
 Submit Manuscript
Submit Manuscript Peer Review
Peer Review Editor Work
Editor Work- Home
- Articles & Issues
-
Data
- Dataset of Radar Detecting Sea
- SAR Dataset
- SARGroundObjectsTypes
- SARMV3D
- AIRSAT Constellation SAR Land Cover Classification Dataset
- 3DRIED
- UWB-HA4D
- LLS-LFMCWR
- FAIR-CSAR
- MSAR
- SDD-SAR
- FUSAR
- SpaceborneSAR3Dimaging
- Sea-land Segmentation
- SAR Multi-domain Ship Detection Dataset
- SAR-Airport
- Hilly and mountainous farmland time-series SAR and ground quadrat dataset
- SAR images for interference detection and suppression
- HP-SAR Evaluation & Analytical Dataset
- GDHuiYan-ATRNet
- Multi-System Maritime Low Observable Target Dataset
- DatasetinthePaper
- DatasetintheCompetition
- Report
- Course
- About
- Publish
- Editorial Board
- Chinese

| Citation: | DU Lan, WU Qingsen, GUO Yuchen, et al. Knowledge transfer method for vision-language models for processing synthetic aperture radar images[J]. Journal of Radars, 2026, 15(3): 996–1012. doi: 10.12000/JR25174

|
Knowledge Transfer Method for Vision-language Models for Processing Synthetic Aperture Radar Images
DOI: 10.12000/JR25174 CSTR: 32380.14.JR25174
More Information-
Abstract
A large-scale Vision-Language Model (VLM) pre-trained on massive image-text datasets performs well when processing natural images. However, there are two major challenges in applying it to Synthetic Aperture Radar (SAR) images: (1) The high cost of high-quality text annotation limits the construction of SAR image-text paired datasets, and (2) The considerable differences in image features between SAR images and optical natural images increase the difficulty of cross-domain knowledge transfer. To address these problems, this study developed a knowledge transfer method for VLM tailored to SAR images. First, this study leveraged paired SAR and optical remote sensing images and employed a generative VLM to automatically produce textual descriptions of the optical images, thereby indirectly constructing a low-cost SAR-text paired dataset. Second, a two-stage transfer strategy was designed to address