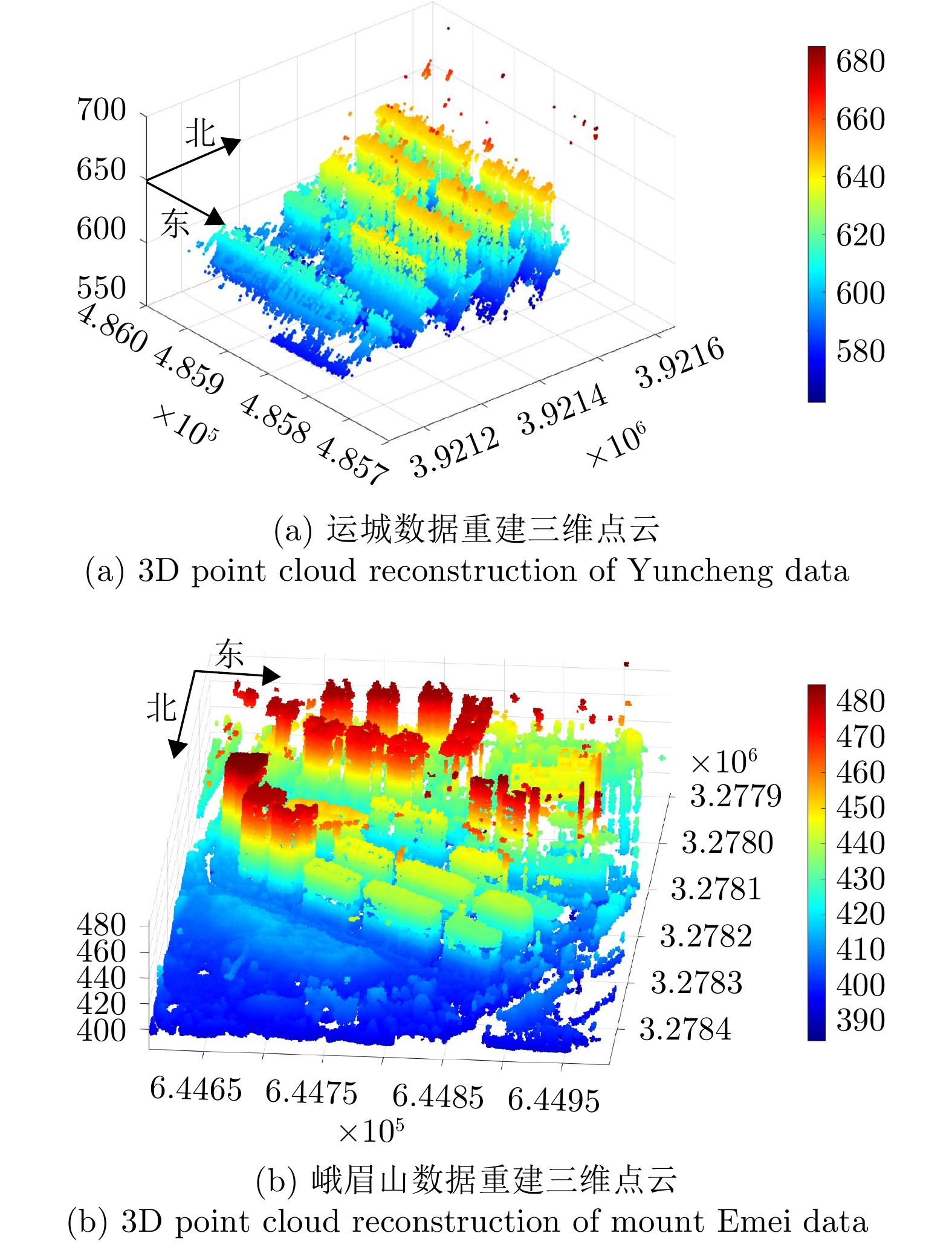
图 19 SARMV3D Imaging数据集三维成像结果
Figure 19. 3D imaging results of SARMV3D Imaging dataset
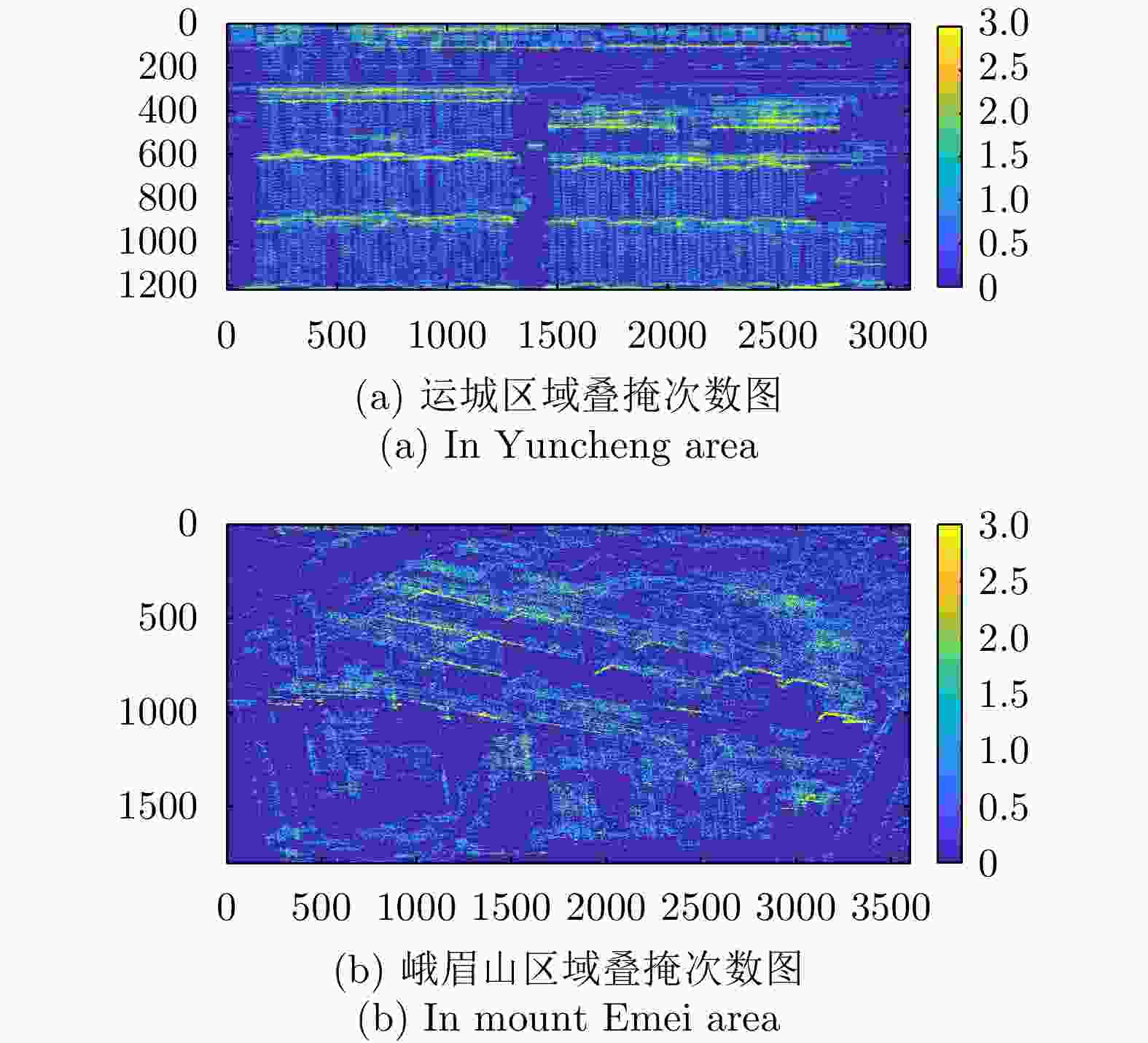
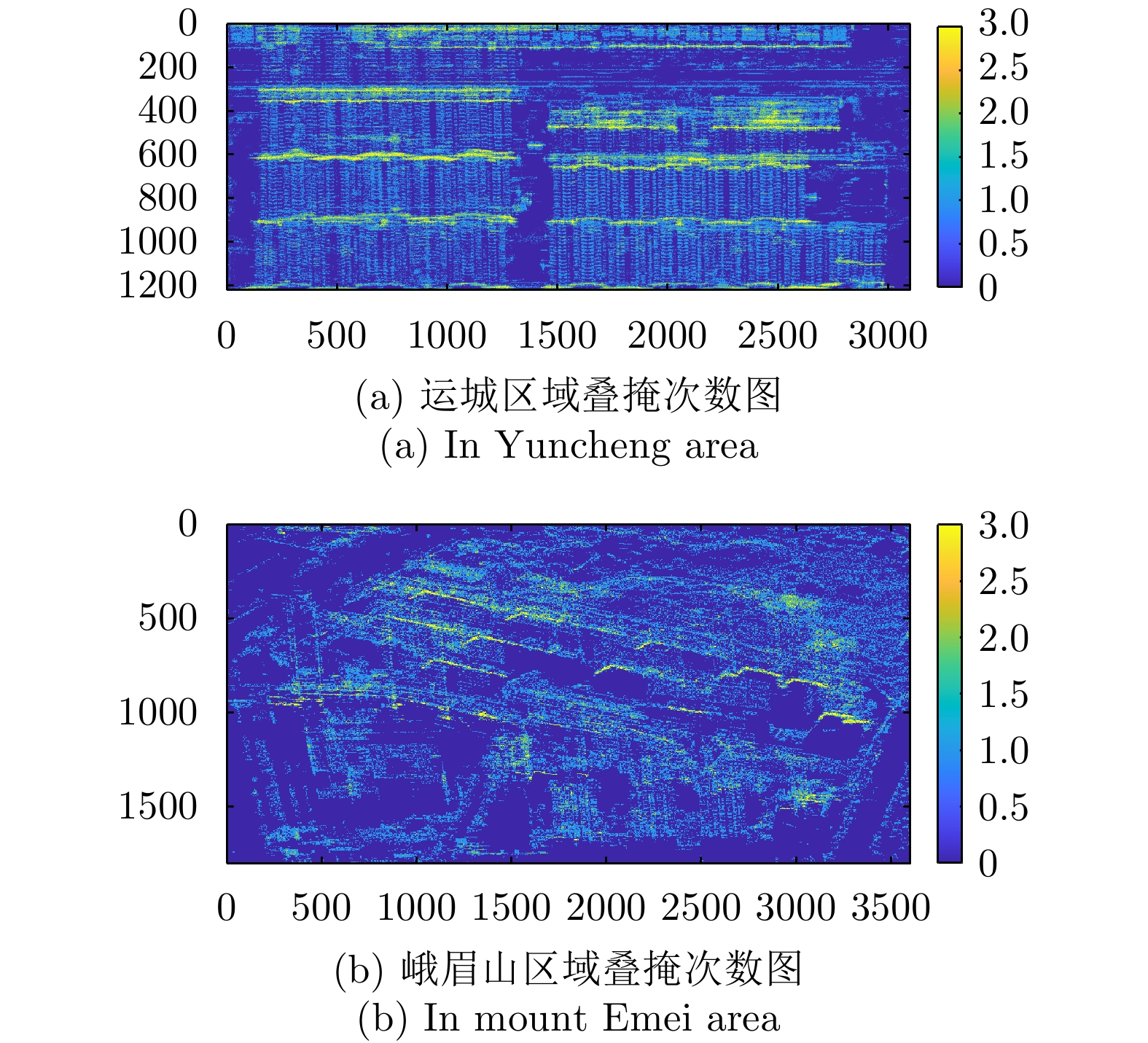
图 20 SARMV3D Imaging数据集区域叠掩次数图
Figure 20. Overlay times map of SARMV3D Imaging dataset

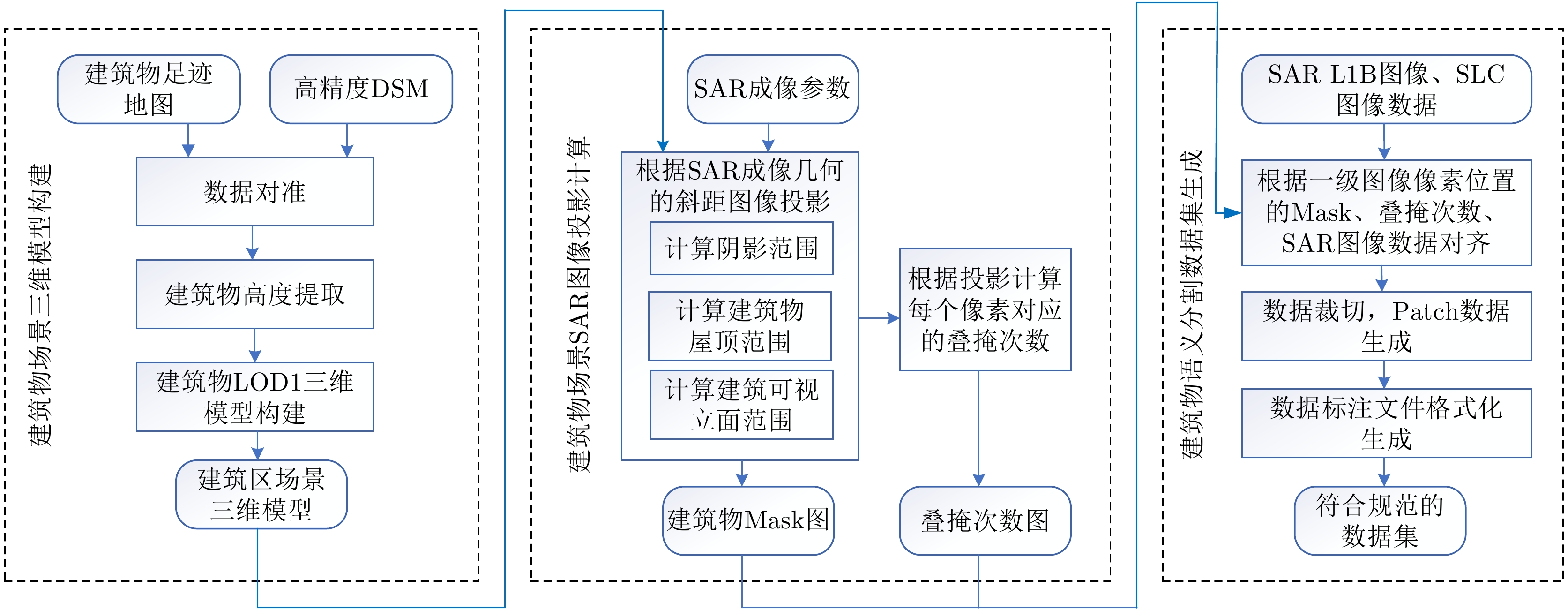
1 SAR微波视觉三维成像数据集发布网页
1. Release webpage of Synthetic Aperture Radar Microwave Vision 3D Imaging Dataset
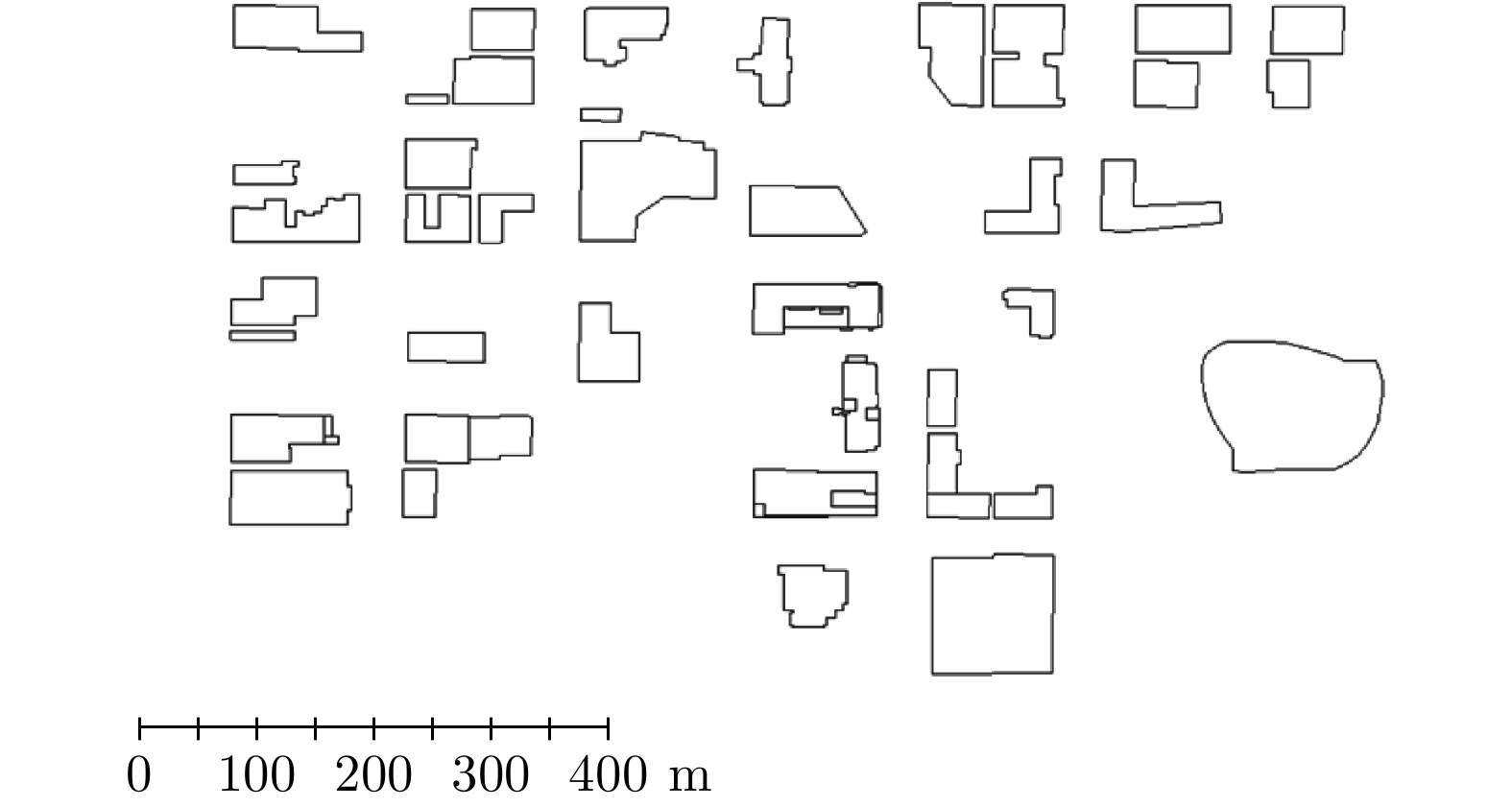
表 1 SAR建筑物语义分割数据集构成
Table 1. Composition of SARMV3D-BIS dataset
序号 内容 文件后缀 说明 1 1B级图像切片 *L1B.jpgf 切片尺寸 1024 ×1024
uint8量化2 SLC图像切片 *L1A.dat 切片尺寸 1024 ×1024 ,与1B图像严格对应,int16量化,实部虚部交替存储3 叠掩次数图 *Layover.jpgf 切片每个像素对应的叠掩次数,uint8量化 4 Mask图像 *Mask.jpgf 每个切片对应的建筑物分割可视化结果图像,黑色表示地面、红色表示立面、白色表示屋顶、蓝色表示阴影,如图2所示 5 标注文件 *.json 训练、测试和验证各一个JSON文件,详见3.2.3小节  下载: 导出CSV
下载: 导出CSV
表 2 SARMV3D-BIS数据集的标注文件
Table 2. Annotation file of SARMV3D-BIS dataset
