
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
Multi-band SAR Coherent Change Detection Method Based on Coherent Representation Differences of Targets
-
摘要: 相干变化检测(Coherent Change Detection, CCD)利用变化前后SAR图像间的相位相干性检测场景中发生的微小变化。传统的CCD方法由于对目标探测尺度单一,难以区分场景中目标变化区域与低相干干扰区域。多波段SAR对目标进行多尺度探测,依据电磁波对目标的穿透特性、目标的结构特性以及目标发生的变化尺度形成不同的相干性表征。该文据此提出一种多波段CCD方法。该方法先分别获取各个波段的相干变化差异图,然后依据目标的多波段相干性表征使用改进的期望最大化(Expectation-Maximization, EM)算法对场景分类,接下来根据少量监督样本确定目标变化类别,最后用Dempster-Shafer (DS)证据理论处理,获取多波段融合相干变化差异图。该结果可有效排除各个单波段存在的低相干干扰,达到降低虚警概率的目的。该文采用变化前后的L波段与P波段重轨SAR数据进行方法验证,实验结果与指标参数证明了该方法的有效性与正确性。Abstract: Coherent Change Detection (CCD) detects micro changes in a scene using phase coherence of SAR images before and after a change. It is difficult for conventional CCD method to distinguish low coherence interference region from objective change region because of a single detection scale. Multi-band SAR target detection in a multiscale way develops variable coherent representation according to the diversity of electromagnetic wave penetration, target structure, and change magnitude. In this paper, a multi-band CCD method is proposed. Firstly, the CCD images of every band were acquired; secondly, the detected scene was classified on the basis of coherent representation of targets in each single band using improved Expectation-Maximization (EM) algorithm; thirdly, the objective change class in each single band was selected by a few supervised samples; lastly, multi-band fusion CCD image was acquired by the use of Dempster-Shafer (DS) evidence theory. This multi-band CCD result can eliminate low coherent interference in each single band and decrease false alarm probability. The method is validated by L- and P-band repeat-pass SAR images acquired before and after change. Results and index parameters demonstrate the validity and correctness of the proposed method.
-

图 2 待检测场景各波段变化前后SAR图像与光学参考图像
Figure 2. SAR images of each band of scene before and after change to be detected and optical reference image
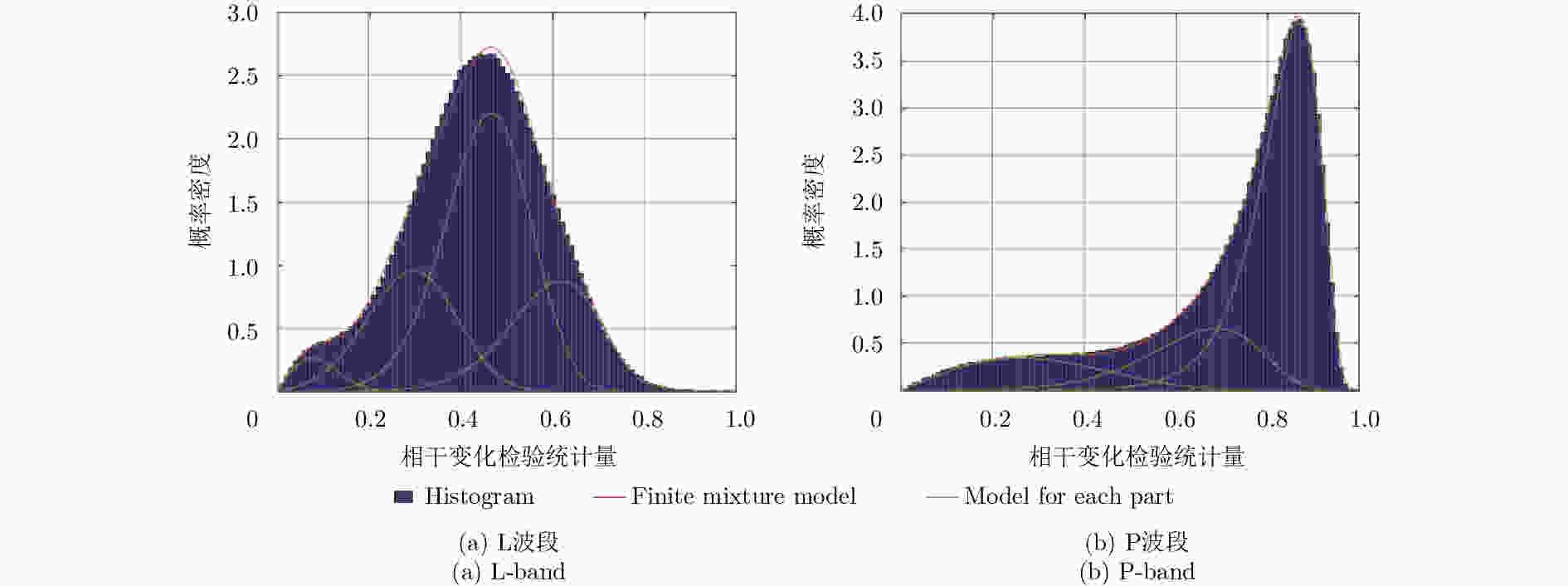
图 4 相干变化差异图的统计直方图及其拟合分布模型对比结果
Figure 4. Comparison results between histogram of CCD image and fitting distribution model

