
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor Work- Home
- Articles & Issues
-
Data
- Dataset of Radar Detecting Sea
- SAR Dataset
- SARGroundObjectsTypes
- SARMV3D
- AIRSAT Constellation SAR Land Cover Classification Dataset
- 3DRIED
- UWB-HA4D
- LLS-LFMCWR
- FAIR-CSAR
- MSAR
- SDD-SAR
- FUSAR
- SpaceborneSAR3Dimaging
- Sea-land Segmentation
- SAR Multi-domain Ship Detection Dataset
- SAR-Airport
- Hilly and mountainous farmland time-series SAR and ground quadrat dataset
- SAR images for interference detection and suppression
- HP-SAR Evaluation & Analytical Dataset
- GDHuiYan-ATRNet
- Multi-System Maritime Low Observable Target Dataset
- DatasetinthePaper
- DatasetintheCompetition
- Report
- Course
- About
- Publish
- Editorial Board
- Chinese

| Citation: | WANG Junyu, SUN Hao, HUANG Qihao, et al. SAR image target interpretation based on vision-language model: A survey[J]. Journal of Radars, 2026, 15(2): 409–440. doi: 10.12000/JR25256

|
SAR Image Target Interpretation Based on Vision-language Model: A Survey
DOI: 10.12000/JR25256 CSTR: 32380.14.JR25256
More Information-
Abstract
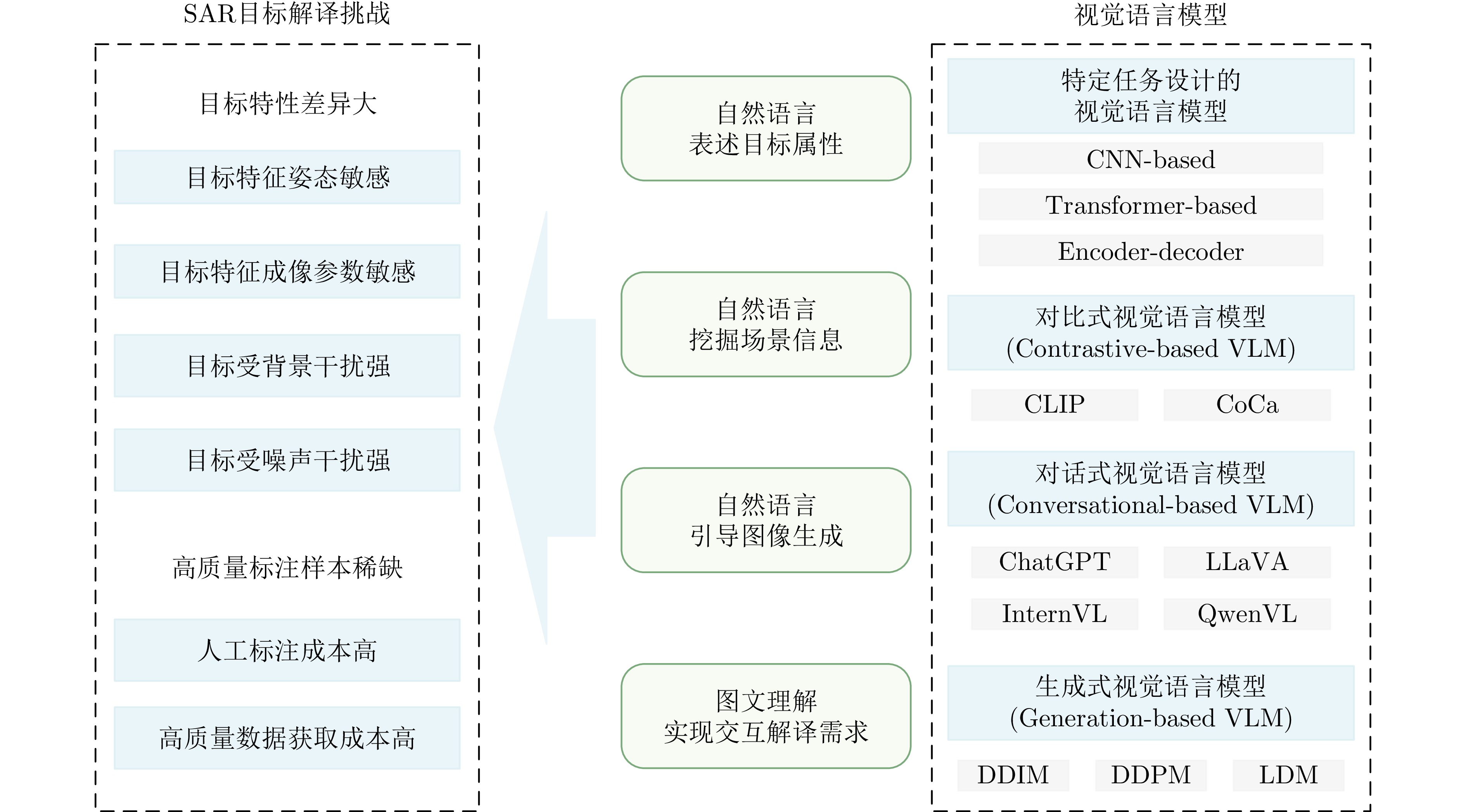
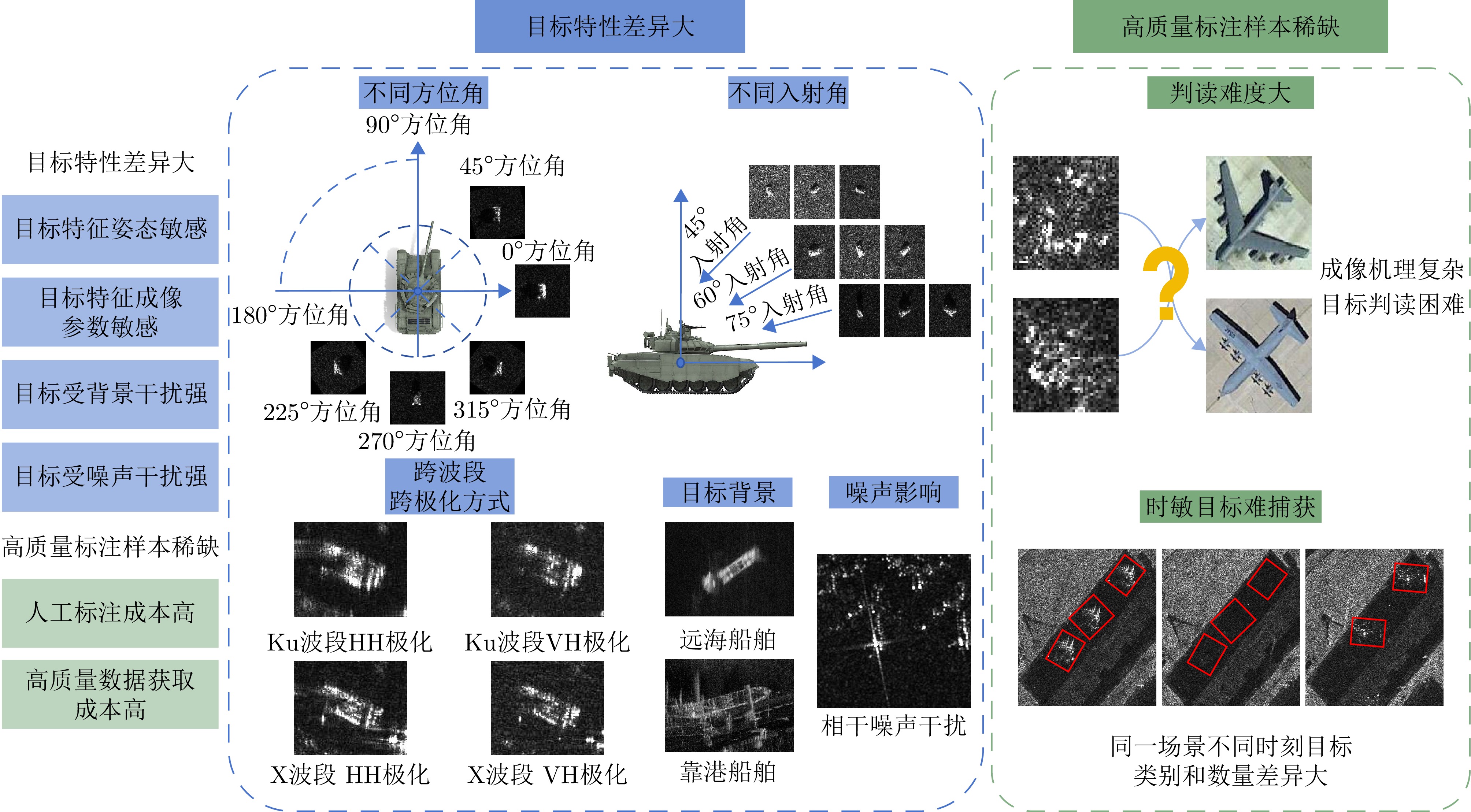
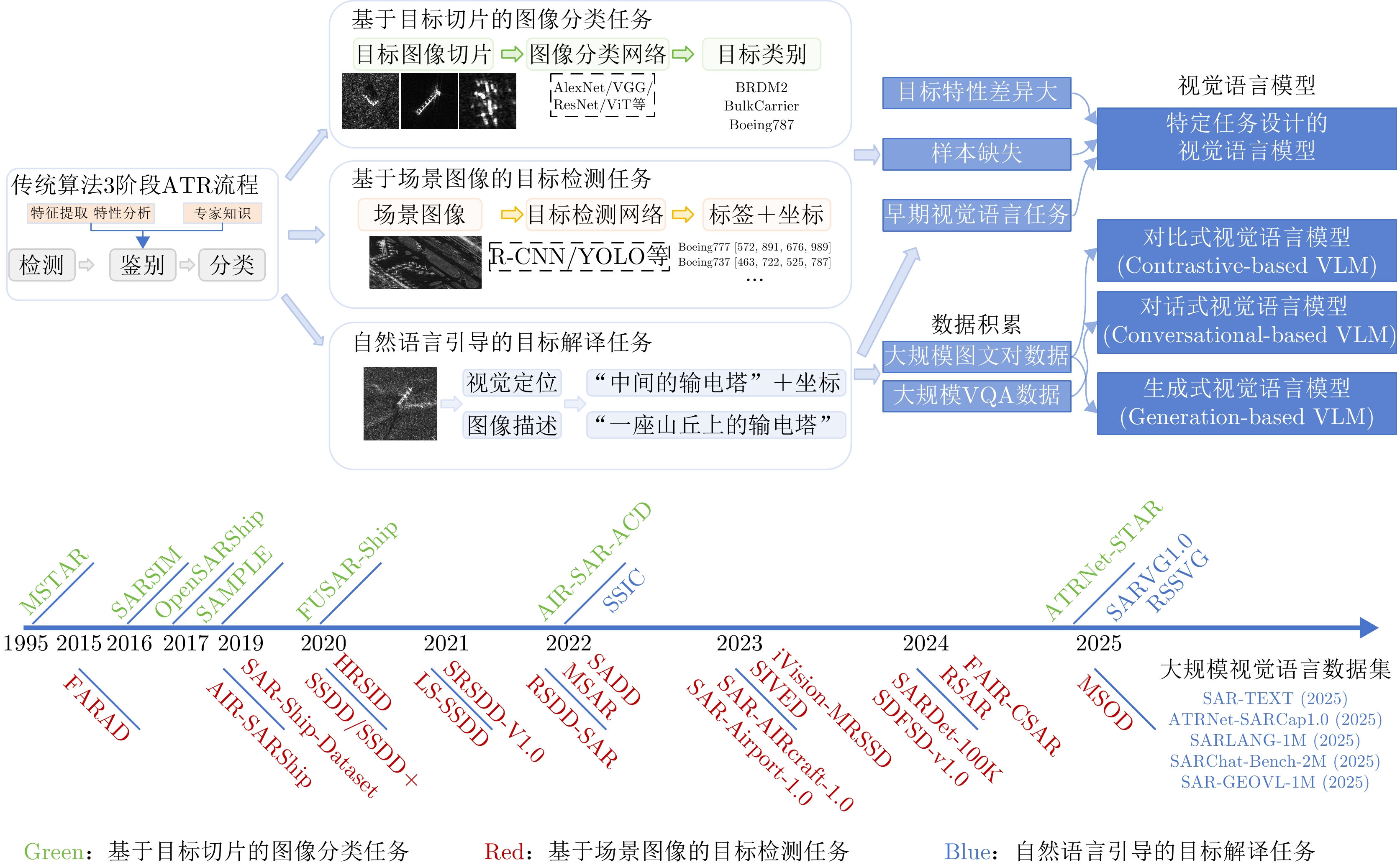
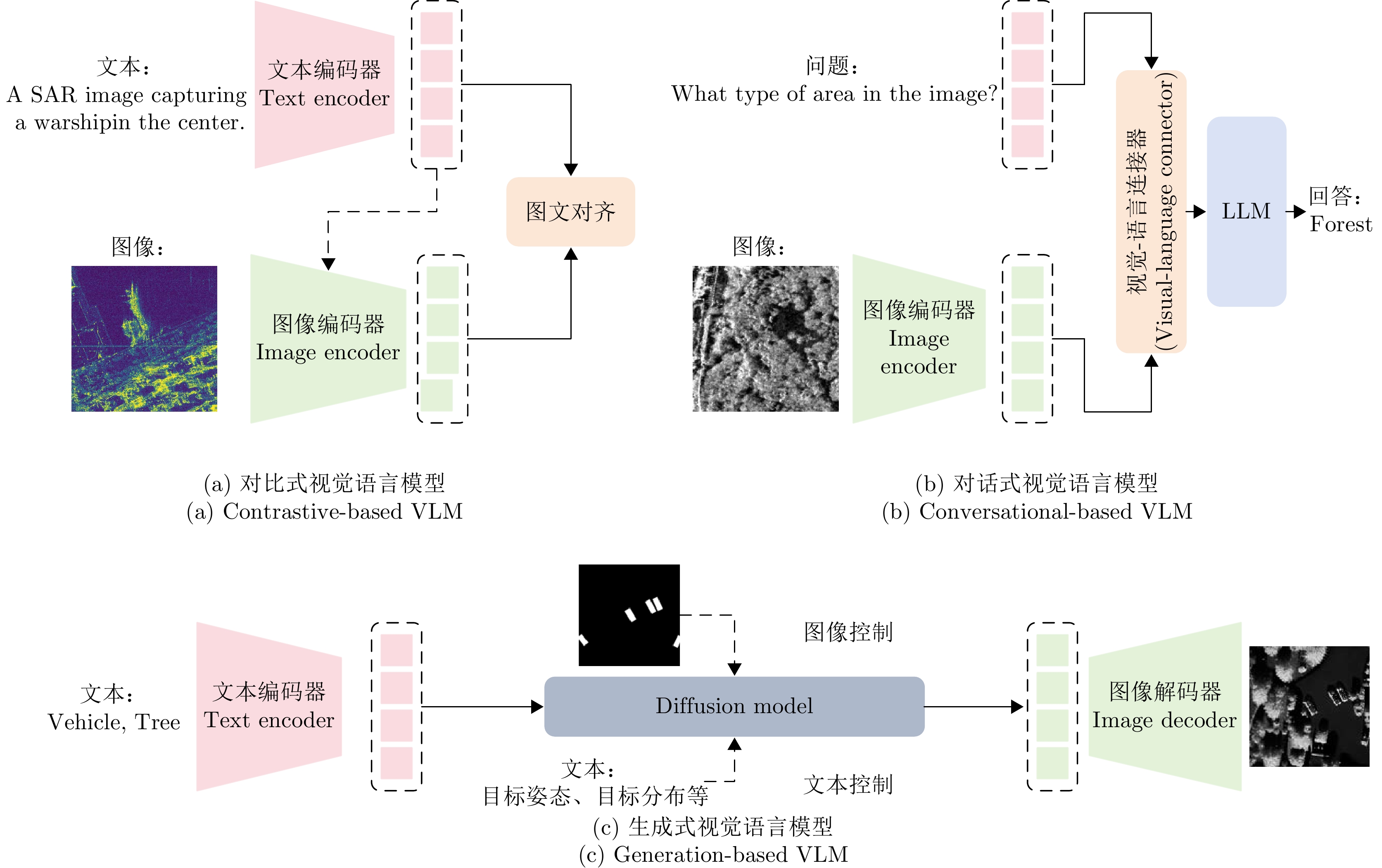
Synthetic Aperture Radar (SAR) is widely used in military and civilian applications, with intelligent target interpretation of SAR images being a crucial component of SAR applications. Vision-Language Models (VLMs) play an important role in SAR target interpretation. By incorporating natural language understanding, VLMs effectively address the challenges posed by large intraclass variability in target characteristics and the scarcity of high-quality labeled samples, thereby advancing the field from purely visual interpretation toward semantic understanding of targets. Drawing upon our team’s extensive research experience in SAR target interpretation theory, algorithms, and applications, this paper provides a comprehensive review of intelligent SAR target interpretation based on VLMs. We provide an in-depth analysis of existing challenges and tasks, summarize the current state of research, and compile available open-source datasets. Furthermore, we systematically outline the evolution, ranging from task-specific VLMs to contrastive-, conversational-, and generative-based VLMs and foundational models. Finally, we discuss the latest challenges and future outlooks in SAR target interpretation by VLMs. -

-
References
[1] MOREIRA A, PRATS-IRAOLA P, YOUNIS M, et al. A tutorial on synthetic aperture radar[J]. IEEE Geoscience and Remote Sensing Magazine, 2013, 1(1): 6–43. doi: 10.1109/MGRS.2013.2248301.[2] SINGH P, DIWAKAR M, SHANKAR A, et al. A review on SAR image and its despeckling[J]. Archives of Computational Methods in Engineering, 2021, 28(7): 4633–4653. doi: 10.1007/s11831-021-09548-z.[3] KECHAGIAS-STAMATIS O and AOUF N. Automatic target recognition on synthetic aperture radar imagery: A survey[J]. IEEE Aerospace and Electronic Systems Magazine, 2021, 36(3): 56–81. doi: 10.1109/MAES.2021.3049857.[4] ZHAO Zhi, JI Kefeng, XING Xiangwei, et al. Ship surveillance by integration of space-borne SAR and AIS-review of current research[J]. The Journal of Navigation, 2014, 67(1): 177–189. doi: 10.1017/S0373463313000659.[5] AMITRANO D, DI MARTINO G, DI SIMONE A, et al. Flood detection with SAR: A review of techniques and datasets[J]. Remote Sensing, 2024, 16(4): 656. doi: 10.3390/rs16040656.[6] LANG Ping, FU Xiongjun, DONG Jian, et al. Recent advances in deep-learning-based SAR image targets detection and recognition[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 6884–6915. doi: 10.1109/JSTARS.2025.3543531.[7] 徐丰, 王海鹏, 金亚秋. 合成孔径雷达图像智能解译[M]. 北京: 科学出版社, 2020: 463.XU Feng, WANG Haipeng, and JIN Yaqiu. Intelligent Interpretation of Synthetic Aperture Radar Images[M]. Beijing: Science Press, 2020: 463.[8] 何奇山, 赵凌君, 计科峰, 等. 面向SAR目标识别成像参数敏感性的深度学习技术研究进展[J]. 电子与信息学报, 2024, 46(10): 3827–3848. doi: 10.11999/JEIT240155.HE Qishan, ZHAO Lingjun, JI Kefeng, et al. Research progress of deep learning technology for imaging parameter sensitivity of SAR target recognition[J]. Journal of Electronics & Information Technology, 2024, 46(10): 3827–3848. doi: 10.11999/JEIT240155.[9] ZHAO Yan, ZHAO Lingjun, ZHANG Siqian, et al. Azimuth-aware subspace classifier for few-shot class-incremental SAR ATR[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5203020. doi: 10.1109/tgrs.2024.3354800.[10] YIN Junjun, DUAN Changxian, WANG Hongbo, et al. A review on the few-shot SAR target recognition[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 16411–16425. doi: 10.1109/JSTARS.2024.3454266.[11] 罗汝, 赵凌君, 何奇山, 等. SAR图像飞机目标智能检测识别技术研究进展与展望[J]. 雷达学报(中英文), 2024, 13(2): 307–330. doi: 10.12000/JR23056.LUO Ru, ZHAO Lingjun, HE Qishan, et al. Intelligent technology for aircraft detection and recognition through SAR imagery: Advancements and prospects[J]. Journal of Radars, 2024, 13(2): 307–330. doi: 10.12000/JR23056.