
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Forward-looking Imaging via Doppler Estimates of Sum-difference Measurements in Scanning Monopulse Radar(in English)
-
摘要: 单脉冲测角技术用于扫描雷达前视成像可有效提高图像的清晰度,但单个脉冲对同分辨单元多目标测角时会发生角闪烁现象,造成图像模糊。该文提出了一种基于单脉冲雷达和差通道多普勒估计的前视成像算法,利用目标和平台之间相对运动引起的多普勒梯度差异实现同分辨单元内不同方向目标的分离,然后在多普勒域采用和差比幅测角(SDAC)技术测量目标的方位角,完成能量投影。为提高测角精度,进一步提出了采用调频Z变换(CZT)重建和差多普勒估计并进行比幅测角的算法。点目标仿真实验结果表明,所提出的算法在前斜视方向具有分离多目标的能力,对实测数据成像结果验证了基于CZT的成像算法相比传统算法能显著提高对场景成像的轮廓清晰度。Abstract: Monopulse technique is used in scanning radar systems to improve image quality in the forward-looking area. However, monopulse measurements fail to resolve multiple targets in the same resolution cell because of angular glint which often results to image blurring. In response to this, we propose a monopulse forward-looking imaging method utilizing Doppler estimates of sum-difference measurements. First, target multiplicity is resolved by exploiting the different Doppler shifts caused by the relative motion between the platform and the targets at different directions. High azimuthal angle measurement accuracy of the Doppler estimates is then obtained using