




② (中国科学院电子学研究所 北京 100190)
③ (赣南师范大学物理与电子信息学院 赣州 341000)
② (Institute of Electronics, Chinese Academy of Sciences, Beijing 100190, China)
③ (School of Physics and Electronic Information, Gannan Normal University, Ganzhou 341000, China)
合成孔径雷达(Synthetic Aperture Radar, SAR)自动目标识别(Automatic Target Recognition, ATR)在军事和民用领域中具有十分重要的意义。近年来,基于卷积神经网络(Convolutional Neural Network, CNN)的SAR-ATR方法已得到深入研究,并取得了较好的识别结果[1–5]。与传统的SAR-ATR方法相同,MSTAR是验证方法有效性的常用数据集之一。文献[6–8]直接利用CNN实现该数据集的SAR目标识别。Chen等人在CNN结构基础上,利用卷积层替代全连接层,并通过扩充带标签的训练样本,获得了高达99%的识别率[2]。Wagner提出了一种利用CNN提取SAR图像特征和SVM目标分类相结合的方法[9],并通过仿射变换和弹性畸变扩充训练样本,进一步提高了算法的鲁棒性[1]。Furukawa等人分析了训练样本扩充后,CNN具有更好的平移不变性,并采用18层Resnet模型获得了高达99.6%的识别率[4]。Pei等人利用多视方法扩充SAR图像,并构建一种多视深度学习框架,以提高目标的识别率[10]。由此可见,扩充带标签的训练样本,能够获得比扩充前更高的识别率。
为了在不扩充带标签训练样本的情况下获得较高的识别率,文献[11–14] 提出了一些基于CNN的改进方法。其中,自编码器(Auto-Encoder, AE)和CNN相结合的方法较为简单、有效。Chen等人提出先用无监督稀疏AE训练卷积核,再用带标签的训练样本经过卷积和池化后得到一系列特征图,最后用这些特征图训练Softmax分类器。该方法获得三分类目标和十分类目标的识别率分别为90.1%和84.7%[12]。Housseini等人提出一种结合CNN和卷积自编码器(Convolutional Auto-Encoder, CAE)的方法,该方法能够用比CNN更少的卷积层和每层更少的卷积核,获得与CNN相接近的识别率,从而在保证识别率的同时,有效减少运算时间[13]。
本文在CNN和CAE相结合的基础上,提出一种基于全卷积神经网络(Fully Convolutional Neural Network, FCNN)和改进的卷积自编码器(Improved Convolutional Auto-Encoder, ICAE)的识别方法。其中,FCNN是CNN结构上的改进[15],ICAE是按照FCNN结构对CAE的编码器改进得到。由于FCNN能够获得比CNN更高的识别率,而ICAE是一种无监督训练方式,且具有一定的抗噪声能力,因此,该方法不仅能在带标签训练样本不扩充的情况下获得较高的识别率,而且具有较强的抗噪声能力。MSTAR实验结果验证了该方法的有效性。
2 FCNN和CAE的基本理论 2.1 FCNN传统的CNN 由一系列交替的卷积层和池化层,再加上若干全连接层构成。FCNN与CNN相比,结构的改进之处包括:①步长为
(1) 卷积层
假定
第

|
其中,
输出特征图的高
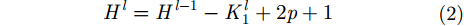
|
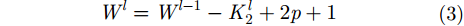
|
其中,
(2) 步长为
考虑上述第
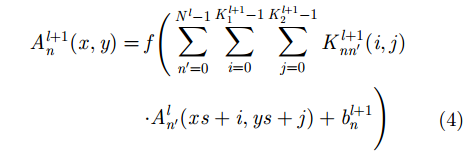
|
其输出特征图的高
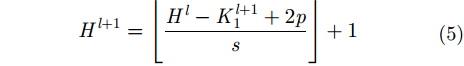
|
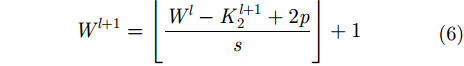
|
其中,
传统的AE包括编码器和解码器两部分[16–18],编码器从输入信号中提取特征,解码器则利用提取的特征重构原信号。在重构信号逐渐逼近输入信号的过程中,实现编码和解码网络参数的训练,因此,AE是一种无监督训练方式。由于AE的编码和解码网络都采用全连接方式,若加深AE的深度,将导致网络参数量多、容易过拟合等问题。CAE是一种利用CNN改进AE的网络[19],仍然包括编码器和解码器两部分。其中,编码器由卷积层和池化层构成,解码器则由反池化层和反卷积层构成,该结构更适合于图像的编码和重构。又由于AE具有一定的抗噪声能力[20],因此,CAE编码器可用于带噪声的图像目标特征提取。
考虑一个简单的CAE,编码器只包含1个卷积层和1个池化层,解码器包含1个反池化层和1个反卷积层,如图1所示。输入图像