[12] YAN Kaijia, SUN Yuchuang, and LI Wangzhe. Feature generation-aided zero-shot fast sar target recognition with semantic attributes[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 4006805. doi: 10.1109/lgrs.2024.3380202.[13] HUANG Zhongling, ZHANG Xidan, TANG Zuqian, et al. Generative artificial intelligence meets synthetic aperture radar: A survey[J]. IEEE Geoscience and Remote Sensing Magazine, 2024: 2–44. doi: 10.1109/mgrs.2024.3483459.[14] XIAO Aoran, XUAN Weihao, WANG Junjue, et al. Foundation models for remote sensing and earth observation: A survey[J]. IEEE Geoscience and Remote Sensing Magazine, 2025, 13(4): 297–324. doi: 10.1109/mgrs.2025.3576766.[15] ZHOU Jie, LIU Yongxiang, LIU Li, et al. Fifty years of SAR automatic target recognition: The road forward[EB/OL]. https://arxiv.org/abs/2509.22159, 2025.[16] ZHOU Zheng, CUI Zongyong, TIAN Yu, et al. Dynamic semantics-guided meta-transfer learning for few-shot SAR target detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5209517. doi: 10.1109/TGRS.2025.3561682.[17] LIU Bo, XU Jiping, ZENG Hui, et al. Semantic space analysis for zero-shot learning on SAR images[J]. Remote Sensing, 2024, 16(14): 2627. doi: 10.3390/rs16142627.[18] ZHANG Jinqi, ZHANG Lamei, and ZOU Bin. FSAR-Cap: A fine-grained two-stage annotated dataset for SAR image captioning[EB/OL]. https://arxiv.org/abs/2510.16394, 2025.[19] LI Xiang, WEN Congcong, HU Yuan, et al. Vision-language models in remote sensing: Current progress and future trends[J]. IEEE Geoscience and Remote Sensing Magazine, 2024, 12(2): 32–66. doi: 10.1109/MGRS.2024.3383473.[20] RUDANI K, GALA R, SHAH Y, et al. VLM in remote sensing: A comprehensive review[C]. 2nd International Conference on Advanced Computing Techniques in Engineering and Technology, Jaipur, India, 2025: 66–76. doi: 10.1007/978-3-031-95540-2_6.[21] XIE Nishang, ZHANG Tao, ZHANG Lanyu, et al. VLF-SAR: A novel vision-language framework for few-shot SAR target recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(9): 9530–9544. doi: 10.1109/TCSVT.2025.3558801.[22] LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 1516.[23] XIAO Linhui, YANG Xiaoshan, LAN Xiangyuan, et al. Towards visual grounding: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025: 1–20. doi: 10.1109/TPAMI.2025.3630635.[24] LI Weijie, YANG Wei, HOU Yuenan, et al. SARATR-X: Towards building a foundation model for SAR target recognition[J]. IEEE Transactions on Image Processing, 2025, 34: 869–884. doi: 10.1109/TIP.2025.3531988.[25] JIANG Chaowei, WANG Chao, WU Fan, et al. SARCLIP: A multimodal foundation framework for SAR imagery via contrastive language-image pre-training[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2026, 231: 17–34. doi: 10.1016/j.isprsjprs.2025.10.017.[26] MA Qiwei, WANG Zhiyu, LIU Wang, et al. SARVLM: A vision language foundation model for semantic understanding and target recognition in SAR imagery[EB/OL]. https://arxiv.org/abs/2510.22665, 2025.[27] HE Yiguo, CHENG Xinjun, ZHU Junjie, et al. SAR-TEXT: A large-scale SAR image-text dataset built with SAR-narrator and a progressive learning strategy for downstream tasks[EB/OL]. https://arxiv.org/abs/2507.18743, 2025.[28] DEBUYSÈRE S, TROUVÉ N, LETHEULE N, et al. Quantitative comparison of fine-tuning techniques for pretrained latent diffusion models in the generation of unseen SAR images[EB/OL]. https://arxiv.org/abs/2506.13307, 2025.[29] LIU Chenyang, ZHANG Jiafan, CHEN Keyan, et al. Remote sensing spatiotemporal vision-language models: A comprehensive survey[J]. IEEE Geoscience and Remote Sensing Magazine, 2025: 2–42. doi: 10.1109/mgrs.2025.3598283.[30] ZHANG Jingyi, HUANG Jiaxing, JIN Sheng, et al. Vision-language models for vision tasks: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5625–5644. doi: 10.1109/TPAMI.2024.3369699.[31] NOVAK L M, OWIRKA G J, and NETISHEN C M. Performance of a high-resolution polarimetric SAR automatic target recognition system[J]. The Lincoln Laboratory Journal, 1993, 6(1): 11–24.[32] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90.[33] SIMONYAN K and ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. ICLR, 2015: 1–14.[34] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. International Conference on Learning Representations, Vienna, Austria, 2021.[35] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA, 2014: 580–587. doi: 10.1109/CVPR.2014.81.[36] REDMON J and FARHADI A. YOLOv3: An incremental improvement[EB/OL]. https://arxiv.org/abs/1804.02767, 2018.[37] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]. European Conference on Computer Vision, Glasgow, UK, 2020: 213–229. doi: 10.1007/978-3-030-58452-8_13.[38] NARAYANAN R M, ZAUNEGGER J S, SINGERMAN P G, et al. Emerging trends in radar: Natural language processing[J]. IEEE Aerospace and Electronic Systems Magazine, 2025, 40(6): 122–126. doi: 10.1109/MAES.2025.3533946.[39] GRAVES A. Long Short-term Memory[M]. GRAVES A. Supervised Sequence Labelling with Recurrent Neural Networks. Berlin: Springer, 2012: 37–45. doi: 10.1007/978-3-642-24797-2_4.