the large domain discrepancy between natural and SAR images, reducing the difficulty of each transfer stage. Finally, experimental validation was conducted through the zero-shot scene classification, image retrieval, and object recognition of SAR images. The results demonstrated that the proposed method enables effective knowledge transfer from a large-scale VLM to the SAR image domain. -

-
References
[1] RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C/OL]. The 38th International Conference on Machine Learning, 2021: 8748–8763. https://icml.cc/virtual/2021/oral/9194.[2] LI Junnan, LI Dongxu, SAVARESE S, et al. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models[C]. The 40th International Conference on Machine Learning, Honolulu, USA, 2023: 19730–19742.[3] ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 10674–10685. doi: 10.1109/CVPR52688.2022.01042.[4] LIU Fan, CHEN Delong, GUAN Zhangqingyun, et al. RemoteCLIP: A vision language foundation model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5622216. doi: 10.1109/TGRS.2024.3390838.[5] HU Yuan, YUAN Jianlong, WEN Congcong, et al. RSGPT: A remote sensing vision language model and benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2025, 224: 272–286. doi: 10.1016/j.isprsjprs.2025.03.028.[6] KHANNA S, LIU P, Zhou Linqi, et al. DiffusionSat: A generative foundation model for satellite imagery[C]. The 12th International Conference on Learning Representations, Vienna, Austria, 2024: 5586–5604.[7] ZHANG Wei, CAI Miaoxin, ZHANG Tong, et al. EarthGPT: A universal multimodal large language model for multisensor image comprehension in remote sensing domain[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5917820. doi: 10.1109/TGRS.2024.3409624.[8] LI Weijie, YANG Wei, HOU Yuenan, et al. SARATR-X: Toward building a foundation model for SAR target recognition[J]. IEEE Transactions on Image Processing, 2025, 34: 869–884. doi: 10.1109/TIP.2025.3531988.[9] WANG Yi, ALBRECHT C M, and ZHU Xiaoxiang. Multilabel-guided soft contrastive learning for efficient earth observation pretraining[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5644516. doi: 10.1109/TGRS.2024.3466896.