层级1字段 层级2字段 说明 info description 描述数据集基本信息 url 数据集的网络链接 version 数据集版本 contributor 数据集贡献的单位和团队等信息 images file_name 对应图像切片的文件名,包含切片编号 height 图像切片的高度尺寸 width 图像切片的宽度尺寸 date_captured 标注信息生成时间 annotations instance_id 建筑实例的唯一编号 segmentation 实例分割信息,见表3 area 建筑物投影于图像上所占的像素面积(不含阴影区域) image_id 该建筑实例对应的图像切片编号 bbox 包括[X,Y,W,H]四个数值,[X,Y]为该建筑实例的外接矩形在对应图像切片中的左上角像素,[W,H]为外接矩形的宽度及高度
下载: 导出CSV
表 3 segmentation字段信息
Table 3. Information of ‘segmentation’ field
层级2字段 层级3字段 说明 segmentation category_id 1;表示立面 mask [X1,Y1], [X2,Y2], ···, [Xn,Yn],为立面多边形的角点像素坐标 category_id 2;表示屋顶 mask [X1,Y1], [X2,Y2], ···,[Xn,Yn],为屋顶多边形的角点像素坐标 category_id 3;表示阴影 mask [X1,Y1], [X2,Y2], ···, [Xn,Yn],为阴影多边形的角点像素坐标
下载: 导出CSV
表 4 使用Mask RCNN在SARMV3D-BIS 1.0(S)验证集上的实例分割损失
Table 4. Loss of instance segmentation on the SARMV3D-BIS 1.0(S) validation set by using Mask RCNN
backbone LOSS $ {\rm{LOSS}}_{{\rm{mrcnn}}}^{{\rm{bb}}} $ $ {\rm{LOSS}}_{{\rm{mrcnn}}}^{{\rm{cls}}} $ $ {\rm{LOSS}}_{{\rm{mrcnn}}}^{\rm{m}} $ $ {\rm{LOSS}}_{{\rm{RPN}}}^{{\rm{bb}}}$ ${\rm{LOSS}}_{{\rm{RPN}}}^{{\rm{cls}}}$ ResNet-50-FPN 0.3785 0.0478 0.0405 0.1890 0.0667 0.0346 ResNet-101-FPN 0.3473 0.0422 0.0359 0.1856 0.0498 0.0338