[40] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]. The 38th International Conference on Machine Learning, 2021: 8748–8763.[41] ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10674–10685. doi: 10.1109/CVPR52688.2022.01042.[42] MALL U, PHOO C P, LIU M K, et al. Remote sensing vision-language foundation models without annotations via ground remote alignment[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024.[43] LIU Fan, CHEN Delong, GUAN Zhangqingyun, et al. RemoteCLIP: A vision language foundation model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5622216. doi: 10.1109/TGRS.2024.3390838.[44] ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M and GeoRSCLIP: A large-scale vision-language dataset and a large vision-language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5642123. doi: 10.1109/TGRS.2024.3449154.[45] WANG Zhecheng, PRABHA R, HUANG Tianyuan, et al. SkyScript: A large and semantically diverse vision-language dataset for remote sensing[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 5805–5813. doi: 10.1609/aaai.v38i6.28393.[46] YANG Yi, ZHANG Xiaokun, FANG Qingchen, et al. SAR-KnowLIP: Towards multimodal foundation models for remote sensing[EB/OL]. https://arxiv.org/abs/2509.23927v1, 2025.[47] HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: A remote sensing vision language model and benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 224: 272–286. doi: 10.1016/j.isprsjprs.2025.03.028.[48] KUCKREJA K, DANISH M S, NASEER M, et al. GeoChat: Grounded large vision-language model for remote sensing[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 27831–27840. doi: 10.1109/CVPR52733.2024.02629.[49] LUO Junwei, PANG Zhen, ZHANG Yongjun, et al. SkySenseGPT: A fine-grained instruction tuning dataset and model for remote sensing vision-language understanding[EB/OL]. https://arxiv.org/abs/2406.10100, 2024.[50] BAZI Y, BASHMAL L, AL RAHHAL M M, et al. RS-LLaVA: A large vision-language model for joint captioning and question answering in remote sensing imagery[J]. Remote Sensing, 2024, 16(9): 1477. doi: 10.3390/rs16091477.[51] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5917820. doi: 10.1109/tgrs.2024.3409624.[52] PANG Chao, WENG Xingxing, WU Jiang, et al. VHM: Versatile and honest vision language model for remote sensing image analysis[C]. The 39th AAAI Conference on Artificial Intelligence, Philadelphia, Pennsylvania, 2025: 6381–6388. doi: 10.1609/aaai.v39i6.32683.[53] MUHTAR D, LI Zhenshi, GU Feng, et al. LHRs-Bot: Empowering remote sensing with VGI-enhanced large multimodal language model[C]. 18th European Conference on Computer Vision, Milan, Italy, 2024: 440–457. doi: 10.1007/978-3-031-72904-1_26.[54] ZHAO Xuezhi, YANG Zhigang, LI Qiang, et al. Parameter-efficient transfer learning for remote sensing image captioning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5630512. doi: 10.1109/tgrs.2025.3584887.[55] ZHAN Yang, XIONG Zhitong, and YUAN Yuan. SkyEyeGPT: Unifying remote sensing vision-language tasks via instruction tuning with large language model[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 221: 64–77. doi: 10.1016/j.isprsjprs.2025.01.020.[56] TANG Datao, CAO Xiangyong, HOU Xingsong, et al. CRS-Diff: Controllable remote sensing image generation with diffusion model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5638714. doi: 10.1109/TGRS.2024.3453414.[57] SEBAQ A and ELHElW M. RSDiff: Remote sensing image generation from text using diffusion model[J]. Neural Computing and Applications, 2024, 36(36): 23103–23111. doi: 10.1007/s00521-024-10363-3.[58] KHANNA S, LIU P, ZHOU Linqi, et al. DiffusionSat: A generative foundation model for satellite imagery[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024.[59] ALAPARTHI S and MISHRA M. Bidirectional Encoder Representations from Transformers (BERT): A sentiment analysis odyssey[EB/OL]. https://arxiv.org/abs/2007.01127, 2020.[60] ZHANG Sheng, XU Yanbo, USUYAMA N, et al. Large-scale domain-specific pretraining for biomedical vision-language processing[EB/OL]. https://huggingface.co/papers/2303.00915, 2023.[61] MOONEY P and MINGHINI M. A Review of OpenStreetMap Data[M]. FOODY G, SEE L, FRITZ S, et al. Mapping and the Citizen Sensor. Ubiquity Press, 2017: 37–59. doi: 10.5334/bbf.c.[62] LI Junnan, LI Dongxu, XIONG Caiming, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 12888–12900.[63] CHEN Zhe, WU Jiannan, WANG Wenhai, et al. Intern VL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA , 2024: 24185–24198. doi: 10.1109/CVPR52733.2024.02283.[64] ZHENG Lianmin, CHIANG Weilin, SHENG Ying, et al. Judging LLM-as-a-judge with MT-bench and chatbot arena[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 2020.[65] SONG Jiaming, MENG Chenlin, and ERMON S. Denoising diffusion implicit models[C]. International Conference on Learning Representations, Vienna, Austria, 2021.[66] HO J, JAIN A, and ABBEEL P. Denoising diffusion probabilistic models[C]. The 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020: 574.