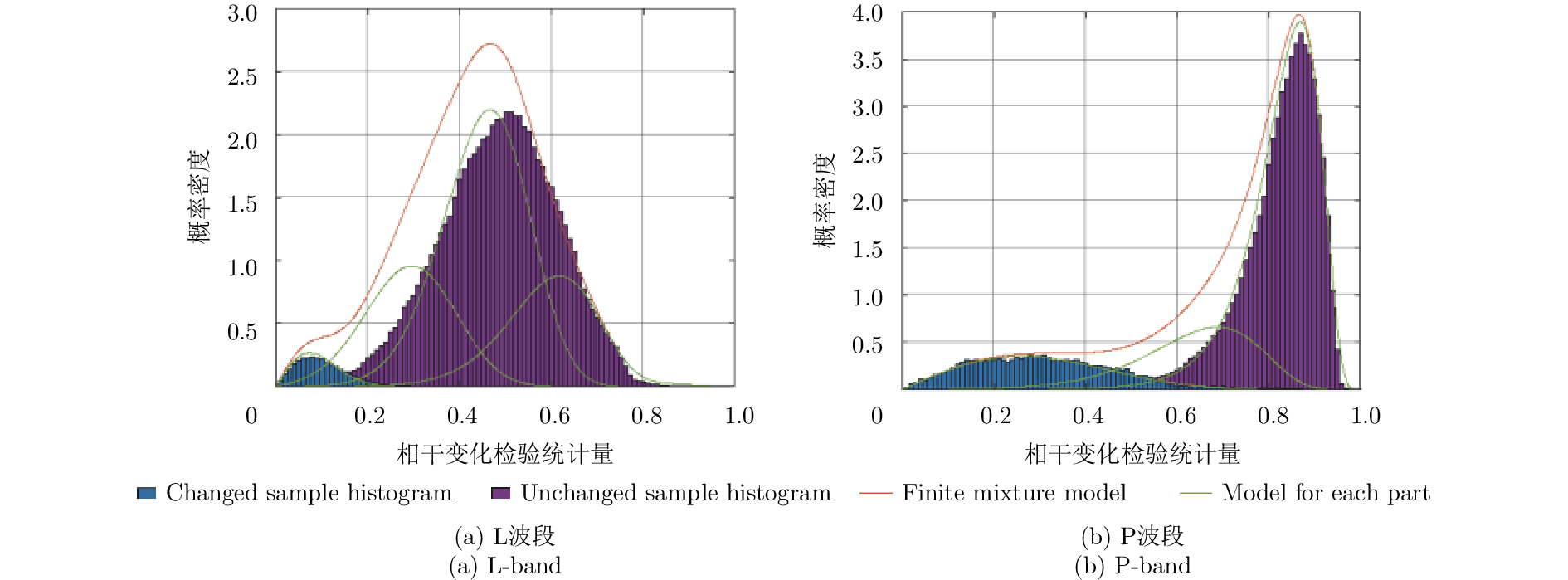
图 5 样本监督数据直方图与拟合分布模型比较结果(为方便比较,将样本监督数据直方图乘以相应的倍数,使其与拟合分布分模型的概率密度大小相当)
Figure 5. Comparison results between histogram of supervised sample data and fitting distribution model(For the reason of comparing conveniently, the histogram of supervised sample data times a corresponding multiple, so that it can be equal to the probability density of some fitting model part)
-
[1] Preiss M and Stacy N J S. Coherent change detection: Theoretical description and experimental results[R]. DSTO-TR-1851, 2006 [2] Jung J, Kim D J, Lavalle M, et al. Coherent change detection using InSAR temporal decorrelation model: A case study for volcanic ash detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(10): 5765–5775. DOI: 10.1109/TGRS.2016.2572166 [3] Barber J and Kogon S. Probabilistic three-pass SAR coherent change detection[C]. Proceedings of 2012 Conference Record of the Forty Sixth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, California, USA, 2012: 1723–1726. DOI: 10.1109/ACSSC.2012.6489327 [4] Muhuri A, Ratha D, and Bhattacharya A. Seasonal snow cover change detection over the Indian Himalayas using polarimetric SAR images[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(12): 2340–2344. DOI: 10.1109/LGRS.2017.2764123 [5] Wahl D E, Yocky D A, Jakowatz C V, et al. A new maximum-likelihood change estimator for two-pass SAR coherent change detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(4): 2460–2469. DOI: 10.1109/TGRS.2015.2502219 [6] 冷英, 李宁. 一种改进的变化检测方法及其在洪水监测中的应用[J]. 雷达学报, 2017, 6(2): 204–212. DOI: 10.12000/JR16139Leng Ying and Li Ning. Improved change detection method for flood monitoring[J]. Journal of radars, 2017, 6(2): 204–212. DOI: 10.12000/JR16139 [7] An L, Li M, Zhang P, et al. Discriminative random fields based on maximum entropy principle for semisupervised SAR image change detection[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2016, 9(8): 3395–3404. DOI: 10.1109/JSTARS.2015.2483320 [8] 徐真, 王宇, 李宁, 等. 一种基于CNN的SAR图像变化检测方法[J]. 