[10] DU Yuntao, CHEN Yushi, HUANG Lingbo, et al. SUMMIT: A SAR foundation model with multiple auxiliary tasks enhanced intrinsic characteristics[J]. International Journal of Applied Earth Observation and Geoinformation, 2025, 141: 104624. doi: 10.1016/j.jag.2025.104624.[11] WANG Mengyu, BI Hanbo, FENG Yingchao, et al. A complex-valued SAR foundation model based on physically inspired representation learning[OL]. https://arxiv.org/abs/ 2504.11999v1, 2025.[12] REN Zhongle, DING Hui, WANG Kai, et al. DI3CL: Contrastive learning with dynamic instances and contour consistency for SAR land-cover classification foundation model[OL]. https://arxiv.org/abs/2511.07808, 2025.[13] REN Zhongle, DU Zhe, HOU Biao, et al. Self-supervised learning of contrast-diffusion models for land cover classification in SAR Images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2025, 63: 5219620. doi: 10.1109/TGRS.2025.3600895.[14] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016. 90.[15] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C/OL]. The 9th International Conference on Learning Representations, 2021: 611–631. https://iclr.cc /virtual/2021/oral/3458.[16] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]. The 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 6000–6010.[17] JIA Chao, YANG Yinfei, XIA Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C/OL]. The 38th International Conference on Machine Learning, 2021: 4904–4916. https://icml.cc/virtual /2021/oral/10658.[18] ZHANG Zilun, ZHAO Tiancheng, GUO Yulong, et al. RS5M and GeoRSCLIP: A large-scale vision- language dataset and a large vision-language model for remote sensing[J]. IEEE Transactions on Geoscience and Remote Sensing, 2024, 62: 5642123. doi: 10.1109/TGRS.2024.3449154.[19] LI Xiang, WEN Congcong, HU Yuan, et al. RS-CLIP: Zero shot remote sensing scene classification via contrastive vision-language supervision[J]. International Journal of Applied Earth Observation and Geoinformation, 2023, 124: 103497. doi: 10.1016/j.jag.2023.103497.