[67] ZHANG Lvmin, RAO Anyi, and AGRAWALA M. Adding conditional control to text-to-image diffusion models[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 3813–3824. doi: 10.1109/ICCV51070.2023.00355.[68] MA Jian, BIAN Mingming, FAN Fan, et al. Vision-language guided semantic diffusion sampling for small object detection in remote sensing imagery[J]. Remote Sensing, 2025, 17(18): 3203. doi: 10.3390/rs17183203.[69] ZHAO Kai and XIONG Wei. Exploring data and models in SAR ship image captioning[J]. IEEE Access, 2022, 10: 91150–91159. doi: 10.1109/ACCESS.2022.3202193.[70] LI Tianyang, WANG Chao, TIAN Sirui, et al. TACMT: Text-aware cross-modal transformer for visual grounding on high-resolution SAR images[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 222: 152–166. doi: 10.1016/j.isprsjprs.2025.02.022.[71] CHEN Yaxiong, ZHAN Liwen, ZHAO Yichen, et al. VGRSS: Datasets and models for visual grounding in remote sensing ship images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 4703411. doi: 10.1109/TGRS.2025.3562717.[72] WEI Qianru, CHEN Chengyu, HE Mingyi, et al. Zero-shot SAR target recognition based on classification assistance[J]. IEEE Geoscience and Remote Sensing Letters, 2023, 20: 4003705. doi: 10.1109/lgrs.2023.3258939.[73] CHEN Jian, YONG Qifeng, DU Lan, et al. SAR target zero-shot recognition with optical image assistance[C]. 2024 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Zhuhai, China, 2024: 1–6. doi: 10.1109/ICSIDP62679.2024.10868138.[74] WANG Junyu, SUN Hao, TANG Tao, et al. Leveraging visual language model and generative diffusion model for zero-shot SAR target recognition[J]. Remote Sensing, 2024, 16(16): 2927. doi: 10.3390/rs16162927.[75] CHEN Liang, LI Jianhao, ZHONG Honghu, et al. PGMNet: A prototype-guided multimodal network for ship recognition in SAR images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5215517. doi: 10.1109/tgrs.2025.3583282.[76] CHEN Jinyue, WU Youming, DAI Wei, et al. Text-enhanced multimodal method for SAR ship classification with geometry and polarization information[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 8659–8671. doi: 10.1109/JSTARS.2025.3551239.[77] JIN Yuhao, LIANG Qiujin, ZHANG Tao, et al. Open vocabulary SAR object detection with denoising and scaled box loss[C]. 2024 China Automation Congress (CAC), Qingdao, China, 2024: 2756–2759. doi: 10.1109/CAC63892.2024.10865046.[78] LIU Wei, ZHOU Lifan, ZHONG Shan, et al. Semantic assistance in SAR object detection: A mask-guided approach[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 19395–19407. doi: 10.1109/JSTARS.2024.3481368.[79] ZHANG Chaochen, CHEN Jie, HUANG Zhongling, et al. SAR image target segmentation guided by the scattering mechanism-based visual foundation model[J]. Remote Sensing, 2025, 17(7): 1209. doi: 10.3390/rs17071209.[80] CHEN Keyan, LIU Chenyang, CHEN Hao, et al. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 4701117. doi: 10.1109/tgrs.2024.3356074.[81] GAO Ziyi, SUN Shuzhou, CHENG Mingming, et al. Multimodal large models driven SAR image captioning: A benchmark dataset and baselines[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 24011–24026. doi: 10.1109/JSTARS.2025.3603036.[82] LI Yuanli, LIU Wei, LU Wanjie, et al. Synthetic aperture radar image captioning: Building a dataset and explore models[C]. 2025 5th International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 2025: 465–472. doi: 10.1109/NNICE64954.2025.11063765.[83] CAO Qinglong, CHEN Yuntian, LU Lu, et al. Generalized domain prompt learning for accessible scientific vision-language models[J]. Nexus, 2025, 2(2): 100069. doi: 10.1016/j.ynexs.2025.100069.[84] WANG Siyuan, WANG Yinghua, ZHANG Xiaoting, et al. Visual-semantic cooperative learning for few-shot SAR target classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 6532–6550. doi: 10.1109/JSTARS.2025.3530442.[85] GUO Weilong, LIV Shengyang, and YANG Jian. Scattering prompt tuning: A fine-tuned foundation model for SAR object recognition[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, USA, 2024: 3056–3065. doi: 10.1109/CVPRW63382.2024.00311.[86] QI Xiyu, YANG Kunyu, SHI Hanru, et al. Multimodal bind for few-shot SAR object detection in drone remote sensing images[C]. 2025 5th International Conference on Data Information in Online Environments, Sanya, China, 2024: 3–15. doi: 10.1007/978-3-031-97352-9_1.[87] XU Xueru, CHEN Zhong, HU Yuxin, et al. More signals matter to detection: Integrating language knowledge and frequency representations for boosting fine-grained aircraft recognition[J]. Neural Networks, 2025, 187: 107402. doi: 10.1016/j.neunet.2025.107402.[88] ZHAO Guowei, JIANG Jiaqing, DONG Ganggang, et al. SAR ship detection via knowledge transfer: From optical image[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 17526–17538. doi: 10.1109/JSTARS.2025.3582808.[89] RAMIREZ D F, OVERMAN T L, JASKIE K, et al. Towards a large language-vision question answering model for MSTAR automatic target recognition[C]. Automatic Target Recognition XXXV, Orlando, USA, 2025: 122–137. doi: 10.1117/12.3053859.