雷达学报, 2017, 6(5): 483–491. DOI: 10.12000/JR17075Xu Zhen, Wang Robert, Li Ning et al. A novel approach to change detection in SAR images with CNN classification[J]. Journal of radars, 2017, 6(5): 483–491. DOI: 10.12000/JR17075 [9] Nielsen A A, Conradsen K, and Skriver H. Change detection in full and dual polarization, single-and multifrequency SAR data[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(8): 4041–4048. DOI: 10.1109/JSTARS.2015.2416434 [10] Nielsen A A, Conradsen K, and Skriver H. Corrections to " change detection in full and dual polarization, single-and multi-frequency SAR data”[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(11): 5143–5144. DOI: 10.1109/JSTARS.2017.2761038 [11] Reigber A, Jäger M, and Krogager E. Polarimetric SAR change detection in multiple frequency bands for environmental monitoring in Arctic regions[C]. IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 2016: 5702–5705. DOI: 10.1109/IGARSS.2016.7730489 [12] Li Y L, Liang X D, Zhou L J, et al.. Introduction to IECAS-SAR — A multi-frequency polarimetric airborne SAR[C]. IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, Quebec, Canada, 2014: 1085–1088. DOI: 10.1109/IGARSS.2014.6946617 [13] Jackson J A and Moses R L. Feature extraction algorithm for 3D scene modeling and visualization using monostatic SAR[C]. Proceedings of SPIE 6237 Algorithms for Synthetic Aperture Radar Imagery XIII, Orlando, 2006, 6237: 623708. DOI: 10.1117/12.666558 [14] 文贡坚, 朱国强, 殷红成, 等. 基于三维电磁散射参数化模型的SAR目标识别方法[J]. 雷达学报, 2017, 6(2): 115–135. DOI: 10.12000/JR17034Wen Gongjian, Zhu Guoqiang, Yin Hongcheng, et al. SAR ATR based on 3D parametric electromagnetic scattering model[J]. Journal of radars, 2017, 6(2): 115–135. DOI: 10.12000/JR17034 [15] 袁孝康. 星载合成孔径雷达导论[M]. 北京: 国防工业出版社, 2003: 234–235Yuan Xiao-kang. Introduce to the Spaceborne Sythetic Aperture Radar[M]. Beijing: National Defense Industry Press, 2003: 234–235 [16] 陈述彭, 童庆禧, 郭华东. 遥感信息机理研究[M]. 北京: 科学出版社, 1998: 274–288Chen Shu-peng, Tong Qing-xi, and Guo Hua-dong. Mechanism of Remote Sensing Information[M]. Beijing: Science Press, 1998: 274–288 [17] 周智敏, 黄晓涛. VHF/UHF超宽带合成孔径雷达穿透性能分析[J]. 