
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor Work- Home
- Articles & Issues
-
Data
- Dataset of Radar Detecting Sea
- SAR Dataset
- SARGroundObjectsTypes
- SARMV3D
- AIRSAT Constellation SAR Land Cover Classification Dataset
- 3DRIED
- UWB-HA4D
- LLS-LFMCWR
- FAIR-CSAR
- MSAR
- SDD-SAR
- FUSAR
- SpaceborneSAR3Dimaging
- Sea-land Segmentation
- SAR Multi-domain Ship Detection Dataset
- SAR-Airport
- Hilly and mountainous farmland time-series SAR and ground quadrat dataset
- SAR images for interference detection and suppression
- HP-SAR Evaluation & Analytical Dataset
- GDHuiYan-ATRNet
- Multi-System Maritime Low Observable Target Dataset
- DatasetinthePaper
- DatasetintheCompetition
- Report
- Course
- About
- Publish
- Editorial Board
- Chinese

Article Navigation >
Journal of Radars
>
2026
> Proofreading [3rd]
| Citation: | YANG Boyang, LI Kang, JIU Bo, et al. Offline reward backfilling-based intelligent cooperative jamming strategy learning method[J]. Journal of Radars, in press. doi: 10.12000/JR26061

|
Offline Reward Backfilling-based Intelligent Cooperative Jamming Strategy Learning Method
DOI: 10.12000/JR26061 CSTR: 32380.14.JR26061
More Information-
Abstract
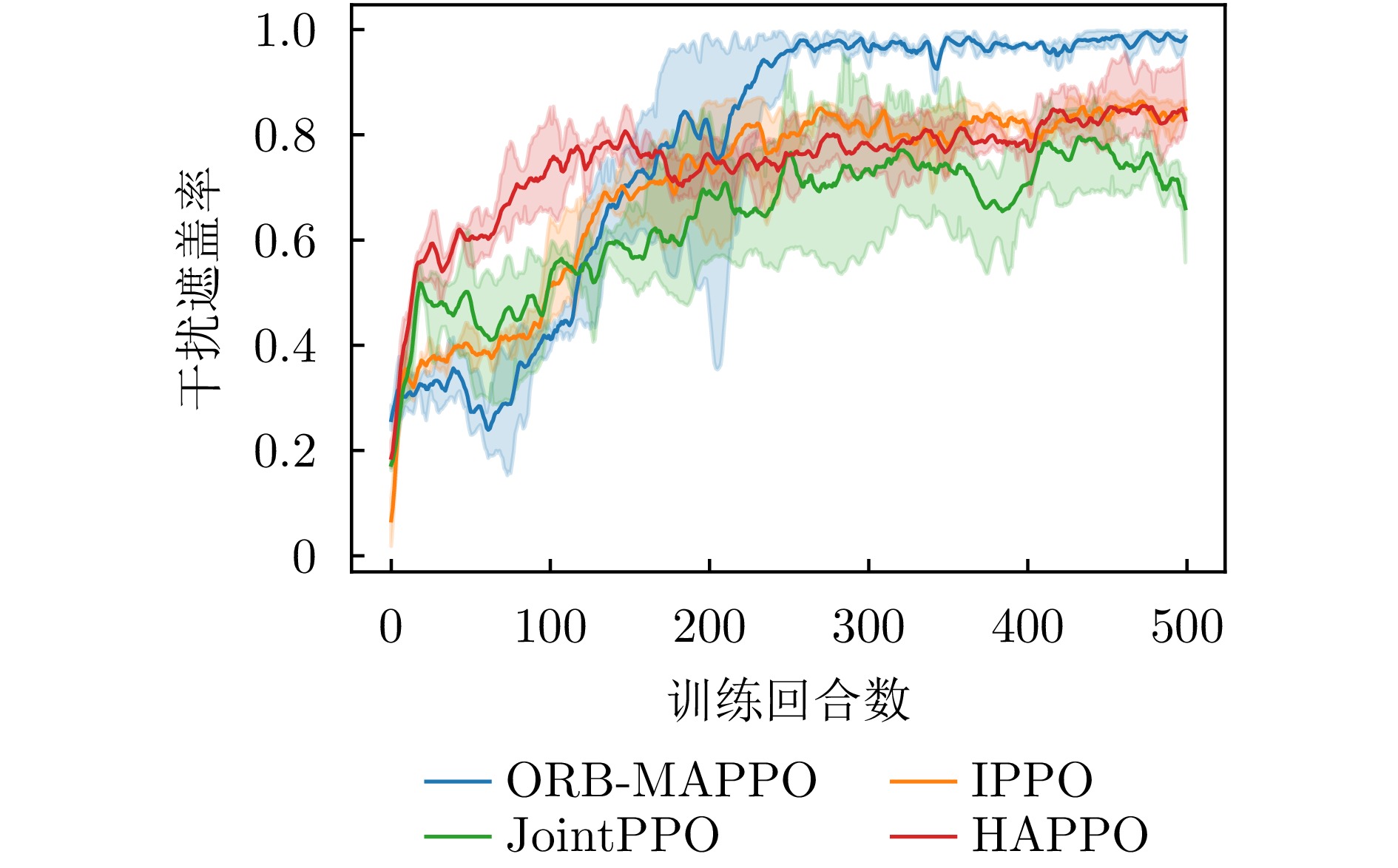
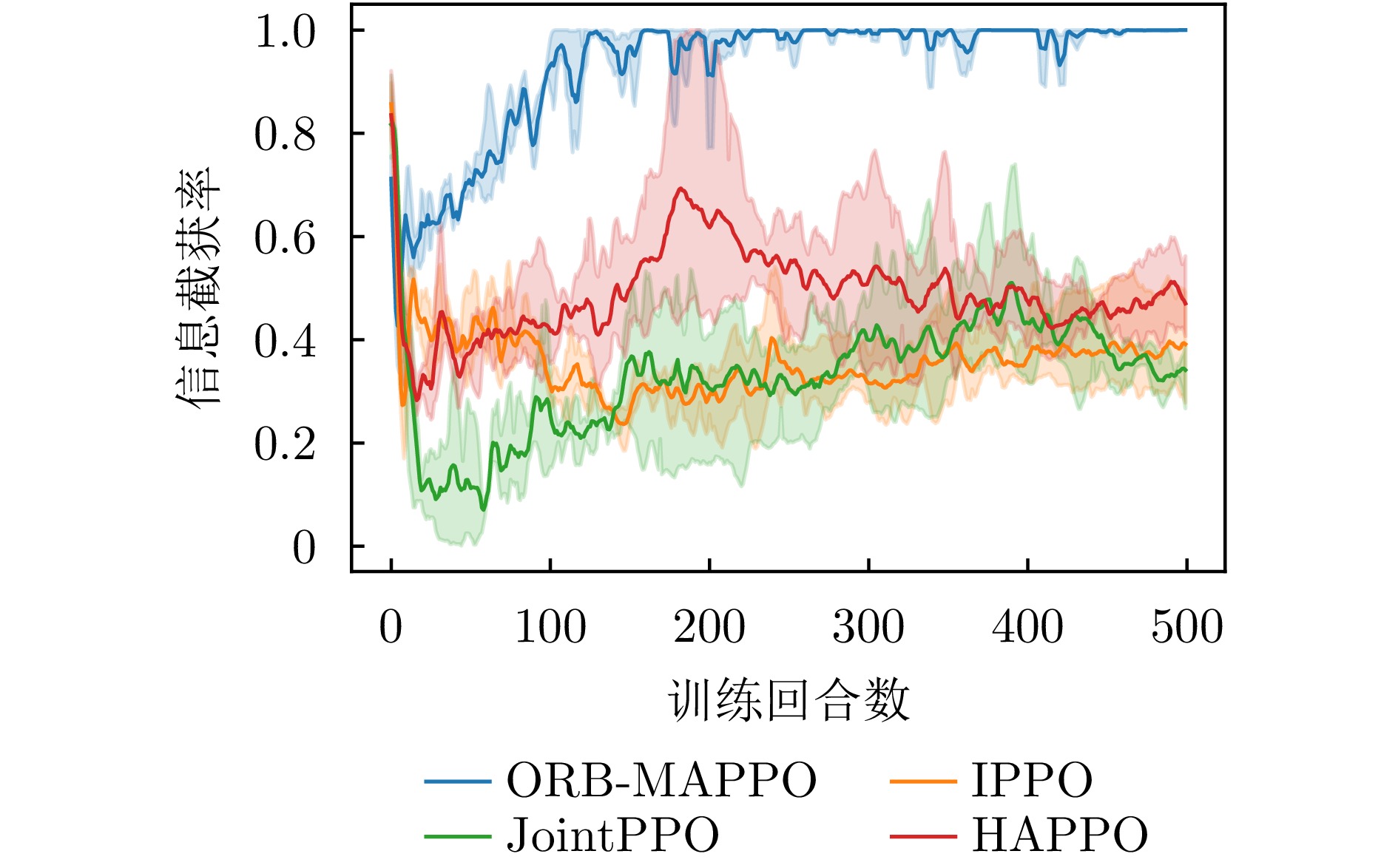
To address partial observability, reward sparsity, and distorted credit assignment in cooperative jamming against networked radars in complex electromagnetic environments, this paper proposes an intelligent cooperative jamming strategy learning method with an offline reward backfilling