[20] HE Yiguo, CHENG Xinjun, ZHU Junjie, et al. SAR-TEXT: A large-scale SAR image-text dataset built with SAR-Narrator and a progressive learning strategy for downstream tasks[OL]. https://arxiv.org/abs/2507.18743, 2025.[21] JIANG Chaowei, WANG Chao, WU Fan, et al. SARCLIP: A multimodal foundation framework for SAR imagery via contrastive language-image pre-training[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2026, 231: 17–34. doi: 10.1016/j.isprsjprs.2025.10.017.[22] MA Qiwei, WANG Zhiyu, LIU Wang, et al. SARVLM: A vision language foundation model for semantic understanding and target recognition in SAR imagery[OL]. https://arxiv. org/abs/2510.22665, 2025.[23] YANG Yi, ZHANG Xiaokun, FANG Qingchen, et al. SAR-KnowLIP: Towards multimodal foundation models for remote sensing[OL]. https://arxiv.org/abs/2509.23927v1, 2025.[24] DAI Wenyuan, YANG Qiang, XUE Guirong, et al. Boosting for transfer learning[C]. The 24th International Conference on Machine Learning, Corvalis, USA, 2007: 193–200. doi: 10.1145/ 1273496.1273521.[25] HINTON G, VINYALS O, and DEAN J. Distilling the knowledge in a neural network[OL]. https://arxiv.org/abs/ 1503.02531, 2015.[26] KARIMI MAHABADI R, HENDERSON J, and RUDER S. COMPACTER: Efficient low-rank hypercomplex adapter layers[C/OL]. The 35th International Conference on Neural Information Processing Systems, 2021: 1022–1035. https://proceedings.neurips.cc/paper/2021/hash/081be9fdff07f3bc808f935906ef70c0-Abstract.html.[27] ZHOU Kaiyang, YANG Jingkang, LOY C C, et al. Learning to prompt for vision-language models[J]. International Journal of Computer Vision, 2022, 130(9): 2337–2348. doi: 10.1007/s11263-022-01653-1.[28] ZAKEN E B, GOLDBERG Y, and RAVFOGEL S. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models[C]. The 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 2022: 1–9. doi: 10.18653/v1/2022.acl-short.1.[29] HU E J, SHEN Yelong, WALLIS P, et al. LoRA: Low-rank adaptation of large language models[C/OL]. The 10th International Conference on Learning Representations, 2022. https://iclr.cc/virtual/2022/poster/6319.