[90] TOSATO L, LOBRY S, WEISSGERBER F, et al. SAR strikes back: A new hope for RSVQA[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 20624–20635. doi: 10.1109/JSTARS.2025.3596678.[91] WANG Fei, CHEN Chengcheng, CHEN Hongyu, et al. A visual question answering method for SAR ship: Breaking the requirement for multimodal dataset construction and model fine-tuning[EB/OL]. https://arxiv.org/abs/2411.01445, 2024.[92] WANG Fei, CHEN Chengcheng, CHEN Hongyu, et al. Bring remote sensing object detect into nature language model: Using SFT method[EB/OL]. https://arxiv.org/abs/2503.08144, 2025.[93] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. Popeye: A unified visual-language model for multisource ship detection from remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024, 17: 20050–20063. doi: 10.1109/JSTARS.2024.3488034.[94] LI Yuxuan, ZHANG Yicheng, TANG Wenhao, et al. Visual instruction pretraining for domain-specific foundation models[EB/OL]. https://arxiv.org/abs/2509.17562, 2025.[95] MA Zhiming, XIAO Xiayang, DONG Sihao, et al. SARChat-Bench-2M: A multi-task vision-language benchmark for SAR image interpretation[EB/OL]. https://arxiv.org/pdf/2502.08168v1, 2025.[96] ZHANG Xin, LI Yang, LI Feng, et al. Ship-Go: SAR ship images inpainting via instance-to-image generative diffusion models[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2024, 207: 203–217. doi: 10.1016/j.isprsjprs.2023.12.002.[97] WANG Lu, QI Yuhang, MATHIOPOULOS P T, et al. An improved SAR ship classification method using text-to-image generation-based data augmentation and squeeze and excitation[J]. Remote Sensing, 2024, 16(7): 1299. doi: 10.3390/rs16071299.[98] NI He, JIANG Yicheng, CHEN Ruida, et al. STRE-Diffusion: Few-shot spaceborne ISAR target recognition via spatial-time relationship estimation and improved diffusion model[J]. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(6): 17906–17923. doi: 10.1109/taes.2025.3608122.[99] TROUVÉ N, LETHEULE N, LEVEQUE O, et al. SAR image synthesis using text conditioned pre-trained generative AI models[C]. EUSAR 2024; 15th European Conference on Synthetic Aperture Radar, Munich, Germany, 2024: 1387–1392.[100] DEBUYSÈRE S, TROUVÉ N, LETHEULE N, et al. Synthesizing SAR images with generative AI: Expanding to large-scale imagery[C]. 2024 International Radar Conference (RADAR), Florence, Italy, 2024: 1–6. doi: 10.1109/RADAR58436.2024.10993695.[101] TIAN Zichen, CHEN Zhaozheng, and SUN Qianru. Non-visible light data synthesis: A case study for synthetic aperture radar imagery[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024.[102] DEBUYSERE S, TROUVE N, LETHEULE N, et al. From spaceborne to airborne: SAR image synthesis using foundation models for multi-scale adaptation[EB/OL]. https://arxiv.org/abs/2106.03844, 2025.[103] European Space Agency. Satellite constellation[EB/OL]. https://sentinels.copernicus.eu/copernicus/sentinel-1, 2025.[104] KROUPNIK G, DE LISLE D, CÔTÉ S, et al. RADARSAT constellation mission overview and status[C]. 2021 IEEE Radar Conference (RadarConf21), Atlanta, USA, 2021: 1–5. doi: 10.1109/RadarConf2147009.2021.9455298.[105] ZHANG Heng, DENG Yunkai, WANG Robert, et al. Spaceborne/stationary bistatic SAR imaging with TerraSAR-X as an illuminator in staring-spotlight mode[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(9): 5203–5216. doi: 10.1109/tgrs.2016.2558294.[106] JI Yifei, DONG Zhen, ZHANG Yongsheng, et al. Equatorial ionospheric scintillation measurement in advanced land observing satellite phased array-type L-band synthetic aperture radar observations[J]. Engineering, 2025, 47: 70–85. doi: 10.1016/j.eng.2024.01.027.[107] Gunter’s Space Page. Qilu 1[EB/OL]. https://space.skyrocket.de/doc_sdat/qilu-1.htm, 2025.[108] ZHANG Tian, QIAN Yonggang, LI Chengming, et al. Imaging and interferometric mapping exploration for PIESAT-01: The world’s first four-satellite “Cartwheel” formation constellation[J]. Atmosphere, 2024, 15(6): 621. doi: 10.3390/atmos15060621.[109] IGNATENKO V, LAURILA P, RADIUS A, et al. ICEYE microsatellite SAR constellation status update: Evaluation of first commercial imaging modes[C]. 2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, USA, 2020: 3581–3584. doi: 10.1109/IGARSS39084.2020.9324531.[110] CASTELLETTI D, FARQUHARSON G, STRINGHAM C, et al. Capella space first operational SAR satellite[C]. 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 2021: 1483–1486. doi: 10.1109/IGARSS47720.2021.9554100.[111] Umbra. Space systems[EB/OL]. https://umbra.space/space-systems/, 2025.[112] Gunter’s Space Page. Haisi 1[EB/OL]. https://space.skyrocket.de/doc_sdat/haisi-1.htm, 2025.[113] Spacety. New SAR satellite launched, with improved capabilities[EB/OL]. https://en.spacety.com/index.php/2022/03/01/, 2025.[114] DIEMUNSCH J R and WISSINGER J. Moving and Stationary Target Acquisition and Recognition (MSTAR) model-based automatic target recognition: Search technology for a robust ATR[C]. Algorithms for Synthetic Aperture Radar Imagery V, Orlando, USA, 1998: 481–492. doi: 10.1117/12.321851.