mechanism. The multi-jammer cooperative jamming process is formulated as a partially observable Markov decision process. A two-level reward design is introduced, integrating immediate rewards with offline reward backfilling to improve the evaluation of jamming effectiveness and policy learning. Specifically, within each aggregation period, each jammer performs online adaptations of interception rhythm and transmission behavior based on local observations. At the end of the period, multi-jammer interaction data are aggregated to retrospectively assess the effectiveness of joint jamming actions. The resulting evaluation is backfilled into policy optimization to refine the policy gradient signal. This design enhances the policy’s ability to capture the actual jamming effectiveness. Accordingly, under the centralized training and decentralized execution framework, an offline reward backfilling-based multi-agent proximal policy optimization algorithm, termed ORB-MAPPO, is developed to realize collaborative time-frequency jamming strategy learning for multiple jammers. Simulation results demonstrate that the proposed method stably learns effective time-frequency cooperative jamming strategies, achieving a jamming coverage rate of over 95% and an information interception rate close to 100%. Compared with typical multi-agent policy optimization methods, the proposed method improves the jamming coverage rate by approximately 20%, demonstrating superior cooperative jamming performance and training stability. -

-
References
[1] 崔国龙, 余显祥, 魏文强, 等. 认知智能雷达抗干扰技术综述与展望[J]. 雷达学报, 2022, 11(6): 974–1002. doi: 10.12000/JR22191.CUI Guolong, YU Xianxiang, WEI Wenqiang, et al. An overview of antijamming methods and future works on cognitive intelligent radar[J]. Journal of Radars, 2022, 11(6): 974–1002. doi: 10.12000/JR22191.[2] LIU Yongxiang, YANG Wei, QIU Xiangfeng, et al. Advanced cognitive radar: Principles, systems, and essential applications[J]. IEEE Aerospace and Electronic Systems Magazine, 2026, 41(4): 68–81. doi: 10.1109/MAES.2025.3648682.[3] QIU Xiangfeng, JIANG Weidong, LIU Yongxiang, et al. Constrained riemannian manifold optimization for the simultaneous shaping of ambiguity function and transmit Beampattern[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(3): 5771–5787. doi: 10.1109/TAES.2024.3520951.[4] QIU Xiangfeng, JIANG Weidong, ZHANG Xinyu, et al. Design of complementary PCFM waveform set for smearing spectrum jamming suppression in MIMO radar systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(4): 10149–10168. doi: 10.1109/TAES.2025.3560612.[5] 张大琳, 易伟, 孔令讲. 面向组网雷达干扰任务的多干扰机资源联合优化分配方法[J]. 雷达学报, 2021, 10(4): 595–606. doi: 10.12000/JR21071.ZHANG Dalin, YI Wei, and KONG Lingjiang. Optimal joint allocation of multijammer resources for jamming netted radar system[J]. Journal of Radars, 2021, 10(4): 595–606. doi: 10.12000/JR21071.[6] 蒋雯, 贾琼, 刘真, 等. 面向主被动雷达复合探测的全脉冲多机协同干扰方法[J]. 雷达学报(中英文), 2025, 14(6): 1515–1530. doi: 10.12000/JR25016.JIANG Wen, JIA Qiong, LIU Zhen, et al. Full-pulse multi-jammer cooperative jamming method for active-passive radar composite detection[J]. Journal of Radars, 2025, 14(6): 1515–1530. doi: 10.12000/JR25016.