the Sum-Difference Amplitude-Comparison (SDAC) monopulse technique. Subsequently, the intensity of the sum channel estimates is projected onto the image plane according to the range and angle measurements. To further improve the precision of angle measurements, a Chirp-Z Transform (CZT)-based algorithm is proposed for the reconstruction of the Doppler estimates of the sum-difference channels. Simulation results demonstrate the capability of the proposed methods in resolving multiple targets at high squint angles in a large scanning field. Real data experiments show significant improvement of image profiles using the CZT-based algorithm compared to that of the conventional monopulse imaging method.
-
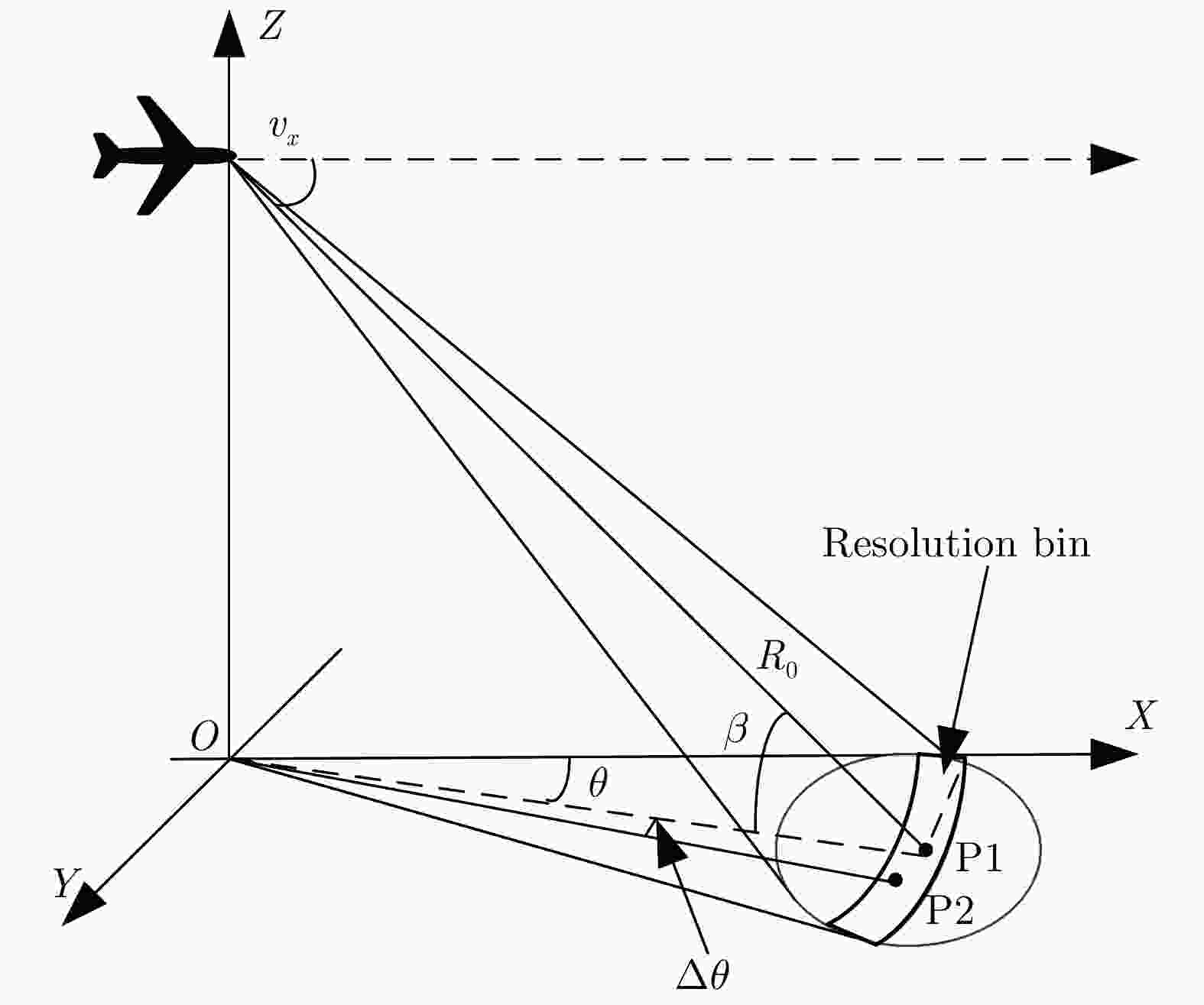
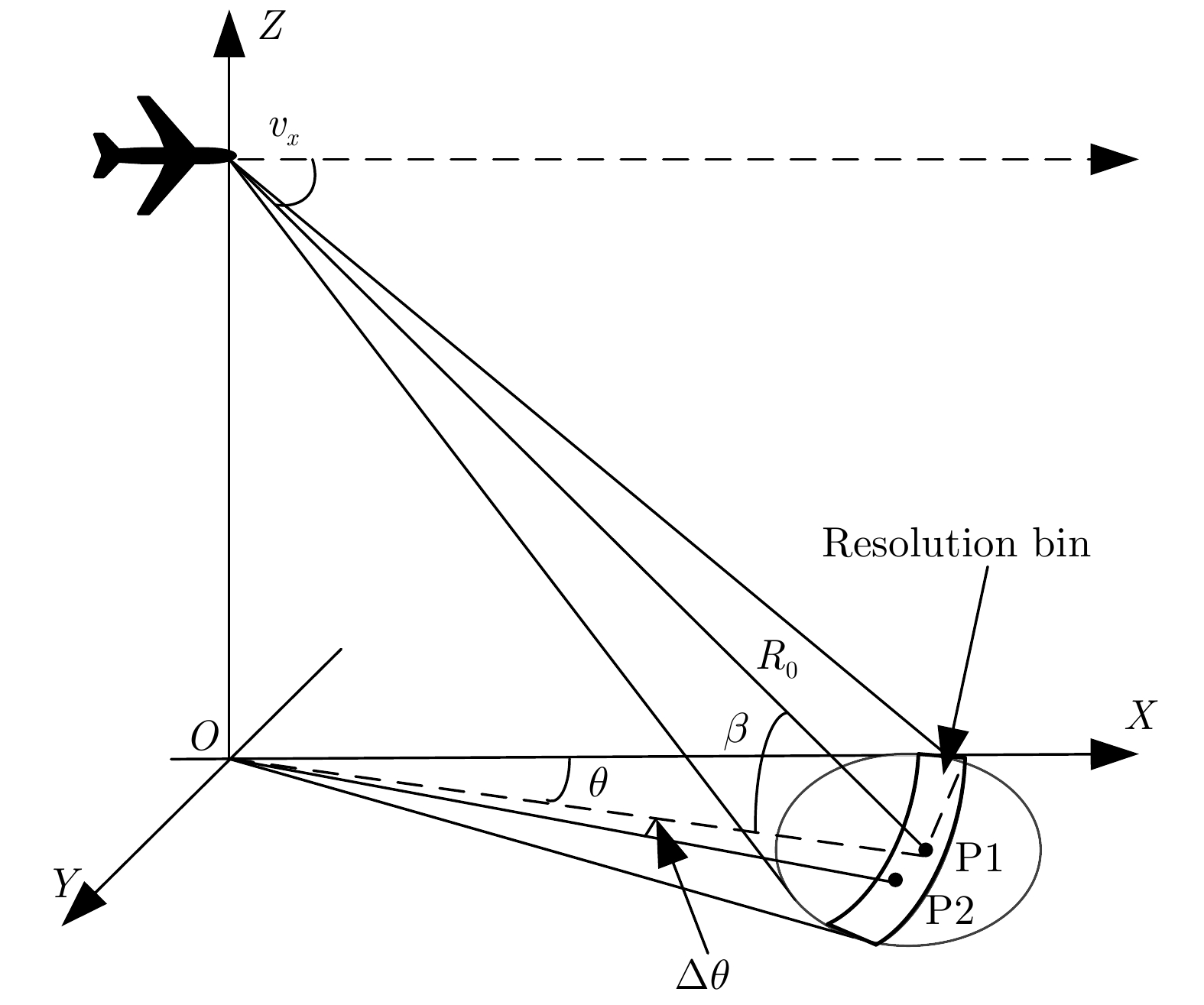
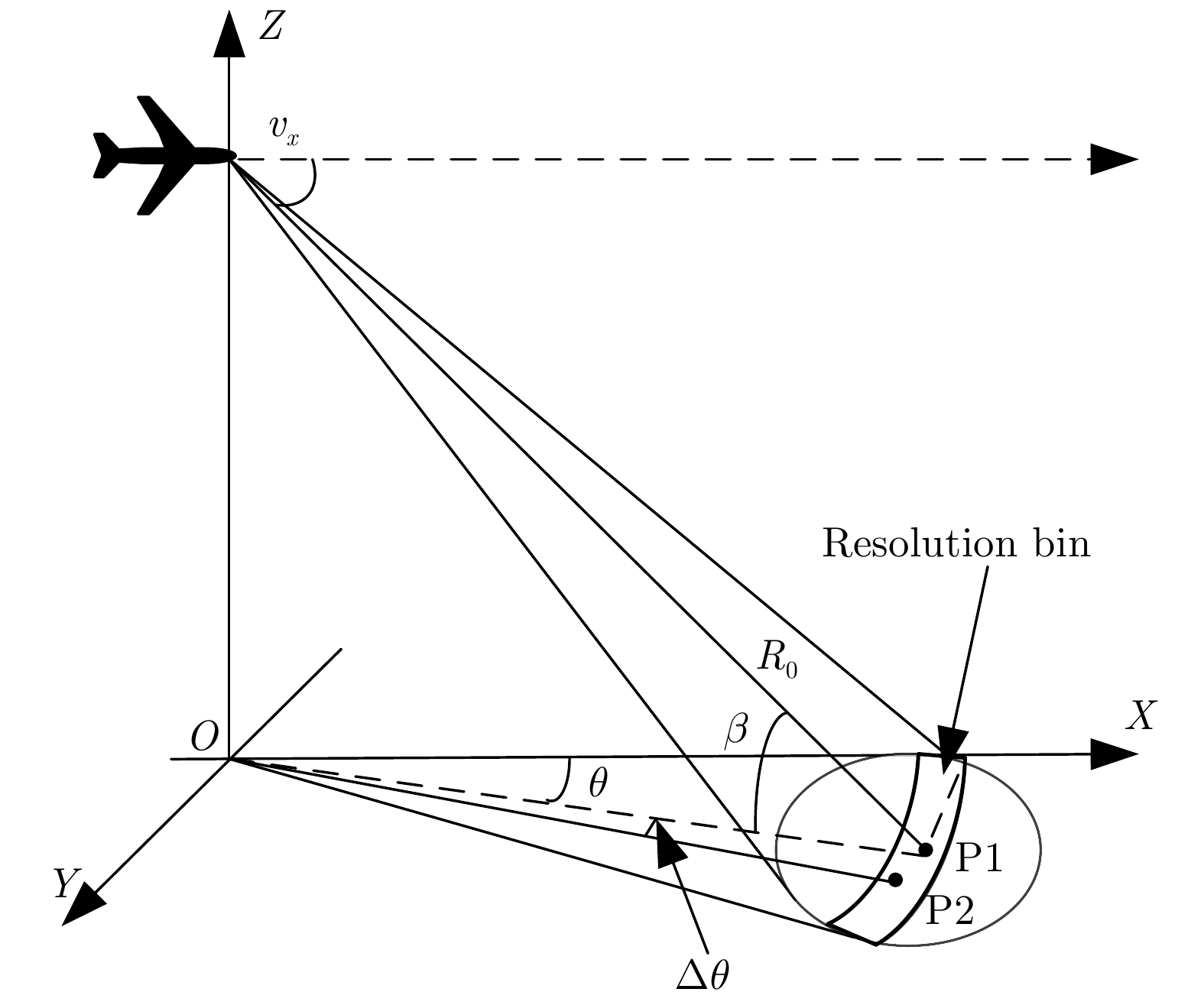
图 1 雷达扫描前视成像几何关系示意图
Figure 1. Geometry for forward-looking imaging of a scanning radar
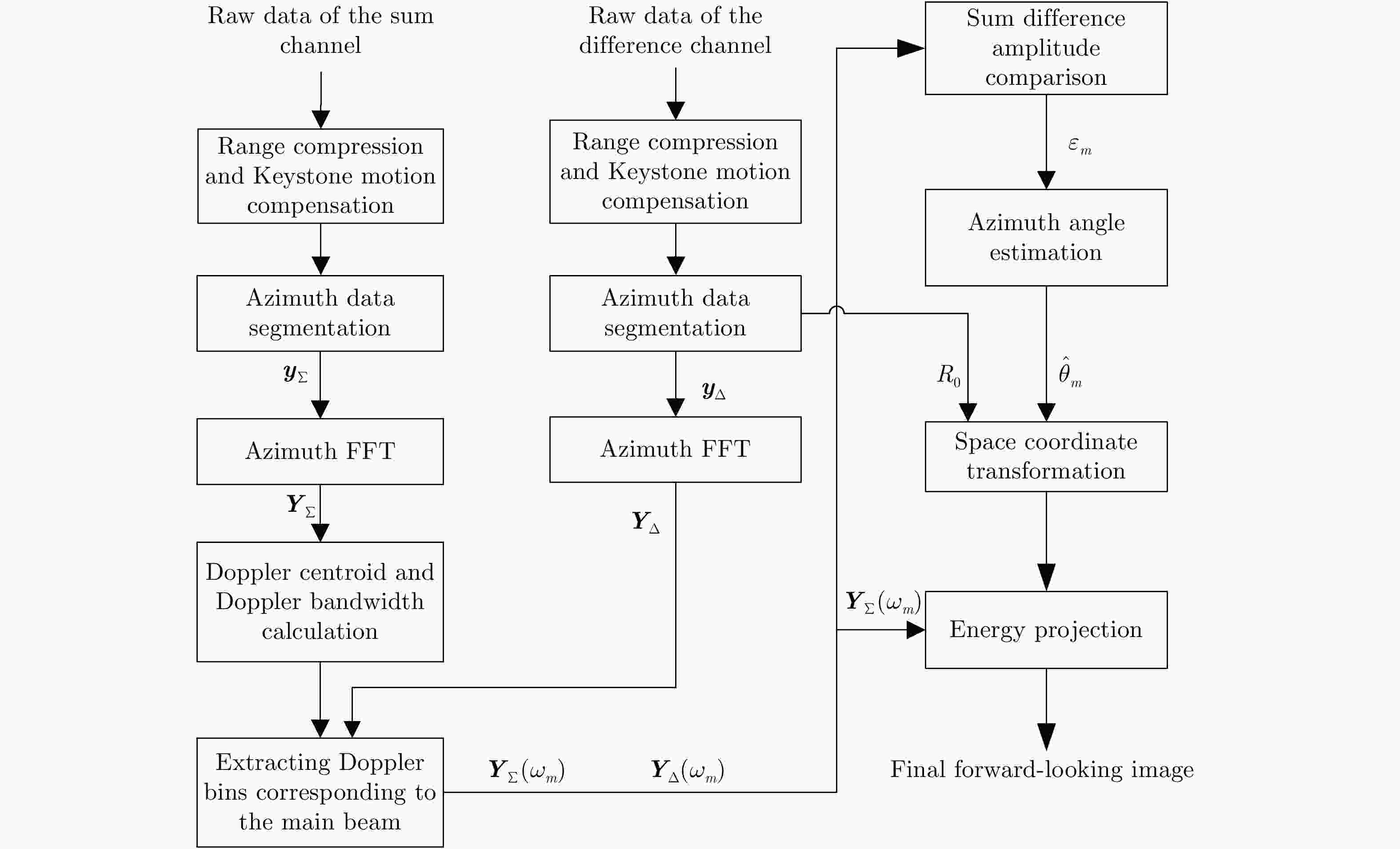
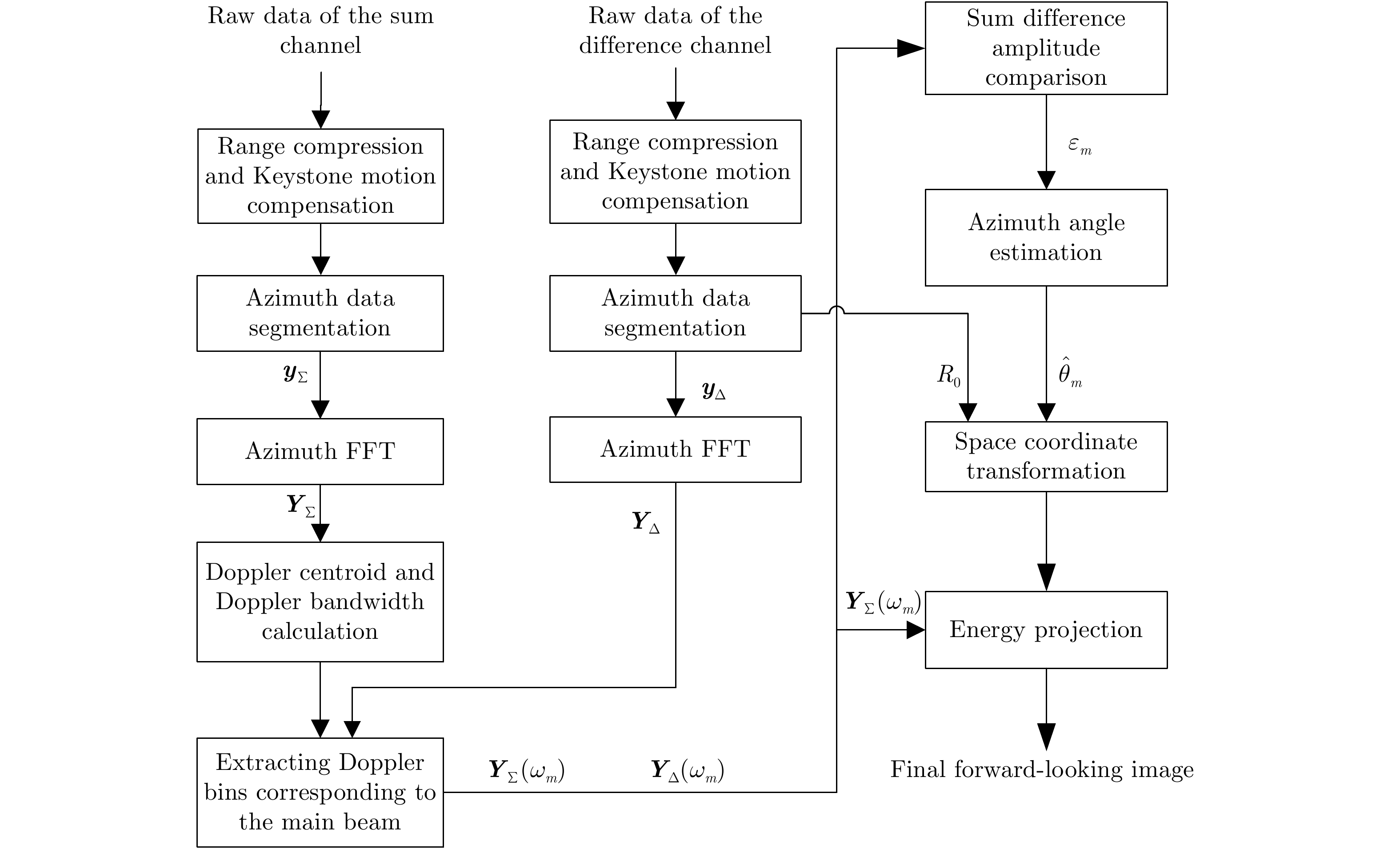
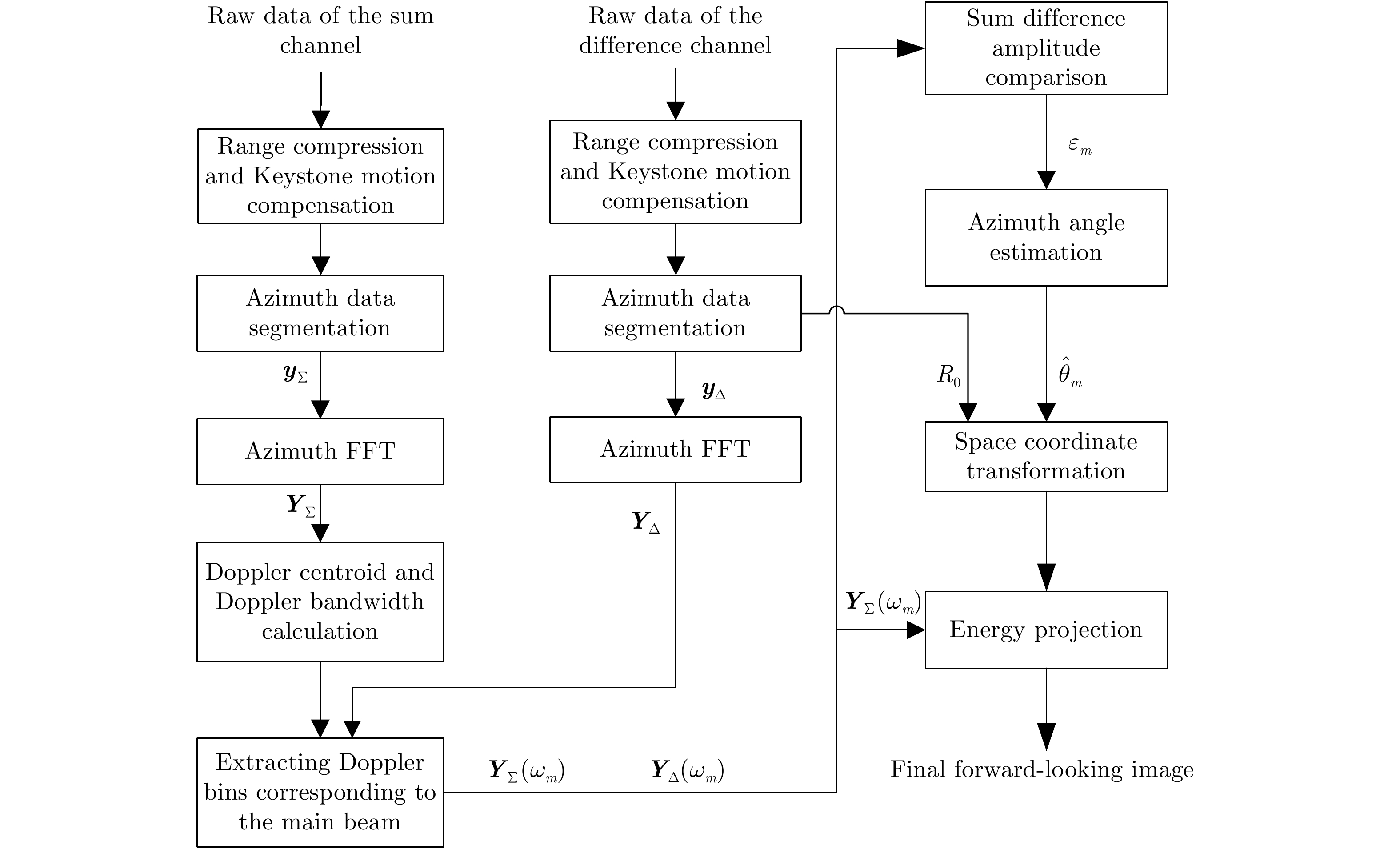
图 2 基于多普勒估计的单脉冲前视成像流程
Figure 2. Flowchart of mono pulse forward-looking imagination based on Doppler estimates