|
图 1 CAE结构示意图 Fig.1 The structure of CAE |
(1) 编码
假设输入图像的高和宽分别为
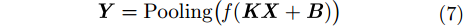
|
其中,
编码器中卷积后,特征图的高和宽分别按照式(2)和式(3)计算。
(2) 解码
假设反卷积核为
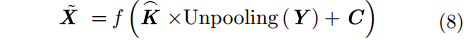
|
其中,
解码器中反卷积通常用卷积的转置来实现,反卷积后特征图的高和宽仍然分别按照式(2)和式(3)计算。
3 基于FCNN和ICAE的SAR图像目标识别方法本文针对MSTAR数据集,按照FCNN结构改进CAE,提出一种基于FCNN和ICAE的SAR图像目标识别方法,其结构及流程如图2所示。

|
图 2 基于FCNN和ICAE的识别方法 Fig.2 The recognition method based on FCNN and ICAE |
算法实现的具体步骤如下:
(1) 定义FCNN结构包括4个交替的卷积层和步长
(2) 按照FCNN结构设计ICAE的编码器结构,即用步长为2的卷积层替代CAE编码器的池化层。因此,ICAE的编码器包括4个交替的卷积层和步长
(3) 将MSTAR的训练样本作为ICAE的输入图像,经过编码器得到提取的特征图像,再经过解码器重构图像。在使重构图像与输入图像的误差最小的过程中,利用误差的后向传播完成ICAE的参数训练。
(4) 将训练好的ICAE编码器参数初始化FCNN中相应层的参数。
(5) 将MSTAR的带标签训练样本输入FCNN,在使目标输出类别与标签一致的过程中,利用误差的后向传播完成FCNN参数训练。
(6) 将MSTAR测试样本输入已训练好的FCNN网络,完成分类输出。
有关FCNN和ICAE的结构及前向传播流程进一步介绍如下。
3.1 FCNN图2中已定义FCNN包括4个交替的卷积层和步长为2的卷积层、1个卷积层和Softmax分类器,图3进一步给出包含每层卷积核通道数和卷积核尺寸的结构及前向传播流程。前4个交替的卷积层和步长为2的卷积层所采用的卷积核尺寸均为3×3,通道数分别为16, 32, 64, 128,每层卷积之后都需要经过Selu非线性激活函数[22],以避免训练过程中产生梯度爆炸或者梯度消失问题。最后一个卷积层的尺寸为4×4,通道数为10,卷积之后经过Softmax分类器分类。此外,前两个卷积层和步长为2的卷积层在卷积前需要对输入的图像或特征图补零,后两个步长为2的卷积层在卷积前需要对特征图补零,而后3个卷积层在卷积前无需补零。

|
图 3 FCNN的结构和前向传播 Fig.3 The structure and forward propagation of FCNN |
FCNN识别SAR图像的具体过程如下:
(1) 输入1幅88×88的SAR图像,卷积前对图像周围补零,经过16个卷积核的卷积后,根据式(2)和式(3) (式中
(2) 16幅88×88的特征图卷积前周围先补零,经过16个步长为2的卷积核的卷积后,根据式(5)和式(6) (式中
(3) 与步骤(1)类似,16幅44×44的特征图卷积前先补零,经过32个卷积核的卷积后,输出为32幅44×44的特征图。
(4) 与步骤(2)类似,32幅44×44的特征图卷积前先补零,经过32个步长为2的卷积核的卷积后,输出为32幅22×22的特征图。
(5) 32幅22×22的特征图卷积前无需补零,经过64个卷积核的卷积后,根据式(2)和式(3) (式中
(6) 64幅20×20的特征图卷积前先补零,经过64个步长为2的卷积核的卷积后,根据式(5)和式(6) (式中
(7) 与步骤(5)类似,64幅10×10的特征图卷积前无需补零,经过128个卷积核的卷积后,输出为128幅8×8的特征图。
(8) 与步骤(6)类似,128幅8×8的特征图卷积前先补零,经过128个步长为2的卷积核的卷积后,输出为128幅4×4的特征图。
(9) 128幅4×4的特征图卷积前无需补零,经过10个4×4卷积核的卷积后,根据式(2)和式(3) (式中
(10) 将10个数值输入Softmax分类器得到目标的所属类别。
为了使目标输出的所属类别与标签一致,需要不断调整各层卷积核权重和偏置参数,从而完成FCNN的网络参数训练。
3.2 ICAE图2中,ICAE的编码器结构与FCNN前4个交替的卷积层和步长