[7] GONG Liangliang, WU Shilong, and LV Tao. A radar emitter identification method based on pulse match template sequence[C]. 2010 2nd International Conference on Signal Processing Systems, Dalian, China, 2010: V3-153–V3-156. doi: 10.1109/ICSPS.2010.5555410.[8] SONG Xiufeng, WILLETT P, ZHOU Shengli, et al. The MIMO radar and jammer games[J]. IEEE Transactions on Signal Processing, 2012, 60(2): 687–699. doi: 10.1109/TSP.2011.2169251.[9] ZHANG Chudi, WANG Lei, JIANG Rundong, et al. Radar jamming decision-making in cognitive electronic warfare: A review[J]. IEEE Sensors Journal, 2023, 23(11): 11383–11403. doi: 10.1109/JSEN.2023.3267068.[10] 王俊, 郑彤, 雷鹏, 等. 深度学习在雷达中的研究综述[J]. 雷达学报, 2018, 7(4): 395–411. doi: 10.12000/JR18040.WANG Jun, ZHENG Tong, LEI Peng, et al. Study on deep learning in radar[J]. Journal of Radars, 2018, 7(4): 395–411. doi: 10.12000/JR18040.[11] 解烽, 刘环宇, 胡锡坤, 等. 基于复数域深度强化学习的多干扰场景雷达抗干扰方法[J]. 雷达学报, 2023, 12(6): 1290–1304. doi: 10.12000/JR23139.XIE Feng, LIU Huanyu, HU Xikun, et al. A radar anti-jamming method under multi-jamming scenarios based on deep reinforcement learning in complex domains[J]. Journal of Radars, 2023, 12(6): 1290–1304. doi: 10.12000/JR23139.[12] 杜兰, 王梓霖, 郭昱辰, 等. 结合强化学习自适应候选框挑选的SAR目标检测方法[J]. 雷达学报, 2022, 11(5): 884–896. doi: 10.12000/JR22121.DU Lan, WANG Zilin, GUO Yuchen, et al. Adaptive region proposal selection for SAR target detection using reinforcement learning[J]. Journal of Radars, 2022, 11(5): 884–896. doi: 10.12000/JR22121.