
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
-
摘要:
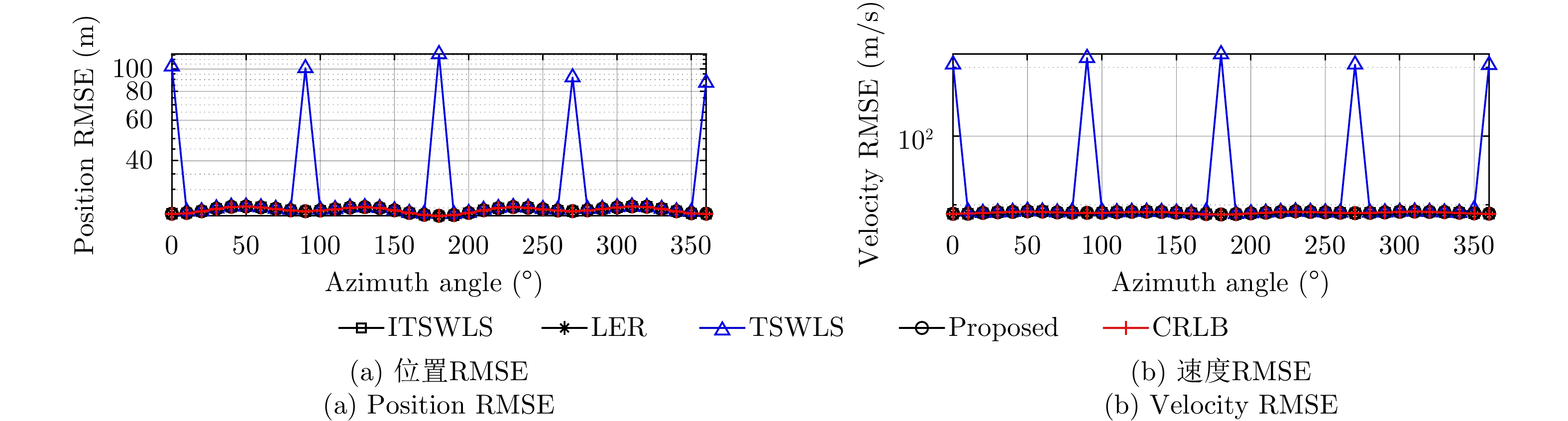
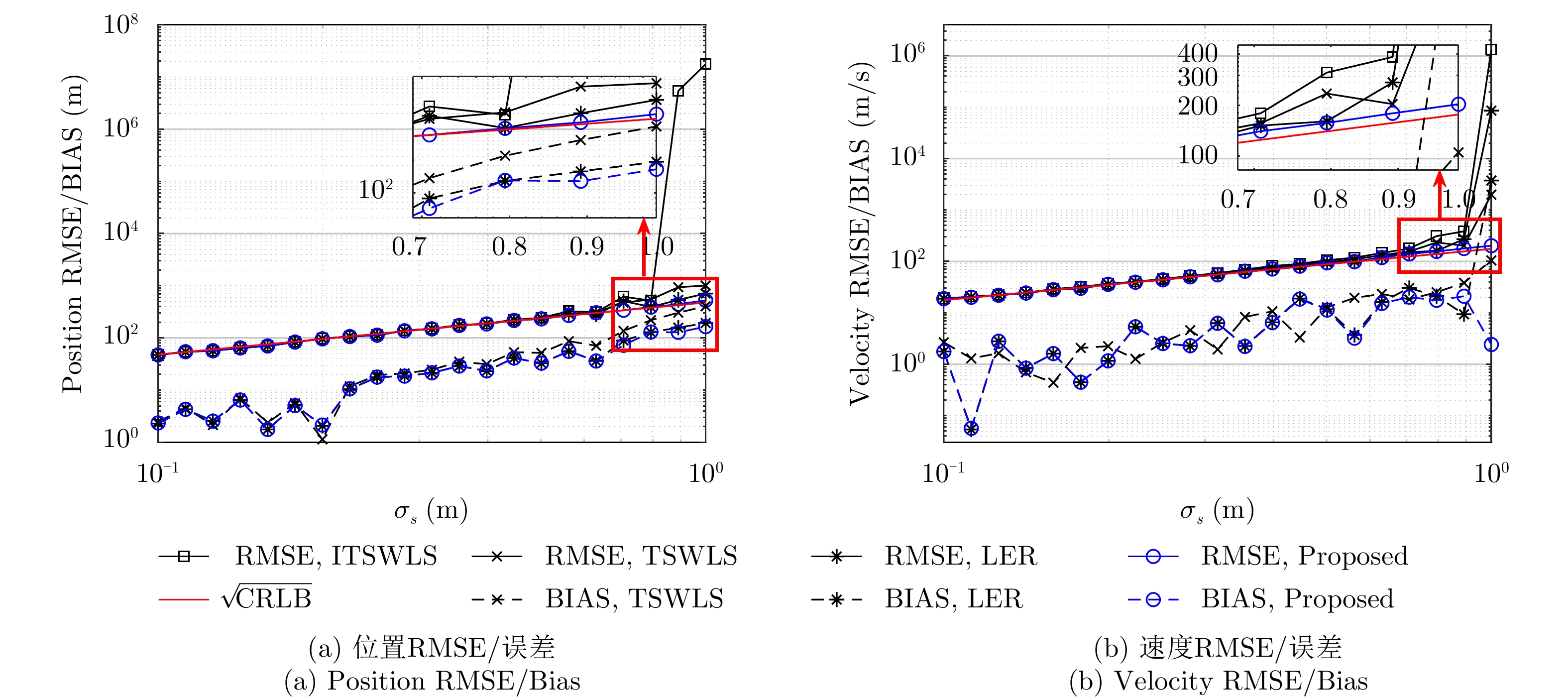
针对现有算法定位精度低,稳健性差的问题,该文基于误差校正的思想,改进了经典两步加权最小二乘(TSWLS)算法的步骤2,提出一种站址误差条件下基于到达时间差(TDOA)和到达频率差(FDOA)的高精度、稳健动目标无源定位算法。所提算法的步骤2对步骤1中引入的辅助变量进行泰勒展开以构建误差校正方程,避免了经典两步加权最小二乘算法中的矩阵缺秩问题和非线性运算,提高了算法的稳健性和定位精度。理论分析表明,在小噪声条件下该算法定位精度可达克拉美罗下界(CRLB)。仿真结果表明,在常见量级的站值误差及测量误差下,相比于现有算法,该文算法具有更强的稳健性和更优的抗噪性。
-
关键词:
- 动目标定位 /
- 到达时间差(TDOA) /
- 到达频率差(FDOA) /
- 站址误差 /
- 误差校正 /
- 稳健性
Abstract:To address the low location accuracy and poor robustness of existing methods, error correction to improve the Stage 2 of the original Two-Stage Weighted Least Squares (TSWLS)-based methods is proposed, which involves a robust moving source localization method with high accuracy based on Time Difference Of Arrival (TDOA) and Frequency Difference Of Arrival (FDOA) in the presence of receiver location errors. This newly proposed Stage 2 performs Taylor expansion on the nuisance variables introduced in Stage 1 to construct the error correction equation, thereby avoiding the rank deficiency problem and nonlinear mathematical operations in the original TSWLS-based methods; and improving the robustness and location accuracy of the method. Theoretical analysis indicates that the proposed method can attain the Cramer-Rao Lower Bound (CRLB) under small noise condition. Simulation results show the proposed method has stronger localization robustness and better anti-noise performance over the existing methods under the common level of receiver location and measurement error.