|
图 4 ICAE的结构和前向传播 Fig.4 The structure and forward propagation of ICAE |
ICAE的解码器包括4个交替的反池化层和反卷积层,其中,前两个反卷积层在反卷积前需对特征图的周围补两个零,而后两个反卷积层在反卷积前需补一个零。其具体过程如下:
(1) 编码输出的128幅4×4的特征图作为解码器的输入,经过反池化后,输出为128幅8×8的特征图。
(2) 128幅8×8的特征图在反卷积前补零,经过64个3×3反卷积核的反卷积后,根据式(2)和式(3) (式中
(3) 与步骤(1)类似,64幅10×10的特征图,经过反池化后,输出为64幅20×20的特征图。
(4) 与步骤(2)类似,64幅20×20的特征图在反卷积前补零,经过32个3×3反卷积核的反卷积后,输出为32幅22×22的特征图。
(5) 与步骤(1)类似,32幅22×22的特征图,经过反池化后,输出为32幅44×44的特征图。
(6) 32幅44×44的特征图在反卷积前补零,经过16个3×3反卷积核的反卷积后,根据式(2)和式(3) (式中
(7) 与步骤(1)类似,16幅44×44的特征图,经过反池化后,输出为16幅88×88的特征图。
(8) 与步骤(6)类似,16幅88×88的特征图在反卷积前补零,经过1个3×3反卷积核的反卷积后,最终输出为1幅88×88的图像。
为了使重构图像尽可能逼近输入图像,需要不断调整编码器和解码器各层卷积核权重和偏置参数,从而无监督地完成ICAE的网络参数训练。
4 实验结果及分析本文采用MSTAR数据集进行十分类实验,10类目标的光学图像及其SAR图像如图5所示。将下视角为17°的图像作为训练集,下视角为15°的图像作为测试集。训练集和测试集包含的各类目标的型号、数量如表1所示,共有2747个训练样本,2425个测试样本。实验前先将所有目标的SAR图像截取其中心88×88大小的区域,以作为训练和测试的原始输入图像。此外,将所有样本进行标准化预处理,即减去均值、除以标准差。

|
图 5 10类地面军事目标光学图像及其SAR图像 Fig.5 Ten types of ground military targets: Optical images versus SAR images |
| 表 1 训练样本和测试样本数量 Tab.1 The number of training and testing images |
由于ICAE是CAE结构的改进,因此,ICAE也具有一定的抗噪声能力。实验分别考虑不加噪声和加噪声两种情况。其中,不加噪声情况,进一步考虑数据集不扩充和扩充实验;加噪声情况,又进一步考虑加不同比例和不同功率的噪声实验。为验证本文所提方法的有效性,采用基于CNN和CAE的方法、基于FCNN的方法,以及基于CNN的方法进行对比。这3种方法所采用的FCNN, CNN和CAE的结构如表2所示。
| 表 2 FCNN, ICAE, CNN和CAE的网络结构 Tab.2 The network structures of FCNN, ICAE, CNN and CAE |
网络训练前,卷积核权重初始化方面,基于FCNN和ICAE的方法中,用训练好的ICAE编码器参数初始化FCNN对应层的参数;基于CNN和CAE的方法中,用训练好的CAE编码器参数初始化CNN对应层的参数;4种方法中其余的卷积核权重均采用均值为0,标准差为
数据集不扩充时,包括2747个训练样本和2425个测试样本。按照第3节阐述的实现步骤,采用基于FCNN和ICAE的方法进行10类目标识别,得到的混淆矩阵如表3所示。进一步地,其余3种方法得到的各类目标的正确识别率和平均正确识别率如表4所示。实验结果表明,在训练样本没有扩充的情况下,基于FCNN和ICAE的方法的平均正确识别率能够达到98.14%,比基于CAE和CNN的方法提高了1.03%,比基于FCNN的方法提高了1.56%,比基于CNN的方法提高了2.43%。
| 表 3 基于FCNN和ICAE的识别结果 Tab.3 The recognition results based on FCNN and ICAE |
| 表 4 基于不同方法的实验结果对比 Tab.4 The comparison of experimental results based on different methods |
采用随机采样方式[2]对带标签的训练样本进行数量扩充,即实验采用的训练样本数为2747乘以扩充倍数。图6为4种方法的平均正确识别率随其扩充倍数的变化情况。实验结果表明,基于FCNN和ICAE的方法在训练集不扩充时,平均正确识别率为98.14%;基于CNN和CAE的方法在训练集扩充7倍后,平均正确识别率为98.08%;基于FCNN的方法在训练集扩充8倍后,平均正确识别率为98.1%;而基于CNN的方法在训练集扩充10倍后,平均正确识别率只有97.43%。因此,基于FCNN和ICAE的方法能够在训练集不扩充的情况下获得较高的识别率。