[13] ZHANG Yujie, HUO Weibo, HUANG Yulin, et al. Jamming policy generation via heuristic programming reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(6): 8782–8799. doi: 10.1109/TAES.2023.3312231.[14] ZHANG Chudi, YANG Biao, WANG Lei, et al. A cognitive jamming decision-making method based on heuristic improved A2C algorithm[J]. IEEE Transactions on Vehicular Technology, 2025, 74(2): 2871–2883. doi: 10.1109/TVT.2024.3470832.[15] LIU Hongdi, ZHANG Hongtao, HE Yuan, et al. Jamming strategy optimization through dual Q-learning model against adaptive radar[J]. Sensors, 2022, 22(1): 145. doi: 10.3390/s22010145.[16] PAN Zesi, LI Yunjie, WANG Shafei, et al. Joint optimization of jamming type selection and power control for countering multifunction radar based on deep reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2023, 59(4): 4651–4665. doi: 10.1109/TAES.2023.3272307.[17] 王跃东, 顾以静, 梁彦, 等. 伴随压制干扰与组网雷达功率分配的深度博弈研究[J]. 雷达学报, 2023, 12(3): 642–656. doi: 10.12000/JR23023.WANG Yuedong, GU Yijing, LIANG Yan, et al. Deep game of escorting suppressive jamming and networked radar power allocation[J]. Journal of Radars, 2023, 12(3): 642–656. doi: 10.12000/JR23023.[18] YANG Boyang, LI Kang, JIU Bo, et al. Execute-evaluate two-stage framework for intelligent jamming decision-making based on reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(4): 8624–8640. doi: 10.1109/TAES.2025.3548594.[19] ZHANG Wenxu, ZHAO Tong, ZHAO Zhongkai, et al. An intelligent strategy decision method for collaborative jamming based on hierarchical multi-agent reinforcement learning[J]. IEEE Transactions on Cognitive Communications and Networking, 2024, 10(4): 1467–1480. doi: 10.1109/TCCN.2024.3373640.