[115] HOU Xiyue, AO Wei, SONG Qian, et al. FUSAR-Ship: Building a high-resolution SAR-AIS matchup dataset of Gaofen-3 for ship detection and recognition[J]. Science China Information Sciences, 2020, 63(4): 140303. doi: 10.1007/s11432-019-2772-5.[116] SUN Xian, LV Yixuan, WANG Zhirui, et al. SCAN: Scattering characteristics analysis network for few-shot aircraft classification in high-resolution SAR images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 5226517. doi: 10.1109/tgrs.2022.3166174.[117] WEI Shunjun, ZENG Xiangfeng, QU Qizhe, et al. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation[J]. IEEE Access, 2020, 8: 120234–120254. doi: 10.1109/ACCESS.2020.3005861.[118] LIN Xin, ZHANG Bo, WU Fan, et al. SIVED: A SAR image dataset for vehicle detection based on rotatable bounding box[J]. Remote Sensing, 2023, 15(11): 2825. doi: 10.3390/rs15112825.[119] 王智睿, 康玉卓, 曾璇, 等. SAR-AIRcraft-1.0:高分辨率SAR飞机检测识别数据集[J]. 雷达学报, 2023, 12(4): 906–922. doi: 10.12000/JR23043.WANG Zhirui, KANG Yuzhuo, ZENG Xuan, et al. SAR-AIRcraft-1.0: High-resolution SAR aircraft detection and recognition dataset[J]. Journal of Radars, 2023, 12(4): 906–922. doi: 10.12000/JR23043.[120] LI Yuxuan, LI Xiang, LI Weijie, et al. SARDet-100K: Towards open-source benchmark and toolkit for large-scale SAR object detection[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 4079.[121] ZHANG Xin, YANG Xue, LI Yuxuan, et al. RSAR: Restricted state angle resolver and rotated SAR benchmark[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 7416–7426. doi: 10.1109/CVPR52734.2025.00695.[122] WU Youming, SUO Yuxi, MENG Qingbiao, et al. FAIR-CSAR: A benchmark dataset for fine-grained object detection and recognition based on single-look complex SAR images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5201022. doi: 10.1109/tgrs.2024.3519891.[123] LIU Yongxiang, LI Weijie, LIU Li, et al. ATRNet-STAR: A large dataset and benchmark towards remote sensing object recognition in the wild[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. doi: 10.1109/TPAMI.2026.3658649.[124] KUSK A, ABULAITIJIANG A, and DALL J. Synthetic SAR image generation using sensor, terrain and target models[C]. The 11th European Conference on Synthetic Aperture Radar, Hamburg, Germany, 2016: 1–5.[125] LEWIS B, SCARNATI T, SUDKAMP E, et al. A SAR dataset for ATR development: The Synthetic and Measured Paired Labeled Experiment (SAMPLE)[C]. SPIE 10987, Algorithms for Synthetic Aperture Radar Imagery XXVI, Baltimore, USA, 2019: 39–54. doi: 10.1117/12.2523460.[126] HUANG Lanqing, LIU Bin, LI Boying, et al. OpenSARShip: A dataset dedicated to Sentinel-1 ship interpretation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2018, 11(1): 195–208. doi: 10.1109/JSTARS.2017.2755672.[127] Sandia National Laboratories. Pathfinder radar ISR & SAR systems: Complex SAR data[EB/OL]. https://www.sandia.gov/radar/pathfinder-radar-isr-and-synthetic-aperture-radar-sar-systems/complex-data/, 2025.[128] 孙显, 王智睿, 孙元睿, 等. AIR-SARShip-1.0:高分辨率SAR舰船检测数据集[J]. 雷达学报, 2019, 8(6): 852–862. doi: 10.12000/JR19097.SUN Xian, WANG Zhirui, SUN Yuanrui, et al. AIR-SARShip-1.0: High-resolution SAR ship detection dataset[J]. Journal of Radars, 2019, 8(6): 852–862. doi: 10.12000/JR19097.[129] WANG Yuanyuan, WANG Chao, ZHANG Hong, et al. A SAR dataset of ship detection for deep learning under complex backgrounds[J]. Remote Sensing, 2019, 11(7): 765. doi: 10.3390/rs11070765.[130] ZHANG Tianwen, ZHANG Xiaoling, LI Jianwei, et al. SAR Ship Detection Dataset (SSDD): Official release and comprehensive data analysis[J]. Remote Sensing, 2021, 13(18): 3690. doi: 10.3390/rs13183690.[131] ZHANG Tianwen, ZHANG Xiaoling, KE Xiao, et al. LS-SSDD-v1.0: A deep learning dataset dedicated to small ship detection from large-scale Sentinel-1 SAR images[J]. Remote Sensing, 2020, 12(18): 2997. doi: 10.3390/rs12182997.[132] LEI Songlin, LU Dongdong, QIU Xiaolan, et al. SRSDD-v1.0: A high-resolution SAR rotation ship detection dataset[J]. Remote Sensing, 2021, 13(24): 5104. doi: 10.3390/rs13245104.[133] 徐从安, 苏航, 李健伟, 等. RSDD-SAR: SAR舰船斜框检测数据集[J]. 雷达学报, 2022, 11(4): 581–599. doi: 10.12000/JR22007.XU Congan, SU Hang, LI Jianwei, et al. RSDD-SAR: Rotated ship detection dataset in SAR images[J]. Journal of Radars, 2022, 11(4): 581–599. doi: 10.12000/JR22007.[134] XIA Runfang, CHEN Jie, HUANG Zhixiang, et al. CRTransSAR: A visual transformer based on contextual joint representation learning for SAR ship detection[J]. Remote Sensing, 2022, 14(6): 1488. doi: 10.3390/rs14061488.[135] ZHANG Peng, XU Hao, TIAN Tian, et al. SEFEPNet: Scale expansion and feature enhancement pyramid network for SAR aircraft detection with small sample dataset[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 3365–3375. doi: 10.1109/JSTARS.2022.3169339.[136] WANG Daochang, ZHANG Fan, MA Fei, et al. A benchmark Sentinel-1 SAR dataset for airport detection[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 6671–6686. doi: 10.1109/JSTARS.2022.3192063.