下载: 导出CSV
表 5 使用Mask RCNN在SARMV3D-BIS 1.0(S)验证集上的检测框mAP
Table 5. mAP of bounding box on the SARMV3D-BIS 1.0(S) validation set by using Mask RCNN
backbone APbb $ {\rm{AP}}_{{\rm{50}}}^{{\rm{bb}}} $ $ {\rm{AP}}_{{\rm{75}}}^{{\rm{bb}}} $ $ {\rm{AP}}_{{\rm{S}}}^{{\rm{bb}}} $ $ {\rm{AP}}_{{\rm{M}}}^{{\rm{bb}}} $ $ {\rm{AP}}_{{\rm{L}}}^{{\rm{bb}}} $ ResNet-50-FPN 16.9 29.2 17.4 23.9 23.2 15.9 ResNet-101-FPN 19.1 30.4 22.5 27.4 28.2 16.1
下载: 导出CSV
表 6 使用Mask RCNN在SARMV3D-BIS 1.0(S)验证集上的掩膜mAP
Table 6. mAP of mask on the SARMV3D-BIS 1.0(S) validation set by using Mask RCNN
backbone APm $ {\rm{AP}}_{{\rm{50}}}^{\rm{m}} $ ${\rm{AP}}_{{\rm{75}}}^{\rm{m}} $ $ {\rm{AP}}_{{\rm{S}}}^{\rm{m}} $ $ {\rm{AP}}_{{\rm{M}}}^{\rm{m}} $ $ {\rm{AP}}_{{\rm{L}}}^{\rm{m}} $ ResNet-50-FPN 14.4 27.0 14.7 23.7 18.8 13.7 ResNet-101-FPN 16.8 29.5 18.6 28.6 24.1 14.5