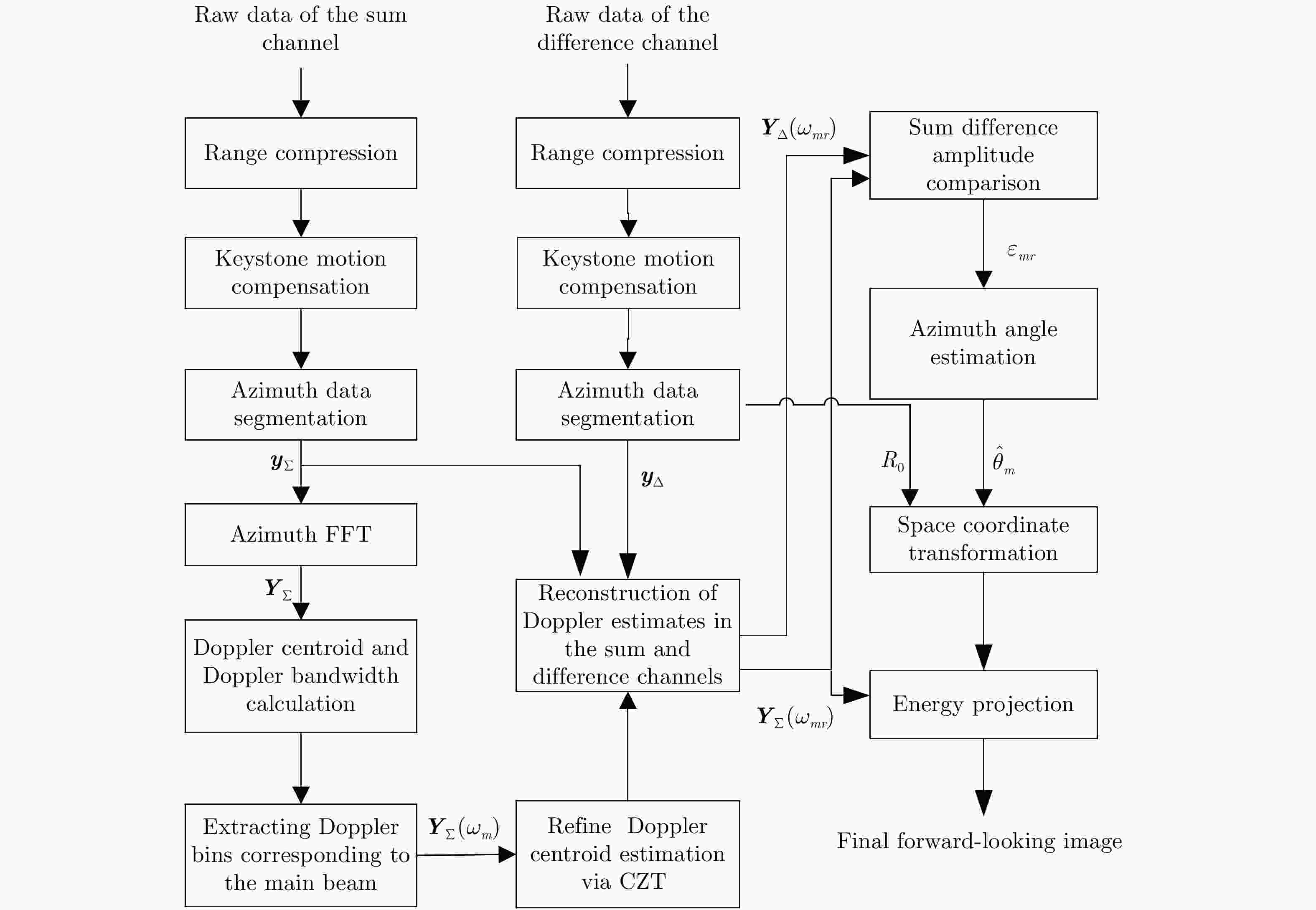
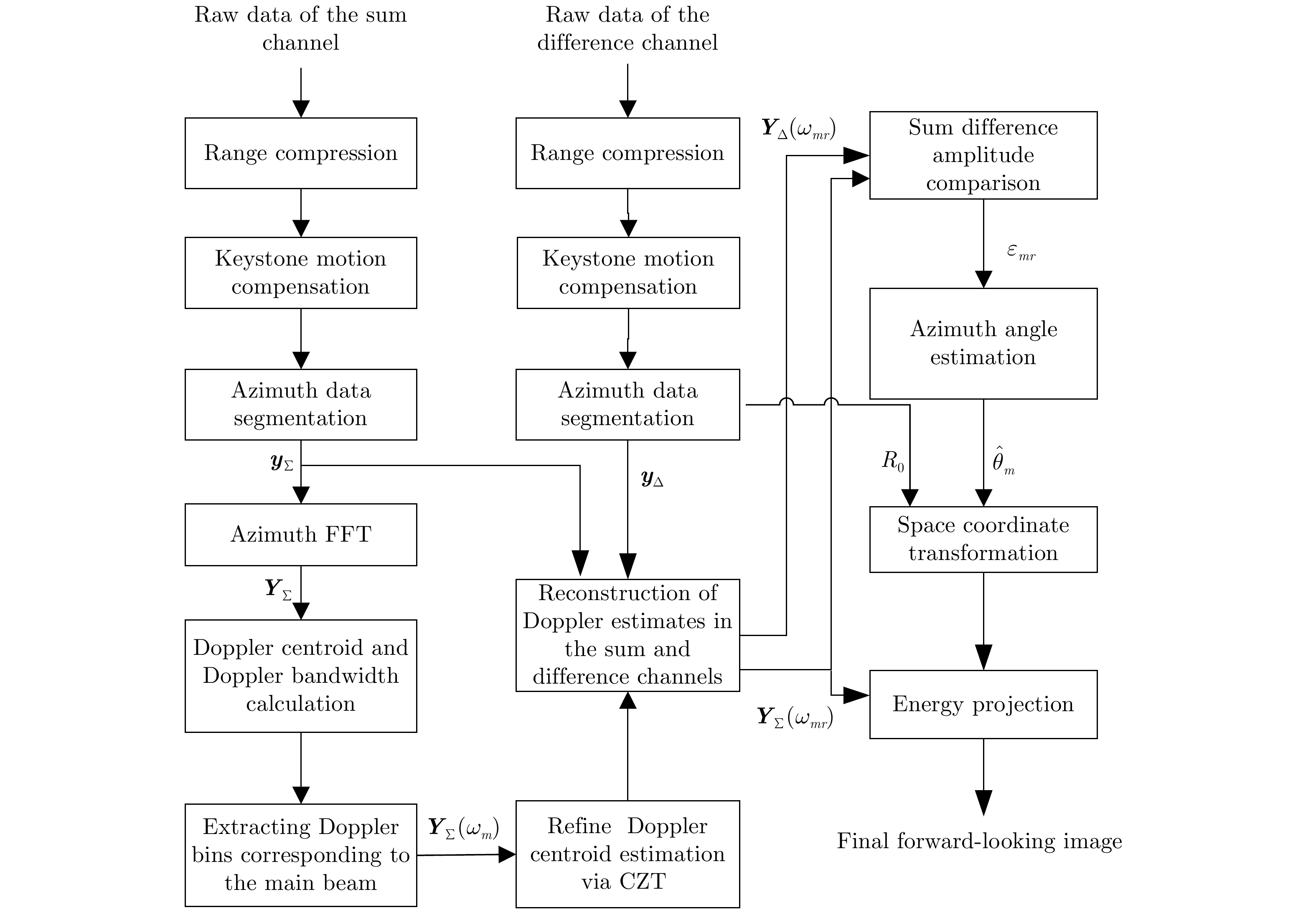
图 3 基于重建多普勒估计的单脉冲前视成像流程
Figure 3. Flowchart of monopulse forward-looking imaging based on the reconstructed Doppler estimates
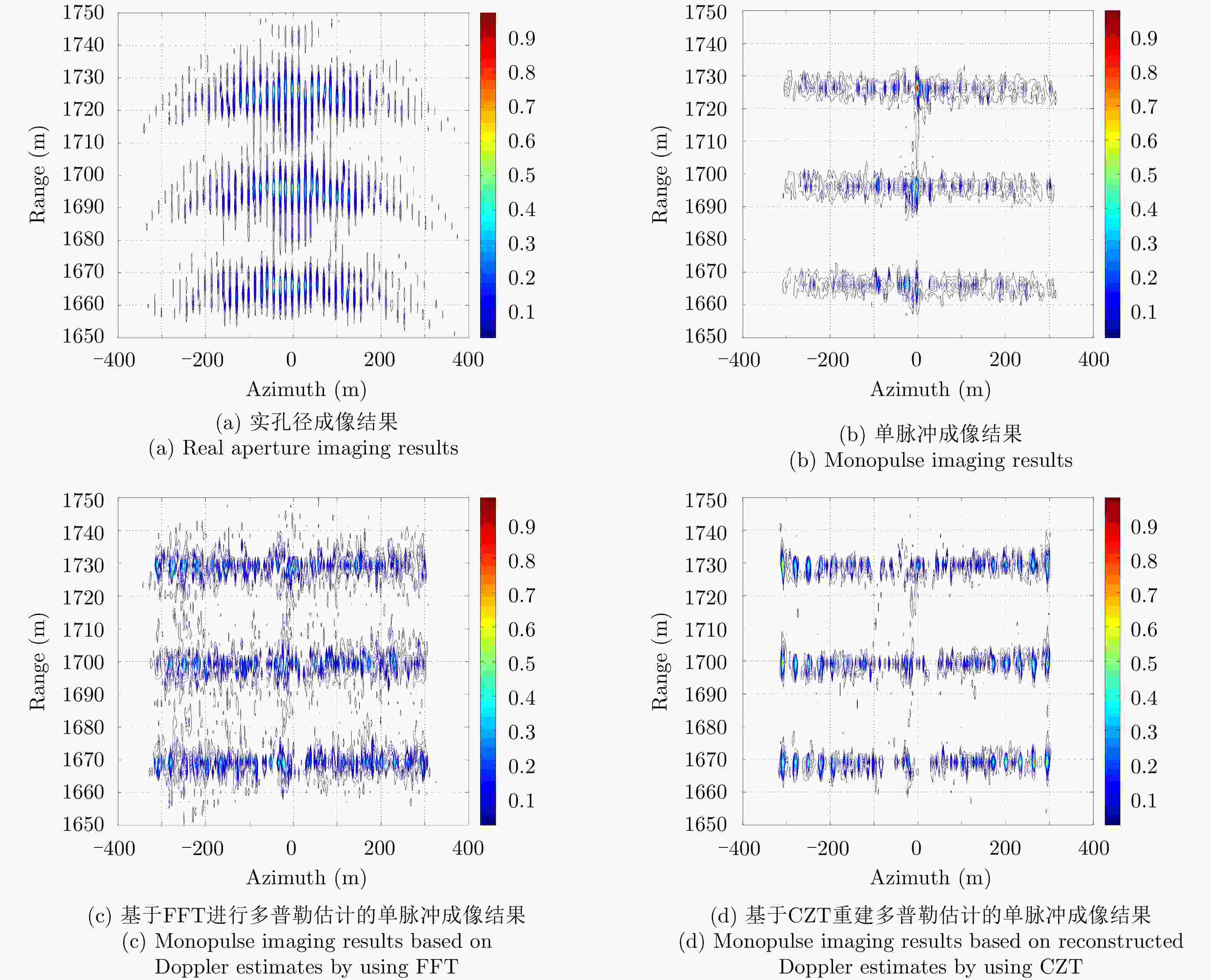
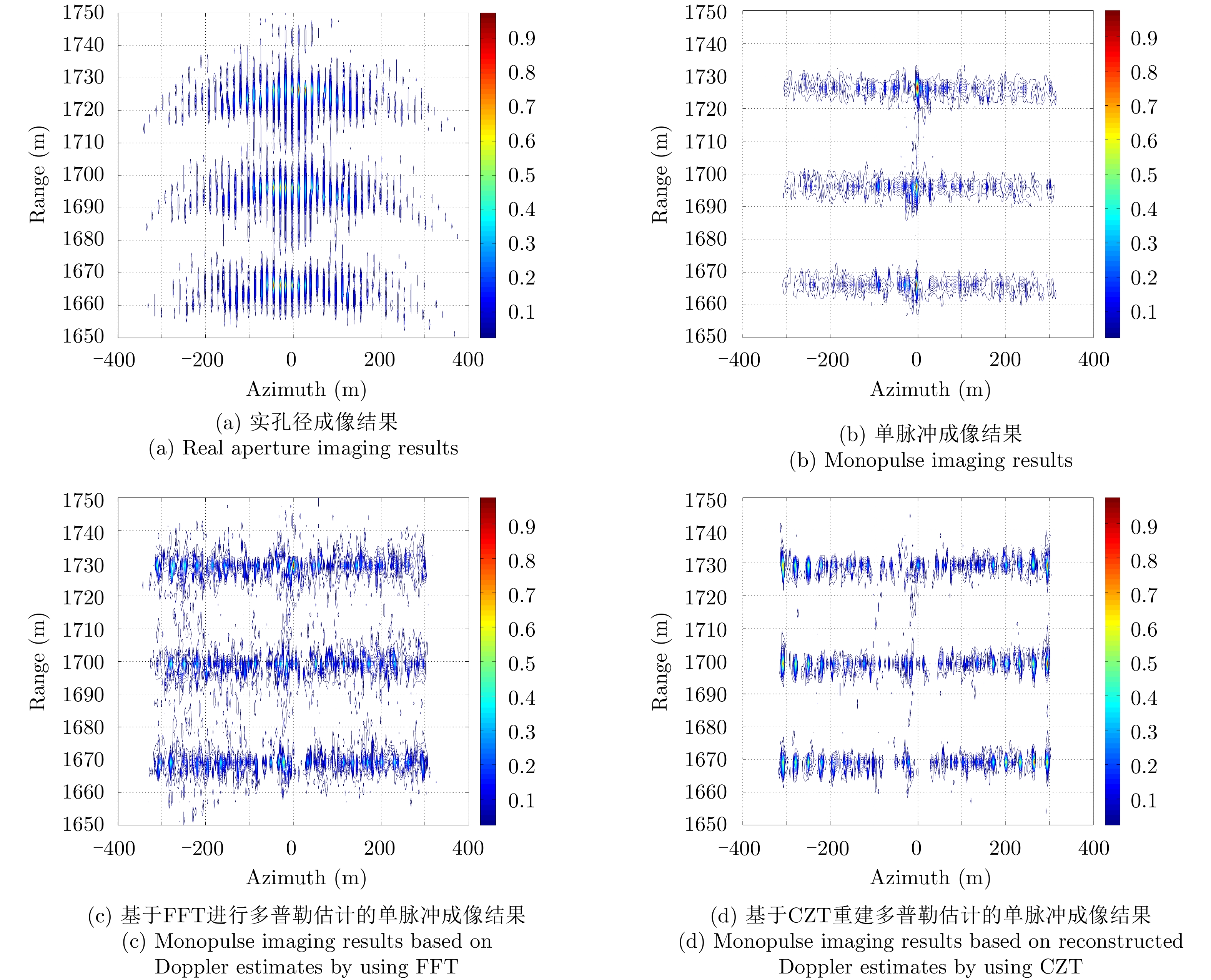
图 4 点阵目标单脉冲前视成像效果对比(SNR=20 dB)
Figure 4. Comparison of forward-looking imaging performance (SNR=20 dB)
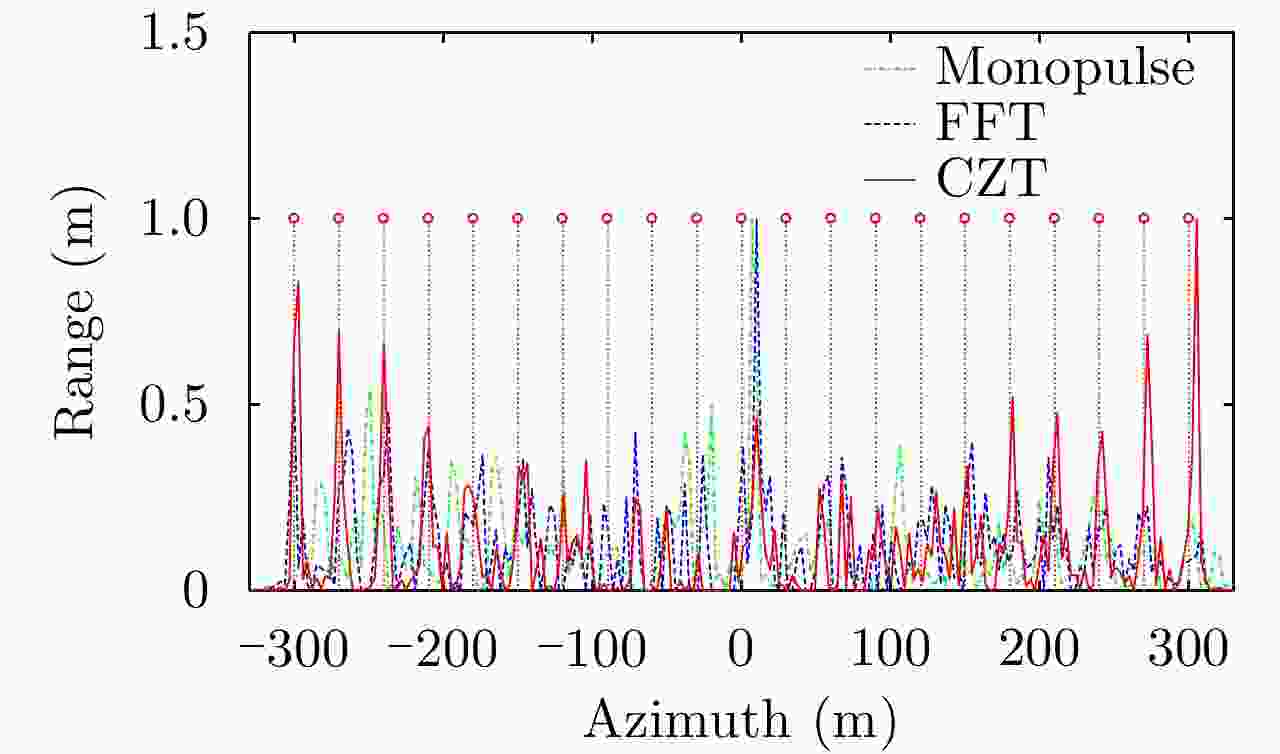
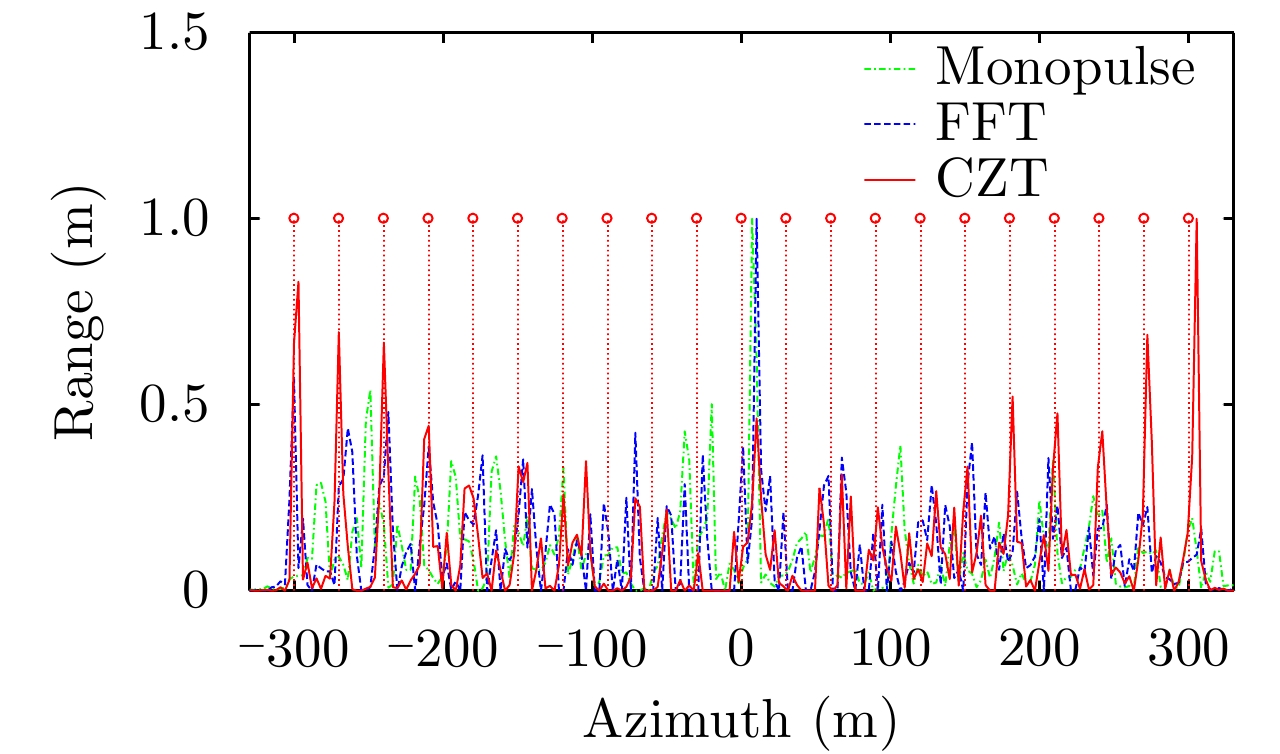
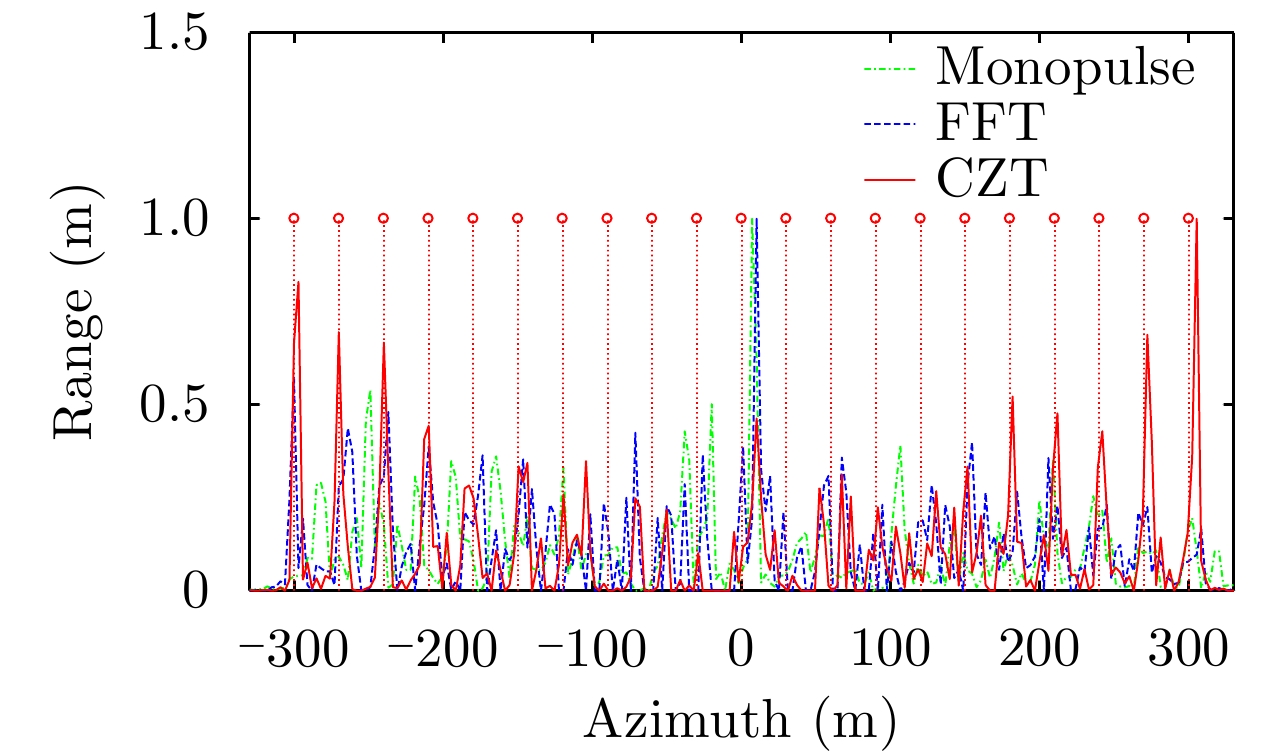
图 5 距离1730 m处目标的方位向剖面图(SNR=20 dB)
Figure 5. Azimuthal contour plots for point targets at the range cell 1730 m (SNR=20 dB)
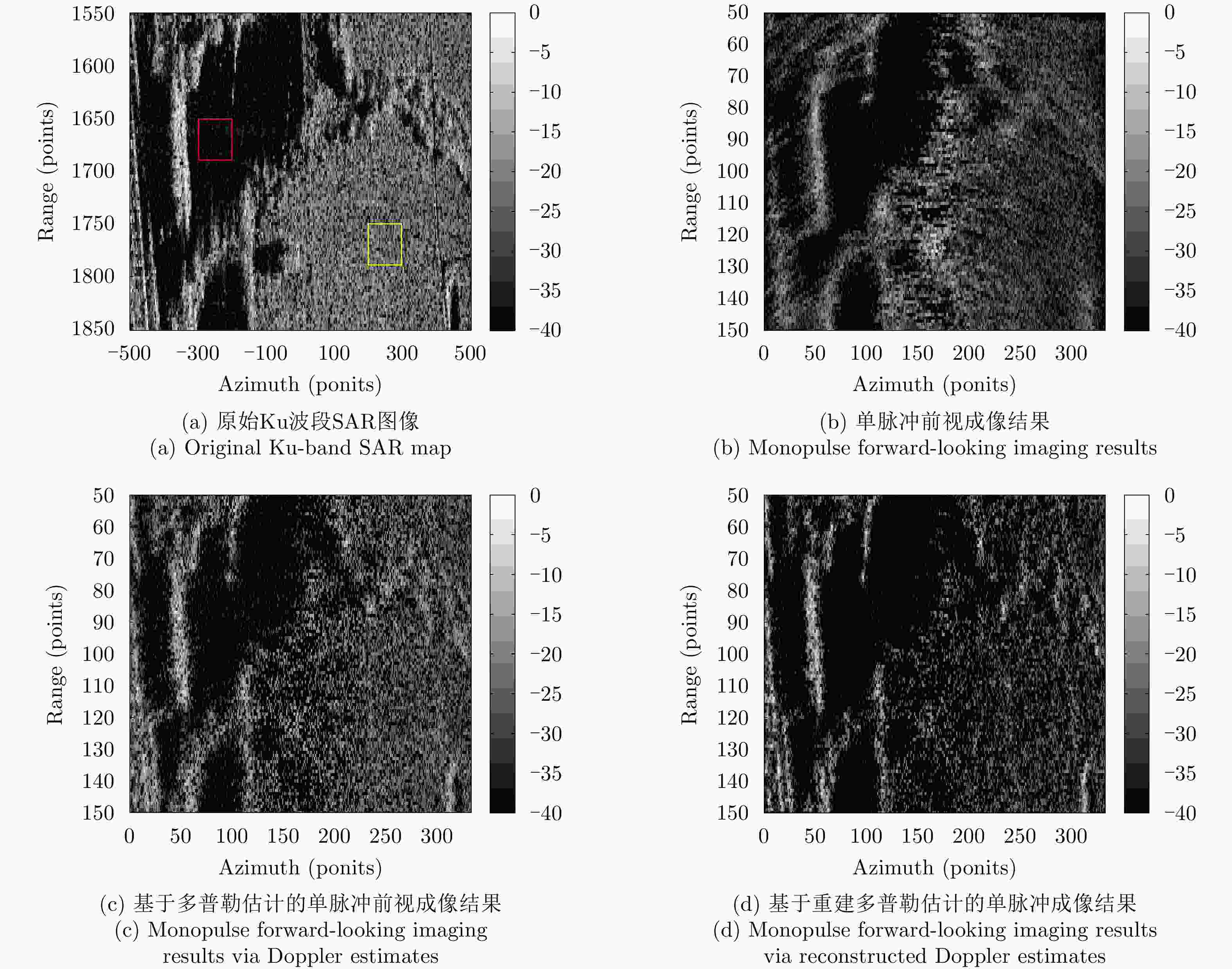
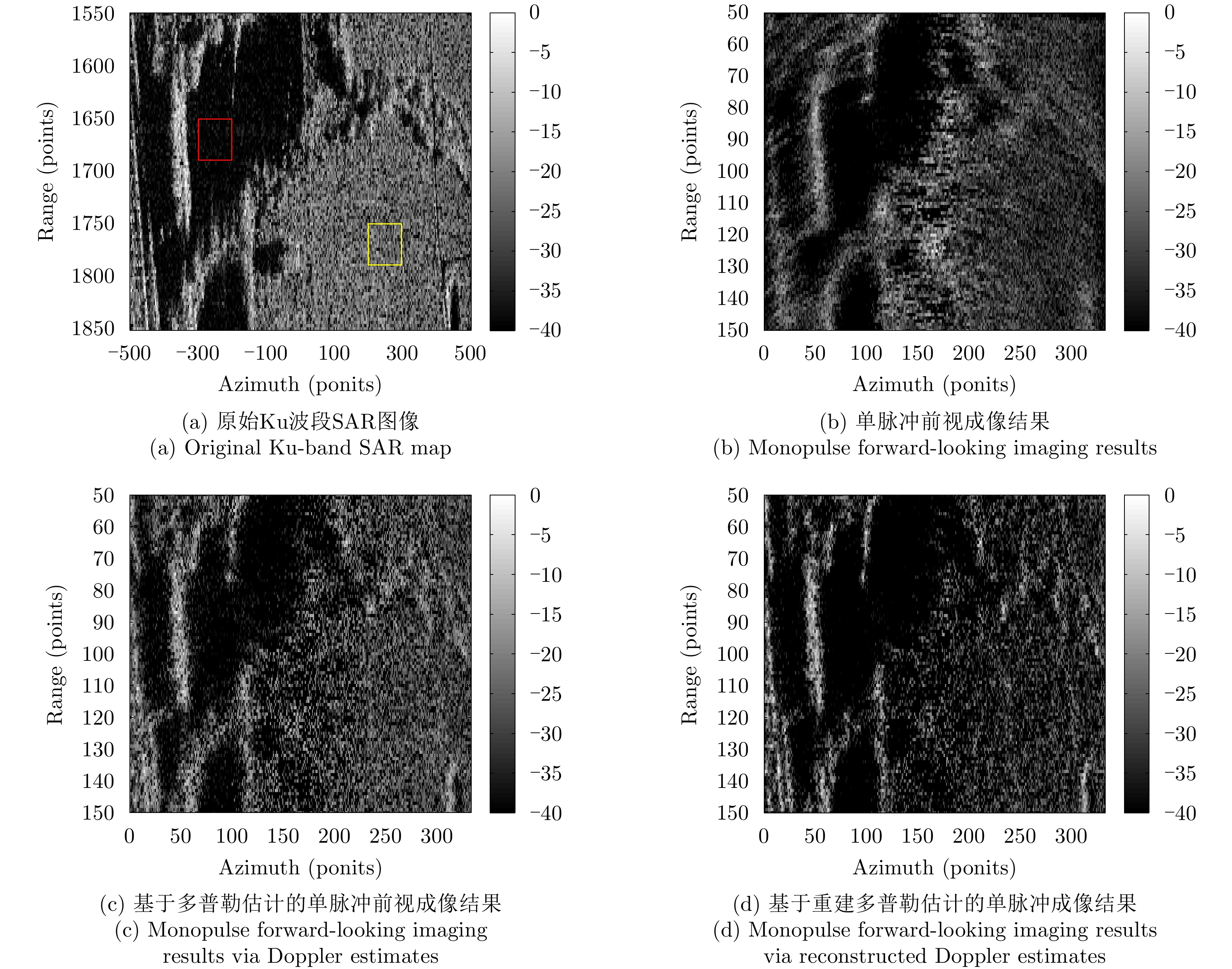
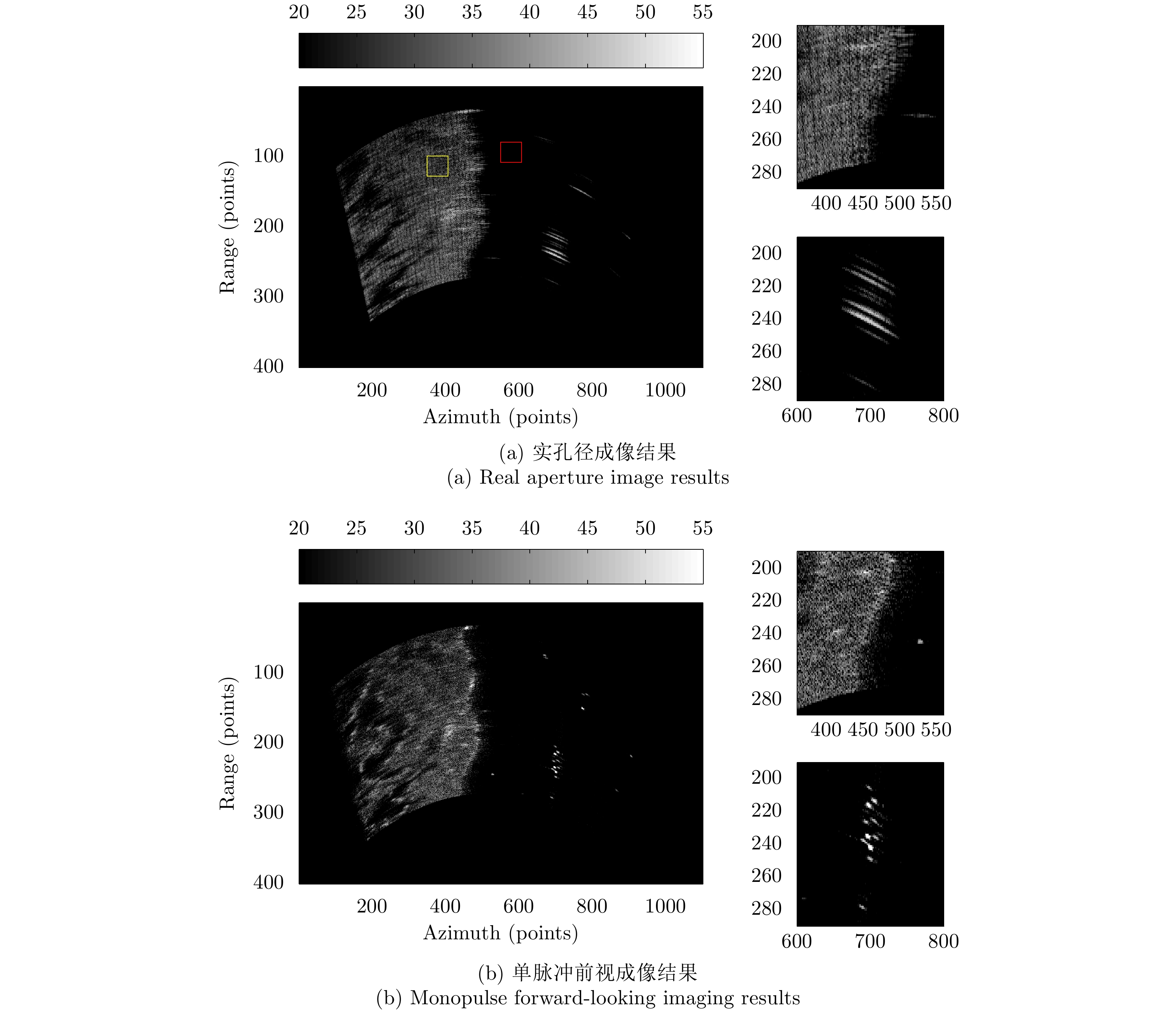
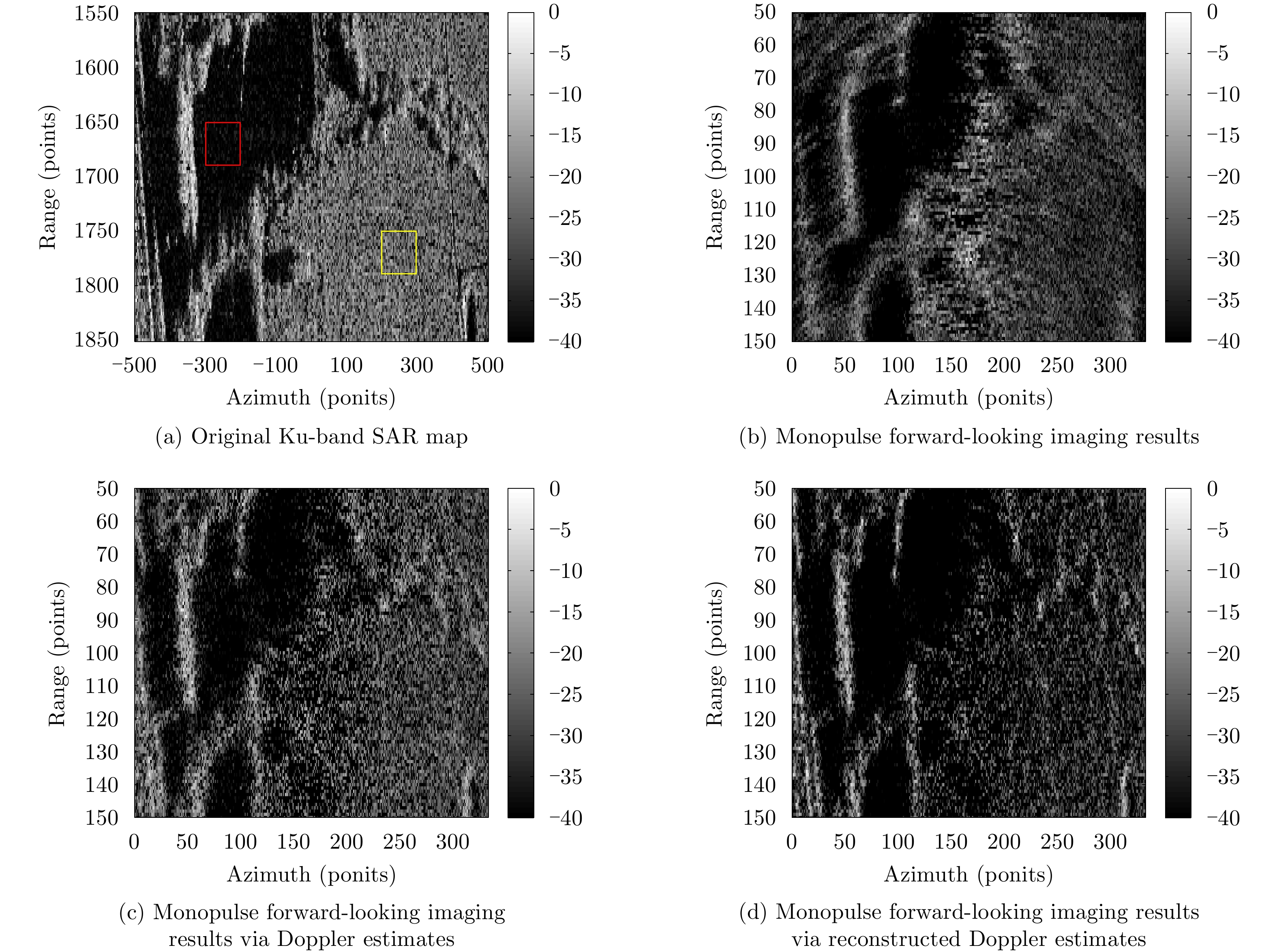
图 6 仿真场景前视成像效果对比
Figure 6. Comparison of experimental results in forward looking imaging

图 3 Flowchart of monopulse forward-looking imaging based on the reconstructed Doppler estimates
表 1 波束扫描前视成像实验仿真参数
Table 1. Simulation parameters of a forward-looking scanning radar