[30] GAO Peng, GENG Shijie, ZHANG Renrui, et al. CLIP-adapter: Better vision-language models with feature adapters[J]. International Journal of Computer Vision, 2024, 132(2): 581–595. doi: 10.1007/s11263-023-01891-x.[31] ZHANG Renrui, ZHANG Wei, FANG Rongyao, et al. Tip-adapter: Training-free adaption of CLIP for few-shot classification[C]. The 17th European Conference on Computer Vision. Tel Aviv, Israel, 2022: 493–510. doi: 10.1007/978-3-031-19833-5_29.[32] CHENG Cheng, SONG Lin, XUE Ruoyi, et al. Meta-adapter: An online few-shot learner for vision-language model[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, Dec. 2023: 55361–55374.[33] KRISHNA R, ZHU Yuke, GROTH O, et al. Visual Genome: Connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123(1): 32–73. doi: 10.1007/s11263-016-0981-7.[34] SHARMA P, DING Nan, GOODMAN S, et al. Conceptual Captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning[C]. The 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018: 2556–2565. doi: 10.18653/v1/P18-1238.[35] CHANGPINYO S, SHARMA P, DING Nan, et al. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 3557–3567. doi: 10.1109/CVPR46437. 2021.00356.[36] ORDONEZ V, KULKARNI G, and BERG T L. Im2Text: Describing images using 1 million captioned photographs[C]. The 25th International Conference on Neural Information Processing Systems, Granada, Spain, 2011: 1143–1151.[37] LIU Haotian, LI Chunyuan, WU Qingyang, et al. Visual instruction tuning[C]. The 37th International Conference on Neural Information Processing Systems, New Orleans, USA, 2023: 34892–34916.[38] BAI Shuai, CHEN Keqin, LIU Xuejing, et al. Qwen2.5-VL technical report[OL]. https://arxiv.org/abs/2502.13923, 2025.[39] WEI Yimin, XIAO Aoran, REN Yexian, et al. SARLANG-1M: A benchmark for vision-language modeling in SAR image understanding[OL]. https://arxiv.org/abs/2504.03254v1, 2025.[40] LI Junnan, LI Dongxu, XIONG Caiming, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 12888–12900.[41] OpenAI. GPT-4 technical report[OL]. https://arxiv.org/abs/2303.08774, 2024.