下载: 导出CSV
表 7 SARMV3D Imaging数据集信息
Table 7. Information of SARMV3D Imaging dataset
地区 通道数 带宽 图像尺寸 极化 山西运城 8 500 MHz 3100 (方位)×1220 (距离)HH 四川峨眉山 12 810 MHz 3600 (方位)×1800 (距离)HH
下载: 导出CSV
表 8 SARMV3D Imaging数据集构成
Table 8. Composition of SARMV3D Imaging dataset
文件夹名 文件名后缀 说明 运城、峨眉山 *.jpg 1B级SAR图像,uint16量化 *ch1~chN.dat SLC数据,float32格式,实部虚部交替存放 *3Dresult.dat 三维成像结果数据,float32格式,5个一组,记录每个散射点(X, Y、高度、散射系数实部及散射系数虚部) *Layover.jpg 叠掩次数图,uint8格式 *AuxPara.dat 三维成像所需辅助数据,数据格式见辅助数据说明文件 *readme.pdf 说明文件,包括各个通道天线相位中心相对位置等处理所需要的信息
下载: 导出CSV
-
[1] MAGGIORI E, TARABALKA Y, CHARPIAT G, et al. Can semantic labeling methods generalize to any city? The Inria aerial image labeling benchmark[C]. IEEE International Geoscience and Remote Sensing Symposium, Fort Worth, USA, 2017: 3226–3229. [2] 季顺平, 魏世清. 遥感影像建筑物提取的卷积神经元网络与开源数据集方法[J]. 