[20] SUN Sizhe and SHI Yanling. Joint optimization of resource utilization and jamming method selection for cluster asymmetrical multifunction radars based on deep reinforcement learning[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(2): 5116–5131. doi: 10.1109/TAES.2024.3515942.[21] LI Yan, JIA Yubo, and PAN Zesi. ALI-MAPPO: Attention on local information aided MAPPO algorithm for power allocation of wireless cognitive jamming systems[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(5): 13759–13774. doi: 10.1109/TAES.2025.3580014.[22] FENG Cheng, FU Xiongjun, WANG Ziyi, et al. An optimization method for collaborative radar antijamming based on multi-agent reinforcement learning[J]. Remote Sensing, 2023, 15(11): 2893. doi: 10.3390/rs15112893.[23] 王子怡, 傅雄军, 董健, 等. 基于分层多智能体强化学习的雷达协同抗干扰策略优化[J]. 系统工程与电子技术, 2025, 47(4): 1108–1114. doi: 10.12305/j.issn.1001-506X.2025.04.07.WANG Ziyi, FU Xiongjun, DONG Jian, et al. Optimization of radar collaborative anti-jamming strategies based on hierarchical multi-agent reinforcement learning[J]. Systems Engineering and Electronics, 2025, 47(4): 1108–1114. doi: 10.12305/j.issn.1001-506X.2025.04.07.[24] YU C, SAHU A K, TALAKOUB S, et al. MAPPO: A PPO variant for multi-agent cooperative competition[J]. arXiv preprint arXiv: 2103.01955, 2021.[25] KRAEMER L and BANERJEE B. Multi-agent reinforcement learning as a centralized training decentralized execution problem[J]. arXiv preprint arXiv: 1604.07239.