[42] GRETTON A, BORGWARDT K M, RASCH M, et al. A Kernel Method for the Two-sample-problem[M]. SCHÖLKOPF B, PLATT J, and HOFMANN T. Advances in Neural Information Processing Systems 19. Cambridge: The MIT Press, 2007: 19. doi: 10.7551/mitpress/7503.003.0069.[43] VAN DEN OORD A, LI Yazhe, and VINYALS O. Representation learning with contrastive predictive coding[OL]. https://arxiv.org/abs/1807.03748, 2019.[44] HUANG Meiyu, XU Yao, QIAN Lixin, et al. The QXS- SAROPT dataset for deep learning in SAR-optical data fusion[OL]. https://arxiv.org/abs/2103.08259, 2021.[45] LI Xue, ZHANG Guo, CUI Hao, et al. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 106: 102638. doi: 10.1016/j.jag.2021.102638.[46] LIU Kang, WU Aodi, WAN Xue, et al. MRSSC: A benchmark dataset for multimodal remote sensing scene classification[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2021, XLIII-B2-2021: 785–792. doi: 10.5194/isprs- archives-XLIII-B2-2021-785-2021.[47] 吴樊, 张红, 王超, 等. SARBuD1.0: 面向深度学习的GF-3 精细模式SAR建筑数据集[J]. 遥感学报, 2022, 26(4): 620–631. doi: 10.11834/jrs.20220296.WU Fan, ZHANG Hong, WANG Chao, et al. SARBuD1.0: A SAR building dataset based on GF-3 FSII imageries for built-up area extraction with deep learning method[J]. National Remote Sensing Bulletin, 2022, 26(4): 620–631. doi: 10.11834/jrs.20220296.[48] ROSS T D, WORRELL S W, VELTEN V J, et al. Standard SAR ATR evaluation experiments using the MSTAR public release data set[C]. SPIE 3370, Algorithms for Synthetic Aperture Radar Imagery V, Orlando, USA, 1998: 566–573. doi: 10.1117/12.321859.[49] REIMERS N and GUREVYCH I. Sentence-BERT: Sentence embeddings using siamese BERT-networks[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 2019: 3982–3992. doi: 10.18653/v1/D19-1410.[50] LI Weijie, YANG Wei, LIU Tianpeng, et al. Predicting gradient is better: Exploring self-supervised learning for SAR ATR with a joint-embedding predictive architecture[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2024, 218: 326–338. doi: 10.1016/j.isprsjprs.2024.09.013.