[137] HUMAYUN M F, BHATTI F A, and KHURSHID K. iVision MRSSD: A comprehensive multi-resolution SAR ship detection dataset for state of the art satellite based maritime surveillance applications[J]. Data in Brief, 2023, 50: 109505. doi: 10.1016/j.dib.2023.109505.[138] CAI Peixin, LIU Bingxin, WANG Peilin, et al. SDFSD-v1.0: A sub-meter SAR dataset for fine-grained ship detection[J]. Remote Sensing, 2024, 16(21): 3952. doi: 10.3390/rs16213952.[139] WANG Chao, FANG Wenxuan, LI Xiang, et al. MSOD: A large-scale multiscene dataset and a novel Diagonal-Geometry loss for SAR object detection[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5220413. doi: 10.1109/tgrs.2025.3605720.[140] WEI Yimin, XIAO Aoran, REN Yexian, et al. SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding[J]. IEEE Transactions on Geoscience and Remote Sensing, in press. 2026. doi: 10.1109/TGRS.2026.3652099.[141] LI Chaoran, XU Xingguo, and MU Siyuan. Reframing SAR target recognition as visual reasoning: A chain-of-thought dataset with multimodal LLMs[EB/OL]. https://arxiv.org/abs/2507.09535, 2025.[142] LU Da, CAO Lanying, and LIU Hongwei. Few-shot learning neural network for SAR target recognition[C]. 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 2019: 1–4. doi: 10.1109/APSAR46974.2019.9048517.[143] Fu Yanwei, Xiang Tao, Jiang Yugang, et al. Recent advances in zero-shot recognition: Toward data-efficient understanding of visual content[J]. IEEE Signal Processing Magazine, 2018, 35(1): 112–125. doi: 10.1109/MSP.2017.2763441.[144] RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[J]. OpenAI, 2019, 1(8): 9.[145] ZHANG Susan, ROLLER S, GOYAL N, et al. OPT: Open pre-trained transformer language models[EB/OL]. https://arxiv.org/abs/2205.01068, 2022.[146] WU Jianzong, LI Xiangtai, XU Shilin, et al. Towards open vocabulary learning: A survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(7): 5092–5113. doi: 10.1109/TPAMI.2024.3361862.[147] LIU Shilong, ZENG Zhaoyang, REN Tianhe, et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection[C]. 18th European Conference on Computer Vision, Milan, Italy, 2024: 38–55. doi: 10.1007/978-3-031-72970-6_3.[148] KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 3992–4003. doi: 10.1109/ICCV51070.2023.00371.[149] DENG Jiajun, YANG Zhengyuan, CHEN Tianlang, et al. TransVG: End-to-end visual grounding with transformers[C]. The IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 2021: 1749–1759. doi: 10.1109/ICCV48922.2021.00179.[150] SUN Zhongzhen, LENG Xiangguang, ZHANG Xianghui, et al. Ship recognition for complex SAR images via dual-branch transformer fusion network[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 4009905. doi: 10.1109/lgrs.2024.3398013.[151] ZHANG Hao, LI Feng, LIU Shilong, et al. DINO: DETR with improved denoising anchor boxes for end-to-end object detection[C]. The 11th International Conference on Learning Representations, Kigali, Rwanda, 2023.[152] HE Kaiming, FAN Haoqi, WU Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2020: 9726–9735. doi: 10.1109/CVPR42600.2020.00975.[153] ZHANG Hongyi, CISSÉ M, DAUPHIN Y N, et al. Mixup: Beyond empirical risk minimization[C]. 6th International Conference on Learning Representations, Vancouver, Canada, 2018.[154] GENG Zhe, LI Wei, YU Xiang, et al. Out-of-library SAR target recognition with deep learning from synthetic data and multiview information fusion[C]. 2023 24th International Radar Symposium (IRS), Berlin, Germany, 2023: 1–10. doi: 10.23919/IRS57608.2023.10172440.[155] GENG Zhe, XU Ying, WANG Beining, et al. Target recognition in SAR images by deep learning with training data augmentation[J]. Sensors, 2023, 23(2): 941. doi: 10.3390/s23020941.[156] FU Shilei and XU Feng. Differentiable SAR renderer and image-based target reconstruction[J]. IEEE Transactions on Image Processing, 2022, 31: 6679–6693. doi: 10.1109/TIP.2022.3215069.[157] WANG Ke, ZHANG Gong, LENG Yang, et al. Synthetic aperture radar image generation with deep generative models[J]. IEEE Geoscience and Remote Sensing Letters, 2019, 16(6): 912–916. doi: 10.1109/LGRS.2018.2884898.[158] QIN Jikai, LIU Zheng, RAN Lei, et al. A target SAR image expansion method based on conditional Wasserstein deep convolutional GAN for automatic target recognition[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 7153–7170. doi: 10.1109/JSTARS.2022.3199091.[159] WANG Keao, PAN Zongxu, and WEN Zixiao. SVDDD: SAR vehicle target detection dataset augmentation based on diffusion model[J]. Remote Sensing, 2025, 17(2): 286. doi: 10.3390/rs17020286.[160] DEBUYSÈRE S, LETHEULE N, TROUVÉ N, et al. Bridging text and synthetic aperture radar with multimodal vision-language models[C]. ESA Workshop-Living Planet Symposium 2025, Vienna, Austria, 2025.[161] HU Xuran, XU Ziqiang, CHEN Zhihan, et al. SAR despeckling via regional denoising diffusion probabilistic model[C]. 2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 2024: 7226–7230. doi: 10.1109/IGARSS53475.2024.10641283.[162] PAUL A and SAVAKIS A. On denoising diffusion probabilistic models for synthetic aperture radar despeckling[J]. Sensors, 2025, 25(7): 2149. doi: 10.3390/s25072149.