[26] FILAR J and VRIEZE K. Competitive Markov Decision Processes[M]. New York, NY, USA: Springer, 1997.[27] SONDIK E J. The optimal control of partially observable markov decision processes[D]. Stanford: Stanford University, 1971.[28] ELMAN J L. Finding structure in time[J]. Cognitive Science, 1990, 14(2): 179–211. doi: 10.1207/s15516709cog1402_1.[29] HOCHREITER S and SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735.[30] CHUNG J, GULCEHRE C, CHO K H, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv: 1412.3555, 2014. doi: 10.48550/arXiv.1412.3555. -
Proportional views

- Publishing Ethics
- Journal Insights
- Abstracting & Indexing
- Peer Review Policies
- Guide for Authors
- Conference
- ISSN 2095-283X (Print)ISSN 2097-339X (Online)
- CN 10-1030/TN
- CODEN LXEUAO
About Journal
- Sponsor: China Radio Detection and Ranging Industry Association (CRIA)
- Phone: 010-58887062
- Email:radars@aircas.ac.cn
- Publisher: Leida Xuebao Bianjibu (Editorial office of the Journal of Radars)
Contacts Us

京ICP备20021838号-14
Supported by: Beijing Renhe Information Technology Co. Ltd

Export File
Citation
Format
Content
 DownLoad:
DownLoad:
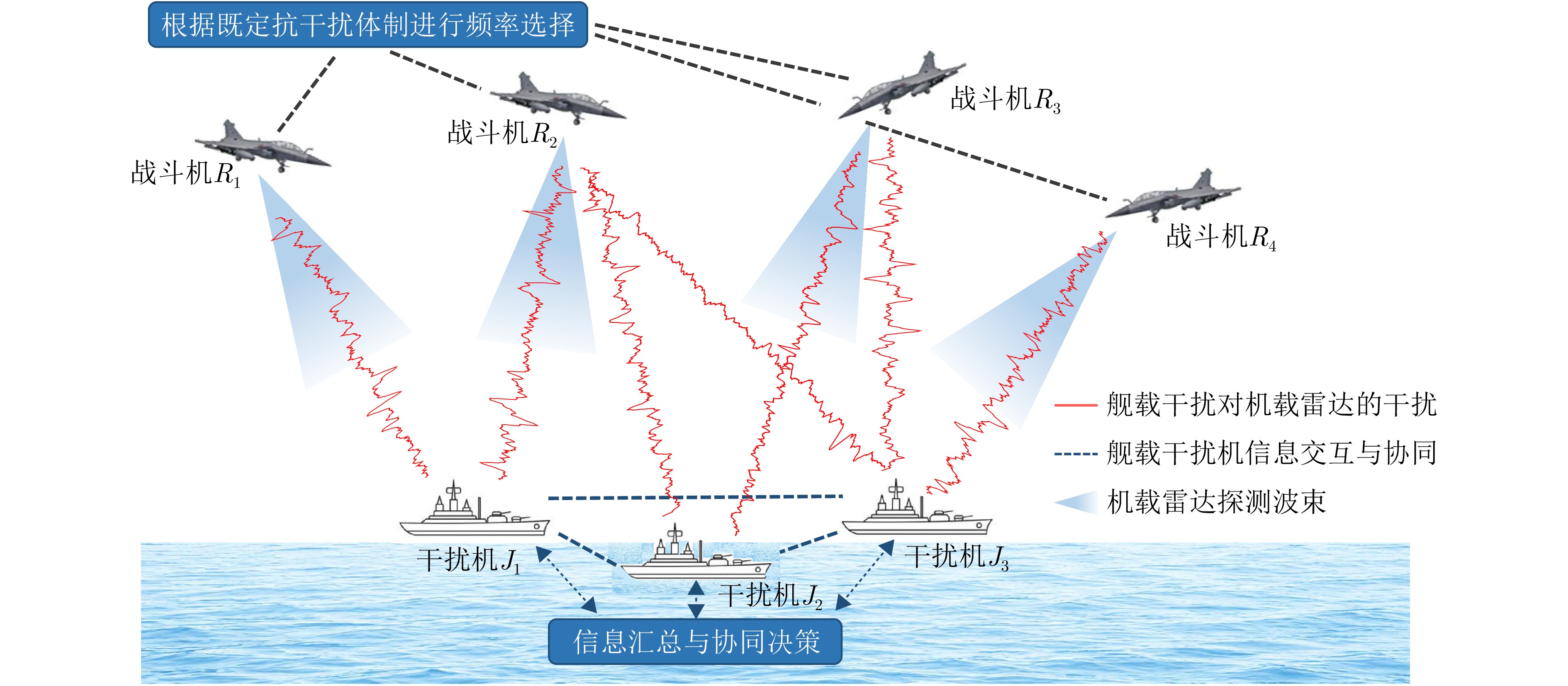
- Figure 1. Schematic diagram of a sea-to-air cooperative adversarial scenario under jammer-side resource superiority
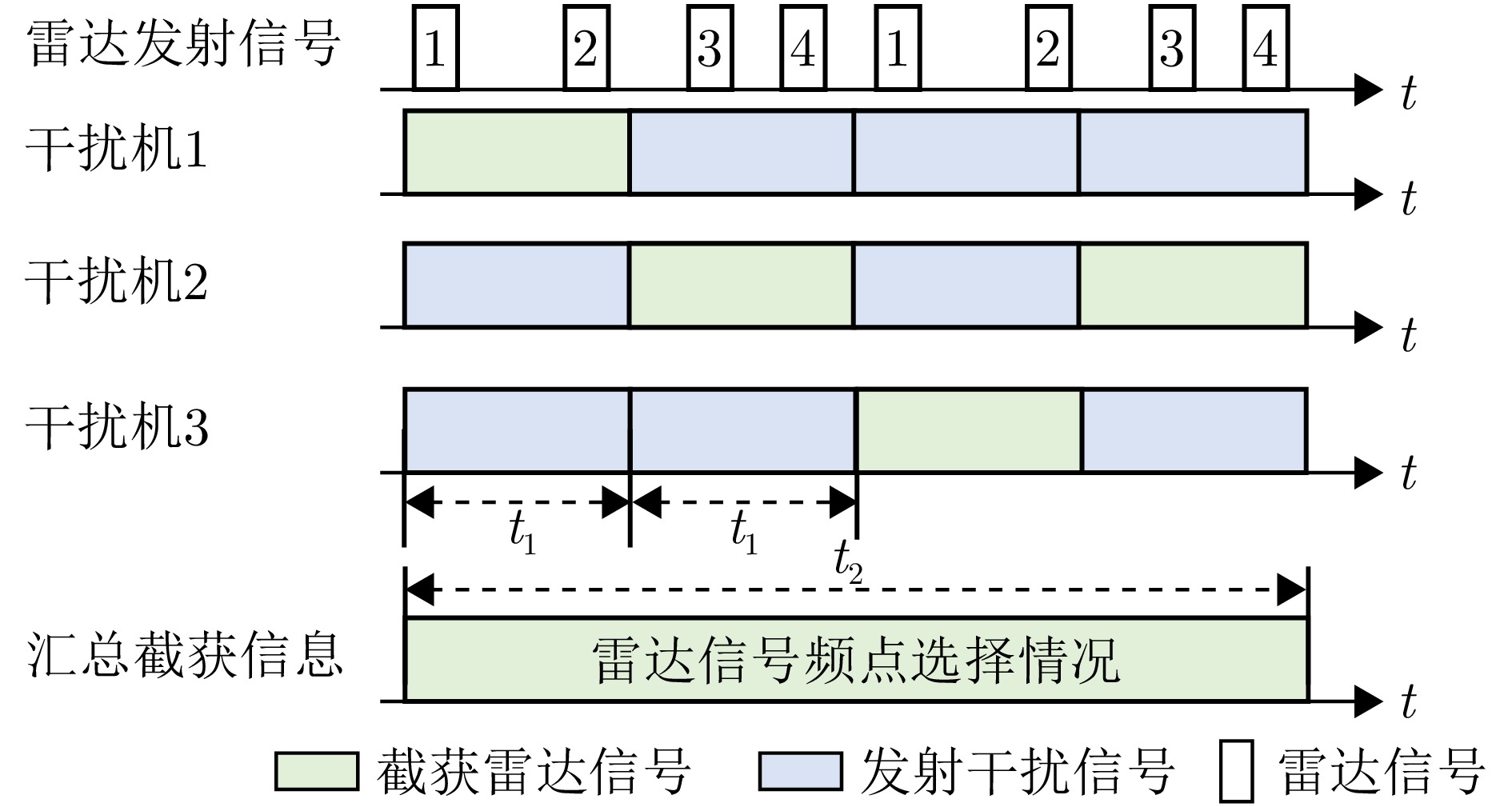
- Figure 2. Schematic diagram of two-level temporal units
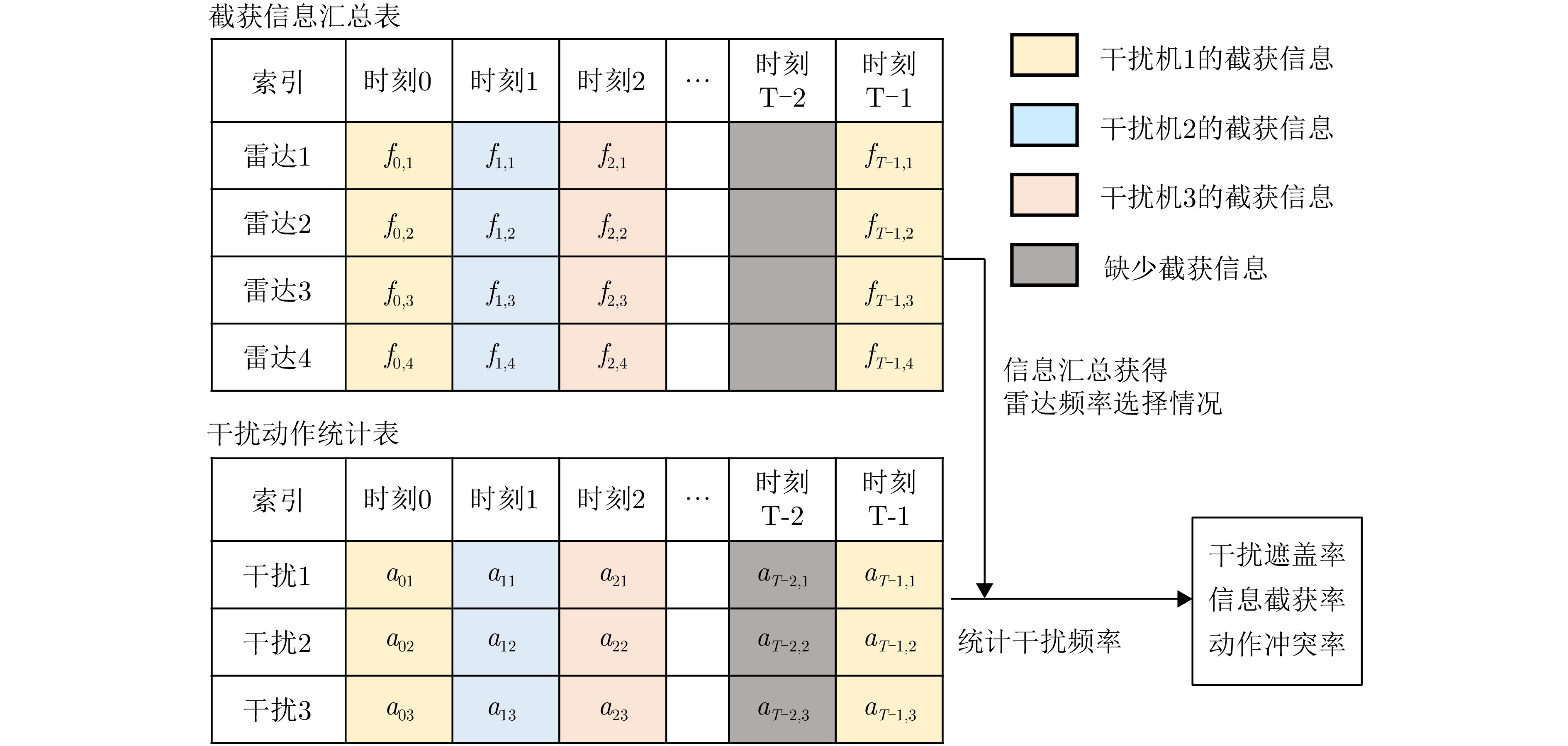
- Figure 3. Schematic diagram of information summary process
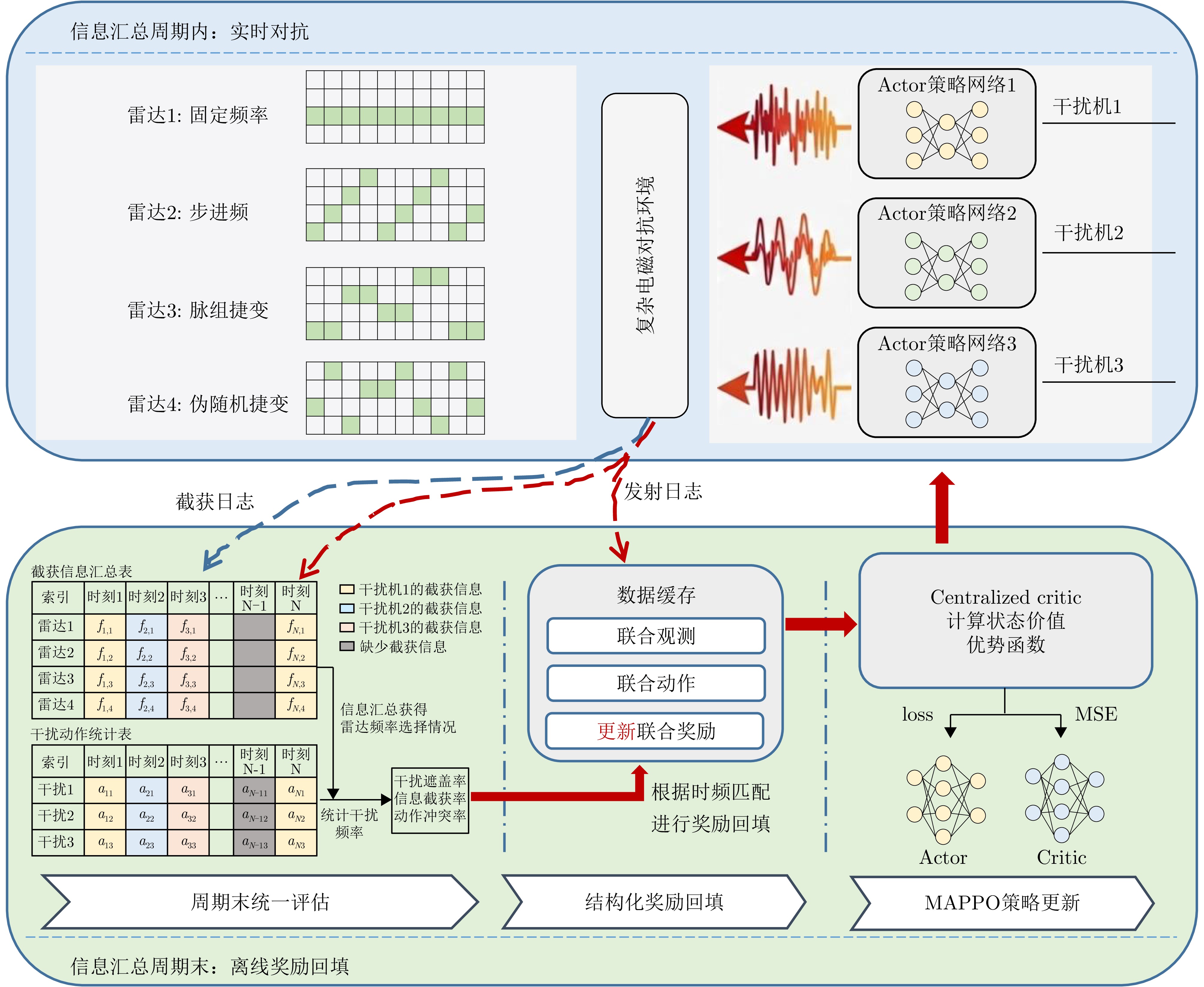