[51] GAO Ziyi, SUN Shuzhou, CHENG Mingming, et al. Multimodal large models driven SAR image captioning: A benchmark dataset and baselines[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2025, 18: 24011–24026. doi: 10.1109/JSTARS.2025.3603036.[52] XIAO Rui, KIM S, GEORGESCU M I, et al. FLAIR: VLM with fine-grained language-informed image representations[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 24884–24894. doi: 10.1109/CVPR52734.2025.02317.[53] ZHENG Kecheng, ZHANG Yifei, WU Wei, et al. DreamLIP: Language-image pre-training with long captions[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2025: 73–90. doi: 10.1007/978-3-031-72649-1_5. -
Proportional views

- Publishing Ethics
- Journal Insights
- Abstracting & Indexing
- Peer Review Policies
- Guide for Authors
- Conference
- ISSN 2095-283X (Print)ISSN 2097-339X (Online)
- CN 10-1030/TN
- CODEN LXEUAO
About Journal
- Sponsor: China Radio Detection and Ranging Industry Association (CRIA)
- Phone: 010-58887062
- Email:radars@aircas.ac.cn
- Publisher: Leida Xuebao Bianjibu (Editorial office of the Journal of Radars)
Contacts Us

京ICP备20021838号-14
Supported by: Beijing Renhe Information Technology Co. Ltd

Export File
Citation
Format
Content
 DownLoad:
DownLoad:







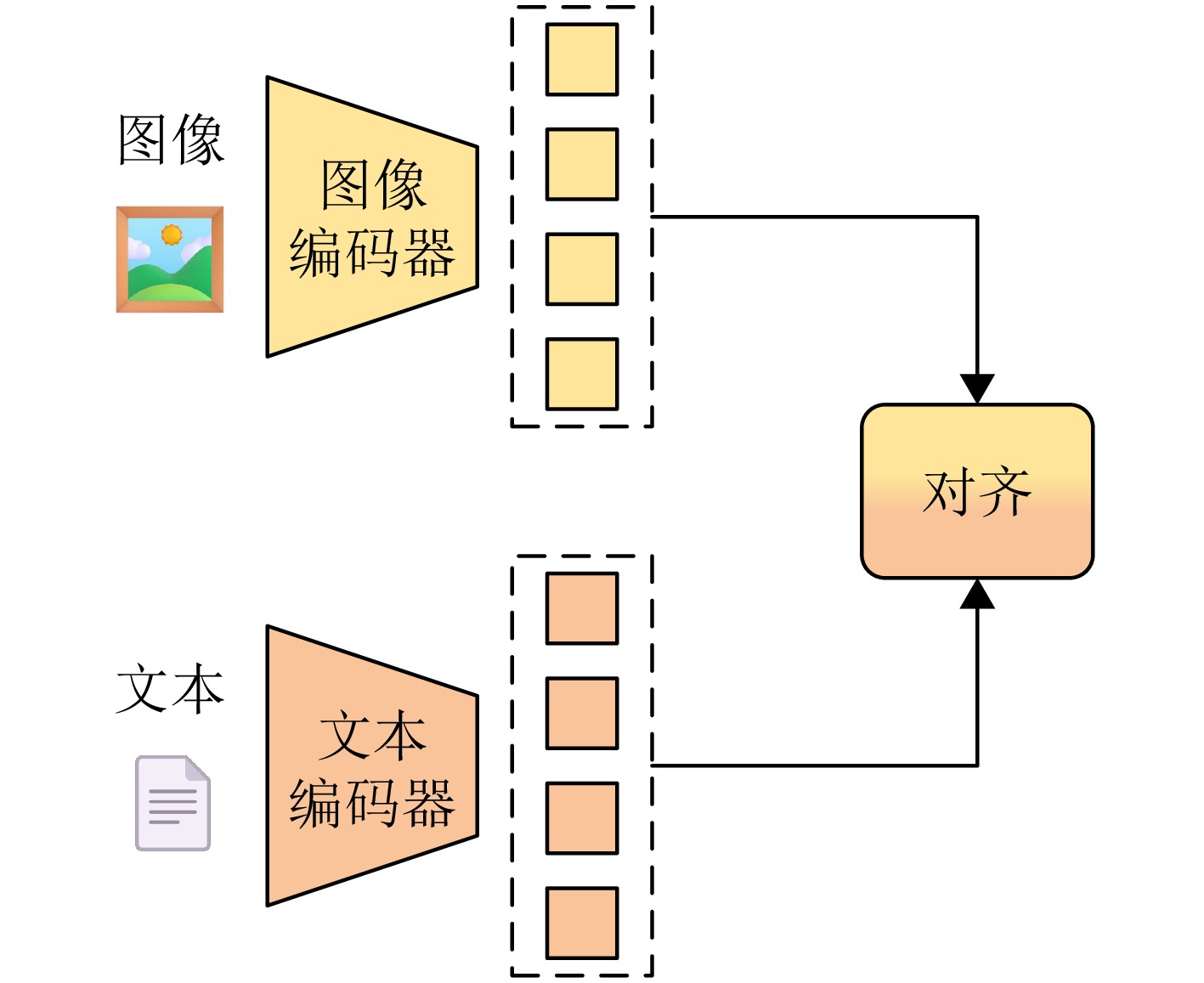
- Figure 1. The dual-tower structure of the visual encoder and the text encoder
- Figure 2. Overall process of the method
- Figure 3. The specific workflow of the BLIP-2 model for generating text descriptions
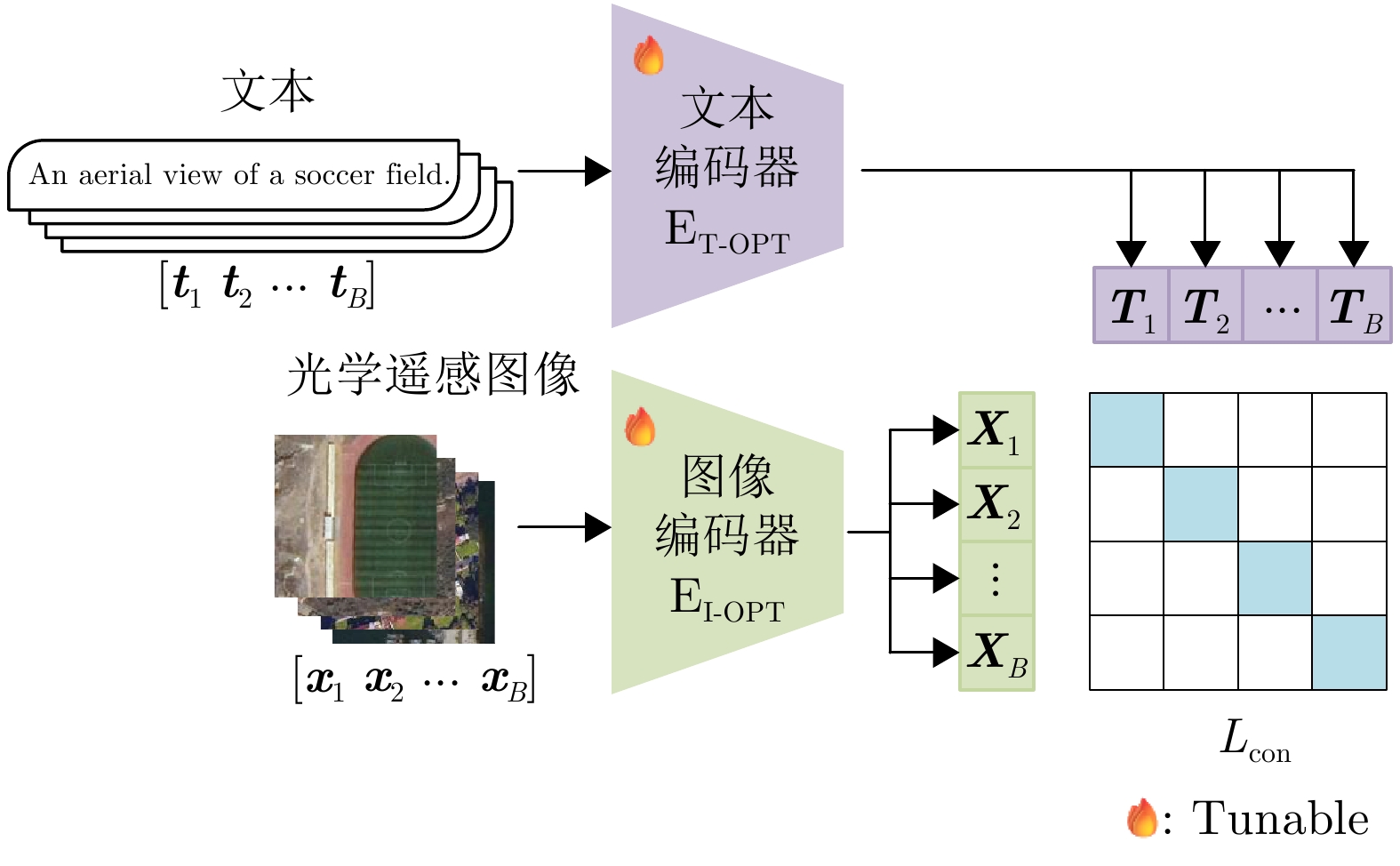
- Figure 4. Workflow of the first-stage knowledge transfer
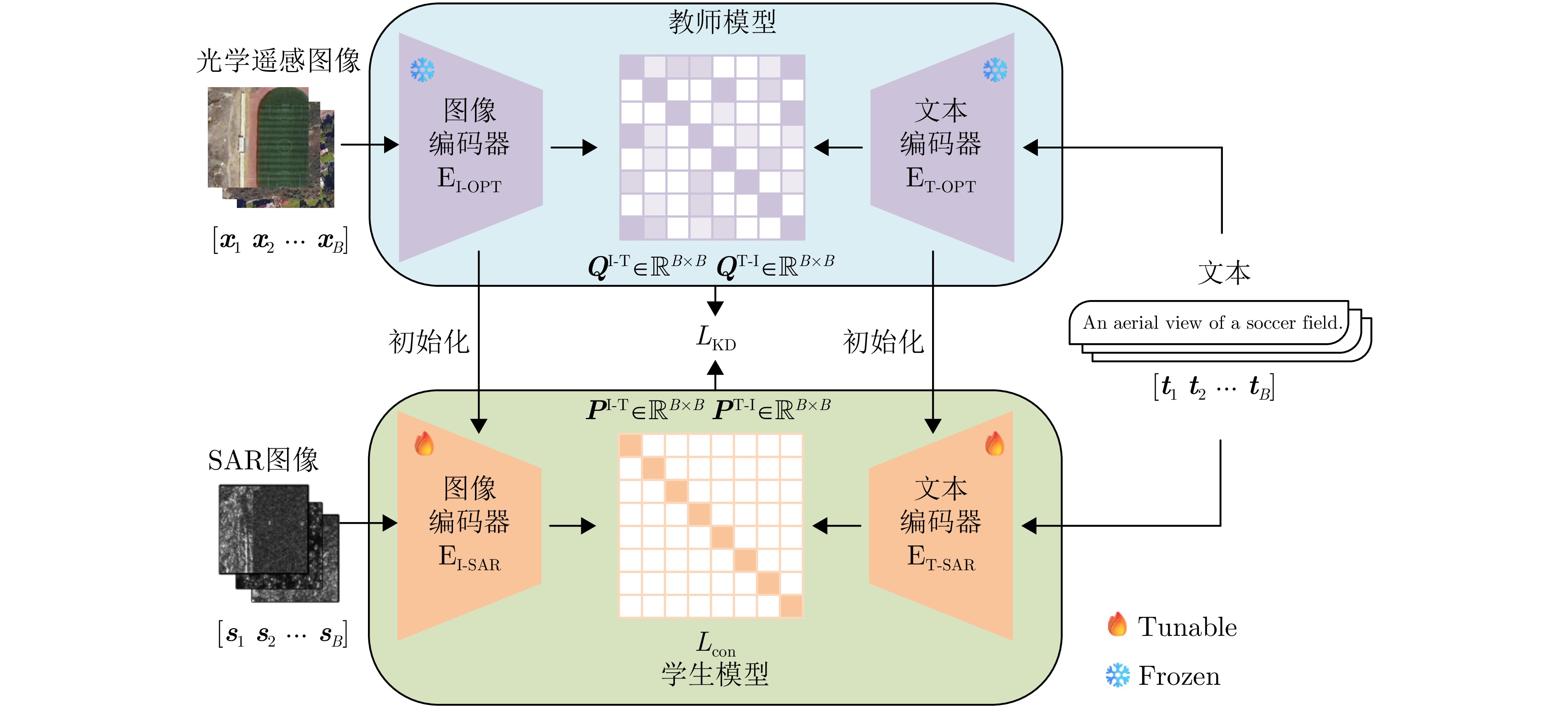
- Figure 5. Workflow of the second-stage knowledge transfer
- Figure 6. Examples of optical remote sensing images and corresponding SAR images of QXS-SAROPT dataset and WHU-OPT-SAR dataset
- Figure 7. Examples of SAR images of MRSSC dataset, SARBuD1.0 dataset and MSTAR dataset
- Figure 8. Text data visualization
- Figure 9. Examples of SAR image retrieval experimental results
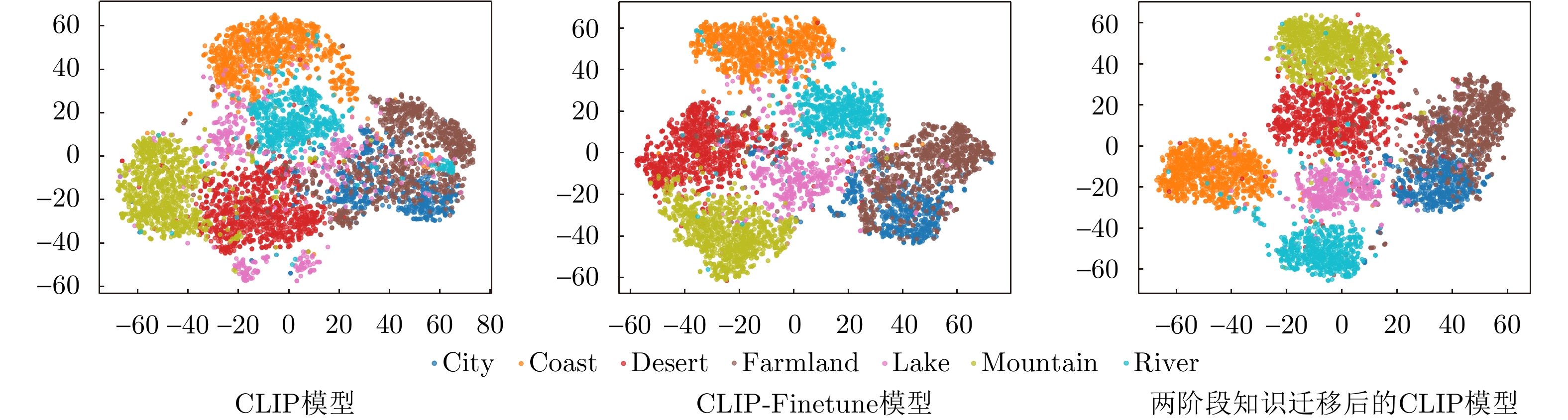
- Figure 10. Feature visualization of MRSSC dataset on different models
- Figure 11. SAR image-text attention heatmap