参数 取值 参数 取值 场景中心地距 1700 m 平台飞行速度 100 m/s 雷达中心频率 18 GHz 距离×方位分辨单元 3 m×3 m 信号带宽 50 MHz 信号脉宽 1 μs 和通道3 dB波束宽度 5° 波束扫描范围 –15°~15° 脉冲重复频率PRF 2000 Hz 天线扫描速度 30°/s  下载: 导出CSV
下载: 导出CSV
表 1 Simulation parameters of a forward-looking scanning radar
Parameters Value Parameters Value Center ground range 1700 m Platform velocity 100 m/s Center frequency 18 GHz Pixel resolution 3 m × 3 m Bandwidth 50 MHz Pulse width 1 μs 3 dB beamwidth of the sum channel 5° Antenna scanning area –15°–15° Pulse repeat frequency 2000 Hz Scanning rate 30°/s
下载: 导出CSV
-
[1] 杨建宇. 雷达对地成像技术多向演化趋势与规律分析[J]. 雷达学报, 2019, 8(6): 669–692. doi: 10.12000/JR19099YANG Jianyu. Multi-directional evolution trend and law analysis of radar ground imaging technology[J]. Journal of Radars, 2019, 8(6): 669–692. doi: 10.12000/JR19099 [2] ZHANG Yongchao, ZHANG Yin, HUANG Yulin, et al. Angular superresolution for scanning radar with improved regularized iterative adaptive approach[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(6): 846–850. doi: 10.1109/LGRS.2016.2550491 [3] 吴迪, 朱岱寅, 朱兆达. 机载雷达单脉冲前视成像算法[J]. 中国图象图形学报, 2010, 15(3): 462–469. doi: 10.11834/jig.20100317WU Di, ZHU Daiyin, and ZHU Zhaoda. Research on nomopulse forward-looking imaging algorithm for airborne radar[J]. Journal of Image and Graphics, 2010, 15(3): 462–469. doi: 10.11834/jig.20100317 [4] 吴迪, 朱岱寅, 田斌, 等. 