系统工程与电子技术, 2003, 25(11): 1336–1340. DOI: 10.3321/j.issn:1001-506X.2003.11.007Zhou Zhi-min and Huang Xiao-tao. Penetration performance analysis of VHF/UHF ultra-wideband synthetic aperture radar[J]. Systems Engineering and Electronics, 2003, 25(11): 1336–1340. DOI: 10.3321/j.issn:1001-506X.2003.11.007 [18] Yin Q, Li Y, Huang P P, et al. Analysis of InSAR coherence loss caused by soil moisture variation[J]. Journal of Radars, 2015, 4(6): 689–697. DOI: 10.12000/JR15075 [19] 黄培康, 殷红成, 许小剑. 雷达目标特性[M]. 北京: 电子工业出版社, 2005: 9–62Huang Pei-kang, Yin Hong-cheng, and Xu Xiao-jian. Radar Target Characteristics[M]. Beijing: Publishing House of Electronics Industry, 2005: 9–62 [20] 冀广宇, 董勇伟, 李焱磊, 等. 一种基于概率图模型的多时相SAR相干变化检测方法[J]. 电子与信息学报, 2017, 39(12): 2912–2920. DOI: 10.11999/JEIT170208Ji Guang-yu, Dong Yong-wei, Li Yan-lei, et al. A multi-temporal SAR coherent change detection method based on probabilistic graphical models[J]. Journal of Electronics&Information Technology, 2017, 39(12): 2912–2920. DOI: 10.11999/JEIT170208 [21] 尤红建, 付琨. 合成孔径雷达图像精准处理[M]. 北京: 科学出版社, 2011: 125–139You Hong-jian and Fu Kun. Precise Processing of Synthetic Aperture Radar Images[M]. Beijing: Science Press, 2011: 125–139 [22] Touzi R, Lopes A, Bruniquel J, et al. Coherence estimation for SAR imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 1999, 37(1): 135–149. DOI: 10.1109/36.739146 [23] Anfinsen S N and Eltoft T. Application of the matrix-variate mellin transform to analysis of polarimetric radar images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2011, 49(6): 2281–2295. DOI: 10.1109/TGRS.2010.2103945 [24] 杨祥立, 徐德伟, 黄平平, 等. 融合相干/非相干信息的高分辨率SAR图像变化检测[J]. 雷达学报, 2015, 4(5): 582–590. DOI: 10.12000/JR15073Yang Xiang-li, Xu De-wei, Huang Ping-ping, et al. Change detection of high resolution SAR images by the fusion of coherent/incoherent information[J]. Journal of Radars, 2015, 4(5): 582–590. DOI: 10.12000/JR15073 [25] 王桂婷, 王幼亮, 焦李成. 基于快速EM算法和模糊融合的多波段遥感影像变化检测[J]. 红外与毫米波学报, 2010, 29(5): 383–388Wang Gui-ting, Wang You-liang, and Jiao Li-cheng. Change detection method of multiband remote sensing images based on fast expectation-maximization algorithm and fuzzy fusion[J]. Journal of Infrared and Millimeter Waves, 2010, 29(5): 383–388 -

 下载:
下载:





计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