- Figure 4. Flowchart of collaborative interference strategy learning method
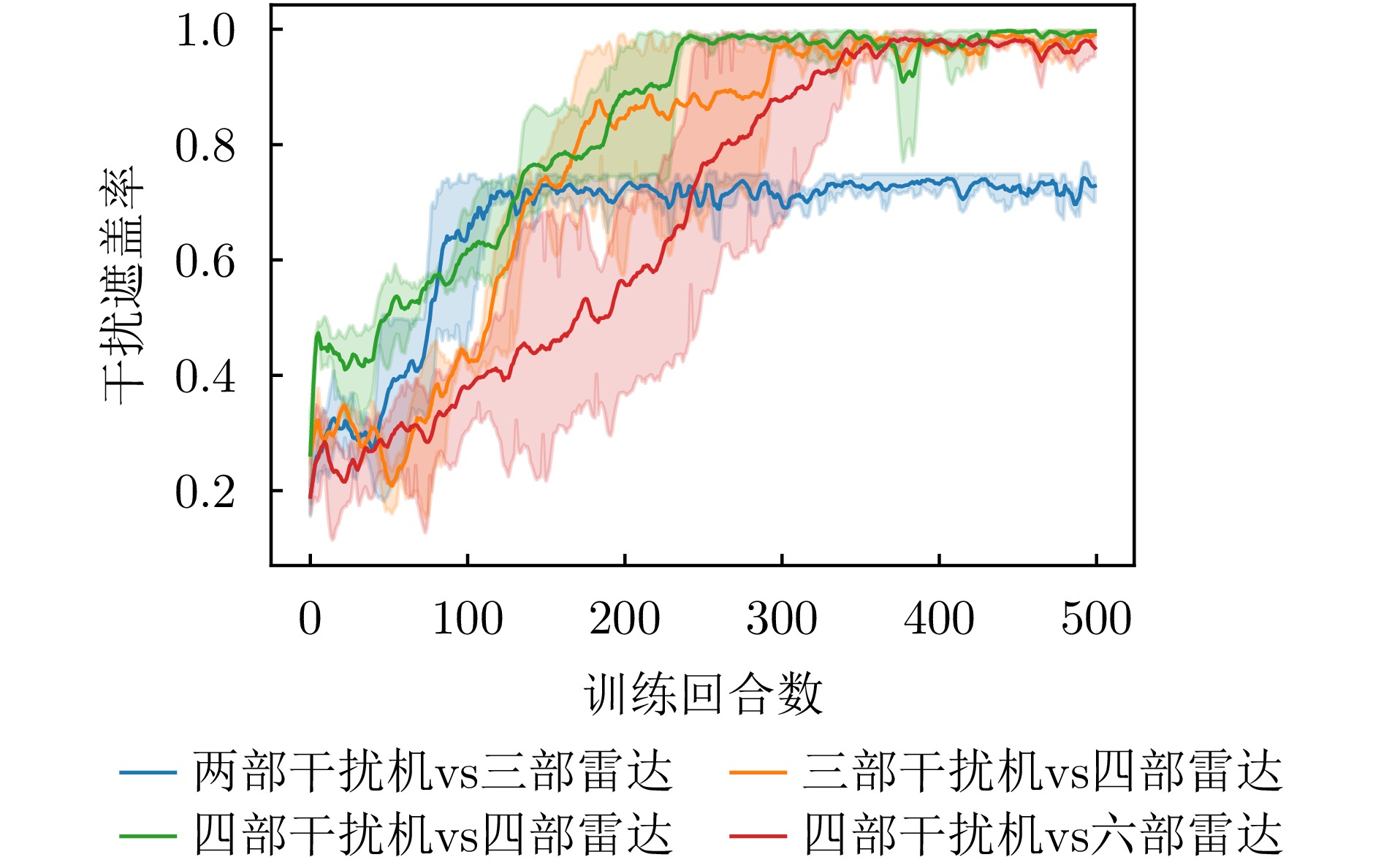
- Figure 5. Comparison of jamming coverage rate curves
- Figure 6. Comparison of information interception rate curves
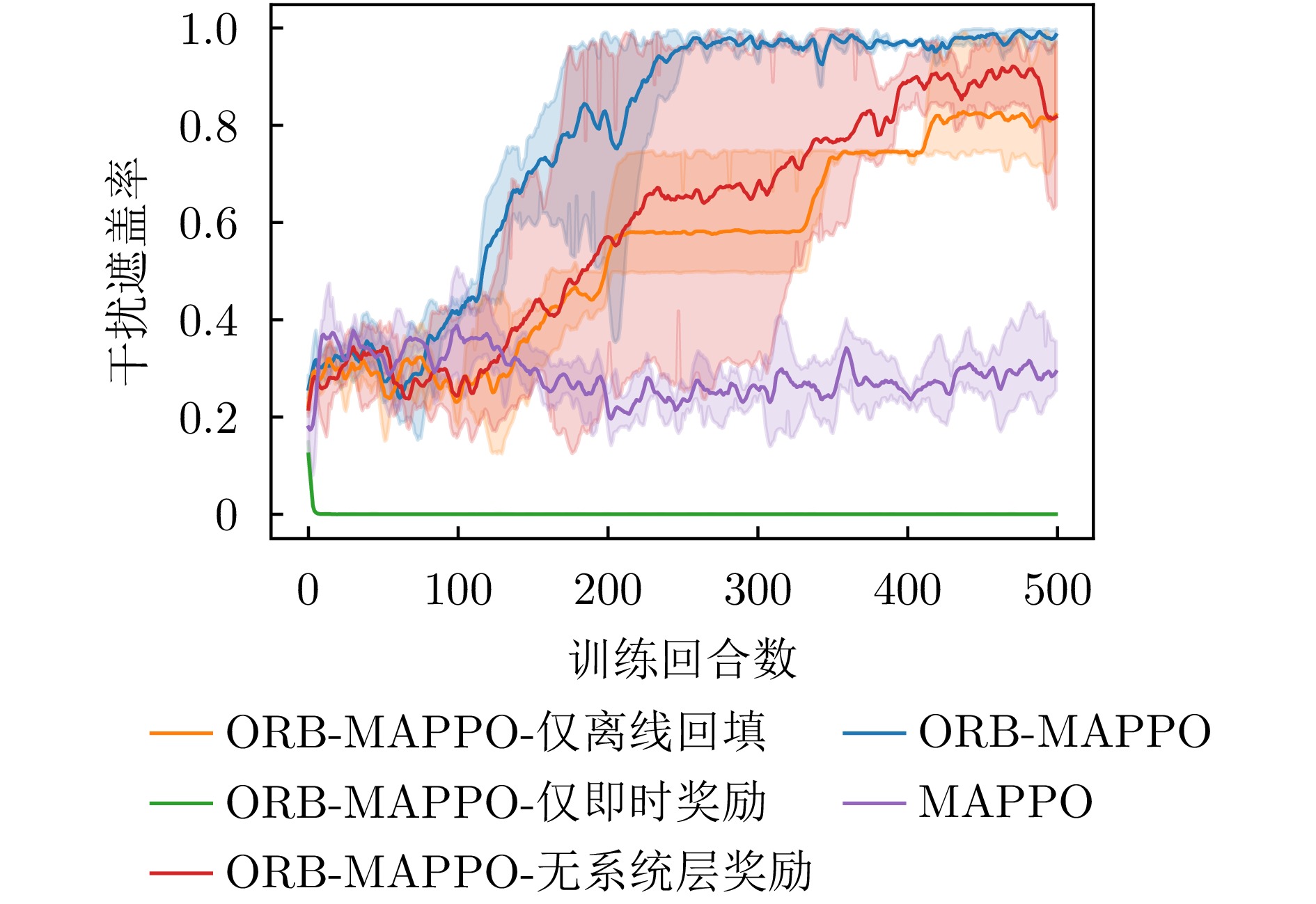
- Figure 7. Comparison chart of jamming coverage rate in ablation experiment
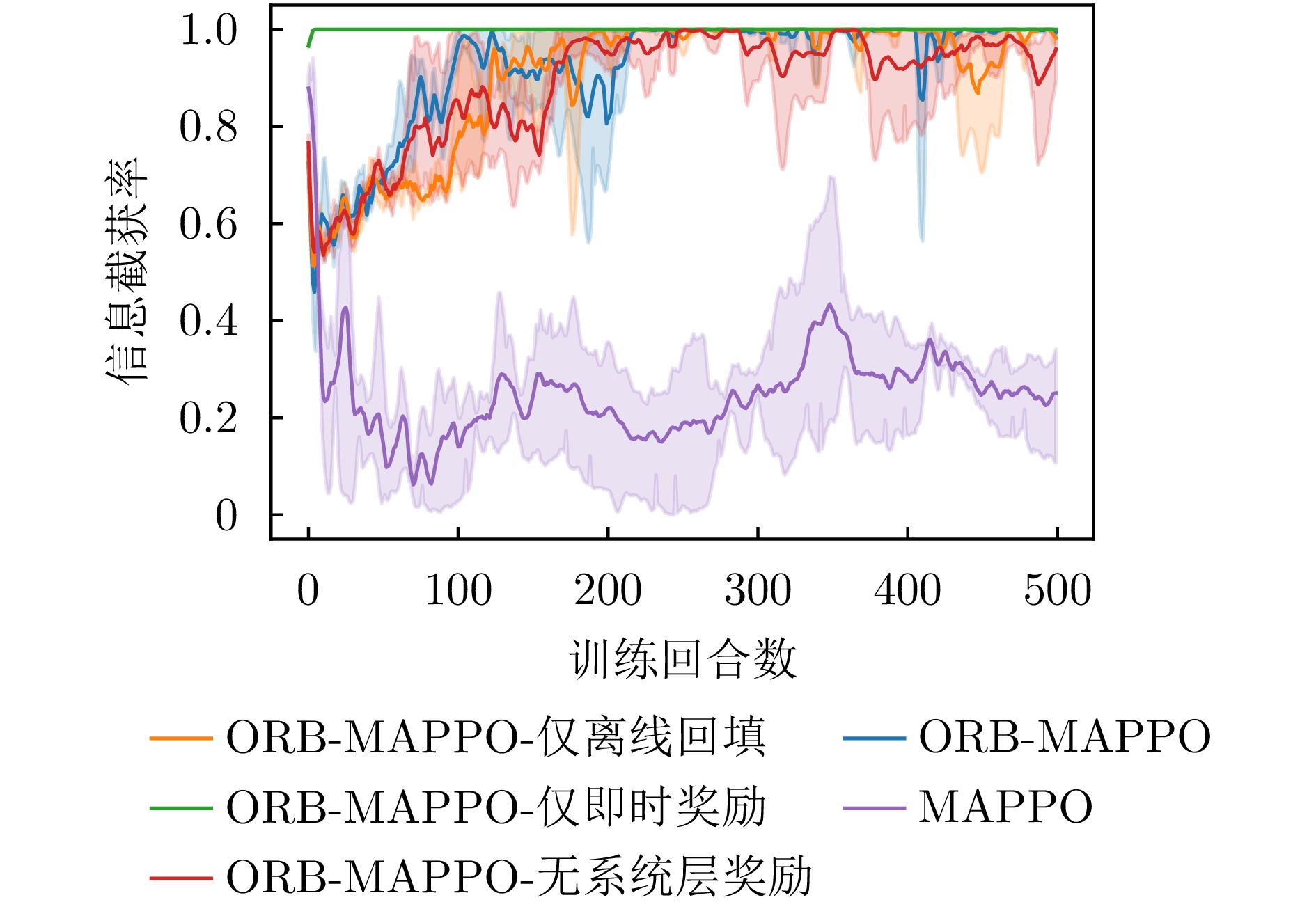
- Figure 8. Comparison of information interception rate curves in ablation experiments
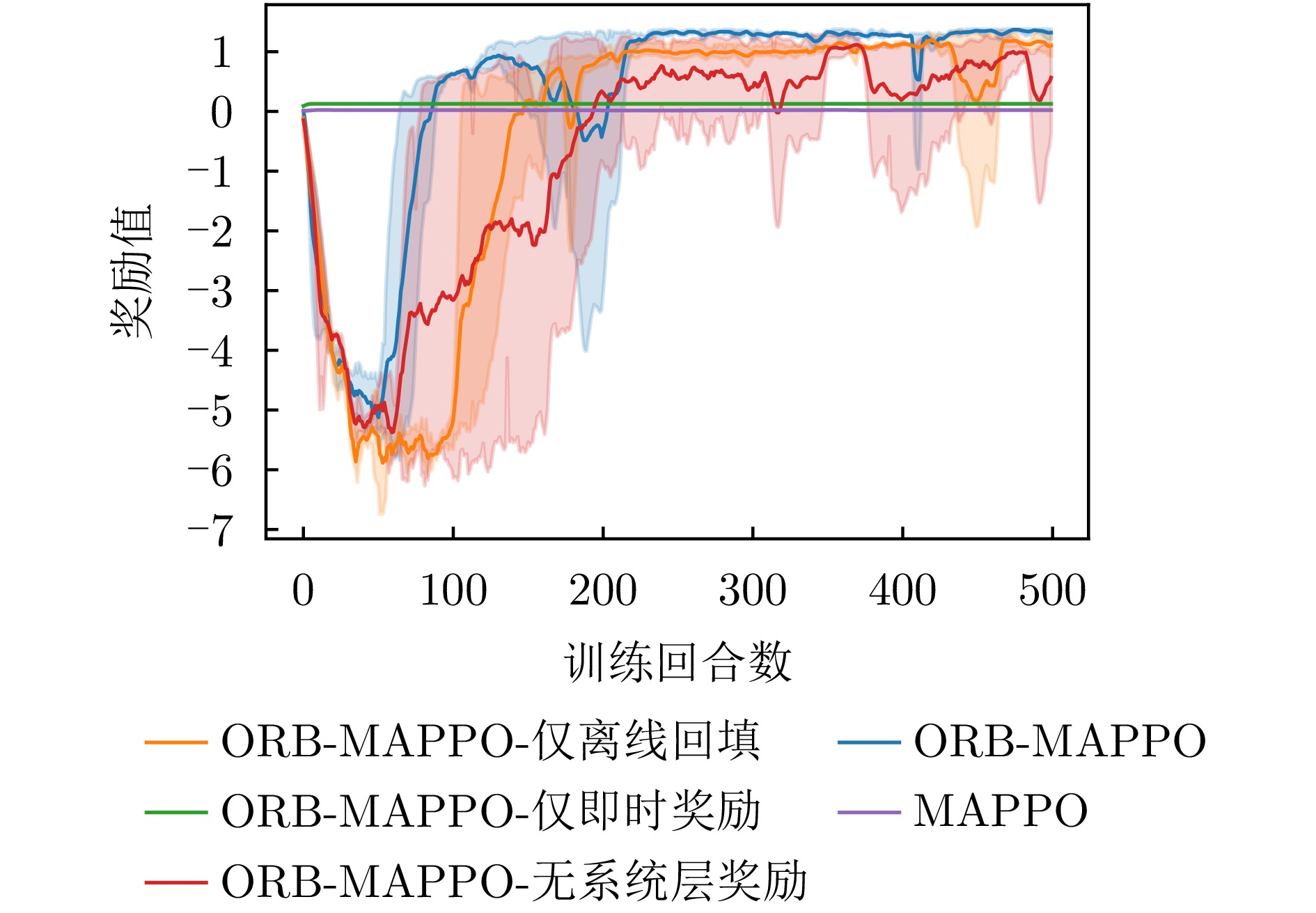
- Figure 9. Comparison of reward curves in ablation experiment
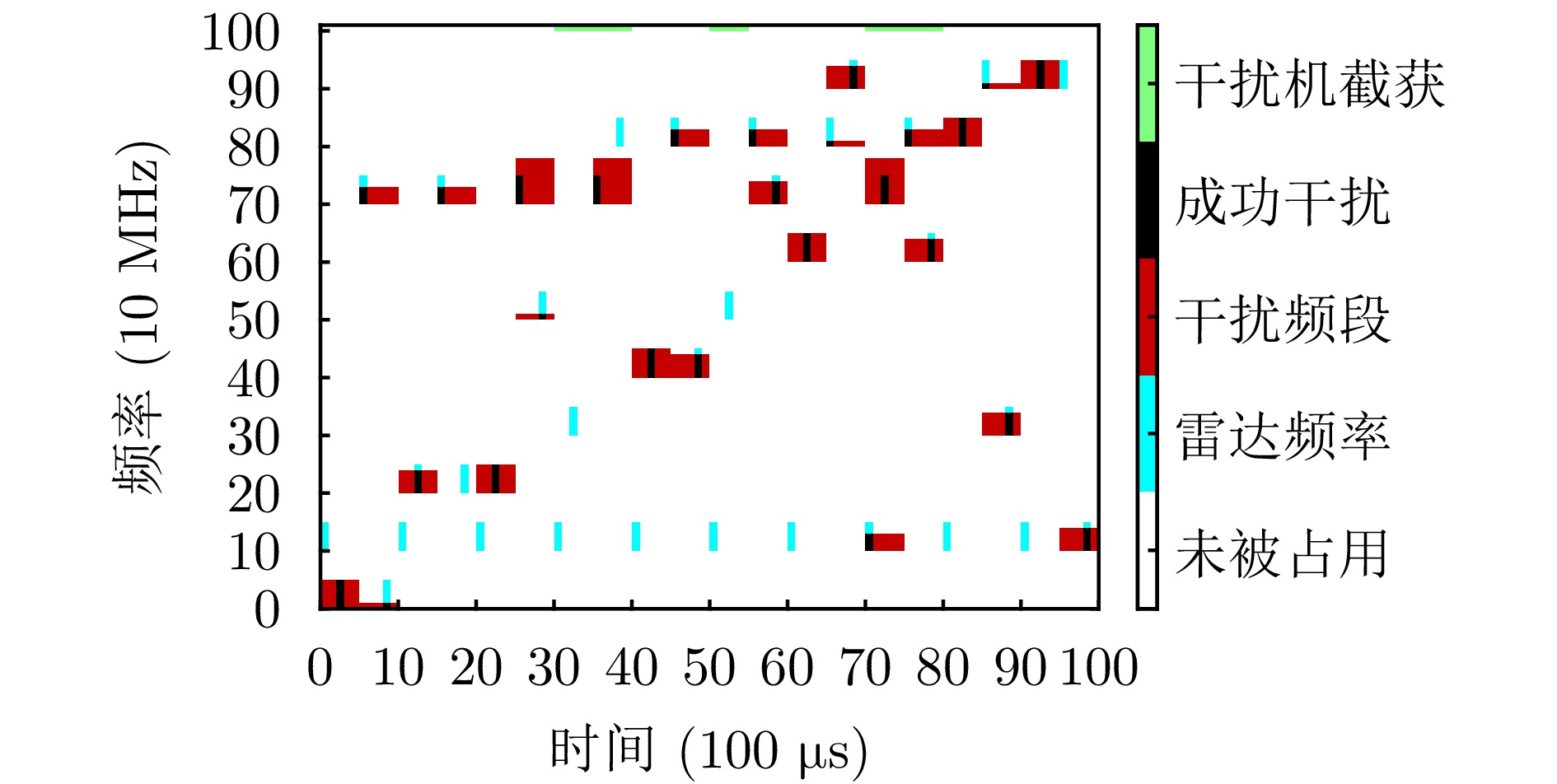
- Figure 10. Schematic diagram of the proposed method
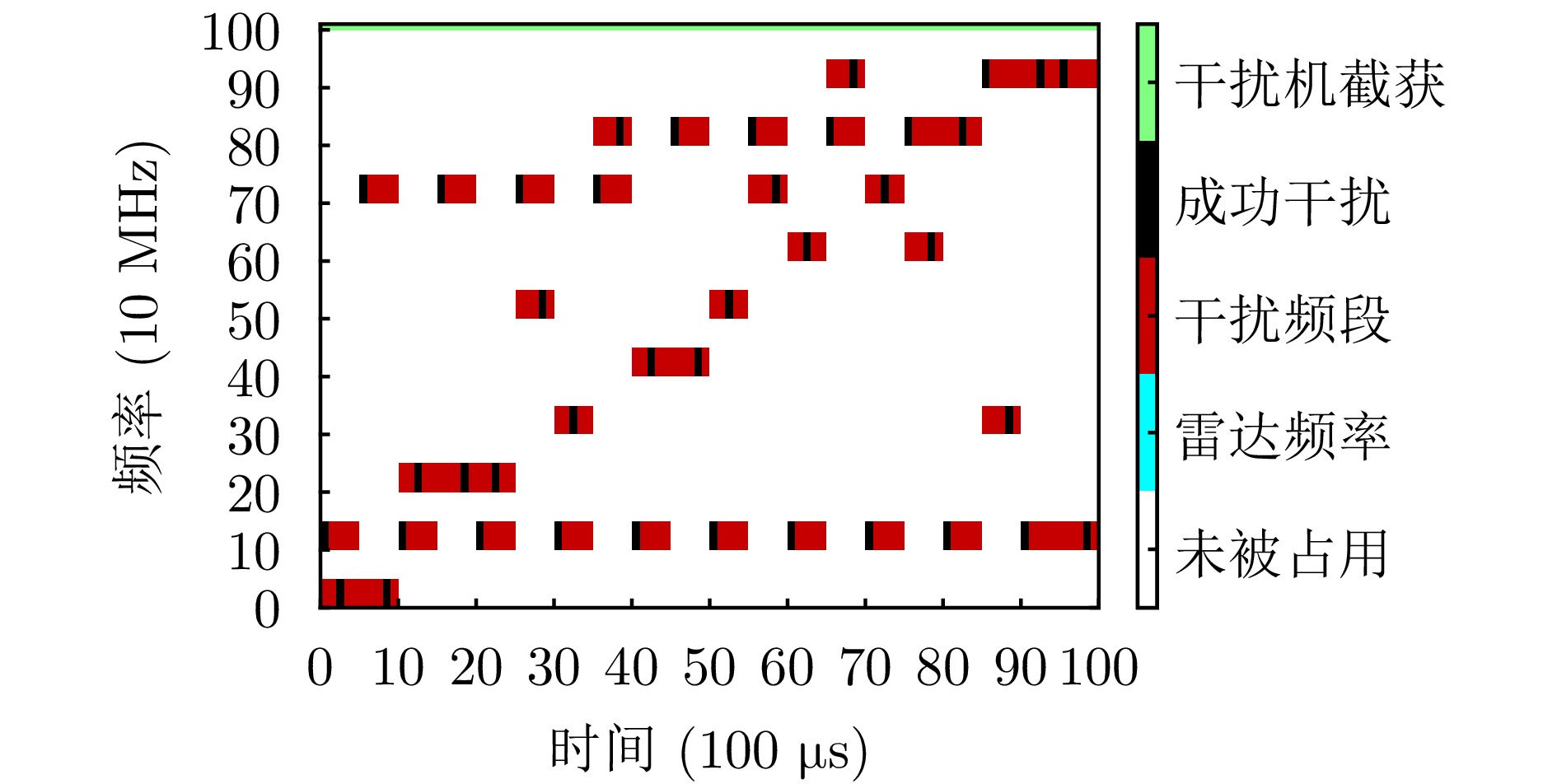
- Figure 11. Schematic diagram of action of the baseline method MAPPO
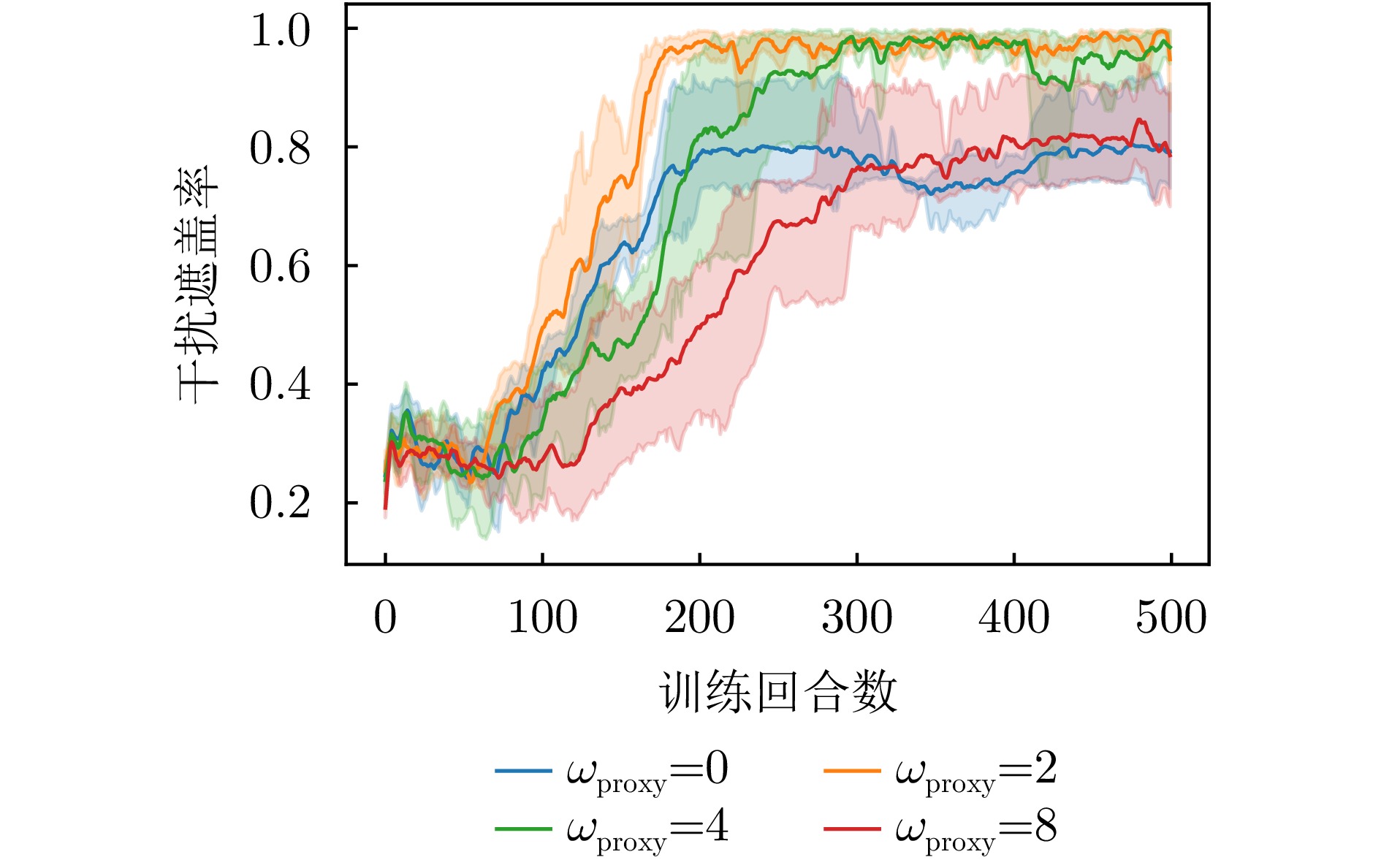
- Figure 12. Curve of jamming coverage rate variation under different weights
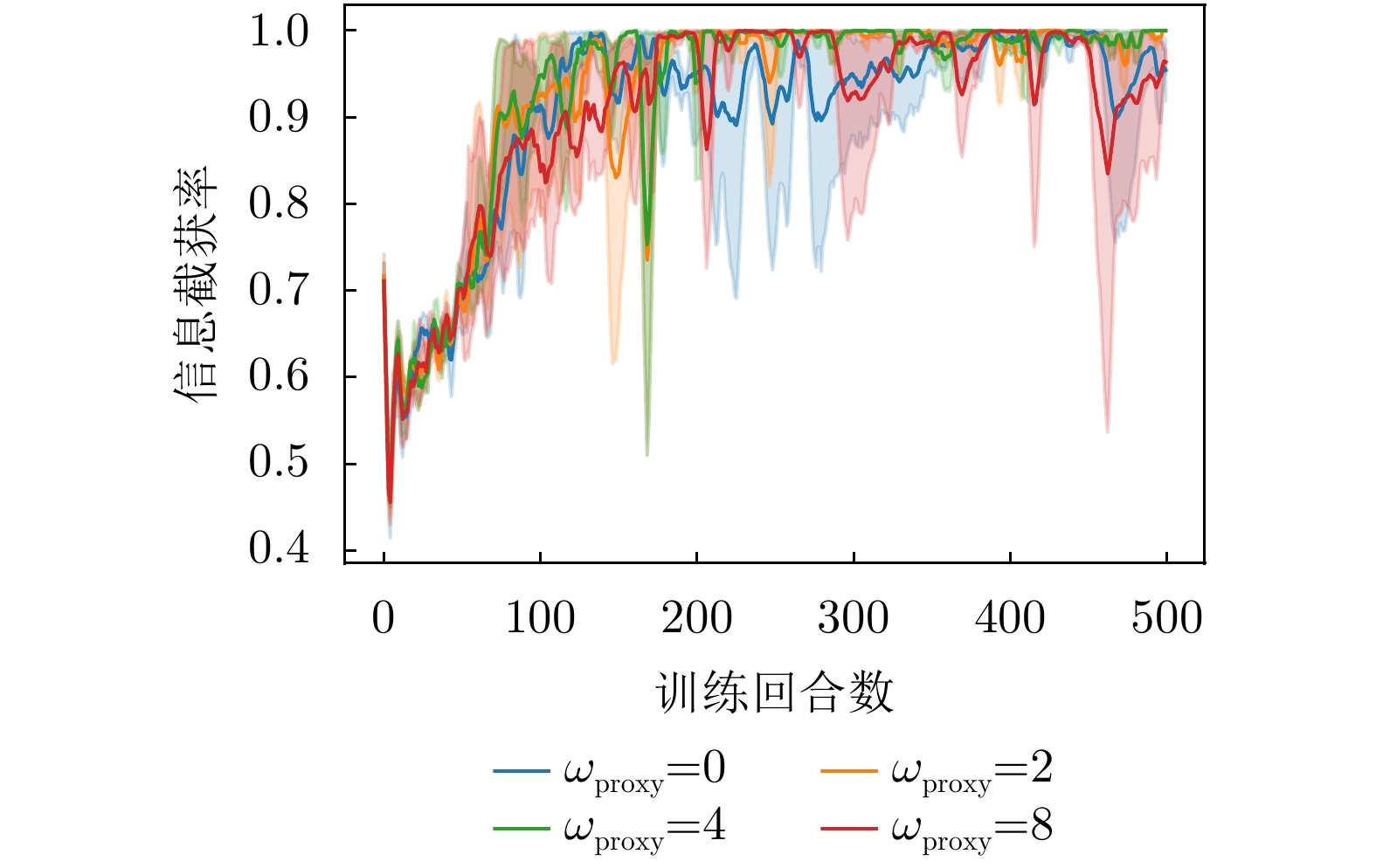
- Figure 13. Curve of information interception rate variation under different weights
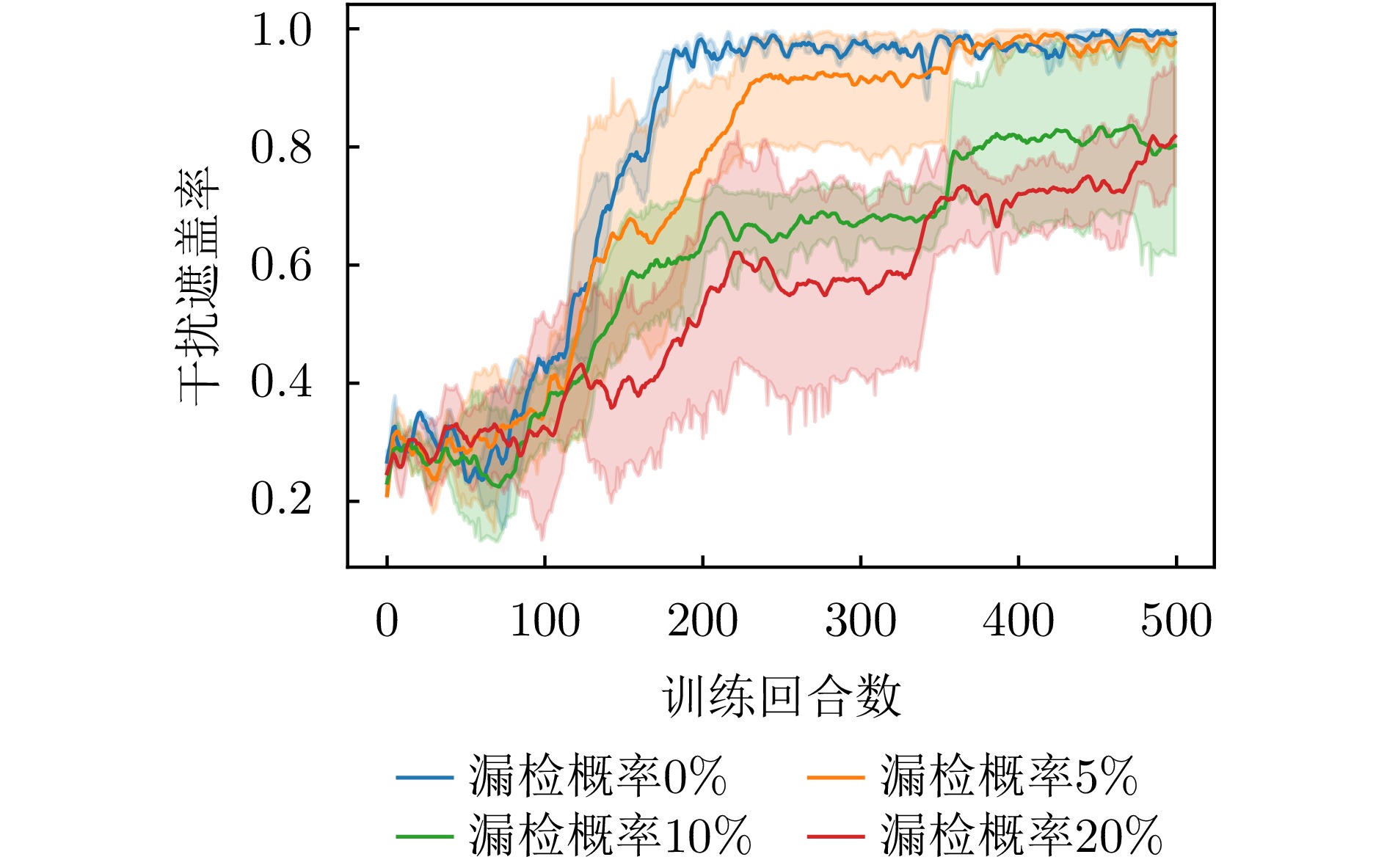
- Figure 14. Change curve of jamming coverage rate under different missed detection probabilities
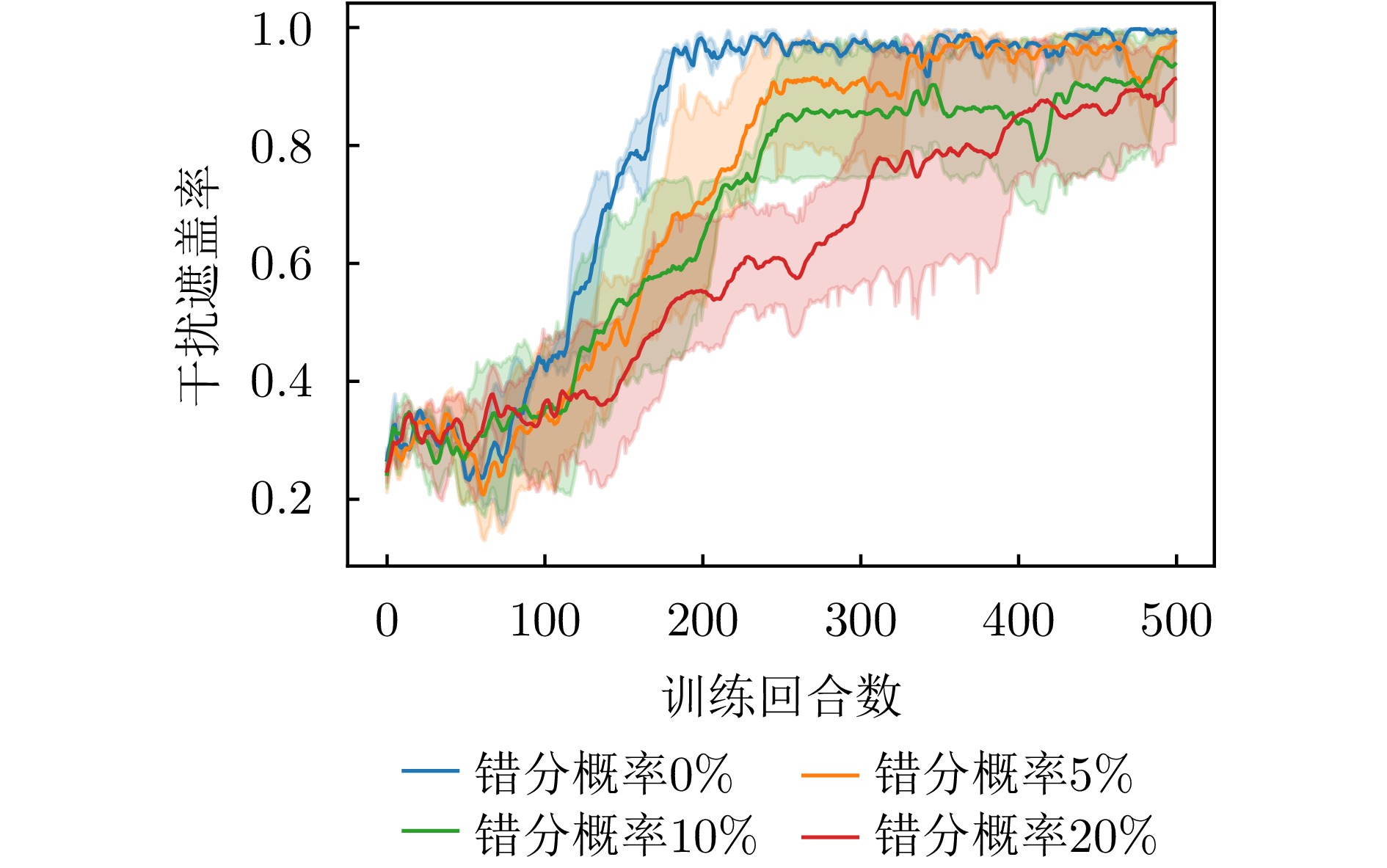
- Figure 15. Change curve of jamming coverage rate under different misclassification probabilities
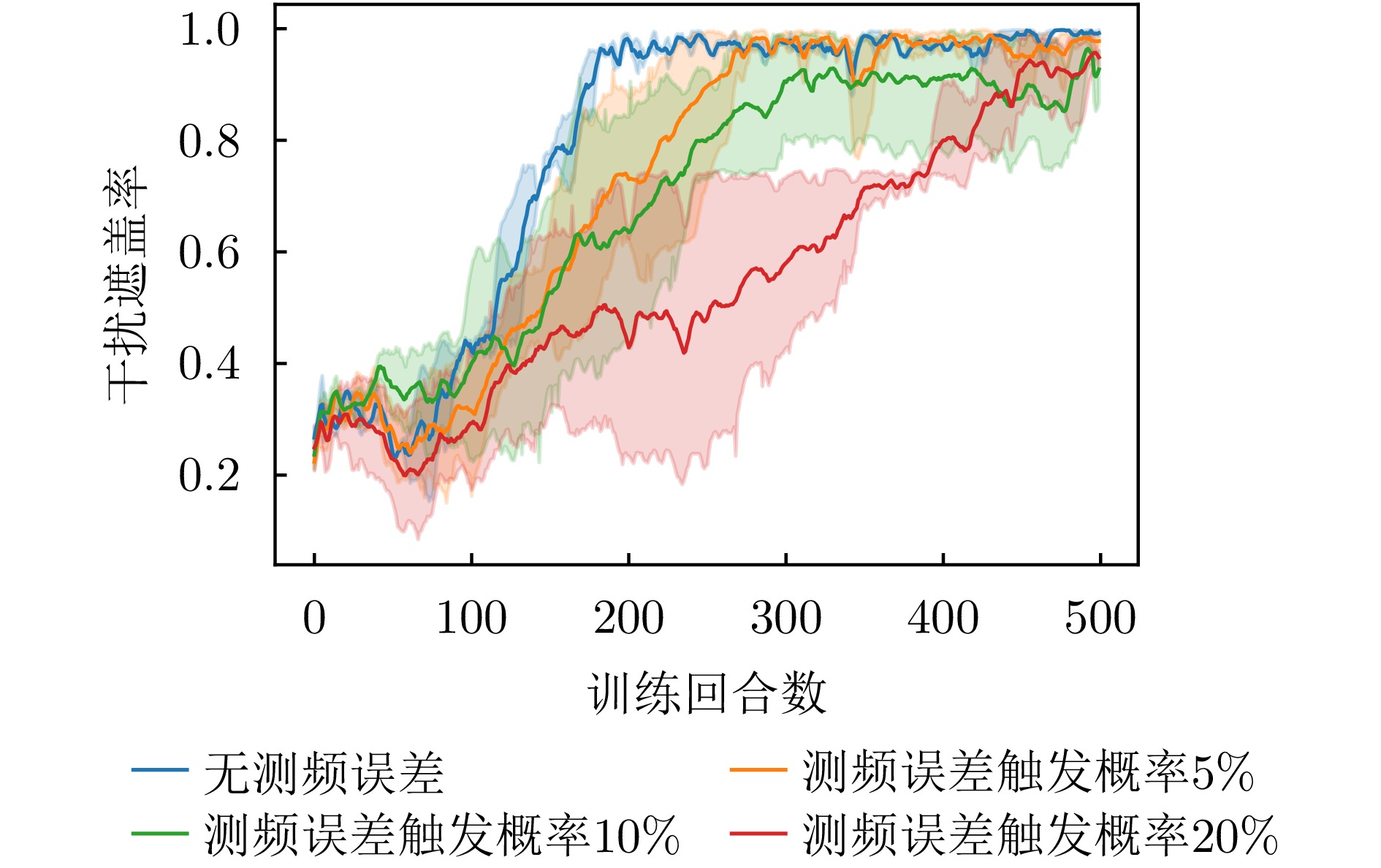
- Figure 16. Change curve of jamming coverage rate under different frequency measurement error probabilities
- Figure 17. Change curve of jamming coverage rate under different adversarial scales