单脉冲成像算法性能分析[J]. 航空学报, 2012, 33(10): 1905–1914.WU Di, ZHU Daiyin, TIAN Bin, et al. Performance evaluation for monopulse imaging algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2012, 33(10): 1905–1914. [5] 吴迪, 杨成杰, 朱岱寅, 等. 一种用于单脉冲成像的自聚焦算法[J]. 电子学报, 2016, 44(8): 1962–1968. doi: 10.3969/j.issn.0372-2112.2016.08.027WU Di, YANG Chengjie, ZHU Daiyin, et al. An autofocusing algorithm for monopulse imaging[J]. Acta Electronica Sinica, 2016, 44(8): 1962–1968. doi: 10.3969/j.issn.0372-2112.2016.08.027 [6] 李悦丽, 梁甸农, 黄晓涛. 一种单脉冲雷达多通道解卷积前视成像方法[J]. 信号处理, 2007, 23(5): 699–703. doi: 10.3969/j.issn.1003-0530.2007.05.013LI Yueli, LIANG Diannong, and HUANG Xiaotao. A multi-channel deconvolution based on forword-looking imaging method in monopulse radar[J]. Signal Processing, 2007, 23(5): 699–703. doi: 10.3969/j.issn.1003-0530.2007.05.013 [7] 唐琳, 焦淑红, 齐欢, 等. 一种单脉冲雷达多通道L1正则化波束锐化方法[J]. 