|
图 6 4种方法的平均正确识别率随带标签的训练样本扩充倍数的变化 Fig.6 The average correct recognition rate of the four methods varies with the multiples of labeled training samples |
数据集不扩充时,在测试样本中加入噪声,具体方法为将服从均匀分布的噪声随机取代测试样本的像素单元[24]。图7为添加不同比例噪声的SAR图像,图7(a)–图7(e)的噪声比例分别为1%, 5%, 10%, 15%, 20%。图8为4种方法的平均正确识别率随噪声比例变化的情况。实验结果表明,随着噪声比例的增加,基于FCNN和ICAE方法的抗噪声能力最强,其次为基于CNN和CAE的方法,再次是基于FCNN的方法,最后为基于CNN的方法。

|
图 7 加不同比例噪声的SAR图像 Fig.7 SAR images with noise of different proportions |

|
图 8 4种方法的平均正确识别率随噪声所占比例的变化 Fig.8 The average correct recognition rate of the four methods varies with the noise proportion |
数据集不扩充时,在测试样本中加入不同功率的高斯白噪声。定义SAR图像功率

|
图 9 不同信噪比的SAR图像 Fig.9 SAR images with different SNR |

|
图 10 4种方法的平均正确识别率随信噪比的变化 Fig.10 The average correct recognition rate of the four methods varies with SNR |
本文介绍了FCNN和CAE的结构,FCNN包含卷积层和步长为
| [1] |
Wagner S A. SAR ATR by a combination of convolutional neural network and support vector machines[J].
IEEE Transactions on Aerospace and Electronic Systems, 2016, 52(6): 2861-2872. DOI:10.1109/TAES.2016.160061 ( 0) 0)
|
| [2] |
Chen S Z, Wang H P, Xu F, et al. Target classification using the deep convolutional networks for SAR images[J].
IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(8): 4806-4817. DOI:10.1109/TGRS.2016.2551720 (0)
|
| [3] |
Zhang Z M, Wang H P, Xu F, et al. Complex-valued convolutional neural network and its application in polarimetric SAR image classification[J].
IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(12): 7177-7188. DOI:10.1109/TGRS.2017.2743222 (0)
|
| [4] |
Furukawa H. Deep learning for target classification from SAR imagery: Data augmentation and translation invariance[J].
IEICE Technical Report, 2017, 117(182): 13-17. (0)
|
| [5] |
徐丰, 王海鹏, 金亚秋. 深度学习在SAR目标识别与地物分类中的应用[J].
雷达学报, 2017, 6(2): 136-148. Xu Feng, Wang Haipeng, and Jin Yaqiu. Deep learning as applied in SAR target recognition and terrain classification[J]. Journal of Radars, 2017, 6(2): 136-148. DOI:10.12000/JR16130 ( 0)
|
| [6] |
Morgan D A E. Deep convolutional neural networks for ATR from SAR imagery[C]. Proceedings of SPIE 9475, Algorithms for Synthetic Aperture Radar Imagery XXII, Baltimore, Maryland, United States, 2015: 94750F.
(0)
|
| [7] |
Profeta A, Rodriguez A, and Clouse H S. Convolutional neural networks for synthetic aperture radar classification[C]. Proceedings of SPIE 9843, Algorithms for Synthetic Aperture Radar Imagery XXIII, Baltimore, Maryland, United States, 2016: 98430M.
(0)
|
| [8] |
Wilmanski M, Kreucher C, and Lauer J. Modern approaches in deep learning for SAR ATR[C]. Proceedings of SPIE 9843, Algorithms for Synthetic Aperture Radar Imagery XXIII, Baltimore, Maryland, United States, 2016: 98430N.
(0)
|
| [9] |
Wagner S. Combination of convolutional feature extraction and support vector machines for radar ATR[C]. Proceedings of the 17th International Conference on Information Fusion, Salamanca, Spain, 2014: 1–6.
(0)
|
| [10] |
Pei J F, Huang Y L, Huo W B, et al. SAR automatic target recognition based on multiview deep learning framework[J].
IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(4): 2196-2210. DOI:10.1109/TGRS.2017.2776357 (0)
|
| [11] |
Lin Z, Ji K F, Kang M, et al. Deep convolutional highway unit network for SAR target classification with limited labeled training data[J].
IEEE Geoscience and Remote Sensing Letters, 2017, 14(7): 1091-1095. DOI:10.1109/LGRS.2017.2698213 (0)
|
| [12] |
Chen S Z and Wang H P. SAR target recognition based on deep learning[C]. Proceedings of 2014 International Conference on Data Science and Advanced Analytics, Shanghai, China, 2015: 541–547.
(0)
|
| [13] |
El Housseini A, Toumi A, and Khenchaf A. Deep learning for target recognition from SAR images[C]. Proceedings of 2017 Seminar on Detection Systems Architectures and Technologies, Algiers, Algeria, 2017: 1–5.
(0)
|
| [14] |
田壮壮, 占荣辉, 胡杰民, 等. 基于卷积神经网络的SAR图像目标识别研究[J].
雷达学报, 2016, 5(3): 320-325. Tian Zhuangzhuang, Zhan Ronghui, Hu Jiemin, et al. SAR ATR based on convolutional neural network[J]. Journal of Radars, 2016, 5(3): 320-325. DOI:10.12000/JR16037 ( 0)
|
| [15] |
Springenberg J T, Dosovitskiy A, Brox T, et al.. Striving for simplicity: The all convolutional net[OL]. arXiv preprint arXiv:1412.6806, 2015.
(0)
|
| [16] |
Hinton G E and Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J].
Science, 2006, 313(5786): 504-507. DOI:10.1126/science.1127647 (0)
|
| [17] |
康妙, 计科峰, 冷祥光, 等. 基于栈式自编码器特征融合的SAR图像车辆目标识别[J].
雷达学报, 2017, 6(2): 167-176. Kang Miao, Ji Kefeng, Leng Xiangguang, et al. SAR target recognition with feature fusion based on stacked autoencoder[J]. Journal of Radars, 2017, 6(2): 167-176. DOI:10.12000/JR16112 ( 0)
|
| [18] |
赵飞翔, 刘永祥, 霍凯. 基于栈式降噪稀疏自动编码器的雷达目标识别方法[J].
雷达学报, 2017, 6(2): 149-156. Zhao Feixiang, Liu Yongxiang, and Huo Kai. Radar target recognition based on stacked denoising sparse autoencoder[J]. Journal of Radars, 2017, 6(2): 149-156. DOI:10.12000/JR16151 ( 0)
|
| [19] |
Masci J, Meier U, Cireşan D, et al.. Stacked convolutional auto-encoders for hierarchical feature extraction[C]. Proceedings of the 21st International Conference on Artificial Neural Networks on Artificial Neural Networks and Machine Learning – ICANN 2011, Espoo, Finland, 2011: 52–59.
(0)
|
| [20] |
Vincent P, Larochelle H, Bengio Y, et al.. Extracting and composing robust features with denoising autoencoders[C]. Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 2008: 1096–1103.
(0)
|
| [21] |
Rumelhart D E, Hinton G E, and Williams R J. Learning representations by back-propagating errors[J].
Nature, 1986, 323(6088): 533-536. DOI:10.1038/323533a0 (0)
|
| [22] |
Klambauer G, Unterthiner T, Mayr A, et al.. Self-normalizing neural networks[C]. Proceedings of the 31st Neural Information Processing Systems, Long Beach, CA, United States, 2017: 972–981.
(0)
|
| [23] |
Kingma D P and Ba J L. Adam: A method for stochastic optimization[OL]. arXiv preprint arXiv:1412.6980, 2015.
(0)
|
| [24] |
Dong G G, Wang N, and Kuang G Y. Sparse representation of monogenic signal: With application to target recognition in SAR images[J].
IEEE Signal Processing Letters, 2014, 21(8): 952-956. DOI:10.1109/LSP.2014.2321565 (0)
|