测绘学报, 2019, 48(4): 448–459. doi: 10.11947/j.AGCS.2019.20180206.JI Shunping and WEI Shiqing. Building extraction via convolutional neural networks from an open remote sensing building dataset[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(4): 448–459. doi: 10.11947/j.AGCS.2019.20180206. [3] https://spacenet.ai/sn6-challenge/. [4] LE S B, YOKOYA N, HAENSCH R, et al. 2019 IEEE GRSS data fusion contest: Large-scale semantic 3D reconstruction [technical committees][J]. IEEE Geoscience and Remote Sensing Magazine, 2019, 7(4): 33–36. doi: 10.1109/MGRS.2019.2949679. [5] ZHANG Guo, QIANG Qiang, LUO Ying, et al. Application of RPC model in orthorectification of spaceborne SAR imagery[J]. The Photogrammetric Record, 2012, 27(137): 94–110. doi: 10.1111/j.1477-9730.2011.00667.x. [6] ZHANG Guo, FEI Wenbo, LI Zhen, et al. Evaluation of the RPC model for spaceborne SAR imagery[J]. Photogrammetric Engineering &Remote Sensing, 2010, 76(6): 727–733. [7] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 740–755. [8] HE Kaiming, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]. IEEE International Conference on Computer Vision, Venice, Italy, 2017: 2980–2988. [9] WANG Xinlong, ZHANG Rufeng, KONG Tao, et al. SOLOv2: Dynamic, faster and stronger[OL]. https://arxiv.org/abs/2003.10152v2. 2020. [10] BOLYA D, ZHOU Chong, XIAO Fanyi, et al. YOLACT: Real-time instance segmentation[C]. IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 2019: 9156–9165. [11] https://cocodataset.org/#detection-eval. [12] Everingham M, Gool L V, Williams C K I, et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303–338. [13] ERTIN E, AUSTIN C D, SHARMA S, et al. GOTCHA experience report: Three-dimensional SAR imaging with complete circular apertures[C]. Proceedings of SPIE, Algorithms for Synthetic Aperture Radar Imagery XIV, Orlando, USA, 2007: 656802. [14] 丁赤飚, 仇晓兰, 徐丰, 等. 合成孔径雷达三维成像——从层析、阵列到微波视觉[J]. 雷达学报, 2019, 8(6): 693–709. doi: 10.12000/JR19090.DING Chibiao, QIU Xiaolan, XU Feng, et al. Synthetic aperture radar three-dimensional imaging—from TomoSAR and array InSAR to microwave vision[J]. Journal of Radars, 2019, 8(6): 693–709. doi: 10.12000/JR19090. [15] 卜运成. 阵列干涉SAR定标技术研究[D]. [博士论文], 中国科学院大学, 2018: 71–95.BU Yuncheng. Research on calibration technology of array synthetic aperture radar interferometry[D]. [Ph.D. dissertation], University of Chinese Academy of Sciences, 2018: 71–95. [16] 崔磊, 仇晓兰, 郭嘉逸, 等. 一种基于误差反向传播优化的多通道SAR相位误差估计方法[J]. 雷达学报, 2020, 9(5): 878–885. doi: 10.12000/JR20096.CUI Lei, QIU Xiaolan, GUO Jiayi, et al. Multi-channel phase error estimation method based on an error backpropagation algorithm for a multichannel SAR[J]. Journal of Radars, 2020, 9(5): 878–885. doi: 10.12000/JR20096. [17] JIAO Zekun, DING Chibiao, QIU Xiaolan, et al. Urban 3D imaging using airborne TomoSAR: Contextual information-based approach in the statistical way[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 170: 127–141. doi: 10.1016/j.isprsjprs.2020.10.013. -














计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