电子与信息学报, 2014, 36(9): 2201–2206. doi: 10.3724/SP.J.1146.2013.01792TANG Lin, JIAO Shuhong, QI Huan, et al. A new mono-pulse radar beam sharpening method with multichannel L1 regularization[J]. Journal of Electronics&Information Technology, 2014, 36(9): 2201–2206. doi: 10.3724/SP.J.1146.2013.01792 [8] SHERMAN S M, BARTON D K, 周颖, 陈远征, 赵锋, 等译. 单脉冲测向原理与技术[M]. 2版. 北京: 国防工业出版社, 2013: 172–197.SHERMAN S M, BARTON D K, ZHOU Ying, CHEN Yuanzheng, ZHAO Feng, et al. translation. Monopulse Principles and Techniques[M]. 2nd ed. Beijing: National Defense Industry Press, 2013: 172–197. [9] ZHANG Xin, WILLETT P K, and BAR-SHALOM Y. Monopulse radar detection and localization of multiple unresolved targets via joint bin processing[J]. IEEE Transactions on Signal Processing, 2005, 53(4): 1225–1236. doi: 10.1109/TSP.2005.843732 [10] 杨洋, 李悦丽. 单脉冲前视成像多目标分辨算法[J]. 信号处理, 2016, 32(9): 1055–1064. doi: 10.16798/j.issn.1003-0530.2016.09.07YANG Yang and LI Yueli. Multi-targets discrimination algorithm in monopulse forward-looking imaging[J]. Journal of Signal Processing, 2016, 32(9): 1055–1064. doi: 10.16798/j.issn.1003-0530.2016.09.07 [11] LONG Teng, LU Zheng, DING Zegang, et al. A DBS Doppler centroid estimation algorithm based on entropy minimization[J]. IEEE Transactions on Geoscience and Remote