-
表 1 接收站位置(m)及速度(m/s)
Table 1. Position(m) and velocity(m/s) of receivers
接收站 ${x_i}$ ${y_i}$ ${z_i}$ ${\dot x_i}$ ${\dot y_i}$ ${\dot z_i}$ 1 300 100 150 30 –20 20 2 400 150 100 –30 10 20 3 300 500 200 10 –20 10 4 350 200 150 10 20 30 5 –100 –100 –100 –20 10 10 6 200 –300 –200 20 –10 10  下载: 导出CSV
下载: 导出CSV
-
[1] 田中成, 刘聪锋. 无源定位技术[M]. 北京: 国防工业出版社, 2015: 8–12.TIAN Zhongcheng and LIU Congfeng. Passive Locating Technology[M]. Beijing: National Defense Industry Press, 2015: 8–12. [2] 孙霆, 董春曦. 传感器参数误差下的运动目标TDOA/FDOA无源定位算法[J]. 航空学报, 2020, 41(2): 323317. doi: 10.7527/S1000-7527.2019.23317SUN Ting and DONG Chunxi. TDOA/FDOA passive localization algorithm for moving target with sensor parameter errors[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41(2): 323317. doi: 10.7527/S1000-7527.2019.23317 [3] LIU Congfeng, YANG Jie, and WANG Fengshuai. Joint TDOA and AOA location algorithm[J]. Journal of Systems Engineering and Electronics, 2013, 24(2): 183–188. doi: 10.1109/JSEE.2013.00023 [4] CHEN Xin, WANG Ding, LIU Ruirui, et al. Structural total least squares algorithm for locating multiple disjoint sources based on AOA/TOA/FOA in the presence of system error[J]. Frontiers of Information Technology & Electronic Engineering, 2018, 19(7): 917–936. doi: 10.1631/FITEE.&1700735 [5] LIU Zhixin, HU Dexiu, ZHAO Yongjun, et al. Computationally efficient TDOA, FDOA and differential Doppler rate estimation algorithm for passive emitter localization[J]. Digital Signal Processing, 2020, 96: 102598. doi: 10.1016/j.dsp.2019.102598 [6] LIU Zhixin, WANG Rui, and ZHAO Yongjun. Computationally efficient TDOA and FDOA estimation algorithm in passive emitter localisation[J]. IET Radar, Sonar & Navigation, 2019, 13(10): 1731–1740. doi: 10.1049/&iet-rsn.2019.0101 [7] KIM D G, PARK G H, KIM H N, et al. Computationally efficient TDOA/FDOA estimation for unknown communication signals in electronic warfare systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2018, 54(1): 77–89. doi: 10.1109/TAES.2017.2735118 [8] YU H, HYANG G, and GAO J. Constrained total least-squares localisation algorithm using time difference of arrival and frequency difference of arrival measurements with sensor location uncertainties[J]. IET Radar, Sonar & Navigation, 2012, 6(9): 891–899. [9] HO K C, LU Xiaoning, and KOVAVISARUCH L. Source localization using TDOA and FDOA measurements in the presence of receiver location errors: Analysis and solution[J]. IEEE Transactions on Signal Processing, 2007, 55(2): 684–696. doi: 10.1109/TSP.2006.885744 [10] NOROOZI A, OVEIS A H, HOSSEINI S M, et al. Improved algebraic solution for source localization from TDOA and FDOA measurements[J]. IEEE Wireless Communications Letters, 2018, 7(3): 352–355. doi: 10.1109/LWC.2017.2777995 [11] LIU Yang, GUO Fucheng, YANG Le, et al. An improved algebraic solution for TDOA localization with sensor position errors[J]. IEEE Communications Letters, 2015, 19(12): 2218–2221. doi: 10.1109/LCOMM.2015.2486769 [12] 刘洋, 杨乐, 郭福成, 等. 基于定位误差修正的运动目标TDOA/FDOA无源定位方法[J]. 航空学报, 2015, 36(5): 1617–1626.LIU Yang, YANG Le, GUO Fucheng, et al. Moving targets TDOA/FDOA passive localization algorithm based on localization error refinement[J]. Acta Aeronauticaet Astronautica Sinica, 2015, 36(5): 1617–1626. [13] SORENSON H W. Parameter Estimation: Principles and Problems[M]. New York: Marcel Dekker Inc., 1980. [14] LIU Zhixin, HU Dexiu, ZHAO Yongsheng, et al. An algebraic method for moving source localization using TDOA, FDOA, and differential Doppler rate measurements with receiver location errors[J]. EURASIP Journal on Advances in Signal Processing, 2019, 2019(1): 25. doi: 10.1186/s13634-019-0621-9 [15] LIU Zhixin, HU Dexiu, ZHAO Yongsheng, et al. An improved closed-form method for moving source localization using TDOA, FDOAs, differential Doppler rate measurements[J]. IEICE Transactions on Communications, 2019, E102. B(6): 1219–1228. doi: 10.1587/transcom.&2018ebp3249 -

计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