[163] GUO Zhengyu, HU Weidong, ZHENG Shichao, et al. Efficient conditional diffusion model for SAR despeckling[J]. Remote Sensing, 2025, 17(17): 2970. doi: 10.3390/rs17172970.[164] LI Weijie, YANG Wei, LIU Tianpeng, et al. Predicting gradient is better: Exploring self-supervised learning for SAR ATR with a joint-embedding predictive architecture[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2024, 218: 326–338. doi: 10.1016/j.isprsjprs.2024.09.013.[165] INKAWHICH N. On the status of foundation models for SAR imagery[EB/OL]. https://arxiv.org/abs/2509.21722, 2025.[166] ASSRAN M, DUVAL Q, MISRA I, et al. Self-supervised learning from images with a joint-embedding predictive architecture[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 15619–15629. doi: 10.1109/CVPR52729.2023.01499.[167] OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: Learning robust visual features without supervision[EB/OL]. https://arxiv.org/abs/2304.07193, 2023.[168] SIMÉONI O, VO H V, SEITZER M, et al. DINOv3[EB/OL]. https://arxiv.org/abs/2508.10104, 2025.[169] KIM Y, KIM M, PARK H, et al. PBVS 2024 solution: Self-supervised learning and sampling strategies for SAR classification in extreme long-tail distribution[EB/OL]. https://arxiv.org/abs/2412.12565, 2024.[170] CHEN Zhe, WANG Weiyun, CAO Yue, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling[EB/OL]. https://arxiv.org/abs/2412.05271, 2024.[171] BAI Shuai, CHEN Keqin, LIU Xuejing, et al. Qwen2.5-VL technical report[EB/OL]. https://arxiv.org/abs/2502.13923, 2025.[172] LIU Haotian, LI Chunyuan, LI Yuheng, et al. Improved baselines with visual instruction tuning[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 26286–26296. doi: 10.1109/CVPR52733.2024.02484.[173] LU Haoyu, LIU Wen, ZHANG Bo, et al. DeepSeek-VL: Towards real-world vision-language understanding[EB/OL]. https://arxiv.org/abs/2403.05525, 2024.[174] ZHAO Qiang, YU Le, LI Xuecao, et al. Progress and trends in the application of Google Earth and Google Earth Engine[J]. Remote Sensing, 2021, 13(18): 3778. doi: 10.3390/rs13183778.[175] DAVIS E and MARCUS G. Commonsense reasoning and commonsense knowledge in artificial intelligence[J]. Communications of the ACM, 2015, 58(9): 92–103. doi: 10.1145/2701413.[176] BHARGAVA P and NG V. Commonsense knowledge reasoning and generation with pre-trained language models: A survey[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 12317–12325. doi: 10.1609/aaai.v36i11.21496.[177] SPEER R, CHIN J, and HAVASI C. ConceptNet 5.5: An open multilingual graph of general knowledge[C]. The 31st AAAI Conference on Artificial Intelligence, San Francisco, USA, 2017: 4444–4451. doi: 10.1609/aaai.v31i1.11164.[178] XU Xiao, WU Chenfei, ROSENMAN S, et al. BridgeTower: Building bridges between encoders in vision-language representation learning[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 10637–10647. doi: 10.1609/aaai.v37i9.26263.[179] TAN Xiangdong, LENG Xiangguang, JI Kefeng, et al. RCShip: A dataset dedicated to ship detection in range-compressed SAR data[J]. IEEE Geoscience and Remote Sensing Letters, 2024, 21: 4004805. doi: 10.1109/lgrs.2024.3366749.[180] ZHANG Lvmin, RAO Anyi, and AGRAWALA M. Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing consistent light transport[C]. The 13th International Conference on Learning Representations, Singapore, Singapore, 2025. -
Proportional views

- Publishing Ethics
- Journal Insights
- Abstracting & Indexing
- Peer Review Policies
- Guide for Authors
- Conference
- ISSN 2095-283X (Print)ISSN 2097-339X (Online)
- CN 10-1030/TN
- CODEN LXEUAO
About Journal
- Sponsor: China Radio Detection and Ranging Industry Association (CRIA)
- Phone: 010-58887062
- Email:radars@aircas.ac.cn
- Publisher: Leida Xuebao Bianjibu (Editorial office of the Journal of Radars)
Contacts Us

京ICP备20021838号-14
Supported by: Beijing Renhe Information Technology Co. Ltd

Export File
Citation
Format
Content
 DownLoad:
DownLoad:




- Figure 1. SAR ATR challenges and VLM-based approaches
- Figure 2. Development of SAR VLMs
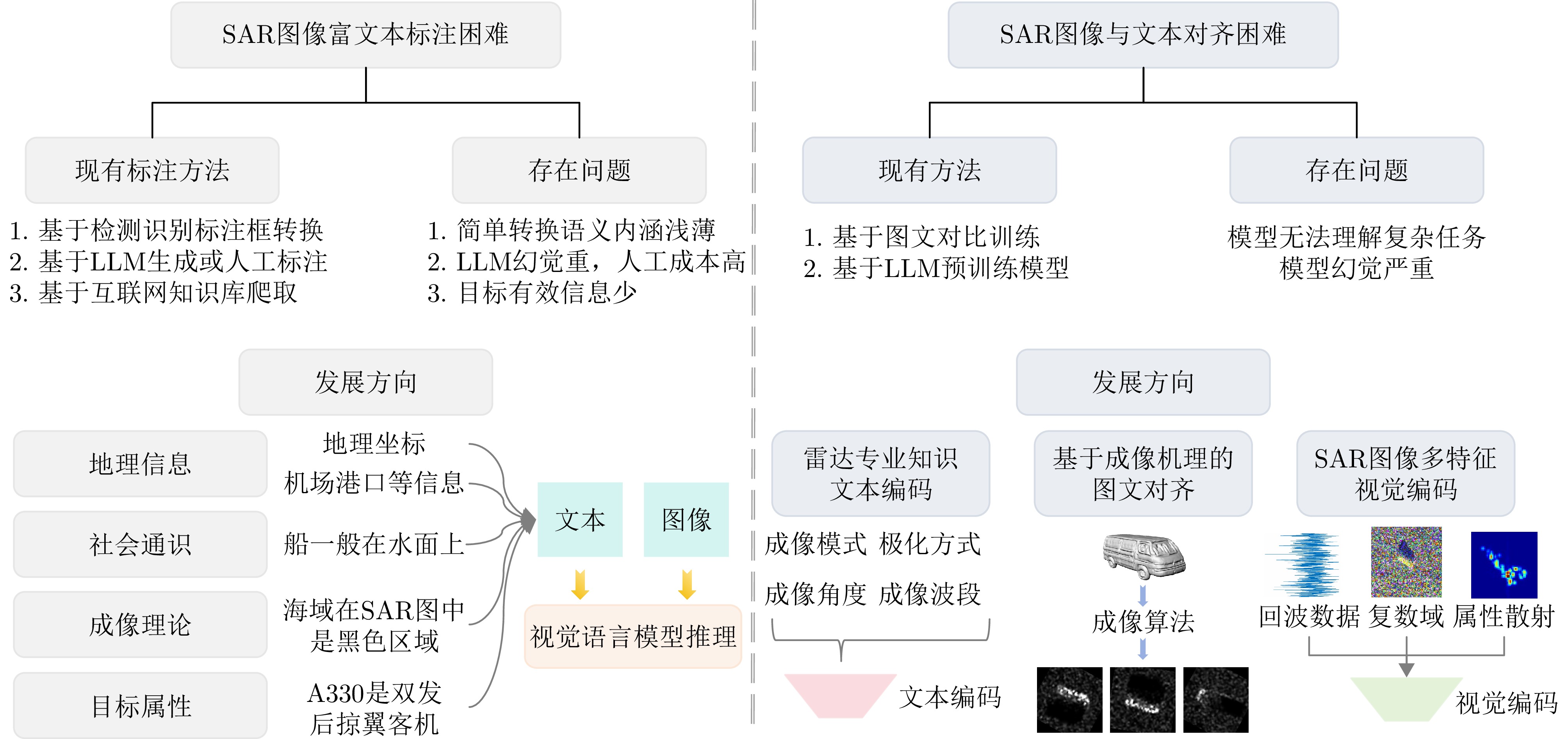
- Figure 3. The challenges of target interpretation in SAR images
- Figure 4. SAR image target interpretation from vision to vision-language
- Figure 5. Nature language understanding aiding visual interpretation
- Figure 6. Classical vision-language model structure based on foundation model
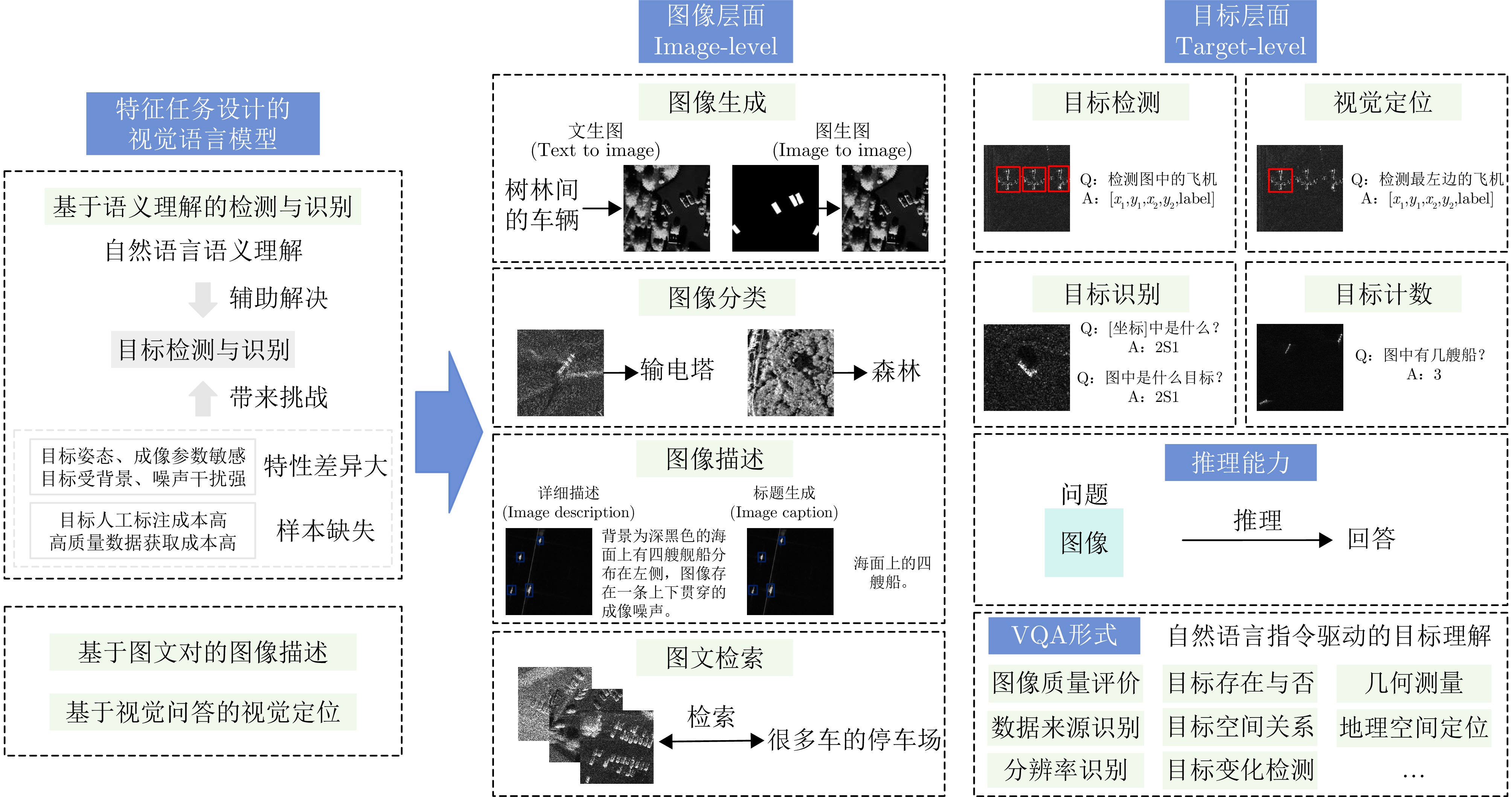
- Figure 7. SAR vision-language target interpretation tasks
- Figure 8. SAR image target interpretation dataset and data format
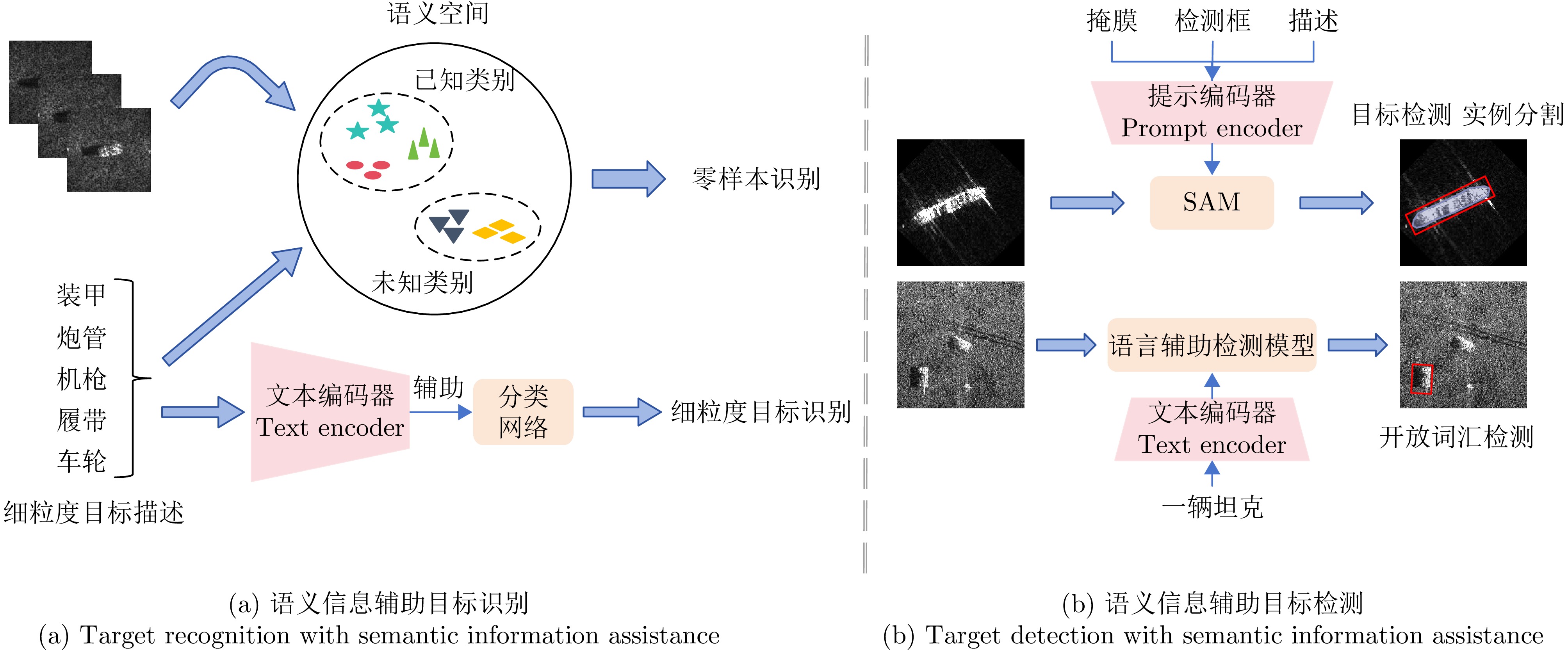
- Figure 9. Target detection and recognition guided by natural language
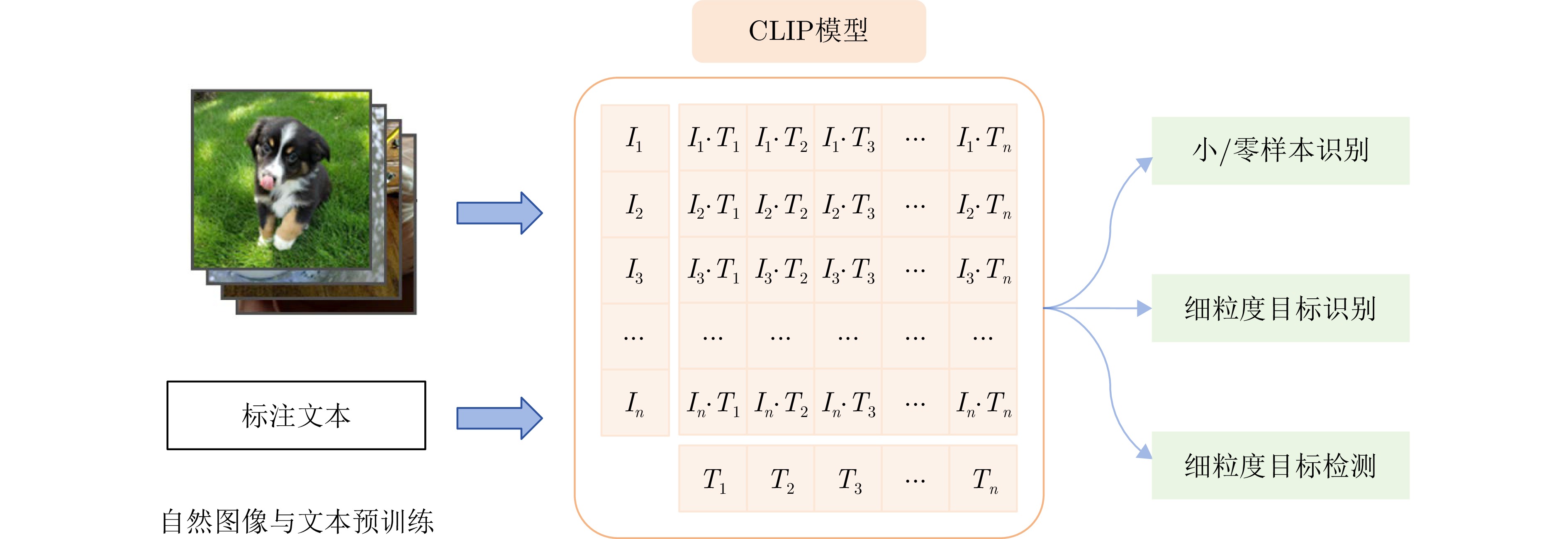
- Figure 10. Target interpretation based on contrastive VLM
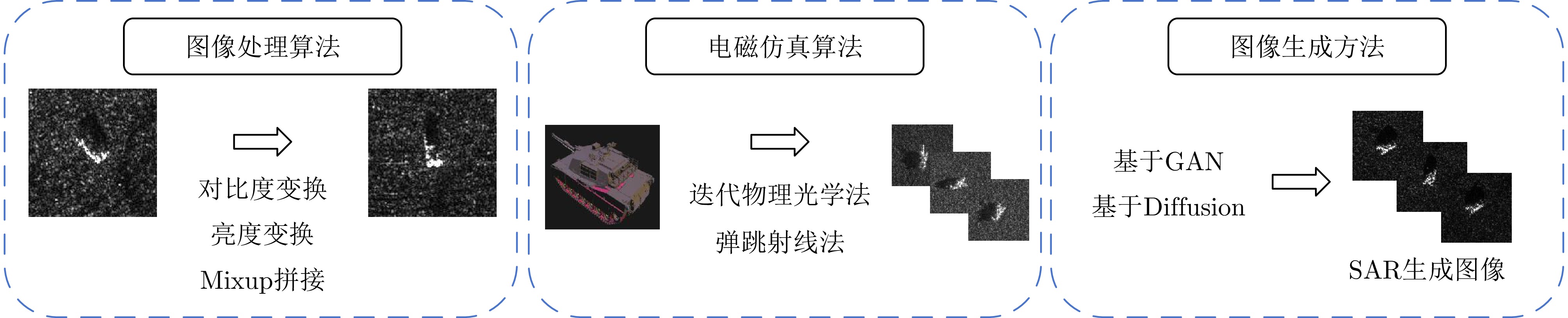
- Figure 11. Methods for SAR target sample expansion
- Figure 12. The challenge of VLM for SAR target interpretation
- Figure 13. Traditional annotation and rich information annotation