Sensing, 2011, 49(10): 3703–3712. doi: 10.1109/TGRS.2011.2142316 [12] ZHANG Shouhong, MA Changzheng, and CHEN Baixiao. Monopulse radar three-dimensional imaging of maneuvering targets[C]. SPIE 3545, International Symposium on Multispectral Image Processing, Wuhan, China, 1998: 193–196. doi: 10.1117/12.323634. [13] LI Jian and STOICA P. An adaptive filtering approach to spectral estimation and SAR imaging[J]. IEEE Transactions on Signal Processing, 1996, 44(6): 1469–1484. doi: 10.1109/78.506612 [14] 马长征, 张守宏. 超分辨在单脉冲雷达三维成像中的应用[J]. 西安电子科技大学学报, 1999, 26(3): 379–382. doi: 10.3969/j.issn.1001-2400.1999.03.027MA Changzheng and ZHANG Shouhong. Applications of super-resolution signal processing on monopulse radar three dimensional imaging[J]. Journal of Xidian University, 1999, 26(3): 379–382. doi: 10.3969/j.issn.1001-2400.1999.03.027 [15] LIU Xiaocong and LI Yueli. Parameter estimation of narrowband radio frequency interference based on local refinement search in frequency domain[C]. 2015 IEEE International Conference on Communication Problem-Solving, Guilin, China, 2015: 145–148. doi: 10.1109/ICCPS.2015.7454112. [16] CHEN Hongmeng, LI Ming, ZHANG Peng, et al. Resolution enhancement for Doppler beam sharpening imaging[J]. IET Radar,Sonar&Navigation, 2015, 9(7): 843–851. doi: 10.1049/iet-rsn.2014.0384 [17] 孙泓波, 顾红, 苏卫民, 等. 机载脉冲多普勒雷达DBS成像实验研究[J]. 数据采集与处理, 2001, 16(4): 423–427. doi: 10.3969/j.issn.1004-9037.2001.04.007SUN Hongbo, GU Hong, SU Weimin, et al. Experimental research of DBS imaging based on airborne pulse Doppler radar[J]. Journal of Data Acquisition&Processing, 2001, 16(4): 423–427. doi: 10.3969/j.issn.1004-9037.2001.04.007 [18] 毛士艺, 李少洪, 黄永红, 等. 机载PD雷达DBS实时成像研究[J]. 电子学报, 2000, 28(3): 32–34. doi: 10.3321/j.issn:0372-2112.2000.03.009MAO Shiyi, LI Shaohong, HUANG Yonghong, et al. Study of real-time image by DBS on airborne PD radar[J]. Acta Electronica Sinica, 2000, 28(3): 32–34. doi: 10.3321/j.issn:0372-2112.2000.03.009 [19] 王娟, 赵永波. Keystone变换实现方法研究[J]. 火控雷达技术, 2011, 40(1): 45–51. doi: 10.3969/j.issn.1008-8652.2011.01.010WANG Juan and ZHAO Yongbo. Research on implementation of Keystone transform[J]. Fire Control Radar Technology, 2011, 40(1): 45–51. doi: 10.3969/j.issn.1008-8652.2011.01.010 -






计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

